
diff options
475 files changed, 12067 insertions, 2517 deletions
diff --git a/RELEASE.md b/RELEASE.md index 4b03394427..7bb1e3e1c8 100644 --- a/RELEASE.md +++ b/RELEASE.md @@ -21,7 +21,7 @@ * The [distributions.Bijector](https://www.tensorflow.org/versions/r1.9/api_docs/python/tf/contrib/distributions/bijectors/Bijector) API supports broadcasting for Bijectors with new API changes. -## Breaking Chances +## Breaking Changes * If you're opening empty variable scopes; replace `variable_scope('', ...)` by `variable_scope(tf.get_variable_scope(), ...)`. * Headers used for building custom ops have been moved from site-packages/external into site-packages/tensorflow/include/external. diff --git a/tensorflow/compiler/tests/BUILD b/tensorflow/compiler/tests/BUILD index 69ff0d99cb..8b25147899 100644 --- a/tensorflow/compiler/tests/BUILD +++ b/tensorflow/compiler/tests/BUILD @@ -98,6 +98,19 @@ tf_xla_py_test( ) tf_xla_py_test( + name = "adagrad_da_test", + size = "small", + srcs = ["adagrad_da_test.py"], + deps = [ + ":xla_test", + "//tensorflow/python:array_ops", + "//tensorflow/python:framework", + "//tensorflow/python:platform_test", + "//tensorflow/python:training", + ], +) + +tf_xla_py_test( name = "adam_test", size = "small", srcs = ["adam_test.py"], @@ -112,6 +125,20 @@ tf_xla_py_test( ) tf_xla_py_test( + name = "adamax_test", + size = "small", + srcs = ["adamax_test.py"], + deps = [ + ":xla_test", + "//tensorflow/contrib/opt:opt_py", + "//tensorflow/python:array_ops", + "//tensorflow/python:client_testlib", + "//tensorflow/python:framework", + "//tensorflow/python:training", + ], +) + +tf_xla_py_test( name = "addsign_test", size = "small", srcs = ["addsign_test.py"], diff --git a/tensorflow/compiler/tests/adagrad_da_test.py b/tensorflow/compiler/tests/adagrad_da_test.py new file mode 100644 index 0000000000..dc1625793a --- /dev/null +++ b/tensorflow/compiler/tests/adagrad_da_test.py @@ -0,0 +1,165 @@ +# Copyright 2016 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for AdagradDA optimizer.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import numpy as np + +from tensorflow.compiler.tests import xla_test +from tensorflow.python.framework import constant_op +from tensorflow.python.framework import dtypes +from tensorflow.python.ops import resource_variable_ops +from tensorflow.python.ops import variables +from tensorflow.python.platform import test +from tensorflow.python.training import adagrad_da + + +class AdagradDAOptimizerTest(xla_test.XLATestCase): + + def testAdagradDAWithoutRegularizationBasic1(self): + for dtype in self.float_types: + with self.test_session(), self.test_scope(): + global_step = resource_variable_ops.ResourceVariable( + 0, dtype=dtypes.int64) + var0 = resource_variable_ops.ResourceVariable([0.0, 0.0], dtype=dtype) + var1 = resource_variable_ops.ResourceVariable([0.0, 0.0], dtype=dtype) + grads0 = constant_op.constant([0.1, 0.2], dtype=dtype) + grads1 = constant_op.constant([0.01, 0.02], dtype=dtype) + opt = adagrad_da.AdagradDAOptimizer( + 3.0, + global_step, + initial_gradient_squared_accumulator_value=0.1, + l1_regularization_strength=0.0, + l2_regularization_strength=0.0) + update = opt.apply_gradients( + zip([grads0, grads1], [var0, var1]), global_step=global_step) + variables.global_variables_initializer().run() + + self.assertAllClose([0.0, 0.0], var0.eval()) + self.assertAllClose([0.0, 0.0], var1.eval()) + + # Run a step of AdagradDA + update.run() + + # Let g to be gradient accumulator, gg to be gradient squared + # accumulator, T be the global step, lr is the learning rate, and k the + # initial gradient squared accumulator value. + # w = \dfrac{sign(-g)*lr*|g - l1*T|_{+}}{l2*T*lr + \sqrt{k+gg})} + # For -0.1*3.0*(0.1 - 0)/(0 + sqrt(0.1 + 0.1*0.1)) = -0.904534 + # similarly for others. + self.assertAllCloseAccordingToType( + np.array([-0.904534, -1.603567]), var0.eval()) + self.assertAllCloseAccordingToType( + np.array([-0.094821, -0.189358]), var1.eval()) + + def testAdagradDAwithoutRegularizationBasic2(self): + for dtype in self.float_types: + with self.test_session(), self.test_scope(): + global_step = resource_variable_ops.ResourceVariable( + 0, dtype=dtypes.int64) + var0 = resource_variable_ops.ResourceVariable([1.0, 2.0], dtype=dtype) + var1 = resource_variable_ops.ResourceVariable([4.0, 3.0], dtype=dtype) + grads0 = constant_op.constant([0.1, 0.2], dtype=dtype) + grads1 = constant_op.constant([0.01, 0.02], dtype=dtype) + + opt = adagrad_da.AdagradDAOptimizer( + 3.0, + global_step, + initial_gradient_squared_accumulator_value=0.1, + l1_regularization_strength=0.0, + l2_regularization_strength=0.0) + update = opt.apply_gradients( + zip([grads0, grads1], [var0, var1]), global_step=global_step) + variables.global_variables_initializer().run() + + self.assertAllCloseAccordingToType([1.0, 2.0], var0.eval()) + self.assertAllCloseAccordingToType([4.0, 3.0], var1.eval()) + + # Run a step of AdagradDA + update.run() + + self.assertAllCloseAccordingToType( + np.array([-0.904534, -1.603567]), var0.eval()) + self.assertAllCloseAccordingToType( + np.array([-0.094821, -0.189358]), var1.eval()) + + def testAdagradDAWithL1(self): + for dtype in self.float_types: + with self.test_session(), self.test_scope(): + global_step = resource_variable_ops.ResourceVariable( + 0, dtype=dtypes.int64) + var0 = resource_variable_ops.ResourceVariable([1.0, 2.0], dtype=dtype) + var1 = resource_variable_ops.ResourceVariable([4.0, 3.0], dtype=dtype) + grads0 = constant_op.constant([0.1, 0.2], dtype=dtype) + grads1 = constant_op.constant([0.01, 0.02], dtype=dtype) + + opt = adagrad_da.AdagradDAOptimizer( + 3.0, + global_step, + initial_gradient_squared_accumulator_value=0.1, + l1_regularization_strength=0.001, + l2_regularization_strength=0.0) + update = opt.apply_gradients( + zip([grads0, grads1], [var0, var1]), global_step=global_step) + variables.global_variables_initializer().run() + + self.assertAllCloseAccordingToType([1.0, 2.0], var0.eval()) + self.assertAllCloseAccordingToType([4.0, 3.0], var1.eval()) + + # Run a step of AdagradDA + update.run() + + self.assertAllCloseAccordingToType( + np.array([-0.895489, -1.59555]), var0.eval()) + self.assertAllCloseAccordingToType( + np.array([-0.085339, -0.17989]), var1.eval()) + + def testAdagradDAWithL1_L2(self): + for dtype in self.float_types: + with self.test_session(), self.test_scope(): + global_step = resource_variable_ops.ResourceVariable( + 0, dtype=dtypes.int64) + var0 = resource_variable_ops.ResourceVariable([1.0, 2.0], dtype=dtype) + var1 = resource_variable_ops.ResourceVariable([4.0, 3.0], dtype=dtype) + grads0 = constant_op.constant([0.1, 0.2], dtype=dtype) + grads1 = constant_op.constant([0.01, 0.02], dtype=dtype) + + opt = adagrad_da.AdagradDAOptimizer( + 3.0, + global_step, + initial_gradient_squared_accumulator_value=0.1, + l1_regularization_strength=0.001, + l2_regularization_strength=2.0) + update = opt.apply_gradients( + zip([grads0, grads1], [var0, var1]), global_step=global_step) + variables.global_variables_initializer().run() + + self.assertAllCloseAccordingToType([1.0, 2.0], var0.eval()) + self.assertAllCloseAccordingToType([4.0, 3.0], var1.eval()) + + # Run a step of AdagradDA + update.run() + + self.assertAllCloseAccordingToType( + np.array([-0.046907, -0.093659]), var0.eval()) + self.assertAllCloseAccordingToType( + np.array([-0.004275, -0.009023]), var1.eval()) + + +if __name__ == "__main__": + test.main() diff --git a/tensorflow/compiler/tests/adamax_test.py b/tensorflow/compiler/tests/adamax_test.py new file mode 100644 index 0000000000..c4fdbc5974 --- /dev/null +++ b/tensorflow/compiler/tests/adamax_test.py @@ -0,0 +1,139 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for AdaMax optimizer.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import numpy as np + +from tensorflow.compiler.tests import xla_test +from tensorflow.contrib.opt.python.training import adamax +from tensorflow.python.framework import constant_op +from tensorflow.python.framework import ops +from tensorflow.python.ops import resource_variable_ops +from tensorflow.python.ops import variable_scope +from tensorflow.python.ops import variables +from tensorflow.python.platform import test + + +def adamax_update_numpy(param, + g_t, + t, + m, + v, + alpha=0.001, + beta1=0.9, + beta2=0.999, + epsilon=1e-8): + m_t = beta1 * m + (1 - beta1) * g_t + v_t = np.maximum(beta2 * v, np.abs(g_t)) + param_t = param - (alpha / (1 - beta1**t)) * (m_t / (v_t + epsilon)) + return param_t, m_t, v_t + + +class AdaMaxOptimizerTest(xla_test.XLATestCase): + + def testBasic(self): + for i, dtype in enumerate(self.float_types): + with self.test_session(), self.test_scope(): + variable_scope.get_variable_scope().set_use_resource(True) + # Initialize variables for numpy implementation. + m0, v0, m1, v1 = 0.0, 0.0, 0.0, 0.0 + var0_np = np.array([1.0, 2.0], dtype=dtype) + grads0_np = np.array([0.1, 0.1], dtype=dtype) + var1_np = np.array([3.0, 4.0], dtype=dtype) + grads1_np = np.array([0.01, 0.01], dtype=dtype) + + var0 = resource_variable_ops.ResourceVariable( + var0_np, name="var0_%d" % i) + var1 = resource_variable_ops.ResourceVariable( + var1_np, name="var1_%d" % i) + grads0 = constant_op.constant(grads0_np) + grads1 = constant_op.constant(grads1_np) + + opt = adamax.AdaMaxOptimizer() + update = opt.apply_gradients(zip([grads0, grads1], [var0, var1])) + opt_variables = opt.variables() + beta1_power = opt._get_beta_accumulators() + self.assertTrue(beta1_power is not None) + self.assertIn(beta1_power, opt_variables) + + with ops.Graph().as_default(): + # Shouldn't return non-slot variables from other graphs. + self.assertEqual(0, len(opt.variables())) + + variables.global_variables_initializer().run() + # Fetch params to validate initial values + self.assertAllClose([1.0, 2.0], var0.eval()) + self.assertAllClose([3.0, 4.0], var1.eval()) + + beta1_power = opt._get_beta_accumulators() + + # Run 3 steps of AdaMax + for t in range(1, 4): + update.run() + + self.assertAllCloseAccordingToType(0.9**(t + 1), beta1_power.eval()) + + var0_np, m0, v0 = adamax_update_numpy(var0_np, grads0_np, t, m0, v0) + var1_np, m1, v1 = adamax_update_numpy(var1_np, grads1_np, t, m1, v1) + + # Validate updated params + self.assertAllCloseAccordingToType(var0_np, var0.eval(), rtol=1e-2) + self.assertAllCloseAccordingToType(var1_np, var1.eval(), rtol=1e-2) + self.assertEqual("var0_%d/AdaMax:0" % (i,), + opt.get_slot(var=var0, name="m").name) + + def testTensorLearningRate(self): + for dtype in self.float_types: + with self.test_session(), self.test_scope(): + variable_scope.get_variable_scope().set_use_resource(True) + # Initialize variables for numpy implementation. + m0, v0, m1, v1 = 0.0, 0.0, 0.0, 0.0 + var0_np = np.array([1.0, 2.0], dtype=dtype) + grads0_np = np.array([0.1, 0.1], dtype=dtype) + var1_np = np.array([3.0, 4.0], dtype=dtype) + grads1_np = np.array([0.01, 0.01], dtype=dtype) + + var0 = resource_variable_ops.ResourceVariable(var0_np) + var1 = resource_variable_ops.ResourceVariable(var1_np) + grads0 = constant_op.constant(grads0_np) + grads1 = constant_op.constant(grads1_np) + opt = adamax.AdaMaxOptimizer(constant_op.constant(0.001)) + update = opt.apply_gradients(zip([grads0, grads1], [var0, var1])) + variables.global_variables_initializer().run() + + # Fetch params to validate initial values + self.assertAllClose([1.0, 2.0], var0.eval()) + self.assertAllClose([3.0, 4.0], var1.eval()) + + beta1_power = opt._get_beta_accumulators() + + # Run 3 steps of AdaMax + for t in range(1, 4): + self.assertAllCloseAccordingToType(0.9**t, beta1_power.eval()) + update.run() + + var0_np, m0, v0 = adamax_update_numpy(var0_np, grads0_np, t, m0, v0) + var1_np, m1, v1 = adamax_update_numpy(var1_np, grads1_np, t, m1, v1) + + # Validate updated params + self.assertAllCloseAccordingToType(var0_np, var0.eval()) + self.assertAllCloseAccordingToType(var1_np, var1.eval()) + +if __name__ == "__main__": + test.main() diff --git a/tensorflow/compiler/tf2xla/BUILD b/tensorflow/compiler/tf2xla/BUILD index fd31c26544..ff002d15b0 100644 --- a/tensorflow/compiler/tf2xla/BUILD +++ b/tensorflow/compiler/tf2xla/BUILD @@ -139,12 +139,14 @@ cc_library( "xla_op_registry.cc", "xla_resource.cc", "xla_cpu_backend.cc", + "legacy_flags/backend_registration_flags.cc", ] + if_cuda_is_configured([ "xla_gpu_backend.cc", ]), hdrs = [ "const_analysis.h", "graph_compiler.h", + "legacy_flags/backend_registration_flags.h", "xla_compilation_device.h", "xla_compiler.h", "xla_context.h", @@ -175,9 +177,11 @@ cc_library( "//tensorflow/compiler/xla/client/lib:numeric", "//tensorflow/compiler/xla/client/xla_client:xla_builder", "//tensorflow/compiler/xla/client/xla_client:xla_computation", + "//tensorflow/compiler/xla/legacy_flags:parse_flags_from_env", "//tensorflow/core:core_cpu", "//tensorflow/core:core_cpu_internal", "//tensorflow/core:framework", + "//tensorflow/core:framework_internal", "//tensorflow/core:lib", "//tensorflow/core:lib_internal", "//tensorflow/core:protos_all_cc", diff --git a/tensorflow/compiler/tf2xla/kernels/training_ops.cc b/tensorflow/compiler/tf2xla/kernels/training_ops.cc index a1877ebf7a..03902f012c 100644 --- a/tensorflow/compiler/tf2xla/kernels/training_ops.cc +++ b/tensorflow/compiler/tf2xla/kernels/training_ops.cc @@ -268,6 +268,83 @@ REGISTER_XLA_OP( Name("ResourceApplyProximalAdagrad").TypeConstraint("T", kFloatTypes), ResourceApplyProximalAdagrad); +class ResourceApplyAdagradDA : public XlaOpKernel { + public: + explicit ResourceApplyAdagradDA(OpKernelConstruction* ctx) + : XlaOpKernel(ctx) { + OP_REQUIRES_OK(ctx, ctx->GetAttr("T", &dtype_)); + } + + void Compile(XlaOpKernelContext* ctx) override { + TensorShape var_shape, accum_shape, squared_accum_shape; + xla::XlaOp var, accum, squared_accum; + OP_REQUIRES_OK(ctx, ctx->ReadVariableInput(0, dtype_, &var_shape, &var)); + OP_REQUIRES_OK(ctx, + ctx->ReadVariableInput(1, dtype_, &accum_shape, &accum)); + OP_REQUIRES_OK(ctx, ctx->ReadVariableInput(2, dtype_, &squared_accum_shape, + &squared_accum)); + OP_REQUIRES(ctx, var_shape.IsSameSize(accum_shape), + errors::InvalidArgument( + "var and accum do not have the same shape", + var_shape.DebugString(), " ", accum_shape.DebugString())); + OP_REQUIRES( + ctx, var_shape.IsSameSize(squared_accum_shape), + errors::InvalidArgument( + "var and squared accum do not have the same shape", + var_shape.DebugString(), " ", squared_accum_shape.DebugString())); + + TensorShape grad_shape = ctx->InputShape(3); + TensorShape lr_shape = ctx->InputShape(4); + TensorShape l1_shape = ctx->InputShape(5); + TensorShape l2_shape = ctx->InputShape(6); + TensorShape global_step_shape = ctx->InputShape(7); + + OP_REQUIRES(ctx, var_shape.IsSameSize(grad_shape), + errors::InvalidArgument( + "var and grad do not have the same shape", + var_shape.DebugString(), " ", grad_shape.DebugString())); + OP_REQUIRES(ctx, TensorShapeUtils::IsScalar(lr_shape), + errors::InvalidArgument("lr is not a scalar: ", + lr_shape.DebugString())); + OP_REQUIRES(ctx, TensorShapeUtils::IsScalar(l1_shape), + errors::InvalidArgument("l1 is not a scalar: ", + l1_shape.DebugString())); + OP_REQUIRES(ctx, TensorShapeUtils::IsScalar(l2_shape), + errors::InvalidArgument("l2 is not a scalar: ", + l2_shape.DebugString())); + OP_REQUIRES(ctx, TensorShapeUtils::IsScalar(global_step_shape), + errors::InvalidArgument("global step is not a scalar: ", + global_step_shape.DebugString())); + + xla::XlaOp grad = ctx->Input(3); + xla::XlaOp lr = ctx->Input(4); + xla::XlaOp l1 = ctx->Input(5); + xla::XlaOp l2 = ctx->Input(6); + xla::XlaBuilder* const b = ctx->builder(); + xla::XlaOp global_step = + XlaHelpers::ConvertElementType(b, ctx->Input(7), dtype_); + + accum = accum + grad; + squared_accum = squared_accum + xla::Square(grad); + xla::XlaOp zero = xla::ScalarLike(lr, 0.0); + xla::XlaOp denominator = global_step * lr * l2 + xla::Sqrt(squared_accum); + xla::XlaOp l1_le_zero = -lr * accum / denominator; + xla::XlaOp l1_gt_zero = -lr * xla::Sign(accum) * + xla::Max(xla::Abs(accum) - global_step * l1, zero) / + denominator; + + var = xla::Select(xla::Gt(l1, zero), l1_gt_zero, l1_le_zero); + OP_REQUIRES_OK(ctx, ctx->AssignVariable(0, dtype_, var)); + OP_REQUIRES_OK(ctx, ctx->AssignVariable(1, dtype_, accum)); + OP_REQUIRES_OK(ctx, ctx->AssignVariable(2, dtype_, squared_accum)); + } + + private: + DataType dtype_; +}; +REGISTER_XLA_OP(Name("ResourceApplyAdagradDA").TypeConstraint("T", kFloatTypes), + ResourceApplyAdagradDA); + class ResourceApplyAdam : public XlaOpKernel { public: explicit ResourceApplyAdam(OpKernelConstruction* ctx) : XlaOpKernel(ctx) { @@ -353,6 +430,77 @@ class ResourceApplyAdam : public XlaOpKernel { REGISTER_XLA_OP(Name("ResourceApplyAdam").TypeConstraint("T", kFloatTypes), ResourceApplyAdam); +class ResourceApplyAdaMax : public XlaOpKernel { + public: + explicit ResourceApplyAdaMax(OpKernelConstruction* ctx) : XlaOpKernel(ctx) { + OP_REQUIRES_OK(ctx, ctx->GetAttr("T", &dtype_)); + } + + void Compile(XlaOpKernelContext* ctx) override { + TensorShape var_shape, m_shape, v_shape; + xla::XlaOp var, m, v; + OP_REQUIRES_OK(ctx, ctx->ReadVariableInput(0, dtype_, &var_shape, &var)); + OP_REQUIRES_OK(ctx, ctx->ReadVariableInput(1, dtype_, &m_shape, &m)); + OP_REQUIRES_OK(ctx, ctx->ReadVariableInput(2, dtype_, &v_shape, &v)); + + TensorShape beta1_power_shape = ctx->InputShape(3); + TensorShape lr_shape = ctx->InputShape(4); + TensorShape beta1_shape = ctx->InputShape(5); + TensorShape beta2_shape = ctx->InputShape(6); + TensorShape epsilon_shape = ctx->InputShape(7); + TensorShape grad_shape = ctx->InputShape(8); + + OP_REQUIRES(ctx, TensorShapeUtils::IsScalar(beta1_power_shape), + errors::InvalidArgument("beta1_power is not a scalar: ", + beta1_power_shape.DebugString())); + OP_REQUIRES(ctx, TensorShapeUtils::IsScalar(lr_shape), + errors::InvalidArgument("lr is not a scalar : ", + lr_shape.DebugString())); + OP_REQUIRES(ctx, TensorShapeUtils::IsScalar(beta1_shape), + errors::InvalidArgument("beta1 is not a scalar: ", + beta1_shape.DebugString())); + OP_REQUIRES(ctx, TensorShapeUtils::IsScalar(beta2_shape), + errors::InvalidArgument("beta2 is not a scalar: ", + beta2_shape.DebugString())); + OP_REQUIRES(ctx, TensorShapeUtils::IsScalar(epsilon_shape), + errors::InvalidArgument("epsilon is not a scalar: ", + epsilon_shape.DebugString())); + OP_REQUIRES(ctx, var_shape.IsSameSize(m_shape), + errors::InvalidArgument("var and m do not have the same shape", + var_shape.DebugString(), " ", + m_shape.DebugString())); + OP_REQUIRES(ctx, var_shape.IsSameSize(v_shape), + errors::InvalidArgument("var and v do not have the same shape", + var_shape.DebugString(), " ", + v_shape.DebugString())); + OP_REQUIRES(ctx, var_shape.IsSameSize(grad_shape), + errors::InvalidArgument( + "var and grad do not have the same shape", + var_shape.DebugString(), " ", grad_shape.DebugString())); + + xla::XlaOp beta1_power = ctx->Input(3); + xla::XlaOp lr = ctx->Input(4); + xla::XlaOp beta1 = ctx->Input(5); + xla::XlaOp beta2 = ctx->Input(6); + xla::XlaOp epsilon = ctx->Input(7); + xla::XlaOp grad = ctx->Input(8); + + xla::XlaOp one = xla::ScalarLike(lr, 1.0); + m = beta1 * m + (one - beta1) * grad; + v = xla::Max(beta2 * v, xla::Abs(grad)); + var = var - lr / (one - beta1_power) * (m / (v + epsilon)); + + OP_REQUIRES_OK(ctx, ctx->AssignVariable(0, dtype_, var)); + OP_REQUIRES_OK(ctx, ctx->AssignVariable(1, dtype_, m)); + OP_REQUIRES_OK(ctx, ctx->AssignVariable(2, dtype_, v)); + } + + private: + DataType dtype_; +}; +REGISTER_XLA_OP(Name("ResourceApplyAdaMax").TypeConstraint("T", kFloatTypes), + ResourceApplyAdaMax); + class ResourceApplyRMSProp : public XlaOpKernel { public: explicit ResourceApplyRMSProp(OpKernelConstruction* ctx) : XlaOpKernel(ctx) {} diff --git a/tensorflow/compiler/tf2xla/legacy_flags/backend_registration_flags.cc b/tensorflow/compiler/tf2xla/legacy_flags/backend_registration_flags.cc new file mode 100644 index 0000000000..661505021f --- /dev/null +++ b/tensorflow/compiler/tf2xla/legacy_flags/backend_registration_flags.cc @@ -0,0 +1,63 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +// Legacy flags for the XLA bridge's backend registration modules. + +#include <mutex> // NOLINT +#include <vector> + +#include "tensorflow/compiler/tf2xla/legacy_flags/backend_registration_flags.h" +#include "tensorflow/compiler/xla/legacy_flags/parse_flags_from_env.h" +#include "tensorflow/core/platform/types.h" +#include "tensorflow/core/util/command_line_flags.h" + +namespace tensorflow { +namespace legacy_flags { + +// Pointers to the parsed value of the flags and flag descriptors, initialized +// via flags_init. +static BackendRegistrationFlags* flags; +static std::vector<Flag>* flag_list; +static std::once_flag flags_init; + +// Allocate *flags. Called via call_once(&flags_init,...). +static void AllocateFlags() { + flags = new BackendRegistrationFlags; + flags->tf_enable_prng_ops_gpu = false; + flag_list = new std::vector<Flag>({ + Flag("tf_enable_prng_ops_gpu", &flags->tf_enable_prng_ops_gpu, + "Whether to enable PRNG ops: [RandomStandardNormal | RandomUniform " + "| RandomUniformInt | TruncatedNormal] on GPU."), + }); + xla::legacy_flags::ParseFlagsFromEnv(*flag_list); +} + +// Append to *append_to flag definitions associated with the XLA bridge's +// backend registration modules. +void AppendBackendRegistrationFlags(std::vector<Flag>* append_to) { + std::call_once(flags_init, &AllocateFlags); + append_to->insert(append_to->end(), flag_list->begin(), flag_list->end()); +} + +// Return a pointer to the BackendRegistrationFlags struct; +// repeated calls return the same pointer. +// This should be called only after Flags::Parse() has returned. +BackendRegistrationFlags* GetBackendRegistrationFlags() { + std::call_once(flags_init, &AllocateFlags); + return flags; +} + +} // namespace legacy_flags +} // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/legacy_flags/backend_registration_flags.h b/tensorflow/compiler/tf2xla/legacy_flags/backend_registration_flags.h new file mode 100644 index 0000000000..861c923dd5 --- /dev/null +++ b/tensorflow/compiler/tf2xla/legacy_flags/backend_registration_flags.h @@ -0,0 +1,49 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_COMPILER_TF2XLA_LEGACY_FLAGS_BACKEND_REGISTRATION_FLAGS_H_ +#define TENSORFLOW_COMPILER_TF2XLA_LEGACY_FLAGS_BACKEND_REGISTRATION_FLAGS_H_ + +// Legacy flags for the XLA bridge's backend registration modules. + +#include <vector> + +#include "tensorflow/core/platform/types.h" +#include "tensorflow/core/util/command_line_flags.h" + +namespace tensorflow { +namespace legacy_flags { + +// Append to *flag_list flag definitions associated with the XLA bridge's +// backend registration modules. +void AppendBackendRegistrationFlags(std::vector<tensorflow::Flag>* append_to); + +// The values of flags associated with the XLA bridge's backend registration +// module. +typedef struct { + // Whether to enable RandomUniform op on GPU backend. + // TODO (b/32333178): Remove this flag or set its default to true. + bool tf_enable_prng_ops_gpu; +} BackendRegistrationFlags; + +// Return a pointer to the BackendRegistrationFlags struct; +// repeated calls return the same pointer. +// This should be called only after Flags::Parse() has returned. +BackendRegistrationFlags* GetBackendRegistrationFlags(); + +} // namespace legacy_flags +} // namespace tensorflow + +#endif // TENSORFLOW_COMPILER_TF2XLA_LEGACY_FLAGS_BACKEND_REGISTRATION_FLAGS_H_ diff --git a/tensorflow/compiler/tf2xla/xla_gpu_backend.cc b/tensorflow/compiler/tf2xla/xla_gpu_backend.cc index 62168b6483..3217db3e73 100644 --- a/tensorflow/compiler/tf2xla/xla_gpu_backend.cc +++ b/tensorflow/compiler/tf2xla/xla_gpu_backend.cc @@ -13,6 +13,7 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ +#include "tensorflow/compiler/tf2xla/legacy_flags/backend_registration_flags.h" #include "tensorflow/compiler/tf2xla/tf2xla_util.h" #include "tensorflow/compiler/tf2xla/xla_op_registry.h" #include "tensorflow/core/framework/kernel_def.pb.h" @@ -22,8 +23,12 @@ namespace tensorflow { bool GpuOpFilter(KernelDef* kdef) { // TODO(b/31361304): The GPU backend does not parallelize PRNG ops, leading to // slow code. - if (kdef->op() == "RandomStandardNormal" || kdef->op() == "RandomUniform" || - kdef->op() == "RandomUniformInt" || kdef->op() == "TruncatedNormal") { + legacy_flags::BackendRegistrationFlags* flags = + legacy_flags::GetBackendRegistrationFlags(); + VLOG(2) << "flags->tf_enable_prng_ops_gpu: " << flags->tf_enable_prng_ops_gpu; + if (!flags->tf_enable_prng_ops_gpu && + (kdef->op() == "RandomStandardNormal" || kdef->op() == "RandomUniform" || + kdef->op() == "RandomUniformInt" || kdef->op() == "TruncatedNormal")) { return false; } if (kdef->op() == "Const") { diff --git a/tensorflow/compiler/xla/client/xla_client/xla_builder.cc b/tensorflow/compiler/xla/client/xla_client/xla_builder.cc index d4759a0fff..aac7df4383 100644 --- a/tensorflow/compiler/xla/client/xla_client/xla_builder.cc +++ b/tensorflow/compiler/xla/client/xla_client/xla_builder.cc @@ -1117,6 +1117,35 @@ XlaOp XlaBuilder::Infeed(const Shape& shape, const string& config) { }); } +XlaOp XlaBuilder::InfeedWithToken(const XlaOp& token, const Shape& shape, + const string& config) { + return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { + HloInstructionProto instr; + if (!LayoutUtil::HasLayout(shape)) { + return InvalidArgument("Given shape to Infeed must have a layout"); + } + const Shape infeed_instruction_shape = + ShapeUtil::MakeTupleShape({shape, ShapeUtil::MakeTokenShape()}); + *instr.mutable_shape() = infeed_instruction_shape; + instr.set_infeed_config(config); + + if (ShapeUtil::IsArray(shape) && sharding() && + sharding()->type() == OpSharding::Type::OpSharding_Type_OTHER) { + // TODO(b/110793772): Support tiled array-shaped infeeds. + return InvalidArgument( + "Tiled sharding is not yet supported for array-shaped infeeds"); + } + + if (sharding() && + sharding()->type() == OpSharding::Type::OpSharding_Type_REPLICATED) { + return InvalidArgument( + "Replicated sharding is not yet supported for infeeds"); + } + + return AddInstruction(std::move(instr), HloOpcode::kInfeed, {token}); + }); +} + void XlaBuilder::Outfeed(const XlaOp& operand, const Shape& shape_with_layout, const string& outfeed_config) { ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { @@ -1162,6 +1191,53 @@ void XlaBuilder::Outfeed(const XlaOp& operand, const Shape& shape_with_layout, }); } +XlaOp XlaBuilder::OutfeedWithToken(const XlaOp& operand, const XlaOp& token, + const Shape& shape_with_layout, + const string& outfeed_config) { + return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { + HloInstructionProto instr; + + *instr.mutable_shape() = ShapeUtil::MakeTokenShape(); + + // Check and set outfeed shape. + if (!LayoutUtil::HasLayout(shape_with_layout)) { + return InvalidArgument("Given shape to Outfeed must have a layout"); + } + TF_ASSIGN_OR_RETURN(const Shape& operand_shape, GetShape(operand)); + if (!ShapeUtil::Compatible(operand_shape, shape_with_layout)) { + return InvalidArgument( + "Outfeed shape %s must be compatible with operand shape %s", + ShapeUtil::HumanStringWithLayout(shape_with_layout).c_str(), + ShapeUtil::HumanStringWithLayout(operand_shape).c_str()); + } + *instr.mutable_outfeed_shape() = shape_with_layout; + + instr.set_outfeed_config(outfeed_config); + + return AddInstruction(std::move(instr), HloOpcode::kOutfeed, + {operand, token}); + }); +} + +XlaOp XlaBuilder::CreateToken() { + return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { + HloInstructionProto instr; + *instr.mutable_shape() = ShapeUtil::MakeTokenShape(); + return AddInstruction(std::move(instr), HloOpcode::kAfterAll); + }); +} + +XlaOp XlaBuilder::AfterAll(tensorflow::gtl::ArraySlice<XlaOp> tokens) { + return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { + if (tokens.empty()) { + return InvalidArgument("AfterAll requires at least one operand"); + } + HloInstructionProto instr; + *instr.mutable_shape() = ShapeUtil::MakeTokenShape(); + return AddInstruction(std::move(instr), HloOpcode::kAfterAll, tokens); + }); +} + XlaOp XlaBuilder::CustomCall(const string& call_target_name, tensorflow::gtl::ArraySlice<XlaOp> operands, const Shape& shape) { @@ -1365,7 +1441,8 @@ XlaOp XlaBuilder::Rev(const XlaOp& operand, }); } -XlaOp XlaBuilder::Sort(XlaOp keys, tensorflow::gtl::optional<XlaOp> values) { +XlaOp XlaBuilder::Sort(XlaOp keys, tensorflow::gtl::optional<XlaOp> values, + int64 dimension) { return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { HloInstructionProto instr; std::vector<const Shape*> operand_shape_ptrs; @@ -1379,6 +1456,11 @@ XlaOp XlaBuilder::Sort(XlaOp keys, tensorflow::gtl::optional<XlaOp> values) { TF_ASSIGN_OR_RETURN(*instr.mutable_shape(), ShapeInference::InferVariadicOpShape( HloOpcode::kSort, operand_shape_ptrs)); + if (dimension == -1) { + TF_ASSIGN_OR_RETURN(const Shape& keys_shape, GetShape(keys)); + dimension = ShapeUtil::Rank(keys_shape) - 1; + } + instr.add_dimensions(dimension); return values.has_value() ? AddInstruction(std::move(instr), HloOpcode::kSort, {keys, *values}) @@ -1877,6 +1959,28 @@ void XlaBuilder::Send(const XlaOp& operand, const ChannelHandle& handle) { }); } +XlaOp XlaBuilder::SendWithToken(const XlaOp& operand, const XlaOp& token, + const ChannelHandle& handle) { + return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { + // Send instruction produces a tuple of {aliased operand, U32 context, + // token}. + HloInstructionProto send_instr; + TF_ASSIGN_OR_RETURN(const Shape& shape, GetShape(operand)); + *send_instr.mutable_shape() = ShapeUtil::MakeTupleShape( + {shape, ShapeUtil::MakeShape(U32, {}), ShapeUtil::MakeTokenShape()}); + send_instr.set_channel_id(handle.handle()); + TF_ASSIGN_OR_RETURN(XlaOp send, + AddInstruction(std::move(send_instr), HloOpcode::kSend, + {operand, token})); + + HloInstructionProto send_done_instr; + *send_done_instr.mutable_shape() = ShapeUtil::MakeTokenShape(); + send_done_instr.set_channel_id(handle.handle()); + return AddInstruction(std::move(send_done_instr), HloOpcode::kSendDone, + {send}); + }); +} + XlaOp XlaBuilder::Recv(const Shape& shape, const ChannelHandle& handle) { return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { // Recv HLO takes a single token operand. Generate the token to pass into @@ -1917,6 +2021,27 @@ XlaOp XlaBuilder::Recv(const Shape& shape, const ChannelHandle& handle) { }); } +XlaOp XlaBuilder::RecvWithToken(const XlaOp& token, const Shape& shape, + const ChannelHandle& handle) { + return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { + // Recv instruction produces a tuple of {receive buffer, U32 context, + // token}. + HloInstructionProto recv_instr; + *recv_instr.mutable_shape() = ShapeUtil::MakeTupleShape( + {shape, ShapeUtil::MakeShape(U32, {}), ShapeUtil::MakeTokenShape()}); + recv_instr.set_channel_id(handle.handle()); + TF_ASSIGN_OR_RETURN(XlaOp recv, AddInstruction(std::move(recv_instr), + HloOpcode::kRecv, {token})); + + HloInstructionProto recv_done_instr; + *recv_done_instr.mutable_shape() = + ShapeUtil::MakeTupleShape({shape, ShapeUtil::MakeTokenShape()}); + recv_done_instr.set_channel_id(handle.handle()); + return AddInstruction(std::move(recv_done_instr), HloOpcode::kRecvDone, + {recv}); + }); +} + StatusOr<bool> XlaBuilder::IsConstant(const XlaOp& operand) const { TF_RETURN_IF_ERROR(first_error_); @@ -2565,8 +2690,9 @@ XlaOp Rev(const XlaOp& operand, tensorflow::gtl::ArraySlice<int64> dimensions) { return operand.builder()->Rev(operand, dimensions); } -XlaOp Sort(XlaOp keys, tensorflow::gtl::optional<XlaOp> values) { - return keys.builder()->Sort(keys, std::move(values)); +XlaOp Sort(XlaOp keys, tensorflow::gtl::optional<XlaOp> values, + int64 dimension) { + return keys.builder()->Sort(keys, std::move(values), dimension); } XlaOp Clamp(const XlaOp& min, const XlaOp& operand, const XlaOp& max) { @@ -2624,6 +2750,34 @@ XlaOp Recv(XlaBuilder* builder, const Shape& shape, return builder->Recv(shape, handle); } +XlaOp SendWithToken(const XlaOp& operand, const XlaOp& token, + const ChannelHandle& handle) { + return operand.builder()->SendWithToken(operand, token, handle); +} + +XlaOp RecvWithToken(const XlaOp& token, const Shape& shape, + const ChannelHandle& handle) { + return token.builder()->RecvWithToken(token, shape, handle); +} + +XlaOp InfeedWithToken(const XlaOp& token, const Shape& shape, + const string& config) { + return token.builder()->InfeedWithToken(token, shape, config); +} + +XlaOp OutfeedWithToken(const XlaOp& operand, const XlaOp& token, + const Shape& shape_with_layout, + const string& outfeed_config) { + return operand.builder()->OutfeedWithToken(operand, token, shape_with_layout, + outfeed_config); +} + +XlaOp CreateToken(XlaBuilder* builder) { return builder->CreateToken(); } + +XlaOp AfterAll(XlaBuilder* builder, tensorflow::gtl::ArraySlice<XlaOp> tokens) { + return builder->AfterAll(tokens); +} + XlaOp BatchNormTraining(const XlaOp& operand, const XlaOp& scale, const XlaOp& offset, float epsilon, int64 feature_index) { diff --git a/tensorflow/compiler/xla/client/xla_client/xla_builder.h b/tensorflow/compiler/xla/client/xla_client/xla_builder.h index fbcdb4c802..2be6f4a553 100644 --- a/tensorflow/compiler/xla/client/xla_client/xla_builder.h +++ b/tensorflow/compiler/xla/client/xla_client/xla_builder.h @@ -533,6 +533,8 @@ class XlaBuilder { // Enqueues an infeed instruction onto the computation, which writes data of // the given shape to the infeed buffer of the device. XlaOp Infeed(const Shape& shape, const string& config = ""); + XlaOp InfeedWithToken(const XlaOp& token, const Shape& shape, + const string& config = ""); // Enqueues an outfeed instruction onto the computation. This instruction // generates outgoing data transfers for the given data. @@ -542,6 +544,9 @@ class XlaBuilder { // will occur. void Outfeed(const XlaOp& operand, const Shape& shape_with_layout, const string& outfeed_config); + XlaOp OutfeedWithToken(const XlaOp& operand, const XlaOp& token, + const Shape& shape_with_layout, + const string& outfeed_config); // Enqueues a call instruction onto the computation. XlaOp Call(const XlaComputation& computation, @@ -789,17 +794,23 @@ class XlaBuilder { // Enqueues a sort (as increasing order) instruction onto the computation. // If only keys are provided: - // * The keys must be a rank-1 tensor (i.e. an array). - // * The result is a sorted array of keys. + // * If the keys are an rank-1 tensor (an array), the result is a sorted array + // of keys, in ascending order. + // * If the keys have higher rank, the keys are sorted along the provided + // dimension. For example, for a rank-2 tensor (a matrix) of keys, a dimension + // value of 0 will indepenently sort every column, and a dimension value of 1 + // will independently sort each row. If no dimension number is provided, then + // the last dimension is chosen by default. // // If both keys and values are provided: - // * The keys and the values must be rank-1 tensors with the same dimensions. - // The element types of the tensors may be different. - // * The result is a tuple that consists of a sorted array of keys as the - // first element, and an array with their corresponding values as the second - // element. - XlaOp Sort(XlaOp keys, tensorflow::gtl::optional<XlaOp> values = - tensorflow::gtl::nullopt); + // * The keys and the values must tensors with the same dimensions. The + // element types of the tensors may be different. + // * The result is a tuple that consists of a sorted tensor of keys (along the + // provided dimension, as above) as the first element, and a tensor with their + // corresponding values as the second element. + XlaOp Sort(XlaOp keys, + tensorflow::gtl::optional<XlaOp> values = tensorflow::gtl::nullopt, + int64 dimension = -1); // Enqueues a clamp instruction onto the computation. XlaOp Clamp(const XlaOp& min, const XlaOp& operand, const XlaOp& max); @@ -840,11 +851,23 @@ class XlaBuilder { // Enqueues a Send node onto the computation, to send the given operand to // a Recv instruction that shares the same channel handle. void Send(const XlaOp& operand, const ChannelHandle& handle); + XlaOp SendWithToken(const XlaOp& operand, const XlaOp& token, + const ChannelHandle& handle); + + // Enqueues an AfterAll operation with no operands producing a token-shaped + // value. + XlaOp CreateToken(); + + // Enqueues an AfterAll operation with no operands producing a token-shaped + // value. + XlaOp AfterAll(tensorflow::gtl::ArraySlice<XlaOp> tokens); // Enqueues a Recv node onto the computation. The data comes from a Send // instruction that shares the same channel handle and its shape must // be the same as the given shape. XlaOp Recv(const Shape& shape, const ChannelHandle& handle); + XlaOp RecvWithToken(const XlaOp& token, const Shape& shape, + const ChannelHandle& handle); // Normalizes operand across spatial and batch dimensions for each feature. // @@ -1230,7 +1253,8 @@ class XlaBuilder { tensorflow::gtl::ArraySlice<int64> permutation); friend XlaOp Rev(const XlaOp& operand, tensorflow::gtl::ArraySlice<int64> dimensions); - friend XlaOp Sort(XlaOp keys, tensorflow::gtl::optional<XlaOp> values); + friend XlaOp Sort(XlaOp keys, tensorflow::gtl::optional<XlaOp> values, + int64 dimension); friend XlaOp Clamp(const XlaOp& min, const XlaOp& operand, const XlaOp& max); friend XlaOp Map(XlaBuilder* builder, tensorflow::gtl::ArraySlice<XlaOp> operands, @@ -1265,6 +1289,18 @@ class XlaBuilder { const XlaOp& batch_mean, const XlaOp& batch_var, const XlaOp& grad_output, float epsilon, int64 feature_index); + friend XlaOp SendWithToken(const XlaOp& operand, const XlaOp& token, + const ChannelHandle& handle); + friend XlaOp RecvWithToken(const XlaOp& token, const Shape& shape, + const ChannelHandle& handle); + friend XlaOp InfeedWithToken(const XlaOp& token, const Shape& shape, + const string& config); + friend XlaOp OutfeedWithToken(const XlaOp& operand, const XlaOp& token, + const Shape& shape_with_layout, + const string& outfeed_config); + friend XlaOp CreateToken(XlaBuilder* builder); + friend XlaOp AfterAll(XlaBuilder* builder, + tensorflow::gtl::ArraySlice<XlaOp> tokens); }; // RAII-style object: sets the current sharding assignment in builder on @@ -1596,6 +1632,13 @@ XlaOp Fft(const XlaOp& operand, FftType fft_type, XlaOp Infeed(XlaBuilder* builder, const Shape& shape, const string& config = ""); +// Variant of Infeed which takes a token-shaped operand and produces a +// two-element tuple containing the data value and a token-shaped value. +// Tokens are used for ordering side-effecting operations. +// TODO(b/110532604): Replace all uses of the non-token form with this variant. +XlaOp InfeedWithToken(const XlaOp& token, const Shape& shape, + const string& config = ""); + // Enqueues an outfeed instruction onto the computation. This instruction // generates outgoing data transfers for the given data. // @@ -1605,6 +1648,13 @@ XlaOp Infeed(XlaBuilder* builder, const Shape& shape, void Outfeed(const XlaOp& operand, const Shape& shape_with_layout, const string& outfeed_config); +// Variant of Outfeed which takes a token-shaped operand and produces a +// token-shaped value. Tokens are used for ordering side-effecting operations. +// TODO(b/110532604): Replace all uses of the non-token form with this variant. +XlaOp OutfeedWithToken(const XlaOp& operand, const XlaOp& token, + const Shape& shape_with_layout, + const string& outfeed_config); + // Enqueues a call instruction onto the computation. XlaOp Call(XlaBuilder* builder, const XlaComputation& computation, tensorflow::gtl::ArraySlice<XlaOp> operands); @@ -1845,16 +1895,25 @@ XlaOp Transpose(const XlaOp& operand, // is moved to index dimension_size - 1 - i). XlaOp Rev(const XlaOp& operand, tensorflow::gtl::ArraySlice<int64> dimensions); -// * The result is a sorted array of keys. +// Enqueues a sort (as increasing order) instruction onto the computation. +// If only keys are provided: +// * If the keys are an rank-1 tensor (an array), the result is a sorted array +// of keys, in ascending order. +// * If the keys have higher rank, the keys are sorted along the provided +// dimension. For example, for a rank-2 tensor (a matrix) of keys, a dimension +// value of 0 will indepenently sort every column, and a dimension value of 1 +// will independently sort each row. If no dimension number is provided, then +// the last dimension is chosen by default. // // If both keys and values are provided: -// * The keys and the values must be rank-1 tensors with the same dimensions. -// The element types of the tensors may be different. -// * The result is a tuple that consists of a sorted array of keys as the -// first element, and an array with their corresponding values as the second -// element. +// * The keys and the values must tensors with the same dimensions. The +// element types of the tensors may be different. +// * The result is a tuple that consists of a sorted tensor of keys (along the +// provided dimension, as above) as the first element, and a tensor with their +// corresponding values as the second element. XlaOp Sort(XlaOp keys, - tensorflow::gtl::optional<XlaOp> values = tensorflow::gtl::nullopt); + tensorflow::gtl::optional<XlaOp> values = tensorflow::gtl::nullopt, + int64 dimension = -1); // Enqueues a clamp instruction onto the computation. XlaOp Clamp(const XlaOp& min, const XlaOp& operand, const XlaOp& max); @@ -1896,12 +1955,38 @@ XlaOp Gather(const XlaOp& input, const XlaOp& gather_indices, // a Recv instruction that shares the same channel handle. void Send(const XlaOp& operand, const ChannelHandle& handle); +// Variant of Send which takes a token-shaped operand and produces a +// token-shaped value. Tokens are used for ordering side-effecting operations. +// TODO(b/110532604): Replace all uses of the non-token form with this variant. +XlaOp SendWithToken(const XlaOp& operand, const XlaOp& token, + const ChannelHandle& handle); + // Enqueues a Recv node onto the computation. The data comes from a Send // instruction that shares the same channel handle and its shape must // be the same as the given shape. XlaOp Recv(XlaBuilder* builder, const Shape& shape, const ChannelHandle& handle); +// Variant of Recv which takes a token-shaped operand and produces a two-element +// tuple containing the data value and a token-shaped value. Tokens are used +// for ordering side-effecting operations. +// TODO(b/110532604): Replace all uses of the non-token form with this variant. +XlaOp RecvWithToken(const XlaOp& token, const Shape& shape, + const ChannelHandle& handle); + +// Enqueues an operation (AfterAll) with no operands that produces a +// token-shaped value. Tokens are used for ordering side-effecting operations. +// This is a separate method from AfterAll to facility the removal of +// operand-less AfterAll instructions. +// TODO(b/110532604): Remove this function when all tokens are derived from a +// single token generated or passed into the entry computation. +XlaOp CreateToken(XlaBuilder* builder); + +// Enqueues an AfterAll instruction which produces a token-shaped value and +// takes a variadic number of token-shaped operands. The number of operands must +// be greater than zero. Used for joining tokens. +XlaOp AfterAll(XlaBuilder* builder, tensorflow::gtl::ArraySlice<XlaOp> tokens); + // Normalizes operand across spatial and batch dimensions for each feature. // // Returns a tuple (normalized, batch_mean, batch_var) where `normalized` diff --git a/tensorflow/compiler/xla/python/xla_client.py b/tensorflow/compiler/xla/python/xla_client.py index 27aee634ba..e2b6eaa096 100644 --- a/tensorflow/compiler/xla/python/xla_client.py +++ b/tensorflow/compiler/xla/python/xla_client.py @@ -461,14 +461,16 @@ class LocalComputation(object): if self.is_compiled: raise ValueError('Attempt to compile a compiled local XLA computation.') + result_shape = _wrap_shape(self.c_local_computation.GetReturnValueShape()) + if layout_fn: argument_shapes = [ shape.map_leaves(layout_fn) for shape in argument_shapes ] - result_shape = _wrap_shape(self.c_local_computation.GetReturnValueShape()) result_shape = result_shape.map_leaves(layout_fn) - compile_options = compile_options or CompileOptions() - compile_options.result_shape = result_shape + + compile_options = compile_options or CompileOptions() + compile_options.result_shape = result_shape return LocalComputation( self.c_local_computation.Compile(argument_shapes, compile_options), is_compiled=True) diff --git a/tensorflow/compiler/xla/service/bfloat16_propagation.cc b/tensorflow/compiler/xla/service/bfloat16_propagation.cc index b6f3c84c7e..b21c83a07f 100644 --- a/tensorflow/compiler/xla/service/bfloat16_propagation.cc +++ b/tensorflow/compiler/xla/service/bfloat16_propagation.cc @@ -615,7 +615,6 @@ Status BFloat16Propagation::ResolveInconsistentFusions(HloModule* module) { // (1) a is F32 but tuple is BF16 // (2) after adding conversion // (3) after tuple simplifier and DCE. - bool needs_tuple_simplifier = false; for (auto computation : module->MakeComputationPostOrder()) { auto insts = computation->MakeInstructionPostOrder(); for (auto inst_it = insts.rbegin(); inst_it != insts.rend(); ++inst_it) { @@ -629,67 +628,25 @@ Status BFloat16Propagation::ResolveInconsistentFusions(HloModule* module) { continue; } ShapeTree<HloInstruction*> converted_outputs(hlo->shape()); - // Iterate through nodes in the shape tree in pre-order and initialize - // each non-root node with a corresponding get-tuple-element. For a leaf - // node, if its shape does not match the fusion output, create a - // conversion node to overwrite the node value. - for (auto it = converted_outputs.begin(); it != converted_outputs.end(); - ++it) { - ShapeIndex output_index = it->first; - HloInstruction*& output = it->second; - const Shape subshape = - ShapeUtil::GetSubshape(hlo->shape(), output_index); - if (output_index.empty()) { - output = fusion_root; - } else { - ShapeIndex parent_index = output_index; - parent_index.pop_back(); - output = fusion_computation->AddInstruction( - HloInstruction::CreateGetTupleElement( - subshape, converted_outputs.element(parent_index), - output_index.back())); - } - if (!ShapeUtil::IsArray(subshape)) { - continue; - } - if (!ShapeUtil::Compatible( - subshape, - ShapeUtil::GetSubshape(fusion_root->shape(), output_index))) { - output = fusion_computation->AddInstruction( - HloInstruction::CreateConvert(subshape, output)); - } - } - // Iterate through nodes in the shape tree in reverse pre-order and create - // a tuple instruction for each non-leaf node where the elements are the - // values of its child nodes. - for (auto it = converted_outputs.rbegin(); it != converted_outputs.rend(); - ++it) { - ShapeIndex output_index = it->first; - HloInstruction*& output = it->second; - const Shape& subshape = - ShapeUtil::GetSubshape(hlo->shape(), output_index); - if (!ShapeUtil::IsTuple(subshape)) { - continue; - } - std::vector<HloInstruction*> elements( - ShapeUtil::TupleElementCount(subshape)); - ShapeIndex child_index = output_index; - for (int64 i = 0; i < elements.size(); ++i) { - child_index.push_back(i); - elements[i] = converted_outputs.element(child_index); - child_index.pop_back(); - } - output = fusion_computation->AddInstruction( - HloInstruction::CreateTuple(elements)); - } - fusion_computation->set_root_instruction(converted_outputs.element({})); - needs_tuple_simplifier |= ShapeUtil::IsTuple(hlo->shape()); + // Deep copy the fusion root, and convert a leaf node only if its shape + // does not match the fusion output. + TF_ASSIGN_OR_RETURN( + HloInstruction * copy, + fusion_computation->DeepCopyInstructionWithCustomCopier( + fusion_root, + [hlo](HloInstruction* leaf, const ShapeIndex& leaf_index, + HloComputation* comp) { + const Shape& hlo_subshape = + ShapeUtil::GetSubshape(hlo->shape(), leaf_index); + if (ShapeUtil::Compatible(leaf->shape(), hlo_subshape)) { + return leaf; + } + return comp->AddInstruction( + HloInstruction::CreateConvert(hlo_subshape, leaf)); + })); + fusion_computation->set_root_instruction(copy); } } - if (needs_tuple_simplifier) { - TupleSimplifier tuple_simplifier; - TF_RETURN_IF_ERROR(tuple_simplifier.Run(module).status()); - } return Status::OK(); } @@ -758,10 +715,38 @@ StatusOr<bool> BFloat16Propagation::Run(HloModule* module) { changes_to_bf16_.clear(); changed_ = false; + auto computations_topological_order = module->MakeComputationPostOrder(); + + // Before running the propagation pass, we insert copies (kConvert to the same + // type) of F32 inputs to while loops. This prevents other uses of the same + // input from aliasing the while loop input/output, so that there's greater + // chance to use BF16 inside the loop. If some of these added copies do not + // help, they will remain F32 after BF16 propagation and will be removed since + // they are no-ops. + for (auto computation : computations_topological_order) { + for (auto inst : computation->MakeInstructionPostOrder()) { + if (inst->opcode() != HloOpcode::kWhile) { + continue; + } + + auto operand = inst->mutable_operand(0); + TF_ASSIGN_OR_RETURN( + HloInstruction * copy, + computation->DeepCopyInstructionWithCustomCopier( + operand, [](HloInstruction* leaf, const ShapeIndex& leaf_index, + HloComputation* comp) { + if (leaf->shape().element_type() != F32) { + return leaf; + } + return comp->AddInstruction( + HloInstruction::CreateConvert(leaf->shape(), leaf)); + })); + TF_RETURN_IF_ERROR(operand->ReplaceUseWith(inst, copy)); + } + } + TF_ASSIGN_OR_RETURN(dataflow_, HloDataflowAnalysis::Run(*module)); - const auto& computations_topological_order = - module->MakeComputationPostOrder(); // The first step is a forward pass (parameters to root), where we determine // the potential candidate instructions to use bfloat16 in the outputs that // are not likely to cause overhead from extra explicit conversions. This is @@ -810,23 +795,27 @@ StatusOr<bool> BFloat16Propagation::Run(HloModule* module) { } } + // Removes redundant HLOs added by this pass, either when inserting + // de-aliasing copies to while loop inputs, or later when converting output + // types. + auto clean_up = [this, module]() { + TF_RETURN_IF_ERROR(SkipNoopConversions(module)); + TupleSimplifier tuple_simplifier; + TF_RETURN_IF_ERROR(tuple_simplifier.Run(module).status()); + HloDCE dce; + TF_RETURN_IF_ERROR(dce.Run(module).status()); + return Status::OK(); + }; + if (!changed_) { + TF_RETURN_IF_ERROR(clean_up()); return false; } TF_RETURN_IF_ERROR(ResolveInconsistentFusions(module)); TF_RETURN_IF_ERROR(ResolveConvertedConstants(module)); - // This pass could have turned an F32 -> BF16 conversion to a no-op (BF16 -> - // BF16), so we skip them now. - TF_RETURN_IF_ERROR(SkipNoopConversions(module)); - - { - // We may have dead HLOs after ResolveInconsistentFusions, - // ResolveConvertedConstants and SkipNoopConversions. - HloDCE dce; - TF_RETURN_IF_ERROR(dce.Run(module).status()); - } + TF_RETURN_IF_ERROR(clean_up()); return true; } diff --git a/tensorflow/compiler/xla/service/bfloat16_propagation_test.cc b/tensorflow/compiler/xla/service/bfloat16_propagation_test.cc index 23aa83ea88..aeafb25ad7 100644 --- a/tensorflow/compiler/xla/service/bfloat16_propagation_test.cc +++ b/tensorflow/compiler/xla/service/bfloat16_propagation_test.cc @@ -240,12 +240,10 @@ TEST_F(BFloat16PropagationTest, SameValueReferencedTwice) { EXPECT_TRUE(PropagatePrecision(module.get())); EXPECT_EQ(computation->root_instruction(), dot); - EXPECT_TRUE(OutputsBF16(add0)); EXPECT_TRUE(OutputsBF16(add1)); EXPECT_TRUE(OutputsBF16(lhs)); - // rhs is a get-tuple-element, which does not define a buffer, but its shape - // should also be adjusted accordingly. - EXPECT_TRUE(OutputsBF16(rhs)); + + // add0 and rhs have been eliminated by simplification and DCE. } // Tests that a non-fusion computation's root should not be changed. @@ -734,10 +732,8 @@ TEST_F(BFloat16PropagationTest, NoopConversionRemoved) { EXPECT_TRUE(PropagatePrecision(module.get())); EXPECT_EQ(computation->root_instruction(), add2); - EXPECT_EQ(add2->operand(0), gte0); - EXPECT_EQ(add2->operand(1), gte1); - EXPECT_EQ(gte0->shape().element_type(), BF16); - EXPECT_EQ(gte1->shape().element_type(), BF16); + EXPECT_EQ(add2->operand(0), add0); + EXPECT_EQ(add2->operand(1), add1); EXPECT_EQ(add0->shape().element_type(), BF16); EXPECT_EQ(add1->shape().element_type(), BF16); } diff --git a/tensorflow/compiler/xla/service/buffer_assignment_test.cc b/tensorflow/compiler/xla/service/buffer_assignment_test.cc index eb19babf77..125ade2a11 100644 --- a/tensorflow/compiler/xla/service/buffer_assignment_test.cc +++ b/tensorflow/compiler/xla/service/buffer_assignment_test.cc @@ -1876,7 +1876,7 @@ TEST_F(WhileBufferAssignmentTest, ColocatedBuffers) { auto module = CreateNewModule(); auto builder = HloComputation::Builder("entry"); - auto token = builder.AddInstruction(HloInstruction::CreateAfterAll({})); + auto token = builder.AddInstruction(HloInstruction::CreateToken()); auto infeed = builder.AddInstruction(HloInstruction::CreateInfeed(r0s32, token, "")); auto infeed_data = builder.AddInstruction( diff --git a/tensorflow/compiler/xla/service/buffer_liveness_test.cc b/tensorflow/compiler/xla/service/buffer_liveness_test.cc index c5e4b72fbc..4a927b5767 100644 --- a/tensorflow/compiler/xla/service/buffer_liveness_test.cc +++ b/tensorflow/compiler/xla/service/buffer_liveness_test.cc @@ -327,7 +327,7 @@ TEST_F(BufferLivenessTest, RootInstructionIsNotLastInSequentialOrder) { builder.AddInstruction(HloInstruction::CreateParameter(0, vec_, "param")); auto add = builder.AddInstruction( HloInstruction::CreateBinary(vec_, HloOpcode::kAdd, param, param)); - auto token = builder.AddInstruction(HloInstruction::CreateAfterAll({})); + auto token = builder.AddInstruction(HloInstruction::CreateToken()); auto recv = builder.AddInstruction( HloInstruction::CreateRecv(vec_, token, /*channel_id=*/0)); auto recv_done = builder.AddInstruction(HloInstruction::CreateRecvDone(recv)); diff --git a/tensorflow/compiler/xla/service/call_inliner_test.cc b/tensorflow/compiler/xla/service/call_inliner_test.cc index dcec2babcb..ff968bca29 100644 --- a/tensorflow/compiler/xla/service/call_inliner_test.cc +++ b/tensorflow/compiler/xla/service/call_inliner_test.cc @@ -148,7 +148,7 @@ TEST_F(CallInlinerTest, CallToOutfeedComputationIsInlined) { HloComputation::Builder outfeeder(TestName() + ".outfeeder"); auto value = outfeeder.AddInstruction( HloInstruction::CreateConstant(LiteralUtil::CreateR0<float>(42.0))); - auto token = outfeeder.AddInstruction(HloInstruction::CreateAfterAll({})); + auto token = outfeeder.AddInstruction(HloInstruction::CreateToken()); outfeeder.AddInstruction( HloInstruction::CreateOutfeed(f32, value, token, /*outfeed_config=*/"")); diff --git a/tensorflow/compiler/xla/service/conditional_simplifier_test.cc b/tensorflow/compiler/xla/service/conditional_simplifier_test.cc index 834878426f..c43a31b167 100644 --- a/tensorflow/compiler/xla/service/conditional_simplifier_test.cc +++ b/tensorflow/compiler/xla/service/conditional_simplifier_test.cc @@ -119,8 +119,7 @@ TEST_F(ConditionalSimplifierTest, NotRemovedIfContainsSend) { ASSERT_EQ(conditional->opcode(), HloOpcode::kConditional); auto* true_computation = conditional->true_computation(); - auto* token = - true_computation->AddInstruction(HloInstruction::CreateAfterAll({})); + auto* token = true_computation->AddInstruction(HloInstruction::CreateToken()); auto* send = true_computation->AddInstruction(HloInstruction::CreateSend( true_computation->AddInstruction( HloInstruction::CreateConstant(LiteralUtil::CreateR0<bool>(true))), @@ -135,8 +134,7 @@ TEST_F(ConditionalSimplifierTest, NotRemovedIfContainsRecv) { ASSERT_EQ(conditional->opcode(), HloOpcode::kConditional); auto* true_computation = conditional->true_computation(); - auto* token = - true_computation->AddInstruction(HloInstruction::CreateAfterAll({})); + auto* token = true_computation->AddInstruction(HloInstruction::CreateToken()); auto* recv = true_computation->AddInstruction(HloInstruction::CreateRecv( ShapeUtil::MakeShape(F32, {1}), token, /*channel_id=*/0)); true_computation->AddInstruction(HloInstruction::CreateRecvDone(recv)); @@ -148,8 +146,7 @@ TEST_F(ConditionalSimplifierTest, NotRemovedIfContainsNonRemovableInstruction) { auto* conditional = computation->root_instruction(); ASSERT_EQ(conditional->opcode(), HloOpcode::kConditional); auto* false_computation = conditional->false_computation(); - auto token = - false_computation->AddInstruction(HloInstruction::CreateAfterAll({})); + auto token = false_computation->AddInstruction(HloInstruction::CreateToken()); false_computation->AddInstruction(HloInstruction::CreateInfeed( ShapeUtil::MakeShape(F32, {1}), token, "config")); EXPECT_FALSE(ConditionalSimplifier().Run(&module()).ValueOrDie()); diff --git a/tensorflow/compiler/xla/service/cpu/cpu_compiler.cc b/tensorflow/compiler/xla/service/cpu/cpu_compiler.cc index b6b19ecb3d..29fa29d33a 100644 --- a/tensorflow/compiler/xla/service/cpu/cpu_compiler.cc +++ b/tensorflow/compiler/xla/service/cpu/cpu_compiler.cc @@ -30,6 +30,7 @@ limitations under the License. #include "llvm/ADT/Triple.h" #include "llvm/IR/Function.h" #include "llvm/IR/LLVMContext.h" +#include "llvm/IR/Mangler.h" #include "llvm/IR/Module.h" #include "llvm/IR/Verifier.h" #include "llvm/Object/ObjectFile.h" @@ -604,7 +605,13 @@ StatusOr<std::unique_ptr<Executable>> CpuCompiler::RunBackend( /*is_top_level_computation=*/true, &module_sequence.at(entry_computation))); - string function_name = llvm_ir::AsString(entry_function->getName()); + string function_name = [&]() { + llvm::SmallVector<char, 40> function_name_vector; + llvm::Mangler::getNameWithPrefix( + function_name_vector, entry_function->getName(), jit->data_layout()); + return string(function_name_vector.begin(), function_name_vector.end()); + }(); + string ir_module_string; if (embed_ir_in_executable) { ir_module_string = llvm_ir::DumpModuleToString(*llvm_module); diff --git a/tensorflow/compiler/xla/service/generic_transfer_manager.cc b/tensorflow/compiler/xla/service/generic_transfer_manager.cc index 7490728b44..33730049c4 100644 --- a/tensorflow/compiler/xla/service/generic_transfer_manager.cc +++ b/tensorflow/compiler/xla/service/generic_transfer_manager.cc @@ -166,8 +166,7 @@ Status GenericTransferManager::TransferBufferToInfeed( Status GenericTransferManager::TransferLiteralFromOutfeed( se::StreamExecutor* executor, const Shape& literal_shape, Literal* literal) { - return Unimplemented( - "Outfeed is not supported on this platform (b/30467474)"); + return Unimplemented("Generic transfer from Outfeed"); } Status GenericTransferManager::ResetDevices( diff --git a/tensorflow/compiler/xla/service/gpu/BUILD b/tensorflow/compiler/xla/service/gpu/BUILD index aaab455281..9fca3a51c8 100644 --- a/tensorflow/compiler/xla/service/gpu/BUILD +++ b/tensorflow/compiler/xla/service/gpu/BUILD @@ -266,6 +266,7 @@ cc_library( "infeed_thunk.cc", "kernel_thunk.cc", "memset_thunk.cc", + "outfeed_thunk.cc", "sequential_thunk.cc", "thunk_schedule.cc", "tuple_thunk.cc", @@ -283,6 +284,7 @@ cc_library( "infeed_thunk.h", "kernel_thunk.h", "memset_thunk.h", + "outfeed_thunk.h", "sequential_thunk.h", "thunk.h", "thunk_schedule.h", @@ -290,15 +292,16 @@ cc_library( "while_thunk.h", ], deps = [ - ":backend_configs", ":buffer_allocations", ":cudnn_convolution_runner", ":hlo_execution_profiler", ":infeed_manager", ":ir_emission_utils", + ":outfeed_manager", ":partition_assignment", ":stream_assignment", "//tensorflow/compiler/xla:array2d", + "//tensorflow/compiler/xla:literal", "//tensorflow/compiler/xla:shape_tree", "//tensorflow/compiler/xla:shape_util", "//tensorflow/compiler/xla:status", @@ -536,7 +539,9 @@ cc_library( hdrs = ["gpu_transfer_manager.h"], deps = [ ":gpu_compiler", + ":outfeed_manager", "//tensorflow/compiler/xla:literal", + "//tensorflow/compiler/xla:literal_util", "//tensorflow/compiler/xla:shape_util", "//tensorflow/compiler/xla:status_macros", "//tensorflow/compiler/xla:statusor", @@ -647,6 +652,19 @@ cc_library( ) cc_library( + name = "outfeed_manager", + srcs = ["outfeed_manager.cc"], + hdrs = ["outfeed_manager.h"], + deps = [ + "//tensorflow/compiler/xla:literal", + "//tensorflow/compiler/xla:shape_tree", + "//tensorflow/compiler/xla:shape_util", + "//tensorflow/compiler/xla:util", + "//tensorflow/core:lib", + ], +) + +cc_library( name = "gpu_layout_assignment", srcs = ["gpu_layout_assignment.cc"], hdrs = ["gpu_layout_assignment.h"], diff --git a/tensorflow/compiler/xla/service/gpu/gpu_compiler.cc b/tensorflow/compiler/xla/service/gpu/gpu_compiler.cc index decfc40daf..e1da8d940c 100644 --- a/tensorflow/compiler/xla/service/gpu/gpu_compiler.cc +++ b/tensorflow/compiler/xla/service/gpu/gpu_compiler.cc @@ -552,8 +552,7 @@ StatusOr<std::unique_ptr<Executable>> GpuCompiler::RunBackend( &ir_emitter_context); { XLA_SCOPED_LOGGING_TIMER("GpuCompiler::RunBackend - IR emission"); - TF_RETURN_IF_ERROR( - entry_computation->root_instruction()->Accept(&ir_emitter)); + TF_RETURN_IF_ERROR(entry_computation->Accept(&ir_emitter)); } if (user_pre_optimization_hook_) { diff --git a/tensorflow/compiler/xla/service/gpu/gpu_transfer_manager.cc b/tensorflow/compiler/xla/service/gpu/gpu_transfer_manager.cc index 83d5083b95..3c8018a030 100644 --- a/tensorflow/compiler/xla/service/gpu/gpu_transfer_manager.cc +++ b/tensorflow/compiler/xla/service/gpu/gpu_transfer_manager.cc @@ -21,7 +21,9 @@ limitations under the License. #include "llvm/IR/DataLayout.h" #include "tensorflow/compiler/xla/literal.h" +#include "tensorflow/compiler/xla/literal_util.h" #include "tensorflow/compiler/xla/service/gpu/gpu_compiler.h" +#include "tensorflow/compiler/xla/service/gpu/outfeed_manager.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/status_macros.h" #include "tensorflow/compiler/xla/statusor.h" @@ -139,6 +141,63 @@ StatusOr<gpu::InfeedBuffer*> GpuTransferManager::TransferBufferToInfeedInternal( return buffer; } +static std::unique_ptr<Literal> ShapeTreeToLiteral( + ShapeTree<std::unique_ptr<gpu::OutfeedBuffer>>* shape_tree) { + // This is a struct instead of a lambda for std::function-free recursion. + struct Helper { + static std::unique_ptr<Literal> helper( + ShapeTree<std::unique_ptr<gpu::OutfeedBuffer>>* shape_tree, + ShapeIndex* index) { + const Shape& shape = ShapeUtil::GetSubshape(shape_tree->shape(), *index); + if (ShapeUtil::IsArray(shape)) { + return (*shape_tree->mutable_element(*index))->WaitUntilAvailable(); + } + + CHECK(ShapeUtil::IsTuple(shape)) + << ShapeUtil::HumanStringWithLayout(shape); + const int64 tuple_element_count = ShapeUtil::TupleElementCount(shape); + index->push_back(0); + std::vector<std::unique_ptr<Literal>> tuple_operands; + for (int64 i = 0; i < tuple_element_count; ++i) { + index->back() = i; + tuple_operands.push_back(helper(shape_tree, index)); + } + index->pop_back(); + return LiteralUtil::MakeTupleOwned(std::move(tuple_operands)); + } + }; + ShapeIndex index; + return Helper::helper(shape_tree, &index); +} + +Status GpuTransferManager::TransferLiteralFromOutfeed( + se::StreamExecutor* /*executor*/, const Shape& literal_shape, + Literal* literal) { + ShapeTree<std::unique_ptr<gpu::OutfeedBuffer>> outfeed_buffers( + &literal_shape); + + // First create a tree of literal buffers that the device can write to. + outfeed_buffers.ForEachMutableElement( + [&](const ShapeIndex& index, + std::unique_ptr<gpu::OutfeedBuffer>* buffer) { + const Shape& shape = ShapeUtil::GetSubshape(literal_shape, index); + // Do not transfer tuple index buffers. + if (ShapeUtil::IsTuple(shape)) { + return; + } + *buffer = MakeUnique<gpu::OutfeedBuffer>(GetByteSizeRequirement(shape)); + }); + + // Give the tree of buffers to the outfeed mananger. The device will fill it + // while we're waiting for it below. + gpu::OutfeedManager* outfeed_manager = gpu::GetOrCreateOutfeedManager(); + outfeed_manager->EnqueueOutfeedDestination(&outfeed_buffers); + + // Now turn the tree of buffers back into a literal. + *literal = std::move(*ShapeTreeToLiteral(&outfeed_buffers)); + return Status::OK(); +} + } // namespace xla static std::unique_ptr<xla::TransferManager> CreateGpuTransferManager() { diff --git a/tensorflow/compiler/xla/service/gpu/gpu_transfer_manager.h b/tensorflow/compiler/xla/service/gpu/gpu_transfer_manager.h index 09f8227f50..9dff1e5a50 100644 --- a/tensorflow/compiler/xla/service/gpu/gpu_transfer_manager.h +++ b/tensorflow/compiler/xla/service/gpu/gpu_transfer_manager.h @@ -40,6 +40,9 @@ class GpuTransferManager : public GenericTransferManager { const LiteralSlice& literal) override; Status TransferBufferToInfeed(se::StreamExecutor* executor, int64 size, const void* source) override; + Status TransferLiteralFromOutfeed(se::StreamExecutor* executor, + const Shape& literal_shape, + Literal* literal) override; private: // Initiates the infeed data transfers. InfeedBuffer->Done() must be diff --git a/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.cc b/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.cc index 186672047b..59edba30e6 100644 --- a/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.cc +++ b/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.cc @@ -48,6 +48,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/gpu/ir_emitter_context.h" #include "tensorflow/compiler/xla/service/gpu/kernel_thunk.h" #include "tensorflow/compiler/xla/service/gpu/memset_thunk.h" +#include "tensorflow/compiler/xla/service/gpu/outfeed_thunk.h" #include "tensorflow/compiler/xla/service/gpu/parallel_loop_emitter.h" #include "tensorflow/compiler/xla/service/gpu/partition_assignment.h" #include "tensorflow/compiler/xla/service/gpu/sequential_thunk.h" @@ -2028,6 +2029,11 @@ Status IrEmitterUnnested::HandleInfeed(HloInstruction* infeed) { return Status::OK(); } +Status IrEmitterUnnested::HandleOutfeed(HloInstruction* outfeed) { + thunk_sequence_->emplace_back(BuildOutfeedThunk(outfeed)); + return Status::OK(); +} + // Figures out how to access the buffers for all subshapes of hlo's operands and // for hlo itself (i.e. all the buffers produced by HLO). // @@ -2275,7 +2281,7 @@ std::unique_ptr<Thunk> IrEmitterUnnested::BuildInfeedThunk( ShapeTree<BufferAllocation::Slice> slices(inst->shape()); slices.ForEachMutableElement( - [this, inst](const ShapeIndex& index, BufferAllocation::Slice* slice) { + [&](const ShapeIndex& index, BufferAllocation::Slice* slice) { *slice = ir_emitter_context_->buffer_assignment() .GetUniqueSlice(inst, index) .ConsumeValueOrDie(); @@ -2283,6 +2289,23 @@ std::unique_ptr<Thunk> IrEmitterUnnested::BuildInfeedThunk( return MakeUnique<InfeedThunk>(slices, inst); } +std::unique_ptr<Thunk> IrEmitterUnnested::BuildOutfeedThunk( + const HloInstruction* inst) { + CHECK_EQ(HloOpcode::kOutfeed, inst->opcode()); + + ShapeTree<BufferAllocation::Slice> slices(inst->operand(0)->shape()); + slices.ForEachMutableElement( + [&](const ShapeIndex& index, BufferAllocation::Slice* slice) { + auto status_or_slice = + ir_emitter_context_->buffer_assignment().GetUniqueSlice( + inst->operand(0), index); + if (status_or_slice.ok()) { + *slice = status_or_slice.ConsumeValueOrDie(); + } + }); + return MakeUnique<OutfeedThunk>(std::move(slices), inst); +} + namespace { double GetScalarConstantAsDouble(const Literal& literal) { switch (literal.shape().element_type()) { @@ -3040,12 +3063,10 @@ LaunchDimensions IrEmitterUnnested::EmitHlo021Tile( llvm_ir::IrArray& input_in_logical_shape = param_in_reduced_shape_arrays[id]; llvm::Value* buffer = param_buffers[id]; - llvm::Instruction* store_to_buffer = ir_builder_.CreateStore( + ir_builder_.CreateStore( input_in_logical_shape.EmitReadArrayElement(index, &ir_builder_, "input_element"), ir_builder_.CreateGEP(buffer, {index_typed_const(0), y_loc, x})); - param_arrays[id].AnnotateBufferLoadStoreInstructionWithMetadata( - store_to_buffer); } }; @@ -3073,8 +3094,6 @@ LaunchDimensions IrEmitterUnnested::EmitHlo021Tile( ir_builder_.CreateGEP(param_buffers[0], {ir_builder_.getInt64(0), x, y_loc}), "output_element"); - param_arrays[0].AnnotateBufferLoadStoreInstructionWithMetadata( - load_from_buffer); output_in_reduced_shape_arrays[0].EmitWriteArrayElement( index, load_from_buffer, &ir_builder_); } else { diff --git a/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.h b/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.h index 0913e855cf..a1cc38401c 100644 --- a/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.h +++ b/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.h @@ -74,6 +74,7 @@ class IrEmitterUnnested : public IrEmitter { Status HandleTuple(HloInstruction* tuple) override; Status HandleWhile(HloInstruction* xla_while) override; Status HandleInfeed(HloInstruction* xla_infeed) override; + Status HandleOutfeed(HloInstruction* outfeed) override; Status HandleRng(HloInstruction* random) override; Status HandleSelect(HloInstruction* select) override; Status HandleTupleSelect(HloInstruction* tuple_select) override; @@ -254,10 +255,14 @@ class IrEmitterUnnested : public IrEmitter { std::unique_ptr<Thunk> BuildDeviceToDeviceCopyThunk( const HloInstruction* inst); - // Returns an InfeedThunk that performs device-to-device memcpy to implement + // Returns an InfeedThunk that performs a host-to-device memcpy to implement // `inst`. std::unique_ptr<Thunk> BuildInfeedThunk(const HloInstruction* inst); + // Returns an OutfeedThunk that performs a device-to-host memcpy to implement + // `inst`. + std::unique_ptr<Thunk> BuildOutfeedThunk(const HloInstruction* inst); + // Returns a WhileThunk that invokes thunk sequences for 'condition' and // 'body' sub-computations of while instruction 'hlo'. std::unique_ptr<Thunk> BuildWhileThunk(const HloInstruction* hlo); diff --git a/tensorflow/compiler/xla/service/gpu/outfeed_manager.cc b/tensorflow/compiler/xla/service/gpu/outfeed_manager.cc new file mode 100644 index 0000000000..47744548b9 --- /dev/null +++ b/tensorflow/compiler/xla/service/gpu/outfeed_manager.cc @@ -0,0 +1,51 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/compiler/xla/service/gpu/outfeed_manager.h" + +#include "tensorflow/compiler/xla/map_util.h" +#include "tensorflow/compiler/xla/ptr_util.h" +#include "tensorflow/compiler/xla/shape_util.h" +#include "tensorflow/core/platform/logging.h" + +namespace xla { +namespace gpu { + +void OutfeedManager::EnqueueOutfeedDestination( + ShapeTree<std::unique_ptr<OutfeedBuffer>>* buffers) { + tensorflow::mutex_lock l(mu_); + enqueued_buffers_.push_back(buffers); + cv_.notify_one(); +} + +ShapeTree<std::unique_ptr<OutfeedBuffer>>* +OutfeedManager::BlockingGetNextOutfeedDestination() { + tensorflow::mutex_lock l(mu_); + while (enqueued_buffers_.empty()) { + cv_.wait(l); + } + ShapeTree<std::unique_ptr<OutfeedBuffer>>* current_buffer = + enqueued_buffers_.front(); + enqueued_buffers_.pop_front(); + return current_buffer; +} + +OutfeedManager* GetOrCreateOutfeedManager() { + static auto* manager = new OutfeedManager; + return manager; +} + +} // namespace gpu +} // namespace xla diff --git a/tensorflow/compiler/xla/service/gpu/outfeed_manager.h b/tensorflow/compiler/xla/service/gpu/outfeed_manager.h new file mode 100644 index 0000000000..f580c24e17 --- /dev/null +++ b/tensorflow/compiler/xla/service/gpu/outfeed_manager.h @@ -0,0 +1,92 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_COMPILER_XLA_SERVICE_GPU_OUTFEED_MANAGER_H_ +#define TENSORFLOW_COMPILER_XLA_SERVICE_GPU_OUTFEED_MANAGER_H_ + +#include <deque> +#include <vector> + +#include "tensorflow/compiler/xla/literal.h" +#include "tensorflow/compiler/xla/shape_tree.h" +#include "tensorflow/core/platform/mutex.h" +#include "tensorflow/core/platform/notification.h" + +namespace xla { +namespace gpu { + +// TODO(b/30467474) Once GPU outfeed implementation settles, consider +// folding back the cpu and gpu outfeed implementations into a generic +// one if possible. + +// Defines a buffer holding the destination for an outfeed in host memory and a +// notification when that triggers when the transfer is done. +class OutfeedBuffer { + public: + OutfeedBuffer(int64 length) : length_(length) {} + + // Waits for the device transfer to be finished. + std::unique_ptr<Literal> WaitUntilAvailable() { + done_.WaitForNotification(); + return std::move(destination_); + } + + int64 length() const { return length_; } + void set_destination(std::unique_ptr<Literal> destination) { + destination_ = std::move(destination); + } + Literal* destination() { return destination_.get(); } + + // Callback to signal that this buffer is consumed. + void Done() { done_.Notify(); } + + private: + std::unique_ptr<Literal> destination_; + const int64 length_; + tensorflow::Notification done_; +}; + +// Manages a thread-safe queue of buffers. The buffers are supposed to be +// produced by the transfer manager and consumed by the device. +class OutfeedManager { + public: + // Adds a tree of buffers to the queue. The individual buffers correspond to + // the elements of a tuple and may be nullptr if the buffer is a tuple index + // buffer. + void EnqueueOutfeedDestination( + ShapeTree<std::unique_ptr<OutfeedBuffer>>* buffers); + + // Blocks until the queue is non-empty, then returns the buffer at the head of + // the queue. + ShapeTree<std::unique_ptr<OutfeedBuffer>>* + BlockingGetNextOutfeedDestination(); + + private: + tensorflow::mutex mu_; + + // Condition variable that is signaled every time a buffer is enqueued. + tensorflow::condition_variable cv_; + + // The queue of trees of buffers. OutfeedBuffer* queue contents are not owned. + std::deque<ShapeTree<std::unique_ptr<OutfeedBuffer>>*> enqueued_buffers_; +}; + +// Singleton creator-or-accessor: Returns the GPU outfeed manager. +OutfeedManager* GetOrCreateOutfeedManager(); + +} // namespace gpu +} // namespace xla + +#endif // TENSORFLOW_COMPILER_XLA_SERVICE_GPU_OUTFEED_MANAGER_H_ diff --git a/tensorflow/compiler/xla/service/gpu/outfeed_thunk.cc b/tensorflow/compiler/xla/service/gpu/outfeed_thunk.cc new file mode 100644 index 0000000000..4c0f1421e9 --- /dev/null +++ b/tensorflow/compiler/xla/service/gpu/outfeed_thunk.cc @@ -0,0 +1,111 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/compiler/xla/service/gpu/outfeed_thunk.h" +#include "tensorflow/compiler/xla/literal.h" +#include "tensorflow/compiler/xla/service/gpu/hlo_execution_profiler.h" +#include "tensorflow/compiler/xla/service/gpu/outfeed_manager.h" +#include "tensorflow/compiler/xla/util.h" +#include "tensorflow/core/platform/stream_executor_no_cuda.h" + +namespace xla { +namespace gpu { + +OutfeedThunk::OutfeedThunk(ShapeTree<BufferAllocation::Slice> outfeed_slices, + const HloInstruction* hlo_instruction) + : Thunk(Kind::kOutfeed, hlo_instruction), + outfeed_slices_(std::move(outfeed_slices)) {} + +Status OutfeedThunk::ExecuteOnStream( + const BufferAllocations& buffer_allocations, se::Stream* stream, + HloExecutionProfiler* profiler) { + VLOG(2) << "Outfeeding from GPU: " << hlo_instruction()->ToString(); + + auto op_profiler = profiler->MakeScopedInstructionProfiler(hlo_instruction()); + OutfeedManager* outfeed_manager = GetOrCreateOutfeedManager(); + ShapeTree<std::unique_ptr<OutfeedBuffer>>* outfeed_buffers = + outfeed_manager->BlockingGetNextOutfeedDestination(); + + // Nothing to be done for empty tuples. + if (ShapeUtil::IsEmptyTuple(hlo_instruction()->operand(0)->shape())) { + return Status::OK(); + } + CHECK(ShapeUtil::Compatible(hlo_instruction()->operand(0)->shape(), + outfeed_buffers->shape())); + + TF_RETURN_IF_ERROR(outfeed_buffers->ForEachMutableElementWithStatus( + [&](const ShapeIndex& index, std::unique_ptr<OutfeedBuffer>* buffer) { + if (!*buffer) { // Tuple pointers. + return Status::OK(); + } + // Allocate storage for the literal data. + const Shape& shape = + ShapeUtil::GetSubshape(outfeed_buffers->shape(), index); + (*buffer)->set_destination(Literal::CreateFromShape(shape)); + + BufferAllocation::Slice slice = outfeed_slices_.element(index); + se::DeviceMemoryBase data_address; + if (slice.allocation()) { + // If we have a static allocation, read it from there. This avoids + // synchronizing the host and device just to read a pointer. + data_address = buffer_allocations.GetDeviceAddress(slice); + } else { + // Otherwise we have to read the tuple pointer first. + CHECK(!index.empty()); + // Copy the parent buffer to the host. + BufferAllocation::Slice tuple_slice = + outfeed_slices_.element(ShapeIndexView(index).ConsumeFront()); + if (!tuple_slice.allocation()) { + return Unimplemented( + "Nested dynamic tuples are not supported on GPU"); + } + se::DeviceMemoryBase tuple_address = + buffer_allocations.GetDeviceAddress(tuple_slice); + CHECK(tuple_slice.size() % sizeof(void*) == 0) + << "Tuple size must be a multiple of pointer size"; + std::vector<void*> tuple_element_buffer_addresses(tuple_slice.size() / + sizeof(void*)); + stream->ThenMemcpy(tuple_element_buffer_addresses.data(), + tuple_address, tuple_slice.size()); + TF_RETURN_IF_ERROR(stream->BlockHostUntilDone()); + // The data address is specified by the element of the tuple pointer + // buffer. + data_address = + se::DeviceMemoryBase(tuple_element_buffer_addresses[index.back()], + (*buffer)->length()); + } + + // TODO(b/111309141): Run this on a separate stream so it doesn't block + // the GPU from doing work during the transfer. This could be handled by + // making StreamAssignment do something intelligent with outfeed thunks. + stream + ->ThenMemcpy((*buffer)->destination()->untyped_data(), data_address, + (*buffer)->length()) + .ThenDoHostCallback([buffer]() { (*buffer)->Done(); }); + return Status::OK(); + })); + + Status block_status = stream->BlockHostUntilDone(); + if (!block_status.ok()) { + return InternalError("Failed to complete data transfer on stream %p: %s", + stream, block_status.error_message().c_str()); + } + + VLOG(2) << "Outfeeding from GPU complete"; + return Status::OK(); +} + +} // namespace gpu +} // namespace xla diff --git a/tensorflow/compiler/xla/service/gpu/outfeed_thunk.h b/tensorflow/compiler/xla/service/gpu/outfeed_thunk.h new file mode 100644 index 0000000000..8ed89f05f0 --- /dev/null +++ b/tensorflow/compiler/xla/service/gpu/outfeed_thunk.h @@ -0,0 +1,52 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_COMPILER_XLA_SERVICE_GPU_OUTFEED_THUNK_H_ +#define TENSORFLOW_COMPILER_XLA_SERVICE_GPU_OUTFEED_THUNK_H_ + +#include "tensorflow/compiler/xla/service/gpu/buffer_allocations.h" +#include "tensorflow/compiler/xla/service/gpu/hlo_execution_profiler.h" +#include "tensorflow/compiler/xla/service/gpu/thunk.h" +#include "tensorflow/compiler/xla/service/hlo_instruction.h" +#include "tensorflow/core/platform/stream_executor_no_cuda.h" + +namespace xla { +namespace gpu { + +// A thunk that outfeeds data. Data must be already resident on the host. This +// thunk performs a host to device copy from the buffer allocated for the +// outfeed op to the host location. +class OutfeedThunk : public Thunk { + public: + // Constructs a OutfeedThunk that copies data to the host-side + // outfeed queue from the buffers in the given shape tree. + OutfeedThunk(ShapeTree<BufferAllocation::Slice> outfeed_slices, + const HloInstruction* hlo_instruction); + + OutfeedThunk(const OutfeedThunk&) = delete; + OutfeedThunk& operator=(const OutfeedThunk&) = delete; + + Status ExecuteOnStream(const BufferAllocations& buffer_allocations, + se::Stream* stream, + HloExecutionProfiler* profiler) override; + + private: + const ShapeTree<BufferAllocation::Slice> outfeed_slices_; +}; + +} // namespace gpu +} // namespace xla + +#endif // TENSORFLOW_COMPILER_XLA_SERVICE_GPU_OUTFEED_THUNK_H_ diff --git a/tensorflow/compiler/xla/service/gpu/thunk.h b/tensorflow/compiler/xla/service/gpu/thunk.h index 14d41033c2..99a1a0eae9 100644 --- a/tensorflow/compiler/xla/service/gpu/thunk.h +++ b/tensorflow/compiler/xla/service/gpu/thunk.h @@ -54,6 +54,7 @@ class Thunk { kKernel, kMemset32BitValue, kMemzero, + kOutfeed, kSequential, kTuple, kWhile, diff --git a/tensorflow/compiler/xla/service/hlo_computation.cc b/tensorflow/compiler/xla/service/hlo_computation.cc index d4b13e0599..166a83fade 100644 --- a/tensorflow/compiler/xla/service/hlo_computation.cc +++ b/tensorflow/compiler/xla/service/hlo_computation.cc @@ -528,8 +528,10 @@ HloInstruction* HloComputation::CreateFusionInstruction( } StatusOr<HloInstruction*> HloComputation::DeepCopyHelper( - HloInstruction* instruction, const ShapeTree<bool>* indices_to_copy, - ShapeTree<HloInstruction*>* copies_added, ShapeIndex* index) { + HloInstruction* instruction, ShapeIndex* index, + const std::function< + HloInstruction*(HloInstruction* leaf, const ShapeIndex& leaf_index, + HloComputation* computation)>& copy_leaf) { if (ShapeUtil::IsTuple(instruction->shape())) { std::vector<HloInstruction*> elements; for (int64 i = 0; i < ShapeUtil::TupleElementCount(instruction->shape()); @@ -540,9 +542,8 @@ StatusOr<HloInstruction*> HloComputation::DeepCopyHelper( instruction, i)); index->push_back(i); - TF_ASSIGN_OR_RETURN( - HloInstruction * element, - DeepCopyHelper(gte, indices_to_copy, copies_added, index)); + TF_ASSIGN_OR_RETURN(HloInstruction * element, + DeepCopyHelper(gte, index, copy_leaf)); elements.push_back(element); index->pop_back(); } @@ -556,19 +557,7 @@ StatusOr<HloInstruction*> HloComputation::DeepCopyHelper( // Array shape. TF_RET_CHECK(ShapeUtil::IsArray(instruction->shape())); - if (indices_to_copy == nullptr || indices_to_copy->element(*index)) { - // Use kCopy to copy array elements - HloInstruction* copy = AddInstruction(HloInstruction::CreateUnary( - instruction->shape(), HloOpcode::kCopy, instruction)); - if (copies_added != nullptr) { - *copies_added->mutable_element(*index) = copy; - } - return copy; - } else { - // Elements which are not to be copied are passed through - // transparently. - return instruction; - } + return copy_leaf(instruction, *index, this); } StatusOr<HloInstruction*> HloComputation::DeepCopyInstruction( @@ -590,7 +579,36 @@ StatusOr<HloInstruction*> HloComputation::DeepCopyInstruction( } ShapeIndex index; - return DeepCopyHelper(instruction, indices_to_copy, copies_added, &index); + auto copy_leaf = [indices_to_copy, copies_added]( + HloInstruction* leaf, const ShapeIndex& leaf_index, + HloComputation* computation) { + if (indices_to_copy == nullptr || indices_to_copy->element(leaf_index)) { + HloInstruction* copy = computation->AddInstruction( + HloInstruction::CreateUnary(leaf->shape(), HloOpcode::kCopy, leaf)); + if (copies_added != nullptr) { + *copies_added->mutable_element(leaf_index) = copy; + } + return copy; + } + // Elements which are not to be copied are passed through + // transparently. + return leaf; + }; + return DeepCopyHelper(instruction, &index, copy_leaf); +} + +StatusOr<HloInstruction*> HloComputation::DeepCopyInstructionWithCustomCopier( + HloInstruction* instruction, + const std::function< + HloInstruction*(HloInstruction* leaf, const ShapeIndex& leaf_index, + HloComputation* computation)>& copy_leaf) { + if (instruction->parent() != this) { + return FailedPrecondition( + "Can't deep copy instruction %s: instruction is not in computation %s", + instruction->name().c_str(), name().c_str()); + } + ShapeIndex index; + return DeepCopyHelper(instruction, &index, copy_leaf); } ProgramShape HloComputation::ComputeProgramShape() const { diff --git a/tensorflow/compiler/xla/service/hlo_computation.h b/tensorflow/compiler/xla/service/hlo_computation.h index c1c3e79ebc..abc1da4da3 100644 --- a/tensorflow/compiler/xla/service/hlo_computation.h +++ b/tensorflow/compiler/xla/service/hlo_computation.h @@ -16,6 +16,7 @@ limitations under the License. #ifndef TENSORFLOW_COMPILER_XLA_SERVICE_HLO_COMPUTATION_H_ #define TENSORFLOW_COMPILER_XLA_SERVICE_HLO_COMPUTATION_H_ +#include <functional> #include <list> #include <memory> #include <string> @@ -254,6 +255,14 @@ class HloComputation { const ShapeTree<bool>* indices_to_copy = nullptr, ShapeTree<HloInstruction*>* copies_added = nullptr); + // As above, but uses a custom function to copy the leaf nodes, which could + // create alternative HLOs other than kCopy, or even pass-throughs. + StatusOr<HloInstruction*> DeepCopyInstructionWithCustomCopier( + HloInstruction* instruction, + const std::function< + HloInstruction*(HloInstruction* leaf, const ShapeIndex& leaf_index, + HloComputation* computation)>& copy_leaf); + // Computes and returns the ProgramShape of this computation (shape of // parameters and result with layout). ProgramShape ComputeProgramShape() const; @@ -378,8 +387,10 @@ class HloComputation { // Internal helper for recursive copying of an instruction. Creates and // returns a deep copy of the given instruction. StatusOr<HloInstruction*> DeepCopyHelper( - HloInstruction* instruction, const ShapeTree<bool>* indices_to_copy, - ShapeTree<HloInstruction*>* copies_added, ShapeIndex* index); + HloInstruction* instruction, ShapeIndex* index, + const std::function< + HloInstruction*(HloInstruction* leaf, const ShapeIndex& leaf_index, + HloComputation* computation)>& copy_leaf); // Internal helper to collect unreachable roots. std::vector<HloInstruction*> CollectUnreachableRoots() const; diff --git a/tensorflow/compiler/xla/service/hlo_computation_test.cc b/tensorflow/compiler/xla/service/hlo_computation_test.cc index af4628cf58..1abb89be08 100644 --- a/tensorflow/compiler/xla/service/hlo_computation_test.cc +++ b/tensorflow/compiler/xla/service/hlo_computation_test.cc @@ -375,7 +375,7 @@ TEST_F(HloComputationTest, DeepCopyToken) { // Test that DeepCopyInstruction properly handles tokens which should not be // copied. auto builder = HloComputation::Builder(TestName()); - auto token = builder.AddInstruction(HloInstruction::CreateAfterAll({})); + auto token = builder.AddInstruction(HloInstruction::CreateToken()); auto module = CreateNewModule(); auto computation = module->AddEntryComputation(builder.Build()); auto copy = computation->DeepCopyInstruction(token).ValueOrDie(); @@ -388,7 +388,7 @@ TEST_F(HloComputationTest, DeepCopyTokenTuple) { // Test that DeepCopyInstruction properly handles tokens which should not be // copied. auto builder = HloComputation::Builder(TestName()); - auto token = builder.AddInstruction(HloInstruction::CreateAfterAll({})); + auto token = builder.AddInstruction(HloInstruction::CreateToken()); auto constant = builder.AddInstruction( HloInstruction::CreateConstant(LiteralUtil::CreateR0<float>(42.0))); auto tuple = diff --git a/tensorflow/compiler/xla/service/hlo_cse.cc b/tensorflow/compiler/xla/service/hlo_cse.cc index 3f1deec2df..06484f4012 100644 --- a/tensorflow/compiler/xla/service/hlo_cse.cc +++ b/tensorflow/compiler/xla/service/hlo_cse.cc @@ -143,10 +143,8 @@ StatusOr<bool> HloCSE::Run(HloModule* module) { if (instruction->operand_count() == 0) { continue; } - // Skip instructions which have side effects or are a domain (which must - // not be CSE-ed). - if (instruction->HasSideEffect() || - instruction->opcode() == HloOpcode::kDomain) { + // Skip instructions which have side effects. + if (instruction->HasSideEffect()) { continue; } diff --git a/tensorflow/compiler/xla/service/hlo_cse_test.cc b/tensorflow/compiler/xla/service/hlo_cse_test.cc index c98a79fc71..76b9c66651 100644 --- a/tensorflow/compiler/xla/service/hlo_cse_test.cc +++ b/tensorflow/compiler/xla/service/hlo_cse_test.cc @@ -536,5 +536,40 @@ TEST_F(HloCseTest, ConstantsSameValueInDifferentDomains) { EXPECT_EQ(2, computation->instruction_count()); } +TEST_F(HloCseTest, Domain) { + auto module = ParseHloString(R"( +HloModule module +ENTRY %entry { + %param = f32[] parameter(0), sharding={maximal device=0} + %domain.0 = f32[] domain(%param), + domain={kind="sharding", entry={maximal device=0}, exit={maximal device=1}} + %domain.1 = f32[] domain(%param), + domain={kind="sharding", entry={maximal device=0}, exit={maximal device=1}} + %domain.2 = f32[] domain(%param), + domain={kind="sharding", entry={maximal device=0}, exit={maximal device=2}} + %negate.0 = f32[] negate(%domain.0) + %negate.1 = f32[] negate(%domain.1) + %negate.2 = f32[] negate(%domain.2) + %domain.3 = f32[] domain(%negate.0), + domain={kind="sharding", entry={maximal device=1}, exit={maximal device=0}} + %domain.4 = f32[] domain(%negate.1), + domain={kind="sharding", entry={maximal device=1}, exit={maximal device=0}} + %domain.5 = f32[] domain(%negate.2), + domain={kind="sharding", entry={maximal device=2}, exit={maximal device=0}} + %add = f32[] add(%domain.3, %domain.4) + ROOT %sub = f32[] subtract(%add, %domain.5) +})") + .ValueOrDie(); + + HloCSE cse(/*is_layout_sensitive=*/false); + EXPECT_TRUE(cse.Run(module.get()).ValueOrDie()); + LOG(INFO) << "AAAAA " << module->ToString(); + const HloInstruction* sub = module->entry_computation()->root_instruction(); + const HloInstruction* add = sub->operand(0); + EXPECT_EQ(add->operand(0), add->operand(1)); + EXPECT_NE(add->operand(0), sub->operand(1)); + EXPECT_NE(add->operand(1), sub->operand(1)); +} + } // namespace } // namespace xla diff --git a/tensorflow/compiler/xla/service/hlo_dataflow_analysis_test.cc b/tensorflow/compiler/xla/service/hlo_dataflow_analysis_test.cc index da3a02f11c..37bc2d2c9d 100644 --- a/tensorflow/compiler/xla/service/hlo_dataflow_analysis_test.cc +++ b/tensorflow/compiler/xla/service/hlo_dataflow_analysis_test.cc @@ -1157,7 +1157,7 @@ TEST_P(HloDataflowAnalysisTest, SendAndSendDone) { auto builder = HloComputation::Builder(TestName()); auto param = builder.AddInstruction( HloInstruction::CreateParameter(0, scalar_shape_, "param0")); - auto token = builder.AddInstruction(HloInstruction::CreateAfterAll({})); + auto token = builder.AddInstruction(HloInstruction::CreateToken()); auto send = builder.AddInstruction( HloInstruction::CreateSend(param, token, /*channel_id=*/0)); auto send_done = builder.AddInstruction(HloInstruction::CreateSendDone(send)); @@ -1182,7 +1182,7 @@ TEST_P(HloDataflowAnalysisTest, RecvAndRecvDone) { // Test that a RecvDone forwards its operand tuple element at {0} to element // {0} of the output. auto builder = HloComputation::Builder(TestName()); - auto token = builder.AddInstruction(HloInstruction::CreateAfterAll({})); + auto token = builder.AddInstruction(HloInstruction::CreateToken()); auto recv = builder.AddInstruction( HloInstruction::CreateRecv(scalar_shape_, token, /*channel_id=*/0)); auto recv_done = builder.AddInstruction(HloInstruction::CreateRecvDone(recv)); diff --git a/tensorflow/compiler/xla/service/hlo_dce_test.cc b/tensorflow/compiler/xla/service/hlo_dce_test.cc index 4fa13c975a..26e3736e01 100644 --- a/tensorflow/compiler/xla/service/hlo_dce_test.cc +++ b/tensorflow/compiler/xla/service/hlo_dce_test.cc @@ -75,7 +75,7 @@ TEST_F(HloDceTest, InstructionsWithSideEffect) { auto builder = HloComputation::Builder(TestName()); auto constant = builder.AddInstruction( HloInstruction::CreateConstant(LiteralUtil::CreateR0<float>(42.0f))); - auto token = builder.AddInstruction(HloInstruction::CreateAfterAll({})); + auto token = builder.AddInstruction(HloInstruction::CreateToken()); builder.AddInstruction( HloInstruction::CreateSend(constant, token, /*channel_id=*/0)); builder.AddInstruction(HloInstruction::CreateTuple({})); @@ -235,8 +235,7 @@ TEST_F(HloDceTest, CalledComputationWithSideEffect) { { auto param = body_builder.AddInstruction( HloInstruction::CreateParameter(0, shape, "param")); - auto token = - body_builder.AddInstruction(HloInstruction::CreateAfterAll({})); + auto token = body_builder.AddInstruction(HloInstruction::CreateToken()); auto infeed = body_builder.AddInstruction( HloInstruction::CreateInfeed(shape, token, "")); body_builder.AddInstruction( @@ -280,8 +279,8 @@ TEST_F(HloDceTest, CalledComputationWithNestedSideEffect) { { auto param = nested_callee_builder.AddInstruction( HloInstruction::CreateParameter(0, shape, "param")); - auto token = nested_callee_builder.AddInstruction( - HloInstruction::CreateAfterAll({})); + auto token = + nested_callee_builder.AddInstruction(HloInstruction::CreateToken()); nested_callee_builder.AddInstruction( HloInstruction::CreateOutfeed(shape, param, token, "")); } diff --git a/tensorflow/compiler/xla/service/hlo_evaluator.cc b/tensorflow/compiler/xla/service/hlo_evaluator.cc index f68b4ca353..f4fd9ba926 100644 --- a/tensorflow/compiler/xla/service/hlo_evaluator.cc +++ b/tensorflow/compiler/xla/service/hlo_evaluator.cc @@ -330,6 +330,24 @@ StatusOr<std::unique_ptr<Literal>> HloEvaluator::EvaluateElementwiseUnaryOp( return result; } +StatusOr<std::unique_ptr<Literal>> HloEvaluator::EvaluateDotOp( + const DotDimensionNumbers& dim_numbers, const Literal& lhs, + const Literal& rhs) { + std::unique_ptr<HloInstruction> lhs_instr = + HloInstruction::CreateConstant(lhs.CloneToUnique()); + std::unique_ptr<HloInstruction> rhs_instr = + HloInstruction::CreateConstant(rhs.CloneToUnique()); + + TF_ASSIGN_OR_RETURN( + Shape dot_shape, + ShapeInference::InferDotOpShape(lhs.shape(), rhs.shape(), dim_numbers)); + + std::unique_ptr<HloInstruction> cloned_instruction = + HloInstruction::CreateDot(dot_shape, lhs_instr.get(), rhs_instr.get(), + dim_numbers); + return Evaluate(cloned_instruction.get()); +} + Status HloEvaluator::HandleParameter(HloInstruction* parameter) { CHECK_LT(parameter->parameter_number(), arg_literals_.size()); const Literal* input_literal = arg_literals_[parameter->parameter_number()]; @@ -774,7 +792,7 @@ class OutputWindowIndexToInputIndex { // input_dim_value_to_index_vector_[i] tells us how to compute dimension i of // the input index from the output index. See - // PropagateOutputIndexToInputIndex. + // PropagateOutputIndexWindowDimsToInputIndex. std::vector<int64> input_dim_value_to_output_index_; // The result computed by this functor. operator() returns an ArraySlice into diff --git a/tensorflow/compiler/xla/service/hlo_evaluator.h b/tensorflow/compiler/xla/service/hlo_evaluator.h index 2850c5cb1a..a4c37ef328 100644 --- a/tensorflow/compiler/xla/service/hlo_evaluator.h +++ b/tensorflow/compiler/xla/service/hlo_evaluator.h @@ -23,6 +23,7 @@ limitations under the License. #include "tensorflow/compiler/xla/service/hlo_computation.h" #include "tensorflow/compiler/xla/service/hlo_instruction.h" #include "tensorflow/compiler/xla/service/hlo_module.h" +#include "tensorflow/compiler/xla/service/shape_inference.h" #include "tensorflow/compiler/xla/statusor.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/compiler/xla/xla_data.pb.h" @@ -115,6 +116,10 @@ class HloEvaluator : public DfsHloVisitorWithDefault { StatusOr<std::unique_ptr<Literal>> EvaluateElementwiseUnaryOp( HloOpcode opcode, const Literal& operand); + StatusOr<std::unique_ptr<Literal>> EvaluateDotOp( + const DotDimensionNumbers& dim_numbers, const Literal& lhs, + const Literal& rhs); + protected: // Make HloEvaluatorTypedVisitor a friend because it is logically part of this // class. diff --git a/tensorflow/compiler/xla/service/hlo_instruction.cc b/tensorflow/compiler/xla/service/hlo_instruction.cc index b396042f52..830ebfb125 100644 --- a/tensorflow/compiler/xla/service/hlo_instruction.cc +++ b/tensorflow/compiler/xla/service/hlo_instruction.cc @@ -163,6 +163,20 @@ StatusOr<std::unique_ptr<HloInstruction>> HloInstruction::CreateFromProto( proto.dimensions().end()), computations(0)); break; + case HloOpcode::kSort: { + TF_RET_CHECK(proto.operand_ids_size() == 1 || + proto.operand_ids_size() == 2) + << "Sort instruction should have 1 or 2 operands but has " + << proto.operand_ids_size(); + TF_RET_CHECK(proto.dimensions().size() == 1) + << "Sort instruction should have 1 dimension"; + HloInstruction* keys = operands(0); + HloInstruction* values = + proto.operand_ids_size() == 2 ? operands(1) : nullptr; + instruction = + CreateSort(proto.shape(), proto.dimensions(0), keys, values); + break; + } case HloOpcode::kTranspose: TF_RET_CHECK(proto.operand_ids_size() == 1) << "Transpose instruction should have 1 operand but sees " @@ -271,7 +285,7 @@ StatusOr<std::unique_ptr<HloInstruction>> HloInstruction::CreateFromProto( // converted to take tokens. instruction = CreateInfeed(data_shape, proto.infeed_config()); } else { - CHECK_EQ(proto.operand_ids_size(), 2); + CHECK_EQ(proto.operand_ids_size(), 1); instruction = CreateInfeed(data_shape, operands(0), proto.infeed_config()); } @@ -684,6 +698,7 @@ HloInstruction::CreateCrossReplicaSum( /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateAfterAll( tensorflow::gtl::ArraySlice<HloInstruction*> operands) { + CHECK(!operands.empty()); auto instruction = WrapUnique( new HloInstruction(HloOpcode::kAfterAll, ShapeUtil::MakeTokenShape())); for (auto operand : operands) { @@ -692,6 +707,11 @@ HloInstruction::CreateCrossReplicaSum( return instruction; } +/* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateToken() { + return WrapUnique( + new HloInstruction(HloOpcode::kAfterAll, ShapeUtil::MakeTokenShape())); +} + /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateWhile( const Shape& shape, HloComputation* condition, HloComputation* body, HloInstruction* init) { @@ -909,13 +929,9 @@ HloInstruction::CreateBroadcastSequence( } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateSort( - const Shape& shape, HloInstruction* keys, HloInstruction* values) { - auto instruction = WrapUnique(new HloInstruction(HloOpcode::kSort, shape)); - instruction->AppendOperand(keys); - if (values) { - instruction->AppendOperand(values); - } - return instruction; + const Shape& shape, int64 dimension, HloInstruction* keys, + HloInstruction* values) { + return MakeUnique<HloSortInstruction>(shape, dimension, keys, values); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateFusion( @@ -1110,6 +1126,7 @@ std::unique_ptr<HloInstruction> HloInstruction::CloneWithNewOperands( case HloOpcode::kHostCompute: case HloOpcode::kPad: case HloOpcode::kDynamicSlice: + case HloOpcode::kSort: clone = CloneWithNewOperandsImpl(shape, new_operands, context); break; // Unary ops. @@ -1223,15 +1240,11 @@ std::unique_ptr<HloInstruction> HloInstruction::CloneWithNewOperands( user_side_metadata_->Clone()); break; case HloOpcode::kAfterAll: - clone = CreateAfterAll(new_operands); - break; - case HloOpcode::kSort: - CHECK(new_operands.size() == 1 || new_operands.size() == 2) - << "Too many operands for sort: " << new_operands.size(); - HloInstruction* keys = new_operands[0]; - HloInstruction* values = - new_operands.size() == 2 ? new_operands[1] : nullptr; - clone = CreateSort(shape, keys, values); + if (new_operands.empty()) { + clone = CreateToken(); + } else { + clone = CreateAfterAll(new_operands); + } break; } SetupDerivedInstruction(clone.get()); @@ -1509,7 +1522,6 @@ bool HloInstruction::IdenticalSlowPath( case HloOpcode::kShiftRightArithmetic: case HloOpcode::kShiftRightLogical: case HloOpcode::kSign: - case HloOpcode::kSort: case HloOpcode::kSin: case HloOpcode::kSubtract: case HloOpcode::kTanh: @@ -1518,7 +1530,6 @@ bool HloInstruction::IdenticalSlowPath( return true; // These opcodes have complex or special behavior so just return false. - case HloOpcode::kDomain: case HloOpcode::kWhile: case HloOpcode::kAfterAll: return false; @@ -1540,6 +1551,10 @@ bool HloInstruction::IdenticalSlowPath( return eq_computations(true_computation(), other.true_computation()) && eq_computations(false_computation(), other.false_computation()); + case HloOpcode::kDomain: + return operand_side_metadata().Matches(other.operand_side_metadata()) && + user_side_metadata().Matches(other.user_side_metadata()); + // Ops migrated to subclasses should never come to this line. // TODO(b/80131774): Remove this switch when migration is complete. case HloOpcode::kBatchNormTraining: @@ -1553,6 +1568,7 @@ bool HloInstruction::IdenticalSlowPath( case HloOpcode::kReverse: case HloOpcode::kConcatenate: case HloOpcode::kReduce: + case HloOpcode::kSort: case HloOpcode::kTranspose: case HloOpcode::kBroadcast: case HloOpcode::kMap: diff --git a/tensorflow/compiler/xla/service/hlo_instruction.h b/tensorflow/compiler/xla/service/hlo_instruction.h index 17cc6d35cc..b392d65636 100644 --- a/tensorflow/compiler/xla/service/hlo_instruction.h +++ b/tensorflow/compiler/xla/service/hlo_instruction.h @@ -615,7 +615,7 @@ class HloInstruction { // Creates a sort op, with a keys operand, and an optional values operand. static std::unique_ptr<HloInstruction> CreateSort( - const Shape& shape, HloInstruction* keys, + const Shape& shape, int64 dimension, HloInstruction* keys, HloInstruction* values = nullptr); // Creates a while instruction, given a condition computation, a body @@ -687,11 +687,19 @@ class HloInstruction { const Shape& shape, HloInstruction* operand, tensorflow::gtl::ArraySlice<int64> dimensions); - // Creates a token instruction used for joining or creating new values of - // token type which thread through side-effecting operations. + // Creates a Afterall instruction used for joining or creating new values of + // token type which thread through side-effecting operations. Operands must + // all be tokens, and there must be at least one operand. static std::unique_ptr<HloInstruction> CreateAfterAll( tensorflow::gtl::ArraySlice<HloInstruction*> operands); + // Creates an AfterAll instruction which creates a token type out of thin air + // (no operands). This is a separate method from CreateAfterAll to facility + // the removal of operand-less AfterAll instructions. + // TODO(b/110532604): Remove this capability of creating a token from nothing + // when we plumb a primordial token from the entry computation. + static std::unique_ptr<HloInstruction> CreateToken(); + // Creates an instance of GatherDimensionNumbers. static GatherDimensionNumbers MakeGatherDimNumbers( tensorflow::gtl::ArraySlice<int64> output_window_dims, diff --git a/tensorflow/compiler/xla/service/hlo_instruction_test.cc b/tensorflow/compiler/xla/service/hlo_instruction_test.cc index e37556ac8d..19b56008bd 100644 --- a/tensorflow/compiler/xla/service/hlo_instruction_test.cc +++ b/tensorflow/compiler/xla/service/hlo_instruction_test.cc @@ -716,7 +716,7 @@ TEST_F(HloInstructionTest, PreserveOutfeedShapeThroughClone) { }))); auto shape10 = ShapeUtil::MakeShapeWithLayout(F32, {2, 2}, {1, 0}); auto shape01 = ShapeUtil::MakeShapeWithLayout(F32, {2, 2}, {0, 1}); - auto token = builder.AddInstruction(HloInstruction::CreateAfterAll({})); + auto token = builder.AddInstruction(HloInstruction::CreateToken()); auto outfeed10 = builder.AddInstruction( HloInstruction::CreateOutfeed(shape10, constant, token, "")); auto outfeed01 = builder.AddInstruction( diff --git a/tensorflow/compiler/xla/service/hlo_instructions.cc b/tensorflow/compiler/xla/service/hlo_instructions.cc index c160647f7a..7ea42caa7b 100644 --- a/tensorflow/compiler/xla/service/hlo_instructions.cc +++ b/tensorflow/compiler/xla/service/hlo_instructions.cc @@ -469,6 +469,46 @@ std::unique_ptr<HloInstruction> HloReduceInstruction::CloneWithNewOperandsImpl( shape, new_operands[0], new_operands[1], dimensions(), to_apply()); } +HloSortInstruction::HloSortInstruction(const Shape& shape, int64 dimension, + HloInstruction* keys, + HloInstruction* values) + : HloInstruction(HloOpcode::kSort, shape), dimensions_({dimension}) { + AppendOperand(keys); + if (values) { + AppendOperand(values); + } +} + +HloInstructionProto HloSortInstruction::ToProto() const { + HloInstructionProto proto = HloInstruction::ToProto(); + for (int64 dimension : dimensions_) { + proto.add_dimensions(dimension); + } + return proto; +} + +std::vector<string> HloSortInstruction::ExtraAttributesToStringImpl( + const HloPrintOptions& options) const { + return {StrCat("dimensions={", Join(dimensions(), ","), "}")}; +} + +bool HloSortInstruction::IdenticalSlowPath( + const HloInstruction& other, + const std::function<bool(const HloComputation*, const HloComputation*)>& + eq_computations) const { + const auto& casted_other = static_cast<const HloSortInstruction&>(other); + return dimensions() == casted_other.dimensions(); +} + +std::unique_ptr<HloInstruction> HloSortInstruction::CloneWithNewOperandsImpl( + const Shape& shape, + tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, + HloCloneContext* context) const { + HloInstruction* keys = new_operands[0]; + HloInstruction* values = new_operands.size() == 2 ? new_operands[1] : nullptr; + return MakeUnique<HloSortInstruction>(shape, dimensions(0), keys, values); +} + HloTransposeInstruction::HloTransposeInstruction( const Shape& shape, HloInstruction* operand, tensorflow::gtl::ArraySlice<int64> dimensions) diff --git a/tensorflow/compiler/xla/service/hlo_instructions.h b/tensorflow/compiler/xla/service/hlo_instructions.h index df6969c410..e922d94234 100644 --- a/tensorflow/compiler/xla/service/hlo_instructions.h +++ b/tensorflow/compiler/xla/service/hlo_instructions.h @@ -349,6 +349,35 @@ class HloReduceInstruction : public HloInstruction { std::vector<int64> dimensions_; }; +class HloSortInstruction : public HloInstruction { + public: + explicit HloSortInstruction(const Shape& shape, int64 dimension, + HloInstruction* keys, + HloInstruction* values = nullptr); + // Returns the dimension sizes or numbers associated with this instruction. + const std::vector<int64>& dimensions() const override { return dimensions_; } + int64 dimensions(int64 index) const override { return dimensions()[index]; } + // Returns the sort dimension for this instruction + int64 sort_dimension() { return dimensions(0); } + // Returns a serialized representation of this instruction. + HloInstructionProto ToProto() const override; + + private: + std::vector<string> ExtraAttributesToStringImpl( + const HloPrintOptions& options) const override; + bool IdenticalSlowPath( + const HloInstruction& other, + const std::function<bool(const HloComputation*, const HloComputation*)>& + eq_computations) const override; + // Implementation for non-common logic of CloneWithNewOperands. + std::unique_ptr<HloInstruction> CloneWithNewOperandsImpl( + const Shape& shape, + tensorflow::gtl::ArraySlice<HloInstruction*> new_operands, + HloCloneContext* context) const override; + + std::vector<int64> dimensions_; +}; + class HloTransposeInstruction : public HloInstruction { public: explicit HloTransposeInstruction( diff --git a/tensorflow/compiler/xla/service/hlo_module.cc b/tensorflow/compiler/xla/service/hlo_module.cc index 39bc25ba42..55ff073d3f 100644 --- a/tensorflow/compiler/xla/service/hlo_module.cc +++ b/tensorflow/compiler/xla/service/hlo_module.cc @@ -537,10 +537,11 @@ uint64 HloModule::RandomNew64() const { HloComputation* HloModule::GetComputationWithName( tensorflow::StringPiece name) { - auto it = c_find_if(computations(), [&](HloComputation* computation) { + auto computations_in_module = computations(); + auto it = c_find_if(computations_in_module, [&](HloComputation* computation) { return computation->name() == name; }); - return it == computations().end() ? nullptr : *it; + return it == computations_in_module.end() ? nullptr : *it; } /* static */ std::atomic<int> HloModule::next_unique_module_id_(0); diff --git a/tensorflow/compiler/xla/service/hlo_parser.cc b/tensorflow/compiler/xla/service/hlo_parser.cc index 54fc34b862..f162d52d3c 100644 --- a/tensorflow/compiler/xla/service/hlo_parser.cc +++ b/tensorflow/compiler/xla/service/hlo_parser.cc @@ -622,23 +622,32 @@ bool HloParser::ParseInstruction(HloComputation::Builder* builder, if (!ParseOperands(&operands) || !ParseAttributes(attrs)) { return false; } - instruction = - builder->AddInstruction(HloInstruction::CreateAfterAll(operands)); + if (operands.empty()) { + instruction = builder->AddInstruction(HloInstruction::CreateToken()); + } else { + instruction = + builder->AddInstruction(HloInstruction::CreateAfterAll(operands)); + } break; } case HloOpcode::kSort: { auto loc = lexer_.GetLoc(); - if (!ParseOperands(&operands) || !ParseAttributes(attrs)) { + + optional<std::vector<tensorflow::int64>> dimensions; + attrs["dimensions"] = {/*required=*/true, AttrTy::kBracedInt64List, + &dimensions}; + if (!ParseOperands(&operands) || !ParseAttributes(attrs) || + dimensions->size() != 1) { return false; } switch (operands.size()) { case 1: - instruction = builder->AddInstruction( - HloInstruction::CreateSort(shape, /*keys=*/operands[0])); + instruction = builder->AddInstruction(HloInstruction::CreateSort( + shape, dimensions->at(0), /*keys=*/operands[0])); break; case 2: instruction = builder->AddInstruction(HloInstruction::CreateSort( - shape, + shape, dimensions->at(0), /*keys=*/operands[0], /*values=*/operands[1])); break; default: diff --git a/tensorflow/compiler/xla/service/hlo_parser_test.cc b/tensorflow/compiler/xla/service/hlo_parser_test.cc index 88f3309baa..f06c705c42 100644 --- a/tensorflow/compiler/xla/service/hlo_parser_test.cc +++ b/tensorflow/compiler/xla/service/hlo_parser_test.cc @@ -840,7 +840,7 @@ R"(HloModule sort ENTRY Sort { x = f32[1024]{0} parameter(0) - ROOT sorted = f32[1024]{0} sort(x) + ROOT sorted = f32[1024]{0} sort(x), dimensions={0} } )" @@ -853,7 +853,32 @@ R"(HloModule sort ENTRY Sort { keys = f32[1024]{0} parameter(0) values = s32[1024]{0} parameter(1) - ROOT sorted = (f32[1024]{0}, s32[1024]{0}) sort(keys, values) + ROOT sorted = (f32[1024]{0}, s32[1024]{0}) sort(keys, values), dimensions={0} +} + +)" +}, +// R2 Sort (Key) +{ +"SortKeyR2", +R"(HloModule sort + +ENTRY Sort { + x = f32[1024,16]{0,1} parameter(0) + ROOT sorted = f32[1024,16]{0,1} sort(x), dimensions={0} +} + +)" +}, +// R2 Sort (Key, Value) +{ +"SortKeyValueR2", +R"(HloModule sort + +ENTRY Sort { + keys = f32[1024,16]{0,1} parameter(0) + values = s32[1024,16]{0,1} parameter(1) + ROOT sorted = (f32[1024,16]{0,1}, s32[1024,16]{0,1}) sort(keys, values), dimensions={0} } )" diff --git a/tensorflow/compiler/xla/service/indexed_array_analysis.cc b/tensorflow/compiler/xla/service/indexed_array_analysis.cc index 1985d20578..8b2df32567 100644 --- a/tensorflow/compiler/xla/service/indexed_array_analysis.cc +++ b/tensorflow/compiler/xla/service/indexed_array_analysis.cc @@ -19,6 +19,7 @@ limitations under the License. #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/gtl/flatset.h" #include "tensorflow/core/lib/gtl/inlined_vector.h" +#include "tensorflow/core/lib/gtl/optional.h" #include "tensorflow/core/lib/strings/strcat.h" namespace xla { @@ -160,6 +161,12 @@ StatusOr<Analysis::Array*> IndexedArrayAnalysis::ComputeArrayFor( computed_array, ComputeArrayForReshape(instr->shape(), FindOrDie(cache_, instr->operand(0)))); + } else if (instr->opcode() == HloOpcode::kDot) { + TF_ASSIGN_OR_RETURN( + computed_array, + ComputeArrayForDot(instr->shape(), instr->dot_dimension_numbers(), + FindOrDie(cache_, instr->operand(0)), + FindOrDie(cache_, instr->operand(1)))); } else { computed_array = nullptr; } @@ -290,8 +297,7 @@ StatusOr<Analysis::Array*> IndexedArrayAnalysis::ComputeArrayForGather( } if (auto* indexed = dynamic_cast<ScalarIndexedArray*>(source)) { - auto it = c_find(indexed->output_dims(), source_dim); - if (it != indexed->output_dims().end()) { + if (c_linear_search(indexed->output_dims(), source_dim)) { return FoldGatherOfGather(indexed, indices, source_dim, output_dims, shape); } @@ -956,11 +962,177 @@ IndexedArrayAnalysis::ComputeArrayForElementwiseUnaryOp(HloOpcode opcode, return Construct<ScalarIndexedConstantArray>( new_source, scalar_indexed_const->indices(), scalar_indexed_const->source_dim(), - std::vector<int64>(scalar_indexed_const->output_dims().begin(), - scalar_indexed_const->output_dims().end()), + ArraySliceToVector(scalar_indexed_const->output_dims()), scalar_indexed_const->shape()); } +namespace { + +// Returns the non-contracting non-batch dimension (as per `contracting_dims` +// and `batch_dims`) if there is exactly one, otherwise returns nullopt. +gtl::optional<int64> GetOnlyNonContractingNonBatchDim( + int64 rank, ArraySlice<int64> contracting_dims, + ArraySlice<int64> batch_dims) { + gtl::optional<int64> result; + for (int64 dim = 0; dim < rank; dim++) { + if (!ArrayContains(contracting_dims, dim) && + !ArrayContains(batch_dims, dim)) { + if (result.has_value()) { + return gtl::nullopt; + } + result = dim; + } + } + return result; +} + +// Returns true if `indexed_array`, which is either the LHS or the RHS of a Dot +// HLO, can be folded into the dot operation. For now these conditions are both +// necessary and sufficient. +// +// `tag` describes the caller. Used only for logging. +// +// `contracting_dims` and `batch_dims` are the contracting and batch dimensions +// of whatever operand `indexed_array` is to the dot (LHS or RHS). +bool CanFoldDotIntoIndexedArray( + tensorflow::StringPiece tag, + Analysis::ScalarIndexedConstantArray* indexed_array, + ArraySlice<int64> contracting_dims, ArraySlice<int64> batch_dims) { + gtl::optional<int64> non_contracting_non_batch_dim = + GetOnlyNonContractingNonBatchDim(ShapeUtil::Rank(indexed_array->shape()), + contracting_dims, batch_dims); + if (!non_contracting_non_batch_dim.has_value()) { + VLOG(3) << tag << ": multiple or no non-contracting non-batch dimensions"; + return false; + } + + if (indexed_array->output_dims().size() != 1 || + indexed_array->output_dims()[0] != *non_contracting_non_batch_dim) { + VLOG(3) << tag << ": output dims != the lhs non-contracting non-batch dim"; + return false; + } + + int64 indexed_array_rank = ShapeUtil::Rank(indexed_array->shape()); + if (indexed_array->source_dim() < (indexed_array_rank - 2)) { + // This restriction can be lifted by inserting reshape nodes. + VLOG(3) << tag + << ": source dim is not in the low two dims, won't be able to form " + "a matmul"; + return false; + } + + return true; +} + +} // namespace + +StatusOr<Analysis::Array*> +IndexedArrayAnalysis::ComputeArrayForDotWithIndexedLhs( + const Shape& shape, const DotDimensionNumbers& dim_numbers, + ScalarIndexedConstantArray* lhs, ConstantArray* rhs) { + VLOG(3) << "ComputeArrayForDotWithIndexedLhs(" << ToString(lhs) << " " + << ToString(rhs); + if (!CanFoldDotIntoIndexedArray( + "ComputeArrayForDotWithIndexedLhs", lhs, /*contracting_dims=*/ + AsInt64Slice(dim_numbers.lhs_contracting_dimensions()), + /*batch_dims=*/AsInt64Slice(dim_numbers.lhs_batch_dimensions()))) { + return nullptr; + } + + int64 lhs_rank = ShapeUtil::Rank(lhs->shape()); + DotDimensionNumbers new_dim_numbers = dim_numbers; + new_dim_numbers.set_lhs_contracting_dimensions( + 0, lhs->source_dim() == (lhs_rank - 1) ? (lhs_rank - 2) : (lhs_rank - 1)); + + TF_ASSIGN_OR_RETURN(Literal * literal_for_new_source, + TakeOwnership(HloEvaluator{}.EvaluateDotOp( + new_dim_numbers, lhs->literal(), *rhs->literal()))); + + // The new source dimension is wherever the non-batch non-contracting LHS + // dimension "went". + int64 new_source_dim = dim_numbers.lhs_batch_dimensions_size() + + dim_numbers.rhs_batch_dimensions_size(); + + ConstantArray* new_source = Construct<ConstantArray>(literal_for_new_source); + return Construct<ScalarIndexedConstantArray>( + new_source, lhs->indices(), new_source_dim, + ArraySliceToVector(lhs->output_dims()), shape); +} + +StatusOr<Analysis::Array*> +IndexedArrayAnalysis::ComputeArrayForDotWithIndexedRhs( + const Shape& shape, const DotDimensionNumbers& dim_numbers, + ConstantArray* lhs, ScalarIndexedConstantArray* rhs) { + VLOG(3) << "ComputeArrayForDotWithIndexedRhs(" << ToString(lhs) << " " + << ToString(rhs); + if (!CanFoldDotIntoIndexedArray( + "ComputeArrayForDotWithIndexedRhs", rhs, /*contracting_dims=*/ + AsInt64Slice(dim_numbers.rhs_contracting_dimensions()), + /*batch_dims=*/AsInt64Slice(dim_numbers.rhs_batch_dimensions()))) { + return nullptr; + } + + int64 rhs_rank = ShapeUtil::Rank(rhs->shape()); + + DotDimensionNumbers new_dim_numbers = dim_numbers; + new_dim_numbers.set_rhs_contracting_dimensions( + 0, rhs->source_dim() == (rhs_rank - 1) ? (rhs_rank - 2) : (rhs_rank - 1)); + + TF_ASSIGN_OR_RETURN(Literal * literal_for_new_source, + TakeOwnership(HloEvaluator{}.EvaluateDotOp( + new_dim_numbers, *lhs->literal(), rhs->literal()))); + + // The new source dimension is wherever the non-batch non-contracting RHS + // dimension "went". + int64 new_source_dim = dim_numbers.lhs_batch_dimensions_size() + + dim_numbers.rhs_batch_dimensions_size() + 1; + + ConstantArray* new_source = Construct<ConstantArray>(literal_for_new_source); + return Construct<ScalarIndexedConstantArray>( + new_source, rhs->indices(), new_source_dim, + ArraySliceToVector(rhs->output_dims()), shape); +} + +StatusOr<Analysis::Array*> IndexedArrayAnalysis::ComputeArrayForDot( + const Shape& shape, const DotDimensionNumbers& dim_numbers, Array* lhs, + Array* rhs) { + // Intuitively, if + // + // - The LHS of a dot product is a gathered sequence of rows from a constant + // array (i.e. LHS[I,J] = Const[Indices[I],J]) and the RHS is a constant + // + // OR + // + // - If the RHS of a dot product is a gathered sequence of columns from a + // constant array (i.e. RHS[I,J] = Const[I, Indices[J]]) and the LHS is a + // constant + // + // then the result of the dot product itself is a gather from a constant + // array. E.g. Dot(LHS, ConstRhs) where LHS[I,J] = Const[Indices[I],J] can be + // rewritten as Result where Result[I,J] = Dot(Const, ConstRhs)[Indices[I], + // J]. + // + // We do a general version of this rewrite here. + VLOG(3) << "ComputeArrayForDot(" << ToString(lhs) << " " << ToString(rhs); + if (auto* lhs_indexed_array = + dynamic_cast<ScalarIndexedConstantArray*>(lhs)) { + if (auto* rhs_constant = dynamic_cast<ConstantArray*>(rhs)) { + return ComputeArrayForDotWithIndexedLhs(shape, dim_numbers, + lhs_indexed_array, rhs_constant); + } + } + + if (auto* rhs_indexed_array = + dynamic_cast<ScalarIndexedConstantArray*>(rhs)) { + if (auto* lhs_constant = dynamic_cast<ConstantArray*>(lhs)) { + return ComputeArrayForDotWithIndexedRhs(shape, dim_numbers, lhs_constant, + rhs_indexed_array); + } + } + + return nullptr; +} + tensorflow::StringPiece IndexedArrayAnalysisPrinterPass::name() const { return "indexed-array-analysis-printer-pass"; } diff --git a/tensorflow/compiler/xla/service/indexed_array_analysis.h b/tensorflow/compiler/xla/service/indexed_array_analysis.h index 8684430231..e923dc39f7 100644 --- a/tensorflow/compiler/xla/service/indexed_array_analysis.h +++ b/tensorflow/compiler/xla/service/indexed_array_analysis.h @@ -268,6 +268,18 @@ class IndexedArrayAnalysis { tensorflow::gtl::ArraySlice<int64> window_bounds, Array* source, Array* indices); + StatusOr<Array*> ComputeArrayForDotWithIndexedLhs( + const Shape& shape, const DotDimensionNumbers& dim_numbers, + ScalarIndexedConstantArray* lhs, ConstantArray* rhs); + + StatusOr<Array*> ComputeArrayForDotWithIndexedRhs( + const Shape& shape, const DotDimensionNumbers& dim_numbers, + ConstantArray* lhs, ScalarIndexedConstantArray* rhs); + + StatusOr<Array*> ComputeArrayForDot(const Shape& shape, + const DotDimensionNumbers& dim_numbers, + Array* lhs, Array* rhs); + // This tries to fold a ScalarIndexedArray which has another // ScalarIndexedArray as a source into a ScalarIndexedArray that instead has a // ScalarIndexedArray as indices. If `source` happened to be a diff --git a/tensorflow/compiler/xla/service/indexed_array_analysis_test.cc b/tensorflow/compiler/xla/service/indexed_array_analysis_test.cc index fc2befe05b..5f4b42799b 100644 --- a/tensorflow/compiler/xla/service/indexed_array_analysis_test.cc +++ b/tensorflow/compiler/xla/service/indexed_array_analysis_test.cc @@ -799,5 +799,170 @@ ENTRY main { AssertArrayForRootExpressionIs(hlo_text, "%add"); } +TEST_F(IndexedArrayAnalysisTest, DotOpBasic_0) { + string hlo_text = R"( +HloModule DotOp + +ENTRY main { + gather_operand = s32[3,4] constant(s32[3,4]{{1,2,3,4},{5,6,7,8},{9,10,11,12}}) + dot_rhs_constant = s32[4,3] constant(s32[4,3]{{1,2,3},{4,5,6},{7,8,9},{10,11,12}}) + indices = s32[5] parameter(0) + dot_lhs = s32[5,4] gather(gather_operand, indices), + output_window_dims={1}, + elided_window_dims={0}, + gather_dims_to_operand_dims={0}, + index_vector_dim=1, + window_bounds={1,4} + ROOT dot = s32[5,3] dot(dot_lhs, dot_rhs_constant), lhs_contracting_dims={1}, rhs_contracting_dims={0} +} +)"; + + AssertArrayWithConstantsForRootExpressionIs(hlo_text, R"( +(scalar-indexed-const + (constant s32[3,3] s32[3,3] { + { 70, 80, 90 }, + { 158, 184, 210 }, + { 246, 288, 330 } }) + %indices 0->[0]))"); +} + +TEST_F(IndexedArrayAnalysisTest, DotOpBasic_1) { + string hlo_text = R"( +HloModule DotOp + +ENTRY main { + gather_operand = s32[3,4] constant(s32[3,4]{{1,2,3,4},{5,6,7,8},{9,10,11,12}}) + dot_rhs_constant = s32[3,3] constant(s32[3,3]{{1,2,3},{4,5,6},{7,8,9}}) + indices = s32[5] parameter(0) + dot_lhs = s32[3,5] gather(gather_operand, indices), + output_window_dims={0}, + elided_window_dims={1}, + gather_dims_to_operand_dims={1}, + index_vector_dim=1, + window_bounds={3,1} + ROOT dot = s32[5,3] dot(dot_lhs, dot_rhs_constant), lhs_contracting_dims={0}, rhs_contracting_dims={0} +} +)"; + + AssertArrayWithConstantsForRootExpressionIs(hlo_text, R"( +(scalar-indexed-const + (constant s32[4,3] s32[4,3] { + { 84, 99, 114 }, + { 96, 114, 132 }, + { 108, 129, 150 }, + { 120, 144, 168 } }) + %indices 0->[1]))"); +} + +TEST_F(IndexedArrayAnalysisTest, DotOpBasic_2) { + string hlo_text = R"( +HloModule DotOp + +ENTRY main { + gather_operand = s32[3,4] constant(s32[3,4]{{1,2,3,4},{5,6,7,8},{9,10,11,12}}) + dot_lhs_constant = s32[4,3] constant(s32[4,3]{{1,2,3},{4,5,6},{7,8,9},{10,11,12}}) + indices = s32[5] parameter(0) + dot_rhs = s32[3,5] gather(gather_operand, indices), + output_window_dims={0}, + elided_window_dims={1}, + gather_dims_to_operand_dims={1}, + index_vector_dim=1, + window_bounds={3,1} + ROOT dot = s32[4,5] dot(dot_lhs_constant, dot_rhs), lhs_contracting_dims={1}, rhs_contracting_dims={0} +} +)"; + + AssertArrayWithConstantsForRootExpressionIs(hlo_text, R"( +(scalar-indexed-const + (constant s32[4,4] s32[4,4] { + { 38, 44, 50, 56 }, + { 83, 98, 113, 128 }, + { 128, 152, 176, 200 }, + { 173, 206, 239, 272 } }) + %indices 1->[1]) +)"); +} + +TEST_F(IndexedArrayAnalysisTest, DotOpBasic_3) { + string hlo_text = R"( +HloModule DotOp + +ENTRY main { + gather_operand = s32[4,3] constant(s32[4,3]{{1,2,3},{4,5,6},{7,8,9},{10,11,12}}) + dot_lhs_constant = s32[4,3] constant(s32[4,3]{{1,2,3},{4,5,6},{7,8,9},{10,11,12}}) + indices = s32[5] parameter(0) + dot_rhs = s32[5,3] gather(gather_operand, indices), + output_window_dims={1}, + elided_window_dims={0}, + gather_dims_to_operand_dims={0}, + index_vector_dim=1, + window_bounds={1,3} + ROOT dot = s32[4,5] dot(dot_lhs_constant, dot_rhs), lhs_contracting_dims={1}, rhs_contracting_dims={1} +} +)"; + + AssertArrayWithConstantsForRootExpressionIs(hlo_text, R"( +(scalar-indexed-const + (constant s32[4,4] s32[4,4] { + { 14, 32, 50, 68 }, + { 32, 77, 122, 167 }, + { 50, 122, 194, 266 }, + { 68, 167, 266, 365 } }) + %indices 1->[0]) +)"); +} + +TEST_F(IndexedArrayAnalysisTest, DotOpWithBatch) { + string hlo_text = R"( +HloModule DotOp + +ENTRY main { + gather_operand = s32[2,3,2] constant(s32[2,3,2]{{{1,2},{3,4},{5,6}},{{7,8},{9,10},{11,12}}}) + dot_lhs_constant = s32[2,2,3] constant(s32[2,2,3]{{{1,2,3},{4,5,6}},{{7,8,9},{10,11,12}}}) + indices = s32[4] parameter(0) + dot_rhs = s32[2,3,4] gather(gather_operand, indices), + output_window_dims={0,1}, + elided_window_dims={2}, + gather_dims_to_operand_dims={2}, + index_vector_dim=1, + window_bounds={2,3,1} + ROOT dot = s32[2,2,4] dot(dot_lhs_constant, dot_rhs), + lhs_contracting_dims={2}, rhs_contracting_dims={1}, + lhs_batch_dims={0}, rhs_batch_dims={0} +} +)"; + + AssertArrayWithConstantsForRootExpressionIs(hlo_text, R"( +(scalar-indexed-const + (constant s32[2,2,2] s32[2,2,2] { + { { 22, 28 }, + { 49, 64 } }, + { { 220, 244 }, + { 301, 334 } } }) + %indices 3->[2]) +)"); +} + +TEST_F(IndexedArrayAnalysisTest, DotOpNegative) { + string hlo_text = R"( +HloModule DotOp + +ENTRY main { + gather_operand = s32[3,4] constant(s32[3,4]{{1,2,3,4},{5,6,7,8},{9,10,11,12}}) + dot_rhs_constant = s32[2,3] constant(s32[2,3]{{1,2,3},{4,5,6}}) + indices = s32[2] parameter(0) + dot_lhs = s32[3,2] gather(gather_operand, indices), + output_window_dims={0}, + elided_window_dims={1}, + gather_dims_to_operand_dims={1}, + index_vector_dim=1, + window_bounds={3,1} + ROOT dot = s32[3,3] dot(dot_lhs, dot_rhs_constant), lhs_contracting_dims={1}, rhs_contracting_dims={0} +} +)"; + + AssertArrayWithConstantsForRootExpressionIs(hlo_text, "%dot"); +} + } // namespace } // namespace xla diff --git a/tensorflow/compiler/xla/service/instruction_fusion_test.cc b/tensorflow/compiler/xla/service/instruction_fusion_test.cc index bb7231c8c8..9e7a15f033 100644 --- a/tensorflow/compiler/xla/service/instruction_fusion_test.cc +++ b/tensorflow/compiler/xla/service/instruction_fusion_test.cc @@ -167,7 +167,7 @@ TEST_F(InstructionFusionTest, AvoidDuplicationIfNotAllFusable) { builder.AddInstruction(HloInstruction::CreateParameter(1, shape, "1")); HloInstruction* binary1 = builder.AddInstruction( HloInstruction::CreateBinary(shape, HloOpcode::kAdd, param0, param1)); - auto token = builder.AddInstruction(HloInstruction::CreateAfterAll({})); + auto token = builder.AddInstruction(HloInstruction::CreateToken()); builder.AddInstruction(HloInstruction::CreateSend(binary1, token, 0)); HloInstruction* unary = builder.AddInstruction( HloInstruction::CreateUnary(shape, HloOpcode::kAbs, binary1)); @@ -356,7 +356,7 @@ TEST_F(InstructionFusionTest, AllowUnaryDuplication) { builder.AddInstruction(HloInstruction::CreateParameter(0, shape, "0")); HloInstruction* unary1 = builder.AddInstruction( HloInstruction::CreateUnary(shape, HloOpcode::kFloor, param0)); - auto token = builder.AddInstruction(HloInstruction::CreateAfterAll({})); + auto token = builder.AddInstruction(HloInstruction::CreateToken()); builder.AddInstruction(HloInstruction::CreateSend(unary1, token, 0)); HloInstruction* unary2 = builder.AddInstruction( HloInstruction::CreateUnary(shape, HloOpcode::kAbs, unary1)); @@ -380,7 +380,7 @@ TEST_F(InstructionFusionTest, AllowEffectiveUnaryDuplication) { builder.AddInstruction(HloInstruction::CreateParameter(1, shape, "1")); HloInstruction* binary1 = builder.AddInstruction( HloInstruction::CreateBinary(shape, HloOpcode::kAdd, param0, param1)); - auto token = builder.AddInstruction(HloInstruction::CreateAfterAll({})); + auto token = builder.AddInstruction(HloInstruction::CreateToken()); builder.AddInstruction(HloInstruction::CreateSend(binary1, token, 0)); HloInstruction* unary = builder.AddInstruction( HloInstruction::CreateUnary(shape, HloOpcode::kAbs, binary1)); diff --git a/tensorflow/compiler/xla/service/layout_assignment_test.cc b/tensorflow/compiler/xla/service/layout_assignment_test.cc index ebd7f696e6..a16fa75e30 100644 --- a/tensorflow/compiler/xla/service/layout_assignment_test.cc +++ b/tensorflow/compiler/xla/service/layout_assignment_test.cc @@ -770,8 +770,7 @@ TEST_F(LayoutAssignmentTest, ConditionalAsymmetricLayout) { false_builder.AddInstruction( HloInstruction::CreateParameter(0, tshape, "param")); // Using infeed as layout assignment does not mess up with it. - auto token = - false_builder.AddInstruction(HloInstruction::CreateAfterAll({})); + auto token = false_builder.AddInstruction(HloInstruction::CreateToken()); auto infeed = false_builder.AddInstruction( HloInstruction::CreateInfeed(xshape, token, "")); auto infeed_data = false_builder.AddInstruction( diff --git a/tensorflow/compiler/xla/service/llvm_ir/fused_ir_emitter.cc b/tensorflow/compiler/xla/service/llvm_ir/fused_ir_emitter.cc index 21160a770f..d2a9e8a328 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/fused_ir_emitter.cc +++ b/tensorflow/compiler/xla/service/llvm_ir/fused_ir_emitter.cc @@ -125,15 +125,12 @@ Status FusedIrEmitter::HandleParameter(HloInstruction* parameter) { parameter->parameter_number()); if (param_buffer) { VLOG(3) << "Use buffer for " << parameter->ToString(); - llvm::Instruction* load_from_buffer = ir_builder_->CreateLoad( + return ir_builder_->CreateLoad( ir_builder_->CreateGEP( param_buffer, {index.GetConstantWithIndexType(0), tiled_parameter_info_->x(), tiled_parameter_info_->y()}), "tiled_buffer"); - parameter_arrays_[parameter->parameter_number()] - .AnnotateBufferLoadStoreInstructionWithMetadata(load_from_buffer); - return load_from_buffer; } } return parameter_arrays_[parameter->parameter_number()] diff --git a/tensorflow/compiler/xla/service/llvm_ir/ir_array.cc b/tensorflow/compiler/xla/service/llvm_ir/ir_array.cc index f389cc283f..dcf9838d80 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/ir_array.cc +++ b/tensorflow/compiler/xla/service/llvm_ir/ir_array.cc @@ -401,19 +401,6 @@ void IrArray::AnnotateLoadStoreInstructionWithMetadata( } } -void IrArray::AnnotateBufferLoadStoreInstructionWithMetadata( - llvm::Instruction* instruction) const { - CHECK(llvm::isa<llvm::LoadInst>(instruction) || - llvm::isa<llvm::StoreInst>(instruction)); - CHECK(is_invariant_) << "IrArray for a parameter is not marked as invariant."; - - for (const auto& kind_md_pair : metadata_) { - if (kind_md_pair.first != llvm::LLVMContext::MD_invariant_load) { - instruction->setMetadata(kind_md_pair.first, kind_md_pair.second); - } - } -} - llvm::Value* IrArray::EmitReadArrayElement(const Index& index, llvm::IRBuilder<>* ir_builder, tensorflow::StringPiece name) const { diff --git a/tensorflow/compiler/xla/service/llvm_ir/ir_array.h b/tensorflow/compiler/xla/service/llvm_ir/ir_array.h index fb1f01ab6b..5135233aa8 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/ir_array.h +++ b/tensorflow/compiler/xla/service/llvm_ir/ir_array.h @@ -114,19 +114,19 @@ class IrArray { size_t size() const { return multidim().size(); } llvm::Value* operator[](size_t i) const { return multidim()[i]; } - llvm::Value*& operator[](size_t i) { return multidim()[i]; } + llvm::Value*& operator[](size_t i) { return mutable_multidim()[i]; } - void push_back(llvm::Value* value) { multidim().push_back(value); } + void push_back(llvm::Value* value) { mutable_multidim().push_back(value); } void InsertAt(int64 index, llvm::Value* value) { CHECK_LE(index, size()); - multidim().insert(multidim().begin() + index, value); + mutable_multidim().insert(multidim().begin() + index, value); } using iterator = std::vector<llvm::Value*>::iterator; using const_iterator = std::vector<llvm::Value*>::const_iterator; - iterator begin() { return multidim().begin(); } - iterator end() { return multidim().end(); } + iterator begin() { return mutable_multidim().begin(); } + iterator end() { return mutable_multidim().end(); } const_iterator begin() const { return multidim().begin(); } const_iterator end() const { return multidim().end(); } @@ -185,7 +185,7 @@ class IrArray { private: // Changing the multi-dimensional index invalidates the linear index. - std::vector<llvm::Value*>& multidim() { + std::vector<llvm::Value*>& mutable_multidim() { linear_ = nullptr; return multidim_; } @@ -248,11 +248,6 @@ class IrArray { void AnnotateLoadStoreInstructionWithMetadata( llvm::Instruction* instruction) const; - // Uses the metadata for a parameter IrArray to annotate the load/store of the - // tile buffer for the parameter. - void AnnotateBufferLoadStoreInstructionWithMetadata( - llvm::Instruction* instruction) const; - // Emit IR to read an array element at the given index. Returns the read // result (effectively, a Value loaded from memory). This method seamlessly // handles scalar shapes by broadcasting their value to all indices (index is diff --git a/tensorflow/compiler/xla/service/tuple_points_to_analysis_test.cc b/tensorflow/compiler/xla/service/tuple_points_to_analysis_test.cc index d52091487f..0ac8df4271 100644 --- a/tensorflow/compiler/xla/service/tuple_points_to_analysis_test.cc +++ b/tensorflow/compiler/xla/service/tuple_points_to_analysis_test.cc @@ -318,7 +318,7 @@ TEST_F(TuplePointsToAnalysisTest, SendAndSendDone) { auto builder = HloComputation::Builder(TestName()); auto constant = builder.AddInstruction( HloInstruction::CreateConstant(LiteralUtil::CreateR0<float>(1.0))); - auto token = builder.AddInstruction(HloInstruction::CreateAfterAll({})); + auto token = builder.AddInstruction(HloInstruction::CreateToken()); auto send = builder.AddInstruction( HloInstruction::CreateSend(constant, token, /*channel_id=*/0)); auto send_done = builder.AddInstruction(HloInstruction::CreateSendDone(send)); @@ -343,7 +343,7 @@ TEST_F(TuplePointsToAnalysisTest, SendAndSendDone) { TEST_F(TuplePointsToAnalysisTest, RecvAndRecvDone) { // RecvDone forwards its operand tuple element at {0} to the output. auto builder = HloComputation::Builder(TestName()); - auto token = builder.AddInstruction(HloInstruction::CreateAfterAll({})); + auto token = builder.AddInstruction(HloInstruction::CreateToken()); auto recv = builder.AddInstruction(HloInstruction::CreateRecv( ShapeUtil::MakeShape(F32, {1, 2, 3}), token, /*channel_id=*/0)); auto recv_done = builder.AddInstruction(HloInstruction::CreateRecvDone(recv)); diff --git a/tensorflow/compiler/xla/service/while_loop_invariant_code_motion_test.cc b/tensorflow/compiler/xla/service/while_loop_invariant_code_motion_test.cc index a652aafc50..32e69c335b 100644 --- a/tensorflow/compiler/xla/service/while_loop_invariant_code_motion_test.cc +++ b/tensorflow/compiler/xla/service/while_loop_invariant_code_motion_test.cc @@ -273,7 +273,7 @@ TEST_F(WhileLoopInvariantCodeMotionTest, DontHoistInstructionWithSideEffects) { HloComputation::Builder builder(TestName()); auto* scalar_param = builder.AddInstruction( HloInstruction::CreateParameter(0, scalar_s32, "param")); - auto* token = builder.AddInstruction(HloInstruction::CreateAfterAll({})); + auto* token = builder.AddInstruction(HloInstruction::CreateToken()); auto* init_value = builder.AddInstruction( HloInstruction::CreateTuple({scalar_param, scalar_param, token})); auto* while_inst = builder.AddInstruction(HloInstruction::CreateWhile( @@ -323,7 +323,7 @@ TEST_F(WhileLoopInvariantCodeMotionTest, DontHoistBitcastAlone) { HloComputation::Builder builder(TestName()); auto* scalar_param = builder.AddInstruction( HloInstruction::CreateParameter(0, scalar_s32, "param")); - auto* token = builder.AddInstruction(HloInstruction::CreateAfterAll({})); + auto* token = builder.AddInstruction(HloInstruction::CreateToken()); auto* init_value = builder.AddInstruction( HloInstruction::CreateTuple({scalar_param, scalar_param, token})); auto* while_inst = builder.AddInstruction(HloInstruction::CreateWhile( diff --git a/tensorflow/compiler/xla/service/while_loop_simplifier_test.cc b/tensorflow/compiler/xla/service/while_loop_simplifier_test.cc index e8e9ce200b..2e1571943e 100644 --- a/tensorflow/compiler/xla/service/while_loop_simplifier_test.cc +++ b/tensorflow/compiler/xla/service/while_loop_simplifier_test.cc @@ -175,7 +175,7 @@ TEST_F(WhileLoopSimplifierTest, LoopWithSendNotSimplified) { auto* while_op = computation->root_instruction(); ASSERT_EQ(while_op->opcode(), HloOpcode::kWhile); auto* while_body = while_op->while_body(); - auto* token = while_body->AddInstruction(HloInstruction::CreateAfterAll({})); + auto* token = while_body->AddInstruction(HloInstruction::CreateToken()); auto* send = while_body->AddInstruction(HloInstruction::CreateSend( while_body->AddInstruction( HloInstruction::CreateConstant(LiteralUtil::CreateR0<bool>(true))), @@ -192,7 +192,7 @@ TEST_F(WhileLoopSimplifierTest, LoopWithRecvNotSimplified) { auto* while_op = computation->root_instruction(); ASSERT_EQ(while_op->opcode(), HloOpcode::kWhile); auto* while_body = while_op->while_body(); - auto* token = while_body->AddInstruction(HloInstruction::CreateAfterAll({})); + auto* token = while_body->AddInstruction(HloInstruction::CreateToken()); auto* recv = while_body->AddInstruction( HloInstruction::CreateRecv(ShapeUtil::MakeShape(F32, {1}), token, /*channel_id=*/0)); @@ -211,7 +211,7 @@ TEST_F(WhileLoopSimplifierTest, LoopWithInfeedNotSimplified) { auto* while_op = computation->root_instruction(); ASSERT_EQ(while_op->opcode(), HloOpcode::kWhile); auto* while_body = while_op->while_body(); - auto token = while_body->AddInstruction(HloInstruction::CreateAfterAll({})); + auto token = while_body->AddInstruction(HloInstruction::CreateToken()); while_body->AddInstruction(HloInstruction::CreateInfeed( ShapeUtil::MakeShape(F32, {1}), token, "config")); EXPECT_FALSE(WhileLoopSimplifier().Run(the_module).ValueOrDie()); diff --git a/tensorflow/compiler/xla/service/zero_sized_hlo_elimination_test.cc b/tensorflow/compiler/xla/service/zero_sized_hlo_elimination_test.cc index 1da5339826..b9ef18892d 100644 --- a/tensorflow/compiler/xla/service/zero_sized_hlo_elimination_test.cc +++ b/tensorflow/compiler/xla/service/zero_sized_hlo_elimination_test.cc @@ -67,7 +67,7 @@ TEST_F(ZeroSizedHloEliminationTest, DoesNotEliminateParameter) { } TEST_F(ZeroSizedHloEliminationTest, DoesNotEliminateSideEffects) { - auto token = builder_.AddInstruction(HloInstruction::CreateAfterAll({})); + auto token = builder_.AddInstruction(HloInstruction::CreateToken()); builder_.AddInstruction( HloInstruction::CreateSend(zero_sized_param_, token, 0)); TF_ASSERT_OK_AND_ASSIGN(bool changed, RunZeroSizedElimination()); diff --git a/tensorflow/compiler/xla/shape_util.cc b/tensorflow/compiler/xla/shape_util.cc index 101881f2f5..f4668c0f55 100644 --- a/tensorflow/compiler/xla/shape_util.cc +++ b/tensorflow/compiler/xla/shape_util.cc @@ -46,28 +46,14 @@ namespace xla { using ::tensorflow::strings::StrAppend; using ::tensorflow::strings::StrCat; -string ShapeIndex::ToString() const { - return StrCat("{", tensorflow::str_util::Join(indices_, ","), "}"); -} +string ShapeIndex::ToString() const { return ShapeIndexView(*this).ToString(); } string ShapeIndexView::ToString() const { - return StrCat("{", - tensorflow::str_util::Join( - tensorflow::gtl::make_range(begin_, end_), ","), - "}"); + return StrCat("{", tensorflow::str_util::Join(indices_, ","), "}"); } bool ShapeIndexView::operator==(const ShapeIndexView& other) const { - if (size() != other.size()) { - return false; - } - for (auto it = begin(), other_it = other.begin(); it != end(); - ++it, ++other_it) { - if (*it != *other_it) { - return false; - } - } - return true; + return indices_ == other.indices_; } bool ShapeIndexView::operator!=(const ShapeIndexView& other) const { diff --git a/tensorflow/compiler/xla/shape_util.h b/tensorflow/compiler/xla/shape_util.h index 56906c0a4f..d576be724e 100644 --- a/tensorflow/compiler/xla/shape_util.h +++ b/tensorflow/compiler/xla/shape_util.h @@ -110,31 +110,33 @@ class ShapeIndex { class ShapeIndexView { public: ShapeIndexView(const ShapeIndex& shape_index, int64 offset = 0) - : ShapeIndexView(shape_index.data() + offset, - shape_index.data() + shape_index.size()) { + : indices_(shape_index.data() + offset, shape_index.size()) { CHECK_LE(offset, shape_index.size()); } - ShapeIndexView(std::initializer_list<int64> indices) - : ShapeIndexView(indices.begin(), indices.end()) {} + ShapeIndexView(std::initializer_list<int64> indices) : indices_(indices) {} ShapeIndexView(const ShapeIndexView& other) = default; using iterator = const int64*; - iterator begin() const { return begin_; } - iterator end() const { return end_; } - int64 size() const { return std::distance(begin_, end_); } - bool empty() const { return begin_ == end_; } + iterator begin() const { return indices_.begin(); } + iterator end() const { return indices_.end(); } + int64 size() const { return indices_.size(); } + bool empty() const { return indices_.empty(); } int64 front() const { CHECK(!empty()); - return *begin_; + return indices_.front(); } ShapeIndexView ConsumeFront() const { - CHECK(!empty()); - auto new_begin = begin_; - ++new_begin; - return ShapeIndexView(new_begin, end_); + ShapeIndexView result = *this; + result.indices_.pop_front(); + return result; } - ShapeIndex ToShapeIndex() const { return ShapeIndex(begin_, end_); } + ShapeIndexView ConsumeBack() const { + ShapeIndexView result = *this; + result.indices_.pop_back(); + return result; + } + ShapeIndex ToShapeIndex() const { return ShapeIndex(begin(), end()); } bool operator==(const ShapeIndexView& other) const; bool operator!=(const ShapeIndexView& other) const; @@ -142,10 +144,7 @@ class ShapeIndexView { string ToString() const; private: - ShapeIndexView(iterator begin, iterator end) : begin_(begin), end_(end) {} - - iterator begin_; - iterator end_; + tensorflow::gtl::ArraySlice<int64> indices_; }; std::ostream& operator<<(std::ostream& out, const ShapeIndex& shape_index); diff --git a/tensorflow/compiler/xla/tests/hlo_test_base.cc b/tensorflow/compiler/xla/tests/hlo_test_base.cc index 242cc5db11..b662e83716 100644 --- a/tensorflow/compiler/xla/tests/hlo_test_base.cc +++ b/tensorflow/compiler/xla/tests/hlo_test_base.cc @@ -276,9 +276,10 @@ StatusOr<::testing::AssertionResult> HloTestBase::RunAndCompareInternal( HloComputation* HloTestBase::FindComputation(HloModule* module, tensorflow::StringPiece name) { - auto it = c_find_if(module->computations(), + auto computations = module->computations(); + auto it = c_find_if(computations, [&](HloComputation* c) { return c->name() == name; }); - if (it == module->computations().end()) { + if (it == computations.end()) { return nullptr; } return *it; @@ -287,9 +288,10 @@ HloComputation* HloTestBase::FindComputation(HloModule* module, HloInstruction* HloTestBase::FindInstruction(HloModule* module, tensorflow::StringPiece name) { for (const HloComputation* c : module->computations()) { - auto it = c_find_if(c->instructions(), + auto instructions = c->instructions(); + auto it = c_find_if(instructions, [&](HloInstruction* i) { return i->name() == name; }); - if (it != c->instructions().end()) { + if (it != instructions.end()) { return *it; } } diff --git a/tensorflow/compiler/xla/tests/token_hlo_test.cc b/tensorflow/compiler/xla/tests/token_hlo_test.cc index f6f4a17bca..2bdbd08309 100644 --- a/tensorflow/compiler/xla/tests/token_hlo_test.cc +++ b/tensorflow/compiler/xla/tests/token_hlo_test.cc @@ -31,7 +31,7 @@ class TokenHloTest : public HloTestBase {}; XLA_TEST_F(TokenHloTest, SingleTokenInstruction) { std::unique_ptr<HloModule> module = CreateNewModule(); auto builder = HloComputation::Builder(TestName()); - builder.AddInstruction(HloInstruction::CreateAfterAll({})); + builder.AddInstruction(HloInstruction::CreateToken()); module->AddEntryComputation(builder.Build()); @@ -43,9 +43,9 @@ XLA_TEST_F(TokenHloTest, SingleTokenInstruction) { XLA_TEST_F(TokenHloTest, TokenTree) { std::unique_ptr<HloModule> module = CreateNewModule(); auto builder = HloComputation::Builder(TestName()); - auto token0 = builder.AddInstruction(HloInstruction::CreateAfterAll({})); - auto token1 = builder.AddInstruction(HloInstruction::CreateAfterAll({})); - auto token2 = builder.AddInstruction(HloInstruction::CreateAfterAll({})); + auto token0 = builder.AddInstruction(HloInstruction::CreateToken()); + auto token1 = builder.AddInstruction(HloInstruction::CreateToken()); + auto token2 = builder.AddInstruction(HloInstruction::CreateToken()); builder.AddInstruction( HloInstruction::CreateAfterAll({token0, token0, token1, token2})); diff --git a/tensorflow/compiler/xla/tests/xla_hlo_profile_test.cc b/tensorflow/compiler/xla/tests/xla_hlo_profile_test.cc index cb6228221a..4d4dd62a3f 100644 --- a/tensorflow/compiler/xla/tests/xla_hlo_profile_test.cc +++ b/tensorflow/compiler/xla/tests/xla_hlo_profile_test.cc @@ -79,7 +79,9 @@ struct ParsedProfileOutputLine { Status ParseOneProfileOutputLine( const string& line, bool expect_hlo, - gtl::FlatMap<string, ParsedProfileOutputLine>* parsed_results) { + gtl::FlatMap<string, ParsedProfileOutputLine>* parsed_results, + tensorflow::gtl::ArraySlice<tensorflow::StringPiece> opcodes_to_ignore = + {}) { string separator = "[^:]*:: +"; string match_percentage = "\\d+\\.\\d\\d%"; string match_cycles = "(\\d+) cycles +\\( *(" + match_percentage + ")\\)"; @@ -113,7 +115,9 @@ Status ParseOneProfileOutputLine( ", Regexp: ", regexp_pattern); } - InsertOrDie(parsed_results, parsed_line.opcode, parsed_line); + if (!c_linear_search(opcodes_to_ignore, parsed_line.opcode)) { + InsertOrDie(parsed_results, parsed_line.opcode, parsed_line); + } return Status::OK(); } @@ -266,7 +270,7 @@ XLA_TEST_F(HloProfileTest, ProfileWhileComputation) { auto matrix = GetTupleElement(state, 1); auto next_iteration = Add(GetTupleElement(state, 0), ConstantR0<int32>(&builder, 1)); - Tuple(&builder, {next_iteration, Add(matrix, matrix)}); + Tuple(&builder, {next_iteration, Mul(matrix, matrix)}); TF_ASSERT_OK_AND_ASSIGN(body, builder.Build()); } @@ -288,36 +292,50 @@ XLA_TEST_F(HloProfileTest, ProfileWhileComputation) { tensorflow::str_util::Split(profile_output, '\n'); auto while_body_profile_start = - std::find_if(profile_output_lines.begin(), profile_output_lines.end(), + c_find_if(profile_output_lines, [](tensorflow::StringPiece s) { + return tensorflow::str_util::StartsWith(s, + "Execution profile for body"); + }); + + ASSERT_NE(while_body_profile_start, profile_output_lines.cend()); + + auto while_body_profile_end = + std::find_if(while_body_profile_start, profile_output_lines.end(), [](tensorflow::StringPiece s) { return tensorflow::str_util::StartsWith( - s, "Execution profile for body"); + s, "********** microseconds report **********"); }); - ASSERT_NE(while_body_profile_start, profile_output_lines.end()); + // We emit a blank line before the "********** microseconds report **********" + // line. + while_body_profile_end--; - gtl::FlatMap<string, ParsedProfileOutputLine> parsed_profile_lines; + ASSERT_NE(while_body_profile_end, profile_output_lines.end()); - TF_ASSERT_OK( - ParseOneProfileOutputLine(*std::next(while_body_profile_start, 1), - /*expect_hlo=*/false, &parsed_profile_lines)); + gtl::FlatMap<string, ParsedProfileOutputLine> parsed_profile_lines; - TF_ASSERT_OK( - ParseOneProfileOutputLine(*std::next(while_body_profile_start, 2), - /*expect_hlo=*/true, &parsed_profile_lines)); + for (auto while_body_profile_i = while_body_profile_start + 1; + while_body_profile_i != while_body_profile_end; while_body_profile_i++) { + // There are multiple "get-tuple-element" instructions in the while body so + // we ignore them -- we don't want parsed_profile_lines to be a multi-map. + TF_ASSERT_OK(ParseOneProfileOutputLine( + *while_body_profile_i, + /*expect_hlo=*/while_body_profile_i != (while_body_profile_start + 1), + &parsed_profile_lines, {"get-tuple-element"})); + } TF_ASSERT_OK_AND_ASSIGN(ParsedProfileOutputLine total_while_body_profile, MaybeFind(parsed_profile_lines, "[total]")); - TF_ASSERT_OK_AND_ASSIGN(ParsedProfileOutputLine dot_profile, - MaybeFind(parsed_profile_lines, "add")); + TF_ASSERT_OK_AND_ASSIGN(ParsedProfileOutputLine multiply_profile, + MaybeFind(parsed_profile_lines, "multiply")); EXPECT_GT(total_while_body_profile.cycles, 0); EXPECT_EQ(total_while_body_profile.opcode, "[total]"); EXPECT_EQ(total_while_body_profile.cycles_percentage, "100.00%"); - EXPECT_GT(total_while_body_profile.cycles, dot_profile.cycles); - EXPECT_NE(dot_profile.cycles_percentage, "0.00%"); - EXPECT_NE(dot_profile.cycles_percentage, "100.00%"); + EXPECT_GT(total_while_body_profile.cycles, multiply_profile.cycles); + EXPECT_NE(multiply_profile.cycles_percentage, "0.00%"); + EXPECT_NE(multiply_profile.cycles_percentage, "100.00%"); } } // namespace } // namespace xla diff --git a/tensorflow/compiler/xla/util.h b/tensorflow/compiler/xla/util.h index b23b968aae..5ae099a462 100644 --- a/tensorflow/compiler/xla/util.h +++ b/tensorflow/compiler/xla/util.h @@ -500,17 +500,17 @@ bool c_is_sorted(const C& c, Compare&& comp) { } template <typename C> -auto c_adjacent_find(const C& c) -> decltype(std::begin(c)) { +auto c_adjacent_find(C& c) -> decltype(std::begin(c)) { return std::adjacent_find(std::begin(c), std::end(c)); } template <typename C, typename Pred> -auto c_find_if(const C& c, Pred&& pred) -> decltype(std::begin(c)) { +auto c_find_if(C& c, Pred&& pred) -> decltype(std::begin(c)) { return std::find_if(std::begin(c), std::end(c), std::forward<Pred>(pred)); } template <typename C, typename Value> -auto c_find(const C& c, Value&& value) -> decltype(std::begin(c)) { +auto c_find(C& c, Value&& value) -> decltype(std::begin(c)) { return std::find(std::begin(c), std::end(c), std::forward<Value>(value)); } @@ -562,6 +562,11 @@ void EraseAt(C* c, int64 index) { c->erase(c->begin() + index); } +template <typename T> +std::vector<T> ArraySliceToVector(tensorflow::gtl::ArraySlice<T> slice) { + return std::vector<T>(slice.begin(), slice.end()); +} + template <typename T, int N> std::vector<T> InlinedVectorToVector( const tensorflow::gtl::InlinedVector<T, N>& inlined_vector) { diff --git a/tensorflow/contrib/autograph/examples/notebooks/autograph_vs_eager_mnist_benchmark.ipynb b/tensorflow/contrib/autograph/examples/notebooks/autograph_vs_eager_mnist_benchmark.ipynb new file mode 100644 index 0000000000..fff673921a --- /dev/null +++ b/tensorflow/contrib/autograph/examples/notebooks/autograph_vs_eager_mnist_benchmark.ipynb @@ -0,0 +1,666 @@ +{ + "cells": [ + { + "cell_type": "code", + "execution_count": 0, + "metadata": { + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + }, + "colab_type": "code", + "id": "Pa2qpEmoVOGe" + }, + "outputs": [], + "source": [ + "from __future__ import absolute_import\n", + "from __future__ import division\n", + "from __future__ import print_function\n", + "\n", + "import os\n", + "import time\n", + "\n", + "import tensorflow as tf\n", + "\n", + "import matplotlib.pyplot as plt\n", + "import numpy as np\n", + "import six\n", + "\n", + "from tensorflow.contrib import autograph\n", + "from tensorflow.contrib.eager.python import tfe\n", + "from tensorflow.python.eager import context\n" + ] + }, + { + "cell_type": "code", + "execution_count": 0, + "metadata": { + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + }, + "colab_type": "code", + "id": "YfnHJbBOBKae" + }, + "outputs": [], + "source": [ + "import gzip\n", + "import shutil\n", + "\n", + "from six.moves import urllib\n", + "\n", + "\n", + "def download(directory, filename):\n", + " filepath = os.path.join(directory, filename)\n", + " if tf.gfile.Exists(filepath):\n", + " return filepath\n", + " if not tf.gfile.Exists(directory):\n", + " tf.gfile.MakeDirs(directory)\n", + " url = 'https://storage.googleapis.com/cvdf-datasets/mnist/' + filename + '.gz'\n", + " zipped_filepath = filepath + '.gz'\n", + " print('Downloading %s to %s' % (url, zipped_filepath))\n", + " urllib.request.urlretrieve(url, zipped_filepath)\n", + " with gzip.open(zipped_filepath, 'rb') as f_in, open(filepath, 'wb') as f_out:\n", + " shutil.copyfileobj(f_in, f_out)\n", + " os.remove(zipped_filepath)\n", + " return filepath\n", + "\n", + "\n", + "def dataset(directory, images_file, labels_file):\n", + " images_file = download(directory, images_file)\n", + " labels_file = download(directory, labels_file)\n", + "\n", + " def decode_image(image):\n", + " # Normalize from [0, 255] to [0.0, 1.0]\n", + " image = tf.decode_raw(image, tf.uint8)\n", + " image = tf.cast(image, tf.float32)\n", + " image = tf.reshape(image, [784])\n", + " return image / 255.0\n", + "\n", + " def decode_label(label):\n", + " label = tf.decode_raw(label, tf.uint8)\n", + " label = tf.reshape(label, [])\n", + " return tf.to_int32(label)\n", + "\n", + " images = tf.data.FixedLengthRecordDataset(\n", + " images_file, 28 * 28, header_bytes=16).map(decode_image)\n", + " labels = tf.data.FixedLengthRecordDataset(\n", + " labels_file, 1, header_bytes=8).map(decode_label)\n", + " return tf.data.Dataset.zip((images, labels))\n", + "\n", + "\n", + "def mnist_train(directory):\n", + " return dataset(directory, 'train-images-idx3-ubyte',\n", + " 'train-labels-idx1-ubyte')\n", + "\n", + "def mnist_test(directory):\n", + " return dataset(directory, 't10k-images-idx3-ubyte', 't10k-labels-idx1-ubyte')\n", + "\n", + "def setup_mnist_data(is_training, hp, batch_size):\n", + " if is_training:\n", + " ds = mnist_train('/tmp/autograph_mnist_data')\n", + " ds = ds.cache()\n", + " ds = ds.shuffle(batch_size * 10)\n", + " else:\n", + " ds = mnist_test('/tmp/autograph_mnist_data')\n", + " ds = ds.cache()\n", + " ds = ds.repeat()\n", + " ds = ds.batch(batch_size)\n", + " return ds\n" + ] + }, + { + "cell_type": "code", + "execution_count": 0, + "metadata": { + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + }, + "colab_type": "code", + "id": "x_MU13boiok2" + }, + "outputs": [], + "source": [ + "def mlp_model(input_shape):\n", + " model = tf.keras.Sequential((\n", + " tf.keras.layers.Dense(100, activation='relu', input_shape=input_shape),\n", + " tf.keras.layers.Dense(100, activation='relu'),\n", + " tf.keras.layers.Dense(10, activation='softmax')))\n", + " model.build()\n", + " return model\n" + ] + }, + { + "cell_type": "code", + "execution_count": 0, + "metadata": { + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + }, + "colab_type": "code", + "id": "kfZk9EFZ5TeQ" + }, + "outputs": [], + "source": [ + "# Test-only parameters. Test checks successful completion not correctness. \n", + "burn_ins = 1\n", + "trials = 1\n", + "max_steps = 2" + ] + }, + { + "cell_type": "code", + "execution_count": 0, + "metadata": { + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + }, + "colab_type": "code", + "id": "gWXV8WHn43iZ" + }, + "outputs": [], + "source": [ + "#@test {\"skip\": true} \n", + "burn_ins = 3\n", + "trials = 10\n", + "max_steps = 500" + ] + }, + { + "cell_type": "markdown", + "metadata": { + "colab_type": "text", + "id": "DXt4GoTxtvn2" + }, + "source": [ + "# Autograph" + ] + }, + { + "cell_type": "code", + "execution_count": 0, + "metadata": { + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + }, + "colab_type": "code", + "id": "W51sfbONiz_5" + }, + "outputs": [], + "source": [ + "def predict(m, x, y):\n", + " y_p = m(x)\n", + " losses = tf.keras.losses.categorical_crossentropy(y, y_p)\n", + " l = tf.reduce_mean(losses)\n", + " accuracies = tf.keras.metrics.categorical_accuracy(y, y_p)\n", + " accuracy = tf.reduce_mean(accuracies)\n", + " return l, accuracy\n" + ] + }, + { + "cell_type": "code", + "execution_count": 0, + "metadata": { + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + }, + "colab_type": "code", + "id": "CsAD0ajbi9iZ" + }, + "outputs": [], + "source": [ + "def fit(m, x, y, opt):\n", + " l, accuracy = predict(m, x, y)\n", + " opt.minimize(l)\n", + " return l, accuracy\n" + ] + }, + { + "cell_type": "code", + "execution_count": 0, + "metadata": { + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + }, + "colab_type": "code", + "id": "RVw57HdTjPzi" + }, + "outputs": [], + "source": [ + "def get_next_batch(ds):\n", + " itr = ds.make_one_shot_iterator()\n", + " image, label = itr.get_next()\n", + " x = tf.to_float(tf.reshape(image, (-1, 28 * 28)))\n", + " y = tf.one_hot(tf.squeeze(label), 10)\n", + " return x, y\n" + ] + }, + { + "cell_type": "code", + "execution_count": 0, + "metadata": { + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + }, + "colab_type": "code", + "id": "UUI0566FjZPx" + }, + "outputs": [], + "source": [ + "def train(train_ds, test_ds, hp):\n", + " m = mlp_model((28 * 28,))\n", + " opt = tf.train.MomentumOptimizer(hp.learning_rate, 0.9)\n", + " train_losses = []\n", + " train_losses = autograph.utils.set_element_type(train_losses, tf.float32)\n", + " test_losses = []\n", + " test_losses = autograph.utils.set_element_type(test_losses, tf.float32)\n", + " train_accuracies = []\n", + " train_accuracies = autograph.utils.set_element_type(train_accuracies,\n", + " tf.float32)\n", + " test_accuracies = []\n", + " test_accuracies = autograph.utils.set_element_type(test_accuracies,\n", + " tf.float32)\n", + " i = tf.constant(0)\n", + " while i \u003c hp.max_steps:\n", + " train_x, train_y = get_next_batch(train_ds)\n", + " test_x, test_y = get_next_batch(test_ds)\n", + " step_train_loss, step_train_accuracy = fit(m, train_x, train_y, opt)\n", + " step_test_loss, step_test_accuracy = predict(m, test_x, test_y)\n", + "\n", + " train_losses.append(step_train_loss)\n", + " test_losses.append(step_test_loss)\n", + " train_accuracies.append(step_train_accuracy)\n", + " test_accuracies.append(step_test_accuracy)\n", + " i += 1\n", + " return (autograph.stack(train_losses), autograph.stack(test_losses), autograph.stack(train_accuracies),\n", + " autograph.stack(test_accuracies))\n" + ] + }, + { + "cell_type": "code", + "execution_count": 37, + "metadata": { + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + }, + "height": 789 + }, + "colab_type": "code", + "executionInfo": { + "elapsed": 11529, + "status": "ok", + "timestamp": 1531163743912, + "user": { + "displayName": "", + "photoUrl": "", + "userId": "" + }, + "user_tz": 240 + }, + "id": "K1m8TwOKjdNd", + "outputId": "59db8f19-23a5-413a-e9d0-fb756b0e4757" + }, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Duration: 0.592790126801\n", + "Duration: 0.594069957733\n", + "Duration: 0.591835975647\n", + "Duration: 0.592386007309\n", + "Duration: 0.595040082932\n", + "Duration: 0.594245910645\n", + "Duration: 0.624264001846\n", + "Duration: 0.6021900177\n", + "Duration: 0.592960119247\n", + "Duration: 0.599496841431\n", + "Mean duration: 0.597927904129 +/- 0.0093268291102\n" + ] + }, + { + "data": { + "image/png": "iVBORw0KGgoAAAANSUhEUgAAAYkAAAEcCAYAAAAydkhNAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAAIABJREFUeJzs3Xd8FGX+wPHPbMum90IKvQSQ3jtSbYCAqHee9TxPT0VF\njztRT+9UzvMOsdzPUxTO3gURsYsgTRBFmvROQkJ63T7z+2OS3Wx2EwIkBC7f9+vFi+zO7Mwzz84+\n33nKPKNomqYhhBBCBGFo7gQIIYQ4d0mQEEIIUScJEkIIIeokQUIIIUSdJEgIIYSokwQJIYQQdZIg\nIYQQok4SJISow6ZNm7j44oubOxknlZWVRWZmJqqqNndSxP8gCRLilI0ZM4YePXpQXFzs9/6UKVPI\nzMwkOzsbgD//+c9kZmaybds27zpHjhwhMzPT+/raa6/lgw8+8L5+4YUXGDt2LH379mX06NHMmjUL\ngMsuu4y+ffvSt29funXrRs+ePenTpw99+/ZlwYIFAWn897//zezZs8/oOPv3789nn312Sp958cUX\nmT9/Phs3bmTUqFFntP9qtfMoGEVRGmVfQtRmau4EiPNTeno6y5cv55prrgFgz549OBwOv8JKURRi\nYmJ4+umnWbhwod/7wSxZsoRly5bx6quvkp6eTkFBAStWrADgk08+8a537bXXcvnllzN9+vQzOgZN\n0xq9cF21ahX33XcfLpdLCm7xP0FqEuK0TJkyhSVLlnhfL1myhKlTpwasN3XqVHbv3s2mTZtOus3t\n27czfPhw0tPTAYiPj2fGjBlB161vNpnVq1fzwgsv8Omnn9KnTx8uv/xyQA8u8+fP51e/+hW9e/fm\n2LFjLF68mEsuuYS+ffsyfvx43n33Xe92atcGxowZw6JFi5g8eTIDBgxg1qxZOJ1O7/LS0lIOHz5M\nt27duOWWWzhx4oS3tpOXl4emaSxYsIDx48czePBg7rnnHkpLSwFwOp388Y9/ZNCgQQwYMIAZM2ZQ\nWFjI/Pnz+fHHH3n00Ufp27cvjz322Enz8cSJE9x2220MGjSIiRMn8v7773uXbd26lenTp9OvXz+G\nDx/OP/7xj3r3D1BeXs4DDzzA8OHDGTVqFE8//bQ3/48cOcK1115L//79GTJkiLfmJ/53SE1CnJZe\nvXqxdOlSDhw4QNu2bfn888956623mD9/vt96VquVW2+9laeeeoq33nrrpNt8/PHHSUpKYtCgQXTr\n1g2D4dSvY0aMGMGtt97KkSNHePLJJ/2WLVu2jJdeeol27dqhqirx8fEsWLCA9PR0Nm3axM0330zP\nnj3p2rUrEFjr+fzzz1m0aBEWi4Wrr76aJUuWcNVVVwGwZs0aBg8ejNVq5aWXXmL27NmsXLnS+9lX\nXnmFFStW8OabbxIbG8tjjz3GX//6V+bNm8eSJUsoLy9n9erVmM1mdu7cSUhICPfccw8//fQTU6ZM\n4YorrmjQ8c+aNYsuXbrw7LPPsn//fm688UYyMjIYPHgwc+fO5frrr2fy5MnYbDb27t0LUOf+AWbP\nnk1SUhLffPMNFRUV3HrrraSmpnLllVfyzDPPMHz4cF5//XWcTifbt28/5e9LnNukJiFO25QpU/jo\no49Yu3Yt7du3JykpKeh6V155JcePH2f16tX1bm/y5Mk89NBDrF27lmuvvZahQ4cG7W84E1OnTqVD\nhw4YDAZMJhOjRo3y1lz69+/PsGHD6q31XHfddSQkJBAVFcWFF17Izp07vctWrlxZbz/Ee++9x913\n301SUhJms5nbb7+dL774AlVVMZlMFBcXc/DgQRRFoVu3boSHh5/y8R0/fpzNmzdz3333YTabyczM\nZMaMGSxduhQAk8nEkSNHKCoqIjQ0lJ49e3rfD7b/goICVq9ezZw5cwgJCSEuLo7rr7+e5cuXez+X\nlZVFbm4uFouFvn37nnKaxblNahLitE2ePJnf/OY3HDt2jClTptS5nsVi4Q9/+APPPPMM8+bNq3eb\nl112GZdddhkej4evv/6ae++9l+7duzNs2LBGSXNKSorf61WrVvH8889z6NAhVFXFbrfTpUuXOj8f\nHx/v/Ts0NJS8vDxAb/5at24d999/f52fzc7O5o477vDWjjRNw2QykZ+fz5QpU8jJyWHWrFmUlZUx\nadIkZs2ahdFoPKXjy8vLIzo6mtDQUO97qamp7NixA4C5c+fyzDPPcPHFF5ORkcHtt9/O6NGjA/Y/\nefJk7rnnHrKysnC73QwfPtybZk3TaNWqFaDXMp5++mmuuOIKYmJiuOGGG864r0icWyRIiNOWmppK\nWloa3333HXPnzq133WnTpvHyyy/z1VdfNWjbRqORiRMnsmDBAvbu3dtoQaJm85HT6eSuu+7in//8\nJ2PHjsVgMHD77bfX299Rl23btpGenk5sbGzAfqq1atWKuXPn0qdPn6DbuP3227n99tvJzs7md7/7\nHe3bt2f69Omn1AGelJRESUkJlZWVhIWFAXrtorqW17p1a2+g/uKLL5g5cyYbN27EarUG7L9du3aM\nHDmSkJAQNmzYEDQd8fHxPProowD8+OOP3HjjjQwcOJCMjIwGp1mc26S5SZyRuXPn8uqrr2K1Wutd\nz2g0cscdd/DSSy/Vuc6SJUtYtWoVFRUVaJrGqlWr2L9/v7dJ5FQkJCSQlZVVb4HvcrlwuVzExsZi\nMBhYtWoVa9euPeV9gd7UNHLkSO/r+Ph4iouLKS8v97531VVX8dRTT3mHCBcWFvLNN98AsGHDBvbs\n2YOqqoSFhWEymby1iISEBI4ePVrv/quPMyUlhT59+vDUU0/hdDrZtWsXH3zwAZMnTwbg448/9nZI\nR0ZGoigKBoOhzv0nJiYybNgw5s6dS3l5OZqmcfToUX744QdA76PJzc0FICoqCoPBcFr9SOLc1aQ1\niTlz5rBy5Uri4+NZtmyZ9/3XX3+dN998E7PZzKhRo7jvvvuaMhmikdW8oqx9xVjfVe9ll13GggUL\nKCsrC7p+REQEL7zwAgcOHMDj8ZCamsojjzwS0M7dkCvriy66iI8//phBgwaRnp7O4sWLAz4XHh7O\nAw88wF133YXL5eLCCy9k7NixdW6zvv2uWrWKv/3tb97X7du359JLL2Xs2LFomsby5cu5/vrrAbjp\nppvIy8sjPj6eiy++mLFjx5Kfn8/DDz9Mbm4u4eHhXHLJJd6C/brrruNPf/oT77zzDpMnT+aBBx6o\nN23z5s3j4YcfZsSIEURHR3PXXXcxZMgQQB/59cQTT2C320lLS2P+/PlYLJZ69/+Pf/yDf/3rX1x6\n6aVUVlaSkZHBzTffDOg1qOoAkpCQwAMPPEBaWlq93404vyhN+WS6TZs2ER4ezuzZs71BYsOGDbz4\n4ossWLAAk8lEYWEhcXFxTZUEIZpcQUEBl19++Uk75oU4HzVpvbB///5ERUX5vff222/zu9/9DpNJ\nr8RIgBDnu7Kysno7rIU4n531xsNDhw6xadMmrrzySq699lq/KRuEOB+1bduWSy65pLmTIUSTOOuj\nmzweD6Wlpbz33nts3bqVu+++29t5J4QQ4txy1msSKSkpTJgwAYCePXtiMBgoKio66eeasOtECCFE\nHZq8JlG7cB83bhzr169nwIABHDx4ELfb7R1bXh9FUcjLKzvpei1BYmKk5EUVyQsfyQsfyQufxMTI\nM/p8kwaJe++9lw0bNlBcXMzo0aO58847mT59Ovfffz+TJk3CbDZ7JxgTQghx7mnSIbCNTa4MdHKV\n5CN54SN54SN54XOmNQm5NVIIIUSdJEgIIYSokwQJIYQQdZIgIYQQok4SJM4zTo+LVza/T7GjpFG3\nuyn3Z37I2dyo22xqdredV356jzJn+clXPgUbjv/ITye2Nuo2m1qlq5JXfnqPSldlo253bfYGtubt\naNRtNrUyZzmvbH4fu9veqNv97tg6dhTsbtRtng8kSJxndhXu4dM9K1ifffJnRp+K/+54i1d+ebtR\nt9nUtufv5NO937Ix56dG3e5rO99l4fY3GnWbTe3nvO18uvdbfjyxpdG2qWoqb+36kBe3vdpo2zwb\nfszdwqd7VrDlFIJbeXk5S5Z8UOdyl8fFu3s+4vktCwOWzZ59NxUVDb9QWbRoAe+8c/6cXxIkzjO2\nqqujEmdpo23To3q8f2eX57CnaD+bT2zD5razLf+XRttPY7N5qvLC0Xh5YXc7vH8fLctmT9F+tuRt\np9JVyY6CXY22n8bmPS8aMS8qatRKjpQeY0/Rfrbl/0K5s4KdhXsabT+N7XTyoqyslCVL3g+6TFVV\nSp2+4bQHS46wt2g/2/N3UuIo47d/voPw8IgzS/Q5TJ5Md55xePRCrDELgzKX7yro8Y1PBSy/reeN\nXJDQtdH211iqC/STBUxN0xr8dLfSGtt64oenA5bf0/c2Osa0O4VUnh32Jjgvam7rH5ueDVh+/4C7\nSY9MbbT9NRbvb+QULqReeOHfZGdncdNN19C//yCGDBnGf//7EvHxCezbt4e//vtJDr69FVeJg9+5\nryVhSAbx/fRj3/nUOhYufJ1Qzcp9982kR4/ebN++hcTEZJ54Yh4Wi6XO/e7du5t//esJHA4HaWlp\n3H//w0RERPD++++wdOliTCYTbdu245FHHmfz5h959tl5Veeywv/930t+j6ltKhIkzpCmaVS6bYSb\nw87K/uwN+AFUuioJNYX6P6rT40QDQoyBJ+zJCpYiR3GD0na28sLudLN8/WGUVjag/vS//90vfLbu\nOM/eNZKIUDMADo8TBbAEzYv6b8CqeUVZH1VTsbvthDVSXmiaRoXd7T2G2nwFY93pq3BVBnw3drcD\ng2LAYgzc7skK2XJXxcmSDVTnhYMwc8MKtPdW7OOHXScatG4wFW4LDvcoVmwzs/HrdQAMyEziyjEd\nfevUyovbbruTAwf38+LLr2I2mNi8+Ud27vyF119/j+jYBP67bgWtL++KMdSM6vKw98VNRHdLxBRq\nBgUq3TZCjVaOHTvKX//6d/70pwe4/e57eP29pfz2NzP88sKtur2vH3vsEWbN+hO9evVm4cIX+e9/\nF3DnnbN4881X+eCDZZhMJm9T1jvvvMG99/6ZCy7oid1urzf4NCZpbjpDa7K/Z/bqR065KeLjNQf5\neV/+Ke/P4XECUFpHYXao9Ah/XP0Inx9a4ff+X7//J/ev+Rvf/nSM1Vuy/ZadLEgYGnCafL8jh/9b\ns5TZqx9hX/HBk65/Jj5YuZ/l6w+zeV8OUHfBvadoHyvdr2BMPszOw75JJB9c+zgPrw8+HczJCsaa\nP/D6fHrwK/64+hGOlB1r0Pons2brcWY+s7rOc8ZRVasqDfJdbj9YwIsrVzB79SOsy97ot+yPqx9m\nbpDaI5w8YFYHppNZvO8T/rj6YXIqcimtcFJS3rDPna7qSSTUOiaT2JSzmdmrH+HH3J+976mayvGK\nHP616d/e97p1605KSgqb9+ax+VAWeeuPsvv5jex96UdcpQ6cBbaqHYLNpTdxpbRKJTw2FVXTyCqP\n5ONv/fuI3t71IV8c/pZKVyUVFeVUVJTTq1dvAC666FJ+/lkfPNKxYyceeeQBvvzyMwwG/TG2PXr0\n4tlnn+KDD96hrKz0rD0mVmoSp2HBxzvYe6yEf/5hqLcw/jF3C93jMxv0+bJKJx+t0QvSRX8ec0r7\ndtRoYlE1lez8SkLMRr79KYvIcDPuhJ0AfHLwCy5u53sUZ/VoqDdW/ozmDGNEr1Q278nj25+z6DOo\n/hExFQ0YMbNg2S9Y+3+PYoCteTvqbJL5YuMRsvMruOHizAY3AdWWX2KvSpcNrHUHuR9z9R+oOW0/\n+SU27/uV7uoaSBnRIf5TFgQrZGtqSF4AfHZIn/5+V+FeWkemN+gz9fl84xEA3vxyN+1aRREd7n8V\nWV3DLA4S5J56dwuWjpsxxsFnB74lM6IncVFW3KobVVPJsxVQ6bIFXOmXniRgNjQvvj26BoADJYd5\n+TW9M7m+8/7KMR39rvpP1YKtr7Ilfwfx1jj+NvTPActXZ30PwMpj6+iXrBfQDrd+8XWsPNt7IWa1\nWvn+lxxe/mQnDsMhyg8W0emW/hhMBvYt+gnV7evLq3BV6udihYc5C77n4RsGgKKA6vFr7lx3XH82\neHFVAK5rVqR//vMZfv75J9asWcUrr7zMG2+8z29+cwNDh45g/fo1/P73N/L008/TunWb086nhpKa\nxClwq26e2byAH078SEGpHYfT472aCjGGeNf75sh3vLj1Vb8TQFU13B6VnIpc/rX5GZRQ31Xatz8d\n4+/vr+TR7+dxsOQIa7cdx+HST8D/W7KNj1Yf8K5bXRiomkqFq5K/vPYdf1n9L778ZQuLt6zh88O+\nGsTS/Z+xL6uEQ8d9P3Zr7+8wZeyiuNzBc4u3sf1AIUeK6q/RbMr9mbkb5/sNNV26/zNe/+U9lu7/\njEXb3gJAMah6Xph8efHujs94euN/ASgstfPuin2s3nqcrPwKjpZl8/iGpzhRmee3v6Nl2Ty2YR7Z\n5Tne93KLKtm63z+dmuL25ond7aDAVsjcjfM5UnqM9cc3sSZ7g54uk4tNRWsB/5rAnLWPsmz/537b\nDFbI1rT++A/8bd1T/HI01/veB3s+5u3di/lw7zLe3Ok/QsZa47xYduALXv/lvaDbPVhymMc3PEWB\nzVfj+WTdIf65dAWPbZiH26TnfUGpg4cXbQz4fHXBVu6swKN6yK04weMbniK7PAdj4hGMcXp6C50F\nzPnoTUBvgqz2x9UP89lB/+e6nKyG+d2xdTy56Tm/zv63d33Ih3uX8fbuxby3Z6nf+jWbOt/asZS3\ndy8Out09RfuYu3F+wP73Fu3n8Q1PUWiv/9EC3tq2sxRVVckqP151nuWz4sh37CvRL9AOlBxi5VH9\nvDBZTagO/Td376qHvKPElq87DIDqKccYasZgMmDPq6DymH/aVmWt48Utr+Fw6efXL4cKMcYfxxBV\nwKJt7/DRvk/91jcaDISHRxAVFcX8T57jw73L+OKLT+ndW3+ee25uDn369GPUlRPILTpBXkk+WVnH\naNeuPddccz2p7TKY99WzJ63tNQapSZyCnIoT7Cnah6U92PLTKat0en8gZoOvTXfxvk8Avc020hKB\nzeHmLws3UlLhoP3wneQ78jC3dePcOQiA17/cQ0i39RgqS3hr2yfsX5OJ060yuFsyP+7O48fdeVw6\npC1mk4Gf9h2HcH0/eeXFmNP2Ywgvw9JpM4rZ6ZfeLw9/y9KNIaCohA7wvW9udYgdBwu9r/fmnIB6\nmjezKo4DekHWM7G7d9t+DON8f6tGlq8/xMSBrfkuV1+v0mnn281ZvjxadYATSV9S5D7Bkn2f8vue\n13uXvbztNfLthXx5+Ftu6P4rAF77fDe7jhTx9J3Dvc0ImsFX4Jc6S1m6/3Oyyo/z6s53yanwFeIA\nOZaf0bRf+RWMAJ8fXsGkDhfhcquYjArlzvrb2bPK9bx4atkqXv7DlWiaxrfH1vitM639ZO/fRsXo\n21dV7eKarlfgdmuYTAYMVVeYL29/g2JHCV8c/oZfZ16h59F3B7D2/Rqlwo0lej/kdtKPtcL/GMBX\nw9TQKHOV89buD8muyOHdPUuwtPNv/jOm70ZVNW9hWu2Tg18wvvWFAJiMBspO0udwtFxvtnzmkzUc\nO2TmsVsGegNztRmdfHlRZvPtb22uXjhf3XlqQI3y+S2LcKluvj26hovbTCTErOfh05tfBGD98U1c\n2m48ALuPFHGi2MaInr4O9OoLKZfqZua/vyWmzyaKXAUs/Gkxx5z7/Pb1/t6lDE8dginUQljraHb/\n3wYiO8VT1qmQeHcYefl6HkR2TKR4j8bu5zcSkhBGeEaNxzIr+nmhOt1g0M/N3ccKMISXgtnDT/l6\nE1JbbaD3I9UjCufMeYTbH7oV1a1iNbbnuXlP4Ha7+dvfHqKiooKs8mzihqSyrWwnP727nq9WriUq\nwoojvpLWrbuy5siPXNppNJt2nWDBsh08evMgkmMbt09QgsQpcKo1flRmOw98thBTsn5SHMwug05Q\nXKO99VD+CY45NnAiK4SC0qorPbu+XDHbMbfZQZG9n/66qmbhcIIhooifStYRltMdU9pe3Fkd2X20\niHatoqh02akudnLKCqGqoNRUI8Eab4xJhzHGBnYCHsotxZSxG09eGnllpZjiT378Jc5SPKqHd/d8\nFLDM0vlH79/rtmdxfKf/8v15eazKWYkhIhq1PI6f9+UTYq3EEAZF9iLe3r2YSe0mEm4OI9+uB7Cs\nvEp2F+7jYMkR9pcWYmxVRG5RX28h6cHlS5ujzFerMwSPeB/t/oYDFYFDNw8cL+KJFW9zUYcRVIQ2\nrAlFMTsoLKvk2R9eC1h2z/JnMMbofwdrt88qLuDR5R8S7kjjst59GNsv3VvDyass4I1fPmRC+jhA\nQzFVfb9oGKLzUKwVaPZw5q/8kLEZo+nZQf/i7DX2U+Io9QaNEEMIwXy460t2lwQOb571/CqsbfZx\n54gplDkaNvZ/b24uqjOR//z8SsCy/+54y/v3m9/8ArT2W17hquTrI6vol9yLjMg0QC/cAbZnH+az\nH/7Db/tNZc+RUm+7h8vjYmveDoocJbz31TGchnKslssYkJkUkBc2tQJPeQWGEDiUXYkpITD9d727\nEEvCCdpc0d3v/ZFdb+azQ1/iyu6AMcRD+2t7BT3+rvcM1f8IM9P+sutRy9zsMn1B0jD/Y/3Pj29h\nSoKUC9sxrKsejDt27ESnW/rrad00jle2f8rvYy7i+edfBuD2FbMBOFh0lMjR7chQ+4ECof2/AuBY\nYREbsn7m5bVb0KLMvPnTl8wae3nQdJ4uCRKnoGYbrDltH6YkX6dkYUUFJ4pt/PmF9YRWXTA89+UK\nzK33YHEkAnowsLtcYAKD1YbBepR3dn0EhlQUo95UU+YuIaTbIQ6ocOLQLsxpZaglCRzMLtVHthh9\n7aB5FUUo1a89vivWmixtdwZ9/5eyzZhbHcQYdxzNHt6g4/9h3xGiLJGsrXW1CGCM8jUBFJTrV18H\nskuh6nlSH21ZiydxN0nx6VT8kkxZpQsUPcAeLc/maHk2HtXD5R18z4o+WnKCZ39eAICSEYrZamNP\n3lGKyvRCwK25vO2lr3+zBWua/v3UbO6q6evsL4O+P3/VYsytDvFVXgGt4qKCrlObYnHw+sZvyVMO\nBCwzxviaz9b+coztG7fSKsF3dffNgQ2YUw9gK6zgza/CGd6jlXfZnuL9wH427shHsfj6MjymckK6\n6PtS7WHsUyvZvszC87dfQojZSIXTd3dxsaOU/LJyUPxruDWtzAn+yGBH/C94Ig7z+MpFGMwulAZc\nlCoWB8bEoxy1B+ZFzZv7vOcqqve99cd/4KsjKylxljI67lKS43z9IsfdBzElw8vfL8dTmIK1p/7+\nCVs+Xx1ZqW+pVSgWq421u7oxIDOJVT9nkVdS5i3ZFIsDxVhV4/TUUdyl7CWwbgafHfsUU0o2isUB\nJleQNQIpZgemlEN+v4dqNcuL6lpczYsIU9IR8i17WHUskl9lTvf77M8F+gwAxqSuqGUx3vcLHYW8\ntns9lnagOqzsx065czwRlob9phvC+MgjjzzSaFtrYpWVwb7Ks+dAyWG25usdb4Zw/zZJm1bGVxty\nUEwuTAl6NVwJsaGYXHg0D1HGeLSoXNyR2WDw/UgqXXYcDg1jjN7e7tZcKFVVVqemH6/mslBuc7P8\nl42Ya5xoRwrz8eBGsThQ7WEYQho+DYGt3IwSVqIX1KoBxXLyvM0vUNlS9JNfM08wSkglmtuMS7Hh\njDwKQKm7BMXkIizESNu4ZE549BpO9bGCHkC//fkITqte81EMqrdgqb6iLiyAwjIbhpgTmBJ9zVfl\n7grsaiWqwYmzPAynoeFj5F12M4awcjTViN3lRDOePC80l4Vi6x4weOpdr9RVQk6ek30ncjDF630s\n+bZCPIoTNAXNGcIvBbsoVI56gyaAR1XB6PYWNqqmevNAqSqwNEcoTs3OcechNuf7RuqU2MvJrSxA\nMahY3LGUeAoanBeax4jBagO3BUxO7z7rz4sQTMlH/L7LYBSLHTx6Xlf3kezNO45mcIJqYOmqY3y+\ncxPG6Nrp1VDMToyR+lBsg6J4h996a1r2cBIS4J0f1uKO9J0XitGNIVyvpau2CO/fDaPvV3OEYbBW\nevvc6mM1hKElHORkYzKK7MWEmUM5VHrUOzKyurywGq2YFCM7Cnazq2hvwGcNFjuGCH0gSnGpSw9i\nVOWFAqnhKWSX5fHV7p8IDzWSEZ9yCsccSB46dAq+PrKKJfuWn/X9qg4ritlR74/Q6orHbm54YeAp\niccYXYBqCwODekoBpjmp9lCUEDuKUndeeMpivAVKQ1Sv7ymLwWCtQDE37KrxbNI0Agoe1R6GElJZ\nb4HkKY0NelVbF9UWjiG0Ak9REoaofG8N95yiKX4BFcDgCkc119+Hcqp5obnMKGYX7rw0jAlZJy34\nm4OmKgHlQrgSQ4Wmn/9RxlhevmLuGe1DRjedgoYO+atLvJKBY08f7FtH0J0JeAqT/ZarDmvQzxlC\n7CgGDdVWdxXSHO7f9q1WBD6NynW8LVHGOAAUa9WxeMz1Bgj7z6Ow/zwKrUZzln3bUFxHO3tfR+YN\nDPbRevVI6EYXzzguib0ex56+eIoS/ZZrzuBNRgarDUXRSAlLqnPbhhD/7ynCEBOwjiu7Pao9tGqb\nVeurxnoDhG3zaD0vavwm7VuH48rq4H2tHAvebl0fd0GKngc7RhJybBCeEv8OIs0ZErSAMlj1AFHf\neWGw+heccdbA58m7jnX05rdiqToXFK3eAGH/eRT2LSP939s6HFe2b+iz89Cp36Xvzk/Fsacv9q3D\n6eIZj6fUP72aMyQgQADeAFH9nQYTHu3/G9GcgX1XriNd0NxmvfCtOhcUs7PeAGH/eSSGPaP93vvL\n4D8yMm2I97Vy/DTy4kS6Ny8ce/qilvs3haoOa9ALx+oA4cpqT6ZnwinvtzYJEqegooF3mNZU86Tt\nndaRSHcGwzp15IL4bqiV/gW5pyBwigPV7msUbu0aVOd+as+EqlZEB6wzoFM6mQn6j9gQot8rUF1t\nrYvmDNWX+CEEAAAgAElEQVT/ufUflKcwGc0WhafYV6ifONywdvwQzXe87aPbMHP8BC7t050h6T1R\nbf5z37jz0wI+H2uJ8/49o/OUOvdTu+ksxRqYr5rL4s2j6lFhgc0ctbisaM5QcJur0tgKzR7BbWP1\nTkjNY6TyRFx9W/AyeXzHO65rT4a36Y2zIozi7FjC8Q9qwfIiMdQXSK7ObHheVHcO16S5Qogx6kG3\nunmvZr9KMJozFM0Rhqbqpaf7RDqaPQK1TC/UFbcVQ3lyfZvwqvkbUUvjUIuT0OwRzBw/HrPH/zcS\nLC9q/kZcR+oujO2a/8WDWhl43mquENTKSL/C9+R5EUZFse+i5sKM4SSHJdI+uq2+H1s4tvyGnRf+\neRFPa2sHnrxxAjFqBqrD/2LAk19/eeHOaUduzplXf5o0SMyZM4ehQ4cyadKkgGULFy4kMzOT4uKG\nNws0txK7HiSc+3riPHBBwHJ3rm80g0kxMrHNGK7v6RtpkBgew5O3DuWGSzIZkJmEBf9eQa0yArVC\nP3E1txlrcRfu7nsLIYVdcB7O5OpBQ7ilx3WMib7K70q+pgszhhObeyFakE66CIsVax2dusE4dumj\nLtISw/l1l2l0CumD65g+DFOzReI82B37lhGgBu7LneO7ycegmXBldaBnuO/KKtri+4EO79kKzeWf\nLrU8mhBVL8Q1p4XBCcO4p9/vmdhmDFd1nkpmXCda20Zh3zGE0OIuQdPvym6HfcdgIq1Bri5VI3ER\nDe/cc+z0jSF2HuhBO1MvrulxGXfP6EnvVp0w5/TAsW243pZfy7jWo3wvPGZcWR3I0Hp73+qYlEy/\nLr6g2ybBv1allsZ5a5kxIdFc1HYsd/a+hQltLuSazCsY1aE3N3b7FTd1vhV3bkbQ9F/Udix/GjAz\n6LQsqEZaxTb8OciOX3wXK7+94BouTB+BO1uvTd13yQRMORdwRer1PH3b2IDPTmzju4lOc1kYlz6W\nXtG+mmiUJZKkmFCuv0j/Tnu39Q8KanECmks/BtVhxZXVAeeuAbiy2+Hc34P/u2kGkzMux75tGO78\nVgRzabvx3D/gbvp2DGyr1zzGOgeBBGPfMbjqLwXnvl70iBjo/b77JffCmNMdx85BaM7AVoKaNVDV\nYcV1tBOeE74y5OaL+vDAdf2Ij7bStXVsQO26Z2J3NLf+21PtYSQ5ejHAPEnPi329MCsh5BbZOFNN\nGiSmTZvGwoWBU+vm5OSwbt06UlPPvcnB6lNaNSTQU5jCr/sF/gA8RUmYNP1kGNyqP5M7XESneF9h\nGW2Jwlw1Nj40xMTYnv53lY7r0554RV/ffbwdtw28gi4pqTw44RpmjppCu1bR9Eq8gFsvGs2Q1L4B\n+7cYLUzpcAndEzuCGniiR4eFBi8k6qCWJtA5PZpHfzuIEe17cfewX9Exwfej9eRloDmCF7Ttw3wF\n99jWI7ip7xTGd/cNMYwO8QWJLq1juWxArbvV3RZaW/Uf0YiUkVzbcwrxobFM7nARI9P1YHPjsDG0\nj23NNf0D7941ahbcxzqhVcQQExaYxoGdU+nRNjHg/eAU1DLflbtakkTfiFGM7NqJnh0SUBQFa2lH\nvZYRZCBy/2RfQBiRPJJ0T18m9KiZF5H0aB/PA9f2487pPRjQwX/opOa2oBbrV/qXthvPpPYTiQ+N\nZUqHixmaqhew/VP6MDyzG+68wLu7oy1RXNZuAq0j0/1u7vPyGIkNb9jYejNW1HJfE1C/lJ5c0XlS\n1bFDZps4nvn1dYy+oAOh5sB9DWrVz/t3iqMPUztPJMnqazq8uF9nnrh1CKN66+dZp2T/gtyshGK2\n6e+5j3bGndUJzRmK+1gXopztCbEYubDtIDRbJJ4TgQEzMTSei9uOIz0ylVCTr+D22N3kbzwGqpGo\nBk6al2hNJC1Mz++iA2tw5SUwIX0CMSH6xY1BMeDJbcvR1Yvo0yrwvHDXSJ/7aGfcxzv41ajbJSRi\nrJp646qxnRjS2f/u6mtG98BToo/p7RcxkocvvoabxvfjotYTGNiqNw9e15/fXdatQcdSnyYNEv37\n9ycqKrBKN3fuXGbPnt2Uu24Sdre9KnIb6N0xAeeBC3Adb+tdrrlCvEMOnarenhlr9TUd1CwYAdKi\n/augQ7q05t5xk8iwdqBP0gW0T9XXj4uy0qO9fzt1sKvjtlGtMRtMXD6iHWN6tw1YnhQdGXQiN4BB\nyb4r5R4J3fDs0a8WQ0P8awmpCXqB2yY5kumj2gNgtRgZETfB7yqxf4cMbz+GBzeDu6eQFOYbpB5l\n8b9ybZ/oX2DfNLEXv+47ngviM5nQZQDBJMWE8vQ9o2mbFNjOnmpNp/r0DgtSWA3skkqYOXgfUBK+\nK7wL4rsywBTYnFM7Xyod+iibET1bcUWnyd6bvQCiatSaYqPM/OWGAXRKTA1Y3iEtmj6dEompdZ7E\nhUXgzm1N97jMeqd+iQg1c8flvQPe7xjTznvDWkiQIHHLZb2wBAsewAU19ucpTmRm35v58zV9uWRw\nG349rpN32dSR7bk6yFQal3e4xG9Yc3SN731YD72wbxXh++7jQ/2bSaNqTZvisBm5od/FhDvTCPf4\n1xTiIvVjsFTdfKcFuVDqUDMvatSqPTYXBRuzQDXSvU3w/q4orSpgadA9PpPf9fwNf/vtQB67eRCu\nnO/p3ymW1sn+zaa3XX4BUWEWRvdJ49J245na4TLvsh6tfenXtKo01xiOXvO8iQg1k5nu33wXbg7D\nfbwdnqIkojTftqaN7MDvJnUnIymCzDaBv41Tddbvk1ixYgWtWrWiS5fgTQTnMpvHjuYxcdnQNsRG\nhnD7qEvILark43J9UrBhXdpy1LoHm60Mp0cPEgbFF4drF4yt4xOgxs2wVpOVWGsMfx76+5OmRfUE\nxvekqnbq0BATaXHRUKsp1WwwB5351J2bQaeu7diQq88rc2vPG3js500cKC7lRLF/dTU1Xj+JI8LM\nXDSoNf0zk/zu8PyialqQoZltWZZnxoXHe5ezuUaAql0QJkf6t8P3aJNCpCWC23rdVHcmVAl2TB0T\n0zhgVOjRPh6rMbBJM8RkCRowx2SMQHWGcCJ3PwC39bqRNVuP8x07SY4LI7ewsupY/PPfVhUkwqwm\nLswYDsDyg/oNT5E1xqxXXzyEmnxBPrrWeRFaK3g98KuhoBmJiTh5U2HbpFjwv6mYpDBfIRwsSMRH\nhpNlD8yLi9qOxaN62F6wC0014NzTj/bTWkMMdM7w/74mDW0bND3j24wG4KP9+rQU1hpX7waT3u6f\nFOEryOLC/M8Lk1KroHeb6ZPRgT4Zd1FYaueTdYcoLHOwdX8B7VNr9cMFCRLJfnnhO2+Of70fZ5GN\nrG9e5aeSNjAklBNrjlC8IxfNozFw6BC6TEjj+2NZZL2/i0r1GBvUL7n++pspLMynoqyIH5bPZ+/a\nGJ555j/e7V7QLp7UhHAsJiOXtBvPV199zu4X9PuMLhiXAfGgqRrH132GpaKcUKuJskojiUMyWLZk\nid904Rf/fprfsViMFq4Y2Jf3V0YzaNiZzw9Wl7MaJOx2Oy+88AKLFi3yvncejcDFoerjvKunCejd\nSb8yzv2lH9sLdnLjhT35pdDK81sW+rVDD08dxPaCXQFBIikyBqshDLtaidUYQmxIYGdzXRKjwqFW\n2RcT4vvhBmtW0DQ1aHNT/05paJr/SJZRvVI5kF1KXJR/gZWaqBd4kaFmjAZDwBQAvRN7cLj0KKHm\nEG7ocSUvbXuNETVGeQxI7sPBksN+hSRArDWWMFMolW4bEebwU5pu3BLkhrGksASeu2sgRqPiDX41\nGRVj0OASbg7HYFGgxqweQy9IoazSyYCuScz+z3oAbE7/+wc6pkWz+2gxrZN833G3uC4U2IswKAau\n73Y1r/7yDgNTfM2EvRIvIK8y3y94AqSEJWMxWnB6nMSERBMdFtrgyRCDHVPNGlywPqkQoyXoeRFu\nDvNODKmgMLBr3SPKTqZDdDtcVQHy6i7TeGf3Ynom6E1ukeEWPMUJ+n00VjOL933C5hPbAPzOS01V\nCOm1iofW1Zi7KgrUCI3YeA87Qow8tE7Pp5ThGk63G1utAVo1A2bN30ir8R2wn6jgv68uZEPuJj78\n5kMchZV0/v0ANE3jxNLjxOxPpPRoAdaYMP47T7+TvLKygrCwcN59922ee+7FoC0n1fLz83nhhX8z\n8s5LiYyIZNfrW+macgE/VmynbXQoz73yKgZF4R9rn8YaFsabz/pPF+4xaygoaGjeAQgXDWrNhX3T\nsFqarig/q0HiyJEjZGVlMWXKFDRNIzc3l+nTp/P+++8TH3/yeSESExveudbYVE3FqTrQPGHExYb5\npeXeUTd7/05K6s/ozP5+n52ZeEOd231txrzTSs8V4zP5oNaDtNITEr3piqoMbI4Kj7R4O4Nr6tI6\nkXCr7weTmBjJ1LGdiYsNo0fHBOKjfdsaGGml87pDDOuTHvT7mDPmD96/xycOYXy3IX7L/zj6ljqP\n6ZXpwaesPplWyYFV6tZJyaSn6UEzrDwwiERFhxBvCPxBJ8fGUOH01Z6qj/G6SfpAhTk3DODtL3cz\nYUg7IsJ8BetDNw/mx125XNgvw1ugPzL+bu/ySxNHcWmPGh3YwANjbq/jiCJ544pn6lhWv7TkwFE0\nHVulk5igH4fxROBFWWxsGDFB+pZaxcXjKKq6i91i4qFfDQlYp6H+fpGveXla4nim9fY1x4VHWnHu\n0X8z6VfHEFZhwWioDopGEsPi0DQoKncQGm6qsaxqDYOC2WQIeM9kMmOrNWo9M60NidF6XriPBd40\nmZYcR3hZCGX7CynfX8ie/2xE0yDaGEFFUQmhyRGc+Oogr722gFGjRtG/v55ugwHi48OJiQn8TZjN\nRmJjw8jOPsDQoUN4YsajAHxQ8QH79+/nrdue54rPruClBc8yatQo/jnlQRRF4Xfv7+Lvf3+YcePG\nMW7cOMLCwnj3qucbkNuNq8mDRM2aQufOnVm7dq339ZgxY1iyZAnR0Q27gm7Om+mqH4mIx4Tb4W7W\ntCQmRlJQEDivTqIh2Zsui0sv2N0FKWSkWjjuOEKoO5KcysB5nBw2D1FVtZBu8V282+jeOgbVGXis\nf/61fjXc3Dc3gp4X+fmBeRGlxnrTF1o1jHJoqwHsKThKvjMHg91KaVngyA9bhYd4q3612S+pV8Ax\ndkyJ5KHr+mOrcGCr8B9336NNbNC0nC2JiZEUFQQek8UZ7j2OKEUPqGMyRrA9fycnbPm4yg0Ulgam\n21WpkWLR+076J/Vusu+7ZhlRUWbjorQJXJR2ZuP7ExMjOZ5bxF0r5/i9b7BZyat6/kiCUf+eL2k7\njq926M2kFSUuCstKQdNIG92RqD567emuPr+nwFbIG7ve56a/3Ul8bgT/+Mc/GThwMDfccDOqqlFQ\nUI7LFdjE5XJ5KCqqpKSkEpvN6c3HsjI7lZVOHA6FhQvfZMOG9fz3v6+yZMnH3H//X3j88Xne6cKf\ne+7fvPHG+6f1DIkzvbhu0iBx7733smHDBoqLixk9ejR33nkn06f75iRRFOW8aW6yVwUJzW0ixNLw\nIXJnw+UdLqFnQjeSw33NAe2i22DfPhStMoJx3buSlqGQHpnK4bKjAZ83Goy0i27DnwfcRXI9N6md\nD67oNJnu8V38bhrLjOvEnwbMJD0iFafHRYG9kMSweOwnAm8iNBmMdI3rzJ/6z6RVxJlNZ9AcajZL\n/brLdDrHdiTC7Ksl9Erozp8GzCQjIo1L2o2jyF5CdEik9/w2G8zeZiGTwUSPuM7M7n8naRHBh5M2\ndppNxsYbS2My+Iq367peRYeYdn79UANS+tAqIpmMiDT6RffkD69sw2qyYnc7iOwYT/7KI4R3j8do\nMWIrrqBLdHt+1/4auqR0JrRXKKGhVj77TJ+BISwsnIqKCqKi6r7g7dbtAp599ilKS0sID4/g66+/\n4IorrqakpBiz2cyoUReSmprG3//+V8A3XXiPHr34+usvsNkqm+VZ2k0aJObNq78p5Ztvgk8ydi6q\nflANHrN39MS5IsoS6RcgqoW4Y7HjIToslIxIvRmiui8gMTQeDci3FXgL1GA3Wp1vokOi/Nqdq1U/\n+MdqCvEWeNWFZ5vIDPJtBVS4K70d6q2jmq4j8GyJsUaTGObfjKsoijcvQk2hhEbo50N1f1mH6Lbs\nLtqHhkakJRJFUWgTFfzei8aUnhiuT/rYROKsMSSE+jfFGRSDNy9S4lPo3asv119/NfFdWhE5OI5E\nezRbXtoEwHPxOfztkb/jPGHj1odvwlDVnHXfffcDMHny5dx330wSEhL9Oq7BFwTj4xP4/e9v5847\n9YEpQ4YMZ/jwkezbt5e5c/+KpqkoisKtt97pN104aFx11TXNEiBAZoFtsOrmJs1j8nZcnyvqmvX0\n4RsHsHV/gd8wuD6JPbi6y1R6JlyAqnnYUbCLXgndg37+fBT0PoA6DEkdgEtz0z+pNw6Pg91F++kc\ne/pPRDvXBBvJVJcxGSMwGUwMbtWPMmc5B0uOkBF59u5j+ttv655NoDHU9Rup6S9/0fsKXKqb1Vnr\nGTZqEEW/LeJYWTb9U/oAkJqaxsCBgwM+O336VUyfflXQ7T777Avev8eNm8i4cRP9lnfs2IlFi94I\n+Fz1dOHNTYJEA9mqaxJuE9ZzrLnJbAj+NSbHhjG+v/8oIUVR/EYbDU8LPOHPZ6dyR7lBMTA6fRgA\nEYQzNLRhUyecL04lYBoNRu/Q3VBTaNDa2PnsVPLCbDAxJmMEACnhyaSEN2x6kf9VMndTA9WsSZxr\nzU1K0McNtUwmRa57qp1KTeJ/neTF6ZMg0UB27+gmMyHmcyvbGjqGviWQvPAxGyVgVpMgcfrOrdLu\nHFZUdVOR5gpp0htXTsWENvrso9Wdby3ZqKpmo8TQIM+nbGEGt9LH7tcc1dRS9U3qiclgqnM6GnFy\n8tChBlqw9VW25O/A9tOFvHj3BMym5mtySkyM9OaFqql+U3+0NJIXPpIXPpIXPmd6n0TLzblTdLQ0\nB8VjRvFYGnUs95lqySd/bZIXPpIXPpIXZ0ZyrwFKKuwU2AtxV4bTNiVa2r2FEC2GBIkGyC4tQDFo\naI5QxvQ9/284E0KIhpIg0QA2pz4RWKg5hCEXnH9TNQghxOmSINEAdrc+XUByTDgGaWoSQrQgEiQa\nwO7yTXgmhBAtiQSJBnC4q56sFuThNkII8b9MgkQDVNck5A5WIURLI0GiAZxVfRIWCRJCiBZGgkQD\nODzVQUKam4QQLYsEiQZweqQmIYRomSRINIDT7QYgxGQ5yZpCCPG/RYJEA1TXJELM0twkhGhZmjRI\nzJkzh6FDhzJp0iTve08++SQXX3wxU6ZM4c4776S8vLwpk3DaDpcepdJVCYDLo9ckrNInIYRoYZo0\nSEybNo2FCxf6vTd8+HCWL1/O0qVLadOmDS+++GJTJuG0fPLjLzy56Tn+svopnl+yDZeqBwmL1CSE\nEC1MkwaJ/v37ExUV5ffe0KFDMRj03fbu3ZucnJymTMJpWbJ2NwA2Stm0O88bJKzSJyGEaGGatU/i\ngw8+YOTIkc2ZhAZxVt1xHWaRmoQQomVptjGd//nPfzCbzX79FSdzpk9Yaij/ViUNZ1WfREpi7FlL\nw8mcK+k4F0he+Ehe+EheNI5mCRJLlixh1apVvPbaa6f0ubP1+FLFqPpemFzeaTls5U7ylOZ7hGq1\nmo9mbOkkL3wkL3wkL3zONFg2eZCo/Qjt7777jpdffpk33ngDi+XcbOM3GHxBQrHYcHpcmACzzAIr\nhGhhmrTUu/fee9mwYQPFxcWMHj2aO++8kxdffBGXy8VNN90EQK9evXjkkUeaMhmnTFVUb2eNEmKH\nqqAhU4ULIVqaJi315s2bF/De9OnTm3KXjULV3N4gYQipBKU6SEjHtRCiZZE7rmtRNQ0Vj/e1ElKJ\nUlWTMBuMzZUsIYRoFtJ+UovHo3qblwAUayWKUR/dJM1NQoiWRkq9Wlxuzdu8BGCMLvD+LUFCCNHS\nSHNTLW6P6m1eqs2gSHYJIVoWKfVqcXtUMOh9EjVH75qVc3O4rhBCNCUJErW4PKqvucntG800NfU3\nzZQiIYRoPhIkanG7fc1NmttXe+iakdBcSRJCiGYjQaIWt8fXca3VqElYTSHNlSQhhGg2EiRqcdUc\nAlsjSFgM0ichhGh5JEjU4qnZcV2juckiT6UTQrRAEiRqcXlUlCDNTTL8VQjREknJV4vbrXmbm6YP\n69rMqRFCiOYlQaIWd40+iQhzWDOnRgghmpcEiVqq75NQMMiIJiFEiydBohb9PgkPRsVIiFGChBCi\nZZMgUYvbo4LRjVmxYJbnRwghWjgJErW4PBqK0U2IIQRFae7UCCFE85IgUYvL7QGjG4tBmpqEEEKC\nRC02pxPFoGE1WkkJTwagT2KPZk6VEEI0jyZ9is6cOXNYuXIl8fHxLFu2DICSkhLuuecesrKySE9P\n5+mnnyYyMrIpk3FKyl2VYIBQs5UoSyT/HPFXGeUkhGixmrQmMW3aNBYuXOj33oIFCxgyZAhffPEF\ngwYN4sUXX2zKJJyyCqcNgDBzqPd/udtaCNFSNWnp179/f6Kiovze++abb5g6dSoAU6dO5euvv27K\nJJyySpcdgAhLaDOnRAghmt9Zv0QuLCwkIUF/NkNiYiJFRUVnOwn1srklSAghRLUm7ZNobImJTd93\n4dIcACTHxZ6V/Z2uczltZ5vkhY/khY/kReM460EiPj6e/Px8EhISyMvLIy4ursGfzcsra8KU6aqb\nm9x25azs73QkJkaes2k72yQvfCQvfCQvfM40WDZ5c5OmaX6vx4wZw+LFiwFYsmQJY8eObeoknBKn\nqtckQk3WZk6JEEI0vyYNEvfeey9XX301Bw8eZPTo0Xz44YfccsstrFu3jokTJ7J+/XpuueWWpkzC\nKatubgo1SpAQQogmbW6aN29e0PdfeeWVptztaXO5VTSDC4AwmSZcCCHkjuuabA43mKqChElGNwkh\nhASJGmxON0p1kDBLkBBCCAkSNdgcbjC6QFOwyrMkhBBCgkRNNrtekzArISgyT7gQQkiQqKnS4UEx\nurEoMrJJCCFAgoSfSrsLTC55bKkQQlSRIFFDudOOYlAJNUqntRBCgAQJP2WOCgDCTHKPhBBCgAQJ\nP2VOPUhEWCRICCEESJDwU+4sByA6RGaPFEIIkCDhp8Kj1yRiQ6ObOSVCCHFukCBRg60qSMSFRp1k\nTSGEaBkkSNTg0CoBiJUgIYQQgAQJPy7FBkifhBBCVJMgUYPHoD+VLtIc0cwpEUKIc0ODgsSnn35K\nebk+8ueZZ57ht7/9Ldu3b2/ShDUH1WgDjxmz0dzcSRFCiHNCg4LEf/7zHyIiIti6dStr1qzh8ssv\n57HHHmvqtJ1VTo8LzVKOySn9EUIIUa1BQcJk0h9gt3btWmbMmMGkSZNwOBxNmrCzLacyFxQwu2Oa\nOylCCHHOaFCQUBSFjz/+mOXLlzNkyBAAXC5XkybsbMsqzwEgxCNBQgghqjUoSDz44IN8/vnnzJgx\ng4yMDA4dOsSgQYPOaMevvPIKl112GZMmTeLee+/F6XSe0fbOVKGtCIAQTUY2CSFEtQYFib59+/L8\n889z/fXXA9C2bVseeuih095pbm4ur7/+OosXL2bZsmV4PB4+/fTT095eY3B53ACYDKZmTYcQQpxL\nGhQknnjiCcrKynC73fz617+md+/eLF269Ix2rKoqNpsNt9uN3W4nKSnpjLZ3plweDwBmo7FZ0yGE\nEOeSBgWJdevWERkZyZo1a0hOTuaLL75g0aJFp73T5ORkbrzxRkaPHs3IkSOJjIxk6NChp729xiBB\nQgghAp1S28oPP/zA+PHjSU5OPqNnQJeWlvLNN9/w7bffEhkZycyZM1m2bBmTJk2q93OJiU3XX2C0\n6McTHmpt0v00lvMhjWeL5IWP5IWP5EXjaFCQiI+P58EHH2Tt2rXccsstuN1uPFVX3qdj3bp1ZGRk\nEBOjjyQaP348mzdvPmmQyMsrO+19nkx5hT6kV3VrTbqfxpCYGHnOp/FskbzwkbzwkbzwOdNg2aDm\npnnz5tGxY0fmz59PdHQ0OTk53Hjjjae909TUVLZs2YLD4UDTNL7//ns6dOhw2ttrDG5V77i2mKTj\nWgghqjWoRIyLi+M3v/kNBw8eZN++fbRt25Zp06ad9k579uzJxIkTufzyyzGZTHTr1o0rr7zytLfX\nGNyq9EkIIURtDQoS27ZtY+bMmVgsFjRNw+1289xzz9G9e/fT3vEdd9zBHXfccdqfb2zVQcJilJqE\nEEJUa1CJ+PjjjzN37lzv3dbff/89jz76KO+8806TJu5s8kiQEEKIAA3qk7DZbN4AATB48GBsNluT\nJao5eFQVkD4JIYSoqUFBIjQ0lO+//977euPGjYSGhjZZopqDt7lJgoQQQng1qEScM2cOd911FxaL\nBdAn93v22WebNGFnm0eT5iYhhKitQSViz549+fLLLzl48CCaptGuXTsmTJjAypUrmzh5Z4+3ucks\nQUIIIao1uEQ0m8107tzZ+1rTtCZJUHOprkmESHOTEEJ4nfYzrs9kWo5zkaqpaBqESE1CCCG86i0R\n9+3bV+cyt9vd6IlpTh7NA5qC2XTacVMIIf7n1BskbrnlljqXhYSENHpimpOqqaAZJEgIIUQN9QaJ\nFStWnK10NDsVVa9JGCVICCFENSkRq+g1CWluEkKImqRErKJR3dwkE/wJIUQ1CRJV9NFNUpMQQoia\npESsokmfhBBCBJASsUp1kDCZ/rfu/xBCiDMhQaKKhgoYMBokS4QQopqUiFU0RUOR7BBCCD9SKlbR\nUFE0aWoSQoiaJEhUU1SpSQghRC3NViqWlZUxc+ZMLr74Yi699FK2bNnSXEmpomFQJEgIIURNzTbl\n6eOPP86oUaN49tlncbvd2O325kqKfre1gtQkhBCilmYpFcvLy9m0aRPTp08HwGQyERER0RxJAcCj\n6eCf+HkAABL8SURBVA8cMkiQEEIIP81SKh47dozY2Fjuv/9+pk6dykMPPdSsNQmn2wUgzU1CCFGL\nojXDI+a2b9/OVVddxTvvvEOPHj14/PHHiYyMZObMmWc7KQDc/I9PKW27jAhXOot+80CzpEEIIc5F\nzdInkZKSQkpKCj169ABg4sSJvPzyyyf9XF5eWZOkJ7ewgtC24HY13T4aU2Ji5HmRzrNB8sJH8sJH\n8sInMTHyjD7fLO0rCQkJtGrVioMHDwLw/fff06FDh+ZIik7R+yQczv+t53YLIcSZarbRTQ8++CD3\n3XcfbrebjIwM/v73vzdXUlAUPTi43BIkhBCipmYLEpmZmXz44YfNtXt/VUEiKvR/65GsQghxpmQ4\nD2C16v/3bJ/YvAkRQohzjAQJwGPQh9/GhUU3c0qEEOLc0uKDhKZp3iARZWm+G/qEEOJc1OKDhKpp\nYHICEGk5s6FiQgjxv6bFBwm3R0MxOwCIkiAhhBB+WnyQ8HjUGkFCmpuEEKKmFh8kXB4NxSzNTUII\nEUyLDxJ6TcKJQTMRYrQ0d3KEEOKc0uKDhNujgtGNEXNzJ0UIIc45LT5IuDwaisGDQYKEEEIEaPFB\nwuNRweDB2HwzlAghxDmrxQcJt0cDgweTIjUJIYSorcUHCYfbhWLQMCpSkxBCiNpafJCwu/R7JEzS\nJyGEEAEkSLj1eyRMBqlJCCFEbS0+SDiqgoRZkXskhBCithYfJOwevbnJbJDmJiGEqK3FBwmnxwVI\nkBBCiGBafJDwNjdJkBBCiADNGiRUVWXq1KnceuutzZYGp6oHCZm3SQghAjVrkHjttdfo0KFDcybB\n29xkMUpNQgghamu2IJGTk8OqVauYMWNGcyUB8NUkLMaQZk2HEEKci5otSMydO5fZs2ejKEpzJQEA\npyo1CSGEqEuz3EG2cuVKEhIS6Nq1Kxs2bGjw5xITG/+hQIrRA25IiI5qku03lfMprU1N8sJH8sJH\n8qJxNEuQ+Omnn1ixYgWrVq3C4XBQUVHB7NmzefLJJ+v9XF5eWaOnpcJhB8DtUJtk+00hMTHyvElr\nU5O88JG88JG88DnTYNksQWLWrFnMmjULgI0bN7Jo0aKTBoim4lLdYACrWUY3CSFEbS3+PgmP6gbA\napIgIYQQtTX7rHYDBw5k4MCBzbZ/t+YBIFRqEkIIEaDF1yTc1TUJCRJCCBGgxQcJD3qQCLVIkBBC\niNpafJBQpblJCCHqJEECPUiEyM10QggRoMUHCY+mNzfJk+mEECJQiw8SGh5QDc0+PYgQQpyLWnyQ\nUBUPaC0+G4QQIqgWXzpqeFA0Y3MnQwghzkkSJBQVBQkSQggRTIsPEigqBgkSQggRVIsOEm6PCgZp\nbhJCiLq06CDhcqtgUDEoEiSEECKYFh0knC4PikHFKM1NQggRVIsOEjaX/nxroyI30gkhRDAtOkjY\nXfrzrY3S3CSEEEG16CBRWqk/utRskHmbhBAimPMmSLg8LrLLcwBQNRW724GqqWe0zRKbDYAQkwQJ\nIYQI5rxpjL9l8UNUqCVYK9NwhRTgMdoxYuKC+K5M7XQJiWHxp7zNUptek5AgIYQQwTVLTSInJ4fr\nrruOSy65hEmTJvHaa6+d9DMVagkA9rAsPEY7amUELruZLQXbeHLj8xTaik45HcW2cgDCLaGn/Fkh\nhGgJmqUmYTQauf/+++natSsVFRVMmzaNYcOG0aFDhzo/MzTqUoa37cH3ew6SEBnJ/7d390FR1f8e\nwN+7KynyoCIrGJKDOPhTygdMsOCiFwkMQXYn0IlxakbNMgt5SMKdUeeq6Uw4zNRtHDMrs7g5eUt/\nU/izudH4dMW1SLQGLdExWIpdEZAnZV32c//gsoayiLl4kH2//trztPs9n+Hw3u+ec76nuXEIrDc7\n8H3NEbQF/YatJ7cjL+qVe+pRNLY3AQD8ho28730iIhqMFAkJrVYLrVYLAPDy8kJoaCgsFkuvIZH1\nbDKuXGnGeH+/bvP/vSEIm//nv9Dm/xt2nP4Mhqdeg0bdebWSpa0OgGDMcK1jfXOrBaOGjcIjGg80\nW5uAR4DRwxkSREQ9UfzEtclkwvnz5zF16tS/tb121HBk/dsi2K+NRm17DTaWFuJi42WUmc9gk3Eb\n/uNkAX6trwQAXL5WhY3GbfjvC/8EALTYOn9uCvBmSBAR9UTRE9etra3IzMyEwWCAl5fX336fkLG+\nmD92IQ5W/wt1o2tR+NP2bsvfLd+JkCHTUWW+BowG/vePU8j4RxpuSCsAQOvFkCAi6oliIWGz2ZCZ\nmYnU1FTEx8f3aRut1sfpsuUpkZhW8RgKSoogI6vQcU0LsQ4D7GoMefQSLtnPAD4e6Hr+nHXITdyw\nd4ZE6LggDBsy9H536YHqrRbuhrW4hbW4hbVwDZWIiBIfnJeXh1GjRmHt2rV93ubKlea7rtN24yaq\nLS34s74NlaZrmBg0Akfr/wWz6rfuK3YMATQ2qMUD/znvrXttvqK0Wp8+1cIdsBa3sBa3sBa33G9Y\nKtKTKCsrw9dff42wsDDodDqoVCpkZ2cjNjb2vt97+DAPTHpsFCY9NgpzpwcBAOzVk/Dlhc6QiBoT\nBaPFCGhsAABP9d//mYuIaLBTJCRmzpyJc+fOPbDPG+sV4HidEBLTGRL/z8+T5yOIiJx5aO64vh9h\nI0Mxd1w0IgMjoPX077Ys0MfPyVZEROQWIaFRa5AeluqYHj1sFK7e6LxDe8RQntwiInJG8fsklGCI\nzHG8fkTziIItISIa2NwyJP56uatCF3cRET0U3DIkACBxfBwAIHz0JIVbQkQ0cLnFOYmeJE9IwJxx\n0TwnQUTUC7ftSahVagYEEdFduG1IEBHR3TEkiIjIKYYEERE5xZAgIiKnGBJEROQUQ4KIiJxiSBAR\nkVMMCSIicoohQURETjEkiIjIKYYEERE5xZAgIiKnFAuJo0ePYv78+UhMTMTOnTuVagYREfVCkZCw\n2+3YtGkTPvzwQ3zzzTcoLi7GxYsXlWgKERH1QpGQOHv2LMaPH4+goCB4eHhgwYIFKCkpUaIpRETU\nC0VCwmw2Y+zYsY7pgIAAWCwWJZpCRES9UCQk+FxpIqKHgyKPLw0MDMQff/zhmDabzRgzZsxdt9Nq\n+SS5LqzFLazFLazFLayFayjSk3jiiSdQVVWFmpoaWK1WFBcXY968eUo0hYiIeqFIT0Kj0WDdunVY\nunQpRARpaWkIDQ1VoilERNQLlfAEAREROcE7romIyCmGBBEROcWQICIipwZ8SLjjGE8GgwFPP/00\nUlJSHPOuXbuGpUuXIjExEcuWLUNzc7Nj2ebNm5GQkIDU1FScO3dOiSb3i9raWrzwwgtISkpCSkoK\n9uzZA8A9a2G1WpGeng6dToeUlBS89957AACTyYRFixYhMTEROTk5sNlsjvWzs7ORkJCAxYsXd7vk\nfLCw2+3Q6/V45ZVXALhvLeLi4rBw4ULodDqkpaUBcPExIgNYR0eHxMfHi8lkEqvVKgsXLpTKykql\nm9XvfvjhB6moqJDk5GTHvLffflt27twpIiLvv/++FBQUiIjI4cOH5aWXXhIRkfLycklPT3/wDe4n\nFotFKioqRESkpaVFEhISpLKy0i1rISLS1tYmIiI2m03S09OlvLxcVq9eLQcPHhQRkfXr18vnn38u\nIiJFRUWyYcMGEREpLi6WrKwsRdrcnz7++GPJzc2Vl19+WUTEbWsRFxcnjY2N3ea58hgZ0D0Jdx3j\n6cknn4Svr2+3eSUlJdDr9QAAvV7vqENJSQl0Oh0AYNq0aWhubkZdXd2DbXA/0Wq1mDx5MgDAy8sL\noaGhMJvNblkLAPD09ATQ+c3YZrNBpVLBaDQiMTERQGctvvvuOwDd/14SExNRWlqqTKP7SW1tLY4c\nOYL09HTHvJMnT7plLUQEdru92zxXHiMDOiQ4xtMt9fX18Pf3B9D5z7O+vh4AYLFYEBgY6FgvICAA\nZrNZkTb2J5PJhPPnz2PatGm4evWqW9bCbrdDp9MhOjoa0dHRCA4Ohq+vL9TqzsM4MDDQsb9/rYVG\no4Gvry8aGxsVa7urbdmyBXl5eVCpVACAhoYGjBgxwi1roVKpsGzZMjz33HPYt28fALj0GFHkZrq+\nEt7CcVc91ajrwBksWltbkZmZCYPBAC8vL6f7N9hroVarceDAAbS0tGDVqlU9Dq/ftb+310JEBk0t\nDh8+DH9/f0yePBlGoxFA5/7dvs/uUAsA2Lt3ryMIli5dipCQEJceIwM6JP7uGE+D0ejRo1FXVwd/\nf39cuXIFfn5+ADq/CdTW1jrWq62tHVQ1stlsyMzMRGpqKuLj4wG4by26eHt7Y9asWThz5gyamppg\nt9uhVqu77W9XLQICAtDR0YGWlhaMGDFC4Za7xk8//YTvv/8eR44cQXt7O1pbW7FlyxY0Nze7XS2A\nzp4CAPj5+SE+Ph5nz5516TEyoH9ucucxnm5P/Li4OHz11VcAgP379zvqMG/ePBw4cAAAUF5eDl9f\nX0c3czAwGAyYOHEiXnzxRcc8d6xFfX294wqVGzduoLS0FBMnTkRUVBQOHToEoHst4uLisH//fgDA\noUOHMHv2bGUa3g9ycnJw+PBhlJSUoLCwEFFRUdi2bZtb1uL69etobW0FALS1teH48eMICwtz6TEy\n4IflOHr0KN566y3HGE8rVqxQukn9Ljc3F0ajEY2NjfD398frr7+O+Ph4rF69Gn/++SceffRRvPPO\nO46T2xs3bsSxY8fg6emJrVu3Ijw8XOE9cI2ysjIsWbIEYWFhUKlUUKlUyM7OxtSpU5GVleVWtfj1\n11+Rn58Pu90Ou92OpKQkrFy5EtXV1cjJyUFTUxMmT56MgoICeHh4wGq1Ys2aNTh37hxGjhyJwsJC\njBs3TundcLlTp07ho48+wo4dO9yyFtXV1XjttdegUqnQ0dGBlJQUrFixAo2NjS47RgZ8SBARkXIG\n9M9NRESkLIYEERE5xZAgIiKnGBJEROQUQ4KIiJxiSBARkVMMCXroLFq0CHq9HgsWLEB4eDj0ej30\nej0MBsM9v9fy5cv7NHT02rVrUV5e/neae08qKirw7bff9vvnEPUV75Ogh1ZNTQ3S0tJ6HdWza5iG\nh8W+fftQWlqKwsJCpZtCBGCAj91EdK9KS0tRUFCA6dOno6KiAqtWrUJ9fT2KioocD6HJz89HZGQk\nAGDOnDnYvXs3QkJCkJGRgRkzZuD06dOwWCxITk5GVlYWACAjIwOvvvoqYmJisGbNGnh7e+PixYsw\nm82IiIjA1q1bAXSOhZOXl4eGhgYEBwejo6MDcXFxWLx4cbd21tXVITc3Fw0NDQCAmJgYLF++HNu3\nb0dbWxv0ej2ioqKQn5+P06dPo7CwENevXwcAZGZmIjY2FlVVVcjIyEBycjLKyspgtVqxYcMGRERE\nPJBak5u4n4ddECnJZDLJ7Nmzu807ceKETJkyRX7++WfHvL8+kKWyslLmzp3rmI6NjZVLly6JiMjz\nzz8vubm5IiLS1NQkkZGRYjKZHMuOHTsmIiJvvPGGLFmyRG7evCnt7e0yf/58MRqNIiKycuVK+eCD\nD0REpLq6WmbMmCF79+69o+27du2S9evXO6abmppEROSLL76QnJycbm3X6XRy9epVERGpra2V2NhY\naWlpkd9//10mTZokxcXFjn2fO3eu2Gy2vheR6C7Yk6BBZ8KECXj88ccd05cvX8a7774Li8UCjUYD\ni8WCxsZGjBw58o5tn332WQCAj48PQkJCUFVVhaCgoDvWe+aZZzBkSOfhM2XKFFRVVSEyMhJGoxGb\nN28GAIwbN87RY7nd9OnT8dlnn2Hbtm2YNWsWYmJielyvrKwMJpMJy5Ytcwz6qNFoUF1djeHDh8PT\n0xNJSUkAgKeeegoajQaXL19GaGhoX8tF1CuGBA06Xl5e3aazs7OxYcMGzJkzB3a7HVOnTkV7e3uP\n2w4dOtTxWq1Wo6Oj457W6+tzCmbOnIn9+/fjxIkT+PLLL7Fr1y58+umnd6wnIggPD8fu3bvvWFZV\nVXXHPLvdPqielUDKe3jO6BH1QPpw3UVLS4tj1M+9e/c6/cfvCpGRkY4hmmtqanDq1Kke1zOZTPD2\n9kZSUhLy8/Pxyy+/AOh8VsRfH1ofERGByspK/Pjjj455Z8+edby+fv06Dh48CKDz8Z0AMH78eNfu\nFLk19iToodaXb80GgwErVqzA2LFjERUVBR8fnx63v/29nC3rbb1169bhzTffRHFxMSZMmICIiIhu\nn9eltLQUe/bsgUajgYhg06ZNAIDo6Gh88skn0Ol0mD17NvLz87F9+3YUFBSgubkZN2/eRHBwMHbs\n2AEA8Pf3x4ULF5Ceng6r1YrCwkJoNJq71oSor3gJLJELtbe3w8PDA2q1GmazGenp6SgqKkJwcLDL\nP6vr6qbjx4+7/L2JurAnQeRCly5dwtq1ayEisNvtyM7O7peAIHpQ2JMgIiKneOKaiIicYkgQEZFT\nDAkiInKKIUFERE4xJIiIyCmGBBEROfV/smX5vm0Z6kkAAAAASUVORK5CYII=\n", + "text/plain": [ + "\u003cmatplotlib.figure.Figure at 0x7f970d490590\u003e" + ] + }, + "metadata": { + "tags": [] + }, + "output_type": "display_data" + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "test_accuracy 0.1\n" + ] + }, + { + "data": { + "image/png": "iVBORw0KGgoAAAANSUhEUgAAAYwAAAEcCAYAAADUX4MJAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAAIABJREFUeJzsnXl4FFW6/79V1Vv2BEhIAG/AuCAIsgjoCEFgFDSsio7I\n6Dg4l/GODgpu4wxcnWHEHYXBDQVllJ/LRUAhDKCgYd+XsCVhS0IWOnvSSXqtqt8f1V1d1V2d7iwN\nIbyf5+Ghu6q66tRJ1fmedznnMKIoiiAIgiCIILCXuwAEQRDElQEJBkEQBBESJBgEQRBESJBgEARB\nECFBgkEQBEGEBAkGQRAEERIkGARBEERIkGAQVx0HDhzAPffcc7mL0eEZOHAgioqKLncxiDaEBIOQ\nGT16NPr164eamhrV9kmTJqF3794oKSkBAPzlL39B7969cezYMfmYwsJC9O7dW/7+yCOPYNWqVfL3\njz76CGPGjMGgQYNw5513Ys6cOQCA8ePHY9CgQRg0aBD69OmD/v37Y+DAgRg0aBCWLl3qV8YlS5bg\nhRdeaNV93nrrrfjPf/7TrN98/PHHePfdd7Fv3z6MHDmyVdf34FtHHY3Dhw+jR48el7sYRBuiu9wF\nINoXPXr0QGZmJqZPnw4AyMvLg91uB8Mw8jEMwyA+Ph7vvfceli1bptquxZo1a7Bu3TqsWLECPXr0\nQGVlJbZu3QoAWL9+vXzcI488gsmTJ+P+++9v1T2IohiwLC0lKysLzz33HJxOZ5ufu73C8zw4jrvc\nxSDaEWRhEComTZqENWvWyN/XrFmDKVOm+B03ZcoU5Obm4sCBA0HPefz4cQwfPlzubXbu3BkPPPCA\n5rFNzVSzfft2fPTRR9iwYQMGDhyIyZMnA5CE5t1338W0adMwYMAAFBUVYfXq1bj33nsxaNAg3HXX\nXfjmm2/k8/haCaNHj8by5csxceJEDBkyBHPmzIHD4ZD319XVoaCgAH369MHMmTNRVlYmW0Hl5eUQ\nRRFLly7FXXfdhdtuuw2zZ89GXV0dAMDhcOD555/HsGHDMGTIEDzwwAOoqqrCu+++i4MHD2L+/PkY\nNGgQ/vnPf2re89NPP43hw4djyJAheOSRR3DmzBl5n91ux+uvv47Ro0djyJAhmD59ulzuAwcO4KGH\nHsKQIUMwatQorF27Vq4rpVWzZs0aPPzww/L33r17Y+XKlRg7dizGjh0LAHj11Vdx5513YvDgwbj/\n/vtVf3NBEPDRRx/hrrvukvebzWb5XBcuXJDr4Y033sCoUaMwfPhwvPLKK3JZq6ur8cQTT2DIkCEY\nNmwYfvvb3wZ8BojLCwkGoeKWW25BQ0MDzp07B0EQsHHjRkycONGvITeZTHjiiSewcOHCkM65du1a\nLFu2DMePH4cgCC0q24gRI/DEE0/g3nvvxeHDh+VGEADWrVuHf/7znzh06BBSUlLQuXNnLF26FIcO\nHcJrr72G1157DadOnZKP97USNm7ciOXLl2PLli3IyclRieaOHTtw2223wWQy4ZNPPkFSUhIOHz6M\nQ4cOITExEStWrMDWrVuxcuVKbN++HbGxsfj73/8OQGqQ6+vrsX37duzbtw9///vfYTQaMXv2bAwe\nPBjz5s3DoUOHMHfuXM17HjlyJH788Ufs2rULffr0wXPPPSfve/3113Hy5El888032LdvH55//nkw\nDIPS0lLMnDkTjz76KPbs2YO1a9eq3IW++NbF1q1bsWrVKmzYsAEA0L9/f/zwww/Yv38/JkyYgGee\neUZu7JcvX44NGzbg008/xcGDB7FgwQKYTCa/87711lsoKCjADz/8gM2bN8NsNuP9998HAHz22WdI\nTk7G3r17sWvXLsyePTtgWYnLCwkG4cekSZOwdu1a7Ny5E9deey2SkpI0j3vwwQdRWlqK7du3N3m+\niRMnYt68edi5cyceeeQR/OpXv9KMT7SGKVOmIC0tDSzLQqfTYeTIkbJFc+utt+KOO+5o0hp69NFH\n0aVLF8TGxmLUqFEqcfnll1+ajFt8++23eOaZZ5CUlAS9Xo8nn3wSmzZtgiAI0Ol0qKmpwfnz58Ew\nDPr06YOoqKiQ7+u+++5DRESEfN6cnBzU19dDFEWsXr0ac+fORWJiIhiGwYABA6DX67Fu3Trccccd\nuPfee8FxHOLi4poUDF/++Mc/IiYmBgaDAQAwYcIExMbGgmVZPPbYY3A4HDh//jwAYNWqVZg9ezZS\nU1MBADfeeCPi4uIAqK3FVatW4aWXXkJMTAwiIyMxc+ZM2R2p0+lQXl6OoqIicByHwYMHh1xW4tJC\nMQzCj4kTJ+K3v/0tioqKMGnSpIDHGQwG/OlPf8KiRYvwzjvvNHnO8ePHY/z48eB5Hj/99BOeffZZ\n9O3bF3fccUeblDk5OVn1PSsrCx988AHy8/MhCAJsNhtuvPHGgL/v3Lmz/DkiIgLl5eUApEZv165d\neOmllwL+tqSkBE899RRYlpV/o9PpUFFRgUmTJuHixYuYM2cOLBYLJkyYgDlz5oQUGxAEAQsXLsSm\nTZtQXV0NhmHAMAyqq6vhcDjgcDhwzTXX+P2utLRUc3uo+Nbl8uXLsWrVKrlOGhoaUF1dDQC4ePFi\n0GtVVVXBarWqYlOCIMiC8vjjj2PJkiWYMWMGGIbBAw88gJkzZ7a4/ET4IAuD8KNbt27o3r07tm3b\nhrvvvrvJY++77z5YLBb8+OOPIZ2b4ziMHTsWN954I06fPt0WxQWgdn84HA48/fTT+MMf/oDdu3dj\n//79SE9PbzI+Eohjx46hR48eSEhI8LuOh5SUFHzyySfYt28f9u3bh/379+PIkSNISkqCTqfDk08+\niczMTHz99df45ZdfZFdasOD5unXr8PPPP2PFihU4cOAAtm7dKt9DQkICjEYjCgsLNcujtR0AIiMj\nYbPZ5O8eEVCiLNeBAwfw6aefYvHixdi/fz/279+P6OhouRzJyckBr+UhISEBERERWL9+vVxHBw4c\nwMGDBwEAUVFRePHFF/HTTz/ho48+wueff449e/Y0eU7i8kCCQWiyYMECrFixQvZHB4LjODz11FP4\n5JNPAh6zZs0aZGVloaGhAaIoIisrC2fPnkX//v2bXa4uXbqguLi4ycbf6XTC6XQiISEBLMsiKysL\nO3fubPa1AMkdlZ6eLn/v3LkzampqUF9fL2/7zW9+g4ULF8ppx1VVVdiyZQsAYO/evcjLy4MgCIiM\njIROp5Otiy5dushBYS0aGhpgMBgQGxuLxsZGvPPOO3JjzjAM7rvvPrz++usoKyuDIAg4cuQInE4n\nJkyYgN27d2Pjxo3geR41NTXIyckBIAWiN2/eDJvNhoKCAnz33XdN3n9DQwN0Oh3i4+PhcDiwZMkS\nNDQ0yPsfeOABLFq0CAUFBQCA3Nxc1NbWqs7hsRoWLFiAqqoqAIDZbMaOHTvkOvaITmRkJDiOo+ys\ndkrYBWPbtm0YN24cxo4dG9BvvWHDBmRkZGDChAmqoB5xaVH2LK+55hr07dtXc58v48ePR1JSkl/q\nrYfo6Gh89NFHcjbPO++8g1deeQWDBg0KeP1AjBs3DqIoYtiwYbjvvvs0fxcVFYW//e1vePrppzF0\n6FBs2LABY8aMCXjOpq6blZWlil9ce+21yMjIwJgxYzB06FCUl5fjd7/7HcaMGYMZM2Zg8ODBeOih\nh5CdnQ0AqKiowKxZszB48GCMHz8ew4YNw8SJEwFIcZONGzdi2LBhePXVV/2uPXnyZKSkpCA9PR3j\nx4/HwIEDVftffPFF3HDDDZg6dSqGDRuGd955B6IoIiUlBUuXLsXy5csxdOhQTJkyRRaMxx57DHq9\nHnfccQdeeuklTJgwocm6GDFiBEaMGIGxY8dizJgxiIiIULmsfv/73+Oee+6R733u3LmyBaM813PP\nPYfU1FQ8+OCDuPXWWzFjxgzk5+cDAPLz8/HYY49h4MCBmDZtGqZPn44hQ4YE/JsQlw8mnCvuCYKA\nsWPH4vPPP0dSUhKmTp2KhQsXIi0tTT6moKAAs2fPxr///W9ER0ejqqoKnTp1CleRCCJkKisrMXny\n5KBBfYK4WgirhZGdnY3U1FR0794der0eGRkZsqnu4dtvv8XDDz+M6OhoACCxINoNFoulyWA3QVxt\nhDVLymw2IyUlRf7etWtX1XQSAGSzdNq0aRBFEU8++SRGjBgRzmIRREj07NkTPXv2vNzFIIh2Q1gF\nIxRvF8/zKCwsxMqVK1FSUoLp06cjMzNTtjgIgiCI9kFYXVLJycly5gggWRy+g8C6du2KMWPGgGVZ\n9OjRA7169ZKtjkCEMexCEARBBCCsFka/fv1QWFiI4uJiJCYmIjMz028qiV//+tfIzMzE5MmTUVVV\nhYKCgqADgRiGQXm5JZxFv2JITIyhunBDdeGF6sIL1YWXxMSYVv0+rILBcRzmzZuHGTNmQBRFTJ06\nFWlpaVi8eDH69euHUaNGYcSIEdi5cycyMjLAcRxeeOEFeWoBgiAIov0Q1rTacEI9BgnqPXmhuvBC\ndeGF6sJLay0MGulNEARBhAQJBkEQBBESJBgEQRBESJBgEARBECFBgkEQBEGEBAkGQRAEERIkGARB\nEERIkGAQBEEQIUGCQRAEQYQECQZBEAQREiQYBEEQREiQYBAEQRAhQYJBEARBhAQJBoA6hwX/PvkN\nNpz/8XIXhSAIot0S1vUwrhROVuZi78WDAIDR16TDpDNe5hIRBEG0P8jCAMCLvPxZEIXLWBKCIIj2\nCwkGAEGxhhQJBkEQhDYkGFCLhAASDIIgCC1IMOAjGGRhEARBaEKCAUBUiAQvkGAQBEFocVUKRo29\nFg7eKX/nFYIhkkuKIAhCk6tOMGwuO/6281W8tv9deZuoCHrz5JIiCILQ5OoTDN4GAChrrJC3KQPd\nIgkGQRCEJledYDAat6y0KsjCIAiC0KZDC0aj04ptRbtU8QqtGIWoypIS/fYTBEEQHXxqkK9yv8Oh\nsmzUOiyYcO1YANpZUOqBe7zffoIgCKKDWxhFlhIAQLkiXqFlYQhkYRAEQQSlQwuGRwhYxnubWjEK\nGrhHEAQRnLALxrZt2zBu3DiMHTsWS5cu9du/Zs0a3H777ZgyZQqmTJmCVatWtdm1BUjWglIwtARB\nmSVFgkEQBKFNWGMYgiBg/vz5+Pzzz5GUlISpU6dizJgxSEtLUx2XkZGBuXPntvn1PeMrGDDeMmla\nGDT5IEEQRDDCamFkZ2cjNTUV3bt3h16vR0ZGBrZs2eJ3nBimuIHXJeUVDK2pzMklRRAEEZywCobZ\nbEZKSor8vWvXrigrK/M7bvPmzZg0aRKefvppXLx4sc2u73E1MQFcUk7B5beNpywpgiAITcIqGKFY\nDqNHj8bWrVvx/fff4/bbb8eLL77Y5tcPFMNw8A73cd5tDXbvmA2CIAjCS1hjGMnJySgpKZG/m81m\nJCUlqY6Ji4uTPz/44IN4++23Qzp3YmJM8IPcnqjICIN8fAVM8u7YeCO6RMVAf46Tt8XEGEM7dzvi\nSitvOKG68EJ14YXqom0Iq2D069cPhYWFKC4uRmJiIjIzM7Fw4ULVMeXl5UhMTAQAbNmyBdddd11I\n5y4vtwQ9hhck95Ld5pKPr6qul/dfLK+G2KhHo9Uhb6uubQjp3O2FxMSYK6q84YTqwgvVhReqCy+t\nFc6wCgbHcZg3bx5mzJgBURQxdepUpKWlYfHixejXrx9GjRqFL774Alu3boVOp0NcXBxee+21Nrt+\nsHEYDncMQzmYT6D1MAiCIDQJ+9Qg6enpSE9PV22bNWuW/HnOnDmYM2dOWK7tSZdlGO20WqcgWRZK\nEXEJFPQmCILQokOP9BY9A/cQKOgtBbhpxT2CIIjgdFjBqKi1yu4lRjUOQ2lhSIIhqBZQIguDIAhC\niw4rGC98uFsWBzbASG+tcRgusjAIgiA06bCCAQAKw0JGaxyGQC4pgiCIoHRowfDgmYQQ8LUmtEZ6\nk2AQBEFocXUIRgBB8GREKbdRWi1BEIQ2V51gKFfUcwpO/FSYhdM1Z+VtFPQmCILQpkMu0eobhxAD\nTF/uElxYf35zk78lCIIgJDqkhWF3qK0E5QJJvEYMQwnFMAiCILTpkIJh8xGMBpt3riilteHUEAyK\nYRAEQWhzVQjGmeIa+TOvimFoWRgUwyAIgtDiqhCMQEuwarukwrP6H0EQxJVOBxUMtRAEWoJV2yVF\nFgZBEIQWHVQw1I0+H3Achv/qehT0JgiC0KaDCoYLUIzuFgNYGC5Rw8IgwSAIgtCkQwqG3cEDjFIk\ntGMYTp7SagmCIEKlQwqGwyUAjLZIBLMwRBIMgiAITTrkSG8XLwCst+G3O1348PtjiE7LwxnLGXm7\ndlotCQZBEIQWHVIweF5UuaTAiDhwthCmmL2q47TSaimGQRAEoU2HdEm5BAEMq8iU0lgXQzqOBIMg\nCCJUOqZg8KLKJRVl4jSP0xyHQQP3CIIgNOmYguESAIWFkdQpAso0WwBgwcpreitRTlRIEARBeOmY\ngiGIYBQWBsOIqqwpAICokxdQUkIuKYIgCG06pmDwagtDSzAYgdMc6U2CQRAEoU0HFQwX2Ngq+ftF\n60UweofqGJHnNGMYNA6DIAhCmw4pGMW6Q9CnnJe/23g7jDftUx0j8tqBcAEU9CYIgtCiQwqGhSsO\negzv1B6CQhYGQRCENh1SMBhRH/QY0aUtGJQlRRAEoU2HFAwI2u4mJSIfQDDIwiAIgtAk7IKxbds2\njBs3DmPHjsXSpUsDHrdx40b07t0bJ06caPU1GSGEGU98BCMlojtEgYFIMQyCIAhNwioYgiBg/vz5\nWLZsGdavX4/MzEycPXvW77iGhgZ8+eWXGDBgQBtdOLhgKC2MCFs3PNzzdwAYimEQBEEEIKyCkZ2d\njdTUVHTv3h16vR4ZGRnYsmWL33GLFi3Cf//3f0OvDx57CIkA7iYPDBjVMRwM0LEcIDKUJUUQBBGA\nsAqG2WxGSkqK/L1r164oKytTHXPq1ClcvHgRI0eObLPrBkqZ9aBnjBAVcQ6O4cCyDCAyECnoTRAE\noUlYpzcXg0zkJ4oiFixYgDfeeCPk33hITIwJfN4gv43QG1GvEBW9jkOXztEAGDBM0+duj1xp5Q0n\nVBdeqC68UF20DWEVjOTkZJSUlMjfzWYzkpKS5O8NDQ04c+YMHnnkEYiiiIqKCvzpT3/Chx9+iL59\n+zZ57vJyS8B9vMYcUUoMPhaGKDCorWkERAa8wDd57vZGYmLMFVXecEJ14YXqwgvVhZfWCmdYBaNf\nv34oLCxEcXExEhMTkZmZiYULF8r7o6OjsXv3bvn7I488gpdeegl9+vRp1XWDTVEeoTepUm85hiWX\nFEEQRBDCKhgcx2HevHmYMWMGRFHE1KlTkZaWhsWLF6Nfv34YNWqU6niGYUJ2STVFsLEUPWJScFpp\nhIgsWIaBKFJaLUEQRCDCvkRreno60tPTVdtmzZqleey///3vNrmmCAEMgFE9huPnoh2qfcmRSXjg\nhonY+mOm4geMZGGALAyCIIhAdMiR3h6X1K+6DfXbd0+vX8PA6QFVJhUDTnZJkYVBEAShRYcTDFEU\nZSuBZfxvz7NNFfT2WBgkGARBEAHpcILh4r0NPsswfvs5t2BE6k3ejQIjHSsyCJ6USxAEcXXSAQVD\nkFfXa8rCeO0Pw+Vtouh2SVEMgyAIIiAdTjB4wbscK6NxeywjuaJiIg3ejeSSIgiCCEqHEwwXL8Dj\nVmrKJaVEEL1Bb9+1vwmCIAiJDicYgsLCYBkWg5NuUe3XEozrr4kiC4MgCCIIHU4weEEEoxCMGTdP\nx8ged8j7PS4pADByklsqMtojEgxAMQyCIAhNOpxgCILXQmDcLikd6xUJZSA8UhcJAGhwNkrHgwEY\nWnWPIAhCi6CCYTabL0U52gxl0Jt1356eUax9oRCMLhGdAACe2Ug8QfIXtr8SdAJDgiCIq42ggnH/\n/ffjz3/+s2qSwPaMSjDcFgYXwMJ45KbfYHDSLZiUNs69RTre6rLB4qy/NAUmCIK4QggqGFu3bsWY\nMWPw3nvv4d5778XKlStRX99+G1PJJaUeh6FjvRaGUjA6RyRgxs3TkWCKB6BOw9Uaw0EQBHE1E7RV\nNBgMmDx5Mr755hv885//xCeffIL09HTMnz8flZWVl6KMzUI1DkNDMJTWhi8svGm4bTFrLkEQREci\npG50cXEx3nnnHTz77LO4/fbb8emnn6Jz5854/PHHw12+ZqNKq3ULgC5ADMMfr2BQ4JsgCEJN0OnN\nn3jiCeTl5eGhhx7C6tWrkZCQAAAYNGgQNmzYEPYCNhdeUA7ck8Qh2hAl72/K1cSChSfUzZNgEARB\nqAgqGJMmTcLdd98NjvN35axfvz4shWoNXguDkdNqY/TR8v6mBINR7BNEypIiCIJQEtQlFRcXh8bG\nRvl7XV1du86Y4kVp4B6jcC/FGryCwTGBYxgMuaQIgiACElQw3nzzTURHexvc6OhovPnmm2EtVGvg\nec/Eg97GP8bgXfi8qRiG0voglxRBEISaoIIhiqLs2gEAlmXB8+3XXeNxSSlTZCN03rUvmnRJKUSG\nJ5cUQRCEiqCCERUVhaNHj8rfjx49isjIyLAWqjXw7nEYysZfJXhNuKRYKGMYZGEQBEEoCRr0fv75\n5/Hkk0/iuuuuAwCcOXMGS5YsCXvBWoogui0MjanNAe0pzz2og94kGARBEEqCCsbAgQORmZmJI0eO\nQBRFDBw4EHFxcZeibC3CM3CP9TGeJl47Dudq85sMeivFhOaSIgiCUBNUMAApU2rkyJHhLkubIGi4\npABgbM/RQX+rtEoo6E0QBKEmaAwjJycHv/nNb3DLLbfgpptukv+1VyQLAwFdUk2iWG3vqy25KC5v\nv3NmEQRBXGqCCsYrr7yCZ555BqmpqcjKysLMmTMxe/bsS1G2FqGVJRUqjEIwiivqsXxDTlsWjSAI\n4oomaKvqcDhw++23QxRFJCUlYfbs2di+ffulKFuL8GRJNRXcDoTqJ4wIp4vcUgRBEB6CCgbLSofE\nxcUhJycH1dXVKC4uDnvBWopnidaWWBhKlxQY0T0vFUEQBAGEEPTOyMhAdXU1Zs6ciWnTpkEQBMya\nNetSlK1FCK2yMETVZ8+ocYIgCCKIYAiCgNtvvx0JCQlIT0/Hvn37YLfbVVOFBGPbtm1YsGABRFHE\n/fffj5kzZ6r2f/3111i5ciU4jkNUVBT+8Y9/IC0trWV3A/dstYzYsgWQfFxSZGEQBEF4abJVZVkW\nf/vb3+Tver2+WWIhCALmz5+PZcuWYf369cjMzMTZs2dVx0yYMAHr1q3D2rVr8fjjj+O1115r5i34\nXrMVQW8oXVICXAJZGARBEB6CtqppaWkoKipq0cmzs7ORmpqK7t27Q6/XIyMjA1u2bFEdExXlXaui\nsbFRjpm0FHngXossDJ8YBrmkCIIgZILGMKqqqjBx4kQMHjxYNYfUokWLgp7cbDYjJSVF/t61a1cc\nO3bM77iVK1fi888/h8vlwooVK0ItuyaC6Fk8qXXjMMCI4LucxvGKLri5S/sdd0IQBHGpCCnonZGR\n0aKTh7ou9vTp0zF9+nRkZmbigw8+wOuvvx70N4mJMZrbjUY94BCh1+kCHhMInY4BXNJnhnMBKXn4\nMDsH3/7mw2ad51LT3PvsyFBdeKG68EJ10TYEFYwpU6a0+OTJyckoKSmRv5vNZiQlJQU8/t5778XL\nL78c0rnLyy2a2y31dgAiRCHwMYHgeUWQW+cIeq32QGJiTLsu36WE6sIL1YUXqgsvrRXOoIIxa9Ys\nzWk2QnFJ9evXD4WFhSguLkZiYiIyMzOxcOFC1TEFBQVITU0FAPz888/o2bNniEXXRhBEgG1ZWq3I\niJ7lwMHonK0qB0EQREcjqGCMGjVK/my327Fp06aQ0145jsO8efMwY8YMiKKIqVOnIi0tDYsXL0a/\nfv0watQofPnll9i9ezf0ej1iY2PxxhtvtPxuALhEAQzT9EJJAcurmMmWBIMgCEJNs11S9913H/7n\nf/4n5Aukp6cjPT1dtU058E+ZttsWCO6xEy0RjP6mdGyuKwTD8SqXFEEQBBFCWq0vDMO0OM32UuCS\nBaP5LqkYXRwceYMBAAwJBkEQhIpmxTBEUURubi5uv/32sBespbTGwuBYBhCleyWXFEEQhJpmxTA4\njsOMGTMwYMCAsBaqNXim8+BaKBiiRzD0JBgEQRBKwppWezngW2Fh6DhWtjAIgiAINUFb1WnTpqG2\ntlb+XlNTg+nTp4e1UK3B5V5atSVTjBgNHCD6/47W9yYIgghBMBobGxEXFyd/j4+PR319+126VGiF\nS8pk4DQtDJdIgkEQBBG0VRUEAY2NjfL3hoYG8Hz7bUB5d+POsVyQI/0xGXTagiG4Wl0ugiCIK52g\nMYzx48djxowZmDZtGgDgq6++wsSJE8NesJbiEqV0WBNnaPZvA1kYToEC4ARBEEEF449//COSkpKw\ndetWiKKIhx56CJMnT74UZWsRLlFq3I06Y7N/azJwUK+i5D4nWRgEQRDBBQOQMqWulGwpwT3dbEst\nDJFcUgRBEJoEjWH8+c9/Rk1Njfy9uroaTz/9dFgL1RpccFsYXPMtjEBZUk4SDIIgiOCCceHCBcTH\nx8vfExISUFhYGNZCtQaXKDXuhhZYGByrPQ7DwVMMgyAIIqhg8DyvyopyOp1wONrvPEs8pLIZWyAY\nADQFw+4kwSAIgggawxg+fDhmz56NRx99FACwYsUKv9ln2xOeGEZLLAwAmoJhdbZfgSQIgrhUBBWM\nOXPm4OOPP5aXTR01ahSGDRsW9oK1FF6OYbRUMPyNLhIMgiCIEFxSer0eTz31FN5//33cdddd+OGH\nH/DXv/71UpStRQiMZGG0JOgtwUAU1NXicJFLiiAIokkLw+VyYevWrfjuu+9w5MgRuFwuLFu2rF3P\nVutxSbXYwgAAgQNY7/reNhIMgiCIwBbGa6+9hjvvvBNff/01xo8fj6ysLMTFxbVrsQCUFkbLBOOv\nvx2MCL36txabDau3nUNtA7mmCIK4egloYXz11VcYOHAgZs6cidtuuw0A5IWU2jMi4wKDlge9r+sR\nh+hCI2yoDujAAAAgAElEQVS2BnnbgbwSVJ5lcMFswdMP3NJGJSUIgriyCCgYO3bswLp16/Dmm2+i\ntrYWkydPbteTDnoQWUkwWh7DUE6NzgAQYbHbAACVdfZWl48gCOJKJaBLKjY2FtOnT8fq1avx/vvv\no7a2FjabDdOnT8fXX399KcvYLES29TEMxl0tBkYSHY+b6wowsAiCIMJGSItG9O7dG3PnzsX27dsx\nffp0bNmyJdzlahGCKIJheUBkWjS9uQfWrQwGxgQA0jmhNS0hQRDE1UNIkw960Ov1uPfee3HvvfeG\nqzytgudFgBHAiC0XC8C7vKue1QMCAM49lxQpBkEQVzHNX5auHePiBYAVwKJ1gsG4lUHHSHoqWxjk\nkyII4iqmQwkGL7gtjFYKhsclpWP07g28e3urTksQBHFF0+EEg2EFsK10SXmC3hzLQRQBcLy8hyAI\n4mqlYwmGxyXFtI2FAYiAwIFhKUuKIAiiQwmGy+2SanUMg/FUiwjwOtnCIMEgCOJqJuyCsW3bNowb\nNw5jx47F0qVL/fZ//vnnyMjIwKRJk/D73/8epaWlLb6WZGHwbRb0FhkRosAp0mpJMQiCuHoJq2AI\ngoD58+dj2bJlWL9+PTIzM3H27FnVMX369MHq1avx/fff4+6778abb77Z4us5XTwYBuCaly3sh8ol\nxXNyWi1ZGARBXM2EVTCys7ORmpqK7t27Q6/XIyMjw2/Q39ChQ2E0SiOqBwwYALPZ3OLr2d1LqbY2\nhqF0SYkC586SEsm+IAjiqiasgmE2m5GSkiJ/79q1K8rKygIev2rVqlat5md3L3TEtTbo7XFJuWMY\nDAMpXZdMDIIgrmJa57sJgiiKIR/7/fff48SJE/jiiy9COj4xMcZvm6myAgBg1Bk194fKr3oNQk71\naQxM6Y8LxYekjRwPg0HXqvOGi/ZYpssF1YUXqgsvVBdtQ1gFIzk5GSUlJfJ3s9mMpKQkv+N27dqF\npUuX4ssvv4Rerw/p3OXlFr9tFVW1AABRYDT3h8rAuIH429Du4BzR+F48LG1kBDidrladNxwkJsa0\nuzJdLqguvFBdeKG68NJa4QyrS6pfv34oLCxEcXExHA4HMjMzMWbMGNUxJ0+exMsvv4wPP/wQCQkJ\nrbqeJ4aha/U4DBbdopOh43SAe7lWhlxSBEFc5YTVwuA4DvPmzcOMGTMgiiKmTp2KtLQ0LF68GP36\n9cOoUaPw1ltvwWq14umnn4YoiujWrRs++OCDFl3PyUvZTJ45oFqLjmMA0T3V+fWHwdti2+S8BEEQ\nVyJhFQwASE9P9wtkz5o1S/782Weftdm1HG4Lg2Pb5rY4jpUFg42yoNywF0DLg/IEQRBXMh1qpLfD\nbWHo20owWAai4K0igXG2yXkJgiCuRDqUYDgFdwyjDQXDY2FIUAyDIIirlw4lGK42jmFwHCMHvQFp\napAfC37Bq3sXwim42uQaBEEQVwodSjAcotslxbWNYLAMA4hKq4JBTtVplDRcRJ2d0vQIgri66FCC\n4XIHvfVsaGM5gsEwjHoxJhGwOOsBAA7B0SbXIAiCuFLoUIJhd0mCYdS1jWAAUM98KzKoc0iWhZ23\nt9k12gKn4EJ+XWGzRtd3VBy8EwV1Fy53MdoFdt6Bwrqiy12MdoHNZcMFS/HlLsYVTYcSjEaH1OuP\ndk9m2BawiioSIaLe0QAAcPDty8JYeWoV3jqwBMcqTl7uolx2lp9YiTcP/At51WeDH9zB+fDocrxx\nYDE1lADePfQRXt+/CGWN5Ze7KFcsHUowrC6pEY+JMLXZOZUz3wqMQ5qQEFLPrT1xwCxNYZJPPWtZ\nNIuokcTpmnMAgNKGls8C3VEoqpemKaqwVl3mkly5dCjBsDsll1SbCobCJcVzXjdUexMMz7QlHkEj\nQDVBaELPRcvpUIJhc1sYkQZDm51TKRgi6xWJ9hbDoNUA/SHx9EKxLSVUFy2lQwmGZ2qQthq4BwRe\nW6PdWRju/6lhIIimoXek5XQYwRBFUZ58sK3SaoHAq/fll1Uj70JNm12n1dBMun5Qw+CFrC0vVBct\np8MIht3JQwAPoO1Gekvn0haMPaeK8frKQ6i3to/5pbyrkNPLQPhDT4UXXhQudxGuWDqMYNRbnQAr\nPQhtNdIbCOySYlhJnBrajWA0HfQ+W1KLV784gGqLN/bCCzyWHPkUe0sP4oKlGG8fWNKhMkiaI55O\nwYVFh5fiUFk2ztcW4O0D76PGXhvG0l1axGY0knbegXcPfYhjFSeRV30W7xx8X04nvxQIogi7kw/b\n+V3NmNan0WnFOwc/wKmqPJyszMXCgx/A6rKGrWztnbBPb36psDl4MIz0UrRpDIMNsBgTJz3Q4Xyw\nm4XHJRWgjVy8KhuWRic27C7A9LtvAACUNJhxqioPp6rykBLVFaUNZvxw9j+YcfP0S1ToMNOMbvXZ\nmvPIqz6DvOoziDXEoM5hwab8n/GbGyeHr3yXkOY0kscqTuJMzXmcqTkPlmEhiAKyincho9ddYSyh\nl7e/Ooycwhosff5O6Li279M2Zx64/ebDOFebjyVHPpW37bt4GCN7/KrNy3Ul0GEsDLuDly2MtnRJ\ncYHO5bYwbI52IhhuAvWqBcF/u15DDHmxfd1Pa2iO60HZyfDUYUeqi+Y0klodLkG4dHWRUyjFBsP1\nbrmE0L0CWi7pjvRcNJcrVjB4gVdlKtkcPMBIf8i2Wg8D8HdJiU4pZZdxWxiOdmJhsB6XlChqZnBJ\n8R0RDCOZ2YBk+su/Z6RHwdPIWl02CFe4r9cpODVH5Dt4h3xvnrpQ/p09nwW5Lqwdti7s7roQRVGu\nC2XSiP9zYb1kyQROV3jq3Mlr14XNZYcoihBFUXY76Tn/BBrls3O1JVZcsYLxjz1vYU7WXPm7zeEC\nWAEMmMBupBZQWmFTfRftEdIHzuW+bvsQDE/Y++eiHZiTNRfnawvkPQ3ORqD/f6C/NhvFTDae3/4y\nTlXlwSV6e52cu2EQRAE2lw3Pbftf/Ethhl+JbCrYitlZc1FcXypvq7XXYXbWXHyduwbrz23G89tf\nxrnafFWvkVXUhcVRj+e2vYxPjn1xycvflqw7twmzs+aqpsWosFZhTtZcrD2zAavPrMfz219GcX2p\n3PkAvB0RQRRQbavBc9texoqTX1+SMjtd4Xm3vjuzHrOz5qLa5s1yLG0w49lt87Dh/I/4Kvc7PLft\nZZQ1VgSwtgRcbCjD89tfxjd5a8NSxvbKFSsYFTYpOOtRe5uDB8MK6skC24CGRvVDK7oMEGwRYE31\nAMIbnGsOvlm1+y4ekj97gre6LqUoZrIBAEfKj4MXlI2kt1dd655gMa/6TDiLfMk4XHZM/lzWWAEA\n2FmyF//J/wkAcKIy16cuPL1qHuVW6fjsihOXqrhh5WRlnvzZM1XGlgvbsPXCdgBAXvVZVUdCfi4g\nyPNR7XdPQxNuHGGyMDycrc33fq45DwDYkP8TdpbsAwAU1F3QTBYQIOCc+7fbi3eHtYztjStWMDxY\n3Wa05JIS2jR+AQBjh/RUfTewRojWGDB6J6B3tBvB8A1dWF1ey0hpNovuxAAWjCoQyroVhxcFzTHj\nVrsLLl798giiiCWrj+GnA+17/iqboi60rE8GjE8j6XXvNbXKYqHZglc+24eKWv+smUZb+8ie80X5\nXJg4/0k6GTBwKcRTaXkyl3isTyCXlCiK+GDtcWzcW9iq8yvrItYQ47efYdR14UFyz12d456uSMHI\nyfemflocVjh4J/KteQArgGvD+AUATBl+neq7iTNBaJQeLjbCIgXbFdTYa+XJ7wRRwKGybFUansVR\nj1NVedCiuL4UedVncaTsWLN8o5W1NjTa1eVQvgzKxtAFyXfr+zJ4PgsiD9+XodHmxJPvbsPSH9S9\nbEujE4fyynEoT3v2zypbNU5U5gKQYk4HzUdhc3nTemvtloBWTKGlCKerzyK7vPU9e1VdaAR/pbrw\nbmfg9ds3NeXK+2uOodBcj9Xbzqm27zlxEU+9tx0HcsrkbRXWSvnv7hRcOGg+qvKj19hrcbpafR4P\nBXUXcLr6LI5XnGrqNkPCynufRa26YBnfjoR2XRRcbPkCYubGcvnv7uAdOGg+KgflRVEEY7CCja7W\nFIzztQXINufhUOkJfPtz6yxgm+od8RcG346E5/4FgW8z8SxtMOOM27qxuew4aD6qsnYrrJU4X6st\njGdqziOv+ixyqk63SVlC4YoUjL9+uFP+XN3YgG/z1uKQYyNYU2ObWxg6nx5plF4hGJEWPwvj9f2L\n8FH25yipv4jdJfux7PiX+PLU/8n7Fx78AEuOfIpCi/8aBQv2vYtFhz/GJ8e/aNbU3BfK6jUsDG/D\n4BkBr4QFq3oZPI1XlcXmZ4afKZZcWgdy1cJQ4x7TESiO8/c9b+GDo8tQbavBz0U7sPzESvzf6e/l\n/Qv2LcSiw0s1p5t+Y/9ivHf4Y3x8bEWr13NQ1YVWIwlWJZ4WmycpQPBz9YmiiHU7z+NMUS3sTqme\nDDr1M/LzYcl1s+Wgt9wv734DS458ikanFRvP/4TlJ1Zi3blN3v27Xsd7hz9Crc9KjqIo4s0D/8J7\nhz/Gh9mftXpqbmUjqVUXDMOqGk9PxpggqJ+Jv3++v8Vl+Meet7Do8FLwAo81ZzZg+YmV2FzwMwDA\nxQswDciCsc9eNDjUlptLcOHtg+9j6cllMN54END5z+dmd/BY+WOearxRXmE11mzzf58aVe+Iv0XI\nMqymq9IpuNrMvvjn3nfw7qEPAQBf567B8hMrsU3h5np59xt4++ASv6SLRmcj3j30IRYd/hj/OvLJ\nJZuq6IoUDGXPo87WgNOKxrUtB+0B0kMyb9hz8vdoYyREqyQYTKRFbixdvIB6qxMWh7QiX3Fthezz\n9UwxDQBlbp94sCVeq+yhTzui0/k/vqH1qr0vg+eBq6hthM2pfnnyA/QmaxuklzKQW85z3TqHBWer\npSC8Mhhf75QGgzU41Q2D78tR66jTPH+oWF02rNych882nNJMqfTtVTfYbe5y8H6B1+LyBqzZfh4L\nvjwoZ8gZ9OrXyKCXBETLB2912WTfuXKRJ08jbePVSRYOn/L61lVzaQzyXPi6Kj3PhUt0+fWqeaF1\nMQYbb8cZ97vhSUxQdj58BUP5TAPeTEUPdQ0OZO7Jx5aDRVj0f0fl7c8u2oZ1u8/7XT+QFe5h+9FS\nVV14EiPsgqPNJ/t08k7kVkuWwoYjx5F1RD01v83n3n3rwsE7UFzRgL98vBtF5fVtWjYlV6RgKLHY\nG1UpkW2ZUushOSpJ/hylj8DYW24ECx3YCIvcaHy49jhmLdouH/fxumMoqZL+cKFYPXaXuofg8R2H\ngsMp+LlUg70MDMOAV7wMckPFiKi1qh/G/FJJMDrFqn3eNfVSmW0OHrwgYM/Ji35xDkBaCfHwGck9\no5V14tuI+84EHGg+r1BpdNmw5VARtmeXajaSosioc+vdDREvCigqV4ulskHzCKVRry6fQSf97Rwa\nWT523i5fS6su/BsGdaNpaXTg2LlKv99poZUKHNzCYFS9aqf7byNZoL6uytDHdmhhddnkZ9Mz3kHp\n4m1wNt1IesZCAcCR0xV45l87sHmfJMLFFT4j0xn/uvB07gDtusg+VwGHhnVudzlk67qtsPI2ud7r\n6l1YsTEXh097rUnfe7f5vCN23oGVm3NRVm3FF5ty27RsSq5IwdD18FaIxdaA+kbvw6CVN92WROhM\neHDUDegW1RVMRD1+OVqEilorjpaehq6HNzbBsALqGqU/slag1bdhqKhXP+AsGDgFFz47ugqf/LRb\nsyH2YLW7/F4Ia5CGgQULp6KR9BzPRtXhZIXXJ7rmTCYuOiWrwGRQN3A19W4Lw8Fj874LWPrDScx8\n6xdsOH4Qmec2y8eVVNXJ5dOaasX3ZWj0szh4OHgnvsldi4sNZWgKrdiPxe6tW6tTYyyCg1fHMNwD\nQE9V5aHI6vUfr8r7AWdqvdas51K+o5E9FobTKeBkZS425W/1Xt9lky27UOrC9zn5dMMxvLvqID49\n8g0qrE0Lh1bA1mPVSfv9rS1RFDU7GEfKjyO/zlsX+tSTOFUh1cWBnDKV++1gbjl+3O+fCHGs4iR+\nKsySv1tdVjhd0rUEQRIjq8N77UZno+r3vnUBlkdlfR1e+XEZ1uyR4oYeq473HajKagmGtzOgaYWz\nAup8Ok8AsN98CHkV3vv7Kuc7Vd2UVjbgi025ftZpWXUj/r0pF1a7C4fKsvHLBa9r/bON2bB6LHtR\nqot/rT4i728M8o44eAecsELf8zhELnxLL1yRU4Pou3nNy3qnDQLPyHdivASCAQBdIrqgqKEYjN6O\n1VnnYOyzV30gy0trjBu8vSdlY2b1cT1U1qt7snbeiUMlOThQuQ+uslSkHb0Gowf10CyTJ0NMtY23\nSWZuYR2+2HUSSPH/DR+h3UPcXu5t4H4qzAK6AigY5zdI0WNhNNpdqpl7M8u+UR13zlwll88TE1L2\nfn0byYp6tUm9YvNJpPevwbayXTDpjJiUdo9muStrrfIU90osTgukIA+Depv/y9RodyEmUtuttqdq\nm/z556Id7k/jVMf4irnn71xRa8P7R5ep9lldVtnC4FgOlbU2REcxiv0+DYNfQ2EHl1CPw1XH0MPc\nBeN6jtEsNwAsyzwORKu3VVqrpMCyjxvOQ1b2BQy6qZPm+Tac/1H+rOtaiBVnPsOGLVNRaJb+XqMH\ndQfDMHh/jZTGPGZwD7Cs994+yv5cdT6ry4Z6uwNggNOFdUB/oMZqUe1X3buPtcWwPD7ZsQXlhlw4\nXAyAnprllg72FwzlvGmaU6cwAsw12nNo5dgOyp93lOzFjpK9eHXofPyw4zx+OSKlK3dPjFK9s59t\nyEHuhRpwLINd3Jeq82UXmGG8yQWGAURB6oAwesXAZJ9793Vd2nk7GkwF0MUXwVbnfdkdTh42B4/Y\nqLZZI+iKtDCUNDqsqh68oY1jGL6Y9JJbJlLvXtWP5REVoSFSnEsSDHhdD0pXi+/LUNWgbiR3nSzC\nsi173OdyykG8eqsTe0+a1eJjd4Jh/XvWFxvLcPR0pWYjeaGsXrMH2hS+PnmlWX70bODe7skLZsBd\nPo7hsOt4KaoavHEJ37ow16on/attbMSmbClbqqC8StOKKDRb8Ng/NuOrrf7muAAejEnqrTbY/evi\nXGk1LBo9yVBxOH3E2uHJOPMvp2RhSI2Tpd6F5z/chR8Pn1HtBwBzdSP2nTLLaeMeGJYHEyk1qr4N\nqBKeF7A/76Lf9kaXVR6Xo2V55ptrYXWEHkD1iAXgH8uqD5JabHVZIbpnZ6ixSGWptgUWDD8Lg+NR\naZcsTkbX9LUYDcGoddTJFpfm1CmsgBP5FU2eV8mcJTtlsdDC8zyczPef4JPhXN53WHQ3y3rt9sLh\n5HHkXKny57DzDjj0UqdNUCz09q/Vx/DMv3bgfGmdKmuvpVz5guGywil6K6gt18LQwshJSm3SuRWb\n42EyaOT2cy44eG9PEpCCvx58X4Zaq1owTpdUgYmwyOdqtEsP9NIfTuDjH05g9wmpMcgvrcPq7drp\nhcX1pdLvNF4WvV47ttEUdQ0OrPwxT0468AS9g/7O1ii/sJW1Dny6/hS+yjou71fWhdXuwsqtJ9Un\n4FzgoqX6OVFYhiNn/F/i00VSI7gtW3sdb09dNmg0hgVldfjpYMtz+n1dD02N/le6pKrqpEYu6+R5\nxX4raurtePXfB/HR9yewJ9fnfjgXWLdgWJ2BRa6i1ia71nzxBJg1G0lGQKWlZTPT+sY0ausd+H8/\n5uGERgMJSHUhwlvGaosdtQrBsPE2rN1+Tvbl1/uJpwt2TmokGc7/XmwOlzdBJkBdlNRL75FTa34p\nRoCIlo+z8nWLJcRInc3Sykb/g5Xld78rSgtD+Y5k7i7AtuPq5zWvuAINkOq5rM6CI6eld+TEeWnb\nu98exQdrj6O1hN0ltW3bNixYsACiKOL+++/HzJkzVfsPHDiABQsWIDc3F++++y7uvvvuZp3/jOMw\nlIO723KmWi0i3BaG0T3oSZ9yDj/VHQcbpT5Ol3Ieojt4esFSjKd/fglDEofJ+60uG+oaHWAZBrwg\nYt3eMzBerzgB620YuE5l2C0sR3XW7TgbfxCmgQJOFMUhB1uxP6cM+l7aZf3i1LcwGDqBYRP99rkE\nV7MsDOMtv8B+dCS2HCxCgXgQxdwRONleAG4AIMLQex+E+ni4im70+62u+xk5o6VKLILp1hKcr0sD\nIjx14W0IDuSUQWDULy/D8oBJskh0XUqxrPAd3G8aj435W8AyLP46dDZ2NayDvpcDjF5bxIzXHwFf\nlwCro7f/TlaA3eVEqF0NY7/tsB8bIZWnRy726jeh9KfBEC6m4flpt6C002bohAS4iq/3++33ZzfI\nAcs6w3mYBhfAXuP9A1pdNhw7Vymvs5JbXA50UZaVBxshieeu0n3YZz6EKddlIPPcZhg4A/42dA6W\nHf8SUboEGK7L0Sz/h9mfoW/n3ugWlaxZF1WW0DOxjH13wX5Cmrn1q1NrcarhMLiuN4I398T6PeeQ\nzfyAnTu6YX6nh/1++395P4CH2wrvWohX9v8DaRE3y/uPnr+Ig6WRAIDlfxmN/Xm+4snDZagFA0CX\nXAAu8QKcF26EvsdpiC499uddj12N30N3DQuuk1mz/IsOf4wBXfrByET67WMYIaDQaGHovReOHOkd\n1/c6hu/rNsFUPAUjut8GO+9AbsT34JK6gS/7L//f9vI25vpu56HrWgi+3OvO2pNbhBuib0ZCjBFl\nNVY/gVy39wz0PS3u35/D0vx34Np+A0yD8yA6TKg/fgdMhtZ3psNqYQiCgPnz52PZsmVYv349MjMz\ncfasOh+6W7dueP311zFhwoRWX++G+DQMS7m11efRwp43CC7zNegaIWVMeSwNrpMZbJR/2qlvyp9L\n5LGr2Ju73ui04pnFO/Dy8n3IL63zewAYnROMydvTY1gRObb9gN4ORu9Efv15HCw7CrZTKXRd1Oap\nEoe+SvOhd/Au2TUi8sEfA9Zok3tBhY35ACOC6+R2eXAucLHV0Hc7j+t7xPn91rcuGFaAI8abXqvs\nPVXX2wHORzD0dvA6b12IjID/nP8J9c4G1DksyK0+g4uu89AlFoOLD+xC4GKrNd0tyoYhpLqIaPAG\n8eMqAUZEfmMeThfV4qKlBi5jFfTdz/pllQH+2S0MJ4CP8/YWyyx1qKhRWFw+bifWaAVj8J7DJbiw\n4fyPsqsppyoPOdWncbB8H9jowOnIJypzAvjtRdS6kzVEPnh2GhtVB88goOOVORAhgkuQGucD5/Kl\n/d1y8NyHO/x+6+uHd8GJHIuiF+zzHJRb1O8ZG1EPRqdIVuAE6LufAaNzgTVZsWLndhTWF0Kfkg/W\nGFgEj1Qcw84TGpYpKwKMdG+iEDyNlout9n6OL4MIUR54WmQpgUNXC0PPU2prwlN2nc/7z/HgOnvd\nWycKzXj2/Z1wuni4XALg44JjI+tUbmmG4+WOGhvRACbCgi5xEUHvIRhhFYzs7Gykpqaie/fu0Ov1\nyMjIwJYtW1THdOvWDTfccEObjJx8etAf0bezfw+3LRBqkuAs6CtnwHgEozkweu8fuapBevirLXZY\nGp1+DxEbVecXl1D+vhL5Aa/j55Zj/R9QycJwC4ZDepBEgYVgjfI7Vr6+u4zy/6ZGgOFVYhdhCvhz\nFSKnMLcVDcfFqkY/8WSj/RcyanB5zfpD5qN+++XruNQWp+8YEwAAI4DxNAzuuhDsJgj2Jm7GU0Z3\n3TKR9QAEfLjOm9kSGer7qXj59+YUyVONdIo1wi74pBhH+4/PaVBkEy3d/qPffg++dRHIDVNRJ51P\ndEj3LzTEQHQ10Tt1p7d6FhWTLGNRTk8GoNlIaqGMRSifA0EQYfcRGK26UL4jus6BO1IRnM/fVsuS\nUFoYLkn8+drOclBaGxFRJp2cgexx/ymTPIb01U4q8Lu84l489feXj/fgTEmtxjvSdF2wkRYkxof4\ncjZBWAXDbDYjJcUbse/atSvKylofeLmceATD0ALBUFLeUA02tgKMwYq9F05IvVYFWo2kEq5T4Hrk\nGE41sEjrYSqutOBAgWTteRoGhhUAIXCvkjFYwRisgLs3xDAAl1AGNtrbs7JFNX9UdqW1CvNXb8Ci\n7/di/4WT4CLUPt5gdXG0iYkBRd4nFVjQqDfOG0iW60LnbLoujFZAb5N7hgwrgI2rQJldEfSMD9xg\nBTyvqRF7L5wAY7QisUcDGGPz6qKp50J0qZ/Z0gZ/N01kBMC4XV6eqfzBuZq0Njx14WnUGJ0LbEwV\n2Cjvc+exOpoDY2oAG1sB6G34n6XfoYFXW0zB6yLwNRle3XhKk4mqiYpSbHd5ljVwAU3UBWu0Ys70\n3rJ1VOuoQ2FdkSrtNqVn8wfWsRH1YGMrUG2rhYUtAWPwFc+m64KNq4CDa/l0Lh7C6vC/lHPF63h/\nH2RbMvvBW3DsXCW6dZauY9SYuK051KMKxt5SQOocAF2IvVHRqYco6Jo0sR28EzpGB6coPbRKU9mD\nrvNFeLZ6GkmgaTeEsY80i6eyh2W4Tt27v2DcieZSaCkC4otwEYBBI8QQCMFuAsMKquBgMCysf+aQ\nrou3kRed0t+V4XiITQiGqa80fYPSVWG88ZDqmMq4fSGXywMXUwOu9wEAQCEAXXTTx3sQbJFgdA4/\n14b6IHX/UDlbqwdnfL43JOhpJHUur3hoYOrn/zc33qSeOsTQq/lzgnFxVeDimr9ksGiNhj7Kpu1y\nc+OwsYBCM7Tcd474s3KPWnAYwEUC0DkhChwYaGdlGW/ZhrePbVNNKfPGgcWqY368+J9Qb0WGi69o\n0t0aiO7RKSiuvwhd54vIRyZ8U8KbS1gFIzk5GSUl3pfRbDYjKSmpiV+0DMFuwi2GSUhM9J9xsq0Y\nnRiD0cN6yt+TXP6+eiXOwhsh2KJgvEFqRETROwW57sKtiO3sRKUuR+WPBgDHuZthuDZwNoNgjQFn\nvtSov7cAACAASURBVAlOUxn013gH2Ik8B74mCbrOpRDAQ+ARsv2oFIymetUeGFaA0BArWRz6ptMZ\nAcBR0Bs6PhrstVJDqKyLJ2/9A1Zs2QNLVK5PaiQDR/5NMPQ86X9CNzpnHKyFqTAm1AIp3nRa0aUH\n6juDib8ITic0Z6VWVcNo0hkRTIoYVgRviQcXaVG7YLTOLQLOwt4Q7ZHyc+EeHgJRBBynByE6wQpH\npzxV3EfkWbiKr4f+vwKP4BUaYjGwy63o05fFN8d/kLcnmOJQYdaBi6tE5zgjqp2h9269FoYTsIXW\nIePrOoGNqZZdfAHPLbBwXrgRoj3C7x0xsHpYcm4GG1EPXfezqmwv0aWD62JP6HtImYEMGL9VJjl7\nAl4YOxmL1/2M+jjvuyTYIgBeDzaqDnanCF+vVJPlVVgYTYmnqhwNSeCjgntUInQmTOs/CZ0i4vH2\nzo+l67nrIkofiT8OmY4SixnfHFunulfRYYSrops8Lk0UWL/MuL7J1+PhpEnIyjmF265XT6TaEsLq\nkurXrx8KCwtRXFwMh8OBzMxMjBkTeKBRSy0SobYLOhvjUV5uuWT/rPWKF9qp9u/ytZ1xW9KvINR4\nxVGwJLgPZlB/sTMcRb3AOvy7jwZLapM+UrExBjd06olZI+4DX9VV3j6g8wCIivhDc6rSxHobA18X\nTsByOI3ISNUeQKc6t7UbeHNPRNq7y9s8daFnDDh+gEV5bg+IPg0SyzB444HfeK+ncT8pkcmIZ1Ng\nvdALfI03lchV3h2dTPEAgGYnhijcNjGmEM0+pxGdGwcGPYyvSgZv7ql6LroaesjXFWqSMOPWCUiO\n7uLzQz1cZdd4v2uIumiNwU0JaUhPGo4Ywftc3J48RLaaWK5575fcSDJo0tpS/cZuguvCDUGP4ytT\nwJtTVXXRKyYVABBtiMZN8b0xrtdoxBli1ed3mFR1EaX3FzK9Mw7dddfgGnEghAbv7/mya7wrZmqk\nmjd5Xwr3XCidKgBwNJjgLAreSA9NHoTB8YPRy5gmb/O8I9G6aKSZrseIxOGINqjji4ItEryiLvSi\nvwJ24rqgp+la/G5ABm6Man18N6yCwXEc5s2bhxkzZmD8+PHIyMhAWloaFi9ejJ9/lmanPHbsGEaO\nHImNGzfi5ZdfbnG2VJe41gd0moMy6M3XqV/waKMRv79H7VsRLFKgSyeaIIoMymtsMDD+DRLLMPID\nyYoaq301xiA6Qo8eSdEqYYmLiAr5QfYlWq8QrhDP0aNTPPp3D5DPq8CzJnqUydtyJ+ok8eAEEyxW\nqQ+v1WvrFBPhnRvMpbFfn4iYCPd2RV2kxMXhum5SfWtNW90UUTrvS9k1LjSLVXTp0SMmJehxqUnx\nuHvINZh4R09527VxUh167j8hxoR4k8Z1FX8XTlC4EN3TSAiNMeifJj2HKZ28jWSEzoTru0uNT3PW\nslaWCUCTfnsVvB6CNQQ/msZz1ruL1LjGGmLw7EMDcV96GjpHxvodp/xtjMF7LUaQnhUjL93vrwf3\nQJTB6zoWeZ13UFwz0mUBAO6gP8MKIYun4OL8OkJaaK7q524vYo3eZyFa75uQwqjKYlLk9nv+dt2j\ngz+XzSHsA/fS09OxadMmbN68WR6DMWvWLIwaNQqAZIVkZWXh8OHD2LNnD9atW9fsa/CVKUiMb33K\nWHNQCUZliqoH7OKlqRfmPupN8R3V93p0jUhCDOMVlwifwRsjuqbD4RLkjBQjEwlnaU8AwJCkWyEK\nDIT6BMRGGRAdofc+/ACiDRFBsjcAoV7bjZZolHp5fHViyIJxXUoXJEcGdy96Jg5U+nRv6poK0R4B\nV0M0KmvdKZxOdUxo4rWSrzVSF+neb8CAToOk+yi/BqLAontUD0SapJdNVNTFqFt6IjFW+h0fQDDi\nWe2yj+s7AADgqkhBbERoz5TI69A3uWfQ43p1jcNDY67H5BHXytuu75wK0WGE0Cg1jF3iTH695ju6\njgDAyFlOejECrkqpIeDLu0PkOSQZU+SBYUadV5xNughc00X6uwcadxPPddHcLtRK22+JH4S+qf5j\nebQQeZ2qVx/wOI1nNS2uJ6L1UeihaOSUsULe5kL5zxYfwYjBzZ1vAgBwlu4QXTpEuweu9E5NwH8l\nSfd+7suj4K2C97qMdl0IARr4G+Ikq8lZ2rN54lmfEPQwrcHGQl0niC49ronpJm9jfSYkdZlTAV7x\nt2Yj0TO6p3TpmkQwvEF7rE0ruKJHeg/pOgjWQ6MhWDpfBgvD+yALNYmwHR4tN8icTlKPa7t5X5zr\nuyXghSFPYWrqA/K2CL23QbIeGo1f9xgNp0uQXUscy8B14Ub0a5yGaTfeB9uRURBtUeiRGC1NeKd4\n6WKMkSoB0cKeeytsx37lF9hOik6A9eAYOM4MDCn3HpB6rnpOj7dG/N1vn+PczZK/GN6pv5Vz2XSK\nikavugxYTvVFbqE7k8Z9LybOhNeH/y9+/V8jAQBdIjoDkHrnM/o/gLdGvILOllthO3InkqO7yIKh\nrIsInSnoiP+HUh/FX4fOhu8MrCP7XIdOhRMx7YapoSc28Dpc0zkefx86129XVNlQGFnpPFqLeyVG\nxeKGhkkYl5KBJc+MQIRRJzcMXSI647Xh8/DwgLsAeEVVzxjhPNcP1oNj4Mzvg/8d+iJenj5cPqey\nxxqpM8lWmmYaLYCpPR7Bi0Nm+W0fe8tNGGB7GI8PeACdogKnW6vgdYDLiGHib/12/bHf7+TPCdH+\nYhxnjMXLt72AqTdM8tvXPbI7os6MgL40H+/NGiH3tmP0Ufjvfo/gzeEvgynuB9vRkRjRN1X+nefe\nr/3tLWC5qKAWxq3Mfegv+ns5pgwdAOvBMXBduDF095xLB9ERAduRkX777DlD5M+cxrLSoiMCMQV3\na86bdnPnm/Dszc9BqO6qeuc5wYTZt85Er4oH4Mzvi8TSe2DStS45x5crcvJBDxzLyq6K+Ji2rZhg\nqNNqGcQao5GSHI/C+lokd/YvC8fqYNKZ0LdnEgApkBtl1EOeecBlQKRRauQ8QWi7aAXAIMoQCaNe\nJ99rjyS3Ga54WCL1EcGtA14H0RorNa6KoGqXmEhvT0UI7ZHwTMIYqfd/8QVrtFyW7okm9L61BzJu\n74m/uudnjDQacH23KJw6Xw8R0pQJid1icUGQLBGlmyHW/bnR1QiO5RDJRqJrQhRKKqyIidAj0ugu\nr+i99widSTVOQ4teyQmIjtCDY1iVFWIy6DH/Manx/f5saFMpiLwe8TFGxEb6u82eGT8ciw+fhF2w\nq6aTl6+nM+GZ+wMPNlUuHSo6jUBEAwTWLv3t3YMMk+PiVb9RTvFvUghGIPdccnwskqP9e9YPjvb6\n30NNI/dYxz27dMFen+nFukWnyEHqO25OwVqfBQQjdCbN5wkA9DoO0ZX7UV5Wimee+j2c3VmwPU3I\n/PJbXEg9hTNn8vC/ry3Fq/94Cf/O/RKfOhx44IFp0PWU7v3Uwl1IHdUfMXE8sv+1B7GpXWAprIQ+\n1oieD/cH656S/vF7+sPBO/H40s9gzsqHyIvgInWIfNMhWQwuB4o374Wt6iLAMEi+sxfi+iSi7nQl\nLv50DqIoQhepR9pjA1F+6AAYZz5uHT4eJQByl+xFr9/eAkBE1c8rwZ8R0XihDqNe+hXefvt15Oae\nxPnKAsT1TUJc3Gjc0ee/cDo3F4sX///2zjwgynJ7/J+ZYdgZkE1kEVEUccEdUMktrpgrXEWvZup1\nrVxyqUS+Zd+ytG96vdXtdjXNTLMsb9mvm7bp1dJETZOstMUV0QABkX0GmOf3xzADA4MMCiLwfP5i\n3vV5D+/7nOc85zzn/I2iomIydVn4P9SVr/7+EYOejDTJ5vzmU/iO6YitnwIbpQ2d/Dw5cyGP0IDW\nFiR5ZzRthaFQsmZeJEXaUlMd5rtF1YV7M0Z05nBBeSoGC4kAjVla1TZKEh/qQ+r1fHKdfuZcpSzQ\nduU5qYwjyTJRitpGiZ+n+eiuTXlo76Du/hy5blgx7WBT+5SUh8aBrNxibO2gcr48D03FR9on2IfT\nxbWXfDQqDIuUVkyX6SljSrS5E9TTxQkP/4pOblAPX0q8s7iSWt3sdrUzWGk6fUW8Ukd/N36+mI2P\nh2MNFoZDrXVRnMsTRtY0ZQV1WJxZamO6XlVcbJ1NI35LU0KWLCFjidiq77TQGd4LPbdeBFe5/oqj\njQM25fewVB8DwENjX+vC2arWVklKCGXZ1ac7nNVO4KjiP99eorjYfGT94i9nKSoeBMAXP1W00TgC\n/0yfxoPR5lM4xvdBqVDwyCMLuXTpAlu27OC15M18d/IYWZczmLd6AT4+hrb8428v4eLiglarZc6c\naQxYEGO4kALG39eZayWlnMguos3kQHzHBnPpg5+4eSaDVmEVz2KjVOEU6EbHuQZFnnXyGh/9+11a\nufTlt+N7UTnbEzLfkAKkrLiU0gIdqZ/8QvCsPti62VNWntbF+E56t3LkWnkbjGRl/EH7sb3wHx2C\nq4cb8+bNx8XFhUf3PcH5raeYMdONmHB/pj44gVWr/o+QkM68cHgdV4vT6TiwG/v37SXhwVno8q+z\n/AclDq2daeVm6D9G929HgJczYcEeNf9Db5MmrjBUtG7VsOsvakKpUBLh04fDxw2LYezUSpNSqGz6\nz+gymYOp3xLSqiKvULCfK8F+ruSXuHH2xq/8/p3hZVUplSyOD+M/R+2xdSlhVPtoggZ2MCmSByLa\noivRm+ovuDk7QnmNFQcbe/Q3PdHnu1Ka1g6hszdLuT6gTTgTB0VSWqbn8W8/N20vve6Lb1jFiN5W\neetO0sfRG7VKTadWFaPPv4T8mTNZv9LFI4Sfs85yXOtoUl6VE9xNDhnP0T9O0MmzLcK94uvx93Im\nOHAoF3IvE99xrNn9YtoN43LuFTPTfHi/AAb39MXBzgbHcme6qDIl1ce7J99eO84D7e7HwcaeV069\nYdpvn1sRjVKZKN8Is9+1TUn5OvmgVKiY8ZcHTJ37hI5juXDzEu1d23E+5yLOaieLU0ITO8WSfP0n\nPByqz3GP6zCC9MIMpnSeYNo2d0wXvjljh975JJqcXmTXsA4AzKtO2tvYE+UXwanrpxnXYSR//yDZ\nUN60nJI/2pkWo1ZmqH+U2W/7WmRhTLBpo7JBWa7wHNQOlOnLsFGqKNWXoUCBQqFACPNAWDuVPXpR\natH5G99pHFt+3sGDnSdAXoXC+0tIHJfPXsC+c6hJWQB88MG7HDpkqLmRkZFBQWaeYb2FgB5BrelU\npOFD97dZ/KcFFJYU8sKh59HdMPjRHihPFa9UKNHdLOba++cozdfiqHTgYuB5fPsNJjnzdwL6RWH8\n8FT2NuT+molzOzdsy1dSt/MKRKlQkVpyBYUSfNwdKLnQAVHyPX1ahYO6mJutU3D0MwyGSvQl7N//\nBZ988jE5RTmU5WhxFHmkXrmMp6cXISGGAJq/9pzK9rPvMzU+nmUPL2D+/MVs2vQO8eMmkuacR2z5\nN6JUKujVyTqfU11pkgrDaNZWHY3ebaZ1mcTBTwy1I1QqpWkkV3nBUD+fXvTzsRxy6ax24vG+85nz\n34OmbWEdPMujXQZUOz5+qHmIXuVRtIONPQvjelGk7c7mMwZbf1HPubyabOgoHww1dD5qmwqZ6S52\npex6ABonW8I6eHD6fJbBF3KL2Zy2Gn+md/mL2bb7/CK5zy/S9Pfxvf81WRiVZRHlF0GUX3mnrDQ4\neDNvFhPg7YSrnSNP9l1Y7X4aWxce77vAbJtSqcChfCpKbSxeJMwVhqPagYR+j5m2ze72EJt/2g6A\nT1F4tfvM6DK52v/pllYU0N41kMmdx5ttGxoQxdCAKNPfQCULo0IWg/0HMNi/+v8YoJW9WzWfQmRX\nHyK7+gAD2fbFr4Ah99Hi+LBq59tUeS9cbJ3L/TWgv3kV3cUu2AYZpkVn9x5f7fy53afRw6ub2Tb7\nKrJQt/3VbF3IsID7GN+x9gjHxMOruKnLY0CbcPb/P0Mk0HMzBtSY58jb0dP0f0zLq1g57+ngwZTO\n49mZXFFX4tSpk3z//QneeGMrtra2LFw4j8rGmL2NA2pbG3w0renUyjBoCPUM4ec0w/cyun2M6dir\ne37De2BbEiclUHw5j7fe2kRg6/LpwSrTtlVDvrt6hjKmfQzjNvwPQgjUNipKr3ZEX6xioO9AvFzt\nSXLYh1KhRC/0ZKZfZ+/OXbz55nacnJxZvfpZdDpttev6OvuwvFwW/fpFcOjQQQ4c2MfmzdtxcWm4\nNWiVaZpO7/LBaWMrjMooFFQaSVqfNlylvP1nqNox9OroxYBubVgzL5LnZlbvFKuiLzS8ZPa2Khb8\nuTuLJoTRJeDWkU9WO4ItWBhVeWp6X5ZP6YV3fViJVaakqu2uNPVkmsaqhKXww9oUhrWysLmN9+JW\nGG0zJ3sbUyhtZdQK8/ei+gUqeqLw0Orz3LcnC+um7yrLomuQQWG0stL/6OjoSGFhzaOZgoJ8XFxc\nsLW15fLlS/z8808mqx/AVmmMqKvcE1tem6LXlmGjscPPuQ2fffYpAKP6B9ItrA/ZP1WsWi8rKsEp\nQEP+pRx0OYbsC/oiw/95YJ/OaG9epXt7d4pvplJSdANHu4piakZZFBYW4uDggKOjE9nZWRw9egSA\nwMB2ZGVl8ssvZ03H6cvrqI8ePY6XX15HaGjXu6YsoIlaGEoUlCEslrhsLOzUKtztDPPybna3XgVe\nlRHhbU3RRHXB3MKo6CSN03QXbt46Umh8eA/Ss3SmKa6ewZ5cyr21s9jGQrnZqswaFcpnqRe4QSau\ndjW/zBpHWzRt66cSWGULw1JkiLFzF0JhSA5XhdaO1U14S4qnMtY6gr0cPEjJSzVz5t8Jrs6G+3q3\nstw+o6WrVqqrTfMsndSDXT/kkImluH4D7vbVp8nqS3l6O3qRVXwDZ1tHpsX3oEwvrB40aTSudO/e\ng+nT/0JExAD69x9otj8iYgAff/whM2ZMoW3bQLp1627qIxQKpclPU9lfY5yCrfr/bz20HZd3/khi\n0jK6dOlGWtofONjZ8NcZs0l8IYFfXzsGSgU+Q4NwDfXCf2xnLr33I0JAgfc1xr0+ikUz47n221Ge\nXj6Pm8Vu2Dp5mSxjhUKBj6M3KXmpBAa1I7tjCA89NAlfXz/CwnoAYGNjw7PPruHvf38JrVaLvb09\nL7/8Ovb29oSEdMbJyYlRo+48y3ddaJIKw7D0lHrJcHunPDWtLz9fzCLA2xlvj6GUCT2D/PvX6RqV\no1HqgrFjUCqU2FpwngZp2jKyXTTdvbqYbV/Ycw452ptEtqk+l19bJ1lioQRqVQZ2b0Ovzg/y5eUD\npmmZhiKgtaET9nXXcB3DXLsly7OLRwhlf3SgJNMHx7AKWT3aYyZFJUUW667X1kmKGpzIVZnYKZZW\n9m6mUOE7JaZfW7S6Mob29rO43+jDsNT+bkEehAaO49OLDkT49DHbN7f7dMpEmUX51fZeqKy09h8K\nnciBK4cZHjgUpVJhVsLVGlauXGX2u1evimdQq9WsW2eet2nvxa84e/EiUStGotG4otG48vbbO037\nl89NYM/FrxhYxX+1dMISbOJVhHl1Ndvu6a7BN3I0duX5voxoOnqg6WhwMj/Y2RA6b+jg/wnAzBcN\nU9e+bQzrKt5+eyfZxTf4JjWJoQH38UBitMXn7dw5lI0b36q2PTPzOkII+vWLtHBWw9E0FcY9RHtf\njWm9hb2NHbHBI+/avdXloycHG8tRLgqFglHtqxek6uxevbCPkdo6Sa0VCgMM4bZ3QxZd27mzYmpv\nrul/4YNz39XYsSkVSsZ3Gsl7V36nf9cKJ2lXj5qzHdbWSWr11iU9dLZ1Ii54lFXHWoOdraqaP6sy\nxiipmtqvUqosxvf3qNI5Vqa290Jn5SpyVzvNXf1GjBaWQ03huiq1xfb09q7uGwJDgMbU+7uy6+oJ\ni/vBfPrTyEsP96ekSu13d/tWtyWLzz/fw6ZN/2LRoqV1PvdOaZIKw5i6+25mw70XsVEZRsrVcvvf\nAbVdS1dmXVnWu0lHfzdupBmmFm7VsUX39WdYHz+rp0BqVZ6l1mfJvZsYpypra39dqH0gca/Kov6/\nkVB/L2PMgUV0FmThWY+ZKEaMGMWIEfU3AKkL947XuA40/kTUvUFDdAxqlWW/h/HDC27V3uL+xsbY\nvqrRPJVRKBR1CjKoKZTU6LsIcg20uL+xsbmLCsMoi7Yu/hb3NzYNIosarBXjtHAb5/pNx3Ev0SQt\nDGNioqppjVsatU093CkrIx6nVJRRUFJAB9cgLuam0P6e7SQN03OO9dgxVPZrPNd/BcVlxRSUFNDe\ntR2Xcq/QwbVdvd2rPmmITrKyU/v5AYkUlhZRUFJIkGsgKbmpdHBrV2/3qk8qZFF/30hla+W5/ivQ\nlmkpKCkgUNOWq/nX7tmBRH3QJBWG0cJo6QrjVs7N+sDN3s0sXDLYrfbstI2FNRbGneBu72bmJ7q3\nZVH/70XlZ29l70YrKlbq36vKAhreCq+68LI5KwtoslNS5S9vy9YXDTJ6qoy1kS/3AkZZODaQLO6F\niDxrMc3bN5AsmhINoTBaMk2nR7BAS7cw3O1b4ah2IMDFcnjl7RLqbsj9dC+tc6kNTwd37G3s6l0W\nHVzbWQxZvpfxcvTEzsaOAGff2g+uA/7Ovrio62ctye2Qn5/P7t3/rtM53o5e2Kls8Xfx5YMP3kOr\nrZ+gDU8HDzzt3evlWk0JhWiCoUbTPlxMcanW6nQEzRl3D0eys2692K6uCCHQC73FtQn3MlIWFTSU\nLBozJc8ff1xj+fIlbNv2fp3OM8oiPn4sb765HY2mbgtrLWFM5FhXWZSVlaFSNd67dKdlrJuoD0M6\nvY00REemUCialHVhRMqigoaShaIRYxQ3bHiNa9euMnPmg/TtG8Gjjy7i3Xe3c+DAV5SUlDJo0BBm\nzpxLcXExK1cmcP16Bnq9noULF3DpUiqZmddZuPBh3NzceOWVf5lde+vWzXz77SF0Oi3duoXxxBOJ\nAFy9msratavJyclBpVKxatWL+Pr68d672/nyy89QKpVERg5k3rz5LFw4jwULlhAS0pmbN3OYPXsa\nu3Z9wmeffcqRI4fR6bQUF2t58cW/kZCwjPz8PEpLS5kz52Giosoz9n72KTt37kCpVNChQ0eWLl3O\n9OmT2bnzI1QqFYWFBeW/dzeK4mmSCqOS11sikTQCH537lFMZP9brNXt5d+fPwaNr3F85vTnAd98d\nJTU1hU2btiGEYPnypfzwQzI5Odl4enrx0ksvA+DgoKBvX8H777/HP/6xEY2mekXA8eMnMWPGbABW\nrVrJkSOHGTAgimeffYpp0/5KVNRgSkpK0Ov1HD16hMOHv2HTpm3Y2tqSl5dXQ4srlOvPP//Itm3v\n4+zsjF6vZ82adTg6OnLzZg7z5hmuf+HCed55Zyv/+tcWNBoNeXl5ODo60rt3H5KSDhMVNZh9+75k\nyJD7G81KaZIKQ1oYEonk+PFjfPfdcWbOfBAhBEVFxaSmphAW1pN//vMVNmx4jf79o4iOvo+iojwM\nI0zLfcbJk8d5993taLXF5OXl0b59B3r27E1m5nXT6F+tNviyTpw4zqhRY7C1NUQQWpP8r1+/CJyd\nDf4fvV7Pxo2vkZx8CqVSQWbmdW7cyObUqRMMGXK/SaEZrzt69DjefXc7UVGD2bv3PyxfXr2y492i\nSSoMiUTSuPw5ePQtrYG7gRCChx6awdixcdX2vfnmOyQlfcvGja/x228/Eh//UI3X0el0rF//Elu2\nvIOnpxdbtryBTqejJuVicPtWn5pTqVSm/GKG8ytwqFQf/quvPicnJ4e33tqBUqkkPn4sWq2uxswV\n3bv3IC3t/0hO/h69Xk9QUOMtnm2SUVJyRkoiaXlUTW8eERHJnj2fUFRkSCtuGKnfIDMzEzs7O4YP\nH8HkyVM5c+ZM+flOFBQUVLuuTqdDoTBkwy0sLOTgwf2m4729W3Po0EEASkpK0GqLCQ833FerNRRe\nys3NBaBNGz9++cVwrwMH9tX4HPn5+bRq5Y5SqeT770+Qlmao89GnTzgHDuwjN/em2XUBYmJG8r//\n+z+MGjXW4jXvFk3Swujg3o7T6WfxtJCGWSKRNE+qpjd/9NFFXLp0iYcf/itgUChPP72K1NQr/POf\nr6BUKrCxUfPCC4YMt2PHxvL444vw9PQyc3o7OzszZkwc06ZNok0bX0JDK5IwPvXUs6xdu5rNmzei\nVqtZtepFIiL6c+7cb8yaNQ1bWzWRkQOZO/dRJk9+kKefXsEXX3xGnz79anyO4cNHsHz5UubMmUZw\ncAiBgYZFoEFB7Zk2bSYLFsxFpVLRsWMIiYnPlJ/zAJs3byA6unoy0btJkwyrzdXm89WZIwzw7Wex\nrGNLwsvLhevXa3K6tSykLCqQsqigOcjiwIF9fPvtIZ566tk7uk6LDKvV2DnXueaERCKRNEVefnkt\nR48msW7dK43dlKapMCQSiaSlsHjxE43dBBNN0uktkUgkkruPVBgSiUQisQqpMCQSiURiFQ2uML75\n5htGjBhBTEwMb7zxRrX9Op2OJUuWMHz4cCZNmsS1a9caukkSiUQiuQ0aVGHo9XpWrVrFm2++yaef\nfsqePXs4f/682TH//ve/cXV15csvv2T69OmsXbu2IZskkUgkktukQRXG6dOnCQwMxM/PD7VazahR\no9i/f7/ZMfv37ycuzrC0PyYmhqSkpIZskkQikUhukwZVGOnp6bRp08b0u3Xr1mRkZJgdk5GRgY+P\noWi6SqVCo9GQk5PTkM2SSCQSyW3QoArDmkXkVY8RQjSpcpgSiUTSUmjQhXs+Pj5mTuz09HS8vb2r\nHZOWlkbr1q0pKysjPz8fV9faK2Ld6RL35oSURQVSFhVIWVQgZVE/NKiF0b17d1JSUrh69So6nY49\ne/Zw//33mx0zdOhQdu/eDcDnn39OZGRkQzZJIpFIJLdJgycf/Oabb3jhhRcQQjBhwgTmzp3Ls8Qs\nGwAACZ5JREFUq6++Svfu3Rk6dCg6nY4nnniCs2fP4ubmxvr16/H392/IJkkkEonkNmiS2WolEolE\ncveRK70lEolEYhVSYUgkEonEKqTCkEgkEolVNDmFUVtuquZGYmIiAwYMYMyYMaZtN2/eZObMmcTE\nxDBr1izy8iqqiT3//PMMHz6ccePGcfbs2cZocoOQlpbGtGnTGDlyJGPGjGHbtm1Ay5SFTqcjPj6e\n2NhYxowZw2uvvQZAamoqEydOJCYmhqVLl1JaWmo6vrnna9Pr9cTFxfHwww8DLVcWw4YNY+zYscTG\nxjJhwgSgnr8R0YQoKysT0dHRIjU1Veh0OjF27Fhx7ty5xm5Wg/Ldd9+JM2fOiNGjR5u2vfTSS+KN\nN94QQgixceNGsXbtWiGEEAcPHhRz5swRQgiRnJws4uPj736DG4iMjAxx5swZIYQQ+fn5Yvjw4eLc\nuXMtUhZCCFFYWCiEEKK0tFTEx8eL5ORk8dhjj4m9e/cKIYRYuXKleO+994QQQuzYsUM888wzQggh\n9uzZIxYvXtwobW5I3nrrLbFs2TIxb948IYRosbIYNmyYyMnJMdtWn99Ik7IwrMlN1dzo27cvGo3G\nbFvl/FtxcXEmGezfv5/Y2FgAevToQV5eHpmZmXe3wQ2El5cXoaGhADg5OdGhQwfS09NbpCwAHBwc\nAMOIubS0FIVCwbFjx4iJiQEMsti3bx/Q/PO1paWl8fXXXxMfH2/advTo0RYpCyEEer3ebFt9fiNN\nSmFYk5uqJZCdnY2npydg6Eizs7MB87xcYJBPenp6o7SxIUlNTeWXX36hR48eZGVltUhZ6PV6YmNj\nGThwIAMHDiQgIACNRoNSafikfXx8TM/b3PO1rV69mieffNKUUujGjRu4urq2SFkoFApmzZrF+PHj\n2bVrF0C9fiNNqqa3kEtGbokl+TS3vFwFBQUsWrSIxMREnJycany+5i4LpVLJxx9/TH5+PvPnz69W\nNgAqnreqLEQzytd28OBBPD09CQ0N5dixY4Dh+ao+c0uQBcDOnTtNSmHmzJkEBQXV6zfSpBSGNbmp\nWgIeHh5kZmbi6enJ9evXcXd3BwwjhLS0NNNxaWlpzUo+paWlLFq0iHHjxhEdHQ20XFkYcXZ2pl+/\nfvzwww/k5uai1+tRKpVmz2uURV3ztTUFvv/+e/773//y9ddfo9VqKSgoYPXq1eTl5bU4WYDBggBw\nd3cnOjqa06dP1+s30qSmpKzJTdUcqToSGDZsGB999BEAu3fvNsng/vvv5+OPPwYgOTkZjUZjMkWb\nA4mJiQQHBzN9+nTTtpYoi+zsbFOkS3FxMUlJSQQHBxMREcHnn38OmMti2LBhzTZf29KlSzl48CD7\n9+9n/fr1REREsG7duhYpi6KiIgoKCgAoLCzk8OHDdOrUqV6/kSaXGsRSbqrmzLJlyzh27Bg5OTl4\nenqycOFCoqOjeeyxx/jjjz/w9fXllVdeMTnGn3vuOQ4dOoSDgwNr1qyha9eujfwE9cPJkyeZOnUq\nnTp1QqFQoFAoWLJkCWFhYSxevLhFyeLXX38lISEBvV6PXq9n5MiRPPLII1y5coWlS5eSm5tLaGgo\na9euRa1Wt5h8bcePH2fLli1s2LChRcriypUrLFiwAIVCQVlZGWPGjGHu3Lnk5OTU2zfS5BSGRCKR\nSBqHJjUlJZFIJJLGQyoMiUQikViFVBgSiUQisQqpMCQSiURiFVJhSCQSicQqpMKQSCQSiVVIhSFp\n0kycOJG4uDhGjRpF165diYuLIy4ujsTExDpfa/bs2Valu16xYgXJycm309w6cebMGb744osGv49E\nYi1yHYakWXD16lUmTJhwy+yjxlQRTYVdu3aRlJTE+vXrG7spEgnQxHJJSSR1ISkpibVr19KzZ0/O\nnDnD/Pnzyc7OZseOHaaCOgkJCYSHhwMwePBgtm7dSlBQEFOmTKFXr16cOnWKjIwMRo8ezeLFiwGY\nMmUKjz76KFFRUTzxxBM4Oztz/vx50tPT6d27N2vWrAEMuXmefPJJbty4QUBAAGVlZQwbNoxJkyaZ\ntTMzM5Nly5Zx48YNAKKiopg9ezavv/46hYWFxMXFERERQUJCAqdOnWL9+vUUFRUBsGjRIgYNGkRK\nSgpTpkxh9OjRnDx5Ep1OxzPPPEPv3r3viqwlLYQ7KdYhkdwrpKamisjISLNtR44cEV26dBE//vij\naVvl4jLnzp0TQ4YMMf0eNGiQuHDhghBCiMmTJ4tly5YJIYTIzc0V4eHhIjU11bTv0KFDQgghHn/8\ncTF16lRRUlIitFqtGDFihDh27JgQQohHHnlEbNq0SQghxJUrV0SvXr3Ezp07q7V98+bNYuXKlabf\nubm5QgghPvjgA7F06VKztsfGxoqsrCwhhBBpaWli0KBBIj8/X1y+fFmEhISIPXv2mJ59yJAhorS0\n1HohSiS1IC0MSbOmffv2dOvWzfT70qVLvPrqq2RkZKBSqcjIyCAnJwc3N7dq5z7wwAMAuLi4EBQU\nREpKCn5+ftWO+9Of/oSNjeFT6tKlCykpKYSHh3Ps2DGef/55APz9/U2WTFV69uzJO++8w7p16+jX\nrx9RUVEWjzt58iSpqanMmjXLlJBSpVJx5coVHB0dcXBwYOTIkQD0798flUrFpUuX6NChg7Xikkhu\niVQYkmaNk5OT2e8lS5bwzDPPMHjwYPR6PWFhYWi1Wovn2tnZmf5WKpWUlZXV6Thr6yz06dOH3bt3\nc+TIET788EM2b97M9u3bqx0nhKBr165s3bq12r6UlJRq2/R6fbOq9SBpfJqOB1AiqQVhRfxGfn6+\nKTvpzp07a1QC9UF4eLgprfTVq1c5fvy4xeNSU1NxdnZm5MiRJCQk8NNPPwGGWhfGNOYAvXv35ty5\nc5w4ccK07fTp06a/i4qK2Lt3L2AoUQoQGBhYvw8ladFIC0PSbLBmNJ2YmMjcuXNp06YNERERuLi4\nWDy/6rVq2ner455++mmWL1/Onj17aN++Pb179za7n5GkpCS2bduGSqVCCMGqVasAGDhwIG+//Tax\nsbFERkaSkJDA66+/ztq1a8nLy6OkpISAgAA2bNgAgKenJ7///jvx8fHodDrWr1+PSqWqVSYSibXI\nsFqJpIHQarWo1WqUSiXp6enEx8ezY8cOAgIC6v1exiipw4cP1/u1JRIj0sKQSBqICxcusGLFCoQQ\n6PV6lixZ0iDKQiK5W0gLQyKRSCRWIZ3eEolEIrEKqTAkEolEYhVSYUgkEonEKqTCkEgkEolVSIUh\nkUgkEquQCkMikUgkVvH/AcQ/YGad+SX7AAAAAElFTkSuQmCC\n", + "text/plain": [ + "\u003cmatplotlib.figure.Figure at 0x7f971b401110\u003e" + ] + }, + "metadata": { + "tags": [] + }, + "output_type": "display_data" + } + ], + "source": [ + "with tf.Graph().as_default():\n", + " hp = tf.contrib.training.HParams(\n", + " learning_rate=0.05,\n", + " max_steps=max_steps,\n", + " )\n", + " train_ds = setup_mnist_data(True, hp, 500)\n", + " test_ds = setup_mnist_data(False, hp, 100)\n", + " tf_train = autograph.to_graph(train)\n", + " (train_losses_, test_losses_, train_accuracies_,\n", + " test_accuracies_) = tf_train(train_ds, test_ds, hp)\n", + "\n", + " with tf.Session() as sess:\n", + " durations = []\n", + " for t in range(burn_ins + trials):\n", + " sess.run(tf.global_variables_initializer())\n", + " start = time.time()\n", + " (train_losses, test_losses, train_accuracies,\n", + " test_accuracies) = sess.run([train_losses_, \n", + " test_losses_, \n", + " train_accuracies_,\n", + " test_accuracies_])\n", + " if t \u003c burn_ins:\n", + " continue\n", + " duration = time.time() - start\n", + " durations.append(duration)\n", + " print('Duration:', duration)\n", + "\n", + " print('Mean duration:', np.mean(durations), '+/-', np.std(durations))\n", + " plt.title('MNIST train/test losses')\n", + " plt.plot(train_losses, label='train loss')\n", + " plt.plot(test_losses, label='test loss')\n", + " plt.legend()\n", + " plt.xlabel('Training step')\n", + " plt.ylabel('Loss')\n", + " plt.show()\n", + " plt.title('MNIST train/test accuracies')\n", + " plt.plot(train_accuracies, label='train accuracy')\n", + " plt.plot(test_accuracies, label='test accuracy')\n", + " print('test_accuracy', test_accuracies[-1])\n", + " plt.legend(loc='lower right')\n", + " plt.xlabel('Training step')\n", + " plt.ylabel('Accuracy')\n", + " plt.show()\n" + ] + }, + { + "cell_type": "markdown", + "metadata": { + "colab_type": "text", + "id": "A06kdgtZtlce" + }, + "source": [ + "# Eager" + ] + }, + { + "cell_type": "code", + "execution_count": 0, + "metadata": { + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + }, + "colab_type": "code", + "id": "hBKOKGrWty4e" + }, + "outputs": [], + "source": [ + "def predict(m, x, y):\n", + " y_p = m(x)\n", + " losses = tf.keras.losses.categorical_crossentropy(tf.cast(y, tf.float32), y_p)\n", + " l = tf.reduce_mean(losses)\n", + " accuracies = tf.keras.metrics.categorical_accuracy(y, y_p)\n", + " accuracy = tf.reduce_mean(accuracies)\n", + " return l, accuracy\n" + ] + }, + { + "cell_type": "code", + "execution_count": 0, + "metadata": { + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + }, + "colab_type": "code", + "id": "HCgTZ0MTt6vt" + }, + "outputs": [], + "source": [ + "def train(ds, hp):\n", + " m = mlp_model((28 * 28,))\n", + " opt = tf.train.MomentumOptimizer(hp.learning_rate, 0.9)\n", + " train_losses = []\n", + " test_losses = []\n", + " train_accuracies = []\n", + " test_accuracies = []\n", + " i = 0\n", + " train_test_itr = tfe.Iterator(ds)\n", + " for (train_x, train_y), (test_x, test_y) in train_test_itr:\n", + " train_x = tf.to_float(tf.reshape(train_x, (-1, 28 * 28)))\n", + " train_y = tf.one_hot(tf.squeeze(train_y), 10)\n", + " test_x = tf.to_float(tf.reshape(test_x, (-1, 28 * 28)))\n", + " test_y = tf.one_hot(tf.squeeze(test_y), 10)\n", + " if i \u003e hp.max_steps:\n", + " break\n", + " with tf.GradientTape() as tape:\n", + " step_train_loss, step_train_accuracy = predict(m, train_x, train_y)\n", + " grad = tape.gradient(step_train_loss, m.variables)\n", + " opt.apply_gradients(zip(grad, m.variables))\n", + " step_test_loss, step_test_accuracy = predict(m, test_x, test_y)\n", + "\n", + " train_losses.append(step_train_loss)\n", + " test_losses.append(step_test_loss)\n", + " train_accuracies.append(step_train_accuracy)\n", + " test_accuracies.append(step_test_accuracy)\n", + " i += 1\n", + " return train_losses, test_losses, train_accuracies, test_accuracies\n" + ] + }, + { + "cell_type": "code", + "execution_count": 40, + "metadata": { + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + }, + "height": 789 + }, + "colab_type": "code", + "executionInfo": { + "elapsed": 56025, + "status": "ok", + "timestamp": 1531163800231, + "user": { + "displayName": "", + "photoUrl": "", + "userId": "" + }, + "user_tz": 240 + }, + "id": "plv_yrn_t8Dy", + "outputId": "68be955d-61dd-43e4-b540-3794e3c8f990" + }, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Duration: 4.2232978344\n", + "Duration: 4.2386469841\n", + "Duration: 4.24286484718\n", + "Duration: 4.24036884308\n", + "Duration: 4.25758385658\n", + "Duration: 4.23242998123\n", + "Duration: 4.4213449955\n", + "Duration: 4.29613113403\n", + "Duration: 4.28209114075\n", + "Duration: 4.24192905426\n", + "Mean duration: 4.26766886711 +/- 0.055508619589\n" + ] + }, + { + "data": { + "image/png": "iVBORw0KGgoAAAANSUhEUgAAAYwAAAEcCAYAAADUX4MJAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAAIABJREFUeJzsnXdgFGX6x78zW7KbTSE9JIA0pQkIooCgqBx2qiK/O0XU\n8zyFAw/w8MSCFcuJCHqKoFiwIHIgIgooaGjSCU1aaCEJ6W1btszM74/ZmZ2tWchuQjbP55/s7szO\nvDPZeb/vU97nZQRBEEAQBEEQ9cA2dQMIgiCI5gEJBkEQBBESJBgEQRBESJBgEARBECFBgkEQBEGE\nBAkGQRAEERIkGARBEERIkGAQRIjs3r0bt99+e1M3o14KCwvRtWtX8Dzf1E0hogwSDKLB3HzzzejZ\nsyeqq6s9Ph85ciS6du2KoqIiAMC///1vdO3aFQcPHpT3yc/PR9euXeX348ePx/Lly+X3CxYswNCh\nQ9G3b1/ceOONmDZtGgDgrrvuQt++fdG3b190794dvXr1Qp8+fdC3b18sXLjQp43vvfceZsyY0aDr\n7NevH3766acL+s6HH36IuXPnYufOnRgyZEiDzi/hfY/8wTBMWM5FEErUTd0AIjpo06YN1qxZg/vu\nuw8AcPz4cdhsNo+Oi2EYtGrVCu+88w4+/vhjj8/9sXLlSqxevRqfffYZ2rRpg4qKCmzcuBEA8MMP\nP8j7jR8/HqNGjcLdd9/doGsQBCHsHW1OTg6efPJJOBwO6sSJZg9ZGERYGDlyJFauXCm/X7lyJUaP\nHu2z3+jRo3Hs2DHs3r273mMeOnQIgwcPRps2bQAAKSkpGDt2rN99g1W42bx5MxYsWIAff/wRffr0\nwahRowCIQjN37lz8+c9/xlVXXYWCggKsWLECd9xxB/r27Ythw4bhm2++kY/jbSXcfPPNWLx4MUaM\nGIFrrrkG06ZNg91ul7fX1tbi7Nmz6N69Ox599FGUlpbKVlBZWRkEQcDChQsxbNgwDBgwAFOnTkVt\nbS0AwG6341//+hf69++Pa665BmPHjkVlZSXmzp2LPXv24OWXX0bfvn3xyiuv1HsfS0tL8fjjj6N/\n//649dZb8e2338rbDhw4gLvvvhtXX301Bg8ejDfeeCPo+QHAZDLhmWeeweDBgzFkyBC888478v3P\nz8/H+PHj0a9fPwwcOFC2CInogCwMIiz07t0bq1atwqlTp9C+fXusXbsWX331FebOneuxn06nw2OP\nPYa3334bX331Vb3HfPXVV5Geno7+/fuje/fuYNkLH+Ncf/31eOyxx5Cfn48333zTY9vq1auxaNEi\ndOjQATzPIyUlBQsXLkSbNm2we/duPPLII+jVqxe6desGwNcaWrt2LRYvXgytVov/+7//w8qVKzFu\n3DgAwJYtWzBgwADodDosWrQIM2bMwG+//SZ/99NPP8XGjRvx5ZdfIikpCa+88gpefPFFzJkzBytX\nroTJZMLmzZuh0Whw5MgRxMTEYOrUqdi7dy9GjhyJe+65J6TrnzZtGrp06YL58+fj5MmTeOihh9C2\nbVsMGDAAs2fPxoQJEzBixAhYrVacOHECAAKeHwBmzJiB9PR0bNiwAWazGY899hiysrJw7733Yt68\neRg8eDCWLFkCu92OQ4cOXfD/i7h0IQuDCBsjR47Ed999h61bt6Jjx45IT0/3u9+9996L8+fPY/Pm\nzUGPN2LECDz33HPYunUrxo8fj+uuu85vfKIhjB49Gp06dQLLslCr1RgyZIhs0fTr1w+DBg0Kag09\n8MADSE1NRUJCAm666SYcOXJE3vbbb78FjVssW7YM//znP5Geng6NRoNJkyZh3bp14HkearUa1dXV\nOH36NBiGQffu3WEwGC74+s6fP499+/bhySefhEajQdeuXTF27FisWrUKAKBWq5Gfn4+qqiro9Xr0\n6tVL/tzf+SsqKrB582bMnDkTMTExSE5OxoQJE7BmzRr5e4WFhSgpKYFWq0Xfvn0vuM3EpQtZGETY\nGDFiBO6//34UFBRg5MiRAffTarWYOHEi5s2bhzlz5gQ95l133YW77roLHMfhl19+wfTp09GjRw8M\nGjQoLG3OzMz0eJ+Tk4P3338fZ86cAc/zqKurQ5cuXQJ+PyUlRX6t1+tRVlYGQHSRbdu2DU8//XTA\n7xYVFeEf//iHbDUJggC1Wo3y8nKMHDkSxcXFmDZtGoxGI4YPH45p06ZBpVJd0PWVlZUhMTERer1e\n/iwrKwuHDx8GAMyePRvz5s3D7bffjrZt22LSpEm48cYbfc4/YsQITJ06FYWFhXA6nRg8eLDcZkEQ\n0Lp1awCi9fHOO+/gnnvuQatWrfDggw82OLZEXDqQYBBhIysrC9nZ2di0aRNmz54ddN8xY8bgo48+\nws8//xzSsVUqFW699VYsXLgQJ06cCJtgKF1MdrsdTzzxBP7zn/9g6NChYFkWkyZNChofCcTBgwfR\npk0bJCUl+ZxHonXr1pg9ezb69Onj9xiTJk3CpEmTUFRUhL/97W/o2LEj7r777gsKnqenp6OmpgYW\niwWxsbEARKtDsv7atWsni/a6deswZcoU7Ny5Ezqdzuf8HTp0wA033ICYmBjs2LHDbztSUlLw8ssv\nAwD27NmDhx56CNdeey3atm0bcpuJSxdySRFhZfbs2fjss8+g0+mC7qdSqfCPf/wDixYtCrjPypUr\nkZOTA7PZDEEQkJOTg5MnT8pukwshNTUVhYWFQTt/h8MBh8OBpKQksCyLnJwcbN269YLPBYjuqBtu\nuEF+n5KSgurqaphMJvmzcePG4e2335bTjisrK7FhwwYAwI4dO3D8+HHwPI/Y2Fio1WrZukhNTcW5\nc+eCnl+6zszMTPTp0wdvv/027HY7jh49iuXLl2PEiBEAgO+//14OZsfHx4NhGLAsG/D8aWlpGDRo\nEGbPng2TyQRBEHDu3Dns2rULgBjTKSkpAQAkJCSAZdmLijsRlyYRtTCKi4sxY8YMlJeXQ6VSYezY\nsXjggQc89tm5cycmTpwoj0CGDRuGiRMnRrJZRJhRjjS9R5LBRsN33XUXFi5cCKPR6Hf/uLg4LFiw\nAKdOnQLHccjKysILL7zg4xcPZcR922234fvvv0f//v3Rpk0brFixwud7BoMBzzzzDJ544gk4HA7c\ndNNNGDp0aMBjBjtvTk4OXnrpJfl9x44dceedd2Lo0KEQBAFr1qzBhAkTAAAPP/wwysrKkJKSgttv\nvx1Dhw5FeXk5Zs2ahZKSEhgMBtxxxx1yJ//AAw/gqaeewtKlSzFixAg888wzQds2Z84czJo1C9df\nfz0SExPxxBNPYODAgQDEDLLXX38ddXV1yM7Oxty5c6HVaoOe/4033sBbb72FO++8ExaLBW3btsUj\njzwCQLSsJDFJTU3FM888g+zs7KD/G6L5wERyxb2ysjKUl5ejW7duMJvNGDNmDN5//3106tRJ3mfn\nzp1YvHgxFixYEKlmEESjUlFRgVGjRtUb1CeI5kZEbcW0tDQ5HdFgMKBTp04oLS2N5CkJoskxGo1B\ng90E0VxptKB3QUEBjh496tf/nJubi1GjRiE9PR0zZsxA586dG6tZBBF22rdvj/bt2zd1Mwgi7ETU\nJSVhNpsxfvx4TJw4EX/60598trEsC71ej5ycHMyePRvr1q2LdJMIgiCICyTi6QtOpxNTpkzByJEj\nfcQCEF1VUo74kCFD4HA4fIrYedMIGkcQBEF4EXGX1MyZM9G5c2c5I8Sb8vJypKamAhDr2gBAq1at\ngh6TYRiUlRmD7tNSSEuLp3vhgu6FG7oXbuheuElLi2/Q9yMqGHv27MHq1atxxRVXYNSoUWAYBlOn\nTkVRUREYhsG4ceOwbt06fP3111Cr1dDpdD61hwiCIIhLg0aJYUQCGjGI0OjJDd0LN3Qv3NC9cNNQ\nC4OmYBIEQRAhQYJBEARBhAQJBkEQBBESJBgEQRBESJBgEARBECFBgkEQBKHAZDJh5crlF/XdGTP+\nCbPZVP+OLhYvXoilS7+4qHM1BSQYBEEQCozGWqxc+a3fbTzPB/3um2++A4MhLhLNuiSgFfcIgiAU\nLFjwHoqKCvHww/ehX7/+GDhwED75ZBFSUlKRl3ccS5Ysw9NPP4myslLY7TaMHftnDB8+CgAwduwI\nfPzxElgsFjz55BT07HkVDh3aj7S0DLz++hxotdqA5z1x4hjeeut12Gw2ZGdn4+mnZyEuLg7ffrsU\nq1atgFqtRvv2HfDCC69i3749mD9/jmvdEwb//e8ij2V4IwUJBkEQlyzLNuZh19GGLYmgUjHgOPf8\n5Gu6puPemwNXxH788ck4c+YUFi/+EgCwb98eHDnyB5YsWSavAT9z5izEx8fDZrPhb397AEOG3IyE\nhAQA7oWrCgrO4cUXX8NTTz2D559/Gr/9thG33HJbwPO+8soLmDbtKfTufRU+/vhDfPLJQkyePA1f\nfvkZli9fDbVaLbu7li79AtOn/xtXXtkLdXV1QYUonDRLl9T3m042dRMIgmhBdO/eQxYLAFi27Cs8\n+OBf8Pe/P4TS0lIUFOS7triFqXXrLHTqJApTly5dUVxcFPD4ZrMJZrMJvXtfBQC47bY7kZu7DwDQ\nufPleOGFZ7B+/U9gWXGZ3p49e2P+/LexfPlSGI21jbYMbrO0MBatOoTOrQcirVXkTTCCIJqOe2/u\nHNQaCIVwlAZRrlG/b98e7N27GwsXfgqtVovJk/8Ou93u8x3lqJ9lVX73URKoStN//jMPubl7sWVL\nDj799CN88cW3uP/+B3Hdddfj99+34O9/fwjvvPM+2rW77CKvLnSapYUBAAVloWciEARBhEpsbCws\nFkvA7WazCfHx8dBqtTh79gwOHz7kd78LKdNnMMQhISEBBw7kAgDWrfsRV10lrl1fUlKMPn2uxuOP\nT4HZbILVakFhYQE6duyE++6bgC5duiE//0zoF9gAmqWFAQAFZWb0uTytqZtBEESUkZCQiJ49e2PC\nhP9D//7XYeDAQR7b+/e/Dt999z88+OBf0K7dZbjyyp6Kre4YhhiQDp2ZM1/AW2+9BpvNhqysbMyc\nOQtOpxMvvfQczGYzAAHjxt0HgyEOixZ9gL17d0OlUqF9+44YMGBQvccPB82yWu3w6atwbbd0PDby\nyqZuSpNDlTjd0L1wQ/fCDd0LNy2yWq1Wo0JJpbWpm0EQBNGiaJYuqYTsMpTXNk4aGUEQBCHSLC0M\nc/pO8J23wGbnmropBEEQLYZmKRgSFbV1Td0EgiCIFgMJBkEQBBESzVIwkrViOm1JTW0Tt4QgCKLl\n0CwFIzsuGwBQYa5p4pYQBBFtNKS8OQAsW/Y1bDab322TJ/8dx44dvehjNzXNUjCS9YkAgCorWRgE\nQYSXYOXNQ+Hbb7+GzRad7vJmmVabFp8EAKi1U3kQgiDCi3d584kTp+Crr5bg119/hsPhxA033IiH\nH34UdXV1eP75f6OsrBQ8z2PChEdQWVmO8vIyTJ78GFq1aoV58z4IeJ6ff16LL774FAAwYMAgPP74\nZPA8j9dffxnHjh0BwODOO0fg3nv/7LfEeVPQLAWjdWIyAMDoJJcUQUQzK/J+wL7Sgw06hoplwPHu\nghZ90ntiTOe7Au7vXd58167tKCjIx6JFn0MQBDz11DTs35+L6upKpKam4c033wEAWCxmxMYa8M03\nX+Pddz90lTv3T3l5ORYseA+ffPIl4uLiMXXqJGzZkoO0tAyUlZXis8+WAoBcztxfifOmoFm6pDol\ntwUAmJmKJm4JQRDRzs6dO7Br1048/PB9ePjh+5CffxYFBfno2LEzdu/eiQUL3sP+/bmIjTW4viFA\nWebcH0ePHkbfvv2QkJAIlmUxbNhtyM3dh6ysbJw/X4R33nkLO3b8Lh/TX4nzpqBZWhiZ8ekAp4Zd\nU9nUTSEIIoKM6XxXUGsgFBpaS0oQBIwf/yBGjBjts+3jj7/A779vxYcfvodrrx2ABx98JORj+ivj\nFx8fj08//Ro7dvyOFSuWYePGn/H008/7LXHeWGtgKGmWFgbLsNA6kiHEmGB1RGdwiSCIpsG7vHn/\n/gOwZs33sFrF+nXl5WWoqqpCeXk5YmJicMstt+HPf74fx48fc33f4KouG5ju3a/E/v37UFtbA47j\n8Msv63DVVX1RU1MNnucwZMhNeOSRx3HihHhMfyXOm4JmaWEAgA7xsKMUJaZKtE/KaurmEAQRJXiX\nN584cQrOnDmDxx57CIAoKM899zIKCs7hv/+dB5ZloFZr8OSTTwMARowYhSefnILU1DSfoLdU8jwl\nJRV///skTJ78dwDAwIGDMXjwDcjLO4HZs1+EIPBgGAaPPTY5YInzpqBZljcHgH9+tQBFqv24r8ME\nXNehR1M3p8mg0s1u6F64oXvhhu6FmxZZ3hwAWunECy+urWrilhAEQbQMmq1gpBrEyXtlJkqtJQiC\naAyarWBkJoiT96rqyNQkCIJoDJqtYGS3EgXDaCfBIAiCaAyarWBkuMqDWLmmSS8jCIJoaTRbwTBo\nYwEBcIDW9iYIgmgMmq1gsAwLhteCY2x+Z0wSBEEQ4SWiglFcXIwHHngAd9xxB4YPH47PP//c736v\nvPIKbrnlFowcORJHjhwJ+fhq6AC1A1Ybre1NEAQRaSI601ulUuHpp59Gt27dYDabMWbMGAwaNAid\nOnWS98nJyUF+fj7Wr1+P/fv3Y9asWVi2bFlIx9cyMbCrjKgx2xCra7aT1gmCIJoFEbUw0tLS0K1b\nNwCAwWBAp06dUFpa6rHPhg0bMGrUKABA7969YTQaUV5eHtLxdaweDCug3EiZUgRBEJGm0WIYBQUF\nOHr0KHr16uXxeWlpKTIzM+X3GRkZKCkpCemYsepYAEC5iVbeIwiCiDSN4scxm82YMmUKZs6cCYPB\n4LHNX8BaKtAVjLS0eCTHJeBcNWCFrcE1UpozLfnavaF74YbuhRu6F+Eh4oLhdDoxZcoUjBw5En/6\n0598tmdkZKC4uFh+X1xcjPT09HqPW1ZmRCyrAwAUlFe02OJiVFjNDd0LN3Qv3NC9cHPJFx+cOXMm\nOnfujAkTJvjdPnToUHz33XcAgNzcXCQkJCA1NTWkYycbxCUQq620tjdBEESkiaiFsWfPHqxevRpX\nXHEFRo0aBYZhMHXqVBQVFYFhGIwbNw5DhgxBTk4Ohg0bBr1ej9deey3k46fFiYJRS+VBCIIgIk5E\nBePqq68OaV7F888/f1HHz4gTLRETRxVrCYIgIk2znekNAGl6UTDsrJFmexMEQUSYZi0YerUOKl4H\nQWuGxeZs6uYQBEFENc1aMABAJySAibHCaLU1dVMIgiCimuYvGEwcGEZAhYUm7xEEQUSSZi8YWlYL\nALDY6pq4JQRBENFN8xcMlQYAYCLBIAiCiCjNXjBiVC4Lw06CQRAEEUmav2CoYwAAFoe9iVtCEAQR\n3TR7wdCpRQvD6iALgyAIIpI0e8HQa0QLo85JabUEQRCRpNkLRqwsGOSSIgiCiCTNXjAkC8NGgkEQ\nBBFRmr1gGGLENTFsPAkGQRBEJIkawbBzJBgEQRCRpNkLRrxWFAwH72jilhAEQUQ3zV4w9FoxhkEW\nBkEQRGRp9oKhkyfu2cDTmhgEQRARo9kLhlR8UGCcqKihyXsEQRCRotkLhlRLCiyP8xXmpm0MQRBE\nFNPsBUPFqsBCBUblREmltambQxAEEbU0e8EAgBiVDlA7YKVlWgmCICJGVAiGXqUDo3LQut4EQRAR\nJCoEI1YTC6idsNhoLgZBEESkiArBMGhiwTACzDaKYRAEQUSKqBCMeK0eAGB2UlotQRBEpIgKwTBo\nDQAAq9PSxC0hCIKIXqJCMGLVooVhJQuDIAgiYkSFYBg0sQAAG08xDIIgiEgRFYIhWRh2gZZpJQiC\niBRRIRgJMfEAAE5lAcfzTdwagiCI6CQqBCPLkAkAYPUmWG1cE7eGIAgiOokKwUjQxkMlxICJNVJ5\nEIIgiAgRFYLBMAwMSAITY0GNlVJrCYIgIkFUCAYAxLFJYBig1FTR1E0hCIKISqJGMOLVCQCACmt1\nE7eEIAgiOomoYMycORPXXXcdhg8f7nf7zp070a9fP4wePRqjR4/G+++/f9HnStSKglFlI8EgCIKI\nBOpIHnzMmDEYP348ZsyYEXCffv36YcGCBQ0+V6uYVoAZqLHXNvhYBEEQhC8RtTD69euHhISESJ5C\nJlnfCgBgcpJgEARBRIImj2Hk5uZi1KhRePTRR5GXl3fRx0mLTQIAmDljuJpGEARBKIioS6o+evTo\ngV9//RV6vR45OTmYNGkS1q1bd1HHitfpIDjVsKmonhRBEEQkaFLBMBgM8ushQ4bgxRdfRHV1NVq1\nalXvd9PS4j3eMxo1hF0aOFQ2n23RTku73mDQvXBD98IN3YvwEHHBEAQh4Lby8nKkpqYCAA4cOAAA\nIYkFAJSVebqerDYnwGnghNlnWzSTlhbfoq43GHQv3NC9cEP3wk1DhTOigjF9+nTs2LED1dXVuPHG\nGzF58mQ4HA4wDINx48Zh3bp1+Prrr6FWq6HT6TB37tyLPpdOq4Lg1EBgONg5B7QqTRivhCAIgoio\nYMyZMyfo9vvuuw/33XdfWM7FMAzUgg4CAIvTAq0qMSzHJQiCIESaPEsqnGjZGACA2UH1pAiCIMJN\nVAmGjhVX3qutMzVxSwiCIKKPqBIMaeW99w4sgpOnMucEQRDhJLoEQxsjv66xUVYEQRBEOIkqwcjW\nXSa/5gRaeY8gCCKcRJVgZMalwlnSFgAJBkEQRLiJKsGI02sBgQEAcDwJBkEQRDiJKsHQaVUQBPGS\nyMIgCIIIL1ElGDEaldvCIMEgCIIIK1ElGFoNC0gWBrmkCIIgwkpIgvHjjz/CZBInw82bNw9//etf\ncejQoYg27GIQLQzxkpxkYRAEQYSVkATjgw8+QFxcHA4cOIAtW7Zg1KhReOWVVyLdtgtGq1EBPAW9\nCYIgIkFIgqFWizUKt27dirFjx2L48OGw2WwRbdjFEKNhKehNEAQRIUISDIZh8P3332PNmjUYOHAg\nAMDhcES0YReD1iPozTdxawiCIKKLkATj2Wefxdq1azF27Fi0bdsWZ86cQf/+/SPdtgtGrWLBgoLe\nBEEQkSCk9TD69u2L999/X37fvn17PPfccxFrVENQs+IlUdCbIAgivIRkYbz++uswGo1wOp34y1/+\ngquuugqrVq2KdNsuCjWrAgDwZGEQBEGElZAEY9u2bYiPj8eWLVuQkZGBdevWYfHixZFu20WhUYmC\nQRYGQRBEeLmgiXu7du3CsGHDkJGRAYZhItWmBqFWiS4pypIiCIIILyEJRkpKCp599ln8+OOPGDRo\nEJxOJzju0uyQta4YBgW9CYIgwktIgjFnzhx07twZc+fORWJiIoqLi/HQQw9Fum0XhUYtuqTsHK24\nRxAEEU5CEozk5GTcf//9MBgMyMvLQ2ZmJsaMGRPptl0UGpdLyu4kwSAIgggnIaXVHjx4EFOmTIFW\nq4UgCHA6nXj33XfRo0ePSLfvgolRawAANuelN7GQIAiiOROSYLz66quYPXu2PMt7+/btePnll7F0\n6dKINu5i0GlEwSALgyAIIryE5JKyWq2yWADAgAEDYLVaI9aohhCjcbmkKIZBEAQRVkISDL1ej+3b\nt8vvd+7cCb1eH7FGNQS9RgsAsJGFQRAEEVZCcknNnDkTTzzxBLRasTN2OByYP39+RBt2scRqtYAd\ncJBgEARBhJWQBKNXr15Yv349Tp8+DUEQ0KFDB9xyyy347bffIty8C0cfowZMgIMnwSAIgggnIQkG\nAGg0GlxxxRXye0EQItKghhKrjQEAOCiGQRAEEVYuek3vS7U0iCHG5Ta7RGeiEwRBNFeCWhh5eXkB\ntzkv0RhBrEswnFQahCAIIqwEFYxHH3004LaYmJiwNyYcGHTiPAwnxTAIgiDCSlDB2LhxY2O1I2wY\nXEJG1WoJgiDCy0XHMC5VpBgGVaslCIIIL1EnGFqNCgLPws6aYeeonhRBEES4iDrBAABVdTvwagt2\nFu9p6qYQBEFEDREVjJkzZ+K6667D8OHDA+7zyiuv4JZbbsHIkSNx5MiRsJzXYGsDAKi1G8NyPIIg\nCCLCgjFmzBh8/PHHAbfn5OQgPz8f69evx0svvYRZs2aF5bx6jQ4AYHPaw3I8giAIIsKC0a9fPyQk\nJATcvmHDBowaNQoA0Lt3bxiNRpSXlzf4vAaXYJjtdQ0+FkEQBCHSpDGM0tJSZGZmyu8zMjJQUlLS\n4OPG6UgwCIIgwk2TCoa/elThKDkSFyOWXrc6bA0+FkEQBCEScvHBSJCRkYHi4mL5fXFxMdLT00P6\nblpafMBtrVNbAeWAE46g+wXCzjnwxf4VGNbperRNzLrg7zc2F3ON0QrdCzd0L9zQvQgPEReMYFVt\nhw4dii+//BJ33HEHcnNzkZCQgNTU1JCOW1YWOANKzbMQBMBkswbdLxCbCrZh7YnfsOXMLrxxfXgC\n8ZEiLS3+oq4xGqF74YbuhRu6F24aKpwRFYzp06djx44dqK6uxo033ojJkyfD4XCAYRiMGzcOQ4YM\nQU5ODoYNGwa9Xo/XXnstLOeN02sAXgU7d3FZUmaHuPysyWEOS3sIgiCigYgKxpw5c+rd5/nnnw/7\neRMMWoBTw666OMHgqQ4VQRCED1E50zsxLgYCr4JDcJcGKbdWYMf50GZ+8wIPAGCZqLw9BEEQF0WT\nBr0jRaJBC3AqcIJV/mzW728AANrGZyMrLjPQVwEAnCQYuDQXiSIIgmgKonIIHaNRgRXUEBgnzhkL\nPSrXStZDMHiQhUEQBOFNVFoYAKBmtHAywOu75uGWy26SPw9lnQy3S0oVsfYRBEE0N6J2CK1hNfLr\nXcX75NehLN0qCYaKLAyCIAiZqO0RdSq9/Fq5XKuDr3+NDCmGEY5Z5wRBENFC1ApGK1WK/FoZtwhl\nrW+BLAyCIAgforZHTNG6S4ywrPsyQxEMjmIYBEEQPkStYGTo3amzVoc7vdYRimDwlCVFEAThTdT2\niK1iDXCWtwYAOBWZUaEIhtMV5yCXFEEQhJuo7RENOg0c57r4fB6KS0oKjDMkGARBEDJR2yMaXAUI\nvXGGkCXCp1jIAAAgAElEQVRld4kKS1lSBEEQMtErGDo1IPheXiguKYerym3gwuwEQRAtj+gVDL0G\n4C9OMOwuK4T3M8nvaOUJvLN3AaxOq882giCIaCZ6BUOnBsAAgqdb6UJiGP7KiLybuwgnqk9hx/m9\nYWknQRBEcyFqBUPFstDHqHzcUiEJBud07Ru4jIhADiuCIFoYUSsYgJgp5R34DqU0iCQqoRQqJAiC\naClEvWAIvLdLKvTig1yQUuhkYRAE0dKIbsHQqyF4Bb5DKz7Iefz1i0CCQRBEyyK6BUOnkWMYrOtS\nL6SWlL8sKQmSC4IgWhrRLRiK1NoYVgcgxFpSLsvCKXAQAlgS5JIiCKKlEd2CoZy8x4kLKtVnYQiC\n4FEOPZQlXRsbk92M8+aSpm4GQRAtjKgWDH2MGoJLMBw2FipGVa+F4S0Qmwp/xz9/m4kamzFi7bxQ\nntn2Kl7ZMScka4kgCCJcRLVg1Nk5MBobAMBm0ULNqOsNentnRi0/8T0cvBMHyw97fB7IVdUYSFaS\ng6s/gE8QBBEuolowEmI1YLRiCQ/epocKGtQ564J+hw+QGcXg0itESPNECIJoTKJaMG7qmw2GFS0B\nwa6H4FTDytXBZuewcPVhFJabfb4TbO6Fkksh6B1KxhdBEES4iGrBUCmWZtVy8bDZWFiddVi78yy2\nHy7Bf77yrQcVapC7KV1SEqFMQiQIgggXUS0YADD96okY1u5GXNHqcjhsLHiBh91Vvtxo8YwBcDyH\n1afWhXTcxnIH8QKPUkuZX4FyCmRhEATReES9YHRMbI9Rne9AWis9BE4NAMgXDoBtVeLjVPr9/C5s\nLdoR0nG5Rhrdrz/7K17c/h/8fn63zzZySQG1diNKzKVN3QyCaBFEvWBIxMaoAac4F+MUvxsxV+zz\n2cdo941pSHjHLEKNdTSUPSX7AQCHKo74bCPBAJ7e8jJe2vFWUzeDIFoELUYwDDqNbGHIsKFbCd7x\ngkshQ4kEw82lEFMiiGinxQhGrE4NeAkGE+NtUQTudLznbzS6YPiLYVDQW+ZSEHCCiHZalGAIrvIg\nEqw+sAvKG+/OubE6a4YJPP+Dgt5uSDwJIvK0HMGIUfsYEIzOgnOlJuUn8ist6ykuzqa2MPzQWKVB\nmoO7J9CES4IgwkeLEQxlqXMZlQOzFu9UfODuGPVqnceuDq/RPMc3blFCf112fTGMrYU78N/cj33m\nlhypOI5lx1eFJARFpmL849ensOP8ngtpbqPTWEkIBNGSaTGCEatTgyvPgiP/Ctj+6A8AYNSi1eCv\n89ep9R7vvTtnrpHdQf5mltfnhsktP4Q/Ko/B7LB4fP7e/o+QU7AVxZb601G3nRcF9ZvjKy+gtY0P\nJQAQROSJuGBs2rQJt912G2699VYsXLjQZ/vKlSsxcOBAjB49GqNHj8by5csj0o5YnRoAC2dxR/B1\nBgAAoxI7mYpam+/+3hYG5y0YTT+ira+TtDnFCYoNcZ9J1gnLqOrZs2m5FP4fBBHtqOvf5eLheR4v\nv/wyPv30U6Snp+Oee+7B0KFD0alTJ4/97rzzTjz77LORbApiNIoOz5UtpTaYwPTKwYdbq9Cv9ZUo\nV1nlXXReguEdYG6siXvBqC/obeNEIQxkiYRyDbzLbaViLm1j9FKIKRFEtBNRwThw4AAuu+wyZGdn\nAxCFYcOGDT6C0RhBVYZhMLhnazh5HtsPl0DgVECMGSyAYuzAD9U74CjqCE2WuL9PDMPHJdVIWVJy\nIF68R8p4RL0WhkswuAD72UNY31wKJrOXumBcAgJOENFORHuBkpIStG7dWn6fkZGB0lJfv/n69esx\ncuRIPPHEEyguLo5Yex6+sxsevqOb+MZ7Eh8ANq5Kfu0tGD4xjAvooOqcdTAFmEXu5J04VXMmYNFD\n76Ra7gIEo04SjADHDmU9DU52SV3igkEWBkFEnIhaGKFYDjfffDPuuusuaDQaLF26FE899RQ+++yz\ner+XlhbfoLapoAUPz9iFKsEtGMnxCR7bzJwJKSkG+b2d57D5UDEcTh7jhnUJeq57v5kBAFg27gOf\nbR/vWYp1eTl4/JrxuKnjdT7b1WrRlabRqpGWFo86h3s9D61O3BboXkgWRHxiDNKSxX2U/xN9vLre\n+6g96Tq/StXgex5JEhJFgb+U29jY0L1wQ/ciPERUMDIzM1FUVCS/LykpQXp6usc+iYmJ8ut7770X\nb70VWl2gsrKLXzJ1wfQhmL//CE7XBj6GYPcM8p6qysdHO5a53xdV4cgffwAAbr4qK6Tz+mvzznNi\nrah9547gyviePtudnDjCt9ucKCszwuJwx1lWHlmLUd1uhana11LgBR42pyiI5ZW1iOfEc9tclXoB\noLyqFmWa4Pex1iJaRoLANOieR5qyylp0TmnY76K5wws8BEGAihXFvSXfCyV0L9w0VDgj6mfo2bMn\n8vPzUVhYCLvdjjVr1mDo0KEe+5SVlcmvN2zYgM6dO0eySQAArUaFWI0+6D7eLikA+CU/x/2GcY/U\nrTYnVm05jYIyk8936kNy9YSa5ePtevnm0Gq/+9kVwqAMeludVr/7BMLqWqHwUgx6K914NHEPeGPX\nfEzNiWzyCNGyiaiFoVKp8Nxzz+Hhhx+GIAi455570KlTJ8yfPx89e/bETTfdhCVLlmDjxo1Qq9VI\nTEzEa6+9FskmyfgTBCU6dUzwAzDuzmrN72fx4/az+P1wMV7/+8CAXymrsiAtKdbjM6kjrr/DEwXK\nWzACxSGk+IX3d6yKJWrrW99cuf+lOM9BKRj1TaS0OutgcViRok+KdLOajAJTUf07EUQDiKhgAMAN\nN9yAG264weOzKVOmyK+nTZuGadOmRboZPsRpDEG3/7b3PBDMCFFYGL/uKwQAlFZZfXZTjuif+nAb\npo/rix4dkuXPWFkwgge9pbN575cS678DVLqeLE4rquqqkaRr5SEY9hCC3lL7bSFYI42NRwJAPSnG\nL/7+JowOE+bdOBtq1v2zLzGXotRajp6p3SPWzsamOZRyIZonl56foZFI0rUKuj2voB6fp8LCsNrc\nnVVRdSU2F/4OO+dAta0GT26apfiOgEOnKzwOU59geOM9klZ2fkqk+AUAfHzoCzy7bTZMDvNFWxj+\nBEMQBNQpjtfYKDPV6nPpGR2iu9A7PfqlHW9hwYFPfWbD+8PqtOLzP75BhbXyIlrbeDjJPUdEiBYr\nGCm65OA7CAycFZngqlMx54aX8UC3cR6bGdZ/B/W/wxux9NhKzN37Ac6bSzw3MoJP9VlVkBhGjckG\nh9Pzc2/XVSBXkY3znb2+pXAHamw18vtQ0mqlOIeDd/iI2rLjqzB90/Mot1b4+2rEUbraQk1zDnS/\nQonnfH9yHXYU78HHh74MrYFNxKXoPiSig4i7pC5Vkr0sDN6mAxujHC0zcJy8CgCgZbXINHhmd0Hl\n+VBe2y0duXnlyCs7DyQA+cYC6FRecRKWh3e1cqnkhj8LY+p7WxHT3Qw2zl1LyltYvEuWSNT5EYzV\np9Z6vA9l4p5ytGrn7B4z4DcVbgMAnKw+g1R9Sr3HCjceMYwQR9UNEQyTy0qxOOu3RpoSEgwiUrRY\nCyNZ5+n7F2zeAQu3H7isxoo4lWc6GqPiPPbpnJ2I7NQ42AWl6HjXU/f1LdfvkmI8DiUJRvuEdgAC\nlzgPJeZQn2BwPOfRrkDHbKpJc6FaGMoONFCZFBtf//2S7r3qEq+rVZ9gVFirkF9b0EitIZqaalsN\nqhWehYbQYgXDO+gt2Dyzl27sm4Ur2ohzRJ7+cDvmfn3U9yAKK6NVXAwMejWgltJQVT6dE8PwqLN7\nfsa6TI5QO13JJRWj0gIAnAHcSsoYRiCCuaQsDisWH/Z0vfhzcwFNt3iRMp4T7P4p4xPK4LiHGDpD\nEAzXdarYS08wlIHu+mJTXx/7H+bt+zDSTWpSjlXm4VD5kaZuxiXBM1tfxTNbXw3LsVqsYDAMg8d6\nPSi/97YwDDo1+nV1u6GKyn3dEIzKgZf+ei1u6puN3p1TEafXgNG4C/6dr/QKnDMCrHWeoz+3heFp\nfQRKE5U6Rq1LMCQLw8bZsf7Mr6hzCUWgzl1JMAtjw7lNyC075PFZiaUMB8oOB2xTY6M8b7BAr1Iw\njledxObC3wF4phjbQ7IwXIJxCVoYSvGrb2GtKlsN6jibj1X2R8UxbMjfFJH2NTbzcxfigwOfNHUz\noo4WKxgAPFIp777OM62ydWoskhM8YxBclVccQ+1Em7Q4jL+lCzRqFgadCtCIHQ/DAHvzvIPePCw2\nz4dZFSCGYbJ4duZyDMMlJLKF4Xrolx9fhVWnfsL3p34C4D+GIZERmwYAcChcTA7OgV/yc2C0i356\nf4Kz4MCn+PDgZzhZfcbj86bymXtM3Ati5Zgd7jpey45/h6XHVsLssHgISSguPOmeMD4Vvpoeh4fb\nLfj/w+K6bm9h+e/+j7Ei7wd50EEQ3rRowVCSluBZO0rNAu3S46BWsejdKQWPDu8OR35X8DYdeKvo\nzrqqS6LHdzQ6p0dQ21jnNS+DEXDwVAXyCmtQWi1uqzWLwuAtGEYvwTBZXYs9ebmkpIf+ZM0ZAJBT\nPoN1gFL8xq7oMH49twUr89bg08Nfi00N0imWeC28FErAOBJ4xDCCpNWa/KTMztj8AnaV7JPfhyIY\nUgFJK+c736bYXIKcgm1NNgdC6WoLZmEIgiALRqC5K6GkGEcLds7hMVcq2gj377HFZkn5Y1BWf2wt\n2gEAiFHHILWVHv+degM0alFX+1xxO5Zu6AxD+3P4teRnDL4q1eP7lapTgKKfL60xAcpYOcNDEIDZ\nS/YgwaDFv/7cB+fKjFAleqbLWm1O5Jd6urOksiOSsGjlGIYTJocZJRaxxIqaVcPisOCcsTDgdcZp\n4qBlNXLHAQCVtmoAwDmT7/c0rMbDL27xesCCWTNKzhmLkBGbKre9oXi4pIJYGJYAHeCPp3+WX4ci\netJcDmU9L4k3d78LG2dHRmwauiZfXu+xwo0zRAvDwTtk951yP2XHYnKYomZGfH3p1s9ufRVmpwX/\nvfnNRmpR46J8RsIhHi3ewojXxgEAErTx+EvXu/HMtdNwW/uh6JHSFQBksQDERZgm3NYV2UliSm4d\n79lRnnEcgsCpwBld2707IUWWlIk9j+NFJfJndo7DkvXHsOdYGWYu3I6PfvAM2Dk5Hk6Od1sYrGRh\nOPDt8VXyflW2Gry+az6OVeUFvOZYjR7JuiRU1rmr80rBd3/ZWglazwyxyjpRXCQrxBrC5L2ztefw\n+q53sPDg5363VxltKKu+sJGeMs7zw+l1KLf4n1Bn5epvX7CYjyAIKLGUyddpddb5PHyShVJsrn/Z\n20igFMxgguGRAKDYz6xIFfZnkYWTs7XnsOb0zxGzxpTHrS8T0NyAFOkySwUWHVyCKtfzcCmiHOiF\nI9bY4i2MGf0m40TVKXRKbA8AyIrLRFZcZtDv6F2FCyVTluM5LD22AkauGoI1EXCIdagY1hWgFmJh\nZyxol2HA2VPA4GvisYdZi2+LDgCMmJ1VXmvGmX2F+HVvYMvgx9/PIqOD+ANgoQEgPvSVio6y0lol\nj4SVZBkyUWQW1xqJVeuRrE9CsaUU5dZKrMxbA6tD7PAkwVC6pBK0caioc5+jwjVRT8Wq4OSdIc32\nliygI5XH/W6f/t+tAIDF/7653mNJeE9iXH74R9zdfqTPfqH45INZGHtKcvHJH1/L7zmBg513yG5B\nQExe4AUelbYqf4eIOMpFsoK5pJTW4cZzm+HknfhL13tQY6uVP1fGfCLBm7vfBQB0T+6CDontwn58\np8e9qH+uESA+wxea/fbl0W9xovoUVAyLh6+874K+21jYudB+F6HS4i2MZF0S+re+2mcGdjCk9b6l\nEefRqjxsO78LACDYdRAE1211CUasVtz/nps64L1/3oD4BHEExGhtYFwlRjiNCWCD/UMFfLflNL76\n5RgAYOfhcgDixD2T3YxkXRK6Jl3uVywA4OqM3vLrU/kWJKpFK2jx4S+RW3YQx6rF43I8L8dLJOK9\nLAyp85dmqQeyMEwOM/aUiOXbA5Uw8b7GMkvgWeMlljIsObJMdjF5xy10AVxddSFZGIEF41DFMZ/P\njHZPl2FyjHg/KwOMNo9UHsdHB5eIAl9XhUkbZ2BL4fZ62xUqTiE0C0Ppnssp2IatRTvh4J0egmEK\nQTA2FfyOY5WBrdhQECDAyTuxMX8TamzhKz+uFIlgqeOemWWe+31z7Du8vef9oOepC1I2JxR4gceB\nssMRTRpRXlc4ztPiBeNi0KtFC0N6+DSKkYmejQMEl/i4BEOvliwOAbE6NZLjFSm8CjeVpp17rsdl\nGfEY3Ku1z34Wm/jjLCqzQsWo4OCdMNqNiNfGITkmcLmTGJW7+u7BE0YcPyUe52ztOY/9HByHqe9u\n8VjqL8HltpMos1bAZDfL0xKVMYw6uxN1dvGHOW/vh1h8+EscrTwBdZBUVMmFoG57DC9sfyOgFfLR\nwSXYfn431p39FYCviR2r9V8tMpQ5KcqHnuM5HCz/Qy7O6G8sccbrvsVqREuxIkCZlPdyP8K+soPI\nNxZgvys1+etjK+ptV6g4L8LCkKhz1qFaaWEEWB0SEDvg38/vxjfHV2J+7sKQyssEghd4bC3aif/l\n/YBFAVyVF4PSDRXMwlC6IVfk/YBFB5fI7w+UH8bJmjNBxUD6/VucVvzvxOoLDp7nFGzDhwc/w/IT\n/pcoCAeOEO9FqJBgXARS3ENKQVVWfb217+W4tovo0hJngwN6jdhZSx1cWqJSMNyjHFXKeQzskYGJ\no67ErIeuwd1DFGufS8Ii/RVYsGBRW2eEU+CQoI2Dw+w5+VBJnMbd6QucBtZa/6NxhhXAXnbAY/Tl\nbWEAwKmaM3JnoXRJTXx7E6bM2wxe4GUXmNlhCVpcUSreqE4XO+HD5X4mScI98pUsGu+AZqBg+rmK\nwD7m7DhRlJWdx8Zzm7HgwKdYmbcGgKd7Ttr/lCsrTULqpPy5v5QWmCAAWpUmYHsuFs+02sAdg9lP\nwP7fW17C/rKD8vtgFsaPZ37BF0fcC4ntU3zvQrFxdnkGcr4xfDPPleVygsUwlMkLW4t2IrfsIIrN\npR7t8rYk/XGq5gw2ntss/15C5axrtv3hCv+/93CgFHRySTUR0ixx95wF9yhEzaoQqxM7LrVa7CSl\ntTUkF4pe5+6ADLHukTdvTMLfhveQJwwmGrRITxbdWR2yXJ22LBgMnE5GDvSWlfPYsivwjztGUMxs\nd2qgsicG3FedVugRRFXOio9jxJpRO4r3yHNDvF1STk7A3L0L5PecwHn8WJXBdgAwSi4wTrwXoUyi\nA3wD9NJs7RqTDUvWHYOlzoFqkw1nSgPHFeQUY8WDddbVeW0q3IbcskMe7spOiR2gYlTIry2A1WmV\nvyfNafE3Ij1ZfVp+beftcsJCOAk1SypQHaxDik4rmGB4lxTJU1zbhWLjbBdcrTkUPF1SF2Ztvbzj\nLfx6bov8vjaIYAhepX9MfiyzIlMx9pX6F1XJMyH9vywOK7459l2DqiGXmEux/syv8v20k0uq6VGz\nasSq9XK8QBkwbROXJfv2e14udsrSyFcaESs7z1idCq1ixP3aZvq6VGK00r+IR0KsBnBZLe0zWoHn\nGFmEzhU5INTF+XxfQnC4JyEKPAsVFxd0EakCxahco1LLbazKF91eylngUozA5nCLjHIE/sXGQ/hh\n+0n5/XPbPBfJkiYpCrxLMAK4Obw9QzUWT6GycXYsP/49nt3+MjYVbcXKLSfF+SyqwA9Ksi4JDBiY\nHWbwAo8jFZ7usEUHPwerOHOsRo9WMYk4XZuPJzfNwqeuYLjUZn9ip3Rf2TmHd4WxsBCyS8qPhSEh\n/U4tF1Cy/nTNWZ/PVp9ah8m//tuvi0b5v7VxdlkwvDvfhhCqGybQvZAqAQBA7QXEVjR+LMdXd76N\njw75z6RSueJ60v9u7dkN2FS4DYsPfxXyOb15ffd8rDr1E/5wxd3IJXWJEK+N97EwhrW7EV2TL5dn\nb0sTo6RsGs5P/jsncFCzamhYNTR+PBXSSIETeKQk6sGoxXON6H8FILj/fYJDi9v6XBGwvTaz4uBO\nDVgwaBvfJuD+J8vd2Vqck8Hw9L+g7vBAOM939D02Zwcv8O7Z6V7B+zrOiqLKwMvXykF2WTA8O90q\now3Lfs0DL/UprpjH4TOe8QK7045DFUfAs3ZoLzuKU/wu1JrtYLwE4/FeD8mv4zVxSNYlodRajg35\nm/De/o+wr/SAx/5KC0PLajwqHR921SuSihfaOLtPuqgyTnS2tAq/7PXtZC+UIlMxlhxZJrvAQg16\nB0sjzTZkQqvSXpAv/ry5xCdLbu2ZDeAFHqf8iIkyA8vO2SNSZsXOhSgYAa5TmQAQzMLwRs0ETuyo\nqPO1ciWxlP5fVod4H6v87Bsq0rMjXZuHS6oB8SYJEoyLJF5rgNlhAcdz8j/p8iQx5iA9BNLnsoXh\n6vyVI0CO56BiVNCyWr8/bqnGlCAI6N05Ra5VlRrXCjq1wrXhiEHrFIOniHDuhzG/xIwXBjyFbNMQ\nCPZYgAF6p/YIeH2M3v1gf/5THhb+7zQEcyJ8x/kitVYL3l1xANDYoO/3i+ex1A45xVjim40n8NbS\nfdifV+4jGJVmz07tvysPYu2OfNSaxftZXiM+WBVG8aEQHKIYHj5bCqvdAYFTga+LRbHqEEqM1T4W\nhkHjjvXEavRIj02F0W7yqZ2luAL5lValRasYt2BwAg+O5+SHkRd4n7pWysmQq7efxKlid4fgLS5O\njkdFTf0j/PdyP8L287uxqUAsMa8UiR/P/AKjzb9AW4NYGMm6JMSq9bA4rDhaeQKTNs6o1+UkQEB5\nABeKt+sRgFc5FltY1op38k6PtWeUz1GwVSUDueeU1s6FCEawisf+3ExS3Ez6vbBs4LVxLhZPC4Nc\nUk1GvDYeAgSYHBb5Hy9ZEtJD4BYMsUOT6h15+JsFJ1QMC41K43cugKCwMG7vfxlSUljX+eOg07qt\nBsGuQ2ZyLFSu+RlcTQrq9ruXxt19tBSp+mTE2kSrwmx14I+9Bqh5/5lFUsBePLjnz8Rxzncm88b9\nZ5FfYoIqsVz+7NrMvuILlcMjuA8A63adxR9nqjBv+QG5DIrkkjpTKprvuSfK8d6KgzhVVOvxXXOd\nuH+VSez8JKsnv7QKRrsJgtUAriwbYAScNp72sTCUgqFX6eTaWkWm837vhTK4rlVpEKd1f1/sMCs8\nOhnl/5EXeE/fNst5LL7lHfP46ufj+NcH23D6vOc1eyN1ZFKGmrdVsTV/N+ycHW/smo/NivRdY5AM\nqDitAVomBhanFd+d/BEAsO7sxoD7S6nSyjk6Skot5T6f1Sg6YBtnv6B09kB8/sc3eGXHHLnGWUNd\nUkqCxjC8xD5QRQEAKLX63gvJOpS8CNJAM5yCYQ/RVRkqJBgXSbxGypQyyg+9JBisK5gljTiklFZ/\nJRmszjqoWRW0XuU3JKQfDy9w0KhZpCQzYBkWsWo9DFq3hSHYY5CRrIeaEQVDcMQAzhjYT/cA8gai\ntNqKFZtO4dAp8eGuNtmx+0gljLuvB28LHMsQD8bg0eHd8ehwsUCj83xHOMtbe+xSXF3jOq9bxDJi\nxeA9o3YA3isUKiyOo/mukSgv/hwZlsO+E2WY/78D2Hu8zKc5VpuYumu0ivdXcLrOqXaAUfEQnFpw\ntWLZlmO2XWDUTgic+6fOcu77tvC7E+CtogAEyqhR/l9ES9DzwSu2eLZRKRhWZx0ECLK7gmF5D/H0\nniT3W26R2O780GYPS0LlLRh6tQ7Hq04i31iApcdWYHdJLowWO44WBp6JrmV0OF/mgNXhDuaXmMvw\n780v+V0/o7Xr/+s9ek5yWWD+Zr1vK9opv7b5qZh7MewpFef6nDWKrj9HiC6pGntgUZYyIWvtRtTY\narH65Np6Kxr4EwzJ7VTmRzyVrjzR0yAlAISv+rPTI+hNLqkmQ6q1U2otlwVDK1sYomBIIyzvGIZ3\nh6NiVNCoNKixG7Hx3GaPbbwsGOJfo92EOI0BLMNCrxCMB4f1RnysFipB7DylUTVX1hYPDL4O+hgV\n1vx+1qeMOsACXPBJdXcO6IABPTKRKqcDM4hTeWZZ5Ve4On2lMNh0EHgWsQbBQyDE/dzvD5wtAiC4\nM8BYDut2es5zUFJSZcX+vAq54xVc7We04ohRx+qRrE4DBAZmeI1+BeDpD/a43zq1yDsWPGvpWKH7\nYeccLK5OFydBSpaJdzFGKY7x+dqjWL5dLHAYKy3AxXIe114TYATr5HhY6hx44ZOd+GW3773wHpl7\n19Kqc9o8XEKfHP4Kp4trRGsvAJxdDTjVAAOYXPG5irpKGB0mfHlEnDOitKQyDRkAgJ/zc7DkyDL5\nNyp1kiavSaS8wONg+R/y82F12MI7ac3121aOqpceW4kKi/+YQHVd4EWFLotvCzWrRq3NhC+OfIu1\nZzdi+Ynvsfrk2oBVAcyKmAgvCHj3fweghvjb8mepKEvWmJ2WiFgYlFZ7idAmLgsAUGAsCuiSktCy\n7iypM7X5+PbEKo/tKpeFAQD/O7Haw+8qPaBSR2+0m+XRj+QSiFFpcX3PtgDcJUOULqWMZD06tPas\nxqtEUAhG2/g2MDCey9cmxYsWkkHv3q+Dqg+cFa3hrBDnnJQbxc5BGatYsek04NRAq3P6rIF+x3Vt\nkJKgAxNjgb7vr8joc0zuSBmVE8fPBR9hf/j9YberidNA4FkwWvEBTI1LRFK8HoLdbTk5Czu7rlUD\nTtkUpxrxbBKuSOoc8FzKTBmjmccVSZ3wxuBZGNnxDgDAqpM/eexv42z442wVck4cwU6H+L82Vrvi\nSSznIarKAKdUYBIA6uwczhYbkV9iwle/nMD5Cv+uJOlzKcGiZ2o3AKJlU+iaByNxrqpCtPYCYLOq\nIHDi78c7OJ5fVo3P1h7FiQL3/0XKyqu1G7H9/G6UWsphcVhlq8nG2cHxPH7dWwCrzYlauxGcwKF9\ngp5oOOIAACAASURBVPhb3ZtXHHQdk/rILzHi87W+cxi8rYrdhQd89gEQdBW6VrpEJGjjUWs3oszl\nTtp+fjfWnt0ou+u8UVoYNSY79p0oh80h/l/8xVKUc3bqnHXyIMDJcXByDRMNwY94kmA0IZJgnDMV\nyqmUsmB41aSJUQS939nru9KZaGG4R7nVNvdDyStcUg7OgTquTnaHSSM8pR/8xvbXAABu63a1/Jle\n67kYlA+u2IGW1eDf10xB70zPGEVGsmhZGHRud9O9N3ZFRu110NSJrh9G5cSgnplIT3Ffh7MqHQKn\nhsBy0Lg+7p7cBQDQ/8pUvPH4QDx0t3gfazVnkJHsmhGvtfmMhNtlxEGjEn+ukoBJGWOJOgPAq8Cw\n4kPSp0MWurZLguBw3ffaJDgrxPPI7isXAqfG+UoLLk8ILBjSGicAUFhqxQ/bzmDOV39g8Xdn/O5+\ntrQam/cXQRXvtm4cVnd9MaV4StkzgiDg+Y/d7poft5/F5+vcJUmKK7zcHa6B/t7jZeAFQR5JsjZR\n7MtrjSg0esZkfij6Fow6SMqthREtDH+onMjJLYLD6bYwtu2rggbuCgKv75qHf22eJcdV6pw2/LQ9\nH0vWH8dHPx3Egv3igkaJajE12+qou6BUT++YwSuf75FdeEq8j2nQxsLisOD1XfOw8ODn2FYklvGp\nCiIYBnUsErTxqLJV+0zGlFxw3u2p42zILTuE/NoCVyKHIKfB+0u3Vrqk6jibey4KI3gMHi4Gd4IN\nzcO4JIjTGtAqJhGFxiJ5wphkSXinCmoVLil/D4hoYbgfVGU9ImVareRzTYgR3RvXZw8AALR2CQcA\n3NbxBjzVbwqGX+Eu4hejVWFI7yz8c6y7nhQA9OjgKiXisjCkH1m7BK90W9dzEatztzG9lR4v/bU/\n+nfJdl2EExNu64qh/cTYRrZpiChEvAoO3o6+XcRzSQFnB28HyzAex9QoPEOsoQa9O6Wg7xVpmP/E\n9XjhoWsRFyvu0L2Dq/S2a7TMcFqPjLAEXRwG9cyUG945qxX6XS7eIz2rR5u0OGRX34K72t6FyzPT\nUVJpwffrA1s0jEIwNueWYMWmUzhbbISxxn/n+vnPf+Do2SpZsADI1k5KksYjhiH9rw+f9g0cl1S5\nXRw1Fs8OR9lXlVVbsf246LbatV+0hn7cfgJnazw7U9bg6xaRKisDgMkICLz/a2Jj6qBuc8xzXXpe\nBdbhntTp/du2cXbkl4jnPG07iHMmsT0qh8s9p+LgVEysyyuowRfrj+G3fYU+9czeWroP73zraSl4\nj8Klxcm800ctDisOVRzFOWMh9pcdwpdHv8X6M7/6WBgjO90uv47V6OUqzd712Q5VHMU3x1bKMTQA\ncvHSRQc/xxu756OwugxgBDByNWpfwVC6pGzO8LrnpGOFGs8JFRKMBtAmLgs1diPK6yqhYdWyZeHj\nkvLKkvJGxag8ROb387vk0YskGIIgyJN/pKBia0MGXrp5Oib2flj+LsMwaJfQBizDYtq9vXHnwMuQ\naNCCYRj06pSCuf8YhFZxYkd2W3+xUqjUmUkxlnZe8zPaxouioFb5/lx6tBU74lv6t4ZaxcqB41v6\ndUC7jDhkJsXDzjnkY0uCIVlFyrIbyh83a6jBwCsz8Y8xPRGn97IKwGPGn/ugXZY4ur3vph5gBPf9\ni9fGISMpFhkpomWk02rwyJ09wTIsumW3xkt/vRYzx/wJt19+Azq71m231/qWP5HvqZc7rX/3DDw3\noR9iNQGSBVgOtRbPQL+0BHDHbIOHu7DCWonCcjPeXrY/4PkBYEXOKZRWiVZGrcXunpMCYMfhEhTX\n1Hich9GbwTMBgvjn28uv7Sf6yq/PFtqgjg2c6aPJOu3hchR4Vs7K80ed04bjLheWco7Clj01oguR\n5WB1uNs4+8td2Li3EJ+vO4YPvjsEQRDwyY9HsGTdMfxxpgoHT1WgpDJw+77fKqYAe5ezt9itOFzu\nWUBylWtlSo+qzGp3XM6gjgXnDNw9bir83cPF0ye9F2IYd8ZhbuU+j1iVOFdJQG5eOTieh51zeIhI\nHWfzOJ7VduGuui0H3BalFOBWpjF7u04vBhKMBtA2XnRzVNZVedQx8rEwWLdLyh8qRgWHYvWz3SW5\n2OvK/JBiF5zAyyZ0kmLiWNe0znJ5C2+u7JiCu4d08giQJsbFYOb4qzH13t7o0T4ZN/fNxg0dPS2P\nrDh3BtT8G19DnNY9ipw0+kpMH3eV/D5BL25jY0SzXfLVJsXG4oWHrkVKnAECBNn8lgRD2i/QDGVG\nZ8aVHVL8XpeTd6LrZUnQ6DioGRWu6pSJtqnuhz1VJ1ozIy+/BQBwU9vroVVpMfmqRzCm83CPY/W5\nXAxcQ1BhSpfpSFSL91LgGXBVab4n59T489DL0aF1AjKT3fdFa0uFI190t0mxlaREdycpxYlsvN1j\nguahgkJ89pPSDy8AfmY9m6wOvP7lXgDAb/sK3fswYhVjyT0nCQYbJ7q6HIWd4Ch01yRL4LPAlSkG\nBAoXXU0N0DnG/b/1hxQnAgDwKhhNQWZoMwJqXbPxVayiq3HEiGVgWA4HTisyzBQd7JGzVfjw+8PY\nfOA8ck7lQttlF8A68dOOfJQHWTfF5uDkOSh3d74LALD7RAF2FfiuRQ8AYy6/S3596A/Fb9GmwoFz\ngRMvAICHYrKknYWzzu2eO2M+6XE9ds6OX3YXYP7yA/jqtwN4dturHseqc9o8LACr7cKsDUEQsPhH\n9xo6UhJErSN8VYABEowGIcUxAPeoH3BniUhIMYxApcfVrMrHjD5SeQIAwMMdw3BbGIHrQIVCaqIe\nPTuKnfH9t3TB2GuuFdvhEjoNq8bjvR7C9Ksn+cRjru6S7nZlQbRGtCotDpQdhiAIsq9WsqqkYL4U\nRI2VBUOaGe32Dzt5p3xt6rQiLM37xm/7pYfB7LDAoIkFwzAea1Ok6sX29UnviblDXkGPFLEjvyKp\ns89Kch2zEtCvSxr+b+jl6JKdgSSdmBwg2HXgje7rFATAfrInBJsBCQat6z66LYwJfYaDd3XWOh3Q\nKk6L63q5V2S8vpM4SdLBOaBz1RLjbTowGjvyCsWBABNjgf7adVBnncTrfx/gc93VJjtKq61Yt/Oc\nPDKWrB9GbYeKUePqTqIYMCrX78acgPuvHiofQy3o5fRlEQa8yfV74tS4odOVuFn1NzhL2vqcH3DF\nlyR4Vly22BK4JI00adIuKOam1BmgZrSAygmrXXE8ZSYd60Su8ycwhhrEdNkDVWIFVClF2LS/CDMW\nuEt3eMByWPDdIew4kQ8A6JjYAQBwpCwPjNbXJZSh6oCuSe543bY97s71fKkDzoLgKydyikHemUIr\nHA7FhD+hwmP+j5134Gi+6HbcVrJNHvnzZvH3dryoHFa7u42WOv/WYbG5FL8VbAXnyqKTz+e1pPNJ\n1+RQk90ENatGliH4Gj+hQoLRAC5LcD9UbeLd4uHdyUrvt5/f7fc48Zo4H/+lVE5CDnpDkJdRVVoY\n4UCr0uLpa/6J5wf8S/7sytRu6Jh4WQjf1aBnSjeU11Uip3CbbDlIQiFZXmaHBQwYxLpKw0uCoSyN\n7uAdiNfGyYK7p3S/h59Z6iTdxdosMLgKI2YrrCKdokZWfcvBsgyDiaN74pZrxP9lgk48HqOxe8RF\nBEsCuIps/N/N7uB4crwOzhLRrdcpuS2GDxBH8tdfnYSX/tpf7gCnXz0RE/7UGxpWDTvngJQNLdh1\ngNoOyVro3Uf8q2mTh/SkWEwfdxWm3NPLo70vf7oLVpsTLCvei/atXZMI1Q7EaWLx+IjeHgMWwRaL\nHm2y5ffdsjIxqKf7t9o+Mx4JRTfCunsYAAadshPx/+2deVwV57nHfzNzVg5nAQ77JqsiKosKLkQR\nCbihUEEbkza9as1iNKJZDPfT2BtTc29MbZO0ualNW5PWW1vbmn760U+allSjDcFoJGpQEzSKGAHZ\nZD/bvPePOTPMcEBRIQq833/kzHZmXs+8z/u8z/P+nonR/nBcSgSxCyNm4lAjtKNnEah0bcKB2LyQ\nZ30Yhro02M5NBukVNBen37odwv9znCMLcGqg5TTCPlk8R+69qAIvgfO5Bm1Cec9+WYbX1cYOT80B\nlsdn5xtBVN0gThWOfCp00Jyx7/gU59LDSyW0n2A0e674/se14Nv84LjiKYUjIvcwyk8rZWoYlgdr\nUK7zOPWVkH7tsvd4daLBOHSyGqdk3laHree9IITg9FeNuN5uw39/8ir2fvFX7PzgQzzx08NobhOO\n612t8kRVvbBWyd4OL9YAa5fyd3S7UINxB8g77iCvniyk3lNS/ckf6DihY5sTniHN/U+0jke0eQyu\ndtTBxbsU6zDEvHq5NzNYhBlD4Kfvv57GjciLnge9So/3L37gIYciehodjg6oWZW0XXxeeYaXg3dC\nzaolowIA+y/8Q1rcJV+kxhMeXc5ueLmrH4qyLHdKsv9EAO6OThYAJg4tCu6LQk5aT4U4J8/DcSkB\ntmM5MGq8kZuYBL1Kj+MNn0KrgSx7Tuh4NawGNt4OTkVAeAZwaIRaGyoHOJZBcoxyCiw0hMMvq18G\nF9ijydTR7cS89AhpiifIXweDTgVG7YC3xuD2tnqmRhKCQ+Bn6mlPs16PlfenwnI9Gd2fT0eo1YA1\niydImXI+Ri1iQk1ISwiAUSecp2I0eHC2ctoSALzcWQrTxgfC4owCf90ffKcyfXvt0gSEWg1wQmiL\nU+e63OfqBM0xWZxHrhIgBtcZlhfaCnAnORCwxkb856/+7TFxJ8ZXGLUdxKHBB5/UKfbbKtNhvzRO\n+nypxoGNPz2G7opZsJ1JUxwrZdO5biBFL4/nuFRwNgiG2KoR+gLWolyf4xINjCxxQBrocE5FfZc/\nHDqHr6624vi5a1i/cz/+96v/wVN7/iBNW50i74PRt+HVsv/D2x8cx4ef9coWY3gcOXkVzV1taGkB\nPjndf0bYrUANxh2SEiBYbrm30dtA9Bdj2Dj5MZSkFcNP7yv9EERxOwKC6/ZWRfC7svEcfLQWqZO8\nV/D38kOUKQLX7W3SQjRRuVM0EDaXHQQ9noetjykpAgI1q1ZU5/vo6lH84tTbwn638XQSJzocnSAg\nkocxzicWLMNibrjnSPhWmBqUgimBybBfHA9Xqy/CtNGwXxoH+4UJCPBR1htJTwgEwGBFttAJ6VQ6\nTAlMRrujA1931ErZc+J0mU6lQ7ezG3odAxWrgr9RmAoK8ldhTLARKq5noOHiXSit/lBow8gz7pgE\nD4Bgycwo6Tgn78SP1qSB4ZySDL3ObTC81QY8tUxIsxYHGeK6hycz85EcEoOiObEIdD9XsJ/wL8ey\neHTJBPga3OnbZnOfv+HiolQ8/70p8DXpoFa5f/O8crBkNnGIDjH1dK7u/RaDl5AGLXbyYBA/vu9p\nGDUjPA+r6wQXcBnahE+gDvvS80CGF9pIZQfH6wGeAyE9XgPf5Q1X3RjpsxhXInYvmLz0eHZFirTP\n18uIZx5I8UjD7o8N30rF+sw8lKQVY1PaI9CwGqj8lOtgGLcop+gpWfV+SAoRPFaGcyoMEKPtxNa3\nj+Hn+07BbrootIOswBqjckI38d+4pjqDcvu7ioC38F08/lZeBbA8DGoDHsicOKDnuBnUYNwhDycs\nx6bJjyNeNsKVT0k9NXktNJwGP83c5nFugN4qjTASfYVOJ94nBmatMEprsV33kH0eihrIg0GgQRgd\n17QJQntioF/DypMBWMmA/O3Ce/jHpYNSpyiiYlWSYRCpbDwHF++SYhdO3ikV3BFXW3upvbC78DUU\nxC68o+dgGRb/kbgCrvoIwKHDipgHhU7GqUVyrFVxbEyoGT8vnoU5KT1TPqKnea2rUbagU+u+Rz06\nHZ1w8k7o1RpMiRXiDQ8tiMJTy1MUWTPvnj+gWPWvHV8Ofdr7CJh6AloNJ02e2HkHCCecJxoMsY1N\nssJXa5NXIdFvHLLC7wMABPh4Yd3SSTAZNPDWq7FtzTT853d61u4I1xE6S51KA2+1AepeZXYtBh3G\nBAm/VdFgsHaD4hiby4as1DBpPQJxqcCxjJRhpvfiwTEcfHUWNNtasLZgAnpj1rsNmU89NGMqhe/x\nEbyHmRN65ubjI41YlhMBhgGCzT4AGCllnCVqyVtI9he+g3Tr8eO1M1GYGYONy5IwNsJHkrbZtCwV\n8eEWxaJWAODbTXDWek7VhvlZMDFaeJ9NGiMWx8zzOCY8SI+XH50uxXXWJa9GpNVtiDnl4lbOKFud\n7u4COK5v3S1GY4M1uhaKZAmGl1brR/pZMXPczaeXBwI1GHeImlMj2p2DLSKfkopyxwF6v2yA0rAs\niV2ADSmPYEZImlR7QszRH+sTi0luZdlYS/9zqncTUTdKlFUWn1deXW7FuEJp9AugzxWzalYlZZPN\nDElHSsAkt8hjh7Sa2cm7cNadFDBWtkKbY7lBEbMDgJhQoSO0WnSYkxqKB7LjoNV4SnHrtSrFd4oB\n94auRpmWmNCBe6n0sPMOdDm7oWbVUgfvQDe0Gk6hVdRbIkakjalX1qJ2OaQ4j2ggwtyDEPkUY7Ah\nEI8nrZRUAnoT5OsFL51yND0teCqMam+M840DwzAeK4XlnuDksYLhnheRg3mRWZg/Rgi021x2RAYZ\nERUidPrfnjMO6wsnSW2i0bmgZlUwaUxotbchJd4q1H2RxTbkXqgIq+1GTFq1lBoOACZvFcbHCt/j\nbxA8Ko4I3yMmU0QGGvG9xBVYFLgMq+6bDR+jFgumRSIiUGi7ZMcyeF9YiCBfL7Asg4mRymCxr7cR\n8yZ7LvIUi6SJzAnP8DhmyewIWC16RITo3OfoEC4aDFYZz2Hdiz6FMs3C70vFMSB83122JvQr7Fg3\nQ/qs1fasHwo0WqBTaW8azxsINxYRotwW/cUsfpC+CTaXHS8fex2AMptKzaqkeXipWJHbYIij3s+u\nnUZqwOAErwYbeQxHw6qlTlT+I51gTYCaVSEveh4qG8/ifK8ypwCgYtWSweAYVqon3mpvV3gYVS0X\noGI4D2M9WDz17RR02Zww6NT4Ts7YAZ/nrxeyz75ur8Wl60I2k9o9DSfGZq7bWxFkCJQMhqi51OXq\nCVwa1F6KHPpoc6RUX6Ld0aGQyhc1y/y9BA/oO+OXY1xQNCJ1Y275ueVMD56C6cFTpM8+WsELKIpf\nAgaMwoPJmBiMyEAjwgK8wTKxKHOvphZrS+j1AGzA3ORIcCyH02c10rN4qw0waY3gW3l0ODqx+Tsp\n2PX5WVx2O1ydzi6EegfjSi814a9RiRBrj0fjghPN7sSQaP9ATP3WePyr9Qucb70AG+lC8bIkRAYa\noWZVmJ84BX2xZpEyVrN4egxe6ZEeQ0yAFeGWQMCtWB9likSzrUURNxJ5dNL3sPPUO4izRONccxXO\nd55BCuLgbQDQIigla9zTUHERBrQ4HHAQb7R1OMB4CVO7S2ZG4WKZHo0QastzLAO5/23RmkEIQYej\nE1rZLXAckZIIArwFoxRqUAqG3g7UYHyDiFIeWeH39VtDAAAs7ikp0cNgGAYaTo2pQSn9nnO3iTZH\nSh2KXaHu2jNqFUeV88ZkwaI19Wkw1CwnqXWyDCtTDW2VgoI2lx1NthYEewcNSX1sANCqOWjVt17c\nx1fvCwaMpKAK9AgFymNPk6zjpfUtf/zir4qYBeAp4xBhDEOEMQwHa/6N5u4WmZClQ5LOFo2VmlVh\nSUIOrl0b3Bz8J5JXobajHskBnvPhDMNIo3QAUjXHvV/+FVMCk9HtErwq0auWDyTaHR0wu41Pq70N\nH1w9jMv2nhgFT3iYtSbJYCRZE/FZw+fSuSJO3olmt6Cgj9aMlAh/uOqm4fznFxBhDJNSyW8F+X3O\nH5ONtKAUWPV+aOpuRrfThrzoXOn5ezPROh6vZm5DafWHONdchX9dPoLJAUm40n4VWk4DjuXAEhYc\nw4FwDrAuHmqiAt+tAWtswv88NhV+Zh3iIr3ReFWs1kjAdxjBaLvAqJyIMIbBwTtwpukLhVy70ZtD\nu7t2jtifPJmy5pafvzfUYAwBNxNUWxqXd8P9ooch1hlgh8HMIcdyyI6cjb1fKIUV+3ODk/0n4lhd\nBc40KUuiBhoCEGWKxNnmLxHo5S9Ne8hLXIoSKfJU2nsFNatCiHeQx2gYgJTCCQi1QkRj6uSd+MMX\n7yqOtbnsYMBIMSwtp5WmPeTV29rs7ah3y6sHeCljLINNkCFQGvTcjLG+cbBozWixXcf2Y6+jobtJ\n4VH3HpGbNEKndt3Wio9rPdPP5ZlzsZYoWHQWHKr5N2plhZPsLofkYfi4g/STA5Lga/GGH26gpXYD\nQgxBWBh1P8b6xCHGMkbanhM5Z0Dn916T9crxnwPomc5jGAZmrQkttuvgCQ8dp0VSaDhOtzXBxrYB\nMEqGQPwtJIWNwXV7C6o7LiPMGIKGLiGlV66N5WfRYoyPBcebAbO7P+mrhOytMuQ90Ycffoh58+Yh\nNzcXO3fu9Nhvt9tRXFyMnJwcLF++HF9/7SkmNty4U41/i9YMHafD541CVkR/dRruNWaHzsCCMdko\nilsibZN7GHJ0Ki2eSF7tsT3ZfwJWTXgQK8YuRUboNMnD6KsmcvAAO69vmm+P/Vaf2+WdXoDeCj+9\nLzZP3dDvdWaGpkt/q1gOZnen2tDZk/Pfam/DsboKsAw7JOnWt4tepcP65O8DABrcAx957EXbayBh\n1vZ4GH1fr6fttCot/NwGQV6LxME7PBa3MgyD9LAUKZHkVmEYBgui7lcYi1ul3eGpNCz3IEXD2uHo\nhIpVYVyQkHFZ11mP67ZWnGxQrlL3NRjh6yU8X5h3iCRGKn9HCFzSlJTlNp+9L4bUw+B5Hlu3bsWu\nXbsQEBCAwsJCzJ07FzExPRlFf/rTn2A2m/H+++/jwIED2L59O37yk58M5W0NOao+Aty3AsuwCDT4\nS4v36js9iwjdizAMg4XROYptfB8yF3JK0orh5J041XAGHY5OWN3TKmJnKc6Tn7h2yuPcCX7jPLbd\nC0SbI/Fa5kt45vAPFenWetmUlDg1E24MQV50Lg5f+VgKXmtYNUxaE+aEZUDHafHP6kNI9Bsnqab+\nq+aIx3fGW2I8FozebQINAZgbPgttjnYcrf1UsU9uMNSsWurQ93/1jz6vZVB7warzRUN3E8waEwxq\nYVBWJyvSVN1Wg5r2r8Ey7G0biKFgbsQs1HXW41TDGagYzmMGQjRuLuJCp7NLSlr49ef/1+f1vFR6\n+GgtONd8HtHmSKl/+MMX+6Rjvmy5AAAesaY7ZUgNxsmTJxEZGYnQUCHtcOHChSgtLVUYjNLSUqxf\nvx4AkJubixdeeGEob+kbId4nBvMis5B8BwFqcdQAAMvi8wfjtu4KvUuQ9kacVpJ3rHLE/P86mdFc\nHp+PWWEz+jz+XoFjObx83w8VUxJsP/XQ542Zi/sjMrH+4HMAgB/P3goGDBiGwZKY+cgKvw9mrUmK\ne8lH4WaNCQ7eccfpxEPFt+IWgSc8jtZ+ijhZhp98hP1f05+FQe2FsT6xONdc5XENHadDRkg67gud\nhsrGL5DoN06q4d3bePKExxhThMdU0N3EpDHi0Un/geu2Vmg5DT68UqaQ6rDIpH4SfOMRY4mCXqVH\nl7NvzayxPnGItUQhK/w+cCwneeF9VQQ0qL0GdSAxpAajrq4OwcE988yBgYE4dUo5Uqyvr0dQkNB4\nHMfBZDKhpaUFFsu9417fKizDIq+PPOxboTBuMbScBkvjFkvu+nAkziIsMhvonG9veqeBzh+Tfc8b\nC5H+XlT59Ir8WLPGBC2nURoZ2WjZr9fiudzIrD7z/e81WIbFj2dthUrWHvLqdOLzPZG8GicbKlHb\nUY+/XXhP2r9ywoOSqsKMEGEhYn/TkfMis5DZR0rrvYD4nDd6Fx4cVwiGYfB40kqcvPY5ciIz8fTh\nHwIQ4ikTrAmI8xEMr5i+31+qNADMCp0+SHcvMKQGo3eBkYEcQwgZtFz64Yy/lx9WTnjwbt/GHWPV\n++GnmdskYcPbYWlcHv785d+wZuJ3pfUow5G04Mm40lGL2f28xFtnPHfD3z7DMJgckITj9Z9hScx8\nzAm7NzvGvui9TiHRbyzeu1gqZRkBgmFJ9p8A+ANTA1PgIi64iKtP48AwDMb5xOFss5BNtSw+H+lB\nqQodseGCWH9mTliG9P8fbY6UtNz+O+N5qFiVlHnWmyiTclGeWWPCjJCpmBqYgkDD7QX7+4MhA+nV\nb5OKigq8/vrr+NWvfgUAUtB7zZqe9K7Vq1dj3bp1SEpKgsvlQkZGBsrK+lGjpFAoFMpdY0gn+iZO\nnIjq6mpcuXIFdrsd+/fvx9y5cxXHzJkzB/v2CcGa9957D9Omeco6UygUCuXuM6QeBiCk1f7oRz8C\nIQSFhYVYs2YNXnvtNUycOBFz5syB3W7H008/jTNnzsBisWDHjh0ICwu7+YUpFAqF8o0y5AaDQqFQ\nKCODeyf3jEKhUCj3NNRgUCgUCmVAUINBoVAolAEx7AzGzbSpRholJSWYMWMG8vJ6BAuvX7+OlStX\nIjc3F6tWrUJbW8/K3xdffBE5OTlYsmQJzpw5czdueUiora3Fd7/7XSxYsAB5eXl45513AIzOtrDb\n7SgqKkJ+fj7y8vLws5/9DABQU1ODZcuWITc3Fxs3boTT6ZSOH2l6bb3heR4FBQV49NFHAYzetsjK\nysLixYuRn5+PwsJCAIP8jpBhhMvlItnZ2aSmpobY7XayePFiUlVVdbdva0j55JNPSGVlJVm0aJG0\n7eWXXyY7d+4khBDyi1/8gmzfvp0QQsjBgwfJ97//fUIIIRUVFaSoqOibv+Ehor6+nlRWVhJCCGlv\nbyc5OTmkqqpqVLYFIYR0dnYSQghxOp2kqKiIVFRUkCeffJIcOHCAEELI888/T37/+98TQgjZvXs3\n2bJlCyGEkP3795MNGzbclXseSn7zm9+QTZs2kUceeYQQQkZtW2RlZZGWlhbFtsF8R4aVhyHXT7us\nDgAACDZJREFUplKr1ZI21UhmypQpMJmUQmqlpaUoKCgAABQUFEhtUFpaivx8QXcqKSkJbW1taGho\n+GZveIjw9/dHQkICAMBgMCAmJgZ1dXWjsi0AQK8X5EXsdjucTicYhkF5eTlyc4WV0wUFBfjnP/8J\nQPl7yc3NHXELY2tra3Ho0CEUFRVJ2z7++ONR2RaEEPC8ssTxYL4jw8pg9KVNVV9ff4MzRiZNTU2w\nWoXaB/7+/mhqEkTp5LpcgNA+dXV1fV5jOFNTU4OzZ88iKSkJjY2No7IteJ5Hfn4+Zs6ciZkzZyI8\nPBwmkwksK7zSQUFB0vP2p9c2Uti2bRueeeYZSVajubkZZrN5VLYFwzBYtWoVli5dir179wLAoL4j\nw6qAEqFLRm5IX+0z0nS5Ojo6sH79epSUlMBgMPT7fCO9LViWxbvvvov29nasXbsW58+f9zhGfN7e\nbUFGkF7bwYMHYbVakZCQgPLycgDC8/V+5tHQFgCwZ88eySisXLkSUVFRg/qODCuDERQUpAhS1dXV\nISBgcMW1hgN+fn5oaGiA1WrFtWvX4OvrC0AYIdTW1krH1dbWjqj2cTqdWL9+PZYsWYLs7GwAo7ct\nRLy9vTF16lR89tlnaG1tBc/zYFlW8bxiWwQGBsLlcqG9vR1ms/kmVx4efPrpp/jggw9w6NAh2Gw2\ndHR0YNu2bWhraxt1bQEIHgQA+Pr6Ijs7GydPnhzUd2RYTUkNRJtqJNJ7JJCVlYW//OUvAIB9+/ZJ\nbTB37ly8+65Q6rOiogImk0lyRUcCJSUliI2NxcMPPyxtG41t0dTUJGW6dHd3o6ysDLGxsUhPT8d7\n7wmy4PK2yMrKGrF6bRs3bsTBgwdRWlqKHTt2ID09Ha+88sqobIuuri50dAjV/To7O3HkyBHEx8cP\n6jsy7KRB+tKmGsls2rQJ5eXlaGlpgdVqxbp165CdnY0nn3wSV69eRUhICF599VUpMP7CCy/g8OHD\n0Ov1eOmll5CYOHzlwOUcP34cDz30EOLj48EwQnGh4uJiTJo0CRs2bBhVbXHu3Dls3rwZPM+D53ks\nWLAAjz32GC5fvoyNGzeitbUVCQkJ2L59O9Rq9ajRazt69Ch+/etf48033xyVbXH58mU88cQTYBgG\nLpcLeXl5WLNmDVpaWgbtHRl2BoNCoVAod4dhNSVFoVAolLsHNRgUCoVCGRDUYFAoFAplQFCDQaFQ\nKJQBQQ0GhUKhUAYENRgUCoVCGRDUYFCGNcuWLUNBQQEWLlyIxMREFBQUoKCgACUlJbd8rdWrVw9I\n7vq5555DRUXF7dzuLVFZWYm///3vQ/49FMpAoeswKCOCK1euoLCw8Ibqo6JUxHBh7969KCsrw44d\nO+72rVAoAIaZlhSFciuUlZVh+/btSE5ORmVlJdauXYumpibs3r1bKqizefNmpKWlAQBmz56NXbt2\nISoqCitWrEBKSgpOnDiB+vp6LFq0CBs2bAAArFixAo8//jgyMjLw9NNPw9vbG+fPn0ddXR1SU1Px\n0ksvARC0eZ555hk0NzcjPDwcLpcLWVlZWL58ueI+GxoasGnTJjQ3NwMAMjIysHr1arzxxhvo7OxE\nQUEB0tPTsXnzZpw4cQI7duxAV1cXAGD9+vWYNWsWqqursWLFCixatAjHjx+H3W7Hli1bkJqa+o20\nNWWUcCfFOiiUe4Wamhoybdo0xbaPPvqIjB8/npw6dUraJi8uU1VVRTIzM6XPs2bNIhcuXCCEEPLA\nAw+QTZs2EUIIaW1tJWlpaaSmpkbad/jwYUIIIU899RR56KGHiMPhIDabjcybN4+Ul5cTQgh57LHH\nyC9/+UtCCCGXL18mKSkpZM+ePR73/tZbb5Hnn39e+tza2koIIeSPf/wj2bhxo+Le8/PzSWNjIyGE\nkNraWjJr1izS3t5OLl26RMaOHUv2798vPXtmZiZxOp0Db0QK5SZQD4MyoomOjsaECROkzxcvXsRr\nr72G+vp6cByH+vp6tLS0wGKxeJw7f/58AIDRaERUVBSqq6sRGhrqcdz9998PlUp4lcaPH4/q6mqk\npaWhvLwcL774IgAgLCxM8mR6k5ycjN/97nd45ZVXMHXqVGRkZPR53PHjx1FTU4NVq1ZJgpQcx+Hy\n5cvw8vKCXq/HggULAADTp08Hx3G4ePEiYmJiBtpcFMoNoQaDMqIxGAyKz8XFxdiyZQtmz54Nnucx\nadIk2Gy2Ps/VarXS3yzLwuVy3dJxA62zMHnyZOzbtw8fffQR/vznP+Ott97Cb3/7W4/jCCFITEzE\nrl27PPZVV1d7bON5fkTVeqDcfYZPBJBCuQlkAPkb7e3tkjrpnj17+jUCg0FaWpokK33lyhUcPXq0\nz+Nqamrg7e2NBQsWYPPmzTh9+jQAodaFKGMOAKmpqaiqqsKxY8ekbSdPnpT+7urqwoEDBwAIJUoB\nIDIycnAfijKqoR4GZcQwkNF0SUkJ1qxZg+DgYKSnp8NoNPZ5fu9r9bfvRsf94Ac/wLPPPov9+/cj\nOjoaqampiu8TKSsrwzvvvAOO40AIwdatWwEAM2fOxNtvv438/HxMmzYNmzdvxhtvvIHt27ejra0N\nDocD4eHhePPNNwEAVqsVX375JYqKimC327Fjxw5wHHfTNqFQBgpNq6VQhgibzQa1Wg2WZVFXV4ei\noiLs3r0b4eHhg/5dYpbUkSNHBv3aFIoI9TAolCHiwoULeO6550AIAc/zKC4uHhJjQaF8U1APg0Kh\nUCgDgga9KRQKhTIgqMGgUCgUyoCgBoNCoVAoA4IaDAqFQqEMCGowKBQKhTIgqMGgUCgUyoD4f001\n1ZxdsABYAAAAAElFTkSuQmCC\n", + "text/plain": [ + "\u003cmatplotlib.figure.Figure at 0x7f96f1241810\u003e" + ] + }, + "metadata": { + "tags": [] + }, + "output_type": "display_data" + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "test_accuracy tf.Tensor(0.99, shape=(), dtype=float32)\n" + ] + }, + { + "data": { + "image/png": "iVBORw0KGgoAAAANSUhEUgAAAYwAAAEcCAYAAADUX4MJAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAAIABJREFUeJzsnXdgFGXex79TtiabZJNsGoGEBEihhRJAQBQQQaqABQue\n4h3HqYeK7ThFz0NRz8N2nHIoqKe+dyIKJ4KA0gQpofcaSO/JJluSrTPvH7PTtiSBJIIwn792Z6c8\n88zs83t+9SFYlmWhoKCgoKDQAuSVboCCgoKCwq8DRWAoKCgoKLQKRWAoKCgoKLQKRWAoKCgoKLQK\nRWAoKCgoKLQKRWAoKCgoKLQKRWAoKCgoKLQKRWAoXHfs378ft91225VuxjVPv379UFJScqWbodCO\nKAJDQWDUqFHo3bs36uvrZdunTJmCzMxMlJWVAQD+9Kc/ITMzE8eOHRP2KSoqQmZmpvB95syZWLVq\nlfB96dKlGD16NPr374+bb74Z8+bNAwBMnDgR/fv3R//+/ZGdnY0+ffqgX79+6N+/P5YtWxbQxiVL\nluDZZ59t030OHDgQ33///SUd869//Qtvv/028vLycNNNN7Xp+jz+fXStcejQISQnJ1/pZii0I/SV\nboDC1UVycjLWrVuH++67DwBw9uxZOJ1OEAQh7EMQBKKiovDOO+9g+fLlsu3BWL16NdauXYtPP/0U\nycnJqK2txZYtWwAA3333nbDfzJkzcfvtt2P69OltugeWZUO25XLZvn07nn76abjd7nY/99WK1+sF\nRVFXuhkKVxGKhqEgY8qUKVi9erXwffXq1Zg6dWrAflOnTsWZM2ewf//+Fs95/PhxDB8+XJhtxsTE\n4M477wy6b3OVanbs2IGlS5di/fr16NevH26//XYAnKB5++23cc899yAnJwclJSX45ptvMH78ePTv\n3x9jxozBl19+KZzHX0sYNWoUVqxYgcmTJyM3Nxfz5s2Dy+USfrdYLCgsLER2djZmz56NqqoqQQuq\nrq4Gy7JYtmwZxowZgyFDhuDJJ5+ExWIBALhcLjzzzDMYPHgwcnNzceedd6Kurg5vv/02Dhw4gIUL\nF6J///545ZVXgt7z448/juHDhyM3NxczZ87E+fPnhd+cTidef/11jBo1Crm5ubjvvvuEdu/fvx8z\nZsxAbm4uRo4ciTVr1gh9JdVqVq9ejXvvvVf4npmZiS+++AJjx47F2LFjAQCvvvoqbr75ZgwYMADT\np0+XPXOGYbB06VKMGTNG+L2yslI4V3FxsdAPb7zxBkaOHInhw4fjL3/5i9BWs9mMOXPmIDc3F4MH\nD8b9998f8h1QuLIoAkNBRt++fWG323HhwgUwDIMNGzZg8uTJAQO5VqvFnDlz8NZbb7XqnGvWrMHy\n5ctx/PhxMAxzWW278cYbMWfOHIwfPx6HDh0SBkEAWLt2LV555RUcPHgQiYmJiImJwbJly3Dw4EG8\n9tpreO2113Dq1Clhf38tYcOGDVixYgU2b96M06dPy4Tmzp07MWTIEGi1Wnz44YeIi4vDoUOHcPDg\nQZhMJnz66afYsmULvvjiC+zYsQMRERF4+eWXAXADss1mw44dO5CXl4eXX34ZGo0GTz75JAYMGIAF\nCxbg4MGDeOGFF4Le80033YQffvgBu3btQnZ2Np5++mnht9dffx0nT57El19+iby8PDzzzDMgCALl\n5eWYPXs2HnjgAezZswdr1qyRmQv98e+LLVu2YNWqVVi/fj0AoE+fPvj222+xb98+TJo0CU888YQw\n2K9YsQLr16/HRx99hAMHDmDRokXQarUB533zzTdRWFiIb7/9Fps2bUJlZSX++c9/AgA+/vhjJCQk\nYO/evdi1axeefPLJkG1VuLIoAkMhgClTpmDNmjX4+eefkZaWhri4uKD73XXXXSgvL8eOHTuaPd/k\nyZOxYMEC/Pzzz5g5cyaGDh0a1D/RFqZOnYr09HSQJAmapnHTTTcJGs3AgQMxbNiwZrWhBx54ALGx\nsYiIiMDIkSNlwmXbtm3N+i1WrlyJJ554AnFxcVCpVHj00UexceNGMAwDmqZRX1+PixcvgiAIZGdn\nIywsrNX3NW3aNOh0OuG8p0+fhs1mA8uy+Oabb/DCCy/AZDKBIAjk5ORApVJh7dq1GDZsGMaPHw+K\nohAZGdmswPDn97//PQwGA9RqNQBg0qRJiIiIAEmSePDBB+FyuXDx4kUAwKpVq/Dkk08iJSUFAJCR\nkYHIyEgAcm1x1apVmD9/PgwGA/R6PWbPni2YI2maRnV1NUpKSkBRFAYMGNDqtir8sig+DIUAJk+e\njPvvvx8lJSWYMmVKyP3UajUeeeQRvPvuu1i8eHGz55w4cSImTpwIr9eLH3/8EU899RR69uyJYcOG\ntUubExISZN+3b9+O999/HwUFBWAYBg6HAxkZGSGPj4mJET7rdDpUV1cD4Aa9Xbt2Yf78+SGPLSsr\nw2OPPQaSJIVjaJpGTU0NpkyZgoqKCsybNw9WqxWTJk3CvHnzWuUbYBgGb731FjZu3Aiz2QyCIEAQ\nBMxmM1wuF1wuFzp37hxwXHl5edDtrcW/L1esWIFVq1YJfWK322E2mwEAFRUVLV6rrq4OTU1NMt8U\nwzCCQHn44YexZMkSzJo1CwRB4M4778Ts2bMvu/0KHYeiYSgEkJSUhE6dOuGnn37Crbfe2uy+06ZN\ng9VqxQ8//NCqc1MUhbFjxyIjIwPnzp1rj+YCkJs/XC4XHn/8cfz2t7/F7t27sW/fPowYMaJZ/0go\njh07huTkZBiNxoDr8CQmJuLDDz9EXl4e8vLysG/fPhw+fBhxcXGgaRqPPvoo1q1bh//+97/Ytm2b\nYEpryXm+du1abN26FZ9++in279+PLVu2CPdgNBqh0WhQVFQUtD3BtgOAXq+Hw+EQvvNCQIq0Xfv3\n78dHH32E9957D/v27cO+ffsQHh4utCMhISHktXiMRiN0Oh2+++47oY/279+PAwcOAADCwsLw3HPP\n4ccff8TSpUvxySefYM+ePc2eU+HKoAgMhaAsWrQIn376qWCPDgVFUXjsscfw4Ycfhtxn9erV2L59\nO+x2O1iWxfbt25Gfn48+ffpccrtiY2NRWlra7ODvdrvhdrthNBpBkiS2b9+On3/++ZKvBXDmqBEj\nRgjfY2JiUF9fD5vNJmy7++678dZbbwlhx3V1ddi8eTMAYO/evTh79iwYhoFerwdN04J2ERsbKziF\ng2G326FWqxEREYHGxkYsXrxYGMwJgsC0adPw+uuvo6qqCgzD4PDhw3C73Zg0aRJ2796NDRs2wOv1\nor6+HqdPnwbAOaI3bdoEh8OBwsJCfP31183ev91uB03TiIqKgsvlwpIlS2C324Xf77zzTrz77rso\nLCwEAJw5cwYNDQ2yc/Baw6JFi1BXVwcAqKysxM6dO4U+5oWOXq8HRVFKdNZVSocKjD//+c8YOnQo\nJk2aFHKfV155BbfeeiumTJkisxsr/PJIZ5adO3dGz549g/7mz8SJExEXFxcQessTHh6OpUuXCtE8\nixcvxl/+8hf0798/5PVDMW7cOLAsi8GDB2PatGlBjwsLC8Pzzz+Pxx9/HIMGDcL69esxevTokOds\n7rrbt2+X+S/S0tIwYcIEjB49GoMGDUJ1dTV+85vfYPTo0Zg1axYGDBiAGTNm4OjRowCAmpoazJ07\nFwMGDMDEiRMxePBgTJ48GQDnN9mwYQMGDx6MV199NeDat99+OxITEzFixAhMnDgR/fr1k/3+3HPP\noUePHrjjjjswePBgLF68GCzLIjExEcuWLcOKFSswaNAgTJ06VRAYDz74IFQqFYYNG4b58+cH/Df9\n++LGG2/EjTfeiLFjx2L06NHQ6XQyk9VDDz2E2267Tbj3F154QdBgpOd6+umnkZKSgrvuugsDBw7E\nrFmzUFBQAAAoKCjAgw8+iH79+uGee+7Bfffdh9zc3JDPROHKQXTkinv79+9HWFgYnn32Waxduzbg\n9+3bt+OLL77AsmXLcOTIEbz66qtYuXJlRzVHQeGSqK2txe23396iU19B4XqhQzWMgQMHIiIiIuTv\nmzdvFmLp+/btC6vVipqamo5skoJCq7Farc06uxUUrjeuaJRUVVWVTL2Nj49HZWUlYmNjr2CrFBQ4\nUlNTkZqaeqWboaBw1XBFnd7BrGHXS9kFBQUFhV8bV1TDiI+PR0VFhfC9oqIiZJKYlI6oFdSefHpo\nFdad3QwtrcG/p79zWee468s/CJ+jdVFYOvm19mpeh1FurcLj618CAKy8+wMAwHu7V2Bn0T7EhcVg\nycTg5S8W/7wMe0sOAQA+mvI3RGgNwm9bLvyMpfs+DzjmnxNfgSksJmD71cxft76D41Vn0D2mK169\nhSugWGGtwlxfn/nzybS3oFfphO8sy+LulY8I33vG9cBLI6/erOjT1efx4hZ5fg7/Xizc9g6OVZ5B\nt+hULBrzHABgT/FBvLXrQ2hoDT6+/e+4d9UfAQDzhv4OQzrLAyQ2nNuGFQe/RDAitRH4cMob7X07\nbeJ8bQH+/CPXpi/vel82fj2z8VUU1otVfVfe/YHw/3/hprnok5CFnYX78N6eFQCA/9y5BBQpRpF9\neWwtvj65Puh1aZLGx1MXQ0Or2+U+OlxgNOdTHz16NL744guMHz8ehw8fRkRERKvMUQRBoLra2p7N\nbFdcDi8AwMN4L6udDU6L7HtaRGrI85hMhqumL87WivH4fJtcLq4v3J7gffG//O8FYQEAP58/jAh1\nOPIqDuGejGm4UFUa9FrPblyEV4Y+DzWlEra1R194GS/+e+YbDIjPQWZ090s+nmVZfHZqJeocZmhp\nLYYkDEBOXG8AgMvtey/cDKqrrWhwWvDS7tAD2+5zR0CRFI5UH8eMjGmosFfJfj9RdRZPr38FRk0U\nHup5L1Tt3Bdt5Xx5YGlzvk1a6Ll96grww8ndyDH1wt4CLrLM6XHi6e/FqLG3dn2Il4Y8ixJbGc6Y\nz+PuHrejrC60r7PBYUFpRS3UlBpWlw3fFHyLMUmjkBSeEPKYULi8bnx+aiVGdxmBlIjLS4Yss1Xg\nrYMfCN/nb3wD47uOQVZ0DwCAjhAnBUZNlOy5LdnzKSLVEahsFJ/9/gsnUeeoR4GlCNO7TUJhbVnI\na3sYD/acP4rsmAysPLsGjw6beVn3wNOhJqmnnnoKM2bMwMWLF3HzzTfj66+/xn//+1+hEBxfvmHM\nmDF48cUX8dJLwWdavzYogutWL+O9rONP18kT2rSUps1t+iWoaaoN2Eb6XjEWgRMHs6Memwq3Bpzj\n3UPLsLt8H87W56O2iYvbD6P1sv3s7kYUWppPGLscTtSexq7yffjH4dB5Jc3R4LJgb8UBnKu/gGM1\nJ/Hh8c9C7ru1eCfcjDvk7yW2Mrx/ZAV+LstDsbUUp+vOBuxTZC3FkZoTOGM+H+QMV5bqIO8Dj0Ed\nLnz+8Ni/Acjf+zJ7hWz/U3Vnsfz459hZugd1DjOsruDCMCEsHgBQ43tvVp9fh7ySw/jPmW8u6x4O\nVh3Bgaoj+Nv+f1zW8QDwwdGP0eRpEr5faCjEksMfCd/rnGbhc7TWCDfjEb43uhtRaC2Gw+sUtlXa\nq/Hxif/D1uKdsLhsqG2qAwECNCmf/9/ShQsHr2qsgcPjxPaSXZd9DzwdKjAWL16MnTt34vjx49i2\nbRumT5+OGTNm4O677xb2efHFF/HDDz/g22+/lcX9/5ohfeoiCxb1Ti6JqcRaJggQs6MeDU75C+/y\nulBm4/4kp83cH+d3vbjZgJdl4GE8KLaGnklcaRiWwa7yfQHbSV54sty9syyLQksxGJbB2gsbA/b3\nSIRsibUMlY3VoEkaTw98LGDfat+g0J6YnQ0t79QMlhADGQCwLF90kROeUnOTFL7PaiT3d67+Ak76\nBMYfc34XcMy6i5uEgabOYYa5qW33cbkwLIMiSwk8jAe7g7wP/D35TyCqG2tR66hDplGu1fGDoFSA\n1DTVweLiEief6Pd7YfsNibkYkjDAtw8nrEps/H+mddkDdRYHzFZxcFZToinnWM1JVNirUGGvwvGa\nUzhWcxIuryvYaQBwE8Yia0nISUFtkxkMy6CuyYyUiM5Qkyq4GTfOmy8AAAbG5+Dtm1+FilTJjiuQ\nTJRqHbWobqpFrC4a83OfELaPSx2N7lFpALixxeqyoT1Qakl1ABQh2hef//lVPNL3Ybx/ZDluSMzF\n/Vl34oVdiwAA/xz1N2G/5ce/wPHaU3h24B9xvv4iwlVh6GzoBIAbbL8v2IwNBZvx/KB5l6VadzTH\na06h2MqZj6QaEW+q5U2TJ2pP44OjHyNKEykIUym8YAGANfmcXTZBHyczPWkpDRxeJ2qbmcFeLv7m\nwEuluT9mo2+Wyc8WvSGq9kZrolDrMMs0ttXn1wHgZtAmnei7yTB2wxnzeRRZS/Fz6V7c3HkY3j20\nDGEaHZ7tP7dN93IplFTb8PW2fPTKteObC2sQ7e6GelXg831p9+v4x8jX4fKKg2iMNhr5DVwxwz6m\nnrjQUACXb5A1aiJR3VSLY9UnhP2rm2phddlAExQiNWLYvppSIUYXDQAotVRj87bDqDJxpiuPn7Zf\nU98EmiYRFS7X3p9+n5uFr/jTKADA7hOioFp69JOA+xmfegsmpAUvn/Ppyf/iQNWRoL8BwIu7X8Or\nw56Hh/UiRmtEbVMdah11WHKE0z6KS904qKqGs5EGqRX7a2fZXuFzibUcNrcdnQ2doKXFe1GTavyY\nVw5oASfjgtXdPuZJpTRIB0CT8rIGxVbOlhtsxsVzvJbLcr/QUAizox6JYfGCY4thGRyrOQkAqG66\nOvNUpIObRjIrc/pmYIxvdl3la38wYQFwNld/0iJTZbMs3uzQnMnjcuEFRqSac7x7GQb/XH0Mu49X\nNHeYgKUZgcELE6uLqzZ74Dw3+52UNhYP97offWI5DZsiKURro4Ka+LKM3WW+Cj2tw9RuEwBwfepl\nvKhpqkVhfQnqHOaA49uTH/cX46utnCns3a+O4Eh+LfZc4LSgGoZ7529LvSXgOLu7USYwaJIW3odY\nXQxujRDXw6B8GkaDRHOrbaqD1WVFuDoc63aJfhI1qUa4iqsEfKqkCscuVgmze/++fHbpbsxbIi8X\n4/aIAtza6EJxlQ2H85t/7rVN9SF/a05Y8Jgd3H2HqcKgIlWwuxuF30rKXVjyzTGA4cYBLREecPze\n4uMAuH7TkKLAyC9qxLHz3LmdXmez7+WloGgYbeRg1VEcrjqG32TPEAZ4f0e/nhZNDwv3/F34vDZ/\nA1SUGuNSRwnbVp37FgD3AvCaitnRgFJbOYDmB6S28lPJLhRbS3FfVvDFjZpD2q4GlxX/Pvkl7s+6\nEw4PN5vmBYaOEmtTqSk1Mo3dcbRGnD1KNQyeblFdZfbZWF00SqylMpPNt/kbcOrAGUxOvQ1ZMT0u\nuf08dc564R7mb34LpohwHL+QjANnqtE9ORKxUeKzLKm24b+bz+GeW3qgUyw3UAWzrf/f6VWYkTEN\nNjdXg8nubsT8D3fDbKgHHQ/0NfVCYlg8DldxS94SBIlYXUxQv0QPYzpUkr6w2LzYcsgFJHOai9Ut\nPofTdecwNGlQ0Ps8U2TGpn3F+O3EbOg0wYeB7y5sxL7yY4jWRYAFgyaPAwzLQEfr0MXQCet/5Aaw\niUNTUW/jJgaNbANAAKSGKw+SY+qF7wt+lJ3X4rLCzXD7EwyNysYqwTz57bZSnDsHqLOiQBnqg/rv\nCswVsLhsiNfHYceuKuh81dBVlApNjZxK64EThEo0LTV6mvDmyjzcOSIT8UbRH3ax3IIIvRoxkVqY\nbU7Qnc4BXhrnSnrjbHE9QDbvh9xbuR+RWgOmpN+GAksRNhRsxm+y72l1octKO1f8sbLGBcbrN3+n\n5JOnRisF0k9mXLRdAEFx/4ldR8VCkkXlTQDDTdzqbHYcbWgfc7aiYbSRTYVbcaDqCCokUQz+g56W\nFgdJ6X4bCrdg7YUNcHsDbZycwOAeD6+uA8EHpPbiy7NrsKt8nzC4Xwr87FnnE457Kw6g2FoKh5cb\nOPg+kTr0RiYPl5magOAaRh9TT9ASM5+aVCMxLB6ltjLBhry1ZCeKGkqxvfTyigzy1DvEGaOFqEC+\n9TzUXblZ3PnSBtTbnCiv5Qb+XccqcLLAjAUf7QXjGyD4fsiNF8NAfy7LQ4W9SuhXFiyqnZXCgPDN\n1iJsPViCKenj0cXQCQ9l34P+cYGFGRl7BGpKw1FRLXGA1rpQWcP1gcPjkJnE/IMnpCz+8jAOnavB\njqPlQX93ed34vmAzapxVOFt/HufqL6DEVoYyewXyGy5ia8lOYd+iSiu8DHf/UgcuADQ1EtDV9ZJt\nyztbJGgYXpf8+Z8r4N4X98VeiNMmYKZk8kKAAOuhcc56Gm7GDT0ihdk3AOw8VIn3vuQ09WqrBYRK\n7l84XVGK91cfR53ER7Hw0/145oNd8DIMzBYHVJ3yoepyBkv/dxyb9hWDoFoOXNlUuBV/+7+DePvA\nv3Cs5hS2l+zCgdLgdfFU9Wny+63mBvIT5y0wN8jffY1Fvi/rDRTsfPs276rDFz+Iz7vW7BH2P3i+\nAjtPFrR4H61BERhtwOayo8TniJaqvP720pbIbygI2BatjRKcn1KkA0JNUy12Fe2XRWC0B8EG7Zaw\n+GykRk2kuM1lFTQMN+NBdWOtYCKY3fs3mJw+DoTfK9jolt/LY31/Cx2tlcWdqygaGdHd4WG9OF/P\nCVM+qv2c+cJlR6fxbfaHiqoBaBfqbS7MW/Iznv9wLxiGhcPF9xOLjScOg2VZ4fgp6eOQFpkqnKPc\nXik/Z0QNCJ/AOHDSjM82nQXp0YM8PwKEMxLDOw1BnF4eYu48MRSfb8jHwk8PCNusNq8wMDS6HbL2\nHyo/jcIKuU/m+MVavL3yCDxeboCvqGvEiYI6vPb5ASz6/AAaHW7YHW68vqZ15epBMDhUykdvMSDU\n8uf3zdZiNBWnwmsxCtvWHzgnmCrh8csP8H1nHeGYYnoAbnsYWA93f16nFt4GsU+OHyUBVsxnqKl3\ng/VwAsjqsoOK5sxJjJObxNCmUphtTahsaAARJjeJ/ufHc9h58ajYDC8n3DUarp+cpwI1NakScbqo\nHh7fu731cAE+3x184mI52w2sS9SaTpRx1YpZLw2WEf8LjsMjMH2oXNDCK/4HXOf7wms2Cd+rKuX/\nI9ZLi8KU9Mq0rbagCIw2cMZ8Toj2kJpH/DWMlgawiw2FAdvi9LEy5zn/WWr6ef/Ix3hn93JsKNhy\n6Y1vBvdlCAyrywY1qUKYSlT36xz1cHjEtRe+OP2VIDDUPp8EyZfr9g35/iY3qSOPhyZpZBi7AeCE\nLcuywozV4XWi1B581hwMl9uLd746ggNnquD2umXhi1JUyeewcqtoIqq3OYWZKt35DL6r+g92leeh\nys6FOIarw2W+nHJflE+vmCzuvg31osnB98d+e+VhnCo04/3VnGmqpyEnRKvFQdLjJgCfwLA4GoX+\nI1gKDOXEe9+JA1d5rR1vfXkExy6Ik5tth0qx+L+Hca6kAedLGlBQYcWWAyUoaQxddl2EharLKexo\n+hpUdDkItQMEKY6iLEPgTIEVTU4PwrSiJkGonGh0OcEyZOCsmSXRN51z6m8+UIxV2/KF+2UdeoS7\nk4RdGUuMrC/AUABDgWUIUFE1oBO4/xVjjQIA0PFFIDudwr/2rYIme7dMuG07fwQHveuE7zf04drg\nZrn3ShPENEawcl8ly3LDqdnuAGkI5T8i4a0XB/oGt28/6QAPYGhGV4zom4S//eEGDO7MCY5ErZgH\nwro1gEU8D+uUR9yxXhpd431CmvSgU6f2GeoVH0YbkKr8cg1DPuC2NAC7/MLuJqeNQ2pEF5lpKEoT\nGRB/bvY5NWsvMby0zuJAk9OD+Gg9ln17AgMz4zAoK17S3tC5AaGwumwwqA0yX0NNUy0cXid0tA5N\nniY0eRxCX/D78WY3kiDhZb0B0RxScx6PiqCFaJgGpwVuxi0L07S57LL9nS4viqqs6J4cFXCus8X1\nOJpfi6P5tfjDnWkBv/P4z9BqLQ7UWZzQqCgQJs7xes58AYXWYrD2CLhdrExgFPpsyEZtFDcrptyI\nCKdg81LgB72Saq7dZqsTRZVWrF9LgYwcANajBtwhMnUZCnFGPSxeCnZXk/B+UA4jPLoaWJkGeBkG\nBEHgpRV5Ie+Px9bkxs5j5SBi7MF3YAmA8PU1yYCK5e6LNJi5dkrQUlo4fPemogkIUwfahXp7I8BQ\niNLr4K/TZaYYcSS/FicKuPdbN4h7HxmrEXfn3gzSmAG3U4UP8+SJjNyASwBeFUCK5ijGFgXEcpMI\nOqEIrEsDggBuH52AtIiu6GQKw6INX0F6x+kpWuw+CpiiVagD0D0pBv4GPoIQ37pbB3XCT17f5Idk\nQGgb4Q9xhsuLcBdmgfWooEq6CELLXVWn0iI+NhJl7lqwXhI39U0GSRCIjdRhZu8pGGTuiazoHnhs\nK6ddPjV9ENSMAbVkHzRaaHgjo/HFD2KeTlJUBIb2TMLXZgIE7YGZKQ/QWC8HRcNoA6fN56H1OXGr\nmzFJ8Xb8UHhZr0ybGBDPzSwJyexJRakQrgpDfkOBEDHFz3qks/L8sgb87f8Owtoot9+6PQxOFNSB\nZVk8/+FeLFieh1XHf8AR51Ys/d8J2b5v7l+CmqZabC3eiY+OfSY48BiWxbJvT2DHEbkDbfme71Hv\nbADrVqOkUvyjbCneAZvbjnh9LGhGhxJbGTYUcAsL8b4LXnDwUVBVjfIoMA2pxrELtWh0SKNqVIjw\nJX5ZXVaYG+V/Tj589Wh+LQ6fr8Fnm87gtc8P4uDZwNXl+EEapAcf5zeTrOfngDxX0oCSahv0nYtA\n0Nxv52vKQBAsvA0xOFVYL3umpyqLxPtmKNAqBjodEKbWYdygLrJzO1xefLnlPAACTIMJrD0SrEuH\nOGNg3gbLUOjVNRrw0mh0O1Bj40wtTWYuyotVNaKm3oFNecWCGQqkB+qMfSCjKqHJ3g1N9m6A4vq3\nuMoGc/hR0DEVINjA4UHmyyUYkL5XlI4vgiFFrpWEq8W1yylKslaK2gm7ywmCodApNjDyJ6NLoGAH\nOIGRlhiNiARjAAAgAElEQVSJgQn9kJucHbQv/jxzAGjItQHGHin7Tqg54b+h9kswhgosPbUU9uij\nsn2i4zxIufEw6lScmJh2Y2AghXSScnP/RMBnUgozNoEgGTBN4v3H601gHb57ZSl4azlNiX93/jAp\nB0nRvhBhhkZEuCh8KZJCdkyGrJxISkws0pOMGJTQHzf36INeadGytv12Qm9kpxpBsiqQYRa4GBcy\njZcfDMKjaBiXSaO7CXUOM7JjMpBffxE2yaDtZeWDC2/HDwXDMKBICl4vJ2j4wZAgCFAEBS/rBU1Q\n6GFMx4GqIzhafQK9Y7MFDUQ6K3/3q6OwNbmxYW8RGJZFo8ODh8ZnYdW2fPywvxgP3pYJp69ExY7a\nzaDjAHexfK3remcDPjr2GYp9SU9uxg01pUZdgwN7TlZiz8lK3NiXe+Evlluwr/IQKANQcSEKlMEM\nSv7uIpyKhMtVC1KiLPCCYnzXMSi3V2JK+m34+4F/BvRNQVkTlnzFLf6j85mRfz5aCcvFElAEBYvL\nhq+2nwb04P6wJINGdxOKq2x45yt5WOPhczXo38Mk21ZYyfUdGVkDgg6tWRF+AoMzlbBwxB4TttU5\n6kCouBntP1cfQ+oQ8bmwak4wqUgVWC8FimLg8Dpg0IRhZGYnbMiTZ62fKgw0afxhSi98vP4Uiqok\nZjuGwg09E7DnqApNHgd2nSkEogDGZgRwEaS2EQs/3Y9GJ9f+4X0ScaTuEDyRtaAixUkOGV4PpsGE\nw/kVUKVyiWNhap0Q2QUAzrP9oe4mlnEB6QVJEuCnRy6dPAQ1QiMOmCBYIXeOCrMAlBfGsHDQtDgI\nTus6Fd179hKimAgAzz8wEIdrSWw8fRCM1YiYSO4loqlAYXZzn87o1ikSUfnhqPVYfecgsHTuVHx9\nmsDO0j0BCYPBcisA4GTtaVQ5xfsxGcICdyLEc4XrKcGf4lJx/co0GkDquP5TU2poVBSanL4EVpdc\nc9artMLEjPXSiAoLrlHOyJiGgoYiIbhEaF+UDkOy40HrR8GlL0fn6BiQBIkovR5mJzd5TDYkBj3n\npaBoGJdJjYN7KUy6GE71lti+Q2kYj/R9OOi5vCwjMz9Js0t5kw1FUrgnk1thjtco3D7BJHWEe3U1\nAOVG3qlKbMwrxo6j5SivteOH/dzs78CZIGs4awKd5sU2UYvgHZR86CShbsLn+3/A01+sxMJ/54HU\nNIFx6OCtTBUcd6zEQWfwJskcdgDw2ffn8b+dF2FQh+OJ/nNkdXqkM7MlXwVGm1TWObExrxiMS40G\npxVHL3CmCcb3JzxfWY2SahtIQ60wcwaAXQUn8PK/d+F/h/bjpf9swtnqYpwvqYdeQ6Nr99AZuwBA\n6KwgdFb86T4x+onQy40phIq7Vve4JBAEUFYbGAJ9rsgGlqHgVdlgc9uhpTUwRekw766+sv3UKhK3\n5op9Mu+uvkhJMODpe/phwW8GijsyFExROhjDwgDKAw/BvWs9Yrr62miBQ10F0liJxFQr7hndHdOH\nB840CQ2npZU7xbwGqbAYn3oL0BAvP4bywItAcyuvGetVOrzwwEB0T46EXis+f0JnA6FyIUytFfx9\nKRGdMbrrDegSb4BGTeGlB3Px1mPDkJYUgYmZN8KdnwMVTTdbdHRoTy7RNT5STOZ7ov8cJMVGYEbG\nVDwuyQpviQq7/H+iJpsv3udm3IAvYoklfNFwjWIRTQ2lxh+n90Fmlyj8/ZGhePauQbJwey2lgdM3\nhoSrtVCrgi9Re2OnIZiZfVdAP5AEgdmTe2LWkHGY0+chIWBGahb1FzKXgyIwLhPeyR2ri4GW1sq0\nCH8fRpPP8SsNDZXiZtwhI5NI3zE0QUNLaUGTtCAgeGd6k8cBt9eNqsZqoNtuaHruQq1FbM/zH4qZ\noaU1gYMYoWls1jH//PJdyDtViTordx+qlJPYbfkBTYn7QcWWglA7wTp9zm7ejMGSoF2cKWDrT06w\njPzezxZZsX6P6OyXRoSxMnt9kAHCJ5S8Tq64HENyAzU/ayuqqcOpmnPQZO2DOp3TMgi9BZqsPFQl\nr8Em80rUxP+Id4/9A7UWJ/p2i4FHVxV4HR80qwFBstD2/hlpSRHolRaNznHhmDou0HRCgMC8qUPx\ntzlDkRyvD/j91MUGwUkNQEg0M0nMTS88MBB/fXgwpgzvKmwz6Lk+Cdep0DVRHBBZhoRBr4LJYABB\nMoiOYaGjtHjzkVugp/WgDPXQZOVB0/0Q6uN+RoOnFlpt4N9+UA6n1VKRokmwn6m35MYIvP77IaBI\n8XmQ+sCIMpqkkeoT/lGaSKQlRWD+/QNkznAeNaUS3nv//0ZKggGRvixstYrCX2cNwt/m3CDbZ/bk\nbAzKEqtb82ZNad0xaR5H18guCKP1AXXJgiEt9gdAFqUXDIfXGRCCKzWFqSk1uiZG4Nl7+yM6QovM\nFCNidaIqrqXFSWdStNyE1hakk8/2qEmnCIzLhHdyx2qjoaU1Mj8FP2uK13PmD16YSF+6EZ1uwH2Z\ndwCAEBabFJaAv94gX+GNn0jQJAWCIGBQhcPisoJhGVk01v78Ylh9zl5S24RQtXPqfILEaBBfHlLT\nhLe/OhR0fwCwO51Y+r8TKKvhzk/oxJknGc7lLagZ32zKN5jr1DSeGfQHOI4PBevSyQZJAABLwu1h\nsOVgCfJLG3D8oiQT1z/U0h+GxLBeCWDdajDwAj6HNC8wqiwWnK7jIpqoKG4AJOhQGgSLzO5aVDXV\nIDs6A0/0myMrvQEAsWGSPzDBYN5dOXh51iCwFPfMe0WJORNRmkioSBoxkVoYwoJYfBlKJjzvzZwO\nAIiJ4NquVpFIS4pAXJQOOg0tPCfp8/I/H0EQQnCAxWOGQcMN/iZ9YPn3Wkd9UBOph+ImEmRELQiW\nwpP9/4D7/RI4Y6N0MvlNRnGz8Elp44RtYbQeD/e6Hw/1vBeT08XtwXJ7VKRKeIcpsnnreHJcuCBA\neIZkJ2DOFDH0lNdspIUNpUETNEnjqQGPYG6/2SGvw9+LVLtqDXyFgM7hSfhN9gzM7vUg+sSLpt5g\nUVaxkvdMS2vh9D0XLRUY6HG5SDWMYAEkl4oiMC4TqYaho7RwMx5htsSbpLr5in/xAkHqBM2K7iGU\nz270aSBJ4QmI0Ynx6oCYNU6RFEqrbdCSeljdNhw6L58B/XvzMdQ1ijM+QheoScy81WeKIBhQ3UWt\nQ9XlDC7EfBX6Zn3Zrkfya+Efa0+buPpREwdk4ZHbewl2XRVNITk6Gl189bBovwJqg3pw9tTPN53F\nq58dwFtfiv4Gf23En37d45FkCuNCCwFouh/mjvMJDIZwwUKKobXanK3QxAQvI9I9RY+vyrnaPT1j\nMtHdmCYk4fFInbcurwuFlmK8lvcOCiycmW9wsigwpLNGKkgeDRhKMM+pSBpRvrwVmiLx6u8G4405\nQ2W7L3x4EF56MBcRIWzaN/l8SfzskQULg4oT3v6CDwDeP7IcR6qPB2yvcdQBKgdIvQ3xqmR0i+oK\nLa0Vssr5d1caiBEex/lZhiQOEO4jTKWHURuFgfE5gvYkPV4adq2mVMJ26cDWVuQCQz5Qx4fFoVN4\naFv+gLi+IX9rDkFgGJIxKKE/+sZlY+508VyaICYtqcBQS/4f0j5qKxpFw7g64J3cERoDNL6Xklcp\necGh80l0fjtNUvhjzu/QP64PsmMyBDOMwydQgtlJGZ+mQBM0FizPQ0kZZ756f+0B2X5u1oll6w4L\n3wltI/qkiy/kotlDcHM/bvAmdFbYabmDMpjJQPyNExiFFVYx1r5JvlZ7H1M2BmSYkBjLvex8WfPo\nCK5vKFY+gzRFBnEi+khLMGJk8nCMTBgtbJtwQ4rweVBWHBKM+oAY/pRon3mCdsvMJYTaCZguIhgT\nRkcJs9x+vnUr/GfDpETQO70u/OPwRyixlQlVhWO0opCPUIt263sypiMrugf6SbK2WS8lxNtThLz9\niTFhiPQTDHqtCikJBoRiYAbnV5AODHzQRLTWGPQYvt1SKu1V0Edxs+qsBLGvn+z/B/SOzcJNyUMD\njnEwTYhQGxCliRRm0KHs5A9k340exm6YkTFN2Kajdbg/6y5kRffAjIypIe+xJWb1vBc5pl5CUU6D\n5BkEGyQJgsCtKSODnitSI+/rgfE5mJJ+GwBgbs5spEWmIi0yBX/M+R2eGvCosB+fQBoqdDU2iPDO\nMfVC5/AkDO80BARB4MGe9yI7JkOoDdYe6CTmN52iYVw5mnxCQEdphZeSV/X5AYhXLfnkNYqgkBnd\nHQ/3uh80SYvJeE7O4Rh0VSyJhgFAmFUTanmoLkEygCTKJyNNh8nDuoKMqgQVUwozSsTw2yDhkoHX\nFWeS94xJ40IojRWCOcpIibbjGzvdgISweBAEgbQk7g/HC0OSt3n7JTnRFPc9XKfC/Pv7y+oZdUuM\nxh09JmNaFlcFlCCA6Tely47vEm+QtREApt+UBS2lBaltBEF5oWODD5hSLG4uDHV81zFC5VP/SBq3\npIS10+uUZdbTBCUTEtI/ZYzOiMdyfitoWQA4k5RPw6DIdvj7+bpAWpCQHzCpED4zf/qaeoEFi/65\nnKAMV4uDTEpEZ8zp81DIwUa89+ZLtncKT8Tj/WbLZvcGdThiddF4LOe3goZyOQyIz8Hvej8gvHMR\nEg3Df40IninptwlFLKWoSJXMn3JH98mCcMmI7oanBjyCpwY8iszo7kiLTMFknwmLD3XPjA4euhps\nMa6UiM7406AncI9PiCaExeHRvg/LNKS2EtGMtnU5KALjMmBYFnU2K1QkDYqkBNugU9AwuLwKq110\nSgOBVWzF4oKcH0BH63DgTBVe/mSfkHfAD16sLymIL33gLzCmjOgiC/3M7haGiCgvND0OQZ1+DEsO\nf4Q3+UVgWiioBshfrthoNdSpp6DpfhiaFC45qHuMOAuVvuB8e/k/r94nCFS0/FUb2b8TeqfF4Jl7\n+qF7chT+8lCu8JtKkgX+tzk3YPGjw2THEgAXXukn+LQqDQzqMCHOPkmdgpao8/W9NGLFX8OQJlZW\nNsqjZwxqg6ySribIn1IqUITkMoQOgmgNyeGcKSpGy5nApNopb0LrFtU18MAg9PVVyT1v4TSP5gaW\n3Ph+su/8s/f6+kztZ3r0R9rPsn5pR1o74PJtkZrZCIKAXmIS0rcQWcQLaqvbBj2tQye/pQf4SaNs\n0vALIu2LYH6US6XD8zB++uknLFq0CCzLYvr06Zg9W+5wKisrw5///GfU1dUhKioKb775JuLjAyX/\n1cSP+0tQZbFCreW6T+d7ELxg8LAeUASFH/LKoE4VTVLSGd+u4+X4Pu8ikCqag1irEZuPl6CwworC\nCiuyUqMFH4aHlwW8fd8vL8Bk1GDUoDjsKOOcvRaXFS5G7tw0O+u5UhwSgTGmy83IieuFN/cvke2r\nV+kER76bcYMy+ZKytJypZ2DXFOT5cp2ksxh+sOVLfky7KR3WRjf0XapwSJKQHqFX40lJKKlJUgVW\nWpBQWh2Wh5//d4oxQOrJoQgK6ZFdhSTKPp07o1Nxb/zkDlz1LtPYHafN54QS4M0JDGnme4lNXnbE\noA6Xze51QRyW/KAOcFFNvJ+nJUdvczzZfw6qm+oEE4ha1gbufcyM7o75uU9AS2tAgMCLu18Peq7U\nSC5xsMHF2eGbs3XPyJwGFiz2VnAmUX7QZ4Xn3rwQlPazQdV+M2kprRVEYT5tiCAILLxhvtB2Pa2D\nxWWFhlK3GB0lnSwYg9R/e3HIM/CynhbP01FI+yJYbbpLpUM1DIZhsHDhQixfvhzfffcd1q1bh/z8\nfNk+b7zxBqZOnYpvv/0Wjz76KBYvXhzibFcPRZVWEJQXXrevTr1Pw3j74AdwMx54GS9nw/dFDPE+\nDelL8/X2CyitFjOUWYbEN9+bcbqIm/Gabb6y4L7h8WKZzXcObpDhtQn+pf/3qS+xs2y3cD6ryxa0\nxIe622GAFAdEkiCRGtElYD+pw1ZaD4onQmLrldqMeQHHx4lHhqkx944+0Gha/6q1NEvlX/zBWfLZ\nnNPrlKn+iYY4GLVRQvE6KXwJdEFgSEwp/jMx6aBQ5icwItThsnLjwSJRpNFKM0ZmIj6aO39bNAwt\nrUVng1hXSaphSEMpkw1JiNXFCKVUghGtNcp8D81F06hIWgjmAAI1DLKZPAlA/h/oMA2jlYJI77Pv\n0yQNozZK8F/w70Jr8hakzz7Y/URqDCF9Sb8E7WneAjpYYBw9ehQpKSno1KkTVCoVJkyYgM2bN8v2\nyc/Px5AhQwAAgwcPDvj9aoQiCYASywdLVfgfj52Gm/Fwhcj8on1on5OTYVgu81Zig2cdepmdf2Ne\nMSrqGsH4ykY3WDkBMaA7p311T+FeBOlAJ7W9W11W2SI1PISxXKZhhKobJZ2NVNgDcxSkL2JQDcPv\n1Wrt+gAAoAoRMTM3ZzZyTL3RO5YrC6Gm5YJlYFIf9I7NQnZMBrJjMpAemYKMzlEy53jPmExMShsr\nzKJ5k5Q0MmV27wdk5324l7igD78uSW58P6REdMaQxFxZXwWbnUsHkv7dEpAcz5mMyHacdUo1jFCm\nh9vTxwfdriJpmKQ5AS2YLqSDJP8eiBpG64eU9h7MeCiSwm2po3F/ZvPruuTG90NqRBdM6ipfMY+f\n4Blb4VeRTiY66n7agqGdhXKHmqQqKyuRmCg6ueLj43Hs2DHZPpmZmdi0aRNmzpyJTZs2obGxEQ0N\nDYiMbL/klUuhsrEalfYq9DGJ64t7GS/2Vx5GuDoMMVojKMpXh943EDklTtGvd5xBeGYTAEJWrhgA\nVqw7DQpqJETr4XR5uX1YX66Fnz2+uMqGPy/bA20uCwJiJcy4yDDADnTtpENBCaBX64FG0dbDVUoN\nw4WGQlQ1BWZ1A8DtNyfj+1IuoopfT0JF0rIiidI/fqldHlEFyGdx4ZLPjJ8PQ9h+CQIjlIaREd0N\nGdHdhO/SGfp9mXdCRamgpbV4VJJRn5KgRVykATUOTksalzoKaZGp2F/J3b/ZGejDSDYkYU6fB4Wy\nEfF6E+7Pugufn1opmLumpN/GFRL0I9jsXNoXakoFb4hktbYgHbjUIQTumJSbsbFwK5o8TQhXhcly\nDWJ1MSjyLbHbUjQNHWRW7b0MgRGh6RgNAwAmpo1tcZ+smB5BF9sq9i1Z0NmQ3OI51NTVLTDaW4vr\nUIHRmlnls88+i4ULF2L16tUYOHAg4uPjQVEt/5FMpvbriItlDVjwr134y+9uwF/3vAkA+GjKm3j1\no0PomhSJrr3N+PepL4X9E2unAQkAvDRMJgN6etOxmq98Tbnh8no4E4Ff2Ofhs3UB0UJC9U82uCrP\na/jJJgOevnsk8puOA2UAVNwf1D8qJVytR6zeCKvLhnUXNwU9Z2Q0CXBjA4Z0zYHJZICaVsPtEgXG\n6G7D8PmRbwAAlY3ytRwM6jAkxEchOSIRJZZypCclQqviBpnBKX1wpPo4hnfNlT2jwal9sK/yINdF\nJNXs84uOCm/V842yiKG5Rl+YbrDjjPow1Dg44RkfEwWT0YB4t9xM0DnehCideGysVwwbNpkMiHOI\nExiKINEtuVPQwTEhxhi0DSZ9NKob65CcEIvhzoE4Xnsao7oNbbf3ONYptjc+Jkpotz86lYYTGBq9\nIDBMJgO6xCTiYBXnlEoyRcMUEbpdsW7xt86mOJhMBtzSbTjWnNqIYWn9Wrwnoy4S5qYGdE1MANke\nkWKt4FL6+Zb04fghfwduzRwGU2zzx0nfk0RjbLuOS+1BNMNpzjG64O/lpdKhAiMhIQFlZWJNosrK\nSsTFxcn2iYuLwz/+wUXvNDY2YtOmTQgPb1lSV1e338pzH6w6ggabC/9ceRjwBTOcLazCyYt1OHmx\nDr0ZefnwixW10CYAjJdCdbUViVQyRnW+EVuKd3DVJwkGHg9Au4xgGULMcfDTIoZkx+MwSwBgYdBp\nkZMdj9QEg69SqRwtTUNPE2iycyakeht3/2F+AiNMFY4Hs+7DS7tfR4MzeB9VmH2z5LTb0FWTjupq\nK2i/V2FI9GAQWTQ+O7Uy4DxhqnBUV1vxZM4f0ORxwFrvhhVcu/oY+uL5QQlICIuTPaNMfRaeHzQP\nakoFHa1r9vlZrc5WPd8muyjgGm3c9YMdR7HiLNBmcaPaY4XTLndsN1oYuG3isVZJaZXqaiscdtGM\np6f1qK0JngnssHmDtuFPA59Ak8eBhjoHeoX3xoLBTyFeH9du77HDJravyeoB4oP3Bf+c9ZQerw9/\nEQC3n54V/3N2iwfVId4dALBbRTOmysU9y9EJI9Ensg/i1aYW7+n53Hlwel2orb20bOrLxWQyXFI/\nT0geh2GmoTCyMS0eJ+0L0qVq13GpvXh12PPQUGpUV1vbLDQ6VLz37t0bRUVFKC0thcvlwrp16zB6\n9GjZPmazWdBE/vWvf2H69Okd2aQAVp37FsWxawCwcHvFQaTW0gQirB7agRtxplae9KXpxS1KI3Wm\npho4xzHd6TwI2g2vh0CSMdJXNZRH1CLuvaU7Fxnk29TFFInfT+6JsYO6IJjfUKfmrsWbA/jIK38N\nI0IVjhitUWai8IefWXaWhPr5JywRBCH7HRAzhw2+DF4trQ0wyxAEgaTwhIDZN789VhfTYiZr0Azp\nFvZrLgpFaibizV3+Ic6qFiKWpH6BULkG/tfy3873FUEQQt5Ke6FqhQ8DENdmMagNMKjDBTNKrFZS\npqKF0hRSk5RRw90TSZBCKZyW0NG6NuVddDQqShW0rEowpObTjnLit5UoTWS7FB4EOlhgUBSFBQsW\nYNasWZg4cSImTJiA9PR0vPfee9i6dSsAIC8vD+PGjcO4ceNQV1eHOXPmdGSTAthavBNeqgmg3Sis\nEGcHtRY7VMnnQJAsqCi5L4CvYc94SWw7VAqHywPGJzxI38IpnppOiI7QyipW8lnPE25IwS0DO0Or\nocAHiUoHsHf+OBzvPX6j/JqEPHafTxL0H7wM6nAQBCFzRPeKycSwJHGJSb54oXSQeajnvUJsP480\n8oYAgUlpY9E9Kg03JcvzItqb1trBpWGpzfkDpEEJ/D13MSRjeNJgDEro36rMWqmturnY/PYov3A5\nSNsXyocBiD4rg0qeac9nIhMgWizTIRWuVypc9GohKTwBA+L6IsfUC10jW877+bXT4XkYI0aMwIgR\nI2Tb5s6dK3weO3Ysxo5t2UHV4RByE0V1gz1gm6c2EXSMGFZJ6uz498YzWLPjAqyohdZXB411q+Gt\nTEF0sgasVRxA/v7IMFSZGxEbyQ04Xi8raBjSMhF8ZdL3Hr8Rz+3eAACIjfCtSyxoGJwTV6+WD168\nw9KgNqDWFzI6NGkw+pp6IlITifUXf8AZM2fykg4ycXoTHup5DxbuFcOapb+rKBUGxOcIizt1JC3F\n8vNIhWxzA5c0N4IXgiRB4p7M0Nqs/9xfrmGE1pDao8Db5SAV7s0N+E6GExj+CYZGbSQogoKaUrWo\n+VxKAMO1Dk3SmNXrvivdjF8MJdPbB+GX/Xy+3MyV25DANsp9K14z54+xNLoBiXmKcHEDSpIpDGlx\n8toycUa9UC4jK9WIYBoGT7hOkhRk8C0cwwsMn4bhb97hB05pxAavNvsPJP61q/gQPF7TkIdqtl9x\nuFBkGrkcigR9XAt7ckgTIZvTMKTFA1syPfGYfAlx6ZFctrQ0ciiYhsGbWH6JfgpGa58VHzLqXwyP\nJEikRCQjTteyWSnKV0KlV0zm5TRV4VeMsuIej59wKKpqgLqrXIjwdZwAgLFFwlstht2xXvEP27dL\nF4wZOBApCQYYk3pg2fFdQS+ZnhQJgltMLmTNGx6+fEGAhqGSz2j5QTRYPR3/gcTfzxGm0uOVoX8W\nqoxKZ9XBqm22N4/0nYUGl6XViU5SgdFc1jQ/6ANotd8gShOJhUPnC3ZpaRhxMB/Gi0OegcPjaJds\n2stB+iyb81/xBCth8oc+s1p1LaM2CouGLQgIuFC49rkuNYyLDUV4ctvzOFEtqdrpX1+JZBCml89a\npYvcM049ZIYLSQhtosGErokRIAkCRq28qmsoWhQYvA+D9PNh+Jmk+MFemrDDzz79naHSWSmPURsl\n2PlJghTs4cEGmPaGIqlLyoqVmqGac5R3jQzMZG8N0Vqj8FykgiaYhqGh1ELxwiuB1G/RnFDk7ydY\nNrRepWvWoS8lUmNo8Z1VuPa4Lp/4tpKdcDFufHTsc2EbQXrlNUpJBrSKBXw5eRRB4Y+398Oyk1wu\ngX8mM0CgK3JhiG3EIEmBttYm86iIVgoM3358VrdUCPSOzcaozjcGXJefcfo7Q5tzjvJoKQ1cXleL\nS1ReCaRmvOYGL5qkcX/WXSFXNbxULiVr/Zeitaa2ZwY8hr0VBzDwF/BFKVx7XJcCIymMq0HkgmQt\naz8NIz5aI8t81tIaGHSi+Sc90YiTkrJYqQkGPD1qVMC1WiswWjtb899PRYnfH8i6S9AOpCF+oU1S\nLV9TFeLYqwFpoEBLpbxvSBzY7O+tgVu73YFGT+Aa6Fea1prCkg1JSDYktbyjgkIQrkuTVNAoD5LB\ntBGirXvCsM6yOkvcetrioKShxcFq4cOD8Nx9/YNeix+sW4o7D+b0ljXPZ/7yH+SlA7lUY5CaHEST\nVKCjsyV438nVKDDkGkbHh3dOSBsDgFs/4mqlNf4LBYXL5brSMHYfr0DnuPCgBfe0WmDs4GR8v923\ngWACNAxaMqPVSArfRUdooVGFHrAWj1jYYjJaixoGQQTdL0IbqEkAwZ3e0t8Xj1jY/PWEywa/7tWA\nLHGvHesyhWJk8nDkxve7KmsGAcDfR7z8i/SDwvXL1TcKdBAWuwsffsetijVheqDAYDsfxpGabOG7\nw+uUVX/VUhrZoCmtlKpRN/8nbc1KV6H+6FpKA4fXKeQS+O8XFaKAm8zp7Zt1EhKFsrWrb/ECg8HV\nZ7eXmaR+AQ2DIIirVlgArSvHraDQFq4bgeFwS0t6B3d+fnzi/4TP58wXZL/paJ3MHCQ1SbW0BkBr\nCPOJaOkAACAASURBVKWBPDXgUewqy0NuAudIlwktUgWtSouHsu9Bo9+aFTpaC5qg4GG9wjHJ4YmY\nlDYWWSGWkQwG79y/Gh29MpOUMrNWUOhwrnmB4fYwUNEkHE5RSJTUNLR4HL9GL0+YSi8brLWq9rUV\nEyEERlJ4Au7oMVn4Lh0keS1iYEK/gOO42bABVpdV8FUQBIFxqaMD9m2+Xb6lYf1WobsakIXVXoUm\nMwWFa41r2um9+3gFfv/3bThxsQ4Ol6hhnCura+YoDtbPBKOndbLBWku3rxO4tQllJEEGXew+GCkR\nnZEYZKH7S4G/1tVokqJbmemtoKDQPlzT07LvdhcAALYfKcONfRK50FnCK5T8YL0UtxBSK9CpdDKn\nt1atgpCk0Q6QAdWLQsOvatfSalqzet4bIPguFT5K6qrUMCRC4kplWCsoXE9c0wJDit3phDZnGwja\nDdbLDTSsR9VqgRFG62UmEJqkMWt8ulCBtq2EMkk1R0sO2PZwBMfoolFiK7uiWcyhkN5fe5YKV1BQ\nCM51IzAsDjsImouOEoSE34p4BAjZjJwmaSE7WK/SyWaxNEnjhj6JaC8uRcPg8V+voiOYkTEVJl0M\nbk0Z2eHXulQUrUJB4ZfluvnHNbnk5iOWIQG/Nbf91zKWRkX51w9qb5v55WgYWdHd27UNwYhQGzC1\n24QWFz1SUFC49rluBQYYEp4KMbO7d2x2gMCQRkX5F2Vr77j/SzGpdI9KQ7gqTFj0RkFBQeGXoMNN\nUj/99BMWLVoElmUxffp0zJ49W/Z7eXk5nnvuOVitVjAMg3nz5uGmm25ql2uzhAf8ehNNbr9kPYZC\ndlQvPDLiTqF0xuv73gVgFnaROrlV5KXXYboULsUk9Xi/3wuObwUFBYVfig7VMBiGwcKFC7F8+XJ8\n9913WLduHfLz82X7fPDBBxg/fjxWr16Nt956Cy+//HK7XLvR3YiGtG+hSjsKsCwcnkCTVFyUDhpa\nDYIgQBBEwBKl0sJ+ejr4uhNtha//dCkmH4IgrvulMRUUFH55OlTDOHr0KFJSUtCpE+ecnTBhAjZv\n3oz09HRhH4IgYLNxa0xbLBbEx7ctb4CnxMYtpUrHlsNTx8LrdsvuNkKnxR3D02XH3J1xO0z6GKy9\nsBEAV8jt2YF/xMWGIsToomX7tlexu+cGzsWR6uPIjslol/Ndb/y218wW63QpKCi0Dx0qMCorK5GY\nKEYSxcfH49ixY7J9HnvsMcyaNQufffYZHA4HPv7443a5tsVlFT5X06cR5omS/R4drg8oGKim1BiX\nOhqbCrfC6XWBJmikRHRGSkTngPO3VzG+hLA4JIQFlkVXaB394npf6SYoKFw3dKjAaE39oXXr1mH6\n9Ol48MEHcfjwYTzzzDNYt25di8eZTM0nrTmq7cLnuoj9sJcMBiSH6DTakOfQqrRwel3QazUh94mN\njoApuvk2/FK01BfXE0pfiCh9IaL0RfvQoQIjISEBZWVlwvfKykrExcXJ9lm1ahWWL18OAMjJyYHT\n6URdXR2io+UmIH+qq63N/l5YUyb7bnXZIXVbE14y5DlI1ldwz0OE3MdS70C1t/k2/BKYTIYW++J6\nQekLEaUvRJS+EGmr4OxQ42/v3r1RVFSE0tJSuFwurFu3DqNHy4vfJSUlYdeuXQCA/Px8uFyuFoVF\na6h1mGXfNTp5RrfUoe0PnxDWnNlJSRpTUFC43uhQDYOiKCxYsACzZs0Cy7K44447kJ6ejvfeew+9\ne/fGyJEj8dxzz+GFF17AJ598ApIk8cYbb7TLtZ1eeVRUdrcwnBCtVOgcHjpLmmqFwGhrjSYFBQWF\nXxsdnocxYsQIjBgxQrZt7ty5wuf09HT85z//affrerxyjYJWuwGJwMhsZk0IoRx4u7dKQUFB4dfL\nNWtXaWiULyjkJpwAAJMuBrG6GKQGiXziEUp6B0mOG5k8XDiPgoKCwvXENVt80O50Qerltrs59WJq\nt4noa+rZ7LG8wPAGERh39JiM6d0nKdVRFRQUrjuuSQ3D4fLAw8hNUjafwGhN/kRzGgaglNJWUFC4\nPrkmBUZJlR0g5E5pm5vLJm9NlVmqBYGhoKCgcD1yTQqM4iorCEI+2PNRU63RMAhFYCgoKCgEcE0K\nDLPNGaBh8LSmBhTVjA9DQUFB4XrlmhQYDTYXQLAwaePw0pBnZb+1hw9DQUFB4Xrk2hQYdhdAMFBT\ndLOLIoWiiyEZAJBsSGphTwUFBYXrh2syrLbB7gKMLGiSChQYRMu3PL7rGMSHxaGfSamEqqCgoMBz\nTQoMi90FgmBAkRRokoaaUsN1CU5vNaXCDYkDO7qZCgoKCr8qrjmTFMOysNidACE6r/W0uB63Slmp\nTkFBQeGyuOYEhr3JLUQ38cuoSgVGey18pKCgoHC9cc0JDN7hDUBY91q6XnZ7rcWtoKCgcL1xjQoM\nLgfDX8NQkbQgRBQUFBQULo1rTmBYbFKBwd2emuKqEOppfcjjFBQUFBSa55oTGMFMUg4vV+pcr9KF\nPE5BQUFBoXk63AP8008/YdGiRWBZFtOnT8fs2bNlv7/22mvYu3cvCIJAY2MjzGYz8vLyLvt69TYn\nCD+TVKO7CYDc+a2goKCgcGl0qMBgGAYLFy7EJ598gri4ONxxxx0YPXo00tPThX3mz58vfP78889x\n6tSpNl3TItEw+BIf3aPSkN9QgF6xWW06t4KCgsL1TIcKjKNHjyIlJQWdOnHrZ0+YMAGbN2+WCQwp\n3333HR5//PE2XVPu9OYExviuY5Ae1RVZzSzLqqCgoKDQPB3qw6isrERiYqLwPT4+HlVVVUH3LSsr\nQ2lpKYYMGdKma9bbHdBm7QMg+jAokkJ2TIay8JGCgoJCG+hQDYNlg5cYD8a6deswduzYVg/qJpMh\n6Hartw5Qcet3h+t1Ife7lrge7rG1KH0hovSFiNIX7UOHCoyEhASUlZUJ3ysrKxEXFxd03/Xr1+Ol\nl15q9bmrq60B29weBvZGBny5QZfDG3S/awmTyXDN32NrUfpCROkLEaUvRNoqODvUJNW7d28UFRWh\ntLQULpcL69atw+jRowP2u3DhAiwWC3Jyctp0PWujS/ad92EoKCgoKLSdDtUwKIrCggULMGvWLLAs\nizvuuAPp6el477330Lt3b4wcORIAp11MmDChzdeTOrwBgFSyuhUUFBTajQ7PwxgxYgRGjBgh2zZ3\n7lzZ98cee6xdrtVgkwsMpW6UgoKCQvtxTdls6u1OIQcDUExSCgoKCu3JNTWiXii1yE1SisBQUFBQ\naDeumRGVYVkcvVALvVa8JTfjuYItUlBQULi2uGYExsot52Gxu9A1SQwbczPuK9giBQUFhWuLa0Zg\n7G/4Cepuh3BzPzGz3O1VBIaCgoJCe3HNrFfaFHUGFAC1WswUVzQMBQUFhfbjmtAwjteIFW6bPA7h\ns0sRGAoKCgrtxq9eYJRbq/HB0Y+F702eJuFzj6jgVXEVFP6/vTsPbKpKHz7+TdK0LC2b3QCZikVB\nsAqoLMKUdYChBVoBFas4U6SAQNlEFgXGqQNYmAr8FBVBQUBRXwGFMOpYQUAqKIIwLDrgQGmRlq3Q\njaTJPe8fLSmhQFJoUtM+n79yb05Ozn2g98k5595zhRDl5/UJI+PsRYftgpIeRmTjjrQLbVsZTRJC\niCrJacLIysryRDtumk6vOWxv+PVzAG73byTLmQshRAVymjAGDhzI2LFjSUtL80R7yu16V0LJOlJC\nCFGxnCaMr7/+mh49erBgwQL69u3L6tWrycvL80TbXHLJZr7mflkWRAghKpbTs6qvry8xMTF8+OGH\nvPzyy7z99ttERkaSlJTE2bNnPdHGGzJbr93DkIQhhBAVy6WzamZmJv/85z+ZNGkSHTt2ZOnSpdx2\n220MGzbM3e1zymIrfgaGKvJ12C8r1QohRMVyeuPeyJEj+eWXX3j88cdZu3Yt9evXB6Bt27Zs2rTJ\n7Q10xlwyh6Hl18VQ77R9vyw8KIQQFctpwhgwYAC9evXCYCj7i33jxo1Ov2Dr1q3Mnj0bpRQDBw4k\nISGhTJlNmzbx+uuvo9frad68OfPnz3ex+Vf2MIwO+w0y6S2EEBXKacKoW7cuBQUFBAQUL+p38eJF\nDhw4QMeOHZ1WrmkaSUlJLF++nODgYAYNGkSPHj0IDy+9oe748eMsXbqUDz/8EH9/f86dO1euA7CU\n9DCU1c9hvwxJCSFExXI6bpOcnIy/v79929/fn+TkZJcq37dvH2FhYTRu3Bij0UhUVBSpqakOZT76\n6COeeOIJ+3c0aNCgPO2nSCt5jvdVcxgyJCWEEBXL6VlVKeVwA5xer8dms7lUeVZWFg0blq4eGxIS\nQnZ2tkOZY8eO8b///Y8hQ4bw+OOPs23bNlfbDpSuF9Whxe0O+6WHIYQQFcvpkFTt2rX56aefuP/+\n+wH46aefqFWrlkuVK6WclrHZbKSnp7N69WpOnjxJXFwcJpPJoVdzI5dv3PMzOA5JSQ9DCCEqltOE\nMXnyZEaPHk2zZs0AOHLkCK+99ppLlYeGhnLy5En7dlZWFsHBwQ5lQkJCaNOmDXq9nttvv52mTZty\n7Ngx7r333hvWHRRU8qAkHw3McGeDO6gd/Ef+fbS4hxLYIICgBgE3qKHqsMdCSCyuILEoJbGoGE4T\nRps2bTCZTOzduxelFG3atKFu3bouVR4REUF6ejqZmZkEBQVhMplISUlxKNOzZ09MJhMxMTGcO3eO\n48eP06RJE6d1nz6dC0ChuXixwaJLiu53dbUnjIsXLnHalutSO71ZUFCAPRbVncSilMSilMSi1K0m\nTpceoFS3bl26dOlS7soNBgMzZswgPj4epRSDBg0iPDycRYsWERERQbdu3fjjH//It99+S1RUFAaD\ngeeff97lhARgVcXP7a7h44tRX3o4cqe3EEJULKcJ4/Dhw8yaNYvDhw9jsVjs+w8dOnSDT5WKjIwk\nMjLSYV9iYqLD9tSpU5k6dapL9V3NqornMHx9jPjoSg9HL5PeQghRoZz+DP/b3/7G+PHjCQsL45tv\nviEhIYEJEyZ4om0usSorStPhZ/DBx6GHIQlDCCEqktOEYbFY6NixI0opgoODmTBhQrkvfXUnqyoC\nzYDBoHe4/NeglyEpIYSoSE7PqvqSE2/dunU5fPgw58+fJzMz0+0Nc5WN4oThY3A8FOlhCCFExXI6\nhxEVFcX58+dJSEhgyJAhaJpWZg6iMtlUEcrmg4/B8el6ch+GEEJUrBsmDE3T6NixI/Xr1ycyMpJd\nu3ZhNptdvqnOE2xYQfPFUKaHIQlDCCEq0g3Pqnq9nhdeeMG+bTQaf1fJQlMams6KshnK9DBkSEoI\nISqW05/h4eHhZGRkeKIt5VakFd+DgWbAoJchKSGEcCencxjnzp2jf//+PPDAAw5rSC1cuNCtDXOF\nueR53sVzGI4JQhKGEEJULJcmvaOiojzRlnIzW0tuJLziKqm764XzS85Rh0tshRBC3DqnCSM2NtYT\n7bgpFq00YVwekkpsk4CmtEpslRBCVE1OE0ZiYuI1f63/voakSnsYOp1OJryFEMINnCaMbt262V+b\nzWa++OILh0esViaz7XIPwweDQYaghBDCnco9JPXII48watQotzWoPC4nDJ1mQC9zFkII4VblvpRI\np9P9bi6ztZQkDKPeWMktEUKIqq9ccxhKKX7++Wc6duzo9oa54pK1eA4joIZrj4wVQghx88o1h2Ew\nGIiPj6d169ZubZSrLhQUAFDPxWeMCyGEuHluv6x269atzJ49G6UUAwcOJCEhweH9devWkZycTGho\nKABxcXEMGjTIpbovFBQCUN+/5i21UQghhHNO5zCGDBnChQsX7Ns5OTnExcW5VLmmaSQlJbFs2TI2\nbtyIyWTi6NGjZcpFRUWxbt061q1b53KyALhYWDwk1cBfehhCCOFuThNGQUGBwzO269WrR15enkuV\n79u3j7CwMBo3bozRaCQqKorU1NQy5ZRS5WhyqcKi4oRRt1aNm/q8EEII1zlNGJqmUVAyVwCQn5+P\nzWZzqfKsrCwaNmxo3w4JCSE7O7tMuS+//JIBAwYwbtw4Tp065VLdAFatuB1+Bqcja0IIIW6R0zNt\ndHQ08fHxDBkyBIAPPviA/v37u1S5Kz2H7t27Ex0djdFoZM2aNUyZMoUVK1a4VL+1ZLVaPx8/l8oL\nIYS4eU4TxogRIwgODubrr79GKcXjjz9OTEyMS5WHhoZy8uRJ+3ZWVhbBwcEOZa4c7nr00UeZP3++\nS3UHBQWAQYENgm+rU7xdTVXnY7+axKKUxKKUxKJiuDSWExsbe1NXS0VERJCenk5mZiZBQUGYTCZS\nUlIcypw+fZqgoCAAUlNTadasmUt1nz6di7nIAnowFxRx+nRuudtXFQQFBVTbY7+axKKUxKKUxKLU\nrSZOp3MYY8eOJScnx759/vx5xo0b51LlBoOBGTNmEB8fT3R0NFFRUYSHh7No0SI2b94MwMqVK4mO\njiYmJoZVq1YxZ84clxtvU8VzGDWMcqe3EEK4m9MexokTJ6hXr559u379+qSnp7v8BZGRkURGRjrs\nS0xMtL+eOHEiEydOdLm+K11OGH4+vjf1eSGEEK5z2sOw2WwOV0UVFRVhsVjc2ihXaap40lt6GEII\n4X5OexidO3dmwoQJDB06FIAVK1aU6TFUFhsyJCWEEJ7iNGFMnDiRt956i7lz5wLFa0u1b9/e7Q1z\nhYYNpekx+sgDk4QQwt2cDkkZjUbGjBnD66+/zp/+9Cc+++wzpk+f7om2OaVhA01vfzyrEEII97lh\nD8NqtfL111/zySefsHfvXqxWK8uWLfvdrFar0EDpr/kIWSGEEBXruj2MOXPm0LVrV9asWUN0dDTf\nfPMNdevW/d0kCwCFDZ0q9zOghBBC3ITr9jA++OAD2rRpQ0JCAh06dAD43f2SVzoNNJm/EEIIT7hu\nwti+fTsbNmwgOTmZCxcuEBMT4/Kig56idDZ0yBVSQgjhCdcdz6lTpw5xcXGsXbuW119/nQsXLnDp\n0iXi4uJYs2aNJ9t4fToNPdLDEEIIT3BpAqBFixa8+OKLbNu2jbi4uGs+06JS6DR0ShKGEEJ4Qrke\nJGE0Gunbty99+/Z1V3tcpikNdEp6GEII4SFee4lRka0IQBKGEEJ4iNcmjEtFJQlDJwlDCCE8wWsT\nRmFR8QKIBulhCCGER3htwrhklR6GEEJ4ktcmDHPJkJSPrlzz9kIIIW6S2xPG1q1b6dOnD71792bJ\nkiXXLff555/TokULDhw44FK9l6wlQ1J66WEIIYQnuDVhaJpGUlISy5YtY+PGjZhMJo4ePVqmXH5+\nPqtWrSrXOlXSwxBCCM9ya8LYt28fYWFhNG7cGKPRSFRU1DVv+lu4cCHDhw/HWI4HIZlLLqv1kR6G\nEEJ4hFsTRlZWFg0bNrRvh4SEkJ2d7VDm0KFDnDp1ii5dupSrbnPJpLdBLz0MIYTwBLeebZVSTt+f\nPXs2r7zyisufuczoV5zravv5ERQUcPONrAKq+/FfSWJRSmJRSmJRMdyaMEJDQzl58qR9Oysri+Dg\nYPt2fn4+R44c4amnnkIpxZkzZ3j22Wd54403aNWq1Q3rPncxHwBl03H6dK57DsALBAUFVOvjv5LE\nopTEopTEotStJk63JoyIiAjS09PJzMwkKCgIk8lESkqK/X1/f3/S0tLs20899RTTpk2jZcuWTusu\nKhmSMsqQlBBCeIRbz7YGg4EZM2YQHx+PUopBgwYRHh7OokWLiIiIoFu3bg7ldTqdy0NSFs0KgNEg\nCUMIITzB7WfbyMhIIiMjHfYlJiZes+x7773ncr0W2+UehjxASQghPMFr7/S2lvQwfKWHIYQQHuG1\nCaPIVpIwfKSHIYQQnuC9CUN6GEII4VFemzAuD0n5SQ9DCCE8wusThgxJCSGEZ3hvwlDFCaOGJAwh\nhPAIr00YNs0GgJ+PbyW3RAghqgevTRiXexgyhyGEEJ7htQnDpop7GDXKsSS6EEKIm1cFEoYMSQkh\nhCd4bcLQkB6GEEJ4kvcmjJI5jJoy6S2EEB7hvQkDDaXA6CN3egshhCd4ccKwgfLa5gshhNfx2jOu\n0mnoNENlN0MIIaoN700Y0sMQQgiPcvsZd+vWrfTp04fevXuzZMmSMu+vWbOGfv36ERMTQ1xcHEeP\nHnWpXqWThCGEEJ7k1jOupmkkJSWxbNkyNm7ciMlkKpMQ+vXrx4YNG1i/fj3Dhg1jzpw5LtWtdBo6\nJUNSQgjhKW5NGPv27SMsLIzGjRtjNBqJiooiNTXVoUzt2rXtrwsKCtDrXWySTkPnvSNqQgjhddx6\nTWpWVhYNGza0b4eEhLB///4y5VavXs3y5cuxWq2sWLHCtcp1NulhCCGEB7k1YSilXCoXFxdHXFwc\nJpOJxYsXM3fuXOcf0mnodQaCggJusZXeT2JQSmJRSmJRSmJRMdyaMEJDQzl58qR9Oysri+Dg4OuW\n79u3L7NmzXJar02zgQ50Ss/p07kV0lZvFRQUUO1jcJnEopTEopTEotStJk63TgJERESQnp5OZmYm\nFosFk8lEjx49HMocP37c/nrz5s3ccccdTustshUByByGEEJ4kFt7GAaDgRkzZhAfH49SikGDBhEe\nHs6iRYuIiIigW7durFq1irS0NIxGI3Xq1OGVV15xWq+lJGHokTkMIYTwFLcvxBQZGUlkZKTDvsTE\nRPvrF154odx1mq2SMIQQwtO8ckznUpEFkIQhhBCe5JUJw1xUvLS5JAwhhPAcr0wYl6zFPQyDThKG\nEEJ4ilcmDPschiQMIYTwGO9MGCVzGAYZkhJCCI/xzoRhLZ7DMOjkaXtCCOEpXpkwLPY5DEkYQgjh\nKd6ZMGyXexgyJCWEEJ7ilQnDXHKnt49eehhCCOEpXpkwikqukpIehhBCeI5XJozLQ1LSwxBCCM/x\n0oRRPOktCUOI6iMvL4916/7fTX32+efHk5+fV8Etqn68MmEUXe5hyJCUENVGbu5F1q37+JrvaZp2\nw88mJy+gdm1/dzTrlrn6oLnfA6/8iX55eXOjwVjJLRFCeMqbb77GyZOZxMfH8eCD7enYsRPvvvs2\nt90WyJEjv7By5UdMm/Ycp09nY7GYGTx4CP36xQAweHB/li1bSUFBAc89l0hERGv+85+fCAoKYe7c\nf+Lr6+vwXd9+u40VK5ZhtVqpW7cuM2e+TP369SksLOTVV5P5+edD6HR6/vrX4XTp0o3vvtvBkiWL\n0TSNevXqsWDBYt55Zwm1atXi8cefBGDo0MdITl4IKJ57LpE2bR7kwIH9zJkzn5Url/Pzzwcxm810\n7dqD+PgEAA4dOsCiRf+ksPASvr6+LFiwmMmTxzFhwvM0a3YXAKNGDWPy5GnceWczt/8beHfC0EvC\nEKIyfPT1Eb4/nF2hdT7UIphHu1//pDdq1FiOHfuVd95ZDcCePbs5dOggK1d+RGhoKADTp88iICAA\ns9nM8OFD6dKle8lT5nT2ejIyTvDSS3OYMuUFZs6cxpYtX9OrVx+H77r//jYsWbIcgI0b1/P+++8x\nevQ4li9fSkBAACtWrAGKh8lycnJITv4HixcvIzQ0lNzcaz/dT6crbcOJE+m88MLfmDRpCgAjRowm\nICAATdMYN24Uv/56hD/84Q5mzZpOUtIrNG/egoKCAvz8/OjXL4ZNmz4jMXESJ06kY7UWeSRZgJcm\njCKteEjKKHMYQlRrLVu2sicLgI8+ep9t274BIDs7m4yMdMLDGwOlwz4NGzYiPLz4BNu8eQtOnTrJ\n1bKzTzFz5gLOnj2D1WqlYcNGAPzwwy7+/vc59nL+/v58++022rRpa29HQMC1H4N65dBTSEgo99zT\nyr6dmvoFn322HpvNxrlzZ/nf//4HQGBgEM2btwCgVq1aAHTr1oPly5cxevR4TKbP+POf+7kYrVvn\n9jPu1q1bmT17NkopBg4cSEJCgsP7y5cv5+OPP8bHx4cGDRowe/ZsGjZseMM6i0omvWVISojK8Wj3\nZjfsDXhKjRo17K/37NnNjz/+wJIly/H19WXs2BFYLJYyn7ly+EmvN1yzzKuvzmPIkKd4+OHO7Nmz\nm3fffRu49nzD9eYgDAYDmlb63pXfU7NmTfvr3347yZo1q1m2bCW1a/sze/ZLWCxmrje14edXg4ce\nas+2bVvYvPkrli5dee2CbuDWSW9N00hKSmLZsmVs3LgRk8nE0aNHHcq0bNmStWvX8umnn9KrVy+S\nk5Od1nu5h+ErQ1JCVBu1atWioKDguu/n5+cREBCAr68vx48f48CB/1yznCuTzPn5+QQGBgLwr39t\ntO9v164Dn3zyoX07NzeXe++9j71793Dq1G8AXLx4ESjuyfzyy2EAfv75ML/9VtqTubIN+fn51KxZ\nk1q1anPu3Fm++24HAGFhd3D27BkOHz4EQEFBgX1yPzp6AAsWzOeee1pdt0fjDm7tYezbt4+wsDAa\nN24MQFRUFKmpqYSHh9vLtGvXzv66devWbNiwwWm9Vq14DsNXehhCVBt16tQlIuJ+nn76cdq3f5iO\nHTs5vN++/cOsX/8Jf/nLE/zhD2Hce2/EFe+Wzh9cOZdwPfHxw3nxxSkEB4fQsuW99mTw9NPDSEl5\nhaFDH8NgMPDXvyYQGdmV559/genTn0MpRf36DUhJeY0uXbrz+ecm4uPjaNGiJU2ahF2zDc2a3cVd\ndzXnqaceo1Gjxtx33/0A+Pj48NJLc3j11WTMZjM1atRgwYLF1KhRg+bNW1C7dm2iojw3HAWgU268\npuuLL75g+/btJCUlAfDpp5+yf/9+XnzxxWuWT0pKIigoiJEjR96w3omfzifj0lGGhIyhc6s/VHi7\nvUlQUACnT197kq26kViUkliUqoqxOHPmNImJI3n//U/K9bniCwBunlt7GOXJRZ9++ikHDhxg5Urn\n43GXexiB9evccgCqAolBKYlFKYlFqaoUi/Xr17Nw4UKmTZvm8eNya8IIDQ3l5MnScbusrCyCMd1e\n6gAAERdJREFUg4PLlNuxYwdLlixh1apVGI3Oh5msyopSUJhXVOV+OZRXVfz1dLMkFqUkFqWqWiw6\ndepBp049AMp9XLeaYNw66R0REUF6ejqZmZlYLBZMJhM9evRwKHPw4EFmzZrFG2+8Qf369V2q16pZ\nQTPg6yt3egshhKe4tYdhMBiYMWMG8fHxKKUYNGgQ4eHhLFq0iIiICLp168a8efMoLCxk3LhxKKVo\n1KgRixcvvmG9xQlDTw1JGEII4TFuvw8jMjKSyMhIh32JiYn21++++26567SqIpRmoIZREoYQQniK\nVy4+aFNWUHr8pIchhBAe45UJQ8MGmoEavrI0iBDVxa0sbw7w0UcfYDabK7BF1Y+XJgyZwxCiurnR\n8uau+PjjDzCbL1Vgi8rPZrNV6vffKq/8ia50GigDPgavzHdCiJtw9fLmzz6byPvvr2Tz5n9TVGQl\nMrIr8fEJXLp0iZkzp3L6dDaapjF27BiOHcvgzJnTjB07knr16rFw4RsOdS9fvpRvv92GxWLm3nvv\nY/Lk6QBkZmYwb95scnJyMBgMJCXNpVGjxqxevYIvv/wXer2eDh06MWLEaMaOHcGYMRNo3rwFFy7k\n8MwzQ/n448/41782smPHdiwWM5cumZk7959MnTqJvLxcrFYrw4ePpHPnLkDxMiRr1qxGr9cRHn4X\nEydO4emnh7BmzVoMBgMFBfkl2+swGDz/g9krEwaAXknvQojKsvbIRvZk76/QOtsER/BIs+jrvn/1\n8ubff/8dGRnpvP32eyilmDJlIj/9tJecnHMEBgaRnLwAgJo1dTz4oOLDDz/g//7vLerUqVOm7oED\nH+Mvf3kGgKSkmezYsZ2HH+7MSy+9yNChf6Vz5y4UFRWhaRrffbeD7du38vbb7+Hr63vd5cyvXI7k\nwIH9vPfeh/j7+6NpGnPmzKdWrVpcuJDDiBHF9f/661FWrVrOG2+8Q506dcjNzaVWrVq0bfsAaWnb\n6dy5C1999SVdu/aolGQBXpwwDPK0PSGqtV27dvL997uIj49DKUVh4SUyMtK5777WvP76Qt588zU6\nduxMz55/pLAwl+Ilzq+9+sTu3bt4//2VmM2XyM3N5c47w2ndui1nzpy2//q/fFPxDz/sIiqqn33V\nW1cW/3voofb4+xc/8U/TNN566zX27t2DXq/jzJnTnD9/jj17fqBr1x72hHa53ujoAbz//ko6d+7C\npk0bmDLl2ksreYLXJgy9ThYeFKKyPNIs+oa9AU9QSvHUU3+hf//YMu8tW7aKtLRveeut1/jll/0M\nHvzUdeuxWCykpCTzzjurCAwM4p13lpQsRX7t5FK85FHZBQwNBgNKafY6r3Tlcub//vfn5OTk8O67\nq9Hr9Qwe3B+z2XLdpZQiIu7n1KlX2Lv3RzRNo2nTO697LO7mtZMAvqqm80JCiCrj6uXN27fvgMn0\nGYWFhQAlv9TPc+bMGfz8/OjVqw9DhjzJwYMHSz5fm/z8/DL1WiwWdLri1XALCgrYsiXVXj44OIRt\n27YAUFRUhNl8iXbtir/38gR66XLmjTl8uPi7Nm/+6rrHkZeXR/36DdDr9fz44w/2lXAfeKAdmzd/\nxcWLFxzqBejduy9/+9sLREX1L3/gKpBX9jDMhx/iD/XvqOxmCCE86OrlzZ99NpFjx44xcuRfgeKE\nMmNGEhkZJ3j99YXo9Tp8fIz84x/Fq2X37x/Dc88lEhgY5DDp7e/vT79+sQwd+hgNGzZyeBLeiy++\nxLx5s1m69C2MRiNJSXNp374jR478wrBhQ/H1NdKhQycSEp5lyJA4ZsyYxhdf/IsHHnjousfRq1cf\npkyZyPDhQ2nWrDlhYU0BaNr0ToYOjWfMmAQMBgN33dWc6dNnlXzmzyxd+iY9e/aq8LiWh1uXN3eX\nfpM+pc1dgYwdeF9lN6XSVbWF1W6FxKKUxKJUVYjF5s1f8e2323jxxZduqZ7f9fLm7iR3eQshqoMF\nC+bx3XdpzJ+/sLKb4r0JI6Cmr/NCQgjh5caPn1zZTbDz2knv+gF+ld0EIYSoVrw2YdTzlx6GEEJ4\nktcmDOlhCCGEZ7k9YWzdupU+ffrQu3dvlixZUub9H374gUceeYRWrVrx5ZdfulxvPX9JGEII4Ulu\nTRiappGUlMSyZcvYuHEjJpOJo0ePOpRp1KgRc+fOpV+/fuWqu570MIQQwqPcepXUvn37CAsLo3Hj\nxgBERUWRmppKeHi4vUyjRo0A0OnK3mp/PQ1vq42fPG1PCCE8yq09jKysLBo2bGjfDgkJITs7+5br\nfXVCl1uuQwghRPm4NWG46yby2jVl4UEhhPA0tw5JhYaGcvLkSft2VlYWwcHBFVL3rd7iXpVILEpJ\nLEpJLEpJLCqGW3sYERERpKenk5mZicViwWQy0aNHj+uW98JlrYQQotpw++KDW7du5R//+AdKKQYN\nGkRCQgKLFi0iIiKCbt26sX//fsaMGcPFixfx8/MjKCiIDRs2uLNJQgghboJXrlYrhBDC87z2Tm8h\nhBCeJQlDCCGESyRhCCGEcInXJQxna1NVNdOnT+fhhx92WDrlwoULxMfH07t3b4YNG0ZubunTxF5+\n+WV69erFgAEDOHToUGU02S1OnTrF0KFD6du3L/369eO9994DqmcsLBYLgwcPJiYmhn79+vHaa68B\nkJGRwaOPPkrv3r2ZOHEiVqvVXn7ChAn06tWLxx57zOFS96pC0zRiY2MZOXIkUH1j0b17d/r3709M\nTAyDBg0CKvhvRHkRm82mevbsqTIyMpTFYlH9+/dXR44cqexmudX333+vDh48qKKjo+37kpOT1ZIl\nS5RSSr311ltq3rx5SimltmzZooYPH66UUmrv3r1q8ODBnm+wm2RnZ6uDBw8qpZTKy8tTvXr1UkeO\nHKmWsVBKqYKCAqWUUlarVQ0ePFjt3btXjRs3Tm3atEkppdTMmTPVBx98oJRSavXq1WrWrFlKKaVM\nJpMaP358pbTZnd599101adIkNWLECKWUqrax6N69u8rJyXHYV5F/I17Vw7hybSqj0Whfm6oqe/DB\nB6lTp47DvtTUVGJjYwGIjY21xyA1NZWYmBgA7r//fnJzczlz5oxnG+wmQUFB3HPPPQDUrl2b8PBw\nsrKyqmUsAGrWrAkU/2K2Wq3odDp27txJ7969geJYfPXVV4Dj/5fevXuTlpZWOY12k1OnTvHNN98w\nePBg+77vvvuuWsZCKYWmaQ77KvJvxKsShrvWpvI2586dIzAwECg+kZ47dw6A7OxsQkND7eVCQkLI\nysqqlDa6U0ZGBocPH+b+++/n7Nmz1TIWmqYRExNDp06d6NSpE02aNKFOnTro9cV/0qGhofbjvTIW\nBoOBOnXqkJOTU2ltr2izZ8/m+eefty9gev78eerWrVstY6HT6Rg2bBgDBw7k448/BqjQvxGveqa3\nkltGbuha8SnPKsDeID8/n8TERKZPn07t2rWve3xVPRZ6vZ7169eTl5fH6NGjyzw2AEqP9+pYKKWq\nTCy2bNlCYGAg99xzDzt37gSKj+/qY64OsQBYs2aNPSnEx8fTtGnTCv0b8aqE4c61qbzJbbfdxpkz\nZwgMDOT06dM0aNAAKP6FcOrUKXu5U6dOVan4WK1WEhMTGTBgAD179gSqbywu8/f356GHHuKnn37i\n4sWLaJqGXq93ON7LsQgJCcFms5GXl0fdunUrueUV48cff+Trr7/mm2++wWw2k5+fz+zZs8nNza12\nsYDiHgRAgwYN6NmzJ/v27avQvxGvGpIq79pUVcXVvwS6d+/O2rVrAVi3bp09Bj169GD9+vUA7N27\nlzp16ti7olXB9OnTadasGU8//bR9X3WMxblz5+xXuly6dIm0tDSaNWtG+/bt+fzzzwHHWHTv3p11\n69YB8Pnnn9OhQ4fKabgbTJw4kS1btpCamkpKSgrt27dn/vz51TIWhYWF5OfnA1BQUMD27du5++67\nK/RvxOuWBrnW2lRV2aRJk9i5cyc5OTkEBgYyduxYevbsybhx4/jtt99o1KgRCxcutE+M//3vf2fb\ntm3UrFmTOXPm0KpVq0o+goqxe/dunnzySe6++250Oh06nY4JEyZw3333MX78+GoVi59//pmpU6ei\naRqaptG3b19GjRrFiRMnmDhxIhcvXuSee+5h3rx5GI1GLBYLkydP5tChQ9SrV4+UlBRuv/32yj6M\nCrdr1y7eeecd3nzzzWoZixMnTjBmzBh0Oh02m41+/fqRkJBATk5Ohf2NeF3CEEIIUTm8akhKCCFE\n5ZGEIYQQwiWSMIQQQrhEEoYQQgiXSMIQQgjhEkkYQgghXCIJQ3i1Rx99lNjYWKKiomjVqhWxsbHE\nxsYyffr0ctf1zDPPuLTc9bRp09i7d+/NNLdcDh48yBdffOH27xHCVXIfhqgSMjMzGTRo0A1XH728\nVIS3+Pjjj0lLSyMlJaWymyIE4GVrSQlRHmlpacybN4/WrVtz8OBBRo8ezblz51i9erX9gTpTp06l\nXbt2AHTp0oXly5fTtGlTnnjiCdq0acOePXvIzs4mOjqa8ePHA/DEE0/w7LPP0rlzZyZPnoy/vz9H\njx4lKyuLtm3bMmfOHKB4bZ7nn3+e8+fP06RJE2w2G927d+exxx5zaOeZM2eYNGkS58+fB6Bz5848\n88wzLF68mIKCAmJjY2nfvj1Tp05lz549pKSkUFhYCEBiYiKRkZGkp6fzxBNPEB0dze7du7FYLMya\nNYu2bdt6JNaimriVh3UI8XuRkZGhOnTo4LBvx44dqmXLlmr//v32fVc+XObIkSOqa9eu9u3IyEj1\n66+/KqWUGjJkiJo0aZJSSqmLFy+qdu3aqYyMDPt727ZtU0op9dxzz6knn3xSFRUVKbPZrPr06aN2\n7typlFJq1KhR6u2331ZKKXXixAnVpk0btWbNmjJtX7p0qZo5c6Z9++LFi0oppT766CM1ceJEh7bH\nxMSos2fPKqWUOnXqlIqMjFR5eXnq+PHjqnnz5spkMtmPvWvXrspqtboeRCGckB6GqNLuvPNO7r33\nXvv2sWPHWLRoEdnZ2RgMBrKzs8nJyaFevXplPvvnP/8ZgICAAJo2bUp6ejqNGzcuU+5Pf/oTPj7F\nf0otW7YkPT2ddu3asXPnTl5++WUAbr/9dntP5mqtW7dm1apVzJ8/n4ceeojOnTtfs9zu3bvJyMhg\n2LBh9gUpDQYDJ06coFatWtSsWZO+ffsC0LFjRwwGA8eOHSM8PNzVcAlxQ5IwRJVWu3Zth+0JEyYw\na9YsunTpgqZp3HfffZjN5mt+1s/Pz/5ar9djs9nKVc7V5yw88MADrFu3jh07dvDJJ5+wdOlSVq5c\nWaacUopWrVqxfPnyMu+lp6eX2adpWpV61oOofN4zAyiEE8qF6zfy8vLsq5OuWbPmukmgIrRr186+\nrHRmZia7du26ZrmMjAz8/f3p27cvU6dO5T//+Q9Q/KyLy8uYA7Rt25YjR47www8/2Pft27fP/rqw\nsJBNmzYBxY8oBQgLC6vYgxLVmvQwRJXhyq/p6dOnk5CQQMOGDWnfvj0BAQHX/PzVdV3vvRuVmzFj\nBlOmTMFkMnHnnXfStm1bh++7LC0tjffeew+DwYBSiqSkJAA6derEihUriImJoUOHDkydOpXFixcz\nb948cnNzKSoqokmTJrz55psABAYG8t///pfBgwdjsVhISUnBYDA4jYkQrpLLaoVwE7PZjNFoRK/X\nk5WVxeDBg1m9ejVNmjSp8O+6fJXU9u3bK7xuIS6THoYQbvLrr78ybdo0lFJomsaECRPckiyE8BTp\nYQghhHCJTHoLIYRwiSQMIYQQLpGEIYQQwiWSMIQQQrhEEoYQQgiXSMIQQgjhkv8PZHg4l1eLyCQA\nAAAASUVORK5CYII=\n", + "text/plain": [ + "\u003cmatplotlib.figure.Figure at 0x7f96f7389490\u003e" + ] + }, + "metadata": { + "tags": [] + }, + "output_type": "display_data" + } + ], + "source": [ + "with context.eager_mode():\n", + " durations = []\n", + " for t in range(burn_ins + trials):\n", + " hp = tf.contrib.training.HParams(\n", + " learning_rate=0.05,\n", + " max_steps=max_steps,\n", + " )\n", + " train_ds = setup_mnist_data(True, hp, 500)\n", + " test_ds = setup_mnist_data(False, hp, 100)\n", + " ds = tf.data.Dataset.zip((train_ds, test_ds))\n", + " start = time.time()\n", + " (train_losses, test_losses, train_accuracies,\n", + " test_accuracies) = train(ds, hp)\n", + " if t \u003c burn_ins:\n", + " continue\n", + " train_losses[-1].numpy()\n", + " test_losses[-1].numpy()\n", + " train_accuracies[-1].numpy()\n", + " test_accuracies[-1].numpy()\n", + " duration = time.time() - start\n", + " durations.append(duration)\n", + " print('Duration:', duration)\n", + "\n", + "\n", + " print('Mean duration:', np.mean(durations), '+/-', np.std(durations))\n", + " plt.title('MNIST train/test losses')\n", + " plt.plot(train_losses, label='train loss')\n", + " plt.plot(test_losses, label='test loss')\n", + " plt.legend()\n", + " plt.xlabel('Training step')\n", + " plt.ylabel('Loss')\n", + " plt.show()\n", + " plt.title('MNIST train/test accuracies')\n", + " plt.plot(train_accuracies, label='train accuracy')\n", + " plt.plot(test_accuracies, label='test accuracy')\n", + " print('test_accuracy', test_accuracies[-1])\n", + " plt.legend(loc='lower right')\n", + " plt.xlabel('Training step')\n", + " plt.ylabel('Accuracy')\n", + " plt.show()\n" + ] + } + ], + "metadata": { + "colab": { + "collapsed_sections": [], + "default_view": {}, + "last_runtime": { + "build_target": "", + "kind": "local" + }, + "name": "Autograph vs. Eager MNIST benchmark", + "provenance": [ + { + "file_id": "1tAQW5tHUgAc8M4-iwwJm6Xs6dV9nEqtD", + "timestamp": 1530297010607 + }, + { + "file_id": "18dCjshrmHiPTIe1CNsL8tnpdGkuXgpM9", + "timestamp": 1530289467317 + }, + { + "file_id": "1DcfimonWU11tmyivKBGVrbpAl3BIOaRG", + "timestamp": 1522272821237 + }, + { + "file_id": "1wCZUh73zTNs1jzzYjqoxMIdaBWCdKJ2K", + "timestamp": 1522238054357 + }, + { + "file_id": "1_HpC-RrmIv4lNaqeoslUeWaX8zH5IXaJ", + "timestamp": 1521743157199 + }, + { + "file_id": "1mjO2fQ2F9hxpAzw2mnrrUkcgfb7xSGW-", + "timestamp": 1520522344607 + } + ], + "version": "0.3.2", + "views": {} + } + }, + "nbformat": 4, + "nbformat_minor": 0 +} diff --git a/tensorflow/contrib/bigtable/BUILD b/tensorflow/contrib/bigtable/BUILD index a262cd4a49..71538e0770 100644 --- a/tensorflow/contrib/bigtable/BUILD +++ b/tensorflow/contrib/bigtable/BUILD @@ -31,6 +31,7 @@ tf_custom_op_py_library( srcs_version = "PY2AND3", deps = [ ":bigtable_ops", + "//tensorflow/contrib/data/python/ops:interleave_ops", "//tensorflow/contrib/util:util_py", "//tensorflow/python:framework_for_generated_wrappers", "//tensorflow/python:platform", @@ -45,6 +46,7 @@ KERNEL_FILES = [ "kernels/bigtable_prefix_key_dataset_op.cc", "kernels/bigtable_range_key_dataset_op.cc", "kernels/bigtable_sample_keys_dataset_op.cc", + "kernels/bigtable_sample_key_pairs_dataset_op.cc", "kernels/bigtable_scan_dataset_op.cc", ] @@ -55,6 +57,7 @@ tf_custom_op_library( ], deps = [ ":bigtable_lib_cc", + ":bigtable_range_helpers", "@com_github_googlecloudplatform_google_cloud_cpp//google/cloud/bigtable:bigtable_client", ], ) @@ -76,6 +79,7 @@ tf_kernel_library( srcs = KERNEL_FILES, deps = [ ":bigtable_lib_cc", + ":bigtable_range_helpers", "//tensorflow/core:framework_headers_lib", "//third_party/eigen3", "@com_github_googlecloudplatform_google_cloud_cpp//google/cloud/bigtable:bigtable_client", @@ -95,6 +99,15 @@ cc_library( ) cc_library( + name = "bigtable_range_helpers", + srcs = ["kernels/bigtable_range_helpers.cc"], + hdrs = ["kernels/bigtable_range_helpers.h"], + deps = [ + "//tensorflow/core:framework_headers_lib", + ], +) + +cc_library( name = "bigtable_test_client", srcs = ["kernels/test_kernels/bigtable_test_client.cc"], hdrs = ["kernels/test_kernels/bigtable_test_client.h"], @@ -118,6 +131,17 @@ tf_cc_test( ], ) +tf_cc_test( + name = "bigtable_range_helpers_test", + size = "small", + srcs = ["kernels/bigtable_range_helpers_test.cc"], + deps = [ + ":bigtable_range_helpers", + "//tensorflow/core:test", + "//tensorflow/core:test_main", + ], +) + tf_gen_op_wrapper_py( name = "bigtable_test_ops", deps = [":bigtable_test_ops_op_lib"], diff --git a/tensorflow/contrib/bigtable/kernels/bigtable_range_helpers.cc b/tensorflow/contrib/bigtable/kernels/bigtable_range_helpers.cc new file mode 100644 index 0000000000..51965f6214 --- /dev/null +++ b/tensorflow/contrib/bigtable/kernels/bigtable_range_helpers.cc @@ -0,0 +1,68 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/contrib/bigtable/kernels/bigtable_range_helpers.h" + +#include "tensorflow/core/platform/logging.h" + +namespace tensorflow { + +namespace { + +string MakePrefixEndKey(const string& prefix) { + string end = prefix; + while (true) { + if (end.empty()) { + return end; + } + ++end[end.size() - 1]; + if (end[end.size() - 1] == 0) { + // Handle wraparound case. + end = end.substr(0, end.size() - 1); + } else { + return end; + } + } +} + +} // namespace + +/* static */ MultiModeKeyRange MultiModeKeyRange::FromPrefix(string prefix) { + string end = MakePrefixEndKey(prefix); + VLOG(1) << "Creating MultiModeKeyRange from Prefix: " << prefix + << ", with end key: " << end; + return MultiModeKeyRange(std::move(prefix), std::move(end)); +} + +/* static */ MultiModeKeyRange MultiModeKeyRange::FromRange(string begin, + string end) { + return MultiModeKeyRange(std::move(begin), std::move(end)); +} + +const string& MultiModeKeyRange::begin_key() const { return begin_; } + +const string& MultiModeKeyRange::end_key() const { return end_; } + +bool MultiModeKeyRange::contains_key(StringPiece key) const { + if (StringPiece(begin_) > key) { + return false; + } + if (StringPiece(end_) <= key && !end_.empty()) { + return false; + } + return true; +} + +} // namespace tensorflow diff --git a/tensorflow/contrib/bigtable/kernels/bigtable_range_helpers.h b/tensorflow/contrib/bigtable/kernels/bigtable_range_helpers.h new file mode 100644 index 0000000000..44c628e366 --- /dev/null +++ b/tensorflow/contrib/bigtable/kernels/bigtable_range_helpers.h @@ -0,0 +1,67 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CONTRIB_BIGTABLE_KERNELS_BIGTABLE_RANGE_HELPERS_H_ +#define TENSORFLOW_CONTRIB_BIGTABLE_KERNELS_BIGTABLE_RANGE_HELPERS_H_ + +#include <string> + +#include "tensorflow/core/lib/core/stringpiece.h" +#include "tensorflow/core/platform/types.h" + +namespace tensorflow { + +// Represents a continuous range of keys defined by either a prefix or a range. +// +// Ranges are represented as "half-open", where the beginning key is included +// in the range, and the end_key is the first excluded key after the range. +// +// The range of keys can be specified either by a key prefix, or by an explicit +// begin key and end key. All methods on this class are valid no matter which +// way the range was specified. +// +// Example: +// MultiModeKeyRange range = MultiModeKeyRange::FromPrefix("myPrefix"); +// if (range.contains_key("myPrefixedKey")) { +// LOG(INFO) << "range from " << range.begin_key() << " to " +// << range.end_key() << "contains \"myPrefixedKey\""; +// } +// if (!range.contains_key("randomKey")) { +// LOG(INFO) << "range does not contain \"randomKey\""; +// } +// range = MultiModeKeyRange::FromRange("a_start_key", "z_end_key"); +class MultiModeKeyRange { + public: + static MultiModeKeyRange FromPrefix(string prefix); + static MultiModeKeyRange FromRange(string begin, string end); + + // The first valid key in the range. + const string& begin_key() const; + // The first invalid key after the valid range. + const string& end_key() const; + // Returns true if the provided key is a part of the range, false otherwise. + bool contains_key(StringPiece key) const; + + private: + MultiModeKeyRange(string begin, string end) + : begin_(std::move(begin)), end_(std::move(end)) {} + + const string begin_; + const string end_; +}; + +} // namespace tensorflow + +#endif // TENSORFLOW_CONTRIB_BIGTABLE_KERNELS_BIGTABLE_RANGE_HELPERS_H_ diff --git a/tensorflow/contrib/bigtable/kernels/bigtable_range_helpers_test.cc b/tensorflow/contrib/bigtable/kernels/bigtable_range_helpers_test.cc new file mode 100644 index 0000000000..1bfc547271 --- /dev/null +++ b/tensorflow/contrib/bigtable/kernels/bigtable_range_helpers_test.cc @@ -0,0 +1,107 @@ +/* Copyright 2016 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/contrib/bigtable/kernels/bigtable_range_helpers.h" +#include "tensorflow/core/platform/test.h" + +namespace tensorflow { +namespace { + +TEST(MultiModeKeyRangeTest, SimplePrefix) { + MultiModeKeyRange r = MultiModeKeyRange::FromPrefix("prefix"); + EXPECT_EQ("prefix", r.begin_key()); + EXPECT_EQ("prefiy", r.end_key()); + EXPECT_TRUE(r.contains_key("prefixed_key")); + EXPECT_FALSE(r.contains_key("not-prefixed-key")); + EXPECT_FALSE(r.contains_key("prefi")); + EXPECT_FALSE(r.contains_key("prefiy")); + EXPECT_FALSE(r.contains_key("early")); + EXPECT_FALSE(r.contains_key("")); +} + +TEST(MultiModeKeyRangeTest, Range) { + MultiModeKeyRange r = MultiModeKeyRange::FromRange("a", "b"); + EXPECT_EQ("a", r.begin_key()); + EXPECT_EQ("b", r.end_key()); + EXPECT_TRUE(r.contains_key("a")); + EXPECT_TRUE(r.contains_key("ab")); + EXPECT_FALSE(r.contains_key("b")); + EXPECT_FALSE(r.contains_key("bc")); + EXPECT_FALSE(r.contains_key("A")); + EXPECT_FALSE(r.contains_key("B")); + EXPECT_FALSE(r.contains_key("")); +} + +TEST(MultiModeKeyRangeTest, InvertedRange) { + MultiModeKeyRange r = MultiModeKeyRange::FromRange("b", "a"); + EXPECT_FALSE(r.contains_key("a")); + EXPECT_FALSE(r.contains_key("b")); + EXPECT_FALSE(r.contains_key("")); +} + +TEST(MultiModeKeyRangeTest, EmptyPrefix) { + MultiModeKeyRange r = MultiModeKeyRange::FromPrefix(""); + EXPECT_EQ("", r.begin_key()); + EXPECT_EQ("", r.end_key()); + EXPECT_TRUE(r.contains_key("")); + EXPECT_TRUE(r.contains_key("a")); + EXPECT_TRUE(r.contains_key("z")); + EXPECT_TRUE(r.contains_key("A")); + EXPECT_TRUE(r.contains_key("ZZZZZZ")); +} + +TEST(MultiModeKeyRangeTest, HalfRange) { + MultiModeKeyRange r = MultiModeKeyRange::FromRange("start", ""); + EXPECT_EQ("start", r.begin_key()); + EXPECT_EQ("", r.end_key()); + EXPECT_TRUE(r.contains_key("start")); + EXPECT_TRUE(r.contains_key("starting")); + EXPECT_TRUE(r.contains_key("z-end")); + EXPECT_FALSE(r.contains_key("")); + EXPECT_FALSE(r.contains_key("early")); +} + +TEST(MultiModeKeyRangeTest, PrefixWrapAround) { + string prefix = "abc\xff"; + MultiModeKeyRange r = MultiModeKeyRange::FromPrefix(prefix); + EXPECT_EQ(prefix, r.begin_key()); + EXPECT_EQ("abd", r.end_key()); + + EXPECT_TRUE(r.contains_key("abc\xff\x07")); + EXPECT_TRUE(r.contains_key("abc\xff\x15")); + EXPECT_TRUE(r.contains_key("abc\xff\x61")); + EXPECT_TRUE(r.contains_key("abc\xff\xff")); + EXPECT_FALSE(r.contains_key("abc\0")); + EXPECT_FALSE(r.contains_key("abd")); +} + +TEST(MultiModeKeyRangeTest, PrefixSignedWrapAround) { + string prefix = "abc\x7f"; + MultiModeKeyRange r = MultiModeKeyRange::FromPrefix(prefix); + EXPECT_EQ(prefix, r.begin_key()); + EXPECT_EQ("abc\x80", r.end_key()); + + EXPECT_TRUE(r.contains_key("abc\x7f\x07")); + EXPECT_TRUE(r.contains_key("abc\x7f\x15")); + EXPECT_TRUE(r.contains_key("abc\x7f\x61")); + EXPECT_TRUE(r.contains_key("abc\x7f\xff")); + EXPECT_FALSE(r.contains_key("abc\0")); + EXPECT_FALSE(r.contains_key("abc\x01")); + EXPECT_FALSE(r.contains_key("abd")); + EXPECT_FALSE(r.contains_key("ab\x80")); +} + +} // namespace +} // namespace tensorflow diff --git a/tensorflow/contrib/bigtable/kernels/bigtable_sample_key_pairs_dataset_op.cc b/tensorflow/contrib/bigtable/kernels/bigtable_sample_key_pairs_dataset_op.cc new file mode 100644 index 0000000000..a1a63a975a --- /dev/null +++ b/tensorflow/contrib/bigtable/kernels/bigtable_sample_key_pairs_dataset_op.cc @@ -0,0 +1,200 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/contrib/bigtable/kernels/bigtable_lib.h" +#include "tensorflow/contrib/bigtable/kernels/bigtable_range_helpers.h" +#include "tensorflow/core/framework/op_kernel.h" + +namespace tensorflow { +namespace { + +class BigtableSampleKeyPairsDatasetOp : public DatasetOpKernel { + public: + using DatasetOpKernel::DatasetOpKernel; + + void MakeDataset(OpKernelContext* ctx, DatasetBase** output) override { + string prefix; + OP_REQUIRES_OK(ctx, ParseScalarArgument<string>(ctx, "prefix", &prefix)); + + string start_key; + OP_REQUIRES_OK(ctx, + ParseScalarArgument<string>(ctx, "start_key", &start_key)); + string end_key; + OP_REQUIRES_OK(ctx, ParseScalarArgument<string>(ctx, "end_key", &end_key)); + + BigtableTableResource* resource; + OP_REQUIRES_OK(ctx, + LookupResource(ctx, HandleFromInput(ctx, 0), &resource)); + + OP_REQUIRES(ctx, prefix.empty() || start_key.empty(), + errors::InvalidArgument( + "Only one of prefix and start_key can be provided")); + if (!prefix.empty()) { + OP_REQUIRES(ctx, end_key.empty(), + errors::InvalidArgument( + "If prefix is specified, end_key must be empty.")); + } + + *output = new Dataset(ctx, resource, std::move(prefix), + std::move(start_key), std::move(end_key)); + } + + private: + class Dataset : public GraphDatasetBase { + public: + explicit Dataset(OpKernelContext* ctx, BigtableTableResource* table, + string prefix, string start_key, string end_key) + : GraphDatasetBase(ctx), + table_(table), + key_range_(MakeMultiModeKeyRange( + std::move(prefix), std::move(start_key), std::move(end_key))) { + table_->Ref(); + } + + ~Dataset() override { table_->Unref(); } + + std::unique_ptr<IteratorBase> MakeIteratorInternal( + const string& prefix) const override { + return std::unique_ptr<IteratorBase>(new Iterator( + {this, strings::StrCat(prefix, "::BigtableSampleKeyPairsDataset")})); + } + + const DataTypeVector& output_dtypes() const override { + static DataTypeVector* dtypes = + new DataTypeVector({DT_STRING, DT_STRING}); + return *dtypes; + } + + const std::vector<PartialTensorShape>& output_shapes() const override { + static std::vector<PartialTensorShape>* shapes = + new std::vector<PartialTensorShape>({{}, {}}); + return *shapes; + } + + string DebugString() const override { + return "BigtableSampleKeyPairsDatasetOp::Dataset"; + } + + private: + static MultiModeKeyRange MakeMultiModeKeyRange(string prefix, + string start_key, + string end_key) { + if (!start_key.empty()) { + return MultiModeKeyRange::FromRange(std::move(start_key), + std::move(end_key)); + } + return MultiModeKeyRange::FromPrefix(std::move(prefix)); + } + + BigtableTableResource& table() const { return *table_; } + + class Iterator : public DatasetIterator<Dataset> { + public: + explicit Iterator(const Params& params) + : DatasetIterator<Dataset>(params) {} + + // Computes split points (`keys_`) to use when scanning the table. + // + // Initialize first retrieves the sample keys from the table (`row_keys`), + // as these often form good split points within the table. We then iterate + // over them, and copy them to `keys_` if they fall within the requested + // range to scan (`dataset()->key_range_`). Because the requested range + // might start between elements of the sampled keys list, care is taken to + // ensure we don't accidentally miss any subsets of the requested range by + // including `begin_key()` and `end_key()` as appropriate. + Status Initialize(IteratorContext* ctx) override { + grpc::Status status; + std::vector<google::cloud::bigtable::RowKeySample> row_keys = + dataset()->table().table().SampleRows(status); + if (!status.ok()) { + return GrpcStatusToTfStatus(status); + } + + for (size_t i = 0; i < row_keys.size(); ++i) { + string row_key(row_keys[i].row_key); + if (dataset()->key_range_.contains_key(row_key)) { + // First key: check to see if we need to add the begin_key. + if (keys_.empty() && dataset()->key_range_.begin_key() != row_key) { + keys_.push_back(dataset()->key_range_.begin_key()); + } + keys_.push_back(std::move(row_key)); + } else if (!keys_.empty()) { + // If !keys_.empty(), then we have found at least one element of + // `row_keys` that is within our requested range + // (`dataset()->key_range_`). Because `row_keys` is sorted, if we + // have found an element that's not within our key range, then we + // are after our requested range (ranges are contiguous) and can end + // iteration early. + break; + } + } + + // Handle the case where we skip over the selected range entirely. + if (keys_.empty()) { + keys_.push_back(dataset()->key_range_.begin_key()); + } + + // Last key: check to see if we need to add the end_key. + if (keys_.back() != dataset()->key_range_.end_key()) { + keys_.push_back(dataset()->key_range_.end_key()); + } + return Status::OK(); + } + + Status GetNextInternal(IteratorContext* ctx, + std::vector<Tensor>* out_tensors, + bool* end_of_sequence) override { + mutex_lock l(mu_); + if (index_ > keys_.size() - 2) { + *end_of_sequence = true; + return Status::OK(); + } + + *end_of_sequence = false; + out_tensors->emplace_back(ctx->allocator({}), DT_STRING, + TensorShape({})); + out_tensors->back().scalar<string>()() = keys_[index_]; + + out_tensors->emplace_back(ctx->allocator({}), DT_STRING, + TensorShape({})); + out_tensors->back().scalar<string>()() = keys_[index_ + 1]; + ++index_; + + return Status::OK(); + } + + private: + mutex mu_; + size_t index_ GUARDED_BY(mu_) = 0; + // Note: we store the keys_ on the iterator instead of the dataset + // because we want to re-sample the row keys in case there have been + // tablet rebalancing operations since the dataset was created. + // + // Note: keys_ is readonly after Initialize, and thus does not need a + // guarding lock. + std::vector<string> keys_; + }; + + BigtableTableResource* const table_; + const MultiModeKeyRange key_range_; + }; +}; + +REGISTER_KERNEL_BUILDER( + Name("BigtableSampleKeyPairsDataset").Device(DEVICE_CPU), + BigtableSampleKeyPairsDatasetOp); + +} // namespace +} // namespace tensorflow diff --git a/tensorflow/contrib/bigtable/ops/bigtable_ops.cc b/tensorflow/contrib/bigtable/ops/bigtable_ops.cc index 36a392f2a4..416b719e30 100644 --- a/tensorflow/contrib/bigtable/ops/bigtable_ops.cc +++ b/tensorflow/contrib/bigtable/ops/bigtable_ops.cc @@ -79,6 +79,16 @@ REGISTER_OP("BigtableSampleKeysDataset") // stateful to inhibit constant folding. .SetShapeFn(shape_inference::ScalarShape); +REGISTER_OP("BigtableSampleKeyPairsDataset") + .Input("table: resource") + .Input("prefix: string") + .Input("start_key: string") + .Input("end_key: string") + .Output("handle: variant") + .SetIsStateful() // TODO(b/65524810): Source dataset ops must be marked + // stateful to inhibit constant folding. + .SetShapeFn(shape_inference::ScalarShape); + // TODO(saeta): Support continuing despite bad data (e.g. empty string, or // skip incomplete row.) REGISTER_OP("BigtableScanDataset") diff --git a/tensorflow/contrib/bigtable/python/kernel_tests/bigtable_ops_test.py b/tensorflow/contrib/bigtable/python/kernel_tests/bigtable_ops_test.py index 028c861ca3..2f20064619 100644 --- a/tensorflow/contrib/bigtable/python/kernel_tests/bigtable_ops_test.py +++ b/tensorflow/contrib/bigtable/python/kernel_tests/bigtable_ops_test.py @@ -21,6 +21,7 @@ from __future__ import print_function from tensorflow.contrib import bigtable from tensorflow.contrib.bigtable.ops import gen_bigtable_ops from tensorflow.contrib.bigtable.ops import gen_bigtable_test_ops +from tensorflow.contrib.bigtable.python.ops import bigtable_api from tensorflow.contrib.util import loader from tensorflow.python.data.ops import dataset_ops from tensorflow.python.framework import errors @@ -32,6 +33,10 @@ _bigtable_so = loader.load_op_library( resource_loader.get_path_to_datafile("_bigtable_test.so")) +def _ListOfTuplesOfStringsToBytes(values): + return [(compat.as_bytes(i[0]), compat.as_bytes(i[1])) for i in values] + + class BigtableOpsTest(test.TestCase): COMMON_ROW_KEYS = ["r1", "r2", "r3"] COMMON_VALUES = ["v1", "v2", "v3"] @@ -100,12 +105,18 @@ class BigtableOpsTest(test.TestCase): def testScanPrefixListCol(self): self.runScanTest(self._table.scan_prefix("r", cf1=["c1"])) + def testScanPrefixTupleCol(self): + self.runScanTest(self._table.scan_prefix("r", columns=("cf1", "c1"))) + def testScanRangeStringCol(self): self.runScanTest(self._table.scan_range("r1", "r4", cf1="c1")) def testScanRangeListCol(self): self.runScanTest(self._table.scan_range("r1", "r4", cf1=["c1"])) + def testScanRangeTupleCol(self): + self.runScanTest(self._table.scan_range("r1", "r4", columns=("cf1", "c1"))) + def testLookup(self): ds = self._table.keys_by_prefix_dataset("r") ds = ds.apply(self._table.lookup_columns(cf1="c1")) @@ -149,6 +160,113 @@ class BigtableOpsTest(test.TestCase): with self.assertRaises(errors.OutOfRangeError): sess.run(n) + def runSampleKeyPairsTest(self, ds, expected_key_pairs): + itr = ds.make_initializable_iterator() + n = itr.get_next() + with self.test_session() as sess: + self._writeCommonValues(sess) + sess.run(itr.initializer) + for i, elems in enumerate(expected_key_pairs): + output = sess.run(n) + self.assertEqual( + compat.as_bytes(elems[0]), compat.as_bytes(output[0]), + "Unequal key pair (first element) at step %d; want: %s, got %s" % + (i, compat.as_bytes(elems[0]), compat.as_bytes(output[0]))) + self.assertEqual( + compat.as_bytes(elems[1]), compat.as_bytes(output[1]), + "Unequal key pair (second element) at step %d; want: %s, got %s" % + (i, compat.as_bytes(elems[1]), compat.as_bytes(output[1]))) + with self.assertRaises(errors.OutOfRangeError): + sess.run(n) + + def testSampleKeyPairsSimplePrefix(self): + ds = bigtable_api._BigtableSampleKeyPairsDataset( + self._table, prefix="r", start="", end="") + expected_key_pairs = [("r", "r1"), ("r1", "r3"), ("r3", "s")] + self.runSampleKeyPairsTest(ds, expected_key_pairs) + + def testSampleKeyPairsSimpleRange(self): + ds = bigtable_api._BigtableSampleKeyPairsDataset( + self._table, prefix="", start="r1", end="r3") + expected_key_pairs = [("r1", "r3")] + self.runSampleKeyPairsTest(ds, expected_key_pairs) + + def testSampleKeyPairsSkipRangePrefix(self): + ds = bigtable_api._BigtableSampleKeyPairsDataset( + self._table, prefix="r2", start="", end="") + expected_key_pairs = [("r2", "r3")] + self.runSampleKeyPairsTest(ds, expected_key_pairs) + + def testSampleKeyPairsSkipRangeRange(self): + ds = bigtable_api._BigtableSampleKeyPairsDataset( + self._table, prefix="", start="r2", end="r3") + expected_key_pairs = [("r2", "r3")] + self.runSampleKeyPairsTest(ds, expected_key_pairs) + + def testSampleKeyPairsOffsetRanges(self): + ds = bigtable_api._BigtableSampleKeyPairsDataset( + self._table, prefix="", start="r2", end="r4") + expected_key_pairs = [("r2", "r3"), ("r3", "r4")] + self.runSampleKeyPairsTest(ds, expected_key_pairs) + + def testSampleKeyPairEverything(self): + ds = bigtable_api._BigtableSampleKeyPairsDataset( + self._table, prefix="", start="", end="") + expected_key_pairs = [("", "r1"), ("r1", "r3"), ("r3", "")] + self.runSampleKeyPairsTest(ds, expected_key_pairs) + + def testSampleKeyPairsPrefixAndStartKey(self): + ds = bigtable_api._BigtableSampleKeyPairsDataset( + self._table, prefix="r", start="r1", end="") + itr = ds.make_initializable_iterator() + with self.test_session() as sess: + with self.assertRaises(errors.InvalidArgumentError): + sess.run(itr.initializer) + + def testSampleKeyPairsPrefixAndEndKey(self): + ds = bigtable_api._BigtableSampleKeyPairsDataset( + self._table, prefix="r", start="", end="r3") + itr = ds.make_initializable_iterator() + with self.test_session() as sess: + with self.assertRaises(errors.InvalidArgumentError): + sess.run(itr.initializer) + + def testParallelScanPrefix(self): + ds = self._table.parallel_scan_prefix(prefix="r", cf1="c1") + itr = ds.make_initializable_iterator() + n = itr.get_next() + with self.test_session() as sess: + self._writeCommonValues(sess) + sess.run(itr.initializer) + expected_values = list(zip(self.COMMON_ROW_KEYS, self.COMMON_VALUES)) + actual_values = [] + for _ in range(len(expected_values)): + output = sess.run(n) + actual_values.append(output) + with self.assertRaises(errors.OutOfRangeError): + sess.run(n) + self.assertItemsEqual( + _ListOfTuplesOfStringsToBytes(expected_values), + _ListOfTuplesOfStringsToBytes(actual_values)) + + def testParallelScanRange(self): + ds = self._table.parallel_scan_range(start="r1", end="r4", cf1="c1") + itr = ds.make_initializable_iterator() + n = itr.get_next() + with self.test_session() as sess: + self._writeCommonValues(sess) + sess.run(itr.initializer) + expected_values = list(zip(self.COMMON_ROW_KEYS, self.COMMON_VALUES)) + actual_values = [] + for _ in range(len(expected_values)): + output = sess.run(n) + actual_values.append(output) + with self.assertRaises(errors.OutOfRangeError): + sess.run(n) + self.assertItemsEqual( + _ListOfTuplesOfStringsToBytes(expected_values), + _ListOfTuplesOfStringsToBytes(actual_values)) + if __name__ == "__main__": test.main() diff --git a/tensorflow/contrib/bigtable/python/ops/bigtable_api.py b/tensorflow/contrib/bigtable/python/ops/bigtable_api.py index a7ec3a1142..9f73b7223c 100644 --- a/tensorflow/contrib/bigtable/python/ops/bigtable_api.py +++ b/tensorflow/contrib/bigtable/python/ops/bigtable_api.py @@ -28,8 +28,10 @@ from __future__ import division from __future__ import print_function from six import iteritems +from six import string_types from tensorflow.contrib.bigtable.ops import gen_bigtable_ops +from tensorflow.contrib.data.python.ops import interleave_ops from tensorflow.contrib.util import loader from tensorflow.python.data.ops import dataset_ops from tensorflow.python.data.util import nest @@ -251,9 +253,11 @@ class BigTable(object): Note: only the latest value of a cell will be retrieved. Args: - prefix: The prefix all row keys muat match to be retrieved for prefix- + prefix: The prefix all row keys must match to be retrieved for prefix- based scans. - probability: Probabilistically sample rows. + probability: (Optional.) A float between 0 (exclusive) and 1 (inclusive). + A non-1 value indicates to probabilistically sample rows with the + provided probability. columns: The columns to read. Note: most commonly, they are expressed as kwargs. Use the columns value if you are using column families that are reserved. The value of columns and kwargs are merged. Columns is a list @@ -268,26 +272,8 @@ class BigTable(object): Raises: ValueError: If the configured probability is unexpected. """ - if probability is None: - probability = 1.0 - if isinstance(probability, float) and (probability <= 0.0 or - probability > 1.0): - raise ValueError("probability must be in the range (0, 1].") - - normalized = columns - if normalized is None: - normalized = [] - if isinstance(normalized, tuple): - normalized = list(normalized) - for key, value in iteritems(kwargs): - if key == "name": - continue - if isinstance(value, str): - normalized.append((key, value)) - continue - for col in value: - normalized.append((key, col)) - + probability = _normalize_probability(probability) + normalized = _normalize_columns(columns, kwargs) return _BigtableScanDataset(self, prefix, "", "", normalized, probability) def scan_range(self, start, end, probability=None, columns=None, **kwargs): @@ -314,7 +300,9 @@ class BigTable(object): Args: start: The start of the range when scanning by range. end: (Optional.) The end of the range when scanning by range. - probability: Probabilistically sample rows. + probability: (Optional.) A float between 0 (exclusive) and 1 (inclusive). + A non-1 value indicates to probabilistically sample rows with the + provided probability. columns: The columns to read. Note: most commonly, they are expressed as kwargs. Use the columns value if you are using column families that are reserved. The value of columns and kwargs are merged. Columns is a list @@ -329,27 +317,129 @@ class BigTable(object): Raises: ValueError: If the configured probability is unexpected. """ - if probability is None: - probability = 1.0 - if isinstance(probability, float) and (probability <= 0.0 or - probability > 1.0): - raise ValueError("probability must be in the range (0, 1].") + probability = _normalize_probability(probability) + normalized = _normalize_columns(columns, kwargs) + return _BigtableScanDataset(self, "", start, end, normalized, probability) - normalized = columns - if normalized is None: - normalized = [] - if isinstance(normalized, tuple): - normalized = list(normalized) - for key, value in iteritems(kwargs): - if key == "name": - continue - if isinstance(value, str): - normalized.append((key, value)) - continue - for col in value: - normalized.append((key, col)) + def parallel_scan_prefix(self, + prefix, + num_parallel_scans=None, + probability=None, + columns=None, + **kwargs): + """Retrieves row (including values) from the Bigtable service at high speed. - return _BigtableScanDataset(self, "", start, end, normalized, probability) + Rows with row-key prefixed by `prefix` will be retrieved. This method is + similar to `scan_prefix`, but by constrast performs multiple sub-scans in + parallel in order to achieve higher performance. + + Note: The dataset produced by this method is not deterministic! + + Specifying the columns to retrieve for each row is done by either using + kwargs or in the columns parameter. To retrieve values of the columns "c1", + and "c2" from the column family "cfa", and the value of the column "c3" + from column family "cfb", the following datasets (`ds1`, and `ds2`) are + equivalent: + + ``` + table = # ... + ds1 = table.parallel_scan_prefix("row_prefix", columns=[("cfa", "c1"), + ("cfa", "c2"), + ("cfb", "c3")]) + ds2 = table.parallel_scan_prefix("row_prefix", cfa=["c1", "c2"], cfb="c3") + ``` + + Note: only the latest value of a cell will be retrieved. + + Args: + prefix: The prefix all row keys must match to be retrieved for prefix- + based scans. + num_parallel_scans: (Optional.) The number of concurrent scans against the + Cloud Bigtable instance. + probability: (Optional.) A float between 0 (exclusive) and 1 (inclusive). + A non-1 value indicates to probabilistically sample rows with the + provided probability. + columns: The columns to read. Note: most commonly, they are expressed as + kwargs. Use the columns value if you are using column families that are + reserved. The value of columns and kwargs are merged. Columns is a list + of tuples of strings ("column_family", "column_qualifier"). + **kwargs: The column families and columns to read. Keys are treated as + column_families, and values can be either lists of strings, or strings + that are treated as the column qualifier (column name). + + Returns: + A @{tf.data.Dataset} returning the row keys and the cell contents. + + Raises: + ValueError: If the configured probability is unexpected. + """ + probability = _normalize_probability(probability) + normalized = _normalize_columns(columns, kwargs) + ds = _BigtableSampleKeyPairsDataset(self, prefix, "", "") + return self._make_parallel_scan_dataset(ds, num_parallel_scans, probability, + normalized) + + def parallel_scan_range(self, + start, + end, + num_parallel_scans=None, + probability=None, + columns=None, + **kwargs): + """Retrieves rows (including values) from the Bigtable service. + + Rows with row-keys between `start` and `end` will be retrieved. This method + is similar to `scan_range`, but by constrast performs multiple sub-scans in + parallel in order to achieve higher performance. + + Note: The dataset produced by this method is not deterministic! + + Specifying the columns to retrieve for each row is done by either using + kwargs or in the columns parameter. To retrieve values of the columns "c1", + and "c2" from the column family "cfa", and the value of the column "c3" + from column family "cfb", the following datasets (`ds1`, and `ds2`) are + equivalent: + + ``` + table = # ... + ds1 = table.parallel_scan_range("row_start", + "row_end", + columns=[("cfa", "c1"), + ("cfa", "c2"), + ("cfb", "c3")]) + ds2 = table.parallel_scan_range("row_start", "row_end", + cfa=["c1", "c2"], cfb="c3") + ``` + + Note: only the latest value of a cell will be retrieved. + + Args: + start: The start of the range when scanning by range. + end: (Optional.) The end of the range when scanning by range. + num_parallel_scans: (Optional.) The number of concurrent scans against the + Cloud Bigtable instance. + probability: (Optional.) A float between 0 (exclusive) and 1 (inclusive). + A non-1 value indicates to probabilistically sample rows with the + provided probability. + columns: The columns to read. Note: most commonly, they are expressed as + kwargs. Use the columns value if you are using column families that are + reserved. The value of columns and kwargs are merged. Columns is a list + of tuples of strings ("column_family", "column_qualifier"). + **kwargs: The column families and columns to read. Keys are treated as + column_families, and values can be either lists of strings, or strings + that are treated as the column qualifier (column name). + + Returns: + A @{tf.data.Dataset} returning the row keys and the cell contents. + + Raises: + ValueError: If the configured probability is unexpected. + """ + probability = _normalize_probability(probability) + normalized = _normalize_columns(columns, kwargs) + ds = _BigtableSampleKeyPairsDataset(self, "", start, end) + return self._make_parallel_scan_dataset(ds, num_parallel_scans, probability, + normalized) def write(self, dataset, column_families, columns, timestamp=None): """Writes a dataset to the table. @@ -396,6 +486,89 @@ class BigTable(object): columns, timestamp) + def _make_parallel_scan_dataset(self, ds, num_parallel_scans, + normalized_probability, normalized_columns): + """Builds a parallel dataset from a given range. + + Args: + ds: A `_BigtableSampleKeyPairsDataset` returning ranges of keys to use. + num_parallel_scans: The number of concurrent parallel scans to use. + normalized_probability: A number between 0 and 1 for the keep probability. + normalized_columns: The column families and column qualifiers to retrieve. + + Returns: + A @{tf.data.Dataset} representing the result of the parallel scan. + """ + if num_parallel_scans is None: + num_parallel_scans = 50 + + ds = ds.shuffle(buffer_size=10000) # TODO(saeta): Make configurable. + + def _interleave_fn(start, end): + return _BigtableScanDataset( + self, + prefix="", + start=start, + end=end, + normalized=normalized_columns, + probability=normalized_probability) + + # Note prefetch_input_elements must be set in order to avoid rpc timeouts. + ds = ds.apply( + interleave_ops.parallel_interleave( + _interleave_fn, + cycle_length=num_parallel_scans, + sloppy=True, + prefetch_input_elements=1)) + return ds + + +def _normalize_probability(probability): + if probability is None: + probability = 1.0 + if isinstance(probability, float) and (probability <= 0.0 or + probability > 1.0): + raise ValueError("probability must be in the range (0, 1].") + return probability + + +def _normalize_columns(columns, provided_kwargs): + """Converts arguments (columns, and kwargs dict) to C++ representation. + + Args: + columns: a datastructure containing the column families and qualifier to + retrieve. Valid types include (1) None, (2) list of tuples, (3) a tuple of + strings. + provided_kwargs: a dictionary containing the column families and qualifiers + to retrieve + + Returns: + A list of pairs of column family+qualifier to retrieve. + + Raises: + ValueError: If there are no cells to retrieve or the columns are in an + incorrect format. + """ + normalized = columns + if normalized is None: + normalized = [] + if isinstance(normalized, tuple): + if len(normalized) == 2: + normalized = [normalized] + else: + raise ValueError("columns was a tuple of inappropriate length") + for key, value in iteritems(provided_kwargs): + if key == "name": + continue + if isinstance(value, string_types): + normalized.append((key, value)) + continue + for col in value: + normalized.append((key, col)) + if not normalized: + raise ValueError("At least one column + column family must be specified.") + return normalized + class _BigtableKeyDataset(dataset_ops.Dataset): """_BigtableKeyDataset is an abstract class representing the keys of a table. @@ -535,3 +708,34 @@ class _BigtableScanDataset(dataset_ops.Dataset): column_families=self._column_families, columns=self._columns, probability=self._probability) + + +class _BigtableSampleKeyPairsDataset(dataset_ops.Dataset): + """_BigtableKeyRangeDataset returns key pairs from the Bigtable. + """ + + def __init__(self, table, prefix, start, end): + self._table = table + self._prefix = prefix + self._start = start + self._end = end + + @property + def output_classes(self): + return (ops.Tensor, ops.Tensor) + + @property + def output_shapes(self): + return (tensor_shape.TensorShape([]), tensor_shape.TensorShape([])) + + @property + def output_types(self): + return (dtypes.string, dtypes.string) + + def _as_variant_tensor(self): + # pylint: disable=protected-access + return gen_bigtable_ops.bigtable_sample_key_pairs_dataset( + table=self._table._resource, + prefix=self._prefix, + start_key=self._start, + end_key=self._end) diff --git a/tensorflow/contrib/cmake/tf_core_framework.cmake b/tensorflow/contrib/cmake/tf_core_framework.cmake index 872b016d2b..067c299a71 100644 --- a/tensorflow/contrib/cmake/tf_core_framework.cmake +++ b/tensorflow/contrib/cmake/tf_core_framework.cmake @@ -49,48 +49,43 @@ function(RELATIVE_PROTOBUF_GENERATE_CPP SRCS HDRS ROOT_DIR) set(${HDRS} ${${HDRS}} PARENT_SCOPE) endfunction() -function(RELATIVE_PROTOBUF_GENERATE_GRPC_CPP SRCS HDRS ROOT_DIR) - if(NOT ARGN) - message(SEND_ERROR "Error: RELATIVE_PROTOBUF_GENERATE_GRPC_CPP() called without any proto files") - return() - endif() - - set(${SRCS}) - set(${HDRS}) - foreach(FIL ${ARGN}) - set(ABS_FIL ${ROOT_DIR}/${FIL}) - get_filename_component(FIL_WE ${FIL} NAME_WE) - get_filename_component(FIL_DIR ${ABS_FIL} PATH) - file(RELATIVE_PATH REL_DIR ${ROOT_DIR} ${FIL_DIR}) - - list(APPEND ${SRCS} "${CMAKE_CURRENT_BINARY_DIR}/${REL_DIR}/${FIL_WE}.grpc.pb.cc") - list(APPEND ${HDRS} "${CMAKE_CURRENT_BINARY_DIR}/${REL_DIR}/${FIL_WE}.grpc.pb.h") - list(APPEND ${SRCS} "${CMAKE_CURRENT_BINARY_DIR}/${REL_DIR}/${FIL_WE}.pb.cc") - list(APPEND ${HDRS} "${CMAKE_CURRENT_BINARY_DIR}/${REL_DIR}/${FIL_WE}.pb.h") - - # We adust the path of the gRPC code generation accordingly. - if(WIN32) - set(GRPC_PROTOC_PLUGIN_PATH ${GRPC_BUILD}/Release/grpc_cpp_plugin.exe) - else() - set(GRPC_PROTOC_PLUGIN_PATH ${GRPC_BUILD}/grpc_cpp_plugin) +if(NOT WIN32) + function(RELATIVE_PROTOBUF_GENERATE_GRPC_CPP SRCS HDRS ROOT_DIR) + if(NOT ARGN) + message(SEND_ERROR "Error: RELATIVE_PROTOBUF_GENERATE_GRPC_CPP() called without any proto files") + return() endif() - add_custom_command( - OUTPUT "${CMAKE_CURRENT_BINARY_DIR}/${REL_DIR}/${FIL_WE}.grpc.pb.cc" - "${CMAKE_CURRENT_BINARY_DIR}/${REL_DIR}/${FIL_WE}.grpc.pb.h" - "${CMAKE_CURRENT_BINARY_DIR}/${REL_DIR}/${FIL_WE}.pb.cc" - "${CMAKE_CURRENT_BINARY_DIR}/${REL_DIR}/${FIL_WE}.pb.h" - COMMAND ${PROTOBUF_PROTOC_EXECUTABLE} - ARGS --grpc_out ${CMAKE_CURRENT_BINARY_DIR} --cpp_out ${CMAKE_CURRENT_BINARY_DIR} --plugin=protoc-gen-grpc=${GRPC_PROTOC_PLUGIN_PATH} -I ${ROOT_DIR} ${ABS_FIL} -I ${PROTOBUF_INCLUDE_DIRS} - DEPENDS ${ABS_FIL} protobuf grpc - COMMENT "Running C++ protocol buffer grpc compiler on ${FIL}" - VERBATIM ) - endforeach() - - set_source_files_properties(${${SRCS}} ${${HDRS}} PROPERTIES GENERATED TRUE) - set(${SRCS} ${${SRCS}} PARENT_SCOPE) - set(${HDRS} ${${HDRS}} PARENT_SCOPE) -endfunction() + set(${SRCS}) + set(${HDRS}) + foreach(FIL ${ARGN}) + set(ABS_FIL ${ROOT_DIR}/${FIL}) + get_filename_component(FIL_WE ${FIL} NAME_WE) + get_filename_component(FIL_DIR ${ABS_FIL} PATH) + file(RELATIVE_PATH REL_DIR ${ROOT_DIR} ${FIL_DIR}) + + list(APPEND ${SRCS} "${CMAKE_CURRENT_BINARY_DIR}/${REL_DIR}/${FIL_WE}.grpc.pb.cc") + list(APPEND ${HDRS} "${CMAKE_CURRENT_BINARY_DIR}/${REL_DIR}/${FIL_WE}.grpc.pb.h") + list(APPEND ${SRCS} "${CMAKE_CURRENT_BINARY_DIR}/${REL_DIR}/${FIL_WE}.pb.cc") + list(APPEND ${HDRS} "${CMAKE_CURRENT_BINARY_DIR}/${REL_DIR}/${FIL_WE}.pb.h") + + add_custom_command( + OUTPUT "${CMAKE_CURRENT_BINARY_DIR}/${REL_DIR}/${FIL_WE}.grpc.pb.cc" + "${CMAKE_CURRENT_BINARY_DIR}/${REL_DIR}/${FIL_WE}.grpc.pb.h" + "${CMAKE_CURRENT_BINARY_DIR}/${REL_DIR}/${FIL_WE}.pb.cc" + "${CMAKE_CURRENT_BINARY_DIR}/${REL_DIR}/${FIL_WE}.pb.h" + COMMAND ${PROTOBUF_PROTOC_EXECUTABLE} + ARGS --grpc_out ${CMAKE_CURRENT_BINARY_DIR} --cpp_out ${CMAKE_CURRENT_BINARY_DIR} --plugin protoc-gen-grpc=${GRPC_BUILD}/grpc_cpp_plugin -I ${ROOT_DIR} ${ABS_FIL} -I ${PROTOBUF_INCLUDE_DIRS} + DEPENDS ${ABS_FIL} protobuf grpc + COMMENT "Running C++ protocol buffer grpc compiler on ${FIL}" + VERBATIM ) + endforeach() + + set_source_files_properties(${${SRCS}} ${${HDRS}} PROPERTIES GENERATED TRUE) + set(${SRCS} ${${SRCS}} PARENT_SCOPE) + set(${HDRS} ${${HDRS}} PARENT_SCOPE) + endfunction() +endif() function(RELATIVE_PROTOBUF_TEXT_GENERATE_CPP SRCS HDRS ROOT_DIR) if(NOT ARGN) @@ -180,14 +175,17 @@ RELATIVE_PROTOBUF_TEXT_GENERATE_CPP(PROTO_TEXT_SRCS PROTO_TEXT_HDRS ${tensorflow_source_dir} ${tf_proto_text_srcs} ) -file(GLOB_RECURSE tf_protos_grpc_cc_srcs RELATIVE ${tensorflow_source_dir} - "${tensorflow_source_dir}/tensorflow/core/debug/*.proto" - "${tensorflow_source_dir}/tensorflow/core/protobuf/master_service.proto" -) -RELATIVE_PROTOBUF_GENERATE_GRPC_CPP(PROTO_GRPC_SRCS PROTO_GRPC_HDRS - ${tensorflow_source_dir} ${tf_protos_grpc_cc_srcs} -) -add_library(tf_protos_cc ${PROTO_GRPC_SRCS} ${PROTO_GRPC_HDRS} ${PROTO_SRCS} ${PROTO_HDRS}) +if(WIN32) + add_library(tf_protos_cc ${PROTO_SRCS} ${PROTO_HDRS}) +else() + file(GLOB_RECURSE tf_protos_grpc_cc_srcs RELATIVE ${tensorflow_source_dir} + "${tensorflow_source_dir}/tensorflow/core/debug/*.proto" + ) + RELATIVE_PROTOBUF_GENERATE_GRPC_CPP(PROTO_GRPC_SRCS PROTO_GRPC_HDRS + ${tensorflow_source_dir} ${tf_protos_grpc_cc_srcs} + ) + add_library(tf_protos_cc ${PROTO_GRPC_SRCS} ${PROTO_GRPC_HDRS} ${PROTO_SRCS} ${PROTO_HDRS}) +endif() ######################################################## # tf_core_lib library diff --git a/tensorflow/contrib/cmake/tf_python.cmake b/tensorflow/contrib/cmake/tf_python.cmake index e3b59001bc..8a9172b43c 100755 --- a/tensorflow/contrib/cmake/tf_python.cmake +++ b/tensorflow/contrib/cmake/tf_python.cmake @@ -853,6 +853,7 @@ add_custom_command( "--apidir=${CMAKE_CURRENT_BINARY_DIR}/tf_python/tensorflow/python/estimator/api" "--package=tensorflow.python.estimator" "--apiname=estimator" + "--output_package=tensorflow.python.estimator.api" "${estimator_api_init_list_file}" COMMENT "Generating __init__.py files for Python API." diff --git a/tensorflow/contrib/data/python/kernel_tests/BUILD b/tensorflow/contrib/data/python/kernel_tests/BUILD index 784d5faacf..9a454efc4c 100644 --- a/tensorflow/contrib/data/python/kernel_tests/BUILD +++ b/tensorflow/contrib/data/python/kernel_tests/BUILD @@ -233,6 +233,7 @@ cuda_py_test( "//tensorflow/python/data/ops:dataset_ops", "//tensorflow/python/data/ops:iterator_ops", ], + tags = ["no_windows_gpu"], ) py_test( diff --git a/tensorflow/contrib/distribute/BUILD b/tensorflow/contrib/distribute/BUILD index 74b2cd90a1..1126f76f58 100644 --- a/tensorflow/contrib/distribute/BUILD +++ b/tensorflow/contrib/distribute/BUILD @@ -30,6 +30,7 @@ py_library( "//tensorflow/contrib/distribute/python:monitor", "//tensorflow/contrib/distribute/python:one_device_strategy", "//tensorflow/contrib/distribute/python:step_fn", + "//tensorflow/contrib/distribute/python:tpu_strategy", "//tensorflow/python:training", "//tensorflow/python:util", ], diff --git a/tensorflow/contrib/distribute/__init__.py b/tensorflow/contrib/distribute/__init__.py index 76711baf3a..2e2c3be853 100644 --- a/tensorflow/contrib/distribute/__init__.py +++ b/tensorflow/contrib/distribute/__init__.py @@ -24,6 +24,7 @@ from tensorflow.contrib.distribute.python.mirrored_strategy import MirroredStrat from tensorflow.contrib.distribute.python.monitor import Monitor from tensorflow.contrib.distribute.python.one_device_strategy import OneDeviceStrategy from tensorflow.contrib.distribute.python.step_fn import * +from tensorflow.contrib.distribute.python.tpu_strategy import TPUStrategy from tensorflow.python.training.distribute import * from tensorflow.python.util.all_util import remove_undocumented @@ -41,6 +42,7 @@ _allowed_symbols = [ 'StandardInputStep', 'StandardSingleLossStep', 'TowerContext', + 'TPUStrategy', 'get_cross_tower_context', 'get_distribution_strategy', 'get_loss_reduction', diff --git a/tensorflow/contrib/distribute/python/BUILD b/tensorflow/contrib/distribute/python/BUILD index eba0dd0ea3..40dbfa3dd2 100644 --- a/tensorflow/contrib/distribute/python/BUILD +++ b/tensorflow/contrib/distribute/python/BUILD @@ -587,6 +587,7 @@ cuda_py_test( ], tags = [ "multi_and_single_gpu", + "no_windows_gpu", "notsan", ], ) diff --git a/tensorflow/contrib/distribute/python/mirrored_strategy_multigpu_test.py b/tensorflow/contrib/distribute/python/mirrored_strategy_multigpu_test.py index 15161b604a..6a14b833d2 100644 --- a/tensorflow/contrib/distribute/python/mirrored_strategy_multigpu_test.py +++ b/tensorflow/contrib/distribute/python/mirrored_strategy_multigpu_test.py @@ -491,13 +491,14 @@ class MirroredStrategyVariableCreationTest(test.TestCase): components_mean = {} def model_fn(device_id): - tower_context = distribute_lib.get_tower_context() - with tower_context.tower_local_var_scope( - variable_scope.VariableAggregation.SUM): - v_sum = variable_scope.variable(1.0) - with tower_context.tower_local_var_scope( - variable_scope.VariableAggregation.MEAN): - v_mean = variable_scope.variable(4.0) + v_sum = variable_scope.variable( + 1.0, + synchronization=variable_scope.VariableSynchronization.ON_READ, + aggregation=variable_scope.VariableAggregation.SUM) + v_mean = variable_scope.variable( + 4.0, + synchronization=variable_scope.VariableSynchronization.ON_READ, + aggregation=variable_scope.VariableAggregation.MEAN) self.assertTrue(isinstance(v_sum, values.TowerLocalVariable)) self.assertTrue(isinstance(v_mean, values.TowerLocalVariable)) updates = [v_sum.assign_add(2.0 + device_id), @@ -700,10 +701,10 @@ class MirroredStrategyVariableCreationTest(test.TestCase): with context.graph_mode(): def model_fn(): - tower_context = distribute_lib.get_tower_context() - with tower_context.tower_local_var_scope( - variable_scope.VariableAggregation.SUM): - v_sum = variable_scope.variable(1.0) + v_sum = variable_scope.variable( + 1.0, + synchronization=variable_scope.VariableSynchronization.ON_READ, + aggregation=variable_scope.VariableAggregation.SUM) self.assertTrue(isinstance(v_sum, values.TowerLocalVariable)) return v_sum @@ -949,10 +950,10 @@ class MirroredAndTowerLocalVariableInitializerTest(test.TestCase): # upon construction instead of once the initialization op is run. with context.graph_mode(): def model_fn(): - tower_context = distribute_lib.get_tower_context() - with tower_context.tower_local_var_scope( - variable_scope.VariableAggregation.SUM): - v_sum = variable_scope.variable(1.0) + v_sum = variable_scope.variable( + 1.0, + synchronization=variable_scope.VariableSynchronization.ON_READ, + aggregation=variable_scope.VariableAggregation.SUM) self.assertTrue(isinstance(v_sum, values.TowerLocalVariable)) return v_sum diff --git a/tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb b/tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb new file mode 100644 index 0000000000..15e013f219 --- /dev/null +++ b/tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb @@ -0,0 +1,1184 @@ +{ + "nbformat": 4, + "nbformat_minor": 0, + "metadata": { + "colab": { + "name": "image_captioning_with_attention.ipynb", + "version": "0.3.2", + "views": {}, + "default_view": {}, + "provenance": [ + { + "file_id": "1HI8OK2sMjcx9CTWVn0122QAHOuXaOaMg", + "timestamp": 1530222436922 + } + ], + "private_outputs": true, + "collapsed_sections": [], + "toc_visible": true + }, + "kernelspec": { + "display_name": "Python 3", + "language": "python", + "name": "python3" + }, + "accelerator": "GPU" + }, + "cells": [ + { + "metadata": { + "id": "K2s1A9eLRPEj", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "##### Copyright 2018 The TensorFlow Authors.