
diff options
553 files changed, 18793 insertions, 11469 deletions
diff --git a/CODEOWNERS b/CODEOWNERS index 113eaf798f..78f80c8d71 100644 --- a/CODEOWNERS +++ b/CODEOWNERS @@ -54,9 +54,11 @@ /tensorflow/contrib/slim/ @sguada @thenbasilmanran /tensorflow/contrib/stateless/ @girving @alextp /tensorflow/contrib/tensor_forest/ @gilberthendry @thomascolthurst @yupbank -/tensorflow/contrib/tensorrt/ @laigd +/tensorflow/contrib/tensorrt/ @aaroey # NEED OWNER: /tensorflow/contrib/testing/ /tensorflow/contrib/timeseries/ @allenlavoie /tensorflow/contrib/tpu/ @frankchn @saeta @jhseu @sourabhbajaj /tensorflow/contrib/training/ @joel-shor @ebrevdo -/tensorflow/contrib/util/ @sherrym
\ No newline at end of file +/tensorflow/contrib/util/ @sherrym + +/third_party/systemlibs/ @perfinion @@ -90,6 +90,8 @@ The TensorFlow project strives to abide by generally accepted best practices in | **Windows CPU** | [](https://storage.googleapis.com/tensorflow-kokoro-build-badges/windows-cpu.html) | [pypi](https://pypi.org/project/tf-nightly/) | | **Windows GPU** | [](https://storage.googleapis.com/tensorflow-kokoro-build-badges/windows-gpu.html) | [pypi](https://pypi.org/project/tf-nightly-gpu/) | | **Android** | [](https://storage.googleapis.com/tensorflow-kokoro-build-badges/android.html) | [](https://bintray.com/google/tensorflow/tensorflow/_latestVersion) | +| **Raspberry Pi 0 and 1** | [](https://storage.googleapis.com/tensorflow-kokoro-build-badges/rpi01-py2.html) [](https://storage.googleapis.com/tensorflow-kokoro-build-badges/rpi01-py3.html) | [Py2](https://storage.googleapis.com/tensorflow-nightly/tensorflow-1.10.0-cp27-none-linux_armv6l.whl) [Py3](https://storage.googleapis.com/tensorflow-nightly/tensorflow-1.10.0-cp34-none-linux_armv6l.whl) | +| **Raspberry Pi 2 and 3** | [](https://storage.googleapis.com/tensorflow-kokoro-build-badges/rpi23-py2.html) [](https://storage.googleapis.com/tensorflow-kokoro-build-badges/rpi23-py3.html) | [Py2](https://storage.googleapis.com/tensorflow-nightly/tensorflow-1.10.0-cp27-none-linux_armv7l.whl) [Py3](https://storage.googleapis.com/tensorflow-nightly/tensorflow-1.10.0-cp34-none-linux_armv7l.whl) | ### Community Supported Builds diff --git a/configure.py b/configure.py index 7edab53964..361bd4764d 100644 --- a/configure.py +++ b/configure.py @@ -1543,6 +1543,10 @@ def main(): if environ_cp.get('TF_DOWNLOAD_CLANG') != '1': # Set up which clang we should use as the cuda / host compiler. set_clang_cuda_compiler_path(environ_cp) + else: + # Use downloaded LLD for linking. + write_to_bazelrc('build:cuda_clang --config=download_clang_use_lld') + write_to_bazelrc('test:cuda_clang --config=download_clang_use_lld') else: # Set up which gcc nvcc should use as the host compiler # No need to set this on Windows diff --git a/tensorflow/BUILD b/tensorflow/BUILD index b5e0a4e98b..661cba5ff0 100644 --- a/tensorflow/BUILD +++ b/tensorflow/BUILD @@ -433,6 +433,7 @@ package_group( "-//third_party/tensorflow/python/estimator", "//learning/meta_rank/...", "//tensorflow/...", + "//tensorflow_estimator/...", "//tensorflow_fold/llgtm/...", "//third_party/py/tensor2tensor/...", ], diff --git a/tensorflow/c/BUILD b/tensorflow/c/BUILD index 2c3a877edf..109b3b37aa 100644 --- a/tensorflow/c/BUILD +++ b/tensorflow/c/BUILD @@ -117,6 +117,7 @@ tf_cuda_library( deps = [ ":c_api", ":c_api_internal", + "//tensorflow/c/eager:c_api", "//tensorflow/compiler/jit/legacy_flags:mark_for_compilation_pass_flags", "//tensorflow/contrib/tpu:all_ops", "//tensorflow/core:core_cpu", diff --git a/tensorflow/c/c_api_experimental.h b/tensorflow/c/c_api_experimental.h index 6617c5a572..09d482d6df 100644 --- a/tensorflow/c/c_api_experimental.h +++ b/tensorflow/c/c_api_experimental.h @@ -20,6 +20,7 @@ limitations under the License. #include <stdint.h> #include "tensorflow/c/c_api.h" +#include "tensorflow/c/eager/c_api.h" // -------------------------------------------------------------------------- // Experimental C API for TensorFlow. @@ -131,6 +132,9 @@ TF_CAPI_EXPORT extern void TF_EnqueueNamedTensor(TF_Session* session, TF_Tensor* tensor, TF_Status* status); +TF_CAPI_EXPORT extern TFE_Context* TFE_NewContextFromSession( + const TFE_ContextOptions* opts, TF_Session* sess, TF_Status* status); + #ifdef __cplusplus } /* end extern "C" */ #endif diff --git a/tensorflow/c/eager/c_api.cc b/tensorflow/c/eager/c_api.cc index 1ccae3f138..77e3878a94 100755 --- a/tensorflow/c/eager/c_api.cc +++ b/tensorflow/c/eager/c_api.cc @@ -273,7 +273,20 @@ TFE_Context* TFE_NewContext(const TFE_ContextOptions* opts, TF_Status* status) { new tensorflow::IntraProcessRendezvous(device_mgr.get()); return new TFE_Context(opts->session_options.options, opts->policy, - opts->async, std::move(device_mgr), r); + opts->async, device_mgr.release(), + /*device_mgr_owned*/ true, r); +} + +TFE_Context* TFE_NewContextFromSession(const TFE_ContextOptions* opts, + TF_Session* sess, TF_Status* status) { + const tensorflow::DeviceMgr* device_mgr = nullptr; + status->status = sess->session->LocalDeviceManager(&device_mgr); + if (!status->status.ok()) return nullptr; + tensorflow::Rendezvous* r = + new tensorflow::IntraProcessRendezvous(device_mgr); + return new TFE_Context(opts->session_options.options, opts->policy, + opts->async, device_mgr, /*device_mgr_owned*/ false, + r); } void TFE_DeleteContext(TFE_Context* ctx) { delete ctx; } diff --git a/tensorflow/c/eager/c_api_internal.h b/tensorflow/c/eager/c_api_internal.h index a5c0681e2e..104d52430c 100644 --- a/tensorflow/c/eager/c_api_internal.h +++ b/tensorflow/c/eager/c_api_internal.h @@ -62,15 +62,14 @@ struct TFE_ContextOptions { }; struct TFE_Context { - explicit TFE_Context(const tensorflow::SessionOptions& opts, - TFE_ContextDevicePlacementPolicy default_policy, - bool async, - std::unique_ptr<tensorflow::DeviceMgr> device_mgr, - tensorflow::Rendezvous* rendezvous) + TFE_Context(const tensorflow::SessionOptions& opts, + TFE_ContextDevicePlacementPolicy default_policy, bool async, + const tensorflow::DeviceMgr* device_mgr, bool device_mgr_owned, + tensorflow::Rendezvous* rendezvous) : context(opts, static_cast<tensorflow::ContextDevicePlacementPolicy>( default_policy), - async, std::move(device_mgr), rendezvous) {} + async, device_mgr, device_mgr_owned, rendezvous) {} tensorflow::EagerContext context; }; diff --git a/tensorflow/compiler/aot/codegen.cc b/tensorflow/compiler/aot/codegen.cc index 2b1ce34b37..b17bc658fa 100644 --- a/tensorflow/compiler/aot/codegen.cc +++ b/tensorflow/compiler/aot/codegen.cc @@ -20,6 +20,7 @@ limitations under the License. #include <vector> #include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" #include "absl/strings/str_join.h" #include "absl/strings/str_replace.h" #include "absl/types/span.h" @@ -31,7 +32,6 @@ limitations under the License. #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/core/errors.h" -#include "tensorflow/core/lib/strings/strcat.h" namespace tensorflow { namespace tfcompile { @@ -135,12 +135,12 @@ Status AddRewritesForShape(int i, const xla::Shape& shape, indices = "[0]"; } else { for (int dim = 0; dim < shape.dimensions_size(); ++dim) { - dim_vars.push_back(strings::StrCat("size_t dim", dim)); - dim_sizes += strings::StrCat("[", shape.dimensions(dim), "]"); - indices += strings::StrCat("[dim", dim, "]"); + dim_vars.push_back(absl::StrCat("size_t dim", dim)); + dim_sizes += absl::StrCat("[", shape.dimensions(dim), "]"); + indices += absl::StrCat("[dim", dim, "]"); } } - rewrites->push_back({"{{I}}", strings::StrCat(i)}); + rewrites->push_back({"{{I}}", absl::StrCat(i)}); rewrites->push_back({"{{TYPE}}", type}); rewrites->push_back({"{{DIM_VARS}}", absl::StrJoin(dim_vars, ", ")}); rewrites->push_back({"{{DIM_SIZES}}", dim_sizes}); @@ -194,7 +194,7 @@ Status GenArgMethods(const tf2xla::Config& config, const xla::ProgramShape& ps, arg_data({{I}}))){{INDICES}}; } )"; - *methods += RewriteWithName(strings::StrCat(i), code, rewrites); + *methods += RewriteWithName(absl::StrCat(i), code, rewrites); if (!config.feed(i).name().empty()) { *methods += RewriteWithName("_" + config.feed(i).name(), code, rewrites); } @@ -235,7 +235,7 @@ Status GenResultMethods(const tf2xla::Config& config, result_data({{I}}))){{INDICES}}; } )"; - *methods += RewriteWithName(strings::StrCat(i), code, rewrites); + *methods += RewriteWithName(absl::StrCat(i), code, rewrites); if (!config.fetch(i).name().empty()) { *methods += RewriteWithName("_" + config.fetch(i).name(), code, rewrites); } @@ -304,8 +304,8 @@ std::vector<string> BufferInfosToCppExpression( string encoded_second_as_str = encoded.second == ~0ULL ? "~0ULL" - : strings::StrCat(encoded.second, "ULL"); - return strings::StrCat( + : absl::StrCat(encoded.second, "ULL"); + return absl::StrCat( "::tensorflow::cpu_function_runtime::BufferInfo({", encoded.first, "ULL, ", encoded_second_as_str, "})"); }); @@ -352,13 +352,13 @@ Status GenerateHeader(const CodegenOpts& opts, const tf2xla::Config& config, // Create rewrite strings for namespace start and end. string ns_start; for (const string& n : opts.namespaces) { - ns_start += strings::StrCat("namespace ", n, " {\n"); + ns_start += absl::StrCat("namespace ", n, " {\n"); } ns_start += "\n"; string ns_end("\n"); for (int i = opts.namespaces.size() - 1; i >= 0; --i) { const string& n = opts.namespaces[i]; - ns_end += strings::StrCat("} // end namespace ", n, "\n"); + ns_end += absl::StrCat("} // end namespace ", n, "\n"); } // Generate metadata. @@ -568,10 +568,10 @@ class {{CLASS}} : public tensorflow::XlaCompiledCpuFunction { )"; // The replacement strategy is naive, but good enough for our purposes. const std::vector<std::pair<string, string>> rewrites = { - {"{{ARG_BYTES_ALIGNED}}", strings::StrCat(arg_bytes_aligned)}, - {"{{ARG_BYTES_TOTAL}}", strings::StrCat(arg_bytes_total)}, + {"{{ARG_BYTES_ALIGNED}}", absl::StrCat(arg_bytes_aligned)}, + {"{{ARG_BYTES_TOTAL}}", absl::StrCat(arg_bytes_total)}, {"{{ARG_NAMES_CODE}}", arg_names_code}, - {"{{ARG_NUM}}", strings::StrCat(arg_index_table.size())}, + {"{{ARG_NUM}}", absl::StrCat(arg_index_table.size())}, {"{{ARG_INDEX_TABLE}}", absl::StrJoin(arg_index_table, ", ")}, {"{{ASSIGN_PROFILE_COUNTERS_SIZE}}", assign_profile_counters_size}, {"{{CLASS}}", opts.class_name}, @@ -590,11 +590,11 @@ class {{CLASS}} : public tensorflow::XlaCompiledCpuFunction { {"{{PROGRAM_SHAPE}}", xla::ShapeUtil::HumanString(ps)}, {"{{PROGRAM_SHAPE_SHIM_EXPRESSION}}", metadata_result.program_shape_access_shim}, - {"{{RESULT_INDEX}}", strings::StrCat(result_index)}, + {"{{RESULT_INDEX}}", absl::StrCat(result_index)}, {"{{RESULT_NAMES_CODE}}", result_names_code}, - {"{{TEMP_BYTES_ALIGNED}}", strings::StrCat(temp_bytes_aligned)}, - {"{{TEMP_BYTES_TOTAL}}", strings::StrCat(temp_bytes_total)}, - {"{{NUM_BUFFERS}}", strings::StrCat(buffer_infos.size())}, + {"{{TEMP_BYTES_ALIGNED}}", absl::StrCat(temp_bytes_aligned)}, + {"{{TEMP_BYTES_TOTAL}}", absl::StrCat(temp_bytes_total)}, + {"{{NUM_BUFFERS}}", absl::StrCat(buffer_infos.size())}, {"{{BUFFER_INFOS_AS_STRING}}", absl::StrJoin(buffer_infos_as_strings, ",\n")}}; absl::StrReplaceAll(rewrites, header); @@ -602,13 +602,13 @@ class {{CLASS}} : public tensorflow::XlaCompiledCpuFunction { } static string CreateUniqueIdentifier(const CodegenOpts& opts, - StringPiece suffix) { + absl::string_view suffix) { string result = "__tfcompile"; for (const string& n : opts.namespaces) { - strings::StrAppend(&result, "_", n); + absl::StrAppend(&result, "_", n); } - strings::StrAppend(&result, "_", opts.class_name, "_", suffix); + absl::StrAppend(&result, "_", opts.class_name, "_", suffix); return result; } @@ -678,7 +678,7 @@ Status ParseCppClass(const string& cpp_class, string* class_name, return Status::OK(); } -Status ValidateCppIdent(StringPiece ident, StringPiece msg) { +Status ValidateCppIdent(absl::string_view ident, absl::string_view msg) { if (ident.empty()) { return errors::InvalidArgument("empty identifier: ", msg); } diff --git a/tensorflow/compiler/aot/codegen.h b/tensorflow/compiler/aot/codegen.h index 83f2d3ee11..90410c46a8 100644 --- a/tensorflow/compiler/aot/codegen.h +++ b/tensorflow/compiler/aot/codegen.h @@ -19,9 +19,9 @@ limitations under the License. #include <string> #include <vector> +#include "absl/strings/string_view.h" #include "tensorflow/compiler/aot/compile.h" #include "tensorflow/compiler/tf2xla/tf2xla.pb.h" -#include "tensorflow/core/lib/core/stringpiece.h" namespace tensorflow { namespace tfcompile { @@ -96,7 +96,7 @@ Status ParseCppClass(const string& cpp_class, string* class_name, // ValidateCppIdent returns OK iff ident is a valid C++ identifier. The msg is // appended to error messages. -Status ValidateCppIdent(StringPiece ident, StringPiece msg); +Status ValidateCppIdent(absl::string_view ident, absl::string_view msg); } // namespace tfcompile } // namespace tensorflow diff --git a/tensorflow/compiler/aot/codegen_test.cc b/tensorflow/compiler/aot/codegen_test.cc index e3a53edb73..bb288d2300 100644 --- a/tensorflow/compiler/aot/codegen_test.cc +++ b/tensorflow/compiler/aot/codegen_test.cc @@ -19,11 +19,11 @@ limitations under the License. #include <vector> #include "absl/strings/match.h" +#include "absl/strings/string_view.h" #include "llvm/Support/TargetSelect.h" #include "tensorflow/compiler/xla/shape_util.h" #include "tensorflow/core/lib/core/status.h" #include "tensorflow/core/lib/core/status_test_util.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/io/path.h" #include "tensorflow/core/platform/env.h" #include "tensorflow/core/platform/test.h" diff --git a/tensorflow/compiler/aot/embedded_protocol_buffers.cc b/tensorflow/compiler/aot/embedded_protocol_buffers.cc index f1e8e5c084..3c32d533f6 100644 --- a/tensorflow/compiler/aot/embedded_protocol_buffers.cc +++ b/tensorflow/compiler/aot/embedded_protocol_buffers.cc @@ -38,11 +38,11 @@ using xla::llvm_ir::AsStringRef; static void AddEmbeddedProtocolBufferToLlvmModule( llvm::Module* module, const ::tensorflow::protobuf::MessageLite& proto, - StringPiece unique_identifier, string* protobuf_array_symbol_name, + absl::string_view unique_identifier, string* protobuf_array_symbol_name, int64* protobuf_array_size) { string protobuf_array_contents = proto.SerializeAsString(); *protobuf_array_symbol_name = - strings::StrCat(unique_identifier, "_protobuf_array_contents"); + absl::StrCat(unique_identifier, "_protobuf_array_contents"); *protobuf_array_size = protobuf_array_contents.size(); llvm::Constant* protobuf_array_initializer = @@ -55,9 +55,9 @@ static void AddEmbeddedProtocolBufferToLlvmModule( protobuf_array_initializer, AsStringRef(*protobuf_array_symbol_name)); } -static string CreateCPPShimExpression(StringPiece qualified_cpp_protobuf_name, - StringPiece protobuf_array_symbol_name, - int64 protobuf_array_size) { +static string CreateCPPShimExpression( + absl::string_view qualified_cpp_protobuf_name, + absl::string_view protobuf_array_symbol_name, int64 protobuf_array_size) { string code = "[]() {\n" " {{PROTOBUF_NAME}}* proto = new {{PROTOBUF_NAME}};\n" @@ -68,9 +68,9 @@ static string CreateCPPShimExpression(StringPiece qualified_cpp_protobuf_name, return absl::StrReplaceAll( code, { - {"{{ARRAY_SYMBOL}}", strings::StrCat(protobuf_array_symbol_name)}, - {"{{ARRAY_SIZE}}", strings::StrCat(protobuf_array_size)}, - {"{{PROTOBUF_NAME}}", strings::StrCat(qualified_cpp_protobuf_name)}, + {"{{ARRAY_SYMBOL}}", absl::StrCat(protobuf_array_symbol_name)}, + {"{{ARRAY_SIZE}}", absl::StrCat(protobuf_array_size)}, + {"{{PROTOBUF_NAME}}", absl::StrCat(qualified_cpp_protobuf_name)}, }); } @@ -93,7 +93,7 @@ static StatusOr<string> CodegenModule(llvm::TargetMachine* target_machine, } static StatusOr<std::unique_ptr<llvm::TargetMachine>> -GetTargetMachineFromTriple(StringPiece target_triple) { +GetTargetMachineFromTriple(absl::string_view target_triple) { std::string error; std::string normalized_triple = llvm::Triple::normalize(AsStringRef(absl::string_view(target_triple))); @@ -110,7 +110,7 @@ GetTargetMachineFromTriple(StringPiece target_triple) { } StatusOr<EmbeddedProtocolBuffers> CreateEmbeddedProtocolBuffers( - StringPiece target_triple, + absl::string_view target_triple, absl::Span<const ProtobufToEmbed> protobufs_to_embed) { TF_ASSIGN_OR_RETURN(std::unique_ptr<llvm::TargetMachine> target_machine, GetTargetMachineFromTriple(target_triple)); @@ -135,8 +135,8 @@ StatusOr<EmbeddedProtocolBuffers> CreateEmbeddedProtocolBuffers( protobuf_to_embed.qualified_cpp_protobuf_name, protobuf_array_symbol_name, protobuf_array_size); - cpp_variable_decl = strings::StrCat("extern \"C\" char ", - protobuf_array_symbol_name, "[];"); + cpp_variable_decl = + absl::StrCat("extern \"C\" char ", protobuf_array_symbol_name, "[];"); } else { cpp_shim = "nullptr"; } diff --git a/tensorflow/compiler/aot/embedded_protocol_buffers.h b/tensorflow/compiler/aot/embedded_protocol_buffers.h index 4f940c0197..cf5c04ac4b 100644 --- a/tensorflow/compiler/aot/embedded_protocol_buffers.h +++ b/tensorflow/compiler/aot/embedded_protocol_buffers.h @@ -83,7 +83,7 @@ struct ProtobufToEmbed { // is stored in the object_file_data field in the returned // EmbeddedProtocolBuffers instance. StatusOr<EmbeddedProtocolBuffers> CreateEmbeddedProtocolBuffers( - StringPiece target_triple, + absl::string_view target_triple, absl::Span<const ProtobufToEmbed> protobufs_to_embed); } // namespace tfcompile diff --git a/tensorflow/compiler/aot/tests/BUILD b/tensorflow/compiler/aot/tests/BUILD index 723e9bec8a..8d94f5495c 100644 --- a/tensorflow/compiler/aot/tests/BUILD +++ b/tensorflow/compiler/aot/tests/BUILD @@ -67,7 +67,12 @@ genrule( "test_graph_tfmatmulandadd.pb", "test_graph_tfsplits.pb", ], - cmd = "$(location :make_test_graphs) --out_dir $(@D)", + # Set CUDA_VISIBLE_DEVICES='' to prevent the code we launch from using any + # GPUs which might be present. This is important because builds may run + # concurrently with tests, and tests need to be able to assume that they + # have control of the full GPU. + cmd = "CUDA_VISIBLE_DEVICES='' " + + "$(location :make_test_graphs) --out_dir $(@D)", tags = ["manual"], tools = [":make_test_graphs"], ) diff --git a/tensorflow/compiler/aot/tfcompile.bzl b/tensorflow/compiler/aot/tfcompile.bzl index 326f73b975..792b7fe14a 100644 --- a/tensorflow/compiler/aot/tfcompile.bzl +++ b/tensorflow/compiler/aot/tfcompile.bzl @@ -105,12 +105,18 @@ def tf_library( freeze_file = freeze_name + ".pb" # First run tfcompile to generate the list of out_nodes. + # + # Here and below, we set CUDA_VISIBLE_DEVICES='' to prevent the code we + # launch from using any GPUs which might be present. This is important + # because builds may run concurrently with tests, and tests need to be + # able to assume that they have control of the full GPU. out_nodes_file = "out_nodes_" + freeze_name native.genrule( name = ("gen_" + out_nodes_file), srcs = [config], outs = [out_nodes_file], - cmd = ("$(location " + tfcompile_tool + ")" + + cmd = ("CUDA_VISIBLE_DEVICES='' " + + "$(location " + tfcompile_tool + ")" + " --config=$(location " + config + ")" + " --dump_fetch_nodes > $@"), tools = [tfcompile_tool], @@ -142,9 +148,12 @@ def tf_library( out_nodes_file, ] + freeze_saver_srcs, outs = [freeze_file], - cmd = ("$(location " + - "//tensorflow/python/tools:freeze_graph)" + - freeze_args), + cmd = ( + "CUDA_VISIBLE_DEVICES='' " + + "$(location " + + "//tensorflow/python/tools:freeze_graph)" + + freeze_args + ), tools = ["//tensorflow/python/tools:freeze_graph"], tags = tags, ) @@ -177,16 +186,19 @@ def tf_library( metadata_object_file, function_object_file, ], - cmd = ("$(location " + tfcompile_tool + ")" + - " --graph=$(location " + tfcompile_graph + ")" + - " --config=$(location " + config + ")" + - " --entry_point=" + ep + - " --cpp_class=" + cpp_class + - " --target_triple=" + target_llvm_triple() + - " --out_header=$(@D)/" + header_file + - " --out_metadata_object=$(@D)/" + metadata_object_file + - " --out_function_object=$(@D)/" + function_object_file + - " " + flags + " " + profiling_flag), + cmd = ( + "CUDA_VISIBLE_DEVICES='' " + + "$(location " + tfcompile_tool + ")" + + " --graph=$(location " + tfcompile_graph + ")" + + " --config=$(location " + config + ")" + + " --entry_point=" + ep + + " --cpp_class=" + cpp_class + + " --target_triple=" + target_llvm_triple() + + " --out_header=$(@D)/" + header_file + + " --out_metadata_object=$(@D)/" + metadata_object_file + + " --out_function_object=$(@D)/" + function_object_file + + " " + flags + " " + profiling_flag + ), tools = [tfcompile_tool], visibility = visibility, testonly = testonly, @@ -216,14 +228,17 @@ def tf_library( outs = [ session_module_pb, ], - cmd = ("$(location " + tfcompile_tool + ")" + - " --graph=$(location " + tfcompile_graph + ")" + - " --config=$(location " + config + ")" + - " --entry_point=" + ep + - " --cpp_class=" + cpp_class + - " --target_triple=" + target_llvm_triple() + - " --out_session_module=$(@D)/" + session_module_pb + - " " + flags), + cmd = ( + "CUDA_VISIBLE_DEVICES='' " + + "$(location " + tfcompile_tool + ")" + + " --graph=$(location " + tfcompile_graph + ")" + + " --config=$(location " + config + ")" + + " --entry_point=" + ep + + " --cpp_class=" + cpp_class + + " --target_triple=" + target_llvm_triple() + + " --out_session_module=$(@D)/" + session_module_pb + + " " + flags + ), tools = [tfcompile_tool], visibility = visibility, testonly = testonly, diff --git a/tensorflow/compiler/aot/tfcompile_main.cc b/tensorflow/compiler/aot/tfcompile_main.cc index f3c44e9dda..b95b063348 100644 --- a/tensorflow/compiler/aot/tfcompile_main.cc +++ b/tensorflow/compiler/aot/tfcompile_main.cc @@ -20,6 +20,7 @@ limitations under the License. #include "absl/strings/match.h" #include "absl/strings/str_join.h" +#include "absl/strings/string_view.h" #include "tensorflow/compiler/aot/codegen.h" #include "tensorflow/compiler/aot/compile.h" #include "tensorflow/compiler/aot/flags.h" @@ -34,7 +35,6 @@ limitations under the License. #include "tensorflow/core/graph/graph.h" #include "tensorflow/core/graph/tensor_id.h" #include "tensorflow/core/lib/core/errors.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/strings/numbers.h" #include "tensorflow/core/platform/env.h" #include "tensorflow/core/platform/init_main.h" @@ -92,8 +92,9 @@ Status Main(const MainFlags& flags) { // Write output files. Env* env = Env::Default(); const std::vector<char>& obj = compile_result.aot->object_file_data(); - TF_RETURN_IF_ERROR(WriteStringToFile(env, flags.out_function_object, - StringPiece(obj.data(), obj.size()))); + TF_RETURN_IF_ERROR( + WriteStringToFile(env, flags.out_function_object, + absl::string_view(obj.data(), obj.size()))); CodegenOpts codegen_opts; codegen_opts.gen_name_to_index = flags.gen_name_to_index; codegen_opts.gen_program_shape = flags.gen_program_shape; diff --git a/tensorflow/compiler/jit/BUILD b/tensorflow/compiler/jit/BUILD index df81f3c23e..de7cd26d1d 100644 --- a/tensorflow/compiler/jit/BUILD +++ b/tensorflow/compiler/jit/BUILD @@ -410,6 +410,7 @@ cc_library( "//tensorflow/core:graph", "//tensorflow/core:protos_all_cc", "//tensorflow/core/kernels:bounds_check", + "@com_google_absl//absl/strings", "@com_google_absl//absl/types:optional", ], ) @@ -566,6 +567,7 @@ cc_library( "//tensorflow/core/grappler:grappler_item", "//tensorflow/core/grappler/optimizers:custom_graph_optimizer", "//tensorflow/core/grappler/optimizers:custom_graph_optimizer_registry", + "@com_google_absl//absl/strings", ], ) diff --git a/tensorflow/compiler/jit/deadness_analysis.cc b/tensorflow/compiler/jit/deadness_analysis.cc index 82aa03810b..9128b48da3 100644 --- a/tensorflow/compiler/jit/deadness_analysis.cc +++ b/tensorflow/compiler/jit/deadness_analysis.cc @@ -154,7 +154,7 @@ class AndPredicate : public Predicate { std::back_inserter(operands_str), [](Predicate* pred) { return pred->ToString(); }); - return strings::StrCat("(", absl::StrJoin(operands_str, " & "), ")"); + return absl::StrCat("(", absl::StrJoin(operands_str, " & "), ")"); } Kind kind() const override { return Kind::kAnd; } @@ -185,7 +185,7 @@ class OrPredicate : public Predicate { std::back_inserter(operands_str), [](Predicate* pred) { return pred->ToString(); }); - return strings::StrCat("(", absl::StrJoin(operands_str, " | "), ")"); + return absl::StrCat("(", absl::StrJoin(operands_str, " | "), ")"); } Kind kind() const override { return Kind::kOr; } @@ -206,7 +206,7 @@ class NotPredicate : public Predicate { operands_({operand}) {} string ToString() const override { - return strings::StrCat("~", operand()->ToString()); + return absl::StrCat("~", operand()->ToString()); } Kind kind() const override { return Kind::kNot; } @@ -240,8 +240,8 @@ class AndRecurrencePredicate : public Predicate { Predicate* step() const { return operands_[1]; } string ToString() const override { - return strings::StrCat("{", start()->ToString(), ",&,", step()->ToString(), - "}"); + return absl::StrCat("{", start()->ToString(), ",&,", step()->ToString(), + "}"); } Kind kind() const override { return Kind::kAndRecurrence; } @@ -267,7 +267,7 @@ class SymbolPredicate : public Predicate { must_be_true_(must_be_true) {} string ToString() const override { - return must_be_true() ? strings::StrCat("*", tensor_id_.ToString()) + return must_be_true() ? absl::StrCat("*", tensor_id_.ToString()) : tensor_id_.ToString(); } diff --git a/tensorflow/compiler/jit/encapsulate_subgraphs_pass.cc b/tensorflow/compiler/jit/encapsulate_subgraphs_pass.cc index 2788102620..ae7a22f451 100644 --- a/tensorflow/compiler/jit/encapsulate_subgraphs_pass.cc +++ b/tensorflow/compiler/jit/encapsulate_subgraphs_pass.cc @@ -22,6 +22,7 @@ limitations under the License. #include <unordered_map> #include <vector> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/jit/graphcycles/graphcycles.h" #include "tensorflow/compiler/jit/mark_for_compilation_pass.h" #include "tensorflow/compiler/jit/shape_inference_helpers.h" @@ -45,7 +46,6 @@ limitations under the License. #include "tensorflow/core/lib/gtl/flatset.h" #include "tensorflow/core/lib/gtl/map_util.h" #include "tensorflow/core/lib/hash/hash.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/public/session_options.h" #include "tensorflow/core/public/version.h" #include "tensorflow/core/util/device_name_utils.h" @@ -755,7 +755,7 @@ Status Encapsulator::Subgraph::RecordArg( if (inserted) { NodeDef arg_def; NodeDefBuilder builder( - strings::StrCat(src_node->name(), "_", src_slot, "_arg"), kArgOp); + absl::StrCat(src_node->name(), "_", src_slot, "_arg"), kArgOp); DataType dtype = edge->dst()->input_type(edge->dst_input()); builder.Attr("T", dtype); builder.Attr("index", arg_index); @@ -790,7 +790,7 @@ Status Encapsulator::Subgraph::RecordResult( if (inserted) { NodeDef ret_def; NodeDefBuilder builder( - strings::StrCat(src_node->name(), "_", src_slot, "_retval"), kRetValOp); + absl::StrCat(src_node->name(), "_", src_slot, "_retval"), kRetValOp); DataType dtype = src_node->output_type(src_slot); builder.Attr("T", dtype); builder.Attr("index", ret_index); @@ -950,16 +950,15 @@ Status Encapsulator::Subgraph::AddHostComputes( } NodeDef host_compute_def; - NodeDefBuilder builder(strings::StrCat("outside_compilation_", - oc_subgraph_name, "_host_compute"), + NodeDefBuilder builder(absl::StrCat("outside_compilation_", + oc_subgraph_name, "_host_compute"), kHostComputeOp); builder.Input(inputs); builder.Attr("Tinputs", input_dtypes); builder.Attr("Toutputs", output_dtypes); builder.Attr("ancestors", host_compute_ancestors); - builder.Attr("key", - strings::StrCat("host_compute_channel_", subgraph_name, "_", - oc_subgraph_name)); + builder.Attr("key", absl::StrCat("host_compute_channel_", subgraph_name, + "_", oc_subgraph_name)); builder.Attr("_outside_compilation_subgraph", oc_subgraph_name); Status s = builder.Finalize(&host_compute_def); if (!s.ok()) return s; @@ -1017,8 +1016,7 @@ Status Encapsulator::Subgraph::MakeSequencingNode(const string& subgraph_name, Graph* graph_out) { if (sequencer_ == nullptr) { NodeDef seq_def; - NodeDefBuilder builder(strings::StrCat(subgraph_name, "_sequencer"), - "NoOp"); + NodeDefBuilder builder(absl::StrCat(subgraph_name, "_sequencer"), "NoOp"); builder.Attr(kXlaHostTransferSequencerAttr, subgraph_name); builder.Device(device_); Status s = builder.Finalize(&seq_def); @@ -1091,10 +1089,10 @@ Status Encapsulator::Subgraph::BuildFunctionDef( if (VLOG_IS_ON(1)) { VLOG(2) << "Build function def " << name; - dump_graph::DumpGraphToFile( - strings::StrCat("encapsulate_fdef_graph_", name), *graph_, library); - dump_graph::DumpFunctionDefToFile( - strings::StrCat("encapsulate_fdef_", name), fdef); + dump_graph::DumpGraphToFile(absl::StrCat("encapsulate_fdef_graph_", name), + *graph_, library); + dump_graph::DumpFunctionDefToFile(absl::StrCat("encapsulate_fdef_", name), + fdef); } if (!reuse_existing_functions || library->Find(name) == nullptr) { @@ -1130,8 +1128,8 @@ Status Encapsulator::Subgraph::AddShapeInferenceInfo( host_compute->AddAttr("shapes", shapes); } else { string inference_graph_name = - strings::StrCat("_outside_compilation_shape_inference_", subgraph_name, - "_", outside_compilation_subgraph_name); + absl::StrCat("_outside_compilation_shape_inference_", subgraph_name, + "_", outside_compilation_subgraph_name); FunctionDef fdef; TF_RETURN_IF_ERROR( GraphToFunctionDef(*inference_graph, inference_graph_name, &fdef)); @@ -1155,10 +1153,10 @@ Status Encapsulator::Subgraph::ReplaceFunctionDef( if (VLOG_IS_ON(1)) { VLOG(2) << "Replace function def " << name; dump_graph::DumpGraphToFile( - strings::StrCat("replace_encapsulate_fdef_graph_", name), *graph_, + absl::StrCat("replace_encapsulate_fdef_graph_", name), *graph_, library); dump_graph::DumpFunctionDefToFile( - strings::StrCat("replace_encapsulate_fdef_", name), fdef); + absl::StrCat("replace_encapsulate_fdef_", name), fdef); } TF_RETURN_IF_ERROR(library->ReplaceFunction(name, fdef)); @@ -1186,8 +1184,7 @@ Status Encapsulator::Subgraph::AddHostComputeKeyPlaceholder( GraphDefBuilder::Options options(graph_out, /*status=*/nullptr); NodeDef key_def; NodeDefBuilder builder( - strings::StrCat(call_node_def_.name(), "_key_placeholder"), - "Placeholder"); + absl::StrCat(call_node_def_.name(), "_key_placeholder"), "Placeholder"); builder.Attr("dtype", DT_STRING); builder.Attr("shape", shape_proto); builder.Attr("_host_compute_call_node", call_node_def_.name()); @@ -1221,16 +1218,16 @@ Status Encapsulator::Subgraph::AddRecvAtHostNode( } NodeDef recv_def; - NodeDefBuilder builder(strings::StrCat("outside_compilation_", subgraph_name, - "_", oc_subgraph_name, "_recv"), + NodeDefBuilder builder(absl::StrCat("outside_compilation_", subgraph_name, + "_", oc_subgraph_name, "_recv"), kRecvAtHostOp); builder.Device(device_); builder.Attr("Toutputs", dtypes); // The correct device_ordinal will be inserted during replication in a // subsequent rewrite. builder.Attr("device_ordinal", 0); - builder.Attr("key", strings::StrCat("host_compute_channel_", subgraph_name, - "_", oc_subgraph_name)); + builder.Attr("key", absl::StrCat("host_compute_channel_", subgraph_name, "_", + oc_subgraph_name)); builder.Attr(group_attribute, subgraph_name); builder.Attr(outside_compilation_attribute, oc_subgraph_name); builder.Input(host_compute_key_placeholder_->name(), 0, DT_STRING); @@ -1276,13 +1273,13 @@ Status Encapsulator::Subgraph::AddSendFromHostNode( } NodeDef send_def; - NodeDefBuilder builder(strings::StrCat("outside_compilation_", subgraph_name, - "_", oc_subgraph_name, "_send"), + NodeDefBuilder builder(absl::StrCat("outside_compilation_", subgraph_name, + "_", oc_subgraph_name, "_send"), kSendFromHostOp); builder.Device(device_); builder.Attr("Tinputs", dtypes); - builder.Attr("key", strings::StrCat("host_compute_channel_", subgraph_name, - "_", oc_subgraph_name)); + builder.Attr("key", absl::StrCat("host_compute_channel_", subgraph_name, "_", + oc_subgraph_name)); // The correct device_ordinal will be inserted during replication in a // subsequent rewrite. builder.Attr("device_ordinal", 0); @@ -1516,7 +1513,7 @@ Status Encapsulator::SplitIntoSubgraphs(FunctionLibraryDefinition* library) { // Dump subgraphs. for (auto& entry : subgraphs_) { dump_graph::DumpGraphToFile( - strings::StrCat("encapsulate_subgraphs_subgraph_", entry.first), + absl::StrCat("encapsulate_subgraphs_subgraph_", entry.first), *entry.second.GetGraph(), library); } } @@ -2052,7 +2049,7 @@ struct PathDetails { struct SubgraphAndClusterHash { inline std::size_t operator()(const SubgraphAndCluster& v) const { return hash<string>()( - strings::StrCat(v.subgraph, v.outside_compilation_cluster)); + absl::StrCat(v.subgraph, v.outside_compilation_cluster)); } }; diff --git a/tensorflow/compiler/jit/encapsulate_subgraphs_pass_test.cc b/tensorflow/compiler/jit/encapsulate_subgraphs_pass_test.cc index 7bc0ef0303..49958093b8 100644 --- a/tensorflow/compiler/jit/encapsulate_subgraphs_pass_test.cc +++ b/tensorflow/compiler/jit/encapsulate_subgraphs_pass_test.cc @@ -16,6 +16,7 @@ limitations under the License. #include <memory> #include <utility> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/jit/encapsulate_subgraphs_pass.h" #include "absl/strings/match.h" @@ -48,7 +49,7 @@ Status AddGraphDefToFunctionLibrary(const GraphDefBuilder& graphdef_builder, FunctionDef* fdef = library->add_function(); TF_RETURN_IF_ERROR(GraphToFunctionDef( *graph, - strings::StrCat("_outside_compilation_shape_inference_", name_suffix), + absl::StrCat("_outside_compilation_shape_inference_", name_suffix), fdef)); return Status::OK(); } @@ -65,18 +66,18 @@ bool EqualProtoMap(const ::tensorflow::protobuf::Map<Tkey, Tvalue>& a, const auto iter = b.find(elt_a.first); if (iter == b.end()) { if (diff) { - *diff = strings::StrCat( - map_name, " expected: contains element with key '", - key_to_string(elt_a.first), "' got: map has no such element"); + *diff = absl::StrCat(map_name, " expected: contains element with key '", + key_to_string(elt_a.first), + "' got: map has no such element"); } return false; } if (!compare(elt_a.first, elt_a.second, iter->second)) { if (diff) { - *diff = strings::StrCat(map_name, " expected: element with key '", - key_to_string(elt_a.first), "' has value '", - value_to_string(elt_a.second), "' got: '", - value_to_string(iter->second), "'"); + *diff = absl::StrCat(map_name, " expected: element with key '", + key_to_string(elt_a.first), "' has value '", + value_to_string(elt_a.second), "' got: '", + value_to_string(iter->second), "'"); } return false; } @@ -85,9 +86,9 @@ bool EqualProtoMap(const ::tensorflow::protobuf::Map<Tkey, Tvalue>& a, const auto iter = a.find(elt_b.first); if (iter == a.end()) { if (diff) { - *diff = strings::StrCat(map_name, " got: contains element with key '", - key_to_string(elt_b.first), - "' expected: map has no such element"); + *diff = absl::StrCat(map_name, " got: contains element with key '", + key_to_string(elt_b.first), + "' expected: map has no such element"); } return false; } @@ -99,25 +100,25 @@ bool EqualFunctionNodeDef(const NodeDef& a, const NodeDef& b, const string& diff_preamble, string* diff) { if (a.op() != b.op()) { if (diff) { - *diff = strings::StrCat(diff_preamble, " mismatch for node ", a.name(), - ", expected op '", a.op(), "' got '", b.op()); + *diff = absl::StrCat(diff_preamble, " mismatch for node ", a.name(), + ", expected op '", a.op(), "' got '", b.op()); } return false; } if (a.device() != b.device()) { if (diff) { - *diff = strings::StrCat(diff_preamble, " mismatch for node ", a.name(), - ", expected device '", a.device(), "' got '", - b.device()); + *diff = absl::StrCat(diff_preamble, " mismatch for node ", a.name(), + ", expected device '", a.device(), "' got '", + b.device()); } return false; } if (a.input_size() != b.input_size()) { if (diff) { - *diff = strings::StrCat(diff_preamble, " mismatch for node ", a.name(), - ", expected ", a.input_size(), " inputs got ", - b.input_size(), " expected:\n", a.DebugString(), - "\ngot:\n", b.DebugString()); + *diff = absl::StrCat(diff_preamble, " mismatch for node ", a.name(), + ", expected ", a.input_size(), " inputs got ", + b.input_size(), " expected:\n", a.DebugString(), + "\ngot:\n", b.DebugString()); } return false; } @@ -127,10 +128,10 @@ bool EqualFunctionNodeDef(const NodeDef& a, const NodeDef& b, if (absl::StartsWith(a.input(i), "^")) { if (!absl::StartsWith(b.input(i), "^")) { if (diff) { - *diff = strings::StrCat( - diff_preamble, " mismatch for node ", a.name(), " input ", i, - ", expected control input ", a.input(i), " got ", b.input(i), - " expected:\n", a.DebugString(), "\ngot:\n", b.DebugString()); + *diff = absl::StrCat(diff_preamble, " mismatch for node ", a.name(), + " input ", i, ", expected control input ", + a.input(i), " got ", b.input(i), " expected:\n", + a.DebugString(), "\ngot:\n", b.DebugString()); } return false; } @@ -138,19 +139,19 @@ bool EqualFunctionNodeDef(const NodeDef& a, const NodeDef& b, control_input_b.insert(b.input(i)); } else if (a.input(i) != b.input(i)) { if (diff) { - *diff = strings::StrCat(diff_preamble, " mismatch for node ", a.name(), - " input ", i, ", expected ", a.input(i), - " got ", b.input(i), " expected:\n", - a.DebugString(), "\ngot:\n", b.DebugString()); + *diff = absl::StrCat(diff_preamble, " mismatch for node ", a.name(), + " input ", i, ", expected ", a.input(i), " got ", + b.input(i), " expected:\n", a.DebugString(), + "\ngot:\n", b.DebugString()); } return false; } } if (control_input_a != control_input_b) { if (diff) { - *diff = strings::StrCat(diff_preamble, " mismatch for node ", a.name(), - " control inputs differ expected:\n", - a.DebugString(), "\ngot:\n", b.DebugString()); + *diff = absl::StrCat(diff_preamble, " mismatch for node ", a.name(), + " control inputs differ expected:\n", + a.DebugString(), "\ngot:\n", b.DebugString()); } return false; } @@ -170,18 +171,17 @@ bool EqualFunctionNodeDef(const NodeDef& a, const NodeDef& b, return av.DebugString() == bv.DebugString(); } }, - strings::StrCat(diff_preamble, " attr mismatch for node ", a.name()), - diff); + absl::StrCat(diff_preamble, " attr mismatch for node ", a.name()), diff); } bool EqualFunctionDef(const FunctionDef& a, const FunctionDef& b, string* diff) { if (a.signature().DebugString() != b.signature().DebugString()) { if (diff) { - *diff = strings::StrCat("Signature mismatch for function ", - a.signature().name(), ", expected:\n", - a.signature().DebugString(), "\ngot:\n", - b.signature().DebugString()); + *diff = + absl::StrCat("Signature mismatch for function ", a.signature().name(), + ", expected:\n", a.signature().DebugString(), "\ngot:\n", + b.signature().DebugString()); } return false; } @@ -191,7 +191,7 @@ bool EqualFunctionDef(const FunctionDef& a, const FunctionDef& b, [](const string& key, const AttrValue& av, const AttrValue& bv) { return av.DebugString() == bv.DebugString(); }, - strings::StrCat("attr mismatch for function ", a.signature().name()), + absl::StrCat("attr mismatch for function ", a.signature().name()), diff)) { return false; } @@ -201,7 +201,7 @@ bool EqualFunctionDef(const FunctionDef& a, const FunctionDef& b, [](const string& key, const string& av, const string& bv) { return av == bv; }, - strings::StrCat("ret mismatch for function ", a.signature().name()), + absl::StrCat("ret mismatch for function ", a.signature().name()), diff)) { return false; } @@ -211,7 +211,7 @@ bool EqualFunctionDef(const FunctionDef& a, const FunctionDef& b, if (a.node_def(i).name() == b.node_def(j).name()) { if (!EqualFunctionNodeDef( a.node_def(i), b.node_def(j), - strings::StrCat("Function ", a.signature().name()), diff)) { + absl::StrCat("Function ", a.signature().name()), diff)) { return false; } found = true; @@ -220,9 +220,9 @@ bool EqualFunctionDef(const FunctionDef& a, const FunctionDef& b, } if (!found) { if (diff) { - *diff = strings::StrCat("Function ", a.signature().name(), - ", expected: has node '", a.node_def(i).name(), - "' got: no node of that name"); + *diff = absl::StrCat("Function ", a.signature().name(), + ", expected: has node '", a.node_def(i).name(), + "' got: no node of that name"); } return false; } @@ -237,9 +237,9 @@ bool EqualFunctionDef(const FunctionDef& a, const FunctionDef& b, } if (!found) { if (diff) { - *diff = strings::StrCat("Function ", a.signature().name(), - ", got: has node '", b.node_def(i).name(), - "' expected: no node of that name"); + *diff = absl::StrCat("Function ", a.signature().name(), + ", got: has node '", b.node_def(i).name(), + "' expected: no node of that name"); } return false; } @@ -258,8 +258,8 @@ bool EqualFunctionDefLibrary(const FunctionDefLibrary& expected, auto it = actual_index.find(expected_function.signature().name()); if (it == actual_index.end()) { if (diff) { - *diff = strings::StrCat("Did not find expected function '", - expected_function.signature().name(), "'"); + *diff = absl::StrCat("Did not find expected function '", + expected_function.signature().name(), "'"); } return false; } @@ -269,9 +269,9 @@ bool EqualFunctionDefLibrary(const FunctionDefLibrary& expected, if (!actual_index.empty()) { if (diff != nullptr) { - *diff = strings::StrCat("Found unexpected function '", - actual_index.begin()->second->signature().name(), - "'"); + *diff = + absl::StrCat("Found unexpected function '", + actual_index.begin()->second->signature().name(), "'"); } return false; } @@ -420,10 +420,9 @@ Node* RecvAtHost(ops::NodeOut key_input, const string& cluster, const string& oc_cluster, absl::Span<const DataType> dtypes, const GraphDefBuilder::Options& opts) { if (opts.HaveError()) return nullptr; - string key = - strings::StrCat("host_compute_channel_", cluster, "_", oc_cluster); - string name = strings::StrCat("outside_compilation_", cluster, "_", - oc_cluster, "_recv"); + string key = absl::StrCat("host_compute_channel_", cluster, "_", oc_cluster); + string name = + absl::StrCat("outside_compilation_", cluster, "_", oc_cluster, "_recv"); NodeBuilder node_builder(opts.WithName(name).GetNameForOp("_XlaRecvAtHost"), "_XlaRecvAtHost", opts.op_registry()); node_builder.Input(std::move(key_input)); @@ -440,10 +439,9 @@ Node* SendFromHost(ops::NodeOut key_input, const string& cluster, const std::vector<ops::NodeOut>& inputs, const GraphDefBuilder::Options& opts) { if (opts.HaveError()) return nullptr; - string key = - strings::StrCat("host_compute_channel_", cluster, "_", oc_cluster); - string name = strings::StrCat("outside_compilation_", cluster, "_", - oc_cluster, "_send"); + string key = absl::StrCat("host_compute_channel_", cluster, "_", oc_cluster); + string name = + absl::StrCat("outside_compilation_", cluster, "_", oc_cluster, "_send"); NodeBuilder node_builder(opts.WithName(name).GetNameForOp("_XlaSendFromHost"), "_XlaSendFromHost", opts.op_registry()); node_builder.Input(inputs); @@ -682,8 +680,8 @@ std::vector<std::pair<string, string>> GraphEdges(const Graph& graph) { for (const Edge* edge : graph.edges()) { if (edge->src()->IsSource() || edge->dst()->IsSink()) continue; edges.emplace_back( - strings::StrCat(edge->src()->name(), ":", edge->src_output()), - strings::StrCat(edge->dst()->name(), ":", edge->dst_input())); + absl::StrCat(edge->src()->name(), ":", edge->src_output()), + absl::StrCat(edge->dst()->name(), ":", edge->dst_input())); } std::sort(edges.begin(), edges.end()); return edges; diff --git a/tensorflow/compiler/jit/graphcycles/BUILD b/tensorflow/compiler/jit/graphcycles/BUILD index 676f71a75a..8212956adf 100644 --- a/tensorflow/compiler/jit/graphcycles/BUILD +++ b/tensorflow/compiler/jit/graphcycles/BUILD @@ -14,6 +14,7 @@ cc_library( hdrs = ["graphcycles.h"], deps = [ "//tensorflow/core:lib", + "@com_google_absl//absl/container:inlined_vector", ], ) diff --git a/tensorflow/compiler/jit/graphcycles/graphcycles.cc b/tensorflow/compiler/jit/graphcycles/graphcycles.cc index 805bbc62c1..756377bd95 100644 --- a/tensorflow/compiler/jit/graphcycles/graphcycles.cc +++ b/tensorflow/compiler/jit/graphcycles/graphcycles.cc @@ -34,7 +34,7 @@ limitations under the License. #include <algorithm> #include <unordered_set> -#include "tensorflow/core/lib/gtl/inlined_vector.h" +#include "absl/container/inlined_vector.h" #include "tensorflow/core/platform/logging.h" namespace tensorflow { @@ -44,7 +44,7 @@ namespace { typedef std::unordered_set<int32> NodeSet; template <typename T> struct VecStruct { - typedef gtl::InlinedVector<T, 4> type; + typedef absl::InlinedVector<T, 4> type; }; template <typename T> using Vec = typename VecStruct<T>::type; diff --git a/tensorflow/compiler/jit/mark_for_compilation_pass.cc b/tensorflow/compiler/jit/mark_for_compilation_pass.cc index 4e4abade32..44caf0be52 100644 --- a/tensorflow/compiler/jit/mark_for_compilation_pass.cc +++ b/tensorflow/compiler/jit/mark_for_compilation_pass.cc @@ -43,7 +43,6 @@ limitations under the License. #include "tensorflow/core/kernels/bounds_check.h" #include "tensorflow/core/lib/gtl/cleanup.h" #include "tensorflow/core/lib/gtl/flatset.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/lib/strings/stringprintf.h" #include "tensorflow/core/public/version.h" @@ -617,7 +616,7 @@ Status MarkForCompilationPass::Run( } static string RatioToString(int numerator, int denominator) { - return strings::Printf("%d / %d (%.2f%%)", numerator, denominator, + return absl::StrFormat("%d / %d (%.2f%%)", numerator, denominator, (100.0 * numerator) / denominator); } @@ -626,14 +625,14 @@ static void VLogClusteringSummary(const Graph& g) { return; } - std::map<StringPiece, int> cluster_name_to_size; - std::map<StringPiece, std::map<StringPiece, int>> + std::map<absl::string_view, int> cluster_name_to_size; + std::map<absl::string_view, std::map<absl::string_view, int>> cluster_name_to_op_histogram; - std::map<StringPiece, int> unclustered_op_histogram; + std::map<absl::string_view, int> unclustered_op_histogram; int clustered_node_count = 0; for (Node* n : g.nodes()) { - absl::optional<StringPiece> cluster_name = GetXlaClusterForNode(*n); + absl::optional<absl::string_view> cluster_name = GetXlaClusterForNode(*n); if (cluster_name) { clustered_node_count++; cluster_name_to_size[*cluster_name]++; @@ -650,7 +649,7 @@ static void VLogClusteringSummary(const Graph& g) { << RatioToString(clustered_node_count, g.num_nodes()); for (const auto& cluster_name_size_pair : cluster_name_to_size) { - StringPiece cluster_name = cluster_name_size_pair.first; + absl::string_view cluster_name = cluster_name_size_pair.first; int size = cluster_name_size_pair.second; VLOG(2) << " " << cluster_name << " " << RatioToString(size, g.num_nodes()); @@ -670,14 +669,15 @@ static void VLogClusteringSummary(const Graph& g) { } struct EdgeInfo { - StringPiece node_name; - absl::optional<StringPiece> cluster_name; + absl::string_view node_name; + absl::optional<absl::string_view> cluster_name; - StringPiece GetClusterName() const { + absl::string_view GetClusterName() const { return cluster_name ? *cluster_name : "[none]"; } - std::pair<StringPiece, absl::optional<StringPiece>> AsPair() const { + std::pair<absl::string_view, absl::optional<absl::string_view>> AsPair() + const { return {node_name, cluster_name}; } @@ -686,19 +686,21 @@ static void VLogClusteringSummary(const Graph& g) { } }; - using EdgeInfoMap = std::map<StringPiece, std::map<EdgeInfo, int64>>; + using EdgeInfoMap = std::map<absl::string_view, std::map<EdgeInfo, int64>>; EdgeInfoMap incoming_edge_infos; EdgeInfoMap outgoing_edge_infos; - std::set<StringPiece> cluster_names_to_print; + std::set<absl::string_view> cluster_names_to_print; for (const Edge* e : g.edges()) { const Node* from = e->src(); - absl::optional<StringPiece> from_cluster_name = GetXlaClusterForNode(*from); + absl::optional<absl::string_view> from_cluster_name = + GetXlaClusterForNode(*from); const Node* to = e->dst(); - absl::optional<StringPiece> to_cluster_name = GetXlaClusterForNode(*to); + absl::optional<absl::string_view> to_cluster_name = + GetXlaClusterForNode(*to); if (to_cluster_name == from_cluster_name) { continue; @@ -721,9 +723,9 @@ static void VLogClusteringSummary(const Graph& g) { VLOG(2) << " [none]"; } - auto print_edge_info_set_for_cluster = [&](StringPiece cluster_name, + auto print_edge_info_set_for_cluster = [&](absl::string_view cluster_name, const EdgeInfoMap& edge_info_map, - StringPiece desc) { + absl::string_view desc) { auto it = edge_info_map.find(cluster_name); if (it != edge_info_map.end()) { VLOG(2) << " " << it->second.size() << " " << desc << " edges"; @@ -737,7 +739,7 @@ static void VLogClusteringSummary(const Graph& g) { } }; - for (StringPiece cluster_name : cluster_names_to_print) { + for (absl::string_view cluster_name : cluster_names_to_print) { VLOG(2) << " ** Cluster " << cluster_name; print_edge_info_set_for_cluster(cluster_name, incoming_edge_infos, "incoming"); @@ -966,7 +968,7 @@ Status MarkForCompilationPass::RunImpl( string& name = cluster_names[cluster]; if (name.empty()) { - name = strings::StrCat("cluster_", cluster_sequence_num++); + name = absl::StrCat("cluster_", cluster_sequence_num++); } n->AddAttr(kXlaClusterAttr, name); VLOG(3) << "Assigning node " << n->name() << " to cluster " << name; diff --git a/tensorflow/compiler/jit/mark_for_compilation_pass_test.cc b/tensorflow/compiler/jit/mark_for_compilation_pass_test.cc index 807ab51fd3..9473ac0a4c 100644 --- a/tensorflow/compiler/jit/mark_for_compilation_pass_test.cc +++ b/tensorflow/compiler/jit/mark_for_compilation_pass_test.cc @@ -633,7 +633,7 @@ TEST(XlaCompilationTest, IllegalCycle_UsefulErrorMessage) { std::unique_ptr<Graph> graph(new Graph(OpRegistry::Global())); Scope root = Scope::NewRootScope().ExitOnError(); { - auto BuildNoopNode = [](StringPiece name, Graph* graph) { + auto BuildNoopNode = [](absl::string_view name, Graph* graph) { NodeDefBuilder builder(name, "NoOp"); NodeDef def; TF_CHECK_OK(builder.Finalize(&def)); diff --git a/tensorflow/compiler/jit/partially_decluster_pass.cc b/tensorflow/compiler/jit/partially_decluster_pass.cc index a8f09bfa50..584c963f71 100644 --- a/tensorflow/compiler/jit/partially_decluster_pass.cc +++ b/tensorflow/compiler/jit/partially_decluster_pass.cc @@ -14,6 +14,7 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/compiler/jit/partially_decluster_pass.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/jit/xla_cluster_util.h" #include "tensorflow/core/framework/memory_types.h" #include "tensorflow/core/framework/node_def.pb.h" @@ -30,7 +31,7 @@ Status FindNodesToDecluster(const Graph& graph, gtl::FlatSet<Node*>* result, MemoryTypeVector input_mtypes, output_mtypes; for (Node* n : post_order) { - absl::optional<StringPiece> from_cluster = GetXlaClusterForNode(*n); + absl::optional<absl::string_view> from_cluster = GetXlaClusterForNode(*n); if (!from_cluster) { continue; } @@ -79,7 +80,7 @@ Status FindNodesToDecluster(const Graph& graph, gtl::FlatSet<Node*>* result, // Check if `dst` is in a different cluster, unclustered, or about to be // partially declustered (here we rely on the post-order traversal order). // If yes, decluster `n` to avoid the device-to-host memcpy. - absl::optional<StringPiece> dst_cluster = + absl::optional<absl::string_view> dst_cluster = result->count(dst) ? absl::nullopt : GetXlaClusterForNode(*dst); if (from_cluster != dst_cluster) { CHECK(result->insert(n).second); @@ -91,15 +92,16 @@ Status FindNodesToDecluster(const Graph& graph, gtl::FlatSet<Node*>* result, } Status PartiallyDeclusterNode(Graph* graph, Node* n) { - StringPiece cluster_name = *GetXlaClusterForNode(*n); - gtl::InlinedVector<const Edge*, 6> out_edges_to_clone; + absl::string_view cluster_name = *GetXlaClusterForNode(*n); + absl::InlinedVector<const Edge*, 6> out_edges_to_clone; for (const Edge* out_edge : n->out_edges()) { if (out_edge->IsControlEdge()) { continue; } Node* dst = out_edge->dst(); - absl::optional<StringPiece> dst_cluster_name = GetXlaClusterForNode(*dst); + absl::optional<absl::string_view> dst_cluster_name = + GetXlaClusterForNode(*dst); if (dst_cluster_name != cluster_name) { out_edges_to_clone.push_back(out_edge); } @@ -108,7 +110,7 @@ Status PartiallyDeclusterNode(Graph* graph, Node* n) { CHECK(!out_edges_to_clone.empty()) << n->DebugString(); NodeDef ndef = n->def(); - ndef.set_name(strings::StrCat(n->name(), "/declustered")); + ndef.set_name(absl::StrCat(n->name(), "/declustered")); RemoveFromXlaCluster(&ndef); Status s; Node* cloned_node = graph->AddNode(ndef, &s); diff --git a/tensorflow/compiler/jit/resource_operation_safety_analysis.cc b/tensorflow/compiler/jit/resource_operation_safety_analysis.cc index 1ba4a5ef73..56e35c0059 100644 --- a/tensorflow/compiler/jit/resource_operation_safety_analysis.cc +++ b/tensorflow/compiler/jit/resource_operation_safety_analysis.cc @@ -165,7 +165,7 @@ bool IsEdgeSafe(XlaResourceOpKind from, XlaResourceOpKind to) { using ResourceOp = std::pair<int, XlaResourceOpKind>; string ResourceOpToString(const ResourceOp& resource_op) { - return strings::StrCat( + return absl::StrCat( resource_op.first, ": ", XlaResourceOpInfo::XlaResourceOpKindToString(resource_op.second)); } @@ -257,11 +257,11 @@ string ResourceOpSetToString(const ResourceOpSet& resource_op_set) { std::vector<string> elements_debug_string; std::transform(resource_op_set.begin(), resource_op_set.end(), std::back_inserter(elements_debug_string), ResourceOpToString); - return strings::StrCat("{", absl::StrJoin(elements_debug_string, ","), "}"); + return absl::StrCat("{", absl::StrJoin(elements_debug_string, ","), "}"); } string NodeToString(const Node& n, XlaResourceOpKind resource_op_kind) { - return strings::StrCat( + return absl::StrCat( "[", n.name(), ": ", n.type_string(), "(", XlaResourceOpInfo::XlaResourceOpKindToString(resource_op_kind), ")", "]"); } diff --git a/tensorflow/compiler/jit/xla_cluster_util.cc b/tensorflow/compiler/jit/xla_cluster_util.cc index 4f2fabd658..03380e9406 100644 --- a/tensorflow/compiler/jit/xla_cluster_util.cc +++ b/tensorflow/compiler/jit/xla_cluster_util.cc @@ -17,6 +17,7 @@ limitations under the License. #include <unordered_map> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/jit/resource_operation_safety_analysis.h" #include "tensorflow/core/framework/node_def.pb.h" #include "tensorflow/core/graph/control_flow.h" @@ -52,8 +53,8 @@ string DescribeCycle(const GraphCycles* cycles, const Graph& graph, int src, }; string description; - strings::StrAppend(&description, "Edge from ", node_name(src), " to ", - node_name(dst), " would create a cycle.\n"); + absl::StrAppend(&description, "Edge from ", node_name(src), " to ", + node_name(dst), " would create a cycle.\n"); path.resize(path_size); for (int32 node_id : path) { string ascii_art; @@ -64,7 +65,7 @@ string DescribeCycle(const GraphCycles* cycles, const Graph& graph, int src, } else { ascii_art = "+-- "; } - strings::StrAppend(&description, ascii_art, node_name(node_id), "\n"); + absl::StrAppend(&description, ascii_art, node_name(node_id), "\n"); } return description; } @@ -186,7 +187,7 @@ Status CreateCycleDetectionGraph(const Graph* graph, GraphCycles* cycles) { return Status::OK(); } -absl::optional<StringPiece> GetXlaClusterForNode(const Node& node) { +absl::optional<absl::string_view> GetXlaClusterForNode(const Node& node) { const AttrValue* attr_value = node.attrs().Find(kXlaClusterAttr); if (attr_value == nullptr) { return absl::nullopt; diff --git a/tensorflow/compiler/jit/xla_cluster_util.h b/tensorflow/compiler/jit/xla_cluster_util.h index b0439a63ca..17ae510a0e 100644 --- a/tensorflow/compiler/jit/xla_cluster_util.h +++ b/tensorflow/compiler/jit/xla_cluster_util.h @@ -47,7 +47,7 @@ Status CreateCycleDetectionGraph(const Graph* graph, GraphCycles* cycles); // Returns the XLA cluster in which `node` is placed if it is in an XLA cluster, // otherwise returns nullopt. -absl::optional<StringPiece> GetXlaClusterForNode(const Node& node); +absl::optional<absl::string_view> GetXlaClusterForNode(const Node& node); // Removes `node_def` its XLA cluster (by clearing its _XlaCluster attribute). void RemoveFromXlaCluster(NodeDef* node_def); diff --git a/tensorflow/compiler/jit/xla_compilation_cache.cc b/tensorflow/compiler/jit/xla_compilation_cache.cc index ef6b0e67d3..3aa9e9c7ed 100644 --- a/tensorflow/compiler/jit/xla_compilation_cache.cc +++ b/tensorflow/compiler/jit/xla_compilation_cache.cc @@ -67,12 +67,12 @@ string XlaCompilationCache::DebugString() { string XlaCompilationCache::SignatureDebugString(const Signature& sig) { string result = sig.name; for (const auto& a : sig.arg_types) { - strings::StrAppend(&result, ",", DataTypeString(a.first), - a.second.DebugString()); + absl::StrAppend(&result, ",", DataTypeString(a.first), + a.second.DebugString()); } for (const auto& v : sig.arg_values) { - strings::StrAppend(&result, "; ", v.DebugString()); + absl::StrAppend(&result, "; ", v.DebugString()); } return result; } @@ -259,7 +259,7 @@ Status XlaCompilationCache::CompileImpl( const XlaCompiler::CompileOptions& compile_options, bool compile_single_op) { CHECK_NE(executable, nullptr); - VLOG(1) << "XlaCompilationCache::Compile " << DebugString(); + VLOG(2) << "XlaCompilationCache::Compile " << DebugString(); if (VLOG_IS_ON(2)) { VLOG(2) << "num_inputs=" << ctx->num_inputs() @@ -310,7 +310,7 @@ Status XlaCompilationCache::CompileImpl( // cache eviction. mutex_lock entry_lock(entry->mu); if (!entry->compiled) { - VLOG(1) << "Compilation cache miss for signature: " + VLOG(2) << "Compilation cache miss for signature: " << SignatureDebugString(signature); tensorflow::Env* env = tensorflow::Env::Default(); const uint64 compile_start_us = env->NowMicros(); diff --git a/tensorflow/compiler/jit/xla_device.cc b/tensorflow/compiler/jit/xla_device.cc index f31879a2bc..51797def04 100644 --- a/tensorflow/compiler/jit/xla_device.cc +++ b/tensorflow/compiler/jit/xla_device.cc @@ -148,10 +148,9 @@ Status DefaultPaddedShapeFn(const Tensor& tensor, xla::Shape* shape) { } const DeviceAttributes attrs = Device::BuildDeviceAttributes( - strings::StrCat(name_prefix, "/device:", device_name, ":", - device_ordinal), + absl::StrCat(name_prefix, "/device:", device_name, ":", device_ordinal), DeviceType(device_name), Bytes(16ULL << 30), DeviceLocality(), - strings::StrCat("device: ", device_name, " device")); + absl::StrCat("device: ", device_name, " device")); device->reset( new XlaDevice(options, attrs, device_ordinal, DeviceType(jit_device_name), diff --git a/tensorflow/compiler/jit/xla_device_context.cc b/tensorflow/compiler/jit/xla_device_context.cc index ee07c5c964..af83c792e5 100644 --- a/tensorflow/compiler/jit/xla_device_context.cc +++ b/tensorflow/compiler/jit/xla_device_context.cc @@ -203,7 +203,7 @@ void XlaTransferManager::CopyCPUTensorToDevice(const Tensor* cpu_tensor, } void XlaTransferManager::CopyDeviceTensorToCPU(const Tensor* device_tensor, - StringPiece tensor_name, + absl::string_view tensor_name, Device* device, Tensor* cpu_tensor, StatusCallback done) { @@ -339,7 +339,7 @@ void XlaDeviceContext::CopyCPUTensorToDevice(const Tensor* cpu_tensor, } void XlaDeviceContext::CopyDeviceTensorToCPU(const Tensor* device_tensor, - StringPiece tensor_name, + absl::string_view tensor_name, Device* device, Tensor* cpu_tensor, StatusCallback done) { manager_.CopyDeviceTensorToCPU(device_tensor, tensor_name, device, cpu_tensor, diff --git a/tensorflow/compiler/jit/xla_device_context.h b/tensorflow/compiler/jit/xla_device_context.h index 2e7445340c..df82421294 100644 --- a/tensorflow/compiler/jit/xla_device_context.h +++ b/tensorflow/compiler/jit/xla_device_context.h @@ -57,7 +57,7 @@ class XlaTransferManager { void CopyCPUTensorToDevice(const Tensor* cpu_tensor, Device* device, Tensor* device_tensor, StatusCallback done) const; void CopyDeviceTensorToCPU(const Tensor* device_tensor, - StringPiece tensor_name, Device* device, + absl::string_view tensor_name, Device* device, Tensor* cpu_tensor, StatusCallback done); void CopyDeviceTensorToDevice(const Tensor& src_tensor, Tensor* dst_tensor, @@ -111,7 +111,7 @@ class XlaDeviceContext : public DeviceContext { Tensor* device_tensor, StatusCallback done) const override; void CopyDeviceTensorToCPU(const Tensor* device_tensor, - StringPiece tensor_name, Device* device, + absl::string_view tensor_name, Device* device, Tensor* cpu_tensor, StatusCallback done) override; void CopyDeviceTensorToDevice(const Tensor& src_tensor, Tensor* dst_tensor, const StatusCallback& done); diff --git a/tensorflow/compiler/jit/xla_fusion_optimizer.cc b/tensorflow/compiler/jit/xla_fusion_optimizer.cc index 07cfab6151..bc0db558d8 100644 --- a/tensorflow/compiler/jit/xla_fusion_optimizer.cc +++ b/tensorflow/compiler/jit/xla_fusion_optimizer.cc @@ -20,6 +20,7 @@ limitations under the License. #include <unordered_map> #include <unordered_set> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/jit/deadness_analysis.h" #include "tensorflow/compiler/jit/defs.h" #include "tensorflow/compiler/jit/graphcycles/graphcycles.h" @@ -326,7 +327,7 @@ Status XlaFusionOptimizer::Optimize(grappler::Cluster* cluster, string& name = cluster_names[cluster]; if (name.empty()) { - name = strings::StrCat("cluster_", cluster_sequence_num++); + name = absl::StrCat("cluster_", cluster_sequence_num++); } n->AddAttr(kXlaClusterAttr, name); VLOG(3) << "Assigning node " << n->name() << " to cluster " << name; diff --git a/tensorflow/compiler/jit/xla_tensor.h b/tensorflow/compiler/jit/xla_tensor.h index 4c9bb2e27b..d95da63405 100644 --- a/tensorflow/compiler/jit/xla_tensor.h +++ b/tensorflow/compiler/jit/xla_tensor.h @@ -122,7 +122,7 @@ class XlaTensor { std::shared_ptr<se::Event> definition_event_; // A list of all streams for which the tensor's content is defined for any // newly enqueued command. - gtl::InlinedVector<se::Stream*, 2> streams_defined_on_ GUARDED_BY(mu_); + absl::InlinedVector<se::Stream*, 2> streams_defined_on_ GUARDED_BY(mu_); mutex mu_; }; diff --git a/tensorflow/compiler/tests/BUILD b/tensorflow/compiler/tests/BUILD index cf02926e06..050d827a09 100644 --- a/tensorflow/compiler/tests/BUILD +++ b/tensorflow/compiler/tests/BUILD @@ -251,6 +251,7 @@ tf_xla_py_test( tf_xla_py_test( name = "matrix_triangular_solve_op_test", size = "small", + timeout = "moderate", srcs = ["matrix_triangular_solve_op_test.py"], tags = ["optonly"], deps = [ @@ -572,6 +573,7 @@ tf_xla_py_test( tf_xla_py_test( name = "matrix_band_part_test", size = "medium", + timeout = "long", srcs = ["matrix_band_part_test.py"], tags = ["optonly"], deps = [ @@ -1101,6 +1103,7 @@ cc_library( "//tensorflow/core:test", "//tensorflow/core:testlib", "//tensorflow/core/kernels:ops_util", + "@com_google_absl//absl/strings", ], ) diff --git a/tensorflow/compiler/tests/randomized_tests.cc b/tensorflow/compiler/tests/randomized_tests.cc index 0faf0fd8ed..bddda6f302 100644 --- a/tensorflow/compiler/tests/randomized_tests.cc +++ b/tensorflow/compiler/tests/randomized_tests.cc @@ -45,6 +45,8 @@ limitations under the License. #include <random> #include <unordered_map> +#include "absl/strings/str_cat.h" +#include "absl/strings/string_view.h" #include "tensorflow/compiler/jit/defs.h" #include "tensorflow/compiler/tf2xla/type_util.h" #include "tensorflow/core/common_runtime/device.h" @@ -61,7 +63,6 @@ limitations under the License. #include "tensorflow/core/kernels/ops_util.h" #include "tensorflow/core/lib/core/status.h" #include "tensorflow/core/lib/core/status_test_util.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/gtl/flatset.h" #include "tensorflow/core/platform/test.h" #include "tensorflow/core/public/session.h" @@ -81,7 +82,7 @@ string* tf_xla_test_device_ptr; // initial value set in main() bool tf_xla_test_use_jit = true; string LocalDeviceToFullDeviceName(const string& device) { - return strings::StrCat("/job:localhost/replica:0/task:0/device:", device); + return absl::StrCat("/job:localhost/replica:0/task:0/device:", device); } constexpr std::array<DataType, 5> kAllXlaTypes = { @@ -107,11 +108,12 @@ class OpTestBuilder { // Sets an attribute. template <class T> - OpTestBuilder& Attr(StringPiece attr_name, T&& value); + OpTestBuilder& Attr(absl::string_view attr_name, T&& value); // Overload needed to allow {...} expressions for value. template <class T> - OpTestBuilder& Attr(StringPiece attr_name, std::initializer_list<T> value); + OpTestBuilder& Attr(absl::string_view attr_name, + std::initializer_list<T> value); // Adds nodes that executes the operator under test on 'device' to 'graphdef'. // If 'use_jit' is true, marks the operator under test to be compiled by XLA. @@ -185,13 +187,13 @@ OpTestBuilder& OpTestBuilder::RandomUniqueInput(DataType type, } template <class T> -OpTestBuilder& OpTestBuilder::Attr(StringPiece attr_name, T&& value) { +OpTestBuilder& OpTestBuilder::Attr(absl::string_view attr_name, T&& value) { AddNodeAttr(attr_name, std::forward<T>(value), &node_def_); return *this; } template <class T> -OpTestBuilder& OpTestBuilder::Attr(StringPiece attr_name, +OpTestBuilder& OpTestBuilder::Attr(absl::string_view attr_name, std::initializer_list<T> value) { Attr<std::initializer_list<T>>(attr_name, std::move(value)); return *this; @@ -209,7 +211,7 @@ Status OpTestBuilder::BuildGraph(const string& name_prefix, NodeDef* test_def = graphdef->add_node(); *test_def = node_def_; - test_def->set_name(strings::StrCat(name_prefix, "_op_under_test")); + test_def->set_name(absl::StrCat(name_prefix, "_op_under_test")); test_def->set_device(device); AddDefaultsToNodeDef(*op_def, test_def); if (use_jit) { @@ -224,7 +226,7 @@ Status OpTestBuilder::BuildGraph(const string& name_prefix, // Build feed and fetch nodes. for (int i = 0; i < input_types.size(); ++i) { NodeDef* def = graphdef->add_node(); - string name = strings::StrCat(name_prefix, "_input_", i); + string name = absl::StrCat(name_prefix, "_input_", i); TF_RETURN_IF_ERROR(NodeDefBuilder(name, "Placeholder") .Device(device) .Attr("dtype", input_types[i]) @@ -235,7 +237,7 @@ Status OpTestBuilder::BuildGraph(const string& name_prefix, for (int i = 0; i < output_types.size(); ++i) { NodeDef* def = graphdef->add_node(); - string name = strings::StrCat(name_prefix, "_output_", i); + string name = absl::StrCat(name_prefix, "_output_", i); TF_RETURN_IF_ERROR(NodeDefBuilder(name, "Identity") .Device(device) .Attr("T", output_types[i]) @@ -726,11 +728,11 @@ bool IsClose<complex64>(const complex64& x, const complex64& y, double atol, template <typename T> string Str(T x) { - return strings::StrCat(x); + return absl::StrCat(x); } template <> string Str<complex64>(complex64 x) { - return strings::StrCat("(", x.real(), ", ", x.imag(), ")"); + return absl::StrCat("(", x.real(), ", ", x.imag(), ")"); } template <typename T> @@ -740,11 +742,11 @@ Status TensorsAreCloseImpl(const Tensor& x, const Tensor& y, double atol, auto Ty = y.flat<T>(); for (int i = 0; i < Tx.size(); ++i) { if (!IsClose(Tx(i), Ty(i), atol, rtol)) { - return errors::InvalidArgument(strings::StrCat( - i, "-th tensor element isn't close: ", Str(Tx(i)), " vs. ", - Str(Ty(i)), ". x = ", x.DebugString(), "y = ", y.DebugString(), - "atol = ", atol, " rtol = ", rtol, - " tol = ", atol + rtol * Abs(Tx(i)))); + return errors::InvalidArgument( + absl::StrCat(i, "-th tensor element isn't close: ", Str(Tx(i)), + " vs. ", Str(Ty(i)), ". x = ", x.DebugString(), + "y = ", y.DebugString(), "atol = ", atol, + " rtol = ", rtol, " tol = ", atol + rtol * Abs(Tx(i)))); } } return Status::OK(); @@ -756,7 +758,7 @@ Status TensorsAreEqualImpl(const Tensor& x, const Tensor& y) { auto Ty = y.flat<T>(); for (int i = 0; i < Tx.size(); ++i) { if (Tx(i) != Ty(i)) { - return errors::InvalidArgument(strings::StrCat( + return errors::InvalidArgument(absl::StrCat( i, "-th tensor element isn't equal: ", Tx(i), " vs. ", Ty(i), ". x = ", x.DebugString(), "y = ", y.DebugString())); } @@ -771,14 +773,14 @@ Status TensorsAreEqualImpl(const Tensor& x, const Tensor& y) { Status TensorsAreClose(const Tensor& a, const Tensor& b, double atol, double rtol) { if (a.dtype() != b.dtype()) { - return errors::InvalidArgument(strings::StrCat( + return errors::InvalidArgument(absl::StrCat( "Tensors have different types: ", DataTypeString(a.dtype()), " and ", DataTypeString(b.dtype()))); } if (!a.IsSameSize(b)) { - return errors::InvalidArgument(strings::StrCat( - "Tensors have different shapes: ", a.shape().DebugString(), " and ", - b.shape().DebugString())); + return errors::InvalidArgument( + absl::StrCat("Tensors have different shapes: ", a.shape().DebugString(), + " and ", b.shape().DebugString())); } switch (a.dtype()) { @@ -827,7 +829,7 @@ OpTest::TestResult OpTest::ExpectTfAndXlaOutputsAreClose( } string cpu_device = - LocalDeviceToFullDeviceName(strings::StrCat(DEVICE_CPU, ":0")); + LocalDeviceToFullDeviceName(absl::StrCat(DEVICE_CPU, ":0")); string test_device = LocalDeviceToFullDeviceName(*tf_xla_test_device_ptr); DeviceNameUtils::ParsedName parsed_name; @@ -842,7 +844,7 @@ OpTest::TestResult OpTest::ExpectTfAndXlaOutputsAreClose( std::vector<string> expected_inputs, test_inputs; std::vector<string> expected_fetches, test_fetches; Status status = builder.BuildGraph( - strings::StrCat("test", num_tests_, "_expected"), cpu_device, + absl::StrCat("test", num_tests_, "_expected"), cpu_device, /* use_jit= */ false, &graph, /* test_node_def= */ nullptr, &expected_inputs, &expected_fetches); if (!status.ok()) { @@ -851,7 +853,7 @@ OpTest::TestResult OpTest::ExpectTfAndXlaOutputsAreClose( } NodeDef* node_def; - status = builder.BuildGraph(strings::StrCat("test", num_tests_, "_test"), + status = builder.BuildGraph(absl::StrCat("test", num_tests_, "_test"), test_device, tf_xla_test_use_jit, &graph, &node_def, &test_inputs, &test_fetches); if (!status.ok()) { diff --git a/tensorflow/compiler/tests/xla_ops_test.py b/tensorflow/compiler/tests/xla_ops_test.py index b2f026df6c..3f928a1bea 100644 --- a/tensorflow/compiler/tests/xla_ops_test.py +++ b/tensorflow/compiler/tests/xla_ops_test.py @@ -97,9 +97,9 @@ class XlaOpsTest(xla_test.XLATestCase, parameterized.TestCase): args=(np.array([0xFFFFFFFF, 16], dtype=np.uint32), np.uint32(4)), expected=np.array([0xFFFFFFFF, 1], dtype=np.uint32)) - PRECISION_VALUES = (None, xla_data_pb2.PrecisionConfigProto.DEFAULT, - xla_data_pb2.PrecisionConfigProto.HIGH, - xla_data_pb2.PrecisionConfigProto.HIGHEST) + PRECISION_VALUES = (None, xla_data_pb2.PrecisionConfig.DEFAULT, + xla_data_pb2.PrecisionConfig.HIGH, + xla_data_pb2.PrecisionConfig.HIGHEST) @parameterized.parameters(*PRECISION_VALUES) def testConv(self, precision): @@ -120,7 +120,7 @@ class XlaOpsTest(xla_test.XLATestCase, parameterized.TestCase): dnums.output_spatial_dimensions.extend(range(2, 2 + num_spatial_dims)) precision_config = None if precision: - precision_config = xla_data_pb2.PrecisionConfigProto() + precision_config = xla_data_pb2.PrecisionConfig() precision_config.operand_precision.extend([precision, precision]) return xla.conv( lhs, @@ -151,7 +151,7 @@ class XlaOpsTest(xla_test.XLATestCase, parameterized.TestCase): dnums.rhs_batch_dimensions.append(0) precision_config = None if precision: - precision_config = xla_data_pb2.PrecisionConfigProto() + precision_config = xla_data_pb2.PrecisionConfig() precision_config.operand_precision.extend([precision, precision]) return xla.dot_general( lhs, diff --git a/tensorflow/compiler/tf2xla/BUILD b/tensorflow/compiler/tf2xla/BUILD index 0797b2cb17..22be7f048f 100644 --- a/tensorflow/compiler/tf2xla/BUILD +++ b/tensorflow/compiler/tf2xla/BUILD @@ -291,6 +291,7 @@ cc_library( "//tensorflow/core:graph", "//tensorflow/core:lib", "//tensorflow/core:protos_all_cc", + "@com_google_absl//absl/strings", "@com_google_absl//absl/types:optional", ], ) @@ -433,6 +434,7 @@ cc_library( "//tensorflow/core:framework_internal", "//tensorflow/core:lib", "//tensorflow/core:protos_all_cc", + "@com_google_absl//absl/strings", ], ) @@ -609,11 +611,10 @@ cc_library( srcs = ["resource_operation_table.cc"], hdrs = ["resource_operation_table.h"], deps = [ - "//tensorflow/core:framework", "//tensorflow/core:lib", "//tensorflow/core:ops", - "//tensorflow/core:protos_all_cc", "@com_google_absl//absl/algorithm:container", + "@com_google_absl//absl/strings", ], ) diff --git a/tensorflow/compiler/tf2xla/dump_graph.cc b/tensorflow/compiler/tf2xla/dump_graph.cc index 24616c01c7..380c6a7e23 100644 --- a/tensorflow/compiler/tf2xla/dump_graph.cc +++ b/tensorflow/compiler/tf2xla/dump_graph.cc @@ -18,8 +18,8 @@ limitations under the License. #include "tensorflow/compiler/tf2xla/dump_graph.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/tf2xla/dump_graph_flags.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/env.h" #include "tensorflow/core/platform/mutex.h" @@ -52,9 +52,9 @@ string MakeUniqueFilename(string name) { string filename = name; if (count > 0) { - strings::StrAppend(&filename, "_", count); + absl::StrAppend(&filename, "_", count); } - strings::StrAppend(&filename, ".pbtxt"); + absl::StrAppend(&filename, ".pbtxt"); return filename; } @@ -69,7 +69,7 @@ string WriteTextProtoToUniqueFile( << proto_type << ": " << status; return "(unavailable)"; } - string filepath = strings::StrCat(dirname, "/", MakeUniqueFilename(name)); + string filepath = absl::StrCat(dirname, "/", MakeUniqueFilename(name)); status = WriteTextProto(Env::Default(), filepath, proto); if (!status.ok()) { LOG(WARNING) << "Failed to dump " << proto_type << " to file: " << filepath diff --git a/tensorflow/compiler/tf2xla/functionalize_cond.cc b/tensorflow/compiler/tf2xla/functionalize_cond.cc index b5667ca0d3..0911550f1f 100644 --- a/tensorflow/compiler/tf2xla/functionalize_cond.cc +++ b/tensorflow/compiler/tf2xla/functionalize_cond.cc @@ -40,24 +40,9 @@ using xla::StatusOr; namespace tensorflow { namespace functionalize_cond { -string DebugString(const CondStateMap::CondNode& node) { - return node.ToString(); -} - // TODO(jpienaar): Move to OutputTensor. string DebugString(const OutputTensor& tensor) { - return strings::StrCat(tensor.node->name(), ":", tensor.index); -} - -string DebugString(CondStateMap::CondId cond_state) { - if (cond_state == nullptr || cond_state->empty()) return "[]"; - return strings::StrCat( - "[", - absl::StrJoin(*cond_state, ", ", - [](string* output, const CondStateMap::CondNode& node) { - strings::StrAppend(output, node.ToString()); - }), - "]"); + return absl::StrCat(tensor.node->name(), ":", tensor.index); } string Branch_Name(BranchType b) { @@ -73,6 +58,24 @@ string Branch_Name(BranchType b) { } } +string DebugString(StateMap::CondId cond_state) { + if (cond_state == nullptr || cond_state->empty()) return "{}"; + using value_type = StateMap::CondState::value_type; + return absl::StrCat( + "{", + absl::StrJoin(*cond_state, ", ", + [](string* output, const value_type& pred_branch) { + const OutputTensor& pred = pred_branch.first; + const BranchType& branch = pred_branch.second; + if (branch == BranchType::kNeither) + absl::StrAppend(output, "d"); + else + absl::StrAppend(output, "s(", DebugString(pred), ",", + Branch_Name(branch), ")"); + }), + "}"); +} + // Returns the predicate of a switch. Status GetSwitchPredicate(const Node& switch_node, OutputTensor* pred) { const Edge* pred_edge; @@ -86,64 +89,65 @@ Status GetSwitchPredicate(const Node& switch_node, OutputTensor* pred) { return Status::OK(); } -CondStateMap::CondNode::CondNode(Type type, Node* switch_node, - BranchType branch) - : type(type), branch(branch) { - if (type == Type::kSwitch) { - TF_CHECK_OK(GetSwitchPredicate(*switch_node, &predicate)); - } -} - -string CondStateMap::CondNode::ToString() const { - switch (type) { - case Type::kSwitch: - return strings::StrCat("s(", DebugString(predicate), ",", - Branch_Name(branch), ")"); - case Type::kMerge: - return "m"; - case Type::kDead: - return "d"; - } +Status GetSwitchValue(const Node& switch_node, OutputTensor* val) { + const Edge* val_edge; + TF_RETURN_IF_ERROR(switch_node.input_edge(0, &val_edge)); + *val = OutputTensor(val_edge->src(), val_edge->src_output()); + return Status::OK(); } -bool CondStateMap::CondNode::operator==(const CondNode& other) const { - if (type != Type::kSwitch) return type == other.type; - return type == other.type && predicate == other.predicate && - branch == other.branch; +bool StateMap::OutputTensorLess::operator()(const OutputTensor& lhs, + const OutputTensor& rhs) const { + return (lhs.node->id() < rhs.node->id()) || + (lhs.node->id() == rhs.node->id() && lhs.index < rhs.index); } -bool CondStateMap::CondNode::operator!=(const CondNode& other) const { - return !(*this == other); -} +struct CondStateLess { + bool operator()(const StateMap::CondState::value_type& lhs, + const StateMap::CondState::value_type& rhs) const { + if (StateMap::OutputTensorLess().operator()(lhs.first, rhs.first)) + return true; + if (lhs.first.node->id() == rhs.first.node->id() && + lhs.first.index == rhs.first.index) + return lhs.second < rhs.second; + return false; + } +}; -CondStateMap::CondStateMap(Graph* graph) { +StateMap::StateMap(Graph* graph) { node_to_condid_map_.resize(graph->num_node_ids()); + node_to_ancestorid_map_.resize(graph->num_node_ids()); // Initialize the dead state (empty state is designated with a nullptr). - dead_id_ = GetUniqueId({CondNode(CondStateMap::CondNode::Type::kDead)}); + dead_id_ = GetCondId( + {std::make_pair(OutputTensor(nullptr, -1), BranchType::kNeither)}); } -bool CondStateMap::IsDead(CondStateMap::CondId id) const { - return id == dead_id_; -} +bool StateMap::IsDead(StateMap::CondId id) const { return id == dead_id_; } -bool CondStateMap::IsEmpty(CondStateMap::CondId id) const { - return id == nullptr; -} +bool StateMap::IsEmpty(StateMap::CondId id) const { return id == nullptr; } -size_t CondStateMap::CondHash::operator()( - const CondStateMap::CondNode& item) const { - return Hash64Combine(Hash64Combine(OutputTensor::Hash()(item.predicate), - hash<BranchType>()(item.branch)), - hash<CondStateMap::CondNode::Type>()(item.type)); +size_t StateMap::Hash::operator()(const StateMap::CondState& map) const { + if (map.empty()) return 0; + // Compute hash of the front element. + auto it = map.begin(); + size_t h = Hash64Combine(OutputTensor::Hash()(it->first), + hash<BranchType>()(it->second)); + for (++it; it != map.end(); ++it) { + // Combine the has with the different elements in the map. + h = Hash64Combine(h, Hash64Combine(OutputTensor::Hash()(it->first), + hash<BranchType>()(it->second))); + } + return h; } -size_t CondStateMap::CondHash::operator()( - const CondStateMap::CondState& vec) const { - if (vec.empty()) return 0; - size_t h = (*this)(vec.front()); - auto it = vec.begin(); - for (++it; it != vec.end(); ++it) { - h = Hash64Combine(h, (*this)(*it)); +size_t StateMap::Hash::operator()(const StateMap::AncestorState& map) const { + if (map.empty()) return 0; + // Compute hash of the front element. + auto it = map.begin(); + size_t h = hash<Node*>()(*it); + for (++it; it != map.end(); ++it) { + // Combine the has with the different elements in the map. + h = Hash64Combine(h, hash<Node*>()(*it)); } return h; } @@ -155,8 +159,8 @@ struct CondArgNode { : src(src), src_output(src_output) {} string ToString() const { - return strings::StrCat("src=", src->name(), ":", src_output, - " switches=", NodesToString(switches)); + return absl::StrCat("src=", src->name(), ":", src_output, + " switches=", NodesToString(switches)); } Node* src; @@ -167,58 +171,80 @@ struct CondArgNode { using CondArgNodes = std::vector<CondArgNode>; string DebugString(const CondArgNodes& nodes) { - return strings::StrCat( + return absl::StrCat( "[", absl::StrJoin(nodes, ", ", [](string* output, const CondArgNode& node) { - strings::StrAppend(output, node.ToString()); + absl::StrAppend(output, node.ToString()); }), "]"); } -CondStateMap::CondId CondStateMap::LookupId(const Node* node) const { +StateMap::CondId StateMap::LookupCondId(const Node* node) const { if (node->id() < node_to_condid_map_.size()) return node_to_condid_map_[node->id()]; - return added_node_mapping_.at(node->id()); + return added_node_condid_mapping_.at(node->id()); } -CondStateMap::CondId CondStateMap::GetUniqueId( - const CondStateMap::CondState& state) { +StateMap::CondId StateMap::GetCondId(const StateMap::CondState& state) { if (state.empty()) return nullptr; return &*condstate_set_.insert(state).first; } -const CondStateMap::CondState& CondStateMap::LookupState( - const Node* node) const { - return *LookupId(node); -} - -void CondStateMap::ResetId(const Node* node, CondStateMap::CondId id) { +void StateMap::ResetCondId(const Node* node, StateMap::CondId id) { if (node->id() < node_to_condid_map_.size()) node_to_condid_map_[node->id()] = id; else - added_node_mapping_[node->id()] = id; + added_node_condid_mapping_[node->id()] = id; +} + +StateMap::AncestorId StateMap::LookupAncestorId(const Node* node) const { + if (node->id() < node_to_ancestorid_map_.size()) + return node_to_ancestorid_map_[node->id()]; + return added_node_ancestorid_mapping_.at(node->id()); +} + +StateMap::AncestorId StateMap::GetAncestorId( + const StateMap::AncestorState& state) { + if (state.empty()) return nullptr; + return &*ancestorstate_set_.insert(state).first; +} + +void StateMap::ResetAncestorId(const Node* node, StateMap::AncestorId id) { + if (node->id() < node_to_ancestorid_map_.size()) + node_to_ancestorid_map_[node->id()] = id; + else + added_node_ancestorid_mapping_[node->id()] = id; } -void CondStateMap::MarkDead(const Node* node) { ResetId(node, dead_id_); } +const StateMap::CondState& StateMap::LookupState(const Node* node) const { + return *LookupCondId(node); +} + +void StateMap::MarkDead(const Node* node) { ResetCondId(node, dead_id_); } -string CondStateMap::CondStateToString(const Node* node) const { - return CondStateToString(LookupId(node)); +string StateMap::CondStateToString(const Node* node) const { + return CondStateToString(LookupCondId(node)); } -string CondStateMap::CondStateToString(CondStateMap::CondId id) const { +string StateMap::CondStateToString(StateMap::CondId id) const { return DebugString(id); } +string StateMap::AncestorStateToString(const Node* node) const { + if (auto id = LookupAncestorId(node)) return NodesToString(*id); + return "{}"; +} + FunctionalizeCond::FunctionalizeCond(Graph* graph, FunctionLibraryDefinition* library) - : cond_state_map_(graph), library_(library), graph_(graph) {} + : state_map_(graph), library_(library), graph_(graph) {} // Class representing the merge/switch nodes that will become a conditional. class Conditional { public: Conditional(OutputTensor predicate, FunctionalizeCond* parent, - CondStateMap* cond_state_map); + StateMap* cond_state_map); // Adds merge node that is part of this conditional. Status AddMerge(Node* m); @@ -247,6 +273,10 @@ class Conditional { // Adds switch node that is part of this conditional. Status AddSwitch(Node* s); + // Adds a switch node along the edge and rewire the edge to go via the switch. + Status AddSwitchNodeAlongEdge(const Edge* edge, BranchType branch, + Graph* graph); + // Internal name of conditional. The name is based on the first merge node // added. string name() const; @@ -255,7 +285,7 @@ class Conditional { FunctionalizeCond* parent_; // Mapping between nodes and their cond state. - CondStateMap* cond_state_map_; + StateMap* state_map_; // The predicate of the conditional. OutputTensor predicate_; @@ -292,8 +322,8 @@ class Conditional { }; Conditional::Conditional(OutputTensor predicate, FunctionalizeCond* parent, - CondStateMap* cond_state_map) - : parent_(parent), cond_state_map_(cond_state_map), predicate_(predicate) {} + StateMap* cond_state_map) + : parent_(parent), state_map_(cond_state_map), predicate_(predicate) {} Status Conditional::AddMerge(Node* m) { merges_.insert(m); @@ -343,7 +373,7 @@ Status Conditional::BuildArgumentNodes() { for (auto branch : {BranchType::kElseBranch, BranchType::kThenBranch}) { int branch_index = static_cast<int>(branch); TF_RETURN_IF_ERROR( - NodeBuilder(strings::StrCat("_Arg", arg_count), + NodeBuilder(absl::StrCat("_Arg", arg_count), FunctionLibraryDefinition::kArgOp) .Attr("T", dtype) .Attr("index", arg_count) @@ -397,6 +427,35 @@ Status Conditional::BuildArgumentNodes() { return Status::OK(); } +Status Conditional::AddSwitchNodeAlongEdge(const Edge* edge, BranchType branch, + Graph* graph) { + // Previously we had edge: + // src:src_output ---- edge ----> dst:dst_input + // post this we have (in graph) + // src:src_output --> switch<pred> --- new_edge --> dst:dst_input + + // TODO(jpienaar): One could keep a map caching the extra switch nodes added + // to avoid adding another switch to feed a value for which a switch was + // already added. + Node* switch_node; + Node* src = edge->src(); + int src_output = edge->src_output(); + TF_RETURN_IF_ERROR( + NodeBuilder(graph->NewName(absl::StrCat(src->name(), "_added_switch")), + "Switch") + .Input(src, src_output) + .Input(const_cast<Node*>(predicate_.node), predicate_.index) + .Finalize(graph, &switch_node)); + state_map_->ResetCondId(switch_node, state_map_->LookupCondId(src)); + state_map_->ResetAncestorId(switch_node, state_map_->LookupAncestorId(src)); + + Node* dst = edge->dst(); + int dst_input = edge->dst_input(); + graph->RemoveEdge(edge); + graph->AddEdge(switch_node, static_cast<int>(branch), dst, dst_input); + return AddSwitch(switch_node); +} + Status Conditional::ExtractBodies(Graph* graph) { VLOG(2) << "Extracting bodies for " << name(); for (auto b : {BranchType::kElseBranch, BranchType::kThenBranch}) { @@ -405,16 +464,16 @@ Status Conditional::ExtractBodies(Graph* graph) { } auto find_branch = [&](const Edge* e) { - const auto& id = cond_state_map_->LookupId(e->src()); + const auto& id = state_map_->LookupCondId(e->src()); return IsSwitch(e->src()) ? BranchType(e->src_output()) - : cond_state_map_->FindBranchOf(id, predicate_); + : state_map_->FindBranchOf(id, predicate_); }; std::array<std::vector<Node*>, 2> stacks; VLOG(5) << "Merges: " << NodesToString(merges_); for (Node* m : merges_) { VLOG(5) << "For merge: " << m->DebugString() << " " - << cond_state_map_->CondStateToString(m); + << state_map_->CondStateToString(m); for (auto e : m->in_edges()) { if (e->IsControlEdge()) continue; BranchType branch = find_branch(e); @@ -422,7 +481,8 @@ Status Conditional::ExtractBodies(Graph* graph) { branch == BranchType::kElseBranch) << "Error: " << e->src()->name() << " is not on either then or else branch (" << Branch_Name(branch) - << ")."; + << ") for predicate " << DebugString(predicate_) << " [" + << DebugString(state_map_->LookupCondId(e->src())) << "]."; Node* src = e->src(); if (IsSwitch(src)) { // Switch node outputs and dependencies are handled separately. @@ -456,8 +516,8 @@ Status Conditional::ExtractBodies(Graph* graph) { if (IsMerge(dst)) continue; Node* src = e->src(); - auto dst_id = cond_state_map_->LookupId(dst); - auto src_id = cond_state_map_->LookupId(src); + auto dst_id = state_map_->LookupCondId(dst); + auto src_id = state_map_->LookupCondId(src); if (dst_id != src_id) { if (e->IsControlEdge()) { external_control_outputs_.push_back(e->src()); @@ -480,8 +540,11 @@ Status Conditional::ExtractBodies(Graph* graph) { } } - // Copying incomming edges to dst node. - for (const Edge* e : n->in_edges()) { + // Copying incomming edges to dst node. Iterate over a copy of the edges + // as they could be mutated during iteration. + std::vector<const Edge*> in_edges(n->in_edges().begin(), + n->in_edges().end()); + for (const Edge* e : in_edges) { Node* src = e->src(); // Skip src/dst node. if (!src->IsOp()) continue; @@ -494,8 +557,8 @@ Status Conditional::ExtractBodies(Graph* graph) { } // Verify input is from the same context. - auto src_id = cond_state_map_->LookupId(src); - auto dst_id = cond_state_map_->LookupId(dst); + auto src_id = state_map_->LookupCondId(src); + auto dst_id = state_map_->LookupCondId(dst); if (IsMerge(dst) || src_id == dst_id) { // TODO(jpienaar): The merge case can be more strict. if (node_map.at(src->id()) == nullptr) { @@ -506,18 +569,25 @@ Status Conditional::ExtractBodies(Graph* graph) { external_control_inputs_.push_back(src); } else { // This shouldn't happen, this means we have an external data input - // not entering via a switch node. Work around this for constant - // nodes as some constant nodes are inserted without the required - // control context dominance. + // not entering via a switch node. Work around this by for + // * constant nodes copy them; + // * non-constant nodes, insert a switch along the edge; if (IsConstant(src)) { node_map.at(src->id()) = output->CopyNode(src); } else { - return errors::InvalidArgument( - "Graph contains node ", FormatNodeForError(*src), - " that feeds into node ", FormatNodeForError(*dst), - " but these nodes are in different control contexts (", - DebugString(src_id), " vs ", DebugString(dst_id), - " (detected during in edge testing)"); + StateMap::CondState state = *dst_id; + state.erase(predicate_); + if (state_map_->GetCondId(state) == src_id) { + TF_RETURN_IF_ERROR(AddSwitchNodeAlongEdge(e, branch, graph)); + continue; + } else { + return errors::InvalidArgument( + "Graph contains node ", FormatNodeForError(*src), + " that feeds into node ", FormatNodeForError(*dst), + " but these nodes are in different control contexts (", + DebugString(src_id), " vs ", DebugString(dst_id), + " (detected during in edge testing)"); + } } } @@ -580,8 +650,8 @@ Status Conditional::BuildIfNode(Graph* graph, int64 id = ++sequence_num; NameAttrList body_name; - body_name.set_name(strings::StrCat("_functionalize_if_", - branch_name[branch_index], "_", id)); + body_name.set_name( + absl::StrCat("_functionalize_if_", branch_name[branch_index], "_", id)); VLOG(3) << "FunctionalizeControlFlow (" << branch_name[branch_index] << "): " @@ -639,7 +709,8 @@ Status Conditional::BuildIfNode(Graph* graph, VLOG(3) << "Build If node"; NodeDef if_def; TF_RETURN_IF_ERROR(builder.Finalize(&if_def)); - TF_ASSIGN_OR_RETURN(if_node_, parent_->AddIfNode(if_def, *merges_.begin())); + TF_ASSIGN_OR_RETURN(if_node_, + parent_->AddIfNode(if_def, *merges_.begin(), predicate_)); return Status::OK(); } @@ -699,7 +770,8 @@ Status Conditional::AddOutputEdges(Graph* graph) { Status Conditional::BuildAndReplace(Graph* graph, FunctionLibraryDefinition* library) { - VLOG(1) << "Build If and replace merge nodes " << name(); + VLOG(1) << "Build If and replace merge nodes " + << NodesToString(this->merges_); if (replaced_) return Status::OK(); TF_RETURN_IF_ERROR(ExtractBodies(graph)); @@ -719,7 +791,7 @@ Status Conditional::BuildAndReplace(Graph* graph, TF_RETURN_IF_ERROR(AddInputEdges(graph)); TF_RETURN_IF_ERROR(AddOutputEdges(graph)); TF_RETURN_IF_ERROR(parent_->PropagateUpdatedState(if_node_)); - for (Node* m : merges_) cond_state_map_->MarkDead(m); + for (Node* m : merges_) state_map_->MarkDead(m); // Check that the if_node doesn't feed into itself. TF_RETURN_WITH_CONTEXT_IF_ERROR( @@ -732,31 +804,7 @@ Status Conditional::BuildAndReplace(Graph* graph, string Conditional::name() const { CHECK(!merges_.empty()); - return strings::StrCat((*merges_.begin())->name(), "_if"); -} - -bool CondStateMap::ScopeIn(CondStateMap::CondId id, - CondStateMap::CondId* scope) { - if (id == nullptr) { - *scope = nullptr; - return true; - } - CondState state; - for (const CondNode& node : *id) { - if (node.type == CondNode::Type::kSwitch) { - state.push_back(node); - } - if (node.type == CondNode::Type::kMerge) { - if (state.empty()) { - return false; - } - DCHECK(state.back().type == CondNode::Type::kSwitch && - state.back().branch == BranchType::kBoth); - state.pop_back(); - } - } - *scope = GetUniqueId(state); - return true; + return absl::StrCat((*merges_.begin())->name(), "_if"); } Status FunctionalizeCond::AddIdentityNode(const Node* replacee, Node* if_node, @@ -765,25 +813,35 @@ Status FunctionalizeCond::AddIdentityNode(const Node* replacee, Node* if_node, TF_RETURN_IF_ERROR(NodeBuilder(replacee->name(), "Identity") .Input(if_node, port) .Finalize(graph_, &id)); - cond_state_map_.ResetId(id, cond_state_map_.LookupId(if_node)); + state_map_.ResetCondId(id, state_map_.LookupCondId(if_node)); + state_map_.ResetAncestorId(id, state_map_.LookupAncestorId(if_node)); return Status::OK(); } StatusOr<Node*> FunctionalizeCond::AddIfNode(const NodeDef& def, - const Node* replacee) { + const Node* replacee, + const OutputTensor& predicate) { Status status; Node* ret = graph_->AddNode(def, &status); TF_RETURN_IF_ERROR(status); - CondStateMap::CondState state = cond_state_map_.LookupState(replacee); - state.pop_back(); VLOG(1) << "Adding If for " << replacee->name(); - cond_state_map_.ResetId(ret, cond_state_map_.GetUniqueId(state)); + StateMap::CondId id = state_map_.LookupCondId(replacee); + if (id) { + StateMap::CondState state = *id; + state.erase(predicate); + state_map_.ResetCondId(ret, state_map_.GetCondId(state)); + } else { + state_map_.ResetCondId(ret, nullptr); + } + + state_map_.ResetAncestorId(ret, state_map_.LookupAncestorId(replacee)); + return ret; } Status FunctionalizeCond::PropagateUpdatedState(const Node* replacee) { VLOG(2) << "Propagating update state for " << replacee->name() << " " - << cond_state_map_.CondStateToString(replacee); + << state_map_.CondStateToString(replacee); // Redo topological sort as the order could have changed. // TODO(jpienaar): The original topological order could also be updated // dynamically if needed. @@ -801,10 +859,10 @@ Status FunctionalizeCond::PropagateUpdatedState(const Node* replacee) { if (changed.find(*it) != changed.end()) { // Update the node state. Node* n = *it; - CondStateMap::CondId old_state = cond_state_map_.LookupId(n); - cond_state_map_.ResetId(n, nullptr); + StateMap::CondId old_state = state_map_.LookupCondId(n); + state_map_.ResetCondId(n, nullptr); TF_RETURN_IF_ERROR(DetermineCondState(n)); - if (cond_state_map_.LookupId(n) != old_state) { + if (state_map_.LookupCondId(n) != old_state) { for (auto out : n->out_nodes()) if (out->IsOp()) changed.insert(out); } @@ -825,127 +883,44 @@ BranchType MeetBranch(const BranchType& lhs, const BranchType& rhs) { return BranchType::kNeither; } -CondStateMap::ContainsResult CondStateMap::LhsHoldsWhereverRhsHolds( - CondStateMap::CondId lhs, CondStateMap::CondId rhs) { - CondId lhs_scope; - CondId rhs_scope; - bool could_determine_scope = ScopeIn(lhs, &lhs_scope); - could_determine_scope = could_determine_scope && ScopeIn(rhs, &rhs_scope); - if (!could_determine_scope) return kIncomparable; - - // Returns whether a contains b. - auto contains = [&](CondId a, CondId b) { - // Handle empty states. - if (a == nullptr && b != nullptr) return true; - if (a == nullptr && b == nullptr) return true; - if (a != nullptr && b == nullptr) return false; - - if (a->size() > b->size()) return false; - auto a_it = a->begin(); - auto b_it = b->begin(); - while (a_it != a->end()) { - if (*a_it != *b_it) { - if (!(a_it->predicate == b_it->predicate)) return false; - BranchType mb = MeetBranch(a_it->branch, b_it->branch); - if (mb != b_it->branch) return false; - } - ++a_it; - ++b_it; - } - return true; - }; - - bool lhs_contains_rhs = contains(lhs_scope, rhs_scope); - bool rhs_contains_lhs = contains(rhs_scope, lhs_scope); - if (lhs_contains_rhs && rhs_contains_lhs) return kEqual; - if (lhs_contains_rhs) return kLhsContainsRhs; - if (rhs_contains_lhs) return kRhsContainsLhs; - return kIncomparable; -} - -BranchType CondStateMap::FindBranchOf(CondId id, OutputTensor predicate) const { +BranchType StateMap::FindBranchOf(CondId id, OutputTensor predicate) const { if (IsEmpty(id)) return BranchType::kNeither; - absl::optional<BranchType> b; const CondState& nodes = *id; - for (auto it = nodes.rbegin(); it != nodes.rend(); ++it) { - if (it->type == CondStateMap::CondNode::Type::kSwitch && - it->predicate == predicate) { - if (b.has_value()) { - b = MeetBranch(*b, it->branch); - } else { - b = it->branch; - } - if (*b == BranchType::kNeither) { - LOG(FATAL) << "Inconsistent state for node: " << DebugString(id); - } - } - } - return b.has_value() ? *b : BranchType::kNeither; + auto it = nodes.find(predicate); + if (it == nodes.end()) return BranchType::kNeither; + return it->second; } -StatusOr<CondStateMap::CondId> FunctionalizeCond::JoinCondStatesNonMerge( - CondStateMap::CondId src, CondStateMap::CondId dst) { - VLOG(4) << "Joining src=" << DebugString(src) << " [" << src +StatusOr<StateMap::CondId> FunctionalizeCond::JoinCondStatesNonMerge( + StateMap::CondId src, StateMap::CondId dst) { + VLOG(5) << "Joining src=" << DebugString(src) << " [" << src << "] and dst=" << DebugString(dst) << " [" << dst << "]"; - if (cond_state_map_.IsEmpty(dst) || cond_state_map_.IsDead(src)) return src; - if (cond_state_map_.IsDead(dst)) return dst; + if (state_map_.IsEmpty(dst) || state_map_.IsDead(src)) return src; + if (state_map_.IsDead(dst) || state_map_.IsEmpty(src)) return dst; // Nothing to do if the CondState is the same. if (src == dst) return src; - CondStateMap::CondId src_scope; - CondStateMap::CondId dst_scope; - if (!cond_state_map_.ScopeIn(src, &src_scope)) - return errors::Unimplemented( - "Predicates that must hold for node to execute are invalid! ", - DebugString(src)); - if (!cond_state_map_.ScopeIn(dst, &dst_scope)) - return errors::Unimplemented( - "Predicates that must hold for node to execute are invalid! ", - DebugString(dst)); - - auto result = cond_state_map_.LhsHoldsWhereverRhsHolds(src_scope, dst_scope); - switch (result) { - case CondStateMap::kIncomparable: - return errors::InvalidArgument( - "Graph contains node with inputs predicated on incompatible " - "predicates: ", - DebugString(src), " and ", DebugString(dst)); - case CondStateMap::kEqual: - // If both respect the same predicates, propagate the longer constraint. - if ((src != nullptr && dst == nullptr) || - (src != nullptr && dst != nullptr && src->size() > dst->size())) - return src; - else - return dst; - case CondStateMap::kLhsContainsRhs: - // src contains dst, so dst is already more restrictive. - return dst; - case CondStateMap::kRhsContainsLhs: - // dst contains src, so src is more restrictive. - return src; - } -} - -StatusOr<CondStateMap::CondState::const_iterator> -FindThenElseSwitchForPredicate(const OutputTensor& pred, - CondStateMap::CondId id) { - for (auto it = id->begin(); it != id->end(); ++it) { - // Along every path one there can be only one instance of a then or else - // switch for a given predicate, so return once found. - if (it->type == CondStateMap::CondNode::Type::kSwitch && - it->predicate == pred && - (it->branch == BranchType::kThenBranch || - it->branch == BranchType::kElseBranch)) - return it; + StateMap::CondState both = *src; + for (const auto& kv : *dst) { + auto it = both.find(kv.first); + if (it == both.end()) { + both.insert(kv); + } else { + if (it->second != kv.second) { + return errors::InvalidArgument( + "Graph contains node with inputs predicated on incompatible " + "predicates: ", + DebugString(src), " and ", DebugString(dst)); + } + } } - return errors::Internal("Unable to find then/else branch with predicate ", - DebugString(pred), " for ", DebugString(id)); + return state_map_.GetCondId(both); } -StatusOr<CondStateMap::CondId> FunctionalizeCond::JoinCondStatesMerge( - CondStateMap::CondId src, CondStateMap::CondId dst) { +StatusOr<StateMap::CondId> FunctionalizeCond::JoinCondStatesMerge( + Node* merge, StateMap::CondId src, StateMap::CondId dst) { // Determine the flow state when joining two states for a merge // node. Combining the two states for a merge node is effectively performing a // disjunction of the states along the different input edges. For a merge that @@ -956,91 +931,56 @@ StatusOr<CondStateMap::CondId> FunctionalizeCond::JoinCondStatesMerge( // followed by s(p, both). VLOG(4) << "Joining (for merge) " << DebugString(src) << " and " << DebugString(dst); - if (cond_state_map_.IsEmpty(dst)) return src; - - if (cond_state_map_.IsDead(src)) return src; - if (cond_state_map_.IsDead(dst)) return dst; - - CondStateMap::CondId src_scope; - CondStateMap::CondId dst_scope; - if (!cond_state_map_.ScopeIn(src, &src_scope)) - return errors::Unimplemented( - "Predicates that must hold for node to execute are invalid! ", - DebugString(src)); - if (!cond_state_map_.ScopeIn(dst, &dst_scope)) - return errors::Unimplemented( - "Predicates that must hold for node to execute are invalid! ", - DebugString(dst)); - - TF_RET_CHECK(src_scope != nullptr && dst_scope != nullptr) - << "Illegal merge inputs from outer scope: src=" << DebugString(src) - << " dst=" << DebugString(dst); - auto src_it = src_scope->begin(); - auto dst_it = dst_scope->begin(); - - // Find branch divergent condition. - OutputTensor pred; - while (src_it != src_scope->end() && dst_it != dst_scope->end()) { - if (*src_it != *dst_it) { - VLOG(5) << "Diverges with: " << DebugString(*src_it) << " and " - << DebugString(*dst_it); - if (!