\n", + "\n", + "Licensed under the Apache License, Version 2.0 (the \"License\").\n" + ] + }, + { + "metadata": { + "id": "Cffg2i257iMS", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "# Image Captioning with Attention\n", + "\n", + "<table class=\"tfo-notebook-buttons\" align=\"left\"><td>\n", + "<a target=\"_blank\" href=\"https://colab.sandbox.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb\">\n", + " <img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" /><span>Run in Google Colab</span></a> \n", + "</td><td>\n", + "<a target=\"_blank\" href=\"https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb\"><img width=32px src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" /><span>View source on GitHub</span></a></td></table>" + ] + }, + { + "metadata": { + "id": "QASbY_HGo4Lq", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "Image captioning is the task of generating a caption for an image. Given an image like this:\n", + "\n", + " \n", + "\n", + "[Image Source](https://commons.wikimedia.org/wiki/Surfing#/media/File:Surfing_in_Hawaii.jpg), License: Public Domain\n", + "\n", + "Our goal is generate a caption, such as \"a surfer riding on a wave\". Here, we'll use an attention based model. This enables us to see which parts of the image the model focuses on as it generates a caption.\n", + "\n", + "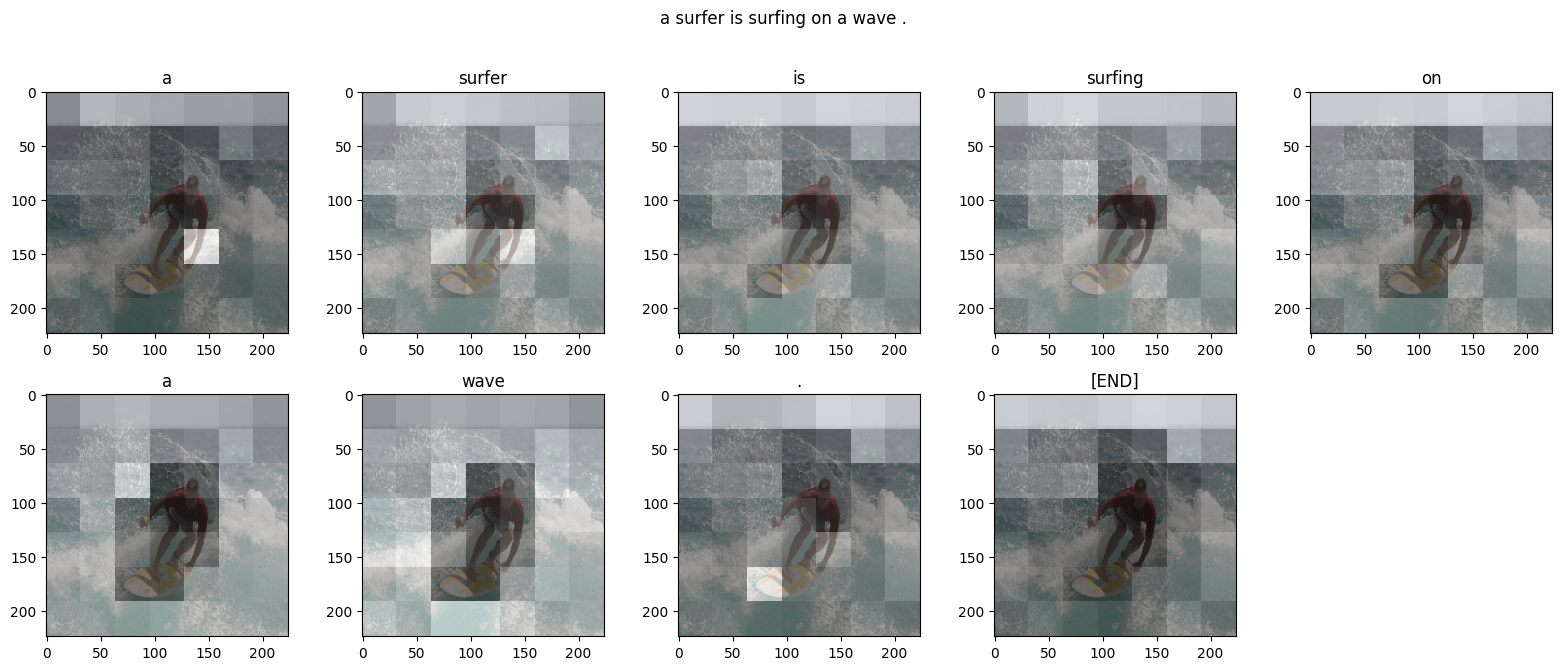\n", + "\n", + "This model architecture below is similar to [Show, Attend and Tell: Neural Image Caption Generation with Visual Attention](https://arxiv.org/abs/1502.03044). \n", + "\n", + "The code uses [tf.keras](https://www.tensorflow.org/programmers_guide/keras) and [eager execution](https://www.tensorflow.org/programmers_guide/eager), which you can learn more about in the linked guides.\n", + "\n", + "This notebook is an end-to-end example. If you run it, it will download the [MS-COCO](http://cocodataset.org/#home) dataset, preprocess and cache a subset of the images using Inception V3, train an encoder-decoder model, and use it to generate captions on new images.\n", + "\n", + "The code requires TensorFlow version >=1.9. If you're running this in [Colab]()\n", + "\n", + "In this example, we're training on a relatively small amount of data as an example. On a single P100 GPU, this example will take about ~2 hours to train. We train on the first 30,000 captions (corresponding to about ~20,000 images depending on shuffling, as there are multiple captions per image in the dataset)\n" + ] + }, + { + "metadata": { + "id": "U8l4RJ0XRPEm", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "# Import TensorFlow and enable eager execution\n", + "# This code requires TensorFlow version >=1.9\n", + "import tensorflow as tf\n", + "tf.enable_eager_execution()\n", + "\n", + "# We'll generate plots of attention in order to see which parts of an image\n", + "# our model focuses on during captioning\n", + "import matplotlib.pyplot as plt\n", + "\n", + "# Scikit-learn includes many helpful utilities\n", + "from sklearn.model_selection import train_test_split\n", + "from sklearn.utils import shuffle\n", + "\n", + "import re\n", + "import numpy as np\n", + "import os\n", + "import time\n", + "import json\n", + "from glob import glob\n", + "from PIL import Image\n", + "import pickle" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "b6qbGw8MRPE5", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "## Download and prepare the MS-COCO dataset\n", + "\n", + "We will use the [MS-COCO dataset](http://cocodataset.org/#home) to train our model. This dataset contains >82,000 images, each of which has been annotated with at least 5 different captions. The code code below will download and extract the dataset automatically. \n", + "\n", + "**Caution: large download ahead**. We'll use the training set, it's a 13GB file." + ] + }, + { + "metadata": { + "id": "krQuPYTtRPE7", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "annotation_zip = tf.keras.utils.get_file('captions.zip', \n", + " cache_subdir=os.path.abspath('.'),\n", + " origin = 'http://images.cocodataset.org/annotations/annotations_trainval2014.zip',\n", + " extract = True)\n", + "annotation_file = os.path.dirname(annotation_zip)+'/annotations/captions_train2014.json'\n", + "\n", + "name_of_zip = 'train2014.zip'\n", + "if not os.path.exists(os.path.abspath('.') + '/' + name_of_zip):\n", + " image_zip = tf.keras.utils.get_file(name_of_zip, \n", + " cache_subdir=os.path.abspath('.'),\n", + " origin = 'http://images.cocodataset.org/zips/train2014.zip',\n", + " extract = True)\n", + " PATH = os.path.dirname(image_zip)+'/train2014/'\n", + "else:\n", + " PATH = os.path.abspath('.')+'/train2014/'" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "aANEzb5WwSzg", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "## Optionally, limit the size of the training set for faster training\n", + "For this example, we'll select a subset of 30,000 captions and use these and the corresponding images to train our model. As always, captioning quality will improve if you choose to use more data." + ] + }, + { + "metadata": { + "id": "4G3b8x8_RPFD", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "# read the json file\n", + "with open(annotation_file, 'r') as f:\n", + " annotations = json.load(f)\n", + "\n", + "# storing the captions and the image name in vectors\n", + "all_captions = []\n", + "all_img_name_vector = []\n", + "\n", + "for annot in annotations['annotations']:\n", + " caption = '<start> ' + annot['caption'] + ' <end>'\n", + " image_id = annot['image_id']\n", + " full_coco_image_path = PATH + 'COCO_train2014_' + '%012d.jpg' % (image_id)\n", + " \n", + " all_img_name_vector.append(full_coco_image_path)\n", + " all_captions.append(caption)\n", + "\n", + "# shuffling the captions and image_names together\n", + "# setting a random state\n", + "train_captions, img_name_vector = shuffle(all_captions,\n", + " all_img_name_vector,\n", + " random_state=1)\n", + "\n", + "# selecting the first 30000 captions from the shuffled set\n", + "num_examples = 30000\n", + "train_captions = train_captions[:num_examples]\n", + "img_name_vector = img_name_vector[:num_examples]" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "mPBMgK34RPFL", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "len(train_captions), len(all_captions)" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "8cSW4u-ORPFQ", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "## Preprocess the images using InceptionV3\n", + "Next, we will use InceptionV3 (pretrained on Imagenet) to classify each image. We will extract features from the last convolutional layer. \n", + "\n", + "First, we will need to convert the images into the format inceptionV3 expects by:\n", + "* Resizing the image to (299, 299)\n", + "* Using the [preprocess_input](https://www.tensorflow.org/api_docs/python/tf/keras/applications/inception_v3/preprocess_input) method to place the pixels in the range of -1 to 1 (to match the format of the images used to train InceptionV3)." + ] + }, + { + "metadata": { + "id": "zXR0217aRPFR", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "def load_image(image_path):\n", + " img = tf.read_file(image_path)\n", + " img = tf.image.decode_jpeg(img, channels=3)\n", + " img = tf.image.resize_images(img, (299, 299))\n", + " img = tf.keras.applications.inception_v3.preprocess_input(img)\n", + " return img, image_path" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "MDvIu4sXRPFV", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "## Initialize InceptionV3 and load the pretrained Imagenet weights\n", + "\n", + "To do so, we'll create a tf.keras model where the output layer is the last convolutional layer in the InceptionV3 architecture. \n", + "* Each image is forwarded through the network and the vector that we get at the end is stored in a dictionary (image_name --> feature_vector). \n", + "* We use the last convolutional layer because we are using attention in this example. The shape of the output of this layer is ```8x8x2048```. \n", + "* We avoid doing this during training so it does not become a bottleneck. \n", + "* After all the images are passed through the network, we pickle the dictionary and save it to disk." + ] + }, + { + "metadata": { + "id": "RD3vW4SsRPFW", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "image_model = tf.keras.applications.InceptionV3(include_top=False, \n", + " weights='imagenet')\n", + "new_input = image_model.input\n", + "hidden_layer = image_model.layers[-1].output\n", + "\n", + "image_features_extract_model = tf.keras.Model(new_input, hidden_layer)" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "rERqlR3WRPGO", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "## Caching the features extracted from InceptionV3\n", + "\n", + "We will pre-process each image with InceptionV3 and cache the output to disk. Caching the output in RAM would be faster but memory intensive, requiring 8 \\* 8 \\* 2048 floats per image. At the time of writing, this would exceed the memory limitations of Colab (although these may change, an instance appears to have about 12GB of memory currently). \n", + "\n", + "Performance could be improved with a more sophisticated caching strategy (e.g., by sharding the images to reduce random access disk I/O) at the cost of more code.\n", + "\n", + "This will take about 10 minutes to run in Colab with a GPU. If you'd like to see a progress bar, you could: install [tqdm](https://github.com/tqdm/tqdm) (```!pip install tqdm```), then change this line: \n", + "\n", + "```for img, path in image_dataset:``` \n", + "\n", + "to:\n", + "\n", + "```for img, path in tqdm(image_dataset):```." + ] + }, + { + "metadata": { + "id": "Dx_fvbVgRPGQ", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "# getting the unique images\n", + "encode_train = sorted(set(img_name_vector))\n", + "\n", + "# feel free to change the batch_size according to your system configuration\n", + "image_dataset = tf.data.Dataset.from_tensor_slices(\n", + " encode_train).map(load_image).batch(16)\n", + "\n", + "for img, path in image_dataset:\n", + " batch_features = image_features_extract_model(img)\n", + " batch_features = tf.reshape(batch_features, \n", + " (batch_features.shape[0], -1, batch_features.shape[3]))\n", + "\n", + " for bf, p in zip(batch_features, path):\n", + " path_of_feature = p.numpy().decode(\"utf-8\")\n", + " np.save(path_of_feature, bf.numpy())" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "nyqH3zFwRPFi", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "## Preprocess and tokenize the captions\n", + "\n", + "* First, we'll tokenize the captions (e.g., by splitting on spaces). This will give us a vocabulary of all the unique words in the data (e.g., \"surfing\", \"football\", etc).\n", + "* Next, we'll limit the vocabulary size to the top 5,000 words to save memory. We'll replace all other words with the token \"UNK\" (for unknown).\n", + "* Finally, we create a word --> index mapping and vice-versa.\n", + "* We will then pad all sequences to the be same length as the longest one. " + ] + }, + { + "metadata": { + "id": "HZfK8RhQRPFj", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "# This will find the maximum length of any caption in our dataset\n", + "def calc_max_length(tensor):\n", + " return max(len(t) for t in tensor)" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "oJGE34aiRPFo", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "# The steps above is a general process of dealing with text processing\n", + "\n", + "# choosing the top 5000 words from the vocabulary\n", + "top_k = 5000\n", + "tokenizer = tf.keras.preprocessing.text.Tokenizer(num_words=top_k, \n", + " oov_token=\"<unk>\", \n", + " filters='!\"#$%&()*+.,-/:;=?@[\\]^_`{|}~ ')\n", + "tokenizer.fit_on_texts(train_captions)\n", + "train_seqs = tokenizer.texts_to_sequences(train_captions)" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "8Q44tNQVRPFt", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "tokenizer.word_index = {key:value for key, value in tokenizer.word_index.items() if value <= top_k}\n", + "# putting <unk> token in the word2idx dictionary\n", + "tokenizer.word_index[tokenizer.oov_token] = top_k + 1\n", + "tokenizer.word_index['<pad>'] = 0" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "0fpJb5ojRPFv", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "# creating the tokenized vectors\n", + "train_seqs = tokenizer.texts_to_sequences(train_captions)" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "olQArbgbRPF1", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "# creating a reverse mapping (index -> word)\n", + "index_word = {value:key for key, value in tokenizer.word_index.items()}" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "AidglIZVRPF4", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "# padding each vector to the max_length of the captions\n", + "# if the max_length parameter is not provided, pad_sequences calculates that automatically\n", + "cap_vector = tf.keras.preprocessing.sequence.pad_sequences(train_seqs, padding='post')" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "gL0wkttkRPGA", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "# calculating the max_length \n", + "# used to store the attention weights\n", + "max_length = calc_max_length(train_seqs)" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "M3CD75nDpvTI", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "## Split the data into training and testing" + ] + }, + { + "metadata": { + "id": "iS7DDMszRPGF", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "# Create training and validation sets using 80-20 split\n", + "img_name_train, img_name_val, cap_train, cap_val = train_test_split(img_name_vector, \n", + " cap_vector, \n", + " test_size=0.2, \n", + " random_state=0)" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "XmViPkRFRPGH", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "len(img_name_train), len(cap_train), len(img_name_val), len(cap_val)" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "uEWM9xrYcg45", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "## Our images and captions are ready! Next, let's create a tf.data dataset to use for training our model.\n", + "\n" + ] + }, + { + "metadata": { + "id": "Q3TnZ1ToRPGV", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "# feel free to change these parameters according to your system's configuration\n", + "\n", + "BATCH_SIZE = 64\n", + "BUFFER_SIZE = 1000\n", + "embedding_dim = 256\n", + "units = 512\n", + "vocab_size = len(tokenizer.word_index)\n", + "# shape of the vector extracted from InceptionV3 is (64, 2048)\n", + "# these two variables represent that\n", + "features_shape = 2048\n", + "attention_features_shape = 64" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "SmZS2N0bXG3T", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "# loading the numpy files \n", + "def map_func(img_name, cap):\n", + " img_tensor = np.load(img_name.decode('utf-8')+'.npy')\n", + " return img_tensor, cap" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "FDF_Nm3tRPGZ", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "dataset = tf.data.Dataset.from_tensor_slices((img_name_train, cap_train))\n", + "\n", + "# using map to load the numpy files in parallel\n", + "# NOTE: Be sure to set num_parallel_calls to the number of CPU cores you have\n", + "# https://www.tensorflow.org/api_docs/python/tf/py_func\n", + "dataset = dataset.map(lambda item1, item2: tf.py_func(\n", + " map_func, [item1, item2], [tf.float32, tf.int32]), num_parallel_calls=8)\n", + "\n", + "# shuffling and batching\n", + "dataset = dataset.shuffle(BUFFER_SIZE)\n", + "# https://www.tensorflow.org/api_docs/python/tf/contrib/data/batch_and_drop_remainder\n", + "dataset = dataset.batch(BATCH_SIZE)\n", + "dataset = dataset.prefetch(1)" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "nrvoDphgRPGd", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "## Model\n", + "\n", + "Fun fact, the decoder below is identical to the one in the example for [Neural Machine Translation with Attention]( https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/nmt_with_attention/nmt_with_attention.ipynb).\n", + "\n", + "The model architecture is inspired by the [Show, Attend and Tell](https://arxiv.org/pdf/1502.03044.pdf) paper.\n", + "\n", + "* In this example, we extract the features from the lower convolutional layer of InceptionV3 giving us a vector of shape (8, 8, 2048). \n", + "* We squash that to a shape of (64, 2048).\n", + "* This vector is then passed through the CNN Encoder(which consists of a single Fully connected layer).\n", + "* The RNN(here GRU) attends over the image to predict the next word." + ] + }, + { + "metadata": { + "id": "AAppCGLKRPGd", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "def gru(units):\n", + " # If you have a GPU, we recommend using the CuDNNGRU layer (it provides a \n", + " # significant speedup).\n", + " if tf.test.is_gpu_available():\n", + " return tf.keras.layers.CuDNNGRU(units, \n", + " return_sequences=True, \n", + " return_state=True, \n", + " recurrent_initializer='glorot_uniform')\n", + " else:\n", + " return tf.keras.layers.GRU(units, \n", + " return_sequences=True, \n", + " return_state=True, \n", + " recurrent_activation='sigmoid', \n", + " recurrent_initializer='glorot_uniform')" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "ja2LFTMSdeV3", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "class BahdanauAttention(tf.keras.Model):\n", + " def __init__(self, units):\n", + " super(BahdanauAttention, self).__init__()\n", + " self.W1 = tf.keras.layers.Dense(units)\n", + " self.W2 = tf.keras.layers.Dense(units)\n", + " self.V = tf.keras.layers.Dense(1)\n", + " \n", + " def call(self, features, hidden):\n", + " # features(CNN_encoder output) shape == (batch_size, 64, embedding_dim)\n", + " \n", + " # hidden shape == (batch_size, hidden_size)\n", + " # hidden_with_time_axis shape == (batch_size, 1, hidden_size)\n", + " hidden_with_time_axis = tf.expand_dims(hidden, 1)\n", + " \n", + " # score shape == (batch_size, 64, hidden_size)\n", + " score = tf.nn.tanh(self.W1(features) + self.W2(hidden_with_time_axis))\n", + " \n", + " # attention_weights shape == (batch_size, 64, 1)\n", + " # we get 1 at the last axis because we are applying score to self.V\n", + " attention_weights = tf.nn.softmax(self.V(score), axis=1)\n", + " \n", + " # context_vector shape after sum == (batch_size, hidden_size)\n", + " context_vector = attention_weights * features\n", + " context_vector = tf.reduce_sum(context_vector, axis=1)\n", + " \n", + " return context_vector, attention_weights" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "AZ7R1RxHRPGf", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "class CNN_Encoder(tf.keras.Model):\n", + " # Since we have already extracted the features and dumped it using pickle\n", + " # This encoder passes those features through a Fully connected layer\n", + " def __init__(self, embedding_dim):\n", + " super(CNN_Encoder, self).__init__()\n", + " # shape after fc == (batch_size, 64, embedding_dim)\n", + " self.fc = tf.keras.layers.Dense(embedding_dim)\n", + " \n", + " def call(self, x):\n", + " x = self.fc(x)\n", + " x = tf.nn.relu(x)\n", + " return x" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "V9UbGQmERPGi", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "class RNN_Decoder(tf.keras.Model):\n", + " def __init__(self, embedding_dim, units, vocab_size):\n", + " super(RNN_Decoder, self).__init__()\n", + " self.units = units\n", + "\n", + " self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)\n", + " self.gru = gru(self.units)\n", + " self.fc1 = tf.keras.layers.Dense(self.units)\n", + " self.fc2 = tf.keras.layers.Dense(vocab_size)\n", + " \n", + " self.attention = BahdanauAttention(self.units)\n", + " \n", + " def call(self, x, features, hidden):\n", + " # defining attention as a separate model\n", + " context_vector, attention_weights = self.attention(features, hidden)\n", + " \n", + " # x shape after passing through embedding == (batch_size, 1, embedding_dim)\n", + " x = self.embedding(x)\n", + " \n", + " # x shape after concatenation == (batch_size, 1, embedding_dim + hidden_size)\n", + " x = tf.concat([tf.expand_dims(context_vector, 1), x], axis=-1)\n", + " \n", + " # passing the concatenated vector to the GRU\n", + " output, state = self.gru(x)\n", + " \n", + " # shape == (batch_size, max_length, hidden_size)\n", + " x = self.fc1(output)\n", + " \n", + " # x shape == (batch_size * max_length, hidden_size)\n", + " x = tf.reshape(x, (-1, x.shape[2]))\n", + " \n", + " # output shape == (batch_size * max_length, vocab)\n", + " x = self.fc2(x)\n", + "\n", + " return x, state, attention_weights\n", + "\n", + " def reset_state(self, batch_size):\n", + " return tf.zeros((batch_size, self.units))" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "Qs_Sr03wRPGk", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "encoder = CNN_Encoder(embedding_dim)\n", + "decoder = RNN_Decoder(embedding_dim, units, vocab_size)" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "-bYN7xA0RPGl", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "optimizer = tf.train.AdamOptimizer()\n", + "\n", + "# We are masking the loss calculated for padding\n", + "def loss_function(real, pred):\n", + " mask = 1 - np.equal(real, 0)\n", + " loss_ = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=real, logits=pred) * mask\n", + " return tf.reduce_mean(loss_)" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "PHod7t72RPGn", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "## Training\n", + "\n", + "* We extract the features stored in the respective `.npy` files and then pass those features through the encoder.\n", + "* The encoder output, hidden state(initialized to 0) and the decoder input (which is the start token) is passed to the decoder.\n", + "* The decoder returns the predictions and the decoder hidden state.\n", + "* The decoder hidden state is then passed back into the model and the predictions are used to calculate the loss.\n", + "* Use teacher forcing to decide the next input to the decoder.\n", + "* Teacher forcing is the technique where the target word is passed as the next input to the decoder.\n", + "* The final step is to calculate the gradients and apply it to the optimizer and backpropagate.\n" + ] + }, + { + "metadata": { + "id": "Vt4WZ5mhJE-E", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "# adding this in a separate cell because if you run the training cell \n", + "# many times, the loss_plot array will be reset\n", + "loss_plot = []" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "UlA4VIQpRPGo", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "EPOCHS = 20\n", + "\n", + "for epoch in range(EPOCHS):\n", + " start = time.time()\n", + " total_loss = 0\n", + " \n", + " for (batch, (img_tensor, target)) in enumerate(dataset):\n", + " loss = 0\n", + " \n", + " # initializing the hidden state for each batch\n", + " # because the captions are not related from image to image\n", + " hidden = decoder.reset_state(batch_size=target.shape[0])\n", + "\n", + " dec_input = tf.expand_dims([tokenizer.word_index['<start>']] * BATCH_SIZE, 1)\n", + " \n", + " with tf.GradientTape() as tape:\n", + " features = encoder(img_tensor)\n", + " \n", + " for i in range(1, target.shape[1]):\n", + " # passing the features through the decoder\n", + " predictions, hidden, _ = decoder(dec_input, features, hidden)\n", + "\n", + " loss += loss_function(target[:, i], predictions)\n", + " \n", + " # using teacher forcing\n", + " dec_input = tf.expand_dims(target[:, i], 1)\n", + " \n", + " total_loss += (loss / int(target.shape[1]))\n", + " \n", + " variables = encoder.variables + decoder.variables\n", + " \n", + " gradients = tape.gradient(loss, variables) \n", + " \n", + " optimizer.apply_gradients(zip(gradients, variables), tf.train.get_or_create_global_step())\n", + " \n", + " if batch % 100 == 0:\n", + " print ('Epoch {} Batch {} Loss {:.4f}'.format(epoch + 1, \n", + " batch, \n", + " loss.numpy() / int(target.shape[1])))\n", + " # storing the epoch end loss value to plot later\n", + " loss_plot.append(total_loss / len(cap_vector))\n", + " \n", + " print ('Epoch {} Loss {:.6f}'.format(epoch + 1, \n", + " total_loss/len(cap_vector)))\n", + " print ('Time taken for 1 epoch {} sec\\n'.format(time.time() - start))" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "1Wm83G-ZBPcC", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "plt.plot(loss_plot)\n", + "plt.xlabel('Epochs')\n", + "plt.ylabel('Loss')\n", + "plt.title('Loss Plot')\n", + "plt.show()" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "xGvOcLQKghXN", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "## Caption!\n", + "\n", + "* The evaluate function is similar to the training loop, except we don't use teacher forcing here. The input to the decoder at each time step is its previous predictions along with the hidden state and the encoder output.\n", + "* Stop predicting when the model predicts the end token.\n", + "* And store the attention weights for every time step." + ] + }, + { + "metadata": { + "id": "RCWpDtyNRPGs", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "def evaluate(image):\n", + " attention_plot = np.zeros((max_length, attention_features_shape))\n", + "\n", + " hidden = decoder.reset_state(batch_size=1)\n", + "\n", + " temp_input = tf.expand_dims(load_image(image)[0], 0)\n", + " img_tensor_val = image_features_extract_model(temp_input)\n", + " img_tensor_val = tf.reshape(img_tensor_val, (img_tensor_val.shape[0], -1, img_tensor_val.shape[3]))\n", + "\n", + " features = encoder(img_tensor_val)\n", + "\n", + " dec_input = tf.expand_dims([tokenizer.word_index['<start>']], 0)\n", + " result = []\n", + "\n", + " for i in range(max_length):\n", + " predictions, hidden, attention_weights = decoder(dec_input, features, hidden)\n", + "\n", + " attention_plot[i] = tf.reshape(attention_weights, (-1, )).numpy()\n", + "\n", + " predicted_id = tf.multinomial(tf.exp(predictions), num_samples=1)[0][0].numpy()\n", + " result.append(index_word[predicted_id])\n", + "\n", + " if index_word[predicted_id] == '<end>':\n", + " return result, attention_plot\n", + "\n", + " dec_input = tf.expand_dims([predicted_id], 0)\n", + "\n", + " attention_plot = attention_plot[:len(result), :]\n", + " return result, attention_plot" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "fD_y7PD6RPGt", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "def plot_attention(image, result, attention_plot):\n", + " temp_image = np.array(Image.open(image))\n", + "\n", + " fig = plt.figure(figsize=(10, 10))\n", + " \n", + " len_result = len(result)\n", + " for l in range(len_result):\n", + " temp_att = np.resize(attention_plot[l], (8, 8))\n", + " ax = fig.add_subplot(len_result//2, len_result//2, l+1)\n", + " ax.set_title(result[l])\n", + " img = ax.imshow(temp_image)\n", + " ax.imshow(temp_att, cmap='gray', alpha=0.6, extent=img.get_extent())\n", + "\n", + " plt.tight_layout()\n", + " plt.show()" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "io7ws3ReRPGv", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "# captions on the validation set\n", + "rid = np.random.randint(0, len(img_name_val))\n", + "image = img_name_val[rid]\n", + "real_caption = ' '.join([index_word[i] for i in cap_val[rid] if i not in [0]])\n", + "result, attention_plot = evaluate(image)\n", + "\n", + "print ('Real Caption:', real_caption)\n", + "print ('Prediction Caption:', ' '.join(result))\n", + "plot_attention(image, result, attention_plot)\n", + "# opening the image\n", + "Image.open(img_name_val[rid])" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "Rprk3HEvZuxb", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "## Try it on your own images\n", + "For fun, below we've provided a method you can use to caption your own images with the model we've just trained. Keep in mind, it was trained on a relatively small amount of data, and your images may be different from the training data (so be prepared for weird results!)\n" + ] + }, + { + "metadata": { + "id": "9Psd1quzaAWg", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "image_url = 'https://tensorflow.org/images/imcap_prediction.png'\n", + "image_extension = image_url[-4:]\n", + "image_path = tf.keras.utils.get_file('image'+image_extension, \n", + " origin=image_url)\n", + "\n", + "result, attention_plot = evaluate(image_path)\n", + "print ('Prediction Caption:', ' '.join(result))\n", + "plot_attention(image_path, result, attention_plot)\n", + "# opening the image\n", + "Image.open(image_path)" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "VJZXyJco6uLO", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "# Next steps\n", + "\n", + "Congrats! You've just trained an image captioning model with attention. Next, we recommend taking a look at this example [Neural Machine Translation with Attention]( https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/nmt_with_attention/nmt_with_attention.ipynb). It uses a similar architecture to translate between Spanish and English sentences. You can also experiment with training the code in this notebook on a different dataset." + ] + } + ] +} diff --git a/tensorflow/contrib/eager/python/examples/generative_examples/text_generation.ipynb b/tensorflow/contrib/eager/python/examples/generative_examples/text_generation.ipynb new file mode 100644 index 0000000000..b0c8773993 --- /dev/null +++ b/tensorflow/contrib/eager/python/examples/generative_examples/text_generation.ipynb @@ -0,0 +1,689 @@ +{ + "nbformat": 4, + "nbformat_minor": 0, + "metadata": { + "colab": { + "name": "text_generation.ipynb", + "version": "0.3.2", + "views": {}, + "default_view": {}, + "provenance": [], + "private_outputs": true, + "collapsed_sections": [], + "toc_visible": true + }, + "kernelspec": { + "display_name": "Python 3", + "language": "python", + "name": "python3" + }, + "accelerator": "GPU" + }, + "cells": [ + { + "metadata": { + "id": "hcD2nPQvPOFM", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "##### Copyright 2018 The TensorFlow Authors.\n", + "\n", + "Licensed under the Apache License, Version 2.0 (the \"License\").\n", + "\n", + "# Text Generation using a RNN\n", + "\n", + "<table align=\"left\"><td>\n", + "<a target=\"_blank\" href=\"https://colab.sandbox.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/generative_examples/text_generation.ipynb\">\n", + " <img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a> \n", + "</td><td>\n", + "<a target=\"_blank\" href=\"https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/eager/python/examples/generative_examples/text_generation.ipynb\"><img width=32px src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />View source on Github</a></td></table>" + ] + }, + { + "metadata": { + "id": "BwpJ5IffzRG6", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "This notebook demonstrates how to generate text using an RNN using [tf.keras](https://www.tensorflow.org/programmers_guide/keras) and [eager execution](https://www.tensorflow.org/programmers_guide/eager). If you like, you can write a similar [model](https://github.com/fchollet/deep-learning-with-python-notebooks/blob/master/8.1-text-generation-with-lstm.ipynb) using less code. Here, we show a lower-level impementation that's useful to understand as prework before diving in to deeper examples in a similar, like [Neural Machine Translation with Attention](https://colab.sandbox.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/contrib/eager/python/examples/nmt_with_attention/nmt_with_attention.ipynb).\n", + "\n", + "This notebook is an end-to-end example. When you run it, it will download a dataset of Shakespeare's writing. We'll use a collection of plays, borrowed from Andrej Karpathy's excellent [The Unreasonable Effectiveness of Recurrent Neural Networks](http://karpathy.github.io/2015/05/21/rnn-effectiveness/). The notebook will train a model, and use it to generate sample output.\n", + " \n", + "Here is the output(with start string='w') after training a single layer GRU for 30 epochs with the default settings below:\n", + "\n", + "```\n", + "were to the death of him\n", + "And nothing of the field in the view of hell,\n", + "When I said, banish him, I will not burn thee that would live.\n", + "\n", + "HENRY BOLINGBROKE:\n", + "My gracious uncle--\n", + "\n", + "DUKE OF YORK:\n", + "As much disgraced to the court, the gods them speak,\n", + "And now in peace himself excuse thee in the world.\n", + "\n", + "HORTENSIO:\n", + "Madam, 'tis not the cause of the counterfeit of the earth,\n", + "And leave me to the sun that set them on the earth\n", + "And leave the world and are revenged for thee.\n", + "\n", + "GLOUCESTER:\n", + "I would they were talking with the very name of means\n", + "To make a puppet of a guest, and therefore, good Grumio,\n", + "Nor arm'd to prison, o' the clouds, of the whole field,\n", + "With the admire\n", + "With the feeding of thy chair, and we have heard it so,\n", + "I thank you, sir, he is a visor friendship with your silly your bed.\n", + "\n", + "SAMPSON:\n", + "I do desire to live, I pray: some stand of the minds, make thee remedies\n", + "With the enemies of my soul.\n", + "\n", + "MENENIUS:\n", + "I'll keep the cause of my mistress.\n", + "\n", + "POLIXENES:\n", + "My brother Marcius!\n", + "\n", + "Second Servant:\n", + "Will't ple\n", + "```\n", + "\n", + "Of course, while some of the sentences are grammatical, most do not make sense. But, consider:\n", + "\n", + "* Our model is character based (when we began training, it did not yet know how to spell a valid English word, or that words were even a unit of text).\n", + "\n", + "* The structure of the output resembles a play (blocks begin with a speaker name, in all caps similar to the original text). Sentences generally end with a period. If you look at the text from a distance (or don't read the invididual words too closely, it appears as if it's an excerpt from a play).\n", + "\n", + "As a next step, you can experiment training the model on a different dataset - any large text file(ASCII) will do, and you can modify a single line of code below to make that change. Have fun!\n" + ] + }, + { + "metadata": { + "id": "R3p22DBDsaCA", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "## Install unidecode library\n", + "A helpful library to convert unicode to ASCII." + ] + }, + { + "metadata": { + "id": "wZ6LOM12wKGH", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "!pip install unidecode" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "WGyKZj3bzf9p", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "## Import tensorflow and enable eager execution." + ] + }, + { + "metadata": { + "id": "yG_n40gFzf9s", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "# Import TensorFlow >= 1.9 and enable eager execution\n", + "import tensorflow as tf\n", + "\n", + "# Note: Once you enable eager execution, it cannot be disabled. \n", + "tf.enable_eager_execution()\n", + "\n", + "import numpy as np\n", + "import re\n", + "import random\n", + "import unidecode\n", + "import time" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "EHDoRoc5PKWz", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "## Download the dataset\n", + "\n", + "In this example, we will use the [shakespeare dataset](https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt). You can use any other dataset that you like.\n", + "\n" + ] + }, + { + "metadata": { + "id": "pD_55cOxLkAb", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "path_to_file = tf.keras.utils.get_file('shakespeare.txt', 'https://storage.googleapis.com/yashkatariya/shakespeare.txt')" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "UHjdCjDuSvX_", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "## Read the dataset\n", + "\n" + ] + }, + { + "metadata": { + "id": "-E5JvY3wzf94", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "text = unidecode.unidecode(open(path_to_file).read())\n", + "# length of text is the number of characters in it\n", + "print (len(text))" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "Il9ww98izf-D", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "Creating dictionaries to map from characters to their indices and vice-versa, which will be used to vectorize the inputs" + ] + }, + { + "metadata": { + "id": "IalZLbvOzf-F", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "# unique contains all the unique characters in the file\n", + "unique = sorted(set(text))\n", + "\n", + "# creating a mapping from unique characters to indices\n", + "char2idx = {u:i for i, u in enumerate(unique)}\n", + "idx2char = {i:u for i, u in enumerate(unique)}" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "1v_qUYfAzf-I", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "# setting the maximum length sentence we want for a single input in characters\n", + "max_length = 100\n", + "\n", + "# length of the vocabulary in chars\n", + "vocab_size = len(unique)\n", + "\n", + "# the embedding dimension \n", + "embedding_dim = 256\n", + "\n", + "# number of RNN (here GRU) units\n", + "units = 1024\n", + "\n", + "# batch size \n", + "BATCH_SIZE = 64\n", + "\n", + "# buffer size to shuffle our dataset\n", + "BUFFER_SIZE = 10000" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "LFjSVAlWzf-N", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "## Creating the input and output tensors\n", + "\n", + "Vectorizing the input and the target text because our model cannot understand strings only numbers.\n", + "\n", + "But first, we need to create the input and output vectors.\n", + "Remember the max_length we set above, we will use it here. We are creating **max_length** chunks of input, where each input vector is all the characters in that chunk except the last and the target vector is all the characters in that chunk except the first.\n", + "\n", + "For example, consider that the string = 'tensorflow' and the max_length is 9\n", + "\n", + "So, the `input = 'tensorflo'` and `output = 'ensorflow'`\n", + "\n", + "After creating the vectors, we convert each character into numbers using the **char2idx** dictionary we created above." + ] + }, + { + "metadata": { + "id": "0UHJDA39zf-O", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "input_text = []\n", + "target_text = []\n", + "\n", + "for f in range(0, len(text)-max_length, max_length):\n", + " inps = text[f:f+max_length]\n", + " targ = text[f+1:f+1+max_length]\n", + "\n", + " input_text.append([char2idx[i] for i in inps])\n", + " target_text.append([char2idx[t] for t in targ])\n", + " \n", + "print (np.array(input_text).shape)\n", + "print (np.array(target_text).shape)" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "MJdfPmdqzf-R", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "## Creating batches and shuffling them using tf.data" + ] + }, + { + "metadata": { + "id": "p2pGotuNzf-S", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "dataset = tf.data.Dataset.from_tensor_slices((input_text, target_text)).shuffle(BUFFER_SIZE)\n", + "dataset = dataset.apply(tf.contrib.data.batch_and_drop_remainder(BATCH_SIZE))" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "m8gPwEjRzf-Z", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "## Creating the model\n", + "\n", + "We use the Model Subclassing API which gives us full flexibility to create the model and change it however we like. We use 3 layers to define our model.\n", + "\n", + "* Embedding layer\n", + "* GRU layer (you can use an LSTM layer here)\n", + "* Fully connected layer" + ] + }, + { + "metadata": { + "id": "P3KTiiInzf-a", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "class Model(tf.keras.Model):\n", + " def __init__(self, vocab_size, embedding_dim, units, batch_size):\n", + " super(Model, self).__init__()\n", + " self.units = units\n", + " self.batch_sz = batch_size\n", + "\n", + " self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)\n", + "\n", + " if tf.test.is_gpu_available():\n", + " self.gru = tf.keras.layers.CuDNNGRU(self.units, \n", + " return_sequences=True, \n", + " return_state=True, \n", + " recurrent_initializer='glorot_uniform')\n", + " else:\n", + " self.gru = tf.keras.layers.GRU(self.units, \n", + " return_sequences=True, \n", + " return_state=True, \n", + " recurrent_activation='sigmoid', \n", + " recurrent_initializer='glorot_uniform')\n", + "\n", + " self.fc = tf.keras.layers.Dense(vocab_size)\n", + " \n", + " def call(self, x, hidden):\n", + " x = self.embedding(x)\n", + "\n", + " # output shape == (batch_size, max_length, hidden_size) \n", + " # states shape == (batch_size, hidden_size)\n", + "\n", + " # states variable to preserve the state of the model\n", + " # this will be used to pass at every step to the model while training\n", + " output, states = self.gru(x, initial_state=hidden)\n", + "\n", + "\n", + " # reshaping the output so that we can pass it to the Dense layer\n", + " # after reshaping the shape is (batch_size * max_length, hidden_size)\n", + " output = tf.reshape(output, (-1, output.shape[2]))\n", + "\n", + " # The dense layer will output predictions for every time_steps(max_length)\n", + " # output shape after the dense layer == (max_length * batch_size, vocab_size)\n", + " x = self.fc(output)\n", + "\n", + " return x, states" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "trpqTWyvk0nr", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "## Call the model and set the optimizer and the loss function" + ] + }, + { + "metadata": { + "id": "7t2XrzEOzf-e", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "model = Model(vocab_size, embedding_dim, units, BATCH_SIZE)" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "dkjWIATszf-h", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "optimizer = tf.train.AdamOptimizer()\n", + "\n", + "# using sparse_softmax_cross_entropy so that we don't have to create one-hot vectors\n", + "def loss_function(real, preds):\n", + " return tf.losses.sparse_softmax_cross_entropy(labels=real, logits=preds)" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "lPrP0XMUzf-p", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "## Train the model\n", + "\n", + "Here we will use a custom training loop with the help of GradientTape()\n", + "\n", + "* We initialize the hidden state of the model with zeros and shape == (batch_size, number of rnn units). We do this by calling the function defined while creating the model.\n", + "\n", + "* Next, we iterate over the dataset(batch by batch) and calculate the **predictions and the hidden states** associated with that input.\n", + "\n", + "* There are a lot of interesting things happening here.\n", + " * The model gets hidden state(initialized with 0), lets call that **H0** and the first batch of input, lets call that **I0**.\n", + " * The model then returns the predictions **P1** and **H1**.\n", + " * For the next batch of input, the model receives **I1** and **H1**.\n", + " * The interesting thing here is that we pass **H1** to the model with **I1** which is how the model learns. The context learned from batch to batch is contained in the **hidden state**.\n", + " * We continue doing this until the dataset is exhausted and then we start a new epoch and repeat this.\n", + "\n", + "* After calculating the predictions, we calculate the **loss** using the loss function defined above. Then we calculate the gradients of the loss with respect to the model variables(input)\n", + "\n", + "* Finally, we take a step in that direction with the help of the optimizer using the apply_gradients function.\n", + "\n", + "Note:- If you are running this notebook in Colab which has a **Tesla K80 GPU** it takes about 23 seconds per epoch.\n" + ] + }, + { + "metadata": { + "id": "d4tSNwymzf-q", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "# Training step\n", + "\n", + "EPOCHS = 30\n", + "\n", + "for epoch in range(EPOCHS):\n", + " start = time.time()\n", + " \n", + " # initializing the hidden state at the start of every epoch\n", + " hidden = model.reset_states()\n", + " \n", + " for (batch, (inp, target)) in enumerate(dataset):\n", + " with tf.GradientTape() as tape:\n", + " # feeding the hidden state back into the model\n", + " # This is the interesting step\n", + " predictions, hidden = model(inp, hidden)\n", + " \n", + " # reshaping the target because that's how the \n", + " # loss function expects it\n", + " target = tf.reshape(target, (-1,))\n", + " loss = loss_function(target, predictions)\n", + " \n", + " grads = tape.gradient(loss, model.variables)\n", + " optimizer.apply_gradients(zip(grads, model.variables), global_step=tf.train.get_or_create_global_step())\n", + "\n", + " if batch % 100 == 0:\n", + " print ('Epoch {} Batch {} Loss {:.4f}'.format(epoch+1,\n", + " batch,\n", + " loss))\n", + " \n", + " print ('Epoch {} Loss {:.4f}'.format(epoch+1, loss))\n", + " print('Time taken for 1 epoch {} sec\\n'.format(time.time() - start))" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "DjGz1tDkzf-u", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "## Predicting using our trained model\n", + "\n", + "The below code block is used to generated the text\n", + "\n", + "* We start by choosing a start string and initializing the hidden state and setting the number of characters we want to generate.\n", + "\n", + "* We get predictions using the start_string and the hidden state\n", + "\n", + "* Then we use a multinomial distribution to calculate the index of the predicted word. **We use this predicted word as our next input to the model**\n", + "\n", + "* **The hidden state returned by the model is fed back into the model so that it now has more context rather than just one word.** After we predict the next word, the modified hidden states are again fed back into the model, which is how it learns as it gets more context from the previously predicted words.\n", + "\n", + "* If you see the predictions, the model knows when to capitalize, make paragraphs and the text follows a shakespeare style of writing which is pretty awesome!" + ] + }, + { + "metadata": { + "id": "WvuwZBX5Ogfd", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "# Evaluation step(generating text using the model learned)\n", + "\n", + "# number of characters to generate\n", + "num_generate = 1000\n", + "\n", + "# You can change the start string to experiment\n", + "start_string = 'Q'\n", + "# converting our start string to numbers(vectorizing!) \n", + "input_eval = [char2idx[s] for s in start_string]\n", + "input_eval = tf.expand_dims(input_eval, 0)\n", + "\n", + "# empty string to store our results\n", + "text_generated = ''\n", + "\n", + "# low temperatures results in more predictable text.\n", + "# higher temperatures results in more surprising text\n", + "# experiment to find the best setting\n", + "temperature = 1.0\n", + "\n", + "# hidden state shape == (batch_size, number of rnn units); here batch size == 1\n", + "hidden = [tf.zeros((1, units))]\n", + "for i in range(num_generate):\n", + " predictions, hidden = model(input_eval, hidden)\n", + "\n", + " # using a multinomial distribution to predict the word returned by the model\n", + " predictions = predictions / temperature\n", + " predicted_id = tf.multinomial(tf.exp(predictions), num_samples=1)[0][0].numpy()\n", + " \n", + " # We pass the predicted word as the next input to the model\n", + " # along with the previous hidden state\n", + " input_eval = tf.expand_dims([predicted_id], 0)\n", + " \n", + " text_generated += idx2char[predicted_id]\n", + "\n", + "print (start_string + text_generated)" + ], + "execution_count": 0, + "outputs": [] + }, + { + "metadata": { + "id": "AM2Uma_-yVIq", + "colab_type": "text" + }, + "cell_type": "markdown", + "source": [ + "## Next steps\n", + "\n", + "* Change the start string to a different character, or the start of a sentence.\n", + "* Experiment with training on a different, or with different parameters. [Project Gutenberg](http://www.gutenberg.org/ebooks/100), for example, contains a large collection of books.\n", + "* Experiment with the temperature parameter.\n", + "* Add another RNN layer.\n" + ] + }, + { + "metadata": { + "id": "gtEd86sX5cB2", + "colab_type": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + } + }, + "cell_type": "code", + "source": [ + "" + ], + "execution_count": 0, + "outputs": [] + } + ] +} diff --git a/tensorflow/contrib/eager/python/examples/workshop/1_basic.ipynb b/tensorflow/contrib/eager/python/examples/workshop/1_basic.ipynb index 3e7abe952d..75cb3f8227 100644 --- a/tensorflow/contrib/eager/python/examples/workshop/1_basic.ipynb +++ b/tensorflow/contrib/eager/python/examples/workshop/1_basic.ipynb @@ -210,7 +210,7 @@ "a = tf.constant(0.0)\n", "b = tf.constant(1.0)\n", "epsilon = tf.constant(0.001)\n", - "x = bisecting_line_search(test_f, a, b, epsilon)\n", + "x = bisecting_line_search(test_f, a, b, epsilon)\n" ], "execution_count": 0, "outputs": [] @@ -279,4 +279,4 @@ ] } ] -}
\ No newline at end of file +} diff --git a/tensorflow/contrib/gan/BUILD b/tensorflow/contrib/gan/BUILD index b305f37791..10a8796bcb 100644 --- a/tensorflow/contrib/gan/BUILD +++ b/tensorflow/contrib/gan/BUILD @@ -45,6 +45,7 @@ py_library( "//tensorflow/python:framework_ops", "//tensorflow/python:init_ops", "//tensorflow/python:training", + "//tensorflow/python:training_util", "//tensorflow/python:variable_scope", "//tensorflow/python/ops/distributions", "//tensorflow/python/ops/losses", @@ -59,6 +60,7 @@ py_test( deps = [ ":features", ":namedtuples", + ":random_tensor_pool", ":train", "//tensorflow/contrib/framework:framework_py", "//tensorflow/contrib/slim:learning", @@ -70,6 +72,7 @@ py_test( "//tensorflow/python:random_ops", "//tensorflow/python:random_seed", "//tensorflow/python:training", + "//tensorflow/python:training_util", "//tensorflow/python:variable_scope", "//tensorflow/python:variables", "//tensorflow/python/ops/distributions", @@ -188,6 +191,7 @@ py_test( srcs = ["python/losses/python/tuple_losses_test.py"], srcs_version = "PY2AND3", deps = [ + ":namedtuples", ":tuple_losses", "//tensorflow/python:client_testlib", "//tensorflow/python:constant_op", @@ -344,9 +348,11 @@ py_library( "//tensorflow/python:image_ops", "//tensorflow/python:linalg_ops", "//tensorflow/python:math_ops", + "//tensorflow/python:nn", "//tensorflow/python:nn_ops", "//tensorflow/python:platform", "//tensorflow/python:util", + "@six_archive//:six", ], ) @@ -470,12 +476,12 @@ py_library( ], srcs_version = "PY2AND3", deps = [ - ":head", ":namedtuples", ":summaries", ":train", "//tensorflow/contrib/framework:framework_py", "//tensorflow/python:framework_ops", + "//tensorflow/python:metrics", "//tensorflow/python:util", "//tensorflow/python:variable_scope", "//tensorflow/python/estimator", @@ -498,16 +504,19 @@ py_test( "//tensorflow/core:protos_all_py", "//tensorflow/python:array_ops", "//tensorflow/python:client_testlib", - "//tensorflow/python:control_flow_ops", "//tensorflow/python:dtypes", "//tensorflow/python:framework_ops", + "//tensorflow/python:math_ops", + "//tensorflow/python:metrics", "//tensorflow/python:parsing_ops", "//tensorflow/python:summary", "//tensorflow/python:training", - "//tensorflow/python/estimator:head", + "//tensorflow/python:training_util", + "//tensorflow/python:variable_scope", "//tensorflow/python/estimator:model_fn", "//tensorflow/python/estimator:numpy_io", "//third_party/py/numpy", + "@absl_py//absl/testing:parameterized", "@six_archive//:six", ], ) diff --git a/tensorflow/contrib/gan/python/estimator/python/gan_estimator_impl.py b/tensorflow/contrib/gan/python/estimator/python/gan_estimator_impl.py index 4092b32004..8e4affb9b4 100644 --- a/tensorflow/contrib/gan/python/estimator/python/gan_estimator_impl.py +++ b/tensorflow/contrib/gan/python/estimator/python/gan_estimator_impl.py @@ -24,11 +24,11 @@ import enum from tensorflow.contrib.framework.python.ops import variables as variable_lib from tensorflow.contrib.gan.python import namedtuples as tfgan_tuples from tensorflow.contrib.gan.python import train as tfgan_train -from tensorflow.contrib.gan.python.estimator.python import head as head_lib from tensorflow.contrib.gan.python.eval.python import summaries as tfgan_summaries from tensorflow.python.estimator import estimator from tensorflow.python.estimator import model_fn as model_fn_lib from tensorflow.python.framework import ops +from tensorflow.python.ops import metrics as metrics_lib from tensorflow.python.ops import variable_scope from tensorflow.python.util import tf_inspect as inspect @@ -154,94 +154,93 @@ class GANEstimator(estimator.Estimator): use_loss_summaries: If `True`, add loss summaries. If `False`, does not. If `None`, uses defaults. config: `RunConfig` object to configure the runtime settings. + + Raises: + ValueError: If loss functions aren't callable. + ValueError: If `use_loss_summaries` isn't boolean or `None`. + ValueError: If `get_hooks_fn` isn't callable or `None`. """ - # TODO(joelshor): Explicitly validate inputs. + if not callable(generator_loss_fn): + raise ValueError('generator_loss_fn must be callable.') + if not callable(discriminator_loss_fn): + raise ValueError('discriminator_loss_fn must be callable.') + if use_loss_summaries not in [True, False, None]: + raise ValueError('use_loss_summaries must be True, False or None.') + if get_hooks_fn is not None and not callable(get_hooks_fn): + raise TypeError('get_hooks_fn must be callable.') def _model_fn(features, labels, mode): - gopt = (generator_optimizer() if callable(generator_optimizer) else - generator_optimizer) - dopt = (discriminator_optimizer() if callable(discriminator_optimizer) - else discriminator_optimizer) - gan_head = head_lib.gan_head( - generator_loss_fn, discriminator_loss_fn, gopt, dopt, - use_loss_summaries, get_hooks_fn=get_hooks_fn, - get_eval_metric_ops_fn=get_eval_metric_ops_fn) - return _gan_model_fn( - features, labels, mode, generator_fn, discriminator_fn, gan_head, + """GANEstimator model function.""" + if mode not in [model_fn_lib.ModeKeys.TRAIN, model_fn_lib.ModeKeys.EVAL, + model_fn_lib.ModeKeys.PREDICT]: + raise ValueError('Mode not recognized: %s' % mode) + real_data = labels # rename inputs for clarity + generator_inputs = features # rename inputs for clarity + + # Make GANModel, which encapsulates the GAN model architectures. + gan_model = _get_gan_model( + mode, generator_fn, discriminator_fn, real_data, generator_inputs, add_summaries) + # Make the EstimatorSpec, which incorporates the GANModel, losses, eval + # metrics, and optimizers (if required). + return _get_estimator_spec( + mode, gan_model, generator_loss_fn, discriminator_loss_fn, + get_eval_metric_ops_fn, generator_optimizer, discriminator_optimizer, + get_hooks_fn) + super(GANEstimator, self).__init__( model_fn=_model_fn, model_dir=model_dir, config=config) -def _gan_model_fn( - features, - labels, - mode, - generator_fn, - discriminator_fn, - head, - add_summaries=None, - generator_scope_name='Generator'): - """The `model_fn` for the GAN estimator. - - We make the following convention: - features -> TFGAN's `generator_inputs` - labels -> TFGAN's `real_data` - - Args: - features: A dictionary to feed to generator. In the unconditional case, - this might be just `noise`. In the conditional GAN case, this - might be the generator's conditioning. The `generator_fn` determines - what the required keys are. - labels: Real data. Can be any structure, as long as `discriminator_fn` - can accept it for the first argument. - mode: Defines whether this is training, evaluation or prediction. - See `ModeKeys`. - generator_fn: A python lambda that takes `generator_inputs` as inputs and - returns the outputs of the GAN generator. - discriminator_fn: A python lambda that takes `real_data`/`generated data` - and `generator_inputs`. Outputs a Tensor in the range [-inf, inf]. - head: A `Head` instance suitable for GANs. - add_summaries: `None`, a single `SummaryType`, or a list of `SummaryType`. - generator_scope_name: The name of the generator scope. We need this to be - the same for GANModels produced by TFGAN's `train.gan_model` and the - manually constructed ones for predictions. - - Returns: - `ModelFnOps` - - Raises: - ValueError: If `labels` isn't `None` during prediction. - """ - real_data = labels - generator_inputs = features - - if mode == model_fn_lib.ModeKeys.TRAIN: - gan_model = _make_train_gan_model( - generator_fn, discriminator_fn, real_data, generator_inputs, - generator_scope_name, add_summaries) - elif mode == model_fn_lib.ModeKeys.EVAL: - gan_model = _make_eval_gan_model( - generator_fn, discriminator_fn, real_data, generator_inputs, - generator_scope_name, add_summaries) - else: +def _get_gan_model( + mode, generator_fn, discriminator_fn, real_data, generator_inputs, + add_summaries, generator_scope='Generator'): + """Makes the GANModel tuple, which encapsulates the GAN model architecture.""" + if mode == model_fn_lib.ModeKeys.PREDICT: if real_data is not None: raise ValueError('`labels` must be `None` when mode is `predict`. ' 'Instead, found %s' % real_data) gan_model = _make_prediction_gan_model( - generator_inputs, generator_fn, generator_scope_name) + generator_inputs, generator_fn, generator_scope) + else: # model_fn_lib.ModeKeys.TRAIN or model_fn_lib.ModeKeys.EVAL + gan_model = _make_gan_model( + generator_fn, discriminator_fn, real_data, generator_inputs, + generator_scope, add_summaries, mode) - return head.create_estimator_spec( - features=None, - mode=mode, - logits=gan_model, - labels=None) + return gan_model + + +def _get_estimator_spec( + mode, gan_model, generator_loss_fn, discriminator_loss_fn, + get_eval_metric_ops_fn, generator_optimizer, discriminator_optimizer, + get_hooks_fn=None): + """Get the EstimatorSpec for the current mode.""" + if mode == model_fn_lib.ModeKeys.PREDICT: + estimator_spec = model_fn_lib.EstimatorSpec( + mode=mode, predictions=gan_model.generated_data) + else: + gan_loss = tfgan_tuples.GANLoss( + generator_loss=generator_loss_fn(gan_model), + discriminator_loss=discriminator_loss_fn(gan_model)) + if mode == model_fn_lib.ModeKeys.EVAL: + estimator_spec = _get_eval_estimator_spec( + gan_model, gan_loss, get_eval_metric_ops_fn) + else: # model_fn_lib.ModeKeys.TRAIN: + gopt = (generator_optimizer() if callable(generator_optimizer) else + generator_optimizer) + dopt = (discriminator_optimizer() if callable(discriminator_optimizer) + else discriminator_optimizer) + get_hooks_fn = get_hooks_fn or tfgan_train.get_sequential_train_hooks() + estimator_spec = _get_train_estimator_spec( + gan_model, gan_loss, gopt, dopt, get_hooks_fn) + + return estimator_spec def _make_gan_model(generator_fn, discriminator_fn, real_data, generator_inputs, generator_scope, add_summaries, mode): - """Make a `GANModel`, and optionally pass in `mode`.""" + """Construct a `GANModel`, and optionally pass in `mode`.""" # If network functions have an argument `mode`, pass mode to it. if 'mode' in inspect.getargspec(generator_fn).args: generator_fn = functools.partial(generator_fn, mode=mode) @@ -264,22 +263,6 @@ def _make_gan_model(generator_fn, discriminator_fn, real_data, return gan_model -def _make_train_gan_model(generator_fn, discriminator_fn, real_data, - generator_inputs, generator_scope, add_summaries): - """Make a `GANModel` for training.""" - return _make_gan_model(generator_fn, discriminator_fn, real_data, - generator_inputs, generator_scope, add_summaries, - model_fn_lib.ModeKeys.TRAIN) - - -def _make_eval_gan_model(generator_fn, discriminator_fn, real_data, - generator_inputs, generator_scope, add_summaries): - """Make a `GANModel` for evaluation.""" - return _make_gan_model(generator_fn, discriminator_fn, real_data, - generator_inputs, generator_scope, add_summaries, - model_fn_lib.ModeKeys.EVAL) - - def _make_prediction_gan_model(generator_inputs, generator_fn, generator_scope): """Make a `GANModel` from just the generator.""" # If `generator_fn` has an argument `mode`, pass mode to it. @@ -303,3 +286,46 @@ def _make_prediction_gan_model(generator_inputs, generator_fn, generator_scope): discriminator_variables=None, discriminator_scope=None, discriminator_fn=None) + + +def _get_eval_estimator_spec(gan_model, gan_loss, get_eval_metric_ops_fn=None, + name=None): + """Return an EstimatorSpec for the eval case.""" + scalar_loss = gan_loss.generator_loss + gan_loss.discriminator_loss + with ops.name_scope(None, 'metrics', + [gan_loss.generator_loss, + gan_loss.discriminator_loss]): + def _summary_key(head_name, val): + return '%s/%s' % (val, head_name) if head_name else val + eval_metric_ops = { + _summary_key(name, 'generator_loss'): + metrics_lib.mean(gan_loss.generator_loss), + _summary_key(name, 'discriminator_loss'): + metrics_lib.mean(gan_loss.discriminator_loss) + } + if get_eval_metric_ops_fn is not None: + custom_eval_metric_ops = get_eval_metric_ops_fn(gan_model) + if not isinstance(custom_eval_metric_ops, dict): + raise TypeError('get_eval_metric_ops_fn must return a dict, ' + 'received: {}'.format(custom_eval_metric_ops)) + eval_metric_ops.update(custom_eval_metric_ops) + return model_fn_lib.EstimatorSpec( + mode=model_fn_lib.ModeKeys.EVAL, + predictions=gan_model.generated_data, + loss=scalar_loss, + eval_metric_ops=eval_metric_ops) + + +def _get_train_estimator_spec( + gan_model, gan_loss, generator_optimizer, discriminator_optimizer, + get_hooks_fn, train_op_fn=tfgan_train.gan_train_ops): + """Return an EstimatorSpec for the train case.""" + scalar_loss = gan_loss.generator_loss + gan_loss.discriminator_loss + train_ops = train_op_fn(gan_model, gan_loss, generator_optimizer, + discriminator_optimizer) + training_hooks = get_hooks_fn(train_ops) + return model_fn_lib.EstimatorSpec( + loss=scalar_loss, + mode=model_fn_lib.ModeKeys.TRAIN, + train_op=train_ops.global_step_inc_op, + training_hooks=training_hooks) diff --git a/tensorflow/contrib/gan/python/estimator/python/gan_estimator_test.py b/tensorflow/contrib/gan/python/estimator/python/gan_estimator_test.py index 955482599b..9ac9c6ca9c 100644 --- a/tensorflow/contrib/gan/python/estimator/python/gan_estimator_test.py +++ b/tensorflow/contrib/gan/python/estimator/python/gan_estimator_test.py @@ -21,30 +21,30 @@ from __future__ import print_function import shutil import tempfile +from absl.testing import parameterized import numpy as np import six from tensorflow.contrib import layers -from tensorflow.contrib.gan.python import namedtuples +from tensorflow.contrib.gan.python import namedtuples as tfgan_tuples from tensorflow.contrib.gan.python.estimator.python import gan_estimator_impl as estimator from tensorflow.contrib.gan.python.losses.python import tuple_losses as losses from tensorflow.contrib.learn.python.learn.learn_io import graph_io from tensorflow.core.example import example_pb2 from tensorflow.core.example import feature_pb2 from tensorflow.python.estimator import model_fn as model_fn_lib -from tensorflow.python.estimator.canned import head as head_lib from tensorflow.python.estimator.inputs import numpy_io from tensorflow.python.framework import dtypes from tensorflow.python.framework import ops from tensorflow.python.ops import array_ops -from tensorflow.python.ops import control_flow_ops +from tensorflow.python.ops import math_ops from tensorflow.python.ops import metrics as metrics_lib from tensorflow.python.ops import parsing_ops +from tensorflow.python.ops import variable_scope from tensorflow.python.platform import test from tensorflow.python.summary.writer import writer_cache from tensorflow.python.training import input as input_lib from tensorflow.python.training import learning_rate_decay -from tensorflow.python.training import monitored_session from tensorflow.python.training import training from tensorflow.python.training import training_util @@ -60,120 +60,109 @@ def discriminator_fn(data, unused_conditioning, mode): return layers.fully_connected(data, 1) -def mock_head(testcase, expected_generator_inputs, expected_real_data, - generator_scope_name): - """Returns a mock head that validates logits values and variable names.""" - discriminator_scope_name = 'Discriminator' # comes from TFGAN defaults - generator_var_names = set([ - '%s/fully_connected/weights:0' % generator_scope_name, - '%s/fully_connected/biases:0' % generator_scope_name]) - discriminator_var_names = set([ - '%s/fully_connected/weights:0' % discriminator_scope_name, - '%s/fully_connected/biases:0' % discriminator_scope_name]) - - def _create_estimator_spec(features, mode, logits, labels): - gan_model = logits # renaming for clarity - is_predict = mode == model_fn_lib.ModeKeys.PREDICT - testcase.assertIsNone(features) - testcase.assertIsNone(labels) - testcase.assertIsInstance(gan_model, namedtuples.GANModel) - - trainable_vars = ops.get_collection(ops.GraphKeys.TRAINABLE_VARIABLES) - expected_var_names = (generator_var_names if is_predict else - generator_var_names | discriminator_var_names) - testcase.assertItemsEqual(expected_var_names, - [var.name for var in trainable_vars]) - - assertions = [] - def _or_none(x): - return None if is_predict else x - testcase.assertEqual(expected_generator_inputs, gan_model.generator_inputs) - # TODO(joelshor): Add check on `generated_data`. - testcase.assertItemsEqual( - generator_var_names, - set([x.name for x in gan_model.generator_variables])) - testcase.assertEqual(generator_scope_name, gan_model.generator_scope.name) - testcase.assertEqual(_or_none(expected_real_data), gan_model.real_data) - # TODO(joelshor): Add check on `discriminator_real_outputs`. - # TODO(joelshor): Add check on `discriminator_gen_outputs`. - if is_predict: - testcase.assertIsNone(gan_model.discriminator_scope) - else: - testcase.assertEqual(discriminator_scope_name, - gan_model.discriminator_scope.name) - - with ops.control_dependencies(assertions): - if mode == model_fn_lib.ModeKeys.TRAIN: - return model_fn_lib.EstimatorSpec( - mode=mode, loss=array_ops.zeros([]), - train_op=control_flow_ops.no_op(), training_hooks=[]) - elif mode == model_fn_lib.ModeKeys.EVAL: - return model_fn_lib.EstimatorSpec( - mode=mode, predictions=gan_model.generated_data, - loss=array_ops.zeros([])) - elif mode == model_fn_lib.ModeKeys.PREDICT: - return model_fn_lib.EstimatorSpec( - mode=mode, predictions=gan_model.generated_data) - else: - testcase.fail('Invalid mode: {}'.format(mode)) - - head = test.mock.NonCallableMagicMock(spec=head_lib._Head) - head.create_estimator_spec = test.mock.MagicMock( - wraps=_create_estimator_spec) - - return head - - -class GANModelFnTest(test.TestCase): - """Tests that _gan_model_fn passes expected logits to mock head.""" - - def setUp(self): - self._model_dir = tempfile.mkdtemp() - - def tearDown(self): - if self._model_dir: - writer_cache.FileWriterCache.clear() - shutil.rmtree(self._model_dir) +class GetGANModelTest(test.TestCase, parameterized.TestCase): + """Tests that `GetGANModel` produces the correct model.""" - def _test_logits_helper(self, mode): - """Tests that the expected logits are passed to mock head.""" + @parameterized.named_parameters( + ('train', model_fn_lib.ModeKeys.TRAIN), + ('eval', model_fn_lib.ModeKeys.EVAL), + ('predict', model_fn_lib.ModeKeys.PREDICT)) + def test_get_gan_model(self, mode): with ops.Graph().as_default(): - training_util.get_or_create_global_step() - generator_inputs = {'x': array_ops.zeros([5, 4])} - real_data = (None if mode == model_fn_lib.ModeKeys.PREDICT else - array_ops.zeros([5, 4])) - generator_scope_name = 'generator' - head = mock_head(self, - expected_generator_inputs=generator_inputs, - expected_real_data=real_data, - generator_scope_name=generator_scope_name) - estimator_spec = estimator._gan_model_fn( - features=generator_inputs, - labels=real_data, - mode=mode, - generator_fn=generator_fn, - discriminator_fn=discriminator_fn, - generator_scope_name=generator_scope_name, - head=head) - with monitored_session.MonitoredTrainingSession( - checkpoint_dir=self._model_dir) as sess: - if mode == model_fn_lib.ModeKeys.TRAIN: - sess.run(estimator_spec.train_op) - elif mode == model_fn_lib.ModeKeys.EVAL: - sess.run(estimator_spec.loss) - elif mode == model_fn_lib.ModeKeys.PREDICT: - sess.run(estimator_spec.predictions) - else: - self.fail('Invalid mode: {}'.format(mode)) - - def test_logits_predict(self): - self._test_logits_helper(model_fn_lib.ModeKeys.PREDICT) - - def test_logits_eval(self): - self._test_logits_helper(model_fn_lib.ModeKeys.EVAL) - - def test_logits_train(self): - self._test_logits_helper(model_fn_lib.ModeKeys.TRAIN) + generator_inputs = {'x': array_ops.ones([3, 4])} + real_data = (array_ops.zeros([3, 4]) if + mode != model_fn_lib.ModeKeys.PREDICT else None) + gan_model = estimator._get_gan_model( + mode, generator_fn, discriminator_fn, real_data, generator_inputs, + add_summaries=False) + + self.assertEqual(generator_inputs, gan_model.generator_inputs) + self.assertIsNotNone(gan_model.generated_data) + self.assertEqual(2, len(gan_model.generator_variables)) # 1 FC layer + self.assertIsNotNone(gan_model.generator_fn) + if mode == model_fn_lib.ModeKeys.PREDICT: + self.assertIsNone(gan_model.real_data) + self.assertIsNone(gan_model.discriminator_real_outputs) + self.assertIsNone(gan_model.discriminator_gen_outputs) + self.assertIsNone(gan_model.discriminator_variables) + self.assertIsNone(gan_model.discriminator_scope) + self.assertIsNone(gan_model.discriminator_fn) + else: + self.assertIsNotNone(gan_model.real_data) + self.assertIsNotNone(gan_model.discriminator_real_outputs) + self.assertIsNotNone(gan_model.discriminator_gen_outputs) + self.assertEqual(2, len(gan_model.discriminator_variables)) # 1 FC layer + self.assertIsNotNone(gan_model.discriminator_scope) + self.assertIsNotNone(gan_model.discriminator_fn) + + +def get_dummy_gan_model(): + # TODO(joelshor): Find a better way of creating a variable scope. + with variable_scope.variable_scope('generator') as gen_scope: + gen_var = variable_scope.get_variable('dummy_var', initializer=0.0) + with variable_scope.variable_scope('discriminator') as dis_scope: + dis_var = variable_scope.get_variable('dummy_var', initializer=0.0) + return tfgan_tuples.GANModel( + generator_inputs=None, + generated_data=array_ops.ones([3, 4]), + generator_variables=[gen_var], + generator_scope=gen_scope, + generator_fn=None, + real_data=array_ops.zeros([3, 4]), + discriminator_real_outputs=array_ops.ones([1, 2, 3]) * dis_var, + discriminator_gen_outputs=array_ops.ones([1, 2, 3]) * gen_var * dis_var, + discriminator_variables=[dis_var], + discriminator_scope=dis_scope, + discriminator_fn=None) + + +def dummy_loss_fn(gan_model): + return math_ops.reduce_sum(gan_model.discriminator_real_outputs - + gan_model.discriminator_gen_outputs) + + +def get_metrics(gan_model): + return { + 'mse_custom_metric': metrics_lib.mean_squared_error( + gan_model.real_data, gan_model.generated_data) + } + + +class GetEstimatorSpecTest(test.TestCase, parameterized.TestCase): + """Tests that the EstimatorSpec is constructed appropriately.""" + + @classmethod + def setUpClass(cls): + cls._generator_optimizer = training.GradientDescentOptimizer(1.0) + cls._discriminator_optimizer = training.GradientDescentOptimizer(1.0) + + @parameterized.named_parameters( + ('train', model_fn_lib.ModeKeys.TRAIN), + ('eval', model_fn_lib.ModeKeys.EVAL), + ('predict', model_fn_lib.ModeKeys.PREDICT)) + def test_get_estimator_spec(self, mode): + with ops.Graph().as_default(): + self._gan_model = get_dummy_gan_model() + spec = estimator._get_estimator_spec( + mode, + self._gan_model, + generator_loss_fn=dummy_loss_fn, + discriminator_loss_fn=dummy_loss_fn, + get_eval_metric_ops_fn=get_metrics, + generator_optimizer=self._generator_optimizer, + discriminator_optimizer=self._discriminator_optimizer) + + self.assertEqual(mode, spec.mode) + if mode == model_fn_lib.ModeKeys.PREDICT: + self.assertEqual(self._gan_model.generated_data, spec.predictions) + elif mode == model_fn_lib.ModeKeys.TRAIN: + self.assertShapeEqual(np.array(0), spec.loss) # must be a scalar + self.assertIsNotNone(spec.train_op) + self.assertIsNotNone(spec.training_hooks) + elif mode == model_fn_lib.ModeKeys.EVAL: + self.assertEqual(self._gan_model.generated_data, spec.predictions) + self.assertShapeEqual(np.array(0), spec.loss) # must be a scalar + self.assertIsNotNone(spec.eval_metric_ops) # TODO(joelshor): Add pandas test. @@ -195,12 +184,6 @@ class GANEstimatorIntegrationTest(test.TestCase): lr = learning_rate_decay.exponential_decay(1.0, gstep, 10, 0.9) return training.GradientDescentOptimizer(lr) - def get_metrics(gan_model): - return { - 'mse_custom_metric': metrics_lib.mean_squared_error( - gan_model.real_data, gan_model.generated_data) - } - gopt = make_opt if lr_decay else training.GradientDescentOptimizer(1.0) dopt = make_opt if lr_decay else training.GradientDescentOptimizer(1.0) est = estimator.GANEstimator( diff --git a/tensorflow/contrib/gan/python/estimator/python/head_impl.py b/tensorflow/contrib/gan/python/estimator/python/head_impl.py index d1441e1eb2..1a0ee6dfc4 100644 --- a/tensorflow/contrib/gan/python/estimator/python/head_impl.py +++ b/tensorflow/contrib/gan/python/estimator/python/head_impl.py @@ -27,16 +27,21 @@ from tensorflow.python.estimator.canned import head from tensorflow.python.estimator.export import export_output from tensorflow.python.framework import ops from tensorflow.python.ops import metrics as metrics_lib +from tensorflow.python.util import deprecation __all__ = [ 'GANHead', 'gan_head', ] + def _summary_key(head_name, val): return '%s/%s' % (val, head_name) if head_name else val +@deprecation.deprecated( + None, 'Please use tf.contrib.gan.GANEstimator without explicitly making a ' + 'GANHead.') def gan_head(generator_loss_fn, discriminator_loss_fn, generator_optimizer, discriminator_optimizer, use_loss_summaries=True, get_hooks_fn=tfgan_train.get_sequential_train_hooks(), @@ -77,6 +82,9 @@ def gan_head(generator_loss_fn, discriminator_loss_fn, generator_optimizer, class GANHead(head._Head): # pylint: disable=protected-access """`Head` for a GAN.""" + @deprecation.deprecated( + None, 'Please use tf.contrib.gan.GANEstimator without explicitly making ' + 'a GANHead.') def __init__(self, generator_loss_fn, discriminator_loss_fn, generator_optimizer, discriminator_optimizer, use_loss_summaries=True, @@ -108,7 +116,7 @@ class GANHead(head._Head): # pylint: disable=protected-access raise TypeError('generator_loss_fn must be callable.') if not callable(discriminator_loss_fn): raise TypeError('discriminator_loss_fn must be callable.') - if not use_loss_summaries in [True, False, None]: + if use_loss_summaries not in [True, False, None]: raise ValueError('use_loss_summaries must be True, False or None.') if get_hooks_fn is not None and not callable(get_hooks_fn): raise TypeError('get_hooks_fn must be callable.') diff --git a/tensorflow/contrib/gan/python/estimator/python/head_test.py b/tensorflow/contrib/gan/python/estimator/python/head_test.py index 5309d87765..8205bc889d 100644 --- a/tensorflow/contrib/gan/python/estimator/python/head_test.py +++ b/tensorflow/contrib/gan/python/estimator/python/head_test.py @@ -67,7 +67,7 @@ class GANHeadTest(test.TestCase): generator_optimizer=training.GradientDescentOptimizer(1.0), discriminator_optimizer=training.GradientDescentOptimizer(1.0), get_eval_metric_ops_fn=self.get_metrics) - self.assertTrue(isinstance(self.gan_head, head.GANHead)) + self.assertIsInstance(self.gan_head, head.GANHead) def get_metrics(self, gan_model): self.assertTrue(isinstance(gan_model, tfgan_tuples.GANModel)) diff --git a/tensorflow/contrib/linear_optimizer/BUILD b/tensorflow/contrib/linear_optimizer/BUILD index 5b89c6cef9..fe0ba19fcb 100644 --- a/tensorflow/contrib/linear_optimizer/BUILD +++ b/tensorflow/contrib/linear_optimizer/BUILD @@ -41,6 +41,7 @@ py_test( size = "medium", srcs = ["python/kernel_tests/sdca_ops_test.py"], srcs_version = "PY2AND3", + tags = ["no_windows_gpu"], deps = [ ":sdca_ops_py", ":sparse_feature_column_py", diff --git a/tensorflow/contrib/lite/build_def.bzl b/tensorflow/contrib/lite/build_def.bzl index 6e1dafefa9..b735d08b4b 100644 --- a/tensorflow/contrib/lite/build_def.bzl +++ b/tensorflow/contrib/lite/build_def.bzl @@ -195,7 +195,7 @@ def json_to_tflite(name, src, out): def generated_test_models(): return [ "add", - "arg_max", + "arg_min_max", "avg_pool", "batch_to_space_nd", "concat", @@ -232,7 +232,7 @@ def generated_test_models(): "not_equal", "pad", "padv2", - # "prelu", + "prelu", "pow", "relu", "relu1", diff --git a/tensorflow/contrib/lite/builtin_op_data.h b/tensorflow/contrib/lite/builtin_op_data.h index cda889bf50..a58dde9a7b 100644 --- a/tensorflow/contrib/lite/builtin_op_data.h +++ b/tensorflow/contrib/lite/builtin_op_data.h @@ -250,6 +250,10 @@ typedef struct { } TfLiteArgMaxParams; typedef struct { + TfLiteType output_type; +} TfLiteArgMinParams; + +typedef struct { TfLitePadding padding; int stride_width; int stride_height; @@ -263,6 +267,12 @@ typedef struct { TfLiteType out_type; } TfLiteShapeParams; +typedef struct { + float min; + float max; + int num_bits; +} TfLiteFakeQuantParams; + #ifdef __cplusplus } // extern "C" #endif // __cplusplus diff --git a/tensorflow/contrib/lite/builtin_ops.h b/tensorflow/contrib/lite/builtin_ops.h index a44e918230..6bde5d2e6d 100644 --- a/tensorflow/contrib/lite/builtin_ops.h +++ b/tensorflow/contrib/lite/builtin_ops.h @@ -104,6 +104,8 @@ typedef enum { kTfLiteBuiltinRsqrt = 76, kTfLiteBuiltinShape = 77, kTfLiteBuiltinPow = 78, + kTfLiteBuiltinArgMin = 79, + kTfLiteBuiltinFakeQuant = 80, } TfLiteBuiltinOperator; #ifdef __cplusplus diff --git a/tensorflow/contrib/lite/delegates/nnapi/nnapi_delegate.cc b/tensorflow/contrib/lite/delegates/nnapi/nnapi_delegate.cc index fd798c209e..f0d16575ec 100644 --- a/tensorflow/contrib/lite/delegates/nnapi/nnapi_delegate.cc +++ b/tensorflow/contrib/lite/delegates/nnapi/nnapi_delegate.cc @@ -452,6 +452,22 @@ class NNAPIDelegateKernel { } else { return nullptr; } + case kTfLiteBuiltinTranspose: + // Transpose requires NNAPI1.1. Also note that the permutation input + // tensor value dictates the output dimensions. + // TODO(b/110888333): Support dynamically-sized tensors in delegates. + if ((version == 1) && + (kAndroidSdkVersion >= kMinSdkVersionForNNAPI11) && + (node->inputs->size > 1) && + (context->tensors[node->inputs->data[1]].allocation_type == + kTfLiteMmapRo)) { + return [](TfLiteContext* context, NNAPIOpBuilder* builder, + TfLiteNode* node) -> ANeuralNetworksOperationType { + return ANEURALNETWORKS_TRANSPOSE; + }; + } else { + return nullptr; + } break; default: return nullptr; diff --git a/tensorflow/contrib/lite/delegates/nnapi/nnapi_delegate_test.cc b/tensorflow/contrib/lite/delegates/nnapi/nnapi_delegate_test.cc index aad10c9ce7..ab2181e8ff 100644 --- a/tensorflow/contrib/lite/delegates/nnapi/nnapi_delegate_test.cc +++ b/tensorflow/contrib/lite/delegates/nnapi/nnapi_delegate_test.cc @@ -27,14 +27,20 @@ using ::testing::ElementsAreArray; // TODO(b/110368244): figure out how to share the existing tests in kernels/ but // with the delegation on. Also, add more unit tests to improve code coverage. -class FloatAddOpModel : public SingleOpModel { +class SingleOpModelWithNNAPI : public SingleOpModel { + public: + SingleOpModelWithNNAPI() { + this->SetApplyDelegate([](Interpreter* interpreter) { + interpreter->ModifyGraphWithDelegate(NnApiDelegate(), false); + }); + } +}; + +class FloatAddOpModel : public SingleOpModelWithNNAPI { public: FloatAddOpModel(const TensorData& input1, const TensorData& input2, const TensorData& output, ActivationFunctionType activation_type) { - this->SetApplyDelegate([](Interpreter* interpreter) { - interpreter->ModifyGraphWithDelegate(NnApiDelegate()); - }); input1_ = AddInput(input1); input2_ = AddInput(input2); output_ = AddOutput(output); @@ -81,9 +87,6 @@ class FloatMulOpModel : public SingleOpModel { FloatMulOpModel(const TensorData& input1, const TensorData& input2, const TensorData& output, ActivationFunctionType activation_type) { - this->SetApplyDelegate([](Interpreter* interpreter) { - interpreter->ModifyGraphWithDelegate(NnApiDelegate()); - }); input1_ = AddInput(input1); input2_ = AddInput(input2); output_ = AddOutput(output); @@ -114,15 +117,11 @@ TEST(NNAPIDelegate, MulWithNoActivation) { ElementsAreArray(ArrayFloatNear({-0.2, 0.04, 0.21, 0.4}))); } -class FloatPoolingOpModel : public SingleOpModel { +class FloatPoolingOpModel : public SingleOpModelWithNNAPI { public: FloatPoolingOpModel(BuiltinOperator type, const TensorData& input, int filter_width, int filter_height, const TensorData& output) { - this->SetApplyDelegate([](Interpreter* interpreter) { - interpreter->ModifyGraphWithDelegate(NnApiDelegate()); - }); - input_ = AddInput(input); output_ = AddOutput(output); @@ -193,10 +192,6 @@ class BaseConvolutionOpModel : public SingleOpModel { enum Padding padding = Padding_VALID, enum ActivationFunctionType activation = ActivationFunctionType_NONE, int dilation_width_factor = 1, int dilation_height_factor = 1) { - this->SetApplyDelegate([](Interpreter* interpreter) { - interpreter->ModifyGraphWithDelegate(NnApiDelegate()); - }); - input_ = AddInput(input); filter_ = AddInput(filter); @@ -344,14 +339,10 @@ TEST(NNAPIDelegate, Conv2DWithNoActivation) { })); } -class DepthwiseConvolutionOpModel : public SingleOpModel { +class DepthwiseConvolutionOpModel : public SingleOpModelWithNNAPI { public: DepthwiseConvolutionOpModel(const TensorData& input, const TensorData& filter, const TensorData& output) { - this->SetApplyDelegate([](Interpreter* interpreter) { - interpreter->ModifyGraphWithDelegate(NnApiDelegate()); - }); - input_ = AddInput(input); filter_ = AddInput(filter); @@ -426,15 +417,11 @@ TEST(NNAPIDelegate, DepthwiseConv2DWithNoActivation) { })); } -class FloatFullyConnectedOpModel : public SingleOpModel { +class FloatFullyConnectedOpModel : public SingleOpModelWithNNAPI { public: FloatFullyConnectedOpModel(int units, int batches, const TensorData& input, const TensorData& output = {TensorType_FLOAT32}) : batches_(batches), units_(units) { - this->SetApplyDelegate([](Interpreter* interpreter) { - interpreter->ModifyGraphWithDelegate(NnApiDelegate()); - }); - int total_input_size = 1; for (int i = 0; i < input.shape.size(); ++i) { total_input_size *= input.shape[i]; @@ -515,14 +502,10 @@ TEST(NNAPIDelegate, FullyConnectedSimpleTest) { EXPECT_THAT(m.GetOutput(), ElementsAre(24, 25, 26, 58, 59, 60)); } -class SoftmaxOpModel : public SingleOpModel { +class SoftmaxOpModel : public SingleOpModelWithNNAPI { public: SoftmaxOpModel(int batches, int size, float beta) : batches_(batches), input_size_(size), beta_(beta) { - this->SetApplyDelegate([](Interpreter* interpreter) { - interpreter->ModifyGraphWithDelegate(NnApiDelegate()); - }); - input_ = AddInput(TensorType_FLOAT32); output_ = AddOutput(TensorType_FLOAT32); SetBuiltinOp(BuiltinOperator_SOFTMAX, BuiltinOptions_SoftmaxOptions, @@ -566,14 +549,10 @@ TEST(NNAPIDelegate, SoftmaxSimpleTest) { 1e-6))); } -class ReshapeOpModel : public SingleOpModel { +class ReshapeOpModel : public SingleOpModelWithNNAPI { public: ReshapeOpModel(std::initializer_list<int> input_shape, std::initializer_list<int> new_shape) { - this->SetApplyDelegate([](Interpreter* interpreter) { - interpreter->ModifyGraphWithDelegate(NnApiDelegate()); - }); - input_ = AddInput(TensorType_FLOAT32); new_shape_ = AddInput(TensorType_INT32); output_ = AddOutput(TensorType_FLOAT32); @@ -605,14 +584,10 @@ TEST(NNAPIDelegate, ReshapeSimpleTest) { EXPECT_THAT(m.GetOutputShape(), ElementsAreArray({2, 2, 2})); } -class SqueezeOpModel : public SingleOpModel { +class SqueezeOpModel : public SingleOpModelWithNNAPI { public: SqueezeOpModel(const TensorData& input, const TensorData& output, std::initializer_list<int> axis) { - this->SetApplyDelegate([](Interpreter* interpreter) { - interpreter->ModifyGraphWithDelegate(NnApiDelegate()); - }); - input_ = AddInput(input); output_ = AddOutput(output); SetBuiltinOp( @@ -666,6 +641,43 @@ TEST(NNAPIDelegate, SqueezeWithAxisTest) { 17.0, 18.0, 19.0, 20.0, 21.0, 22.0, 23.0, 24.0})); } +class TransposeSimpleModel : public SingleOpModelWithNNAPI { + public: + TransposeSimpleModel(std::initializer_list<int> input_shape, + std::initializer_list<int> perm_shape, + std::initializer_list<int> perm) { + input_ = AddInput(TensorType_FLOAT32); + perm_ = AddConstInput(TensorType_INT32, perm, perm_shape); + output_ = AddOutput(TensorType_FLOAT32); + SetBuiltinOp(BuiltinOperator_TRANSPOSE, BuiltinOptions_TransposeOptions, + CreateTransposeOptions(builder_).Union()); + BuildInterpreter({input_shape, perm_shape}); + } + + void SetInput(std::initializer_list<float> data) { + PopulateTensor<float>(input_, data); + } + + std::vector<float> GetOutput() { return ExtractVector<float>(output_); } + std::vector<int> GetOutputShape() { return GetTensorShape(output_); } + + private: + int input_; + int perm_; + int output_; +}; + +TEST(NNAPIDelegate, TransposeSimpleTest) { + TransposeSimpleModel m({2, 3, 4}, {3}, {2, 0, 1}); + m.SetInput({0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, + 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23}); + m.Invoke(); + EXPECT_THAT(m.GetOutputShape(), ElementsAreArray({4, 2, 3})); + EXPECT_THAT(m.GetOutput(), + ElementsAreArray({0, 4, 8, 12, 16, 20, 1, 5, 9, 13, 17, 21, + 2, 6, 10, 14, 18, 22, 3, 7, 11, 15, 19, 23})); +} + } // namespace } // namespace tflite diff --git a/tensorflow/contrib/lite/g3doc/tf_ops_compatibility.md b/tensorflow/contrib/lite/g3doc/tf_ops_compatibility.md index dcd17bbeab..49d00a66ba 100644 --- a/tensorflow/contrib/lite/g3doc/tf_ops_compatibility.md +++ b/tensorflow/contrib/lite/g3doc/tf_ops_compatibility.md @@ -42,6 +42,7 @@ counterparts: *as long as the input tensor is 4D (1 batch + 2 spatial + 1 other) and the crops attribute is not used* * [tf.exp](https://www.tensorflow.org/api_docs/python/tf/exp) +* [tf.fake_quant*](https://www.tensorflow.org/api_docs/python/tf/fake_quant_with_min_max_args) * [tf.matmul](https://www.tensorflow.org/api_docs/python/tf/matmul) - *as long as the second argument is constant and transposition is not used* * [tf.nn.avg_pool](https://www.tensorflow.org/api_docs/python/tf/nn/avg_pool) @@ -790,6 +791,30 @@ Outputs { } ``` +**ARG_MAX** + +``` +Inputs { + 0: a tensor + 1: a tensor +} +Outputs { + 0: A tensor of indices of maximum values. +} +``` + +**ARG_MIN** + +``` +Inputs { + 0: a tensor + 1: a tensor +} +Outputs { + 0: A tensor of indices of minium values. +} +``` + And these are TensorFlow Lite operations that are present but not ready for custom models yet: diff --git a/tensorflow/contrib/lite/interpreter.cc b/tensorflow/contrib/lite/interpreter.cc index 521216a4f1..0641a08636 100644 --- a/tensorflow/contrib/lite/interpreter.cc +++ b/tensorflow/contrib/lite/interpreter.cc @@ -441,6 +441,13 @@ TfLiteStatus Interpreter::AllocateTensors() { TF_LITE_ENSURE_STATUS(PrepareOpsAndTensors()); state_ = kStateInvokable; + + // Reset the variable tensors to zero after (re)allocating the tensors. + // Developers shouldn't rely on the side effect of this function to reset + // variable tesnsors. They should call `ResetVariableTensorsToZero` directly + // instead. + ResetVariableTensorsToZero(); + return kTfLiteOk; } @@ -565,6 +572,8 @@ TfLiteStatus Interpreter::PrepareOpsStartingAt( nodes_and_registration_[node_index].second; EnsureTensorsVectorCapacity(); if (OpPrepare(registration, &node) == kTfLiteError) { + context_.ReportError(&context_, "Node %d failed to prepare.\n", + node_index); return kTfLiteError; } @@ -665,6 +674,8 @@ TfLiteStatus Interpreter::Invoke() { EnsureTensorsVectorCapacity(); tensor_resized_since_op_invoke_ = false; if (OpInvoke(registration, &node) == kTfLiteError) { + context_.ReportError(&context_, "Node %d failed to invoke.\n", + node_index); status = kTfLiteError; } diff --git a/tensorflow/contrib/lite/interpreter_test.cc b/tensorflow/contrib/lite/interpreter_test.cc index 4fa97512fc..10119903fe 100644 --- a/tensorflow/contrib/lite/interpreter_test.cc +++ b/tensorflow/contrib/lite/interpreter_test.cc @@ -57,6 +57,22 @@ TEST(BasicInterpreter, InvokeInvalidModel) { ASSERT_EQ(interpreter.Invoke(), kTfLiteOk); } +TEST(BasicInterpreter, TestAllocateTensorsResetVariableTensors) { + Interpreter interpreter; + int tensor_index; + ASSERT_EQ(interpreter.AddTensors(1, &tensor_index), kTfLiteOk); + constexpr int kTensorSize = 16; + interpreter.SetTensorParametersReadWrite(tensor_index, kTfLiteFloat32, "", + {kTensorSize}, {}, true); + interpreter.SetVariables({tensor_index}); + ASSERT_EQ(interpreter.AllocateTensors(), kTfLiteOk); + TfLiteTensor* tensor = interpreter.tensor(tensor_index); + // Ensure that variable tensors are reset to zero. + for (int i = 0; i < kTensorSize; ++i) { + ASSERT_EQ(tensor->data.f[i], 0.0f); + } +} + // Test size accessor functions. TEST(BasicInterpreter, TestSizeFunctions) { Interpreter interpreter; diff --git a/tensorflow/contrib/lite/java/ovic/src/test/java/org/tensorflow/ovic/OvicClassifierTest.java b/tensorflow/contrib/lite/java/ovic/src/test/java/org/tensorflow/ovic/OvicClassifierTest.java index 56f3e7604a..1587c3c56f 100644 --- a/tensorflow/contrib/lite/java/ovic/src/test/java/org/tensorflow/ovic/OvicClassifierTest.java +++ b/tensorflow/contrib/lite/java/ovic/src/test/java/org/tensorflow/ovic/OvicClassifierTest.java @@ -127,12 +127,8 @@ public final class OvicClassifierTest { try { testResult = classifier.classifyByteBuffer(testImage); fail(); - } catch (RuntimeException e) { - assertThat(e) - .hasMessageThat() - .contains( - "Failed to get input dimensions. 0-th input should have 49152 bytes, " - + "but found 150528 bytes."); + } catch (IllegalArgumentException e) { + // Success. } } diff --git a/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/DataType.java b/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/DataType.java index 75334cd96e..94a1ec65d6 100644 --- a/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/DataType.java +++ b/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/DataType.java @@ -27,10 +27,7 @@ enum DataType { UINT8(3), /** 64-bit signed integer. */ - INT64(4), - - /** A {@link ByteBuffer}. */ - BYTEBUFFER(999); + INT64(4); private final int value; @@ -69,8 +66,6 @@ enum DataType { return 1; case INT64: return 8; - case BYTEBUFFER: - return 1; } throw new IllegalArgumentException( "DataType error: DataType " + this + " is not supported yet"); @@ -87,8 +82,6 @@ enum DataType { return "byte"; case INT64: return "long"; - case BYTEBUFFER: - return "ByteBuffer"; } throw new IllegalArgumentException( "DataType error: DataType " + this + " is not supported yet"); diff --git a/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/Interpreter.java b/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/Interpreter.java index 589fd6426f..7002f82677 100644 --- a/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/Interpreter.java +++ b/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/Interpreter.java @@ -165,20 +165,7 @@ public final class Interpreter implements AutoCloseable { if (wrapper == null) { throw new IllegalStateException("Internal error: The Interpreter has already been closed."); } - Tensor[] tensors = wrapper.run(inputs); - if (outputs == null || tensors == null || outputs.size() > tensors.length) { - throw new IllegalArgumentException("Output error: Outputs do not match with model outputs."); - } - final int size = tensors.length; - for (Integer idx : outputs.keySet()) { - if (idx == null || idx < 0 || idx >= size) { - throw new IllegalArgumentException( - String.format( - "Output error: Invalid index of output %d (should be in range [0, %d))", - idx, size)); - } - tensors[idx].copyTo(outputs.get(idx)); - } + wrapper.run(inputs, outputs); } /** diff --git a/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/NativeInterpreterWrapper.java b/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/NativeInterpreterWrapper.java index 80de88b6a1..767a220f8c 100644 --- a/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/NativeInterpreterWrapper.java +++ b/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/NativeInterpreterWrapper.java @@ -15,10 +15,10 @@ limitations under the License. package org.tensorflow.lite; -import java.lang.reflect.Array; import java.nio.ByteBuffer; import java.nio.ByteOrder; import java.nio.MappedByteBuffer; +import java.util.Arrays; import java.util.HashMap; import java.util.Map; @@ -40,6 +40,8 @@ final class NativeInterpreterWrapper implements AutoCloseable { modelHandle = createModel(modelPath, errorHandle); interpreterHandle = createInterpreter(modelHandle, errorHandle, numThreads); isMemoryAllocated = true; + inputTensors = new Tensor[getInputCount(interpreterHandle)]; + outputTensors = new Tensor[getOutputCount(interpreterHandle)]; } /** @@ -72,6 +74,8 @@ final class NativeInterpreterWrapper implements AutoCloseable { modelHandle = createModelWithBuffer(modelByteBuffer, errorHandle); interpreterHandle = createInterpreter(modelHandle, errorHandle, numThreads); isMemoryAllocated = true; + inputTensors = new Tensor[getInputCount(interpreterHandle)]; + outputTensors = new Tensor[getOutputCount(interpreterHandle)]; } /** Releases resources associated with this {@code NativeInterpreterWrapper}. */ @@ -85,75 +89,63 @@ final class NativeInterpreterWrapper implements AutoCloseable { inputsIndexes = null; outputsIndexes = null; isMemoryAllocated = false; + Arrays.fill(inputTensors, null); + Arrays.fill(outputTensors, null); } /** Sets inputs, runs model inference and returns outputs. */ - Tensor[] run(Object[] inputs) { + void run(Object[] inputs, Map<Integer, Object> outputs) { + inferenceDurationNanoseconds = -1; if (inputs == null || inputs.length == 0) { throw new IllegalArgumentException("Input error: Inputs should not be null or empty."); } - int[] dataTypes = new int[inputs.length]; - Object[] sizes = new Object[inputs.length]; - int[] numsOfBytes = new int[inputs.length]; + if (outputs == null || outputs.isEmpty()) { + throw new IllegalArgumentException("Input error: Outputs should not be null or empty."); + } + + // TODO(b/80431971): Remove implicit resize after deprecating multi-dimensional array inputs. + // Rather than forcing an immediate resize + allocation if an input's shape differs, we first + // flush all resizes, avoiding redundant allocations. for (int i = 0; i < inputs.length; ++i) { - DataType dataType = dataTypeOf(inputs[i]); - dataTypes[i] = dataType.getNumber(); - if (dataType == DataType.BYTEBUFFER) { - ByteBuffer buffer = (ByteBuffer) inputs[i]; - if (buffer == null || !buffer.isDirect() || buffer.order() != ByteOrder.nativeOrder()) { - throw new IllegalArgumentException( - "Input error: ByteBuffer should be a direct ByteBuffer that uses " - + "ByteOrder.nativeOrder()."); - } - numsOfBytes[i] = buffer.limit(); - sizes[i] = getInputDims(interpreterHandle, i, numsOfBytes[i]); - } else if (isNonEmptyArray(inputs[i])) { - int[] dims = shapeOf(inputs[i]); - sizes[i] = dims; - numsOfBytes[i] = dataType.elemByteSize() * numElements(dims); - } else { - throw new IllegalArgumentException( - String.format( - "Input error: %d-th element of the %d inputs is not an array or a ByteBuffer.", - i, inputs.length)); + Tensor tensor = getInputTensor(i); + int[] newShape = tensor.getInputShapeIfDifferent(inputs[i]); + if (newShape != null) { + resizeInput(i, newShape); } } - inferenceDurationNanoseconds = -1; - long[] outputsHandles = - run( - interpreterHandle, - errorHandle, - sizes, - dataTypes, - numsOfBytes, - inputs, - this, - isMemoryAllocated); - if (outputsHandles == null || outputsHandles.length == 0) { - throw new IllegalStateException("Internal error: Interpreter has no outputs."); + + if (!isMemoryAllocated) { + allocateTensors(interpreterHandle, errorHandle); + isMemoryAllocated = true; + // Allocation can trigger dynamic resizing of output tensors, so clear the + // output tensor cache. + Arrays.fill(outputTensors, null); } - isMemoryAllocated = true; - Tensor[] outputs = new Tensor[outputsHandles.length]; - for (int i = 0; i < outputsHandles.length; ++i) { - outputs[i] = Tensor.fromHandle(outputsHandles[i]); + + for (int i = 0; i < inputs.length; ++i) { + getInputTensor(i).setTo(inputs[i]); + } + + long inferenceStartNanos = System.nanoTime(); + run(interpreterHandle, errorHandle); + long inferenceDurationNanoseconds = System.nanoTime() - inferenceStartNanos; + + for (Map.Entry<Integer, Object> output : outputs.entrySet()) { + getOutputTensor(output.getKey()).copyTo(output.getValue()); } - return outputs; + + // Only set if the entire operation succeeds. + this.inferenceDurationNanoseconds = inferenceDurationNanoseconds; } - private static native long[] run( - long interpreterHandle, - long errorHandle, - Object[] sizes, - int[] dtypes, - int[] numsOfBytes, - Object[] values, - NativeInterpreterWrapper wrapper, - boolean memoryAllocated); + private static native boolean run(long interpreterHandle, long errorHandle); /** Resizes dimensions of a specific input. */ void resizeInput(int idx, int[] dims) { if (resizeInput(interpreterHandle, errorHandle, idx, dims)) { isMemoryAllocated = false; + // Resizing will invalidate the Tensor's shape, so invalidate the Tensor handle. + inputTensors[idx] = null; } } @@ -212,78 +204,6 @@ final class NativeInterpreterWrapper implements AutoCloseable { } } - static int numElements(int[] shape) { - if (shape == null) { - return 0; - } - int n = 1; - for (int i = 0; i < shape.length; i++) { - n *= shape[i]; - } - return n; - } - - static boolean isNonEmptyArray(Object o) { - return (o != null && o.getClass().isArray() && Array.getLength(o) != 0); - } - - /** Returns the type of the data. */ - static DataType dataTypeOf(Object o) { - if (o != null) { - Class<?> c = o.getClass(); - while (c.isArray()) { - c = c.getComponentType(); - } - if (float.class.equals(c)) { - return DataType.FLOAT32; - } else if (int.class.equals(c)) { - return DataType.INT32; - } else if (byte.class.equals(c)) { - return DataType.UINT8; - } else if (long.class.equals(c)) { - return DataType.INT64; - } else if (ByteBuffer.class.isInstance(o)) { - return DataType.BYTEBUFFER; - } - } - throw new IllegalArgumentException( - "DataType error: cannot resolve DataType of " + o.getClass().getName()); - } - - /** Returns the shape of an object as an int array. */ - static int[] shapeOf(Object o) { - int size = numDimensions(o); - int[] dimensions = new int[size]; - fillShape(o, 0, dimensions); - return dimensions; - } - - static int numDimensions(Object o) { - if (o == null || !o.getClass().isArray()) { - return 0; - } - if (Array.getLength(o) == 0) { - throw new IllegalArgumentException("Array lengths cannot be 0."); - } - return 1 + numDimensions(Array.get(o, 0)); - } - - static void fillShape(Object o, int dim, int[] shape) { - if (shape == null || dim == shape.length) { - return; - } - final int len = Array.getLength(o); - if (shape[dim] == 0) { - shape[dim] = len; - } else if (shape[dim] != len) { - throw new IllegalArgumentException( - String.format("Mismatched lengths (%d and %d) in dimension %d", shape[dim], len, dim)); - } - for (int i = 0; i < len; ++i) { - fillShape(Array.get(o, i), dim + 1, shape); - } - } - /** * Gets the last inference duration in nanoseconds. It returns null if there is no previous * inference run or the last inference run failed. @@ -293,40 +213,55 @@ final class NativeInterpreterWrapper implements AutoCloseable { } /** - * Gets the dimensions of an input. It throws IllegalArgumentException if input index is invalid. + * Gets the quantization zero point of an output. + * + * @throws IllegalArgumentException if the output index is invalid. */ - int[] getInputDims(int index) { - return getInputDims(interpreterHandle, index, -1); + int getOutputQuantizationZeroPoint(int index) { + return getOutputQuantizationZeroPoint(interpreterHandle, index); } /** - * Gets the dimensions of an input. If numBytes >= 0, it will check whether num of bytes match the - * input. + * Gets the quantization scale of an output. + * + * @throws IllegalArgumentException if the output index is invalid. */ - private static native int[] getInputDims(long interpreterHandle, int inputIdx, int numBytes); - - /** Gets the type of an output. It throws IllegalArgumentException if output index is invalid. */ - String getOutputDataType(int index) { - int type = getOutputDataType(interpreterHandle, index); - return DataType.fromNumber(type).toStringName(); + float getOutputQuantizationScale(int index) { + return getOutputQuantizationScale(interpreterHandle, index); } /** - * Gets the quantization zero point of an output. + * Gets the input {@link Tensor} for the provided input index. * - * @throws IllegalArgumentExeption if the output index is invalid. + * @throws IllegalArgumentException if the input index is invalid. */ - int getOutputQuantizationZeroPoint(int index) { - return getOutputQuantizationZeroPoint(interpreterHandle, index); + Tensor getInputTensor(int index) { + if (index < 0 || index >= inputTensors.length) { + throw new IllegalArgumentException("Invalid input Tensor index: " + index); + } + Tensor inputTensor = inputTensors[index]; + if (inputTensor == null) { + inputTensor = + inputTensors[index] = Tensor.fromHandle(getInputTensor(interpreterHandle, index)); + } + return inputTensor; } /** - * Gets the quantization scale of an output. + * Gets the output {@link Tensor} for the provided output index. * - * @throws IllegalArgumentExeption if the output index is invalid. + * @throws IllegalArgumentException if the output index is invalid. */ - float getOutputQuantizationScale(int index) { - return getOutputQuantizationScale(interpreterHandle, index); + Tensor getOutputTensor(int index) { + if (index < 0 || index >= outputTensors.length) { + throw new IllegalArgumentException("Invalid output Tensor index: " + index); + } + Tensor outputTensor = outputTensors[index]; + if (outputTensor == null) { + outputTensor = + outputTensors[index] = Tensor.fromHandle(getOutputTensor(interpreterHandle, index)); + } + return outputTensor; } private static native int getOutputDataType(long interpreterHandle, int outputIdx); @@ -343,18 +278,30 @@ final class NativeInterpreterWrapper implements AutoCloseable { private long modelHandle; - private int inputSize; - private long inferenceDurationNanoseconds = -1; private ByteBuffer modelByteBuffer; + // Lazily constructed maps of input and output names to input and output Tensor indexes. private Map<String, Integer> inputsIndexes; - private Map<String, Integer> outputsIndexes; + // Lazily constructed and populated arrays of input and output Tensor wrappers. + private final Tensor[] inputTensors; + private final Tensor[] outputTensors; + private boolean isMemoryAllocated = false; + private static native long allocateTensors(long interpreterHandle, long errorHandle); + + private static native long getInputTensor(long interpreterHandle, int inputIdx); + + private static native long getOutputTensor(long interpreterHandle, int outputIdx); + + private static native int getInputCount(long interpreterHandle); + + private static native int getOutputCount(long interpreterHandle); + private static native String[] getInputNames(long interpreterHandle); private static native String[] getOutputNames(long interpreterHandle); diff --git a/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/Tensor.java b/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/Tensor.java index b2a3e04c55..2403570c52 100644 --- a/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/Tensor.java +++ b/tensorflow/contrib/lite/java/src/main/java/org/tensorflow/lite/Tensor.java @@ -15,6 +15,7 @@ limitations under the License. package org.tensorflow.lite; +import java.lang.reflect.Array; import java.nio.ByteBuffer; import java.nio.ByteOrder; import java.util.Arrays; @@ -31,43 +32,179 @@ final class Tensor { return new Tensor(nativeHandle); } + /** Returns the {@link DataType} of elements stored in the Tensor. */ + public DataType dataType() { + return dtype; + } + + /** Returns the size, in bytes, of the tensor data. */ + public int numBytes() { + return numBytes(nativeHandle); + } + + /** + * Returns the <a href="https://www.tensorflow.org/resources/dims_types.html#shape">shape</a> of + * the Tensor, i.e., the sizes of each dimension. + * + * @return an array where the i-th element is the size of the i-th dimension of the tensor. + */ + public int[] shape() { + return shapeCopy; + } + + /** + * Copies the contents of the provided {@code src} object to the Tensor. + * + * <p>The {@code src} should either be a (multi-dimensional) array with a shape matching that of + * this tensor, or a {@link ByteByffer} of compatible primitive type with a matching flat size. + * + * @throws IllegalArgumentException if the tensor is a scalar or if {@code src} is not compatible + * with the tensor (for example, mismatched data types or shapes). + */ + void setTo(Object src) { + throwExceptionIfTypeIsIncompatible(src); + if (isByteBuffer(src)) { + ByteBuffer srcBuffer = (ByteBuffer) src; + // For direct ByteBuffer instances we support zero-copy. Note that this assumes the caller + // retains ownership of the source buffer until inference has completed. + if (srcBuffer.isDirect() && srcBuffer.order() == ByteOrder.nativeOrder()) { + writeDirectBuffer(nativeHandle, srcBuffer); + } else { + buffer().put(srcBuffer); + } + return; + } + writeMultiDimensionalArray(nativeHandle, src); + } + /** * Copies the contents of the tensor to {@code dst} and returns {@code dst}. * * @param dst the destination buffer, either an explicitly-typed array or a {@link ByteBuffer}. * @throws IllegalArgumentException if {@code dst} is not compatible with the tensor (for example, * mismatched data types or shapes). - * @throws BufferOverflowException If {@code dst} is a ByteBuffer with insufficient space for the - * data in this tensor. */ - <T> T copyTo(T dst) { + Object copyTo(Object dst) { + throwExceptionIfTypeIsIncompatible(dst); if (dst instanceof ByteBuffer) { ByteBuffer dstByteBuffer = (ByteBuffer) dst; dstByteBuffer.put(buffer()); return dst; } - if (NativeInterpreterWrapper.dataTypeOf(dst) != dtype) { + readMultiDimensionalArray(nativeHandle, dst); + return dst; + } + + /** Returns the provided buffer's shape if specified and different from this Tensor's shape. */ + // TODO(b/80431971): Remove this method after deprecating multi-dimensional array inputs. + int[] getInputShapeIfDifferent(Object input) { + // Implicit resizes based on ByteBuffer capacity isn't supported, so short-circuit that path. + // The ByteBuffer's size will be validated against this Tensor's size in {@link #setTo(Object)}. + if (isByteBuffer(input)) { + return null; + } + int[] inputShape = shapeOf(input); + if (Arrays.equals(shapeCopy, inputShape)) { + return null; + } + return inputShape; + } + + /** Returns the type of the data. */ + static DataType dataTypeOf(Object o) { + if (o != null) { + Class<?> c = o.getClass(); + while (c.isArray()) { + c = c.getComponentType(); + } + if (float.class.equals(c)) { + return DataType.FLOAT32; + } else if (int.class.equals(c)) { + return DataType.INT32; + } else if (byte.class.equals(c)) { + return DataType.UINT8; + } else if (long.class.equals(c)) { + return DataType.INT64; + } + } + throw new IllegalArgumentException( + "DataType error: cannot resolve DataType of " + o.getClass().getName()); + } + + /** Returns the shape of an object as an int array. */ + static int[] shapeOf(Object o) { + int size = numDimensions(o); + int[] dimensions = new int[size]; + fillShape(o, 0, dimensions); + return dimensions; + } + + /** Returns the number of dimensions of a multi-dimensional array, otherwise 0. */ + static int numDimensions(Object o) { + if (o == null || !o.getClass().isArray()) { + return 0; + } + if (Array.getLength(o) == 0) { + throw new IllegalArgumentException("Array lengths cannot be 0."); + } + return 1 + numDimensions(Array.get(o, 0)); + } + + /** Recursively populates the shape dimensions for a given (multi-dimensional) array. */ + static void fillShape(Object o, int dim, int[] shape) { + if (shape == null || dim == shape.length) { + return; + } + final int len = Array.getLength(o); + if (shape[dim] == 0) { + shape[dim] = len; + } else if (shape[dim] != len) { + throw new IllegalArgumentException( + String.format("Mismatched lengths (%d and %d) in dimension %d", shape[dim], len, dim)); + } + for (int i = 0; i < len; ++i) { + fillShape(Array.get(o, i), dim + 1, shape); + } + } + + private void throwExceptionIfTypeIsIncompatible(Object o) { + if (isByteBuffer(o)) { + ByteBuffer oBuffer = (ByteBuffer) o; + if (oBuffer.capacity() != numBytes()) { + throw new IllegalArgumentException( + String.format( + "Cannot convert between a TensorFlowLite buffer with %d bytes and a " + + "ByteBuffer with %d bytes.", + numBytes(), oBuffer.capacity())); + } + return; + } + DataType oType = dataTypeOf(o); + if (oType != dtype) { throw new IllegalArgumentException( String.format( - "Output error: Cannot convert an TensorFlowLite tensor with type %s to a Java " - + "object of type %s (which is compatible with the TensorFlowLite type %s)", - dtype, dst.getClass().getName(), NativeInterpreterWrapper.dataTypeOf(dst))); + "Cannot convert between a TensorFlowLite tensor with type %s and a Java " + + "object of type %s (which is compatible with the TensorFlowLite type %s).", + dtype, o.getClass().getName(), oType)); } - int[] dstShape = NativeInterpreterWrapper.shapeOf(dst); - if (!Arrays.equals(dstShape, shapeCopy)) { + + int[] oShape = shapeOf(o); + if (!Arrays.equals(oShape, shapeCopy)) { throw new IllegalArgumentException( String.format( - "Output error: Shape of output target %s does not match with the shape of the " - + "Tensor %s.", - Arrays.toString(dstShape), Arrays.toString(shapeCopy))); + "Cannot copy between a TensorFlowLite tensor with shape %s and a Java object " + + "with shape %s.", + Arrays.toString(shapeCopy), Arrays.toString(oShape))); } - readMultiDimensionalArray(nativeHandle, dst); - return dst; } - final long nativeHandle; - final DataType dtype; - final int[] shapeCopy; + private static boolean isByteBuffer(Object o) { + return o instanceof ByteBuffer; + } + + private final long nativeHandle; + private final DataType dtype; + private final int[] shapeCopy; private Tensor(long nativeHandle) { this.nativeHandle = nativeHandle; @@ -81,11 +218,17 @@ final class Tensor { private static native ByteBuffer buffer(long handle); + private static native void writeDirectBuffer(long handle, ByteBuffer src); + private static native int dtype(long handle); private static native int[] shape(long handle); - private static native void readMultiDimensionalArray(long handle, Object value); + private static native int numBytes(long handle); + + private static native void readMultiDimensionalArray(long handle, Object dst); + + private static native void writeMultiDimensionalArray(long handle, Object src); static { TensorFlowLite.init(); diff --git a/tensorflow/contrib/lite/java/src/main/native/BUILD b/tensorflow/contrib/lite/java/src/main/native/BUILD index 4399ed2025..4b4e1c21d8 100644 --- a/tensorflow/contrib/lite/java/src/main/native/BUILD +++ b/tensorflow/contrib/lite/java/src/main/native/BUILD @@ -11,7 +11,6 @@ licenses(["notice"]) # Apache 2.0 cc_library( name = "native_framework_only", srcs = [ - "duration_utils_jni.cc", "exception_jni.cc", "nativeinterpreterwrapper_jni.cc", "tensor_jni.cc", diff --git a/tensorflow/contrib/lite/java/src/main/native/duration_utils_jni.cc b/tensorflow/contrib/lite/java/src/main/native/duration_utils_jni.cc deleted file mode 100644 index 0e08a04370..0000000000 --- a/tensorflow/contrib/lite/java/src/main/native/duration_utils_jni.cc +++ /dev/null @@ -1,38 +0,0 @@ -/* Copyright 2017 The TensorFlow Authors. All Rights Reserved. - -Licensed under the Apache License, Version 2.0 (the "License"); -you may not use this file except in compliance with the License. -You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - -Unless required by applicable law or agreed to in writing, software -distributed under the License is distributed on an "AS IS" BASIS, -WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -See the License for the specific language governing permissions and -limitations under the License. -==============================================================================*/ - -#include <jni.h> -#include <time.h> - -namespace tflite { - -// Gets the elapsed wall-clock timespec. -timespec getCurrentTime() { - timespec time; - clock_gettime(CLOCK_MONOTONIC, &time); - return time; -} - -// Computes the time diff from two timespecs. Returns '-1' if 'stop' is earlier -// than 'start'. -jlong timespec_diff_nanoseconds(struct timespec* start, struct timespec* stop) { - jlong result = stop->tv_sec - start->tv_sec; - if (result < 0) return -1; - result = 1000000000 * result + (stop->tv_nsec - start->tv_nsec); - if (result < 0) return -1; - return result; -} - -} // namespace tflite diff --git a/tensorflow/contrib/lite/java/src/main/native/nativeinterpreterwrapper_jni.cc b/tensorflow/contrib/lite/java/src/main/native/nativeinterpreterwrapper_jni.cc index 31f7b58fbc..e2c1edd9af 100644 --- a/tensorflow/contrib/lite/java/src/main/native/nativeinterpreterwrapper_jni.cc +++ b/tensorflow/contrib/lite/java/src/main/native/nativeinterpreterwrapper_jni.cc @@ -16,9 +16,6 @@ limitations under the License. #include "tensorflow/contrib/lite/java/src/main/native/nativeinterpreterwrapper_jni.h" namespace { -const int kByteBufferValue = 999; -const int kBufferSize = 256; - tflite::Interpreter* convertLongToInterpreter(JNIEnv* env, jlong handle) { if (handle == 0) { throwException(env, kIllegalArgumentException, @@ -62,22 +59,6 @@ std::vector<int> convertJIntArrayToVector(JNIEnv* env, jintArray inputs) { return outputs; } -bool isByteBuffer(jint data_type) { return data_type == kByteBufferValue; } - -TfLiteType resolveDataType(jint data_type) { - switch (data_type) { - case 1: - return kTfLiteFloat32; - case 2: - return kTfLiteInt32; - case 3: - return kTfLiteUInt8; - case 4: - return kTfLiteInt64; - default: - return kTfLiteNoType; - } -} int getDataType(TfLiteType data_type) { switch (data_type) { @@ -108,64 +89,6 @@ void printDims(char* buffer, int max_size, int* dims, int num_dims) { } } -TfLiteStatus checkInputs(JNIEnv* env, tflite::Interpreter* interpreter, - const int input_size, jintArray data_types, - jintArray nums_of_bytes, jobjectArray values, - jobjectArray sizes) { - if (input_size != interpreter->inputs().size()) { - throwException(env, kIllegalArgumentException, - "Input error: Expected num of inputs is %d but got %d", - interpreter->inputs().size(), input_size); - return kTfLiteError; - } - if (input_size != env->GetArrayLength(data_types) || - input_size != env->GetArrayLength(nums_of_bytes) || - input_size != env->GetArrayLength(values)) { - throwException(env, kIllegalArgumentException, - "Internal error: Arrays in arguments should be of the same " - "length, but got %d sizes, %d data_types, %d nums_of_bytes, " - "and %d values", - input_size, env->GetArrayLength(data_types), - env->GetArrayLength(nums_of_bytes), - env->GetArrayLength(values)); - return kTfLiteError; - } - for (int i = 0; i < input_size; ++i) { - int input_idx = interpreter->inputs()[i]; - TfLiteTensor* target = interpreter->tensor(input_idx); - jintArray dims = - static_cast<jintArray>(env->GetObjectArrayElement(sizes, i)); - int num_dims = static_cast<int>(env->GetArrayLength(dims)); - if (target->dims->size != num_dims) { - throwException(env, kIllegalArgumentException, - "Input error: %d-th input should have %d dimensions, but " - "found %d dimensions", - i, target->dims->size, num_dims); - return kTfLiteError; - } - jint* ptr = env->GetIntArrayElements(dims, nullptr); - for (int j = 1; j < num_dims; ++j) { - if (target->dims->data[j] != ptr[j]) { - std::unique_ptr<char[]> expected_dims(new char[kBufferSize]); - std::unique_ptr<char[]> obtained_dims(new char[kBufferSize]); - printDims(expected_dims.get(), kBufferSize, target->dims->data, - num_dims); - printDims(obtained_dims.get(), kBufferSize, ptr, num_dims); - throwException(env, kIllegalArgumentException, - "Input error: %d-th input dimension should be [%s], but " - "found [%s]", - i, expected_dims.get(), obtained_dims.get()); - env->ReleaseIntArrayElements(dims, ptr, JNI_ABORT); - return kTfLiteError; - } - } - env->ReleaseIntArrayElements(dims, ptr, JNI_ABORT); - env->DeleteLocalRef(dims); - if (env->ExceptionCheck()) return kTfLiteError; - } - return kTfLiteOk; -} - // Checks whether there is any difference between dimensions of a tensor and a // given dimensions. Returns true if there is difference, else false. bool areDimsDifferent(JNIEnv* env, TfLiteTensor* tensor, jintArray dims) { @@ -188,74 +111,6 @@ bool areDimsDifferent(JNIEnv* env, TfLiteTensor* tensor, jintArray dims) { return false; } -bool areInputDimensionsTheSame(JNIEnv* env, tflite::Interpreter* interpreter, - int input_size, jobjectArray sizes) { - if (interpreter->inputs().size() != input_size) { - return false; - } - for (int i = 0; i < input_size; ++i) { - int input_idx = interpreter->inputs()[i]; - jintArray dims = - static_cast<jintArray>(env->GetObjectArrayElement(sizes, i)); - TfLiteTensor* target = interpreter->tensor(input_idx); - if (areDimsDifferent(env, target, dims)) return false; - env->DeleteLocalRef(dims); - if (env->ExceptionCheck()) return false; - } - return true; -} - -TfLiteStatus resizeInputs(JNIEnv* env, tflite::Interpreter* interpreter, - int input_size, jobjectArray sizes) { - for (int i = 0; i < input_size; ++i) { - int input_idx = interpreter->inputs()[i]; - jintArray dims = - static_cast<jintArray>(env->GetObjectArrayElement(sizes, i)); - TfLiteStatus status = interpreter->ResizeInputTensor( - input_idx, convertJIntArrayToVector(env, dims)); - if (status != kTfLiteOk) { - return status; - } - env->DeleteLocalRef(dims); - if (env->ExceptionCheck()) return kTfLiteError; - } - return kTfLiteOk; -} - -TfLiteStatus setInputs(JNIEnv* env, tflite::Interpreter* interpreter, - int input_size, jintArray data_types, - jintArray nums_of_bytes, jobjectArray values) { - jint* data_type = env->GetIntArrayElements(data_types, nullptr); - jint* num_bytes = env->GetIntArrayElements(nums_of_bytes, nullptr); - for (int i = 0; i < input_size; ++i) { - int input_idx = interpreter->inputs()[i]; - TfLiteTensor* target = interpreter->tensor(input_idx); - jobject value = env->GetObjectArrayElement(values, i); - bool is_byte_buffer = isByteBuffer(data_type[i]); - if (is_byte_buffer) { - writeByteBuffer(env, value, &(target->data.raw), - static_cast<int>(num_bytes[i])); - } else { - TfLiteType type = resolveDataType(data_type[i]); - if (type != target->type) { - throwException(env, kIllegalArgumentException, - "Input error: DataType (%d) of input data does not " - "match with the DataType (%d) of model inputs.", - type, target->type); - return kTfLiteError; - } - writeMultiDimensionalArray(env, value, target->type, target->dims->size, - &(target->data.raw), - static_cast<int>(num_bytes[i])); - } - env->DeleteLocalRef(value); - if (env->ExceptionCheck()) return kTfLiteError; - } - env->ReleaseIntArrayElements(data_types, data_type, JNI_ABORT); - env->ReleaseIntArrayElements(nums_of_bytes, num_bytes, JNI_ABORT); - return kTfLiteOk; -} - // TODO(yichengfan): evaluate the benefit to use tflite verifier. bool VerifyModel(const void* buf, size_t len) { flatbuffers::Verifier verifier(static_cast<const uint8_t*>(buf), len); @@ -287,6 +142,63 @@ Java_org_tensorflow_lite_NativeInterpreterWrapper_getInputNames(JNIEnv* env, return names; } +JNIEXPORT void JNICALL +Java_org_tensorflow_lite_NativeInterpreterWrapper_allocateTensors( + JNIEnv* env, jclass clazz, jlong handle, jlong error_handle) { + tflite::Interpreter* interpreter = convertLongToInterpreter(env, handle); + if (interpreter == nullptr) return; + BufferErrorReporter* error_reporter = + convertLongToErrorReporter(env, error_handle); + if (error_reporter == nullptr) return; + + if (interpreter->AllocateTensors() != kTfLiteOk) { + throwException(env, kNullPointerException, + "Internal error: Cannot allocate memory for the interpreter:" + " %s", + error_reporter->CachedErrorMessage()); + } +} + +JNIEXPORT jlong JNICALL +Java_org_tensorflow_lite_NativeInterpreterWrapper_getInputTensor(JNIEnv* env, + jclass clazz, + jlong handle, + jint index) { + tflite::Interpreter* interpreter = convertLongToInterpreter(env, handle); + if (interpreter == nullptr) return 0; + return reinterpret_cast<jlong>( + interpreter->tensor(interpreter->inputs()[index])); +} + +JNIEXPORT jlong JNICALL +Java_org_tensorflow_lite_NativeInterpreterWrapper_getOutputTensor(JNIEnv* env, + jclass clazz, + jlong handle, + jint index) { + tflite::Interpreter* interpreter = convertLongToInterpreter(env, handle); + if (interpreter == nullptr) return 0; + return reinterpret_cast<jlong>( + interpreter->tensor(interpreter->outputs()[index])); +} + +JNIEXPORT jint JNICALL +Java_org_tensorflow_lite_NativeInterpreterWrapper_getInputCount(JNIEnv* env, + jclass clazz, + jlong handle) { + tflite::Interpreter* interpreter = convertLongToInterpreter(env, handle); + if (interpreter == nullptr) return 0; + return static_cast<jint>(interpreter->inputs().size()); +} + +JNIEXPORT jint JNICALL +Java_org_tensorflow_lite_NativeInterpreterWrapper_getOutputCount(JNIEnv* env, + jclass clazz, + jlong handle) { + tflite::Interpreter* interpreter = convertLongToInterpreter(env, handle); + if (interpreter == nullptr) return 0; + return static_cast<jint>(interpreter->outputs().size()); +} + JNIEXPORT jobjectArray JNICALL Java_org_tensorflow_lite_NativeInterpreterWrapper_getOutputNames(JNIEnv* env, jclass clazz, @@ -434,114 +346,21 @@ Java_org_tensorflow_lite_NativeInterpreterWrapper_createInterpreter( } // Sets inputs, runs inference, and returns outputs as long handles. -JNIEXPORT jlongArray JNICALL -Java_org_tensorflow_lite_NativeInterpreterWrapper_run( - JNIEnv* env, jclass clazz, jlong interpreter_handle, jlong error_handle, - jobjectArray sizes, jintArray data_types, jintArray nums_of_bytes, - jobjectArray values, jobject wrapper, jboolean memory_allocated) { +JNIEXPORT void JNICALL Java_org_tensorflow_lite_NativeInterpreterWrapper_run( + JNIEnv* env, jclass clazz, jlong interpreter_handle, jlong error_handle) { tflite::Interpreter* interpreter = convertLongToInterpreter(env, interpreter_handle); - if (interpreter == nullptr) return nullptr; + if (interpreter == nullptr) return; BufferErrorReporter* error_reporter = convertLongToErrorReporter(env, error_handle); - if (error_reporter == nullptr) return nullptr; - const int input_size = env->GetArrayLength(sizes); - // validates inputs - TfLiteStatus status = checkInputs(env, interpreter, input_size, data_types, - nums_of_bytes, values, sizes); - if (status != kTfLiteOk) return nullptr; - if (!memory_allocated || - !areInputDimensionsTheSame(env, interpreter, input_size, sizes)) { - // resizes inputs - status = resizeInputs(env, interpreter, input_size, sizes); - if (status != kTfLiteOk) { - throwException(env, kNullPointerException, - "Internal error: Can not resize the input: %s", - error_reporter->CachedErrorMessage()); - return nullptr; - } - // allocates memory - status = interpreter->AllocateTensors(); - if (status != kTfLiteOk) { - throwException(env, kNullPointerException, - "Internal error: Can not allocate memory for the given " - "inputs: %s", - error_reporter->CachedErrorMessage()); - return nullptr; - } - } - // sets inputs - status = setInputs(env, interpreter, input_size, data_types, nums_of_bytes, - values); - if (status != kTfLiteOk) return nullptr; - timespec beforeInference = ::tflite::getCurrentTime(); - // runs inference + if (error_reporter == nullptr) return; + if (interpreter->Invoke() != kTfLiteOk) { throwException(env, kIllegalArgumentException, "Internal error: Failed to run on the given Interpreter: %s", error_reporter->CachedErrorMessage()); - return nullptr; - } - timespec afterInference = ::tflite::getCurrentTime(); - jclass wrapper_clazz = env->GetObjectClass(wrapper); - jfieldID fid = - env->GetFieldID(wrapper_clazz, "inferenceDurationNanoseconds", "J"); - if (env->ExceptionCheck()) { - env->ExceptionClear(); - } else if (fid != nullptr) { - env->SetLongField( - wrapper, fid, - ::tflite::timespec_diff_nanoseconds(&beforeInference, &afterInference)); - } - // returns outputs - const std::vector<int>& results = interpreter->outputs(); - if (results.empty()) { - throwException( - env, kIllegalArgumentException, - "Internal error: The Interpreter does not have any outputs."); - return nullptr; - } - jlongArray outputs = env->NewLongArray(results.size()); - size_t size = results.size(); - for (int i = 0; i < size; ++i) { - TfLiteTensor* source = interpreter->tensor(results[i]); - jlong output = reinterpret_cast<jlong>(source); - env->SetLongArrayRegion(outputs, i, 1, &output); - } - return outputs; -} - -JNIEXPORT jintArray JNICALL -Java_org_tensorflow_lite_NativeInterpreterWrapper_getInputDims( - JNIEnv* env, jclass clazz, jlong handle, jint input_idx, jint num_bytes) { - tflite::Interpreter* interpreter = convertLongToInterpreter(env, handle); - if (interpreter == nullptr) return nullptr; - const int idx = static_cast<int>(input_idx); - if (input_idx < 0 || input_idx >= interpreter->inputs().size()) { - throwException(env, kIllegalArgumentException, - "Input error: Out of range: Failed to get %d-th input out of" - " %d inputs", - input_idx, interpreter->inputs().size()); - return nullptr; - } - TfLiteTensor* target = interpreter->tensor(interpreter->inputs()[idx]); - int size = target->dims->size; - if (num_bytes >= 0) { // verifies num of bytes matches if num_bytes if valid. - int expected_num_bytes = elementByteSize(target->type); - for (int i = 0; i < size; ++i) { - expected_num_bytes *= target->dims->data[i]; - } - if (num_bytes != expected_num_bytes) { - throwException(env, kIllegalArgumentException, - "Input error: Failed to get input dimensions. %d-th input " - "should have %d bytes, but found %d bytes.", - idx, expected_num_bytes, num_bytes); - return nullptr; - } + return; } - jintArray outputs = env->NewIntArray(size); - env->SetIntArrayRegion(outputs, 0, size, &(target->dims->data[0])); - return outputs; } JNIEXPORT jint JNICALL diff --git a/tensorflow/contrib/lite/java/src/main/native/nativeinterpreterwrapper_jni.h b/tensorflow/contrib/lite/java/src/main/native/nativeinterpreterwrapper_jni.h index 128ece4981..618fba480e 100644 --- a/tensorflow/contrib/lite/java/src/main/native/nativeinterpreterwrapper_jni.h +++ b/tensorflow/contrib/lite/java/src/main/native/nativeinterpreterwrapper_jni.h @@ -29,9 +29,6 @@ limitations under the License. namespace tflite { // This is to be provided at link-time by a library. extern std::unique_ptr<OpResolver> CreateOpResolver(); -extern timespec getCurrentTime(); -extern jlong timespec_diff_nanoseconds(struct timespec* start, - struct timespec* stop); } // namespace tflite #ifdef __cplusplus @@ -40,6 +37,57 @@ extern "C" { /* * Class: org_tensorflow_lite_NativeInterpreterWrapper + * Method: allocateTensors + * Signature: (JJ)V + */ +JNIEXPORT void JNICALL +Java_org_tensorflow_lite_NativeInterpreterWrapper_allocateTensors( + JNIEnv* env, jclass clazz, jlong handle, jlong error_handle); + +/* + * Class: org_tensorflow_lite_NativeInterpreterWrapper + * Method: getInputTensor + * Signature: (JI)J + */ +JNIEXPORT jlong JNICALL +Java_org_tensorflow_lite_NativeInterpreterWrapper_getInputTensor(JNIEnv* env, + jclass clazz, + jlong handle, + jint index); + +/* + * Class: org_tensorflow_lite_NativeInterpreterWrapper + * Method: getOutputTensor + * Signature: (JI)J + */ +JNIEXPORT jlong JNICALL +Java_org_tensorflow_lite_NativeInterpreterWrapper_getOutputTensor(JNIEnv* env, + jclass clazz, + jlong handle, + jint index); + +/* + * Class: org_tensorflow_lite_NativeInterpreterWrapper + * Method: getInputCount + * Signature: (J)I + */ +JNIEXPORT jint JNICALL +Java_org_tensorflow_lite_NativeInterpreterWrapper_getInputCount(JNIEnv* env, + jclass clazz, + jlong handle); + +/* + * Class: org_tensorflow_lite_NativeInterpreterWrapper + * Method: getOutputCount + * Signature: (J)I + */ +JNIEXPORT jint JNICALL +Java_org_tensorflow_lite_NativeInterpreterWrapper_getOutputCount(JNIEnv* env, + jclass clazz, + jlong handle); + +/* + * Class: org_tensorflow_lite_NativeInterpreterWrapper * Method: * Signature: (J)[Ljava/lang/Object; */ @@ -118,28 +166,11 @@ Java_org_tensorflow_lite_NativeInterpreterWrapper_createInterpreter( /* * Class: org_tensorflow_lite_NativeInterpreterWrapper - * Method: - * Signature: - * (JJ[Ljava/lang/Object;[I[I[Ljava/lang/Object;Ljava/lang/Object;Z)[J - */ -JNIEXPORT jlongArray JNICALL -Java_org_tensorflow_lite_NativeInterpreterWrapper_run( - JNIEnv* env, jclass clazz, jlong interpreter_handle, jlong error_handle, - jobjectArray sizes, jintArray data_types, jintArray nums_of_bytes, - jobjectArray values, jobject wrapper, jboolean memory_allocated); - -/* - * Class: org_tensorflow_lite_NativeInterpreterWrapper - * Method: - * Signature: (JII)[I - * - * Gets input dimensions. If num_bytes is non-negative, it will check whether - * num_bytes matches num of bytes required by the input, and return null and - * throw IllegalArgumentException if not. + * Method: run + * Signature: (JJ)V */ -JNIEXPORT jintArray JNICALL -Java_org_tensorflow_lite_NativeInterpreterWrapper_getInputDims( - JNIEnv* env, jclass clazz, jlong handle, jint input_idx, jint num_bytes); +JNIEXPORT void JNICALL Java_org_tensorflow_lite_NativeInterpreterWrapper_run( + JNIEnv* env, jclass clazz, jlong interpreter_handle, jlong error_handle); /* * Class: org_tensorflow_lite_NativeInterpreterWrapper diff --git a/tensorflow/contrib/lite/java/src/main/native/tensor_jni.cc b/tensorflow/contrib/lite/java/src/main/native/tensor_jni.cc index 08b4d04280..7ff96a3172 100644 --- a/tensorflow/contrib/lite/java/src/main/native/tensor_jni.cc +++ b/tensorflow/contrib/lite/java/src/main/native/tensor_jni.cc @@ -29,6 +29,35 @@ TfLiteTensor* convertLongToTensor(JNIEnv* env, jlong handle) { return reinterpret_cast<TfLiteTensor*>(handle); } +size_t elementByteSize(TfLiteType data_type) { + // The code in this file makes the assumption that the + // TensorFlow TF_DataTypes and the Java primitive types + // have the same byte sizes. Validate that: + switch (data_type) { + case kTfLiteFloat32: + static_assert(sizeof(jfloat) == 4, + "Interal error: Java float not compatible with " + "kTfLiteFloat"); + return 4; + case kTfLiteInt32: + static_assert(sizeof(jint) == 4, + "Interal error: Java int not compatible with kTfLiteInt"); + return 4; + case kTfLiteUInt8: + static_assert(sizeof(jbyte) == 1, + "Interal error: Java byte not compatible with " + "kTfLiteUInt8"); + return 1; + case kTfLiteInt64: + static_assert(sizeof(jlong) == 8, + "Interal error: Java long not compatible with " + "kTfLiteInt64"); + return 8; + default: + return 0; + } +} + size_t writeOneDimensionalArray(JNIEnv* env, jobject object, TfLiteType type, void* dst, size_t dst_size) { jarray array = static_cast<jarray>(object); @@ -141,48 +170,6 @@ size_t readMultiDimensionalArray(JNIEnv* env, TfLiteType data_type, char* src, } } -} // namespace - -size_t elementByteSize(TfLiteType data_type) { - // The code in this file makes the assumption that the - // TensorFlow TF_DataTypes and the Java primitive types - // have the same byte sizes. Validate that: - switch (data_type) { - case kTfLiteFloat32: - static_assert(sizeof(jfloat) == 4, - "Interal error: Java float not compatible with " - "kTfLiteFloat"); - return 4; - case kTfLiteInt32: - static_assert(sizeof(jint) == 4, - "Interal error: Java int not compatible with kTfLiteInt"); - return 4; - case kTfLiteUInt8: - static_assert(sizeof(jbyte) == 1, - "Interal error: Java byte not compatible with " - "kTfLiteUInt8"); - return 1; - case kTfLiteInt64: - static_assert(sizeof(jlong) == 8, - "Interal error: Java long not compatible with " - "kTfLiteInt64"); - return 8; - default: - return 0; - } -} - -size_t writeByteBuffer(JNIEnv* env, jobject object, char** dst, int dst_size) { - char* buf = static_cast<char*>(env->GetDirectBufferAddress(object)); - if (!buf) { - throwException(env, kIllegalArgumentException, - "Input ByteBuffer is not a direct buffer"); - return 0; - } - *dst = buf; - return dst_size; -} - size_t writeMultiDimensionalArray(JNIEnv* env, jobject src, TfLiteType type, int dims_left, char** dst, int dst_size) { if (dims_left <= 1) { @@ -203,16 +190,37 @@ size_t writeMultiDimensionalArray(JNIEnv* env, jobject src, TfLiteType type, } } +} // namespace + JNIEXPORT jobject JNICALL Java_org_tensorflow_lite_Tensor_buffer(JNIEnv* env, jclass clazz, jlong handle) { TfLiteTensor* tensor = convertLongToTensor(env, handle); if (tensor == nullptr) return nullptr; - + if (tensor->data.raw == nullptr) { + throwException(env, kIllegalArgumentException, + "Internal error: Tensor hasn't been allocated."); + return nullptr; + } return env->NewDirectByteBuffer(static_cast<void*>(tensor->data.raw), static_cast<jlong>(tensor->bytes)); } +JNIEXPORT void JNICALL Java_org_tensorflow_lite_Tensor_writeDirectBuffer( + JNIEnv* env, jclass clazz, jlong handle, jobject src) { + TfLiteTensor* tensor = convertLongToTensor(env, handle); + if (tensor == nullptr) return; + + char* src_data_raw = static_cast<char*>(env->GetDirectBufferAddress(src)); + if (!src_data_raw) { + throwException(env, kIllegalArgumentException, + "Input ByteBuffer is not a direct buffer"); + return; + } + + tensor->data.raw = src_data_raw; +} + JNIEXPORT void JNICALL Java_org_tensorflow_lite_Tensor_readMultiDimensionalArray(JNIEnv* env, jclass clazz, @@ -230,6 +238,27 @@ Java_org_tensorflow_lite_Tensor_readMultiDimensionalArray(JNIEnv* env, num_dims, static_cast<jarray>(value)); } +JNIEXPORT void JNICALL +Java_org_tensorflow_lite_Tensor_writeMultiDimensionalArray(JNIEnv* env, + jclass clazz, + jlong handle, + jobject src) { + TfLiteTensor* tensor = convertLongToTensor(env, handle); + if (tensor == nullptr) return; + if (tensor->data.raw == nullptr) { + throwException(env, kIllegalArgumentException, + "Internal error: Target Tensor hasn't been allocated."); + return; + } + if (tensor->dims->size == 0) { + throwException(env, kIllegalArgumentException, + "Internal error: Cannot copy empty/scalar Tensors."); + return; + } + writeMultiDimensionalArray(env, src, tensor->type, tensor->dims->size, + &tensor->data.raw, tensor->bytes); +} + JNIEXPORT jint JNICALL Java_org_tensorflow_lite_Tensor_dtype(JNIEnv* env, jclass clazz, jlong handle) { @@ -247,3 +276,11 @@ Java_org_tensorflow_lite_Tensor_shape(JNIEnv* env, jclass clazz, jlong handle) { env->SetIntArrayRegion(result, 0, num_dims, tensor->dims->data); return result; } + +JNIEXPORT jint JNICALL Java_org_tensorflow_lite_Tensor_numBytes(JNIEnv* env, + jclass clazz, + jlong handle) { + const TfLiteTensor* tensor = convertLongToTensor(env, handle); + if (tensor == nullptr) return 0; + return static_cast<jint>(tensor->bytes); +} diff --git a/tensorflow/contrib/lite/java/src/main/native/tensor_jni.h b/tensorflow/contrib/lite/java/src/main/native/tensor_jni.h index 9ba95d9ac4..06e2546af8 100644 --- a/tensorflow/contrib/lite/java/src/main/native/tensor_jni.h +++ b/tensorflow/contrib/lite/java/src/main/native/tensor_jni.h @@ -34,6 +34,14 @@ JNIEXPORT jobject JNICALL Java_org_tensorflow_lite_Tensor_buffer(JNIEnv* env, /* * Class: org_tensorflow_lite_Tensor + * Method: writeDirectBuffer + * Signature: (JLjava/nio/ByteBuffer;) + */ +JNIEXPORT void JNICALL Java_org_tensorflow_lite_Tensor_writeDirectBuffer( + JNIEnv* env, jclass clazz, jlong handle, jobject src); + +/* + * Class: org_tensorflow_lite_Tensor * Method: dtype * Signature: (J)I */ @@ -52,6 +60,15 @@ JNIEXPORT jintArray JNICALL Java_org_tensorflow_lite_Tensor_shape(JNIEnv* env, /* * Class: org_tensorflow_lite_Tensor + * Method: numBytes + * Signature: (J)I + */ +JNIEXPORT jint JNICALL Java_org_tensorflow_lite_Tensor_numBytes(JNIEnv* env, + jclass clazz, + jlong handle); + +/* + * Class: org_tensorflow_lite_Tensor * Method: readMultiDimensionalArray * Signature: (JLjava/lang/Object;) */ @@ -59,23 +76,18 @@ JNIEXPORT void JNICALL Java_org_tensorflow_lite_Tensor_readMultiDimensionalArray(JNIEnv* env, jclass clazz, jlong handle, - jobject value); + jobject dst); /* - * Finds the size of each data type. - */ -size_t elementByteSize(TfLiteType data_type); - -/* - * Writes data of a ByteBuffer into dest. - */ -size_t writeByteBuffer(JNIEnv* env, jobject object, char** dst, int dst_size); - -/* - * Writes a multi-dimensional array into dest. + * Class: org_tensorflow_lite_Tensor + * Method: writeMultidimensionalArray + * Signature: (JLjava/lang/Object;) */ -size_t writeMultiDimensionalArray(JNIEnv* env, jobject src, TfLiteType type, - int dims_left, char** dst, int dst_size); +JNIEXPORT void JNICALL +Java_org_tensorflow_lite_Tensor_writeMultiDimensionalArray(JNIEnv* env, + jclass clazz, + jlong handle, + jobject src); #ifdef __cplusplus } // extern "C" diff --git a/tensorflow/contrib/lite/java/src/test/java/org/tensorflow/lite/InterpreterTest.java b/tensorflow/contrib/lite/java/src/test/java/org/tensorflow/lite/InterpreterTest.java index 42096ef9a3..d66a73db94 100644 --- a/tensorflow/contrib/lite/java/src/test/java/org/tensorflow/lite/InterpreterTest.java +++ b/tensorflow/contrib/lite/java/src/test/java/org/tensorflow/lite/InterpreterTest.java @@ -221,7 +221,9 @@ public final class InterpreterTest { assertThat(e) .hasMessageThat() .contains( - "DataType (2) of input data does not match with the DataType (1) of model inputs."); + "Cannot convert between a TensorFlowLite tensor with type " + + "FLOAT32 and a Java object of type [[[[I (which is compatible with the" + + " TensorFlowLite type INT32)"); } interpreter.close(); } @@ -241,8 +243,8 @@ public final class InterpreterTest { assertThat(e) .hasMessageThat() .contains( - "Cannot convert an TensorFlowLite tensor with type " - + "FLOAT32 to a Java object of type [[[[I (which is compatible with the" + "Cannot convert between a TensorFlowLite tensor with type " + + "FLOAT32 and a Java object of type [[[[I (which is compatible with the" + " TensorFlowLite type INT32)"); } interpreter.close(); diff --git a/tensorflow/contrib/lite/java/src/test/java/org/tensorflow/lite/NativeInterpreterWrapperTest.java b/tensorflow/contrib/lite/java/src/test/java/org/tensorflow/lite/NativeInterpreterWrapperTest.java index 029e5853e2..9c4a5acd79 100644 --- a/tensorflow/contrib/lite/java/src/test/java/org/tensorflow/lite/NativeInterpreterWrapperTest.java +++ b/tensorflow/contrib/lite/java/src/test/java/org/tensorflow/lite/NativeInterpreterWrapperTest.java @@ -20,6 +20,8 @@ import static org.junit.Assert.fail; import java.nio.ByteBuffer; import java.nio.ByteOrder; +import java.util.HashMap; +import java.util.Map; import org.junit.Test; import org.junit.runner.RunWith; import org.junit.runners.JUnit4; @@ -101,10 +103,10 @@ public final class NativeInterpreterWrapperTest { float[][][] threeD = {twoD, twoD, twoD, twoD, twoD, twoD, twoD, twoD}; float[][][][] fourD = {threeD, threeD}; Object[] inputs = {fourD}; - Tensor[] outputs = wrapper.run(inputs); - assertThat(outputs.length).isEqualTo(1); float[][][][] parsedOutputs = new float[2][8][8][3]; - outputs[0].copyTo(parsedOutputs); + Map<Integer, Object> outputs = new HashMap<>(); + outputs.put(0, parsedOutputs); + wrapper.run(inputs, outputs); float[] outputOneD = parsedOutputs[0][0][0]; float[] expected = {3.69f, -19.62f, 23.43f}; assertThat(outputOneD).usingTolerance(0.1f).containsExactly(expected).inOrder(); @@ -119,11 +121,11 @@ public final class NativeInterpreterWrapperTest { float[][][] threeD = {twoD, twoD, twoD, twoD, twoD, twoD, twoD, twoD}; float[][][][] fourD = {threeD, threeD}; Object[] inputs = {fourD}; - Tensor[] outputs = wrapper.run(inputs); - assertThat(outputs).hasLength(1); ByteBuffer parsedOutput = ByteBuffer.allocateDirect(2 * 8 * 8 * 3 * 4).order(ByteOrder.nativeOrder()); - outputs[0].copyTo(parsedOutput); + Map<Integer, Object> outputs = new HashMap<>(); + outputs.put(0, parsedOutput); + wrapper.run(inputs, outputs); float[] outputOneD = { parsedOutput.getFloat(0), parsedOutput.getFloat(4), parsedOutput.getFloat(8) }; @@ -140,17 +142,16 @@ public final class NativeInterpreterWrapperTest { float[][][] threeD = {twoD, twoD, twoD, twoD, twoD, twoD, twoD, twoD}; float[][][][] fourD = {threeD, threeD}; Object[] inputs = {fourD}; - Tensor[] outputs = wrapper.run(inputs); - assertThat(outputs.length).isEqualTo(1); float[][][][] parsedOutputs = new float[2][8][8][3]; - outputs[0].copyTo(parsedOutputs); + Map<Integer, Object> outputs = new HashMap<>(); + outputs.put(0, parsedOutputs); + wrapper.run(inputs, outputs); float[] outputOneD = parsedOutputs[0][0][0]; float[] expected = {3.69f, -19.62f, 23.43f}; assertThat(outputOneD).usingTolerance(0.1f).containsExactly(expected).inOrder(); - outputs = wrapper.run(inputs); - assertThat(outputs.length).isEqualTo(1); parsedOutputs = new float[2][8][8][3]; - outputs[0].copyTo(parsedOutputs); + outputs.put(0, parsedOutputs); + wrapper.run(inputs, outputs); outputOneD = parsedOutputs[0][0][0]; assertThat(outputOneD).usingTolerance(0.1f).containsExactly(expected).inOrder(); wrapper.close(); @@ -164,10 +165,10 @@ public final class NativeInterpreterWrapperTest { int[][][] threeD = {twoD, twoD, twoD, twoD, twoD, twoD, twoD, twoD}; int[][][][] fourD = {threeD, threeD}; Object[] inputs = {fourD}; - Tensor[] outputs = wrapper.run(inputs); - assertThat(outputs.length).isEqualTo(1); int[][][][] parsedOutputs = new int[2][4][4][12]; - outputs[0].copyTo(parsedOutputs); + Map<Integer, Object> outputs = new HashMap<>(); + outputs.put(0, parsedOutputs); + wrapper.run(inputs, outputs); int[] outputOneD = parsedOutputs[0][0][0]; int[] expected = {3, 7, -4, 3, 7, -4, 3, 7, -4, 3, 7, -4}; assertThat(outputOneD).isEqualTo(expected); @@ -182,10 +183,10 @@ public final class NativeInterpreterWrapperTest { long[][][] threeD = {twoD, twoD, twoD, twoD, twoD, twoD, twoD, twoD}; long[][][][] fourD = {threeD, threeD}; Object[] inputs = {fourD}; - Tensor[] outputs = wrapper.run(inputs); - assertThat(outputs.length).isEqualTo(1); long[][][][] parsedOutputs = new long[2][4][4][12]; - outputs[0].copyTo(parsedOutputs); + Map<Integer, Object> outputs = new HashMap<>(); + outputs.put(0, parsedOutputs); + wrapper.run(inputs, outputs); long[] outputOneD = parsedOutputs[0][0][0]; long[] expected = {-892834092L, 923423L, 2123918239018L, -892834092L, 923423L, 2123918239018L, -892834092L, 923423L, 2123918239018L, -892834092L, 923423L, 2123918239018L}; @@ -203,10 +204,10 @@ public final class NativeInterpreterWrapperTest { Object[] inputs = {fourD}; int[] inputDims = {2, 8, 8, 3}; wrapper.resizeInput(0, inputDims); - Tensor[] outputs = wrapper.run(inputs); - assertThat(outputs.length).isEqualTo(1); byte[][][][] parsedOutputs = new byte[2][4][4][12]; - outputs[0].copyTo(parsedOutputs); + Map<Integer, Object> outputs = new HashMap<>(); + outputs.put(0, parsedOutputs); + wrapper.run(inputs, outputs); byte[] outputOneD = parsedOutputs[0][0][0]; byte[] expected = {(byte) 0xe0, 0x4f, (byte) 0xd0, (byte) 0xe0, 0x4f, (byte) 0xd0, (byte) 0xe0, 0x4f, (byte) 0xd0, (byte) 0xe0, 0x4f, (byte) 0xd0}; @@ -229,13 +230,14 @@ public final class NativeInterpreterWrapperTest { } } } + bbuf.rewind(); Object[] inputs = {bbuf}; int[] inputDims = {2, 8, 8, 3}; wrapper.resizeInput(0, inputDims); - Tensor[] outputs = wrapper.run(inputs); - assertThat(outputs.length).isEqualTo(1); byte[][][][] parsedOutputs = new byte[2][4][4][12]; - outputs[0].copyTo(parsedOutputs); + Map<Integer, Object> outputs = new HashMap<>(); + outputs.put(0, parsedOutputs); + wrapper.run(inputs, outputs); byte[] outputOneD = parsedOutputs[0][0][0]; byte[] expected = { (byte) 0xe0, 0x4f, (byte) 0xd0, (byte) 0xe0, 0x4f, (byte) 0xd0, @@ -261,21 +263,22 @@ public final class NativeInterpreterWrapperTest { } } Object[] inputs = {bbuf}; + float[][][][] parsedOutputs = new float[4][8][8][3]; + Map<Integer, Object> outputs = new HashMap<>(); + outputs.put(0, parsedOutputs); try { - wrapper.run(inputs); + wrapper.run(inputs, outputs); fail(); } catch (IllegalArgumentException e) { assertThat(e) .hasMessageThat() .contains( - "Failed to get input dimensions. 0-th input should have 768 bytes, but found 3072 bytes"); + "Cannot convert between a TensorFlowLite buffer with 768 bytes and a " + + "ByteBuffer with 3072 bytes."); } int[] inputDims = {4, 8, 8, 3}; wrapper.resizeInput(0, inputDims); - Tensor[] outputs = wrapper.run(inputs); - assertThat(outputs.length).isEqualTo(1); - float[][][][] parsedOutputs = new float[4][8][8][3]; - outputs[0].copyTo(parsedOutputs); + wrapper.run(inputs, outputs); float[] outputOneD = parsedOutputs[0][0][0]; float[] expected = {3.69f, -19.62f, 23.43f}; assertThat(outputOneD).usingTolerance(0.1f).containsExactly(expected).inOrder(); @@ -288,14 +291,18 @@ public final class NativeInterpreterWrapperTest { ByteBuffer bbuf = ByteBuffer.allocateDirect(2 * 7 * 8 * 3); bbuf.order(ByteOrder.nativeOrder()); Object[] inputs = {bbuf}; + Map<Integer, Object> outputs = new HashMap<>(); + ByteBuffer parsedOutput = ByteBuffer.allocateDirect(2 * 7 * 8 * 3); + outputs.put(0, parsedOutput); try { - wrapper.run(inputs); + wrapper.run(inputs, outputs); fail(); } catch (IllegalArgumentException e) { assertThat(e) .hasMessageThat() .contains( - "Failed to get input dimensions. 0-th input should have 192 bytes, but found 336 bytes."); + "Cannot convert between a TensorFlowLite buffer with 192 bytes and a " + + "ByteBuffer with 336 bytes."); } wrapper.close(); } @@ -308,14 +315,18 @@ public final class NativeInterpreterWrapperTest { int[][][] threeD = {twoD, twoD, twoD, twoD, twoD, twoD, twoD, twoD}; int[][][][] fourD = {threeD, threeD}; Object[] inputs = {fourD}; + int[][][][] parsedOutputs = new int[2][8][8][3]; + Map<Integer, Object> outputs = new HashMap<>(); + outputs.put(0, parsedOutputs); try { - wrapper.run(inputs); + wrapper.run(inputs, outputs); fail(); } catch (IllegalArgumentException e) { assertThat(e) .hasMessageThat() .contains( - "DataType (2) of input data does not match with the DataType (1) of model inputs."); + "Cannot convert between a TensorFlowLite tensor with type FLOAT32 and a Java object " + + "of type [[[[I (which is compatible with the TensorFlowLite type INT32)"); } wrapper.close(); } @@ -329,8 +340,11 @@ public final class NativeInterpreterWrapperTest { float[][][] threeD = {twoD, twoD, twoD, twoD, twoD, twoD, twoD, twoD}; float[][][][] fourD = {threeD, threeD}; Object[] inputs = {fourD}; + float[][][][] parsedOutputs = new float[2][8][8][3]; + Map<Integer, Object> outputs = new HashMap<>(); + outputs.put(0, parsedOutputs); try { - wrapper.run(inputs); + wrapper.run(inputs, outputs); fail(); } catch (IllegalArgumentException e) { assertThat(e).hasMessageThat().contains("Invalid handle to Interpreter."); @@ -342,7 +356,7 @@ public final class NativeInterpreterWrapperTest { NativeInterpreterWrapper wrapper = new NativeInterpreterWrapper(FLOAT_MODEL_PATH); try { Object[] inputs = {}; - wrapper.run(inputs); + wrapper.run(inputs, null); fail(); } catch (IllegalArgumentException e) { assertThat(e).hasMessageThat().contains("Inputs should not be null or empty."); @@ -358,11 +372,14 @@ public final class NativeInterpreterWrapperTest { float[][][] threeD = {twoD, twoD, twoD, twoD, twoD, twoD, twoD, twoD}; float[][][][] fourD = {threeD, threeD}; Object[] inputs = {fourD, fourD}; + float[][][][] parsedOutputs = new float[2][8][8][3]; + Map<Integer, Object> outputs = new HashMap<>(); + outputs.put(0, parsedOutputs); try { - wrapper.run(inputs); + wrapper.run(inputs, outputs); fail(); } catch (IllegalArgumentException e) { - assertThat(e).hasMessageThat().contains("Expected num of inputs is 1 but got 2"); + assertThat(e).hasMessageThat().contains("Invalid input Tensor index: 1"); } wrapper.close(); } @@ -374,13 +391,18 @@ public final class NativeInterpreterWrapperTest { float[][] twoD = {oneD, oneD, oneD, oneD, oneD, oneD, oneD}; float[][][] threeD = {twoD, twoD, twoD, twoD, twoD, twoD, twoD, twoD}; Object[] inputs = {threeD}; + float[][][][] parsedOutputs = new float[2][8][8][3]; + Map<Integer, Object> outputs = new HashMap<>(); + outputs.put(0, parsedOutputs); try { - wrapper.run(inputs); + wrapper.run(inputs, outputs); fail(); } catch (IllegalArgumentException e) { assertThat(e) .hasMessageThat() - .contains("0-th input should have 4 dimensions, but found 3 dimensions"); + .contains( + "Cannot copy between a TensorFlowLite tensor with shape [8, 7, 3] and a " + + "Java object with shape [2, 8, 8, 3]."); } wrapper.close(); } @@ -393,92 +415,23 @@ public final class NativeInterpreterWrapperTest { float[][][] threeD = {twoD, twoD, twoD, twoD, twoD, twoD, twoD, twoD}; float[][][][] fourD = {threeD, threeD}; Object[] inputs = {fourD}; + float[][][][] parsedOutputs = new float[2][8][8][3]; + Map<Integer, Object> outputs = new HashMap<>(); + outputs.put(0, parsedOutputs); try { - wrapper.run(inputs); + wrapper.run(inputs, outputs); fail(); } catch (IllegalArgumentException e) { assertThat(e) .hasMessageThat() - .contains("0-th input dimension should be [?,8,8,3], but found [?,8,7,3]"); + .contains( + "Cannot copy between a TensorFlowLite tensor with shape [2, 8, 7, 3] and a " + + "Java object with shape [2, 8, 8, 3]."); } wrapper.close(); } @Test - public void testNumElements() { - int[] shape = {2, 3, 4}; - int num = NativeInterpreterWrapper.numElements(shape); - assertThat(num).isEqualTo(24); - shape = null; - num = NativeInterpreterWrapper.numElements(shape); - assertThat(num).isEqualTo(0); - } - - @Test - public void testIsNonEmtpyArray() { - assertThat(NativeInterpreterWrapper.isNonEmptyArray(null)).isFalse(); - assertThat(NativeInterpreterWrapper.isNonEmptyArray(3.2)).isFalse(); - int[] emptyArray = {}; - assertThat(NativeInterpreterWrapper.isNonEmptyArray(emptyArray)).isFalse(); - int[] validArray = {9, 5, 2, 1}; - assertThat(NativeInterpreterWrapper.isNonEmptyArray(validArray)).isTrue(); - } - - @Test - public void testDataTypeOf() { - float[] testEmtpyArray = {}; - DataType dataType = NativeInterpreterWrapper.dataTypeOf(testEmtpyArray); - assertThat(dataType).isEqualTo(DataType.FLOAT32); - float[] testFloatArray = {0.783f, 0.251f}; - dataType = NativeInterpreterWrapper.dataTypeOf(testFloatArray); - assertThat(dataType).isEqualTo(DataType.FLOAT32); - float[][] testMultiDimArray = {testFloatArray, testFloatArray, testFloatArray}; - dataType = NativeInterpreterWrapper.dataTypeOf(testFloatArray); - assertThat(dataType).isEqualTo(DataType.FLOAT32); - try { - double[] testDoubleArray = {0.783, 0.251}; - NativeInterpreterWrapper.dataTypeOf(testDoubleArray); - fail(); - } catch (IllegalArgumentException e) { - assertThat(e).hasMessageThat().contains("cannot resolve DataType of"); - } - try { - Float[] testBoxedArray = {0.783f, 0.251f}; - NativeInterpreterWrapper.dataTypeOf(testBoxedArray); - fail(); - } catch (IllegalArgumentException e) { - assertThat(e).hasMessageThat().contains("cannot resolve DataType of [Ljava.lang.Float;"); - } - } - - @Test - public void testNumDimensions() { - int scalar = 1; - assertThat(NativeInterpreterWrapper.numDimensions(scalar)).isEqualTo(0); - int[][] array = {{2, 4}, {1, 9}}; - assertThat(NativeInterpreterWrapper.numDimensions(array)).isEqualTo(2); - try { - int[] emptyArray = {}; - NativeInterpreterWrapper.numDimensions(emptyArray); - fail(); - } catch (IllegalArgumentException e) { - assertThat(e).hasMessageThat().contains("Array lengths cannot be 0."); - } - } - - @Test - public void testFillShape() { - int[][][] array = {{{23}, {14}, {87}}, {{12}, {42}, {31}}}; - int num = NativeInterpreterWrapper.numDimensions(array); - int[] shape = new int[num]; - NativeInterpreterWrapper.fillShape(array, 0, shape); - assertThat(num).isEqualTo(3); - assertThat(shape[0]).isEqualTo(2); - assertThat(shape[1]).isEqualTo(3); - assertThat(shape[2]).isEqualTo(1); - } - - @Test public void testGetInferenceLatency() { NativeInterpreterWrapper wrapper = new NativeInterpreterWrapper(FLOAT_MODEL_PATH); float[] oneD = {1.23f, 6.54f, 7.81f}; @@ -486,8 +439,10 @@ public final class NativeInterpreterWrapperTest { float[][][] threeD = {twoD, twoD, twoD, twoD, twoD, twoD, twoD, twoD}; float[][][][] fourD = {threeD, threeD}; Object[] inputs = {fourD}; - Tensor[] outputs = wrapper.run(inputs); - assertThat(outputs.length).isEqualTo(1); + float[][][][] parsedOutputs = new float[2][8][8][3]; + Map<Integer, Object> outputs = new HashMap<>(); + outputs.put(0, parsedOutputs); + wrapper.run(inputs, outputs); assertThat(wrapper.getLastNativeInferenceDurationNanoseconds()).isGreaterThan(0L); wrapper.close(); } @@ -507,13 +462,14 @@ public final class NativeInterpreterWrapperTest { float[][][] threeD = {twoD, twoD, twoD, twoD, twoD, twoD, twoD, twoD}; float[][][][] fourD = {threeD, threeD}; Object[] inputs = {fourD}; + float[][][][] parsedOutputs = new float[2][8][8][3]; + Map<Integer, Object> outputs = new HashMap<>(); + outputs.put(0, parsedOutputs); try { - wrapper.run(inputs); + wrapper.run(inputs, outputs); fail(); } catch (IllegalArgumentException e) { - assertThat(e) - .hasMessageThat() - .contains("0-th input dimension should be [?,8,8,3], but found [?,8,7,3]"); + // Expected. } assertThat(wrapper.getLastNativeInferenceDurationNanoseconds()).isNull(); wrapper.close(); @@ -523,41 +479,7 @@ public final class NativeInterpreterWrapperTest { public void testGetInputDims() { NativeInterpreterWrapper wrapper = new NativeInterpreterWrapper(FLOAT_MODEL_PATH); int[] expectedDims = {1, 8, 8, 3}; - assertThat(wrapper.getInputDims(0)).isEqualTo(expectedDims); - wrapper.close(); - } - - @Test - public void testGetInputDimsOutOfRange() { - NativeInterpreterWrapper wrapper = new NativeInterpreterWrapper(FLOAT_MODEL_PATH); - try { - wrapper.getInputDims(-1); - fail(); - } catch (IllegalArgumentException e) { - assertThat(e).hasMessageThat().contains("Out of range"); - } - try { - wrapper.getInputDims(1); - fail(); - } catch (IllegalArgumentException e) { - assertThat(e).hasMessageThat().contains("Out of range"); - } - wrapper.close(); - } - - @Test - public void testGetOutputDataType() { - NativeInterpreterWrapper wrapper = new NativeInterpreterWrapper(FLOAT_MODEL_PATH); - assertThat(wrapper.getOutputDataType(0)).contains("float"); - wrapper.close(); - wrapper = new NativeInterpreterWrapper(LONG_MODEL_PATH); - assertThat(wrapper.getOutputDataType(0)).contains("long"); - wrapper.close(); - wrapper = new NativeInterpreterWrapper(INT_MODEL_PATH); - assertThat(wrapper.getOutputDataType(0)).contains("int"); - wrapper.close(); - wrapper = new NativeInterpreterWrapper(BYTE_MODEL_PATH); - assertThat(wrapper.getOutputDataType(0)).contains("byte"); + assertThat(wrapper.getInputTensor(0).shape()).isEqualTo(expectedDims); wrapper.close(); } diff --git a/tensorflow/contrib/lite/java/src/test/java/org/tensorflow/lite/TensorTest.java b/tensorflow/contrib/lite/java/src/test/java/org/tensorflow/lite/TensorTest.java index dd9d37eeda..71ef044943 100644 --- a/tensorflow/contrib/lite/java/src/test/java/org/tensorflow/lite/TensorTest.java +++ b/tensorflow/contrib/lite/java/src/test/java/org/tensorflow/lite/TensorTest.java @@ -18,9 +18,10 @@ package org.tensorflow.lite; import static com.google.common.truth.Truth.assertThat; import static org.junit.Assert.fail; -import java.nio.BufferOverflowException; import java.nio.ByteBuffer; import java.nio.ByteOrder; +import java.util.HashMap; +import java.util.Map; import org.junit.After; import org.junit.Before; import org.junit.Test; @@ -35,7 +36,7 @@ public final class TensorTest { "tensorflow/contrib/lite/java/src/testdata/add.bin"; private NativeInterpreterWrapper wrapper; - private long nativeHandle; + private Tensor tensor; @Before public void setUp() { @@ -45,8 +46,10 @@ public final class TensorTest { float[][][] threeD = {twoD, twoD, twoD, twoD, twoD, twoD, twoD, twoD}; float[][][][] fourD = {threeD, threeD}; Object[] inputs = {fourD}; - Tensor[] outputs = wrapper.run(inputs); - nativeHandle = outputs[0].nativeHandle; + Map<Integer, Object> outputs = new HashMap<>(); + outputs.put(0, new float[2][8][8][3]); + wrapper.run(inputs, outputs); + tensor = wrapper.getOutputTensor(0); } @After @@ -55,17 +58,16 @@ public final class TensorTest { } @Test - public void testFromHandle() throws Exception { - Tensor tensor = Tensor.fromHandle(nativeHandle); + public void testBasic() throws Exception { assertThat(tensor).isNotNull(); int[] expectedShape = {2, 8, 8, 3}; - assertThat(tensor.shapeCopy).isEqualTo(expectedShape); - assertThat(tensor.dtype).isEqualTo(DataType.FLOAT32); + assertThat(tensor.shape()).isEqualTo(expectedShape); + assertThat(tensor.dataType()).isEqualTo(DataType.FLOAT32); + assertThat(tensor.numBytes()).isEqualTo(2 * 8 * 8 * 3 * 4); } @Test public void testCopyTo() { - Tensor tensor = Tensor.fromHandle(nativeHandle); float[][][][] parsedOutputs = new float[2][8][8][3]; tensor.copyTo(parsedOutputs); float[] outputOneD = parsedOutputs[0][0][0]; @@ -75,7 +77,6 @@ public final class TensorTest { @Test public void testCopyToByteBuffer() { - Tensor tensor = Tensor.fromHandle(nativeHandle); ByteBuffer parsedOutput = ByteBuffer.allocateDirect(2 * 8 * 8 * 3 * 4).order(ByteOrder.nativeOrder()); tensor.copyTo(parsedOutput); @@ -89,19 +90,17 @@ public final class TensorTest { @Test public void testCopyToInvalidByteBuffer() { - Tensor tensor = Tensor.fromHandle(nativeHandle); ByteBuffer parsedOutput = ByteBuffer.allocateDirect(3 * 4).order(ByteOrder.nativeOrder()); try { tensor.copyTo(parsedOutput); fail(); - } catch (BufferOverflowException e) { + } catch (IllegalArgumentException e) { // Expected. } } @Test public void testCopyToWrongType() { - Tensor tensor = Tensor.fromHandle(nativeHandle); int[][][][] parsedOutputs = new int[2][8][8][3]; try { tensor.copyTo(parsedOutputs); @@ -110,15 +109,13 @@ public final class TensorTest { assertThat(e) .hasMessageThat() .contains( - "Cannot convert an TensorFlowLite tensor with type " - + "FLOAT32 to a Java object of type [[[[I (which is compatible with the TensorFlowLite " - + "type INT32)"); + "Cannot convert between a TensorFlowLite tensor with type FLOAT32 and a Java object " + + "of type [[[[I (which is compatible with the TensorFlowLite type INT32)"); } } @Test public void testCopyToWrongShape() { - Tensor tensor = Tensor.fromHandle(nativeHandle); float[][][][] parsedOutputs = new float[1][8][8][3]; try { tensor.copyTo(parsedOutputs); @@ -127,8 +124,104 @@ public final class TensorTest { assertThat(e) .hasMessageThat() .contains( - "Shape of output target [1, 8, 8, 3] does not match " - + "with the shape of the Tensor [2, 8, 8, 3]."); + "Cannot copy between a TensorFlowLite tensor with shape [2, 8, 8, 3] " + + "and a Java object with shape [1, 8, 8, 3]."); + } + } + + @Test + public void testSetTo() { + float[][][][] input = new float[2][8][8][3]; + float[][][][] output = new float[2][8][8][3]; + ByteBuffer inputByteBuffer = + ByteBuffer.allocateDirect(2 * 8 * 8 * 3 * 4).order(ByteOrder.nativeOrder()); + + input[0][0][0][0] = 2.0f; + tensor.setTo(input); + tensor.copyTo(output); + assertThat(output[0][0][0][0]).isEqualTo(2.0f); + + inputByteBuffer.putFloat(0, 3.0f); + tensor.setTo(inputByteBuffer); + tensor.copyTo(output); + assertThat(output[0][0][0][0]).isEqualTo(3.0f); + } + + @Test + public void testSetToInvalidByteBuffer() { + ByteBuffer input = ByteBuffer.allocateDirect(3 * 4).order(ByteOrder.nativeOrder()); + try { + tensor.setTo(input); + fail(); + } catch (IllegalArgumentException e) { + // Success. + } + } + + @Test + public void testGetInputShapeIfDifferent() { + ByteBuffer bytBufferInput = ByteBuffer.allocateDirect(3 * 4).order(ByteOrder.nativeOrder()); + assertThat(tensor.getInputShapeIfDifferent(bytBufferInput)).isNull(); + + float[][][][] sameShapeInput = new float[2][8][8][3]; + assertThat(tensor.getInputShapeIfDifferent(sameShapeInput)).isNull(); + + float[][][][] differentShapeInput = new float[1][8][8][3]; + assertThat(tensor.getInputShapeIfDifferent(differentShapeInput)) + .isEqualTo(new int[] {1, 8, 8, 3}); + } + + @Test + public void testDataTypeOf() { + float[] testEmptyArray = {}; + DataType dataType = Tensor.dataTypeOf(testEmptyArray); + assertThat(dataType).isEqualTo(DataType.FLOAT32); + float[] testFloatArray = {0.783f, 0.251f}; + dataType = Tensor.dataTypeOf(testFloatArray); + assertThat(dataType).isEqualTo(DataType.FLOAT32); + float[][] testMultiDimArray = {testFloatArray, testFloatArray, testFloatArray}; + dataType = Tensor.dataTypeOf(testFloatArray); + assertThat(dataType).isEqualTo(DataType.FLOAT32); + try { + double[] testDoubleArray = {0.783, 0.251}; + Tensor.dataTypeOf(testDoubleArray); + fail(); + } catch (IllegalArgumentException e) { + assertThat(e).hasMessageThat().contains("cannot resolve DataType of"); + } + try { + Float[] testBoxedArray = {0.783f, 0.251f}; + Tensor.dataTypeOf(testBoxedArray); + fail(); + } catch (IllegalArgumentException e) { + assertThat(e).hasMessageThat().contains("cannot resolve DataType of [Ljava.lang.Float;"); } } + + @Test + public void testNumDimensions() { + int scalar = 1; + assertThat(Tensor.numDimensions(scalar)).isEqualTo(0); + int[][] array = {{2, 4}, {1, 9}}; + assertThat(Tensor.numDimensions(array)).isEqualTo(2); + try { + int[] emptyArray = {}; + Tensor.numDimensions(emptyArray); + fail(); + } catch (IllegalArgumentException e) { + assertThat(e).hasMessageThat().contains("Array lengths cannot be 0."); + } + } + + @Test + public void testFillShape() { + int[][][] array = {{{23}, {14}, {87}}, {{12}, {42}, {31}}}; + int num = Tensor.numDimensions(array); + int[] shape = new int[num]; + Tensor.fillShape(array, 0, shape); + assertThat(num).isEqualTo(3); + assertThat(shape[0]).isEqualTo(2); + assertThat(shape[1]).isEqualTo(3); + assertThat(shape[2]).isEqualTo(1); + } } diff --git a/tensorflow/contrib/lite/java/src/testhelper/java/org/tensorflow/lite/TestHelper.java b/tensorflow/contrib/lite/java/src/testhelper/java/org/tensorflow/lite/TestHelper.java index 3aef0c3bb6..c23521c077 100644 --- a/tensorflow/contrib/lite/java/src/testhelper/java/org/tensorflow/lite/TestHelper.java +++ b/tensorflow/contrib/lite/java/src/testhelper/java/org/tensorflow/lite/TestHelper.java @@ -58,7 +58,7 @@ public class TestHelper { */ public static int[] getInputDims(Interpreter interpreter, int index) { if (interpreter != null && interpreter.wrapper != null) { - return interpreter.wrapper.getInputDims(index); + return interpreter.wrapper.getInputTensor(index).shape(); } else { throw new IllegalArgumentException( "Interpreter has not initialized;" + " Failed to get input dimensions."); @@ -77,7 +77,7 @@ public class TestHelper { */ public static String getOutputDataType(Interpreter interpreter, int index) { if (interpreter != null && interpreter.wrapper != null) { - return interpreter.wrapper.getOutputDataType(index); + return interpreter.wrapper.getOutputTensor(index).dataType().toStringName(); } else { throw new IllegalArgumentException( "Interpreter has not initialized;" + " Failed to get output data type."); diff --git a/tensorflow/contrib/lite/kernels/BUILD b/tensorflow/contrib/lite/kernels/BUILD index e749edc5ee..edce73989c 100644 --- a/tensorflow/contrib/lite/kernels/BUILD +++ b/tensorflow/contrib/lite/kernels/BUILD @@ -155,6 +155,7 @@ cc_library( "embedding_lookup_sparse.cc", "exp.cc", "expand_dims.cc", + "fake_quant.cc", "floor.cc", "fully_connected.cc", "gather.cc", @@ -564,6 +565,19 @@ tf_cc_test( ) tf_cc_test( + name = "fake_quant_test", + size = "small", + srcs = ["fake_quant_test.cc"], + tags = ["tflite_not_portable_ios"], + deps = [ + ":builtin_ops", + "//tensorflow/contrib/lite:framework", + "//tensorflow/contrib/lite/kernels:test_util", + "@com_google_googletest//:gtest", + ], +) + +tf_cc_test( name = "maximum_minimum_test", size = "small", srcs = ["maximum_minimum_test.cc"], diff --git a/tensorflow/contrib/lite/kernels/arg_min_max.cc b/tensorflow/contrib/lite/kernels/arg_min_max.cc index 2e2ec94fab..4f30d09030 100644 --- a/tensorflow/contrib/lite/kernels/arg_min_max.cc +++ b/tensorflow/contrib/lite/kernels/arg_min_max.cc @@ -177,6 +177,10 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node, bool is_arg_max) { return kTfLiteOk; } +TfLiteStatus ArgMinEval(TfLiteContext* context, TfLiteNode* node) { + return Eval(context, node, false); +} + TfLiteStatus ArgMaxEval(TfLiteContext* context, TfLiteNode* node) { return Eval(context, node, true); } @@ -189,6 +193,12 @@ TfLiteRegistration* Register_ARG_MAX() { return &r; } +TfLiteRegistration* Register_ARG_MIN() { + static TfLiteRegistration r = {nullptr, nullptr, arg_min_max::Prepare, + arg_min_max::ArgMinEval}; + return &r; +} + } // namespace builtin } // namespace ops } // namespace tflite diff --git a/tensorflow/contrib/lite/kernels/arg_min_max_test.cc b/tensorflow/contrib/lite/kernels/arg_min_max_test.cc index 31b15fe19a..90e5fdc532 100644 --- a/tensorflow/contrib/lite/kernels/arg_min_max_test.cc +++ b/tensorflow/contrib/lite/kernels/arg_min_max_test.cc @@ -24,16 +24,13 @@ namespace { using ::testing::ElementsAreArray; template <typename T> -class ArgMaxOpModel : public SingleOpModel { +class ArgBaseOpModel : public SingleOpModel { public: - ArgMaxOpModel(std::initializer_list<int> input_shape, TensorType input_type, - TensorType output_type, TensorType index_output_type) { + ArgBaseOpModel(std::initializer_list<int> input_shape, TensorType input_type, + TensorType output_type, TensorType index_output_type) { input_ = AddInput(input_type); axis_ = AddInput(TensorType_INT32); output_ = AddOutput(output_type); - SetBuiltinOp(BuiltinOperator_ARG_MAX, BuiltinOptions_ArgMaxOptions, - CreateArgMaxOptions(builder_, index_output_type).Union()); - BuildInterpreter({input_shape, {1, 1, 1, 1}}); } int input() { return input_; } @@ -42,12 +39,42 @@ class ArgMaxOpModel : public SingleOpModel { std::vector<T> GetOutput() { return ExtractVector<T>(output_); } std::vector<int> GetOutputShape() { return GetTensorShape(output_); } - private: + protected: int input_; int axis_; int output_; }; +template <typename T> +class ArgMaxOpModel : public ArgBaseOpModel<T> { + public: + ArgMaxOpModel(std::initializer_list<int> input_shape, TensorType input_type, + TensorType output_type, TensorType index_output_type) + : ArgBaseOpModel<T>(input_shape, input_type, output_type, + index_output_type) { + ArgBaseOpModel<T>::SetBuiltinOp( + BuiltinOperator_ARG_MAX, BuiltinOptions_ArgMaxOptions, + CreateArgMaxOptions(ArgBaseOpModel<T>::builder_, index_output_type) + .Union()); + ArgBaseOpModel<T>::BuildInterpreter({input_shape, {1, 1, 1, 1}}); + } +}; + +template <typename T> +class ArgMinOpModel : public ArgBaseOpModel<T> { + public: + ArgMinOpModel(std::initializer_list<int> input_shape, TensorType input_type, + TensorType output_type, TensorType index_output_type) + : ArgBaseOpModel<T>(input_shape, input_type, output_type, + index_output_type) { + ArgBaseOpModel<T>::SetBuiltinOp( + BuiltinOperator_ARG_MIN, BuiltinOptions_ArgMinOptions, + CreateArgMinOptions(ArgBaseOpModel<T>::builder_, index_output_type) + .Union()); + ArgBaseOpModel<T>::BuildInterpreter({input_shape, {1, 1, 1, 1}}); + } +}; + TEST(ArgMaxOpTest, GetMaxArgFloat) { ArgMaxOpModel<int32_t> model({1, 1, 1, 4}, TensorType_FLOAT32, TensorType_INT32, TensorType_INT32); @@ -96,6 +123,54 @@ TEST(ArgMaxOpTest, GetMaxArgOutput64) { EXPECT_THAT(model.GetOutputShape(), ElementsAreArray({1, 1, 2, 1})); } +TEST(ArgMinOpTest, GetMinArgFloat) { + ArgMinOpModel<int32_t> model({1, 1, 1, 4}, TensorType_FLOAT32, + TensorType_INT32, TensorType_INT32); + model.PopulateTensor<float>(model.input(), {0.1, 0.9, 0.7, 0.3}); + // Currently only support the last dimension. + model.PopulateTensor<int>(model.axis(), {3}); + model.Invoke(); + + EXPECT_THAT(model.GetOutput(), ElementsAreArray({0})); + EXPECT_THAT(model.GetOutputShape(), ElementsAreArray({1, 1, 1, 1})); +} + +TEST(ArgMinOpTest, GetMinArgInt) { + ArgMinOpModel<int32_t> model({1, 1, 1, 4}, TensorType_INT32, TensorType_INT32, + TensorType_INT32); + model.PopulateTensor<int>(model.input(), {1, 9, 7, 3}); + // Currently only support the last dimension. + model.PopulateTensor<int>(model.axis(), {3}); + model.Invoke(); + + EXPECT_THAT(model.GetOutput(), ElementsAreArray({0})); + EXPECT_THAT(model.GetOutputShape(), ElementsAreArray({1, 1, 1, 1})); +} + +TEST(ArgMinOpTest, GetMinArgMulDimensions) { + ArgMinOpModel<int32_t> model({1, 1, 2, 4}, TensorType_INT32, TensorType_INT32, + TensorType_INT32); + model.PopulateTensor<int>(model.input(), {1, 2, 7, 8, 1, 9, 7, 3}); + // Currently only support the last dimension. + model.PopulateTensor<int>(model.axis(), {3}); + model.Invoke(); + + EXPECT_THAT(model.GetOutput(), ElementsAreArray({0, 0})); + EXPECT_THAT(model.GetOutputShape(), ElementsAreArray({1, 1, 2, 1})); +} + +TEST(ArgMinOpTest, GetMinArgOutput64) { + ArgMinOpModel<int64_t> model({1, 1, 2, 4}, TensorType_INT32, TensorType_INT64, + TensorType_INT64); + model.PopulateTensor<int>(model.input(), {10, 2, 7, 8, 1, 9, 7, 3}); + // Currently only support the last dimension. + model.PopulateTensor<int>(model.axis(), {3}); + model.Invoke(); + + EXPECT_THAT(model.GetOutput(), ElementsAreArray({1, 0})); + EXPECT_THAT(model.GetOutputShape(), ElementsAreArray({1, 1, 2, 1})); +} + } // namespace } // namespace tflite diff --git a/tensorflow/contrib/lite/kernels/fake_quant.cc b/tensorflow/contrib/lite/kernels/fake_quant.cc new file mode 100644 index 0000000000..f8927a0799 --- /dev/null +++ b/tensorflow/contrib/lite/kernels/fake_quant.cc @@ -0,0 +1,81 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ +#include <string.h> +#include <vector> +#include "tensorflow/contrib/lite/builtin_op_data.h" +#include "tensorflow/contrib/lite/context.h" +#include "tensorflow/contrib/lite/kernels/internal/reference/reference_ops.h" +#include "tensorflow/contrib/lite/kernels/internal/tensor.h" +#include "tensorflow/contrib/lite/kernels/kernel_util.h" +#include "tensorflow/contrib/lite/kernels/op_macros.h" + +namespace tflite { +namespace ops { +namespace builtin { +namespace fake_quant { + +// This file has reference implementation of FakeQuant. +enum KernelType { + kReference, +}; + +struct OpContext { + OpContext(TfLiteContext* context, TfLiteNode* node) { + input = GetInput(context, node, 0); + output = GetOutput(context, node, 0); + } + const TfLiteTensor* input; + TfLiteTensor* output; +}; + +TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { + TF_LITE_ENSURE_EQ(context, NumInputs(node), 1); + TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1); + + OpContext op_context(context, node); + TfLiteIntArray* output_dims = TfLiteIntArrayCopy(op_context.input->dims); + op_context.output->type = op_context.input->type; + return context->ResizeTensor(context, op_context.output, output_dims); +} + +template <KernelType kernel_type> +TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { + OpContext op_context(context, node); + + const auto* params = + reinterpret_cast<TfLiteFakeQuantParams*>(node->builtin_data); + + reference_ops::FakeQuant(GetTensorData<float>(op_context.input), + GetTensorDims(op_context.input), params->min, + params->max, params->num_bits, + GetTensorData<float>(op_context.output), + GetTensorDims(op_context.output)); + + return kTfLiteOk; +} + +} // namespace fake_quant + +TfLiteRegistration* Register_FAKE_QUANT_REF() { + static TfLiteRegistration r = {nullptr, nullptr, fake_quant::Prepare, + fake_quant::Eval<fake_quant::kReference>}; + return &r; +} + +TfLiteRegistration* Register_FAKE_QUANT() { return Register_FAKE_QUANT_REF(); } + +} // namespace builtin +} // namespace ops +} // namespace tflite diff --git a/tensorflow/contrib/lite/kernels/fake_quant_test.cc b/tensorflow/contrib/lite/kernels/fake_quant_test.cc new file mode 100644 index 0000000000..11a02f7ed7 --- /dev/null +++ b/tensorflow/contrib/lite/kernels/fake_quant_test.cc @@ -0,0 +1,112 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ +#include <gtest/gtest.h> +#include "tensorflow/contrib/lite/interpreter.h" +#include "tensorflow/contrib/lite/kernels/register.h" +#include "tensorflow/contrib/lite/kernels/test_util.h" +#include "tensorflow/contrib/lite/model.h" + +namespace tflite { +namespace { + +using ::testing::ElementsAreArray; + +class FakeQuantOpModel : public SingleOpModel { + public: + FakeQuantOpModel(const TensorData& input, const TensorType& output, float min, + float max, int num_bits) { + input_ = AddInput(input); + output_ = AddOutput(output); + SetBuiltinOp(BuiltinOperator_FAKE_QUANT, BuiltinOptions_FakeQuantOptions, + CreateFakeQuantOptions(builder_, min, max, num_bits).Union()); + BuildInterpreter({GetShape(input_)}); + } + + template <class T> + void SetInput(std::initializer_list<T> data) { + PopulateTensor(input_, data); + } + + template <class T> + std::vector<T> GetOutput() { + return ExtractVector<T>(output_); + } + std::vector<int> GetOutputShape() { return GetTensorShape(output_); } + + protected: + int input_; + int output_; +}; + +TEST(FakeQuantOpTest, FloatPositiveRange8Test) { + std::initializer_list<float> data = {0.0, 1.0, 0.25, + 0.50, 0.4444444, 0.00001}; + FakeQuantOpModel m({TensorType_FLOAT32, {3, 1, 2}}, TensorType_FLOAT32, 0.0f, + 1.0f, 8); + m.SetInput<float>(data); + m.Invoke(); + EXPECT_THAT(m.GetOutputShape(), ElementsAreArray({3, 1, 2})); + EXPECT_THAT( + m.GetOutput<float>(), + ElementsAreArray(ArrayFloatNear({0, 1, 0.25098, 0.498039, 0.443137, 0}))); +} + +TEST(FakeQuantOpTest, FloatNegativeRange8Test) { + std::initializer_list<float> data = {0.0, -0.9, 0.25, + 0.50, 0.4444444, -0.00001}; + FakeQuantOpModel m({TensorType_FLOAT32, {3, 1, 2}}, TensorType_FLOAT32, -0.9f, + 0.9f, 8); + m.SetInput<float>(data); + m.Invoke(); + EXPECT_THAT(m.GetOutputShape(), ElementsAreArray({3, 1, 2})); + EXPECT_THAT(m.GetOutput<float>(), + ElementsAreArray(ArrayFloatNear( + {0, -0.896471, 0.247059, 0.501176, 0.444706, 0}))); +} + +TEST(FakeQuantOpTest, FloatPositiveRange16Test) { + std::initializer_list<float> data = {0.0, 1.0, 0.25, + 0.50, 0.4444444, 0.00001}; + FakeQuantOpModel m({TensorType_FLOAT32, {3, 1, 2}}, TensorType_FLOAT32, 0.0f, + 1.0f, 16); + m.SetInput<float>(data); + m.Invoke(); + EXPECT_THAT(m.GetOutputShape(), ElementsAreArray({3, 1, 2})); + EXPECT_THAT(m.GetOutput<float>(), + ElementsAreArray(ArrayFloatNear( + {0, 1, 0.250004, 0.500008, 0.44445, 1.5259e-05}))); +} + +TEST(FakeQuantOpTest, FloatNegativeRange16Test) { + std::initializer_list<float> data = {0.0, -0.9, 0.25, + 0.50, 0.4444444, -0.00001}; + FakeQuantOpModel m({TensorType_FLOAT32, {3, 1, 2}}, TensorType_FLOAT32, -0.9f, + 0.9f, 16); + m.SetInput<float>(data); + m.Invoke(); + EXPECT_THAT(m.GetOutputShape(), ElementsAreArray({3, 1, 2})); + EXPECT_THAT(m.GetOutput<float>(), + ElementsAreArray(ArrayFloatNear( + {0, -0.900014, 0.249998, 0.499995, 0.444431, 0}))); +} + +} // namespace +} // namespace tflite + +int main(int argc, char** argv) { + ::tflite::LogToStderr(); + ::testing::InitGoogleTest(&argc, argv); + return RUN_ALL_TESTS(); +} diff --git a/tensorflow/contrib/lite/kernels/internal/optimized/neon_tensor_utils.cc b/tensorflow/contrib/lite/kernels/internal/optimized/neon_tensor_utils.cc index 5ba7e2af9b..c19f8e8a81 100644 --- a/tensorflow/contrib/lite/kernels/internal/optimized/neon_tensor_utils.cc +++ b/tensorflow/contrib/lite/kernels/internal/optimized/neon_tensor_utils.cc @@ -62,72 +62,35 @@ void NeonMatrixBatchVectorMultiplyAccumulate(const float* matrix, int m_rows, sizeof(float32x4_t), (postamble_start >> 2) * sizeof(float32x4_t), &aligned_vector_cache_free)); - const int kUnrollSize = 2; for (int b = 0; b < n_batch; b++) { float* result_in_batch = result + b * m_rows * result_stride; const float* vector_in_batch = vector + b * m_cols; - - const float* matrix_ptr0 = matrix; - // If there is only 1 row, we don't want to assign an illegal pointer. - const float* matrix_ptr1 = nullptr; - if (m_rows > 1) { - matrix_ptr1 = matrix + m_cols; - } + const float* matrix_row = matrix; // Cache the vector. for (int c = 0; c < postamble_start; c += kFloatWeightsPerNeonLane) { vector_cache_float32x4[c >> 2] = vld1q_f32(vector_in_batch + c); } - // Main matrix by vector multiplication loop, which handles two rows of - // matrix by vector multiplication. - for (int r = 0; r < (m_rows & ~(kUnrollSize - 1)); r += kUnrollSize) { - float32x4_t acc0_32x4 = vmovq_n_f32(0.0); - float32x4_t acc1_32x4 = vmovq_n_f32(0.0); - for (int c = 0; c < postamble_start; c += kFloatWeightsPerNeonLane) { - float32x4_t temp = vector_cache_float32x4[c >> 2]; - // Load 4 float values from vector1 and vector2 and accumulator. - float32x4_t v0_f32x4 = vld1q_f32(matrix_ptr0 + c); - float32x4_t v1_f32x4 = vld1q_f32(matrix_ptr1 + c); - // Vector multiply-accumulate 4 float - acc0_32x4 = vmlaq_f32(acc0_32x4, v0_f32x4, temp); - acc1_32x4 = vmlaq_f32(acc1_32x4, v1_f32x4, temp); - } - // Add the 4 intermediate sum values to get the final dot-prod value for - // this column. - *result_in_batch += - (vgetq_lane_f32(acc0_32x4, 0) + vgetq_lane_f32(acc0_32x4, 1) + - vgetq_lane_f32(acc0_32x4, 2) + vgetq_lane_f32(acc0_32x4, 3)); - *(result_in_batch + result_stride) += - (vgetq_lane_f32(acc1_32x4, 0) + vgetq_lane_f32(acc1_32x4, 1) + - vgetq_lane_f32(acc1_32x4, 2) + vgetq_lane_f32(acc1_32x4, 3)); - for (int c = postamble_start; c < m_cols; c++) { - *result_in_batch += matrix_ptr0[c] * vector_in_batch[c]; - *(result_in_batch + result_stride) += - matrix_ptr1[c] * vector_in_batch[c]; - } - matrix_ptr0 += kUnrollSize * m_cols; - matrix_ptr1 += kUnrollSize * m_cols; - result_in_batch += kUnrollSize * result_stride; - } - for (int r = (m_rows & ~(kUnrollSize - 1)); r < m_rows; r++) { - float32x4_t acc0_32x4 = vmovq_n_f32(0.0); + // Main matrix by vector multiplication loop + for (int r = 0; r < m_rows; r++) { + float32x4_t acc_32x4 = vmovq_n_f32(0.0); for (int c = 0; c < postamble_start; c += kFloatWeightsPerNeonLane) { float32x4_t temp = vector_cache_float32x4[c >> 2]; - // Load 4 float values from vector1 and vector2 and accumulator. - float32x4_t v0_f32x4 = vld1q_f32(matrix_ptr0 + c); + // Load 4 float values from vector and accumulator. + float32x4_t v_f32x4 = vld1q_f32(matrix_row + c); // Vector multiply-accumulate 4 float - acc0_32x4 = vmlaq_f32(acc0_32x4, v0_f32x4, temp); + acc_32x4 = vmlaq_f32(acc_32x4, v_f32x4, temp); } // Add the 4 intermediate sum values to get the final dot-prod value for // this column. *result_in_batch += - (vgetq_lane_f32(acc0_32x4, 0) + vgetq_lane_f32(acc0_32x4, 1) + - vgetq_lane_f32(acc0_32x4, 2) + vgetq_lane_f32(acc0_32x4, 3)); + (vgetq_lane_f32(acc_32x4, 0) + vgetq_lane_f32(acc_32x4, 1) + + vgetq_lane_f32(acc_32x4, 2) + vgetq_lane_f32(acc_32x4, 3)); for (int c = postamble_start; c < m_cols; c++) { - *result_in_batch += matrix_ptr0[c] * vector_in_batch[c]; + *result_in_batch += matrix_row[c] * vector_in_batch[c]; } - matrix_ptr0 += m_cols; + matrix_row += m_cols; result_in_batch += result_stride; } } diff --git a/tensorflow/contrib/lite/kernels/register.cc b/tensorflow/contrib/lite/kernels/register.cc index 0ca08cd8f3..1994e85ce3 100644 --- a/tensorflow/contrib/lite/kernels/register.cc +++ b/tensorflow/contrib/lite/kernels/register.cc @@ -82,6 +82,7 @@ TfLiteRegistration* Register_PRELU(); TfLiteRegistration* Register_MAXIMUM(); TfLiteRegistration* Register_MINIMUM(); TfLiteRegistration* Register_ARG_MAX(); +TfLiteRegistration* Register_ARG_MIN(); TfLiteRegistration* Register_GREATER(); TfLiteRegistration* Register_GREATER_EQUAL(); TfLiteRegistration* Register_LESS(); @@ -102,6 +103,7 @@ TfLiteRegistration* Register_SQRT(); TfLiteRegistration* Register_RSQRT(); TfLiteRegistration* Register_SHAPE(); TfLiteRegistration* Register_POW(); +TfLiteRegistration* Register_FAKE_QUANT(); BuiltinOpResolver::BuiltinOpResolver() { AddBuiltin(BuiltinOperator_RELU, Register_RELU()); @@ -167,6 +169,7 @@ BuiltinOpResolver::BuiltinOpResolver() { AddBuiltin(BuiltinOperator_MAXIMUM, Register_MAXIMUM()); AddBuiltin(BuiltinOperator_MINIMUM, Register_MINIMUM()); AddBuiltin(BuiltinOperator_ARG_MAX, Register_ARG_MAX()); + AddBuiltin(BuiltinOperator_ARG_MIN, Register_ARG_MIN()); AddBuiltin(BuiltinOperator_GREATER, Register_GREATER()); AddBuiltin(BuiltinOperator_GREATER_EQUAL, Register_GREATER_EQUAL()); AddBuiltin(BuiltinOperator_LESS, Register_LESS()); @@ -187,6 +190,7 @@ BuiltinOpResolver::BuiltinOpResolver() { AddBuiltin(BuiltinOperator_RSQRT, Register_RSQRT()); AddBuiltin(BuiltinOperator_SHAPE, Register_SHAPE()); AddBuiltin(BuiltinOperator_POW, Register_POW()); + AddBuiltin(BuiltinOperator_FAKE_QUANT, Register_FAKE_QUANT()); // TODO(andrewharp, ahentz): Move these somewhere more appropriate so that // custom ops aren't always included by default. diff --git a/tensorflow/contrib/lite/kernels/select.cc b/tensorflow/contrib/lite/kernels/select.cc index 9b6cee3cb5..3cdb5db209 100644 --- a/tensorflow/contrib/lite/kernels/select.cc +++ b/tensorflow/contrib/lite/kernels/select.cc @@ -89,6 +89,9 @@ TfLiteStatus SelectEval(TfLiteContext* context, TfLiteNode* node) { case kTfLiteUInt8: \ TF_LITE_SELECT(uint8_t, op); \ break; \ + case kTfLiteInt16: \ + TF_LITE_SELECT(int16_t, op); \ + break; \ case kTfLiteInt32: \ TF_LITE_SELECT(int32_t, op); \ break; \ diff --git a/tensorflow/contrib/lite/kernels/select_test.cc b/tensorflow/contrib/lite/kernels/select_test.cc index 4664b9acb4..5b2e61cd29 100644 --- a/tensorflow/contrib/lite/kernels/select_test.cc +++ b/tensorflow/contrib/lite/kernels/select_test.cc @@ -96,6 +96,19 @@ TEST(SelectOpTest, SelectUInt8) { EXPECT_THAT(model.GetOutputShape(), ElementsAreArray({1, 1, 1, 4})); } +TEST(SelectOpTest, SelectInt16) { + SelectOpModel model({1, 1, 1, 4}, {1, 1, 1, 4}, {1, 1, 1, 4}, + TensorType_INT16); + + model.PopulateTensor<bool>(model.input1(), {false, true, false, false}); + model.PopulateTensor<int16_t>(model.input2(), {1, 2, 3, 4}); + model.PopulateTensor<int16_t>(model.input3(), {5, 6, 7, 8}); + model.Invoke(); + + EXPECT_THAT(model.GetOutput<int16_t>(), ElementsAreArray({5, 2, 7, 8})); + EXPECT_THAT(model.GetOutputShape(), ElementsAreArray({1, 1, 1, 4})); +} + TEST(SelectOpTest, SelectInt32) { SelectOpModel model({1, 1, 1, 4}, {1, 1, 1, 4}, {1, 1, 1, 4}, TensorType_INT32); diff --git a/tensorflow/contrib/lite/model.cc b/tensorflow/contrib/lite/model.cc index 0bc717bfca..93b3df98f3 100644 --- a/tensorflow/contrib/lite/model.cc +++ b/tensorflow/contrib/lite/model.cc @@ -206,8 +206,9 @@ TfLiteStatus InterpreterBuilder::BuildLocalIndexToRegistrationMapping() { } else if (builtin_code != BuiltinOperator_CUSTOM) { registration = op_resolver_.FindOp(builtin_code, version); if (registration == nullptr) { - error_reporter_->Report("Didn't find op for builtin opcode '%s'\n", - EnumNameBuiltinOperator(builtin_code)); + error_reporter_->Report( + "Didn't find op for builtin opcode '%s' version '%d'\n", + EnumNameBuiltinOperator(builtin_code), version); status = kTfLiteError; } } else if (!opcode->custom_code()) { @@ -663,6 +664,15 @@ TfLiteStatus ParseOpData(const Operator* op, BuiltinOperator op_type, *builtin_data = reinterpret_cast<void*>(params); break; } + case BuiltinOperator_ARG_MIN: { + auto* params = MallocPOD<TfLiteArgMinParams>(); + if (const auto* schema_params = op->builtin_options_as_ArgMinOptions()) { + ConvertTensorType(schema_params->output_type(), ¶ms->output_type, + error_reporter); + } + *builtin_data = reinterpret_cast<void*>(params); + break; + } case BuiltinOperator_TRANSPOSE_CONV: { TfLiteTransposeConvParams* params = MallocPOD<TfLiteTransposeConvParams>(); @@ -699,6 +709,16 @@ TfLiteStatus ParseOpData(const Operator* op, BuiltinOperator op_type, error_reporter->Report("DELEGATE op shouldn't exist in model."); return kTfLiteError; } + case BuiltinOperator_FAKE_QUANT: { + auto* params = MallocPOD<TfLiteFakeQuantParams>(); + if (auto* schema_params = op->builtin_options_as_FakeQuantOptions()) { + params->min = schema_params->min(); + params->max = schema_params->max(); + params->num_bits = schema_params->num_bits(); + } + *builtin_data = static_cast<void*>(params); + break; + } // Below are the ops with no builtin_data strcture. case BuiltinOperator_BATCH_TO_SPACE_ND: diff --git a/tensorflow/contrib/lite/nnapi_delegate.cc b/tensorflow/contrib/lite/nnapi_delegate.cc index 905c0919cb..cc668485a4 100644 --- a/tensorflow/contrib/lite/nnapi_delegate.cc +++ b/tensorflow/contrib/lite/nnapi_delegate.cc @@ -548,6 +548,18 @@ TfLiteStatus AddOpsAndParams( add_squeeze_params(node.builtin_data); nn_op_type = ANEURALNETWORKS_SQUEEZE; break; + case tflite::BuiltinOperator_TRANSPOSE: + // The permutation input tensor value dictates the output dimensions. + // TODO(b/110888333): Support dynamically-sized tensors in delegates. + if ((node.inputs->size > 1) && + (interpreter->tensor(node.inputs->data[1])->allocation_type != + kTfLiteMmapRo)) { + logError("NNAPI does not yet support dynamic tensors."); + return kTfLiteError; + } + nnapi_version = 11; // require NNAPI 1.1 + nn_op_type = ANEURALNETWORKS_TRANSPOSE; + break; case tflite::BuiltinOperator_CONCAT_EMBEDDINGS: case tflite::BuiltinOperator_LSH_PROJECTION: case tflite::BuiltinOperator_HASHTABLE_LOOKUP: @@ -567,7 +579,6 @@ TfLiteStatus AddOpsAndParams( case tflite::BuiltinOperator_SPACE_TO_BATCH_ND: case tflite::BuiltinOperator_BATCH_TO_SPACE_ND: case tflite::BuiltinOperator_TOPK_V2: - case tflite::BuiltinOperator_TRANSPOSE: case tflite::BuiltinOperator_SPLIT: case tflite::BuiltinOperator_STRIDED_SLICE: case tflite::BuiltinOperator_EXP: @@ -579,6 +590,7 @@ TfLiteStatus AddOpsAndParams( case tflite::BuiltinOperator_MAXIMUM: case tflite::BuiltinOperator_MINIMUM: case tflite::BuiltinOperator_ARG_MAX: + case tflite::BuiltinOperator_ARG_MIN: case tflite::BuiltinOperator_GREATER: case tflite::BuiltinOperator_GREATER_EQUAL: case tflite::BuiltinOperator_LESS: @@ -599,6 +611,7 @@ TfLiteStatus AddOpsAndParams( case tflite::BuiltinOperator_RSQRT: case tflite::BuiltinOperator_SHAPE: case tflite::BuiltinOperator_POW: + case tflite::BuiltinOperator_FAKE_QUANT: logError("Op code %d is currently not delegated to NNAPI", builtin); return kTfLiteError; break; diff --git a/tensorflow/contrib/lite/schema/schema.fbs b/tensorflow/contrib/lite/schema/schema.fbs index 5e6467f676..17ea26052d 100644 --- a/tensorflow/contrib/lite/schema/schema.fbs +++ b/tensorflow/contrib/lite/schema/schema.fbs @@ -160,6 +160,8 @@ enum BuiltinOperator : byte { RSQRT = 76, SHAPE = 77, POW = 78, + ARG_MIN = 79, + FAKE_QUANT = 80, } // Options for the builtin operators. @@ -220,6 +222,8 @@ union BuiltinOptions { NotEqualOptions, ShapeOptions, PowOptions, + ArgMinOptions, + FakeQuantOptions, } enum Padding : byte { SAME, VALID } @@ -469,6 +473,10 @@ table ArgMaxOptions { output_type : TensorType; } +table ArgMinOptions { + output_type : TensorType; +} + table GreaterOptions { } @@ -517,6 +525,12 @@ table ShapeOptions { table PowOptions { } +table FakeQuantOptions { + min:float; + max:float; + num_bits:int; +} + // An OperatorCode can be an enum value (BuiltinOperator) if the operator is a // builtin, or a string if the operator is custom. table OperatorCode { diff --git a/tensorflow/contrib/lite/schema/schema_generated.h b/tensorflow/contrib/lite/schema/schema_generated.h index fe0ff9a7a5..37489ebc68 100755 --- a/tensorflow/contrib/lite/schema/schema_generated.h +++ b/tensorflow/contrib/lite/schema/schema_generated.h @@ -157,6 +157,9 @@ struct TileOptionsT; struct ArgMaxOptions; struct ArgMaxOptionsT; +struct ArgMinOptions; +struct ArgMinOptionsT; + struct GreaterOptions; struct GreaterOptionsT; @@ -199,6 +202,9 @@ struct ShapeOptionsT; struct PowOptions; struct PowOptionsT; +struct FakeQuantOptions; +struct FakeQuantOptionsT; + struct OperatorCode; struct OperatorCodeT; @@ -343,11 +349,13 @@ enum BuiltinOperator { BuiltinOperator_RSQRT = 76, BuiltinOperator_SHAPE = 77, BuiltinOperator_POW = 78, + BuiltinOperator_ARG_MIN = 79, + BuiltinOperator_FAKE_QUANT = 80, BuiltinOperator_MIN = BuiltinOperator_ADD, - BuiltinOperator_MAX = BuiltinOperator_POW + BuiltinOperator_MAX = BuiltinOperator_FAKE_QUANT }; -inline BuiltinOperator (&EnumValuesBuiltinOperator())[78] { +inline BuiltinOperator (&EnumValuesBuiltinOperator())[80] { static BuiltinOperator values[] = { BuiltinOperator_ADD, BuiltinOperator_AVERAGE_POOL_2D, @@ -426,7 +434,9 @@ inline BuiltinOperator (&EnumValuesBuiltinOperator())[78] { BuiltinOperator_SQRT, BuiltinOperator_RSQRT, BuiltinOperator_SHAPE, - BuiltinOperator_POW + BuiltinOperator_POW, + BuiltinOperator_ARG_MIN, + BuiltinOperator_FAKE_QUANT }; return values; } @@ -512,6 +522,8 @@ inline const char **EnumNamesBuiltinOperator() { "RSQRT", "SHAPE", "POW", + "ARG_MIN", + "FAKE_QUANT", nullptr }; return names; @@ -580,11 +592,13 @@ enum BuiltinOptions { BuiltinOptions_NotEqualOptions = 54, BuiltinOptions_ShapeOptions = 55, BuiltinOptions_PowOptions = 56, + BuiltinOptions_ArgMinOptions = 57, + BuiltinOptions_FakeQuantOptions = 58, BuiltinOptions_MIN = BuiltinOptions_NONE, - BuiltinOptions_MAX = BuiltinOptions_PowOptions + BuiltinOptions_MAX = BuiltinOptions_FakeQuantOptions }; -inline BuiltinOptions (&EnumValuesBuiltinOptions())[57] { +inline BuiltinOptions (&EnumValuesBuiltinOptions())[59] { static BuiltinOptions values[] = { BuiltinOptions_NONE, BuiltinOptions_Conv2DOptions, @@ -642,7 +656,9 @@ inline BuiltinOptions (&EnumValuesBuiltinOptions())[57] { BuiltinOptions_EqualOptions, BuiltinOptions_NotEqualOptions, BuiltinOptions_ShapeOptions, - BuiltinOptions_PowOptions + BuiltinOptions_PowOptions, + BuiltinOptions_ArgMinOptions, + BuiltinOptions_FakeQuantOptions }; return values; } @@ -706,6 +722,8 @@ inline const char **EnumNamesBuiltinOptions() { "NotEqualOptions", "ShapeOptions", "PowOptions", + "ArgMinOptions", + "FakeQuantOptions", nullptr }; return names; @@ -944,6 +962,14 @@ template<> struct BuiltinOptionsTraits<PowOptions> { static const BuiltinOptions enum_value = BuiltinOptions_PowOptions; }; +template<> struct BuiltinOptionsTraits<ArgMinOptions> { + static const BuiltinOptions enum_value = BuiltinOptions_ArgMinOptions; +}; + +template<> struct BuiltinOptionsTraits<FakeQuantOptions> { + static const BuiltinOptions enum_value = BuiltinOptions_FakeQuantOptions; +}; + struct BuiltinOptionsUnion { BuiltinOptions type; void *value; @@ -1423,6 +1449,22 @@ struct BuiltinOptionsUnion { return type == BuiltinOptions_PowOptions ? reinterpret_cast<const PowOptionsT *>(value) : nullptr; } + ArgMinOptionsT *AsArgMinOptions() { + return type == BuiltinOptions_ArgMinOptions ? + reinterpret_cast<ArgMinOptionsT *>(value) : nullptr; + } + const ArgMinOptionsT *AsArgMinOptions() const { + return type == BuiltinOptions_ArgMinOptions ? + reinterpret_cast<const ArgMinOptionsT *>(value) : nullptr; + } + FakeQuantOptionsT *AsFakeQuantOptions() { + return type == BuiltinOptions_FakeQuantOptions ? + reinterpret_cast<FakeQuantOptionsT *>(value) : nullptr; + } + const FakeQuantOptionsT *AsFakeQuantOptions() const { + return type == BuiltinOptions_FakeQuantOptions ? + reinterpret_cast<const FakeQuantOptionsT *>(value) : nullptr; + } }; bool VerifyBuiltinOptions(flatbuffers::Verifier &verifier, const void *obj, BuiltinOptions type); @@ -4486,6 +4528,60 @@ inline flatbuffers::Offset<ArgMaxOptions> CreateArgMaxOptions( flatbuffers::Offset<ArgMaxOptions> CreateArgMaxOptions(flatbuffers::FlatBufferBuilder &_fbb, const ArgMaxOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr); +struct ArgMinOptionsT : public flatbuffers::NativeTable { + typedef ArgMinOptions TableType; + TensorType output_type; + ArgMinOptionsT() + : output_type(TensorType_FLOAT32) { + } +}; + +struct ArgMinOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table { + typedef ArgMinOptionsT NativeTableType; + enum { + VT_OUTPUT_TYPE = 4 + }; + TensorType output_type() const { + return static_cast<TensorType>(GetField<int8_t>(VT_OUTPUT_TYPE, 0)); + } + bool Verify(flatbuffers::Verifier &verifier) const { + return VerifyTableStart(verifier) && + VerifyField<int8_t>(verifier, VT_OUTPUT_TYPE) && + verifier.EndTable(); + } + ArgMinOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const; + void UnPackTo(ArgMinOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const; + static flatbuffers::Offset<ArgMinOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const ArgMinOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr); +}; + +struct ArgMinOptionsBuilder { + flatbuffers::FlatBufferBuilder &fbb_; + flatbuffers::uoffset_t start_; + void add_output_type(TensorType output_type) { + fbb_.AddElement<int8_t>(ArgMinOptions::VT_OUTPUT_TYPE, static_cast<int8_t>(output_type), 0); + } + explicit ArgMinOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb) + : fbb_(_fbb) { + start_ = fbb_.StartTable(); + } + ArgMinOptionsBuilder &operator=(const ArgMinOptionsBuilder &); + flatbuffers::Offset<ArgMinOptions> Finish() { + const auto end = fbb_.EndTable(start_); + auto o = flatbuffers::Offset<ArgMinOptions>(end); + return o; + } +}; + +inline flatbuffers::Offset<ArgMinOptions> CreateArgMinOptions( + flatbuffers::FlatBufferBuilder &_fbb, + TensorType output_type = TensorType_FLOAT32) { + ArgMinOptionsBuilder builder_(_fbb); + builder_.add_output_type(output_type); + return builder_.Finish(); +} + +flatbuffers::Offset<ArgMinOptions> CreateArgMinOptions(flatbuffers::FlatBufferBuilder &_fbb, const ArgMinOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr); + struct GreaterOptionsT : public flatbuffers::NativeTable { typedef GreaterOptions TableType; GreaterOptionsT() { @@ -5112,6 +5208,84 @@ inline flatbuffers::Offset<PowOptions> CreatePowOptions( flatbuffers::Offset<PowOptions> CreatePowOptions(flatbuffers::FlatBufferBuilder &_fbb, const PowOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr); +struct FakeQuantOptionsT : public flatbuffers::NativeTable { + typedef FakeQuantOptions TableType; + float min; + float max; + int32_t num_bits; + FakeQuantOptionsT() + : min(0.0f), + max(0.0f), + num_bits(0) { + } +}; + +struct FakeQuantOptions FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table { + typedef FakeQuantOptionsT NativeTableType; + enum { + VT_MIN = 4, + VT_MAX = 6, + VT_NUM_BITS = 8 + }; + float min() const { + return GetField<float>(VT_MIN, 0.0f); + } + float max() const { + return GetField<float>(VT_MAX, 0.0f); + } + int32_t num_bits() const { + return GetField<int32_t>(VT_NUM_BITS, 0); + } + bool Verify(flatbuffers::Verifier &verifier) const { + return VerifyTableStart(verifier) && + VerifyField<float>(verifier, VT_MIN) && + VerifyField<float>(verifier, VT_MAX) && + VerifyField<int32_t>(verifier, VT_NUM_BITS) && + verifier.EndTable(); + } + FakeQuantOptionsT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const; + void UnPackTo(FakeQuantOptionsT *_o, const flatbuffers::resolver_function_t *_resolver = nullptr) const; + static flatbuffers::Offset<FakeQuantOptions> Pack(flatbuffers::FlatBufferBuilder &_fbb, const FakeQuantOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher = nullptr); +}; + +struct FakeQuantOptionsBuilder { + flatbuffers::FlatBufferBuilder &fbb_; + flatbuffers::uoffset_t start_; + void add_min(float min) { + fbb_.AddElement<float>(FakeQuantOptions::VT_MIN, min, 0.0f); + } + void add_max(float max) { + fbb_.AddElement<float>(FakeQuantOptions::VT_MAX, max, 0.0f); + } + void add_num_bits(int32_t num_bits) { + fbb_.AddElement<int32_t>(FakeQuantOptions::VT_NUM_BITS, num_bits, 0); + } + explicit FakeQuantOptionsBuilder(flatbuffers::FlatBufferBuilder &_fbb) + : fbb_(_fbb) { + start_ = fbb_.StartTable(); + } + FakeQuantOptionsBuilder &operator=(const FakeQuantOptionsBuilder &); + flatbuffers::Offset<FakeQuantOptions> Finish() { + const auto end = fbb_.EndTable(start_); + auto o = flatbuffers::Offset<FakeQuantOptions>(end); + return o; + } +}; + +inline flatbuffers::Offset<FakeQuantOptions> CreateFakeQuantOptions( + flatbuffers::FlatBufferBuilder &_fbb, + float min = 0.0f, + float max = 0.0f, + int32_t num_bits = 0) { + FakeQuantOptionsBuilder builder_(_fbb); + builder_.add_num_bits(num_bits); + builder_.add_max(max); + builder_.add_min(min); + return builder_.Finish(); +} + +flatbuffers::Offset<FakeQuantOptions> CreateFakeQuantOptions(flatbuffers::FlatBufferBuilder &_fbb, const FakeQuantOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher = nullptr); + struct OperatorCodeT : public flatbuffers::NativeTable { typedef OperatorCode TableType; BuiltinOperator builtin_code; @@ -5413,6 +5587,12 @@ struct Operator FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table { const PowOptions *builtin_options_as_PowOptions() const { return builtin_options_type() == BuiltinOptions_PowOptions ? static_cast<const PowOptions *>(builtin_options()) : nullptr; } + const ArgMinOptions *builtin_options_as_ArgMinOptions() const { + return builtin_options_type() == BuiltinOptions_ArgMinOptions ? static_cast<const ArgMinOptions *>(builtin_options()) : nullptr; + } + const FakeQuantOptions *builtin_options_as_FakeQuantOptions() const { + return builtin_options_type() == BuiltinOptions_FakeQuantOptions ? static_cast<const FakeQuantOptions *>(builtin_options()) : nullptr; + } const flatbuffers::Vector<uint8_t> *custom_options() const { return GetPointer<const flatbuffers::Vector<uint8_t> *>(VT_CUSTOM_OPTIONS); } @@ -5668,6 +5848,14 @@ template<> inline const PowOptions *Operator::builtin_options_as<PowOptions>() c return builtin_options_as_PowOptions(); } +template<> inline const ArgMinOptions *Operator::builtin_options_as<ArgMinOptions>() const { + return builtin_options_as_ArgMinOptions(); +} + +template<> inline const FakeQuantOptions *Operator::builtin_options_as<FakeQuantOptions>() const { + return builtin_options_as_FakeQuantOptions(); +} + struct OperatorBuilder { flatbuffers::FlatBufferBuilder &fbb_; flatbuffers::uoffset_t start_; @@ -7333,6 +7521,32 @@ inline flatbuffers::Offset<ArgMaxOptions> CreateArgMaxOptions(flatbuffers::FlatB _output_type); } +inline ArgMinOptionsT *ArgMinOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const { + auto _o = new ArgMinOptionsT(); + UnPackTo(_o, _resolver); + return _o; +} + +inline void ArgMinOptions::UnPackTo(ArgMinOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const { + (void)_o; + (void)_resolver; + { auto _e = output_type(); _o->output_type = _e; }; +} + +inline flatbuffers::Offset<ArgMinOptions> ArgMinOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const ArgMinOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) { + return CreateArgMinOptions(_fbb, _o, _rehasher); +} + +inline flatbuffers::Offset<ArgMinOptions> CreateArgMinOptions(flatbuffers::FlatBufferBuilder &_fbb, const ArgMinOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) { + (void)_rehasher; + (void)_o; + struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const ArgMinOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va; + auto _output_type = _o->output_type; + return tflite::CreateArgMinOptions( + _fbb, + _output_type); +} + inline GreaterOptionsT *GreaterOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const { auto _o = new GreaterOptionsT(); UnPackTo(_o, _resolver); @@ -7670,6 +7884,38 @@ inline flatbuffers::Offset<PowOptions> CreatePowOptions(flatbuffers::FlatBufferB _fbb); } +inline FakeQuantOptionsT *FakeQuantOptions::UnPack(const flatbuffers::resolver_function_t *_resolver) const { + auto _o = new FakeQuantOptionsT(); + UnPackTo(_o, _resolver); + return _o; +} + +inline void FakeQuantOptions::UnPackTo(FakeQuantOptionsT *_o, const flatbuffers::resolver_function_t *_resolver) const { + (void)_o; + (void)_resolver; + { auto _e = min(); _o->min = _e; }; + { auto _e = max(); _o->max = _e; }; + { auto _e = num_bits(); _o->num_bits = _e; }; +} + +inline flatbuffers::Offset<FakeQuantOptions> FakeQuantOptions::Pack(flatbuffers::FlatBufferBuilder &_fbb, const FakeQuantOptionsT* _o, const flatbuffers::rehasher_function_t *_rehasher) { + return CreateFakeQuantOptions(_fbb, _o, _rehasher); +} + +inline flatbuffers::Offset<FakeQuantOptions> CreateFakeQuantOptions(flatbuffers::FlatBufferBuilder &_fbb, const FakeQuantOptionsT *_o, const flatbuffers::rehasher_function_t *_rehasher) { + (void)_rehasher; + (void)_o; + struct _VectorArgs { flatbuffers::FlatBufferBuilder *__fbb; const FakeQuantOptionsT* __o; const flatbuffers::rehasher_function_t *__rehasher; } _va = { &_fbb, _o, _rehasher}; (void)_va; + auto _min = _o->min; + auto _max = _o->max; + auto _num_bits = _o->num_bits; + return tflite::CreateFakeQuantOptions( + _fbb, + _min, + _max, + _num_bits); +} + inline OperatorCodeT *OperatorCode::UnPack(const flatbuffers::resolver_function_t *_resolver) const { auto _o = new OperatorCodeT(); UnPackTo(_o, _resolver); @@ -8083,6 +8329,14 @@ inline bool VerifyBuiltinOptions(flatbuffers::Verifier &verifier, const void *ob auto ptr = reinterpret_cast<const PowOptions *>(obj); return verifier.VerifyTable(ptr); } + case BuiltinOptions_ArgMinOptions: { + auto ptr = reinterpret_cast<const ArgMinOptions *>(obj); + return verifier.VerifyTable(ptr); + } + case BuiltinOptions_FakeQuantOptions: { + auto ptr = reinterpret_cast<const FakeQuantOptions *>(obj); + return verifier.VerifyTable(ptr); + } default: return false; } } @@ -8325,6 +8579,14 @@ inline void *BuiltinOptionsUnion::UnPack(const void *obj, BuiltinOptions type, c auto ptr = reinterpret_cast<const PowOptions *>(obj); return ptr->UnPack(resolver); } + case BuiltinOptions_ArgMinOptions: { + auto ptr = reinterpret_cast<const ArgMinOptions *>(obj); + return ptr->UnPack(resolver); + } + case BuiltinOptions_FakeQuantOptions: { + auto ptr = reinterpret_cast<const FakeQuantOptions *>(obj); + return ptr->UnPack(resolver); + } default: return nullptr; } } @@ -8555,6 +8817,14 @@ inline flatbuffers::Offset<void> BuiltinOptionsUnion::Pack(flatbuffers::FlatBuff auto ptr = reinterpret_cast<const PowOptionsT *>(value); return CreatePowOptions(_fbb, ptr, _rehasher).Union(); } + case BuiltinOptions_ArgMinOptions: { + auto ptr = reinterpret_cast<const ArgMinOptionsT *>(value); + return CreateArgMinOptions(_fbb, ptr, _rehasher).Union(); + } + case BuiltinOptions_FakeQuantOptions: { + auto ptr = reinterpret_cast<const FakeQuantOptionsT *>(value); + return CreateFakeQuantOptions(_fbb, ptr, _rehasher).Union(); + } default: return 0; } } @@ -8785,6 +9055,14 @@ inline BuiltinOptionsUnion::BuiltinOptionsUnion(const BuiltinOptionsUnion &u) FL value = new PowOptionsT(*reinterpret_cast<PowOptionsT *>(u.value)); break; } + case BuiltinOptions_ArgMinOptions: { + value = new ArgMinOptionsT(*reinterpret_cast<ArgMinOptionsT *>(u.value)); + break; + } + case BuiltinOptions_FakeQuantOptions: { + value = new FakeQuantOptionsT(*reinterpret_cast<FakeQuantOptionsT *>(u.value)); + break; + } default: break; } @@ -9072,6 +9350,16 @@ inline void BuiltinOptionsUnion::Reset() { delete ptr; break; } + case BuiltinOptions_ArgMinOptions: { + auto ptr = reinterpret_cast<ArgMinOptionsT *>(value); + delete ptr; + break; + } + case BuiltinOptions_FakeQuantOptions: { + auto ptr = reinterpret_cast<FakeQuantOptionsT *>(value); + delete ptr; + break; + } default: break; } value = nullptr; diff --git a/tensorflow/contrib/lite/testing/generate_examples.py b/tensorflow/contrib/lite/testing/generate_examples.py index 50237ed792..1093bd2cbe 100644 --- a/tensorflow/contrib/lite/testing/generate_examples.py +++ b/tensorflow/contrib/lite/testing/generate_examples.py @@ -678,6 +678,55 @@ def make_relu6_tests(zip_path): make_zip_of_tests(zip_path, test_parameters, build_graph, build_inputs) +def make_prelu_tests(zip_path): + """Make a set of tests to do PReLU.""" + + test_parameters = [{ + # The canonical case for image processing is having a 4D `input` (NHWC) + # and `shared_axes`=[1, 2], so the alpha parameter is per channel. + "input_shape": [[1, 10, 10, 3], [3, 3, 3, 3]], + "shared_axes": [[1, 2], [1]], + }] + + def build_graph(parameters): + """Build the graph for the test case.""" + + input_tensor = tf.placeholder( + dtype=tf.float32, name="input", shape=parameters["input_shape"]) + prelu = tf.keras.layers.PReLU(shared_axes=parameters["shared_axes"]) + out = prelu(input_tensor) + return [input_tensor], [out] + + def build_inputs(parameters, sess, inputs, outputs): + """Build the inputs for the test case.""" + + input_shape = parameters["input_shape"] + input_values = create_tensor_data( + np.float32, input_shape, min_value=-10, max_value=10) + shared_axes = parameters["shared_axes"] + + alpha_shape = [] + for dim in range(1, len(input_shape)): + alpha_shape.append(1 if dim in shared_axes else input_shape[dim]) + + alpha_values = create_tensor_data(np.float32, alpha_shape) + + # There should be only 1 trainable variable tensor. + variables = tf.all_variables() + assert len(variables) == 1 + sess.run(variables[0].assign(alpha_values)) + + return [input_values], sess.run( + outputs, feed_dict=dict(zip(inputs, [input_values]))) + + make_zip_of_tests( + zip_path, + test_parameters, + build_graph, + build_inputs, + use_frozen_graph=True) + + # This function tests various TensorFLow functions that generates Const op, # including `tf.ones`, `tf.zeros` and random functions. def make_constant_tests(zip_path): @@ -2175,7 +2224,7 @@ def make_topk_tests(zip_path): make_zip_of_tests(zip_path, test_parameters, build_graph, build_inputs) -def make_arg_max_tests(zip_path): +def make_arg_min_max_tests(zip_path): """Make a set of tests to do arg_max.""" test_parameters = [{ @@ -2183,6 +2232,7 @@ def make_arg_max_tests(zip_path): "input_shape": [[1, 1, 1, 3], [2, 3, 4, 5], [2, 3, 3], [5, 5], [10]], "output_type": [tf.int32, tf.int64], "axis_is_last_dim": [True, False], + "is_arg_max": [True], }] def build_graph(parameters): @@ -2195,7 +2245,10 @@ def make_arg_max_tests(zip_path): axis = len(parameters["input_shape"]) - 1 else: axis = random.randint(0, max(len(parameters["input_shape"]) - 2, 0)) - out = tf.arg_max(input_value, axis, output_type=parameters["output_type"]) + if parameters["is_arg_max"]: + out = tf.arg_max(input_value, axis, output_type=parameters["output_type"]) + else: + out = tf.arg_min(input_value, axis, output_type=parameters["output_type"]) return [input_value], [out] def build_inputs(parameters, sess, inputs, outputs): diff --git a/tensorflow/contrib/lite/testing/generated_examples_zip_test.cc b/tensorflow/contrib/lite/testing/generated_examples_zip_test.cc index c4e20312d8..5bc6b53416 100644 --- a/tensorflow/contrib/lite/testing/generated_examples_zip_test.cc +++ b/tensorflow/contrib/lite/testing/generated_examples_zip_test.cc @@ -97,11 +97,12 @@ std::map<string, string> kBrokenTests = { {R"(^\/gather.*axis=1)", "76910444"}, // No support for arbitrary dimensions in ArgMax. - {R"(^\/arg_max.*axis_is_last_dim=False.*input_shape=\[.,.,.,.\])", + {R"(^\/arg_min_max.*axis_is_last_dim=False.*input_shape=\[.,.,.,.\])", "77546240"}, - {R"(^\/arg_max.*axis_is_last_dim=False.*input_shape=\[.,.,.\])", + {R"(^\/arg_min_max.*axis_is_last_dim=False.*input_shape=\[.,.,.\])", + "77546240"}, + {R"(^\/arg_min_max.*axis_is_last_dim=False.*input_shape=\[.,.\])", "77546240"}, - {R"(^\/arg_max.*axis_is_last_dim=False.*input_shape=\[.,.