(src_it->predicate == dst_it->predicate)) { - return errors::InvalidArgument( - "Unable to find common predicate which holds for one input " - "but not the other of the merge node."); - } - pred = src_it->predicate; - break; - } - ++src_it; - ++dst_it; - } - - if (pred.node == nullptr) - return errors::InvalidArgument("Unable to determine predicate for merge."); - - TF_ASSIGN_OR_RETURN(auto div_src_it, - FindThenElseSwitchForPredicate(pred, src)); - TF_ASSIGN_OR_RETURN(auto div_dst_it, - FindThenElseSwitchForPredicate(pred, dst)); - TF_RET_CHECK(*div_src_it != *div_dst_it); - - CondStateMap::CondState result; - // Populate result with the longest/most restrictive path up to the divergent - // node. For example, if the one input is `[switch(pred:0, then)]` and the - // other is `[switch(pred:0, both), merge, switch(pred:0, else)]` (as created - // in gradient of cond test), then the resultant state here should be - // `[switch(pred:0, both), merge, switch(pred:0, both)]`. - if (std::distance(src->begin(), div_src_it) > - std::distance(dst->begin(), div_dst_it)) { - result.assign(src->begin(), std::next(div_src_it)); + if (state_map_.IsEmpty(dst)) return src; + + if (state_map_.IsDead(src)) return src; + if (state_map_.IsDead(dst)) return dst; + + std::vector<StateMap::CondState::value_type> diff; + StateMap::CondState merged; + std::set_symmetric_difference(src->begin(), src->end(), dst->begin(), + dst->end(), std::back_inserter(diff), + CondStateLess()); + std::set_intersection(src->begin(), src->end(), dst->begin(), dst->end(), + std::inserter(merged, merged.begin()), CondStateLess()); + + // Update mapping from merge node to predicate. + if (diff.size() == 2) { + auto pred = diff[0].first; + bool different_branches = (diff[0].second != diff[1].second) && + (diff[0].second == BranchType::kThenBranch || + diff[0].second == BranchType::kElseBranch) && + (diff[1].second == BranchType::kThenBranch || + diff[1].second == BranchType::kElseBranch); + if (!(pred == diff[1].first) || !different_branches) + return errors::InvalidArgument( + "Unable to determine predicate for merge node"); + merge_to_predicate_[merge] = pred; } else { - result.assign(dst->begin(), std::next(div_dst_it)); + return errors::InvalidArgument( + "Merge of two inputs that differ on more than one predicate ", + DebugString(src), " and ", DebugString(dst)); } - result.back().branch = BranchType::kBoth; - return cond_state_map_.GetUniqueId(result); + + return state_map_.GetCondId(merged); } -CondStateMap::CondId FunctionalizeCond::StateAlongEdge(const Edge* e) { +StateMap::CondId FunctionalizeCond::StateAlongEdge(const Edge* e) { Node* src = e->src(); - CondStateMap::CondId id = cond_state_map_.LookupId(e->src()); - if (IsMerge(src)) { - CondStateMap::CondState state; - if (id != nullptr) state = *id; - state.emplace_back(CondStateMap::CondNode::Type::kMerge); - return cond_state_map_.GetUniqueId(state); - } + StateMap::CondId id = state_map_.LookupCondId(e->src()); + + // Dead nodes only propagate dead state. + if (state_map_.IsDead(id)) return id; + if (IsSwitch(src)) { - CondStateMap::CondState state; + StateMap::CondState state; if (id != nullptr) state = *id; - if (e->IsControlEdge()) { - state.emplace_back(CondStateMap::CondNode::Type::kSwitch, src, - BranchType::kBoth); - } else { - state.emplace_back(CondStateMap::CondNode::Type::kSwitch, src, - BranchType(e->src_output())); + OutputTensor predicate; + TF_CHECK_OK(GetSwitchPredicate(*src, &predicate)); + if (!e->IsControlEdge()) { + state[predicate] = BranchType(e->src_output()); } - return cond_state_map_.GetUniqueId(state); + return state_map_.GetCondId(state); } return id; } @@ -1049,22 +989,21 @@ Status FunctionalizeCond::DetermineCondStateMerge(Node* dst) { // Only Merge nodes with two inputs are supported, but if this is a redundant // merge, then the dead edge may already have been removed (if due to a // switch) and so the input count would be incorrect. - if (cond_state_map_.IsDead(cond_state_map_.LookupId(dst))) - return Status::OK(); + if (state_map_.IsDead(state_map_.LookupCondId(dst))) return Status::OK(); int data_inputs = 0; for (auto e : dst->in_edges()) { Node* src = e->src(); VLOG(5) << "Processing forward flow for merge: " << e->DebugString() << " " - << cond_state_map_.CondStateToString(src); + << state_map_.CondStateToString(src); if (!src->IsOp()) continue; if (!e->IsControlEdge()) ++data_inputs; - CondStateMap::CondId prop = StateAlongEdge(e); - auto id_or = JoinCondStatesMerge(prop, cond_state_map_.LookupId(dst)); + StateMap::CondId prop = StateAlongEdge(e); + auto id_or = JoinCondStatesMerge(dst, prop, state_map_.LookupCondId(dst)); TF_RETURN_WITH_CONTEXT_IF_ERROR(id_or.status(), "for node ", FormatNodeForError(*dst)); - cond_state_map_.ResetId(dst, id_or.ValueOrDie()); + state_map_.ResetCondId(dst, id_or.ValueOrDie()); } // Incomplete Merge nodes are not supported. @@ -1076,27 +1015,20 @@ Status FunctionalizeCond::DetermineCondStateMerge(Node* dst) { return Status::OK(); } -Status FunctionalizeCond::DetermineCondState(Node* dst) { - // The logic for the merge and non-merge case differ: for non-merge it is - // the most restrictive CondState, while for merge nodes the - // resultant state is less restrictive than either. - if (IsMerge(dst)) { - TF_RETURN_IF_ERROR(DetermineCondStateMerge(dst)); - } else { - // Handle non-merge join. - for (auto e : dst->in_edges()) { - VLOG(5) << "Processing forward flow for: " << e->DebugString() << " " - << cond_state_map_.CondStateToString(dst); - Node* src = e->src(); - if (!src->IsOp()) continue; - - // Joining the state between the current and propagated state. - CondStateMap::CondId prop = StateAlongEdge(e); - auto id_or = JoinCondStatesNonMerge(prop, cond_state_map_.LookupId(dst)); - TF_RETURN_WITH_CONTEXT_IF_ERROR(id_or.status(), "for node ", - FormatNodeForError(*dst)); - cond_state_map_.ResetId(dst, id_or.ValueOrDie()); - } +Status FunctionalizeCond::DetermineCondStateNonMerge(Node* dst) { + // Handle non-merge join. + for (auto e : dst->in_edges()) { + VLOG(4) << "Processing forward flow for: " << e->DebugString() << " " + << state_map_.CondStateToString(dst); + Node* src = e->src(); + if (!src->IsOp()) continue; + + // Joining the state between the current and propagated state. + StateMap::CondId prop = StateAlongEdge(e); + auto id_or = JoinCondStatesNonMerge(prop, state_map_.LookupCondId(dst)); + TF_RETURN_WITH_CONTEXT_IF_ERROR(id_or.status(), "for node ", + FormatNodeForError(*dst)); + state_map_.ResetCondId(dst, id_or.ValueOrDie()); } return Status::OK(); } @@ -1104,8 +1036,7 @@ Status FunctionalizeCond::DetermineCondState(Node* dst) { Status FunctionalizeCond::RemoveRedundantMerge(Node* node) { // Handle redundant merge nodes. A merge node is considered redundant if // one input edge is dead while the other has a value. - if (!cond_state_map_.IsDead(cond_state_map_.LookupId(node))) - return Status::OK(); + if (!state_map_.IsDead(state_map_.LookupCondId(node))) return Status::OK(); const Edge* non_dead_edge = nullptr; for (auto e : node->in_edges()) { @@ -1113,8 +1044,8 @@ Status FunctionalizeCond::RemoveRedundantMerge(Node* node) { Node* src = e->src(); // Handle merge with dead state. - const auto& src_id = cond_state_map_.LookupId(src); - if (!cond_state_map_.IsDead(src_id)) { + const auto& src_id = state_map_.LookupCondId(src); + if (!state_map_.IsDead(src_id)) { non_dead_edge = e; break; } @@ -1124,7 +1055,7 @@ Status FunctionalizeCond::RemoveRedundantMerge(Node* node) { return errors::InvalidArgument("Merge node ", FormatNodeForError(*node), " has no non-dead inputs."); } - cond_state_map_.MarkDead(node); + state_map_.MarkDead(node); delete_nodes_.push_back(node->id()); VLOG(5) << "removing redundant merge: " << node->name(); while (!node->out_edges().empty()) { @@ -1149,16 +1080,33 @@ Status FunctionalizeCond::RemoveRedundantSwitch(Node* node) { // along one. The checking of predicate is based on the exact predicate // (rather than boolean equivalence) and aimed at redundant switches as // currently generated by gradient code. + StateMap::CondId dst_id = state_map_.LookupCondId(node); + if (state_map_.IsDead(dst_id)) return Status::OK(); + + BranchType b; OutputTensor pred; TF_RETURN_IF_ERROR(GetSwitchPredicate(*node, &pred)); - auto dst_id = cond_state_map_.LookupId(node); - BranchType b = cond_state_map_.FindBranchOf(dst_id, pred); + // Determine if we are already on a branch where the switch predicate is - // true/false. - if (b != BranchType::kThenBranch && b != BranchType::kElseBranch) - return Status::OK(); + // true/false. Consider both the data and predicate to determine if the + // node is redundant (skipping over identity node). + b = state_map_.FindBranchOf(dst_id, pred); + if (b != BranchType::kThenBranch && b != BranchType::kElseBranch) { + OutputTensor val; + const Edge* e; + TF_RETURN_IF_ERROR(node->input_edge(0, &e)); + val = OutputTensor(e->src(), e->src_output()); + while (IsIdentity(val.node)) { + TF_RETURN_IF_ERROR(val.node->input_edge(0, &e)); + val = OutputTensor(e->src(), e->src_output()); + } + b = state_map_.FindBranchOf(dst_id, val); + if (b != BranchType::kThenBranch && b != BranchType::kElseBranch) + return Status::OK(); + } - VLOG(5) << "Redundant switch " << node->name(); + VLOG(5) << "Redundant switch " << node->name() << " " << Branch_Name(b) << " " + << DebugString(dst_id); const Edge* value_edge; TF_RETURN_IF_ERROR(node->input_edge(0, &value_edge)); Node* val_node = value_edge->src(); @@ -1171,19 +1119,19 @@ Status FunctionalizeCond::RemoveRedundantSwitch(Node* node) { graph_->RemoveEdge(e); if (switch_branch == Graph::kControlSlot) { if (IsMerge(dst_node)) { - auto id_or = - JoinCondStatesMerge(dst_id, cond_state_map_.LookupId(dst_node)); + auto id_or = JoinCondStatesMerge(dst_node, dst_id, + state_map_.LookupCondId(dst_node)); TF_RETURN_WITH_CONTEXT_IF_ERROR(id_or.status(), "for node ", FormatNodeForError(*dst_node)); - cond_state_map_.ResetId(dst_node, id_or.ValueOrDie()); + state_map_.ResetCondId(dst_node, id_or.ValueOrDie()); } else { auto id_or = - JoinCondStatesNonMerge(dst_id, cond_state_map_.LookupId(dst_node)); + JoinCondStatesNonMerge(dst_id, state_map_.LookupCondId(dst_node)); TF_RETURN_IF_ERROR(id_or.status()); - cond_state_map_.ResetId(dst_node, id_or.ValueOrDie()); + state_map_.ResetCondId(dst_node, id_or.ValueOrDie()); } } else if (BranchType(switch_branch) != b) { - cond_state_map_.MarkDead(dst_node); + state_map_.MarkDead(dst_node); delete_nodes_.push_back(dst_node->id()); continue; } @@ -1195,17 +1143,44 @@ Status FunctionalizeCond::RemoveRedundantSwitch(Node* node) { return Status::OK(); } -Status FunctionalizeCond::DetermineCondStates( - std::vector<Node*> rev_topo_order) { +Status FunctionalizeCond::DetermineStates(std::vector<Node*> rev_topo_order) { // The state that is propagated along the given edge. for (auto it = rev_topo_order.rbegin(); it != rev_topo_order.rend(); ++it) { Node* dst = *it; TF_RETURN_IF_ERROR(DetermineCondState(dst)); + TF_RETURN_IF_ERROR(DetermineAncestorState(dst)); if (IsSwitch(dst)) TF_RETURN_IF_ERROR(RemoveRedundantSwitch(dst)); if (IsMerge(dst)) TF_RETURN_IF_ERROR(RemoveRedundantMerge(dst)); - VLOG(5) << dst->name() << " :: " << cond_state_map_.CondStateToString(dst); + VLOG(5) << dst->name() << " :: " << state_map_.CondStateToString(dst) + << " @ " << state_map_.AncestorStateToString(dst); + if (VLOG_IS_ON(10)) DumpGraphWithCondState("cond_it"); + } + return Status::OK(); +} + +Status FunctionalizeCond::DetermineAncestorState(Node* dst) { + StateMap::AncestorId id = nullptr; + StateMap::AncestorState state; + + auto insert = [&](StateMap::AncestorId id, Node* src) { + auto other_id = state_map_.LookupAncestorId(src); + if (other_id != id && other_id != nullptr) { + state.insert(other_id->begin(), other_id->end()); + } + if (IsSwitch(src) || IsMerge(src)) { + state.insert(src); + } + return state_map_.GetAncestorId(state); + }; + + // Compute the union of all the switch/merge nodes that affects the input of + // dst. + for (auto e : dst->in_edges()) { + Node* src = e->src(); + id = insert(id, src); } + state_map_.ResetAncestorId(dst, id); return Status::OK(); } @@ -1239,16 +1214,8 @@ void FunctionalizeCond::SortMergeNodes(std::vector<Node*>* merge_order) { inner_to_outer_merge_order.reserve(merge_order->size()); for (auto it = merge_order->rbegin(); it != merge_order->rend(); ++it) { Node* merge = *it; - CondStateMap::CondId id = cond_state_map_.LookupId(merge); - int depth = 0; - for (auto cond_node_it = id->begin(); cond_node_it != id->end(); - ++cond_node_it) { - if (cond_node_it->type == CondStateMap::CondNode::Type::kSwitch && - (cond_node_it->branch == BranchType::kThenBranch || - cond_node_it->branch == BranchType::kElseBranch)) { - ++depth; - } - } + StateMap::CondId id = state_map_.LookupCondId(merge); + int depth = id != nullptr ? id->size() : 0; inner_to_outer_merge_order.emplace_back(depth, merge); } std::stable_sort( @@ -1271,10 +1238,10 @@ Status FunctionalizeCond::FunctionalizeInternal() { // determine deeper equivalence). We shall refer to this structure as the // CondState; // 3. Sort the merge nodes by nesting depth; - // 4. Extract merge nodes together that have the same CondState and whose - // input nodes have the same state from the innermost to the outermost into - // IfOps; Note: In the above only nodes paths that converge to a merge node - // will be considered for removal. + // 4. Extract merge nodes together that have the same CondState and + // AncestorState from the innermost to the outermost into IfOps; + // Note: In the above only nodes that feed into a merge node will be + // considered for functionalization. // Perform a DFS over the graph and // * Determine the reverse topological order of the nodes (there should be no @@ -1306,40 +1273,40 @@ Status FunctionalizeCond::FunctionalizeInternal() { return Status::OK(); } - TF_RETURN_IF_ERROR(DetermineCondStates(std::move(rev_topo_order))); - + TF_RETURN_IF_ERROR(DetermineStates(std::move(rev_topo_order))); if (VLOG_IS_ON(4)) DumpGraphWithCondState("cond_id"); // Sort the merge nodes from innermost outwards. SortMergeNodes(&merge_order); - // Extract from innermost out. - for (auto it = merge_order.begin(); it != merge_order.end(); ++it) { - Node* merge = *it; - auto id = cond_state_map_.LookupId(merge); - if (cond_state_map_.IsDead(id)) continue; - - // Construct a Conditional with the predicate of the merge (which is the - // last entry of the CondState for the merge) and this as parent. - DCHECK(id->back().predicate.node != nullptr); - Conditional cond(id->back().predicate, this, &cond_state_map_); - TF_RETURN_IF_ERROR(cond.AddMerge(merge)); - - // Find all merge nodes with the same CondId. This is done repeatedly as - // the CondId can change due replaced conditionals. E.g., the one branch - // could previously have had a conditional nested in it, and so would have - // had CondState with sub-state [switch(p,b),m] (where p is some predicate), - // post removing the nested conditional that sub-state would no longer be - // path of the propagated state along that path. - auto end = merge_order.end(); - for (auto merge_candidate_it = std::next(it); merge_candidate_it != end; - ++merge_candidate_it) { - auto merge_candidate_it_id = - cond_state_map_.LookupId(*merge_candidate_it); - if (merge_candidate_it_id != id) continue; - TF_RETURN_IF_ERROR(cond.AddMerge(*merge_candidate_it)); + // Cluster merge nodes by CondId and AncestorId in order of nesting. + using ClusterPair = std::pair<StateMap::CondId, StateMap::AncestorId>; + std::deque<std::vector<Node*>> merge_clusters; + std::map<ClusterPair, int> merge_cluster_index; + for (Node* merge : merge_order) { + auto cond_id = state_map_.LookupCondId(merge); + if (state_map_.IsDead(cond_id)) continue; + + ClusterPair key = + std::make_pair(cond_id, state_map_.LookupAncestorId(merge)); + auto idx = merge_cluster_index.find(key); + if (idx == merge_cluster_index.end()) { + merge_cluster_index[key] = merge_clusters.size(); + merge_clusters.push_back({merge}); + } else { + merge_clusters[idx->second].emplace_back(merge); } + } + // Extract the conditionals from inner most to outer most. Extracting from + // innermost to outermost enables the extraction pass to stop once it + // encounters a Switch node instead of having to keep track of Switch/Merge + // nodes seen. + for (const auto& cluster : merge_clusters) { + // Construct a Conditional with the predicate of the merge. + Conditional cond(merge_to_predicate_.at(cluster.front()), this, + &state_map_); + for (Node* merge : cluster) TF_RETURN_IF_ERROR(cond.AddMerge(merge)); TF_RETURN_IF_ERROR(cond.BuildAndReplace(graph_, library_)); if (VLOG_IS_ON(4)) DumpGraphWithCondState("after_extract"); @@ -1359,11 +1326,13 @@ void FunctionalizeCond::DumpGraphWithCondState(const string& name) { for (Node* n : graph_->nodes()) { n->ClearAttr(kCondGroupDebugAttr); - n->AddAttr(kCondGroupDebugAttr, cond_state_map_.CondStateToString(n)); + n->AddAttr(kCondGroupDebugAttr, + absl::StrCat(state_map_.CondStateToString(n), "_", + state_map_.AncestorStateToString(n))); } LOG(INFO) << "FunctionalizeControlFlow (" << name << "): " - << dump_graph::DumpGraphToFile( - strings::StrCat("functionalize_", name), *graph_, library_); + << dump_graph::DumpGraphToFile(absl::StrCat("functionalize_", name), + *graph_, library_); } Status FunctionalizeCond::Functionalize(Graph* graph, diff --git a/tensorflow/compiler/tf2xla/functionalize_cond.h b/tensorflow/compiler/tf2xla/functionalize_cond.h index 86436011c6..28301150ea 100644 --- a/tensorflow/compiler/tf2xla/functionalize_cond.h +++ b/tensorflow/compiler/tf2xla/functionalize_cond.h @@ -43,105 +43,88 @@ enum class BranchType { kNeither = 3, }; -// CondStateMap is responsible for mapping from each graph Node to a CondState, -// where each CondState is the array of CondNodes (corresponding to switch, -// merge or dead states) as described below. For efficiency, this class interns -// the CondState, so that CondState equality comparisons are simply pointer +// StateMap is responsible for mapping from each graph Node to +// * a CondState, where each CondState is a map from predicate to branch (i,e., +// what predicates have to hold or not hold). +// * a AncestorState, where each AncestorState is a set of switch/merge nodes +// that are an ancestor of the node in the graph; +// For efficiency, this class interns the CondState (AncestorState), so that +// CondState (AncestorState) equality comparisons are simply pointer // comparisons. -class CondStateMap { +class StateMap { public: - explicit CondStateMap(Graph* graph); - - // Represents an entry in the CondState. An entry can either be the - // switch (along with predicate), merge, or dead: - // * switch node indicates a node that is executed along a branch with the - // given predicate - a branch can be then, else or both; - // * merge node indicates that the node is executed as output of a merge; - // * dead indicates that this node can never be executed; - struct CondNode { - enum class Type { kSwitch = 1, kMerge = 2, kDead = 3 }; - - CondNode(Type type, Node* switch_node = nullptr, - BranchType branch = BranchType::kNeither); - - string ToString() const; - bool operator==(const CondNode& other) const; - bool operator!=(const CondNode& other) const; - - // Type of node. - Type type; - - // Predicate and branch, only used when type is kSwitch. - OutputTensor predicate; - BranchType branch; + explicit StateMap(Graph* graph); + + // Compare two OutputTensors by (node id, index). + struct OutputTensorLess { + bool operator()(const OutputTensor& lhs, const OutputTensor& rhs) const; }; - // A node in the graph is executed when multiple conditions hold. The order - // represents the nesting of the predicates that hold and is used when - // extracting the nested conditionals. - using CondState = std::vector<CondNode>; + // A node in the graph is executed when multiple conditions hold. Keep track + // of the predicates that must hold for a node to execute. + using CondState = std::map<OutputTensor, BranchType, OutputTensorLess>; // Every unique ID is mapped to a CondState. using CondId = const CondState*; + // Keep track of which switch/merge node's feed into a node's values. + using AncestorState = std::set<Node*>; + + // Every unique ID is mapped to a AncestorState. + using AncestorId = const AncestorState*; + // Returns the CondId for a given node. - CondId LookupId(const Node* node) const; + CondId LookupCondId(const Node* node) const; // Returns the unique CondId for CondState. - CondId GetUniqueId(const CondState& state); + CondId GetCondId(const CondState& state); + + // Resets the CondId for a given node. + void ResetCondId(const Node* node, CondId id); + + // Returns the AncestorId for a given node. + AncestorId LookupAncestorId(const Node* node) const; + + // Returns the unique AncestorId for CondState. + AncestorId GetAncestorId(const AncestorState& state); + + // Resets the AncestorId for a given node. + void ResetAncestorId(const Node* node, AncestorId id); // Returns the CondState for a Node. // REQUIRES: node has a non-empty CondState. const CondState& LookupState(const Node* node) const; - // Resets the CondId for a given node. - void ResetId(const Node* node, CondId id); - // Marks `node` as dead. void MarkDead(const Node* node); // Determine branch execution of CondState. BranchType FindBranchOf(CondId id, OutputTensor predicate) const; - // Enum to represent whether one cond flow state contains another. - enum ContainsResult { - kIncomparable, - kEqual, - kLhsContainsRhs, - kRhsContainsLhs - }; - - // Returns whether the lhs CondState holds wherever rhs CondState hols. I.e., - // [(p,t)] contains [(p,t), (r,t)]. - ContainsResult LhsHoldsWhereverRhsHolds(CondId lhs, CondId rhs); - // Returns textual representation of node's CondState. string CondStateToString(const Node* node) const; string CondStateToString(CondId id) const; + // Returns textual representation of node's AncestorState. + string AncestorStateToString(const Node* node) const; + // Returns whether the cond state is the dead state. bool IsDead(CondId id) const; // Returns whether the cond state is the empty state. bool IsEmpty(CondId id) const; - // Computes the predicates that have to hold for a node to execute and returns - // whether it was possible to determine the predicates that must hold. `scope` - // is populated with these predicates. Scope differs from state in that it - // does not include merge and both nodes. - bool ScopeIn(CondId id, CondId* scope); - private: - // Hash for CondNode and CondState. - struct CondHash { - size_t operator()(const CondNode& item) const; - size_t operator()(const CondState& vec) const; + // Hash for CondState and AncestorState. + struct Hash { + size_t operator()(const CondState& map) const; + size_t operator()(const AncestorState& map) const; }; // Set to keep track of unique CondStates. // Pointers to the entries in the unordered set are used as identifiers: // unordered_set guarantees that the pointers remain the same. - std::unordered_set<CondState, CondHash> condstate_set_; + std::unordered_set<CondState, Hash> condstate_set_; // Mapping from Node id to CondId. std::vector<CondId> node_to_condid_map_; @@ -150,7 +133,12 @@ class CondStateMap { // from Node id in the original graph to the CondId, but there will be nodes // added to the original graph (such as If nodes) whose CondState needs to be // tracked too. - std::unordered_map<int, CondId> added_node_mapping_; + std::unordered_map<int, CondId> added_node_condid_mapping_; + + // AncestorId variants of the CondId members. + std::unordered_set<AncestorState, Hash> ancestorstate_set_; + std::vector<AncestorId> node_to_ancestorid_map_; + std::unordered_map<int, AncestorId> added_node_ancestorid_mapping_; // Identifier of the dead flow state. The empty flow state is represented with // a nullptr. @@ -173,7 +161,8 @@ class FunctionalizeCond { // Add a If node to the graph defined by def that will, amongst other, replace // replacee in the graph. - xla::StatusOr<Node*> AddIfNode(const NodeDef& def, const Node* replacee); + xla::StatusOr<Node*> AddIfNode(const NodeDef& def, const Node* replacee, + const OutputTensor& predicate); // Propagates the state of a newly inserted node. Status PropagateUpdatedState(const Node* replacee); @@ -185,35 +174,42 @@ class FunctionalizeCond { FunctionalizeCond(Graph* graph, FunctionLibraryDefinition* library); // Performs the actual cond functionalization. Iterate over groups of merge - // nodes (linked by common predicate & CondIds of the incomming edges), - // from innermost to outermost, and extract into If nodes. + // nodes (linked by common predicates & ancestor IDs), from innermost to + // outermost, and extract into If nodes. Status FunctionalizeInternal(); // Returns the forward flow state propagated along edge `e`. - // This may modify cond_state_map_. - CondStateMap::CondId StateAlongEdge(const Edge* e); + // This may modify state_map_. + StateMap::CondId StateAlongEdge(const Edge* e); - // Determines the CondState of all the nodes in the given vector where - // the input is expected in reverse topological order. - // This populates the cond_state_map_. - Status DetermineCondStates(std::vector<Node*> rev_topo_order); + // Determines the CondState and AncestorState of all the nodes in the given + // vector where the input is expected in reverse topological order. + // This populates the state_map_. + Status DetermineStates(std::vector<Node*> rev_topo_order); // Determine the CondState for a given node using the incomming edges // to the node. Note: it is expected that this node's CondState is only // determined once its input's CondState is. - Status DetermineCondState(Node* dst); + Status DetermineCondState(Node* dst) { + if (IsMerge(dst)) return DetermineCondStateMerge(dst); + return DetermineCondStateNonMerge(dst); + } // Helper functions for DetermineCondState. + Status DetermineCondStateNonMerge(Node* dst); Status DetermineCondStateMerge(Node* dst); - // Helper functions for DetermineCondStates. Determines the dst node's - // CondState by joining the src and dst's CondState where either - // the dst node is a merge or not. - // These may modify cond_state_map_. - xla::StatusOr<CondStateMap::CondId> JoinCondStatesMerge( - CondStateMap::CondId src, CondStateMap::CondId dst); - xla::StatusOr<CondStateMap::CondId> JoinCondStatesNonMerge( - CondStateMap::CondId src, CondStateMap::CondId dst); + // Determines the dst node's CondState by joining the src and dst's CondState + // where either the dst node is a merge or not. + // These may modify state_map_. + xla::StatusOr<StateMap::CondId> JoinCondStatesMerge(Node* merge, + StateMap::CondId src, + StateMap::CondId dst); + xla::StatusOr<StateMap::CondId> JoinCondStatesNonMerge(StateMap::CondId src, + StateMap::CondId dst); + + // Determines which switch/merge nodes are ancestors of this node. + Status DetermineAncestorState(Node* dst); // Checks if a merge node is redundant and if so removes it from the graph. Status RemoveRedundantMerge(Node* node); @@ -228,9 +224,13 @@ class FunctionalizeCond { // Deletes all nodes in/consumers of `delete_nodes_`. void DeleteReachableNodes(); - // Member used to unique the CondState to a unique CondId and keep track of - // CondState/CondId per Node. - CondStateMap cond_state_map_; + // Member used to unique the CondState to a unique CondId (AncestorState to a + // unique AncestorId) and keep track of CondState/CondId + // (AncestorState/AncestorId) per Node. + StateMap state_map_; + + // Mapping from merge nodes to predicate. + std::unordered_map<Node*, OutputTensor> merge_to_predicate_; // Nodes to be deleted. std::deque<int> delete_nodes_; diff --git a/tensorflow/compiler/tf2xla/functionalize_cond_test.cc b/tensorflow/compiler/tf2xla/functionalize_cond_test.cc index a27f889392..b0aabd63bb 100644 --- a/tensorflow/compiler/tf2xla/functionalize_cond_test.cc +++ b/tensorflow/compiler/tf2xla/functionalize_cond_test.cc @@ -37,28 +37,23 @@ class FunctionalizeCondTest : public ::testing::Test { flib_def_.get())); } - CondStateMap::CondId GetUniqueId( - const CondStateMap::CondStateMap::CondState& state) { - return fc_->cond_state_map_.GetUniqueId(state); + StateMap::CondId GetUniqueId(const StateMap::StateMap::CondState& state) { + return fc_->state_map_.GetCondId(state); } - xla::StatusOr<CondStateMap::CondId> JoinCondStatesNonMerge( - CondStateMap::CondId src, CondStateMap::CondId dst) { - return fc_->JoinCondStatesNonMerge(src, dst); - } - - xla::StatusOr<CondStateMap::CondId> JoinCondStatesMerge( - CondStateMap::CondId src, CondStateMap::CondId dst) { - return fc_->JoinCondStatesMerge(src, dst); + string GetString(const StateMap::StateMap::CondId id) { + return fc_->state_map_.CondStateToString(id); } - bool ScopeIn(CondStateMap::CondId ff, CondStateMap::CondId* scope) { - return fc_->cond_state_map_.ScopeIn(ff, scope); + xla::StatusOr<StateMap::CondId> JoinCondStatesNonMerge(StateMap::CondId src, + StateMap::CondId dst) { + return fc_->JoinCondStatesNonMerge(src, dst); } - CondStateMap::ContainsResult LhsHoldsWhereverRhsHolds( - CondStateMap::CondId lhs, CondStateMap::CondId rhs) { - return fc_->cond_state_map_.LhsHoldsWhereverRhsHolds(lhs, rhs); + xla::StatusOr<StateMap::CondId> JoinCondStatesMerge(Node* n, + StateMap::CondId src, + StateMap::CondId dst) { + return fc_->JoinCondStatesMerge(n, src, dst); } FunctionDefLibrary fdef_lib_; @@ -69,50 +64,6 @@ class FunctionalizeCondTest : public ::testing::Test { namespace { -TEST_F(FunctionalizeCondTest, ScopeIn) { - Tensor pred_tensor(DT_BOOL, TensorShape()); - pred_tensor.flat<bool>().setZero(); - Node* pred = test::graph::Constant(graph_.get(), pred_tensor, "pred"); - Tensor val_tensor(DT_INT32, TensorShape()); - val_tensor.flat<int>().setZero(); - Node* val = test::graph::Constant(graph_.get(), val_tensor, "val"); - Node* s = test::graph::Switch(graph_.get(), val, pred); - - { - CondStateMap::CondStateMap::CondState ss; - ss.emplace_back(CondStateMap::CondNode( - CondStateMap::CondNode::Type::kSwitch, s, BranchType::kThenBranch)); - CondStateMap::CondId id = GetUniqueId(ss); - CondStateMap::CondId scope; - ASSERT_TRUE(ScopeIn(id, &scope)); - ASSERT_TRUE(id == scope); - } - - CondStateMap::CondState empty; - { - CondStateMap::CondState ss; - ss.emplace_back(CondStateMap::CondNode( - CondStateMap::CondNode::Type::kSwitch, s, BranchType::kBoth)); - ss.emplace_back( - CondStateMap::CondNode(CondStateMap::CondNode::Type::kMerge)); - CondStateMap::CondId id = GetUniqueId(ss); - CondStateMap::CondId scope_1; - ASSERT_TRUE(ScopeIn(id, &scope_1)); - ASSERT_TRUE(scope_1 == GetUniqueId(empty)); - ASSERT_TRUE(id != scope_1); - - ss.clear(); - ss.emplace_back(CondStateMap::CondNode( - CondStateMap::CondNode::Type::kSwitch, s, BranchType::kBoth)); - id = GetUniqueId(ss); - CondStateMap::CondId scope_2; - ASSERT_TRUE(ScopeIn(id, &scope_2)); - - ASSERT_TRUE(LhsHoldsWhereverRhsHolds(scope_1, scope_2) == - CondStateMap::ContainsResult::kLhsContainsRhs); - } -} - TEST_F(FunctionalizeCondTest, JoinCondStates) { Tensor pred_tensor(DT_BOOL, TensorShape()); pred_tensor.flat<bool>().setZero(); @@ -120,22 +71,18 @@ TEST_F(FunctionalizeCondTest, JoinCondStates) { Tensor val_tensor(DT_INT32, TensorShape()); val_tensor.flat<int>().setZero(); Node* val = test::graph::Constant(graph_.get(), val_tensor, "val"); - Node* s = test::graph::Switch(graph_.get(), val, pred); + Node* m = test::graph::Merge(graph_.get(), val, val); - CondStateMap::CondId empty = GetUniqueId({}); - - CondStateMap::CondId then_branch; + StateMap::CondId then_branch; { - CondStateMap::CondState ss; - ss.emplace_back(CondStateMap::CondNode( - CondStateMap::CondNode::Type::kSwitch, s, BranchType::kThenBranch)); + StateMap::CondState ss; + ss.insert(std::make_pair(OutputTensor(pred, 0), BranchType::kThenBranch)); then_branch = GetUniqueId(ss); } - CondStateMap::CondId else_branch; + StateMap::CondId else_branch; { - CondStateMap::CondState ss; - ss.emplace_back(CondStateMap::CondNode( - CondStateMap::CondNode::Type::kSwitch, s, BranchType::kElseBranch)); + StateMap::CondState ss; + ss.insert(std::make_pair(OutputTensor(pred, 0), BranchType::kElseBranch)); else_branch = GetUniqueId(ss); } @@ -144,39 +91,14 @@ TEST_F(FunctionalizeCondTest, JoinCondStates) { EXPECT_TRUE(errors::IsInvalidArgument(status)); // Merge between then and else branch. - auto joined_or = JoinCondStatesMerge(then_branch, else_branch); + auto joined_or = JoinCondStatesMerge(m, then_branch, else_branch); TF_EXPECT_OK(joined_or.status()); - CondStateMap::CondId joined = joined_or.ValueOrDie(); + StateMap::CondId joined = joined_or.ValueOrDie(); // Merge between then branch and both branch. auto t = JoinCondStatesNonMerge(then_branch, joined); // Note: this is OK in terms of constraint predication, but TF_EXPECT_OK(t.status()); - - // Post merge the propagated forward flow state has an additional merge. - CondStateMap::CondId post_merge; - { - CondStateMap::CondState ss; - ss = *joined; - ss.emplace_back( - CondStateMap::CondNode(CondStateMap::CondNode::Type::kMerge)); - post_merge = GetUniqueId(ss); - } - - t = JoinCondStatesNonMerge(post_merge, joined); - TF_EXPECT_OK(t.status()); - EXPECT_TRUE(joined == t.ValueOrDie()); - - // No predicate that results in two paths predicated on different conditions - // merge. - t = JoinCondStatesMerge(post_merge, joined); - EXPECT_FALSE(t.ok()); - - // Post the merge we are effectively in the root scope and merging should - // result in the more restrictive post merge state. - t = JoinCondStatesNonMerge(post_merge, empty); - TF_EXPECT_OK(t.status()); - EXPECT_TRUE(post_merge == t.ValueOrDie()); } } // namespace diff --git a/tensorflow/compiler/tf2xla/functionalize_control_flow_util.cc b/tensorflow/compiler/tf2xla/functionalize_control_flow_util.cc index 924fcdd9cd..54cebc6177 100644 --- a/tensorflow/compiler/tf2xla/functionalize_control_flow_util.cc +++ b/tensorflow/compiler/tf2xla/functionalize_control_flow_util.cc @@ -42,7 +42,7 @@ xla::StatusOr<Node*> BuildRetvalNode(Graph* graph, DataType type, int index) { const char* const kRetValOp = "_Retval"; NodeDef ret_def; ret_def.set_op(kRetValOp); - ret_def.set_name(strings::StrCat(kRetValOp, index)); + ret_def.set_name(absl::StrCat(kRetValOp, index)); AddNodeAttr("T", type, &ret_def); AddNodeAttr("index", index, &ret_def); return AddNodeDefToGraph(ret_def, graph); diff --git a/tensorflow/compiler/tf2xla/functionalize_control_flow_util.h b/tensorflow/compiler/tf2xla/functionalize_control_flow_util.h index 61940e3586..582b49d511 100644 --- a/tensorflow/compiler/tf2xla/functionalize_control_flow_util.h +++ b/tensorflow/compiler/tf2xla/functionalize_control_flow_util.h @@ -43,13 +43,12 @@ xla::StatusOr<Node*> BuildRetvalNode(Graph* graph, DataType type, int index); // Returns a textual representation of the names of the nodes in the input. template <typename T> string NodesToString(const T& nodes) { - return strings::StrCat("{", - absl::StrJoin(nodes, ",", - [](string* output, const Node* node) { - strings::StrAppend(output, - node->name()); - }), - "}"); + return absl::StrCat("{", + absl::StrJoin(nodes, ",", + [](string* output, const Node* node) { + absl::StrAppend(output, node->name()); + }), + "}"); } } // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/functionalize_while.cc b/tensorflow/compiler/tf2xla/functionalize_while.cc index 6e3c4b0e0f..7f45e3bffa 100644 --- a/tensorflow/compiler/tf2xla/functionalize_while.cc +++ b/tensorflow/compiler/tf2xla/functionalize_while.cc @@ -132,7 +132,7 @@ Status CopySubgraph(const Graph& graph, const Frame* frame, StatusOr<Node*> BuildArgNode(Graph* graph, DataType type, int index) { const char* const kArgOp = "_Arg"; NodeDef arg_def; - NodeDefBuilder builder(strings::StrCat(kArgOp, index), kArgOp); + NodeDefBuilder builder(absl::StrCat(kArgOp, index), kArgOp); builder.Attr("T", type); builder.Attr("index", index); TF_RETURN_IF_ERROR(builder.Finalize(&arg_def)); @@ -487,9 +487,9 @@ Status FunctionalizeLoop(const FunctionLibraryDefinition* lookup_library, static std::atomic<int64> sequence_num(0LL); int64 id = ++sequence_num; NameAttrList cond_name; - cond_name.set_name(strings::StrCat("_functionalize_cond_", id)); + cond_name.set_name(absl::StrCat("_functionalize_cond_", id)); NameAttrList body_name; - body_name.set_name(strings::StrCat("_functionalize_body_", id)); + body_name.set_name(absl::StrCat("_functionalize_body_", id)); FunctionDef cond_fdef; TF_RETURN_IF_ERROR( GraphToFunctionDef(*cond_graph, cond_name.name(), &cond_fdef)); diff --git a/tensorflow/compiler/tf2xla/graph_compiler.cc b/tensorflow/compiler/tf2xla/graph_compiler.cc index 1ed1fb3b02..bc2e640559 100644 --- a/tensorflow/compiler/tf2xla/graph_compiler.cc +++ b/tensorflow/compiler/tf2xla/graph_compiler.cc @@ -127,7 +127,7 @@ Status GraphCompiler::Compile() { TF_RET_CHECK(!n->IsRecv() && !n->IsSend() && !n->IsSwitch()) << "Not supported node: " << n->DebugString(); params.op_kernel = op_kernel.get(); - gtl::InlinedVector<AllocatorAttributes, 4> output_attr(n->num_outputs()); + absl::InlinedVector<AllocatorAttributes, 4> output_attr(n->num_outputs()); params.output_attr_array = output_attr.data(); // tensor_inputs_ is a buffer reused across graph traversal. We clean up and diff --git a/tensorflow/compiler/tf2xla/graph_compiler.h b/tensorflow/compiler/tf2xla/graph_compiler.h index 127562eb23..ab7cac7100 100644 --- a/tensorflow/compiler/tf2xla/graph_compiler.h +++ b/tensorflow/compiler/tf2xla/graph_compiler.h @@ -89,7 +89,7 @@ class GraphCompiler { ScopedStepContainer* step_container_; // A buffer to hold tensor inputs to a node, this is reused across the graph // traversal. - gtl::InlinedVector<TensorValue, 4> tensor_inputs_; + absl::InlinedVector<TensorValue, 4> tensor_inputs_; }; } // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/kernels/batchtospace_op.cc b/tensorflow/compiler/tf2xla/kernels/batchtospace_op.cc index edced6bc0e..a18e04995b 100644 --- a/tensorflow/compiler/tf2xla/kernels/batchtospace_op.cc +++ b/tensorflow/compiler/tf2xla/kernels/batchtospace_op.cc @@ -26,7 +26,7 @@ void BatchToSpace(XlaOpKernelContext* ctx, const xla::XlaOp& input, absl::Span<const int64> block_shape, const xla::Literal& crops) { const int input_rank = input_tensor_shape.dims(); - const gtl::InlinedVector<int64, 4> input_shape = + const absl::InlinedVector<int64, 4> input_shape = input_tensor_shape.dim_sizes(); const int block_rank = block_shape.size(); diff --git a/tensorflow/compiler/tf2xla/kernels/bcast_ops.cc b/tensorflow/compiler/tf2xla/kernels/bcast_ops.cc index 2e383b1473..182f7c9934 100644 --- a/tensorflow/compiler/tf2xla/kernels/bcast_ops.cc +++ b/tensorflow/compiler/tf2xla/kernels/bcast_ops.cc @@ -39,7 +39,7 @@ class BCastArgsOp : public XlaOpKernel { OP_REQUIRES( ctx, ctx->num_inputs() == 2, errors::Unimplemented("Broadcast for n-ary operations (n > 2)")); - gtl::InlinedVector<BCast::Vec, 2> shapes; + absl::InlinedVector<BCast::Vec, 2> shapes; for (int i = 0; i < ctx->num_inputs(); ++i) { const TensorShape in_shape = ctx->InputShape(i); OP_REQUIRES(ctx, TensorShapeUtils::IsVector(in_shape), @@ -88,7 +88,7 @@ class BCastGradArgsOp : public XlaOpKernel { ctx, ctx->num_inputs() == 2, errors::Unimplemented("Broadcast for n-ary operations (n > 2)")); - gtl::InlinedVector<BCast::Vec, 4> shapes; + absl::InlinedVector<BCast::Vec, 4> shapes; for (int i = 0; i < ctx->num_inputs(); ++i) { const TensorShape in_shape = ctx->InputShape(i); OP_REQUIRES(ctx, TensorShapeUtils::IsVector(in_shape), diff --git a/tensorflow/compiler/tf2xla/kernels/depthtospace_op.cc b/tensorflow/compiler/tf2xla/kernels/depthtospace_op.cc index 12b0e38288..e96a1adce4 100644 --- a/tensorflow/compiler/tf2xla/kernels/depthtospace_op.cc +++ b/tensorflow/compiler/tf2xla/kernels/depthtospace_op.cc @@ -48,7 +48,7 @@ class DepthToSpaceOp : public XlaOpKernel { OP_REQUIRES(ctx, kRequiredDims == input_rank, errors::InvalidArgument("Input rank should be ", kRequiredDims, "; got: ", input_rank)); - const gtl::InlinedVector<int64, 4> input_shape = + const absl::InlinedVector<int64, 4> input_shape = input_tensor_shape.dim_sizes(); xla::XlaOp input = ctx->Input(0); diff --git a/tensorflow/compiler/tf2xla/kernels/pooling_ops.cc b/tensorflow/compiler/tf2xla/kernels/pooling_ops.cc index f6f158a73b..27690c156e 100644 --- a/tensorflow/compiler/tf2xla/kernels/pooling_ops.cc +++ b/tensorflow/compiler/tf2xla/kernels/pooling_ops.cc @@ -138,7 +138,7 @@ xla::TensorFormat XlaTensorFormat(tensorflow::TensorFormat data_format, int num_dims = num_spatial_dims + 2; int batch_dimension = GetTensorBatchDimIndex(num_dims, data_format); int feature_dimension = GetTensorFeatureDimIndex(num_dims, data_format); - gtl::InlinedVector<int64, 4> spatial_dimensions(num_spatial_dims); + absl::InlinedVector<int64, 4> spatial_dimensions(num_spatial_dims); for (int spatial_dim = 0; spatial_dim < num_spatial_dims; ++spatial_dim) { spatial_dimensions[spatial_dim] = GetTensorSpatialDimIndex(num_dims, data_format, spatial_dim); diff --git a/tensorflow/compiler/tf2xla/kernels/reduction_ops_common.cc b/tensorflow/compiler/tf2xla/kernels/reduction_ops_common.cc index 598248563b..118f2798d5 100644 --- a/tensorflow/compiler/tf2xla/kernels/reduction_ops_common.cc +++ b/tensorflow/compiler/tf2xla/kernels/reduction_ops_common.cc @@ -69,7 +69,7 @@ void XlaReductionOp::Compile(XlaOpKernelContext* ctx) { VLOG(1) << "data shape: " << data_shape.DebugString(); VLOG(1) << "axes : " << absl::StrJoin(axes, ","); - gtl::InlinedVector<bool, 4> bitmap(data_shape.dims(), false); + absl::InlinedVector<bool, 4> bitmap(data_shape.dims(), false); std::vector<int64> xla_axes; int64 num_elements_reduced = 1LL; for (int64 i = 0; i < axes_tensor_shape.num_elements(); ++i) { @@ -103,7 +103,7 @@ void XlaReductionOp::Compile(XlaOpKernelContext* ctx) { xla::XlaBuilder* const b = ctx->builder(); // Construct the builder for the reduction lambda. - xla::XlaBuilder r(strings::StrCat(desc, "-reduction")); + xla::XlaBuilder r(absl::StrCat(desc, "-reduction")); xla::PrimitiveType type; TF_CHECK_OK(DataTypeToPrimitiveType(reduction_type_, &type)); diff --git a/tensorflow/compiler/tf2xla/kernels/reverse_op.cc b/tensorflow/compiler/tf2xla/kernels/reverse_op.cc index c0afccaa5b..8494864b33 100644 --- a/tensorflow/compiler/tf2xla/kernels/reverse_op.cc +++ b/tensorflow/compiler/tf2xla/kernels/reverse_op.cc @@ -97,7 +97,7 @@ class ReverseV2Op : public XlaOpKernel { // witnessed_axes is used to ensure that the same axis is not marked to be // reversed multiple times. - gtl::InlinedVector<bool, 8> witnessed_axes(x_shape.dims(), false); + absl::InlinedVector<bool, 8> witnessed_axes(x_shape.dims(), false); for (int d = 0; d < axes.size(); ++d) { OP_REQUIRES( diff --git a/tensorflow/compiler/tf2xla/kernels/shape_op.cc b/tensorflow/compiler/tf2xla/kernels/shape_op.cc index 4e0cf99d8e..2e0a69b70e 100644 --- a/tensorflow/compiler/tf2xla/kernels/shape_op.cc +++ b/tensorflow/compiler/tf2xla/kernels/shape_op.cc @@ -115,7 +115,7 @@ class ExpandDimsOp : public XlaOpKernel { // accept legacy scalars, even when they should be forbidden by the graphdef // version. OP_REQUIRES(ctx, dim_shape.num_elements() == 1, - errors::InvalidArgument(strings::StrCat( + errors::InvalidArgument(absl::StrCat( "dim input to ExpandDims must be a scalar; got ", dim_shape.DebugString()))); diff --git a/tensorflow/compiler/tf2xla/kernels/spacetobatch_op.cc b/tensorflow/compiler/tf2xla/kernels/spacetobatch_op.cc index b7b4f3a546..76b79be6f6 100644 --- a/tensorflow/compiler/tf2xla/kernels/spacetobatch_op.cc +++ b/tensorflow/compiler/tf2xla/kernels/spacetobatch_op.cc @@ -26,7 +26,7 @@ void SpaceToBatch(XlaOpKernelContext* ctx, const xla::XlaOp& input, absl::Span<const int64> block_shape, const xla::Literal& paddings) { const int input_rank = input_tensor_shape.dims(); - const gtl::InlinedVector<int64, 4> input_shape = + const absl::InlinedVector<int64, 4> input_shape = input_tensor_shape.dim_sizes(); const int block_rank = block_shape.size(); diff --git a/tensorflow/compiler/tf2xla/kernels/spacetodepth_op.cc b/tensorflow/compiler/tf2xla/kernels/spacetodepth_op.cc index 4493539fe3..3293c13b21 100644 --- a/tensorflow/compiler/tf2xla/kernels/spacetodepth_op.cc +++ b/tensorflow/compiler/tf2xla/kernels/spacetodepth_op.cc @@ -48,7 +48,7 @@ class SpaceToDepthOp : public XlaOpKernel { OP_REQUIRES(ctx, kRequiredDims == input_rank, errors::InvalidArgument("Input rank should be ", kRequiredDims, "; got ", input_rank)); - const gtl::InlinedVector<int64, 4> input_shape = + const absl::InlinedVector<int64, 4> input_shape = input_tensor_shape.dim_sizes(); xla::XlaOp input = ctx->Input(0); diff --git a/tensorflow/compiler/tf2xla/kernels/stack_ops.cc b/tensorflow/compiler/tf2xla/kernels/stack_ops.cc index df91900570..ee70f508a9 100644 --- a/tensorflow/compiler/tf2xla/kernels/stack_ops.cc +++ b/tensorflow/compiler/tf2xla/kernels/stack_ops.cc @@ -111,7 +111,7 @@ class StackOp : public XlaOpKernel { xla::XlaOp value; XlaContext& xc = XlaContext::Get(ctx); XlaResource* resource; - string name = strings::StrCat("Stack: ", stack_name_); + string name = absl::StrCat("Stack: ", stack_name_); OP_REQUIRES_OK( ctx, xc.CreateResource(XlaResource::kStack, -1, std::move(name), dtype_, TensorShape(), value, /*tensor_array_size=*/size, diff --git a/tensorflow/compiler/tf2xla/kernels/strided_slice_op.cc b/tensorflow/compiler/tf2xla/kernels/strided_slice_op.cc index 472d4744d7..2b2e3de64f 100644 --- a/tensorflow/compiler/tf2xla/kernels/strided_slice_op.cc +++ b/tensorflow/compiler/tf2xla/kernels/strided_slice_op.cc @@ -46,9 +46,9 @@ class StridedSliceOp : public XlaOpKernel { const TensorShape input_shape = ctx->InputShape(0); TensorShape final_shape; - gtl::InlinedVector<int64, 4> begin; - gtl::InlinedVector<int64, 4> end; - gtl::InlinedVector<int64, 4> strides; + absl::InlinedVector<int64, 4> begin; + absl::InlinedVector<int64, 4> end; + absl::InlinedVector<int64, 4> strides; xla::Literal begin_literal, end_literal, strides_literal; OP_REQUIRES_OK(ctx, ctx->ConstantInput(1, &begin_literal)); @@ -72,8 +72,8 @@ class StridedSliceOp : public XlaOpKernel { shrink_axis_mask_, &dummy_processing_shape, &final_shape, &dummy, &dummy, &dummy, &begin, &end, &strides)); - gtl::InlinedVector<int64, 4> dimensions_to_reverse; - gtl::InlinedVector<int64, 4> slice_begin, slice_end, slice_strides; + absl::InlinedVector<int64, 4> dimensions_to_reverse; + absl::InlinedVector<int64, 4> slice_begin, slice_end, slice_strides; for (int i = 0; i < begin.size(); ++i) { if (strides[i] > 0) { @@ -127,9 +127,9 @@ class StridedSliceGradOp : public XlaOpKernel { void Compile(XlaOpKernelContext* ctx) override { TensorShape processing_shape, final_shape; - gtl::InlinedVector<int64, 4> begin; - gtl::InlinedVector<int64, 4> end; - gtl::InlinedVector<int64, 4> strides; + absl::InlinedVector<int64, 4> begin; + absl::InlinedVector<int64, 4> end; + absl::InlinedVector<int64, 4> strides; TensorShape input_shape; OP_REQUIRES_OK(ctx, ctx->ConstantInputAsShape(0, &input_shape)); @@ -175,7 +175,7 @@ class StridedSliceGradOp : public XlaOpKernel { grad = xla::Reshape(grad, processing_shape.dim_sizes()); // Pad the input gradients. - gtl::InlinedVector<int64, 4> dimensions_to_reverse; + absl::InlinedVector<int64, 4> dimensions_to_reverse; xla::PaddingConfig padding_config; for (int i = 0; i < processing_shape.dims(); ++i) { @@ -238,9 +238,9 @@ class StridedSliceAssignOp : public XlaOpKernel { void Compile(XlaOpKernelContext* ctx) override { TensorShape final_shape; - gtl::InlinedVector<int64, 4> begin; - gtl::InlinedVector<int64, 4> end; - gtl::InlinedVector<int64, 4> strides; + absl::InlinedVector<int64, 4> begin; + absl::InlinedVector<int64, 4> end; + absl::InlinedVector<int64, 4> strides; xla::Literal begin_literal, end_literal, strides_literal; OP_REQUIRES_OK(ctx, ctx->ConstantInput(1, &begin_literal)); @@ -287,8 +287,8 @@ class StridedSliceAssignOp : public XlaOpKernel { xla::XlaOp rhs = ctx->Input(4); - gtl::InlinedVector<int64, 4> dimensions_to_reverse; - gtl::InlinedVector<int64, 4> slice_begin, slice_dims; + absl::InlinedVector<int64, 4> dimensions_to_reverse; + absl::InlinedVector<int64, 4> slice_begin, slice_dims; for (int i = 0; i < begin.size(); ++i) { // TODO(phawkins): implement strides != 1 OP_REQUIRES( diff --git a/tensorflow/compiler/tf2xla/kernels/tensor_array_ops.cc b/tensorflow/compiler/tf2xla/kernels/tensor_array_ops.cc index bb114d1aed..94108b764f 100644 --- a/tensorflow/compiler/tf2xla/kernels/tensor_array_ops.cc +++ b/tensorflow/compiler/tf2xla/kernels/tensor_array_ops.cc @@ -167,7 +167,7 @@ class TensorArrayOp : public XlaOpKernel { XlaContext& xc = XlaContext::Get(ctx); XlaResource* var; - string name = strings::StrCat("TensorArray: ", tensor_array_name_); + string name = absl::StrCat("TensorArray: ", tensor_array_name_); OP_REQUIRES_OK( ctx, xc.CreateResource(XlaResource::kTensorArray, -1, std::move(name), dtype_, shape, value, /*tensor_array_size=*/size, diff --git a/tensorflow/compiler/tf2xla/kernels/transpose_op.cc b/tensorflow/compiler/tf2xla/kernels/transpose_op.cc index f9148b3942..6b303b31d4 100644 --- a/tensorflow/compiler/tf2xla/kernels/transpose_op.cc +++ b/tensorflow/compiler/tf2xla/kernels/transpose_op.cc @@ -61,7 +61,7 @@ class TransposeOp : public XlaOpKernel { std::vector<int64> transposed_order; // Check whether permutation is a permutation of integers of [0 .. dims). - gtl::InlinedVector<bool, 8> bits(dims); + absl::InlinedVector<bool, 8> bits(dims); bool is_identity = true; for (int i = 0; i < dims; ++i) { const int32 d = perm[i]; diff --git a/tensorflow/compiler/tf2xla/kernels/xla_conv_op.cc b/tensorflow/compiler/tf2xla/kernels/xla_conv_op.cc index 8848623868..fecc7c556e 100644 --- a/tensorflow/compiler/tf2xla/kernels/xla_conv_op.cc +++ b/tensorflow/compiler/tf2xla/kernels/xla_conv_op.cc @@ -84,7 +84,7 @@ class XlaConvOp : public XlaOpKernel { private: xla::ConvolutionDimensionNumbers dnums_; - xla::PrecisionConfigProto precision_config_; + xla::PrecisionConfig precision_config_; TF_DISALLOW_COPY_AND_ASSIGN(XlaConvOp); }; diff --git a/tensorflow/compiler/tf2xla/kernels/xla_dot_op.cc b/tensorflow/compiler/tf2xla/kernels/xla_dot_op.cc index 2fed53e5c0..40b15b5579 100644 --- a/tensorflow/compiler/tf2xla/kernels/xla_dot_op.cc +++ b/tensorflow/compiler/tf2xla/kernels/xla_dot_op.cc @@ -54,7 +54,7 @@ class XlaDotOp : public XlaOpKernel { private: xla::DotDimensionNumbers dnums_; - xla::PrecisionConfigProto precision_config_; + xla::PrecisionConfig precision_config_; TF_DISALLOW_COPY_AND_ASSIGN(XlaDotOp); }; diff --git a/tensorflow/compiler/tf2xla/lib/BUILD b/tensorflow/compiler/tf2xla/lib/BUILD index 9365d203f0..8597e7f139 100644 --- a/tensorflow/compiler/tf2xla/lib/BUILD +++ b/tensorflow/compiler/tf2xla/lib/BUILD @@ -205,7 +205,7 @@ cc_library( "//tensorflow/compiler/xla:statusor", "//tensorflow/compiler/xla/client:xla_builder", "//tensorflow/compiler/xla/client:xla_computation", - "//tensorflow/core:lib", + "@com_google_absl//absl/strings", "@com_google_absl//absl/types:span", ], ) diff --git a/tensorflow/compiler/tf2xla/lib/batch_dot.cc b/tensorflow/compiler/tf2xla/lib/batch_dot.cc index d8c050d09e..64f2d781a6 100644 --- a/tensorflow/compiler/tf2xla/lib/batch_dot.cc +++ b/tensorflow/compiler/tf2xla/lib/batch_dot.cc @@ -28,7 +28,7 @@ namespace tensorflow { xla::XlaOp BatchDot(xla::XlaOp x, xla::XlaOp y, bool transpose_x, bool transpose_y, bool conjugate_x, bool conjugate_y, - xla::PrecisionConfigProto::Precision precision) { + xla::PrecisionConfig::Precision precision) { xla::XlaBuilder* builder = x.builder(); return builder->ReportErrorOrReturn([&]() -> xla::StatusOr<xla::XlaOp> { TF_ASSIGN_OR_RETURN(xla::Shape x_shape, builder->GetShape(x)); @@ -96,7 +96,7 @@ xla::XlaOp BatchDot(xla::XlaOp x, xla::XlaOp y, bool transpose_x, y = xla::Conj(y); } - xla::PrecisionConfigProto precision_proto; + xla::PrecisionConfig precision_proto; precision_proto.add_operand_precision(precision); precision_proto.add_operand_precision(precision); diff --git a/tensorflow/compiler/tf2xla/lib/batch_dot.h b/tensorflow/compiler/tf2xla/lib/batch_dot.h index 6cfccd5553..6edd63a4d3 100644 --- a/tensorflow/compiler/tf2xla/lib/batch_dot.h +++ b/tensorflow/compiler/tf2xla/lib/batch_dot.h @@ -43,11 +43,11 @@ namespace tensorflow { // It is computed as: // // output[..., :, :] = matrix(x[..., :, :]) * matrix(y[..., :, :]) -xla::XlaOp BatchDot(xla::XlaOp x, xla::XlaOp y, bool transpose_x = false, - bool transpose_y = false, bool conjugate_x = false, - bool conjugate_y = false, - xla::PrecisionConfigProto::Precision precision = - xla::PrecisionConfigProto::DEFAULT); +xla::XlaOp BatchDot( + xla::XlaOp x, xla::XlaOp y, bool transpose_x = false, + bool transpose_y = false, bool conjugate_x = false, + bool conjugate_y = false, + xla::PrecisionConfig::Precision precision = xla::PrecisionConfig::DEFAULT); } // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/lib/cholesky.cc b/tensorflow/compiler/tf2xla/lib/cholesky.cc index c50a8de33e..ab3d0a5668 100644 --- a/tensorflow/compiler/tf2xla/lib/cholesky.cc +++ b/tensorflow/compiler/tf2xla/lib/cholesky.cc @@ -50,7 +50,7 @@ namespace { // l[..., j, j] // return l xla::XlaOp CholeskyUnblocked(xla::XlaOp a, - xla::PrecisionConfigProto::Precision precision) { + xla::PrecisionConfig::Precision precision) { xla::XlaBuilder* builder = a.builder(); return builder->ReportErrorOrReturn([&]() -> xla::StatusOr<xla::XlaOp> { TF_ASSIGN_OR_RETURN(xla::Shape a_shape, builder->GetShape(a)); @@ -150,7 +150,7 @@ xla::XlaOp CholeskyUnblocked(xla::XlaOp a, } // namespace xla::XlaOp Cholesky(xla::XlaOp a, int64 block_size, - xla::PrecisionConfigProto::Precision precision) { + xla::PrecisionConfig::Precision precision) { xla::XlaBuilder* builder = a.builder(); return builder->ReportErrorOrReturn([&]() -> xla::StatusOr<xla::XlaOp> { TF_ASSIGN_OR_RETURN(xla::Shape a_shape, builder->GetShape(a)); diff --git a/tensorflow/compiler/tf2xla/lib/cholesky.h b/tensorflow/compiler/tf2xla/lib/cholesky.h index 60cd7ded53..9a561c34b9 100644 --- a/tensorflow/compiler/tf2xla/lib/cholesky.h +++ b/tensorflow/compiler/tf2xla/lib/cholesky.h @@ -30,9 +30,9 @@ namespace tensorflow { // TODO(phawkins): check for negative values on the diagonal and return an // error, instead of silently yielding NaNs. // TODO(znado): handle the complex Hermitian case -xla::XlaOp Cholesky(xla::XlaOp a, int64 block_size = 256, - xla::PrecisionConfigProto::Precision precision = - xla::PrecisionConfigProto::HIGHEST); +xla::XlaOp Cholesky( + xla::XlaOp a, int64 block_size = 256, + xla::PrecisionConfig::Precision precision = xla::PrecisionConfig::HIGHEST); } // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/lib/qr.cc b/tensorflow/compiler/tf2xla/lib/qr.cc index 0a140fa93c..6b3f2b6e06 100644 --- a/tensorflow/compiler/tf2xla/lib/qr.cc +++ b/tensorflow/compiler/tf2xla/lib/qr.cc @@ -150,7 +150,7 @@ struct QRBlockResult { xla::XlaOp vs; // Shape: [..., m, n] }; xla::StatusOr<QRBlockResult> QRBlock( - xla::XlaOp a, xla::PrecisionConfigProto::Precision precision) { + xla::XlaOp a, xla::PrecisionConfig::Precision precision) { xla::XlaBuilder* builder = a.builder(); TF_ASSIGN_OR_RETURN(xla::Shape a_shape, builder->GetShape(a)); const int num_dims = xla::ShapeUtil::Rank(a_shape); @@ -257,7 +257,7 @@ xla::StatusOr<QRBlockResult> QRBlock( xla::StatusOr<xla::XlaOp> ComputeWYRepresentation( xla::PrimitiveType type, absl::Span<const int64> batch_dims, xla::XlaOp vs, xla::XlaOp taus, int64 m, int64 n, - xla::PrecisionConfigProto::Precision precision) { + xla::PrecisionConfig::Precision precision) { std::vector<int64> batch_dim_indices(batch_dims.size()); std::iota(batch_dim_indices.begin(), batch_dim_indices.end(), 0); int64 n_index = batch_dims.size() + 1; @@ -332,7 +332,7 @@ xla::StatusOr<xla::XlaOp> ComputeWYRepresentation( // rather than WY transformations. xla::StatusOr<QRDecompositionResult> QRDecomposition( xla::XlaOp a, bool full_matrices, int64 block_size, - xla::PrecisionConfigProto::Precision precision) { + xla::PrecisionConfig::Precision precision) { xla::XlaBuilder* builder = a.builder(); TF_ASSIGN_OR_RETURN(xla::Shape a_shape, builder->GetShape(a)); const int num_dims = xla::ShapeUtil::Rank(a_shape); diff --git a/tensorflow/compiler/tf2xla/lib/qr.h b/tensorflow/compiler/tf2xla/lib/qr.h index 8a389fb7b0..24b537ac8b 100644 --- a/tensorflow/compiler/tf2xla/lib/qr.h +++ b/tensorflow/compiler/tf2xla/lib/qr.h @@ -35,8 +35,7 @@ struct QRDecompositionResult { xla::StatusOr<QRDecompositionResult> QRDecomposition( xla::XlaOp a, bool full_matrices, int64 block_size = 128, - xla::PrecisionConfigProto::Precision precision = - xla::PrecisionConfigProto::HIGHEST); + xla::PrecisionConfig::Precision precision = xla::PrecisionConfig::HIGHEST); } // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/lib/triangular_solve.cc b/tensorflow/compiler/tf2xla/lib/triangular_solve.cc index 37b2240b45..6524c2a9b1 100644 --- a/tensorflow/compiler/tf2xla/lib/triangular_solve.cc +++ b/tensorflow/compiler/tf2xla/lib/triangular_solve.cc @@ -110,9 +110,9 @@ xla::XlaOp DiagonalBlocks(xla::XlaOp a, int64 block_size) { }); } -xla::XlaOp InvertDiagonalBlocks( - xla::XlaOp diag_blocks, bool lower, bool transpose_a, bool conjugate_a, - xla::PrecisionConfigProto::Precision precision) { +xla::XlaOp InvertDiagonalBlocks(xla::XlaOp diag_blocks, bool lower, + bool transpose_a, bool conjugate_a, + xla::PrecisionConfig::Precision precision) { xla::XlaBuilder* builder = diag_blocks.builder(); return builder->ReportErrorOrReturn([&]() -> xla::StatusOr<xla::XlaOp> { // Input is a batch of square lower triangular square matrices. Its shape is @@ -216,7 +216,7 @@ xla::XlaOp InvertDiagonalBlocks( dnums.add_rhs_batch_dimensions(0); dnums.add_lhs_contracting_dimensions(2); dnums.add_rhs_contracting_dimensions(1); - xla::PrecisionConfigProto precision_proto; + xla::PrecisionConfig precision_proto; precision_proto.add_operand_precision(precision); precision_proto.add_operand_precision(precision); auto update = -DotGeneral(input_row, body_out, dnums, &precision_proto); @@ -245,7 +245,7 @@ xla::XlaOp InvertDiagonalBlocks( xla::XlaOp SolveWithInvertedDiagonalBlocks( xla::XlaOp a, xla::XlaOp b, xla::XlaOp inv_diag_blocks, bool left_side, bool lower, bool transpose_a, bool conjugate_a, - xla::PrecisionConfigProto::Precision precision) { + xla::PrecisionConfig::Precision precision) { xla::XlaBuilder* builder = a.builder(); return builder->ReportErrorOrReturn([&]() -> xla::StatusOr<xla::XlaOp> { TF_ASSIGN_OR_RETURN(xla::Shape blocks_shape, @@ -346,7 +346,7 @@ xla::XlaOp SolveWithInvertedDiagonalBlocks( xla::XlaOp TriangularSolve(xla::XlaOp a, xla::XlaOp b, bool left_side, bool lower, bool transpose_a, bool conjugate_a, int64 block_size, - xla::PrecisionConfigProto::Precision precision) { + xla::PrecisionConfig::Precision precision) { xla::XlaBuilder* builder = a.builder(); return builder->ReportErrorOrReturn([&]() -> xla::StatusOr<xla::XlaOp> { TF_ASSIGN_OR_RETURN(xla::Shape a_shape, builder->GetShape(a)); diff --git a/tensorflow/compiler/tf2xla/lib/triangular_solve.h b/tensorflow/compiler/tf2xla/lib/triangular_solve.h index ac42a48352..2303234f36 100644 --- a/tensorflow/compiler/tf2xla/lib/triangular_solve.h +++ b/tensorflow/compiler/tf2xla/lib/triangular_solve.h @@ -57,11 +57,10 @@ namespace tensorflow { // // Uses a blocked algorithm if `block_size` is > 1; if block_size == 1 then no // blocking is used. -xla::XlaOp TriangularSolve(xla::XlaOp a, xla::XlaOp b, bool left_side, - bool lower, bool transpose_a, bool conjugate_a, - int64 block_size = 128, - xla::PrecisionConfigProto::Precision precision = - xla::PrecisionConfigProto::HIGHEST); +xla::XlaOp TriangularSolve( + xla::XlaOp a, xla::XlaOp b, bool left_side, bool lower, bool transpose_a, + bool conjugate_a, int64 block_size = 128, + xla::PrecisionConfig::Precision precision = xla::PrecisionConfig::HIGHEST); } // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/lib/while_loop.cc b/tensorflow/compiler/tf2xla/lib/while_loop.cc index 5300e2c878..594ab1dfd0 100644 --- a/tensorflow/compiler/tf2xla/lib/while_loop.cc +++ b/tensorflow/compiler/tf2xla/lib/while_loop.cc @@ -24,7 +24,7 @@ namespace tensorflow { xla::StatusOr<std::vector<xla::XlaOp>> XlaWhileLoop( const LoopConditionFunction& condition_function, const LoopBodyFunction& body_function, - absl::Span<const xla::XlaOp> initial_values, StringPiece name, + absl::Span<const xla::XlaOp> initial_values, absl::string_view name, xla::XlaBuilder* builder) { int arity = initial_values.size(); std::vector<xla::Shape> var_shapes; @@ -47,7 +47,7 @@ xla::StatusOr<std::vector<xla::XlaOp>> XlaWhileLoop( // Build the condition. std::unique_ptr<xla::XlaBuilder> cond_builder = - builder->CreateSubBuilder(strings::StrCat(name, "_condition")); + builder->CreateSubBuilder(absl::StrCat(name, "_condition")); { auto parameter = xla::Parameter(cond_builder.get(), 0, tuple_shape, "parameter"); @@ -61,7 +61,7 @@ xla::StatusOr<std::vector<xla::XlaOp>> XlaWhileLoop( // Build the body. std::unique_ptr<xla::XlaBuilder> body_builder = - builder->CreateSubBuilder(strings::StrCat(name, "_body")); + builder->CreateSubBuilder(absl::StrCat(name, "_body")); { auto parameter = xla::Parameter(body_builder.get(), 0, tuple_shape, "parameter"); @@ -84,7 +84,7 @@ xla::StatusOr<std::vector<xla::XlaOp>> XlaWhileLoop( xla::StatusOr<std::vector<xla::XlaOp>> XlaForEachIndex( int64 num_iterations, xla::PrimitiveType num_iterations_type, const ForEachIndexBodyFunction& body_function, - absl::Span<const xla::XlaOp> initial_values, StringPiece name, + absl::Span<const xla::XlaOp> initial_values, absl::string_view name, xla::XlaBuilder* builder) { auto while_cond_fn = [&](absl::Span<const xla::XlaOp> values, diff --git a/tensorflow/compiler/tf2xla/lib/while_loop.h b/tensorflow/compiler/tf2xla/lib/while_loop.h index 115ebf390d..f2134bb449 100644 --- a/tensorflow/compiler/tf2xla/lib/while_loop.h +++ b/tensorflow/compiler/tf2xla/lib/while_loop.h @@ -19,11 +19,11 @@ limitations under the License. #include <functional> #include <vector> +#include "absl/strings/string_view.h" #include "absl/types/span.h" #include "tensorflow/compiler/xla/client/xla_builder.h" #include "tensorflow/compiler/xla/client/xla_computation.h" #include "tensorflow/compiler/xla/statusor.h" -#include "tensorflow/core/lib/core/stringpiece.h" namespace tensorflow { @@ -50,7 +50,7 @@ typedef std::function<xla::StatusOr<std::vector<xla::XlaOp>>( xla::StatusOr<std::vector<xla::XlaOp>> XlaWhileLoop( const LoopConditionFunction& condition_function, const LoopBodyFunction& body_function, - absl::Span<const xla::XlaOp> initial_values, StringPiece name, + absl::Span<const xla::XlaOp> initial_values, absl::string_view name, xla::XlaBuilder* builder); // Builds an XLA loop that repeats a computation `num_iterations` times. @@ -65,7 +65,7 @@ typedef std::function<xla::StatusOr<std::vector<xla::XlaOp>>( xla::StatusOr<std::vector<xla::XlaOp>> XlaForEachIndex( int64 num_iterations, xla::PrimitiveType num_iterations_type, const ForEachIndexBodyFunction& body_function, - absl::Span<const xla::XlaOp> initial_values, StringPiece name, + absl::Span<const xla::XlaOp> initial_values, absl::string_view name, xla::XlaBuilder* builder); } // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/ops/xla_ops.cc b/tensorflow/compiler/tf2xla/ops/xla_ops.cc index 2cd9ae799f..68cfdc1785 100644 --- a/tensorflow/compiler/tf2xla/ops/xla_ops.cc +++ b/tensorflow/compiler/tf2xla/ops/xla_ops.cc @@ -83,7 +83,7 @@ lhs_dilation: dilation to apply between input elements rhs_dilation: dilation to apply between kernel elements feature_group_count: number of feature groups for grouped convolution. dimension_numbers: a serialized xla::ConvolutionDimensionNumbers proto. -precision_config: a serialized xla::PrecisionConfigProto proto. +precision_config: a serialized xla::PrecisionConfig proto. )doc"); REGISTER_OP("XlaDot") @@ -102,7 +102,7 @@ Wraps the XLA ConvGeneralDilated operator, documented at lhs: the LHS tensor rhs: the RHS tensor dimension_numbers: a serialized xla::DotDimensionNumbers proto. -precision_config: a serialized xla::PrecisionConfigProto proto. +precision_config: a serialized xla::PrecisionConfig proto. )doc"); REGISTER_OP("XlaDynamicUpdateSlice") diff --git a/tensorflow/compiler/tf2xla/resource_operation_table.cc b/tensorflow/compiler/tf2xla/resource_operation_table.cc index 32ba6df2e6..20f2ce2919 100644 --- a/tensorflow/compiler/tf2xla/resource_operation_table.cc +++ b/tensorflow/compiler/tf2xla/resource_operation_table.cc @@ -18,7 +18,7 @@ limitations under the License. #include "tensorflow/core/lib/gtl/flatmap.h" namespace tensorflow { -/*static*/ StringPiece XlaResourceOpInfo::XlaResourceOpKindToString( +/*static*/ absl::string_view XlaResourceOpInfo::XlaResourceOpKindToString( XlaResourceOpKind op_kind) { switch (op_kind) { case XlaResourceOpKind::kRead: @@ -30,11 +30,11 @@ namespace tensorflow { } } -static gtl::FlatMap<StringPiece, XlaResourceOpInfo>* CreateResourceOpInfoMap() { - gtl::FlatMap<StringPiece, XlaResourceOpInfo>* result = - new gtl::FlatMap<StringPiece, XlaResourceOpInfo>; +static gtl::FlatMap<absl::string_view, XlaResourceOpInfo>* +CreateResourceOpInfoMap() { + auto* result = new gtl::FlatMap<absl::string_view, XlaResourceOpInfo>; - auto add = [&](StringPiece op, XlaResourceOpKind op_kind, + auto add = [&](absl::string_view op, XlaResourceOpKind op_kind, XlaResourceKind resource_kind) { auto insert_result = result->insert({op, XlaResourceOpInfo(op_kind, resource_kind)}); @@ -103,23 +103,23 @@ static gtl::FlatMap<StringPiece, XlaResourceOpInfo>* CreateResourceOpInfoMap() { return result; } -static const gtl::FlatMap<StringPiece, XlaResourceOpInfo>& +static const gtl::FlatMap<absl::string_view, XlaResourceOpInfo>& GetStaticResourceOpInfoMap() { - static gtl::FlatMap<StringPiece, XlaResourceOpInfo>* op_info_map = + static gtl::FlatMap<absl::string_view, XlaResourceOpInfo>* op_info_map = CreateResourceOpInfoMap(); return *op_info_map; } -const XlaResourceOpInfo* GetResourceOpInfoForOp(StringPiece op) { - const gtl::FlatMap<StringPiece, XlaResourceOpInfo>& op_infos = +const XlaResourceOpInfo* GetResourceOpInfoForOp(absl::string_view op) { + const gtl::FlatMap<absl::string_view, XlaResourceOpInfo>& op_infos = GetStaticResourceOpInfoMap(); auto it = op_infos.find(op); return it == op_infos.end() ? nullptr : &it->second; } namespace resource_op_table_internal { -std::vector<StringPiece> GetKnownResourceOps() { - std::vector<StringPiece> result; +std::vector<absl::string_view> GetKnownResourceOps() { + std::vector<absl::string_view> result; for (const auto& p : GetStaticResourceOpInfoMap()) { result.push_back(p.first); } diff --git a/tensorflow/compiler/tf2xla/resource_operation_table.h b/tensorflow/compiler/tf2xla/resource_operation_table.h index 7f627a64c6..61c7a56ff0 100644 --- a/tensorflow/compiler/tf2xla/resource_operation_table.h +++ b/tensorflow/compiler/tf2xla/resource_operation_table.h @@ -19,7 +19,7 @@ limitations under the License. #include <string> #include <vector> -#include "tensorflow/core/lib/core/stringpiece.h" +#include "absl/strings/string_view.h" #include "tensorflow/core/platform/logging.h" // Exposes information about the resource operations supported by tf2xla in a @@ -47,7 +47,7 @@ class XlaResourceOpInfo { XlaResourceOpKind kind() const { return op_kind_; } XlaResourceKind resource_kind() const { return resource_kind_; } - static StringPiece XlaResourceOpKindToString(XlaResourceOpKind op_kind); + static absl::string_view XlaResourceOpKindToString(XlaResourceOpKind op_kind); private: XlaResourceOpKind op_kind_; @@ -57,13 +57,13 @@ class XlaResourceOpInfo { // Returns a XlaResourceOpInfo describing `op` if it is a resource operation // supported by tf2xla, otherwise returns null (i.e. if this returns null then // `op` is either not a resource operation or is unsupported by XLA). -const XlaResourceOpInfo* GetResourceOpInfoForOp(StringPiece op); +const XlaResourceOpInfo* GetResourceOpInfoForOp(absl::string_view op); namespace resource_op_table_internal { // NB! Implementation detail exposed for unit testing, do not use. // // Returns the set of resource operations known by this module. -std::vector<StringPiece> GetKnownResourceOps(); +std::vector<absl::string_view> GetKnownResourceOps(); } // namespace resource_op_table_internal } // namespace tensorflow diff --git a/tensorflow/compiler/tf2xla/resource_operation_table_test.cc b/tensorflow/compiler/tf2xla/resource_operation_table_test.cc index 0343f80de9..a85ef040a7 100644 --- a/tensorflow/compiler/tf2xla/resource_operation_table_test.cc +++ b/tensorflow/compiler/tf2xla/resource_operation_table_test.cc @@ -34,7 +34,7 @@ bool HasResourceInputOrOutput(const OpDef& op_def) { TEST(ResourceOperationTableTest, HaveAllResourceOps) { gtl::FlatMap<string, bool> known_resource_ops; - for (StringPiece known_resource_op : + for (absl::string_view known_resource_op : resource_op_table_internal::GetKnownResourceOps()) { ASSERT_TRUE( known_resource_ops.insert({string(known_resource_op), false}).second); diff --git a/tensorflow/compiler/tf2xla/sharding_util.cc b/tensorflow/compiler/tf2xla/sharding_util.cc index 2d7eb8b915..8aae498be1 100644 --- a/tensorflow/compiler/tf2xla/sharding_util.cc +++ b/tensorflow/compiler/tf2xla/sharding_util.cc @@ -17,7 +17,6 @@ limitations under the License. #include "absl/strings/match.h" #include "tensorflow/core/framework/node_def.pb.h" #include "tensorflow/core/lib/core/errors.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/util/device_name_utils.h" namespace tensorflow { diff --git a/tensorflow/compiler/tf2xla/tf2xla.cc b/tensorflow/compiler/tf2xla/tf2xla.cc index f34af2d67d..7dbe3a0b58 100644 --- a/tensorflow/compiler/tf2xla/tf2xla.cc +++ b/tensorflow/compiler/tf2xla/tf2xla.cc @@ -22,6 +22,7 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/strings/str_cat.h" #include "absl/strings/str_join.h" #include "tensorflow/compiler/tf2xla/dump_graph.h" #include "tensorflow/compiler/tf2xla/shape_util.h" @@ -41,7 +42,6 @@ limitations under the License. #include "tensorflow/core/graph/graph_constructor.h" #include "tensorflow/core/graph/node_builder.h" #include "tensorflow/core/lib/core/errors.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/types.h" @@ -75,7 +75,7 @@ Status AddArgNodes(Graph* graph, const NodeMap& node_map, auto node_it = node_map.find(remap_it->second); if (node_it == node_map.end()) { // Strip off the aot_feed_#/ prefix. - StringPiece name(remap_it->second); + absl::string_view name(remap_it->second); const auto index = name.find('/'); if (index > 0) name.remove_prefix(index + 1); return errors::InvalidArgument( @@ -89,7 +89,7 @@ Status AddArgNodes(Graph* graph, const NodeMap& node_map, // explicitly specify or override them. Node* arg_node = nullptr; TF_RETURN_IF_ERROR( - NodeBuilder(strings::StrCat("_arg_", arg_index), kArgOp) + NodeBuilder(absl::StrCat("_arg_", arg_index), kArgOp) .Attr("T", BaseType(feed_node->output_type(output_index))) .Attr("index", arg_index) .Attr(kFeedIdAttr, TensorIdToString(feed.id())) @@ -136,7 +136,7 @@ Status AddRetvalNodes(Graph* graph, const NodeMap& node_map, // Connects fetch_node -> retval_node. Node* retval_node = nullptr; TF_RETURN_IF_ERROR( - NodeBuilder(strings::StrCat("_retval_", ret_index), kRetvalOp) + NodeBuilder(absl::StrCat("_retval_", ret_index), kRetvalOp) .Input(fetch_node, id.output_index()) .Attr("T", BaseType(fetch_node->output_type(id.output_index()))) .Attr("index", ret_index) @@ -256,7 +256,7 @@ Status ConvertGraphToXla(std::unique_ptr<Graph> graph, xla::Client* client, XlaOpRegistry::RegisterCompilationKernels(); for (Node* node : graph->nodes()) { node->set_assigned_device_name( - strings::StrCat("/device:", DEVICE_CPU_XLA_JIT)); + absl::StrCat("/device:", DEVICE_CPU_XLA_JIT)); } std::vector<XlaCompiler::Argument> xla_args; TF_RETURN_IF_ERROR(CreateXlaArgs(*graph, &xla_args)); diff --git a/tensorflow/compiler/tf2xla/tf2xla_util.cc b/tensorflow/compiler/tf2xla/tf2xla_util.cc index e284e0b191..211caf8736 100644 --- a/tensorflow/compiler/tf2xla/tf2xla_util.cc +++ b/tensorflow/compiler/tf2xla/tf2xla_util.cc @@ -20,6 +20,7 @@ limitations under the License. #include <set> #include <unordered_map> +#include "absl/strings/str_cat.h" #include "absl/types/optional.h" #include "tensorflow/compiler/tf2xla/sharding_util.h" #include "tensorflow/compiler/tf2xla/tf2xla.pb.h" @@ -33,7 +34,6 @@ limitations under the License. #include "tensorflow/core/graph/tensor_id.h" #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/core/status.h" -#include "tensorflow/core/lib/strings/strcat.h" namespace tensorflow { @@ -112,8 +112,8 @@ Status AddPlaceholdersForFeeds( const string name_port = TensorIdToString(feed->id()); PlaceholderInfo& info = placeholder_info[name_port]; info.feed = feed; - info.placeholder_name = strings::StrCat( - "aot_feed_", feed->id().output_index(), "/", feed->id().node_name()); + info.placeholder_name = absl::StrCat("aot_feed_", feed->id().output_index(), + "/", feed->id().node_name()); (*feed_remapping)[name_port] = info.placeholder_name; } @@ -258,7 +258,7 @@ Status PruneGraphDefInto(const tf2xla::Config& config, const GraphDef& in, } string TensorIdToString(const tf2xla::TensorId& id) { - return strings::StrCat(id.node_name(), ":", id.output_index()); + return absl::StrCat(id.node_name(), ":", id.output_index()); } Status SetNodeShardingFromNeighbors(Node* n, bool out_edges) { @@ -289,7 +289,7 @@ Status SetNodeShardingFromNeighbors(Node* n, bool out_edges) { return Status::OK(); } -void AddDtypeToKernalDefConstraint(StringPiece name, DataType dtype, +void AddDtypeToKernalDefConstraint(absl::string_view name, DataType dtype, KernelDef* kdef) { for (KernelDef::AttrConstraint& constraint : *kdef->mutable_constraint()) { if (constraint.name() == name) { diff --git a/tensorflow/compiler/tf2xla/tf2xla_util.h b/tensorflow/compiler/tf2xla/tf2xla_util.h index 33620ef810..a29e764466 100644 --- a/tensorflow/compiler/tf2xla/tf2xla_util.h +++ b/tensorflow/compiler/tf2xla/tf2xla_util.h @@ -53,7 +53,7 @@ string TensorIdToString(const tf2xla::TensorId& id); Status SetNodeShardingFromNeighbors(Node* n, bool out_edges); // Add an allowed data type to the AttrConstraint with the given name. -void AddDtypeToKernalDefConstraint(StringPiece name, DataType dtype, +void AddDtypeToKernalDefConstraint(absl::string_view name, DataType dtype, KernelDef* kdef); // Returns the next random seed to use for seeding xla rng. diff --git a/tensorflow/compiler/tf2xla/tf2xla_util_test.cc b/tensorflow/compiler/tf2xla/tf2xla_util_test.cc index 2b1f724dc7..68441b3d47 100644 --- a/tensorflow/compiler/tf2xla/tf2xla_util_test.cc +++ b/tensorflow/compiler/tf2xla/tf2xla_util_test.cc @@ -16,6 +16,8 @@ limitations under the License. #include "tensorflow/compiler/tf2xla/tf2xla_util.h" #include "absl/strings/match.h" +#include "absl/strings/str_cat.h" +#include "absl/strings/string_view.h" #include "tensorflow/cc/framework/ops.h" #include "tensorflow/cc/ops/data_flow_ops.h" #include "tensorflow/cc/ops/function_ops.h" @@ -25,8 +27,6 @@ limitations under the License. #include "tensorflow/core/graph/graph.h" #include "tensorflow/core/lib/core/status.h" #include "tensorflow/core/lib/core/status_test_util.h" -#include "tensorflow/core/lib/core/stringpiece.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/test.h" namespace tensorflow { @@ -153,7 +153,7 @@ static tf2xla::Config FetchesConfig(std::vector<string> fetches) { tf2xla::Config config; for (const auto& fetch_node_name : fetches) { auto* fetch = config.add_fetch(); - fetch->set_name(strings::StrCat("fetch_", fetch_node_name)); + fetch->set_name(absl::StrCat("fetch_", fetch_node_name)); fetch->mutable_id()->set_node_name(fetch_node_name); } return config; diff --git a/tensorflow/compiler/tf2xla/xla_compilation_device.cc b/tensorflow/compiler/tf2xla/xla_compilation_device.cc index d98237bd5c..7f860500c7 100644 --- a/tensorflow/compiler/tf2xla/xla_compilation_device.cc +++ b/tensorflow/compiler/tf2xla/xla_compilation_device.cc @@ -76,12 +76,11 @@ class XlaCompilationAllocator : public Allocator { XlaCompilationDevice::XlaCompilationDevice(const SessionOptions& options, DeviceType type) - : LocalDevice( - options, - Device::BuildDeviceAttributes( - strings::StrCat("/device:", type.type(), ":0"), type, - Bytes(256 << 20), DeviceLocality(), - strings::StrCat("device: XLA compilation device ", type.type()))), + : LocalDevice(options, Device::BuildDeviceAttributes( + absl::StrCat("/device:", type.type(), ":0"), + type, Bytes(256 << 20), DeviceLocality(), + absl::StrCat("device: XLA compilation device ", + type.type()))), allocator_(new XlaCompilationAllocator()) {} XlaCompilationDevice::~XlaCompilationDevice() {} diff --git a/tensorflow/compiler/tf2xla/xla_compiler.cc b/tensorflow/compiler/tf2xla/xla_compiler.cc index 0c300c282e..41d305d461 100644 --- a/tensorflow/compiler/tf2xla/xla_compiler.cc +++ b/tensorflow/compiler/tf2xla/xla_compiler.cc @@ -198,14 +198,14 @@ Status XlaCompiler::CompileFunction(const XlaCompiler::CompileOptions& options, // lowest-numbered core that consumes the argument. We choose the // lowest-numbered core so the assignment is deterministic. for (Node* n : graph->nodes()) { - if (StringPiece(n->type_string()) == "_Arg") { + if (absl::string_view(n->type_string()) == "_Arg") { TF_RETURN_IF_ERROR(SetNodeShardingFromNeighbors(n, /*out_edges=*/true)); } } // Do _Retval as a second loop, in case the retval's input is an _Arg (which // may have gotten a device assignment from the first loop). for (Node* n : graph->nodes()) { - if (StringPiece(n->type_string()) == "_Retval") { + if (absl::string_view(n->type_string()) == "_Retval") { TF_RETURN_IF_ERROR(SetNodeShardingFromNeighbors(n, /*out_edges=*/false)); } } @@ -213,8 +213,7 @@ Status XlaCompiler::CompileFunction(const XlaCompiler::CompileOptions& options, if (VLOG_IS_ON(2)) { VLOG(2) << "XlaCompiler::CompileFunction: " << dump_graph::DumpGraphToFile( - strings::StrCat("xla_compile_function_", function_id), - *graph); + absl::StrCat("xla_compile_function_", function_id), *graph); } VLOG(1) << "===================================================="; @@ -522,7 +521,7 @@ Status XlaCompiler::BuildArguments( // Use the _Arg nodes in the graph to resolve core assignments. for (const Node* n : graph.nodes()) { - if (StringPiece(n->type_string()) != "_Arg") continue; + if (absl::string_view(n->type_string()) != "_Arg") continue; int index; TF_RETURN_IF_ERROR(GetNodeAttr(n->attrs(), "index", &index)); TF_RET_CHECK(index >= 0 && index < args.size()) @@ -581,7 +580,7 @@ Status XlaCompiler::BuildArguments( builder, core == -1 ? absl::optional<xla::OpSharding>() : xla::sharding_builder::AssignDevice(core)); arg_handles[i] = xla::Parameter(builder, i, (*input_shapes)[i], - strings::StrCat("arg", i)); + absl::StrCat("arg", i)); } } @@ -644,7 +643,7 @@ Status XlaCompiler::CompileSingleOp( // dependency edge to the _SOURCE node. for (int64 i = 0; i < ctx->num_inputs(); ++i) { Node* node; - string name = strings::StrCat(ctx->op_kernel().name(), "_", i, "_arg"); + string name = absl::StrCat(ctx->op_kernel().name(), "_", i, "_arg"); Status status = NodeBuilder(name, "_Arg") .ControlInput(graph->source_node()) .Attr("T", ctx->input_dtype(i)) @@ -657,7 +656,7 @@ Status XlaCompiler::CompileSingleOp( // Similarly with return values, create dummy _Retval nodes fed by `node`. for (int64 i = 0; i < ctx->num_outputs(); ++i) { Node* node; - string name = strings::StrCat(ctx->op_kernel().name(), "_", i, "_retval"); + string name = absl::StrCat(ctx->op_kernel().name(), "_", i, "_retval"); Status status = NodeBuilder(name, "_Retval") .Input(main_node, i) .Attr("T", ctx->expected_output_dtype(i)) @@ -693,7 +692,7 @@ Status ValidateGraph(const Graph* graph, const DeviceType& device_type, const string& name) { auto maybe_error = [&](const Node* node, const Status& s) -> Status { if (!s.ok()) { - return errors::InvalidArgument(strings::StrCat( + return errors::InvalidArgument(absl::StrCat( "Detected unsupported operations when trying to compile graph ", name, " on ", device_type.type_string(), ": ", node->def().op(), " (", s.error_message(), ")", FormatNodeForError(*node))); @@ -734,7 +733,7 @@ Status XlaCompiler::CompileGraph(const XlaCompiler::CompileOptions& options, if (VLOG_IS_ON(2)) { VLOG(2) << "XlaCompiler::CompileGraph: " << dump_graph::DumpGraphToFile( - strings::StrCat("xla_compile_graph_", name), *graph); + absl::StrCat("xla_compile_graph_", name), *graph); } // Report the error here if initialization failed. diff --git a/tensorflow/compiler/tf2xla/xla_context.cc b/tensorflow/compiler/tf2xla/xla_context.cc index 24a4b92b45..e8b4b0eb36 100644 --- a/tensorflow/compiler/tf2xla/xla_context.cc +++ b/tensorflow/compiler/tf2xla/xla_context.cc @@ -32,7 +32,6 @@ limitations under the License. #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/statusor.h" #include "tensorflow/core/common_runtime/dma_helper.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/logging.h" namespace tensorflow { diff --git a/tensorflow/compiler/tf2xla/xla_op_kernel.cc b/tensorflow/compiler/tf2xla/xla_op_kernel.cc index 1499c99ed1..d67e50375b 100644 --- a/tensorflow/compiler/tf2xla/xla_op_kernel.cc +++ b/tensorflow/compiler/tf2xla/xla_op_kernel.cc @@ -67,7 +67,7 @@ const xla::XlaOp& XlaOpKernelContext::Input(int index) { return GetComputationFromTensor(context_->input(index)); } -const xla::XlaOp& XlaOpKernelContext::Input(StringPiece name) { +const xla::XlaOp& XlaOpKernelContext::Input(absl::string_view name) { return GetComputationFromTensor(GetInputTensorByName(name)); } @@ -75,7 +75,7 @@ TensorShape XlaOpKernelContext::InputShape(int index) { return context_->input(index).shape(); } -TensorShape XlaOpKernelContext::InputShape(StringPiece name) { +TensorShape XlaOpKernelContext::InputShape(absl::string_view name) { return GetInputTensorByName(name).shape(); } @@ -100,7 +100,7 @@ Status XlaOpKernelContext::ConstantInput(int index, } static xla::StatusOr<int> InputIndex(XlaOpKernelContext* context, - StringPiece name) { + absl::string_view name) { int start, stop; TF_RETURN_IF_ERROR(context->op_kernel().InputRange(name, &start, &stop)); if (stop != start + 1) { @@ -112,7 +112,7 @@ static xla::StatusOr<int> InputIndex(XlaOpKernelContext* context, return start; } -Status XlaOpKernelContext::ConstantInput(StringPiece name, +Status XlaOpKernelContext::ConstantInput(absl::string_view name, xla::Literal* constant_literal) { TF_ASSIGN_OR_RETURN(int index, InputIndex(this, name)); return ConstantInput(index, constant_literal); @@ -265,7 +265,7 @@ Status XlaOpKernelContext::ConstantInputAsIntScalar(int index, int64* out) { return LiteralToInt64Scalar(literal, out); } -Status XlaOpKernelContext::ConstantInputAsIntScalar(StringPiece name, +Status XlaOpKernelContext::ConstantInputAsIntScalar(absl::string_view name, int64* out) { TF_ASSIGN_OR_RETURN(int index, InputIndex(this, name)); return ConstantInputAsIntScalar(index, out); @@ -305,7 +305,7 @@ Status XlaOpKernelContext::ConstantInputAsIntVector(int index, return LiteralToInt64Vector(literal, out); } -Status XlaOpKernelContext::ConstantInputAsIntVector(StringPiece name, +Status XlaOpKernelContext::ConstantInputAsIntVector(absl::string_view name, std::vector<int64>* out) { TF_ASSIGN_OR_RETURN(int index, InputIndex(this, name)); return ConstantInputAsIntVector(index, out); @@ -344,7 +344,7 @@ Status XlaOpKernelContext::ConstantInputAsInt64Literal(int index, } } -Status XlaOpKernelContext::ConstantInputAsInt64Literal(StringPiece name, +Status XlaOpKernelContext::ConstantInputAsInt64Literal(absl::string_view name, xla::Literal* out) { TF_ASSIGN_OR_RETURN(int index, InputIndex(this, name)); return ConstantInputAsInt64Literal(index, out); @@ -361,7 +361,7 @@ Status XlaOpKernelContext::ConstantInputAsShape(int index, TensorShape* shape) { return Status::OK(); } -Status XlaOpKernelContext::InputList(StringPiece name, +Status XlaOpKernelContext::InputList(absl::string_view name, std::vector<xla::XlaOp>* handles, std::vector<TensorShape>* shapes) { OpInputList inputs; @@ -376,7 +376,7 @@ Status XlaOpKernelContext::InputList(StringPiece name, } Status XlaOpKernelContext::ConstantInputList( - StringPiece name, std::vector<xla::Literal>* outputs) { + absl::string_view name, std::vector<xla::Literal>* outputs) { int start, stop; TF_RETURN_IF_ERROR(op_kernel().InputRange(name, &start, &stop)); outputs->resize(stop - start); @@ -429,8 +429,8 @@ Status XlaOpKernelContext::ReadVariableInput(int index, DataType type, value); } -Status XlaOpKernelContext::ReadVariableInput(StringPiece name, DataType type, - TensorShape* shape, +Status XlaOpKernelContext::ReadVariableInput(absl::string_view name, + DataType type, TensorShape* shape, xla::XlaOp* value) { return ReadVariableInputTensor(GetInputTensorByName(name), type, context_, shape, value); @@ -564,7 +564,7 @@ Status XlaOpKernelContext::AssignVariable(int input_index, DataType type, handle, builder()); } -Status XlaOpKernelContext::AssignVariable(StringPiece name, DataType type, +Status XlaOpKernelContext::AssignVariable(absl::string_view name, DataType type, xla::XlaOp handle) { TF_RET_CHECK(handle.valid()); return AssignVariableTensor(GetInputTensorByName(name), type, context_, @@ -610,7 +610,7 @@ const xla::XlaComputation* XlaOpKernelContext::GetOrCreateMul( return XlaContext::Get(context_).GetOrCreateMul(type); } -const Tensor& XlaOpKernelContext::GetInputTensorByName(StringPiece name) { +const Tensor& XlaOpKernelContext::GetInputTensorByName(absl::string_view name) { const Tensor* tensor; CHECK(context_->input(name, &tensor).ok()); return *tensor; diff --git a/tensorflow/compiler/tf2xla/xla_op_kernel.h b/tensorflow/compiler/tf2xla/xla_op_kernel.h index 45cfa7da74..962c86d3a5 100644 --- a/tensorflow/compiler/tf2xla/xla_op_kernel.h +++ b/tensorflow/compiler/tf2xla/xla_op_kernel.h @@ -80,14 +80,14 @@ class XlaOpKernelContext { TensorShape InputShape(int index); // Returns the shape of input `name`. - TensorShape InputShape(StringPiece name); + TensorShape InputShape(absl::string_view name); // Returns input `index` as a XlaOp. Unlike // OpKernelContext::Input returns a symbolic value rather than a concrete // Tensor. const xla::XlaOp& Input(int index); // Returns input `name` as a XlaOp. - const xla::XlaOp& Input(StringPiece name); + const xla::XlaOp& Input(absl::string_view name); // Returns true if all inputs are the same shape, otherwise sets the // status to a non-OK value and returns false. @@ -97,7 +97,7 @@ class XlaOpKernelContext { // Returns the named list-valued immutable input in "list", as // defined in the OpDef. If the named output is not list-valued, // returns a one-element list. - Status InputList(StringPiece name, std::vector<xla::XlaOp>* handles, + Status InputList(absl::string_view name, std::vector<xla::XlaOp>* handles, std::vector<TensorShape>* shapes); // Helper methods for constant inputs. @@ -106,7 +106,7 @@ class XlaOpKernelContext { // expression cannot be evaluated, e.g., because it depends on unbound // parameters, returns a non-OK status. Status ConstantInput(int index, xla::Literal* constant_literal); - Status ConstantInput(StringPiece name, xla::Literal* constant_literal); + Status ConstantInput(absl::string_view name, xla::Literal* constant_literal); // Evaluates input `index`, reshapes it to `new_shape` if new_shape != // InputShape(index), and stores it in `*constant_literal`. If the input @@ -118,14 +118,15 @@ class XlaOpKernelContext { // Converts a constant scalar int32 or int64 tensor into an int64. Status ConstantInputAsIntScalar(int index, int64* out); - Status ConstantInputAsIntScalar(StringPiece name, int64* out); + Status ConstantInputAsIntScalar(absl::string_view name, int64* out); // Converts a constant scalar float32 or float64 tensor into a float64. Status ConstantInputAsFloatScalar(int index, double* out); // Converts a constant 1D int32 or int64 tensor into a vector of int64s. Status ConstantInputAsIntVector(int index, std::vector<int64>* out); - Status ConstantInputAsIntVector(StringPiece name, std::vector<int64>* out); + Status ConstantInputAsIntVector(absl::string_view name, + std::vector<int64>* out); // Reshapes and converts a constant int32 or int64 tensor into a vector of // int64s. @@ -133,7 +134,7 @@ class XlaOpKernelContext { // Converts a constant int32 or int64 Tensor into an xla int64 Literal. Status ConstantInputAsInt64Literal(int index, xla::Literal* out); - Status ConstantInputAsInt64Literal(StringPiece name, xla::Literal* out); + Status ConstantInputAsInt64Literal(absl::string_view name, xla::Literal* out); // Converts a constant 1D int32 or int64 tensor into a TensorShape. Status ConstantInputAsShape(int index, TensorShape* shape); @@ -141,7 +142,7 @@ class XlaOpKernelContext { // Returns the named list-valued immutable input in "list", as // defined in the OpDef. If the named output is not list-valued, // returns a one-element list. - Status ConstantInputList(StringPiece name, + Status ConstantInputList(absl::string_view name, std::vector<xla::Literal>* literals); // Outputs @@ -190,8 +191,8 @@ class XlaOpKernelContext { xla::XlaOp* value); // Reads the current value of the resouce variable referred to by input // `name`. - Status ReadVariableInput(StringPiece name, DataType type, TensorShape* shape, - xla::XlaOp* value); + Status ReadVariableInput(absl::string_view name, DataType type, + TensorShape* shape, xla::XlaOp* value); // Assigns the value `handle` to the variable referenced by input // `input_index`. The variable must be of `type`. Returns an error if the @@ -199,7 +200,8 @@ class XlaOpKernelContext { // different shape. Status AssignVariable(int input_index, DataType type, xla::XlaOp handle); // Assigns the value `handle` to the variable referenced by input `name`. - Status AssignVariable(StringPiece name, DataType type, xla::XlaOp handle); + Status AssignVariable(absl::string_view name, DataType type, + xla::XlaOp handle); // Helper routines for the OP_REQUIRES macros void CtxFailure(const Status& s); @@ -248,7 +250,7 @@ class XlaOpKernelContext { private: // Returns the tensor of input `name`. - const Tensor& GetInputTensorByName(StringPiece name); + const Tensor& GetInputTensorByName(absl::string_view name); OpKernelContext* const context_; }; diff --git a/tensorflow/compiler/tf2xla/xla_op_registry.cc b/tensorflow/compiler/tf2xla/xla_op_registry.cc index dae2d956ca..b0eeee3174 100644 --- a/tensorflow/compiler/tf2xla/xla_op_registry.cc +++ b/tensorflow/compiler/tf2xla/xla_op_registry.cc @@ -371,26 +371,28 @@ XlaOpRegistry& XlaOpRegistry::Instance() { return *r; } -XlaOpRegistrationBuilder::XlaOpRegistrationBuilder(StringPiece name) { +XlaOpRegistrationBuilder::XlaOpRegistrationBuilder(absl::string_view name) { registration_.reset(new XlaOpRegistry::OpRegistration); registration_->name = string(name); } -XlaOpRegistrationBuilder XlaOpRegistrationBuilder::Name(StringPiece name) { +XlaOpRegistrationBuilder XlaOpRegistrationBuilder::Name( + absl::string_view name) { XlaOpRegistrationBuilder registration(name); return registration; } XlaOpRegistrationBuilder& XlaOpRegistrationBuilder::Device( - absl::Span<const StringPiece> devices) { + absl::Span<const absl::string_view> devices) { registration_->has_device_whitelist = true; - for (StringPiece device : devices) { + for (absl::string_view device : devices) { registration_->device_whitelist.emplace(device); } return *this; } -XlaOpRegistrationBuilder& XlaOpRegistrationBuilder::Device(StringPiece device) { +XlaOpRegistrationBuilder& XlaOpRegistrationBuilder::Device( + absl::string_view device) { registration_->has_device_whitelist = true; registration_->device_whitelist.emplace(device); return *this; @@ -407,7 +409,7 @@ XlaOpRegistrationBuilder& XlaOpRegistrationBuilder::AllowResourceTypes() { } XlaOpRegistrationBuilder& XlaOpRegistrationBuilder::TypeConstraint( - StringPiece attr_name, DataType allowed) { + absl::string_view attr_name, DataType allowed) { std::set<DataType>& types = registration_->type_constraints[string(attr_name)]; types.insert(allowed); @@ -415,7 +417,7 @@ XlaOpRegistrationBuilder& XlaOpRegistrationBuilder::TypeConstraint( } XlaOpRegistrationBuilder& XlaOpRegistrationBuilder::TypeConstraint( - StringPiece attr_name, absl::Span<const DataType> allowed) { + absl::string_view attr_name, absl::Span<const DataType> allowed) { std::set<DataType>& types = registration_->type_constraints[string(attr_name)]; for (DataType t : allowed) { @@ -425,7 +427,7 @@ XlaOpRegistrationBuilder& XlaOpRegistrationBuilder::TypeConstraint( } XlaOpRegistrationBuilder& XlaOpRegistrationBuilder::CompileTimeConstInput( - StringPiece input_name) { + absl::string_view input_name) { registration_->compile_time_constant_inputs.emplace(input_name); return *this; } @@ -452,7 +454,7 @@ XlaOpRegistrar::XlaOpRegistrar( } XlaBackendRegistrar::XlaBackendRegistrar( - StringPiece name, absl::Span<const DataType> types, + absl::string_view name, absl::Span<const DataType> types, XlaOpRegistry::BackendOpFilter op_filter) { XlaOpRegistry& registry = XlaOpRegistry::Instance(); registry.RegisterBackend(string(name), types, op_filter); diff --git a/tensorflow/compiler/tf2xla/xla_op_registry.h b/tensorflow/compiler/tf2xla/xla_op_registry.h index c640842dc0..74a4885f1f 100644 --- a/tensorflow/compiler/tf2xla/xla_op_registry.h +++ b/tensorflow/compiler/tf2xla/xla_op_registry.h @@ -232,18 +232,18 @@ class XlaOpRegistry { class XlaOpRegistrationBuilder { public: // Starts an operator registration chain. - static XlaOpRegistrationBuilder Name(StringPiece name); + static XlaOpRegistrationBuilder Name(absl::string_view name); // Specifies a whitelist of devices on which the operator may run. - XlaOpRegistrationBuilder& Device(StringPiece devices); - XlaOpRegistrationBuilder& Device(absl::Span<const StringPiece> devices); + XlaOpRegistrationBuilder& Device(absl::string_view devices); + XlaOpRegistrationBuilder& Device(absl::Span<const absl::string_view> devices); // Specifies a type constraint for a type variable attribute. Each constraint // specifies the set of types that the type variable may assume. - XlaOpRegistrationBuilder& TypeConstraint(StringPiece attr_name, + XlaOpRegistrationBuilder& TypeConstraint(absl::string_view attr_name, DataType allowed); - XlaOpRegistrationBuilder& TypeConstraint(StringPiece attr_name, + XlaOpRegistrationBuilder& TypeConstraint(absl::string_view attr_name, absl::Span<const DataType> allowed); // Specifies that a dummy copy of this operator should not be registered on @@ -254,13 +254,13 @@ class XlaOpRegistrationBuilder { XlaOpRegistrationBuilder& AllowResourceTypes(); // Mark 'input_name' as an argument whose value must be known at compile-time. - XlaOpRegistrationBuilder& CompileTimeConstInput(StringPiece input_name); + XlaOpRegistrationBuilder& CompileTimeConstInput(absl::string_view input_name); std::unique_ptr<XlaOpRegistry::OpRegistration> Build( XlaOpRegistry::Factory factory); private: - XlaOpRegistrationBuilder(StringPiece name); + XlaOpRegistrationBuilder(absl::string_view name); std::unique_ptr<XlaOpRegistry::OpRegistration> registration_; }; @@ -288,7 +288,7 @@ class XlaOpRegistrar { class XlaBackendRegistrar { public: - XlaBackendRegistrar(StringPiece name, absl::Span<const DataType> types, + XlaBackendRegistrar(absl::string_view name, absl::Span<const DataType> types, XlaOpRegistry::BackendOpFilter op_filter = nullptr); }; diff --git a/tensorflow/compiler/tf2xla/xla_resource.cc b/tensorflow/compiler/tf2xla/xla_resource.cc index 7928fa0347..56c2e01055 100644 --- a/tensorflow/compiler/tf2xla/xla_resource.cc +++ b/tensorflow/compiler/tf2xla/xla_resource.cc @@ -43,7 +43,7 @@ XlaResource::XlaResource(Kind kind, int arg_num, string name, DataType type, for (const string& gradient : tensor_array_gradients) { tensor_array_gradients_[gradient].reset(new XlaResource( /*kind=*/kTensorArray, /*arg_num=*/-1, - /*name=*/strings::StrCat("TensorArrayGrad: ", name_), type_, shape_, + /*name=*/absl::StrCat("TensorArrayGrad: ", name_), type_, shape_, xla::XlaOp(), tensor_array_size_, /*tensor_array_gradients=*/{})); } } @@ -135,7 +135,7 @@ Status XlaResource::GetOrCreateTensorArrayGradient(const string& source, xla::Broadcast(XlaHelpers::Zero(builder, type_), ta_shape.dim_sizes()); gradient.reset( new XlaResource(/*kind=*/kTensorArray, /*arg_num=*/-1, - /*name=*/strings::StrCat("TensorArrayGrad: ", name_), + /*name=*/absl::StrCat("TensorArrayGrad: ", name_), type_, shape_, gradient_value, tensor_array_size_, /*tensor_array_gradients=*/{})); } diff --git a/tensorflow/compiler/xla/BUILD b/tensorflow/compiler/xla/BUILD index d448bad614..76e36f3c46 100644 --- a/tensorflow/compiler/xla/BUILD +++ b/tensorflow/compiler/xla/BUILD @@ -517,6 +517,7 @@ cc_library( ":util", ":xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/base", "@com_google_absl//absl/memory", ], ) diff --git a/tensorflow/compiler/xla/client/lib/conv_grad_size_util.h b/tensorflow/compiler/xla/client/lib/conv_grad_size_util.h index c18087ce6b..0ad01728e6 100644 --- a/tensorflow/compiler/xla/client/lib/conv_grad_size_util.h +++ b/tensorflow/compiler/xla/client/lib/conv_grad_size_util.h @@ -17,7 +17,6 @@ limitations under the License. #define TENSORFLOW_COMPILER_XLA_CLIENT_LIB_CONV_GRAD_SIZE_UTIL_H_ #include "tensorflow/compiler/xla/client/padding.h" -#include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/platform/types.h" namespace xla { diff --git a/tensorflow/compiler/xla/client/xla_builder.cc b/tensorflow/compiler/xla/client/xla_builder.cc index e639028ccd..887b970661 100644 --- a/tensorflow/compiler/xla/client/xla_builder.cc +++ b/tensorflow/compiler/xla/client/xla_builder.cc @@ -820,7 +820,7 @@ XlaOp XlaBuilder::Lt(const XlaOp& lhs, const XlaOp& rhs, } XlaOp XlaBuilder::Dot(const XlaOp& lhs, const XlaOp& rhs, - const PrecisionConfigProto* precision_config_proto) { + const PrecisionConfig* precision_config) { return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { TF_ASSIGN_OR_RETURN(const Shape& lhs_shape, GetShape(lhs)); @@ -828,14 +828,13 @@ XlaOp XlaBuilder::Dot(const XlaOp& lhs, const XlaOp& rhs, dimension_numbers.add_lhs_contracting_dimensions( lhs_shape.dimensions_size() == 1 ? 