\])", "77546240"}, }; // Allows test data to be unzipped into a temporary directory and makes diff --git a/tensorflow/contrib/lite/toco/export_tensorflow.cc b/tensorflow/contrib/lite/toco/export_tensorflow.cc index 6be6b25f93..a08cdbfba6 100644 --- a/tensorflow/contrib/lite/toco/export_tensorflow.cc +++ b/tensorflow/contrib/lite/toco/export_tensorflow.cc @@ -1135,6 +1135,22 @@ void ConvertArgMaxOperator(const Model& model, const ArgMaxOperator& src_op, GetTensorFlowDataType(model, src_op.outputs[0])); } +void ConvertArgMinOperator(const Model& model, const ArgMinOperator& src_op, + GraphDef* tensorflow_graph) { + tensorflow::NodeDef* argmin_op = tensorflow_graph->add_node(); + argmin_op->set_op("ArgMin"); + argmin_op->set_name(src_op.outputs[0]); + CHECK_EQ(src_op.inputs.size(), 2); + *argmin_op->add_input() = src_op.inputs[0]; + *argmin_op->add_input() = src_op.inputs[1]; + (*argmin_op->mutable_attr())["T"].set_type( + GetTensorFlowDataType(model, src_op.inputs[0])); + (*argmin_op->mutable_attr())["Tidx"].set_type( + GetTensorFlowDataType(model, src_op.inputs[1])); + (*argmin_op->mutable_attr())["output_type"].set_type( + GetTensorFlowDataType(model, src_op.outputs[0])); +} + void ConvertTransposeOperator(const Model& model, const TransposeOperator& src_op, GraphDef* tensorflow_graph) { @@ -1964,6 +1980,9 @@ void ConvertOperator(const Model& model, const Operator& src_op, } else if (src_op.type == OperatorType::kArgMax) { ConvertArgMaxOperator(model, static_cast<const ArgMaxOperator&>(src_op), tensorflow_graph); + } else if (src_op.type == OperatorType::kArgMin) { + ConvertArgMinOperator(model, static_cast<const ArgMinOperator&>(src_op), + tensorflow_graph); } else if (src_op.type == OperatorType::kTopK_V2) { ConvertTopKV2Operator(model, static_cast<const TopKV2Operator&>(src_op), tensorflow_graph); diff --git a/tensorflow/contrib/lite/toco/graph_transformations/identify_prelu.cc b/tensorflow/contrib/lite/toco/graph_transformations/identify_prelu.cc index 30be4ac0aa..b90a156a0d 100644 --- a/tensorflow/contrib/lite/toco/graph_transformations/identify_prelu.cc +++ b/tensorflow/contrib/lite/toco/graph_transformations/identify_prelu.cc @@ -74,14 +74,30 @@ bool IdentifyPRelu::Run(Model* model, std::size_t op_index) { const auto* relu_neg_input_op = GetOpWithOutput(*model, mul_op->inputs[1]); if (relu_neg_input_op == nullptr || - relu_neg_input_op->type != OperatorType::kNeg || - relu_neg_input_op->fused_activation_function != - FusedActivationFunctionType::kRelu || relu_neg_input_op->inputs.size() != 1) { return false; } - if (relu_input_op->inputs[0] != relu_neg_input_op->inputs[0]) { + const Operator* final_input_op; + if (relu_neg_input_op->type == OperatorType::kNeg && + relu_neg_input_op->fused_activation_function == + FusedActivationFunctionType::kRelu) { + // This detects a Neg op with fused Relu activation function. + final_input_op = relu_neg_input_op; + } else { + // This detects a Neg op followed by a separated Relu op. + const auto* neg_input_op = + GetOpWithOutput(*model, relu_neg_input_op->inputs[0]); + if (neg_input_op == nullptr || neg_input_op->inputs.size() != 1 || + relu_neg_input_op->type != OperatorType::kRelu || + relu_neg_input_op->fused_activation_function != + FusedActivationFunctionType::kNone) { + return false; + } + final_input_op = neg_input_op; + } + + if (relu_input_op->inputs[0] != final_input_op->inputs[0]) { return false; } @@ -112,7 +128,6 @@ bool IdentifyPRelu::Run(Model* model, std::size_t op_index) { // intermediate tensors aren't used by other ops, those will be removed by // other graph transformation rules. model->operators.erase(FindOp(*model, add_op)); - return true; } diff --git a/tensorflow/contrib/lite/toco/graph_transformations/propagate_array_data_types.cc b/tensorflow/contrib/lite/toco/graph_transformations/propagate_array_data_types.cc index 00ab7cbaa9..670bcf64e7 100644 --- a/tensorflow/contrib/lite/toco/graph_transformations/propagate_array_data_types.cc +++ b/tensorflow/contrib/lite/toco/graph_transformations/propagate_array_data_types.cc @@ -100,6 +100,13 @@ bool PropagateArrayDataTypes::Run(Model* model, std::size_t op_index) { model->GetArray(op->outputs[0]).data_type = argmax_op->output_data_type; break; } + case OperatorType::kArgMin: { + // Data type of the ArgMin op is specified. + CHECK_EQ(op->outputs.size(), 1); + auto* argmin_op = static_cast<ArgMinOperator*>(op); + model->GetArray(op->outputs[0]).data_type = argmin_op->output_data_type; + break; + } case OperatorType::kRange: { auto* range_op = static_cast<RangeOperator*>(op); // Output type of the Range op can be set via an attribute diff --git a/tensorflow/contrib/lite/toco/graph_transformations/propagate_fake_quant_num_bits.cc b/tensorflow/contrib/lite/toco/graph_transformations/propagate_fake_quant_num_bits.cc index 0f2592d05f..53fc87da7b 100644 --- a/tensorflow/contrib/lite/toco/graph_transformations/propagate_fake_quant_num_bits.cc +++ b/tensorflow/contrib/lite/toco/graph_transformations/propagate_fake_quant_num_bits.cc @@ -30,15 +30,9 @@ namespace { bool ChangeArrayDataType(GraphTransformation* transformation, Array* array, ArrayDataType new_data_type, const MinMax* new_minmax) { - // The code below assumes kInt16, see - // GetQuantizationParamsFromMinMax<ArrayDataType::kInt16> - if (new_data_type != ArrayDataType::kInt16) { - return false; - } - - bool changed = false; // Ensure the array ends up in the new type (if it hasn't yet been quantized). - if ((array->final_data_type != new_data_type)) { + bool changed = false; + if (array->final_data_type != new_data_type) { array->final_data_type = new_data_type; changed = true; } @@ -75,8 +69,20 @@ bool ChangeArrayDataType(GraphTransformation* transformation, Array* array, array_minmax.min = min; array_minmax.max = max; - GetQuantizationParamsFromMinMax<ArrayDataType::kInt16>( - array_minmax, array->quantization_params.get()); + switch (new_data_type) { + case ArrayDataType::kUint8: + GetQuantizationParamsFromMinMax<ArrayDataType::kUint8>( + array_minmax, array->quantization_params.get()); + break; + case ArrayDataType::kInt16: + GetQuantizationParamsFromMinMax<ArrayDataType::kInt16>( + array_minmax, array->quantization_params.get()); + break; + default: + CHECK(false) << "Unsupported quantized data type: " + << ArrayDataTypeName(new_data_type); + return false; + } // Directly change the type as the array was already quantized. array->data_type = new_data_type; @@ -95,6 +101,7 @@ bool ChangeArrayDataType(GraphTransformation* transformation, Array* array, changed = true; } } + return changed; } diff --git a/tensorflow/contrib/lite/toco/graph_transformations/propagate_fixed_sizes.cc b/tensorflow/contrib/lite/toco/graph_transformations/propagate_fixed_sizes.cc index 8eb0423283..4f95c57451 100644 --- a/tensorflow/contrib/lite/toco/graph_transformations/propagate_fixed_sizes.cc +++ b/tensorflow/contrib/lite/toco/graph_transformations/propagate_fixed_sizes.cc @@ -1404,7 +1404,8 @@ void ProcessTransposeOperator(Model* model, TransposeOperator* op) { } } -void ProcessArgMaxOperator(Model* model, ArgMaxOperator* op) { +template <typename Op> +void ProcessArgMinMaxOperator(Model* model, Op* op) { CHECK_EQ(op->inputs.size(), 2); const auto& input_array = model->GetArray(op->inputs[0]); // Yield until input dims have been resolved. @@ -1696,7 +1697,12 @@ bool PropagateFixedSizes::Run(Model* model, std::size_t op_index) { static_cast<StridedSliceOperator*>(op)); break; case OperatorType::kArgMax: - ProcessArgMaxOperator(model, static_cast<ArgMaxOperator*>(op)); + ProcessArgMinMaxOperator<ArgMaxOperator>( + model, static_cast<ArgMaxOperator*>(op)); + break; + case OperatorType::kArgMin: + ProcessArgMinMaxOperator<ArgMinOperator>( + model, static_cast<ArgMinOperator*>(op)); break; case OperatorType::kUnsupported: break; diff --git a/tensorflow/contrib/lite/toco/import_tensorflow.cc b/tensorflow/contrib/lite/toco/import_tensorflow.cc index 5c32a39035..bc439a2feb 100644 --- a/tensorflow/contrib/lite/toco/import_tensorflow.cc +++ b/tensorflow/contrib/lite/toco/import_tensorflow.cc @@ -1230,10 +1230,11 @@ tensorflow::Status ConvertGatherOperator( return tensorflow::Status::OK(); } -tensorflow::Status ConvertArgMaxOperator( +template <typename Op, const char* op_name> +tensorflow::Status ConvertArgMinMaxOperator( const NodeDef& node, const TensorFlowImportFlags& tf_import_flags, Model* model) { - CHECK_EQ(node.op(), "ArgMax"); + CHECK_EQ(node.op(), op_name); TF_QCHECK_OK(CheckInputsCount(node, tf_import_flags, 2)); const auto axis_data_type = HasAttr(node, "Tidx") ? GetDataTypeAttr(node, "Tidx") : DT_INT32; @@ -1242,7 +1243,7 @@ tensorflow::Status ConvertArgMaxOperator( : DT_INT64; CHECK(axis_data_type == DT_INT64 || axis_data_type == DT_INT32); CHECK(output_type == DT_INT64 || output_type == DT_INT32); - auto* op = new ArgMaxOperator; + auto* op = new Op; op->output_data_type = ConvertDataType(output_type); op->inputs.push_back(node.input(0)); op->inputs.push_back(node.input(1)); @@ -1833,12 +1834,16 @@ using ConverterType = tensorflow::Status (*)( Model* model); using ConverterMapType = std::unordered_map<std::string, ConverterType>; +constexpr char kArgMax[] = "ArgMax"; +constexpr char kArgMin[] = "ArgMin"; + ConverterMapType GetTensorFlowNodeConverterMap() { return std::unordered_map<std::string, ConverterType>({ {"Add", ConvertSimpleOperator<AddOperator, 2>}, {"AddN", ConvertSimpleOperator<AddNOperator>}, {"All", ConvertSimpleOperator<TensorFlowAllOperator>}, - {"ArgMax", ConvertArgMaxOperator}, + {"ArgMax", ConvertArgMinMaxOperator<ArgMaxOperator, kArgMax>}, + {"ArgMin", ConvertArgMinMaxOperator<ArgMinOperator, kArgMin>}, {"Assert", ConvertSimpleOperator<TensorFlowAssertOperator>}, {"AvgPool", ConvertAvgPoolOperator}, {"BatchMatMul", ConvertBatchMatMulOperator}, diff --git a/tensorflow/contrib/lite/toco/model.h b/tensorflow/contrib/lite/toco/model.h index 3a1d243f87..8660464fdb 100644 --- a/tensorflow/contrib/lite/toco/model.h +++ b/tensorflow/contrib/lite/toco/model.h @@ -140,6 +140,7 @@ enum class OperatorType : uint8 { kEqual, kNotEqual, kPow, + kArgMin, }; // Helper to deal with TensorFlow arrays using a different ordering of @@ -1528,6 +1529,17 @@ struct ArgMaxOperator : Operator { ArrayDataType output_data_type = ArrayDataType::kInt64; }; +// ArgMin operator. It returns the index of the minimum value along axis. +// +// Inputs: +// inputs[0]: required: the input tensor +// +// TensorFlow equivalent: ArgMin +struct ArgMinOperator : Operator { + ArgMinOperator() : Operator(OperatorType::kArgMin) {} + ArrayDataType output_data_type = ArrayDataType::kInt64; +}; + // ResizeBilinear operator. It resizes input images with bilinear interpolation. // It does not support align_corners at the moment. // diff --git a/tensorflow/contrib/lite/toco/tflite/export.cc b/tensorflow/contrib/lite/toco/tflite/export.cc index 1972246807..5ad307af14 100644 --- a/tensorflow/contrib/lite/toco/tflite/export.cc +++ b/tensorflow/contrib/lite/toco/tflite/export.cc @@ -336,17 +336,13 @@ void Export( auto op_codes = ExportOperatorCodes(model, ops_by_type, operators_map, &builder, &error_summary); - const string fake_quant_operation_name = "FAKE_QUANT"; - - if (error_summary.count(fake_quant_operation_name) != 0) { - LOG(ERROR) - << fake_quant_operation_name - << " operation was not converted. If running quantized make sure you " - "are passing --inference_type=QUANTIZED_UINT8 and values for " - "--std_values and --mean_values."; - // Remove the fake quant operation from the errors, since it shouldn't - // be provided a custom implementation. - error_summary.erase(fake_quant_operation_name); + for (const auto& op : model.operators) { + if (op->type == OperatorType::kFakeQuant) { + LOG(WARNING) << "FAKE_QUANT operation " << LogName(*op) + << " was not converted. If running quantized make sure you " + "are passing --inference_type=QUANTIZED_UINT8 and values " + "for --std_values and --mean_values."; + } } if (!allow_custom_ops && !error_summary.empty()) { // Remove ExpandDims and ReorderAxes from unimplemented list unless they diff --git a/tensorflow/contrib/lite/toco/tflite/operator.cc b/tensorflow/contrib/lite/toco/tflite/operator.cc index 7e55ae92bd..8377ba6a03 100644 --- a/tensorflow/contrib/lite/toco/tflite/operator.cc +++ b/tensorflow/contrib/lite/toco/tflite/operator.cc @@ -282,22 +282,24 @@ class DepthToSpace : public CustomOperator<DepthToSpaceOperator> { int GetVersion(const Operator& op) const override { return 1; } }; -class FakeQuant : public CustomOperator<FakeQuantOperator> { +class FakeQuant + : public BuiltinOperator<FakeQuantOperator, ::tflite::FakeQuantOptions, + ::tflite::BuiltinOptions_FakeQuantOptions> { public: - using CustomOperator::CustomOperator; - void WriteOptions(const TocoOperator& op, - flexbuffers::Builder* fbb) const override { - fbb->Float("min", op.minmax->min); - fbb->Float("max", op.minmax->max); - fbb->Int("num_bits", op.num_bits); + using BuiltinOperator::BuiltinOperator; + flatbuffers::Offset<TfLiteOptions> WriteOptions( + const TocoOperator& op, + flatbuffers::FlatBufferBuilder* builder) const override { + return ::tflite::CreateFakeQuantOptions(*builder, op.minmax->min, + op.minmax->max, op.num_bits); } - void ReadOptions(const flexbuffers::Map& m, TocoOperator* op) const override { + void ReadOptions(const TfLiteOptions& options, + TocoOperator* op) const override { auto* minmax = new MinMax; - minmax->min = m["min"].AsFloat(); - minmax->max = m["max"].AsFloat(); + minmax->min = options.min(); + minmax->max = options.max(); op->minmax.reset(minmax); - const auto& num_bits = m["num_bits"]; - op->num_bits = num_bits.IsInt() ? num_bits.AsInt32() : 8; + op->num_bits = options.num_bits(); } int GetVersion(const Operator& op) const override { return 1; } @@ -885,6 +887,25 @@ class ArgMax : public BuiltinOperator<ArgMaxOperator, ::tflite::ArgMaxOptions, int GetVersion(const Operator& op) const override { return 1; } }; +class ArgMin : public BuiltinOperator<ArgMinOperator, ::tflite::ArgMinOptions, + ::tflite::BuiltinOptions_ArgMinOptions> { + public: + using BuiltinOperator::BuiltinOperator; + flatbuffers::Offset<TfLiteOptions> WriteOptions( + const TocoOperator& op, + flatbuffers::FlatBufferBuilder* builder) const override { + return ::tflite::CreateArgMinOptions( + *builder, DataType::Serialize(op.output_data_type)); + } + + void ReadOptions(const TfLiteOptions& options, + TocoOperator* op) const override { + op->output_data_type = DataType::Deserialize(options.output_type()); + } + + int GetVersion(const Operator& op) const override { return 1; } +}; + class TransposeConv : public BuiltinOperator<TransposeConvOperator, ::tflite::TransposeConvOptions, @@ -1175,6 +1196,8 @@ std::vector<std::unique_ptr<BaseOperator>> BuildOperatorList() { ops.emplace_back( new ArgMax(::tflite::BuiltinOperator_ARG_MAX, OperatorType::kArgMax)); ops.emplace_back( + new ArgMin(::tflite::BuiltinOperator_ARG_MIN, OperatorType::kArgMin)); + ops.emplace_back( new Tile(::tflite::BuiltinOperator_TILE, OperatorType::kTile)); ops.emplace_back(new ExpandDims(::tflite::BuiltinOperator_EXPAND_DIMS, OperatorType::kExpandDims)); @@ -1184,11 +1207,12 @@ std::vector<std::unique_ptr<BaseOperator>> BuildOperatorList() { OperatorType::kSparseToDense)); ops.emplace_back( new Shape(::tflite::BuiltinOperator_SHAPE, OperatorType::kShape)); + ops.emplace_back(new FakeQuant(::tflite::BuiltinOperator_FAKE_QUANT, + OperatorType::kFakeQuant)); // Custom Operators. ops.emplace_back( new DepthToSpace("DEPTH_TO_SPACE", OperatorType::kDepthToSpace)); - ops.emplace_back(new FakeQuant("FAKE_QUANT", OperatorType::kFakeQuant)); ops.emplace_back(new TensorFlowUnsupported("TENSORFLOW_UNSUPPORTED", OperatorType::kUnsupported)); diff --git a/tensorflow/contrib/lite/toco/tflite/operator_test.cc b/tensorflow/contrib/lite/toco/tflite/operator_test.cc index 8b6808d3c7..ff2d35b1f5 100644 --- a/tensorflow/contrib/lite/toco/tflite/operator_test.cc +++ b/tensorflow/contrib/lite/toco/tflite/operator_test.cc @@ -416,6 +416,13 @@ TEST_F(OperatorTest, BuiltinArgMax) { EXPECT_EQ(op.output_data_type, output_toco_op->output_data_type); } +TEST_F(OperatorTest, BuiltinArgMin) { + ArgMinOperator op; + auto output_toco_op = SerializeAndDeserialize( + GetOperator("ARG_MIN", OperatorType::kArgMin), op); + EXPECT_EQ(op.output_data_type, output_toco_op->output_data_type); +} + TEST_F(OperatorTest, BuiltinTransposeConv) { TransposeConvOperator op; op.stride_width = 123; diff --git a/tensorflow/contrib/lite/toco/tooling_util.cc b/tensorflow/contrib/lite/toco/tooling_util.cc index 8abdb014e4..4ec74e351f 100644 --- a/tensorflow/contrib/lite/toco/tooling_util.cc +++ b/tensorflow/contrib/lite/toco/tooling_util.cc @@ -387,6 +387,7 @@ const char* OperatorTypeName(OperatorType type) { HANDLE_OPERATORTYPENAME_CASE(Mean) HANDLE_OPERATORTYPENAME_CASE(Svdf) HANDLE_OPERATORTYPENAME_CASE(ArgMax) + HANDLE_OPERATORTYPENAME_CASE(ArgMin) HANDLE_OPERATORTYPENAME_CASE(TopK_V2) HANDLE_OPERATORTYPENAME_CASE(Unsupported) HANDLE_OPERATORTYPENAME_CASE(Exp) diff --git a/tensorflow/contrib/lite/tools/BUILD b/tensorflow/contrib/lite/tools/BUILD index a3df37358f..d070018e83 100644 --- a/tensorflow/contrib/lite/tools/BUILD +++ b/tensorflow/contrib/lite/tools/BUILD @@ -14,6 +14,7 @@ py_binary( srcs = ["visualize.py"], data = [ "//tensorflow/contrib/lite/schema:schema.fbs", + "//tensorflow/python:platform", "@flatbuffers//:flatc", ], srcs_version = "PY2AND3", diff --git a/tensorflow/contrib/lite/tools/benchmark/benchmark_model.cc b/tensorflow/contrib/lite/tools/benchmark/benchmark_model.cc index 08648bcfe2..19b9a9c7ba 100644 --- a/tensorflow/contrib/lite/tools/benchmark/benchmark_model.cc +++ b/tensorflow/contrib/lite/tools/benchmark/benchmark_model.cc @@ -98,10 +98,13 @@ void BenchmarkModel::LogFlags() { << "]"; } +void BenchmarkModel::PrepareInputsAndOutputs() {} + Stat<int64_t> BenchmarkModel::Run(int num_times, RunType run_type) { Stat<int64_t> run_stats; TFLITE_LOG(INFO) << "Running benchmark for " << num_times << " iterations "; for (int run = 0; run < num_times; run++) { + PrepareInputsAndOutputs(); listeners_.OnSingleRunStart(run_type); int64_t start_us = profiling::time::NowMicros(); RunImpl(); diff --git a/tensorflow/contrib/lite/tools/benchmark/benchmark_model.h b/tensorflow/contrib/lite/tools/benchmark/benchmark_model.h index 942e21f67a..3c7063b2d4 100644 --- a/tensorflow/contrib/lite/tools/benchmark/benchmark_model.h +++ b/tensorflow/contrib/lite/tools/benchmark/benchmark_model.h @@ -150,6 +150,7 @@ class BenchmarkModel { virtual std::vector<Flag> GetFlags(); virtual uint64_t ComputeInputBytes() = 0; virtual tensorflow::Stat<int64_t> Run(int num_times, RunType run_type); + virtual void PrepareInputsAndOutputs(); virtual void RunImpl() = 0; BenchmarkParams params_; BenchmarkListeners listeners_; diff --git a/tensorflow/contrib/lite/tools/visualize.py b/tensorflow/contrib/lite/tools/visualize.py index f571dd59da..e07f899e4d 100644 --- a/tensorflow/contrib/lite/tools/visualize.py +++ b/tensorflow/contrib/lite/tools/visualize.py @@ -28,11 +28,24 @@ import json import os import sys +from tensorflow.python.platform import resource_loader + # Schema to use for flatbuffers _SCHEMA = "third_party/tensorflow/contrib/lite/schema/schema.fbs" -# Where the binary will be once built in for the flatc converter -_BINARY = "third_party/flatbuffers/flatc" +# TODO(angerson): fix later when rules are simplified.. +_SCHEMA = resource_loader.get_path_to_datafile("../schema/schema.fbs") +_BINARY = resource_loader.get_path_to_datafile("../../../../flatbuffers/flatc") +# Account for different package positioning internal vs. external. +if not os.path.exists(_BINARY): + _BINARY = resource_loader.get_path_to_datafile( + "../../../../../flatbuffers/flatc") + +if not os.path.exists(_SCHEMA): + raise RuntimeError("Sorry, schema file cannot be found at %r" % _SCHEMA) +if not os.path.exists(_BINARY): + raise RuntimeError("Sorry, flatc is not available at %r" % _BINARY) + # A CSS description for making the visualizer _CSS = """ diff --git a/tensorflow/contrib/rnn/BUILD b/tensorflow/contrib/rnn/BUILD index 4eb5c920b3..2a84629080 100644 --- a/tensorflow/contrib/rnn/BUILD +++ b/tensorflow/contrib/rnn/BUILD @@ -118,7 +118,6 @@ cuda_py_tests( "//tensorflow/python:framework_for_generated_wrappers", "//tensorflow/python:init_ops", "//tensorflow/python:math_ops", - "//tensorflow/python:random_ops", "//tensorflow/python:rnn", "//tensorflow/python:rnn_cell", "//tensorflow/python:variable_scope", diff --git a/tensorflow/contrib/rnn/__init__.py b/tensorflow/contrib/rnn/__init__.py index 07227bcb77..cb437f2a2f 100644 --- a/tensorflow/contrib/rnn/__init__.py +++ b/tensorflow/contrib/rnn/__init__.py @@ -59,6 +59,9 @@ See @{$python/contrib.rnn} guide. @@HighwayWrapper @@GLSTMCell @@SRUCell +@@IndRNNCell +@@IndyGRUCell +@@IndyLSTMCell <!--RNNCell wrappers--> @@AttentionCellWrapper diff --git a/tensorflow/contrib/rnn/python/kernel_tests/core_rnn_cell_test.py b/tensorflow/contrib/rnn/python/kernel_tests/core_rnn_cell_test.py index 86f1e27abd..85f0f8ced9 100644 --- a/tensorflow/contrib/rnn/python/kernel_tests/core_rnn_cell_test.py +++ b/tensorflow/contrib/rnn/python/kernel_tests/core_rnn_cell_test.py @@ -18,7 +18,6 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function -import functools import os import numpy as np @@ -35,7 +34,6 @@ from tensorflow.python.framework import test_util from tensorflow.python.ops import array_ops from tensorflow.python.ops import init_ops from tensorflow.python.ops import math_ops -from tensorflow.python.ops import random_ops from tensorflow.python.ops import rnn from tensorflow.python.ops import rnn_cell_impl from tensorflow.python.ops import variable_scope @@ -117,6 +115,27 @@ class RNNCellTest(test.TestCase): }) self.assertEqual(res[0].shape, (1, 2)) + def testIndRNNCell(self): + with self.test_session() as sess: + with variable_scope.variable_scope( + "root", initializer=init_ops.constant_initializer(0.5)): + x = array_ops.zeros([1, 2]) + m = array_ops.zeros([1, 2]) + cell = contrib_rnn_cell.IndRNNCell(2) + g, _ = cell(x, m) + self.assertEqual([ + "root/ind_rnn_cell/%s_w:0" % rnn_cell_impl._WEIGHTS_VARIABLE_NAME, + "root/ind_rnn_cell/%s_u:0" % rnn_cell_impl._WEIGHTS_VARIABLE_NAME, + "root/ind_rnn_cell/%s:0" % rnn_cell_impl._BIAS_VARIABLE_NAME + ], [v.name for v in cell.trainable_variables]) + self.assertFalse(cell.non_trainable_variables) + sess.run([variables_lib.global_variables_initializer()]) + res = sess.run([g], { + x.name: np.array([[1., 1.]]), + m.name: np.array([[0.1, 0.1]]) + }) + self.assertEqual(res[0].shape, (1, 2)) + def testGRUCell(self): with self.test_session() as sess: with variable_scope.variable_scope( @@ -145,6 +164,34 @@ class RNNCellTest(test.TestCase): # Smoke test self.assertAllClose(res[0], [[0.156736, 0.156736]]) + def testIndyGRUCell(self): + with self.test_session() as sess: + with variable_scope.variable_scope( + "root", initializer=init_ops.constant_initializer(0.5)): + x = array_ops.zeros([1, 2]) + m = array_ops.zeros([1, 2]) + g, _ = contrib_rnn_cell.IndyGRUCell(2)(x, m) + sess.run([variables_lib.global_variables_initializer()]) + res = sess.run([g], { + x.name: np.array([[1., 1.]]), + m.name: np.array([[0.1, 0.1]]) + }) + # Smoke test + self.assertAllClose(res[0], [[0.185265, 0.17704]]) + with variable_scope.variable_scope( + "other", initializer=init_ops.constant_initializer(0.5)): + # Test IndyGRUCell with input_size != num_units. + x = array_ops.zeros([1, 3]) + m = array_ops.zeros([1, 2]) + g, _ = contrib_rnn_cell.IndyGRUCell(2)(x, m) + sess.run([variables_lib.global_variables_initializer()]) + res = sess.run([g], { + x.name: np.array([[1., 1., 1.]]), + m.name: np.array([[0.1, 0.1]]) + }) + # Smoke test + self.assertAllClose(res[0], [[0.155127, 0.157328]]) + def testSRUCell(self): with self.test_session() as sess: with variable_scope.variable_scope( @@ -345,6 +392,72 @@ class RNNCellTest(test.TestCase): self.assertAllClose(res[1], expected_mem0) self.assertAllClose(res[2], expected_mem1) + def testIndyLSTMCell(self): + for dtype in [dtypes.float16, dtypes.float32]: + np_dtype = dtype.as_numpy_dtype + with self.test_session(graph=ops.Graph()) as sess: + with variable_scope.variable_scope( + "root", initializer=init_ops.constant_initializer(0.5)): + x = array_ops.zeros([1, 2], dtype=dtype) + state_0 = (array_ops.zeros([1, 2], dtype=dtype),) * 2 + state_1 = (array_ops.zeros([1, 2], dtype=dtype),) * 2 + cell = rnn_cell_impl.MultiRNNCell( + [contrib_rnn_cell.IndyLSTMCell(2) for _ in range(2)]) + self.assertEqual(cell.dtype, None) + self.assertEqual("cell-0", cell._checkpoint_dependencies[0].name) + self.assertEqual("cell-1", cell._checkpoint_dependencies[1].name) + cell.get_config() # Should not throw an error + g, (out_state_0, out_state_1) = cell(x, (state_0, state_1)) + # Layer infers the input type. + self.assertEqual(cell.dtype, dtype.name) + expected_variable_names = [ + "root/multi_rnn_cell/cell_0/indy_lstm_cell/%s_w:0" % + rnn_cell_impl._WEIGHTS_VARIABLE_NAME, + "root/multi_rnn_cell/cell_0/indy_lstm_cell/%s_u:0" % + rnn_cell_impl._WEIGHTS_VARIABLE_NAME, + "root/multi_rnn_cell/cell_0/indy_lstm_cell/%s:0" % + rnn_cell_impl._BIAS_VARIABLE_NAME, + "root/multi_rnn_cell/cell_1/indy_lstm_cell/%s_w:0" % + rnn_cell_impl._WEIGHTS_VARIABLE_NAME, + "root/multi_rnn_cell/cell_1/indy_lstm_cell/%s_u:0" % + rnn_cell_impl._WEIGHTS_VARIABLE_NAME, + "root/multi_rnn_cell/cell_1/indy_lstm_cell/%s:0" % + rnn_cell_impl._BIAS_VARIABLE_NAME + ] + self.assertEqual(expected_variable_names, + [v.name for v in cell.trainable_variables]) + self.assertFalse(cell.non_trainable_variables) + sess.run([variables_lib.global_variables_initializer()]) + res = sess.run( + [g, out_state_0, out_state_1], { + x.name: np.array([[1., 1.]]), + state_0[0].name: 0.1 * np.ones([1, 2]), + state_0[1].name: 0.1 * np.ones([1, 2]), + state_1[0].name: 0.1 * np.ones([1, 2]), + state_1[1].name: 0.1 * np.ones([1, 2]), + }) + self.assertEqual(len(res), 3) + variables = variables_lib.global_variables() + self.assertEqual(expected_variable_names, [v.name for v in variables]) + # Only check the range of outputs as this is just a smoke test. + self.assertAllInRange(res[0], -1.0, 1.0) + self.assertAllInRange(res[1], -1.0, 1.0) + self.assertAllInRange(res[2], -1.0, 1.0) + with variable_scope.variable_scope( + "other", initializer=init_ops.constant_initializer(0.5)): + # Test IndyLSTMCell with input_size != num_units. + x = array_ops.zeros([1, 3], dtype=dtype) + state = (array_ops.zeros([1, 2], dtype=dtype),) * 2 + g, out_state = contrib_rnn_cell.IndyLSTMCell(2)(x, state) + sess.run([variables_lib.global_variables_initializer()]) + res = sess.run( + [g, out_state], { + x.name: np.array([[1., 1., 1.]], dtype=np_dtype), + state[0].name: 0.1 * np.ones([1, 2], dtype=np_dtype), + state[1].name: 0.1 * np.ones([1, 2], dtype=np_dtype), + }) + self.assertEqual(len(res), 2) + def testLSTMCell(self): with self.test_session() as sess: num_units = 8 @@ -935,50 +1048,6 @@ class DropoutWrapperTest(test.TestCase): self.assertAllClose(res0[1].h, res1[1].h) -class SlimRNNCellTest(test.TestCase): - - def testBasicRNNCell(self): - with self.test_session() as sess: - with variable_scope.variable_scope( - "root", initializer=init_ops.constant_initializer(0.5)): - x = array_ops.zeros([1, 2]) - m = array_ops.zeros([1, 2]) - my_cell = functools.partial(basic_rnn_cell, num_units=2) - # pylint: disable=protected-access - g, _ = rnn_cell_impl._SlimRNNCell(my_cell)(x, m) - # pylint: enable=protected-access - sess.run([variables_lib.global_variables_initializer()]) - res = sess.run([g], { - x.name: np.array([[1., 1.]]), - m.name: np.array([[0.1, 0.1]]) - }) - self.assertEqual(res[0].shape, (1, 2)) - - def testBasicRNNCellMatch(self): - batch_size = 32 - input_size = 100 - num_units = 10 - with self.test_session() as sess: - with variable_scope.variable_scope( - "root", initializer=init_ops.constant_initializer(0.5)): - inputs = random_ops.random_uniform((batch_size, input_size)) - _, initial_state = basic_rnn_cell(inputs, None, num_units) - rnn_cell = rnn_cell_impl.BasicRNNCell(num_units) - outputs, state = rnn_cell(inputs, initial_state) - variable_scope.get_variable_scope().reuse_variables() - my_cell = functools.partial(basic_rnn_cell, num_units=num_units) - # pylint: disable=protected-access - slim_cell = rnn_cell_impl._SlimRNNCell(my_cell) - # pylint: enable=protected-access - slim_outputs, slim_state = slim_cell(inputs, initial_state) - self.assertEqual(slim_outputs.get_shape(), outputs.get_shape()) - self.assertEqual(slim_state.get_shape(), state.get_shape()) - sess.run([variables_lib.global_variables_initializer()]) - res = sess.run([slim_outputs, slim_state, outputs, state]) - self.assertAllClose(res[0], res[2]) - self.assertAllClose(res[1], res[3]) - - def basic_rnn_cell(inputs, state, num_units, scope=None): if state is None: if inputs is not None: diff --git a/tensorflow/contrib/rnn/python/ops/rnn_cell.py b/tensorflow/contrib/rnn/python/ops/rnn_cell.py index b12e2cd5ed..bcfabf19f3 100644 --- a/tensorflow/contrib/rnn/python/ops/rnn_cell.py +++ b/tensorflow/contrib/rnn/python/ops/rnn_cell.py @@ -23,6 +23,7 @@ import math from tensorflow.contrib.compiler import jit from tensorflow.contrib.layers.python.layers import layers from tensorflow.contrib.rnn.python.ops import core_rnn_cell +from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes from tensorflow.python.framework import op_def_registry from tensorflow.python.framework import ops @@ -30,6 +31,7 @@ from tensorflow.python.framework import tensor_shape from tensorflow.python.layers import base as base_layer from tensorflow.python.ops import array_ops from tensorflow.python.ops import clip_ops +from tensorflow.python.ops import gen_array_ops from tensorflow.python.ops import init_ops from tensorflow.python.ops import math_ops from tensorflow.python.ops import nn_impl # pylint: disable=unused-import @@ -3050,3 +3052,333 @@ class WeightNormLSTMCell(rnn_cell_impl.RNNCell): new_state = rnn_cell_impl.LSTMStateTuple(new_c, new_h) return new_h, new_state + + +class IndRNNCell(rnn_cell_impl.LayerRNNCell): + """Independently Recurrent Neural Network (IndRNN) cell + (cf. https://arxiv.org/abs/1803.04831). + + Args: + num_units: int, The number of units in the RNN cell. + activation: Nonlinearity to use. Default: `tanh`. + reuse: (optional) Python boolean describing whether to reuse variables + in an existing scope. If not `True`, and the existing scope already has + the given variables, an error is raised. + name: String, the name of the layer. Layers with the same name will + share weights, but to avoid mistakes we require reuse=True in such + cases. + dtype: Default dtype of the layer (default of `None` means use the type + of the first input). Required when `build` is called before `call`. + """ + + def __init__(self, + num_units, + activation=None, + reuse=None, + name=None, + dtype=None): + super(IndRNNCell, self).__init__(_reuse=reuse, name=name, dtype=dtype) + + # Inputs must be 2-dimensional. + self.input_spec = base_layer.InputSpec(ndim=2) + + self._num_units = num_units + self._activation = activation or math_ops.tanh + + @property + def state_size(self): + return self._num_units + + @property + def output_size(self): + return self._num_units + + def build(self, inputs_shape): + if inputs_shape[1].value is None: + raise ValueError( + "Expected inputs.shape[-1] to be known, saw shape: %s" % inputs_shape) + + input_depth = inputs_shape[1].value + # pylint: disable=protected-access + self._kernel_w = self.add_variable( + "%s_w" % rnn_cell_impl._WEIGHTS_VARIABLE_NAME, + shape=[input_depth, self._num_units]) + self._kernel_u = self.add_variable( + "%s_u" % rnn_cell_impl._WEIGHTS_VARIABLE_NAME, + shape=[1, self._num_units], + initializer=init_ops.random_uniform_initializer( + minval=-1, maxval=1, dtype=self.dtype)) + self._bias = self.add_variable( + rnn_cell_impl._BIAS_VARIABLE_NAME, + shape=[self._num_units], + initializer=init_ops.zeros_initializer(dtype=self.dtype)) + # pylint: enable=protected-access + + self.built = True + + def call(self, inputs, state): + """IndRNN: output = new_state = act(W * input + u * state + B).""" + + gate_inputs = math_ops.matmul(inputs, self._kernel_w) + ( + state * self._kernel_u) + gate_inputs = nn_ops.bias_add(gate_inputs, self._bias) + output = self._activation(gate_inputs) + return output, output + + +class IndyGRUCell(rnn_cell_impl.LayerRNNCell): + r"""Independently Gated Recurrent Unit cell. + + Based on IndRNNs (https://arxiv.org/abs/1803.04831) and similar to GRUCell, + yet with the \(U_r\), \(U_z\), and \(U\) matrices in equations 5, 6, and + 8 of http://arxiv.org/abs/1406.1078 respectively replaced by diagonal + matrices, i.e. a Hadamard product with a single vector: + + $$r_j = \sigma\left([\mathbf W_r\mathbf x]_j + + [\mathbf u_r\circ \mathbf h_{(t-1)}]_j\right)$$ + $$z_j = \sigma\left([\mathbf W_z\mathbf x]_j + + [\mathbf u_z\circ \mathbf h_{(t-1)}]_j\right)$$ + $$\tilde{h}^{(t)}_j = \phi\left([\mathbf W \mathbf x]_j + + [\mathbf u \circ \mathbf r \circ \mathbf h_{(t-1)}]_j\right)$$ + + where \(\circ\) denotes the Hadamard operator. This means that each IndyGRU + node sees only its own state, as opposed to seeing all states in the same + layer. + + TODO(gonnet): Write a paper describing this and add a reference here. + + Args: + num_units: int, The number of units in the GRU cell. + activation: Nonlinearity to use. Default: `tanh`. + reuse: (optional) Python boolean describing whether to reuse variables + in an existing scope. If not `True`, and the existing scope already has + the given variables, an error is raised. + kernel_initializer: (optional) The initializer to use for the weight and + projection matrices. + bias_initializer: (optional) The initializer to use for the bias. + name: String, the name of the layer. Layers with the same name will + share weights, but to avoid mistakes we require reuse=True in such + cases. + dtype: Default dtype of the layer (default of `None` means use the type + of the first input). Required when `build` is called before `call`. + """ + + def __init__(self, + num_units, + activation=None, + reuse=None, + kernel_initializer=None, + bias_initializer=None, + name=None, + dtype=None): + super(IndyGRUCell, self).__init__(_reuse=reuse, name=name, dtype=dtype) + + # Inputs must be 2-dimensional. + self.input_spec = base_layer.InputSpec(ndim=2) + + self._num_units = num_units + self._activation = activation or math_ops.tanh + self._kernel_initializer = kernel_initializer + self._bias_initializer = bias_initializer + + @property + def state_size(self): + return self._num_units + + @property + def output_size(self): + return self._num_units + + def build(self, inputs_shape): + if inputs_shape[1].value is None: + raise ValueError( + "Expected inputs.shape[-1] to be known, saw shape: %s" % inputs_shape) + + input_depth = inputs_shape[1].value + # pylint: disable=protected-access + self._gate_kernel_w = self.add_variable( + "gates/%s_w" % rnn_cell_impl._WEIGHTS_VARIABLE_NAME, + shape=[input_depth, 2 * self._num_units], + initializer=self._kernel_initializer) + self._gate_kernel_u = self.add_variable( + "gates/%s_u" % rnn_cell_impl._WEIGHTS_VARIABLE_NAME, + shape=[1, 2 * self._num_units], + initializer=init_ops.random_uniform_initializer( + minval=-1, maxval=1, dtype=self.dtype)) + self._gate_bias = self.add_variable( + "gates/%s" % rnn_cell_impl._BIAS_VARIABLE_NAME, + shape=[2 * self._num_units], + initializer=(self._bias_initializer + if self._bias_initializer is not None else + init_ops.constant_initializer(1.0, dtype=self.dtype))) + self._candidate_kernel_w = self.add_variable( + "candidate/%s" % rnn_cell_impl._WEIGHTS_VARIABLE_NAME, + shape=[input_depth, self._num_units], + initializer=self._kernel_initializer) + self._candidate_kernel_u = self.add_variable( + "candidate/%s_u" % rnn_cell_impl._WEIGHTS_VARIABLE_NAME, + shape=[1, self._num_units], + initializer=init_ops.random_uniform_initializer( + minval=-1, maxval=1, dtype=self.dtype)) + self._candidate_bias = self.add_variable( + "candidate/%s" % rnn_cell_impl._BIAS_VARIABLE_NAME, + shape=[self._num_units], + initializer=(self._bias_initializer + if self._bias_initializer is not None else + init_ops.zeros_initializer(dtype=self.dtype))) + # pylint: enable=protected-access + + self.built = True + + def call(self, inputs, state): + """Gated recurrent unit (GRU) with nunits cells.""" + + gate_inputs = math_ops.matmul(inputs, self._gate_kernel_w) + ( + gen_array_ops.tile(state, [1, 2]) * self._gate_kernel_u) + gate_inputs = nn_ops.bias_add(gate_inputs, self._gate_bias) + + value = math_ops.sigmoid(gate_inputs) + r, u = array_ops.split(value=value, num_or_size_splits=2, axis=1) + + r_state = r * state + + candidate = math_ops.matmul(inputs, self._candidate_kernel_w) + ( + r_state * self._candidate_kernel_u) + candidate = nn_ops.bias_add(candidate, self._candidate_bias) + + c = self._activation(candidate) + new_h = u * state + (1 - u) * c + return new_h, new_h + + +class IndyLSTMCell(rnn_cell_impl.LayerRNNCell): + r"""Basic IndyLSTM recurrent network cell. + + Based on IndRNNs (https://arxiv.org/abs/1803.04831) and similar to + BasicLSTMCell, yet with the \(U_f\), \(U_i\), \(U_o\) and \(U_c\) + matrices in + https://en.wikipedia.org/wiki/Long_short-term_memory#LSTM_with_a_forget_gate + replaced by diagonal matrices, i.e. a Hadamard product with a single vector: + + $$f_t = \sigma_g\left(W_f x_t + u_f \circ h_{t-1} + b_f\right)$$ + $$i_t = \sigma_g\left(W_i x_t + u_i \circ h_{t-1} + b_i\right)$$ + $$o_t = \sigma_g\left(W_o x_t + u_o \circ h_{t-1} + b_o\right)$$ + $$c_t = f_t \circ c_{t-1} + + i_t \circ \sigma_c\left(W_c x_t + u_c \circ h_{t-1} + b_c\right)$$ + + where \(\circ\) denotes the Hadamard operator. This means that each IndyLSTM + node sees only its own state \(h\) and \(c\), as opposed to seeing all + states in the same layer. + + We add forget_bias (default: 1) to the biases of the forget gate in order to + reduce the scale of forgetting in the beginning of the training. + + It does not allow cell clipping, a projection layer, and does not + use peep-hole connections: it is the basic baseline. + + For advanced models, please use the full @{tf.nn.rnn_cell.LSTMCell} + that follows. + + TODO(gonnet): Write a paper describing this and add a reference here. + """ + + def __init__(self, + num_units, + forget_bias=1.0, + activation=None, + reuse=None, + name=None, + dtype=None): + """Initialize the IndyLSTM cell. + + Args: + num_units: int, The number of units in the LSTM cell. + forget_bias: float, The bias added to forget gates (see above). + Must set to `0.0` manually when restoring from CudnnLSTM-trained + checkpoints. + activation: Activation function of the inner states. Default: `tanh`. + reuse: (optional) Python boolean describing whether to reuse variables + in an existing scope. If not `True`, and the existing scope already has + the given variables, an error is raised. + name: String, the name of the layer. Layers with the same name will + share weights, but to avoid mistakes we require reuse=True in such + cases. + dtype: Default dtype of the layer (default of `None` means use the type + of the first input). Required when `build` is called before `call`. + """ + super(IndyLSTMCell, self).__init__(_reuse=reuse, name=name, dtype=dtype) + + # Inputs must be 2-dimensional. + self.input_spec = base_layer.InputSpec(ndim=2) + + self._num_units = num_units + self._forget_bias = forget_bias + self._activation = activation or math_ops.tanh + + @property + def state_size(self): + return rnn_cell_impl.LSTMStateTuple(self._num_units, self._num_units) + + @property + def output_size(self): + return self._num_units + + def build(self, inputs_shape): + if inputs_shape[1].value is None: + raise ValueError( + "Expected inputs.shape[-1] to be known, saw shape: %s" % inputs_shape) + + input_depth = inputs_shape[1].value + # pylint: disable=protected-access + self._kernel_w = self.add_variable( + "%s_w" % rnn_cell_impl._WEIGHTS_VARIABLE_NAME, + shape=[input_depth, 4 * self._num_units]) + self._kernel_u = self.add_variable( + "%s_u" % rnn_cell_impl._WEIGHTS_VARIABLE_NAME, + shape=[1, 4 * self._num_units], + initializer=init_ops.random_uniform_initializer( + minval=-1, maxval=1, dtype=self.dtype)) + self._bias = self.add_variable( + rnn_cell_impl._BIAS_VARIABLE_NAME, + shape=[4 * self._num_units], + initializer=init_ops.zeros_initializer(dtype=self.dtype)) + # pylint: enable=protected-access + + self.built = True + + def call(self, inputs, state): + """Independent Long short-term memory cell (IndyLSTM). + + Args: + inputs: `2-D` tensor with shape `[batch_size, input_size]`. + state: An `LSTMStateTuple` of state tensors, each shaped + `[batch_size, num_units]`. + + Returns: + A pair containing the new hidden state, and the new state (a + `LSTMStateTuple`). + """ + sigmoid = math_ops.sigmoid + one = constant_op.constant(1, dtype=dtypes.int32) + c, h = state + + gate_inputs = math_ops.matmul(inputs, self._kernel_w) + gate_inputs += gen_array_ops.tile(h, [1, 4]) * self._kernel_u + gate_inputs = nn_ops.bias_add(gate_inputs, self._bias) + + # i = input_gate, j = new_input, f = forget_gate, o = output_gate + i, j, f, o = array_ops.split( + value=gate_inputs, num_or_size_splits=4, axis=one) + + forget_bias_tensor = constant_op.constant(self._forget_bias, dtype=f.dtype) + # Note that using `add` and `multiply` instead of `+` and `*` gives a + # performance improvement. So using those at the cost of readability. + add = math_ops.add + multiply = math_ops.multiply + new_c = add( + multiply(c, sigmoid(add(f, forget_bias_tensor))), + multiply(sigmoid(i), self._activation(j))) + new_h = multiply(self._activation(new_c), sigmoid(o)) + + new_state = rnn_cell_impl.LSTMStateTuple(new_c, new_h) + return new_h, new_state diff --git a/tensorflow/contrib/tensorrt/kernels/trt_calib_op.cc b/tensorflow/contrib/tensorrt/kernels/trt_calib_op.cc deleted file mode 100644 index aea44fd8a2..0000000000 --- a/tensorflow/contrib/tensorrt/kernels/trt_calib_op.cc +++ /dev/null @@ -1,136 +0,0 @@ -/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. - -Licensed under the Apache License, Version 2.0 (the "License"); -you may not use this file except in compliance with the License. -You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - -Unless required by applicable law or agreed to in writing, software -distributed under the License is distributed on an "AS IS" BASIS, -WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -See the License for the specific language governing permissions and -limitations under the License. -==============================================================================*/ - -#include "tensorflow/contrib/tensorrt/kernels/trt_calib_op.h" -#include "tensorflow/contrib/tensorrt/resources/trt_int8_calibrator.h" -#include "tensorflow/contrib/tensorrt/resources/trt_resource_manager.h" -#include "tensorflow/contrib/tensorrt/resources/trt_resources.h" -#include "tensorflow/core/framework/tensor.h" -#include "tensorflow/core/framework/tensor_shape.h" -#include "tensorflow/core/framework/tensor_types.h" -#include "tensorflow/core/framework/types.h" -#include "tensorflow/core/platform/stream_executor.h" - -#if GOOGLE_CUDA -#if GOOGLE_TENSORRT -#include "cuda/include/cuda_runtime_api.h" -#include "tensorrt/include/NvInfer.h" - -namespace tensorflow { -namespace tensorrt { - -TRTCalibOp::TRTCalibOp(OpKernelConstruction* context) : OpKernel(context) { - OP_REQUIRES_OK(context, context->GetAttr("segment_nodes", &segment_nodes_)); - OP_REQUIRES_OK(context, context->GetAttr("input_names", &input_names_)); - OP_REQUIRES_OK(context, context->GetAttr("resource_name", &resource_name_)); -}; - -#define TYPECASE(dt, X, Y) \ - case dt: { \ - return (void*)X->flat<tensorflow::EnumToDataType<dt>::Type>().data(); \ - } - -void* GetTensorAddress(const Tensor* tensor_ptr) { - auto tensor_type = tensor_ptr->dtype(); - switch (tensor_type) { - TYPECASE(tensorflow::DT_FLOAT, tensor_ptr, dest_ptr); - TYPECASE(tensorflow::DT_HALF, tensor_ptr, dest_ptr); - TYPECASE(tensorflow::DT_INT8, tensor_ptr, dest_ptr); - default: { - LOG(FATAL) << "Unsupported Data type " - << tensorflow::DataTypeString(tensor_type); - return nullptr; - } - } -} - -void TRTCalibOp::Compute(tensorflow::OpKernelContext* ctx) { - // TODO(aaroey): make sure ctx->resource_mgr() is used in future PR. - auto trt_rm = tensorflow::tensorrt::TRTResourceManager::instance(); - auto res_mgr = trt_rm->getManager("TRTCalibOps"); - tensorflow::tensorrt::TRTCalibrationResource* calib_res = nullptr; - auto status = res_mgr->Lookup(resource_name_, resource_name_, &calib_res); - - if (!status.ok()) { - ctx->SetStatus(status); - return; - } - int num_inputs = ctx->num_inputs(); - // first run instantiate calibrator - if (calib_res->calibrator_ == nullptr) { - dev_tensors_.resize(num_inputs); - int batch_size = ctx->input(0).dim_size(0); - VLOG(1) << " Constructing calibrator"; - for (int i = 0; i < num_inputs; i++) { - // allocate workspace on device for inputs - const tensorflow::Tensor& t = ctx->input(i); - OP_REQUIRES_OK(ctx, - ctx->allocate_persistent(t.dtype(), t.shape(), - &dev_tensors_.at(i), nullptr)); - const auto device_tensor = dev_tensors_.at(i).AccessTensor(ctx); - CHECK_EQ(t.TotalBytes(), device_tensor->TotalBytes()); - void* device_address = GetTensorAddress(device_tensor); - device_buffers_.emplace(input_names_.at(i), - std::pair<void*, size_t>( - device_address, device_tensor->TotalBytes())); - } - - calib_res->calibrator_ = - new TRTInt8Calibrator(device_buffers_, batch_size, resource_name_); - string label(resource_name_); - calib_res->thr_ = new std::thread([calib_res, label]() { - VLOG(1) << "Starting calibration thread, Calibration Resource @ " - << calib_res; - calib_res->builder_->setInt8Calibrator(calib_res->calibrator_); - calib_res->builder_->setInt8Mode(true); - calib_res->engine_ = calib_res->builder_->buildCudaEngine( - *calib_res->network_); // will loop until we terminate calibrator - VLOG(1) << "Calibration loop terminated " << label; - }); - VLOG(1) << "initialized calibrator resource"; - } // calibrator initialized - - // Pass input data to calibrator - std::unordered_map<string, void*> input_data; - for (int i = 0; i < num_inputs; i++) { - const Tensor& t = ctx->input(i); - void* data_address = GetTensorAddress(&t); - const auto device_tensor = dev_tensors_.at(i).AccessTensor(ctx); - CHECK_EQ(t.TotalBytes(), - device_tensor->TotalBytes()); // use the tensor so FW keeps it - input_data.emplace(input_names_.at(i), data_address); - ctx->set_output(i, t); - } - VLOG(2) << "Filled map for sending"; - // copied from cuda_kernel_helper since it seems only valid in *.cu.cc files - const cudaStream_t* stream = CHECK_NOTNULL( - reinterpret_cast<const cudaStream_t*>(ctx->op_device_context() - ->stream() - ->implementation() - ->CudaStreamMemberHack())); - calib_res->calibrator_->setBatch(input_data, *stream); - VLOG(2) << "Passed calibration data"; - // TODO(aaroey): make sure we wait for the completion of calibration on the - // last batch in future PR. -}; - -#undef TYPECASE - -REGISTER_KERNEL_BUILDER(Name("TRTCalibOp").Device(DEVICE_GPU), TRTCalibOp); - -} // namespace tensorrt -} // namespace tensorflow -#endif -#endif diff --git a/tensorflow/contrib/tensorrt/kernels/trt_calib_op.h b/tensorflow/contrib/tensorrt/kernels/trt_calib_op.h deleted file mode 100644 index 23df9db32f..0000000000 --- a/tensorflow/contrib/tensorrt/kernels/trt_calib_op.h +++ /dev/null @@ -1,52 +0,0 @@ -/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. - -Licensed under the Apache License, Version 2.0 (the "License"); -you may not use this file except in compliance with the License. -You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - -Unless required by applicable law or agreed to in writing, software -distributed under the License is distributed on an "AS IS" BASIS, -WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -See the License for the specific language governing permissions and -limitations under the License. -==============================================================================*/ - -#ifndef TENSORFLOW_CONTRIB_TENSORRT_KERNELS_TRT_CALIB_OP_H -#define TENSORFLOW_CONTRIB_TENSORRT_KERNELS_TRT_CALIB_OP_H - -#include <memory> -#include <string> -#include <unordered_map> -#include <utility> -#include <vector> -#include "tensorflow/core/framework/op.h" -#include "tensorflow/core/framework/op_kernel.h" -#include "tensorflow/core/framework/tensor_shape.h" -#include "tensorflow/core/platform/types.h" - -#if GOOGLE_CUDA -#if GOOGLE_TENSORRT -namespace tensorflow { -namespace tensorrt { -// TODO(sami): Convert this to async kernel! -class TRTCalibOp : public OpKernel { - public: - explicit TRTCalibOp(OpKernelConstruction* context); - - void Compute(OpKernelContext* context) override; - - private: - string resource_name_; - std::vector<string> segment_nodes_; - std::vector<string> input_names_; - std::vector<tensorflow::TensorShape> shapes_; - std::unordered_map<string, std::pair<void*, size_t>> device_buffers_; - std::vector<tensorflow::PersistentTensor> dev_tensors_; -}; -} // namespace tensorrt -} // namespace tensorflow -#endif -#endif -#endif // TENSORFLOW_CONTRIB_TENSORRT_KERNELS_TRT_CALIB_OP_H diff --git a/tensorflow/contrib/tensorrt/ops/trt_calib_op.cc b/tensorflow/contrib/tensorrt/ops/trt_calib_op.cc deleted file mode 100644 index 4835e50650..0000000000 --- a/tensorflow/contrib/tensorrt/ops/trt_calib_op.cc +++ /dev/null @@ -1,37 +0,0 @@ -/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. - -Licensed under the Apache License, Version 2.0 (the "License"); -you may not use this file except in compliance with the License. -You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - -Unless required by applicable law or agreed to in writing, software -distributed under the License is distributed on an "AS IS" BASIS, -WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -See the License for the specific language governing permissions and -limitations under the License. -==============================================================================*/ - -#include "tensorflow/core/framework/op.h" -#include "tensorflow/core/framework/shape_inference.h" -namespace tensorflow { - -REGISTER_OP("TRTCalibOp") - .Attr("segment_nodes: list(string)") // names of the ops in segment - .Attr("segment_output_names: list(string)") // names of the output ops in - // segment - .Attr("input_names: list(string)") // names of the inputs for - // passing into tensorrt - .Attr("resource_name: string") - .Attr("InT: list({int8, float16, float32})") - .Input("in_tensor: InT") - .Output("out_tensor: InT") - .SetShapeFn([](tensorflow::shape_inference::InferenceContext* c) { - for (int i = 0; i < c->num_inputs(); i++) { - c->set_output(i, c->input(i)); - } - return Status::OK(); - }); - -} // namespace tensorflow diff --git a/tensorflow/contrib/tpu/python/tpu/tpu_optimizer.py b/tensorflow/contrib/tpu/python/tpu/tpu_optimizer.py index 15f99d7eeb..53d33f4077 100644 --- a/tensorflow/contrib/tpu/python/tpu/tpu_optimizer.py +++ b/tensorflow/contrib/tpu/python/tpu/tpu_optimizer.py @@ -23,6 +23,7 @@ import collections from tensorflow.contrib.tpu.python.ops import tpu_ops from tensorflow.contrib.tpu.python.tpu import tpu_function +from tensorflow.python.framework import ops from tensorflow.python.ops.losses import losses from tensorflow.python.platform import tf_logging as logging from tensorflow.python.training import optimizer @@ -153,8 +154,9 @@ class CrossShardOptimizer(optimizer.Optimizer): if grad is None: summed_grads_and_vars.append((grad, var)) else: - summed_grads_and_vars.append((tpu_ops.cross_replica_sum( - grad, self._group_assignment), var)) + with ops.colocate_with(grad): + summed_grads_and_vars.append((tpu_ops.cross_replica_sum( + grad, self._group_assignment), var)) return self._opt.apply_gradients(summed_grads_and_vars, global_step, name) def get_slot(self, *args, **kwargs): diff --git a/tensorflow/core/BUILD b/tensorflow/core/BUILD index 5918005f6b..1907d6af0b 100644 --- a/tensorflow/core/BUILD +++ b/tensorflow/core/BUILD @@ -1922,7 +1922,6 @@ tf_proto_library_cc( srcs = ["protobuf/master_service.proto"], has_services = 1, cc_api_version = 2, - cc_grpc_version = 1, cc_stubby_versions = ["2"], protodeps = [":master_proto"], visibility = [ @@ -3600,6 +3599,7 @@ tf_cc_test_mkl( deps = [ ":core", ":core_cpu", + ":core_cpu_internal", ":framework", ":framework_internal", ":test", diff --git a/tensorflow/core/api_def/base_api/api_def_NonMaxSuppressionWithOverlaps.pbtxt b/tensorflow/core/api_def/base_api/api_def_NonMaxSuppressionWithOverlaps.pbtxt new file mode 100644 index 0000000000..180edb15a4 --- /dev/null +++ b/tensorflow/core/api_def/base_api/api_def_NonMaxSuppressionWithOverlaps.pbtxt @@ -0,0 +1,62 @@ +op { + graph_op_name: "NonMaxSuppressionWithOverlaps" + in_arg { + name: "overlaps" + description: <<END +A 2-D float tensor of shape `[num_boxes, num_boxes]` representing +the n-by-n box overlap values. +END + } + in_arg { + name: "scores" + description: <<END +A 1-D float tensor of shape `[num_boxes]` representing a single +score corresponding to each box (each row of boxes). +END + } + in_arg { + name: "max_output_size" + description: <<END +A scalar integer tensor representing the maximum number of +boxes to be selected by non max suppression. +END + } + in_arg { + name: "overlap_threshold" + description: <<END +A 0-D float tensor representing the threshold for deciding whether +boxes overlap too. +END + } + in_arg { + name: "score_threshold" + description: <<END +A 0-D float tensor representing the threshold for deciding when to remove +boxes based on score. +END + } + out_arg { + name: "selected_indices" + description: <<END +A 1-D integer tensor of shape `[M]` representing the selected +indices from the boxes tensor, where `M <= max_output_size`. +END + } + summary: "Greedily selects a subset of bounding boxes in descending order of score," + description: <<END +pruning away boxes that have high overlaps +with previously selected boxes. Bounding boxes with score less than +`score_threshold` are removed. N-by-n overlap values are supplied as square matrix, +which allows for defining a custom overlap criterium (eg. intersection over union, +intersection over area, etc.). + +The output of this operation is a set of integers indexing into the input +collection of bounding boxes representing the selected boxes. The bounding +box coordinates corresponding to the selected indices can then be obtained +using the `tf.gather operation`. For example: + + selected_indices = tf.image.non_max_suppression_with_overlaps( + overlaps, scores, max_output_size, overlap_threshold, score_threshold) + selected_boxes = tf.gather(boxes, selected_indices) +END +} diff --git a/tensorflow/core/api_def/python_api/api_def_Acos.pbtxt b/tensorflow/core/api_def/python_api/api_def_Acos.pbtxt index ca1ee78526..1fd8baf05f 100644 --- a/tensorflow/core/api_def/python_api/api_def_Acos.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Acos.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "acos" - deprecation_message: "tf.acos is deprecated, please use tf.math.acos instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Acosh.pbtxt b/tensorflow/core/api_def/python_api/api_def_Acosh.pbtxt index 7503353e41..f7946652ef 100644 --- a/tensorflow/core/api_def/python_api/api_def_Acosh.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Acosh.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "acosh" - deprecation_message: "tf.acosh is deprecated, please use tf.math.acosh instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Add.pbtxt b/tensorflow/core/api_def/python_api/api_def_Add.pbtxt index cc5d68b15d..fb505a91ac 100644 --- a/tensorflow/core/api_def/python_api/api_def_Add.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Add.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "add" - deprecation_message: "tf.add is deprecated, please use tf.math.add instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_AsString.pbtxt b/tensorflow/core/api_def/python_api/api_def_AsString.pbtxt index 9306eaf373..ea65543a76 100644 --- a/tensorflow/core/api_def/python_api/api_def_AsString.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_AsString.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "as_string" - deprecation_message: "tf.as_string is deprecated, please use tf.dtypes.as_string instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Asin.pbtxt b/tensorflow/core/api_def/python_api/api_def_Asin.pbtxt index 7622af7b45..eedf4553c6 100644 --- a/tensorflow/core/api_def/python_api/api_def_Asin.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Asin.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "asin" - deprecation_message: "tf.asin is deprecated, please use tf.math.asin instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Asinh.pbtxt b/tensorflow/core/api_def/python_api/api_def_Asinh.pbtxt index 395275c21d..10c2fb356e 100644 --- a/tensorflow/core/api_def/python_api/api_def_Asinh.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Asinh.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "asinh" - deprecation_message: "tf.asinh is deprecated, please use tf.math.asinh instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Atan.pbtxt b/tensorflow/core/api_def/python_api/api_def_Atan.pbtxt index dfcd632558..03dd5dc848 100644 --- a/tensorflow/core/api_def/python_api/api_def_Atan.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Atan.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "atan" - deprecation_message: "tf.atan is deprecated, please use tf.math.atan instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Atan2.pbtxt b/tensorflow/core/api_def/python_api/api_def_Atan2.pbtxt index fba79507aa..85b27bd881 100644 --- a/tensorflow/core/api_def/python_api/api_def_Atan2.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Atan2.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "atan2" - deprecation_message: "tf.atan2 is deprecated, please use tf.math.atan2 instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Atanh.pbtxt b/tensorflow/core/api_def/python_api/api_def_Atanh.pbtxt index f7164c33e8..ee7c0600d6 100644 --- a/tensorflow/core/api_def/python_api/api_def_Atanh.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Atanh.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "atanh" - deprecation_message: "tf.atanh is deprecated, please use tf.math.atanh instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_BatchToSpaceND.pbtxt b/tensorflow/core/api_def/python_api/api_def_BatchToSpaceND.pbtxt index 56e49a2221..9552fc92e3 100644 --- a/tensorflow/core/api_def/python_api/api_def_BatchToSpaceND.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_BatchToSpaceND.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "batch_to_space_nd" - deprecation_message: "tf.batch_to_space_nd is deprecated, please use tf.manip.batch_to_space_nd instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Betainc.pbtxt b/tensorflow/core/api_def/python_api/api_def_Betainc.pbtxt index 7c37b534c7..7ad7cbcba9 100644 --- a/tensorflow/core/api_def/python_api/api_def_Betainc.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Betainc.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "betainc" - deprecation_message: "tf.betainc is deprecated, please use tf.math.betainc instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Ceil.pbtxt b/tensorflow/core/api_def/python_api/api_def_Ceil.pbtxt index 0c72cf2edd..f2265bad56 100644 --- a/tensorflow/core/api_def/python_api/api_def_Ceil.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Ceil.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "ceil" - deprecation_message: "tf.ceil is deprecated, please use tf.math.ceil instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_CheckNumerics.pbtxt b/tensorflow/core/api_def/python_api/api_def_CheckNumerics.pbtxt index 7ea52d30b6..541b09a591 100644 --- a/tensorflow/core/api_def/python_api/api_def_CheckNumerics.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_CheckNumerics.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "check_numerics" - deprecation_message: "tf.check_numerics is deprecated, please use tf.debugging.check_numerics instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Cholesky.pbtxt b/tensorflow/core/api_def/python_api/api_def_Cholesky.pbtxt index 568fab4037..942f4e6ed8 100644 --- a/tensorflow/core/api_def/python_api/api_def_Cholesky.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Cholesky.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "cholesky" - deprecation_message: "tf.cholesky is deprecated, please use tf.linalg.cholesky instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Cos.pbtxt b/tensorflow/core/api_def/python_api/api_def_Cos.pbtxt index 6550cd2d4e..1af8c0c2c9 100644 --- a/tensorflow/core/api_def/python_api/api_def_Cos.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Cos.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "cos" - deprecation_message: "tf.cos is deprecated, please use tf.math.cos instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Cosh.pbtxt b/tensorflow/core/api_def/python_api/api_def_Cosh.pbtxt index ef82a45a80..2de87df40d 100644 --- a/tensorflow/core/api_def/python_api/api_def_Cosh.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Cosh.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "cosh" - deprecation_message: "tf.cosh is deprecated, please use tf.math.cosh instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Cross.pbtxt b/tensorflow/core/api_def/python_api/api_def_Cross.pbtxt index 33c1b8c617..e8a871cae6 100644 --- a/tensorflow/core/api_def/python_api/api_def_Cross.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Cross.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "cross" - deprecation_message: "tf.cross is deprecated, please use tf.linalg.cross instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_DecodeBase64.pbtxt b/tensorflow/core/api_def/python_api/api_def_DecodeBase64.pbtxt index 55c43ceba2..8b96eee631 100644 --- a/tensorflow/core/api_def/python_api/api_def_DecodeBase64.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_DecodeBase64.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "decode_base64" - deprecation_message: "tf.decode_base64 is deprecated, please use tf.io.decode_base64 instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_DecodeCompressed.pbtxt b/tensorflow/core/api_def/python_api/api_def_DecodeCompressed.pbtxt index 5f6be24cc4..829608fc8f 100644 --- a/tensorflow/core/api_def/python_api/api_def_DecodeCompressed.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_DecodeCompressed.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "decode_compressed" - deprecation_message: "tf.decode_compressed is deprecated, please use tf.io.decode_compressed instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_DecodeJSONExample.pbtxt b/tensorflow/core/api_def/python_api/api_def_DecodeJSONExample.pbtxt index 3759047f57..9f28bc5f59 100644 --- a/tensorflow/core/api_def/python_api/api_def_DecodeJSONExample.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_DecodeJSONExample.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "decode_json_example" - deprecation_message: "tf.decode_json_example is deprecated, please use tf.io.decode_json_example instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_DecodeRaw.pbtxt b/tensorflow/core/api_def/python_api/api_def_DecodeRaw.pbtxt index a83f702dca..0010a59ca4 100644 --- a/tensorflow/core/api_def/python_api/api_def_DecodeRaw.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_DecodeRaw.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "decode_raw" - deprecation_message: "tf.decode_raw is deprecated, please use tf.io.decode_raw instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Dequantize.pbtxt b/tensorflow/core/api_def/python_api/api_def_Dequantize.pbtxt index c9b4f76fab..5edd0c216b 100644 --- a/tensorflow/core/api_def/python_api/api_def_Dequantize.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Dequantize.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "dequantize" - deprecation_message: "tf.dequantize is deprecated, please use tf.quantization.dequantize instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Diag.pbtxt b/tensorflow/core/api_def/python_api/api_def_Diag.pbtxt index 2043facfa9..cba30e63e8 100644 --- a/tensorflow/core/api_def/python_api/api_def_Diag.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Diag.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "diag" - deprecation_message: "tf.diag is deprecated, please use tf.linalg.tensor_diag instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_DiagPart.pbtxt b/tensorflow/core/api_def/python_api/api_def_DiagPart.pbtxt index 7fa30b2347..54e1f34e82 100644 --- a/tensorflow/core/api_def/python_api/api_def_DiagPart.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_DiagPart.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "diag_part" - deprecation_message: "tf.diag_part is deprecated, please use tf.linalg.tensor_diag_part instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Digamma.pbtxt b/tensorflow/core/api_def/python_api/api_def_Digamma.pbtxt index 03f57678a8..91b4dfead7 100644 --- a/tensorflow/core/api_def/python_api/api_def_Digamma.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Digamma.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "digamma" - deprecation_message: "tf.digamma is deprecated, please use tf.math.digamma instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_EncodeBase64.pbtxt b/tensorflow/core/api_def/python_api/api_def_EncodeBase64.pbtxt index 47b4ab4da4..71bb73cfb2 100644 --- a/tensorflow/core/api_def/python_api/api_def_EncodeBase64.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_EncodeBase64.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "encode_base64" - deprecation_message: "tf.encode_base64 is deprecated, please use tf.io.encode_base64 instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Equal.pbtxt b/tensorflow/core/api_def/python_api/api_def_Equal.pbtxt index 2630962f7d..78aa1b3bc5 100644 --- a/tensorflow/core/api_def/python_api/api_def_Equal.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Equal.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "equal" - deprecation_message: "tf.equal is deprecated, please use tf.math.equal instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Erfc.pbtxt b/tensorflow/core/api_def/python_api/api_def_Erfc.pbtxt index 6a511b3251..e96df0c596 100644 --- a/tensorflow/core/api_def/python_api/api_def_Erfc.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Erfc.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "erfc" - deprecation_message: "tf.erfc is deprecated, please use tf.math.erfc instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Exp.pbtxt b/tensorflow/core/api_def/python_api/api_def_Exp.pbtxt index e1fd718ff0..70323fe5b4 100644 --- a/tensorflow/core/api_def/python_api/api_def_Exp.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Exp.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "exp" - deprecation_message: "tf.exp is deprecated, please use tf.math.exp instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Expm1.pbtxt b/tensorflow/core/api_def/python_api/api_def_Expm1.pbtxt index ca25706407..8ddf9d4d70 100644 --- a/tensorflow/core/api_def/python_api/api_def_Expm1.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Expm1.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "expm1" - deprecation_message: "tf.expm1 is deprecated, please use tf.math.expm1 instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_ExtractImagePatches.pbtxt b/tensorflow/core/api_def/python_api/api_def_ExtractImagePatches.pbtxt index d302e26ad2..f008b1222d 100644 --- a/tensorflow/core/api_def/python_api/api_def_ExtractImagePatches.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_ExtractImagePatches.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "extract_image_patches" - deprecation_message: "tf.extract_image_patches is deprecated, please use tf.image.extract_image_patches instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_FFT.pbtxt b/tensorflow/core/api_def/python_api/api_def_FFT.pbtxt index 57a00a08e3..d79e936b71 100644 --- a/tensorflow/core/api_def/python_api/api_def_FFT.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_FFT.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "fft" - deprecation_message: "tf.fft is deprecated, please use tf.spectral.fft instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_FakeQuantWithMinMaxArgs.pbtxt b/tensorflow/core/api_def/python_api/api_def_FakeQuantWithMinMaxArgs.pbtxt index cd14b13675..d8db83331f 100644 --- a/tensorflow/core/api_def/python_api/api_def_FakeQuantWithMinMaxArgs.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_FakeQuantWithMinMaxArgs.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "fake_quant_with_min_max_args" - deprecation_message: "tf.fake_quant_with_min_max_args is deprecated, please use tf.quantization.fake_quant_with_min_max_args instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_FakeQuantWithMinMaxArgsGradient.pbtxt b/tensorflow/core/api_def/python_api/api_def_FakeQuantWithMinMaxArgsGradient.pbtxt index d55cb69d1d..74f01d1a0c 100644 --- a/tensorflow/core/api_def/python_api/api_def_FakeQuantWithMinMaxArgsGradient.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_FakeQuantWithMinMaxArgsGradient.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "fake_quant_with_min_max_args_gradient" - deprecation_message: "tf.fake_quant_with_min_max_args_gradient is deprecated, please use tf.quantization.fake_quant_with_min_max_args_gradient instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_FakeQuantWithMinMaxVars.pbtxt b/tensorflow/core/api_def/python_api/api_def_FakeQuantWithMinMaxVars.pbtxt index 6ff4f2cdb2..e14fb6d118 100644 --- a/tensorflow/core/api_def/python_api/api_def_FakeQuantWithMinMaxVars.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_FakeQuantWithMinMaxVars.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "fake_quant_with_min_max_vars" - deprecation_message: "tf.fake_quant_with_min_max_vars is deprecated, please use tf.quantization.fake_quant_with_min_max_vars instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_FakeQuantWithMinMaxVarsGradient.pbtxt b/tensorflow/core/api_def/python_api/api_def_FakeQuantWithMinMaxVarsGradient.pbtxt index 817a35cc6c..4611ebdfb8 100644 --- a/tensorflow/core/api_def/python_api/api_def_FakeQuantWithMinMaxVarsGradient.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_FakeQuantWithMinMaxVarsGradient.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "fake_quant_with_min_max_vars_gradient" - deprecation_message: "tf.fake_quant_with_min_max_vars_gradient is deprecated, please use tf.quantization.fake_quant_with_min_max_vars_gradient instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_FakeQuantWithMinMaxVarsPerChannel.pbtxt b/tensorflow/core/api_def/python_api/api_def_FakeQuantWithMinMaxVarsPerChannel.pbtxt index 275c0d5225..0936e513c3 100644 --- a/tensorflow/core/api_def/python_api/api_def_FakeQuantWithMinMaxVarsPerChannel.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_FakeQuantWithMinMaxVarsPerChannel.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "fake_quant_with_min_max_vars_per_channel" - deprecation_message: "tf.fake_quant_with_min_max_vars_per_channel is deprecated, please use tf.quantization.fake_quant_with_min_max_vars_per_channel instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_FakeQuantWithMinMaxVarsPerChannelGradient.pbtxt b/tensorflow/core/api_def/python_api/api_def_FakeQuantWithMinMaxVarsPerChannelGradient.pbtxt index 897312897f..0d9968248c 100644 --- a/tensorflow/core/api_def/python_api/api_def_FakeQuantWithMinMaxVarsPerChannelGradient.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_FakeQuantWithMinMaxVarsPerChannelGradient.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "fake_quant_with_min_max_vars_per_channel_gradient" - deprecation_message: "tf.fake_quant_with_min_max_vars_per_channel_gradient is deprecated, please use tf.quantization.fake_quant_with_min_max_vars_per_channel_gradient instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Floor.pbtxt b/tensorflow/core/api_def/python_api/api_def_Floor.pbtxt index 788d95edc1..9b93caa0b1 100644 --- a/tensorflow/core/api_def/python_api/api_def_Floor.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Floor.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "floor" - deprecation_message: "tf.floor is deprecated, please use tf.math.floor instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_GatherNd.pbtxt b/tensorflow/core/api_def/python_api/api_def_GatherNd.pbtxt index 371dc740df..71257c8855 100644 --- a/tensorflow/core/api_def/python_api/api_def_GatherNd.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_GatherNd.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "gather_nd" - deprecation_message: "tf.gather_nd is deprecated, please use tf.manip.gather_nd instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Greater.pbtxt b/tensorflow/core/api_def/python_api/api_def_Greater.pbtxt index c8c56515b2..7de60d44c4 100644 --- a/tensorflow/core/api_def/python_api/api_def_Greater.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Greater.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "greater" - deprecation_message: "tf.greater is deprecated, please use tf.math.greater instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_GreaterEqual.pbtxt b/tensorflow/core/api_def/python_api/api_def_GreaterEqual.pbtxt index ccb390fb3e..9c8975c2a9 100644 --- a/tensorflow/core/api_def/python_api/api_def_GreaterEqual.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_GreaterEqual.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "greater_equal" - deprecation_message: "tf.greater_equal is deprecated, please use tf.math.greater_equal instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_IFFT.pbtxt b/tensorflow/core/api_def/python_api/api_def_IFFT.pbtxt index 267ad8d0a0..17fbd8ace4 100644 --- a/tensorflow/core/api_def/python_api/api_def_IFFT.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_IFFT.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "ifft" - deprecation_message: "tf.ifft is deprecated, please use tf.spectral.ifft instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Igamma.pbtxt b/tensorflow/core/api_def/python_api/api_def_Igamma.pbtxt index 4e7e3a6e57..8c4815c26e 100644 --- a/tensorflow/core/api_def/python_api/api_def_Igamma.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Igamma.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "igamma" - deprecation_message: "tf.igamma is deprecated, please use tf.math.igamma instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Igammac.pbtxt b/tensorflow/core/api_def/python_api/api_def_Igammac.pbtxt index ea92a0916b..b43b54391b 100644 --- a/tensorflow/core/api_def/python_api/api_def_Igammac.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Igammac.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "igammac" - deprecation_message: "tf.igammac is deprecated, please use tf.math.igammac instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_InvertPermutation.pbtxt b/tensorflow/core/api_def/python_api/api_def_InvertPermutation.pbtxt index bce642b96a..d75fcd63e3 100644 --- a/tensorflow/core/api_def/python_api/api_def_InvertPermutation.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_InvertPermutation.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "invert_permutation" - deprecation_message: "tf.invert_permutation is deprecated, please use tf.math.invert_permutation instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_IsFinite.pbtxt b/tensorflow/core/api_def/python_api/api_def_IsFinite.pbtxt index a2c12f2ea0..27142644bf 100644 --- a/tensorflow/core/api_def/python_api/api_def_IsFinite.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_IsFinite.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "is_finite" - deprecation_message: "tf.is_finite is deprecated, please use tf.debugging.is_finite instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_IsInf.pbtxt b/tensorflow/core/api_def/python_api/api_def_IsInf.pbtxt index 7c29811fd7..4cd92f1cb7 100644 --- a/tensorflow/core/api_def/python_api/api_def_IsInf.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_IsInf.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "is_inf" - deprecation_message: "tf.is_inf is deprecated, please use tf.debugging.is_inf instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_IsNan.pbtxt b/tensorflow/core/api_def/python_api/api_def_IsNan.pbtxt index 459cf3ccbd..07d49f9436 100644 --- a/tensorflow/core/api_def/python_api/api_def_IsNan.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_IsNan.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "is_nan" - deprecation_message: "tf.is_nan is deprecated, please use tf.debugging.is_nan instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Less.pbtxt b/tensorflow/core/api_def/python_api/api_def_Less.pbtxt index 15cbdc6d8e..055df2922a 100644 --- a/tensorflow/core/api_def/python_api/api_def_Less.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Less.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "less" - deprecation_message: "tf.less is deprecated, please use tf.math.less instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_LessEqual.pbtxt b/tensorflow/core/api_def/python_api/api_def_LessEqual.pbtxt index 35aa18698f..d2803ddb69 100644 --- a/tensorflow/core/api_def/python_api/api_def_LessEqual.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_LessEqual.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "less_equal" - deprecation_message: "tf.less_equal is deprecated, please use tf.math.less_equal instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Lgamma.pbtxt b/tensorflow/core/api_def/python_api/api_def_Lgamma.pbtxt index 89886b09d3..0262b838ca 100644 --- a/tensorflow/core/api_def/python_api/api_def_Lgamma.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Lgamma.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "lgamma" - deprecation_message: "tf.lgamma is deprecated, please use tf.math.lgamma instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Log.pbtxt b/tensorflow/core/api_def/python_api/api_def_Log.pbtxt index fb82aa7e43..26d2473b9c 100644 --- a/tensorflow/core/api_def/python_api/api_def_Log.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Log.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "log" - deprecation_message: "tf.log is deprecated, please use tf.math.log instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Log1p.pbtxt b/tensorflow/core/api_def/python_api/api_def_Log1p.pbtxt index 6b451aa546..d85b6dccec 100644 --- a/tensorflow/core/api_def/python_api/api_def_Log1p.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Log1p.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "log1p" - deprecation_message: "tf.log1p is deprecated, please use tf.math.log1p instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_LogicalAnd.pbtxt b/tensorflow/core/api_def/python_api/api_def_LogicalAnd.pbtxt index 403a8c71ff..80bd98b740 100644 --- a/tensorflow/core/api_def/python_api/api_def_LogicalAnd.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_LogicalAnd.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "logical_and" - deprecation_message: "tf.logical_and is deprecated, please use tf.math.logical_and instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_LogicalNot.pbtxt b/tensorflow/core/api_def/python_api/api_def_LogicalNot.pbtxt index f228958c77..b2244c44b1 100644 --- a/tensorflow/core/api_def/python_api/api_def_LogicalNot.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_LogicalNot.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "logical_not" - deprecation_message: "tf.logical_not is deprecated, please use tf.math.logical_not instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_LogicalOr.pbtxt b/tensorflow/core/api_def/python_api/api_def_LogicalOr.pbtxt index ab89f236e7..cf78b52e07 100644 --- a/tensorflow/core/api_def/python_api/api_def_LogicalOr.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_LogicalOr.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "logical_or" - deprecation_message: "tf.logical_or is deprecated, please use tf.math.logical_or instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_MatchingFiles.pbtxt b/tensorflow/core/api_def/python_api/api_def_MatchingFiles.pbtxt index 8930d66940..74145670a8 100644 --- a/tensorflow/core/api_def/python_api/api_def_MatchingFiles.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_MatchingFiles.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "matching_files" - deprecation_message: "tf.matching_files is deprecated, please use tf.io.matching_files instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_MatrixBandPart.pbtxt b/tensorflow/core/api_def/python_api/api_def_MatrixBandPart.pbtxt index bad2f03f32..1122c52ab4 100644 --- a/tensorflow/core/api_def/python_api/api_def_MatrixBandPart.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_MatrixBandPart.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "matrix_band_part" - deprecation_message: "tf.matrix_band_part is deprecated, please use tf.linalg.band_part instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_MatrixDeterminant.pbtxt b/tensorflow/core/api_def/python_api/api_def_MatrixDeterminant.pbtxt index d241d4d721..9563bf0354 100644 --- a/tensorflow/core/api_def/python_api/api_def_MatrixDeterminant.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_MatrixDeterminant.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "matrix_determinant" - deprecation_message: "tf.matrix_determinant is deprecated, please use tf.linalg.det instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_MatrixDiag.pbtxt b/tensorflow/core/api_def/python_api/api_def_MatrixDiag.pbtxt index 208b37e297..8ab0bf75eb 100644 --- a/tensorflow/core/api_def/python_api/api_def_MatrixDiag.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_MatrixDiag.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "matrix_diag" - deprecation_message: "tf.matrix_diag is deprecated, please use tf.linalg.diag instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_MatrixDiagPart.pbtxt b/tensorflow/core/api_def/python_api/api_def_MatrixDiagPart.pbtxt index a8a50e8a89..82ce67853c 100644 --- a/tensorflow/core/api_def/python_api/api_def_MatrixDiagPart.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_MatrixDiagPart.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "matrix_diag_part" - deprecation_message: "tf.matrix_diag_part is deprecated, please use tf.linalg.diag_part instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_MatrixInverse.pbtxt b/tensorflow/core/api_def/python_api/api_def_MatrixInverse.pbtxt index 944513fcd9..85862f6eb5 100644 --- a/tensorflow/core/api_def/python_api/api_def_MatrixInverse.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_MatrixInverse.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "matrix_inverse" - deprecation_message: "tf.matrix_inverse is deprecated, please use tf.linalg.inv instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_MatrixSetDiag.pbtxt b/tensorflow/core/api_def/python_api/api_def_MatrixSetDiag.pbtxt index a6080dbc2d..6325e4f0e6 100644 --- a/tensorflow/core/api_def/python_api/api_def_MatrixSetDiag.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_MatrixSetDiag.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "matrix_set_diag" - deprecation_message: "tf.matrix_set_diag is deprecated, please use tf.linalg.set_diag instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_MatrixSolve.pbtxt b/tensorflow/core/api_def/python_api/api_def_MatrixSolve.pbtxt index caba80326b..6325dff407 100644 --- a/tensorflow/core/api_def/python_api/api_def_MatrixSolve.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_MatrixSolve.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "matrix_solve" - deprecation_message: "tf.matrix_solve is deprecated, please use tf.linalg.solve instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_MatrixTriangularSolve.pbtxt b/tensorflow/core/api_def/python_api/api_def_MatrixTriangularSolve.pbtxt index a4dfa538ed..7f865e23b2 100644 --- a/tensorflow/core/api_def/python_api/api_def_MatrixTriangularSolve.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_MatrixTriangularSolve.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "matrix_triangular_solve" - deprecation_message: "tf.matrix_triangular_solve is deprecated, please use tf.linalg.triangular_solve instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Maximum.pbtxt b/tensorflow/core/api_def/python_api/api_def_Maximum.pbtxt index 90af9e145b..bcff379b71 100644 --- a/tensorflow/core/api_def/python_api/api_def_Maximum.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Maximum.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "maximum" - deprecation_message: "tf.maximum is deprecated, please use tf.math.maximum instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Minimum.pbtxt b/tensorflow/core/api_def/python_api/api_def_Minimum.pbtxt index 33bcd6f667..9aae74226a 100644 --- a/tensorflow/core/api_def/python_api/api_def_Minimum.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Minimum.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "minimum" - deprecation_message: "tf.minimum is deprecated, please use tf.math.minimum instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_NonMaxSuppressionWithOverlaps.pbtxt b/tensorflow/core/api_def/python_api/api_def_NonMaxSuppressionWithOverlaps.pbtxt new file mode 100644 index 0000000000..0d358dff98 --- /dev/null +++ b/tensorflow/core/api_def/python_api/api_def_NonMaxSuppressionWithOverlaps.pbtxt @@ -0,0 +1,4 @@ +op { + graph_op_name: "NonMaxSuppressionWithOverlaps" + visibility: HIDDEN +} diff --git a/tensorflow/core/api_def/python_api/api_def_NotEqual.pbtxt b/tensorflow/core/api_def/python_api/api_def_NotEqual.pbtxt index 385565daaf..f37317854f 100644 --- a/tensorflow/core/api_def/python_api/api_def_NotEqual.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_NotEqual.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "not_equal" - deprecation_message: "tf.not_equal is deprecated, please use tf.math.not_equal instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_ParseTensor.pbtxt b/tensorflow/core/api_def/python_api/api_def_ParseTensor.pbtxt index 29f02ab1ac..10b3aab0c7 100644 --- a/tensorflow/core/api_def/python_api/api_def_ParseTensor.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_ParseTensor.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "parse_tensor" - deprecation_message: "tf.parse_tensor is deprecated, please use tf.io.parse_tensor instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Polygamma.pbtxt b/tensorflow/core/api_def/python_api/api_def_Polygamma.pbtxt index 567a448642..9df81402d5 100644 --- a/tensorflow/core/api_def/python_api/api_def_Polygamma.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Polygamma.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "polygamma" - deprecation_message: "tf.polygamma is deprecated, please use tf.math.polygamma instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Qr.pbtxt b/tensorflow/core/api_def/python_api/api_def_Qr.pbtxt index a9371b5d9b..0260eecc91 100644 --- a/tensorflow/core/api_def/python_api/api_def_Qr.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Qr.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "qr" - deprecation_message: "tf.qr is deprecated, please use tf.linalg.qr instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_QuantizedConcat.pbtxt b/tensorflow/core/api_def/python_api/api_def_QuantizedConcat.pbtxt index 44508ef079..69404b9472 100644 --- a/tensorflow/core/api_def/python_api/api_def_QuantizedConcat.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_QuantizedConcat.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "quantized_concat" - deprecation_message: "tf.quantized_concat is deprecated, please use tf.quantization.quantized_concat instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_ReadFile.pbtxt b/tensorflow/core/api_def/python_api/api_def_ReadFile.pbtxt index 7c38fae31c..9d479be45f 100644 --- a/tensorflow/core/api_def/python_api/api_def_ReadFile.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_ReadFile.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "read_file" - deprecation_message: "tf.read_file is deprecated, please use tf.io.read_file instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Reciprocal.pbtxt b/tensorflow/core/api_def/python_api/api_def_Reciprocal.pbtxt index 0f37e99f4f..c4d4c27722 100644 --- a/tensorflow/core/api_def/python_api/api_def_Reciprocal.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Reciprocal.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "reciprocal" - deprecation_message: "tf.reciprocal is deprecated, please use tf.math.reciprocal instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_RegexReplace.pbtxt b/tensorflow/core/api_def/python_api/api_def_RegexReplace.pbtxt index 6938e20e57..b17806b338 100644 --- a/tensorflow/core/api_def/python_api/api_def_RegexReplace.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_RegexReplace.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "regex_replace" - deprecation_message: "tf.regex_replace is deprecated, please use tf.strings.regex_replace instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Reshape.pbtxt b/tensorflow/core/api_def/python_api/api_def_Reshape.pbtxt index 907d95a6f0..c469665b66 100644 --- a/tensorflow/core/api_def/python_api/api_def_Reshape.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Reshape.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "reshape" - deprecation_message: "tf.reshape is deprecated, please use tf.manip.reshape instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_ReverseV2.pbtxt b/tensorflow/core/api_def/python_api/api_def_ReverseV2.pbtxt index bbe9e97d60..77f595927b 100644 --- a/tensorflow/core/api_def/python_api/api_def_ReverseV2.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_ReverseV2.pbtxt @@ -5,10 +5,10 @@ op { } endpoint { name: "reverse" - deprecation_message: "tf.reverse is deprecated, please use tf.manip.reverse instead." + deprecated: true } endpoint { name: "reverse_v2" - deprecation_message: "tf.reverse_v2 is deprecated, please use tf.manip.reverse instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Rint.pbtxt b/tensorflow/core/api_def/python_api/api_def_Rint.pbtxt index 4330a80d04..ec37a23127 100644 --- a/tensorflow/core/api_def/python_api/api_def_Rint.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Rint.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "rint" - deprecation_message: "tf.rint is deprecated, please use tf.math.rint instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Rsqrt.pbtxt b/tensorflow/core/api_def/python_api/api_def_Rsqrt.pbtxt index 6a45f4aff5..4fc2b81421 100644 --- a/tensorflow/core/api_def/python_api/api_def_Rsqrt.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Rsqrt.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "rsqrt" - deprecation_message: "tf.rsqrt is deprecated, please use tf.math.rsqrt instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_ScatterNd.pbtxt b/tensorflow/core/api_def/python_api/api_def_ScatterNd.pbtxt index cabf171cb0..a65a19b542 100644 --- a/tensorflow/core/api_def/python_api/api_def_ScatterNd.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_ScatterNd.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "scatter_nd" - deprecation_message: "tf.scatter_nd is deprecated, please use tf.manip.scatter_nd instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_SegmentMax.pbtxt b/tensorflow/core/api_def/python_api/api_def_SegmentMax.pbtxt index 65e34a1fcf..2e22c375c0 100644 --- a/tensorflow/core/api_def/python_api/api_def_SegmentMax.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_SegmentMax.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "segment_max" - deprecation_message: "tf.segment_max is deprecated, please use tf.math.segment_max instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_SegmentMean.pbtxt b/tensorflow/core/api_def/python_api/api_def_SegmentMean.pbtxt index f1e19c5571..646348072f 100644 --- a/tensorflow/core/api_def/python_api/api_def_SegmentMean.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_SegmentMean.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "segment_mean" - deprecation_message: "tf.segment_mean is deprecated, please use tf.math.segment_mean instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_SegmentMin.pbtxt b/tensorflow/core/api_def/python_api/api_def_SegmentMin.pbtxt index fd9a3c380d..1a77019a2d 100644 --- a/tensorflow/core/api_def/python_api/api_def_SegmentMin.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_SegmentMin.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "segment_min" - deprecation_message: "tf.segment_min is deprecated, please use tf.math.segment_min instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_SegmentProd.pbtxt b/tensorflow/core/api_def/python_api/api_def_SegmentProd.pbtxt index f2be8baafc..cf4d6f0237 100644 --- a/tensorflow/core/api_def/python_api/api_def_SegmentProd.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_SegmentProd.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "segment_prod" - deprecation_message: "tf.segment_prod is deprecated, please use tf.math.segment_prod instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_SegmentSum.pbtxt b/tensorflow/core/api_def/python_api/api_def_SegmentSum.pbtxt index c7cc1d0c9f..c6d7999455 100644 --- a/tensorflow/core/api_def/python_api/api_def_SegmentSum.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_SegmentSum.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "segment_sum" - deprecation_message: "tf.segment_sum is deprecated, please use tf.math.segment_sum instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Sin.pbtxt b/tensorflow/core/api_def/python_api/api_def_Sin.pbtxt index 0794334987..9c19a1a177 100644 --- a/tensorflow/core/api_def/python_api/api_def_Sin.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Sin.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "sin" - deprecation_message: "tf.sin is deprecated, please use tf.math.sin instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Sinh.pbtxt b/tensorflow/core/api_def/python_api/api_def_Sinh.pbtxt index c42f8678c6..155e58e6d5 100644 --- a/tensorflow/core/api_def/python_api/api_def_Sinh.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Sinh.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "sinh" - deprecation_message: "tf.sinh is deprecated, please use tf.math.sinh instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_SpaceToBatchND.pbtxt b/tensorflow/core/api_def/python_api/api_def_SpaceToBatchND.pbtxt index 63a7547e14..af323a6cf3 100644 --- a/tensorflow/core/api_def/python_api/api_def_SpaceToBatchND.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_SpaceToBatchND.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "space_to_batch_nd" - deprecation_message: "tf.space_to_batch_nd is deprecated, please use tf.manip.space_to_batch_nd instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_SquaredDifference.pbtxt b/tensorflow/core/api_def/python_api/api_def_SquaredDifference.pbtxt index 01a33a3346..4bab8cf00c 100644 --- a/tensorflow/core/api_def/python_api/api_def_SquaredDifference.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_SquaredDifference.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "squared_difference" - deprecation_message: "tf.squared_difference is deprecated, please use tf.math.squared_difference instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_StringJoin.pbtxt b/tensorflow/core/api_def/python_api/api_def_StringJoin.pbtxt index 53c1b8053d..46a7c0361e 100644 --- a/tensorflow/core/api_def/python_api/api_def_StringJoin.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_StringJoin.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "string_join" - deprecation_message: "tf.string_join is deprecated, please use tf.strings.join instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_StringStrip.pbtxt b/tensorflow/core/api_def/python_api/api_def_StringStrip.pbtxt index 364806e1f5..fbcdeaad6d 100644 --- a/tensorflow/core/api_def/python_api/api_def_StringStrip.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_StringStrip.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "string_strip" - deprecation_message: "tf.string_strip is deprecated, please use tf.strings.strip instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_StringToHashBucket.pbtxt b/tensorflow/core/api_def/python_api/api_def_StringToHashBucket.pbtxt index b0e93d2b22..d122e79b39 100644 --- a/tensorflow/core/api_def/python_api/api_def_StringToHashBucket.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_StringToHashBucket.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "string_to_hash_bucket" - deprecation_message: "tf.string_to_hash_bucket is deprecated, please use tf.strings.to_hash_bucket instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_StringToHashBucketFast.pbtxt b/tensorflow/core/api_def/python_api/api_def_StringToHashBucketFast.pbtxt index 9576e1a9de..aef9dffefe 100644 --- a/tensorflow/core/api_def/python_api/api_def_StringToHashBucketFast.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_StringToHashBucketFast.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "string_to_hash_bucket_fast" - deprecation_message: "tf.string_to_hash_bucket_fast is deprecated, please use tf.strings.to_hash_bucket_fast instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_StringToHashBucketStrong.pbtxt b/tensorflow/core/api_def/python_api/api_def_StringToHashBucketStrong.pbtxt index e8c7c12608..385b9fd02a 100644 --- a/tensorflow/core/api_def/python_api/api_def_StringToHashBucketStrong.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_StringToHashBucketStrong.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "string_to_hash_bucket_strong" - deprecation_message: "tf.string_to_hash_bucket_strong is deprecated, please use tf.strings.to_hash_bucket_strong instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_StringToNumber.pbtxt b/tensorflow/core/api_def/python_api/api_def_StringToNumber.pbtxt index 9de1ca0b30..f740b9849d 100644 --- a/tensorflow/core/api_def/python_api/api_def_StringToNumber.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_StringToNumber.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "string_to_number" - deprecation_message: "tf.string_to_number is deprecated, please use tf.strings.to_number instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Substr.pbtxt b/tensorflow/core/api_def/python_api/api_def_Substr.pbtxt index 25d1bb3f51..4778d7927c 100644 --- a/tensorflow/core/api_def/python_api/api_def_Substr.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Substr.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "substr" - deprecation_message: "tf.substr is deprecated, please use tf.strings.substr instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Tan.pbtxt b/tensorflow/core/api_def/python_api/api_def_Tan.pbtxt index 8bcf381dd4..ffa92f5580 100644 --- a/tensorflow/core/api_def/python_api/api_def_Tan.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Tan.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "tan" - deprecation_message: "tf.tan is deprecated, please use tf.math.tan instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Tile.pbtxt b/tensorflow/core/api_def/python_api/api_def_Tile.pbtxt index 0b9053a529..c34061c941 100644 --- a/tensorflow/core/api_def/python_api/api_def_Tile.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Tile.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "tile" - deprecation_message: "tf.tile is deprecated, please use tf.manip.tile instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_UnsortedSegmentMax.pbtxt b/tensorflow/core/api_def/python_api/api_def_UnsortedSegmentMax.pbtxt index 1ea59d2e63..cf81843241 100644 --- a/tensorflow/core/api_def/python_api/api_def_UnsortedSegmentMax.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_UnsortedSegmentMax.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "unsorted_segment_max" - deprecation_message: "tf.unsorted_segment_max is deprecated, please use tf.math.unsorted_segment_max instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_UnsortedSegmentMin.pbtxt b/tensorflow/core/api_def/python_api/api_def_UnsortedSegmentMin.pbtxt index 9857def6fe..475361c85a 100644 --- a/tensorflow/core/api_def/python_api/api_def_UnsortedSegmentMin.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_UnsortedSegmentMin.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "unsorted_segment_min" - deprecation_message: "tf.unsorted_segment_min is deprecated, please use tf.math.unsorted_segment_min instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_UnsortedSegmentProd.pbtxt b/tensorflow/core/api_def/python_api/api_def_UnsortedSegmentProd.pbtxt index d9e3f7be69..a9d741bbc3 100644 --- a/tensorflow/core/api_def/python_api/api_def_UnsortedSegmentProd.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_UnsortedSegmentProd.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "unsorted_segment_prod" - deprecation_message: "tf.unsorted_segment_prod is deprecated, please use tf.math.unsorted_segment_prod instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_UnsortedSegmentSum.pbtxt b/tensorflow/core/api_def/python_api/api_def_UnsortedSegmentSum.pbtxt index 0cffd12404..337678dcff 100644 --- a/tensorflow/core/api_def/python_api/api_def_UnsortedSegmentSum.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_UnsortedSegmentSum.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "unsorted_segment_sum" - deprecation_message: "tf.unsorted_segment_sum is deprecated, please use tf.math.unsorted_segment_sum instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_WriteFile.pbtxt b/tensorflow/core/api_def/python_api/api_def_WriteFile.pbtxt index f28a9151ca..1a58ae19e5 100644 --- a/tensorflow/core/api_def/python_api/api_def_WriteFile.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_WriteFile.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "write_file" - deprecation_message: "tf.write_file is deprecated, please use tf.io.write_file instead." + deprecated: true } } diff --git a/tensorflow/core/api_def/python_api/api_def_Zeta.pbtxt b/tensorflow/core/api_def/python_api/api_def_Zeta.pbtxt index a84ffcdf14..4684a9d624 100644 --- a/tensorflow/core/api_def/python_api/api_def_Zeta.pbtxt +++ b/tensorflow/core/api_def/python_api/api_def_Zeta.pbtxt @@ -5,6 +5,6 @@ op { } endpoint { name: "zeta" - deprecation_message: "tf.zeta is deprecated, please use tf.math.zeta instead." + deprecated: true } } diff --git a/tensorflow/core/distributed_runtime/BUILD b/tensorflow/core/distributed_runtime/BUILD index 693b6b205f..2059b1ce0d 100644 --- a/tensorflow/core/distributed_runtime/BUILD +++ b/tensorflow/core/distributed_runtime/BUILD @@ -638,12 +638,12 @@ tf_cuda_cc_test( "//tensorflow/core:lib", "//tensorflow/core:lib_internal", "//tensorflow/core:master_proto_cc", - "//tensorflow/core:master_service_proto_cc", "//tensorflow/core:protos_all_cc", "//tensorflow/core:test", "//tensorflow/core:test_main", "//tensorflow/core:testlib", "//tensorflow/core/distributed_runtime/rpc:grpc_channel", + "//tensorflow/core/distributed_runtime/rpc:grpc_master_service_impl", "//tensorflow/core/distributed_runtime/rpc:grpc_testlib", "//tensorflow/core/distributed_runtime/rpc:grpc_util", "//tensorflow/core/distributed_runtime/rpc:grpc_worker_cache", diff --git a/tensorflow/core/distributed_runtime/master_test.cc b/tensorflow/core/distributed_runtime/master_test.cc index 09e96cbd40..62b18a45b1 100644 --- a/tensorflow/core/distributed_runtime/master_test.cc +++ b/tensorflow/core/distributed_runtime/master_test.cc @@ -21,6 +21,7 @@ limitations under the License. #include "grpcpp/grpcpp.h" #include "tensorflow/core/distributed_runtime/rpc/grpc_channel.h" +#include "tensorflow/core/distributed_runtime/rpc/grpc_master_service_impl.h" #include "tensorflow/core/distributed_runtime/rpc/grpc_testlib.h" #include "tensorflow/core/distributed_runtime/rpc/grpc_util.h" #include "tensorflow/core/framework/allocator.h" @@ -37,7 +38,6 @@ limitations under the License. #include "tensorflow/core/platform/test.h" #include "tensorflow/core/platform/types.h" #include "tensorflow/core/protobuf/master.pb.h" -#include "tensorflow/core/protobuf/master_service.grpc.pb.h" namespace tensorflow { diff --git a/tensorflow/core/distributed_runtime/rpc/BUILD b/tensorflow/core/distributed_runtime/rpc/BUILD index d6c493c022..4a10d99a60 100644 --- a/tensorflow/core/distributed_runtime/rpc/BUILD +++ b/tensorflow/core/distributed_runtime/rpc/BUILD @@ -201,11 +201,11 @@ cc_library( srcs = ["grpc_remote_master.cc"], hdrs = ["grpc_remote_master.h"], deps = [ + ":grpc_master_service_impl", ":grpc_util", "//tensorflow/core:lib", "//tensorflow/core:lib_internal", "//tensorflow/core:master_proto_cc", - "//tensorflow/core:master_service_proto_cc", "//tensorflow/core/distributed_runtime:call_options", "//tensorflow/core/distributed_runtime:master_interface", ], @@ -219,18 +219,28 @@ cc_library( deps = [ ":async_service_interface", ":grpc_call", + ":grpc_master_service_impl", ":grpc_util", "//tensorflow:grpc++", "//tensorflow/core:lib", "//tensorflow/core:lib_internal", "//tensorflow/core:master_proto_cc", - "//tensorflow/core:master_service_proto_cc", "//tensorflow/core/distributed_runtime:master", ], alwayslink = 1, ) cc_library( + name = "grpc_master_service_impl", + srcs = ["grpc_master_service_impl.cc"], + hdrs = ["grpc_master_service_impl.h"], + deps = [ + "//tensorflow:grpc++", + "//tensorflow/core:master_proto_cc", + ], +) + +cc_library( name = "rpc_rendezvous_mgr", srcs = ["rpc_rendezvous_mgr.cc"], hdrs = ["rpc_rendezvous_mgr.h"], diff --git a/tensorflow/core/distributed_runtime/rpc/grpc_channel.cc b/tensorflow/core/distributed_runtime/rpc/grpc_channel.cc index 0ebc084cb6..b7eb3c9015 100644 --- a/tensorflow/core/distributed_runtime/rpc/grpc_channel.cc +++ b/tensorflow/core/distributed_runtime/rpc/grpc_channel.cc @@ -42,12 +42,12 @@ string MakeAddress(const string& job, int task) { return strings::StrCat("/job:", job, "/replica:0/task:", task); } +// Allows the host to be a raw IP (either v4 or v6). Status ValidateHostPortPair(const string& host_port) { uint32 port; - std::vector<string> parts = str_util::Split(host_port, ':'); - // Must be host:port, port must be a number, host must not contain a '/'. - if (parts.size() != 2 || !strings::safe_strtou32(parts[1], &port) || - parts[0].find("/") != string::npos) { + auto colon_index = host_port.find_last_of(':'); + if (!strings::safe_strtou32(host_port.substr(colon_index + 1), &port) || + host_port.substr(0, colon_index).find("/") != string::npos) { return errors::InvalidArgument("Could not interpret \"", host_port, "\" as a host-port pair."); } diff --git a/tensorflow/core/distributed_runtime/rpc/grpc_channel_test.cc b/tensorflow/core/distributed_runtime/rpc/grpc_channel_test.cc index a17acc85b3..f07a5a0974 100644 --- a/tensorflow/core/distributed_runtime/rpc/grpc_channel_test.cc +++ b/tensorflow/core/distributed_runtime/rpc/grpc_channel_test.cc @@ -150,10 +150,15 @@ TEST(GrpcChannelTest, NewHostPortGrpcChannelValidation) { EXPECT_TRUE(NewHostPortGrpcChannel("127.0.0.1:2222", &mock_ptr).ok()); EXPECT_TRUE(NewHostPortGrpcChannel("example.com:2222", &mock_ptr).ok()); EXPECT_TRUE(NewHostPortGrpcChannel("fqdn.example.com.:2222", &mock_ptr).ok()); + EXPECT_TRUE(NewHostPortGrpcChannel("[2002:a9c:258e::]:2222", &mock_ptr).ok()); + EXPECT_TRUE(NewHostPortGrpcChannel("[::]:2222", &mock_ptr).ok()); EXPECT_FALSE(NewHostPortGrpcChannel("example.com/abc:2222", &mock_ptr).ok()); EXPECT_FALSE(NewHostPortGrpcChannel("127.0.0.1:2222/", &mock_ptr).ok()); EXPECT_FALSE(NewHostPortGrpcChannel("example.com/abc:", &mock_ptr).ok()); + EXPECT_FALSE(NewHostPortGrpcChannel("[::]/:2222", &mock_ptr).ok()); + EXPECT_FALSE(NewHostPortGrpcChannel("[::]:2222/", &mock_ptr).ok()); + EXPECT_FALSE(NewHostPortGrpcChannel("[::]:", &mock_ptr).ok()); } } // namespace tensorflow diff --git a/tensorflow/core/distributed_runtime/rpc/grpc_master_service.cc b/tensorflow/core/distributed_runtime/rpc/grpc_master_service.cc index 2c2c1d484a..127dea2882 100644 --- a/tensorflow/core/distributed_runtime/rpc/grpc_master_service.cc +++ b/tensorflow/core/distributed_runtime/rpc/grpc_master_service.cc @@ -36,12 +36,12 @@ limitations under the License. #include "tensorflow/core/distributed_runtime/master.h" #include "tensorflow/core/distributed_runtime/rpc/async_service_interface.h" #include "tensorflow/core/distributed_runtime/rpc/grpc_call.h" +#include "tensorflow/core/distributed_runtime/rpc/grpc_master_service_impl.h" #include "tensorflow/core/distributed_runtime/rpc/grpc_util.