0 : 1); dimension_numbers.add_rhs_contracting_dimensions(0); - return DotGeneral(lhs, rhs, dimension_numbers, precision_config_proto); + return DotGeneral(lhs, rhs, dimension_numbers, precision_config); }); } -XlaOp XlaBuilder::DotGeneral( - const XlaOp& lhs, const XlaOp& rhs, - const DotDimensionNumbers& dimension_numbers, - const PrecisionConfigProto* precision_config_proto) { +XlaOp XlaBuilder::DotGeneral(const XlaOp& lhs, const XlaOp& rhs, + const DotDimensionNumbers& dimension_numbers, + const PrecisionConfig* precision_config) { return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { HloInstructionProto instr; TF_ASSIGN_OR_RETURN(const Shape& lhs_shape, GetShape(lhs)); @@ -844,8 +843,8 @@ XlaOp XlaBuilder::DotGeneral( ShapeInference::InferDotOpShape(lhs_shape, rhs_shape, dimension_numbers)); *instr.mutable_dot_dimension_numbers() = dimension_numbers; - if (precision_config_proto != nullptr) { - *instr.mutable_precision_config() = *precision_config_proto; + if (precision_config != nullptr) { + *instr.mutable_precision_config() = *precision_config; } return AddInstruction(std::move(instr), HloOpcode::kDot, {lhs, rhs}); }); @@ -899,28 +898,26 @@ Status XlaBuilder::VerifyConvolution( XlaOp XlaBuilder::Conv(const XlaOp& lhs, const XlaOp& rhs, absl::Span<const int64> window_strides, Padding padding, int64 feature_group_count, - const PrecisionConfigProto* precision_config_proto) { + const PrecisionConfig* precision_config) { return ConvWithGeneralDimensions( lhs, rhs, window_strides, padding, CreateDefaultConvDimensionNumbers(window_strides.size()), - feature_group_count, precision_config_proto); + feature_group_count, precision_config); } XlaOp XlaBuilder::ConvWithGeneralPadding( const XlaOp& lhs, const XlaOp& rhs, absl::Span<const int64> window_strides, absl::Span<const std::pair<int64, int64>> padding, - int64 feature_group_count, - const PrecisionConfigProto* precision_config_proto) { + int64 feature_group_count, const PrecisionConfig* precision_config) { return ConvGeneral(lhs, rhs, window_strides, padding, CreateDefaultConvDimensionNumbers(window_strides.size()), - feature_group_count, precision_config_proto); + feature_group_count, precision_config); } XlaOp XlaBuilder::ConvWithGeneralDimensions( const XlaOp& lhs, const XlaOp& rhs, absl::Span<const int64> window_strides, Padding padding, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count, - const PrecisionConfigProto* precision_config_proto) { + int64 feature_group_count, const PrecisionConfig* precision_config) { return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { TF_ASSIGN_OR_RETURN(const Shape& lhs_shape, GetShape(lhs)); TF_ASSIGN_OR_RETURN(const Shape& rhs_shape, GetShape(rhs)); @@ -948,7 +945,7 @@ XlaOp XlaBuilder::ConvWithGeneralDimensions( MakePadding(base_area_dimensions, window_dimensions, window_strides, padding), dimension_numbers, feature_group_count, - precision_config_proto); + precision_config); }); } @@ -956,11 +953,10 @@ XlaOp XlaBuilder::ConvGeneral( const XlaOp& lhs, const XlaOp& rhs, absl::Span<const int64> window_strides, absl::Span<const std::pair<int64, int64>> padding, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count, - const PrecisionConfigProto* precision_config_proto) { + int64 feature_group_count, const PrecisionConfig* precision_config) { return ConvGeneralDilated(lhs, rhs, window_strides, padding, {}, {}, dimension_numbers, feature_group_count, - precision_config_proto); + precision_config); } XlaOp XlaBuilder::ConvGeneralDilated( @@ -968,8 +964,7 @@ XlaOp XlaBuilder::ConvGeneralDilated( absl::Span<const std::pair<int64, int64>> padding, absl::Span<const int64> lhs_dilation, absl::Span<const int64> rhs_dilation, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count, - const PrecisionConfigProto* precision_config_proto) { + int64 feature_group_count, const PrecisionConfig* precision_config) { return ReportErrorOrReturn([&]() -> StatusOr<XlaOp> { HloInstructionProto instr; TF_ASSIGN_OR_RETURN(const Shape& lhs_shape, GetShape(lhs)); @@ -990,14 +985,14 @@ XlaOp XlaBuilder::ConvGeneralDilated( TF_ASSIGN_OR_RETURN(*instr.mutable_shape(), ShapeInference::InferConvolveShape( - lhs_shape, rhs_shape, instr.window(), - dimension_numbers, feature_group_count)); + lhs_shape, rhs_shape, feature_group_count, + instr.window(), dimension_numbers)); *instr.mutable_convolution_dimension_numbers() = dimension_numbers; instr.set_feature_group_count(feature_group_count); - if (precision_config_proto != nullptr) { - *instr.mutable_precision_config() = *precision_config_proto; + if (precision_config != nullptr) { + *instr.mutable_precision_config() = *precision_config; } return AddInstruction(std::move(instr), HloOpcode::kConvolution, @@ -2594,43 +2589,40 @@ XlaOp Le(const XlaOp& lhs, const XlaOp& rhs, } XlaOp Dot(const XlaOp& lhs, const XlaOp& rhs, - const PrecisionConfigProto* precision_config_proto) { - return lhs.builder()->Dot(lhs, rhs, precision_config_proto); + const PrecisionConfig* precision_config) { + return lhs.builder()->Dot(lhs, rhs, precision_config); } XlaOp DotGeneral(const XlaOp& lhs, const XlaOp& rhs, const DotDimensionNumbers& dimension_numbers, - const PrecisionConfigProto* precision_config_proto) { + const PrecisionConfig* precision_config) { return lhs.builder()->DotGeneral(lhs, rhs, dimension_numbers, - precision_config_proto); + precision_config); } XlaOp Conv(const XlaOp& lhs, const XlaOp& rhs, absl::Span<const int64> window_strides, Padding padding, - int64 feature_group_count, - const PrecisionConfigProto* precision_config_proto) { + int64 feature_group_count, const PrecisionConfig* precision_config) { return lhs.builder()->Conv(lhs, rhs, window_strides, padding, - feature_group_count, precision_config_proto); + feature_group_count, precision_config); } -XlaOp ConvWithGeneralPadding( - const XlaOp& lhs, const XlaOp& rhs, absl::Span<const int64> window_strides, - absl::Span<const std::pair<int64, int64>> padding, - int64 feature_group_count, - const PrecisionConfigProto* precision_config_proto) { - return lhs.builder()->ConvWithGeneralPadding(lhs, rhs, window_strides, - padding, feature_group_count, - precision_config_proto); +XlaOp ConvWithGeneralPadding(const XlaOp& lhs, const XlaOp& rhs, + absl::Span<const int64> window_strides, + absl::Span<const std::pair<int64, int64>> padding, + int64 feature_group_count, + const PrecisionConfig* precision_config) { + return lhs.builder()->ConvWithGeneralPadding( + lhs, rhs, window_strides, padding, feature_group_count, precision_config); } XlaOp ConvWithGeneralDimensions( const XlaOp& lhs, const XlaOp& rhs, absl::Span<const int64> window_strides, Padding padding, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count, - const PrecisionConfigProto* precision_config_proto) { + int64 feature_group_count, const PrecisionConfig* precision_config) { return lhs.builder()->ConvWithGeneralDimensions( lhs, rhs, window_strides, padding, dimension_numbers, feature_group_count, - precision_config_proto); + precision_config); } XlaOp ConvGeneral(const XlaOp& lhs, const XlaOp& rhs, @@ -2638,10 +2630,10 @@ XlaOp ConvGeneral(const XlaOp& lhs, const XlaOp& rhs, absl::Span<const std::pair<int64, int64>> padding, const ConvolutionDimensionNumbers& dimension_numbers, int64 feature_group_count, - const PrecisionConfigProto* precision_config_proto) { + const PrecisionConfig* precision_config) { return lhs.builder()->ConvGeneral(lhs, rhs, window_strides, padding, dimension_numbers, feature_group_count, - precision_config_proto); + precision_config); } XlaOp ConvGeneralDilated(const XlaOp& lhs, const XlaOp& rhs, @@ -2651,10 +2643,10 @@ XlaOp ConvGeneralDilated(const XlaOp& lhs, const XlaOp& rhs, absl::Span<const int64> rhs_dilation, const ConvolutionDimensionNumbers& dimension_numbers, int64 feature_group_count, - const PrecisionConfigProto* precision_config_proto) { + const PrecisionConfig* precision_config) { return lhs.builder()->ConvGeneralDilated( lhs, rhs, window_strides, padding, lhs_dilation, rhs_dilation, - dimension_numbers, feature_group_count, precision_config_proto); + dimension_numbers, feature_group_count, precision_config); } XlaOp Fft(const XlaOp& operand, FftType fft_type, diff --git a/tensorflow/compiler/xla/client/xla_builder.h b/tensorflow/compiler/xla/client/xla_builder.h index 59fbc664f2..58e8f4e7fa 100644 --- a/tensorflow/compiler/xla/client/xla_builder.h +++ b/tensorflow/compiler/xla/client/xla_builder.h @@ -496,20 +496,19 @@ class XlaBuilder { // Enqueues a dot instruction onto the computation. XlaOp Dot(const XlaOp& lhs, const XlaOp& rhs, - const PrecisionConfigProto* precision_config_proto = nullptr); + const PrecisionConfig* precision_config = nullptr); // Enqueues a general dot instruction onto the computation. - XlaOp DotGeneral( - const XlaOp& lhs, const XlaOp& rhs, - const DotDimensionNumbers& dimension_numbers, - const PrecisionConfigProto* precision_config_proto = nullptr); + XlaOp DotGeneral(const XlaOp& lhs, const XlaOp& rhs, + const DotDimensionNumbers& dimension_numbers, + const PrecisionConfig* precision_config = nullptr); // Enqueues a convolution instruction onto the computation, which uses the // default convolution dimension numbers. XlaOp Conv(const XlaOp& lhs, const XlaOp& rhs, absl::Span<const int64> window_strides, Padding padding, int64 feature_group_count = 1, - const PrecisionConfigProto* precision_config_proto = nullptr); + const PrecisionConfig* precision_config = nullptr); // Enqueues a convolution instruction onto the computation, with the caller // provided padding configuration in the format returned by MakePadding(). @@ -518,7 +517,7 @@ class XlaBuilder { absl::Span<const int64> window_strides, absl::Span<const std::pair<int64, int64>> padding, int64 feature_group_count = 1, - const PrecisionConfigProto* precision_config_proto = nullptr); + const PrecisionConfig* precision_config = nullptr); // Enqueues a convolution instruction onto the computation, with the caller // provided dimension numbers configuration. @@ -527,29 +526,27 @@ class XlaBuilder { absl::Span<const int64> window_strides, Padding padding, const ConvolutionDimensionNumbers& dimension_numbers, int64 feature_group_count = 1, - const PrecisionConfigProto* precision_config_proto = nullptr); + const PrecisionConfig* precision_config = nullptr); // Enqueues a convolution instruction onto the computation, with the caller // provided padding configuration as well as the dimension numbers. - XlaOp ConvGeneral( - const XlaOp& lhs, const XlaOp& rhs, - absl::Span<const int64> window_strides, - absl::Span<const std::pair<int64, int64>> padding, - const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count = 1, - const PrecisionConfigProto* precision_config_proto = nullptr); + XlaOp ConvGeneral(const XlaOp& lhs, const XlaOp& rhs, + absl::Span<const int64> window_strides, + absl::Span<const std::pair<int64, int64>> padding, + const ConvolutionDimensionNumbers& dimension_numbers, + int64 feature_group_count = 1, + const PrecisionConfig* precision_config = nullptr); // Enqueues a convolution instruction onto the computation, with the caller // provided padding configuration, dilation factors and dimension numbers. - XlaOp ConvGeneralDilated( - const XlaOp& lhs, const XlaOp& rhs, - absl::Span<const int64> window_strides, - absl::Span<const std::pair<int64, int64>> padding, - absl::Span<const int64> lhs_dilation, - absl::Span<const int64> rhs_dilation, - const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count = 1, - const PrecisionConfigProto* precision_config_proto = nullptr); + XlaOp ConvGeneralDilated(const XlaOp& lhs, const XlaOp& rhs, + absl::Span<const int64> window_strides, + absl::Span<const std::pair<int64, int64>> padding, + absl::Span<const int64> lhs_dilation, + absl::Span<const int64> rhs_dilation, + const ConvolutionDimensionNumbers& dimension_numbers, + int64 feature_group_count = 1, + const PrecisionConfig* precision_config = nullptr); // Enqueues an FFT instruction onto the computation, of the given type and // with the given FFT length. @@ -1150,32 +1147,30 @@ class XlaBuilder { friend XlaOp Le(const XlaOp& lhs, const XlaOp& rhs, absl::Span<const int64> broadcast_dimensions); friend XlaOp Dot(const XlaOp& lhs, const XlaOp& rhs, - const PrecisionConfigProto* precision_config_proto); + const PrecisionConfig* precision_config); friend XlaOp DotGeneral(const XlaOp& lhs, const XlaOp& rhs, const DotDimensionNumbers& dimension_number, - const PrecisionConfigProto* precision_config_proto); + const PrecisionConfig* precision_config); friend XlaOp Conv(const XlaOp& lhs, const XlaOp& rhs, absl::Span<const int64> window_strides, Padding padding, int64 feature_group_count, - const PrecisionConfigProto* precision_config_proto); + const PrecisionConfig* precision_config); friend XlaOp ConvWithGeneralPadding( const XlaOp& lhs, const XlaOp& rhs, absl::Span<const int64> window_strides, absl::Span<const std::pair<int64, int64>> padding, - int64 feature_group_count, - const PrecisionConfigProto* precision_config_proto); + int64 feature_group_count, const PrecisionConfig* precision_config); friend XlaOp ConvWithGeneralDimensions( const XlaOp& lhs, const XlaOp& rhs, absl::Span<const int64> window_strides, Padding padding, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count, - const PrecisionConfigProto* precision_config_proto); + int64 feature_group_count, const PrecisionConfig* precision_config); friend XlaOp ConvGeneral(const XlaOp& lhs, const XlaOp& rhs, absl::Span<const int64> window_strides, absl::Span<const std::pair<int64, int64>> padding, const ConvolutionDimensionNumbers& dimension_numbers, int64 feature_group_count, - const PrecisionConfigProto* precision_config_proto); + const PrecisionConfig* precision_config); friend XlaOp ConvGeneralDilated( const XlaOp& lhs, const XlaOp& rhs, absl::Span<const int64> window_strides, @@ -1183,8 +1178,7 @@ class XlaBuilder { absl::Span<const int64> lhs_dilation, absl::Span<const int64> rhs_dilation, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count, - const PrecisionConfigProto* precision_config_proto); + int64 feature_group_count, const PrecisionConfig* precision_config); friend XlaOp Fft(const XlaOp& operand, FftType fft_type, absl::Span<const int64> fft_length); friend XlaOp Infeed(XlaBuilder* builder, const Shape& shape, @@ -1629,27 +1623,27 @@ XlaOp Le(const XlaOp& lhs, const XlaOp& rhs, // Enqueues a dot instruction onto the computation. XlaOp Dot(const XlaOp& lhs, const XlaOp& rhs, - const PrecisionConfigProto* precision_config_proto = nullptr); + const PrecisionConfig* precision_config = nullptr); // Enqueues a general dot instruction onto the computation. XlaOp DotGeneral(const XlaOp& lhs, const XlaOp& rhs, const DotDimensionNumbers& dimension_numbers, - const PrecisionConfigProto* precision_config_proto = nullptr); + const PrecisionConfig* precision_config = nullptr); // Enqueues a convolution instruction onto the computation, which uses the // default convolution dimension numbers. XlaOp Conv(const XlaOp& lhs, const XlaOp& rhs, absl::Span<const int64> window_strides, Padding padding, int64 feature_group_count = 1, - const PrecisionConfigProto* precision_config_proto = nullptr); + const PrecisionConfig* precision_config = nullptr); // Enqueues a convolution instruction onto the computation, with the caller // provided padding configuration in the format returned by MakePadding(). -XlaOp ConvWithGeneralPadding( - const XlaOp& lhs, const XlaOp& rhs, absl::Span<const int64> window_strides, - absl::Span<const std::pair<int64, int64>> padding, - int64 feature_group_count = 1, - const PrecisionConfigProto* precision_config_proto = nullptr); +XlaOp ConvWithGeneralPadding(const XlaOp& lhs, const XlaOp& rhs, + absl::Span<const int64> window_strides, + absl::Span<const std::pair<int64, int64>> padding, + int64 feature_group_count = 1, + const PrecisionConfig* precision_config = nullptr); // Enqueues a convolution instruction onto the computation, with the caller // provided dimension numbers configuration. @@ -1657,7 +1651,7 @@ XlaOp ConvWithGeneralDimensions( const XlaOp& lhs, const XlaOp& rhs, absl::Span<const int64> window_strides, Padding padding, const ConvolutionDimensionNumbers& dimension_numbers, int64 feature_group_count = 1, - const PrecisionConfigProto* precision_config_proto = nullptr); + const PrecisionConfig* precision_config = nullptr); // Enqueues a convolution instruction onto the computation, with the caller // provided padding configuration as well as the dimension numbers. @@ -1666,17 +1660,18 @@ XlaOp ConvGeneral(const XlaOp& lhs, const XlaOp& rhs, absl::Span<const std::pair<int64, int64>> padding, const ConvolutionDimensionNumbers& dimension_numbers, int64 feature_group_count = 1, - const PrecisionConfigProto* precision_config_proto = nullptr); + const PrecisionConfig* precision_config = nullptr); // Enqueues a convolution instruction onto the computation, with the caller // provided padding configuration, dilation factors and dimension numbers. -XlaOp ConvGeneralDilated( - const XlaOp& lhs, const XlaOp& rhs, absl::Span<const int64> window_strides, - absl::Span<const std::pair<int64, int64>> padding, - absl::Span<const int64> lhs_dilation, absl::Span<const int64> rhs_dilation, - const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count = 1, - const PrecisionConfigProto* precision_config_proto = nullptr); +XlaOp ConvGeneralDilated(const XlaOp& lhs, const XlaOp& rhs, + absl::Span<const int64> window_strides, + absl::Span<const std::pair<int64, int64>> padding, + absl::Span<const int64> lhs_dilation, + absl::Span<const int64> rhs_dilation, + const ConvolutionDimensionNumbers& dimension_numbers, + int64 feature_group_count = 1, + const PrecisionConfig* precision_config = nullptr); // Enqueues an FFT instruction onto the computation, of the given type and // with the given FFT length. diff --git a/tensorflow/compiler/xla/packed_literal_reader.cc b/tensorflow/compiler/xla/packed_literal_reader.cc index 83429b8fd3..f9473d372b 100644 --- a/tensorflow/compiler/xla/packed_literal_reader.cc +++ b/tensorflow/compiler/xla/packed_literal_reader.cc @@ -19,6 +19,7 @@ limitations under the License. #include <string> #include <utility> +#include "absl/base/casts.h" #include "absl/memory/memory.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/literal.h" @@ -27,7 +28,6 @@ limitations under the License. #include "tensorflow/compiler/xla/types.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/compiler/xla/xla_data.pb.h" -#include "tensorflow/core/lib/core/casts.h" #include "tensorflow/core/platform/logging.h" #include "tensorflow/core/platform/protobuf.h" #include "tensorflow/core/platform/types.h" @@ -62,9 +62,9 @@ StatusOr<std::unique_ptr<Literal>> PackedLiteralReader::Read( int64 elements = ShapeUtil::ElementsIn(shape); absl::Span<const float> field = result->data<float>(); - char* data = tensorflow::bit_cast<char*>(field.data()); + char* data = absl::bit_cast<char*>(field.data()); uint64 bytes = elements * sizeof(float); - tensorflow::StringPiece sp; // non-absl OK + absl::string_view sp; auto s = file_->Read(offset_, bytes, &sp, data); offset_ += sp.size(); if (!s.ok()) { @@ -85,7 +85,7 @@ bool PackedLiteralReader::IsExhausted() const { // Try to read a single byte from offset_. If we can't, we've // exhausted the data. char single_byte[1]; - tensorflow::StringPiece sp; // non-absl OK + absl::string_view sp; auto s = file_->Read(offset_, sizeof(single_byte), &sp, single_byte); return !s.ok(); } diff --git a/tensorflow/compiler/xla/reference_util.cc b/tensorflow/compiler/xla/reference_util.cc index a4854f593f..9f1afa2671 100644 --- a/tensorflow/compiler/xla/reference_util.cc +++ b/tensorflow/compiler/xla/reference_util.cc @@ -564,18 +564,22 @@ ReferenceUtil::ConvArray4DGeneralDimensionsDilated( dim2.set_base_dilation(lhs_dilation.second); *window.add_dimensions() = dim2; - const Shape& shape = - ShapeInference::InferConvolveShape(lhs_literal->shape(), - rhs_literal->shape(), window, dnums) - .ConsumeValueOrDie(); + const Shape& shape = ShapeInference::InferConvolveShape( + lhs_literal->shape(), rhs_literal->shape(), + /*feature_group_count=*/1, window, dnums) + .ConsumeValueOrDie(); HloInstruction* lhs_instruction = b.AddInstruction(HloInstruction::CreateConstant(std::move(lhs_literal))); HloInstruction* rhs_instruction = b.AddInstruction(HloInstruction::CreateConstant(std::move(rhs_literal))); + PrecisionConfig precision_config; + precision_config.mutable_operand_precision()->Resize( + /*new_size=*/2, PrecisionConfig::DEFAULT); b.AddInstruction(HloInstruction::CreateConvolve( - shape, lhs_instruction, rhs_instruction, window, dnums)); + shape, lhs_instruction, rhs_instruction, /*feature_group_count=*/1, + window, dnums, precision_config)); HloModuleConfig config; HloModule module("ReferenceUtil", config); auto computation = module.AddEntryComputation(b.Build()); diff --git a/tensorflow/compiler/xla/service/BUILD b/tensorflow/compiler/xla/service/BUILD index 26b48cf419..64141ed191 100644 --- a/tensorflow/compiler/xla/service/BUILD +++ b/tensorflow/compiler/xla/service/BUILD @@ -2520,6 +2520,7 @@ cc_library( "//tensorflow/compiler/xla:types", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/core:lib", + "@com_google_absl//absl/container:inlined_vector", ], ) @@ -3187,6 +3188,7 @@ cc_library( "//tensorflow/compiler/xla:util", "//tensorflow/core:lib", "@com_google_absl//absl/algorithm:container", + "@com_google_absl//absl/container:inlined_vector", ], ) @@ -3289,6 +3291,8 @@ tf_cc_test( size = "small", srcs = ["hlo_parser_test.cc"], deps = [ + ":hlo", + ":hlo_casting_utils", ":hlo_matchers", ":hlo_parser", "//tensorflow/compiler/xla:window_util", diff --git a/tensorflow/compiler/xla/service/algebraic_simplifier.cc b/tensorflow/compiler/xla/service/algebraic_simplifier.cc index 95e554c9a5..3d18fe3be2 100644 --- a/tensorflow/compiler/xla/service/algebraic_simplifier.cc +++ b/tensorflow/compiler/xla/service/algebraic_simplifier.cc @@ -127,6 +127,8 @@ class AlgebraicSimplifierVisitor : public DfsHloVisitorWithDefault { Status HandleImag(HloInstruction* imag) override; + Status HandleIota(HloInstruction* instruction) override; + Status HandleConvolution(HloInstruction* convolution) override; Status HandleDivide(HloInstruction* divide) override; @@ -948,9 +950,9 @@ StatusOr<HloInstruction*> AlgebraicSimplifierVisitor::OptimizeDotOfConcatHelper( new_dot_rhs = rhs_slice; } - auto* new_dot = computation_->AddInstruction(HloInstruction::CreateDot( - dot.shape(), new_dot_lhs, new_dot_rhs, new_dot_dnums)); - new_dot->set_precision_config(dot.precision_config()); + auto* new_dot = computation_->AddInstruction( + HloInstruction::CreateDot(dot.shape(), new_dot_lhs, new_dot_rhs, + new_dot_dnums, dot.precision_config())); if (add_result) { add_result = computation_->AddInstruction(HloInstruction::CreateBinary( @@ -1051,9 +1053,9 @@ StatusOr<HloInstruction*> AlgebraicSimplifierVisitor::OptimizeDotOfGather( const int n = right_operand->shape().dimensions(1 - rhs_contracting_dimension); auto memoized_shape = ShapeUtil::MakeShape(F32, {m, n}); - auto* memoized_inst = computation_->AddInstruction(HloInstruction::CreateDot( - memoized_shape, left_operand, right_operand, dnums)); - memoized_inst->set_precision_config(dot->precision_config()); + auto* memoized_inst = computation_->AddInstruction( + HloInstruction::CreateDot(memoized_shape, left_operand, right_operand, + dnums, dot->precision_config())); // Get pair {start, 0} or {0, start}. HloInstruction* original_start_indices = lhs_is_dynamic_slice ? lhs->mutable_operand(1) : rhs->mutable_operand(1); @@ -1149,9 +1151,8 @@ Status AlgebraicSimplifierVisitor::HandleDot(HloInstruction* dot) { dot_dimension_numbers.add_rhs_contracting_dimensions(0); auto new_dot = computation_->AddInstruction(HloInstruction::CreateDot( ShapeUtil::PermuteDimensions({1, 0}, dot->shape()), - rhs->mutable_operand(0), lhs->mutable_operand(0), - dot_dimension_numbers)); - new_dot->set_precision_config(dot->precision_config()); + rhs->mutable_operand(0), lhs->mutable_operand(0), dot_dimension_numbers, + dot->precision_config())); return ReplaceWithNewInstruction( dot, HloInstruction::CreateTranspose(dot->shape(), new_dot, {1, 0})); } @@ -1462,6 +1463,19 @@ Status AlgebraicSimplifierVisitor::HandleImag(HloInstruction* imag) { return Status::OK(); } +Status AlgebraicSimplifierVisitor::HandleIota(HloInstruction* instruction) { + // iota -> zero if the iota dimension never produces an element other than + // zero. + auto* iota = Cast<HloIotaInstruction>(instruction); + if (iota->shape().dimensions(iota->iota_dimension()) <= 1) { + auto zero = computation_->AddInstruction(HloInstruction::CreateConstant( + LiteralUtil::Zero(iota->shape().element_type()).CloneToUnique())); + return ReplaceWithNewInstruction( + iota, HloInstruction::CreateBroadcast(iota->shape(), zero, {})); + } + return Status::OK(); +} + Status AlgebraicSimplifierVisitor::HandlePad(HloInstruction* pad) { if (ShapeUtil::IsZeroElementArray(pad->operand(0)->shape())) { return ReplaceWithNewInstruction( @@ -2462,8 +2476,8 @@ Status AlgebraicSimplifierVisitor::HandleConvolution( dot_dimension_numbers.add_lhs_contracting_dimensions(1); dot_dimension_numbers.add_rhs_contracting_dimensions(0); auto dot = computation_->AddInstruction(HloInstruction::CreateDot( - dot_output_shape, new_lhs, new_rhs, dot_dimension_numbers)); - dot->set_precision_config(convolution->precision_config()); + dot_output_shape, new_lhs, new_rhs, dot_dimension_numbers, + convolution->precision_config())); return ReplaceInstruction(convolution, add_bitcast(convolution_shape, dot)); } diff --git a/tensorflow/compiler/xla/service/algebraic_simplifier_test.cc b/tensorflow/compiler/xla/service/algebraic_simplifier_test.cc index b4ff048db0..aa40fba9bb 100644 --- a/tensorflow/compiler/xla/service/algebraic_simplifier_test.cc +++ b/tensorflow/compiler/xla/service/algebraic_simplifier_test.cc @@ -1044,7 +1044,8 @@ TEST_F(AlgebraicSimplifierTest, ZeroSizedConvolution) { dim->set_window_reversal(false); // Create add computation. builder.AddInstruction(HloInstruction::CreateConvolve( - ShapeUtil::MakeShape(F32, {3, 3, 3}), lhs, rhs, window, dnums)); + ShapeUtil::MakeShape(F32, {3, 3, 3}), lhs, rhs, /*feature_group_count=*/1, + window, dnums, DefaultPrecisionConfig(2))); module().AddEntryComputation(builder.Build()); HloPassFix<AlgebraicSimplifier> simplifier(/*is_layout_sensitive=*/false, non_bitcasting_callback()); @@ -1858,12 +1859,33 @@ TEST_F(AlgebraicSimplifierTest, IotaAndReshapeMerged) { ShapeUtil::Equal(computation->root_instruction()->shape(), result_shape)); } -TEST_F(AlgebraicSimplifierTest, IotaAndReshape_1_3x1_3) { +TEST_F(AlgebraicSimplifierTest, IotaEffectiveScalar) { HloComputation::Builder builder(TestName()); auto iota = builder.AddInstruction( - HloInstruction::CreateIota(ShapeUtil::MakeShape(F32, {3, 1}), 1)); + HloInstruction::CreateIota(ShapeUtil::MakeShape(F32, {1, 1}), 0)); + auto result_shape = iota->shape(); + + auto computation = module().AddEntryComputation(builder.Build()); + + EXPECT_THAT(computation->root_instruction(), op::Iota()); + + AlgebraicSimplifier simplifier(/*is_layout_sensitive=*/false, + non_bitcasting_callback()); + ASSERT_TRUE(simplifier.Run(&module()).ValueOrDie()); + + auto root = computation->root_instruction(); + EXPECT_THAT(root, op::Broadcast(op::Constant())); + EXPECT_EQ(0.0f, root->operand(0)->literal().GetFirstElement<float>()); + EXPECT_TRUE( + ShapeUtil::Equal(computation->root_instruction()->shape(), result_shape)); +} + +TEST_F(AlgebraicSimplifierTest, IotaAndReshape_1_3x2_6) { + HloComputation::Builder builder(TestName()); + auto iota = builder.AddInstruction( + HloInstruction::CreateIota(ShapeUtil::MakeShape(F32, {3, 2}), 1)); builder.AddInstruction( - HloInstruction::CreateReshape(ShapeUtil::MakeShape(F32, {3}), iota)); + HloInstruction::CreateReshape(ShapeUtil::MakeShape(F32, {6}), iota)); auto computation = module().AddEntryComputation(builder.Build()); @@ -1897,12 +1919,12 @@ TEST_F(AlgebraicSimplifierTest, IotaAndReshape_4_3x2x4_6x1x1x4) { 3); } -TEST_F(AlgebraicSimplifierTest, IotaAndReshape_1_3x2x1_6x1x1x1) { +TEST_F(AlgebraicSimplifierTest, IotaAndReshape_1_3x2x2_6x1x1x2) { HloComputation::Builder builder(TestName()); auto iota = builder.AddInstruction( - HloInstruction::CreateIota(ShapeUtil::MakeShape(F32, {3, 2, 1}), 2)); + HloInstruction::CreateIota(ShapeUtil::MakeShape(F32, {3, 2, 2}), 2)); builder.AddInstruction(HloInstruction::CreateReshape( - ShapeUtil::MakeShape(F32, {6, 1, 1, 1}), iota)); + ShapeUtil::MakeShape(F32, {6, 1, 1, 2}), iota)); HloComputation* computation = module().AddEntryComputation(builder.Build()); @@ -2239,9 +2261,11 @@ TEST_P(ConvInputPaddingTest, DoTest) { .ValueOrDie(); builder.AddInstruction(HloInstruction::CreateConvolve( ShapeInference::InferConvolveShape(lhs_pad->shape(), filter->shape(), - window, dnums) + /*feature_group_count=*/1, window, + dnums) .ValueOrDie(), - lhs_pad, filter, window, dnums)); + lhs_pad, filter, /*feature_group_count=*/1, window, dnums, + DefaultPrecisionConfig(2))); auto module = CreateNewModule(); module->AddEntryComputation(builder.Build()); @@ -2347,15 +2371,17 @@ TEST_P(ConvFilterPaddingTest, DoIt) { .ValueOrDie(); auto* orig_conv = builder.AddInstruction(HloInstruction::CreateConvolve( ShapeInference::InferConvolveShape(input->shape(), rhs_pad->shape(), - window, dnums) + /*feature_group_count=*/1, window, + dnums) .ValueOrDie(), - input, rhs_pad, window, dnums)); + input, rhs_pad, /*feature_group_count=*/1, window, dnums, + DefaultPrecisionConfig(2))); // Add a PrecisionConfig and check that AlgebraicSimplifier keeps it in place // after the transformation. - PrecisionConfigProto precision_config; - precision_config.add_operand_precision(PrecisionConfigProto::HIGH); - precision_config.add_operand_precision(PrecisionConfigProto::HIGHEST); + PrecisionConfig precision_config; + precision_config.add_operand_precision(PrecisionConfig::HIGH); + precision_config.add_operand_precision(PrecisionConfig::HIGHEST); orig_conv->set_precision_config(precision_config); auto module = CreateNewModule(); @@ -2375,9 +2401,8 @@ TEST_P(ConvFilterPaddingTest, DoIt) { conv->operand(1)->shape().dimensions(2), conv->operand(1)->shape().dimensions(3), testcase.expected_conv_window)); - EXPECT_THAT( - conv->precision_config().operand_precision(), - ElementsAre(PrecisionConfigProto::HIGH, PrecisionConfigProto::HIGHEST)); + EXPECT_THAT(conv->precision_config().operand_precision(), + ElementsAre(PrecisionConfig::HIGH, PrecisionConfig::HIGHEST)); } } @@ -2501,8 +2526,9 @@ TEST_F(AlgebraicSimplifierTest, ConvertConvToMatmul) { HloInstruction* filter = b.AddInstruction(HloInstruction::CreateParameter(1, f_shape, "filter")); - b.AddInstruction(HloInstruction::CreateConvolve(out_shape, input, filter, - window, dnums)); + b.AddInstruction(HloInstruction::CreateConvolve( + out_shape, input, filter, + /*feature_group_count=*/1, window, dnums, DefaultPrecisionConfig(2))); // TODO(b/80488902): verify this module. auto module = HloTestBase::CreateNewModule(); @@ -2880,7 +2906,8 @@ TEST_F(AlgebraicSimplifierTest, IteratorInvalidation) { DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); - builder.AddInstruction(HloInstruction::CreateDot(r1f32, x, y, dot_dnums)); + builder.AddInstruction(HloInstruction::CreateDot(r1f32, x, y, dot_dnums, + DefaultPrecisionConfig(2))); std::unique_ptr<HloComputation> dot_computation(builder.Build()); HloComputation::Builder call_builder(TestName() + ".Call"); @@ -3232,8 +3259,8 @@ TEST_P(DotStrengthReductionTest, DotStrengthReduction) { DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); - builder.AddInstruction( - HloInstruction::CreateDot(dot_shape, lhs, rhs, dot_dnums)); + builder.AddInstruction(HloInstruction::CreateDot( + dot_shape, lhs, rhs, dot_dnums, DefaultPrecisionConfig(2))); auto computation = module().AddEntryComputation(builder.Build()); AlgebraicSimplifier simplifier(/*is_layout_sensitive=*/false, non_bitcasting_callback()); @@ -3308,8 +3335,8 @@ TEST_P(DotOfConcatSimplificationTest, ConstantLHS) { dot_dnums.add_rhs_contracting_dimensions(0); Shape dot_shape = ShapeUtil::MakeShape(F32, {spec.m, spec.n}); - builder.AddInstruction( - HloInstruction::CreateDot(dot_shape, lhs, rhs, dot_dnums)); + builder.AddInstruction(HloInstruction::CreateDot( + dot_shape, lhs, rhs, dot_dnums, DefaultPrecisionConfig(2))); auto computation = module().AddEntryComputation(builder.Build()); AlgebraicSimplifier simplifier(/*is_layout_sensitive=*/false, @@ -3372,8 +3399,8 @@ TEST_P(DotOfConcatSimplificationTest, ConstantRHS) { dot_dnums.add_rhs_contracting_dimensions(0); Shape dot_shape = ShapeUtil::MakeShape(F32, {spec.m, spec.n}); - builder.AddInstruction( - HloInstruction::CreateDot(dot_shape, lhs, rhs, dot_dnums)); + builder.AddInstruction(HloInstruction::CreateDot( + dot_shape, lhs, rhs, dot_dnums, DefaultPrecisionConfig(2))); auto computation = module().AddEntryComputation(builder.Build()); AlgebraicSimplifier simplifier(/*is_layout_sensitive=*/false, @@ -3490,8 +3517,8 @@ TEST_P(DotOfGatherSimplificationTest, ConstantRHS) { int64 dot_row_size = 1; int64 dot_col_size = spec.n; Shape dot_shape = ShapeUtil::MakeShape(F32, {dot_row_size, dot_col_size}); - builder.AddInstruction( - HloInstruction::CreateDot(dot_shape, ds, rhs, dot_dnums)); + builder.AddInstruction(HloInstruction::CreateDot( + dot_shape, ds, rhs, dot_dnums, DefaultPrecisionConfig(2))); auto computation = module().AddEntryComputation(builder.Build()); AlgebraicSimplifier simplifier(/*is_layout_sensitive=*/false, @@ -3560,8 +3587,8 @@ TEST_P(DotOfGatherSimplificationTest, ConstantLHS) { int64 dot_row_size = spec.m; int64 dot_col_size = 1; Shape dot_shape = ShapeUtil::MakeShape(F32, {dot_row_size, dot_col_size}); - builder.AddInstruction( - HloInstruction::CreateDot(dot_shape, lhs, ds, dot_dnums)); + builder.AddInstruction(HloInstruction::CreateDot( + dot_shape, lhs, ds, dot_dnums, DefaultPrecisionConfig(2))); auto computation = module().AddEntryComputation(builder.Build()); AlgebraicSimplifier simplifier(/*is_layout_sensitive=*/false, diff --git a/tensorflow/compiler/xla/service/batch_dot_simplification.cc b/tensorflow/compiler/xla/service/batch_dot_simplification.cc index a16b85a0a5..eda026ac56 100644 --- a/tensorflow/compiler/xla/service/batch_dot_simplification.cc +++ b/tensorflow/compiler/xla/service/batch_dot_simplification.cc @@ -63,8 +63,8 @@ BatchDotSimplification::ElideDegenerateBatchDimensionFromBatchDot( new_dim_numbers.rhs_contracting_dimensions(0) - degenerate_dims.size()); TF_ASSIGN_OR_RETURN(HloInstruction * new_dot, - MakeDotHlo(new_lhs, new_rhs, new_dim_numbers)); - new_dot->set_precision_config(batch_dot->precision_config()); + MakeDotHlo(new_lhs, new_rhs, new_dim_numbers, + batch_dot->precision_config())); TF_ASSIGN_OR_RETURN(HloInstruction * new_dot_reshaped, MakeReshapeHlo(batch_dot->shape(), new_dot)); diff --git a/tensorflow/compiler/xla/service/bfloat16_normalization_test.cc b/tensorflow/compiler/xla/service/bfloat16_normalization_test.cc index b08705d4c2..933cf873e0 100644 --- a/tensorflow/compiler/xla/service/bfloat16_normalization_test.cc +++ b/tensorflow/compiler/xla/service/bfloat16_normalization_test.cc @@ -308,8 +308,11 @@ TEST_F(BFloat16NormalizationTest, DoNotAddUnsupportedMixedPrecision) { DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); + PrecisionConfig precision_config; + precision_config.mutable_operand_precision()->Resize( + 2, PrecisionConfig::DEFAULT); HloInstruction* dot = builder.AddInstruction( - HloInstruction::CreateDot(bf16_shape, a, b, dot_dnums)); + HloInstruction::CreateDot(bf16_shape, a, b, dot_dnums, precision_config)); auto module = CreateNewModule(); auto computation = module->AddEntryComputation(builder.Build()); diff --git a/tensorflow/compiler/xla/service/buffer_assignment.cc b/tensorflow/compiler/xla/service/buffer_assignment.cc index b11f15ec7b..8b8c6bfd26 100644 --- a/tensorflow/compiler/xla/service/buffer_assignment.cc +++ b/tensorflow/compiler/xla/service/buffer_assignment.cc @@ -58,12 +58,65 @@ string ColocatedBufferSetsToString(const T& container, const char* title) { return result; } -// Walk the call graph of the HLO module and place each computation into either -// thread_local_computations or global_computations depending upon whether the -// computation requires thread-local allocations or global allocations. The -// elements in thread_local_computations and global_computations are in post -// order (if computation A has an instruction which calls computation B, then A -// will appear after B in the vector). +// Checks that points-to set of 'instruction' is unambiguous and distinct +// (ensured by CopyInsertion), then adds the buffer from the points-to set at +// 'index' to 'colocated_set'. +const LogicalBuffer* AddBufferToColocatedSet( + const HloInstruction* instruction, const ShapeIndex& index, + const TuplePointsToAnalysis& points_to_analysis, + std::vector<const LogicalBuffer*>* colocated_set) { + // CopyInsertion ensures root points-to set is unambiguous and distinct. + const auto& points_to = points_to_analysis.GetPointsToSet(instruction); + DCHECK(!points_to.IsAmbiguous()); + colocated_set->push_back(points_to.element(index)[0]); + return colocated_set->back(); +} + +// Given the interference map of a graph (the list of interfering node indices +// for each node), perform graph coloring such that interfering nodes are +// assigned to different colors. Returns the assigned color of the nodes, where +// the colors are represented as integer values [0, color_count). +std::vector<int64> ColorInterferenceGraph( + const std::vector<std::vector<int64>>& interference_map) { + const int64 node_count = interference_map.size(); + + // Sort the nodes such that we assign nodes with more interference first. This + // relies on the common heuristic of assigning the most constrained node + // first, but it would be good to investigate other ordering heuristics too. + std::vector<int64> nodes(node_count); + std::iota(nodes.begin(), nodes.end(), 0); + std::sort(nodes.begin(), nodes.end(), + [&interference_map](const int64 i, const int64 j) { + return interference_map[i].size() > interference_map[j].size(); + }); + + const int64 kColorUnassigned = -1; + std::vector<int64> assigned_colors(node_count, kColorUnassigned); + for (int64 node : nodes) { + // Mark the colors that are already assigned to the neighbors. + std::vector<bool> available_colors(node_count, true); + for (int64 neighbor : interference_map[node]) { + int64 color = assigned_colors[neighbor]; + if (color != kColorUnassigned) { + available_colors[color] = false; + } + } + + // Find the color that is not yet assigned to the neighbors. + int64 color = kColorUnassigned; + for (color = 0; color < available_colors.size(); ++color) { + if (available_colors[color]) { + break; + } + } + CHECK_NE(color, kColorUnassigned); + assigned_colors[node] = color; + } + return assigned_colors; +} + +} // namespace + Status GatherComputationsByAllocationType( const HloModule* module, std::vector<const HloComputation*>* thread_local_computations, @@ -165,65 +218,6 @@ Status GatherComputationsByAllocationType( return Status::OK(); } -// Checks that points-to set of 'instruction' is unambiguous and distinct -// (ensured by CopyInsertion), then adds the buffer from the points-to set at -// 'index' to 'colocated_set'. -const LogicalBuffer* AddBufferToColocatedSet( - const HloInstruction* instruction, const ShapeIndex& index, - const TuplePointsToAnalysis& points_to_analysis, - std::vector<const LogicalBuffer*>* colocated_set) { - // CopyInsertion ensures root points-to set is unambiguous and distinct. - const auto& points_to = points_to_analysis.GetPointsToSet(instruction); - DCHECK(!points_to.IsAmbiguous()); - colocated_set->push_back(points_to.element(index)[0]); - return colocated_set->back(); -} - -// Given the interference map of a graph (the list of interfering node indices -// for each node), perform graph coloring such that interfering nodes are -// assigned to different colors. Returns the assigned color of the nodes, where -// the colors are represented as integer values [0, color_count). -std::vector<int64> ColorInterferenceGraph( - const std::vector<std::vector<int64>>& interference_map) { - const int64 node_count = interference_map.size(); - - // Sort the nodes such that we assign nodes with more interference first. This - // relies on the common heuristic of assigning the most constrained node - // first, but it would be good to investigate other ordering heuristics too. - std::vector<int64> nodes(node_count); - std::iota(nodes.begin(), nodes.end(), 0); - std::sort(nodes.begin(), nodes.end(), - [&interference_map](const int64 i, const int64 j) { - return interference_map[i].size() > interference_map[j].size(); - }); - - const int64 kColorUnassigned = -1; - std::vector<int64> assigned_colors(node_count, kColorUnassigned); - for (int64 node : nodes) { - // Mark the colors that are already assigned to the neighbors. - std::vector<bool> available_colors(node_count, true); - for (int64 neighbor : interference_map[node]) { - int64 color = assigned_colors[neighbor]; - if (color != kColorUnassigned) { - available_colors[color] = false; - } - } - - // Find the color that is not yet assigned to the neighbors. - int64 color = kColorUnassigned; - for (color = 0; color < available_colors.size(); ++color) { - if (available_colors[color]) { - break; - } - } - CHECK_NE(color, kColorUnassigned); - assigned_colors[node] = color; - } - return assigned_colors; -} - -} // namespace - size_t BufferAllocation::Slice::Hasher::operator()(Slice s) const { uint64 h = std::hash<int64>()(s.index()); h = tensorflow::Hash64Combine(h, std::hash<int64>()(s.offset())); diff --git a/tensorflow/compiler/xla/service/buffer_assignment.h b/tensorflow/compiler/xla/service/buffer_assignment.h index 9617d51a87..24ba7c16f5 100644 --- a/tensorflow/compiler/xla/service/buffer_assignment.h +++ b/tensorflow/compiler/xla/service/buffer_assignment.h @@ -41,6 +41,17 @@ limitations under the License. namespace xla { +// Walk the call graph of the HLO module and place each computation into either +// thread_local_computations or global_computations depending upon whether the +// computation requires thread-local allocations or global allocations. The +// elements in thread_local_computations and global_computations are in post +// order (if computation A has an instruction which calls computation B, then A +// will appear after B in the vector). +Status GatherComputationsByAllocationType( + const HloModule* module, + std::vector<const HloComputation*>* thread_local_computations, + std::vector<const HloComputation*>* global_computations); + // This class abstracts an allocation of contiguous memory which can hold the // values described by LogicalBuffers. Each LogicalBuffer occupies a sub-range // of the allocation, represented by a Slice. A single BufferAllocation may hold diff --git a/tensorflow/compiler/xla/service/buffer_assignment_test.cc b/tensorflow/compiler/xla/service/buffer_assignment_test.cc index 8bd1533972..56bd67fb55 100644 --- a/tensorflow/compiler/xla/service/buffer_assignment_test.cc +++ b/tensorflow/compiler/xla/service/buffer_assignment_test.cc @@ -1490,10 +1490,13 @@ TEST_F(BufferAssignmentTest, OneTempAllocation) { DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); - auto dot_ab = builder.AddInstruction( - HloInstruction::CreateDot(shape_2x4, param_a, param_b, dot_dnums)); - auto dot_bc = builder.AddInstruction( - HloInstruction::CreateDot(shape_3x4, param_b, param_c, dot_dnums)); + PrecisionConfig precision_config; + precision_config.mutable_operand_precision()->Resize( + 2, PrecisionConfig::DEFAULT); + auto dot_ab = builder.AddInstruction(HloInstruction::CreateDot( + shape_2x4, param_a, param_b, dot_dnums, precision_config)); + auto dot_bc = builder.AddInstruction(HloInstruction::CreateDot( + shape_3x4, param_b, param_c, dot_dnums, precision_config)); builder.AddInstruction( HloInstruction::CreateConcatenate(shape_5x4, {dot_ab, dot_bc}, 0)); diff --git a/tensorflow/compiler/xla/service/convolution_feature_group_converter.cc b/tensorflow/compiler/xla/service/convolution_feature_group_converter.cc index 9c81a86bbb..0826380f65 100644 --- a/tensorflow/compiler/xla/service/convolution_feature_group_converter.cc +++ b/tensorflow/compiler/xla/service/convolution_feature_group_converter.cc @@ -223,8 +223,8 @@ Status ConvolutionVisitor::HandleConvolution(HloInstruction* convolution) { filter_mask, expanded_filter, zero_filter)); auto new_convolution = HloInstruction::CreateConvolve( convolution->shape(), convolution->mutable_operand(0), new_filter, - convolution->window(), dim_numbers, /*feature_group_count=*/1); - new_convolution->set_precision_config(convolution->precision_config()); + /*feature_group_count=*/1, convolution->window(), dim_numbers, + convolution->precision_config()); TF_RETURN_IF_ERROR(computation_->ReplaceWithNewInstruction( convolution, std::move(new_convolution))); return Status::OK(); diff --git a/tensorflow/compiler/xla/service/cpu/conv_canonicalization.cc b/tensorflow/compiler/xla/service/cpu/conv_canonicalization.cc index 098ce17a56..2d9978404c 100644 --- a/tensorflow/compiler/xla/service/cpu/conv_canonicalization.cc +++ b/tensorflow/compiler/xla/service/cpu/conv_canonicalization.cc @@ -130,9 +130,9 @@ StatusOr<bool> ConvCanonicalization::Run(HloModule* module) { // change the dimension mapping but not the dimension sizes. For // example, input height and width are the same as before the reshapes. HloInstruction* new_conv = module->entry_computation()->AddInstruction( - HloInstruction::CreateConvolve(new_conv_shape, new_input, new_kernel, - hlo->window(), new_dnums)); - new_conv->set_precision_config(hlo->precision_config()); + HloInstruction::CreateConvolve( + new_conv_shape, new_input, new_kernel, hlo->feature_group_count(), + hlo->window(), new_dnums, hlo->precision_config())); // Reshape the output back to the shape of the original convolution. TF_RETURN_IF_ERROR(module->entry_computation()->ReplaceWithNewInstruction( diff --git a/tensorflow/compiler/xla/service/cpu/conv_canonicalization_test.cc b/tensorflow/compiler/xla/service/cpu/conv_canonicalization_test.cc index 547d4c696d..05792795a1 100644 --- a/tensorflow/compiler/xla/service/cpu/conv_canonicalization_test.cc +++ b/tensorflow/compiler/xla/service/cpu/conv_canonicalization_test.cc @@ -84,7 +84,8 @@ TEST_F(ConvCanonicalizationTest, NonCanonicalToCanonical) { builder.AddInstruction(HloInstruction::CreateConvolve( ShapeUtil::MakeShape( F32, {kOutputFeatureCount, kBatchSize, output_size, output_size}), - input, kernel, conv_window_, dnums)); + input, kernel, /*feature_group_count=*/1, conv_window_, dnums, + DefaultPrecisionConfig(2))); auto module = CreateNewModule(); HloComputation* entry_computation = @@ -146,7 +147,8 @@ TEST_F(ConvCanonicalizationTest, CanonicalStaysTheSame) { builder.AddInstruction(HloInstruction::CreateConvolve( ShapeUtil::MakeShape( F32, {kBatchSize, output_size, output_size, kOutputFeatureCount}), - input, kernel, conv_window_, dnums)); + input, kernel, /*feature_group_count=*/1, conv_window_, dnums, + DefaultPrecisionConfig(2))); auto module = CreateNewModule(); module->AddEntryComputation(builder.Build()); diff --git a/tensorflow/compiler/xla/service/cpu/cpu_compiler.cc b/tensorflow/compiler/xla/service/cpu/cpu_compiler.cc index 6420180b13..796f36510e 100644 --- a/tensorflow/compiler/xla/service/cpu/cpu_compiler.cc +++ b/tensorflow/compiler/xla/service/cpu/cpu_compiler.cc @@ -588,8 +588,7 @@ StatusOr<std::unique_ptr<Executable>> CpuCompiler::RunBackend( ScheduleComputationsInModule(*module, BufferSizeBytesFunction(), DFSMemoryScheduler)); - // Run buffer analysis on the HLO graph. This analysis figures out which - // temporary buffers are required to run the computation. + // Run buffer allocation on the HLO graph. TF_ASSIGN_OR_RETURN( std::unique_ptr<BufferAssignment> assignment, BufferAssigner::Run(module.get(), diff --git a/tensorflow/compiler/xla/service/cpu/cpu_executable.cc b/tensorflow/compiler/xla/service/cpu/cpu_executable.cc index 9b00f2eaa5..29abf38e43 100644 --- a/tensorflow/compiler/xla/service/cpu/cpu_executable.cc +++ b/tensorflow/compiler/xla/service/cpu/cpu_executable.cc @@ -75,7 +75,7 @@ CpuExecutable::CpuExecutable( StatusOr<std::pair<std::vector<se::DeviceMemoryBase>, std::vector<OwningDeviceMemory>>> -CpuExecutable::CreateTempArray( +CpuExecutable::CreateBufferTable( DeviceMemoryAllocator* memory_allocator, int device_ordinal, absl::Span<const ShapedBuffer* const> arguments) { std::vector<se::DeviceMemoryBase> unowning_buffers( @@ -141,14 +141,14 @@ Status CpuExecutable::ExecuteComputeFunction( // The calling convention for JITed functions is: // // void function(void* result, const void* run_options, void** args_array, - // void** temps_array) + // void** buffer_table) // // result: Points at the result. // run_options: the ExecutableRunOptions object. // args_array: null - // temps_array: An array of pointers, containing pointers to temporary buffers - // required by the executable adn pointers to entry computation - // parameters. + // buffer_table: An array of pointers, containing pointers to temporary + // buffers required by the executable adn pointers to entry computation + // parameters. // uint64 