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/macros.h" #include "tensorflow/core/platform/tracing.h" #include "tensorflow/core/protobuf/master.pb.h" -#include "tensorflow/core/protobuf/master_service.grpc.pb.h" namespace tensorflow { diff --git a/tensorflow/core/distributed_runtime/rpc/grpc_master_service_impl.cc b/tensorflow/core/distributed_runtime/rpc/grpc_master_service_impl.cc new file mode 100644 index 0000000000..770a0fcf14 --- /dev/null +++ b/tensorflow/core/distributed_runtime/rpc/grpc_master_service_impl.cc @@ -0,0 +1,164 @@ +/* Copyright 2016 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/core/distributed_runtime/rpc/grpc_master_service_impl.h" + +#include "grpcpp/impl/codegen/async_stream.h" +#include "grpcpp/impl/codegen/async_unary_call.h" +#include "grpcpp/impl/codegen/channel_interface.h" +#include "grpcpp/impl/codegen/client_unary_call.h" +#include "grpcpp/impl/codegen/method_handler_impl.h" +#include "grpcpp/impl/codegen/rpc_service_method.h" +#include "grpcpp/impl/codegen/service_type.h" +#include "grpcpp/impl/codegen/sync_stream.h" + +namespace tensorflow { + +namespace grpc { + +static const char* grpcMasterService_method_names[] = { + "/tensorflow.MasterService/CreateSession", + "/tensorflow.MasterService/ExtendSession", + "/tensorflow.MasterService/PartialRunSetup", + "/tensorflow.MasterService/RunStep", + "/tensorflow.MasterService/CloseSession", + "/tensorflow.MasterService/ListDevices", + "/tensorflow.MasterService/Reset", + "/tensorflow.MasterService/MakeCallable", + "/tensorflow.MasterService/RunCallable", + "/tensorflow.MasterService/ReleaseCallable", +}; + +std::unique_ptr<MasterService::Stub> MasterService::NewStub( + const std::shared_ptr< ::grpc::ChannelInterface>& channel, + const ::grpc::StubOptions& options) { + std::unique_ptr<MasterService::Stub> stub(new MasterService::Stub(channel)); + return stub; +} + +MasterService::Stub::Stub( + const std::shared_ptr< ::grpc::ChannelInterface>& channel) + : channel_(channel), + rpcmethod_CreateSession_(grpcMasterService_method_names[0], + ::grpc::internal::RpcMethod::NORMAL_RPC, + channel), + rpcmethod_ExtendSession_(grpcMasterService_method_names[1], + ::grpc::internal::RpcMethod::NORMAL_RPC, + channel), + rpcmethod_PartialRunSetup_(grpcMasterService_method_names[2], + ::grpc::internal::RpcMethod::NORMAL_RPC, + channel), + rpcmethod_RunStep_(grpcMasterService_method_names[3], + ::grpc::internal::RpcMethod::NORMAL_RPC, channel), + rpcmethod_CloseSession_(grpcMasterService_method_names[4], + ::grpc::internal::RpcMethod::NORMAL_RPC, channel), + rpcmethod_ListDevices_(grpcMasterService_method_names[5], + ::grpc::internal::RpcMethod::NORMAL_RPC, channel), + rpcmethod_Reset_(grpcMasterService_method_names[6], + ::grpc::internal::RpcMethod::NORMAL_RPC, channel), + rpcmethod_MakeCallable_(grpcMasterService_method_names[7], + ::grpc::internal::RpcMethod::NORMAL_RPC, channel), + rpcmethod_RunCallable_(grpcMasterService_method_names[8], + ::grpc::internal::RpcMethod::NORMAL_RPC, channel), + rpcmethod_ReleaseCallable_(grpcMasterService_method_names[9], + ::grpc::internal::RpcMethod::NORMAL_RPC, + channel) {} + +::grpc::Status MasterService::Stub::CreateSession( + ::grpc::ClientContext* context, const CreateSessionRequest& request, + CreateSessionResponse* response) { + return ::grpc::internal::BlockingUnaryCall( + channel_.get(), rpcmethod_CreateSession_, context, request, response); +} + +::grpc::Status MasterService::Stub::ExtendSession( + ::grpc::ClientContext* context, const ExtendSessionRequest& request, + ExtendSessionResponse* response) { + return ::grpc::internal::BlockingUnaryCall( + channel_.get(), rpcmethod_ExtendSession_, context, request, response); +} + +::grpc::Status MasterService::Stub::PartialRunSetup( + ::grpc::ClientContext* context, const PartialRunSetupRequest& request, + PartialRunSetupResponse* response) { + return ::grpc::internal::BlockingUnaryCall( + channel_.get(), rpcmethod_PartialRunSetup_, context, request, response); +} + +::grpc::Status MasterService::Stub::RunStep(::grpc::ClientContext* context, + const RunStepRequest& request, + RunStepResponse* response) { + return ::grpc::internal::BlockingUnaryCall(channel_.get(), rpcmethod_RunStep_, + context, request, response); +} + +::grpc::Status MasterService::Stub::CloseSession( + ::grpc::ClientContext* context, const CloseSessionRequest& request, + CloseSessionResponse* response) { + return ::grpc::internal::BlockingUnaryCall( + channel_.get(), rpcmethod_CloseSession_, context, request, response); +} + +::grpc::Status MasterService::Stub::ListDevices( + ::grpc::ClientContext* context, const ListDevicesRequest& request, + ListDevicesResponse* response) { + return ::grpc::internal::BlockingUnaryCall( + channel_.get(), rpcmethod_ListDevices_, context, request, response); +} + +::grpc::Status MasterService::Stub::Reset(::grpc::ClientContext* context, + const ResetRequest& request, + ResetResponse* response) { + return ::grpc::internal::BlockingUnaryCall(channel_.get(), rpcmethod_Reset_, + context, request, response); +} + +::grpc::Status MasterService::Stub::MakeCallable( + ::grpc::ClientContext* context, const MakeCallableRequest& request, + MakeCallableResponse* response) { + return ::grpc::internal::BlockingUnaryCall( + channel_.get(), rpcmethod_MakeCallable_, context, request, response); +} + +::grpc::Status MasterService::Stub::RunCallable( + ::grpc::ClientContext* context, const RunCallableRequest& request, + RunCallableResponse* response) { + return ::grpc::internal::BlockingUnaryCall( + channel_.get(), rpcmethod_RunCallable_, context, request, response); +} + +::grpc::Status MasterService::Stub::ReleaseCallable( + ::grpc::ClientContext* context, const ReleaseCallableRequest& request, + ReleaseCallableResponse* response) { + return ::grpc::internal::BlockingUnaryCall( + channel_.get(), rpcmethod_ReleaseCallable_, context, request, response); +} + +MasterService::AsyncService::AsyncService() { + int method_len = sizeof(grpcMasterService_method_names) / + sizeof(grpcMasterService_method_names[0]); + for (int i = 0; i < method_len; ++i) { + AddMethod(new ::grpc::internal::RpcServiceMethod( + grpcMasterService_method_names[i], + ::grpc::internal::RpcMethod::NORMAL_RPC, nullptr)); + ::grpc::Service::MarkMethodAsync(i); + } +} + +MasterService::AsyncService::~AsyncService() {} + +} // namespace grpc + +} // namespace tensorflow diff --git a/tensorflow/core/distributed_runtime/rpc/grpc_master_service_impl.h b/tensorflow/core/distributed_runtime/rpc/grpc_master_service_impl.h new file mode 100644 index 0000000000..751f2633e7 --- /dev/null +++ b/tensorflow/core/distributed_runtime/rpc/grpc_master_service_impl.h @@ -0,0 +1,224 @@ +/* Copyright 2016 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CORE_DISTRIBUTED_RUNTIME_RPC_GRPC_MASTER_SERVICE_IMPL_H_ +#define TENSORFLOW_CORE_DISTRIBUTED_RUNTIME_RPC_GRPC_MASTER_SERVICE_IMPL_H_ + +#include "grpcpp/impl/codegen/async_stream.h" +#include "grpcpp/impl/codegen/async_unary_call.h" +#include "grpcpp/impl/codegen/proto_utils.h" +#include "grpcpp/impl/codegen/rpc_method.h" +#include "grpcpp/impl/codegen/service_type.h" +#include "grpcpp/impl/codegen/status.h" +#include "grpcpp/impl/codegen/stub_options.h" +#include "grpcpp/impl/codegen/sync_stream.h" + +#include "tensorflow/core/protobuf/master.pb.h" + +namespace grpc { +class CompletionQueue; +class Channel; +class RpcService; +class ServerCompletionQueue; +class ServerContext; +} // namespace grpc + +namespace tensorflow { + +namespace grpc { + +// Implementation of `tensorflow.MasterService`, based on the +// definition in "//tensorflow/core/protobuf/master_service.proto", +// and the gRPC generated stub and service classes. +// See that file for the definition of methods and messages. +class MasterService final { + public: + class StubInterface { + public: + virtual ~StubInterface() {} + virtual ::grpc::Status CreateSession(::grpc::ClientContext* context, + const CreateSessionRequest& request, + CreateSessionResponse* response) = 0; + virtual ::grpc::Status ExtendSession(::grpc::ClientContext* context, + const ExtendSessionRequest& request, + ExtendSessionResponse* response) = 0; + virtual ::grpc::Status PartialRunSetup( + ::grpc::ClientContext* context, const PartialRunSetupRequest& request, + PartialRunSetupResponse* response) = 0; + virtual ::grpc::Status RunStep(::grpc::ClientContext* context, + const RunStepRequest& request, + RunStepResponse* response) = 0; + virtual ::grpc::Status CloseSession(::grpc::ClientContext* context, + const CloseSessionRequest& request, + CloseSessionResponse* response) = 0; + virtual ::grpc::Status ListDevices(::grpc::ClientContext* context, + const ListDevicesRequest& request, + ListDevicesResponse* response) = 0; + virtual ::grpc::Status Reset(::grpc::ClientContext* context, + const ResetRequest& request, + ResetResponse* response) = 0; + virtual ::grpc::Status MakeCallable(::grpc::ClientContext* context, + const MakeCallableRequest& request, + MakeCallableResponse* response) = 0; + virtual ::grpc::Status RunCallable(::grpc::ClientContext* context, + const RunCallableRequest& request, + RunCallableResponse* response) = 0; + virtual ::grpc::Status ReleaseCallable( + ::grpc::ClientContext* context, const ReleaseCallableRequest& request, + ReleaseCallableResponse* response) = 0; + }; + class Stub final : public StubInterface { + public: + Stub(const std::shared_ptr< ::grpc::ChannelInterface>& channel); + ::grpc::Status CreateSession(::grpc::ClientContext* context, + const CreateSessionRequest& request, + CreateSessionResponse* response) override; + ::grpc::Status ExtendSession(::grpc::ClientContext* context, + const ExtendSessionRequest& request, + ExtendSessionResponse* response) override; + ::grpc::Status PartialRunSetup(::grpc::ClientContext* context, + const PartialRunSetupRequest& request, + PartialRunSetupResponse* response) override; + ::grpc::Status RunStep(::grpc::ClientContext* context, + const RunStepRequest& request, + RunStepResponse* response) override; + ::grpc::Status CloseSession(::grpc::ClientContext* context, + const CloseSessionRequest& request, + CloseSessionResponse* response) override; + ::grpc::Status ListDevices(::grpc::ClientContext* context, + const ListDevicesRequest& request, + ListDevicesResponse* response) override; + ::grpc::Status Reset(::grpc::ClientContext* context, + const ResetRequest& request, + ResetResponse* response) override; + ::grpc::Status MakeCallable(::grpc::ClientContext* context, + const MakeCallableRequest& request, + MakeCallableResponse* response) override; + ::grpc::Status RunCallable(::grpc::ClientContext* context, + const RunCallableRequest& request, + RunCallableResponse* response) override; + ::grpc::Status ReleaseCallable(::grpc::ClientContext* context, + const ReleaseCallableRequest& request, + ReleaseCallableResponse* response) override; + + private: + std::shared_ptr< ::grpc::ChannelInterface> channel_; + const ::grpc::internal::RpcMethod rpcmethod_CreateSession_; + const ::grpc::internal::RpcMethod rpcmethod_ExtendSession_; + const ::grpc::internal::RpcMethod rpcmethod_PartialRunSetup_; + const ::grpc::internal::RpcMethod rpcmethod_RunStep_; + const ::grpc::internal::RpcMethod rpcmethod_CloseSession_; + const ::grpc::internal::RpcMethod rpcmethod_ListDevices_; + const ::grpc::internal::RpcMethod rpcmethod_Reset_; + const ::grpc::internal::RpcMethod rpcmethod_MakeCallable_; + const ::grpc::internal::RpcMethod rpcmethod_RunCallable_; + const ::grpc::internal::RpcMethod rpcmethod_ReleaseCallable_; + }; + static std::unique_ptr<Stub> NewStub( + const std::shared_ptr< ::grpc::ChannelInterface>& channel, + const ::grpc::StubOptions& options = ::grpc::StubOptions()); + + class AsyncService : public ::grpc::Service { + public: + AsyncService(); + virtual ~AsyncService(); + void RequestCreateSession( + ::grpc::ServerContext* context, CreateSessionRequest* request, + ::grpc::ServerAsyncResponseWriter<CreateSessionResponse>* response, + ::grpc::CompletionQueue* new_call_cq, + ::grpc::ServerCompletionQueue* notification_cq, void* tag) { + ::grpc::Service::RequestAsyncUnary(0, context, request, response, + new_call_cq, notification_cq, tag); + } + void RequestExtendSession( + ::grpc::ServerContext* context, ExtendSessionRequest* request, + ::grpc::ServerAsyncResponseWriter<ExtendSessionResponse>* response, + ::grpc::CompletionQueue* new_call_cq, + ::grpc::ServerCompletionQueue* notification_cq, void* tag) { + ::grpc::Service::RequestAsyncUnary(1, context, request, response, + new_call_cq, notification_cq, tag); + } + void RequestPartialRunSetup( + ::grpc::ServerContext* context, PartialRunSetupRequest* request, + ::grpc::ServerAsyncResponseWriter<PartialRunSetupResponse>* response, + ::grpc::CompletionQueue* new_call_cq, + ::grpc::ServerCompletionQueue* notification_cq, void* tag) { + ::grpc::Service::RequestAsyncUnary(2, context, request, response, + new_call_cq, notification_cq, tag); + } + void RequestRunStep( + ::grpc::ServerContext* context, RunStepRequest* request, + ::grpc::ServerAsyncResponseWriter<RunStepResponse>* response, + ::grpc::CompletionQueue* new_call_cq, + ::grpc::ServerCompletionQueue* notification_cq, void* tag) { + ::grpc::Service::RequestAsyncUnary(3, context, request, response, + new_call_cq, notification_cq, tag); + } + void RequestCloseSession( + ::grpc::ServerContext* context, CloseSessionRequest* request, + ::grpc::ServerAsyncResponseWriter<CloseSessionResponse>* response, + ::grpc::CompletionQueue* new_call_cq, + ::grpc::ServerCompletionQueue* notification_cq, void* tag) { + ::grpc::Service::RequestAsyncUnary(4, context, request, response, + new_call_cq, notification_cq, tag); + } + void RequestListDevices( + ::grpc::ServerContext* context, ListDevicesRequest* request, + ::grpc::ServerAsyncResponseWriter<ListDevicesResponse>* response, + ::grpc::CompletionQueue* new_call_cq, + ::grpc::ServerCompletionQueue* notification_cq, void* tag) { + ::grpc::Service::RequestAsyncUnary(5, context, request, response, + new_call_cq, notification_cq, tag); + } + void RequestReset( + ::grpc::ServerContext* context, ResetRequest* request, + ::grpc::ServerAsyncResponseWriter<ResetResponse>* response, + ::grpc::CompletionQueue* new_call_cq, + ::grpc::ServerCompletionQueue* notification_cq, void* tag) { + ::grpc::Service::RequestAsyncUnary(6, context, request, response, + new_call_cq, notification_cq, tag); + } + void RequestMakeCallable( + ::grpc::ServerContext* context, MakeCallableRequest* request, + ::grpc::ServerAsyncResponseWriter<MakeCallableResponse>* response, + ::grpc::CompletionQueue* new_call_cq, + ::grpc::ServerCompletionQueue* notification_cq, void* tag) { + ::grpc::Service::RequestAsyncUnary(7, context, request, response, + new_call_cq, notification_cq, tag); + } + void RequestRunCallable( + ::grpc::ServerContext* context, RunCallableRequest* request, + ::grpc::ServerAsyncResponseWriter<RunCallableResponse>* response, + ::grpc::CompletionQueue* new_call_cq, + ::grpc::ServerCompletionQueue* notification_cq, void* tag) { + ::grpc::Service::RequestAsyncUnary(8, context, request, response, + new_call_cq, notification_cq, tag); + } + void RequestReleaseCallable( + ::grpc::ServerContext* context, ReleaseCallableRequest* request, + ::grpc::ServerAsyncResponseWriter<ReleaseCallableResponse>* response, + ::grpc::CompletionQueue* new_call_cq, + ::grpc::ServerCompletionQueue* notification_cq, void* tag) { + ::grpc::Service::RequestAsyncUnary(9, context, request, response, + new_call_cq, notification_cq, tag); + } + }; +}; + +} // namespace grpc + +} // namespace tensorflow + +#endif // TENSORFLOW_CORE_DISTRIBUTED_RUNTIME_RPC_GRPC_MASTER_SERVICE_IMPL_H_ diff --git a/tensorflow/core/distributed_runtime/rpc/grpc_remote_master.cc b/tensorflow/core/distributed_runtime/rpc/grpc_remote_master.cc index 6c2940553c..b832a2115c 100644 --- a/tensorflow/core/distributed_runtime/rpc/grpc_remote_master.cc +++ b/tensorflow/core/distributed_runtime/rpc/grpc_remote_master.cc @@ -19,13 +19,13 @@ limitations under the License. #include "tensorflow/core/distributed_runtime/call_options.h" #include "tensorflow/core/distributed_runtime/master_interface.h" +#include "tensorflow/core/distributed_runtime/rpc/grpc_master_service_impl.h" #include "tensorflow/core/distributed_runtime/rpc/grpc_util.h" #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/core/status.h" #include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/tracing.h" #include "tensorflow/core/protobuf/master.pb.h" -#include "tensorflow/core/protobuf/master_service.grpc.pb.h" namespace tensorflow { diff --git a/tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc b/tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc index 2c833d11a9..db14f6473e 100644 --- a/tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc +++ b/tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc @@ -152,16 +152,14 @@ Status GrpcServer::Init( " was not defined in job \"", server_def_.job_name(), "\""); } - const std::vector<string> hostname_port = - str_util::Split(iter->second, ':'); - if (hostname_port.size() != 2 || - !strings::safe_strto32(hostname_port[1], &requested_port)) { + auto colon_index = iter->second.find_last_of(':'); + if (!strings::safe_strto32(iter->second.substr(colon_index + 1), + &requested_port)) { return errors::InvalidArgument( "Could not parse port for local server from \"", iter->second, - "\""); - } else { - break; + "\"."); } + break; } } if (requested_port == -1) { @@ -343,11 +341,13 @@ Status GrpcServer::WorkerCacheFactory(const WorkerCacheFactoryOptions& options, const string host_port = channel_cache_->TranslateTask(name_prefix); int requested_port; - if (!strings::safe_strto32(str_util::Split(host_port, ':')[1], + auto colon_index = host_port.find_last_of(':'); + if (!strings::safe_strto32(host_port.substr(colon_index + 1), &requested_port)) { return errors::Internal("Could not parse port for local server from \"", - channel_cache_->TranslateTask(name_prefix), "\"."); + host_port, "\"."); } + if (requested_port != bound_port_) { return errors::InvalidArgument("Requested port ", requested_port, " differs from expected port ", bound_port_); diff --git a/tensorflow/core/framework/api_def.proto b/tensorflow/core/framework/api_def.proto index c6cda06342..f8553cf5bb 100644 --- a/tensorflow/core/framework/api_def.proto +++ b/tensorflow/core/framework/api_def.proto @@ -64,12 +64,6 @@ message ApiDef { // to use a non-deprecated endpoint instead will be printed. If all // endpoints are deprecated, set deprecation_message in ApiDef instead. bool deprecated = 3; - // Deprecated: set deprecated to "true" instead. We can auto-generate - // the message. - // If this endpoint is deprecated, set deprecation_message to a - // message that should be logged when the endpoint is used. - // The message should indicate alternative endpoint to use, if any. - string deprecation_message = 2; } repeated Endpoint endpoint = 3; diff --git a/tensorflow/core/grappler/costs/BUILD b/tensorflow/core/grappler/costs/BUILD index b054068299..f3dc2c2091 100644 --- a/tensorflow/core/grappler/costs/BUILD +++ b/tensorflow/core/grappler/costs/BUILD @@ -41,6 +41,7 @@ cc_library( visibility = ["//visibility:public"], deps = [ ":utils", + "//tensorflow/core/grappler/utils:functions", "//tensorflow/core/grappler/utils:topological_sort", "//tensorflow/core/grappler:graph_view", "//tensorflow/core/grappler:op_types", diff --git a/tensorflow/core/grappler/costs/graph_properties.cc b/tensorflow/core/grappler/costs/graph_properties.cc index 0c02876ac5..83a8326e79 100644 --- a/tensorflow/core/grappler/costs/graph_properties.cc +++ b/tensorflow/core/grappler/costs/graph_properties.cc @@ -28,6 +28,7 @@ limitations under the License. #include "tensorflow/core/grappler/graph_view.h" #include "tensorflow/core/grappler/op_types.h" #include "tensorflow/core/grappler/utils.h" +#include "tensorflow/core/grappler/utils/functions.h" #include "tensorflow/core/grappler/utils/topological_sort.h" #include "tensorflow/core/lib/strings/str_util.h" @@ -422,11 +423,108 @@ class SymbolicShapeRefiner { return it->second.inference_context.get(); } - // Forward the shapes from the function's fanin to the function body, - // then call PropagateShapes. - // Returns an error if 'node' is not a function node. - Status UpdateFunction(const NodeDef* node, bool* refined) { - return UpdateNode(node, refined); + // Forward the shapes from the function input nodes to + // the argument nodes (which are Placeholder nodes), then + // perform shape inference on the function body. + // + // Propagate shape information of final function body node + // to function node `node`. + // + // In the event of an error, UpdateNode will simply set `node`'s + // output shape to be Unknown. + Status UpdateFunction(const NodeDef* node) { + auto it = fun_to_grappler_function_item_.find(node->op()); + if (it == fun_to_grappler_function_item_.end()) { + return errors::InvalidArgument( + node->op(), " was not previously added to SymbolicShapeRefiner."); + } + + GrapplerFunctionItem& grappler_function_item = it->second; + GraphView gv(&grappler_function_item.graph); + + // Forward shapes from function input nodes to argument nodes. + for (int i = 0; i < grappler_function_item.inputs().size(); ++i) { + auto& fun_input = grappler_function_item.input(i); + if (fun_input.placeholders.size() > 1) { + // TODO(jmdecker): Handle case with multiple input placeholders + return errors::Unimplemented( + "Input arguments with multiple placeholders are not yet " + "supported."); + } + NodeDef* fun_node = gv.GetNode(fun_input.input_name); + const string& input = node->input(i); + const string& node_name = NodeName(input); + + if (IsControlInput(input)) { + return errors::FailedPrecondition( + "Function inputs should not contain control nodes."); + } + + NodeDef* input_node = graph_.GetNode(node_name); + if (input_node == nullptr) { + return errors::FailedPrecondition(node_name, + " was not found in the graph."); + } + + InferenceContext* input_inference_context = GetContext(input_node); + if (input_inference_context == nullptr) { + return errors::FailedPrecondition( + "Inference context has not been created for ", node_name); + } + + int output_port_num = NodePosition(input); + AttrValue attr_output_shape; + TensorShapeProto proto; + const auto& handle = input_inference_context->output(output_port_num); + input_inference_context->ShapeHandleToProto(handle, &proto); + *attr_output_shape.mutable_shape() = proto; + (*fun_node->mutable_attr())["shape"] = attr_output_shape; + } + + // Perform inference on function body. + GraphProperties gp(grappler_function_item); + TF_RETURN_IF_ERROR(gp.InferStatically(true)); + + // Add return nodes for output shapes. + auto ic = GetContext(node); + int output = 0; + for (auto const& out_arg : grappler_function_item.outputs()) { + if (out_arg.output_tensors.size() > 1) { + // TODO(jmdecker): Handle case of multiple output tensors + return errors::Unimplemented( + "Output arguments with multiple output tensors are not yet " + "supported."); + } + + string out_tensor = out_arg.output_tensors[0]; + auto out_tensor_pieces = str_util::Split(out_tensor, ","); + string node_name = out_tensor_pieces[0]; + int port_id; + + // Check if port_id was included in out_tensor + if (out_tensor_pieces.size() <= 1) { + port_id = 0; + } else if (!strings::safe_strto32(out_tensor_pieces[1], &port_id)) { + return errors::FailedPrecondition( + "Failed string to integer conversion for ", out_tensor_pieces[1]); + } + + const NodeDef* retnode = gv.GetNode(node_name); + if (retnode == nullptr) { + return errors::FailedPrecondition("Unable to find return node ", + node_name, " for ", node->name()); + } + + auto output_properties = gp.GetOutputProperties(retnode->name()); + auto const& outprop = output_properties[port_id]; + const TensorShapeProto& shape = outprop.shape(); + ShapeHandle out; + TF_RETURN_IF_ERROR(ic->MakeShapeFromShapeProto(shape, &out)); + ic->set_output(output, out); + output++; + } + + return Status::OK(); } Status UpdateNode(const NodeDef* node, bool* refined) { @@ -436,6 +534,7 @@ class SymbolicShapeRefiner { node_context = CHECK_NOTNULL(GetNodeContext(node)); *refined = true; } + // Check if the shapes of the nodes in the fan-in of this node have changed, // and if they have, update the node input shapes. InferenceContext* inference_context = node_context->inference_context.get(); @@ -455,7 +554,8 @@ class SymbolicShapeRefiner { if (c == nullptr) { return errors::FailedPrecondition( "Input ", dst_input, " ('", input->name(), "') for '", - node->name(), "' was not previously added to ShapeRefiner."); + node->name(), + "' was not previously added to SymbolicShapeRefiner."); } if (IsConstant(*input)) { @@ -565,6 +665,21 @@ class SymbolicShapeRefiner { node_context->inference_context->set_input_tensors_as_shapes( input_tensors_as_shapes); + // Properly handle function nodes. + if (node_context->op_data && node_context->op_data->is_function_op) { + // TODO(jmdecker): Detect if the input shapes have changed for this + // function. Note that when we hit a function call node, refined will be + // true, as the updates to the call node will have changed, even if it's + // the same function being called twice with the same input shapes. + // Example: simple_function.pbtxt + if (UpdateFunction(node).ok()) { + return Status::OK(); + } else { + VLOG(1) << "UpdateFunction failed for " << node->op() + << ". Defaulting to ShapeUnknown."; + } + } + // Update the shapes of the outputs. return InferShapes(*node, node_context); } @@ -681,7 +796,39 @@ class SymbolicShapeRefiner { return true; } - Status AddFunction(const NodeDef* node) { return Status::OK(); } + Status AddFunction(const NodeDef* function_node) { + auto it = fun_to_grappler_function_item_.find(function_node->op()); + if (it != fun_to_grappler_function_item_.end()) { + return Status::OK(); + } + + const FunctionDef* function_def = + CHECK_NOTNULL(function_library_.Find(function_node->op())); + + GrapplerFunctionItem grappler_function_item; + TF_RETURN_IF_ERROR(MakeGrapplerFunctionItem( + *function_def, function_library_, &grappler_function_item)); + + if (grappler_function_item.inputs().size() > function_node->input_size()) { + return errors::FailedPrecondition( + "Function input size should be smaller than node input size."); + } + + for (int i = grappler_function_item.inputs().size(); + i < function_node->input_size(); ++i) { + const string& input = function_node->input(i); + if (!IsControlInput(input)) { + return errors::FailedPrecondition( + "Found regular input (", input, + ") instead of control nodes for node ", function_node->name()); + } + } + + fun_to_grappler_function_item_[function_def->signature().name()] = + grappler_function_item; + + return Status::OK(); + } Status AddNode(const NodeDef* node) { NodeContext& node_ctx = node_to_context_[node]; @@ -911,6 +1058,8 @@ class SymbolicShapeRefiner { std::unordered_map<const NodeDef*, NodeContext> node_to_context_; std::unordered_map<ShapeId, ShapeHandle, HashShapeId> unknown_shapes_; std::unordered_map<DimId, DimensionHandle, HashDimId> unknown_dims_; + std::unordered_map<string, GrapplerFunctionItem> + fun_to_grappler_function_item_; FunctionLibraryDefinition function_library_; const std::unordered_map<string, std::unordered_set<int>>& fed_ports_; }; @@ -1082,13 +1231,9 @@ Status GraphProperties::UpdateShapes( // Set shapes and types of Queue ops, if needed. TF_RETURN_IF_ERROR(UpdateQueue(n, shape_refiner, new_shapes)); } else { - auto c = shape_refiner->GetNodeContext(n); - if (c && c->op_data && c->op_data->is_function_op) { - TF_RETURN_IF_ERROR(shape_refiner->UpdateFunction(n, new_shapes)); - } else { - // Rely on regular TF shape refinement for all the other nodes. - TF_RETURN_IF_ERROR(shape_refiner->UpdateNode(n, new_shapes)); - } + // Rely on regular TF shape refinement for all the other nodes. + // UpdateNode calls UpdateFunction if a function node is detected. + TF_RETURN_IF_ERROR(shape_refiner->UpdateNode(n, new_shapes)); } return Status::OK(); } diff --git a/tensorflow/core/grappler/costs/graph_properties_test.cc b/tensorflow/core/grappler/costs/graph_properties_test.cc index aa787ae620..1be19d291a 100644 --- a/tensorflow/core/grappler/costs/graph_properties_test.cc +++ b/tensorflow/core/grappler/costs/graph_properties_test.cc @@ -783,7 +783,7 @@ TEST_F(GraphPropertiesTest, InferRestoreOpShape_WithTwoNodesShareSameOutput) { EXPECT_EQ("float: [128,256]", PropToString(prop)); } -TEST_F(GraphPropertiesTest, FunctionStaticShapeInference) { +TEST_F(GraphPropertiesTest, SimpleFunctionStaticShapeInference) { // Test graph produced in python using: /* @function.Defun(*[tf.float32] * 2, noinline=True) @@ -796,7 +796,6 @@ TEST_F(GraphPropertiesTest, FunctionStaticShapeInference) { z = MyAdd(x, y) z = MyAdd(x, z) */ - // Check that the shape inference code infers what it can. GrapplerItem item; string filename = io::JoinPath(testing::TensorFlowSrcRoot(), kTestDataPath, "simple_function.pbtxt"); @@ -806,15 +805,258 @@ TEST_F(GraphPropertiesTest, FunctionStaticShapeInference) { const auto out_props = properties.GetOutputProperties("MyAdd_55e046a8"); const OpInfo::TensorProperties& out_prop = out_props[0]; EXPECT_EQ(DT_FLOAT, out_prop.dtype()); - EXPECT_TRUE(out_prop.shape().unknown_rank()); + EXPECT_FALSE(out_prop.shape().unknown_rank()); + EXPECT_EQ(2, out_prop.shape().dim_size()); + EXPECT_EQ(1, out_prop.shape().dim(0).size()); + EXPECT_EQ(2, out_prop.shape().dim(1).size()); const auto in_props = properties.GetInputProperties("MyAdd_55e046a8"); + EXPECT_EQ(2, in_props.size()); + + const OpInfo::TensorProperties& in_prop = in_props[0]; + EXPECT_EQ(DT_FLOAT, in_prop.dtype()); + EXPECT_FALSE(in_prop.shape().unknown_rank()); + EXPECT_EQ(2, in_prop.shape().dim_size()); + EXPECT_EQ(1, in_prop.shape().dim(0).size()); + EXPECT_EQ(2, in_prop.shape().dim(1).size()); + + const OpInfo::TensorProperties& in_prop1 = in_props[1]; + EXPECT_EQ(DT_FLOAT, in_prop1.dtype()); + EXPECT_FALSE(in_prop1.shape().unknown_rank()); + EXPECT_EQ(2, in_prop1.shape().dim_size()); + EXPECT_EQ(1, in_prop1.shape().dim(0).size()); + EXPECT_EQ(2, in_prop1.shape().dim(1).size()); +} + +TEST_F(GraphPropertiesTest, LargeFunctionStaticShapeInference) { + GrapplerItem item; + string filename = io::JoinPath(testing::TensorFlowSrcRoot(), kTestDataPath, + "large_function_graph.pbtxt"); + TF_CHECK_OK(ReadGraphDefFromFile(filename, &item.graph)); + GraphProperties properties(item); + TF_CHECK_OK(properties.InferStatically(false)); + + const auto out_props = properties.GetOutputProperties("y0"); + EXPECT_EQ(2, out_props.size()); + + const OpInfo::TensorProperties& out_prop0 = out_props[0]; + EXPECT_EQ(DT_FLOAT, out_prop0.dtype()); + EXPECT_EQ(4, out_prop0.shape().dim_size()); + EXPECT_EQ(128, out_prop0.shape().dim(0).size()); + EXPECT_EQ(112, out_prop0.shape().dim(1).size()); + EXPECT_EQ(112, out_prop0.shape().dim(2).size()); + EXPECT_EQ(64, out_prop0.shape().dim(3).size()); + + const OpInfo::TensorProperties& out_prop1 = out_props[1]; + EXPECT_EQ(DT_FLOAT, out_prop1.dtype()); + EXPECT_EQ(128, out_prop1.shape().dim(0).size()); + EXPECT_EQ(112, out_prop1.shape().dim(1).size()); + EXPECT_EQ(112, out_prop1.shape().dim(2).size()); + EXPECT_EQ(24, out_prop1.shape().dim(3).size()); + + const auto in_props = properties.GetInputProperties("y0"); + EXPECT_EQ(4, in_props.size()); + + const OpInfo::TensorProperties& in_prop0 = in_props[0]; + EXPECT_EQ(DT_FLOAT, in_prop0.dtype()); + EXPECT_EQ(1, in_prop0.shape().dim_size()); + EXPECT_EQ(64, in_prop0.shape().dim(0).size()); + + const OpInfo::TensorProperties& in_prop1 = in_props[1]; + EXPECT_EQ(DT_FLOAT, in_prop1.dtype()); + EXPECT_EQ(4, in_prop1.shape().dim_size()); + EXPECT_EQ(1, in_prop1.shape().dim(0).size()); + EXPECT_EQ(1, in_prop1.shape().dim(1).size()); + EXPECT_EQ(24, in_prop1.shape().dim(2).size()); + EXPECT_EQ(64, in_prop1.shape().dim(3).size()); + + const OpInfo::TensorProperties& in_prop2 = in_props[2]; + EXPECT_EQ(DT_FLOAT, in_prop2.dtype()); + EXPECT_EQ(4, in_prop2.shape().dim_size()); + EXPECT_EQ(128, in_prop2.shape().dim(0).size()); + EXPECT_EQ(224, in_prop2.shape().dim(1).size()); + EXPECT_EQ(224, in_prop2.shape().dim(2).size()); + EXPECT_EQ(3, in_prop2.shape().dim(3).size()); + + const OpInfo::TensorProperties& in_prop3 = in_props[3]; + EXPECT_EQ(DT_FLOAT, in_prop3.dtype()); + EXPECT_EQ(4, in_prop3.shape().dim_size()); + EXPECT_EQ(7, in_prop3.shape().dim(0).size()); + EXPECT_EQ(7, in_prop3.shape().dim(1).size()); + EXPECT_EQ(3, in_prop3.shape().dim(2).size()); + EXPECT_EQ(8, in_prop3.shape().dim(3).size()); +} + +TEST_F(GraphPropertiesTest, FunctionWithErrorStaticShapeInference) { + GrapplerItem item; + string filename = io::JoinPath(testing::TensorFlowSrcRoot(), kTestDataPath, + "function_error.pbtxt"); + TF_CHECK_OK(ReadGraphDefFromFile(filename, &item.graph)); + GraphProperties properties(item); + TF_CHECK_OK(properties.InferStatically(false)); + + const auto out_props = properties.GetOutputProperties("MyAdd_yabA4wXEdM4"); + EXPECT_EQ(1, out_props.size()); + + const OpInfo::TensorProperties& out_prop = out_props[0]; + EXPECT_EQ(DT_FLOAT, out_prop.dtype()); + EXPECT_TRUE(out_prop.shape().unknown_rank()); + + const auto in_props = properties.GetInputProperties("MyAdd_yabA4wXEdM4"); + EXPECT_EQ(2, in_props.size()); + const OpInfo::TensorProperties& in_prop = in_props[0]; EXPECT_EQ(DT_FLOAT, in_prop.dtype()); EXPECT_FALSE(in_prop.shape().unknown_rank()); EXPECT_EQ(2, in_prop.shape().dim_size()); EXPECT_EQ(1, in_prop.shape().dim(0).size()); EXPECT_EQ(2, in_prop.shape().dim(1).size()); + + const OpInfo::TensorProperties& in_prop1 = in_props[1]; + EXPECT_EQ(DT_FLOAT, in_prop1.dtype()); + EXPECT_FALSE(in_prop1.shape().unknown_rank()); + EXPECT_EQ(2, in_prop1.shape().dim_size()); + EXPECT_EQ(1, in_prop1.shape().dim(0).size()); + EXPECT_EQ(2, in_prop1.shape().dim(1).size()); +} + +TEST_F(GraphPropertiesTest, FunctionSwitchStaticShapeInference) { + // Test graph produced in python using: + /* + @function.Defun(*[tf.float32] * 2, noinline=True) + def MyAdd(x, y): + return tf.add(x, y) + + with tf.Graph().as_default(): + x = lambda: tf.constant(2.0, shape=[1, 2], dtype=tf.float32) + y = lambda: tf.constant(2.0, shape=[1, 2], dtype=tf.float32) + z = tf.constant(2.0, shape=[1, 2], dtype=tf.float32) + z2 = MyAdd(tf.case([(tf.less(0, 1), x)], default=y), z) + */ + GrapplerItem item; + string filename = io::JoinPath(testing::TensorFlowSrcRoot(), kTestDataPath, + "function_switch.pbtxt"); + TF_CHECK_OK(ReadGraphDefFromFile(filename, &item.graph)); + GraphProperties properties(item); + TF_CHECK_OK(properties.InferStatically(false)); + const auto out_props = properties.GetOutputProperties("MyAdd_MPaeanipb7o"); + const OpInfo::TensorProperties& out_prop = out_props[0]; + EXPECT_EQ(DT_FLOAT, out_prop.dtype()); + EXPECT_FALSE(out_prop.shape().unknown_rank()); + EXPECT_EQ(2, out_prop.shape().dim_size()); + EXPECT_EQ(1, out_prop.shape().dim(0).size()); + EXPECT_EQ(2, out_prop.shape().dim(1).size()); + + const auto in_props = properties.GetInputProperties("MyAdd_MPaeanipb7o"); + EXPECT_EQ(2, in_props.size()); + + const OpInfo::TensorProperties& in_prop = in_props[0]; + EXPECT_EQ(DT_FLOAT, in_prop.dtype()); + EXPECT_FALSE(in_prop.shape().unknown_rank()); + EXPECT_EQ(2, in_prop.shape().dim_size()); + EXPECT_EQ(1, in_prop.shape().dim(0).size()); + EXPECT_EQ(2, in_prop.shape().dim(1).size()); + + const OpInfo::TensorProperties& in_prop1 = in_props[1]; + EXPECT_EQ(DT_FLOAT, in_prop1.dtype()); + EXPECT_FALSE(in_prop1.shape().unknown_rank()); + EXPECT_EQ(2, in_prop1.shape().dim_size()); + EXPECT_EQ(1, in_prop1.shape().dim(0).size()); + EXPECT_EQ(2, in_prop1.shape().dim(1).size()); +} + +TEST_F(GraphPropertiesTest, FunctionSwitch2StaticShapeInference) { + // Test graph produced in python using: + /* + @function.Defun(*[tf.float32] * 2, noinline=True) + def MyAdd(x, y): + return tf.add(x, y) + + with tf.Graph().as_default(): + x = lambda: tf.constant(2.0, shape=[1, 2], dtype=tf.float32) + y = lambda: tf.constant(2.0, shape=[1, 2], dtype=tf.float32) + z = tf.constant(2.0, shape=[1, 2], dtype=tf.float32) + z2 = MyAdd(tf.case([(tf.less(1, 0), x)], default=y), z) + */ + GrapplerItem item; + string filename = io::JoinPath(testing::TensorFlowSrcRoot(), kTestDataPath, + "function_switch_2.pbtxt"); + TF_CHECK_OK(ReadGraphDefFromFile(filename, &item.graph)); + GraphProperties properties(item); + TF_CHECK_OK(properties.InferStatically(false)); + const auto out_props = properties.GetOutputProperties("MyAdd_MPaeanipb7o"); + const OpInfo::TensorProperties& out_prop = out_props[0]; + EXPECT_EQ(DT_FLOAT, out_prop.dtype()); + EXPECT_FALSE(out_prop.shape().unknown_rank()); + EXPECT_EQ(2, out_prop.shape().dim_size()); + EXPECT_EQ(1, out_prop.shape().dim(0).size()); + EXPECT_EQ(2, out_prop.shape().dim(1).size()); + + const auto in_props = properties.GetInputProperties("MyAdd_MPaeanipb7o"); + EXPECT_EQ(2, in_props.size()); + + const OpInfo::TensorProperties& in_prop = in_props[0]; + EXPECT_EQ(DT_FLOAT, in_prop.dtype()); + EXPECT_FALSE(in_prop.shape().unknown_rank()); + EXPECT_EQ(2, in_prop.shape().dim_size()); + EXPECT_EQ(1, in_prop.shape().dim(0).size()); + EXPECT_EQ(2, in_prop.shape().dim(1).size()); + + const OpInfo::TensorProperties& in_prop1 = in_props[1]; + EXPECT_EQ(DT_FLOAT, in_prop1.dtype()); + EXPECT_FALSE(in_prop1.shape().unknown_rank()); + EXPECT_EQ(2, in_prop1.shape().dim_size()); + EXPECT_EQ(1, in_prop1.shape().dim(0).size()); + EXPECT_EQ(2, in_prop1.shape().dim(1).size()); +} + +TEST_F(GraphPropertiesTest, FunctionSwitchShapesStaticShapeInference) { + // Test graph produced in python using: + /* + @function.Defun(*[tf.float32] * 2, noinline=True) + def MyAdd(x, y): + a = tf.constant(2.0, shape=[1, 2], dtype=tf.float32) + b = tf.constant(2.0, shape=[1, 3], dtype=tf.float32) + c = tf.add(x, a) + d = tf.add(y, b) + return c + + with tf.Graph().as_default(): + x = lambda: tf.constant(2.0, shape=[1, 2], dtype=tf.float32) + y = lambda: tf.constant(2.0, shape=[1, 2], dtype=tf.float32) + z = tf.constant(2.0, shape=[1, 3], dtype=tf.float32) + z2 = MyAdd(tf.case([(tf.less(1, 0), x)], default=y), z) + */ + GrapplerItem item; + string filename = io::JoinPath(testing::TensorFlowSrcRoot(), kTestDataPath, + "function_switch_shapes.pbtxt"); + TF_CHECK_OK(ReadGraphDefFromFile(filename, &item.graph)); + GraphProperties properties(item); + TF_CHECK_OK(properties.InferStatically(false)); + const auto out_props = properties.GetOutputProperties("MyAdd_lEKAAnIwI5I"); + const OpInfo::TensorProperties& out_prop = out_props[0]; + EXPECT_EQ(DT_FLOAT, out_prop.dtype()); + EXPECT_FALSE(out_prop.shape().unknown_rank()); + EXPECT_EQ(2, out_prop.shape().dim_size()); + EXPECT_EQ(1, out_prop.shape().dim(0).size()); + EXPECT_EQ(2, out_prop.shape().dim(1).size()); + + const auto in_props = properties.GetInputProperties("MyAdd_lEKAAnIwI5I"); + EXPECT_EQ(2, in_props.size()); + + const OpInfo::TensorProperties& in_prop = in_props[0]; + EXPECT_EQ(DT_FLOAT, in_prop.dtype()); + EXPECT_FALSE(in_prop.shape().unknown_rank()); + EXPECT_EQ(2, in_prop.shape().dim_size()); + EXPECT_EQ(1, in_prop.shape().dim(0).size()); + EXPECT_EQ(2, in_prop.shape().dim(1).size()); + + const OpInfo::TensorProperties& in_prop1 = in_props[1]; + EXPECT_EQ(DT_FLOAT, in_prop1.dtype()); + EXPECT_FALSE(in_prop1.shape().unknown_rank()); + EXPECT_EQ(2, in_prop1.shape().dim_size()); + EXPECT_EQ(1, in_prop1.shape().dim(0).size()); + EXPECT_EQ(3, in_prop1.shape().dim(1).size()); } TEST_F(GraphPropertiesTest, SymbolicShapes) { diff --git a/tensorflow/core/grappler/costs/graph_properties_testdata/function_error.pbtxt b/tensorflow/core/grappler/costs/graph_properties_testdata/function_error.pbtxt new file mode 100644 index 0000000000..c3f0a6c95d --- /dev/null +++ b/tensorflow/core/grappler/costs/graph_properties_testdata/function_error.pbtxt @@ -0,0 +1,117 @@ +node { + name: "Const" + op: "Const" + attr { + key: "dtype" + value { + type: DT_FLOAT + } + } + attr { + key: "value" + value { + tensor { + dtype: DT_FLOAT + tensor_shape { + dim { + size: 1 + } + dim { + size: 2 + } + } + float_val: 2.0 + } + } + } +} +node { + name: "Const_1" + op: "Const" + attr { + key: "dtype" + value { + type: DT_FLOAT + } + } + attr { + key: "value" + value { + tensor { + dtype: DT_FLOAT + tensor_shape { + dim { + size: 1 + } + dim { + size: 2 + } + } + float_val: 2.0 + } + } + } +} +node { + name: "MyAdd_yabA4wXEdM4" + op: "MyAdd_yabA4wXEdM4" + input: "Const" + input: "Const_1" +} +library { + function { + signature { + name: "MyAdd_yabA4wXEdM4" + input_arg { + name: "x" + type: DT_FLOAT + } + input_arg { + name: "y" + type: DT_FLOAT + } + output_arg { + name: "add_1" + type: DT_FLOAT + } + } + node_def { + name: "Add" + op: "Add" + input: "x" + input: "Add:z:0" + attr { + key: "T" + value { + type: DT_FLOAT + } + } + } + node_def { + name: "Add_1" + op: "Add" + input: "Add:z:0" + input: "y" + attr { + key: "T" + value { + type: DT_FLOAT + } + } + } + ret { + key: "add_1" + value: "Add_1:z:0" + } + attr { + key: "_noinline" + value { + b: true + } + } + } +} +versions { + producer: 26 + min_consumer: 12 +} diff --git a/tensorflow/core/grappler/costs/graph_properties_testdata/function_switch.pbtxt b/tensorflow/core/grappler/costs/graph_properties_testdata/function_switch.pbtxt new file mode 100644 index 0000000000..d6d856ce41 --- /dev/null +++ b/tensorflow/core/grappler/costs/graph_properties_testdata/function_switch.pbtxt @@ -0,0 +1,251 @@ +node { + name: "Const" + op: "Const" + attr { + key: "dtype" + value { + type: DT_FLOAT + } + } + attr { + key: "value" + value { + tensor { + dtype: DT_FLOAT + tensor_shape { + dim { + size: 1 + } + dim { + size: 2 + } + } + float_val: 2.0 + } + } + } +} +node { + name: "Less/x" + op: "Const" + attr { + key: "dtype" + value { + type: DT_INT32 + } + } + attr { + key: "value" + value { + tensor { + dtype: DT_INT32 + tensor_shape { + } + int_val: 0 + } + } + } +} +node { + name: "Less/y" + op: "Const" + attr { + key: "dtype" + value { + type: DT_INT32 + } + } + attr { + key: "value" + value { + tensor { + dtype: DT_INT32 + tensor_shape { + } + int_val: 1 + } + } + } +} +node { + name: "Less" + op: "Less" + input: "Less/x" + input: "Less/y" + attr { + key: "T" + value { + type: DT_INT32 + } + } +} +node { + name: "case/cond/Switch" + op: "Switch" + input: "Less" + input: "Less" + attr { + key: "T" + value { + type: DT_BOOL + } + } +} +node { + name: "case/cond/switch_t" + op: "Identity" + input: "case/cond/Switch:1" + attr { + key: "T" + value { + type: DT_BOOL + } + } +} +node { + name: "case/cond/switch_f" + op: "Identity" + input: "case/cond/Switch" + attr { + key: "T" + value { + type: DT_BOOL + } + } +} +node { + name: "case/cond/pred_id" + op: "Identity" + input: "Less" + attr { + key: "T" + value { + type: DT_BOOL + } + } +} +node { + name: "case/cond/Const" + op: "Const" + input: "^case/cond/switch_t" + attr { + key: "dtype" + value { + type: DT_FLOAT + } + } + attr { + key: "value" + value { + tensor { + dtype: DT_FLOAT + tensor_shape { + dim { + size: 1 + } + dim { + size: 2 + } + } + float_val: 2.0 + } + } + } +} +node { + name: "case/cond/Const_1" + op: "Const" + input: "^case/cond/switch_f" + attr { + key: "dtype" + value { + type: DT_FLOAT + } + } + attr { + key: "value" + value { + tensor { + dtype: DT_FLOAT + tensor_shape { + dim { + size: 1 + } + dim { + size: 2 + } + } + float_val: 2.0 + } + } + } +} +node { + name: "case/cond/Merge" + op: "Merge" + input: "case/cond/Const_1" + input: "case/cond/Const" + attr { + key: "N" + value { + i: 2 + } + } + attr { + key: "T" + value { + type: DT_FLOAT + } + } +} +node { + name: "MyAdd_MPaeanipb7o" + op: "MyAdd_MPaeanipb7o" + input: "case/cond/Merge" + input: "Const" +} +library { + function { + signature { + name: "MyAdd_MPaeanipb7o" + input_arg { + name: "x" + type: DT_FLOAT + } + input_arg { + name: "y" + type: DT_FLOAT + } + output_arg { + name: "Add" + type: DT_FLOAT + } + } + node_def { + name: "Add" + op: "Add" + input: "x" + input: "y" + attr { + key: "T" + value { + type: DT_FLOAT + } + } + } + ret { + key: "Add" + value: "Add:z:0" + } + attr { + key: "_noinline" + value { + b: true + } + } + } +} +versions { + producer: 26 + min_consumer: 12 +} diff --git a/tensorflow/core/grappler/costs/graph_properties_testdata/function_switch_2.pbtxt b/tensorflow/core/grappler/costs/graph_properties_testdata/function_switch_2.pbtxt new file mode 100644 index 0000000000..e57d9d7076 --- /dev/null +++ b/tensorflow/core/grappler/costs/graph_properties_testdata/function_switch_2.pbtxt @@ -0,0 +1,251 @@ +node { + name: "Const" + op: "Const" + attr { + key: "dtype" + value { + type: DT_FLOAT + } + } + attr { + key: "value" + value { + tensor { + dtype: DT_FLOAT + tensor_shape { + dim { + size: 1 + } + dim { + size: 2 + } + } + float_val: 2.0 + } + } + } +} +node { + name: "Less/x" + op: "Const" + attr { + key: "dtype" + value { + type: DT_INT32 + } + } + attr { + key: "value" + value { + tensor { + dtype: DT_INT32 + tensor_shape { + } + int_val: 1 + } + } + } +} +node { + name: "Less/y" + op: "Const" + attr { + key: "dtype" + value { + type: DT_INT32 + } + } + attr { + key: "value" + value { + tensor { + dtype: DT_INT32 + tensor_shape { + } + int_val: 0 + } + } + } +} +node { + name: "Less" + op: "Less" + input: "Less/x" + input: "Less/y" + attr { + key: "T" + value { + type: DT_INT32 + } + } +} +node { + name: "case/cond/Switch" + op: "Switch" + input: "Less" + input: "Less" + attr { + key: "T" + value { + type: DT_BOOL + } + } +} +node { + name: "case/cond/switch_t" + op: "Identity" + input: "case/cond/Switch:1" + attr { + key: "T" + value { + type: DT_BOOL + } + } +} +node { + name: "case/cond/switch_f" + op: "Identity" + input: "case/cond/Switch" + attr { + key: "T" + value { + type: DT_BOOL + } + } +} +node { + name: "case/cond/pred_id" + op: "Identity" + input: "Less" + attr { + key: "T" + value { + type: DT_BOOL + } + } +} +node { + name: "case/cond/Const" + op: "Const" + input: "^case/cond/switch_t" + attr { + key: "dtype" + value { + type: DT_FLOAT + } + } + attr { + key: "value" + value { + tensor { + dtype: DT_FLOAT + tensor_shape { + dim { + size: 1 + } + dim { + size: 2 + } + } + float_val: 2.0 + } + } + } +} +node { + name: "case/cond/Const_1" + op: "Const" + input: "^case/cond/switch_f" + attr { + key: "dtype" + value { + type: DT_FLOAT + } + } + attr { + key: "value" + value { + tensor { + dtype: DT_FLOAT + tensor_shape { + dim { + size: 1 + } + dim { + size: 2 + } + } + float_val: 2.0 + } + } + } +} +node { + name: "case/cond/Merge" + op: "Merge" + input: "case/cond/Const_1" + input: "case/cond/Const" + attr { + key: "N" + value { + i: 2 + } + } + attr { + key: "T" + value { + type: DT_FLOAT + } + } +} +node { + name: "MyAdd_MPaeanipb7o" + op: "MyAdd_MPaeanipb7o" + input: "case/cond/Merge" + input: "Const" +} +library { + function { + signature { + name: "MyAdd_MPaeanipb7o" + input_arg { + name: "x" + type: DT_FLOAT + } + input_arg { + name: "y" + type: DT_FLOAT + } + output_arg { + name: "Add" + type: DT_FLOAT + } + } + node_def { + name: "Add" + op: "Add" + input: "x" + input: "y" + attr { + key: "T" + value { + type: DT_FLOAT + } + } + } + ret { + key: "Add" + value: "Add:z:0" + } + attr { + key: "_noinline" + value { + b: true + } + } + } +} +versions { + producer: 26 + min_consumer: 12 +} diff --git a/tensorflow/core/grappler/costs/graph_properties_testdata/function_switch_shapes.pbtxt b/tensorflow/core/grappler/costs/graph_properties_testdata/function_switch_shapes.pbtxt new file mode 100644 index 0000000000..e9afa91886 --- /dev/null +++ b/tensorflow/core/grappler/costs/graph_properties_testdata/function_switch_shapes.pbtxt @@ -0,0 +1,317 @@ +node { + name: "Const" + op: "Const" + attr { + key: "dtype" + value { + type: DT_FLOAT + } + } + attr { + key: "value" + value { + tensor { + dtype: DT_FLOAT + tensor_shape { + dim { + size: 1 + } + dim { + size: 3 + } + } + float_val: 2.0 + } + } + } +} +node { + name: "Less/x" + op: "Const" + attr { + key: "dtype" + value { + type: DT_INT32 + } + } + attr { + key: "value" + value { + tensor { + dtype: DT_INT32 + tensor_shape { + } + int_val: 1 + } + } + } +} +node { + name: "Less/y" + op: "Const" + attr { + key: "dtype" + value { + type: DT_INT32 + } + } + attr { + key: "value" + value { + tensor { + dtype: DT_INT32 + tensor_shape { + } + int_val: 0 + } + } + } +} +node { + name: "Less" + op: "Less" + input: "Less/x" + input: "Less/y" + attr { + key: "T" + value { + type: DT_INT32 + } + } +} +node { + name: "case/cond/Switch" + op: "Switch" + input: "Less" + input: "Less" + attr { + key: "T" + value { + type: DT_BOOL + } + } +} +node { + name: "case/cond/switch_t" + op: "Identity" + input: "case/cond/Switch:1" + attr { + key: "T" + value { + type: DT_BOOL + } + } +} +node { + name: "case/cond/switch_f" + op: "Identity" + input: "case/cond/Switch" + attr { + key: "T" + value { + type: DT_BOOL + } + } +} +node { + name: "case/cond/pred_id" + op: "Identity" + input: "Less" + attr { + key: "T" + value { + type: DT_BOOL + } + } +} +node { + name: "case/cond/Const" + op: "Const" + input: "^case/cond/switch_t" + attr { + key: "dtype" + value { + type: DT_FLOAT + } + } + attr { + key: "value" + value { + tensor { + dtype: DT_FLOAT + tensor_shape { + dim { + size: 1 + } + dim { + size: 2 + } + } + float_val: 2.0 + } + } + } +} +node { + name: "case/cond/Const_1" + op: "Const" + input: "^case/cond/switch_f" + attr { + key: "dtype" + value { + type: DT_FLOAT + } + } + attr { + key: "value" + value { + tensor { + dtype: DT_FLOAT + tensor_shape { + dim { + size: 1 + } + dim { + size: 2 + } + } + float_val: 2.0 + } + } + } +} +node { + name: "case/cond/Merge" + op: "Merge" + input: "case/cond/Const_1" + input: "case/cond/Const" + attr { + key: "N" + value { + i: 2 + } + } + attr { + key: "T" + value { + type: DT_FLOAT + } + } +} +node { + name: "MyAdd_lEKAAnIwI5I" + op: "MyAdd_lEKAAnIwI5I" + input: "case/cond/Merge" + input: "Const" +} +library { + function { + signature { + name: "MyAdd_lEKAAnIwI5I" + input_arg { + name: "x" + type: DT_FLOAT + } + input_arg { + name: "y" + type: DT_FLOAT + } + output_arg { + name: "Add" + type: DT_FLOAT + } + } + node_def { + name: "Const" + op: "Const" + attr { + key: "dtype" + value { + type: DT_FLOAT + } + } + attr { + key: "value" + value { + tensor { + dtype: DT_FLOAT + tensor_shape { + dim { + size: 1 + } + dim { + size: 2 + } + } + float_val: 2.0 + } + } + } + } + node_def { + name: "Const_1" + op: "Const" + attr { + key: "dtype" + value { + type: DT_FLOAT + } + } + attr { + key: "value" + value { + tensor { + dtype: DT_FLOAT + tensor_shape { + dim { + size: 1 + } + dim { + size: 3 + } + } + float_val: 2.0 + } + } + } + } + node_def { + name: "Add" + op: "Add" + input: "x" + input: "Const:output:0" + attr { + key: "T" + value { + type: DT_FLOAT + } + } + } + node_def { + name: "Add_1" + op: "Add" + input: "y" + input: "Const_1:output:0" + attr { + key: "T" + value { + type: DT_FLOAT + } + } + } + ret { + key: "Add" + value: "Add:z:0" + } + attr { + key: "_noinline" + value { + b: true + } + } + } +} +versions { + producer: 26 + min_consumer: 12 +} diff --git a/tensorflow/core/grappler/costs/graph_properties_testdata/large_function_graph.pbtxt b/tensorflow/core/grappler/costs/graph_properties_testdata/large_function_graph.pbtxt new file mode 100644 index 0000000000..415c347a1d --- /dev/null +++ b/tensorflow/core/grappler/costs/graph_properties_testdata/large_function_graph.pbtxt @@ -0,0 +1,597 @@ +node { + name: "Const/Const" + op: "Const" + device: "/cpu:0" + attr { + key: "dtype" + value { + type: DT_INT32 + } + } + attr { + key: "value" + value { + tensor { + dtype: DT_INT32 + tensor_shape { + dim { + size: 1 + } + } + int_val: 64 + } + } + } +} +node { + name: "input_0_0" + op: "RandomUniform" + input: "Const/Const" + device: "/cpu:0" + attr { + key: "T" + value { + type: DT_INT32 + } + } + attr { + key: "dtype" + value { + type: DT_FLOAT + } + } + attr { + key: "seed" + value { + i: 0 + } + } + attr { + key: "seed2" + value { + i: 0 + } + } +} +node { + name: "Const_1/Const" + op: "Const" + device: "/cpu:0" + attr { + key: "dtype" + value { + type: DT_INT32 + } + } + attr { + key: "value" + value { + tensor { + dtype: DT_INT32 + tensor_shape { + dim { + size: 4 + } + } + tensor_content: "\001\000\000\000\001\000\000\000\030\000\000\000@\000\000\000" + } + } + } +} +node { + name: "input_1_0" + op: "RandomUniform" + input: "Const_1/Const" + device: "/cpu:0" + attr { + key: "T" + value { + type: DT_INT32 + } + } + attr { + key: "dtype" + value { + type: DT_FLOAT + } + } + attr { + key: "seed" + value { + i: 0 + } + } + attr { + key: "seed2" + value { + i: 0 + } + } +} +node { + name: "Const_2/Const" + op: "Const" + device: "/cpu:0" + attr { + key: "dtype" + value { + type: DT_INT32 + } + } + attr { + key: "value" + value { + tensor { + dtype: DT_INT32 + tensor_shape { + dim { + size: 4 + } + } + tensor_content: "\200\000\000\000\340\000\000\000\340\000\000\000\003\000\000\000" + } + } + } +} +node { + name: "input_2_0" + op: "RandomUniform" + input: "Const_2/Const" + device: "/cpu:0" + attr { + key: "T" + value { + type: DT_INT32 + } + } + attr { + key: "dtype" + value { + type: DT_FLOAT + } + } + attr { + key: "seed" + value { + i: 0 + } + } + attr { + key: "seed2" + value { + i: 0 + } + } +} +node { + name: "Const_3/Const" + op: "Const" + device: "/cpu:0" + attr { + key: "dtype" + value { + type: DT_INT32 + } + } + attr { + key: "value" + value { + tensor { + dtype: DT_INT32 + tensor_shape { + dim { + size: 4 + } + } + tensor_content: "\007\000\000\000\007\000\000\000\003\000\000\000\010\000\000\000" + } + } + } +} +node { + name: "input_3_0" + op: "RandomUniform" + input: "Const_3/Const" + device: "/cpu:0" + attr { + key: "T" + value { + type: DT_INT32 + } + } + attr { + key: "dtype" + value { + type: DT_FLOAT + } + } + attr { + key: "seed" + value { + i: 0 + } + } + attr { + key: "seed2" + value { + i: 0 + } + } +} +node { + name: "y0" + op: "BiasAddx1_Conv2Dx1_DepthwiseConv2dNativex1_Relux1_95" + input: "input_0_0" + input: "input_1_0" + input: "input_2_0" + input: "input_3_0" + input: "^input_0_0" + input: "^input_1_0" + input: "^input_2_0" + input: "^input_3_0" + device: "/cpu:0" +} +node { + name: "shape" + op: "Shape" + input: "y0" + input: "^input_0_0" + input: "^input_1_0" + input: "^input_2_0" + input: "^input_3_0" + device: "/cpu:0" + attr { + key: "T" + value { + type: DT_FLOAT + } + } + attr { + key: "out_type" + value { + type: DT_INT32 + } + } +} +node { + name: "zeros" + op: "ZerosLike" + input: "shape" + input: "^input_0_0" + input: "^input_1_0" + input: "^input_2_0" + input: "^input_3_0" + device: "/cpu:0" + attr { + key: "T" + value { + type: DT_INT32 + } + } +} +node { + name: "ones" + op: "OnesLike" + input: "shape" + input: "^input_0_0" + input: "^input_1_0" + input: "^input_2_0" + input: "^input_3_0" + device: "/cpu:0" + attr { + key: "T" + value { + type: DT_INT32 + } + } +} +node { + name: "slice_0" + op: "Slice" + input: "y0" + input: "zeros" + input: "ones" + input: "^input_0_0" + input: "^input_1_0" + input: "^input_2_0" + input: "^input_3_0" + device: "/cpu:0" + attr { + key: "Index" + value { + type: DT_INT32 + } + } + attr { + key: "T" + value { + type: DT_FLOAT + } + } +} +node { + name: "identity_0" + op: "Identity" + input: "slice_0" + input: "^input_0_0" + input: "^input_1_0" + input: "^input_2_0" + input: "^input_3_0" + device: "/cpu:0" + attr { + key: "T" + value { + type: DT_FLOAT + } + } +} +node { + name: "shape_1" + op: "Shape" + input: "y0:1" + input: "^input_0_0" + input: "^input_1_0" + input: "^input_2_0" + input: "^input_3_0" + device: "/cpu:0" + attr { + key: "T" + value { + type: DT_FLOAT + } + } + attr { + key: "out_type" + value { + type: DT_INT32 + } + } +} +node { + name: "zeros_1" + op: "ZerosLike" + input: "shape_1" + input: "^input_0_0" + input: "^input_1_0" + input: "^input_2_0" + input: "^input_3_0" + device: "/cpu:0" + attr { + key: "T" + value { + type: DT_INT32 + } + } +} +node { + name: "ones_1" + op: "OnesLike" + input: "shape_1" + input: "^input_0_0" + input: "^input_1_0" + input: "^input_2_0" + input: "^input_3_0" + device: "/cpu:0" + attr { + key: "T" + value { + type: DT_INT32 + } + } +} +node { + name: "slice_1" + op: "Slice" + input: "y0:1" + input: "zeros_1" + input: "ones_1" + input: "^input_0_0" + input: "^input_1_0" + input: "^input_2_0" + input: "^input_3_0" + device: "/cpu:0" + attr { + key: "Index" + value { + type: DT_INT32 + } + } + attr { + key: "T" + value { + type: DT_FLOAT + } + } +} +node { + name: "identity_1" + op: "Identity" + input: "slice_1" + input: "^input_0_0" + input: "^input_1_0" + input: "^input_2_0" + input: "^input_3_0" + device: "/cpu:0" + attr { + key: "T" + value { + type: DT_FLOAT + } + } +} +library { + function { + signature { + name: "BiasAddx1_Conv2Dx1_DepthwiseConv2dNativex1_Relux1_95" + input_arg { + name: "InceptionV2/Conv2d_1a_7x7/biases/read" + type: DT_FLOAT + } + input_arg { + name: "InceptionV2/Conv2d_1a_7x7/pointwise_weights/read" + type: DT_FLOAT + } + input_arg { + name: "random_uniform" + type: DT_FLOAT + } + input_arg { + name: "InceptionV2/Conv2d_1a_7x7/depthwise_weights/read" + type: DT_FLOAT + } + output_arg { + name: "InceptionV2/InceptionV2/Conv2d_1a_7x7/Relu" + type: DT_FLOAT + } + output_arg { + name: "InceptionV2/InceptionV2/Conv2d_1a_7x7/separable_conv2d/depthwise" + type: DT_FLOAT + } + } + node_def { + name: "InceptionV2/InceptionV2/Conv2d_1a_7x7/BiasAdd" + op: "BiasAdd" + input: "InceptionV2/InceptionV2/Conv2d_1a_7x7/separable_conv2d:output:0" + input: "InceptionV2/Conv2d_1a_7x7/biases/read" + attr { + key: "T" + value { + type: DT_FLOAT + } + } + attr { + key: "data_format" + value { + s: "NHWC" + } + } + } + node_def { + name: "InceptionV2/InceptionV2/Conv2d_1a_7x7/Relu" + op: "Relu" + input: "InceptionV2/InceptionV2/Conv2d_1a_7x7/BiasAdd:output:0" + attr { + key: "T" + value { + type: DT_FLOAT + } + } + } + node_def { + name: "InceptionV2/InceptionV2/Conv2d_1a_7x7/separable_conv2d" + op: "Conv2D" + input: "InceptionV2/InceptionV2/Conv2d_1a_7x7/separable_conv2d/depthwise:output:0" + input: "InceptionV2/Conv2d_1a_7x7/pointwise_weights/read" + attr { + key: "T" + value { + type: DT_FLOAT + } + } + attr { + key: "data_format" + value { + s: "NHWC" + } + } + attr { + key: "dilations" + value { + list { + i: 1 + i: 1 + i: 1 + i: 1 + } + } + } + attr { + key: "padding" + value { + s: "VALID" + } + } + attr { + key: "strides" + value { + list { + i: 1 + i: 1 + i: 1 + i: 1 + } + } + } + attr { + key: "use_cudnn_on_gpu" + value { + b: true + } + } + } + node_def { + name: "InceptionV2/InceptionV2/Conv2d_1a_7x7/separable_conv2d/depthwise" + op: "DepthwiseConv2dNative" + input: "random_uniform" + input: "InceptionV2/Conv2d_1a_7x7/depthwise_weights/read" + attr { + key: "T" + value { + type: DT_FLOAT + } + } + attr { + key: "data_format" + value { + s: "NHWC" + } + } + attr { + key: "dilations" + value { + list { + i: 1 + i: 1 + i: 1 + i: 1 + } + } + } + attr { + key: "padding" + value { + s: "SAME" + } + } + attr { + key: "strides" + value { + list { + i: 1 + i: 2 + i: 2 + i: 1 + } + } + } + } + ret { + key: "InceptionV2/InceptionV2/Conv2d_1a_7x7/Relu" + value: "InceptionV2/InceptionV2/Conv2d_1a_7x7/Relu:activations:0" + } + ret { + key: "InceptionV2/InceptionV2/Conv2d_1a_7x7/separable_conv2d/depthwise" + value: "InceptionV2/InceptionV2/Conv2d_1a_7x7/separable_conv2d/depthwise:output:0" + } + attr { + key: "_noinline" + value { + b: true + } + } + } +} +versions { + producer: 26 + min_consumer: 12 +} diff --git a/tensorflow/core/kernels/BUILD b/tensorflow/core/kernels/BUILD index 07360d594b..3b3e1af2d5 100644 --- a/tensorflow/core/kernels/BUILD +++ b/tensorflow/core/kernels/BUILD @@ -882,7 +882,6 @@ tf_kernel_library( "tile_functor_gpu.cu.cc", ], prefix = "tile_ops", - textual_hdrs = ["tile_ops_gpu_impl.h"], deps = ARRAY_DEPS, ) diff --git a/tensorflow/core/kernels/non_max_suppression_op.cc b/tensorflow/core/kernels/non_max_suppression_op.cc index f08dd4f750..f59843a07a 100644 --- a/tensorflow/core/kernels/non_max_suppression_op.cc +++ b/tensorflow/core/kernels/non_max_suppression_op.cc @@ -19,6 +19,7 @@ limitations under the License. #include "tensorflow/core/kernels/non_max_suppression_op.h" +#include <functional> #include <queue> #include <vector> @@ -38,9 +39,32 @@ namespace { typedef Eigen::ThreadPoolDevice CPUDevice; +static inline void CheckScoreSizes(OpKernelContext* context, int num_boxes, + const Tensor& scores) { + // The shape of 'scores' is [num_boxes] + OP_REQUIRES(context, scores.dims() == 1, + errors::InvalidArgument("scores must be 1-D", + scores.shape().DebugString())); + OP_REQUIRES(context, scores.dim_size(0) == num_boxes, + errors::InvalidArgument("scores has incompatible shape")); +} + +static inline void ParseAndCheckOverlapSizes(OpKernelContext* context, + const Tensor& overlaps, + int* num_boxes) { + // the shape of 'overlaps' is [num_boxes, num_boxes] + OP_REQUIRES(context, overlaps.dims() == 2, + errors::InvalidArgument("overlaps must be 2-D", + overlaps.shape().DebugString())); + + *num_boxes = overlaps.dim_size(0); + OP_REQUIRES(context, overlaps.dim_size(1) == *num_boxes, + errors::InvalidArgument("overlaps must be square", + overlaps.shape().DebugString())); +} + static inline void ParseAndCheckBoxSizes(OpKernelContext* context, - const Tensor& boxes, - const Tensor& scores, int* num_boxes) { + const Tensor& boxes, int* num_boxes) { // The shape of 'boxes' is [num_boxes, 4] OP_REQUIRES(context, boxes.dims() == 2, errors::InvalidArgument("boxes must be 2-D", @@ -48,18 +72,12 @@ static inline void ParseAndCheckBoxSizes(OpKernelContext* context, *num_boxes = boxes.dim_size(0); OP_REQUIRES(context, boxes.dim_size(1) == 4, errors::InvalidArgument("boxes must have 4 columns")); - - // The shape of 'scores' is [num_boxes] - OP_REQUIRES(context, scores.dims() == 1, - errors::InvalidArgument("scores must be 1-D", - scores.shape().DebugString())); - OP_REQUIRES(context, scores.dim_size(0) == *num_boxes, - errors::InvalidArgument("scores has incompatible shape")); } // Return intersection-over-union overlap between boxes i and j -static inline float IOU(typename TTypes<float, 2>::ConstTensor boxes, int i, - int j) { +static inline float IOUGreaterThanThreshold( + typename TTypes<float, 2>::ConstTensor boxes, int i, int j, + float iou_threshold) { const float ymin_i = std::min<float>(boxes(i, 0), boxes(i, 2)); const float xmin_i = std::min<float>(boxes(i, 1), boxes(i, 3)); const float ymax_i = std::max<float>(boxes(i, 0), boxes(i, 2)); @@ -78,24 +96,36 @@ static inline float IOU(typename TTypes<float, 2>::ConstTensor boxes, int i, const float intersection_area = std::max<float>(intersection_ymax - intersection_ymin, 0.0) * std::max<float>(intersection_xmax - intersection_xmin, 0.0); - return intersection_area / (area_i + area_j - intersection_area); + const float iou = intersection_area / (area_i + area_j - intersection_area); + return iou > iou_threshold; } -void DoNonMaxSuppressionOp(OpKernelContext* context, const Tensor& boxes, - const Tensor& scores, const Tensor& max_output_size, - const float iou_threshold, - const float score_threshold) { - OP_REQUIRES(context, iou_threshold >= 0 && iou_threshold <= 1, - errors::InvalidArgument("iou_threshold must be in [0, 1]")); - - int num_boxes = 0; - ParseAndCheckBoxSizes(context, boxes, scores, &num_boxes); - if (!context->status().ok()) { - return; - } +static inline bool OverlapsGreaterThanThreshold( + typename TTypes<float, 2>::ConstTensor overlaps, int i, int j, + float overlap_threshold) { + return overlaps(i, j) > overlap_threshold; +} + +static inline std::function<bool(int, int)> CreateIOUSuppressCheckFn( + const Tensor& boxes, float threshold) { + typename TTypes<float, 2>::ConstTensor boxes_data = boxes.tensor<float, 2>(); + return std::bind(&IOUGreaterThanThreshold, boxes_data, std::placeholders::_1, + std::placeholders::_2, threshold); +} + +static inline std::function<bool(int, int)> CreateOverlapsSuppressCheckFn( + const Tensor& overlaps, float threshold) { + typename TTypes<float, 2>::ConstTensor overlaps_data = + overlaps.tensor<float, 2>(); + return std::bind(&OverlapsGreaterThanThreshold, overlaps_data, + std::placeholders::_1, std::placeholders::_2, threshold); +} +void DoNonMaxSuppressionOp(OpKernelContext* context, const Tensor& scores, + int num_boxes, const Tensor& max_output_size, + const float score_threshold, + std::function<bool(int, int)> suppress_check_fn) { const int output_size = std::min(max_output_size.scalar<int>()(), num_boxes); - TTypes<float, 2>::ConstTensor boxes_data = boxes.tensor<float, 2>(); std::vector<float> scores_data(num_boxes); std::copy_n(scores.flat<float>().data(), num_boxes, scores_data.begin()); @@ -120,11 +150,9 @@ void DoNonMaxSuppressionOp(OpKernelContext* context, const Tensor& boxes, std::vector<int> selected; std::vector<float> selected_scores; Candidate next_candidate; - float iou, original_score; while (selected.size() < output_size && !candidate_priority_queue.empty()) { next_candidate = candidate_priority_queue.top(); - original_score = next_candidate.score; candidate_priority_queue.pop(); // Overlapping boxes are likely to have similar scores, @@ -132,8 +160,10 @@ void DoNonMaxSuppressionOp(OpKernelContext* context, const Tensor& boxes, // in order to see if `next_candidate` should be suppressed. bool should_select = true; for (int j = selected.size() - 1; j >= 0; --j) { - iou = IOU(boxes_data, next_candidate.box_index, selected[j]); - if (iou > iou_threshold) should_select = false; + if (suppress_check_fn(next_candidate.box_index, selected[j])) { + should_select = false; + break; + } } if (should_select) { @@ -173,9 +203,19 @@ class NonMaxSuppressionOp : public OpKernel { errors::InvalidArgument("max_output_size must be 0-D, got shape ", max_output_size.shape().DebugString())); + OP_REQUIRES(context, iou_threshold_ >= 0 && iou_threshold_ <= 1, + errors::InvalidArgument("iou_threshold must be in [0, 1]")); + int num_boxes = 0; + ParseAndCheckBoxSizes(context, boxes, &num_boxes); + CheckScoreSizes(context, num_boxes, scores); + if (!context->status().ok()) { + return; + } + auto suppress_check_fn = CreateIOUSuppressCheckFn(boxes, iou_threshold_); + const float score_threshold_val = std::numeric_limits<float>::lowest(); - DoNonMaxSuppressionOp(context, boxes, scores, max_output_size, - iou_threshold_, score_threshold_val); + DoNonMaxSuppressionOp(context, scores, num_boxes, max_output_size, + score_threshold_val, suppress_check_fn); } private: @@ -206,9 +246,19 @@ class NonMaxSuppressionV2Op : public OpKernel { iou_threshold.shape().DebugString())); const float iou_threshold_val = iou_threshold.scalar<float>()(); + OP_REQUIRES(context, iou_threshold_val >= 0 && iou_threshold_val <= 1, + errors::InvalidArgument("iou_threshold must be in [0, 1]")); + int num_boxes = 0; + ParseAndCheckBoxSizes(context, boxes, &num_boxes); + CheckScoreSizes(context, num_boxes, scores); + if (!context->status().ok()) { + return; + } + auto suppress_check_fn = CreateIOUSuppressCheckFn(boxes, iou_threshold_val); + const float score_threshold_val = std::numeric_limits<float>::lowest(); - DoNonMaxSuppressionOp(context, boxes, scores, max_output_size, - iou_threshold_val, score_threshold_val); + DoNonMaxSuppressionOp(context, scores, num_boxes, max_output_size, + score_threshold_val, suppress_check_fn); } }; @@ -244,8 +294,65 @@ class NonMaxSuppressionV3Op : public OpKernel { score_threshold.shape().DebugString())); const float score_threshold_val = score_threshold.scalar<float>()(); - DoNonMaxSuppressionOp(context, boxes, scores, max_output_size, - iou_threshold_val, score_threshold_val); + OP_REQUIRES(context, iou_threshold_val >= 0 && iou_threshold_val <= 1, + errors::InvalidArgument("iou_threshold must be in [0, 1]")); + int num_boxes = 0; + ParseAndCheckBoxSizes(context, boxes, &num_boxes); + CheckScoreSizes(context, num_boxes, scores); + if (!context->status().ok()) { + return; + } + auto suppress_check_fn = CreateIOUSuppressCheckFn(boxes, iou_threshold_val); + + DoNonMaxSuppressionOp(context, scores, num_boxes, max_output_size, + score_threshold_val, suppress_check_fn); + } +}; + +template <typename Device> +class NonMaxSuppressionWithOverlapsOp : public OpKernel { + public: + explicit NonMaxSuppressionWithOverlapsOp(OpKernelConstruction* context) + : OpKernel(context) {} + + void Compute(OpKernelContext* context) override { + // overlaps: [num_boxes, num_boxes] + const Tensor& overlaps = context->input(0); + // scores: [num_boxes] + const Tensor& scores = context->input(1); + // max_output_size: scalar + const Tensor& max_output_size = context->input(2); + OP_REQUIRES( + context, TensorShapeUtils::IsScalar(max_output_size.shape()), + errors::InvalidArgument("max_output_size must be 0-D, got shape ", + max_output_size.shape().DebugString())); + // overlap_threshold: scalar + const Tensor& overlap_threshold = context->input(3); + OP_REQUIRES( + context, TensorShapeUtils::IsScalar(overlap_threshold.shape()), + errors::InvalidArgument("overlap_threshold must be 0-D, got shape ", + overlap_threshold.shape().DebugString())); + const float overlap_threshold_val = overlap_threshold.scalar<float>()(); + + // score_threshold: scalar + const Tensor& score_threshold = context->input(4); + OP_REQUIRES( + context, TensorShapeUtils::IsScalar(score_threshold.shape()), + errors::InvalidArgument("score_threshold must be 0-D, got shape ", + score_threshold.shape().DebugString())); + const float score_threshold_val = score_threshold.scalar<float>()(); + + int num_boxes = 0; + ParseAndCheckOverlapSizes(context, overlaps, &num_boxes); + CheckScoreSizes(context, num_boxes, scores); + if (!context->status().ok()) { + return; + } + auto suppress_check_fn = + CreateOverlapsSuppressCheckFn(overlaps, overlap_threshold_val); + + DoNonMaxSuppressionOp(context, scores, num_boxes, max_output_size, + score_threshold_val, suppress_check_fn); } }; @@ -258,4 +365,8 @@ REGISTER_KERNEL_BUILDER(Name("NonMaxSuppressionV2").Device(DEVICE_CPU), REGISTER_KERNEL_BUILDER(Name("NonMaxSuppressionV3").Device(DEVICE_CPU), NonMaxSuppressionV3Op<CPUDevice>); +REGISTER_KERNEL_BUILDER( + Name("NonMaxSuppressionWithOverlaps").Device(DEVICE_CPU), + NonMaxSuppressionWithOverlapsOp<CPUDevice>); + } // namespace tensorflow diff --git a/tensorflow/core/kernels/non_max_suppression_op_test.cc b/tensorflow/core/kernels/non_max_suppression_op_test.cc index ed7db313bd..055161a35f 100644 --- a/tensorflow/core/kernels/non_max_suppression_op_test.cc +++ b/tensorflow/core/kernels/non_max_suppression_op_test.cc @@ -569,4 +569,241 @@ TEST_F(NonMaxSuppressionV3OpTest, TestEmptyInput) { test::ExpectTensorEqual<int>(expected, *GetOutput(0)); } +// +// NonMaxSuppressionWithOverlapsOp Tests +// + +class NonMaxSuppressionWithOverlapsOpTest : public OpsTestBase { + protected: + void MakeOp() { + TF_EXPECT_OK(NodeDefBuilder("non_max_suppression_op", + "NonMaxSuppressionWithOverlaps") + .Input(FakeInput(DT_FLOAT)) + .Input(FakeInput(DT_FLOAT)) + .Input(FakeInput(DT_INT32)) + .Input(FakeInput(DT_FLOAT)) + .Input(FakeInput(DT_FLOAT)) + .Finalize(node_def())); + TF_EXPECT_OK(InitOp()); + } + + void AddIoUInput(const std::vector<float>& boxes) { + ASSERT_EQ((boxes.size() % 4), 0); + size_t num_boxes = boxes.size() / 4; + std::vector<float> iou_overlaps(num_boxes * num_boxes); + + // compute the pairwise IoU overlaps + auto corner_access = [&boxes](size_t box_idx, size_t corner_idx) { + return boxes[box_idx * 4 + corner_idx]; + }; + for (size_t i = 0; i < num_boxes; ++i) { + for (size_t j = 0; j < num_boxes; ++j) { + const float ymin_i = + std::min<float>(corner_access(i, 0), corner_access(i, 2)); + const float xmin_i = + std::min<float>(corner_access(i, 1), corner_access(i, 3)); + const float ymax_i = + std::max<float>(corner_access(i, 0), corner_access(i, 2)); + const float xmax_i = + std::max<float>(corner_access(i, 1), corner_access(i, 3)); + const float ymin_j = + std::min<float>(corner_access(j, 0), corner_access(j, 2)); + const float xmin_j = + std::min<float>(corner_access(j, 1), corner_access(j, 3)); + const float ymax_j = + std::max<float>(corner_access(j, 0), corner_access(j, 2)); + const float xmax_j = + std::max<float>(corner_access(j, 1), corner_access(j, 3)); + const float area_i = (ymax_i - ymin_i) * (xmax_i - xmin_i); + const float area_j = (ymax_j - ymin_j) * (xmax_j - xmin_j); + + float iou; + if (area_i <= 0 || area_j <= 0) { + iou = 0.0; + } else { + const float intersection_ymin = std::max<float>(ymin_i, ymin_j); + const float intersection_xmin = std::max<float>(xmin_i, xmin_j); + const float intersection_ymax = std::min<float>(ymax_i, ymax_j); + const float intersection_xmax = std::min<float>(xmax_i, xmax_j); + const float intersection_area = + std::max<float>(intersection_ymax - intersection_ymin, 0.0) * + std::max<float>(intersection_xmax - intersection_xmin, 0.0); + iou = intersection_area / (area_i + area_j - intersection_area); + } + iou_overlaps[i * num_boxes + j] = iou; + } + } + + AddInputFromArray<float>(TensorShape({static_cast<signed>(num_boxes), + static_cast<signed>(num_boxes)}), + iou_overlaps); + } +}; + +TEST_F(NonMaxSuppressionWithOverlapsOpTest, TestSelectFromThreeClusters) { + MakeOp(); + AddIoUInput({0, 0, 1, 1, 0, 0.1f, 1, 1.1f, 0, -0.1f, 1, 0.9f, + 0, 10, 1, 11, 0, 10.1f, 1, 11.1f, 0, 100, 1, 101}); + AddInputFromArray<float>(TensorShape({6}), {.9f, .75f, .6f, .95f, .5f, .3f}); + AddInputFromArray<int>(TensorShape({}), {3}); + AddInputFromArray<float>(TensorShape({}), {.5f}); + AddInputFromArray<float>(TensorShape({}), {0.0f}); + TF_ASSERT_OK(RunOpKernel()); + + Tensor expected(allocator(), DT_INT32, TensorShape({3})); + test::FillValues<int>(&expected, {3, 0, 5}); + test::ExpectTensorEqual<int>(expected, *GetOutput(0)); +} + +TEST_F(NonMaxSuppressionWithOverlapsOpTest, + TestSelectFromThreeClustersFlippedCoordinates) { + MakeOp(); + AddIoUInput({1, 1, 0, 0, 0, 0.1f, 1, 1.1f, 0, .9f, 1, -0.1f, + 0, 10, 1, 11, 1, 10.1f, 0, 11.1f, 1, 101, 0, 100}); + AddInputFromArray<float>(TensorShape({6}), {.9f, .75f, .6f, .95f, .5f, .3f}); + AddInputFromArray<int>(TensorShape({}), {3}); + AddInputFromArray<float>(TensorShape({}), {.5f}); + AddInputFromArray<float>(TensorShape({}), {0.0f}); + TF_ASSERT_OK(RunOpKernel()); + + Tensor expected(allocator(), DT_INT32, TensorShape({3})); + test::FillValues<int>(&expected, {3, 0, 5}); + test::ExpectTensorEqual<int>(expected, *GetOutput(0)); +} + +TEST_F(NonMaxSuppressionWithOverlapsOpTest, + TestSelectAtMostTwoBoxesFromThreeClusters) { + MakeOp(); + AddIoUInput({0, 0, 1, 1, 0, 0.1f, 1, 1.1f, 0, -0.1f, 1, 0.9f, + 0, 10, 1, 11, 0, 10.1f, 1, 11.1f, 0, 100, 1, 101}); + AddInputFromArray<float>(TensorShape({6}), {.9f, .75f, .6f, .95f, .5f, .3f}); + AddInputFromArray<int>(TensorShape({}), {2}); + AddInputFromArray<float>(TensorShape({}), {.5f}); + AddInputFromArray<float>(TensorShape({}), {0.0f}); + TF_ASSERT_OK(RunOpKernel()); + + Tensor expected(allocator(), DT_INT32, TensorShape({2})); + test::FillValues<int>(&expected, {3, 0}); + test::ExpectTensorEqual<int>(expected, *GetOutput(0)); +} + +TEST_F(NonMaxSuppressionWithOverlapsOpTest, + TestSelectAtMostThirtyBoxesFromThreeClusters) { + MakeOp(); + AddIoUInput({0, 0, 1, 1, 0, 0.1f, 1, 1.1f, 0, -0.1f, 1, 0.9f, + 0, 10, 1, 11, 0, 10.1f, 1, 11.1f, 0, 100, 1, 101}); + AddInputFromArray<float>(TensorShape({6}), {.9f, .75f, .6f, .95f, .5f, .3f}); + AddInputFromArray<int>(TensorShape({}), {30}); + AddInputFromArray<float>(TensorShape({}), {.5f}); + AddInputFromArray<float>(TensorShape({}), {0.0f}); + TF_ASSERT_OK(RunOpKernel()); + + Tensor expected(allocator(), DT_INT32, TensorShape({3})); + test::FillValues<int>(&expected, {3, 0, 5}); + test::ExpectTensorEqual<int>(expected, *GetOutput(0)); +} + +TEST_F(NonMaxSuppressionWithOverlapsOpTest, TestSelectSingleBox) { + MakeOp(); + AddIoUInput({0, 0, 1, 1}); + AddInputFromArray<float>(TensorShape({1}), {.9f}); + AddInputFromArray<int>(TensorShape({}), {3}); + AddInputFromArray<float>(TensorShape({}), {.5f}); + AddInputFromArray<float>(TensorShape({}), {0.0f}); + TF_ASSERT_OK(RunOpKernel()); + + Tensor expected(allocator(), DT_INT32, TensorShape({1})); + test::FillValues<int>(&expected, {0}); + test::ExpectTensorEqual<int>(expected, *GetOutput(0)); +} + +TEST_F(NonMaxSuppressionWithOverlapsOpTest, TestSelectFromTenIdenticalBoxes) { + MakeOp(); + + int num_boxes = 10; + std::vector<float> corners(num_boxes * 4); + std::vector<float> scores(num_boxes); + for (int i = 0; i < num_boxes; ++i) { + corners[i * 4 + 0] = 0; + corners[i * 4 + 1] = 0; + corners[i * 4 + 2] = 1; + corners[i * 4 + 3] = 1; + scores[i] = .9; + } + AddIoUInput(corners); + AddInputFromArray<float>(TensorShape({num_boxes}), scores); + AddInputFromArray<int>(TensorShape({}), {3}); + AddInputFromArray<float>(TensorShape({}), {.5f}); + AddInputFromArray<float>(TensorShape({}), {0.0f}); + TF_ASSERT_OK(RunOpKernel()); + + Tensor expected(allocator(), DT_INT32, TensorShape({1})); + test::FillValues<int>(&expected, {0}); + test::ExpectTensorEqual<int>(expected, *GetOutput(0)); +} + +TEST_F(NonMaxSuppressionWithOverlapsOpTest, TestInconsistentBoxAndScoreShapes) { + MakeOp(); + AddIoUInput({0, 0, 1, 1, 0, 0.1f, 1, 1.1f, 0, -0.1f, 1, 0.9f, + 0, 10, 1, 11, 0, 10.1f, 1, 11.1f, 0, 100, 1, 101}); + AddInputFromArray<float>(TensorShape({5}), {.9f, .75f, .6f, .95f, .5f}); + AddInputFromArray<int>(TensorShape({}), {30}); + AddInputFromArray<float>(TensorShape({}), {.5f}); + AddInputFromArray<float>(TensorShape({}), {0.0f}); + Status s = RunOpKernel(); + + ASSERT_FALSE(s.ok()); + EXPECT_TRUE( + str_util::StrContains(s.ToString(), "scores has incompatible shape")) + << s; +} + +TEST_F(NonMaxSuppressionWithOverlapsOpTest, TestInvalidOverlapsShape) { + MakeOp(); + AddInputFromArray<float>(TensorShape({2, 3}), {0, 0, 0, 0, 0, 0}); + AddInputFromArray<float>(TensorShape({2}), {0.5f, 0.5f}); + AddInputFromArray<int>(TensorShape({}), {30}); + AddInputFromArray<float>(TensorShape({}), {0.f}); + AddInputFromArray<float>(TensorShape({}), {0.0f}); + Status s = RunOpKernel(); + + ASSERT_FALSE(s.ok()); + EXPECT_TRUE(str_util::StrContains(s.ToString(), "overlaps must be square")) + << s; +} + +TEST_F(NonMaxSuppressionWithOverlapsOpTest, TestThresholdGreaterOne) { + MakeOp(); + AddIoUInput({0, 0, 1, 1}); + AddInputFromArray<float>(TensorShape({1}), {.9f}); + AddInputFromArray<int>(TensorShape({}), {3}); + AddInputFromArray<float>(TensorShape({}), {1.2f}); + AddInputFromArray<float>(TensorShape({}), {0.0f}); + TF_ASSERT_OK(RunOpKernel()); +} + +TEST_F(NonMaxSuppressionWithOverlapsOpTest, TestThresholdSmallerZero) { + MakeOp(); + AddIoUInput({0, 0, 1, 1}); + AddInputFromArray<float>(TensorShape({1}), {.9f}); + AddInputFromArray<int>(TensorShape({}), {3}); + AddInputFromArray<float>(TensorShape({}), {-0.2f}); + AddInputFromArray<float>(TensorShape({}), {0.0f}); + TF_ASSERT_OK(RunOpKernel()); +} + +TEST_F(NonMaxSuppressionWithOverlapsOpTest, TestEmptyInput) { + MakeOp(); + AddIoUInput({}); + AddInputFromArray<float>(TensorShape({0}), {}); + AddInputFromArray<int>(TensorShape({}), {30}); + AddInputFromArray<float>(TensorShape({}), {.5f}); + AddInputFromArray<float>(TensorShape({}), {0.0f}); + TF_ASSERT_OK(RunOpKernel()); + + Tensor expected(allocator(), DT_INT32, TensorShape({0})); + test::FillValues<int>(&expected, {}); + test::ExpectTensorEqual<int>(expected, *GetOutput(0)); +} + } // namespace tensorflow diff --git a/tensorflow/core/ops/compat/ops_history.v1.pbtxt b/tensorflow/core/ops/compat/ops_history.v1.pbtxt index 5b3056fed1..6cdd03e6a0 100644 --- a/tensorflow/core/ops/compat/ops_history.v1.pbtxt +++ b/tensorflow/core/ops/compat/ops_history.v1.pbtxt @@ -36356,6 +36356,33 @@ op { } } op { + name: "NonMaxSuppressionWithOverlaps" + input_arg { + name: "overlaps" + type: DT_FLOAT + } + input_arg { + name: "scores" + type: DT_FLOAT + } + input_arg { + name: "max_output_size" + type: DT_INT32 + } + input_arg { + name: "overlap_threshold" + type: DT_FLOAT + } + input_arg { + name: "score_threshold" + type: DT_FLOAT + } + output_arg { + name: "selected_indices" + type: DT_INT32 + } +} +op { name: "NotEqual" input_arg { name: "x" diff --git a/tensorflow/core/ops/functional_ops.cc b/tensorflow/core/ops/functional_ops.cc index b49ad8e387..5f262db2ce 100644 --- a/tensorflow/core/ops/functional_ops.cc +++ b/tensorflow/core/ops/functional_ops.cc @@ -40,7 +40,11 @@ REGISTER_OP("SymbolicGradient") if (types[i] == DT_RESOURCE) { const std::vector<shape_inference::ShapeAndType>* handle_type = c->input_handle_shapes_and_types(i); - c->set_output(i, handle_type->at(0).shape); + if (handle_type != nullptr) { + c->set_output(i, handle_type->at(0).shape); + } else { + c->set_output(i, c->UnknownShape()); + } } else { c->set_output(i, c->input(i)); } diff --git a/tensorflow/core/ops/image_ops.cc b/tensorflow/core/ops/image_ops.cc index 87f4991134..50ced1ff73 100644 --- a/tensorflow/core/ops/image_ops.cc +++ b/tensorflow/core/ops/image_ops.cc @@ -709,4 +709,36 @@ REGISTER_OP("NonMaxSuppressionV3") return Status::OK(); }); +REGISTER_OP("NonMaxSuppressionWithOverlaps") + .Input("overlaps: float") + .Input("scores: float") + .Input("max_output_size: int32") + .Input("overlap_threshold: float") + .Input("score_threshold: float") + .Output("selected_indices: int32") + .SetShapeFn([](InferenceContext* c) { + // Get inputs and validate ranks. + ShapeHandle overlaps; + TF_RETURN_IF_ERROR(c->WithRank(c->input(0), 2, &overlaps)); + ShapeHandle scores; + TF_RETURN_IF_ERROR(c->WithRank(c->input(1), 1, &scores)); + ShapeHandle max_output_size; + TF_RETURN_IF_ERROR(c->WithRank(c->input(2), 0, &max_output_size)); + ShapeHandle overlap_threshold; + TF_RETURN_IF_ERROR(c->WithRank(c->input(3), 0, &overlap_threshold)); + ShapeHandle score_threshold; + TF_RETURN_IF_ERROR(c->WithRank(c->input(4), 0, &score_threshold)); + // The boxes is a 2-D float Tensor of shape [num_boxes, 4]. + DimensionHandle unused; + // The boxes[0] and scores[0] are both num_boxes. + TF_RETURN_IF_ERROR( + c->Merge(c->Dim(overlaps, 0), c->Dim(scores, 0), &unused)); + // The boxes[1] is 4. + TF_RETURN_IF_ERROR( + c->Merge(c->Dim(overlaps, 0), c->Dim(overlaps, 1), &unused)); + + c->set_output(0, c->Vector(c->UnknownDim())); + return Status::OK(); + }); + } // namespace tensorflow diff --git a/tensorflow/core/ops/ops.pbtxt b/tensorflow/core/ops/ops.pbtxt index ea49119784..9a9f10f01f 100644 --- a/tensorflow/core/ops/ops.pbtxt +++ b/tensorflow/core/ops/ops.pbtxt @@ -17024,6 +17024,33 @@ op { } } op { + name: "NonMaxSuppressionWithOverlaps" + input_arg { + name: "overlaps" + type: DT_FLOAT + } + input_arg { + name: "scores" + type: DT_FLOAT + } + input_arg { + name: "max_output_size" + type: DT_INT32 + } + input_arg { + name: "overlap_threshold" + type: DT_FLOAT + } + input_arg { + name: "score_threshold" + type: DT_FLOAT + } + output_arg { + name: "selected_indices" + type: DT_INT32 + } +} +op { name: "NotEqual" input_arg { name: "x" diff --git a/tensorflow/core/platform/profile_utils/cpu_utils.cc b/tensorflow/core/platform/profile_utils/cpu_utils.cc index 02de7d1362..b0136b52f4 100644 --- a/tensorflow/core/platform/profile_utils/cpu_utils.cc +++ b/tensorflow/core/platform/profile_utils/cpu_utils.cc @@ -15,6 +15,7 @@ limitations under the License. #include "tensorflow/core/platform/profile_utils/cpu_utils.h" +#include <fstream> #include <limits> #include <mutex> @@ -67,22 +68,32 @@ static ICpuUtilsHelper* cpu_utils_helper_instance_ = nullptr; #if defined(__ANDROID__) return GetCpuUtilsHelperSingletonInstance().CalculateCpuFrequency(); #elif defined(__linux__) - double bogomips; - FILE* fp = popen("grep '^bogomips' /proc/cpuinfo | head -1", "r"); - if (fp == nullptr) { - return INVALID_FREQUENCY; - } - const int retval_of_bogomips = fscanf(fp, "bogomips : %lf", &bogomips); - if (retval_of_bogomips <= 0) { + // Read the contents of /proc/cpuinfo. + std::ifstream cpuinfo("/proc/cpuinfo"); + if (!cpuinfo) { + LOG(WARNING) << "Failed to open /proc/cpuinfo"; return INVALID_FREQUENCY; } - pclose(fp); - const double freq_ghz = bogomips / 1000.0 / 2.0; - if (retval_of_bogomips != 1 || freq_ghz < 0.01) { - LOG(WARNING) << "Failed to get CPU frequency: " << freq_ghz << " Hz"; - return INVALID_FREQUENCY; + string line; + while (std::getline(cpuinfo, line)) { + double bogomips; + const int retval_of_bogomips = + sscanf(line.c_str(), "bogomips : %lf", &bogomips); + if (retval_of_bogomips > 0) { + const double freq_ghz = bogomips / 1000.0 / 2.0; + if (retval_of_bogomips != 1 || freq_ghz < 0.01) { + LOG(WARNING) << "Failed to get CPU frequency: " << freq_ghz << " Hz"; + return INVALID_FREQUENCY; + } + const int64 freq_n = + static_cast<int64>(freq_ghz * 1000.0 * 1000.0 * 1000.0); + LOG(INFO) << "CPU Frequency: " << freq_n << " Hz"; + return freq_n; + } } - return static_cast<int64>(freq_ghz * 1000.0 * 1000.0 * 1000.0); + LOG(WARNING) << "Failed to find bogomips in /proc/cpuinfo; cannot determine " + "CPU frequency"; + return INVALID_FREQUENCY; #elif defined(__APPLE__) int64 freq_hz; FILE* fp = diff --git a/tensorflow/docs_src/deploy/s3.md b/tensorflow/docs_src/deploy/s3.md index 9ef9674338..7028249e94 100644 --- a/tensorflow/docs_src/deploy/s3.md +++ b/tensorflow/docs_src/deploy/s3.md @@ -90,4 +90,4 @@ S3 was invented by Amazon, but the S3 API has spread in popularity and has sever * [Amazon S3](https://aws.amazon.com/s3/) * [Google Storage](https://cloud.google.com/storage/docs/interoperability) -* [Minio](https://www.minio.io/kubernetes.html)(Standalone mode only) +* [Minio](https://www.minio.io/kubernetes.html) diff --git a/tensorflow/docs_src/guide/eager.md b/tensorflow/docs_src/guide/eager.md index 003ca265fe..e98206eef9 100644 --- a/tensorflow/docs_src/guide/eager.md +++ b/tensorflow/docs_src/guide/eager.md @@ -421,7 +421,7 @@ class Model(tf.keras.Model): super(Model, self).__init__() self.W = tfe.Variable(5., name='weight') self.B = tfe.Variable(10., name='bias') - def predict(self, inputs): + def call(self, inputs): return inputs * self.W + self.B # A toy dataset of points around 3 * x + 2 @@ -432,7 +432,7 @@ training_outputs = training_inputs * 3 + 2 + noise # The loss function to be optimized def loss(model, inputs, targets): - error = model.predict(inputs) - targets + error = model(inputs) - targets return tf.reduce_mean(tf.square(error)) def grad(model, inputs, targets): diff --git a/tensorflow/docs_src/javascript/index.md b/tensorflow/docs_src/javascript/index.md deleted file mode 100644 index ad63eeb255..0000000000 --- a/tensorflow/docs_src/javascript/index.md +++ /dev/null @@ -1,5 +0,0 @@ -# JavaScript - -You may develop TensorFlow programs in JavaScript, training and deploying -models right in your browser. For details, see -[js.tensorflow.org](https://js.tensorflow.org). diff --git a/tensorflow/docs_src/javascript/leftnav_files b/tensorflow/docs_src/javascript/leftnav_files deleted file mode 100644 index fc0ab8a543..0000000000 --- a/tensorflow/docs_src/javascript/leftnav_files +++ /dev/null @@ -1 +0,0 @@ -index.md diff --git a/tensorflow/docs_src/performance/xla/operation_semantics.md b/tensorflow/docs_src/performance/xla/operation_semantics.md index 4c4f3f3934..68c427a316 100644 --- a/tensorflow/docs_src/performance/xla/operation_semantics.md +++ b/tensorflow/docs_src/performance/xla/operation_semantics.md @@ -2015,30 +2015,37 @@ two-operand version. <b>`Sort(operand)`</b> -Arguments | Type | Semantics ---------- | ------- | -------------------- -`operand` | `XlaOp` | The operand to sort. - -Sorts the elements in the operand in ascending order. The operand must be rank-1. -If the operand's elements have floating point type, and the operand contains -NaN elements, the order of elements in the output is implementation-defined. +Arguments | Type | Semantics +----------- | ------- | -------------------- +`operand` | `XlaOp` | The operand to sort. +`dimension` | `int64` | The dimension along which to sort. + +Sorts the elements in the operand in ascending order along the provided +dimension. For example, for a rank-2 (matrix) operand, a `dimension` value of 0 +will sort each column independently, and a `dimension` value of 1 will sort each +row independently. If the operand's elements have floating point type, and the +operand contains NaN elements, the order of elements in the output is +implementation-defined. <b>`Sort(key, value)`</b> Sorts both the key and the value operands. The keys are sorted as in the single-operand version. The values are sorted according to the order of their corresponding keys. For example, if the inputs are `keys = [3, 1]` and -`values = [42, 50]`, then the output of the sort is the tuple `{[1, 3], [50, 42]}`. +`values = [42, 50]`, then the output of the sort is the tuple +`{[1, 3], [50, 42]}`. + The sort is not guaranteed to be stable, that is, if the keys array contains duplicates, the order of their corresponding values may not be preserved. -Arguments | Type | Semantics ---------- | ------- | ------------------- -`keys` | `XlaOp` | The sort keys. -`values` | `XlaOp` | The values to sort. +Arguments | Type | Semantics +----------- | ------- | ------------------- +`keys` | `XlaOp` | The sort keys. +`values` | `XlaOp` | The values to sort. +`dimension` | `int64` | The dimension along which to sort. -The `keys` and `values` operand must both be rank-1, and must have the same -dimensions, but may have different element types. +The `keys` and `values` must have the same dimensions, but may have different +element types. ## Transpose diff --git a/tensorflow/java/src/main/native/session_jni.cc b/tensorflow/java/src/main/native/session_jni.cc index cb54daf137..8b11525785 100644 --- a/tensorflow/java/src/main/native/session_jni.cc +++ b/tensorflow/java/src/main/native/session_jni.cc @@ -86,20 +86,22 @@ JNIEXPORT jlong JNICALL Java_org_tensorflow_Session_allocate2( TF_Graph* graph = reinterpret_cast<TF_Graph*>(graph_handle); TF_Status* status = TF_NewStatus(); TF_SessionOptions* opts = TF_NewSessionOptions(); - const char* ctarget = nullptr; jbyte* cconfig = nullptr; - if (target != nullptr) { - ctarget = env->GetStringUTFChars(target, nullptr); - } if (config != nullptr) { cconfig = env->GetByteArrayElements(config, nullptr); TF_SetConfig(opts, cconfig, static_cast<size_t>(env->GetArrayLength(config)), status); if (!throwExceptionIfNotOK(env, status)) { env->ReleaseByteArrayElements(config, cconfig, JNI_ABORT); + TF_DeleteSessionOptions(opts); + TF_DeleteStatus(status); return 0; } } + const char* ctarget = nullptr; + if (target != nullptr) { + ctarget = env->GetStringUTFChars(target, nullptr); + } TF_Session* session = TF_NewSession(graph, opts, status); if (config != nullptr) { env->ReleaseByteArrayElements(config, cconfig, JNI_ABORT); diff --git a/tensorflow/python/BUILD b/tensorflow/python/BUILD index ebfcfff4a5..d60d37df50 100644 --- a/tensorflow/python/BUILD +++ b/tensorflow/python/BUILD @@ -4079,6 +4079,7 @@ cuda_py_test( ":math_ops", "//tensorflow/core:protos_all_py", ], + tags = ["no_windows_gpu"], ) py_test( diff --git a/tensorflow/python/debug/BUILD b/tensorflow/python/debug/BUILD index 18a1948a6a..27b8ebd362 100644 --- a/tensorflow/python/debug/BUILD +++ b/tensorflow/python/debug/BUILD @@ -803,6 +803,7 @@ cuda_py_test( "//tensorflow/python:platform_test", "//tensorflow/python:variables", ], + tags = ["no_windows_gpu"], ) py_test( diff --git a/tensorflow/python/eager/backprop.py b/tensorflow/python/eager/backprop.py index 3e3c82e56a..9e0bbce4a1 100644 --- a/tensorflow/python/eager/backprop.py +++ b/tensorflow/python/eager/backprop.py @@ -713,10 +713,15 @@ class GradientTape(object): if self._recording: self._pop_tape() - def _push_tape(self): + def _push_tape(self, existing_tape=False): if self._recording: raise ValueError("Tape is already recording.") - self._tape = tape.push_new_tape(persistent=self._persistent) + if existing_tape: + if self._tape is None: + raise ValueError("There is no existing tape.") + tape.push_tape(self._tape) + else: + self._tape = tape.push_new_tape(persistent=self._persistent) self._recording = True def _pop_tape(self): @@ -764,7 +769,7 @@ class GradientTape(object): try: yield finally: - self._push_tape() + self._push_tape(existing_tape=True) def reset(self): """Clears all information stored in this tape. diff --git a/tensorflow/python/eager/backprop_test.py b/tensorflow/python/eager/backprop_test.py index ebbd3cd98e..bdda200ff6 100644 --- a/tensorflow/python/eager/backprop_test.py +++ b/tensorflow/python/eager/backprop_test.py @@ -223,11 +223,23 @@ class BackpropTest(test.TestCase): def testTapeStopRecording(self): with backprop.GradientTape() as t: - x = constant_op.constant(1.0) + x = resource_variable_ops.ResourceVariable(1.0) with t.stop_recording(): y = x * x self.assertEqual(t.gradient(y, x), None) + def testTapeStopStartRecording(self): + with backprop.GradientTape(persistent=True) as t: + x = resource_variable_ops.ResourceVariable(1.0) + x2 = x * 2 # This should be differentiated through. + with t.stop_recording(): + y = x2 * x2 + z = x2 * x2 + self.assertEqual(t.gradient(y, x2), None) + + # If the x*2 was not differentiated through, this would be 2.0, not 4.0 + self.assertEqual(t.gradient(z, x2).numpy(), 4.0) + def testTapeReset(self): with backprop.GradientTape() as t: v = resource_variable_ops.ResourceVariable(1.0) diff --git a/tensorflow/python/eager/function_test.py b/tensorflow/python/eager/function_test.py index fe9d7aece4..a3e63c3153 100644 --- a/tensorflow/python/eager/function_test.py +++ b/tensorflow/python/eager/function_test.py @@ -43,7 +43,7 @@ from tensorflow.python.ops import resource_variable_ops from tensorflow.python.ops import variable_scope from tensorflow.python.ops import variables from tensorflow.python.platform import test -from tensorflow.python.training import gradient_descent +from tensorflow.python.training import momentum from tensorflow.python.training import training_ops from tensorflow.python.util import compat @@ -1140,7 +1140,7 @@ class AutomaticControlDependenciesTest(test.TestCase): def loss(v): return v**2 - optimizer = gradient_descent.GradientDescentOptimizer(learning_rate=1.0) + optimizer = momentum.MomentumOptimizer(learning_rate=1.0, momentum=1.0) @function.defun def train(): @@ -1157,7 +1157,7 @@ class AutomaticControlDependenciesTest(test.TestCase): def loss(): return v**2 - optimizer = gradient_descent.GradientDescentOptimizer(learning_rate=1.0) + optimizer = momentum.MomentumOptimizer(learning_rate=1.0, momentum=1.0) @function.defun def train(): diff --git a/tensorflow/python/eager/graph_callable.py b/tensorflow/python/eager/graph_callable.py index 848adf4fd3..2c6f04d8ad 100644 --- a/tensorflow/python/eager/graph_callable.py +++ b/tensorflow/python/eager/graph_callable.py @@ -118,7 +118,7 @@ class _VariableCapturingScope(object): initializer=None, regularizer=None, reuse=None, - trainable=True, + trainable=None, collections=None, caching_device=None, # pylint: disable=redefined-outer-name partitioner=None, @@ -156,7 +156,7 @@ class _VariableCapturingScope(object): initializer=None, regularizer=None, reuse=None, - trainable=True, + trainable=None, collections=None, caching_device=None, # pylint: disable=redefined-outer-name partitioner=None, diff --git a/tensorflow/python/eager/pywrap_tfe_src.cc b/tensorflow/python/eager/pywrap_tfe_src.cc index 57b4dab51c..ec7e2371e9 100644 --- a/tensorflow/python/eager/pywrap_tfe_src.cc +++ b/tensorflow/python/eager/pywrap_tfe_src.cc @@ -1898,14 +1898,39 @@ PyObject* RecordGradient(PyObject* op_name, PyObject* inputs, PyObject* attrs, void MaybeWatchVariable(PyObject* input) { DCHECK(CheckResourceVariable(input)); - DCHECK(PyObject_HasAttrString(input, "trainable")); + DCHECK(PyObject_HasAttrString(input, "_trainable")); tensorflow::Safe_PyObjectPtr trainable( - PyObject_GetAttrString(input, "trainable")); + PyObject_GetAttrString(input, "_trainable")); if (trainable.get() == Py_False) return; TFE_Py_TapeSetWatchVariable(input); } +bool CastTensor(const FastPathOpExecInfo& op_exec_info, + const TF_DataType& desired_dtype, + tensorflow::Safe_TFE_TensorHandlePtr* handle, + TF_Status* status) { + TF_DataType input_dtype = TFE_TensorHandleDataType(handle->get()); + TF_DataType output_dtype = input_dtype; + + if (desired_dtype >= 0 && desired_dtype != input_dtype) { + *handle = tensorflow::make_safe( + tensorflow::EagerCast(op_exec_info.ctx, handle->get(), input_dtype, + static_cast<TF_DataType>(desired_dtype), status)); + if (!status->status.ok()) return false; + output_dtype = desired_dtype; + } + + if (output_dtype != TF_INT32) { + // Note that this is a shallow copy and will share the underlying buffer + // if copying to the same device. + *handle = tensorflow::make_safe(TFE_TensorHandleCopyToDevice( + handle->get(), op_exec_info.ctx, op_exec_info.device_name, status)); + if (!status->status.ok()) return false; + } + return true; +} + bool ReadVariableOp(const FastPathOpExecInfo& parent_op_exec_info, PyObject* input, tensorflow::Safe_PyObjectPtr* output, TF_Status* status) { @@ -1938,9 +1963,31 @@ bool ReadVariableOp(const FastPathOpExecInfo& parent_op_exec_info, TFE_Execute(op, &output_handle, &num_retvals, status); if (MaybeRaiseExceptionFromTFStatus(status, nullptr)) return false; - // Always create the py object (and correctly DECREF it) from the returned - // value, else the data will leak. - output->reset(EagerTensorFromHandle(output_handle)); + if (!PyObject_HasAttrString(input, "_read_dtype")) { + // Always create the py object (and correctly DECREF it) from the returned + // value, else the data will leak. + output->reset(EagerTensorFromHandle(output_handle)); + } else { + // This is a _MixedPrecisionVariable which potentially does casting when + // being read. + tensorflow::Safe_PyObjectPtr read_dtype( + PyObject_GetAttrString(input, "_read_dtype")); + int desired_dtype = -1; + if (!ParseTypeValue("_read_dtype", read_dtype.get(), status, + &desired_dtype)) { + return false; + } + + auto safe_output_handle = tensorflow::make_safe(output_handle); + // Retires output_handle in the future. + output_handle = nullptr; + if (!CastTensor(parent_op_exec_info, + static_cast<TF_DataType>(desired_dtype), + &safe_output_handle, status)) { + return false; + } + output->reset(EagerTensorFromHandle(safe_output_handle.release())); + } // TODO(nareshmodi): Should we run post exec callbacks here? if (parent_op_exec_info.run_gradient_callback) { @@ -2010,27 +2057,13 @@ bool ConvertToTensor( } } - TF_DataType handle_dtype = TFE_TensorHandleDataType(handle.get()); - if (desired_dtype >= 0 && desired_dtype != handle_dtype) { - handle = tensorflow::make_safe( - tensorflow::EagerCast(op_exec_info.ctx, handle.get(), handle_dtype, - static_cast<TF_DataType>(desired_dtype), status)); - if (!status->status.ok()) return false; - - handle_dtype = TFE_TensorHandleDataType(handle.get()); - } - - if (handle_dtype != TF_INT32) { - // Note that this is a shallow copy and will share the underlying buffer - // if copying to the same device. - handle = tensorflow::make_safe(TFE_TensorHandleCopyToDevice( - handle.get(), op_exec_info.ctx, op_exec_info.device_name, status)); - if (!status->status.ok()) return false; + if (!CastTensor(op_exec_info, static_cast<TF_DataType>(desired_dtype), + &handle, status)) { + return false; } - + TF_DataType output_dtype = TFE_TensorHandleDataType(handle.get()); output_handle->reset(EagerTensorFromHandle(handle.release())); - - dtype_setter(handle_dtype); + dtype_setter(output_dtype); return true; } diff --git a/tensorflow/python/eager/pywrap_tfe_test.py b/tensorflow/python/eager/pywrap_tfe_test.py index faaae40b3f..fd8ab695b8 100644 --- a/tensorflow/python/eager/pywrap_tfe_test.py +++ b/tensorflow/python/eager/pywrap_tfe_test.py @@ -23,6 +23,7 @@ from tensorflow.python.eager import backprop from tensorflow.python.eager import context from tensorflow.python.eager import test from tensorflow.python.framework import constant_op +from tensorflow.python.framework import dtypes from tensorflow.python.framework import test_util from tensorflow.python.ops import array_ops from tensorflow.python.ops import math_ops @@ -71,6 +72,25 @@ class Tests(test.TestCase): @test_util.assert_no_new_tensors @test_util.assert_no_garbage_created + def testFastpathExecute_MixedPrecisionVariableMatMulCorrectResponse(self): + ctx = context.context() + a_2_by_2 = constant_op.constant(1.0, shape=[2, 2]) + a_2_by_2_fp16 = math_ops.cast(a_2_by_2, dtype=dtypes.float16) + m = resource_variable_ops.ResourceVariable(a_2_by_2) + m = resource_variable_ops._MixedPrecisionVariable( + m, read_dtype=dtypes.float16) + x = pywrap_tensorflow.TFE_Py_FastPathExecute( + ctx._handle, ctx.device_name, "MatMul", None, None, m, m, "transpose_a", + False, "transpose_b", False) + y = pywrap_tensorflow.TFE_Py_FastPathExecute( + ctx._handle, ctx.device_name, "MatMul", None, None, a_2_by_2_fp16, + a_2_by_2_fp16, "transpose_a", False, "transpose_b", False) + + self.assertEqual(x.dtype, dtypes.float16) + self.assertAllEqual(x, y) + + @test_util.assert_no_new_tensors + @test_util.assert_no_garbage_created def testFastpathExecute_TapeWrite(self): ctx = context.context() with backprop.GradientTape(persistent=True) as tape: @@ -98,6 +118,29 @@ class Tests(test.TestCase): self.assertAllEqual(dz_dy.numpy(), constant_op.constant(4.0, shape=[2, 2]).numpy()) + @test_util.assert_no_new_tensors + @test_util.assert_no_garbage_created + def testFastpathExecute_MixedPrecisionVariableTapeWrite(self): + ctx = context.context() + with backprop.GradientTape(persistent=True) as tape: + a_2_by_2 = constant_op.constant( + [[1.0, 2.0], [3.0, 4.0]], dtype=dtypes.float32) + a_2_by_2_fp16 = math_ops.cast(a_2_by_2, dtype=dtypes.float16) + m1 = resource_variable_ops.ResourceVariable(a_2_by_2) + m2 = resource_variable_ops._MixedPrecisionVariable( + m1, read_dtype=dtypes.float16) + tape.watch(m2) + z = pywrap_tensorflow.TFE_Py_FastPathExecute( + ctx._handle, ctx.device_name, "MatMul", None, None, a_2_by_2_fp16, m2, + "transpose_a", False, "transpose_b", False) + dz_dy = tape.gradient(z, [m2])[0] + self.assertEqual(dz_dy.dtype, dtypes.float16) + + expected_grads = math_ops.matmul( + array_ops.transpose(a_2_by_2_fp16), + constant_op.constant(1., shape=[2, 2], dtype=dtypes.float16)).numpy() + self.assertAllEqual(dz_dy.numpy(), expected_grads) + # Tests homogeneous list op @test_util.assert_no_new_tensors @test_util.assert_no_garbage_created diff --git a/tensorflow/python/estimator/api/BUILD b/tensorflow/python/estimator/api/BUILD index aa5a29e6dd..ceb9baef4d 100644 --- a/tensorflow/python/estimator/api/BUILD +++ b/tensorflow/python/estimator/api/BUILD @@ -13,6 +13,7 @@ gen_api_init_files( name = "estimator_python_api_gen", api_name = "estimator", output_files = ESTIMATOR_API_INIT_FILES, + output_package = "tensorflow.python.estimator.api", package = "tensorflow.python.estimator", package_dep = "//tensorflow/python/estimator:estimator_py", ) diff --git a/tensorflow/python/estimator/canned/boosted_trees.py b/tensorflow/python/estimator/canned/boosted_trees.py index a22e9745c1..3c832c7569 100644 --- a/tensorflow/python/estimator/canned/boosted_trees.py +++ b/tensorflow/python/estimator/canned/boosted_trees.py @@ -669,6 +669,8 @@ def _bt_model_fn( name='wait_until_n_batches_for_bias_accumulated') return center_bias_op + else: + return control_flow_ops.no_op() def grow_not_in_mem(): """Accumulates the data and grows a layer when ready.""" @@ -715,6 +717,8 @@ def _bt_model_fn( name='wait_until_n_batches_accumulated') return grow_model + else: + return control_flow_ops.no_op() update_model = control_flow_ops.cond( center_bias_var, center_bias_not_in_mem, grow_not_in_mem) diff --git a/tensorflow/python/framework/common_shapes.py b/tensorflow/python/framework/common_shapes.py index 3c5aebbce8..40788e24c4 100644 --- a/tensorflow/python/framework/common_shapes.py +++ b/tensorflow/python/framework/common_shapes.py @@ -28,6 +28,18 @@ from tensorflow.python.framework import tensor_shape from tensorflow.python.framework import tensor_util +def has_fully_defined_shape(tensor): + """Returns true if tensor has a fully defined shape.""" + return isinstance(tensor, ops.EagerTensor) or tensor.shape.is_fully_defined() + + +def rank(tensor): + """Return a rank if it is a tensor, else return None.""" + if isinstance(tensor, ops.Tensor): + return tensor._rank() # pylint: disable=protected-access + return None + + def scalar_shape(unused_op): """Shape function for ops that output a scalar value.""" return [tensor_shape.scalar()] diff --git a/tensorflow/python/framework/ops.py b/tensorflow/python/framework/ops.py index cf0b1e36fb..b07c57d265 100644 --- a/tensorflow/python/framework/ops.py +++ b/tensorflow/python/framework/ops.py @@ -706,7 +706,7 @@ class _EagerTensorBase(Tensor): """ if self.dtype == dtypes.resource: raise ValueError("Resource handles are not convertible to numpy.") - return self.cpu()._numpy() # pylint: disable=protected-access + return self._cpu_nograd()._numpy() # pylint: disable=protected-access # __int__ and __float__ may copy the tensor to CPU and # only work for scalars; values are cast as per numpy. @@ -780,8 +780,8 @@ class _EagerTensorBase(Tensor): def _override_operator(name, func): setattr(_EagerTensorBase, name, func) - def _copy(self, ctx=None, device_name=None): - """Copies tensor to dest device.""" + def _copy_nograd(self, ctx=None, device_name=None): + """Copies tensor to dest device, but doesn't record the operation.""" # pylint: disable=protected-access # Creates a new tensor on the dest device. if ctx is None: @@ -793,7 +793,11 @@ class _EagerTensorBase(Tensor): new_tensor = self._copy_to_device(context=ctx._handle, device=device_name) except core._NotOkStatusException as e: six.raise_from(core._status_to_exception(e.code, e.message), None) + return new_tensor + def _copy(self, ctx=None, device_name=None): + """Copies tensor to dest device.""" + new_tensor = self._copy_nograd(ctx, device_name) # Record the copy on tape and define backprop copy as well. if context.executing_eagerly(): self_device = self.device @@ -824,6 +828,16 @@ class _EagerTensorBase(Tensor): """Returns the number of Tensor dimensions.""" return self.shape.ndims + def _cpu_nograd(self): + """A copy of this Tensor with contents backed by host memory. + + The copy cannot be differentiated through. + + Returns: + A CPU-memory backed Tensor object with the same contents as this Tensor. + """ + return self._copy_nograd(context.context(), "CPU:0") + def cpu(self): """A copy of this Tensor with contents backed by host memory.""" return self._copy(context.context(), "CPU:0") diff --git a/tensorflow/python/framework/tensor_util_test.py b/tensorflow/python/framework/tensor_util_test.py index d6edc13643..395cf43b3f 100644 --- a/tensorflow/python/framework/tensor_util_test.py +++ b/tensorflow/python/framework/tensor_util_test.py @@ -50,13 +50,13 @@ class TensorUtilTest(test.TestCase): def testFloatN(self): t = tensor_util.make_tensor_proto([10.0, 20.0, 30.0]) if sys.byteorder == "big": - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_FLOAT tensor_shape { dim { size: 3 } } tensor_content: "A \000\000A\240\000\000A\360\000\000" """, t) else: - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_FLOAT tensor_shape { dim { size: 3 } } tensor_content: "\000\000 A\000\000\240A\000\000\360A" @@ -68,13 +68,13 @@ class TensorUtilTest(test.TestCase): def testFloatTyped(self): t = tensor_util.make_tensor_proto([10.0, 20.0, 30.0], dtype=dtypes.float32) if sys.byteorder == "big": - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_FLOAT tensor_shape { dim { size: 3 } } tensor_content: "A \000\000A\240\000\000A\360\000\000" """, t) else: - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_FLOAT tensor_shape { dim { size: 3 } } tensor_content: "\000\000 A\000\000\240A\000\000\360A" @@ -86,13 +86,13 @@ class TensorUtilTest(test.TestCase): def testFloatTypeCoerce(self): t = tensor_util.make_tensor_proto([10, 20, 30], dtype=dtypes.float32) if sys.byteorder == "big": - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_FLOAT tensor_shape { dim { size: 3 } } tensor_content: "A \000\000A\240\000\000A\360\000\000" """, t) else: - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_FLOAT tensor_shape { dim { size: 3 } } tensor_content: "\000\000 A\000\000\240A\000\000\360A" @@ -105,13 +105,13 @@ class TensorUtilTest(test.TestCase): arr = np.asarray([10, 20, 30], dtype="int") t = tensor_util.make_tensor_proto(arr, dtype=dtypes.float32) if sys.byteorder == "big": - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_FLOAT tensor_shape { dim { size: 3 } } tensor_content: "A \000\000A\240\000\000A\360\000\000" """, t) else: - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_FLOAT tensor_shape { dim { size: 3 } } tensor_content: "\000\000 A\000\000\240A\000\000\360A" @@ -123,13 +123,13 @@ class TensorUtilTest(test.TestCase): def testFloatSizes(self): t = tensor_util.make_tensor_proto([10.0, 20.0, 30.0], shape=[1, 3]) if sys.byteorder == "big": - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_FLOAT tensor_shape { dim { size: 1 } dim { size: 3 } } tensor_content: "A \000\000A\240\000\000A\360\000\000" """, t) else: - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_FLOAT tensor_shape { dim { size: 1 } dim { size: 3 } } tensor_content: "\000\000 A\000\000\240A\000\000\360A" @@ -141,13 +141,13 @@ class TensorUtilTest(test.TestCase): def testFloatSizes2(self): t = tensor_util.make_tensor_proto([10.0, 20.0, 30.0], shape=[3, 1]) if sys.byteorder == "big": - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_FLOAT tensor_shape { dim { size: 3 } dim { size: 1 } } tensor_content: "A \000\000A\240\000\000A\360\000\000" """, t) else: - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_FLOAT tensor_shape { dim { size: 3 } dim { size: 1 } } tensor_content: "\000\000 A\000\000\240A\000\000\360A" @@ -169,13 +169,13 @@ class TensorUtilTest(test.TestCase): t = tensor_util.make_tensor_proto( np.array([[10.0, 20.0, 30.0]], dtype=np.float64)) if sys.byteorder == "big": - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_DOUBLE tensor_shape { dim { size: 1 } dim { size: 3 } } tensor_content: "@$\000\000\000\000\000\000@4\000\000\000\000\000\000@>\000\000\000\000\000\000" """, t) else: - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_DOUBLE tensor_shape { dim { size: 1 } dim { size: 3 } } tensor_content: "\000\000\000\000\000\000$@\000\000\000\000\000\0004@\000\000\000\000\000\000>@" @@ -206,13 +206,13 @@ class TensorUtilTest(test.TestCase): self.assertEquals(np.float32, a.dtype) self.assertAllClose(np.array([5.0, 20.0, 30.0], dtype=np.float32), a) if sys.byteorder == "big": - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_FLOAT tensor_shape { dim { size: 3 } } tensor_content: "A \000\000A\240\000\000A\360\000\000" """, t) else: - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_FLOAT tensor_shape { dim { size: 3 } } tensor_content: "\000\000 A\000\000\240A\000\000\360A" @@ -299,16 +299,16 @@ class TensorUtilTest(test.TestCase): def testIntNDefaultType(self): t = tensor_util.make_tensor_proto([10, 20, 30, 40], shape=[2, 2]) if sys.byteorder == "big": - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_INT32 tensor_shape { dim { size: 2 } dim { size: 2 } } - tensor_content: "\000\000\000\\n\000\000\000\024\000\000\000\036\000\000\000(" + tensor_content: "\000\000\000\n\000\000\000\024\000\000\000\036\000\000\000(" """, t) else: - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_INT32 tensor_shape { dim { size: 2 } dim { size: 2 } } - tensor_content: "\\n\000\000\000\024\000\000\000\036\000\000\000(\000\000\000" + tensor_content: "\n\000\000\000\024\000\000\000\036\000\000\000(\000\000\000" """, t) a = tensor_util.MakeNdarray(t) self.assertEquals(np.int32, a.dtype) @@ -380,16 +380,16 @@ class TensorUtilTest(test.TestCase): t = tensor_util.make_tensor_proto( [10, 20, 30], shape=[1, 3], dtype=dtypes.int64) if sys.byteorder == "big": - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_INT64 tensor_shape { dim { size: 1 } dim { size: 3 } } - tensor_content: "\000\000\000\000\000\000\000\\n\000\000\000\000\000\000\000\024\000\000\000\000\000\000\000\036" + tensor_content: "\000\000\000\000\000\000\000\n\000\000\000\000\000\000\000\024\000\000\000\000\000\000\000\036" """, t) else: - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_INT64 tensor_shape { dim { size: 1 } dim { size: 3 } } - tensor_content: "\\n\000\000\000\000\000\000\000\024\000\000\000\000\000\000\000\036\000\000\000\000\000\000\000" + tensor_content: "\n\000\000\000\000\000\000\000\024\000\000\000\000\000\000\000\036\000\000\000\000\000\000\000" """, t) a = tensor_util.MakeNdarray(t) self.assertEquals(np.int64, a.dtype) @@ -398,16 +398,16 @@ class TensorUtilTest(test.TestCase): def testLongNpArray(self): t = tensor_util.make_tensor_proto(np.array([10, 20, 30])) if sys.byteorder == "big": - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_INT64 tensor_shape { dim { size: 3 } } - tensor_content: "\000\000\000\000\000\000\000\\n\000\000\000\000\000\000\000\024\000\000\000\000\000\000\000\036" + tensor_content: "\000\000\000\000\000\000\000\n\000\000\000\000\000\000\000\024\000\000\000\000\000\000\000\036" """, t) else: - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_INT64 tensor_shape { dim { size: 3 } } - tensor_content: "\\n\000\000\000\000\000\000\000\024\000\000\000\000\000\000\000\036\000\000\000\000\000\000\000" + tensor_content: "\n\000\000\000\000\000\000\000\024\000\000\000\000\000\000\000\036\000\000\000\000\000\000\000" """, t) a = tensor_util.MakeNdarray(t) self.assertEquals(np.int64, a.dtype) @@ -419,13 +419,13 @@ class TensorUtilTest(test.TestCase): t = tensor_util.make_tensor_proto(data, dtype=dtypes.qint32) if sys.byteorder == "big": - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_QINT32 tensor_shape { dim { size: 3 } } tensor_content: "\000\000\000\025\000\000\000\026\000\000\000\027" """, t) else: - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_QINT32 tensor_shape { dim { size: 3 } } tensor_content: "\025\000\000\000\026\000\000\000\027\000\000\000" @@ -435,7 +435,7 @@ class TensorUtilTest(test.TestCase): self.assertAllEqual(np.array(data, dtype=a.dtype), a) t = tensor_util.make_tensor_proto(data, dtype=dtypes.quint8) - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_QUINT8 tensor_shape { dim { size: 3 } } tensor_content: "\025\026\027" @@ -445,7 +445,7 @@ class TensorUtilTest(test.TestCase): self.assertAllEqual(np.array(data, dtype=a.dtype), a) t = tensor_util.make_tensor_proto(data, dtype=dtypes.qint8) - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_QINT8 tensor_shape { dim { size: 3 } } tensor_content: "\025\026\027" @@ -456,13 +456,13 @@ class TensorUtilTest(test.TestCase): t = tensor_util.make_tensor_proto(data, dtype=dtypes.quint16) if sys.byteorder == "big": - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_QUINT16 tensor_shape { dim { size: 3 } } tensor_content: "\000\025\000\026\000\027" """, t) else: - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_QUINT16 tensor_shape { dim { size: 3 } } tensor_content: "\025\000\026\000\027\000" @@ -473,13 +473,13 @@ class TensorUtilTest(test.TestCase): t = tensor_util.make_tensor_proto(data, dtype=dtypes.qint16) if sys.byteorder == "big": - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_QINT16 tensor_shape { dim { size: 3 } } tensor_content: "\000\025\000\026\000\027" """, t) else: - self.assertProtoEquals(""" + self.assertProtoEquals(r""" dtype: DT_QINT16 tensor_shape { dim { size: 3 } } tensor_content: "\025\000\026\000\027\000" diff --git a/tensorflow/python/keras/BUILD b/tensorflow/python/keras/BUILD index 8739d9eed5..4056818a95 100755 --- a/tensorflow/python/keras/BUILD +++ b/tensorflow/python/keras/BUILD @@ -451,6 +451,7 @@ cuda_py_test( "//tensorflow/python:client_testlib", ], shard_count = 2, + tags = ["no_windows_gpu"], ) py_test( diff --git a/tensorflow/python/keras/callbacks.py b/tensorflow/python/keras/callbacks.py index 3ae06d7ab8..d01c0cd2e2 100644 --- a/tensorflow/python/keras/callbacks.py +++ b/tensorflow/python/keras/callbacks.py @@ -32,8 +32,10 @@ import numpy as np import six from tensorflow.python.keras import backend as K +from tensorflow.python.keras import optimizers from tensorflow.python.keras.utils.generic_utils import Progbar from tensorflow.python.ops import array_ops +from tensorflow.python.ops.resource_variable_ops import ResourceVariable as Variable from tensorflow.python.platform import tf_logging as logging from tensorflow.python.summary import summary as tf_summary from tensorflow.python.util.tf_export import tf_export @@ -642,17 +644,35 @@ class LearningRateScheduler(Callback): self.verbose = verbose def on_epoch_begin(self, epoch, logs=None): - if not hasattr(self.model.optimizer, 'lr'): - raise ValueError('Optimizer must have a "lr" attribute.') + # TODO(yashkatariya): Change the property checking when the learning + # rate attribute is unified across all TF Optimizers. + if isinstance(self.model.optimizer, optimizers.TFOptimizer): + if not hasattr(self.model.optimizer.optimizer, '_lr') and not hasattr( + self.model.optimizer.optimizer, '_learning_rate'): + raise ValueError( + 'TF Optimizer must have a "_lr" or "_learning_rate" attribute.') + else: + opt = self.model.optimizer.optimizer + if hasattr(opt, '_lr'): + opt_lr = Variable(opt._lr) # pylint: disable=protected-access + elif hasattr(opt, '_learning_rate'): + opt_lr = Variable(opt._learning_rate) # pylint: disable=protected-access + else: + if not hasattr(self.model.optimizer, 'lr'): + raise ValueError('Optimizer must have a "lr" attribute.') + else: + opt = self.model.optimizer + opt_lr = opt.lr + try: # new API - lr = float(K.get_value(self.model.optimizer.lr)) + lr = float(K.get_value(opt_lr)) lr = self.schedule(epoch, lr) except TypeError: # Support for old API for backward compatibility lr = self.schedule(epoch) if not isinstance(lr, (float, np.float32, np.float64)): raise ValueError('The output of the "schedule" function ' 'should be float.') - K.set_value(self.model.optimizer.lr, lr) + K.set_value(opt_lr, lr) if self.verbose > 0: print('\nEpoch %05d: LearningRateScheduler reducing learning ' 'rate to %s.' % (epoch + 1, lr)) diff --git a/tensorflow/python/keras/callbacks_test.py b/tensorflow/python/keras/callbacks_test.py index d56f2f5bfc..4a5772f402 100644 --- a/tensorflow/python/keras/callbacks_test.py +++ b/tensorflow/python/keras/callbacks_test.py @@ -29,10 +29,16 @@ import numpy as np from tensorflow.core.framework import summary_pb2 from tensorflow.python import keras +from tensorflow.python.eager import context +from tensorflow.python.framework import test_util from tensorflow.python.keras import testing_utils +from tensorflow.python.ops.resource_variable_ops import ResourceVariable as Variable from tensorflow.python.platform import test from tensorflow.python.platform import tf_logging as logging from tensorflow.python.summary.writer import writer_cache +from tensorflow.python.training.adam import AdamOptimizer +from tensorflow.python.training.gradient_descent import GradientDescentOptimizer + try: import h5py # pylint:disable=g-import-not-at-top @@ -370,6 +376,76 @@ class KerasCallbacksTest(test.TestCase): float(keras.backend.get_value( model.optimizer.lr)) - 0.01 / 4) < keras.backend.epsilon() + @test_util.run_in_graph_and_eager_modes + def test_TF_LearningRateScheduler_Adam(self): + with self.test_session(): + with context.eager_mode(): + np.random.seed(1337) + (x_train, y_train), (x_test, y_test) = testing_utils.get_test_data( + train_samples=TRAIN_SAMPLES, + test_samples=TEST_SAMPLES, + input_shape=(INPUT_DIM,), + num_classes=NUM_CLASSES) + y_test = keras.utils.to_categorical(y_test) + y_train = keras.utils.to_categorical(y_train) + model = keras.models.Sequential() + model.add( + keras.layers.Dense( + NUM_HIDDEN, input_dim=INPUT_DIM, activation='relu')) + model.add(keras.layers.Dense(NUM_CLASSES, activation='softmax')) + model.compile( + loss='categorical_crossentropy', + optimizer=AdamOptimizer(), + metrics=['accuracy']) + cbks = [keras.callbacks.LearningRateScheduler(lambda x: 1. / (1. + x))] + model.fit( + x_train, + y_train, + batch_size=BATCH_SIZE, + validation_data=(x_test, y_test), + callbacks=cbks, + epochs=5, + verbose=0) + opt_lr = model.optimizer.optimizer._lr + self.assertLess( + float(keras.backend.get_value( + Variable(opt_lr))) - 0.2, keras.backend.epsilon()) + + @test_util.run_in_graph_and_eager_modes + def test_TF_LearningRateScheduler_GradientDescent(self): + with self.test_session(): + with context.eager_mode(): + np.random.seed(1337) + (x_train, y_train), (x_test, y_test) = testing_utils.get_test_data( + train_samples=TRAIN_SAMPLES, + test_samples=TEST_SAMPLES, + input_shape=(INPUT_DIM,), + num_classes=NUM_CLASSES) + y_test = keras.utils.to_categorical(y_test) + y_train = keras.utils.to_categorical(y_train) + model = keras.models.Sequential() + model.add( + keras.layers.Dense( + NUM_HIDDEN, input_dim=INPUT_DIM, activation='relu')) + model.add(keras.layers.Dense(NUM_CLASSES, activation='softmax')) + model.compile( + loss='categorical_crossentropy', + optimizer=GradientDescentOptimizer(1e-3), + metrics=['accuracy']) + cbks = [keras.callbacks.LearningRateScheduler(lambda x: 1. / (1. + x))] + model.fit( + x_train, + y_train, + batch_size=BATCH_SIZE, + validation_data=(x_test, y_test), + callbacks=cbks, + epochs=5, + verbose=0) + opt_lr = model.optimizer.optimizer._learning_rate + self.assertLess( + float(keras.backend.get_value( + Variable(opt_lr))) - 0.2, keras.backend.epsilon()) + def test_ReduceLROnPlateau(self): with self.test_session(): np.random.seed(1337) diff --git a/tensorflow/python/keras/engine/base_layer.py b/tensorflow/python/keras/engine/base_layer.py index 5c668345b7..e02792208b 100644 --- a/tensorflow/python/keras/engine/base_layer.py +++ b/tensorflow/python/keras/engine/base_layer.py @@ -460,14 +460,18 @@ class Layer(checkpointable.CheckpointableBase): """Alias for `add_weight`.""" return self.add_weight(*args, **kwargs) - def add_weight(self, name, shape, + def add_weight(self, + name, + shape, dtype=None, initializer=None, regularizer=None, - trainable=True, + trainable=None, constraint=None, partitioner=None, use_resource=None, + synchronization=vs.VariableSynchronization.AUTO, + aggregation=vs.VariableAggregation.NONE, getter=None): """Adds a new variable to the layer, or gets an existing one; returns it. @@ -482,10 +486,20 @@ class Layer(checkpointable.CheckpointableBase): or "non_trainable_variables" (e.g. BatchNorm mean, stddev). Note, if the current variable scope is marked as non-trainable then this parameter is ignored and any added variables are also - marked as non-trainable. + marked as non-trainable. `trainable` defaults to `True` unless + `synchronization` is set to `ON_READ`. constraint: constraint instance (callable). partitioner: Partitioner to be passed to the `Checkpointable` API. use_resource: Whether to use `ResourceVariable`. + synchronization: Indicates when a distributed a variable will be + aggregated. Accepted values are constants defined in the class + @{tf.VariableSynchronization}. By default the synchronization is set to + `AUTO` and the current `DistributionStrategy` chooses + when to synchronize. If `synchronization` is set to `ON_READ`, + `trainable` must not be set to `True`. + aggregation: Indicates how a distributed variable will be aggregated. + Accepted values are constants defined in the class + @{tf.VariableAggregation}. getter: Variable getter argument to be passed to the `Checkpointable` API. Returns: @@ -496,7 +510,8 @@ class Layer(checkpointable.CheckpointableBase): Raises: RuntimeError: If called with partioned variable regularization and eager execution is enabled. - ValueError: When giving unsupported dtype and no initializer. + ValueError: When giving unsupported dtype and no initializer or when + trainable has been set to True with synchronization set as `ON_READ`. """ if dtype is None: dtype = self.dtype or backend.floatx() @@ -505,6 +520,19 @@ class Layer(checkpointable.CheckpointableBase): regularizer = regularizers.get(regularizer) constraint = constraints.get(constraint) + if synchronization == vs.VariableSynchronization.ON_READ: + if trainable: + raise ValueError( + 'Synchronization value can be set to ' + 'VariableSynchronization.ON_READ only for non-trainable variables. ' + 'You have specified trainable=True and ' + 'synchronization=VariableSynchronization.ON_READ.') + else: + # Set trainable to be false when variable is to be synced on read. + trainable = False + elif trainable is None: + trainable = True + # Initialize variable when no initializer provided if initializer is None: # If dtype is DT_FLOAT, provide a uniform unit scaling initializer @@ -532,7 +560,9 @@ class Layer(checkpointable.CheckpointableBase): constraint=constraint, trainable=trainable and self.trainable, partitioner=partitioner, - use_resource=use_resource) + use_resource=use_resource, + synchronization=synchronization, + aggregation=aggregation) if regularizer is not None: # TODO(fchollet): in the future, this should be handled at the @@ -655,8 +685,8 @@ class Layer(checkpointable.CheckpointableBase): # Handle Keras mask propagation from previous layer to current layer. previous_mask = None - if (not hasattr(self, '_compute_previous_mask') or - self._compute_previous_mask): + if build_graph and (not hasattr(self, '_compute_previous_mask') or + self._compute_previous_mask): previous_mask = collect_previous_mask(inputs) if not hasattr(self, '_call_fn_args'): self._call_fn_args = self._no_dependency( @@ -696,6 +726,7 @@ class Layer(checkpointable.CheckpointableBase): if all(hasattr(x, 'shape') for x in input_list): input_shapes = nest.map_structure(lambda x: x.shape, inputs) self.build(input_shapes) + self.built = True # Check input assumptions set after layer building, e.g. input shape. if build_graph or in_deferred_mode: @@ -731,8 +762,6 @@ class Layer(checkpointable.CheckpointableBase): if in_deferred_mode or build_graph and have_all_keras_metadata(inputs): inputs, outputs = self._set_connectivity_metadata_( inputs, outputs, args, kwargs) - - self.built = True if context.executing_eagerly(): return outputs @@ -1806,11 +1835,13 @@ def make_variable(name, dtype=dtypes.float32, initializer=None, partition_info=None, - trainable=True, + trainable=None, caching_device=None, validate_shape=True, constraint=None, use_resource=None, + synchronization=vs.VariableSynchronization.AUTO, + aggregation=vs.VariableAggregation.NONE, partitioner=None): # pylint: disable=unused-argument """Temporary util to create a variable (relies on `variable_scope.variable`). @@ -1836,11 +1867,21 @@ def make_variable(name, or "non_trainable_variables" (e.g. BatchNorm mean, stddev). Note, if the current variable scope is marked as non-trainable then this parameter is ignored and any added variables are also - marked as non-trainable. + marked as non-trainable. `trainable` defaults to `True` unless + `synchronization` is set to `ON_READ`. caching_device: Passed to `vs.variable`. validate_shape: Passed to `vs.variable`. constraint: Constraint instance (callable). use_resource: Whether to use a `ResourceVariable`. + synchronization: Indicates when a distributed a variable will be + aggregated. Accepted values are constants defined in the class + @{tf.VariableSynchronization}. By default the synchronization is set to + `AUTO` and the current `DistributionStrategy` chooses + when to synchronize. If `synchronization` is set to `ON_READ`, + `trainable` must not be set to `True`. + aggregation: Indicates how a distributed variable will be aggregated. + Accepted values are constants defined in the class + @{tf.VariableAggregation}. partitioner: Not handled at this time. Returns: @@ -1872,5 +1913,7 @@ def make_variable(name, dtype=variable_dtype, validate_shape=validate_shape, constraint=constraint, - use_resource=use_resource) + use_resource=use_resource, + synchronization=synchronization, + aggregation=aggregation) return v diff --git a/tensorflow/python/keras/initializers.py b/tensorflow/python/keras/initializers.py index b9b2e9ad59..28beb6760d 100644 --- a/tensorflow/python/keras/initializers.py +++ b/tensorflow/python/keras/initializers.py @@ -23,6 +23,9 @@ import six from tensorflow.python.keras.utils.generic_utils import deserialize_keras_object from tensorflow.python.keras.utils.generic_utils import serialize_keras_object from tensorflow.python.ops.init_ops import Constant +from tensorflow.python.ops.init_ops import glorot_normal_initializer +from tensorflow.python.ops.init_ops import glorot_uniform_initializer + from tensorflow.python.ops.init_ops import Identity from tensorflow.python.ops.init_ops import Initializer # pylint: disable=unused-import from tensorflow.python.ops.init_ops import Ones @@ -80,52 +83,6 @@ def lecun_uniform(seed=None): scale=1., mode='fan_in', distribution='uniform', seed=seed) -@tf_export('keras.initializers.glorot_normal') -def glorot_normal(seed=None): - """Glorot normal initializer, also called Xavier normal initializer. - - It draws samples from a truncated normal distribution centered on 0 - with `stddev = sqrt(2 / (fan_in + fan_out))` - where `fan_in` is the number of input units in the weight tensor - and `fan_out` is the number of output units in the weight tensor. - - Arguments: - seed: A Python integer. Used to seed the random generator. - - Returns: - An initializer. - - References: - Glorot & Bengio, AISTATS 2010 - http://jmlr.org/proceedings/papers/v9/glorot10a/glorot10a.pdf - """ - return VarianceScaling( - scale=1., mode='fan_avg', distribution='normal', seed=seed) - - -@tf_export('keras.initializers.glorot_uniform') -def glorot_uniform(seed=None): - """Glorot uniform initializer, also called Xavier uniform initializer. - - It draws samples from a uniform distribution within [-limit, limit] - where `limit` is `sqrt(6 / (fan_in + fan_out))` - where `fan_in` is the number of input units in the weight tensor - and `fan_out` is the number of output units in the weight tensor. - - Arguments: - seed: A Python integer. Used to seed the random generator. - - Returns: - An initializer. - - References: - Glorot & Bengio, AISTATS 2010 - http://jmlr.org/proceedings/papers/v9/glorot10a/glorot10a.pdf - """ - return VarianceScaling( - scale=1., mode='fan_avg', distribution='uniform', seed=seed) - - @tf_export('keras.initializers.he_normal') def he_normal(seed=None): """He normal initializer. @@ -179,6 +136,8 @@ normal = random_normal = RandomNormal truncated_normal = TruncatedNormal identity = Identity orthogonal = Orthogonal +glorot_normal = glorot_normal_initializer +glorot_uniform = glorot_uniform_initializer # pylint: enable=invalid-name diff --git a/tensorflow/python/keras/layers/core.py b/tensorflow/python/keras/layers/core.py index 2bf6229ccb..f28cade474 100644 --- a/tensorflow/python/keras/layers/core.py +++ b/tensorflow/python/keras/layers/core.py @@ -26,6 +26,7 @@ import warnings import numpy as np from tensorflow.python.eager import context +from tensorflow.python.framework import common_shapes from tensorflow.python.framework import ops from tensorflow.python.framework import tensor_shape from tensorflow.python.keras import activations @@ -929,13 +930,13 @@ class Dense(Layer): def call(self, inputs): inputs = ops.convert_to_tensor(inputs, dtype=self.dtype) - shape = inputs.get_shape().as_list() - if len(shape) > 2: + rank = common_shapes.rank(inputs) + if rank > 2: # Broadcasting is required for the inputs. - outputs = standard_ops.tensordot(inputs, self.kernel, [[len(shape) - 1], - [0]]) + outputs = standard_ops.tensordot(inputs, self.kernel, [[rank - 1], [0]]) # Reshape the output back to the original ndim of the input. if not context.executing_eagerly(): + shape = inputs.get_shape().as_list() output_shape = shape[:-1] + [self.units] outputs.set_shape(output_shape) else: diff --git a/tensorflow/python/keras/layers/normalization.py b/tensorflow/python/keras/layers/normalization.py index 8b894ca6b1..58c8a8a66d 100644 --- a/tensorflow/python/keras/layers/normalization.py +++ b/tensorflow/python/keras/layers/normalization.py @@ -181,12 +181,6 @@ class BatchNormalization(Layer): self.renorm_clipping = renorm_clipping self.renorm_momentum = renorm_momentum - def _add_tower_local_variable(self, *args, **kwargs): - tower_context = distribute_lib.get_tower_context() - with tower_context.tower_local_var_scope( - variable_scope.VariableAggregation.MEAN): - return self.add_weight(*args, **kwargs) - def build(self, input_shape): input_shape = tensor_shape.TensorShape(input_shape) if not input_shape.ndims: @@ -314,19 +308,23 @@ class BatchNormalization(Layer): self._scope.set_partitioner(None) else: partitioner = None - self.moving_mean = self._add_tower_local_variable( + self.moving_mean = self.add_weight( name='moving_mean', shape=param_shape, dtype=param_dtype, initializer=self.moving_mean_initializer, - trainable=False) + synchronization=variable_scope.VariableSynchronization.ON_READ, + trainable=False, + aggregation=variable_scope.VariableAggregation.MEAN) - self.moving_variance = self._add_tower_local_variable( + self.moving_variance = self.add_weight( name='moving_variance', shape=param_shape, dtype=param_dtype, initializer=self.moving_variance_initializer, - trainable=False) + synchronization=variable_scope.VariableSynchronization.ON_READ, + trainable=False, + aggregation=variable_scope.VariableAggregation.MEAN) if self.renorm: # Create variables to maintain the moving mean and standard deviation. @@ -337,12 +335,14 @@ class BatchNormalization(Layer): # stack to be cleared. The nested ones use a `lambda` to set the desired # device and ignore any devices that may be set by the custom getter. def _renorm_variable(name, shape): - var = self._add_tower_local_variable( + var = self.add_weight( name=name, shape=shape, dtype=param_dtype, initializer=init_ops.zeros_initializer(), - trainable=False) + synchronization=variable_scope.VariableSynchronization.ON_READ, + trainable=False, + aggregation=variable_scope.VariableAggregation.MEAN) return var with distribute_lib.get_distribution_strategy().colocate_vars_with( diff --git a/tensorflow/python/kernel_tests/BUILD b/tensorflow/python/kernel_tests/BUILD index 276a24b084..838cf836f1 100644 --- a/tensorflow/python/kernel_tests/BUILD +++ b/tensorflow/python/kernel_tests/BUILD @@ -1525,6 +1525,7 @@ cuda_py_test( "//tensorflow/python:framework_for_generated_wrappers", "//tensorflow/python:math_ops", ], + tags = ["no_windows_gpu"], ) cuda_py_test( @@ -2057,6 +2058,7 @@ cuda_py_test( "//tensorflow/python:framework_for_generated_wrappers", "//tensorflow/python:math_ops", ], + tags = ["no_windows_gpu"], ) tf_py_test( diff --git a/tensorflow/python/kernel_tests/resource_variable_ops_test.py b/tensorflow/python/kernel_tests/resource_variable_ops_test.py index 0fb0b8895c..e358293a90 100644 --- a/tensorflow/python/kernel_tests/resource_variable_ops_test.py +++ b/tensorflow/python/kernel_tests/resource_variable_ops_test.py @@ -852,5 +852,62 @@ class ResourceVariableOpsTest(test_util.TensorFlowTestCase): state_ops.scatter_update(v, [0, 1], [0, 1, 2]) +class _MixedPrecisionVariableTest(test_util.TensorFlowTestCase): + + @test_util.run_in_graph_and_eager_modes() + def test_dense_var_to_tensor_read_dtype_same_as_var_dtype(self): + # read_dtype is same as dtype + v = resource_variable_ops.ResourceVariable(1.0, dtype=dtypes.float32) + v = resource_variable_ops._MixedPrecisionVariable(v, dtypes.float32) + if not context.executing_eagerly(): + v.initializer.run() + + # dtype is not read_dtype, return NotImplemented + self.assertEqual( + NotImplemented, v._dense_var_to_tensor(dtype=dtypes.float16)) + self.assertEqual(NotImplemented, + v._dense_var_to_tensor(dtype=dtypes.float16, as_ref=True)) + + # as_ref is False + t = v._dense_var_to_tensor(as_ref=False) + self.assertTrue(isinstance(t, ops.Tensor)) + self.assertEqual(t.dtype, dtypes.float32) + self.assertEqual(self.evaluate(t), 1.0) + + t = v._dense_var_to_tensor(dtype=dtypes.float32, as_ref=False) + self.assertTrue(isinstance(t, ops.Tensor)) + self.assertEqual(t.dtype, dtypes.float32) + self.assertEqual(self.evaluate(t), 1.0) + + # as_ref is True + self.assertEqual(NotImplemented, v._dense_var_to_tensor(as_ref=True)) + self.assertEqual(NotImplemented, + v._dense_var_to_tensor(dtype=dtypes.float32, as_ref=True)) + + @test_util.run_in_graph_and_eager_modes() + def test_dense_var_to_tensor_read_dtype_different_from_var_dtype(self): + # read_dtype is different from dtype + v = resource_variable_ops.ResourceVariable(1.0, dtype=dtypes.float32) + v = resource_variable_ops._MixedPrecisionVariable(v, dtypes.float16) + if not context.executing_eagerly(): + v.initializer.run() + + # as_ref is False + t = v._dense_var_to_tensor(as_ref=False) + self.assertTrue(isinstance(t, ops.Tensor)) + self.assertEqual(t.dtype, dtypes.float16) + self.assertEqual(self.evaluate(t), 1.0) + + t = v._dense_var_to_tensor(dtype=dtypes.float16, as_ref=False) + self.assertTrue(isinstance(t, ops.Tensor)) + self.assertEqual(t.dtype, dtypes.float16) + self.assertEqual(self.evaluate(t), 1.0) + + # as_ref is True + self.assertEqual(NotImplemented, v._dense_var_to_tensor(as_ref=True)) + self.assertEqual(NotImplemented, + v._dense_var_to_tensor(dtype=dtypes.float16, as_ref=True)) + + if __name__ == "__main__": test.main() diff --git a/tensorflow/python/kernel_tests/rnn_test.py b/tensorflow/python/kernel_tests/rnn_test.py index 957baf8c60..acee180a6c 100644 --- a/tensorflow/python/kernel_tests/rnn_test.py +++ b/tensorflow/python/kernel_tests/rnn_test.py @@ -268,6 +268,12 @@ class RNNTest(test.TestCase): self._assert_cell_builds(rnn_cell_impl.GRUCell, f64, 5, 7, 3) self._assert_cell_builds(rnn_cell_impl.LSTMCell, f32, 5, 7, 3) self._assert_cell_builds(rnn_cell_impl.LSTMCell, f64, 5, 7, 3) + self._assert_cell_builds(contrib_rnn.IndRNNCell, f32, 5, 7, 3) + self._assert_cell_builds(contrib_rnn.IndRNNCell, f64, 5, 7, 3) + self._assert_cell_builds(contrib_rnn.IndyGRUCell, f32, 5, 7, 3) + self._assert_cell_builds(contrib_rnn.IndyGRUCell, f64, 5, 7, 3) + self._assert_cell_builds(contrib_rnn.IndyLSTMCell, f32, 5, 7, 3) + self._assert_cell_builds(contrib_rnn.IndyLSTMCell, f64, 5, 7, 3) ######### Benchmarking RNN code diff --git a/tensorflow/python/kernel_tests/variable_scope_test.py b/tensorflow/python/kernel_tests/variable_scope_test.py index 054c6f9dd7..ae2a0ab29a 100644 --- a/tensorflow/python/kernel_tests/variable_scope_test.py +++ b/tensorflow/python/kernel_tests/variable_scope_test.py @@ -1054,7 +1054,7 @@ class VariableScopeTest(test.TestCase): "testGetCollection_foo/testGetCollection_a:0" ]) - def testGetTrainableVariables(self): + def testGetTrainableVariablesWithGetVariable(self): with self.test_session(): _ = variable_scope.get_variable("testGetTrainableVariables_a", []) with variable_scope.variable_scope( @@ -1062,10 +1062,72 @@ class VariableScopeTest(test.TestCase): _ = variable_scope.get_variable("testGetTrainableVariables_b", []) _ = variable_scope.get_variable( "testGetTrainableVariables_c", [], trainable=False) + + # sync `ON_READ` sets trainable=False + _ = variable_scope.get_variable( + "testGetTrainableVariables_d", [], + synchronization=variable_scope.VariableSynchronization.ON_READ) self.assertEqual( [v.name for v in scope.trainable_variables()], - ["testGetTrainableVariables_foo/" - "testGetTrainableVariables_b:0"]) + ["testGetTrainableVariables_foo/testGetTrainableVariables_b:0"]) + + # All other sync values sets trainable=True + _ = variable_scope.get_variable( + "testGetTrainableVariables_e", [], + synchronization=variable_scope.VariableSynchronization.ON_WRITE) + self.assertEqual([v.name for v in scope.trainable_variables()], [ + "testGetTrainableVariables_foo/testGetTrainableVariables_b:0", + "testGetTrainableVariables_foo/testGetTrainableVariables_e:0" + ]) + + with self.assertRaisesRegexp( + ValueError, "Synchronization value can be set to " + "VariableSynchronization.ON_READ only for non-trainable variables. " + "You have specified trainable=True and " + "synchronization=VariableSynchronization.ON_READ."): + _ = variable_scope.get_variable( + "testGetTrainableVariables_e", [], + synchronization=variable_scope.VariableSynchronization.ON_READ, + trainable=True) + + def testGetTrainableVariablesWithVariable(self): + with self.test_session(): + _ = variable_scope.variable(1.0, name="testGetTrainableVariables_a") + with variable_scope.variable_scope( + "testGetTrainableVariables_foo") as scope: + _ = variable_scope.variable(1.0, name="testGetTrainableVariables_b") + _ = variable_scope.variable( + 1.0, name="testGetTrainableVariables_c", trainable=False) + + # sync `ON_READ` sets trainable=False + _ = variable_scope.variable( + 1.0, + name="testGetTrainableVariables_d", + synchronization=variable_scope.VariableSynchronization.ON_READ) + self.assertEqual( + [v.name for v in scope.trainable_variables()], + ["testGetTrainableVariables_foo/testGetTrainableVariables_b:0"]) + + # All other sync values sets trainable=True + _ = variable_scope.variable( + 1.0, + name="testGetTrainableVariables_e", + synchronization=variable_scope.VariableSynchronization.ON_WRITE) + self.assertEqual([v.name for v in scope.trainable_variables()], [ + "testGetTrainableVariables_foo/testGetTrainableVariables_b:0", + "testGetTrainableVariables_foo/testGetTrainableVariables_e:0" + ]) + + with self.assertRaisesRegexp( + ValueError, "Synchronization value can be set to " + "VariableSynchronization.ON_READ only for non-trainable variables. " + "You have specified trainable=True and " + "synchronization=VariableSynchronization.ON_READ."): + _ = variable_scope.variable( + 1.0, + name="testGetTrainableVariables_e", + synchronization=variable_scope.VariableSynchronization.ON_READ, + trainable=True) def testGetGlobalVariables(self): with self.test_session(): diff --git a/tensorflow/python/kernel_tests/variables_test.py b/tensorflow/python/kernel_tests/variables_test.py index 62d596da91..2b9c62ad6f 100644 --- a/tensorflow/python/kernel_tests/variables_test.py +++ b/tensorflow/python/kernel_tests/variables_test.py @@ -642,6 +642,8 @@ class PartitionedVariableTest(test.TestCase): iterated_partitions = list(partitioned_variable) self.assertEqual(2, num_partitions) self.assertEqual([v0, v1], iterated_partitions) + self.assertEqual([2], partitioned_variable.get_shape()) + self.assertEqual([2], partitioned_variable.shape) self.assertEqual([2], concatenated.get_shape()) self.assertEqual([2], concatenated.shape) diff --git a/tensorflow/python/layers/base.py b/tensorflow/python/layers/base.py index b8969a41ab..cf13b52617 100644 --- a/tensorflow/python/layers/base.py +++ b/tensorflow/python/layers/base.py @@ -152,10 +152,17 @@ class Layer(base_layer.Layer): scope, default_name=self._base_name) as captured_scope: self._scope = captured_scope - def add_weight(self, name, shape, dtype=None, - initializer=None, regularizer=None, - trainable=True, constraint=None, + def add_weight(self, + name, + shape, + dtype=None, + initializer=None, + regularizer=None, + trainable=None, + constraint=None, use_resource=None, + synchronization=vs.VariableSynchronization.AUTO, + aggregation=vs.VariableAggregation.NONE, partitioner=None): """Adds a new variable to the layer, or gets an existing one; returns it. @@ -170,9 +177,19 @@ class Layer(base_layer.Layer): or "non_trainable_variables" (e.g. BatchNorm mean, stddev). Note, if the current variable scope is marked as non-trainable then this parameter is ignored and any added variables are also - marked as non-trainable. + marked as non-trainable. `trainable` defaults to `True` unless + `synchronization` is set to `ON_READ`. constraint: constraint instance (callable). use_resource: Whether to use `ResourceVariable`. + synchronization: Indicates when a distributed a variable will be + aggregated. Accepted values are constants defined in the class + @{tf.VariableSynchronization}. By default the synchronization is set to + `AUTO` and the current `DistributionStrategy` chooses + when to synchronize. If `synchronization` is set to `ON_READ`, + `trainable` must not be set to `True`. + aggregation: Indicates how a distributed variable will be aggregated. + Accepted values are constants defined in the class + @{tf.VariableAggregation}. partitioner: (optional) partitioner instance (callable). If provided, when the requested variable is created it will be split into multiple partitions according to `partitioner`. In this case, @@ -190,7 +207,21 @@ class Layer(base_layer.Layer): Raises: RuntimeError: If called with partioned variable regularization and eager execution is enabled. + ValueError: When trainable has been set to True with synchronization + set as `ON_READ`. """ + if synchronization == vs.VariableSynchronization.ON_READ: + if trainable: + raise ValueError( + 'Synchronization value can be set to ' + 'VariableSynchronization.ON_READ only for non-trainable variables. ' + 'You have specified trainable=True and ' + 'synchronization=VariableSynchronization.ON_READ.') + else: + # Set trainable to be false when variable is to be synced on read. + trainable = False + elif trainable is None: + trainable = True def _should_add_regularizer(variable, existing_variable_set): if isinstance(variable, tf_variables.PartitionedVariable): @@ -240,6 +271,8 @@ class Layer(base_layer.Layer): constraint=constraint, partitioner=partitioner, use_resource=use_resource, + synchronization=synchronization, + aggregation=aggregation, getter=vs.get_variable) if regularizer: diff --git a/tensorflow/python/layers/base_test.py b/tensorflow/python/layers/base_test.py index 298e96e711..d2443db665 100644 --- a/tensorflow/python/layers/base_test.py +++ b/tensorflow/python/layers/base_test.py @@ -90,12 +90,34 @@ class BaseLayerTest(test.TestCase): # regularizers only supported in GRAPH mode. regularizer = lambda x: math_ops.reduce_sum(x) * 1e-3 - variable = layer.add_variable( + _ = layer.add_variable( 'reg_var', [2, 2], initializer=init_ops.zeros_initializer(), regularizer=regularizer) self.assertEqual(len(layer.losses), 1) + # Test that sync `ON_READ` variables are defaulted to be non-trainable. + variable_3 = layer.add_variable( + 'sync_on_read_var', [2, 2], + initializer=init_ops.zeros_initializer(), + synchronization=variable_scope.VariableSynchronization.ON_READ, + aggregation=variable_scope.VariableAggregation.SUM) + self.assertEqual(layer.non_trainable_variables, [variable_2, variable_3]) + + def testInvalidTrainableSynchronizationCombination(self): + layer = base_layers.Layer(name='my_layer') + + with self.assertRaisesRegexp( + ValueError, 'Synchronization value can be set to ' + 'VariableSynchronization.ON_READ only for non-trainable variables. ' + 'You have specified trainable=True and ' + 'synchronization=VariableSynchronization.ON_READ.'): + _ = layer.add_variable( + 'v', [2, 2], + initializer=init_ops.zeros_initializer(), + synchronization=variable_scope.VariableSynchronization.ON_READ, + trainable=True) + def testReusePartitionedVaraiblesAndRegularizers(self): regularizer = lambda x: math_ops.reduce_sum(x) * 1e-3 partitioner = partitioned_variables.fixed_size_partitioner(3) @@ -104,7 +126,7 @@ class BaseLayerTest(test.TestCase): partitioner=partitioner, reuse=reuse): layer = base_layers.Layer(name='my_layer') - variable = layer.add_variable( + _ = layer.add_variable( 'reg_part_var', [4, 4], initializer=init_ops.zeros_initializer(), regularizer=regularizer) diff --git a/tensorflow/python/ops/image_ops_impl.py b/tensorflow/python/ops/image_ops_impl.py index a2eae452ae..5b384fd596 100644 --- a/tensorflow/python/ops/image_ops_impl.py +++ b/tensorflow/python/ops/image_ops_impl.py @@ -55,6 +55,7 @@ ops.NotDifferentiable('SampleDistortedBoundingBoxV2') ops.NotDifferentiable('ExtractGlimpse') ops.NotDifferentiable('NonMaxSuppression') ops.NotDifferentiable('NonMaxSuppressionV2') +ops.NotDifferentiable('NonMaxSuppressionWithOverlaps') # pylint: disable=invalid-name @@ -2093,6 +2094,50 @@ def non_max_suppression(boxes, iou_threshold, score_threshold) +@tf_export('image.non_max_suppression_overlaps') +def non_max_suppression_with_overlaps(overlaps, + scores, + max_output_size, + overlap_threshold=0.5, + score_threshold=float('-inf'), + name=None): + """Greedily selects a subset of bounding boxes in descending order of score. + + Prunes away boxes that have high overlap with previously selected boxes. + N-by-n overlap values are supplied as square matrix. + The output of this operation is a set of integers indexing into the input + collection of bounding boxes representing the selected boxes. The bounding + box coordinates corresponding to the selected indices can then be obtained + using the `tf.gather operation`. For example: + selected_indices = tf.image.non_max_suppression_overlaps( + overlaps, scores, max_output_size, iou_threshold) + selected_boxes = tf.gather(boxes, selected_indices) + + Args: + overlaps: A 2-D float `Tensor` of shape `[num_boxes, num_boxes]`. + scores: A 1-D float `Tensor` of shape `[num_boxes]` representing a single + score corresponding to each box (each row of boxes). + max_output_size: A scalar integer `Tensor` representing the maximum number + of boxes to be selected by non max suppression. + overlap_threshold: A float representing the threshold for deciding whether + boxes overlap too much with respect to the provided overlap values. + score_threshold: A float representing the threshold for deciding when to + remove boxes based on score. + name: A name for the operation (optional). + + Returns: + selected_indices: A 1-D integer `Tensor` of shape `[M]` representing the + selected indices from the overlaps tensor, where `M <= max_output_size`. + """ + with ops.name_scope(name, 'non_max_suppression_overlaps'): + overlap_threshold = ops.convert_to_tensor( + overlap_threshold, name='overlap_threshold') + # pylint: disable=protected-access + return gen_image_ops._non_max_suppression_v3( + overlaps, scores, max_output_size, overlap_threshold, score_threshold) + # pylint: enable=protected-access + + _rgb_to_yiq_kernel = [[0.299, 0.59590059, 0.2115], [0.587, -0.27455667, -0.52273617], [0.114, -0.32134392, 0.31119955]] diff --git a/tensorflow/python/ops/init_ops.py b/tensorflow/python/ops/init_ops.py index 5bfc5ce2a7..3132f7467f 100644 --- a/tensorflow/python/ops/init_ops.py +++ b/tensorflow/python/ops/init_ops.py @@ -1136,7 +1136,7 @@ convolutional_orthogonal_3d = ConvolutionOrthogonal3D # pylint: enable=invalid-name -@tf_export("glorot_uniform_initializer") +@tf_export("glorot_uniform_initializer", "keras.initializers.glorot_uniform") def glorot_uniform_initializer(seed=None, dtype=dtypes.float32): """The Glorot uniform initializer, also called Xavier uniform initializer. @@ -1160,7 +1160,7 @@ def glorot_uniform_initializer(seed=None, dtype=dtypes.float32): scale=1.0, mode="fan_avg", distribution="uniform", seed=seed, dtype=dtype) -@tf_export("glorot_normal_initializer") +@tf_export("glorot_normal_initializer", "keras.initializers.glorot_normal") def glorot_normal_initializer(seed=None, dtype=dtypes.float32): """The Glorot normal initializer, also called Xavier normal initializer. diff --git a/tensorflow/python/ops/logging_ops.py b/tensorflow/python/ops/logging_ops.py index 8276047cb6..df41933f8a 100644 --- a/tensorflow/python/ops/logging_ops.py +++ b/tensorflow/python/ops/logging_ops.py @@ -35,9 +35,12 @@ from tensorflow.python.util.tf_export import tf_export # Assert and Print are special symbols in python, so we must -# have an upper-case version of them. For users with Python 3 or Python 2.7 -# with `from __future__ import print_function`, we also allow lowercase. -@tf_export("Print", "print") +# have an upper-case version of them. +# +# For users with Python 3 or Python 2.7 +# with `from __future__ import print_function`, we could also allow lowercase. +# See https://github.com/tensorflow/tensorflow/issues/18053 +@tf_export("Print") def Print(input_, data, message=None, first_n=None, summarize=None, name=None): """Prints a list of tensors. diff --git a/tensorflow/python/ops/math_ops.py b/tensorflow/python/ops/math_ops.py index cdb6dc8f22..c28dca5137 100644 --- a/tensorflow/python/ops/math_ops.py +++ b/tensorflow/python/ops/math_ops.py @@ -37,11 +37,11 @@ from tensorflow.python.ops import gen_math_ops from tensorflow.python.ops import gen_nn_ops from tensorflow.python.ops import gen_sparse_ops from tensorflow.python.ops import gen_spectral_ops -from tensorflow.python.platform import tf_logging as logging # go/tf-wildcard-import # pylint: disable=wildcard-import from tensorflow.python.ops.gen_math_ops import * # pylint: enable=wildcard-import +from tensorflow.python.platform import tf_logging as logging from tensorflow.python.util import compat from tensorflow.python.util import deprecation from tensorflow.python.util import nest @@ -651,6 +651,9 @@ def cast(x, dtype, name=None): TypeError: If `x` cannot be cast to the `dtype`. """ base_type = dtypes.as_dtype(dtype).base_dtype + if isinstance(x, + (ops.Tensor, _resource_variable_type)) and base_type == x.dtype: + return x with ops.name_scope(name, "Cast", [x]) as name: if isinstance(x, sparse_tensor.SparseTensor): values_cast = cast(x.values, base_type, name=name) @@ -1222,8 +1225,9 @@ def _ReductionDims(x, axis, reduction_indices): return axis else: # Fast path: avoid creating Rank and Range ops if ndims is known. - if isinstance(x, ops.Tensor) and x._rank() is not None: # pylint: disable=protected-access - return constant_op.constant(np.arange(x._rank()), dtype=dtypes.int32) # pylint: disable=protected-access + rank = common_shapes.rank(x) + if rank is not None: + return constant_op.constant(np.arange(rank), dtype=dtypes.int32) if (isinstance(x, sparse_tensor.SparseTensor) and x.dense_shape.get_shape().is_fully_defined()): rank = x.dense_shape.get_shape()[0].value # sparse.dense_shape is 1-D. @@ -1234,8 +1238,8 @@ def _ReductionDims(x, axis, reduction_indices): def _may_reduce_to_scalar(keepdims, axis, reduction_indices, output): - """Set a reduction's output's shape to be a scalar if we are certain.""" - if (not output.shape.is_fully_defined()) and (not keepdims) and ( + """Set a reduction's output shape to be a scalar if we are certain.""" + if not common_shapes.has_fully_defined_shape(output) and (not keepdims) and ( axis is None) and (reduction_indices is None): output.set_shape(()) return output diff --git a/tensorflow/python/ops/metrics_impl.py b/tensorflow/python/ops/metrics_impl.py index bfd225b0d8..3aedeb6acd 100644 --- a/tensorflow/python/ops/metrics_impl.py +++ b/tensorflow/python/ops/metrics_impl.py @@ -73,16 +73,16 @@ def metric_variable(shape, dtype, validate_shape=True, name=None): A (non-trainable) variable initialized to zero, or if inside a `DistributionStrategy` scope a tower-local variable container. """ - with distribute_lib.get_tower_context().tower_local_var_scope( - variable_scope.VariableAggregation.SUM): - # Note that "tower local" implies trainable=False. - return variable_scope.variable( - lambda: array_ops.zeros(shape, dtype), - collections=[ - ops.GraphKeys.LOCAL_VARIABLES, ops.GraphKeys.METRIC_VARIABLES - ], - validate_shape=validate_shape, - name=name) + # Note that synchronization "ON_READ" implies trainable=False. + return variable_scope.variable( + lambda: array_ops.zeros(shape, dtype), + collections=[ + ops.GraphKeys.LOCAL_VARIABLES, ops.GraphKeys.METRIC_VARIABLES + ], + validate_shape=validate_shape, + synchronization=variable_scope.VariableSynchronization.ON_READ, + aggregation=variable_scope.VariableAggregation.SUM, + name=name) def _remove_squeezable_dimensions(predictions, labels, weights): diff --git a/tensorflow/python/ops/resource_variable_ops.py b/tensorflow/python/ops/resource_variable_ops.py index 972c74b1b3..70a89e5ebb 100644 --- a/tensorflow/python/ops/resource_variable_ops.py +++ b/tensorflow/python/ops/resource_variable_ops.py @@ -1104,6 +1104,113 @@ class _UnreadVariable(ResourceVariable): ops.register_tensor_conversion_function(_UnreadVariable, _dense_var_to_tensor) ops.register_dense_tensor_like_type(_UnreadVariable) + +class _MixedPrecisionVariable(ResourceVariable): + """Represents a variable that can return in desired dtype when read. + + In mixed precision training, it is usually desirable to use different dtypes + for variables and computation. This class will be used to wrap created + ResourceVariable when mixed precision training is enabled. It allows layers to + perform computation in a different dtype than their variable dtypes, in order + to achieve higher performance without causing quality loss. + """ + + def __init__(self, var, read_dtype): + """Creates a MixedPrecisionVariable. + + Args: + var: A ResourceVariable instance. + read_dtype: A tf.DType, the returned dtype when read, default to None. + Casting is performed if read_dtype is not None and differs from + var.dtype. + Returns: + An MixedPrecisionVariable instance. + Raises: + ValueError: if var is not a ResourceVariable instance, or read_dtype is + not a tf.DType instance. + """ + # pylint: disable=super-init-not-called + # We do not call super init on purpose. + if not isinstance(var, ResourceVariable): + raise ValueError("InvalidArgument: var must be a ResourceVariable type.") + if not isinstance(read_dtype, dtypes.DType): + raise ValueError("InvalidArgument: read_dtype must be a tf.DType type.") + + self._var = var + self._trainable = var.trainable + self._save_slice_info = None + self._graph_key = ops.get_default_graph()._graph_key # pylint: disable=protected-access + self._in_graph_mode = var._in_graph_mode # pylint: disable=protected-access + self._handle = var.handle + self._shape = var.shape + self._initial_value = None + if isinstance(self.handle, ops.EagerTensor): + self._handle_name = "" + else: + self._handle_name = self.handle.name + self._unique_id = var._unique_id # pylint: disable=protected-access + self._dtype = var.dtype + self._constraint = None + self._cached_value = None + self._is_initialized_op = var._is_initialized_op # pylint: disable=protected-access + self._initializer_op = var._initializer_op # pylint: disable=protected-access + # This needs to be set before read_value() is called. + self._read_dtype = read_dtype + if context.executing_eagerly(): + self._graph_element = None + else: + self._graph_element = self.read_value() + self._handle_deleter = ( + var._handle_deleter if not self._in_graph_mode # pylint: disable=protected-access + else None) + # pylint: enable=super-init-not-called + + @property + def name(self): + return self._var.name + + def value(self): + return self._read_variable_op() + + def read_value(self): + return self._read_variable_op() + + def _read_variable_op(self): + with ops.colocate_with(self._handle): + res = gen_resource_variable_ops.read_variable_op(self._handle, + self._dtype) + if self._read_dtype != self._dtype: + return math_ops.cast(res, self._read_dtype) + else: + return res + + def set_shape(self, shape): + self._shape = shape + self._cached_shape_as_list = None + + @property + def op(self): + """The op for this variable.""" + return self._var.op + + @property + def read_dtype(self): + """The dtype of the returned tensor when reading the var.""" + return self._read_dtype + + def _dense_var_to_tensor(self, dtype=None, name=None, as_ref=False): + del name + dtype = dtype or self.read_dtype + if dtype != self.read_dtype or as_ref: + return NotImplemented + else: + res = self.value() + return res + + def _should_act_as_resource_variable(self): + """To pass resource_variable_ops.is_resource_variable check.""" + pass + # Register a conversion function which reads the value of the variable, # allowing instances of the class to be used as tensors. diff --git a/tensorflow/python/ops/rnn_cell_impl.py b/tensorflow/python/ops/rnn_cell_impl.py index 82a044a0d4..70805fd572 100644 --- a/tensorflow/python/ops/rnn_cell_impl.py +++ b/tensorflow/python/ops/rnn_cell_impl.py @@ -47,7 +47,6 @@ from tensorflow.python.ops import variable_scope as vs from tensorflow.python.ops import variables as tf_variables from tensorflow.python.platform import tf_logging as logging from tensorflow.python.training.checkpointable import base as checkpointable -from tensorflow.python.training.checkpointable import tracking as checkpointable_tracking from tensorflow.python.util import nest from tensorflow.python.util.tf_export import tf_export @@ -55,16 +54,6 @@ from tensorflow.python.util.tf_export import tf_export _BIAS_VARIABLE_NAME = "bias" _WEIGHTS_VARIABLE_NAME = "kernel" - -# TODO(jblespiau): Remove this function when we are sure there are no longer -# any usage (even if protected, it is being used). Prefer assert_like_rnncell. -def _like_rnncell(cell): - """Checks that a given object is an RNNCell by using duck typing.""" - conditions = [hasattr(cell, "output_size"), hasattr(cell, "state_size"), - hasattr(cell, "zero_state"), callable(cell)] - return all(conditions) - - # This can be used with self.assertRaisesRegexp for assert_like_rnncell. ASSERT_LIKE_RNNCELL_ERROR_REGEXP = "is not an RNNCell" @@ -1330,48 +1319,3 @@ class MultiRNNCell(RNNCell): array_ops.concat(new_states, 1)) return cur_inp, new_states - - -class _SlimRNNCell(RNNCell, checkpointable_tracking.NotCheckpointable): - """A simple wrapper for slim.rnn_cells.""" - - def __init__(self, cell_fn): - """Create a SlimRNNCell from a cell_fn. - - Args: - cell_fn: a function which takes (inputs, state, scope) and produces the - outputs and the new_state. Additionally when called with inputs=None and - state=None it should return (initial_outputs, initial_state). - - Raises: - TypeError: if cell_fn is not callable - ValueError: if cell_fn cannot produce a valid initial state. - """ - if not callable(cell_fn): - raise TypeError("cell_fn %s needs to be callable", cell_fn) - self._cell_fn = cell_fn - self._cell_name = cell_fn.func.__name__ - init_output, init_state = self._cell_fn(None, None) - output_shape = init_output.get_shape() - state_shape = init_state.get_shape() - self._output_size = output_shape.with_rank(2)[1].value - self._state_size = state_shape.with_rank(2)[1].value - if self._output_size is None: - raise ValueError("Initial output created by %s has invalid shape %s" % - (self._cell_name, output_shape)) - if self._state_size is None: - raise ValueError("Initial state created by %s has invalid shape %s" % - (self._cell_name, state_shape)) - - @property - def state_size(self): - return self._state_size - - @property - def output_size(self): - return self._output_size - - def __call__(self, inputs, state, scope=None): - scope = scope or self._cell_name - output, state = self._cell_fn(inputs, state, scope=scope) - return output, state diff --git a/tensorflow/python/ops/variable_scope.py b/tensorflow/python/ops/variable_scope.py index 1e06bf07d5..77f67c18ee 100644 --- a/tensorflow/python/ops/variable_scope.py +++ b/tensorflow/python/ops/variable_scope.py @@ -255,7 +255,7 @@ class _VariableStore(object): initializer=None, regularizer=None, reuse=None, - trainable=True, + trainable=None, collections=None, caching_device=None, partitioner=None, @@ -300,6 +300,8 @@ class _VariableStore(object): forced to be False. trainable: If `True` also add the variable to the graph collection `GraphKeys.TRAINABLE_VARIABLES` (see `tf.Variable`). + `trainable` defaults to `True` unless `synchronization` is + set to `ON_READ`. collections: List of graph collections keys to add the `Variable` to. Defaults to `[GraphKeys.GLOBAL_VARIABLES]` (see `tf.Variable`). caching_device: Optional device string or function describing where the @@ -341,7 +343,8 @@ class _VariableStore(object): aggregated. Accepted values are constants defined in the class @{tf.VariableSynchronization}. By default the synchronization is set to `AUTO` and the current `DistributionStrategy` chooses - when to synchronize. + when to synchronize. If `synchronization` is set to `ON_READ`, + `trainable` must not be set to `True`. aggregation: Indicates how a distributed variable will be aggregated. Accepted values are constants defined in the class @{tf.VariableAggregation}. @@ -404,7 +407,7 @@ class _VariableStore(object): initializer=None, regularizer=None, reuse=None, - trainable=True, + trainable=None, collections=None, caching_device=None, partitioner=None, @@ -477,6 +480,10 @@ class _VariableStore(object): synchronization=synchronization, aggregation=aggregation) + # Set trainable value based on synchronization value. + trainable = _get_trainable_value( + synchronization=synchronization, trainable=trainable) + if custom_getter is not None: # Handle backwards compatibility with getter arguments that were added # to the API after users started writing custom getters. @@ -519,11 +526,20 @@ class _VariableStore(object): synchronization=synchronization, aggregation=aggregation) - def _get_partitioned_variable( - self, name, partitioner, shape=None, dtype=dtypes.float32, - initializer=None, regularizer=None, reuse=None, - trainable=True, collections=None, caching_device=None, - validate_shape=True, use_resource=None, constraint=None): + def _get_partitioned_variable(self, + name, + partitioner, + shape=None, + dtype=dtypes.float32, + initializer=None, + regularizer=None, + reuse=None, + trainable=None, + collections=None, + caching_device=None, + validate_shape=True, + use_resource=None, + constraint=None): """Gets or creates a sharded variable list with these parameters. The `partitioner` must be a callable that accepts a fully defined @@ -773,7 +789,7 @@ class _VariableStore(object): regularizer=None, partition_info=None, reuse=None, - trainable=True, + trainable=None, collections=None, caching_device=None, validate_shape=True, @@ -1136,7 +1152,7 @@ class VariableScope(object): initializer=None, regularizer=None, reuse=None, - trainable=True, + trainable=None, collections=None, caching_device=None, partitioner=None, @@ -1207,7 +1223,7 @@ class VariableScope(object): dtype=None, initializer=None, regularizer=None, - trainable=True, + trainable=None, collections=None, caching_device=None, partitioner=None, @@ -1422,7 +1438,7 @@ def get_variable(name, dtype=None, initializer=None, regularizer=None, - trainable=True, + trainable=None, collections=None, caching_device=None, partitioner=None, @@ -2334,11 +2350,28 @@ def _compute_slice_dim_and_shape(full_shape, slicing): return slice_dim, slice_shape +def _get_trainable_value(synchronization, trainable): + """Computes the trainable value based on the given arguments.""" + if synchronization == VariableSynchronization.ON_READ: + if trainable: + raise ValueError( + "Synchronization value can be set to " + "VariableSynchronization.ON_READ only for non-trainable variables. " + "You have specified trainable=True and " + "synchronization=VariableSynchronization.ON_READ.") + else: + # Set trainable to be false when variable is to be synced on read. + trainable = False + elif trainable is None: + trainable = True + return trainable + + def default_variable_creator(next_creator=None, **kwargs): """Default variable creator.""" assert next_creator is None initial_value = kwargs.get("initial_value", None) - trainable = kwargs.get("trainable", True) + trainable = kwargs.get("trainable", None) collections = kwargs.get("collections", None) validate_shape = kwargs.get("validate_shape", True) caching_device = kwargs.get("caching_device", None) @@ -2347,10 +2380,10 @@ def default_variable_creator(next_creator=None, **kwargs): constraint = kwargs.get("constraint", None) use_resource = kwargs.get("use_resource", None) - # Enforce `ON_READ` variables to be not trainable. + # Set trainable value based on synchronization value. synchronization = kwargs.get("synchronization", VariableSynchronization.AUTO) - if synchronization == VariableSynchronization.ON_READ: - trainable = False + trainable = _get_trainable_value( + synchronization=synchronization, trainable=trainable) if use_resource is None: use_resource = get_variable_scope().use_resource @@ -2379,7 +2412,7 @@ def _make_getter(captured_getter, captured_previous): def variable(initial_value=None, - trainable=True, + trainable=None, collections=None, validate_shape=True, caching_device=None, @@ -2441,6 +2474,8 @@ def variable_creator_scope(variable_creator): trainable: If `True`, the default, also adds the variable to the graph collection `GraphKeys.TRAINABLE_VARIABLES`. This collection is used as the default list of variables to use by the `Optimizer` classes. + `trainable` defaults to `True` unless `synchronization` is + set to `ON_READ`. collections: List of graph collections keys. The new variable is added to these collections. Defaults to `[GraphKeys.GLOBAL_VARIABLES]`. validate_shape: If `False`, allows the variable to be initialized with a @@ -2463,7 +2498,8 @@ def variable_creator_scope(variable_creator): aggregated. Accepted values are constants defined in the class @{tf.VariableSynchronization}. By default the synchronization is set to `AUTO` and the current `DistributionStrategy` chooses - when to synchronize. + when to synchronize. If `synchronization` is set to `ON_READ`, + `trainable` must not be set to `True`. aggregation: Indicates how a distributed variable will be aggregated. Accepted values are constants defined in the class @{tf.VariableAggregation}. diff --git a/tensorflow/python/ops/variables.py b/tensorflow/python/ops/variables.py index 9a09cdaa52..d3b8da6d2a 100644 --- a/tensorflow/python/ops/variables.py +++ b/tensorflow/python/ops/variables.py @@ -1404,6 +1404,10 @@ class PartitionedVariable(object): def dtype(self): return self._dtype + @property + def shape(self): + return self.get_shape() + def get_shape(self): return self._shape diff --git a/tensorflow/python/platform/self_check.py b/tensorflow/python/platform/self_check.py index 966a094e55..844ae99918 100644 --- a/tensorflow/python/platform/self_check.py +++ b/tensorflow/python/platform/self_check.py @@ -78,7 +78,7 @@ def preload_check(): "Could not find %r. TensorFlow requires that this DLL be " "installed in a directory that is named in your %%PATH%% " "environment variable. Download and install CUDA %s from " - "this URL: https://developer.nvidia.com/cuda-toolkit" + "this URL: https://developer.nvidia.com/cuda-90-download-archive" % (build_info.cudart_dll_name, build_info.cuda_version_number)) if hasattr(build_info, "cudnn_dll_name") and hasattr( diff --git a/tensorflow/python/training/distribute.py b/tensorflow/python/training/distribute.py index d33fd7376a..c719045c7f 100644 --- a/tensorflow/python/training/distribute.py +++ b/tensorflow/python/training/distribute.py @@ -614,48 +614,6 @@ class DistributionStrategy(object): # Note: should support "colocate_with" argument. raise NotImplementedError("must be implemented in descendants") - def tower_local_var_scope(self, aggregation): - """Inside this scope, new variables will not be mirrored. - - There will still be one component variable per tower, but there is - no requirement that they stay in sync. Instead, when saving them - or calling `read_var()`, we use the value that results when - calling `reduce()` on all the towers' variables. - - Note: tower-local implies not trainable. Instead, it is expected - that each tower will directly update (using `assign_add()` or - whatever) its local variable instance but only the aggregated - value (accessible using `read_var()`) will be exported from the - model. When it is acceptable to only aggregate on export, we - greatly reduce communication overhead by using tower-local - variables. - - Note: All component variables will be initialized to the same - value, using the initialization expression from the first tower. - The values will match even if the initialization expression uses - random numbers. - - Args: - aggregation: Indicates how a variable will be aggregated. Accepted values - are @{tf.VariableAggregation.SUM}, @{tf.VariableAggregation.MEAN}. - - Returns: - A context manager. - """ - # TODO(psv): Remove this after adding support for synchronization and - # aggregation parameters in get_variable() and mirrored strategy. - def create_tower_local_variable(next_creator, *args, **kwargs): - _require_distribution_strategy_scope(self) - kwargs["use_resource"] = True - - # Set synchronization to be ON_READ for tower local variables. - kwargs["synchronization"] = variable_scope.VariableSynchronization.ON_READ - kwargs["aggregation"] = aggregation - return next_creator(*args, **kwargs) - - _require_distribution_strategy_scope(self) - return variable_scope.variable_creator_scope(create_tower_local_variable) - def read_var(self, v): """Reads the value of a variable. @@ -1103,10 +1061,6 @@ class TowerContext(object): finally: _pop_per_thread_mode() - def tower_local_var_scope(self, aggregation): - """Alias for distribution_strategy.tower_local_var_scope().""" - return self._distribution_strategy.tower_local_var_scope(aggregation) - @property def is_single_tower(self): """Returns whether there is a single tower or multiple.""" @@ -1158,16 +1112,6 @@ class _DefaultDistributionStrategy(DistributionStrategy): return _CurrentDistributionContext( self, variable_scope.variable_creator_scope(creator)) - def tower_local_var_scope(self, aggregation): - """Does not set to resource variables.""" - def create_tower_local_variable(next_creator, *args, **kwargs): - _require_distribution_strategy_scope(self) - kwargs["trainable"] = False - return next_creator(*args, **kwargs) - - _require_distribution_strategy_scope(self) - return variable_scope.variable_creator_scope(create_tower_local_variable) - def colocate_vars_with(self, colocate_with_variable): """Does not require `self.scope`.""" _require_distribution_strategy_scope(self) diff --git a/tensorflow/python/training/optimizer.py b/tensorflow/python/training/optimizer.py index 971ed5c8b5..f75db08059 100644 --- a/tensorflow/python/training/optimizer.py +++ b/tensorflow/python/training/optimizer.py @@ -77,9 +77,10 @@ def _deduplicate_indexed_slices(values, indices): def _var_key(var): - if context.executing_eagerly(): - return var._unique_id # pylint: disable=protected-access - return (var.op.graph, var.op.name) + # TODO(ashankar): Consolidate handling for eager and graph + if hasattr(var, "op"): + return (var.op.graph, var.op.name) + return var._unique_id # pylint: disable=protected-access class _OptimizableVariable(object): diff --git a/tensorflow/python/util/deprecation.py b/tensorflow/python/util/deprecation.py index 376be39978..c8ed2b715d 100644 --- a/tensorflow/python/util/deprecation.py +++ b/tensorflow/python/util/deprecation.py @@ -87,6 +87,27 @@ def _call_location(outer=False): return '%s:%d' % (entry[1], entry[2]) +def _wrap_decorator(wrapped_function): + """Indicate that one function wraps another. + + This decorator wraps a function using `tf_decorator.make_decorator` + so that doc generation scripts can pick up original function + signature. + It would be better to use @functools.wrap decorator, but it would + not update function signature to match wrapped function in Python 2. + + Args: + wrapped_function: The function that decorated function wraps. + + Returns: + Function that accepts wrapper function as an argument and returns + `TFDecorator` instance. + """ + def wrapper(wrapper_func): + return tf_decorator.make_decorator(wrapped_function, wrapper_func) + return wrapper + + def deprecated_alias(deprecated_name, name, func_or_class, warn_once=True): """Deprecate a symbol in favor of a new name with identical semantics. @@ -144,7 +165,7 @@ def deprecated_alias(deprecated_name, name, func_or_class, warn_once=True): if tf_inspect.isclass(func_or_class): # Make a new class with __init__ wrapped in a warning. - class NewClass(func_or_class): # pylint: disable=missing-docstring + class _NewClass(func_or_class): # pylint: disable=missing-docstring __doc__ = decorator_utils.add_notice_to_docstring( func_or_class.__doc__, 'Please use %s instead.' % name, 'DEPRECATED CLASS', @@ -153,27 +174,28 @@ def deprecated_alias(deprecated_name, name, func_or_class, warn_once=True): __name__ = func_or_class.__name__ __module__ = _call_location(outer=True) + @_wrap_decorator(func_or_class.__init__) def __init__(self, *args, **kwargs): - if hasattr(NewClass.__init__, '__func__'): + if hasattr(_NewClass.__init__, '__func__'): # Python 2 - NewClass.__init__.__func__.__doc__ = func_or_class.__init__.__doc__ + _NewClass.__init__.__func__.__doc__ = func_or_class.__init__.__doc__ else: # Python 3 - NewClass.__init__.__doc__ = func_or_class.__init__.__doc__ + _NewClass.__init__.__doc__ = func_or_class.__init__.__doc__ if _PRINT_DEPRECATION_WARNINGS: # We're making the alias as we speak. The original may have other # aliases, so we cannot use it to check for whether it's already been # warned about. - if NewClass.__init__ not in _PRINTED_WARNING: + if _NewClass.__init__ not in _PRINTED_WARNING: if warn_once: - _PRINTED_WARNING[NewClass.__init__] = True + _PRINTED_WARNING[_NewClass.__init__] = True logging.warning( 'From %s: The name %s is deprecated. Please use %s instead.\n', _call_location(), deprecated_name, name) - super(NewClass, self).__init__(*args, **kwargs) + super(_NewClass, self).__init__(*args, **kwargs) - return NewClass + return _NewClass else: decorator_utils.validate_callable(func_or_class, 'deprecated') diff --git a/tensorflow/python/util/deprecation_test.py b/tensorflow/python/util/deprecation_test.py index bdd0bc48d2..1ea695e4d6 100644 --- a/tensorflow/python/util/deprecation_test.py +++ b/tensorflow/python/util/deprecation_test.py @@ -22,6 +22,7 @@ from __future__ import print_function from tensorflow.python.platform import test from tensorflow.python.platform import tf_logging as logging from tensorflow.python.util import deprecation +from tensorflow.python.util import tf_inspect class DeprecatedAliasTest(test.TestCase): @@ -73,6 +74,11 @@ class DeprecatedAliasTest(test.TestCase): self.assertEqual(["test", "deprecated", "deprecated again"], MyClass.init_args) + # Check __init__ signature matches for doc generation. + self.assertEqual( + tf_inspect.getfullargspec(MyClass.__init__), + tf_inspect.getfullargspec(deprecated_cls.__init__)) + class DeprecationTest(test.TestCase): diff --git a/tensorflow/stream_executor/host/host_gpu_executor.cc b/tensorflow/stream_executor/host/host_gpu_executor.cc index 2c4819651a..3cd97b3cf1 100644 --- a/tensorflow/stream_executor/host/host_gpu_executor.cc +++ b/tensorflow/stream_executor/host/host_gpu_executor.cc @@ -26,8 +26,6 @@ limitations under the License. #include "tensorflow/stream_executor/lib/statusor.h" #include "tensorflow/stream_executor/plugin_registry.h" -bool FLAGS_stream_executor_cpu_real_clock_rate = false; - namespace stream_executor { namespace host { @@ -190,11 +188,8 @@ DeviceDescription *HostExecutor::PopulateDeviceDescription() const { // doesn't result in thrashing or other badness? 4GiB chosen arbitrarily. builder.set_device_memory_size(static_cast<uint64>(4) * 1024 * 1024 * 1024); - float cycle_counter_frequency = 1e9; - if (FLAGS_stream_executor_cpu_real_clock_rate) { - cycle_counter_frequency = static_cast<float>( - tensorflow::profile_utils::CpuUtils::GetCycleCounterFrequency()); - } + float cycle_counter_frequency = static_cast<float>( + tensorflow::profile_utils::CpuUtils::GetCycleCounterFrequency()); builder.set_clock_rate_ghz(cycle_counter_frequency / 1e9); auto built = builder.Build(); diff --git a/tensorflow/tensorflow.bzl b/tensorflow/tensorflow.bzl index e4632c4811..e4241667ad 100644 --- a/tensorflow/tensorflow.bzl +++ b/tensorflow/tensorflow.bzl @@ -825,6 +825,9 @@ def tf_cc_test_mkl(srcs, tags=[], size="medium", args=None): + # -fno-exceptions in nocopts breaks compilation if header modules are enabled. + disable_header_modules = ["-use_header_modules"] + for src in srcs: native.cc_test( name=src_to_test_name(src), @@ -850,6 +853,7 @@ def tf_cc_test_mkl(srcs, tags=tags, size=size, args=args, + features=disable_header_modules, nocopts="-fno-exceptions") @@ -984,16 +988,17 @@ register_extension_info( label_regex_for_dep = "{extension_name}", ) -def tf_kernel_library(name, - prefix=None, - srcs=None, - gpu_srcs=None, - hdrs=None, - deps=None, - alwayslink=1, - copts=None, - is_external=False, - **kwargs): +def tf_kernel_library( + name, + prefix = None, + srcs = None, + gpu_srcs = None, + hdrs = None, + deps = None, + alwayslink = 1, + copts = None, + is_external = False, + **kwargs): """A rule to build a TensorFlow OpKernel. May either specify srcs/hdrs or prefix. Similar to tf_cuda_library, @@ -1023,6 +1028,7 @@ def tf_kernel_library(name, deps = [] if not copts: copts = [] + textual_hdrs = [] copts = copts + tf_copts(is_external=is_external) if prefix: if native.glob([prefix + "*.cu.cc"], exclude=["*test*"]): @@ -1033,8 +1039,13 @@ def tf_kernel_library(name, srcs = srcs + native.glob( [prefix + "*.cc"], exclude=[prefix + "*test*", prefix + "*.cu.cc"]) hdrs = hdrs + native.glob( - [prefix + "*.h"], exclude=[prefix + "*test*", prefix + "*.cu.h"]) - + [prefix + "*.h"], + exclude = [prefix + "*test*", prefix + "*.cu.h", prefix + "*impl.h"], + ) + textual_hdrs = native.glob( + [prefix + "*impl.h"], + exclude = [prefix + "*test*", prefix + "*.cu.h"], + ) cuda_deps = [clean_dep("//tensorflow/core:gpu_lib")] if gpu_srcs: for gpu_src in gpu_srcs: @@ -1048,6 +1059,7 @@ def tf_kernel_library(name, name=name, srcs=srcs, hdrs=hdrs, + textual_hdrs = textual_hdrs, copts=copts, cuda_deps=cuda_deps, linkstatic=1, # Needed since alwayslink is broken in bazel b/27630669 @@ -1081,6 +1093,9 @@ def tf_mkl_kernel_library(name, hdrs = hdrs + native.glob( [prefix + "*.h"]) + # -fno-exceptions in nocopts breaks compilation if header modules are enabled. + disable_header_modules = ["-use_header_modules"] + native.cc_library( name=name, srcs=if_mkl(srcs), @@ -1088,7 +1103,8 @@ def tf_mkl_kernel_library(name, deps=deps, alwayslink=alwayslink, copts=copts, - nocopts=nocopts + nocopts=nocopts, + features = disable_header_modules ) register_extension_info( diff --git a/tensorflow/tools/api/generator/api_gen.bzl b/tensorflow/tools/api/generator/api_gen.bzl index d746b5d3e4..ed164bf9e4 100644 --- a/tensorflow/tools/api/generator/api_gen.bzl +++ b/tensorflow/tools/api/generator/api_gen.bzl @@ -131,7 +131,8 @@ def gen_api_init_files( srcs = [], api_name = "tensorflow", package = "tensorflow.python", - package_dep = "//tensorflow/python:no_contrib"): + package_dep = "//tensorflow/python:no_contrib", + output_package = "tensorflow"): root_init_template_flag = "" if root_init_template: root_init_template_flag = "--root_init_template=$(location " + root_init_template + ")" @@ -154,7 +155,9 @@ def gen_api_init_files( outs = output_files, cmd = ( "$(location :" + api_gen_binary_target + ") " + - root_init_template_flag + " --apidir=$(@D) --apiname=" + api_name + " --package=" + package + " $(OUTS)"), + root_init_template_flag + " --apidir=$(@D) --apiname=" + + api_name + " --package=" + package + " --output_package=" + + output_package + " $(OUTS)"), srcs = srcs, tools = [":" + api_gen_binary_target ], visibility = ["//tensorflow:__pkg__"], diff --git a/tensorflow/tools/api/generator/create_python_api.py b/tensorflow/tools/api/generator/create_python_api.py index 48d7dcd09e..7f17360c91 100644 --- a/tensorflow/tools/api/generator/create_python_api.py +++ b/tensorflow/tools/api/generator/create_python_api.py @@ -45,7 +45,7 @@ _GENERATED_FILE_HEADER = """# This file is MACHINE GENERATED! Do not edit. from __future__ import print_function """ -_GENERATED_FILE_FOOTER = "\n\ndel print_function\n" +_GENERATED_FILE_FOOTER = '\n\ndel print_function\n' class SymbolExposedTwiceError(Exception): @@ -159,7 +159,7 @@ __all__.remove('print_function') return module_text_map -def get_api_init_text(package, api_name): +def get_api_init_text(package, output_package, api_name): """Get a map from destination module to __init__.py code for that module. Args: @@ -218,7 +218,6 @@ def get_api_init_text(package, api_name): # For e.g. if we import 'foo.bar.Value'. Then, we also # import 'bar' in 'foo'. imported_modules = set(module_code_builder.module_imports.keys()) - import_from = '.' for module in imported_modules: if not module: continue @@ -229,6 +228,9 @@ def get_api_init_text(package, api_name): if submodule_index > 0: parent_module += ('.' + module_split[submodule_index-1] if parent_module else module_split[submodule_index-1]) + import_from = output_package + if submodule_index > 0: + import_from += '.' + '.'.join(module_split[:submodule_index]) module_code_builder.add_import( -1, parent_module, import_from, module_split[submodule_index], module_split[submodule_index]) @@ -294,7 +296,8 @@ def get_module_docstring(module_name, package, api_name): def create_api_files( - output_files, package, root_init_template, output_dir, api_name): + output_files, package, root_init_template, output_dir, output_package, + api_name): """Creates __init__.py files for the Python API. Args: @@ -323,7 +326,7 @@ def create_api_files( os.makedirs(os.path.dirname(file_path)) open(file_path, 'a').close() - module_text_map = get_api_init_text(package, api_name) + module_text_map = get_api_init_text(package, output_package, api_name) # Add imports to output files. missing_output_files = [] @@ -381,6 +384,9 @@ def main(): '--apiname', required=True, type=str, choices=API_ATTRS.keys(), help='The API you want to generate.') + parser.add_argument( + '--output_package', default='tensorflow', type=str, + help='Root output package.') args = parser.parse_args() @@ -395,7 +401,7 @@ def main(): # Populate `sys.modules` with modules containing tf_export(). importlib.import_module(args.package) create_api_files(outputs, args.package, args.root_init_template, - args.apidir, args.apiname) + args.apidir, args.output_package, args.apiname) if __name__ == '__main__': diff --git a/tensorflow/tools/api/generator/create_python_api_test.py b/tensorflow/tools/api/generator/create_python_api_test.py index 651ec9d040..1a7187463a 100644 --- a/tensorflow/tools/api/generator/create_python_api_test.py +++ b/tensorflow/tools/api/generator/create_python_api_test.py @@ -58,6 +58,7 @@ class CreatePythonApiTest(test.TestCase): def testFunctionImportIsAdded(self): imports = create_python_api.get_api_init_text( package=create_python_api._DEFAULT_PACKAGE, + output_package='tensorflow', api_name='tensorflow') expected_import = ( 'from tensorflow.python.test_module ' @@ -75,6 +76,7 @@ class CreatePythonApiTest(test.TestCase): def testClassImportIsAdded(self): imports = create_python_api.get_api_init_text( package=create_python_api._DEFAULT_PACKAGE, + output_package='tensorflow', api_name='tensorflow') expected_import = ('from tensorflow.python.test_module ' 'import TestClass') @@ -85,6 +87,7 @@ class CreatePythonApiTest(test.TestCase): def testConstantIsAdded(self): imports = create_python_api.get_api_init_text( package=create_python_api._DEFAULT_PACKAGE, + output_package='tensorflow', api_name='tensorflow') expected = ('from tensorflow.python.test_module ' 'import _TEST_CONSTANT') diff --git a/tensorflow/tools/api/golden/tensorflow.-variable-scope.pbtxt b/tensorflow/tools/api/golden/tensorflow.-variable-scope.pbtxt index ec1f72453f..c13eb7b8bb 100644 --- a/tensorflow/tools/api/golden/tensorflow.-variable-scope.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.-variable-scope.pbtxt @@ -56,7 +56,7 @@ tf_class { } member_method { name: "get_variable" - argspec: "args=[\'self\', \'var_store\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'reuse\', \'trainable\', \'collections\', \'caching_device\', \'partitioner\', \'validate_shape\', \'use_resource\', \'custom_getter\', \'constraint\', \'synchronization\', \'aggregation\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " + argspec: "args=[\'self\', \'var_store\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'reuse\', \'trainable\', \'collections\', \'caching_device\', \'partitioner\', \'validate_shape\', \'use_resource\', \'custom_getter\', \'constraint\', \'synchronization\', \'aggregation\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "global_variables" diff --git a/tensorflow/tools/api/golden/tensorflow.image.pbtxt b/tensorflow/tools/api/golden/tensorflow.image.pbtxt index e89b4dbffd..6ec3aba775 100644 --- a/tensorflow/tools/api/golden/tensorflow.image.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.image.pbtxt @@ -121,6 +121,10 @@ tf_module { argspec: "args=[\'boxes\', \'scores\', \'max_output_size\', \'iou_threshold\', \'score_threshold\', \'name\'], varargs=None, keywords=None, defaults=[\'0.5\', \'-inf\', \'None\'], " } member_method { + name: "non_max_suppression_overlaps" + argspec: "args=[\'overlaps\', \'scores\', \'max_output_size\', \'overlap_threshold\', \'score_threshold\', \'name\'], varargs=None, keywords=None, defaults=[\'0.5\', \'-inf\', \'None\'], " + } + member_method { name: "pad_to_bounding_box" argspec: "args=[\'image\', \'offset_height\', \'offset_width\', \'target_height\', \'target_width\'], varargs=None, keywords=None, defaults=None" } diff --git a/tensorflow/tools/api/golden/tensorflow.keras.-model.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.-model.pbtxt index 11cdd6f0b5..40e82b18b6 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.-model.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.-model.pbtxt @@ -119,7 +119,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.-sequential.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.-sequential.pbtxt index 4afad3e4df..8295905975 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.-sequential.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.-sequential.pbtxt @@ -124,7 +124,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.initializers.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.initializers.pbtxt index 14a667870d..8645e54302 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.initializers.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.initializers.pbtxt @@ -90,11 +90,11 @@ tf_module { } member_method { name: "glorot_normal" - argspec: "args=[\'seed\'], varargs=None, keywords=None, defaults=[\'None\'], " + argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " } member_method { name: "glorot_uniform" - argspec: "args=[\'seed\'], varargs=None, keywords=None, defaults=[\'None\'], " + argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " } member_method { name: "he_normal" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-activation.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-activation.pbtxt index 2bf973debb..86e328888e 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-activation.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-activation.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-activity-regularization.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-activity-regularization.pbtxt index 03f20e72c2..b0ed545781 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-activity-regularization.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-activity-regularization.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-add.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-add.pbtxt index 4b46b8d15a..42f98ed03d 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-add.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-add.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-alpha-dropout.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-alpha-dropout.pbtxt index d8a1c76fd0..000898a4be 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-alpha-dropout.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-alpha-dropout.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-average-pooling1-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-average-pooling1-d.pbtxt index 622926bc4b..380b49f99c 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-average-pooling1-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-average-pooling1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-average-pooling2-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-average-pooling2-d.pbtxt index 82100d8e09..82db5e6137 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-average-pooling2-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-average-pooling2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-average-pooling3-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-average-pooling3-d.pbtxt index 408061077c..b6ff688ec3 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-average-pooling3-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-average-pooling3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-average.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-average.pbtxt index a3c8031104..b41290f8b0 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-average.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-average.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-avg-pool1-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-avg-pool1-d.pbtxt index e2dfaca29f..88a033e61f 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-avg-pool1-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-avg-pool1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-avg-pool2-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-avg-pool2-d.pbtxt index 4f068d2066..c1b9b96044 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-avg-pool2-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-avg-pool2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-avg-pool3-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-avg-pool3-d.pbtxt index b8c261a743..f59f7727a3 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-avg-pool3-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-avg-pool3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-batch-normalization.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-batch-normalization.pbtxt index 4ccd6cace6..7d3744ed92 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-batch-normalization.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-batch-normalization.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-bidirectional.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-bidirectional.pbtxt index 2790e5fd85..3fd4ccdab2 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-bidirectional.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-bidirectional.pbtxt @@ -107,7 +107,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-concatenate.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-concatenate.pbtxt index b1326bd0e6..ba21b50be4 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-concatenate.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-concatenate.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-conv-l-s-t-m2-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-conv-l-s-t-m2-d.pbtxt index e3ac3dbf28..46f9fa2bbb 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-conv-l-s-t-m2-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-conv-l-s-t-m2-d.pbtxt @@ -188,7 +188,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-conv1-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-conv1-d.pbtxt index 1117a695a3..c3ad326589 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-conv1-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-conv1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-conv2-d-transpose.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-conv2-d-transpose.pbtxt index b9de142142..fd9eb43066 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-conv2-d-transpose.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-conv2-d-transpose.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-conv2-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-conv2-d.pbtxt index deb535e06e..40d61688f2 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-conv2-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-conv2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-conv3-d-transpose.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-conv3-d-transpose.pbtxt index 9a9a223fba..b8c227d725 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-conv3-d-transpose.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-conv3-d-transpose.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-conv3-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-conv3-d.pbtxt index 1c59b0bdf6..095d35e574 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-conv3-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-conv3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-convolution1-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-convolution1-d.pbtxt index 30cf5489f4..8f99961198 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-convolution1-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-convolution1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-convolution2-d-transpose.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-convolution2-d-transpose.pbtxt index 0ec69508d5..96d522a016 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-convolution2-d-transpose.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-convolution2-d-transpose.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-convolution2-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-convolution2-d.pbtxt index 4cd8928403..de2824dab4 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-convolution2-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-convolution2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-convolution3-d-transpose.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-convolution3-d-transpose.pbtxt index 4b4912496d..1d563241d8 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-convolution3-d-transpose.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-convolution3-d-transpose.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-convolution3-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-convolution3-d.pbtxt index d0ad9cf567..c87e52c537 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-convolution3-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-convolution3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-cropping1-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-cropping1-d.pbtxt index 98cff95a7f..dccf5523e3 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-cropping1-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-cropping1-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-cropping2-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-cropping2-d.pbtxt index 2357498b46..7ac4116d92 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-cropping2-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-cropping2-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-cropping3-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-cropping3-d.pbtxt index 3324cbff30..024f72705d 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-cropping3-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-cropping3-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-cu-d-n-n-g-r-u.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-cu-d-n-n-g-r-u.pbtxt index 6c81823654..4e0233331b 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-cu-d-n-n-g-r-u.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-cu-d-n-n-g-r-u.pbtxt @@ -108,7 +108,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-cu-d-n-n-l-s-t-m.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-cu-d-n-n-l-s-t-m.pbtxt index 487e04fd07..32d46ce8f3 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-cu-d-n-n-l-s-t-m.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-cu-d-n-n-l-s-t-m.pbtxt @@ -108,7 +108,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-dense.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-dense.pbtxt index 137e7cced4..858486c725 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-dense.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-dense.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-depthwise-conv2-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-depthwise-conv2-d.pbtxt index 7161665d25..f65d750926 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-depthwise-conv2-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-depthwise-conv2-d.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-dot.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-dot.pbtxt index 24affa2481..2e71ef503d 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-dot.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-dot.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-dropout.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-dropout.pbtxt index 7ba19a4269..42533bcd21 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-dropout.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-dropout.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-e-l-u.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-e-l-u.pbtxt index 503aa9162c..b5df169417 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-e-l-u.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-e-l-u.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-embedding.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-embedding.pbtxt index 1737e590a2..0ea17919a9 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-embedding.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-embedding.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-flatten.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-flatten.pbtxt index 021d024dc2..a33248bc00 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-flatten.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-flatten.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-g-r-u-cell.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-g-r-u-cell.pbtxt index 65387008bf..4ba21a25cd 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-g-r-u-cell.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-g-r-u-cell.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-g-r-u.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-g-r-u.pbtxt index 4f791acf05..a7a570418e 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-g-r-u.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-g-r-u.pbtxt @@ -171,7 +171,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-gaussian-dropout.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-gaussian-dropout.pbtxt index abc30e54e0..763bc23113 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-gaussian-dropout.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-gaussian-dropout.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-gaussian-noise.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-gaussian-noise.pbtxt index 20791bb448..3c50a3d7f2 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-gaussian-noise.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-gaussian-noise.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-average-pooling1-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-average-pooling1-d.pbtxt index 449a91d873..ac78bdafad 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-average-pooling1-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-average-pooling1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-average-pooling2-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-average-pooling2-d.pbtxt index bb361e1297..275282d9d2 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-average-pooling2-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-average-pooling2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-average-pooling3-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-average-pooling3-d.pbtxt index e564bf3216..0e31e6058b 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-average-pooling3-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-average-pooling3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-avg-pool1-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-avg-pool1-d.pbtxt index 4cb9cc3ec8..aacd0b1791 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-avg-pool1-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-avg-pool1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-avg-pool2-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-avg-pool2-d.pbtxt index 5ed52b88ae..c236548663 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-avg-pool2-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-avg-pool2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-avg-pool3-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-avg-pool3-d.pbtxt index f4559d29d7..6b9c0290aa 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-avg-pool3-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-avg-pool3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-max-pool1-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-max-pool1-d.pbtxt index 64e2d061e2..0d7b2211e6 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-max-pool1-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-max-pool1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-max-pool2-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-max-pool2-d.pbtxt index 3372ad6453..d080ad6aed 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-max-pool2-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-max-pool2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-max-pool3-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-max-pool3-d.pbtxt index 08a6860bcd..fcb0a109da 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-max-pool3-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-max-pool3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-max-pooling1-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-max-pooling1-d.pbtxt index 22c9eab64f..1d0e22abd0 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-max-pooling1-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-max-pooling1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-max-pooling2-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-max-pooling2-d.pbtxt index 74c405ba9b..653c9f547b 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-max-pooling2-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-max-pooling2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-max-pooling3-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-max-pooling3-d.pbtxt index 39f6f98193..cdbaf82cf6 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-max-pooling3-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-global-max-pooling3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-input-layer.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-input-layer.pbtxt index 7b25e80b6b..230c5e9034 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-input-layer.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-input-layer.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-l-s-t-m-cell.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-l-s-t-m-cell.pbtxt index 3619b8bfc4..511456e740 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-l-s-t-m-cell.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-l-s-t-m-cell.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-l-s-t-m.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-l-s-t-m.pbtxt index 8ef3d71dd8..4a3492ebd6 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-l-s-t-m.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-l-s-t-m.pbtxt @@ -171,7 +171,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-lambda.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-lambda.pbtxt index ecbaa9ce2c..5d05cf689f 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-lambda.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-lambda.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-layer.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-layer.pbtxt index 9b90db1e5e..7efa29be77 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-layer.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-layer.pbtxt @@ -97,7 +97,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-leaky-re-l-u.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-leaky-re-l-u.pbtxt index 3c60eaab7f..0ca8e0b52c 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-leaky-re-l-u.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-leaky-re-l-u.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-locally-connected1-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-locally-connected1-d.pbtxt index 3dac1ff342..f754fa1da8 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-locally-connected1-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-locally-connected1-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-locally-connected2-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-locally-connected2-d.pbtxt index 7f1b5db4d3..c9516b8f07 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-locally-connected2-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-locally-connected2-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-masking.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-masking.pbtxt index b3e31000f3..850ecff974 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-masking.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-masking.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-max-pool1-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-max-pool1-d.pbtxt index bbd9d1b0dc..7c69e31f9a 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-max-pool1-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-max-pool1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-max-pool2-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-max-pool2-d.pbtxt index fe72beea80..fba42642d7 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-max-pool2-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-max-pool2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-max-pool3-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-max-pool3-d.pbtxt index e9bf57b2b0..9c277411ea 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-max-pool3-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-max-pool3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-max-pooling1-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-max-pooling1-d.pbtxt index 0eecc58a2b..7c2f6ccc8a 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-max-pooling1-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-max-pooling1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-max-pooling2-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-max-pooling2-d.pbtxt index 96785a7d85..802178dba6 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-max-pooling2-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-max-pooling2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-max-pooling3-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-max-pooling3-d.pbtxt index 42c46cccb3..e870dfe9ad 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-max-pooling3-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-max-pooling3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-maximum.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-maximum.pbtxt index ac816f68d4..c1337ce0cb 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-maximum.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-maximum.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-minimum.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-minimum.pbtxt index 56e32e9d36..ed27a62765 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-minimum.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-minimum.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-multiply.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-multiply.pbtxt index 9ae99563e9..b9f05cb3e5 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-multiply.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-multiply.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-p-re-l-u.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-p-re-l-u.pbtxt index 815f3bc2d1..336d9f76fb 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-p-re-l-u.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-p-re-l-u.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-permute.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-permute.pbtxt index e704992b4a..46282217e0 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-permute.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-permute.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-r-n-n.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-r-n-n.pbtxt index b3a58fa11e..42cd7e87ee 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-r-n-n.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-r-n-n.pbtxt @@ -102,7 +102,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-re-l-u.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-re-l-u.pbtxt index f3a96ab895..c00fa79adf 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-re-l-u.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-re-l-u.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-repeat-vector.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-repeat-vector.pbtxt index 78f464583b..9f094a877a 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-repeat-vector.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-repeat-vector.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-reshape.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-reshape.pbtxt index 222344fd04..2f519a2438 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-reshape.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-reshape.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-separable-conv1-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-separable-conv1-d.pbtxt index 55fddf576c..6b93116ba0 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-separable-conv1-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-separable-conv1-d.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-separable-conv2-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-separable-conv2-d.pbtxt index 96314ce498..fd17115e27 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-separable-conv2-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-separable-conv2-d.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-separable-convolution1-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-separable-convolution1-d.pbtxt index 88bdf99566..4b37a94478 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-separable-convolution1-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-separable-convolution1-d.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-separable-convolution2-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-separable-convolution2-d.pbtxt index 6eeea7a8d1..5bdadca74a 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-separable-convolution2-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-separable-convolution2-d.pbtxt @@ -100,7 +100,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-simple-r-n-n-cell.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-simple-r-n-n-cell.pbtxt index 3050d46249..9dfda96fc8 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-simple-r-n-n-cell.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-simple-r-n-n-cell.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-simple-r-n-n.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-simple-r-n-n.pbtxt index dda4c9358b..7b7684ccd2 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-simple-r-n-n.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-simple-r-n-n.pbtxt @@ -159,7 +159,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-softmax.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-softmax.pbtxt index cc6275158b..3b15407fca 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-softmax.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-softmax.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-spatial-dropout1-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-spatial-dropout1-d.pbtxt index 5eb7e75047..6d04415267 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-spatial-dropout1-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-spatial-dropout1-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-spatial-dropout2-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-spatial-dropout2-d.pbtxt index 500cb8c14e..04950654d5 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-spatial-dropout2-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-spatial-dropout2-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-spatial-dropout3-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-spatial-dropout3-d.pbtxt index 1113a7634f..c424e6dcc8 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-spatial-dropout3-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-spatial-dropout3-d.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-stacked-r-n-n-cells.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-stacked-r-n-n-cells.pbtxt index c4b9f93561..1160d2840f 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-stacked-r-n-n-cells.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-stacked-r-n-n-cells.pbtxt @@ -102,7 +102,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-subtract.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-subtract.pbtxt index 35ad87ad5d..740a03367b 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-subtract.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-subtract.pbtxt @@ -99,7 +99,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-thresholded-re-l-u.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-thresholded-re-l-u.pbtxt index 282c98d79a..a08c583adb 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-thresholded-re-l-u.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-thresholded-re-l-u.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-time-distributed.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-time-distributed.pbtxt index acab93706b..c1294fed0f 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-time-distributed.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-time-distributed.pbtxt @@ -103,7 +103,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-up-sampling1-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-up-sampling1-d.pbtxt index a5ec228a07..dc401d3ed0 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-up-sampling1-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-up-sampling1-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-up-sampling2-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-up-sampling2-d.pbtxt index d8d8e0bfe9..4b5165ae97 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-up-sampling2-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-up-sampling2-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-up-sampling3-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-up-sampling3-d.pbtxt index 97d6dc06fb..789af15fea 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-up-sampling3-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-up-sampling3-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-wrapper.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-wrapper.pbtxt index ea9bb41b99..0536a7cee7 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-wrapper.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-wrapper.pbtxt @@ -102,7 +102,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-zero-padding1-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-zero-padding1-d.pbtxt index e6d1d2e089..8915353ec3 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-zero-padding1-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-zero-padding1-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-zero-padding2-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-zero-padding2-d.pbtxt index f62017305f..6efb5ef15a 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-zero-padding2-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-zero-padding2-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.layers.-zero-padding3-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.layers.-zero-padding3-d.pbtxt index 07a1fde5bd..4c33c5d0bf 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.layers.-zero-padding3-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.layers.-zero-padding3-d.pbtxt @@ -98,7 +98,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.models.-model.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.models.-model.pbtxt index 62aa929d32..85f7c2bfed 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.models.-model.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.models.-model.pbtxt @@ -119,7 +119,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.keras.models.-sequential.pbtxt b/tensorflow/tools/api/golden/tensorflow.keras.models.-sequential.pbtxt index 93ecbbce9b..5211657414 100644 --- a/tensorflow/tools/api/golden/tensorflow.keras.models.-sequential.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.keras.models.-sequential.pbtxt @@ -124,7 +124,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'partitioner\', \'use_resource\', \'synchronization\', \'aggregation\', \'getter\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.layers.-average-pooling1-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.layers.-average-pooling1-d.pbtxt index 11067058d5..c82e67526b 100644 --- a/tensorflow/tools/api/golden/tensorflow.layers.-average-pooling1-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.layers.-average-pooling1-d.pbtxt @@ -109,7 +109,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.layers.-average-pooling2-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.layers.-average-pooling2-d.pbtxt index 3259e706d7..1d031cb5f8 100644 --- a/tensorflow/tools/api/golden/tensorflow.layers.-average-pooling2-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.layers.-average-pooling2-d.pbtxt @@ -109,7 +109,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.layers.-average-pooling3-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.layers.-average-pooling3-d.pbtxt index e561f2f415..a8dda6655d 100644 --- a/tensorflow/tools/api/golden/tensorflow.layers.-average-pooling3-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.layers.-average-pooling3-d.pbtxt @@ -109,7 +109,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.layers.-batch-normalization.pbtxt b/tensorflow/tools/api/golden/tensorflow.layers.-batch-normalization.pbtxt index 3124a35c78..97f65ed894 100644 --- a/tensorflow/tools/api/golden/tensorflow.layers.-batch-normalization.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.layers.-batch-normalization.pbtxt @@ -108,7 +108,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.layers.-conv1-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.layers.-conv1-d.pbtxt index b5ec61255a..ccd9578f0d 100644 --- a/tensorflow/tools/api/golden/tensorflow.layers.-conv1-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.layers.-conv1-d.pbtxt @@ -109,7 +109,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.layers.-conv2-d-transpose.pbtxt b/tensorflow/tools/api/golden/tensorflow.layers.-conv2-d-transpose.pbtxt index b2c89ae66f..9cbb58d721 100644 --- a/tensorflow/tools/api/golden/tensorflow.layers.-conv2-d-transpose.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.layers.-conv2-d-transpose.pbtxt @@ -110,7 +110,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.layers.-conv2-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.layers.-conv2-d.pbtxt index 9e4f4969dc..c75ea3911e 100644 --- a/tensorflow/tools/api/golden/tensorflow.layers.-conv2-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.layers.-conv2-d.pbtxt @@ -109,7 +109,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.layers.-conv3-d-transpose.pbtxt b/tensorflow/tools/api/golden/tensorflow.layers.-conv3-d-transpose.pbtxt index 9850e6d765..5dc834e514 100644 --- a/tensorflow/tools/api/golden/tensorflow.layers.-conv3-d-transpose.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.layers.-conv3-d-transpose.pbtxt @@ -110,7 +110,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.layers.-conv3-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.layers.-conv3-d.pbtxt index be113826cc..96ab209874 100644 --- a/tensorflow/tools/api/golden/tensorflow.layers.-conv3-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.layers.-conv3-d.pbtxt @@ -109,7 +109,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.layers.-dense.pbtxt b/tensorflow/tools/api/golden/tensorflow.layers.-dense.pbtxt index 0d951bf633..7e9656b352 100644 --- a/tensorflow/tools/api/golden/tensorflow.layers.-dense.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.layers.-dense.pbtxt @@ -108,7 +108,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.layers.-dropout.pbtxt b/tensorflow/tools/api/golden/tensorflow.layers.-dropout.pbtxt index f1beeed9ef..e9a2269a6e 100644 --- a/tensorflow/tools/api/golden/tensorflow.layers.-dropout.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.layers.-dropout.pbtxt @@ -108,7 +108,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.layers.-flatten.pbtxt b/tensorflow/tools/api/golden/tensorflow.layers.-flatten.pbtxt index b75a012811..7d2eaaab2a 100644 --- a/tensorflow/tools/api/golden/tensorflow.layers.-flatten.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.layers.-flatten.pbtxt @@ -108,7 +108,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.layers.-layer.pbtxt b/tensorflow/tools/api/golden/tensorflow.layers.-layer.pbtxt index 80e0fb228b..8bc3eb26e9 100644 --- a/tensorflow/tools/api/golden/tensorflow.layers.-layer.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.layers.-layer.pbtxt @@ -106,7 +106,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.layers.-max-pooling1-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.layers.-max-pooling1-d.pbtxt index 50ff484d73..6a0dcce56a 100644 --- a/tensorflow/tools/api/golden/tensorflow.layers.-max-pooling1-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.layers.-max-pooling1-d.pbtxt @@ -109,7 +109,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.layers.-max-pooling2-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.layers.-max-pooling2-d.pbtxt index cea809744c..b6c84edf2a 100644 --- a/tensorflow/tools/api/golden/tensorflow.layers.-max-pooling2-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.layers.-max-pooling2-d.pbtxt @@ -109,7 +109,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.layers.-max-pooling3-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.layers.-max-pooling3-d.pbtxt index ab9e89554c..062a02fa59 100644 --- a/tensorflow/tools/api/golden/tensorflow.layers.-max-pooling3-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.layers.-max-pooling3-d.pbtxt @@ -109,7 +109,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.layers.-separable-conv1-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.layers.-separable-conv1-d.pbtxt index 4362568445..eaad0fb23e 100644 --- a/tensorflow/tools/api/golden/tensorflow.layers.-separable-conv1-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.layers.-separable-conv1-d.pbtxt @@ -110,7 +110,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.layers.-separable-conv2-d.pbtxt b/tensorflow/tools/api/golden/tensorflow.layers.-separable-conv2-d.pbtxt index 3cad824cd3..ece28a8ce9 100644 --- a/tensorflow/tools/api/golden/tensorflow.layers.-separable-conv2-d.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.layers.-separable-conv2-d.pbtxt @@ -110,7 +110,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-basic-l-s-t-m-cell.pbtxt b/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-basic-l-s-t-m-cell.pbtxt index a8d9e120cb..c74773000a 100644 --- a/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-basic-l-s-t-m-cell.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-basic-l-s-t-m-cell.pbtxt @@ -117,7 +117,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-basic-r-n-n-cell.pbtxt b/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-basic-r-n-n-cell.pbtxt index c039890e1f..d251f54806 100644 --- a/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-basic-r-n-n-cell.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-basic-r-n-n-cell.pbtxt @@ -117,7 +117,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-device-wrapper.pbtxt b/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-device-wrapper.pbtxt index 62c393de34..8a63b49180 100644 --- a/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-device-wrapper.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-device-wrapper.pbtxt @@ -116,7 +116,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-dropout-wrapper.pbtxt b/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-dropout-wrapper.pbtxt index f121ba7939..db1aae2757 100644 --- a/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-dropout-wrapper.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-dropout-wrapper.pbtxt @@ -120,7 +120,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-g-r-u-cell.pbtxt b/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-g-r-u-cell.pbtxt index 4583dc32b2..d76eab7eb8 100644 --- a/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-g-r-u-cell.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-g-r-u-cell.pbtxt @@ -117,7 +117,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-l-s-t-m-cell.pbtxt b/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-l-s-t-m-cell.pbtxt index 5016b6ac30..944db6ac93 100644 --- a/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-l-s-t-m-cell.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-l-s-t-m-cell.pbtxt @@ -117,7 +117,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-multi-r-n-n-cell.pbtxt b/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-multi-r-n-n-cell.pbtxt index 59623fc983..72b40cc9f7 100644 --- a/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-multi-r-n-n-cell.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-multi-r-n-n-cell.pbtxt @@ -116,7 +116,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-r-n-n-cell.pbtxt b/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-r-n-n-cell.pbtxt index e2ab5aaee9..a5c2b4aefd 100644 --- a/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-r-n-n-cell.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-r-n-n-cell.pbtxt @@ -115,7 +115,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-residual-wrapper.pbtxt b/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-residual-wrapper.pbtxt index bd2a6d61f8..61d5f04b22 100644 --- a/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-residual-wrapper.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.nn.rnn_cell.-residual-wrapper.pbtxt @@ -116,7 +116,7 @@ tf_class { } member_method { name: "add_weight" - argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\'], " + argspec: "args=[\'self\', \'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'constraint\', \'use_resource\', \'synchronization\', \'aggregation\', \'partitioner\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\', \'None\'], " } member_method { name: "apply" diff --git a/tensorflow/tools/api/golden/tensorflow.pbtxt b/tensorflow/tools/api/golden/tensorflow.pbtxt index bf2533e1b5..4f90743fec 100644 --- a/tensorflow/tools/api/golden/tensorflow.pbtxt +++ b/tensorflow/tools/api/golden/tensorflow.pbtxt @@ -1174,7 +1174,7 @@ tf_module { } member_method { name: "get_variable" - argspec: "args=[\'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'collections\', \'caching_device\', \'partitioner\', \'validate_shape\', \'use_resource\', \'custom_getter\', \'constraint\', \'synchronization\', \'aggregation\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " + argspec: "args=[\'name\', \'shape\', \'dtype\', \'initializer\', \'regularizer\', \'trainable\', \'collections\', \'caching_device\', \'partitioner\', \'validate_shape\', \'use_resource\', \'custom_getter\', \'constraint\', \'synchronization\', \'aggregation\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'None\', \'True\', \'None\', \'None\', \'None\', \'VariableSynchronization.AUTO\', \'VariableAggregation.NONE\'], " } member_method { name: "get_variable_scope" @@ -1561,10 +1561,6 @@ tf_module { argspec: "args=[\'x\', \'y\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " } member_method { - name: "print" - argspec: "args=[\'input_\', \'data\', \'message\', \'first_n\', \'summarize\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'None\', \'None\'], " - } - member_method { name: "py_func" argspec: "args=[\'func\', \'inp\', \'Tout\', \'stateful\', \'name\'], varargs=None, keywords=None, defaults=[\'True\', \'None\'], " } diff --git a/tensorflow/tools/api/lib/python_object_to_proto_visitor.py b/tensorflow/tools/api/lib/python_object_to_proto_visitor.py index 1cf330e702..3a48cf683c 100644 --- a/tensorflow/tools/api/lib/python_object_to_proto_visitor.py +++ b/tensorflow/tools/api/lib/python_object_to_proto_visitor.py @@ -88,6 +88,9 @@ def _SanitizedMRO(obj): """ return_list = [] for cls in tf_inspect.getmro(obj): + if cls.__name__ == '_NewClass': + # Ignore class created by @deprecated_alias decorator. + continue str_repr = str(cls) return_list.append(str_repr) if 'tensorflow' not in str_repr: diff --git a/tensorflow/workspace.bzl b/tensorflow/workspace.bzl index c75e5a78b9..677d9f4fbc 100644 --- a/tensorflow/workspace.bzl +++ b/tensorflow/workspace.bzl @@ -405,11 +405,11 @@ def tf_workspace(path_prefix="", tf_repo_name=""): tf_http_archive( name = "com_github_gflags_gflags", urls = [ - "https://mirror.bazel.build/github.com/gflags/gflags/archive/f8a0efe03aa69b3336d8e228b37d4ccb17324b88.tar.gz", - "https://github.com/gflags/gflags/archive/f8a0efe03aa69b3336d8e228b37d4ccb17324b88.tar.gz", + "https://mirror.bazel.build/github.com/gflags/gflags/archive/v2.2.1.tar.gz", + "https://github.com/gflags/gflags/archive/v2.2.1.tar.gz", ], - sha256 = "4d222fab8f1ede4709cdff417d15a1336f862d7334a81abf76d09c15ecf9acd1", - strip_prefix = "gflags-f8a0efe03aa69b3336d8e228b37d4ccb17324b88", + sha256 = "ae27cdbcd6a2f935baa78e4f21f675649271634c092b1be01469440495609d0e", + strip_prefix = "gflags-2.2.1", ) tf_http_archive( diff --git a/third_party/gpus/cuda_configure.bzl b/third_party/gpus/cuda_configure.bzl index c90c66912d..de87d96785 100644 --- a/third_party/gpus/cuda_configure.bzl +++ b/third_party/gpus/cuda_configure.bzl @@ -96,6 +96,16 @@ NVVM_LIBDEVICE_PATHS = [ "share/cuda/", ] +# Files used to detect the NVVM libdevice path. +NVVM_LIBDEVICE_FILES = [ + # CUDA 9.0 has a single file. + "libdevice.10.bc", + + # CUDA 8.0 has separate files for compute versions 2.0, 3.0, 3.5 and 5.0. + # Probing for one of them is sufficient. + "libdevice.compute_20.10.bc", +] + load("//third_party/clang_toolchain:download_clang.bzl", "download_clang") # TODO(dzc): Once these functions have been factored out of Bazel's @@ -718,11 +728,11 @@ def _find_nvvm_libdevice_dir(repository_ctx, cuda_config): The path of the directory containing the CUDA headers. """ cuda_toolkit_path = cuda_config.cuda_toolkit_path - for relative_path in NVVM_LIBDEVICE_PATHS: - if repository_ctx.path("%s/%slibdevice.10.bc" % (cuda_toolkit_path, relative_path)).exists: - return ("%s/%s" % (cuda_toolkit_path, relative_path))[:-1] - auto_configure_fail("Cannot find libdevice.10.bc under %s" % cuda_toolkit_path) - + for libdevice_file in NVVM_LIBDEVICE_FILES: + for relative_path in NVVM_LIBDEVICE_PATHS: + if repository_ctx.path("%s/%s%s" % (cuda_toolkit_path, relative_path, libdevice_file)).exists: + return ("%s/%s" % (cuda_toolkit_path, relative_path))[:-1] + auto_configure_fail("Cannot find libdevice*.bc files under %s" % cuda_toolkit_path) def _cudart_static_linkopt(cpu_value): """Returns additional platform-specific linkopts for cudart.""" |