start_micros = tensorflow::Env::Default()->NowMicros(); @@ -172,7 +172,7 @@ Status CpuExecutable::ExecuteComputeFunction( if (VLOG_IS_ON(3)) { VLOG(3) << "Executing compute function:"; VLOG(3) << absl::StrFormat( - " func(void* result, void* params[null], void* temps[%u], " + " func(void* result, void* params[null], void* buffer_table[%u], " "uint64 profile_counters[%u])", buffer_pointers.size(), profile_counters_size); VLOG(3) << absl::StrFormat(" result = %p", result_buffer); @@ -181,7 +181,8 @@ Status CpuExecutable::ExecuteComputeFunction( }; VLOG(3) << " params = nullptr"; VLOG(3) << absl::StrFormat( - " temps = [%s]", absl::StrJoin(buffer_pointers, ", ", ptr_printer)); + " buffer_table = [%s]", + absl::StrJoin(buffer_pointers, ", ", ptr_printer)); VLOG(3) << absl::StrFormat(" profile_counters = %p", profile_counters); } @@ -281,8 +282,8 @@ StatusOr<ScopedShapedBuffer> CpuExecutable::ExecuteAsyncOnStreamImpl( std::vector<se::DeviceMemoryBase> unowning_buffers; TF_ASSIGN_OR_RETURN( std::tie(unowning_buffers, owning_buffers), - CreateTempArray(memory_allocator, stream->parent()->device_ordinal(), - arguments)); + CreateBufferTable(memory_allocator, stream->parent()->device_ordinal(), + arguments)); TF_ASSIGN_OR_RETURN( ScopedShapedBuffer result, diff --git a/tensorflow/compiler/xla/service/cpu/cpu_executable.h b/tensorflow/compiler/xla/service/cpu/cpu_executable.h index 3571513e02..3c3c047bfe 100644 --- a/tensorflow/compiler/xla/service/cpu/cpu_executable.h +++ b/tensorflow/compiler/xla/service/cpu/cpu_executable.h @@ -74,9 +74,10 @@ class CpuExecutable : public Executable { static int64 ShapeSizeBytes(const Shape& shape); // Type of the computation function we expect in the JIT. - using ComputeFunctionType = void (*)( - void* /*result*/, const ExecutableRunOptions* /*run_options*/, - const void** /*args*/, void** /*temps*/, int64* /*profile_counters*/); + using ComputeFunctionType = + void (*)(void* /*result*/, const ExecutableRunOptions* /*run_options*/, + const void** /*args*/, void** /*buffer_table*/, + int64* /*profile_counters*/); const ComputeFunctionType& compute_function() const { return compute_function_; @@ -95,15 +96,15 @@ class CpuExecutable : public Executable { absl::Span<const ShapedBuffer* const> arguments, HloExecutionProfile* hlo_execution_profile); - // Creates an array suitable for passing as the "temps" argument to the JIT - // compiled function pointer. + // Creates an array suitable for passing as the "buffer_table" argument to the + // JIT compiled function pointer. // // Returns (unowning_buffers, owning_buffers) where: // - // - unowning_buffers.data() can be passed as the temps argument as-is and - // includes pointers to the scratch storage required by the computation, - // the live-out buffer into which the result will be written and entry - // computation parameters. + // - unowning_buffers.data() can be passed as the buffer_table argument as-is + // and includes pointers to the scratch storage required by the + // computation, the live-out buffer into which the result will be written + // and entry computation parameters. // // - owning_buffers contains owning pointers to the buffers that were // allocated by this routine. This routine allocates buffers for temporary @@ -111,8 +112,8 @@ class CpuExecutable : public Executable { // result. StatusOr<std::pair<std::vector<se::DeviceMemoryBase>, std::vector<OwningDeviceMemory>>> - CreateTempArray(DeviceMemoryAllocator* memory_allocator, int device_ordinal, - absl::Span<const ShapedBuffer* const> arguments); + CreateBufferTable(DeviceMemoryAllocator* memory_allocator, int device_ordinal, + absl::Span<const ShapedBuffer* const> arguments); // Calls the generated function performing the computation with the given // arguments using the supplied buffers. diff --git a/tensorflow/compiler/xla/service/cpu/cpu_instruction_fusion_test.cc b/tensorflow/compiler/xla/service/cpu/cpu_instruction_fusion_test.cc index 284929ca07..0fea462c85 100644 --- a/tensorflow/compiler/xla/service/cpu/cpu_instruction_fusion_test.cc +++ b/tensorflow/compiler/xla/service/cpu/cpu_instruction_fusion_test.cc @@ -38,7 +38,11 @@ std::unique_ptr<HloInstruction> MakeDot(const Shape& shape, HloInstruction* lhs, DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); - return HloInstruction::CreateDot(shape, lhs, rhs, dot_dnums); + PrecisionConfig precision_config; + precision_config.mutable_operand_precision()->Resize( + 2, PrecisionConfig::DEFAULT); + return HloInstruction::CreateDot(shape, lhs, rhs, dot_dnums, + precision_config); } TEST_F(InstructionFusionTest, DotOperationFusion_Basic_0) { diff --git a/tensorflow/compiler/xla/service/cpu/ir_emitter.cc b/tensorflow/compiler/xla/service/cpu/ir_emitter.cc index 8eaca57680..e5cf15c686 100644 --- a/tensorflow/compiler/xla/service/cpu/ir_emitter.cc +++ b/tensorflow/compiler/xla/service/cpu/ir_emitter.cc @@ -100,6 +100,11 @@ IrEmitter::IrEmitter( b_.setFastMathFlags(llvm_ir::GetFastMathFlags( /*fast_math_enabled=*/hlo_module_config_.debug_options() .xla_cpu_enable_fast_math())); + Status s = GatherComputationsByAllocationType( + &hlo_module, &thread_local_computations_, &global_computations_); + absl::c_sort(thread_local_computations_); + absl::c_sort(global_computations_); + TF_CHECK_OK(s) << "Should have failed buffer assignment."; } StatusOr<llvm::Function*> IrEmitter::EmitComputation( @@ -337,10 +342,10 @@ Status IrEmitter::HandleInfeed(HloInstruction* instruction) { // Write the tuple index table. TF_ASSIGN_OR_RETURN(BufferAllocation::Slice data_slice, assignment_.GetUniqueSlice(infeed, {0})); - llvm::Value* data_address = EmitTempBufferPointer(data_slice, data_shape); + llvm::Value* data_address = EmitBufferPointer(data_slice, data_shape); TF_ASSIGN_OR_RETURN(BufferAllocation::Slice token_slice, assignment_.GetUniqueSlice(infeed, {1})); - llvm::Value* token_address = EmitTempBufferPointer( + llvm::Value* token_address = EmitBufferPointer( token_slice, ShapeUtil::GetTupleElementShape(infeed->shape(), 1)); llvm_ir::EmitTuple(GetIrArrayFor(infeed), {data_address, token_address}, &b_, module_); @@ -363,9 +368,9 @@ Status IrEmitter::HandleInfeed(HloInstruction* instruction) { // Only the outer tuple buffer's target address is obtained from // GetEmittedValueFor, to handle the case when Infeed is the root // instruction. Target addresses for internal elements can be obtained - // from EmitTempBufferPointer. + // from EmitBufferPointer. llvm::Value* tuple_element_address = - EmitTempBufferPointer(buffer, tuple_element_shape); + EmitBufferPointer(buffer, tuple_element_shape); TF_RETURN_IF_ERROR(EmitXfeedTransfer( XfeedKind::kInfeed, tuple_element_shape, tuple_element_address)); @@ -1200,7 +1205,7 @@ Status IrEmitter::HandleCrossReplicaSum(HloInstruction* crs) { const Shape& operand_shape = crs->operand(i)->shape(); CHECK(ShapeUtil::IsArray(operand_shape)) << "Operands to cross-replica-sum must be arrays: " << crs->ToString(); - operand_ptrs.push_back(EmitTempBufferPointer(out_slice, operand_shape)); + operand_ptrs.push_back(EmitBufferPointer(out_slice, operand_shape)); // TODO(b/63762267): Be more aggressive about specifying alignment. MemCpy(operand_ptrs.back(), /*DstAlign=*/1, in_ptr, @@ -2097,7 +2102,7 @@ Status IrEmitter::HandleCall(HloInstruction* call) { {}, &b_, computation->name(), /*return_value_buffer=*/emitted_value_[call], /*exec_run_options_arg=*/GetExecutableRunOptionsArgument(), - /*temp_buffers_arg=*/GetTempBuffersArgument(), + /*buffer_table_arg=*/GetBufferTableArgument(), /*profile_counters_arg=*/GetProfileCountersArgument()); HloInstruction* root = computation->root_instruction(); @@ -2617,15 +2622,15 @@ llvm::Value* IrEmitter::GetProfileCountersArgument() { return compute_function_->profile_counters_arg(); } -llvm::Value* IrEmitter::GetTempBuffersArgument() { - return compute_function_->temp_buffers_arg(); +llvm::Value* IrEmitter::GetBufferTableArgument() { + return compute_function_->buffer_table_arg(); } llvm::Value* IrEmitter::GetExecutableRunOptionsArgument() { return compute_function_->exec_run_options_arg(); } -llvm::Value* IrEmitter::EmitThreadLocalTempBufferPointer( +llvm::Value* IrEmitter::EmitThreadLocalBufferPointer( const BufferAllocation::Slice& slice, const Shape& target_shape) { const BufferAllocation& allocation = *slice.allocation(); llvm::Value* tempbuf_address = [&]() -> llvm::Value* { @@ -2684,11 +2689,11 @@ llvm::Value* IrEmitter::EmitThreadLocalTempBufferPointer( return BitCast(tempbuf_address, IrShapeType(target_shape)->getPointerTo()); } -llvm::Value* IrEmitter::EmitGlobalTempBufferPointer( +llvm::Value* IrEmitter::EmitGlobalBufferPointer( const BufferAllocation::Slice& slice, const Shape& target_shape) { const BufferAllocation& allocation = *slice.allocation(); llvm::Value* tempbuf_address_ptr = llvm_ir::EmitBufferIndexingGEP( - GetTempBuffersArgument(), slice.index(), &b_); + GetBufferTableArgument(), slice.index(), &b_); llvm::LoadInst* tempbuf_address_base = Load(tempbuf_address_ptr); if (hlo_module_config_.debug_options() .xla_llvm_enable_invariant_load_metadata()) { @@ -2709,14 +2714,14 @@ llvm::Value* IrEmitter::EmitGlobalTempBufferPointer( IrShapeType(target_shape)->getPointerTo()); } -llvm::Value* IrEmitter::EmitTempBufferPointer( - const BufferAllocation::Slice& slice, const Shape& target_shape) { +llvm::Value* IrEmitter::EmitBufferPointer(const BufferAllocation::Slice& slice, + const Shape& target_shape) { if (slice.allocation()->is_thread_local()) { - return EmitThreadLocalTempBufferPointer(slice, target_shape); + return EmitThreadLocalBufferPointer(slice, target_shape); } else if (slice.allocation()->is_constant()) { return FindOrDie(constant_buffer_to_global_, slice.allocation()->index()); } else { - return EmitGlobalTempBufferPointer(slice, target_shape); + return EmitGlobalBufferPointer(slice, target_shape); } } @@ -2724,7 +2729,7 @@ Status IrEmitter::EmitTargetAddressForOp(const HloInstruction* op) { const Shape& target_shape = op->shape(); TF_ASSIGN_OR_RETURN(const BufferAllocation::Slice slice, assignment_.GetUniqueTopLevelSlice(op)); - llvm::Value* addr = EmitTempBufferPointer(slice, target_shape); + llvm::Value* addr = EmitBufferPointer(slice, target_shape); addr->setName(AsStringRef(IrName(op))); emitted_value_[op] = addr; return Status::OK(); @@ -2753,8 +2758,7 @@ Status IrEmitter::EmitTargetElementLoop( TF_ASSIGN_OR_RETURN(BufferAllocation::Slice slice, assignment_.GetUniqueSlice(target_op, {i})); const Shape& element_shape = ShapeUtil::GetSubshape(target_shape, {i}); - llvm::Value* op_target_address = - EmitTempBufferPointer(slice, element_shape); + llvm::Value* op_target_address = EmitBufferPointer(slice, element_shape); output_arrays.push_back( llvm_ir::IrArray(op_target_address, element_shape)); } @@ -2832,6 +2836,8 @@ Status IrEmitter::DefaultAction(HloInstruction* hlo) { llvm::Value* IrEmitter::EmitThreadLocalCall( const HloComputation& callee, absl::Span<llvm::Value* const> parameters, absl::string_view name) { + CHECK(absl::c_binary_search(thread_local_computations_, &callee)); + const Shape& return_shape = callee.root_instruction()->shape(); // Lifting this restriction to allow "small" arrays should be easy. Allowing @@ -2860,7 +2866,7 @@ llvm::Value* IrEmitter::EmitThreadLocalCall( parameter_addrs, &b_, name, /*return_value_buffer=*/return_value_buffer, /*exec_run_options_arg=*/GetExecutableRunOptionsArgument(), - /*temp_buffers_arg=*/ + /*buffer_table_arg=*/ llvm::Constant::getNullValue(b_.getInt8PtrTy()->getPointerTo()), /*profile_counters_arg=*/GetProfileCountersArgument())); @@ -2869,13 +2875,15 @@ llvm::Value* IrEmitter::EmitThreadLocalCall( void IrEmitter::EmitGlobalCall(const HloComputation& callee, absl::string_view name) { + CHECK(absl::c_binary_search(global_computations_, &callee)); + Call(FindOrDie(emitted_functions_, &callee), GetArrayFunctionCallArguments( /*parameter_addresses=*/{}, &b_, name, /*return_value_buffer=*/ llvm::Constant::getNullValue(b_.getInt8PtrTy()), /*exec_run_options_arg=*/GetExecutableRunOptionsArgument(), - /*temp_buffers_arg=*/GetTempBuffersArgument(), + /*buffer_table_arg=*/GetBufferTableArgument(), /*profile_counters_arg=*/GetProfileCountersArgument())); } @@ -2888,7 +2896,7 @@ llvm::Value* IrEmitter::GetBufferForGlobalCallReturnValue( const BufferAllocation::Slice root_buffer = assignment_.GetUniqueTopLevelSlice(root_inst).ValueOrDie(); - return EmitTempBufferPointer(root_buffer, root_inst->shape()); + return EmitBufferPointer(root_buffer, root_inst->shape()); } } // namespace cpu diff --git a/tensorflow/compiler/xla/service/cpu/ir_emitter.h b/tensorflow/compiler/xla/service/cpu/ir_emitter.h index 9cb8162327..58a333b8fb 100644 --- a/tensorflow/compiler/xla/service/cpu/ir_emitter.h +++ b/tensorflow/compiler/xla/service/cpu/ir_emitter.h @@ -62,8 +62,8 @@ class IrEmitter : public DfsHloVisitorWithDefault, // Create a new LLVM IR emitter. // // hlo_module: the HLO module we are emitting IR for. - // assignment: a BufferAssignment from which we know which temporary buffers - // are used by the HLO nodes. + // assignment: a BufferAssignment from which we know which buffers are used by + // the HLO nodes. // llvm_module: the LLVM module to emit IR into. // instruction_to_profile_idx: the mapping from HLO instructions to their // index in the profiling array. @@ -219,24 +219,21 @@ class IrEmitter : public DfsHloVisitorWithDefault, // argument of the computation function being emitted by this emitter. llvm::Value* GetExecutableRunOptionsArgument(); - // Get the llvm::Value* that represents the "temps" argument of the + // Get the llvm::Value* that represents the "buffer_table" argument of the // computation function being emitted by this emitter. - llvm::Value* GetTempBuffersArgument(); + llvm::Value* GetBufferTableArgument(); - // Helper for EmitTempBufferPointer. - llvm::Value* EmitGlobalTempBufferPointer(const BufferAllocation::Slice& slice, - const Shape& target_shape); + // Helper for EmitBufferPointer. + llvm::Value* EmitGlobalBufferPointer(const BufferAllocation::Slice& slice, + const Shape& target_shape); - // Helper for EmitTempBufferPointer. - llvm::Value* EmitThreadLocalTempBufferPointer( + // Helper for EmitBufferPointer. + llvm::Value* EmitThreadLocalBufferPointer( const BufferAllocation::Slice& slice, const Shape& target_shape); // Emits code that computes the address of the given buffer allocation slice. - // - // TODO(sanjoy): This should be renamed to reflect that it no longer provides - // access to just temporaries. - llvm::Value* EmitTempBufferPointer(const BufferAllocation::Slice& slice, - const Shape& target_shape); + llvm::Value* EmitBufferPointer(const BufferAllocation::Slice& slice, + const Shape& target_shape); // Emits a function into the current module. This can be used for // computations embedded inside other computations, such as the @@ -390,8 +387,8 @@ class IrEmitter : public DfsHloVisitorWithDefault, const llvm_ir::IrArray& target_array, const llvm_ir::IrArray& source_array); - // Assignment of the temporary buffers needed by the computation and their - // shape information. + // Assignment of the buffers needed by the computation and their shape + // information. const BufferAssignment& assignment_; // The LLVM module into which IR will be emitted. @@ -571,6 +568,9 @@ class IrEmitter : public DfsHloVisitorWithDefault, tensorflow::gtl::FlatMap<BufferAllocation::Index, llvm::Constant*> constant_buffer_to_global_; + std::vector<const HloComputation*> thread_local_computations_; + std::vector<const HloComputation*> global_computations_; + TF_DISALLOW_COPY_AND_ASSIGN(IrEmitter); }; diff --git a/tensorflow/compiler/xla/service/cpu/ir_function.cc b/tensorflow/compiler/xla/service/cpu/ir_function.cc index 3ecf4b69b7..adfb8392bf 100644 --- a/tensorflow/compiler/xla/service/cpu/ir_function.cc +++ b/tensorflow/compiler/xla/service/cpu/ir_function.cc @@ -78,19 +78,20 @@ void IrFunction::Initialize(const string& function_name, const bool optimize_for_size_requested, const bool enable_fast_math) { // The function signature is: - // void function(i8* retval, i8* run_options, i8** params, i8** temps, + // void function(i8* retval, i8* run_options, i8** params, i8** + // buffer_table, // i64* dynamic_loop_bounds, i64* prof_counters) // // For thread local functions: // retval: points to the returned value. // params: address of an array with pointers to parameters. - // temps: is null + // buffer_table: is null // // For global functions: // retval: is null // params: is null - // temps: address of an array with pointers to temporary buffers and entry - // computation parameters. + // buffer_table: address of an array with pointers to temporary buffers and + // entry computation parameters (but not to constant buffers). // // Therefore, the generated function's signature (FunctionType) is statically // determined - parameter unpacking is done in code generated into the @@ -116,7 +117,7 @@ void IrFunction::Initialize(const string& function_name, // \---------/ \---------/ \-----------/ // // /---------------------------------------------\ - // temps ---------> | temp 0 | temp 1 | ..... | temp N-1 | + // buffer_table---> | buff 0 | guff 1 | ..... | buff N-1 | // | addr | addr | | addr | // \---------------------------------------------/ // | | | @@ -134,9 +135,9 @@ void IrFunction::Initialize(const string& function_name, // prof counters -> | counter 0 | counter 1 | ..... | counter N-1 | // \---------------------------------------------/ - // Even though the type of params and temps is void** in the host's view, in - // LLVM IR this is represented by i8*, similarly to void*. It's up to the code - // to use GEPs to unravel the indirection layers. + // Even though the type of params and buffer_table is void** in the host's + // view, in LLVM IR this is represented by i8*, similarly to void*. It's up to + // the code to use GEPs to unravel the indirection layers. llvm::FunctionType* function_type = llvm::FunctionType::get( /*Result=*/llvm::Type::getVoidTy(llvm_module_->getContext()), /*Params=*/ @@ -160,8 +161,8 @@ void IrFunction::Initialize(const string& function_name, exec_run_options_arg_ = &*arg_iter; (++arg_iter)->setName("params"); parameters_arg_ = &*arg_iter; - (++arg_iter)->setName("temps"); - temp_buffers_arg_ = &*arg_iter; + (++arg_iter)->setName("buffer_table"); + buffer_table_arg_ = &*arg_iter; if (num_dynamic_loop_bounds_ > 0) { (++arg_iter)->setName("dynamic_loop_bounds"); dynamic_loop_bounds_arg_ = &*arg_iter; @@ -202,7 +203,7 @@ llvm::Value* IrFunction::GetDynamicLoopBound(const int64 offset) { std::vector<llvm::Value*> GetArrayFunctionCallArguments( absl::Span<llvm::Value* const> parameter_addresses, llvm::IRBuilder<>* b, absl::string_view name, llvm::Value* return_value_buffer, - llvm::Value* exec_run_options_arg, llvm::Value* temp_buffers_arg, + llvm::Value* exec_run_options_arg, llvm::Value* buffer_table_arg, llvm::Value* profile_counters_arg) { llvm::Value* parameter_addresses_buffer; @@ -230,7 +231,7 @@ std::vector<llvm::Value*> GetArrayFunctionCallArguments( }; std::vector<llvm::Value*> arguments{ to_int8_ptr(return_value_buffer), to_int8_ptr(exec_run_options_arg), - parameter_addresses_buffer, temp_buffers_arg}; + parameter_addresses_buffer, buffer_table_arg}; if (profile_counters_arg != nullptr) { arguments.push_back(profile_counters_arg); } diff --git a/tensorflow/compiler/xla/service/cpu/ir_function.h b/tensorflow/compiler/xla/service/cpu/ir_function.h index 28c69c85a9..623a5f185f 100644 --- a/tensorflow/compiler/xla/service/cpu/ir_function.h +++ b/tensorflow/compiler/xla/service/cpu/ir_function.h @@ -80,8 +80,9 @@ class IrFunction { // Get the llvm::Value* that represents this functions parameters argument. llvm::Value* parameters_arg() { return parameters_arg_; } - // Get the llvm::Value* that represents this functions "temps" argument. - llvm::Value* temp_buffers_arg() { return temp_buffers_arg_; } + // Get the llvm::Value* that represents this functions "buffer_table" + // argument. + llvm::Value* buffer_table_arg() { return buffer_table_arg_; } // Get the llvm::Value* that represents this functions "prof_counters" // argument. @@ -108,7 +109,7 @@ class IrFunction { llvm::Argument* result_arg_; llvm::Value* exec_run_options_arg_; llvm::Value* parameters_arg_; - llvm::Value* temp_buffers_arg_; + llvm::Value* buffer_table_arg_; llvm::Value* dynamic_loop_bounds_arg_ = nullptr; llvm::Value* profile_counters_arg_; }; @@ -117,7 +118,7 @@ class IrFunction { std::vector<llvm::Value*> GetArrayFunctionCallArguments( absl::Span<llvm::Value* const> parameter_addresses, llvm::IRBuilder<>* b, absl::string_view name, llvm::Value* return_value_buffer, - llvm::Value* exec_run_options_arg, llvm::Value* temp_buffers_arg, + llvm::Value* exec_run_options_arg, llvm::Value* buffer_table_arg, llvm::Value* profile_counters_arg); // Emits a call to a runtime fork/join function which dispatches parallel diff --git a/tensorflow/compiler/xla/service/cpu/runtime_fork_join.cc b/tensorflow/compiler/xla/service/cpu/runtime_fork_join.cc index a5f34908d7..2d9492eacf 100644 --- a/tensorflow/compiler/xla/service/cpu/runtime_fork_join.cc +++ b/tensorflow/compiler/xla/service/cpu/runtime_fork_join.cc @@ -61,7 +61,7 @@ using ComputeFunctionType = void (*)(void*, const void*, const void**, void**, // TF_ATTRIBUTE_NO_SANITIZE_MEMORY void __xla_cpu_runtime_ParallelForkJoin( void* result_ptr, const void* run_options_ptr, const void** params, - void** temps, uint64* prof_counters, int32 num_partitions, + void** buffer_table, uint64* prof_counters, int32 num_partitions, int64* partitions, int32 num_partitioned_dims, void* function_ptr) { VLOG(2) << "ParallelForkJoin ENTRY" << " num_partitions: " << num_partitions @@ -81,9 +81,9 @@ TF_ATTRIBUTE_NO_SANITIZE_MEMORY void __xla_cpu_runtime_ParallelForkJoin( for (int32 i = 1; i < num_partitions; ++i) { const int64 offset = i * stride; run_options->intra_op_thread_pool()->enqueueNoNotification( - [i, function, result_ptr, run_options_ptr, temps, prof_counters, + [i, function, result_ptr, run_options_ptr, buffer_table, prof_counters, partitions, offset, &bc]() { - function(result_ptr, run_options_ptr, nullptr, temps, + function(result_ptr, run_options_ptr, nullptr, buffer_table, &partitions[offset], prof_counters); bc.DecrementCount(); VLOG(3) << "ParallelForkJoin partition " << i << " done."; @@ -91,7 +91,7 @@ TF_ATTRIBUTE_NO_SANITIZE_MEMORY void __xla_cpu_runtime_ParallelForkJoin( } // Call first compute function inline. - function(result_ptr, run_options_ptr, params, temps, &partitions[0], + function(result_ptr, run_options_ptr, params, buffer_table, &partitions[0], prof_counters); VLOG(3) << "ParallelForkJoin partition 0 done."; bc.Wait(); diff --git a/tensorflow/compiler/xla/service/cpu/runtime_fork_join.h b/tensorflow/compiler/xla/service/cpu/runtime_fork_join.h index 1cf0ec6e3d..a279c7d2d6 100644 --- a/tensorflow/compiler/xla/service/cpu/runtime_fork_join.h +++ b/tensorflow/compiler/xla/service/cpu/runtime_fork_join.h @@ -24,7 +24,7 @@ extern "C" { // threads before returning. See comments in runtime_fork_join.cc for details. extern void __xla_cpu_runtime_ParallelForkJoin( void* result_ptr, const void* run_options_ptr, const void** params, - void** temps, tensorflow::uint64* prof_counters, + void** buffer_table, tensorflow::uint64* prof_counters, tensorflow::int32 num_partitions, tensorflow::int64* partitions, tensorflow::int32 num_partitioned_dims, void* function_ptr); diff --git a/tensorflow/compiler/xla/service/dot_decomposer.cc b/tensorflow/compiler/xla/service/dot_decomposer.cc index 09cb10d6ee..b2ba261790 100644 --- a/tensorflow/compiler/xla/service/dot_decomposer.cc +++ b/tensorflow/compiler/xla/service/dot_decomposer.cc @@ -134,9 +134,9 @@ Status DecomposeBatchDot(HloInstruction* dot) { DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); - auto dot_r2 = computation->AddInstruction(HloInstruction::CreateDot( - dot_shape_r2, lhs_slice_r2, rhs_slice_r2, dot_dnums)); - dot_r2->set_precision_config(dot->precision_config()); + auto dot_r2 = computation->AddInstruction( + HloInstruction::CreateDot(dot_shape_r2, lhs_slice_r2, rhs_slice_r2, + dot_dnums, dot->precision_config())); // Reshape Dot to R3 so we can concat along batch dimension. auto dot_r3 = computation->AddInstruction( diff --git a/tensorflow/compiler/xla/service/gpu/BUILD b/tensorflow/compiler/xla/service/gpu/BUILD index d780b5751c..a68b7a1bef 100644 --- a/tensorflow/compiler/xla/service/gpu/BUILD +++ b/tensorflow/compiler/xla/service/gpu/BUILD @@ -676,7 +676,6 @@ cc_library( "//tensorflow/compiler/xla/service:buffer_liveness", "//tensorflow/compiler/xla/service:call_inliner", "//tensorflow/compiler/xla/service:conditional_simplifier", - "//tensorflow/compiler/xla/service:convolution_feature_group_converter", "//tensorflow/compiler/xla/service:executable", "//tensorflow/compiler/xla/service:flatten_call_graph", "//tensorflow/compiler/xla/service:hlo", diff --git a/tensorflow/compiler/xla/service/gpu/convolution_thunk.cc b/tensorflow/compiler/xla/service/gpu/convolution_thunk.cc index eea31f3de1..05448d863d 100644 --- a/tensorflow/compiler/xla/service/gpu/convolution_thunk.cc +++ b/tensorflow/compiler/xla/service/gpu/convolution_thunk.cc @@ -37,8 +37,8 @@ ConvolutionThunk::ConvolutionThunk( const BufferAllocation::Slice& tuple_result_buffer, const BufferAllocation::Slice& scratch_buffer, const Shape& input_shape, const Shape& filter_shape, const Shape& output_shape, const Window& window, - const ConvolutionDimensionNumbers& dim_nums, int64 algorithm, - bool tensor_ops_enabled, const HloInstruction* hlo) + const ConvolutionDimensionNumbers& dim_nums, int64 feature_group_count, + int64 algorithm, bool tensor_ops_enabled, const HloInstruction* hlo) : Thunk(Kind::kConvolution, hlo), convolution_kind_(convolution_kind), input_buffer_(input_buffer), @@ -51,6 +51,7 @@ ConvolutionThunk::ConvolutionThunk( output_shape_(output_shape), window_(window), dim_nums_(dim_nums), + feature_group_count_(feature_group_count), algorithm_(algorithm), tensor_ops_enabled_(tensor_ops_enabled) {} @@ -72,8 +73,8 @@ Status ConvolutionThunk::ExecuteOnStream( auto op_profiler = profiler->MakeScopedInstructionProfiler(hlo_instruction()); TF_RETURN_IF_ERROR(RunCudnnConvolution( convolution_kind_, input_shape_, filter_shape_, output_shape_, input_data, - filter_data, output_data, scratch, window_, dim_nums_, algorithm_config, - stream)); + filter_data, output_data, scratch, window_, dim_nums_, + feature_group_count_, algorithm_config, stream)); // Figure out which of output/input/filter is the result produced by // this op, and write the result tuple. diff --git a/tensorflow/compiler/xla/service/gpu/convolution_thunk.h b/tensorflow/compiler/xla/service/gpu/convolution_thunk.h index f7952787c1..68d67c40c5 100644 --- a/tensorflow/compiler/xla/service/gpu/convolution_thunk.h +++ b/tensorflow/compiler/xla/service/gpu/convolution_thunk.h @@ -59,7 +59,8 @@ class ConvolutionThunk : public Thunk { const BufferAllocation::Slice& scratch_buffer, const Shape& input_shape, const Shape& filter_shape, const Shape& output_shape, const Window& window, - const ConvolutionDimensionNumbers& dim_nums, int64 algorithm, + const ConvolutionDimensionNumbers& dim_nums, + int64 feature_group_count, int64 algorithm, bool tensor_ops_enabled, const HloInstruction* hlo); ConvolutionThunk(const ConvolutionThunk&) = delete; @@ -71,19 +72,6 @@ class ConvolutionThunk : public Thunk { HloExecutionProfiler* profiler) override; private: - class ScratchAllocator; - - Status Convolve(const se::dnn::BatchDescriptor& input_descriptor, - se::DeviceMemory<float> input_data, - const se::dnn::FilterDescriptor& filter_descriptor, - se::DeviceMemory<float> filter_data, - const se::dnn::BatchDescriptor& output_descriptor, - se::DeviceMemory<float> output_data, - const se::dnn::ConvolutionDescriptor& convolution_descriptor, - const se::dnn::AlgorithmConfig& algorithm_config, - se::Stream* stream, ScratchAllocator* scratch_allocator, - se::dnn::ProfileResult* profile_result); - const CudnnConvKind convolution_kind_; const BufferAllocation::Slice input_buffer_; @@ -98,6 +86,7 @@ class ConvolutionThunk : public Thunk { const Window window_; const ConvolutionDimensionNumbers dim_nums_; + int64 feature_group_count_; int64 algorithm_; bool tensor_ops_enabled_; }; diff --git a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.cc b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.cc index 2af31a52f9..5c2555148a 100644 --- a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.cc +++ b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.cc @@ -178,7 +178,8 @@ StatusOr<std::tuple<int64, bool, int64>> CudnnConvolutionAlgorithmPicker::PickBestAlgorithm( CudnnConvKind kind, const Shape& input_shape, const Shape& filter_shape, const Shape& output_shape, const Window& window, - const ConvolutionDimensionNumbers& dnums, HloInstruction* instr) { + const ConvolutionDimensionNumbers& dnums, int64 feature_group_count, + HloInstruction* instr) { CHECK_EQ(input_shape.element_type(), filter_shape.element_type()); CHECK_EQ(input_shape.element_type(), output_shape.element_type()); // TODO(timshen): for now only check fp16. It can be expanded to other types, @@ -192,6 +193,12 @@ CudnnConvolutionAlgorithmPicker::PickBestAlgorithm( // concurrently and then run them sequentially. tensorflow::mutex_lock lock = LockGpu(stream_exec_); + // Make sure any previous activity on this executor is done. We don't want to + // interfere with programs that are still running on the GPU. + if (!stream_exec_->SynchronizeAllActivity()) { + return InternalError("Failed to synchronize GPU for autotuning."); + } + // Create a stream for us to do our work on. se::Stream stream{stream_exec_}; stream.Init(); @@ -233,8 +240,8 @@ CudnnConvolutionAlgorithmPicker::PickBestAlgorithm( CHECK_EQ(0, left_over_bytes % 2); constexpr float kBroadcastedConstant = 0.1f; - Eigen::half halfs[2] = {Eigen::half(kBroadcastedConstant), - Eigen::half(kBroadcastedConstant)}; + static const Eigen::half halfs[2] = {Eigen::half(kBroadcastedConstant), + Eigen::half(kBroadcastedConstant)}; uint32 bits; static_assert(sizeof(bits) == sizeof(halfs), ""); memcpy(&bits, halfs, sizeof(bits)); @@ -258,7 +265,6 @@ CudnnConvolutionAlgorithmPicker::PickBestAlgorithm( .ThenMemZero(&filter_buf, filter_buf.size()) .ThenMemZero(&output_buf, output_buf.size()); } - TF_RETURN_IF_ERROR(stream.BlockHostUntilDone()); DeviceMemoryBase* result_buf = [&] { switch (kind) { @@ -289,10 +295,10 @@ CudnnConvolutionAlgorithmPicker::PickBestAlgorithm( << instr->ToString(); bool launch_ok = - RunCudnnConvolution(kind, input_shape, filter_shape, output_shape, - input_buf, filter_buf, output_buf, - &scratch_allocator, window, dnums, - AlgorithmConfig(alg), &stream, &profile_result) + RunCudnnConvolution( + kind, input_shape, filter_shape, output_shape, input_buf, + filter_buf, output_buf, &scratch_allocator, window, dnums, + feature_group_count, AlgorithmConfig(alg), &stream, &profile_result) .ok(); if (launch_ok && profile_result.is_valid()) { @@ -378,17 +384,20 @@ StatusOr<bool> CudnnConvolutionAlgorithmPicker::RunOnInstruction( PickBestAlgorithm(CudnnConvKind::kForward, /*input_shape=*/lhs_shape, /*filter_shape=*/rhs_shape, /*output_shape=*/conv_result_shape, instr->window(), - instr->convolution_dimension_numbers(), instr); + instr->convolution_dimension_numbers(), + instr->feature_group_count(), instr); } else if (call_target == kCudnnConvBackwardInputCallTarget) { alg_scratch_and_tc = PickBestAlgorithm( CudnnConvKind::kBackwardInput, /*input_shape=*/conv_result_shape, /*filter_shape=*/rhs_shape, /*output_shape=*/lhs_shape, instr->window(), - instr->convolution_dimension_numbers(), instr); + instr->convolution_dimension_numbers(), instr->feature_group_count(), + instr); } else if (call_target == kCudnnConvBackwardFilterCallTarget) { alg_scratch_and_tc = PickBestAlgorithm( CudnnConvKind::kBackwardFilter, /*input_shape=*/lhs_shape, /*filter_shape=*/conv_result_shape, /*output_shape=*/rhs_shape, - instr->window(), instr->convolution_dimension_numbers(), instr); + instr->window(), instr->convolution_dimension_numbers(), + instr->feature_group_count(), instr); } else { LOG(FATAL) << "Unknown custom call target for cudnn conv: " << instr->ToString(); @@ -422,14 +431,9 @@ StatusOr<bool> CudnnConvolutionAlgorithmPicker::RunOnInstruction( backend_config.set_algorithm(algorithm); backend_config.set_tensor_ops_enabled(tensor_ops_enabled); - HloInstruction* new_call = - computation->AddInstruction(HloInstruction::CreateCustomCall( - new_call_shape, - {instr->mutable_operand(0), instr->mutable_operand(1)}, - instr->custom_call_target())); - new_call->set_window(instr->window()); - new_call->set_convolution_dimension_numbers( - instr->convolution_dimension_numbers()); + HloInstruction* new_call = computation->AddInstruction( + instr->CloneWithNewOperands(new_call_shape, {instr->mutable_operand(0), + instr->mutable_operand(1)})); TF_RETURN_IF_ERROR(new_call->set_backend_config(backend_config)); // Repackage new_call so it has the same shape as the original call, namely diff --git a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.h b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.h index f76d273e8c..0cb01161b0 100644 --- a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.h +++ b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.h @@ -51,7 +51,8 @@ class CudnnConvolutionAlgorithmPicker : public HloPassInterface { StatusOr<std::tuple<int64, bool, int64>> PickBestAlgorithm( CudnnConvKind kind, const Shape& input_shape, const Shape& filter_shape, const Shape& output_shape, const Window& window, - const ConvolutionDimensionNumbers& dnums, HloInstruction* instr); + const ConvolutionDimensionNumbers& dnums, int64 feature_group_count, + HloInstruction* instr); se::StreamExecutor* stream_exec_; // never null DeviceMemoryAllocator* allocator_; // may be null diff --git a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_rewriter.cc b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_rewriter.cc index 0b1ee2dc33..9bf721ecd2 100644 --- a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_rewriter.cc +++ b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_rewriter.cc @@ -59,6 +59,11 @@ std::tuple<bool, Window, ConvolutionDimensionNumbers> MatchBackwardFilter( HloInstruction* conv) { const auto no_match_result = std::make_tuple(false, Window(), ConvolutionDimensionNumbers()); + // TODO(b/31709653): Figure out if we can use grouped convolutions also on + // backward filter. + if (conv->feature_group_count() > 1) { + return no_match_result; + } // Step 1: match the instruction pattern without considering the paddings and // dimension numbers just yet. We may need some generic pattern matcher // similar to third_party/llvm/llvm/include/llvm/IR/PatternMatch.h @@ -218,6 +223,12 @@ std::tuple<bool, Window, ConvolutionDimensionNumbers> MatchBackwardInput( const auto no_match_result = std::make_tuple(false, Window(), ConvolutionDimensionNumbers()); + // TODO(b/31709653): Figure out if we can use grouped convolutions also on + // backward input. + if (conv->feature_group_count() > 1) { + return no_match_result; + } + // Match instruction pattern. CHECK_EQ(HloOpcode::kConvolution, conv->opcode()); HloInstruction* reverse_filter = conv->mutable_operand(1); @@ -425,7 +436,7 @@ StatusOr<bool> RunOnInstruction(HloInstruction* conv) { if (match) { return CreateCudnnConvBackwardFilter( conv->shape(), conv->mutable_operand(0), conv->mutable_operand(1), - window, dnums); + window, dnums, conv->feature_group_count()); } std::tie(match, window, dnums) = MatchBackwardInput(conv); @@ -435,15 +446,17 @@ StatusOr<bool> RunOnInstruction(HloInstruction* conv) { CHECK_EQ(reverse->opcode(), HloOpcode::kReverse); HloInstruction* rhs = reverse->mutable_operand(0); - return CreateCudnnConvBackwardInput( - conv->shape(), conv->mutable_operand(0), rhs, window, dnums); + return CreateCudnnConvBackwardInput(conv->shape(), + conv->mutable_operand(0), rhs, window, + dnums, conv->feature_group_count()); } // If all else fails, try a forward convolution. if (CanImplementAsCudnnForwardConv(conv)) { return CreateCudnnConvForward(conv->shape(), conv->mutable_operand(0), conv->mutable_operand(1), conv->window(), - conv->convolution_dimension_numbers()); + conv->convolution_dimension_numbers(), + conv->feature_group_count()); } return nullptr; diff --git a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_rewriter_test.cc b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_rewriter_test.cc index 46c23db465..bda8ebe579 100644 --- a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_rewriter_test.cc +++ b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_rewriter_test.cc @@ -107,12 +107,12 @@ TEST_F(CudnnConvolutionRewriterTest, BackwardFilterConvolve) { conv_window.mutable_dimensions(1)->set_size(2); conv_window.mutable_dimensions(1)->set_window_dilation(2); builder.AddInstruction(HloInstruction::CreateConvolve( - ShapeInference::InferConvolveShape(activations->shape(), - gradients->shape(), conv_window, - tf_default_dnums_for_backward_filter_) + ShapeInference::InferConvolveShape( + activations->shape(), gradients->shape(), /*feature_group_count=*/1, + conv_window, tf_default_dnums_for_backward_filter_) .ConsumeValueOrDie(), - activations, gradients, conv_window, - tf_default_dnums_for_backward_filter_)); + activations, gradients, /*feature_group_count=*/1, conv_window, + tf_default_dnums_for_backward_filter_, DefaultPrecisionConfig(2))); auto module = CreateNewModule(); HloComputation* entry_computation = @@ -135,12 +135,12 @@ TEST_F(CudnnConvolutionRewriterTest, Window conv_window = default_conv_window_; conv_window.mutable_dimensions(1)->set_size(3); builder.AddInstruction(HloInstruction::CreateConvolve( - ShapeInference::InferConvolveShape(activations->shape(), - gradients->shape(), conv_window, - tf_default_dnums_for_backward_filter_) + ShapeInference::InferConvolveShape( + activations->shape(), gradients->shape(), /*feature_group_count=*/1, + conv_window, tf_default_dnums_for_backward_filter_) .ConsumeValueOrDie(), - activations, gradients, conv_window, - tf_default_dnums_for_backward_filter_)); + activations, gradients, /*feature_group_count=*/1, conv_window, + tf_default_dnums_for_backward_filter_, DefaultPrecisionConfig(2))); auto module = CreateNewModule(); HloComputation* entry_computation = @@ -170,7 +170,8 @@ TEST_F(CudnnConvolutionRewriterTest, } builder.AddInstruction(HloInstruction::CreateConvolve( ShapeUtil::MakeShape(F32, {32, 3, 3, 32}), activations, gradients, - conv_window, tf_default_dnums_for_backward_filter_)); + /*feature_group_count=*/1, conv_window, + tf_default_dnums_for_backward_filter_, DefaultPrecisionConfig(2))); auto module = CreateNewModule(); HloComputation* entry_computation = @@ -200,7 +201,8 @@ TEST_F(CudnnConvolutionRewriterTest, } builder.AddInstruction(HloInstruction::CreateConvolve( ShapeUtil::MakeShape(F32, {320, 3, 3, 192}), activations, gradients, - conv_window, tf_default_dnums_for_backward_filter_)); + /*feature_group_count=*/1, conv_window, + tf_default_dnums_for_backward_filter_, DefaultPrecisionConfig(2))); auto module = CreateNewModule(); HloComputation* entry_computation = @@ -228,7 +230,8 @@ TEST_F(CudnnConvolutionRewriterTest, BackwardFilterConvolveWithUnevenPadding) { } builder.AddInstruction(HloInstruction::CreateConvolve( ShapeUtil::MakeShape(F32, {32, 2, 2, 32}), activations, gradients, - conv_window, tf_default_dnums_for_backward_filter_)); + /*feature_group_count=*/1, conv_window, + tf_default_dnums_for_backward_filter_, DefaultPrecisionConfig(2))); auto module = CreateNewModule(); HloComputation* entry_computation = @@ -272,13 +275,14 @@ TEST_F(CudnnConvolutionRewriterTest, BackwardInputConvolveEvenPadding) { HloInstruction* conv = builder.AddInstruction(HloInstruction::CreateConvolve( ShapeUtil::MakeShape(F32, {4, 3, 16, 16}), /*lhs=*/output, - /*rhs=*/reverse_kernel, conv_window, conv_dnums)); + /*rhs=*/reverse_kernel, /*feature_group_count=*/1, conv_window, + conv_dnums, DefaultPrecisionConfig(2))); // Verify the convolution's shape is consistent with ShapeInference. CHECK(ShapeUtil::Compatible( - conv->shape(), - ShapeInference::InferConvolveShape( - output->shape(), reverse_kernel->shape(), conv_window, conv_dnums) - .ValueOrDie())); + conv->shape(), ShapeInference::InferConvolveShape( + output->shape(), reverse_kernel->shape(), + /*feature_group_count=*/1, conv_window, conv_dnums) + .ValueOrDie())); auto module = CreateNewModule(); HloComputation* entry_computation = @@ -319,11 +323,11 @@ TEST_F(CudnnConvolutionRewriterTest, BackwardInputConvolve1x1Filter) { builder.AddInstruction(HloInstruction::CreateConvolve( ShapeInference::InferConvolveShape(output->shape(), kernel->shape(), - conv_window, + /*feature_group_count=*/1, conv_window, tf_default_dnums_for_backward_input_) .ConsumeValueOrDie(), - /*lhs=*/output, /*rhs=*/kernel, conv_window, - tf_default_dnums_for_backward_input_)); + /*lhs=*/output, /*rhs=*/kernel, /*feature_group_count=*/1, conv_window, + tf_default_dnums_for_backward_input_, DefaultPrecisionConfig(2))); auto module = CreateNewModule(); HloComputation* entry_computation = @@ -350,12 +354,13 @@ TEST_F(CudnnConvolutionRewriterTest, 1, ShapeUtil::MakeShape(F32, {1, 1, 1, 1}), "kernel")); builder.AddInstruction(HloInstruction::CreateConvolve( - ShapeInference::InferConvolveShape(output->shape(), kernel->shape(), - default_conv_window_, - tf_default_dnums_for_backward_input_) + ShapeInference::InferConvolveShape( + output->shape(), kernel->shape(), /*feature_group_count=*/1, + default_conv_window_, tf_default_dnums_for_backward_input_) .ConsumeValueOrDie(), - /*lhs=*/output, /*rhs=*/kernel, default_conv_window_, - tf_default_dnums_for_backward_input_)); + /*lhs=*/output, /*rhs=*/kernel, /*feature_group_count=*/1, + default_conv_window_, tf_default_dnums_for_backward_input_, + DefaultPrecisionConfig(2))); auto module = CreateNewModule(); HloComputation* entry_computation = @@ -402,13 +407,15 @@ TEST_F(CudnnConvolutionRewriterTest, } HloInstruction* conv = builder.AddInstruction(HloInstruction::CreateConvolve( ShapeUtil::MakeShape(F32, {20, 10, 10, 192}), output, reverse_kernel, - conv_window, tf_default_dnums_for_backward_input_)); + /*feature_group_count=*/1, conv_window, + tf_default_dnums_for_backward_input_, DefaultPrecisionConfig(2))); // Verify the convolution's shape is consistent with ShapeInference. CHECK(ShapeUtil::Compatible( - conv->shape(), ShapeInference::InferConvolveShape( - output->shape(), reverse_kernel->shape(), conv_window, - tf_default_dnums_for_backward_input_) - .ValueOrDie())); + conv->shape(), + ShapeInference::InferConvolveShape( + output->shape(), reverse_kernel->shape(), /*feature_group_count=*/1, + conv_window, tf_default_dnums_for_backward_input_) + .ValueOrDie())); auto module = CreateNewModule(); HloComputation* entry_computation = @@ -449,13 +456,15 @@ TEST_F(CudnnConvolutionRewriterTest, BackwardInputConvolveLowPaddingTooLarge) { } HloInstruction* conv = builder.AddInstruction(HloInstruction::CreateConvolve( ShapeUtil::MakeShape(F32, {20, 10, 10, 192}), output, reverse_kernel, - conv_window, tf_default_dnums_for_backward_input_)); + /*feature_group_count=*/1, conv_window, + tf_default_dnums_for_backward_input_, DefaultPrecisionConfig(2))); // Verify the convolution's shape is consistent with ShapeInference. CHECK(ShapeUtil::Compatible( - conv->shape(), ShapeInference::InferConvolveShape( - output->shape(), reverse_kernel->shape(), conv_window, - tf_default_dnums_for_backward_input_) - .ValueOrDie())); + conv->shape(), + ShapeInference::InferConvolveShape( + output->shape(), reverse_kernel->shape(), /*feature_group_count=*/1, + conv_window, tf_default_dnums_for_backward_input_) + .ValueOrDie())); auto module = CreateNewModule(); HloComputation* entry_computation = @@ -502,13 +511,15 @@ TEST_F(CudnnConvolutionRewriterTest, forward_conv_col_dim->set_base_dilation(2); HloInstruction* conv = builder.AddInstruction(HloInstruction::CreateConvolve( ShapeUtil::MakeShape(F32, {1, 1, 14, 1}), output, reverse_kernel, - conv_window, tf_default_dnums_for_backward_input_)); + /*feature_group_count=*/1, conv_window, + tf_default_dnums_for_backward_input_, DefaultPrecisionConfig(2))); // Verify the convolution's shape is consistent with ShapeInference. CHECK(ShapeUtil::Compatible( - conv->shape(), ShapeInference::InferConvolveShape( - output->shape(), reverse_kernel->shape(), conv_window, - tf_default_dnums_for_backward_input_) - .ValueOrDie())); + conv->shape(), + ShapeInference::InferConvolveShape( + output->shape(), reverse_kernel->shape(), /*feature_group_count=*/1, + conv_window, tf_default_dnums_for_backward_input_) + .ValueOrDie())); auto module = CreateNewModule(); const HloComputation* entry_computation = @@ -554,13 +565,15 @@ TEST_F(CudnnConvolutionRewriterTest, forward_conv_col_dim->set_padding_high(2); HloInstruction* conv = builder.AddInstruction(HloInstruction::CreateConvolve( ShapeUtil::MakeShape(F32, {1, 1, 4, 1}), output, reverse_kernel, - conv_window, tf_default_dnums_for_backward_input_)); + /*feature_group_count=*/1, conv_window, + tf_default_dnums_for_backward_input_, DefaultPrecisionConfig(2))); // Verify the convolution's shape is consistent with ShapeInference. CHECK(ShapeUtil::Compatible( - conv->shape(), ShapeInference::InferConvolveShape( - output->shape(), reverse_kernel->shape(), conv_window, - tf_default_dnums_for_backward_input_) - .ValueOrDie())); + conv->shape(), + ShapeInference::InferConvolveShape( + output->shape(), reverse_kernel->shape(), /*feature_group_count=*/1, + conv_window, tf_default_dnums_for_backward_input_) + .ValueOrDie())); auto module = CreateNewModule(); HloComputation* entry_computation = diff --git a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_runner.cc b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_runner.cc index 07b96fbd3f..05125e9d1f 100644 --- a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_runner.cc +++ b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_runner.cc @@ -77,8 +77,9 @@ Status RunCudnnConvolution( const Shape& output_shape, DeviceMemory<T> input_buf, DeviceMemory<T> filter_buf, DeviceMemory<T> output_buf, se::ScratchAllocator* scratch_allocator, const Window& window, - const ConvolutionDimensionNumbers& dnums, AlgorithmConfig algorithm, - Stream* stream, ProfileResult* profile_result /*= nullptr*/) { + const ConvolutionDimensionNumbers& dnums, int64 feature_group_count, + AlgorithmConfig algorithm, Stream* stream, + ProfileResult* profile_result /*= nullptr*/) { VLOG(3) << "Convolution Algorithm: " << algorithm.algorithm().algo_id(); VLOG(3) << "tensor_ops_enabled: " << algorithm.algorithm().tensor_ops_enabled(); @@ -144,6 +145,7 @@ Status RunCudnnConvolution( } ConvolutionDescriptor convolution_descriptor(effective_num_dimensions); + convolution_descriptor.set_group_count(feature_group_count); for (int dim = 0; dim < num_dimensions; ++dim) { convolution_descriptor .set_zero_padding( @@ -222,14 +224,14 @@ Status RunCudnnConvolution( const Shape& output_shape, se::DeviceMemoryBase input_buf, se::DeviceMemoryBase filter_buf, se::DeviceMemoryBase output_buf, se::DeviceMemoryBase scratch_buf, const Window& window, - const ConvolutionDimensionNumbers& dnums, + const ConvolutionDimensionNumbers& dnums, int64 feature_group_count, se::dnn::AlgorithmConfig algorithm, se::Stream* stream, se::dnn::ProfileResult* profile_result) { ScratchBufAllocator scratch_allocator(scratch_buf); - return RunCudnnConvolution(kind, input_shape, filter_shape, output_shape, - input_buf, filter_buf, output_buf, - &scratch_allocator, window, dnums, algorithm, - stream, profile_result); + return RunCudnnConvolution( + kind, input_shape, filter_shape, output_shape, input_buf, filter_buf, + output_buf, &scratch_allocator, window, dnums, feature_group_count, + algorithm, stream, profile_result); } Status RunCudnnConvolution( @@ -237,32 +239,32 @@ Status RunCudnnConvolution( const Shape& output_shape, se::DeviceMemoryBase input_buf, se::DeviceMemoryBase filter_buf, se::DeviceMemoryBase output_buf, se::ScratchAllocator* scratch_allocator, const Window& window, - const ConvolutionDimensionNumbers& dnums, + const ConvolutionDimensionNumbers& dnums, int64 feature_group_count, se::dnn::AlgorithmConfig algorithm, se::Stream* stream, se::dnn::ProfileResult* profile_result) { PrimitiveType output_primitive_type = output_shape.element_type(); switch (output_primitive_type) { case F16: - return RunCudnnConvolution(kind, input_shape, filter_shape, output_shape, - se::DeviceMemory<Eigen::half>(input_buf), - se::DeviceMemory<Eigen::half>(filter_buf), - se::DeviceMemory<Eigen::half>(output_buf), - scratch_allocator, window, dnums, algorithm, - stream, profile_result); + return RunCudnnConvolution( + kind, input_shape, filter_shape, output_shape, + se::DeviceMemory<Eigen::half>(input_buf), + se::DeviceMemory<Eigen::half>(filter_buf), + se::DeviceMemory<Eigen::half>(output_buf), scratch_allocator, window, + dnums, feature_group_count, algorithm, stream, profile_result); case F32: - return RunCudnnConvolution(kind, input_shape, filter_shape, output_shape, - se::DeviceMemory<float>(input_buf), - se::DeviceMemory<float>(filter_buf), - se::DeviceMemory<float>(output_buf), - scratch_allocator, window, dnums, algorithm, - stream, profile_result); + return RunCudnnConvolution( + kind, input_shape, filter_shape, output_shape, + se::DeviceMemory<float>(input_buf), + se::DeviceMemory<float>(filter_buf), + se::DeviceMemory<float>(output_buf), scratch_allocator, window, dnums, + feature_group_count, algorithm, stream, profile_result); case F64: - return RunCudnnConvolution(kind, input_shape, filter_shape, output_shape, - se::DeviceMemory<double>(input_buf), - se::DeviceMemory<double>(filter_buf), - se::DeviceMemory<double>(output_buf), - scratch_allocator, window, dnums, algorithm, - stream, profile_result); + return RunCudnnConvolution( + kind, input_shape, filter_shape, output_shape, + se::DeviceMemory<double>(input_buf), + se::DeviceMemory<double>(filter_buf), + se::DeviceMemory<double>(output_buf), scratch_allocator, window, + dnums, feature_group_count, algorithm, stream, profile_result); default: LOG(FATAL) << ShapeUtil::HumanString(output_shape); } diff --git a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_runner.h b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_runner.h index 944e4ac686..a1b4fc71d0 100644 --- a/tensorflow/compiler/xla/service/gpu/cudnn_convolution_runner.h +++ b/tensorflow/compiler/xla/service/gpu/cudnn_convolution_runner.h @@ -75,7 +75,7 @@ Status RunCudnnConvolution( const Shape& output_shape, se::DeviceMemoryBase input_buf, se::DeviceMemoryBase filter_buf, se::DeviceMemoryBase output_buf, se::DeviceMemoryBase scratch_buf, const Window& window, - const ConvolutionDimensionNumbers& dnums, + const ConvolutionDimensionNumbers& dnums, int64 feature_group_count, se::dnn::AlgorithmConfig algorithm, se::Stream* stream, se::dnn::ProfileResult* profile_result = nullptr); @@ -84,7 +84,7 @@ Status RunCudnnConvolution( const Shape& output_shape, se::DeviceMemoryBase input_buf, se::DeviceMemoryBase filter_buf, se::DeviceMemoryBase output_buf, se::ScratchAllocator* scratch_allocator, const Window& window, - const ConvolutionDimensionNumbers& dnums, + const ConvolutionDimensionNumbers& dnums, int64 feature_group_count, se::dnn::AlgorithmConfig algorithm, se::Stream* stream, se::dnn::ProfileResult* profile_result = nullptr); diff --git a/tensorflow/compiler/xla/service/gpu/ir_emission_utils.cc b/tensorflow/compiler/xla/service/gpu/ir_emission_utils.cc index 9c90f4d46b..20d523abe0 100644 --- a/tensorflow/compiler/xla/service/gpu/ir_emission_utils.cc +++ b/tensorflow/compiler/xla/service/gpu/ir_emission_utils.cc @@ -144,10 +144,12 @@ bool ImplementedAsLibraryCall(const HloInstruction& hlo) { IsCustomCallToDnnConvolution(hlo); } -static HloInstruction* CreateCudnnConv( - const char* call_target, const Shape& shape, HloInstruction* lhs, - HloInstruction* rhs, const Window& window, - const ConvolutionDimensionNumbers& dnums) { +static HloInstruction* CreateCudnnConv(const char* call_target, + const Shape& shape, HloInstruction* lhs, + HloInstruction* rhs, + const Window& window, + const ConvolutionDimensionNumbers& dnums, + int64 feature_group_count) { HloComputation* computation = lhs->parent(); // This call returns a tuple of (conv_result, scratch_memory), where @@ -165,28 +167,34 @@ static HloInstruction* CreateCudnnConv( HloInstruction::CreateCustomCall(call_shape, {lhs, rhs}, call_target)); custom_call->set_window(window); custom_call->set_convolution_dimension_numbers(dnums); + custom_call->set_feature_group_count(feature_group_count); return custom_call; } -HloInstruction* CreateCudnnConvForward( - const Shape& shape, HloInstruction* input, HloInstruction* kernel, - const Window& window, const ConvolutionDimensionNumbers& dnums) { +HloInstruction* CreateCudnnConvForward(const Shape& shape, + HloInstruction* input, + HloInstruction* kernel, + const Window& window, + const ConvolutionDimensionNumbers& dnums, + int64 feature_group_count) { return CreateCudnnConv(kCudnnConvForwardCallTarget, shape, input, kernel, - window, dnums); + window, dnums, feature_group_count); } HloInstruction* CreateCudnnConvBackwardInput( const Shape& shape, HloInstruction* output, HloInstruction* reverse_filter, - const Window& window, const ConvolutionDimensionNumbers& dnums) { + const Window& window, const ConvolutionDimensionNumbers& dnums, + int64 feature_group_count) { return CreateCudnnConv(kCudnnConvBackwardInputCallTarget, shape, output, - reverse_filter, window, dnums); + reverse_filter, window, dnums, feature_group_count); } HloInstruction* CreateCudnnConvBackwardFilter( const Shape& shape, HloInstruction* input, HloInstruction* output, - const Window& window, const ConvolutionDimensionNumbers& dnums) { + const Window& window, const ConvolutionDimensionNumbers& dnums, + int64 feature_group_count) { return CreateCudnnConv(kCudnnConvBackwardFilterCallTarget, shape, input, - output, window, dnums); + output, window, dnums, feature_group_count); } bool IsReductionToVector(const HloInstruction& reduce) { diff --git a/tensorflow/compiler/xla/service/gpu/ir_emission_utils.h b/tensorflow/compiler/xla/service/gpu/ir_emission_utils.h index d242897e16..59c65fc268 100644 --- a/tensorflow/compiler/xla/service/gpu/ir_emission_utils.h +++ b/tensorflow/compiler/xla/service/gpu/ir_emission_utils.h @@ -109,15 +109,20 @@ bool IsCustomCallToDnnConvolution(const HloInstruction& hlo); // // The created cudnn call will use the default cudnn algorithm and no scratch // space. -HloInstruction* CreateCudnnConvForward( - const Shape& shape, HloInstruction* input, HloInstruction* kernel, - const Window& window, const ConvolutionDimensionNumbers& dnums); +HloInstruction* CreateCudnnConvForward(const Shape& shape, + HloInstruction* input, + HloInstruction* kernel, + const Window& window, + const ConvolutionDimensionNumbers& dnums, + int64 feature_group_count); HloInstruction* CreateCudnnConvBackwardInput( const Shape& shape, HloInstruction* output, HloInstruction* reverse_filter, - const Window& window, const ConvolutionDimensionNumbers& dnums); + const Window& window, const ConvolutionDimensionNumbers& dnums, + int64 feature_group_count); HloInstruction* CreateCudnnConvBackwardFilter( const Shape& shape, HloInstruction* input, HloInstruction* output, - const Window& window, const ConvolutionDimensionNumbers& dnums); + const Window& window, const ConvolutionDimensionNumbers& dnums, + int64 feature_group_count); // Returns true if `hlo` will be implemented as a library call, e.g. cuBLAS gemm // or cuDNN convolution. diff --git a/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.cc b/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.cc index 78f61a4987..389a98facb 100644 --- a/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.cc +++ b/tensorflow/compiler/xla/service/gpu/ir_emitter_unnested.cc @@ -489,8 +489,8 @@ Status IrEmitterUnnested::HandleCustomCall(HloInstruction* custom_call) { /*filter_shape=*/rhs_shape, /*output_shape=*/conv_result_shape, // custom_call->window(), custom_call->convolution_dimension_numbers(), - backend_config.algorithm(), backend_config.tensor_ops_enabled(), - custom_call); + custom_call->feature_group_count(), backend_config.algorithm(), + backend_config.tensor_ops_enabled(), custom_call); } else if (target == kCudnnConvBackwardInputCallTarget) { thunk = absl::make_unique<ConvolutionThunk>( CudnnConvKind::kBackwardInput, @@ -503,8 +503,8 @@ Status IrEmitterUnnested::HandleCustomCall(HloInstruction* custom_call) { /*filter_shape=*/rhs_shape, /*output_shape=*/lhs_shape, // custom_call->window(), custom_call->convolution_dimension_numbers(), - backend_config.algorithm(), backend_config.tensor_ops_enabled(), - custom_call); + custom_call->feature_group_count(), backend_config.algorithm(), + backend_config.tensor_ops_enabled(), custom_call); } else if (target == kCudnnConvBackwardFilterCallTarget) { thunk = absl::make_unique<ConvolutionThunk>( CudnnConvKind::kBackwardFilter, @@ -517,8 +517,8 @@ Status IrEmitterUnnested::HandleCustomCall(HloInstruction* custom_call) { /*filter_shape=*/conv_result_shape, /*output_shape=*/rhs_shape, // custom_call->window(), custom_call->convolution_dimension_numbers(), - backend_config.algorithm(), backend_config.tensor_ops_enabled(), - custom_call); + custom_call->feature_group_count(), backend_config.algorithm(), + backend_config.tensor_ops_enabled(), custom_call); } else { LOG(FATAL) << "Unexpected custom call target: " << custom_call->custom_call_target(); diff --git a/tensorflow/compiler/xla/service/gpu/kernel_thunk.cc b/tensorflow/compiler/xla/service/gpu/kernel_thunk.cc index 878b0b96a1..e09b8fbd3b 100644 --- a/tensorflow/compiler/xla/service/gpu/kernel_thunk.cc +++ b/tensorflow/compiler/xla/service/gpu/kernel_thunk.cc @@ -41,11 +41,7 @@ Status KernelThunk::Initialize(const GpuExecutable& executable, tensorflow::mutex_lock lock(mutex_); if (!loader_spec_) { loader_spec_.reset(new se::MultiKernelLoaderSpec(args_.size())); - absl::string_view ptx = executable.ptx(); - // Convert absl::string_view to se::port::StringPiece because - // StreamExecutor uses the latter. - loader_spec_->AddCudaPtxInMemory( - se::port::StringPiece(ptx.data(), ptx.size()), kernel_name_); + loader_spec_->AddCudaPtxInMemory(executable.ptx(), kernel_name_); if (!executable.cubin().empty()) { loader_spec_->AddCudaCubinInMemory( diff --git a/tensorflow/compiler/xla/service/gpu/multi_output_fusion_test.cc b/tensorflow/compiler/xla/service/gpu/multi_output_fusion_test.cc index c822c94f1b..8a6e5327e0 100644 --- a/tensorflow/compiler/xla/service/gpu/multi_output_fusion_test.cc +++ b/tensorflow/compiler/xla/service/gpu/multi_output_fusion_test.cc @@ -259,7 +259,7 @@ TEST_F(MultiOutputFusionTest, MultiOutputFusionTwoLoops) { TEST_F(MultiOutputFusionTest, MultiOutputFusionLoopReduceToInputFusion) { // Fusing a reduce into a loop fusion would require changing the fusion kind. // That's not supported yet. - auto module = ParseHloString(tensorflow::strings::StrCat(kModulePrefix, R"( + auto module = ParseHloString(absl::StrCat(kModulePrefix, R"( fused_computation_1 { p0.1 = f32[6400]{0} parameter(0) ROOT mul = f32[6400]{0} multiply(p0.1, p0.1) @@ -277,7 +277,7 @@ TEST_F(MultiOutputFusionTest, MultiOutputFusionLoopReduceToInputFusion) { } TEST_F(MultiOutputFusionTest, MultiOutputFusionLoopElementwise) { - auto module = ParseHloString(tensorflow::strings::StrCat(kModulePrefix, R"( + auto module = ParseHloString(absl::StrCat(kModulePrefix, R"( fused_computation_1 { p0.1 = f32[6400]{0} parameter(0) ROOT mul = f32[6400]{0} multiply(p0.1, p0.1) @@ -301,7 +301,7 @@ TEST_F(MultiOutputFusionTest, MultiOutputFusionLoopElementwise) { } TEST_F(MultiOutputFusionTest, MultiOutputFusionSiblingLoopsDifferentShapes) { - auto module = ParseHloString(tensorflow::strings::StrCat(kModulePrefix, R"( + auto module = ParseHloString(absl::StrCat(kModulePrefix, R"( fused_computation_1 { p0.1 = f32[8,1,5,16,1,1]{5,4,3,2,1,0} parameter(0) ROOT mul = f32[8,1,5,16,1,1]{5,4,3,2,1,0} multiply(p0.1, p0.1) @@ -324,7 +324,7 @@ TEST_F(MultiOutputFusionTest, MultiOutputFusionSiblingLoopsDifferentShapes) { } TEST_F(MultiOutputFusionTest, MultiOutputFusionSiblingLoopAndMultiOutputLoop) { - auto module = ParseHloString(tensorflow::strings::StrCat(kModulePrefix, R"( + auto module = ParseHloString(absl::StrCat(kModulePrefix, R"( fused_computation_1 { p0.1 = f32[8,1,5,16,1,1]{5,4,3,2,1,0} parameter(0) mul = f32[8,1,5,16,1,1]{5,4,3,2,1,0} multiply(p0.1, p0.1) @@ -358,7 +358,7 @@ TEST_F(MultiOutputFusionTest, MultiOutputFusionSiblingLoopAndMultiOutputLoop) { TEST_F(MultiOutputFusionTest, MultiOutputFusionSiblingLoopAndMultiOutputLoopDifferentShapes) { - auto module = ParseHloString(tensorflow::strings::StrCat(kModulePrefix, R"( + auto module = ParseHloString(absl::StrCat(kModulePrefix, R"( fused_computation_1 { p0.1 = f32[8,1,5,16,1,1]{5,4,3,2,1,0} parameter(0) mul = f32[8,1,5,16,1,1]{5,4,3,2,1,0} multiply(p0.1, p0.1) diff --git a/tensorflow/compiler/xla/service/gpu/nvptx_compiler.cc b/tensorflow/compiler/xla/service/gpu/nvptx_compiler.cc index 8ce67c03b6..f6325b3368 100644 --- a/tensorflow/compiler/xla/service/gpu/nvptx_compiler.cc +++ b/tensorflow/compiler/xla/service/gpu/nvptx_compiler.cc @@ -36,7 +36,6 @@ limitations under the License. #include "tensorflow/compiler/xla/service/buffer_liveness.h" #include "tensorflow/compiler/xla/service/call_inliner.h" #include "tensorflow/compiler/xla/service/conditional_simplifier.h" -#include "tensorflow/compiler/xla/service/convolution_feature_group_converter.h" #include "tensorflow/compiler/xla/service/flatten_call_graph.h" #include "tensorflow/compiler/xla/service/gpu/cudnn_batchnorm_rewriter.h" #include "tensorflow/compiler/xla/service/gpu/cudnn_convolution_algorithm_picker.h" @@ -208,8 +207,6 @@ Status OptimizeHloModule(HloModule* hlo_module, se::StreamExecutor* stream_exec, HloPassPipeline pipeline("conv_canonicalization"); pipeline.AddInvariantChecker<HloVerifier>(/*layout_sensitive=*/false, /*allow_mixed_precision=*/false); - // TODO(b/31709653): Directly use the grouped convolution support of Cudnn. - pipeline.AddPass<ConvolutionFeatureGroupConverter>(); pipeline.AddPass<CudnnConvolutionRewriter>(); // CudnnConvolutionRewriter may add instructions of the form // reverse(constant), which it expects will be simplified by constant diff --git a/tensorflow/compiler/xla/service/gpu/pad_insertion.cc b/tensorflow/compiler/xla/service/gpu/pad_insertion.cc index 98cc21ccac..9d85d746d8 100644 --- a/tensorflow/compiler/xla/service/gpu/pad_insertion.cc +++ b/tensorflow/compiler/xla/service/gpu/pad_insertion.cc @@ -166,9 +166,9 @@ bool PadInsertion::CanonicalizeForwardConvolution(HloInstruction* conv) { Shape old_conv_shape = conv->shape().tuple_shapes(0); VLOG(1) << "Canonicalizing forward conv"; - auto new_conv = CreateCudnnConvForward(old_conv_shape, new_input, new_kernel, - new_conv_window, - conv->convolution_dimension_numbers()); + auto new_conv = CreateCudnnConvForward( + old_conv_shape, new_input, new_kernel, new_conv_window, + conv->convolution_dimension_numbers(), conv->feature_group_count()); VLOG(1) << "Replacing:\n " << conv->ToString() << "\nwith:\n " << new_conv->ToString(); TF_CHECK_OK(conv->parent()->ReplaceInstruction(conv, new_conv)); @@ -247,7 +247,7 @@ bool PadInsertion::CanonicalizeBackwardFilterConvolution( Shape backward_conv_shape = backward_conv->shape().tuple_shapes(0); HloInstruction* new_backward_conv = CreateCudnnConvBackwardFilter( backward_conv_shape, padded_input, output, new_backward_conv_window, - backward_conv_dnums); + backward_conv_dnums, backward_conv->feature_group_count()); VLOG(1) << "Canonicalizing backward filter conv"; VLOG(1) << "Replacing:\n " << backward_conv->ToString() << "\nwith:\n " @@ -312,7 +312,7 @@ bool PadInsertion::CanonicalizeBackwardInputConvolution( HloInstruction* new_backward_conv_call = CreateCudnnConvBackwardInput( new_backward_conv_shape, output, filter, new_backward_conv_window, - backward_conv_dnums); + backward_conv_dnums, backward_conv->feature_group_count()); // The CustomCall created above returns a tuple (conv_result, scratch_memory). // Extract out the two elements. diff --git a/tensorflow/compiler/xla/service/graphviz_example.cc b/tensorflow/compiler/xla/service/graphviz_example.cc index a2be89511b..ef70b68877 100644 --- a/tensorflow/compiler/xla/service/graphviz_example.cc +++ b/tensorflow/compiler/xla/service/graphviz_example.cc @@ -112,8 +112,11 @@ std::unique_ptr<HloModule> MakeBigGraph() { DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); - auto dot = builder.AddInstruction( - HloInstruction::CreateDot(vshape, clamp, param_v0, dot_dnums)); + PrecisionConfig precision_config; + precision_config.mutable_operand_precision()->Resize( + /*new_size=*/2, PrecisionConfig::DEFAULT); + auto dot = builder.AddInstruction(HloInstruction::CreateDot( + vshape, clamp, param_v0, dot_dnums, precision_config)); auto tuple = builder.AddInstruction( HloInstruction::CreateTuple({dot, param_s, clamp})); auto scalar = builder.AddInstruction( diff --git a/tensorflow/compiler/xla/service/heap_simulator_test.cc b/tensorflow/compiler/xla/service/heap_simulator_test.cc index 5f85f14565..7ad8a107e1 100644 --- a/tensorflow/compiler/xla/service/heap_simulator_test.cc +++ b/tensorflow/compiler/xla/service/heap_simulator_test.cc @@ -366,8 +366,8 @@ TEST_F(HeapSimulatorTest, MultiplyDot) { DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); - auto dot = builder.AddInstruction( - HloInstruction::CreateDot(f32vec4_, mul, paramY, dot_dnums)); + auto dot = builder.AddInstruction(HloInstruction::CreateDot( + f32vec4_, mul, paramY, dot_dnums, DefaultPrecisionConfig(2))); // The buffer for dot is the output, and it cannot be shared with the buffer // for mul, since dot isn't elementwise. @@ -402,8 +402,8 @@ TEST_F(HeapSimulatorTest, MultiplyDotAdd) { DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); - auto dot = builder.AddInstruction( - HloInstruction::CreateDot(f32vec4_, mul, paramY, dot_dnums)); + auto dot = builder.AddInstruction(HloInstruction::CreateDot( + f32vec4_, mul, paramY, dot_dnums, DefaultPrecisionConfig(2))); auto add = builder.AddInstruction( HloInstruction::CreateBinary(f32vec4_, HloOpcode::kAdd, dot, paramA)); @@ -440,10 +440,10 @@ TEST_F(HeapSimulatorTest, MultiplyDotDot) { DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); - auto dot0 = builder.AddInstruction( - HloInstruction::CreateDot(f32vec4_, mul, paramY, dot_dnums)); - auto dot1 = builder.AddInstruction( - HloInstruction::CreateDot(f32vec4_, dot0, paramY, dot_dnums)); + auto dot0 = builder.AddInstruction(HloInstruction::CreateDot( + f32vec4_, mul, paramY, dot_dnums, DefaultPrecisionConfig(2))); + auto dot1 = builder.AddInstruction(HloInstruction::CreateDot( + f32vec4_, dot0, paramY, dot_dnums, DefaultPrecisionConfig(2))); // The buffer for dot1 is the output. No buffers can be shared. The buffer // for mul is freed before the end, since it's no longer used after dot0 @@ -481,10 +481,10 @@ TEST_F(HeapSimulatorTest, MultiplyDotDotTuple) { DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); - auto dot0 = builder.AddInstruction( - HloInstruction::CreateDot(f32vec4_, mul, paramY, dot_dnums)); - auto dot1 = builder.AddInstruction( - HloInstruction::CreateDot(f32vec4_, dot0, paramY, dot_dnums)); + auto dot0 = builder.AddInstruction(HloInstruction::CreateDot( + f32vec4_, mul, paramY, dot_dnums, DefaultPrecisionConfig(2))); + auto dot1 = builder.AddInstruction(HloInstruction::CreateDot( + f32vec4_, dot0, paramY, dot_dnums, DefaultPrecisionConfig(2))); auto tuple = builder.AddInstruction(HloInstruction::CreateTuple({dot0, dot1})); diff --git a/tensorflow/compiler/xla/service/hlo.proto b/tensorflow/compiler/xla/service/hlo.proto index 58b7af93eb..99d0cf50ca 100644 --- a/tensorflow/compiler/xla/service/hlo.proto +++ b/tensorflow/compiler/xla/service/hlo.proto @@ -172,7 +172,7 @@ message HloInstructionProto { xla.ScatterDimensionNumbers scatter_dimension_numbers = 48; // Precision configuration for the instruction. Has backend-specific meaning. - xla.PrecisionConfigProto precision_config = 51; + xla.PrecisionConfig precision_config = 51; // Collective permute field. repeated SourceTarget source_target_pairs = 52; diff --git a/tensorflow/compiler/xla/service/hlo_computation_test.cc b/tensorflow/compiler/xla/service/hlo_computation_test.cc index f7ed1b0316..2aaaef1d36 100644 --- a/tensorflow/compiler/xla/service/hlo_computation_test.cc +++ b/tensorflow/compiler/xla/service/hlo_computation_test.cc @@ -601,8 +601,11 @@ TEST_F(HloComputationTest, Stringification) { DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); + PrecisionConfig precision_config; + precision_config.mutable_operand_precision()->Resize( + 2, PrecisionConfig::DEFAULT); builder.AddInstruction( - HloInstruction::CreateDot(sout, x, reshape, dot_dnums)); + HloInstruction::CreateDot(sout, x, reshape, dot_dnums, precision_config)); auto module = CreateNewModule(); auto* computation = module->AddEntryComputation(builder.Build()); @@ -633,8 +636,11 @@ TEST_F(HloComputationTest, StringificationIndent) { DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); + PrecisionConfig precision_config; + precision_config.mutable_operand_precision()->Resize( + 2, PrecisionConfig::DEFAULT); builder.AddInstruction( - HloInstruction::CreateDot(sout, x, reshape, dot_dnums)); + HloInstruction::CreateDot(sout, x, reshape, dot_dnums, precision_config)); auto module = CreateNewModule(); auto* computation = module->AddEntryComputation(builder.Build()); @@ -666,8 +672,11 @@ TEST_F(HloComputationTest, StringificationCanonical) { DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); + PrecisionConfig precision_config; + precision_config.mutable_operand_precision()->Resize( + 2, PrecisionConfig::DEFAULT); builder.AddInstruction( - HloInstruction::CreateDot(sout, x, reshape, dot_dnums)); + HloInstruction::CreateDot(sout, x, reshape, dot_dnums, precision_config)); auto module = CreateNewModule(); auto* computation = module->AddEntryComputation(builder.Build()); diff --git a/tensorflow/compiler/xla/service/hlo_creation_utils.cc b/tensorflow/compiler/xla/service/hlo_creation_utils.cc index 19ffb465c0..a3fcc0fefa 100644 --- a/tensorflow/compiler/xla/service/hlo_creation_utils.cc +++ b/tensorflow/compiler/xla/service/hlo_creation_utils.cc @@ -61,15 +61,18 @@ StatusOr<HloInstruction*> MakeSliceHlo(HloInstruction* operand, } StatusOr<HloInstruction*> MakeConvolveHlo( - HloInstruction* lhs, HloInstruction* rhs, const Window& window, - const ConvolutionDimensionNumbers& dimension_numbers) { + HloInstruction* lhs, HloInstruction* rhs, int64 feature_group_count, + const Window& window, const ConvolutionDimensionNumbers& dimension_numbers, + const PrecisionConfig& precision_config) { HloComputation* computation = lhs->parent(); CHECK_EQ(computation, rhs->parent()); - TF_ASSIGN_OR_RETURN(Shape convolve_shape, ShapeInference::InferConvolveShape( - lhs->shape(), rhs->shape(), - window, dimension_numbers)); + TF_ASSIGN_OR_RETURN(Shape convolve_shape, + ShapeInference::InferConvolveShape( + lhs->shape(), rhs->shape(), feature_group_count, + window, dimension_numbers)); return computation->AddInstruction(HloInstruction::CreateConvolve( - convolve_shape, lhs, rhs, window, dimension_numbers)); + convolve_shape, lhs, rhs, feature_group_count, window, dimension_numbers, + precision_config)); } StatusOr<HloInstruction*> MakeTransposeHlo(HloInstruction* operand, @@ -165,14 +168,15 @@ StatusOr<HloInstruction*> MakeConcatHlo( } StatusOr<HloInstruction*> MakeDotHlo(HloInstruction* lhs, HloInstruction* rhs, - const DotDimensionNumbers& dim_numbers) { + const DotDimensionNumbers& dim_numbers, + const PrecisionConfig& precision_config) { HloComputation* computation = lhs->parent(); CHECK_EQ(computation, rhs->parent()); TF_ASSIGN_OR_RETURN( Shape dot_shape, ShapeInference::InferDotOpShape(lhs->shape(), rhs->shape(), dim_numbers)); - return computation->AddInstruction( - HloInstruction::CreateDot(dot_shape, lhs, rhs, dim_numbers)); + return computation->AddInstruction(HloInstruction::CreateDot( + dot_shape, lhs, rhs, dim_numbers, precision_config)); } StatusOr<HloInstruction*> MakeMapHlo(absl::Span<HloInstruction* const> operands, diff --git a/tensorflow/compiler/xla/service/hlo_creation_utils.h b/tensorflow/compiler/xla/service/hlo_creation_utils.h index a1c4b374d1..b22058abb4 100644 --- a/tensorflow/compiler/xla/service/hlo_creation_utils.h +++ b/tensorflow/compiler/xla/service/hlo_creation_utils.h @@ -48,8 +48,9 @@ StatusOr<HloInstruction*> MakeSliceHlo(HloInstruction* operand, // Creates a convolution HLO instruction and adds it to the computation // containing `lhs` and `rhs` (`lhs` and `rhs` must be in the same computation). StatusOr<HloInstruction*> MakeConvolveHlo( - HloInstruction* lhs, HloInstruction* rhs, const Window& window, - const ConvolutionDimensionNumbers& dimension_numbers); + HloInstruction* lhs, HloInstruction* rhs, int64 feature_group_count, + const Window& window, const ConvolutionDimensionNumbers& dimension_numbers, + const PrecisionConfig& precision_config); // Creates a transpose HLO instruction and adds it to the computation containing // `operand`. @@ -98,7 +99,8 @@ StatusOr<HloInstruction*> MakeConcatHlo( // Creates a Dot HLO instruction and adds it to the computation containing `lhs` // and `rhs` (both must be in the same computation). StatusOr<HloInstruction*> MakeDotHlo(HloInstruction* lhs, HloInstruction* rhs, - const DotDimensionNumbers& dim_numbers); + const DotDimensionNumbers& dim_numbers, + const PrecisionConfig& precision_config); // Creates a Map HLO instruction and adds it to the computation containing the // operands. All operands must be in the same computation. diff --git a/tensorflow/compiler/xla/service/hlo_cse.cc b/tensorflow/compiler/xla/service/hlo_cse.cc index cb367adf5e..b59c9ba3ed 100644 --- a/tensorflow/compiler/xla/service/hlo_cse.cc +++ b/tensorflow/compiler/xla/service/hlo_cse.cc @@ -23,6 +23,7 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/container/inlined_vector.h" #include "tensorflow/compiler/xla/layout_util.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/service/hlo_computation.h" @@ -34,7 +35,6 @@ limitations under the License. #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/gtl/flatset.h" -#include "tensorflow/core/lib/gtl/inlined_vector.h" #include "tensorflow/core/lib/hash/hash.h" namespace xla { diff --git a/tensorflow/compiler/xla/service/hlo_dataflow_analysis_test.cc b/tensorflow/compiler/xla/service/hlo_dataflow_analysis_test.cc index d1a96c10f8..72b236801a 100644 --- a/tensorflow/compiler/xla/service/hlo_dataflow_analysis_test.cc +++ b/tensorflow/compiler/xla/service/hlo_dataflow_analysis_test.cc @@ -2334,8 +2334,11 @@ TEST_F(CanShareOperandBufferWithUserTest, FusedDotAdd) { DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); + PrecisionConfig precision_config; + precision_config.mutable_operand_precision()->Resize( + 2, PrecisionConfig::DEFAULT); auto dot = builder.AddInstruction( - HloInstruction::CreateDot(data_shape, a, b, dot_dnums)); + HloInstruction::CreateDot(data_shape, a, b, dot_dnums, precision_config)); auto one = builder.AddInstruction( HloInstruction::CreateConstant(LiteralUtil::CreateR0<float>(1.0))); diff --git a/tensorflow/compiler/xla/service/hlo_domain_map.cc b/tensorflow/compiler/xla/service/hlo_domain_map.cc index 8b2846e0c2..113fd18eae 100644 --- a/tensorflow/compiler/xla/service/hlo_domain_map.cc +++ b/tensorflow/compiler/xla/service/hlo_domain_map.cc @@ -51,6 +51,10 @@ int64 HloDomainMap::GetDomainId(HloInstruction* instruction) const { return FindOrDefault(instruction_to_domain_, instruction, -1); } +int64 HloDomainMap::GetDomainMetadataId(HloInstruction* instruction) const { + return FindOrDie(domain_metadata_id_, instruction); +} + Status HloDomainMap::TryProcessEmptyDomain(HloInstruction* instruction) { TF_RET_CHECK(instruction->opcode() == HloOpcode::kDomain); // We only check operands, so we are sure to not process the empty domain from @@ -93,6 +97,43 @@ Status HloDomainMap::Populate(HloComputation* computation) { CreateDomain(instruction, instructions_post_order)); TF_RETURN_IF_ERROR(InsertDomain(std::move(domain))); } + TF_RETURN_IF_ERROR(PopulateDomainMetadataMap()); + return Status::OK(); +} + +Status HloDomainMap::PopulateDomainMetadataMap() { + auto hash = [](const DomainMetadata* m) { return m->Hash(); }; + auto equal = [](const DomainMetadata* a, const DomainMetadata* b) { + return a->Matches(*b); + }; + tensorflow::gtl::FlatMap<const DomainMetadata*, int64, decltype(hash), + decltype(equal)> + domain_metadata(1024, hash, equal); + + for (auto& domain : instruction_domains_) { + int64 domain_metadata_id = -1; + if (!domain->enter_domains.empty()) { + const HloInstruction* domain_instruction = *domain->enter_domains.begin(); + domain_metadata_id = + domain_metadata + .insert({&domain_instruction->user_side_metadata(), + domain_metadata.size() + 1}) + .first->second; + } else if (!domain->exit_domains.empty()) { + const HloInstruction* domain_instruction = *domain->exit_domains.begin(); + domain_metadata_id = + domain_metadata + .insert({&domain_instruction->operand_side_metadata(), + domain_metadata.size() + 1}) + .first->second; + } else { + domain_metadata_id = 0; + } + TF_RET_CHECK(domain_metadata_id >= 0); + for (HloInstruction* instruction : domain->instructions) { + domain_metadata_id_[instruction] = domain_metadata_id; + } + } return Status::OK(); } diff --git a/tensorflow/compiler/xla/service/hlo_domain_map.h b/tensorflow/compiler/xla/service/hlo_domain_map.h index 633109249a..56b557d7ce 100644 --- a/tensorflow/compiler/xla/service/hlo_domain_map.h +++ b/tensorflow/compiler/xla/service/hlo_domain_map.h @@ -69,6 +69,11 @@ class HloDomainMap { // instruction is not found within any domain. int64 GetDomainId(HloInstruction* instruction) const; + // Returns the unique id of the domain metadata for the domain the given + // instruction belongs to. The given instruction must not be a kDomain + // instruction since each domain instruction is associated with 2 domains. + int64 GetDomainMetadataId(HloInstruction* instruction) const; + private: // Map used for representing instruction ordering, i.e. // order_map[a] < order_map[b] means a must be ordered before b. @@ -109,9 +114,14 @@ class HloDomainMap { const tensorflow::gtl::FlatSet<HloInstruction*>& instruction_set, const InstructionOrderMap& instructions_order); + // Populates domain_metadata_id_ that maps each HloInstruction to the unique + // ID of its associated domain metatadata. + Status PopulateDomainMetadataMap(); + string domain_kind_; std::vector<std::unique_ptr<DomainMetadata::Domain>> instruction_domains_; tensorflow::gtl::FlatMap<HloInstruction*, int64> instruction_to_domain_; + tensorflow::gtl::FlatMap<HloInstruction*, int64> domain_metadata_id_; }; } // namespace xla diff --git a/tensorflow/compiler/xla/service/hlo_domain_metadata.h b/tensorflow/compiler/xla/service/hlo_domain_metadata.h index 6c142ee474..302807f816 100644 --- a/tensorflow/compiler/xla/service/hlo_domain_metadata.h +++ b/tensorflow/compiler/xla/service/hlo_domain_metadata.h @@ -72,6 +72,9 @@ class DomainMetadata { // two matches. virtual bool Matches(const DomainMetadata& other) const = 0; + // Returns the hash value of the metadata. + virtual size_t Hash() const = 0; + // Returns a string representation of the metadata. virtual string ToString() const = 0; }; diff --git a/tensorflow/compiler/xla/service/hlo_domain_test.cc b/tensorflow/compiler/xla/service/hlo_domain_test.cc index 974ab94467..43e74d2f6f 100644 --- a/tensorflow/compiler/xla/service/hlo_domain_test.cc +++ b/tensorflow/compiler/xla/service/hlo_domain_test.cc @@ -99,6 +99,8 @@ class OpNameMetadata : public DomainMetadata { static absl::string_view KindName() { return "opname"; } + size_t Hash() const override { return std::hash<string>()(opname_); } + private: string opname_; }; diff --git a/tensorflow/compiler/xla/service/hlo_evaluator.cc b/tensorflow/compiler/xla/service/hlo_evaluator.cc index 441dcad000..d0d955fea8 100644 --- a/tensorflow/compiler/xla/service/hlo_evaluator.cc +++ b/tensorflow/compiler/xla/service/hlo_evaluator.cc @@ -53,7 +53,6 @@ namespace xla { namespace { - template <typename OperandT> StatusOr<std::unique_ptr<Literal>> Compare(const Shape& shape, HloOpcode opcode, LiteralSlice lhs_literal, @@ -345,7 +344,8 @@ StatusOr<std::unique_ptr<Literal>> HloEvaluator::EvaluateElementwiseUnaryOp( } StatusOr<std::unique_ptr<Literal>> HloEvaluator::EvaluateDotOp( - const DotDimensionNumbers& dim_numbers, const Literal& lhs, + const DotDimensionNumbers& dim_numbers, + const PrecisionConfig& precision_config, const Literal& lhs, const Literal& rhs) { std::unique_ptr<HloInstruction> lhs_instr = HloInstruction::CreateConstant(lhs.CloneToUnique()); @@ -358,7 +358,7 @@ StatusOr<std::unique_ptr<Literal>> HloEvaluator::EvaluateDotOp( std::unique_ptr<HloInstruction> cloned_instruction = HloInstruction::CreateDot(dot_shape, lhs_instr.get(), rhs_instr.get(), - dim_numbers); + dim_numbers, precision_config); return Evaluate(cloned_instruction.get()); } diff --git a/tensorflow/compiler/xla/service/hlo_evaluator.h b/tensorflow/compiler/xla/service/hlo_evaluator.h index c2d49e56ac..72252bafc7 100644 --- a/tensorflow/compiler/xla/service/hlo_evaluator.h +++ b/tensorflow/compiler/xla/service/hlo_evaluator.h @@ -115,7 +115,8 @@ class HloEvaluator : public DfsHloVisitorWithDefault { HloOpcode opcode, const Literal& operand); StatusOr<std::unique_ptr<Literal>> EvaluateDotOp( - const DotDimensionNumbers& dim_numbers, const Literal& lhs, + const DotDimensionNumbers& dim_numbers, + const PrecisionConfig& precision_config, const Literal& lhs, const Literal& rhs); protected: diff --git a/tensorflow/compiler/xla/service/hlo_evaluator_test.cc b/tensorflow/compiler/xla/service/hlo_evaluator_test.cc index 7e490d7f32..abd4bb1f73 100644 --- a/tensorflow/compiler/xla/service/hlo_evaluator_test.cc +++ b/tensorflow/compiler/xla/service/hlo_evaluator_test.cc @@ -649,7 +649,8 @@ TEST_P(HloEvaluatorTest, DotRank2AndRank1) { dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); b.AddInstruction(HloInstruction::CreateDot(shape, lhs_instruction, - rhs_instruction, dot_dnums)); + rhs_instruction, dot_dnums, + DefaultPrecisionConfig(2))); module().AddEntryComputation(b.Build()); std::unique_ptr<Literal> result = Evaluate(); @@ -694,7 +695,8 @@ TEST_P(HloEvaluatorTest, DotRank1AndRank2) { dot_dnums.add_lhs_contracting_dimensions(0); dot_dnums.add_rhs_contracting_dimensions(0); b.AddInstruction(HloInstruction::CreateDot(shape, lhs_instruction, - rhs_instruction, dot_dnums)); + rhs_instruction, dot_dnums, + DefaultPrecisionConfig(2))); module().AddEntryComputation(b.Build()); std::unique_ptr<Literal> result = Evaluate(); @@ -737,7 +739,8 @@ TEST_P(HloEvaluatorTest, DotRank2AndRank2) { dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); b.AddInstruction(HloInstruction::CreateDot(shape, lhs_instruction, - rhs_instruction, dot_dnums)); + rhs_instruction, dot_dnums, + DefaultPrecisionConfig(2))); module().AddEntryComputation(b.Build()); std::unique_ptr<Literal> result = Evaluate(); @@ -788,9 +791,10 @@ TEST_P(HloEvaluatorTest, SimpleConv1D) { dnums.set_kernel_input_feature_dimension(1); dnums.add_kernel_spatial_dimensions(2); - const Shape& shape = ShapeUtil::MakeShape(F32, {1, 1, 3}); + Shape shape = ShapeUtil::MakeShape(F32, {1, 1, 3}); b.AddInstruction(HloInstruction::CreateConvolve( - shape, lhs_instruction, rhs_instruction, window, dnums)); + shape, lhs_instruction, rhs_instruction, /*feature_group_count=*/1, + window, dnums, DefaultPrecisionConfig(2))); module().AddEntryComputation(b.Build()); std::unique_ptr<Literal> result = Evaluate(); @@ -842,9 +846,10 @@ TEST_P(HloEvaluatorTest, Simple4x4Conv2DWith2x2Kernel) { ConvolutionDimensionNumbers dnums = XlaBuilder::CreateDefaultConvDimensionNumbers(2); - const Shape& shape = ShapeUtil::MakeShape(F32, {1, 1, 4, 4}); + Shape shape = ShapeUtil::MakeShape(F32, {1, 1, 4, 4}); b.AddInstruction(HloInstruction::CreateConvolve( - shape, lhs_instruction, rhs_instruction, window, dnums)); + shape, lhs_instruction, rhs_instruction, /*feature_group_count=*/1, + window, dnums, DefaultPrecisionConfig(2))); module().AddEntryComputation(b.Build()); std::unique_ptr<Literal> result = Evaluate(); @@ -925,9 +930,10 @@ TEST_P(HloEvaluatorTest, Conv2DGeneralDimensionsReversed) { dnums.add_kernel_spatial_dimensions(3); dnums.add_kernel_spatial_dimensions(1); - const Shape& shape = ShapeUtil::MakeShape(F32, {1, 1, 1, 2}); + Shape shape = ShapeUtil::MakeShape(F32, {1, 1, 1, 2}); b.AddInstruction(HloInstruction::CreateConvolve( - shape, lhs_instruction, rhs_instruction, window, dnums)); + shape, lhs_instruction, rhs_instruction, /*feature_group_count=*/1, + window, dnums, DefaultPrecisionConfig(2))); module().AddEntryComputation(b.Build()); std::unique_ptr<Literal> result = Evaluate(); @@ -1002,9 +1008,10 @@ TEST_P(HloEvaluatorTest, Conv2DGeneralDimensions) { dnums.add_kernel_spatial_dimensions(3); dnums.add_kernel_spatial_dimensions(1); - const Shape& shape = ShapeUtil::MakeShape(F32, {1, 1, 1, 2}); + Shape shape = ShapeUtil::MakeShape(F32, {1, 1, 1, 2}); b.AddInstruction(HloInstruction::CreateConvolve( - shape, lhs_instruction, rhs_instruction, window, dnums)); + shape, lhs_instruction, rhs_instruction, /*feature_group_count=*/1, + window, dnums, DefaultPrecisionConfig(2))); module().AddEntryComputation(b.Build()); std::unique_ptr<Literal> result = Evaluate(); @@ -1061,9 +1068,10 @@ TEST_P(HloEvaluatorTest, DilatedBaseConv2DWithHighPadding) { ConvolutionDimensionNumbers dnums = XlaBuilder::CreateDefaultConvDimensionNumbers(2); - const Shape& shape = ShapeUtil::MakeShape(F32, {1, 1, 7, 7}); + Shape shape = ShapeUtil::MakeShape(F32, {1, 1, 7, 7}); b.AddInstruction(HloInstruction::CreateConvolve( - shape, lhs_instruction, rhs_instruction, window, dnums)); + shape, lhs_instruction, rhs_instruction, /*feature_group_count=*/1, + window, dnums, DefaultPrecisionConfig(2))); module().AddEntryComputation(b.Build()); std::unique_ptr<Literal> result = Evaluate(); @@ -1124,9 +1132,10 @@ TEST_P(HloEvaluatorTest, DilatedBaseConv2DWithLowAndHighPadding) { ConvolutionDimensionNumbers dnums = XlaBuilder::CreateDefaultConvDimensionNumbers(2); - const Shape& shape = ShapeUtil::MakeShape(F32, {1, 1, 8, 8}); + Shape shape = ShapeUtil::MakeShape(F32, {1, 1, 8, 8}); b.AddInstruction(HloInstruction::CreateConvolve( - shape, lhs_instruction, rhs_instruction, window, dnums)); + shape, lhs_instruction, rhs_instruction, /*feature_group_count=*/1, + window, dnums, DefaultPrecisionConfig(2))); module().AddEntryComputation(b.Build()); std::unique_ptr<Literal> result = Evaluate(); @@ -1195,9 +1204,10 @@ TEST_P(HloEvaluatorTest, ConvolutionDimensionNumbers dnums = XlaBuilder::CreateDefaultConvDimensionNumbers(2); - const Shape& shape = ShapeUtil::MakeShape(F32, {1, 1, 9, 3}); + Shape shape = ShapeUtil::MakeShape(F32, {1, 1, 9, 3}); b.AddInstruction(HloInstruction::CreateConvolve( - shape, lhs_instruction, rhs_instruction, window, dnums)); + shape, lhs_instruction, rhs_instruction, /*feature_group_count=*/1, + window, dnums, DefaultPrecisionConfig(2))); module().AddEntryComputation(b.Build()); std::unique_ptr<Literal> result = Evaluate(); @@ -1219,6 +1229,67 @@ TEST_P(HloEvaluatorTest, EXPECT_TRUE(LiteralTestUtil::Equal(*expected, *result)); } +TEST_P(HloEvaluatorTest, Conv2DGroupedConvolution) { + HloComputation::Builder b(TestName()); + std::vector<int64> input_dims = {1, 2, 2, 4}; + std::vector<int64> filter_dims = {2, 2, 2, 8}; + Shape input_shape = ShapeUtil::MakeShapeWithType<float>(input_dims); + Shape filter_shape = ShapeUtil::MakeShapeWithType<float>(filter_dims); + // Tensorflow dimension numbers for 2D convolution. + ConvolutionDimensionNumbers dnums; + dnums.set_input_batch_dimension(0); + dnums.set_output_batch_dimension(0); + dnums.add_input_spatial_dimensions(1); + dnums.add_output_spatial_dimensions(1); + dnums.add_input_spatial_dimensions(2); + dnums.add_output_spatial_dimensions(2); + dnums.set_input_feature_dimension(3); + dnums.set_output_feature_dimension(3); + dnums.add_kernel_spatial_dimensions(0); + dnums.add_kernel_spatial_dimensions(1); + dnums.set_kernel_input_feature_dimension(2); + dnums.set_kernel_output_feature_dimension(3); + + Window window; + WindowDimension dim; + dim.set_size(2); + dim.set_stride(1); + dim.set_padding_low(0); + dim.set_padding_high(0); + dim.set_window_dilation(1); + dim.set_base_dilation(1); + *window.add_dimensions() = dim; + *window.add_dimensions() = dim; + + std::vector<float> input_elems(ShapeUtil::ElementsIn(input_shape)); + std::iota(input_elems.begin(), input_elems.end(), -7); + auto input_r1 = LiteralUtil::CreateR1<float>(input_elems); + auto input_r4 = input_r1->Reshape(input_dims).ConsumeValueOrDie(); + HloInstruction* lhs_instruction = + b.AddInstruction(HloInstruction::CreateConstant(std::move(input_r4))); + + std::vector<float> filter_elems(ShapeUtil::ElementsIn(filter_shape)); + std::iota(filter_elems.begin(), filter_elems.end(), -31); + auto filter_r1 = LiteralUtil::CreateR1<float>(filter_elems); + auto filter_r4 = filter_r1->Reshape(filter_dims).ConsumeValueOrDie(); + HloInstruction* rhs_instruction = + b.AddInstruction(HloInstruction::CreateConstant(std::move(filter_r4))); + + Shape shape = ShapeUtil::MakeShape(F32, {1, 1, 1, 8}); + b.AddInstruction(HloInstruction::CreateConvolve( + shape, lhs_instruction, rhs_instruction, + /*feature_group_count=*/2, window, dnums, DefaultPrecisionConfig(2))); + module().AddEntryComputation(b.Build()); + + std::unique_ptr<Literal> result = Evaluate(); + + Array4D<float> expected_array(1, 1, 1, 8); + expected_array.FillWithYX( + Array2D<float>({{668, 664, 660, 656, 668, 680, 692, 704}})); + auto expected = LiteralUtil::CreateR4FromArray4D<float>(expected_array); + EXPECT_TRUE(LiteralTestUtil::Equal(*expected, *result)); +} + class HloEvaluatorPreciseReduceTest : public HloVerifiedTestBase {}; // Tests that Reduce doesn't lose precision when adding many numbers (because diff --git a/tensorflow/compiler/xla/service/hlo_evaluator_typed_visitor.h b/tensorflow/compiler/xla/service/hlo_evaluator_typed_visitor.h index cb27e13e99..6a09bb08f4 100644 --- a/tensorflow/compiler/xla/service/hlo_evaluator_typed_visitor.h +++ b/tensorflow/compiler/xla/service/hlo_evaluator_typed_visitor.h @@ -1021,9 +1021,10 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { CHECK_EQ(num_spatial_dims + 2, lhs_rank); CHECK_EQ(num_spatial_dims + 2, rhs_rank); - TF_ASSIGN_OR_RETURN(auto inferred_return_shape, - ShapeInference::InferConvolveShape(lhs_shape, rhs_shape, - window, dnums)); + TF_ASSIGN_OR_RETURN( + auto inferred_return_shape, + ShapeInference::InferConvolveShape( + lhs_shape, rhs_shape, conv->feature_group_count(), window, dnums)); CHECK(ShapeUtil::Compatible(result_shape, inferred_return_shape)) << "return shape set to: " << ShapeUtil::HumanString(result_shape) << " but is inferred to be: " @@ -1046,9 +1047,12 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { auto lhs_literal_data = lhs_literal.data<ReturnT>(); auto rhs_literal_data = rhs_literal.data<ReturnT>(); + int64 feature_group_count = conv->feature_group_count(); + auto func = [&window_shape, &dnums, &lhs_shape, &rhs_shape, &window, &lhs_dim_multipliers, &rhs_dim_multipliers, lhs_literal_data, - rhs_literal_data](absl::Span<const int64> out_index) { + rhs_literal_data, + feature_group_count](absl::Span<const int64> out_index) { // Dimension number applicable for input (lhs). const int64 input_batch_dim = dnums.input_batch_dimension(); const int64 input_z_dim = dnums.input_feature_dimension(); @@ -1060,6 +1064,8 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { const int64 output_z_dim = dnums.output_feature_dimension(); const int64 z_size = ShapeUtil::GetDimension(lhs_shape, input_z_dim); + const int64 output_z_size = + ShapeUtil::GetDimension(rhs_shape, kernel_output_z_dim); ElementwiseT result_val = static_cast<ElementwiseT>(0); DimensionVector rhs_spatial_index(dnums.kernel_spatial_dimensions_size(), @@ -1068,6 +1074,33 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { // Convolve input feature with kernel. do { for (int64 iz = 0; iz < z_size; ++iz) { + int64 rhs_iz = iz; + // Handle grouped convolutions. + if (feature_group_count > 1) { + // The size of a feature group. + int64 feature_group_size = z_size / feature_group_count; + rhs_iz = iz % feature_group_size; + + // The output feature dimension is a concatenation of convolution + // results from the different groups. + int64 output_feature_group_size = + output_z_size / feature_group_count; + + // Calculate the group index to which the current input feature + // index belongs. + int64 input_group_index = iz / feature_group_size; + + // Calculate the group index to which the current output index + // belongs. + int64 output_group_index = + out_index[output_z_dim] / output_feature_group_size; + if (input_group_index != output_group_index) { + // If the current output index does not belong to the current + // feature group, skip it. + continue; + } + } + int64 lhs_linear_index = 0; lhs_linear_index += out_index[output_batch_dim] * lhs_dim_multipliers[input_batch_dim]; @@ -1076,7 +1109,7 @@ class HloEvaluatorTypedVisitor : public DfsHloVisitorWithDefault { int64 rhs_linear_index = 0; rhs_linear_index += out_index[output_z_dim] * rhs_dim_multipliers[kernel_output_z_dim]; - rhs_linear_index += iz * rhs_dim_multipliers[kernel_input_z_dim]; + rhs_linear_index += rhs_iz * rhs_dim_multipliers[kernel_input_z_dim]; // Find corresponding spatial dimension index for input (lhs). for (int64 ki = 0; ki < rhs_spatial_index.size(); ++ki) { diff --git a/tensorflow/compiler/xla/service/hlo_graph_dumper.cc b/tensorflow/compiler/xla/service/hlo_graph_dumper.cc index 3041d94fa9..0345a2a5f8 100644 --- a/tensorflow/compiler/xla/service/hlo_graph_dumper.cc +++ b/tensorflow/compiler/xla/service/hlo_graph_dumper.cc @@ -120,12 +120,19 @@ class NodeFilter { std::function<NodeFilterResult(const HloInstruction* instr)> filter_; }; +// We arbitrarily set this as the boundary between "large" and "small" +// instructions. +bool IsSmall(const HloInstruction* instr) { + return ShapeUtil::ElementsInRecursive(instr->shape()) < 4096; +} + // Node color schemes, used by NodeColorAttributes. enum ColorScheme { kBlue, kBrown, kDarkBlue, kDarkGreen, + kDarkOrange, kDarkRed, kGray, kGreen, @@ -158,6 +165,10 @@ NodeColors NodeColorsForScheme(ColorScheme color) { return NodeColors{"filled", "#1565c0", "#003c8f", "white"}; case kDarkGreen: return NodeColors{"filled", "#2e7d32", "#005005", "white"}; + case kDarkOrange: + // This is more of a "medium" orange, made to look close to kOrange; + // there's probably room for a darker weight if desired. + return NodeColors{"filled", "#ffb74d", "#c88719", "black"}; case kDarkRed: return NodeColors{"filled", "#b71c1c", "#7f0000", "white"}; case kGray: @@ -893,7 +904,10 @@ ColorScheme HloDotDumper::GetInstructionColor(const HloInstruction* instr) { sharding_colors_.emplace(instr->sharding(), color); return color; } - const auto kParameterColor = kOrange; + + // Choose different weights of orange for small vs large parameters. This + // distinction is often important, especially in fusion nodes. + auto parameter_color = IsSmall(instr) ? kOrange : kDarkOrange; // Special case: If this instruction has a parameter merged into it, paint it // the same color as a parameter. Unless the merged-in parameter is a @@ -905,7 +919,7 @@ ColorScheme HloDotDumper::GetInstructionColor(const HloInstruction* instr) { ShouldMergeIntoUsers(operand) && TryGetFusionParameterConstant(operand) == nullptr; })) { - return kParameterColor; + return parameter_color; } // Pick different colors or shapes for instructions which are particularly @@ -1015,7 +1029,7 @@ ColorScheme HloDotDumper::GetInstructionColor(const HloInstruction* instr) { case HloOpcode::kReducePrecision: return kRed; case HloOpcode::kParameter: - return kParameterColor; + return parameter_color; case HloOpcode::kBatchNormGrad: case HloOpcode::kBatchNormInference: case HloOpcode::kBatchNormTraining: @@ -1160,20 +1174,6 @@ string HloDotDumper::GetInstructionNodeExtraInfo(const HloInstruction* instr) { return StrJoin(lines, "<br/>"); } -// Gets the total number of array elements in the given shape. For tuples, this -// is the sum of all the sizes of all of the array elements recursively in the -// tuple. -static int64 TotalElementsInShape(const Shape& shape) { - int64 elems = 0; - ShapeUtil::ForEachSubshape( - shape, [&](const Shape& subshape, const ShapeIndex& /*index*/) { - if (ShapeUtil::IsArray(subshape)) { - elems += ShapeUtil::ElementsIn(subshape); - } - }); - return elems; -} - void HloDotDumper::AddInstructionIncomingEdges(const HloInstruction* instr) { auto add_edge = [&](const HloInstruction* from, const HloInstruction* to, int64 operand_num, bool control_edge = false) { @@ -1196,14 +1196,11 @@ void HloDotDumper::AddInstructionIncomingEdges(const HloInstruction* instr) { } // We print "small" arrays using a hollow arrowhead and "large" arrays using - // a filled arrowhead. For now, we use an arbitrary cutoff for what "big" - // means. - bool is_big_array = TotalElementsInShape(from->shape()) >= 4096; - + // a filled arrowhead. constexpr char kEdgeFmt[] = R"(%s -> %s [arrowhead=%s tooltip="%s -> %s" %s];)"; edges_.push_back(StrFormat(kEdgeFmt, InstructionId(from), InstructionId(to), - (is_big_array ? "normal" : "empty"), + (IsSmall(from) ? "empty" : "normal"), from->name(), to->name(), edge_label)); }; diff --git a/tensorflow/compiler/xla/service/hlo_instruction.cc b/tensorflow/compiler/xla/service/hlo_instruction.cc index bd0b6af10d..471a12d6aa 100644 --- a/tensorflow/compiler/xla/service/hlo_instruction.cc +++ b/tensorflow/compiler/xla/service/hlo_instruction.cc @@ -341,17 +341,21 @@ StatusOr<std::unique_ptr<HloInstruction>> HloInstruction::CreateFromProto( source_target_pairs); break; } - case HloOpcode::kConvolution: + case HloOpcode::kConvolution: { TF_RET_CHECK(proto.operand_ids_size() == 2) << "Convolution instruction should have 2 operands but sees " << proto.operand_ids_size(); TF_RET_CHECK(proto.has_window()); TF_RET_CHECK(proto.has_convolution_dimension_numbers()); + PrecisionConfig precision_config = proto.precision_config(); + precision_config.mutable_operand_precision()->Resize( + proto.operand_ids_size(), PrecisionConfig::DEFAULT); instruction = CreateConvolve( - proto.shape(), operands(0), operands(1), proto.window(), - proto.convolution_dimension_numbers(), - std::max(static_cast<int64>(proto.feature_group_count()), 1LL)); + proto.shape(), operands(0), operands(1), + std::max<int64>(proto.feature_group_count(), 1), proto.window(), + proto.convolution_dimension_numbers(), precision_config); break; + } case HloOpcode::kReduceWindow: TF_RET_CHECK(proto.operand_ids_size() == 2) << "ReduceWindow instruction should have 2 operands but sees " @@ -385,6 +389,9 @@ StatusOr<std::unique_ptr<HloInstruction>> HloInstruction::CreateFromProto( ->set_convolution_dimension_numbers( proto.convolution_dimension_numbers()); } + static_cast<HloCustomCallInstruction*>(instruction.get()) + ->set_feature_group_count( + std::max(static_cast<int64>(proto.feature_group_count()), 1LL)); break; case HloOpcode::kPad: TF_RET_CHECK(proto.operand_ids_size() == 2) @@ -465,6 +472,20 @@ StatusOr<std::unique_ptr<HloInstruction>> HloInstruction::CreateFromProto( computation_map.at(computation_id)); } } + if (instruction->opcode() == HloOpcode::kDot) { + instruction->precision_config_ = proto.precision_config(); + instruction->precision_config_.mutable_operand_precision()->Resize( + instruction->operand_count(), PrecisionConfig::DEFAULT); + TF_RET_CHECK(proto.has_dot_dimension_numbers()); + instruction->dot_dimension_numbers_ = + absl::make_unique<DotDimensionNumbers>( + proto.dot_dimension_numbers()); + } else { + TF_RET_CHECK(!proto.has_precision_config()) + << instruction->opcode() << proto.DebugString(); + TF_RET_CHECK(!proto.has_dot_dimension_numbers()) + << instruction->opcode(); + } break; } } @@ -473,12 +494,6 @@ StatusOr<std::unique_ptr<HloInstruction>> HloInstruction::CreateFromProto( instruction->SetAndSanitizeName(proto.name()); instruction->metadata_ = proto.metadata(); instruction->backend_config_ = proto.backend_config(); - instruction->precision_config_ = proto.precision_config(); - - if (proto.has_dot_dimension_numbers()) { - instruction->dot_dimension_numbers_ = - absl::make_unique<DotDimensionNumbers>(proto.dot_dimension_numbers()); - } if (proto.has_sharding()) { TF_ASSIGN_OR_RETURN(const auto& sharding, @@ -640,10 +655,12 @@ HloInstruction::CreateGetTupleElement(const Shape& shape, /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateConvolve( const Shape& shape, HloInstruction* lhs, HloInstruction* rhs, - const Window& window, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count) { + int64 feature_group_count, const Window& window, + const ConvolutionDimensionNumbers& dimension_numbers, + const PrecisionConfig& precision_config) { return absl::make_unique<HloConvolutionInstruction>( - shape, lhs, rhs, window, dimension_numbers, feature_group_count); + shape, lhs, rhs, feature_group_count, window, dimension_numbers, + precision_config); } /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateFft( @@ -655,13 +672,15 @@ HloInstruction::CreateGetTupleElement(const Shape& shape, /* static */ std::unique_ptr<HloInstruction> HloInstruction::CreateDot( const Shape& shape, HloInstruction* lhs, HloInstruction* rhs, - const DotDimensionNumbers& dimension_numbers) { + const DotDimensionNumbers& dimension_numbers, + const PrecisionConfig& precision_config) { auto instruction = absl::WrapUnique(new HloInstruction(HloOpcode::kDot, shape)); instruction->AppendOperand(lhs); instruction->AppendOperand(rhs); instruction->dot_dimension_numbers_ = absl::make_unique<DotDimensionNumbers>(dimension_numbers); + instruction->set_precision_config(precision_config); return instruction; } @@ -1054,7 +1073,6 @@ void HloInstruction::SetupDerivedInstruction( derived_instruction->clear_sharding(); } derived_instruction->set_metadata(metadata_); - derived_instruction->set_precision_config(precision_config_); } bool HloInstruction::HasSideEffectNoRecurse() const { @@ -1275,7 +1293,7 @@ std::unique_ptr<HloInstruction> HloInstruction::CloneWithNewOperands( case HloOpcode::kDot: CHECK_EQ(new_operands.size(), 2); clone = CreateDot(shape, new_operands[0], new_operands[1], - *dot_dimension_numbers_); + *dot_dimension_numbers_, precision_config()); break; case HloOpcode::kReshape: CHECK_EQ(new_operands.size(), 1); @@ -2164,7 +2182,9 @@ HloInstructionProto HloInstruction::ToProto() const { *proto.mutable_metadata() = metadata_; proto.set_backend_config(backend_config_); - *proto.mutable_precision_config() = precision_config_; + if (opcode() == HloOpcode::kConvolution || opcode() == HloOpcode::kDot) { + *proto.mutable_precision_config() = precision_config_; + } if (opcode() != HloOpcode::kFusion) { for (const HloComputation* computation : called_computations_) { proto.add_called_computation_ids(computation->unique_id()); @@ -2868,8 +2888,8 @@ string RandomDistributionToString(const RandomDistribution& distribution) { return absl::AsciiStrToLower(RandomDistribution_Name(distribution)); } -string PrecisionToString(const PrecisionConfigProto::Precision& precision) { - return absl::AsciiStrToLower(PrecisionConfigProto::Precision_Name(precision)); +string PrecisionToString(const PrecisionConfig::Precision& precision) { + return absl::AsciiStrToLower(PrecisionConfig::Precision_Name(precision)); } string ConvolutionDimensionNumbersToString( @@ -2945,30 +2965,33 @@ StatusOr<RandomDistribution> StringToRandomDistribution(const string& name) { } string HloInstruction::PrecisionConfigToString() const { - if (precision_config_.operand_precision().empty()) { + if (absl::c_all_of( + precision_config_.operand_precision(), [](int32 precision) { + return static_cast<PrecisionConfig::Precision>(precision) == + PrecisionConfig::DEFAULT; + })) { return ""; } return StrCat( "operand_precision={", - StrJoin(precision_config_.operand_precision(), ",", - [](string* out, int32 precision) { - CHECK(PrecisionConfigProto::Precision_IsValid(precision)) - << precision; - StrAppend(out, PrecisionToString( - static_cast<PrecisionConfigProto::Precision>( - precision))); - }), + StrJoin( + precision_config_.operand_precision(), ",", + [](string* out, int32 precision) { + CHECK(PrecisionConfig::Precision_IsValid(precision)) << precision; + StrAppend(out, + PrecisionToString( + static_cast<PrecisionConfig::Precision>(precision))); + }), "}"); } -StatusOr<PrecisionConfigProto::Precision> StringToPrecision( - const string& name) { - static std::unordered_map<string, PrecisionConfigProto::Precision>* map = [] { +StatusOr<PrecisionConfig::Precision> StringToPrecision(const string& name) { + static std::unordered_map<string, PrecisionConfig::Precision>* map = [] { static auto* map = - new std::unordered_map<string, PrecisionConfigProto::Precision>; - for (int i = 0; i < PrecisionConfigProto::Precision_ARRAYSIZE; i++) { - if (PrecisionConfigProto::Precision_IsValid(i)) { - auto value = static_cast<PrecisionConfigProto::Precision>(i); + new std::unordered_map<string, PrecisionConfig::Precision>; + for (int i = 0; i < PrecisionConfig::Precision_ARRAYSIZE; i++) { + if (PrecisionConfig::Precision_IsValid(i)) { + auto value = static_cast<PrecisionConfig::Precision>(i); (*map)[PrecisionToString(value)] = value; } } @@ -3269,7 +3292,15 @@ void HloInstruction::set_convolution_dimension_numbers( } int64 HloInstruction::feature_group_count() const { - return Cast<HloConvolutionInstruction>(this)->feature_group_count(); + if (auto convolution = DynCast<HloConvolutionInstruction>(this)) { + return convolution->feature_group_count(); + } + return Cast<HloCustomCallInstruction>(this)->feature_group_count(); +} + +void HloInstruction::set_feature_group_count(int64 feature_group_count) { + Cast<HloCustomCallInstruction>(this)->set_feature_group_count( + feature_group_count); } HloComputation* HloInstruction::select() const { diff --git a/tensorflow/compiler/xla/service/hlo_instruction.h b/tensorflow/compiler/xla/service/hlo_instruction.h index 08f3d5356f..691f8155f9 100644 --- a/tensorflow/compiler/xla/service/hlo_instruction.h +++ b/tensorflow/compiler/xla/service/hlo_instruction.h @@ -405,9 +405,9 @@ class HloInstruction { // and window describes how the filter is applied to lhs. static std::unique_ptr<HloInstruction> CreateConvolve( const Shape& shape, HloInstruction* lhs, HloInstruction* rhs, - const Window& window, + int64 feature_group_count, const Window& window, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count = 1); + const PrecisionConfig& precision_config); // Creates an FFT op, of the type indicated by fft_type. static std::unique_ptr<HloInstruction> CreateFft( @@ -418,7 +418,8 @@ class HloInstruction { // dimensions specified in 'dimension_numbers'. static std::unique_ptr<HloInstruction> CreateDot( const Shape& shape, HloInstruction* lhs, HloInstruction* rhs, - const DotDimensionNumbers& dimension_numbers); + const DotDimensionNumbers& dimension_numbers, + const PrecisionConfig& precision_config); // Creates a dot op with operands 'lhs' and 'rhs' that contracts dimension 1 // of the LHS with dimension 0 of the RHS with no batch dimensions. Both LHS @@ -1261,10 +1262,8 @@ class HloInstruction { // information. Transformations to other HLOs will not preserve this // information but it is presumed that the alternate lowering is strictly // superior. - const PrecisionConfigProto& precision_config() const { - return precision_config_; - } - void set_precision_config(const PrecisionConfigProto& precision_config) { + const PrecisionConfig& precision_config() const { return precision_config_; } + void set_precision_config(const PrecisionConfig& precision_config) { precision_config_ = precision_config; } @@ -1475,6 +1474,8 @@ class HloInstruction { // dimension and output feature dimension. int64 feature_group_count() const; + void set_feature_group_count(int64 feature_group_count); + // Delegates to HloSelectAndScatterInstruction::select. HloComputation* select() const; @@ -1677,7 +1678,7 @@ class HloInstruction { // Information used to communicate to the implementation about the algorithm // used to produce results. See the documentation on precision_config(). - PrecisionConfigProto precision_config_; + PrecisionConfig precision_config_; // String identifier for instruction. string name_; @@ -1701,12 +1702,12 @@ StatusOr<HloInstruction::FusionKind> StringToFusionKind( string PaddingConfigToString(const PaddingConfig& padding); string OpMetadataToString(const OpMetadata& metadata); string RandomDistributionToString(const RandomDistribution& distribution); -string PrecisionToString(const PrecisionConfigProto::Precision& precision); +string PrecisionToString(const PrecisionConfig::Precision& precision); string ConvolutionDimensionNumbersToString( const ConvolutionDimensionNumbers& dnums); StatusOr<RandomDistribution> StringToRandomDistribution(const string& name); -StatusOr<PrecisionConfigProto::Precision> StringToPrecision(const string& name); +StatusOr<PrecisionConfig::Precision> StringToPrecision(const string& name); std::ostream& operator<<(std::ostream& os, HloInstruction::FusionKind kind); diff --git a/tensorflow/compiler/xla/service/hlo_instruction_test.cc b/tensorflow/compiler/xla/service/hlo_instruction_test.cc index 76b0e940a6..c1b7c3832b 100644 --- a/tensorflow/compiler/xla/service/hlo_instruction_test.cc +++ b/tensorflow/compiler/xla/service/hlo_instruction_test.cc @@ -1147,8 +1147,8 @@ TEST_F(HloInstructionTest, CloneOfFusionPreservesShape) { DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); - HloInstruction* dot = builder.AddInstruction( - HloInstruction::CreateDot(sout, x, reshape, dot_dnums)); + HloInstruction* dot = builder.AddInstruction(HloInstruction::CreateDot( + sout, x, reshape, dot_dnums, DefaultPrecisionConfig(2))); auto module = CreateNewModule(); auto* computation = module->AddEntryComputation(builder.Build()); @@ -1188,8 +1188,8 @@ TEST_F(HloInstructionTest, NoRedundantFusionOperandsAfterReplacingUse) { DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); - HloInstruction* dot = builder.AddInstruction( - HloInstruction::CreateDot(s, x, reshape, dot_dnums)); + HloInstruction* dot = builder.AddInstruction(HloInstruction::CreateDot( + s, x, reshape, dot_dnums, DefaultPrecisionConfig(2))); auto module = CreateNewModule(); auto* computation = module->AddEntryComputation(builder.Build()); @@ -1239,8 +1239,8 @@ TEST_F(HloInstructionTest, NestedFusionEquality) { DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); - auto dot = builder.AddInstruction( - HloInstruction::CreateDot(data_shape, a, b_t, dot_dnums)); + auto dot = builder.AddInstruction(HloInstruction::CreateDot( + data_shape, a, b_t, dot_dnums, DefaultPrecisionConfig(2))); auto one = builder.AddInstruction( HloInstruction::CreateConstant(LiteralUtil::CreateR0<float>(1.0))); auto add_operand = builder.AddInstruction( @@ -1320,8 +1320,8 @@ TEST_F(HloInstructionTest, Stringification) { DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); - HloInstruction* dot = builder.AddInstruction( - HloInstruction::CreateDot(sout, x, reshape, dot_dnums)); + HloInstruction* dot = builder.AddInstruction(HloInstruction::CreateDot( + sout, x, reshape, dot_dnums, DefaultPrecisionConfig(2))); auto options = HloPrintOptions().set_print_metadata(false); @@ -1485,8 +1485,8 @@ TEST_F(HloInstructionTest, CanonnicalStringificationFusion) { DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); - HloInstruction* dot = builder.AddInstruction( - HloInstruction::CreateDot(sout, x, reshape, dot_dnums)); + HloInstruction* dot = builder.AddInstruction(HloInstruction::CreateDot( + sout, x, reshape, dot_dnums, DefaultPrecisionConfig(2))); auto options = HloPrintOptions().Canonical(); @@ -1527,8 +1527,8 @@ TEST_F(HloInstructionTest, CanonnicalStringificationWhile) { DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); - HloInstruction* dot = builder.AddInstruction( - HloInstruction::CreateDot(sout, x, reshape, dot_dnums)); + HloInstruction* dot = builder.AddInstruction(HloInstruction::CreateDot( + sout, x, reshape, dot_dnums, DefaultPrecisionConfig(2))); auto module = CreateNewModule(); auto* computation = module->AddEntryComputation(builder.Build()); @@ -1583,8 +1583,8 @@ TEST_F(HloInstructionTest, CanonnicalStringificationConditional) { DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); - HloInstruction* dot = builder.AddInstruction( - HloInstruction::CreateDot(sout, x, reshape, dot_dnums)); + HloInstruction* dot = builder.AddInstruction(HloInstruction::CreateDot( + sout, x, reshape, dot_dnums, DefaultPrecisionConfig(2))); auto module = CreateNewModule(); auto* computation = module->AddEntryComputation(builder.Build()); @@ -1752,9 +1752,9 @@ TEST_F(HloInstructionTest, PreserveOperandPrecisionOnCloneConv) { auto* conv = module->entry_computation()->root_instruction(); auto clone = conv->Clone(); - EXPECT_THAT(clone->precision_config().operand_precision(), - ::testing::ElementsAre(PrecisionConfigProto::HIGH, - PrecisionConfigProto::DEFAULT)); + EXPECT_THAT( + clone->precision_config().operand_precision(), + ::testing::ElementsAre(PrecisionConfig::HIGH, PrecisionConfig::DEFAULT)); } } // namespace diff --git a/tensorflow/compiler/xla/service/hlo_instructions.cc b/tensorflow/compiler/xla/service/hlo_instructions.cc index 6871953755..ad87aa1123 100644 --- a/tensorflow/compiler/xla/service/hlo_instructions.cc +++ b/tensorflow/compiler/xla/service/hlo_instructions.cc @@ -1628,12 +1628,13 @@ std::unique_ptr<HloInstruction> HloOutfeedInstruction::CloneWithNewOperandsImpl( HloConvolutionInstruction::HloConvolutionInstruction( const Shape& shape, HloInstruction* lhs, HloInstruction* rhs, - const Window& window, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count) + int64 feature_group_count, const Window& window, + const ConvolutionDimensionNumbers& dimension_numbers, + const PrecisionConfig& precision_config) : HloInstruction(HloOpcode::kConvolution, shape), + feature_group_count_(feature_group_count), window_(window), - convolution_dimension_numbers_(dimension_numbers), - feature_group_count_(feature_group_count) { + convolution_dimension_numbers_(dimension_numbers) { if (window_util::HasBaseDilation(window)) { SetAndSanitizeName(StrCat(name(), "-base-dilated")); } @@ -1642,6 +1643,7 @@ HloConvolutionInstruction::HloConvolutionInstruction( } AppendOperand(lhs); AppendOperand(rhs); + set_precision_config(precision_config); } string HloConvolutionInstruction::ToCategory() const { @@ -1660,6 +1662,7 @@ HloInstructionProto HloConvolutionInstruction::ToProto() const { *proto.mutable_window() = window_; *proto.mutable_convolution_dimension_numbers() = convolution_dimension_numbers_; + proto.set_feature_group_count(feature_group_count_); return proto; } @@ -1671,7 +1674,9 @@ std::vector<string> HloConvolutionInstruction::ExtraAttributesToStringImpl( } extra.push_back(StrCat("dim_labels=", ConvolutionDimensionNumbersToString( convolution_dimension_numbers_))); - extra.push_back(StrCat("feature_group_count=", feature_group_count_)); + if (feature_group_count_ != 1) { + extra.push_back(StrCat("feature_group_count=", feature_group_count_)); + } return extra; } @@ -1681,6 +1686,9 @@ bool HloConvolutionInstruction::IdenticalSlowPath( eq_computations) const { const auto& casted_other = static_cast<const HloConvolutionInstruction&>(other); + if (feature_group_count_ != other.feature_group_count()) { + return false; + } return protobuf_util::ProtobufEquals(window(), casted_other.window()) && protobuf_util::ProtobufEquals( convolution_dimension_numbers(), @@ -1693,8 +1701,8 @@ HloConvolutionInstruction::CloneWithNewOperandsImpl( HloCloneContext* context) const { CHECK_EQ(new_operands.size(), 2); return absl::make_unique<HloConvolutionInstruction>( - shape, new_operands[0], new_operands[1], window(), - convolution_dimension_numbers_, feature_group_count_); + shape, new_operands[0], new_operands[1], feature_group_count_, window(), + convolution_dimension_numbers_, precision_config()); } HloReduceWindowInstruction::HloReduceWindowInstruction( @@ -1793,8 +1801,8 @@ HloCustomCallInstruction::HloCustomCallInstruction( const Shape& shape, absl::Span<HloInstruction* const> operands, absl::string_view custom_call_target) : HloInstruction(HloOpcode::kCustomCall, shape), - custom_call_target_(custom_call_target.begin(), - custom_call_target.end()) { + custom_call_target_(custom_call_target.begin(), custom_call_target.end()), + feature_group_count_(1) { for (auto operand : operands) { AppendOperand(operand); } @@ -1810,6 +1818,7 @@ HloInstructionProto HloCustomCallInstruction::ToProto() const { *convolution_dimension_numbers_; } proto.set_custom_call_target(custom_call_target_); + proto.set_feature_group_count(feature_group_count_); return proto; } @@ -1824,6 +1833,9 @@ std::vector<string> HloCustomCallInstruction::ExtraAttributesToStringImpl( "dim_labels=", ConvolutionDimensionNumbersToString(*convolution_dimension_numbers_))); } + if (feature_group_count_ != 1) { + extra.push_back(StrCat("feature_group_count=", feature_group_count_)); + } // By contract, we print the custom call target even if // options.print_subcomputation_mode() == kOff, because the call target is not // an HloComputation. @@ -1851,6 +1863,9 @@ bool HloCustomCallInstruction::IdenticalSlowPath( casted_other.convolution_dimension_numbers()))) { return false; } + if (feature_group_count_ != casted_other.feature_group_count_) { + return false; + } return custom_call_target_ == casted_other.custom_call_target_; } @@ -1866,6 +1881,7 @@ HloCustomCallInstruction::CloneWithNewOperandsImpl( if (convolution_dimension_numbers_ != nullptr) { cloned->set_convolution_dimension_numbers(*convolution_dimension_numbers_); } + cloned->set_feature_group_count(feature_group_count_); return std::move(cloned); } diff --git a/tensorflow/compiler/xla/service/hlo_instructions.h b/tensorflow/compiler/xla/service/hlo_instructions.h index 45a648bbe4..e1215a7566 100644 --- a/tensorflow/compiler/xla/service/hlo_instructions.h +++ b/tensorflow/compiler/xla/service/hlo_instructions.h @@ -942,9 +942,9 @@ class HloConvolutionInstruction : public HloInstruction { public: explicit HloConvolutionInstruction( const Shape& shape, HloInstruction* lhs, HloInstruction* rhs, - const Window& window, + int64 feature_group_count, const Window& window, const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count); + const PrecisionConfig& precision_config); const Window& window() const override { return window_; } void set_window(const Window& window) override { window_ = window; } const ConvolutionDimensionNumbers& convolution_dimension_numbers() const { @@ -972,12 +972,13 @@ class HloConvolutionInstruction : public HloInstruction { std::unique_ptr<HloInstruction> CloneWithNewOperandsImpl( const Shape& shape, absl::Span<HloInstruction* const> new_operands, HloCloneContext* context) const override; - Window window_; - // Describes the dimension numbers used for a convolution. - ConvolutionDimensionNumbers convolution_dimension_numbers_; // The number of feature groups. Must be a divisor of the input feature // dimension and output feature dimension. int64 feature_group_count_; + // Describes the window used for a convolution. + Window window_; + // Describes the dimension numbers used for a convolution. + ConvolutionDimensionNumbers convolution_dimension_numbers_; }; class HloReduceWindowInstruction : public HloInstruction { @@ -1079,6 +1080,10 @@ class HloCustomCallInstruction : public HloInstruction { absl::make_unique<ConvolutionDimensionNumbers>(dnums); } const string& custom_call_target() const { return custom_call_target_; } + void set_feature_group_count(int64 feature_group_count) { + feature_group_count_ = feature_group_count; + } + int64 feature_group_count() const { return feature_group_count_; } // Returns a serialized representation of this instruction. HloInstructionProto ToProto() const override; @@ -1099,6 +1104,8 @@ class HloCustomCallInstruction : public HloInstruction { std::unique_ptr<Window> window_; // Describes the dimension numbers used for a convolution. std::unique_ptr<ConvolutionDimensionNumbers> convolution_dimension_numbers_; + // The number of feature groups. This is used for grouped convolutions. + int64 feature_group_count_; }; class HloPadInstruction : public HloInstruction { diff --git a/tensorflow/compiler/xla/service/hlo_lexer.cc b/tensorflow/compiler/xla/service/hlo_lexer.cc index 8350285e67..d9be841dd7 100644 --- a/tensorflow/compiler/xla/service/hlo_lexer.cc +++ b/tensorflow/compiler/xla/service/hlo_lexer.cc @@ -406,11 +406,7 @@ TokKind HloLexer::LexString() { absl::string_view raw = StringPieceFromPointers(token_start_ + 1, current_ptr_ - 1); string error; - // TODO(b/113077997): Change to absl::CUnescape once it works properly with - // copy-on-write std::string implementations. - if (!tensorflow::str_util::CUnescape( // non-absl ok - tensorflow::StringPiece(raw.data(), raw.size()), // non-absl ok - &str_val_, &error)) { + if (!absl::CUnescape(raw, &str_val_, &error)) { LOG(ERROR) << "Failed unescaping string: " << raw << ". error: " << error; return TokKind::kError; } diff --git a/tensorflow/compiler/xla/service/hlo_parser.cc b/tensorflow/compiler/xla/service/hlo_parser.cc index ea8e6a239a..0f26ed4235 100644 --- a/tensorflow/compiler/xla/service/hlo_parser.cc +++ b/tensorflow/compiler/xla/service/hlo_parser.cc @@ -221,7 +221,7 @@ class HloParser { bool ParseWindowPad(std::vector<std::vector<tensorflow::int64>>* pad); bool ParseSliceRanges(SliceRanges* result); - bool ParsePrecisionList(std::vector<PrecisionConfigProto::Precision>* result); + bool ParsePrecisionList(std::vector<PrecisionConfig::Precision>* result); bool ParseInt64List(const TokKind start, const TokKind end, const TokKind delim, std::vector<tensorflow::int64>* result); @@ -240,7 +240,7 @@ class HloParser { bool ParseFftType(FftType* result); bool ParseFusionKind(HloInstruction::FusionKind* result); bool ParseRandomDistribution(RandomDistribution* result); - bool ParsePrecision(PrecisionConfigProto::Precision* result); + bool ParsePrecision(PrecisionConfig::Precision* result); bool ParseInt64(tensorflow::int64* result); bool ParseDouble(double* result); bool ParseBool(bool* result); @@ -530,10 +530,6 @@ bool HloParser::ParseInstruction(HloComputation::Builder* builder, attrs["backend_config"] = {/*required=*/false, AttrTy::kString, &backend_config}; - optional<std::vector<PrecisionConfigProto::Precision>> operand_precision; - attrs["operand_precision"] = {/*required=*/false, AttrTy::kPrecisionList, - &operand_precision}; - HloInstruction* instruction; switch (opcode) { case HloOpcode::kParameter: { @@ -913,6 +909,9 @@ bool HloParser::ParseInstruction(HloComputation::Builder* builder, AttrTy::kConvolutionDimensionNumbers, &dnums}; attrs["feature_group_count"] = {/*required=*/false, AttrTy::kInt64, &feature_group_count}; + optional<std::vector<PrecisionConfig::Precision>> operand_precision; + attrs["operand_precision"] = {/*required=*/false, AttrTy::kPrecisionList, + &operand_precision}; if (!ParseOperands(&operands, /*expected_size=*/2) || !ParseAttributes(attrs)) { return false; @@ -923,9 +922,17 @@ bool HloParser::ParseInstruction(HloComputation::Builder* builder, if (!feature_group_count) { feature_group_count = 1; } + PrecisionConfig precision_config; + if (operand_precision) { + *precision_config.mutable_operand_precision() = { + operand_precision->begin(), operand_precision->end()}; + } else { + precision_config.mutable_operand_precision()->Resize( + operands.size(), PrecisionConfig::DEFAULT); + } instruction = builder->AddInstruction(HloInstruction::CreateConvolve( - shape, /*lhs=*/operands[0], /*rhs=*/operands[1], *window, *dnums, - feature_group_count.value())); + shape, /*lhs=*/operands[0], /*rhs=*/operands[1], + feature_group_count.value(), *window, *dnums, precision_config)); break; } case HloOpcode::kFft: { @@ -1272,6 +1279,9 @@ bool HloParser::ParseInstruction(HloComputation::Builder* builder, optional<std::vector<tensorflow::int64>> rhs_batch_dims; attrs["rhs_batch_dims"] = {/*required=*/false, AttrTy::kBracedInt64List, &rhs_batch_dims}; + optional<std::vector<PrecisionConfig::Precision>> operand_precision; + attrs["operand_precision"] = {/*required=*/false, AttrTy::kPrecisionList, + &operand_precision}; if (!ParseOperands(&operands, /*expected_size=*/2) || !ParseAttributes(attrs)) { @@ -1296,8 +1306,17 @@ bool HloParser::ParseInstruction(HloComputation::Builder* builder, rhs_batch_dims->end()}; } - instruction = builder->AddInstruction( - HloInstruction::CreateDot(shape, operands[0], operands[1], dnum)); + PrecisionConfig precision_config; + if (operand_precision) { + *precision_config.mutable_operand_precision() = { + operand_precision->begin(), operand_precision->end()}; + } else { + precision_config.mutable_operand_precision()->Resize( + operands.size(), PrecisionConfig::DEFAULT); + } + + instruction = builder->AddInstruction(HloInstruction::CreateDot( + shape, operands[0], operands[1], dnum, precision_config)); break; } case HloOpcode::kGather: { @@ -1414,12 +1433,6 @@ bool HloParser::ParseInstruction(HloComputation::Builder* builder, if (backend_config) { instruction->set_raw_backend_config_string(std::move(*backend_config)); } - if (operand_precision) { - PrecisionConfigProto precision_config; - *precision_config.mutable_operand_precision() = {operand_precision->begin(), - operand_precision->end()}; - instruction->set_precision_config(precision_config); - } return AddInstruction(name, instruction, name_loc); } // NOLINT(readability/fn_size) @@ -2397,11 +2410,11 @@ bool HloParser::ParseAttributeHelper( return ParseDomain(static_cast<DomainData*>(attr_out_ptr)); } case AttrTy::kPrecisionList: { - std::vector<PrecisionConfigProto::Precision> result; + std::vector<PrecisionConfig::Precision> result; if (!ParsePrecisionList(&result)) { return false; } - static_cast<optional<std::vector<PrecisionConfigProto::Precision>>*>( + static_cast<optional<std::vector<PrecisionConfig::Precision>>*>( attr_out_ptr) ->emplace(result); return true; @@ -2685,9 +2698,9 @@ bool HloParser::ParseSliceRanges(SliceRanges* result) { // ::= /*empty*/ // ::= precision_val (delim precision_val)* bool HloParser::ParsePrecisionList( - std::vector<PrecisionConfigProto::Precision>* result) { + std::vector<PrecisionConfig::Precision>* result) { auto parse_and_add_item = [&]() { - PrecisionConfigProto::Precision item; + PrecisionConfig::Precision item; if (!ParsePrecision(&item)) { return false; } @@ -3019,7 +3032,7 @@ bool HloParser::ParseRandomDistribution(RandomDistribution* result) { return true; } -bool HloParser::ParsePrecision(PrecisionConfigProto::Precision* result) { +bool HloParser::ParsePrecision(PrecisionConfig::Precision* result) { VLOG(1) << "ParsePrecision"; if (lexer_.GetKind() != TokKind::kIdent) { return TokenError("expects random distribution"); diff --git a/tensorflow/compiler/xla/service/hlo_parser_test.cc b/tensorflow/compiler/xla/service/hlo_parser_test.cc index 759789437c..0dfc0a4d1c 100644 --- a/tensorflow/compiler/xla/service/hlo_parser_test.cc +++ b/tensorflow/compiler/xla/service/hlo_parser_test.cc @@ -19,6 +19,8 @@ limitations under the License. #include "absl/strings/match.h" #include "absl/strings/str_cat.h" #include "absl/strings/string_view.h" +#include "tensorflow/compiler/xla/service/hlo_casting_utils.h" +#include "tensorflow/compiler/xla/service/hlo_instructions.h" #include "tensorflow/compiler/xla/service/hlo_matchers.h" #include "tensorflow/compiler/xla/window_util.h" #include "tensorflow/core/lib/core/status_test_util.h" @@ -382,7 +384,7 @@ ENTRY %Convolve1D1Window_0.v3 (input: f32[1,2,1], filter: f32[1,1,1]) -> f32[1,2 %input = f32[1,2,1]{2,1,0} parameter(0) %copy = f32[1,2,1]{2,0,1} copy(f32[1,2,1]{2,1,0} %input) %filter = f32[1,1,1]{2,1,0} parameter(1) - ROOT %convolution = f32[1,2,1]{2,0,1} convolution(f32[1,2,1]{2,0,1} %copy, f32[1,1,1]{2,1,0} %filter), window={size=1}, dim_labels=b0f_0io->b0f, feature_group_count=1, operand_precision={high,default} + ROOT %convolution = f32[1,2,1]{2,0,1} convolution(f32[1,2,1]{2,0,1} %copy, f32[1,1,1]{2,1,0} %filter), window={size=1}, dim_labels=b0f_0io->b0f, operand_precision={high,default} } )" @@ -395,7 +397,7 @@ R"(HloModule ConvolveR2_module ENTRY %ConvolveR2.v3 (input: f32[1,2], filter: f32[1,1]) -> f32[1,2] { %input = f32[1,2]{1,0} parameter(0) %filter = f32[1,1]{1,0} parameter(1) - ROOT %convolution = f32[1,2]{0,1} convolution(f32[1,2]{1,0} %input, f32[1,1]{1,0} %filter), dim_labels=bf_io->bf, feature_group_count=1 + ROOT %convolution = f32[1,2]{0,1} convolution(f32[1,2]{1,0} %input, f32[1,1]{1,0} %filter), dim_labels=bf_io->bf } )" @@ -408,7 +410,7 @@ R"(HloModule ConvolveBackward_module ENTRY %ConvolveBackward (input: f32[128,7,7,512], filter: f32[3,3,512,512]) -> f32[128,14,14,512] { %input = f32[128,7,7,512]{0,3,2,1} parameter(0) %filter = f32[3,3,512,512]{3,2,1,0} parameter(1) - ROOT %convolution-base-dilated = f32[128,14,14,512]{0,3,2,1} convolution(f32[128,7,7,512]{0,3,2,1} %input, f32[3,3,512,512]{3,2,1,0} %filter), window={size=3x3 pad=1_2x1_2 lhs_dilate=2x2 rhs_reversal=1x1}, dim_labels=b01f_01oi->b01f, feature_group_count=1 + ROOT %convolution-base-dilated = f32[128,14,14,512]{0,3,2,1} convolution(f32[128,7,7,512]{0,3,2,1} %input, f32[3,3,512,512]{3,2,1,0} %filter), window={size=3x3 pad=1_2x1_2 lhs_dilate=2x2 rhs_reversal=1x1}, dim_labels=b01f_01oi->b01f } )" @@ -1775,5 +1777,18 @@ TEST(HloParserSingleOpTest, SingleOpNoShapesProducesError) { ::testing::HasSubstr("Operand broadcast had no shape in HLO text")); } +TEST(HloParserSingleOpTest, ConvolutionTrivialFeatureGroupCount) { + const string text = + R"(%convolution = f32[1,2,1]{2,0,1} convolution(f32[1,2,1]{2,0,1} %copy, f32[1,1,1]{2,1,0} %filter), window={size=1}, dim_labels=b0f_0io->b0f)"; + TF_ASSERT_OK_AND_ASSIGN(auto module, ParseHloOpToModule(text)); + const HloComputation* computation = module->entry_computation(); + ASSERT_NE(computation, nullptr); + EXPECT_THAT(computation->root_instruction(), + op::Convolution(op::Parameter(0), op::Parameter(1))); + auto* convolution = + Cast<HloConvolutionInstruction>(computation->root_instruction()); + EXPECT_EQ(convolution->feature_group_count(), 1); +} + } // namespace } // namespace xla diff --git a/tensorflow/compiler/xla/service/hlo_sharding_metadata.cc b/tensorflow/compiler/xla/service/hlo_sharding_metadata.cc index 34cba6136f..e3f4a9852a 100644 --- a/tensorflow/compiler/xla/service/hlo_sharding_metadata.cc +++ b/tensorflow/compiler/xla/service/hlo_sharding_metadata.cc @@ -422,6 +422,13 @@ bool ShardingMetadata::Matches(const DomainMetadata& other) const { : false; } +size_t ShardingMetadata::Hash() const { + if (sharding_ != nullptr) { + return sharding_->Hash(); + } + return static_cast<size_t>(0x297814aaad196e6dULL); +} + string ShardingMetadata::ToString() const { return sharding_ != nullptr ? sharding_->ToString() : "{}"; } diff --git a/tensorflow/compiler/xla/service/hlo_sharding_metadata.h b/tensorflow/compiler/xla/service/hlo_sharding_metadata.h index cba5db927a..e3ae82a070 100644 --- a/tensorflow/compiler/xla/service/hlo_sharding_metadata.h +++ b/tensorflow/compiler/xla/service/hlo_sharding_metadata.h @@ -36,6 +36,8 @@ class ShardingMetadata : public DomainMetadata { bool Matches(const DomainMetadata& other) const override; + size_t Hash() const override; + string ToString() const override; const HloSharding* sharding() const { return sharding_.get(); } diff --git a/tensorflow/compiler/xla/service/hlo_verifier.cc b/tensorflow/compiler/xla/service/hlo_verifier.cc index 95516dec74..069586a738 100644 --- a/tensorflow/compiler/xla/service/hlo_verifier.cc +++ b/tensorflow/compiler/xla/service/hlo_verifier.cc @@ -86,8 +86,8 @@ Status ShapeVerifier::HandleConvolution(HloInstruction* convolution) { const Shape expected, ShapeInference::InferConvolveShape( convolution->operand(0)->shape(), convolution->operand(1)->shape(), - convolution->window(), convolution->convolution_dimension_numbers(), - convolution->feature_group_count())); + convolution->feature_group_count(), convolution->window(), + convolution->convolution_dimension_numbers())); return CheckShape(convolution, expected); } diff --git a/tensorflow/compiler/xla/service/indexed_array_analysis.cc b/tensorflow/compiler/xla/service/indexed_array_analysis.cc index a4de02a890..37b774b8a5 100644 --- a/tensorflow/compiler/xla/service/indexed_array_analysis.cc +++ b/tensorflow/compiler/xla/service/indexed_array_analysis.cc @@ -165,6 +165,7 @@ StatusOr<Analysis::Array*> IndexedArrayAnalysis::ComputeArrayFor( TF_ASSIGN_OR_RETURN( computed_array, ComputeArrayForDot(instr->shape(), instr->dot_dimension_numbers(), + instr->precision_config(), FindOrDie(cache_, instr->operand(0)), FindOrDie(cache_, instr->operand(1)))); } else { @@ -1030,7 +1031,8 @@ bool CanFoldDotIntoIndexedArray( StatusOr<Analysis::Array*> IndexedArrayAnalysis::ComputeArrayForDotWithIndexedLhs( const Shape& shape, const DotDimensionNumbers& dim_numbers, - ScalarIndexedConstantArray* lhs, ConstantArray* rhs) { + const PrecisionConfig& precision_config, ScalarIndexedConstantArray* lhs, + ConstantArray* rhs) { VLOG(3) << "ComputeArrayForDotWithIndexedLhs(" << ToString(lhs) << " " << ToString(rhs); if (!CanFoldDotIntoIndexedArray( @@ -1045,9 +1047,10 @@ IndexedArrayAnalysis::ComputeArrayForDotWithIndexedLhs( new_dim_numbers.set_lhs_contracting_dimensions( 0, lhs->source_dim() == (lhs_rank - 1) ? (lhs_rank - 2) : (lhs_rank - 1)); - TF_ASSIGN_OR_RETURN(Literal * literal_for_new_source, - TakeOwnership(HloEvaluator{}.EvaluateDotOp( - new_dim_numbers, lhs->literal(), *rhs->literal()))); + TF_ASSIGN_OR_RETURN( + Literal * literal_for_new_source, + TakeOwnership(HloEvaluator{}.EvaluateDotOp( + new_dim_numbers, precision_config, lhs->literal(), *rhs->literal()))); // The new source dimension is wherever the non-batch non-contracting LHS // dimension "went". @@ -1063,7 +1066,8 @@ IndexedArrayAnalysis::ComputeArrayForDotWithIndexedLhs( StatusOr<Analysis::Array*> IndexedArrayAnalysis::ComputeArrayForDotWithIndexedRhs( const Shape& shape, const DotDimensionNumbers& dim_numbers, - ConstantArray* lhs, ScalarIndexedConstantArray* rhs) { + const PrecisionConfig& precision_config, ConstantArray* lhs, + ScalarIndexedConstantArray* rhs) { VLOG(3) << "ComputeArrayForDotWithIndexedRhs(" << ToString(lhs) << " " << ToString(rhs); if (!CanFoldDotIntoIndexedArray( @@ -1079,9 +1083,10 @@ IndexedArrayAnalysis::ComputeArrayForDotWithIndexedRhs( new_dim_numbers.set_rhs_contracting_dimensions( 0, rhs->source_dim() == (rhs_rank - 1) ? (rhs_rank - 2) : (rhs_rank - 1)); - TF_ASSIGN_OR_RETURN(Literal * literal_for_new_source, - TakeOwnership(HloEvaluator{}.EvaluateDotOp( - new_dim_numbers, *lhs->literal(), rhs->literal()))); + TF_ASSIGN_OR_RETURN( + Literal * literal_for_new_source, + TakeOwnership(HloEvaluator{}.EvaluateDotOp( + new_dim_numbers, precision_config, *lhs->literal(), rhs->literal()))); // The new source dimension is wherever the non-batch non-contracting RHS // dimension "went". @@ -1095,8 +1100,8 @@ IndexedArrayAnalysis::ComputeArrayForDotWithIndexedRhs( } StatusOr<Analysis::Array*> IndexedArrayAnalysis::ComputeArrayForDot( - const Shape& shape, const DotDimensionNumbers& dim_numbers, Array* lhs, - Array* rhs) { + const Shape& shape, const DotDimensionNumbers& dim_numbers, + const PrecisionConfig& precision_config, Array* lhs, Array* rhs) { // Intuitively, if // // - The LHS of a dot product is a gathered sequence of rows from a constant @@ -1119,6 +1124,7 @@ StatusOr<Analysis::Array*> IndexedArrayAnalysis::ComputeArrayForDot( dynamic_cast<ScalarIndexedConstantArray*>(lhs)) { if (auto* rhs_constant = dynamic_cast<ConstantArray*>(rhs)) { return ComputeArrayForDotWithIndexedLhs(shape, dim_numbers, + precision_config, lhs_indexed_array, rhs_constant); } } @@ -1126,7 +1132,8 @@ StatusOr<Analysis::Array*> IndexedArrayAnalysis::ComputeArrayForDot( if (auto* rhs_indexed_array = dynamic_cast<ScalarIndexedConstantArray*>(rhs)) { if (auto* lhs_constant = dynamic_cast<ConstantArray*>(lhs)) { - return ComputeArrayForDotWithIndexedRhs(shape, dim_numbers, lhs_constant, + return ComputeArrayForDotWithIndexedRhs(shape, dim_numbers, + precision_config, lhs_constant, rhs_indexed_array); } } diff --git a/tensorflow/compiler/xla/service/indexed_array_analysis.h b/tensorflow/compiler/xla/service/indexed_array_analysis.h index dcfb725535..9746d176cc 100644 --- a/tensorflow/compiler/xla/service/indexed_array_analysis.h +++ b/tensorflow/compiler/xla/service/indexed_array_analysis.h @@ -267,14 +267,17 @@ class IndexedArrayAnalysis { StatusOr<Array*> ComputeArrayForDotWithIndexedLhs( const Shape& shape, const DotDimensionNumbers& dim_numbers, - ScalarIndexedConstantArray* lhs, ConstantArray* rhs); + const PrecisionConfig& precision_config, ScalarIndexedConstantArray* lhs, + ConstantArray* rhs); StatusOr<Array*> ComputeArrayForDotWithIndexedRhs( const Shape& shape, const DotDimensionNumbers& dim_numbers, - ConstantArray* lhs, ScalarIndexedConstantArray* rhs); + const PrecisionConfig& precision_config, ConstantArray* lhs, + ScalarIndexedConstantArray* rhs); StatusOr<Array*> ComputeArrayForDot(const Shape& shape, const DotDimensionNumbers& dim_numbers, + const PrecisionConfig& precision_config, Array* lhs, Array* rhs); // This tries to fold a ScalarIndexedArray which has another diff --git a/tensorflow/compiler/xla/service/layout_assignment_test.cc b/tensorflow/compiler/xla/service/layout_assignment_test.cc index 021fe630ff..69c7e42601 100644 --- a/tensorflow/compiler/xla/service/layout_assignment_test.cc +++ b/tensorflow/compiler/xla/service/layout_assignment_test.cc @@ -874,18 +874,18 @@ TEST_F(LayoutAssignmentTest, CopySliceOperandToAvoidImplicitLayoutChange) { )"; auto module = ParseHloString(module_str).ValueOrDie(); - module = + auto compiled_module = backend() .compiler() ->RunHloPasses(std::move(module), backend().default_stream_executor(), /*device_allocator=*/nullptr) .ConsumeValueOrDie(); - - auto copy = FindInstruction(module.get(), "copy.1"); - auto slice = FindInstruction(module.get(), "slice0"); - EXPECT_EQ(slice->operand(0), copy); - EXPECT_TRUE( - LayoutUtil::Equal(slice->shape().layout(), copy->shape().layout())); + HloInstruction* root = + compiled_module->entry_computation()->root_instruction(); + Shape shape_copy = ShapeUtil::MakeShapeWithLayout(F32, {4, 5}, {1, 0}); + EXPECT_THAT(root, op::Add(op::Parameter(), + op::Slice(AllOf(op::Copy(op::Parameter(1)), + op::ShapeWithLayout(shape_copy))))); } TEST_F(LayoutAssignmentTest, CopyDSliceOperandToAvoidImplicitLayoutChange) { @@ -902,18 +902,20 @@ TEST_F(LayoutAssignmentTest, CopyDSliceOperandToAvoidImplicitLayoutChange) { )"; auto module = ParseHloString(module_str).ValueOrDie(); - module = + auto compiled_module = backend() .compiler() ->RunHloPasses(std::move(module), backend().default_stream_executor(), /*device_allocator=*/nullptr) .ConsumeValueOrDie(); - - auto copy = FindInstruction(module.get(), "copy.1"); - auto dslice = FindInstruction(module.get(), "dslice0"); - EXPECT_EQ(dslice->operand(0), copy); - EXPECT_TRUE( - LayoutUtil::Equal(dslice->shape().layout(), copy->shape().layout())); + HloInstruction* root = + compiled_module->entry_computation()->root_instruction(); + Shape shape_copy = ShapeUtil::MakeShapeWithLayout(F32, {4, 5}, {1, 0}); + EXPECT_THAT(root, + op::Add(op::Parameter(), + op::DynamicSlice(AllOf(op::Copy(op::Parameter(1)), + op::ShapeWithLayout(shape_copy)), + op::Parameter(2)))); } TEST_F(LayoutAssignmentTest, CopyConcatOperandToAvoidImplicitLayoutChange) { @@ -931,18 +933,20 @@ TEST_F(LayoutAssignmentTest, CopyConcatOperandToAvoidImplicitLayoutChange) { )"; auto module = ParseHloString(module_str).ValueOrDie(); - module = + auto compiled_module = backend() .compiler() ->RunHloPasses(std::move(module), backend().default_stream_executor(), /*device_allocator=*/nullptr) .ConsumeValueOrDie(); - - auto copy = FindInstruction(module.get(), "copy.1"); - auto concat = FindInstruction(module.get(), "concat0"); - EXPECT_EQ(concat->operand(0), copy); - EXPECT_TRUE( - LayoutUtil::Equal(concat->shape().layout(), copy->shape().layout())); + HloInstruction* root = + compiled_module->entry_computation()->root_instruction(); + Shape shape_copy = ShapeUtil::MakeShapeWithLayout(F32, {3, 5}, {1, 0}); + EXPECT_THAT(root, + op::Add(op::Parameter(), + op::Concatenate(AllOf(op::Copy(op::Parameter(1)), + op::ShapeWithLayout(shape_copy)), + op::Parameter(2)))); } TEST_F(LayoutAssignmentTest, @@ -960,15 +964,39 @@ TEST_F(LayoutAssignmentTest, )"; auto module = ParseHloString(module_str).ValueOrDie(); - module = + auto compiled_module = backend() .compiler() ->RunHloPasses(std::move(module), backend().default_stream_executor(), /*device_allocator=*/nullptr) .ConsumeValueOrDie(); + HloInstruction* root = + compiled_module->entry_computation()->root_instruction(); + EXPECT_THAT(root, op::Convolution(op::Parameter(0), op::Parameter(1))); +} + +TEST_F(LayoutAssignmentTest, PropagatingLayoutFromResultToOperand) { + const char* module_str = R"( + HloModule PropagatingLayoutFromResultToOperand + + ENTRY PropagatingLayoutFromResultToOperand { + par0 = f32[4,5]{1,0} parameter(0) + ROOT slice0 = f32[3,4]{0,1} slice(par0), slice={[1:4],[1:5]} + } + )"; - auto copy = FindInstruction(module.get(), "copy.1"); - EXPECT_EQ(copy, nullptr); + auto module = ParseHloString(module_str).ValueOrDie(); + auto compiled_module = + backend() + .compiler() + ->RunHloPasses(std::move(module), backend().default_stream_executor(), + /*device_allocator=*/nullptr) + .ConsumeValueOrDie(); + HloInstruction* root = + compiled_module->entry_computation()->root_instruction(); + Shape shape_copy = ShapeUtil::MakeShapeWithLayout(F32, {4, 5}, {0, 1}); + EXPECT_THAT(root, op::Slice(AllOf(op::Copy(op::Parameter(0)), + op::ShapeWithLayout(shape_copy)))); } } // namespace diff --git a/tensorflow/compiler/xla/service/llvm_ir/BUILD b/tensorflow/compiler/xla/service/llvm_ir/BUILD index d863529671..540bbb7c7a 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/BUILD +++ b/tensorflow/compiler/xla/service/llvm_ir/BUILD @@ -204,6 +204,7 @@ cc_library( "@com_google_absl//absl/strings", "@com_google_absl//absl/types:optional", "@llvm//:core", + "@llvm//:support", ], ) diff --git a/tensorflow/compiler/xla/service/llvm_ir/alias_analysis_test.cc b/tensorflow/compiler/xla/service/llvm_ir/alias_analysis_test.cc index fe5ec1cc66..b6ae4932f5 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/alias_analysis_test.cc +++ b/tensorflow/compiler/xla/service/llvm_ir/alias_analysis_test.cc @@ -61,7 +61,7 @@ ENTRY while3 { ; CHECK: store float %[[add_result]], float* %[[store_dest:.*]], !alias.scope ![[alias_scope_md_for_store:[0-9]+]] ; ; CHECK-LABEL: @condition(i8* %retval, i8* noalias %run_options, i8** noalias %params -; CHECK: %[[cond_state_buf_ptr:.*]] = getelementptr inbounds i8*, i8** %temps, i64 0 +; CHECK: %[[cond_state_buf_ptr:.*]] = getelementptr inbounds i8*, i8** %buffer_table, i64 0 ; CHECK: %[[cond_state_buf_untyped:.*]] = load i8*, i8** %[[cond_state_buf_ptr]] ; CHECK: %[[cond_state_buf_typed:.*]] = bitcast i8* %[[cond_state_buf_untyped]] to float* ; CHECK: load float, float* %[[cond_state_buf_typed]], !alias.scope ![[alias_scope_md_for_store]], !noalias ![[noalias_md_for_load:.*]] diff --git a/tensorflow/compiler/xla/service/llvm_ir/sort_util.cc b/tensorflow/compiler/xla/service/llvm_ir/sort_util.cc index 00dd3f1638..944c79580c 100644 --- a/tensorflow/compiler/xla/service/llvm_ir/sort_util.cc +++ b/tensorflow/compiler/xla/service/llvm_ir/sort_util.cc @@ -18,6 +18,7 @@ limitations under the License. // IWYU pragma: no_include "llvm/IR/Intrinsics.gen.inc" #include "absl/strings/string_view.h" #include "absl/types/optional.h" +#include "llvm/ADT/APInt.h" #include "llvm/IR/BasicBlock.h" #include "llvm/IR/Constants.h" #include "llvm/IR/Instructions.h" @@ -59,15 +60,39 @@ void EmitCompareLoop(int64 dimension_to_sort, const IrArray::Index& keys_index, SetToFirstInsertPoint(if_data.true_block, b); auto key1 = keys_array.EmitReadArrayElement(keys_index, b); auto key2 = keys_array.EmitReadArrayElement(compare_keys_index, b); + auto compare_key1 = key1; + auto compare_key2 = key2; auto key_type = keys_array.GetShape().element_type(); + bool is_signed_comparison = true; + if (primitive_util::IsFloatingPointType(key_type)) { + // We would like a total order of floating point numbers so that the sort + // has a predictable behavior in the presence of NaNs. Rather than using + // floating point comparison, we use the following trick: + // If f is a float, and + // x = bit_cast<int32>(f); + // y = x < 0 ? 0x7FFFFFFF - x : x; + // then y is ordered as an int32 such that finite values have the obvious + // order, -0 is ordered before 0, and -NaN and NaN appear at the beginning + // and end of the ordering. + auto k = b->getInt(llvm::APInt::getSignedMaxValue( + key1->getType()->getPrimitiveSizeInBits())); + auto comparison_type = k->getType(); + auto zero = llvm::ConstantInt::get(comparison_type, 0); + auto maybe_flip = [&](llvm::Value* v) { + return b->CreateSelect(b->CreateICmp(llvm::ICmpInst::ICMP_SLT, v, zero), + b->CreateSub(k, v), v); + }; + compare_key1 = b->CreateBitCast(key1, comparison_type); + compare_key2 = b->CreateBitCast(key2, comparison_type); + compare_key1 = maybe_flip(compare_key1); + compare_key2 = maybe_flip(compare_key2); + } else if (!primitive_util::IsSignedIntegralType(key_type)) { + is_signed_comparison = false; + } auto comparison = - primitive_util::IsFloatingPointType(key_type) - // TODO(b/26783907): Figure out how to handle NaNs. - ? b->CreateFCmp(llvm::FCmpInst::FCMP_ULT, key2, key1) - : b->CreateICmp(primitive_util::IsSignedIntegralType(key_type) - ? llvm::ICmpInst::ICMP_SLT - : llvm::ICmpInst::ICMP_ULT, - key2, key1); + b->CreateICmp(is_signed_comparison ? llvm::ICmpInst::ICMP_SLT + : llvm::ICmpInst::ICMP_ULT, + compare_key2, compare_key1); // If key2 < key1 auto if_smaller_data = EmitIfThenElse(comparison, "is_smaller_than", b, /*emit_else=*/false); diff --git a/tensorflow/compiler/xla/service/shape_inference.cc b/tensorflow/compiler/xla/service/shape_inference.cc index 2611749862..74bdf2a2e3 100644 --- a/tensorflow/compiler/xla/service/shape_inference.cc +++ b/tensorflow/compiler/xla/service/shape_inference.cc @@ -1552,8 +1552,8 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, } /* static */ StatusOr<Shape> ShapeInference::InferConvolveShape( - const Shape& lhs, const Shape& rhs, const Window& window, - const ConvolutionDimensionNumbers& dnums, int64 feature_group_count) { + const Shape& lhs, const Shape& rhs, int64 feature_group_count, + const Window& window, const ConvolutionDimensionNumbers& dnums) { TF_RETURN_IF_ERROR(ExpectArray(lhs, "lhs of convolution")); TF_RETURN_IF_ERROR(ExpectArray(rhs, "rhs of convolution")); @@ -1672,6 +1672,16 @@ ShapeInference::InferDegenerateDimensionBroadcastShape(HloOpcode operation, ShapeUtil::HumanString(lhs), ShapeUtil::HumanString(rhs), dnums.DebugString()); } + if (kernel_output_features % feature_group_count > 0) { + return InvalidArgument( + "Expected output feature dimension (value %d) to be divisible by " + "feature_group_count (value %d); " + "got <conv>(%s, %s)\n" + "Dimension numbers: {%s}.", + kernel_output_features, feature_group_count, + ShapeUtil::HumanString(lhs), ShapeUtil::HumanString(rhs), + dnums.DebugString()); + } std::vector<int64> window_dims(num_spatial_dims); for (int i = 0; i < num_spatial_dims; ++i) { window_dims[i] = window.dimensions(i).size(); diff --git a/tensorflow/compiler/xla/service/shape_inference.h b/tensorflow/compiler/xla/service/shape_inference.h index a28345acef..96a0ee165d 100644 --- a/tensorflow/compiler/xla/service/shape_inference.h +++ b/tensorflow/compiler/xla/service/shape_inference.h @@ -108,9 +108,9 @@ class ShapeInference { // Infers the shape produced by applying the given convolutional // filter (rhs) to lhs in the way specified by the fields on window. static StatusOr<Shape> InferConvolveShape( - const Shape& lhs, const Shape& rhs, const Window& window, - const ConvolutionDimensionNumbers& dimension_numbers, - int64 feature_group_count = 1); + const Shape& lhs, const Shape& rhs, int64 feature_group_count, + const Window& window, + const ConvolutionDimensionNumbers& dimension_numbers); // Infers the shape produced by the given FFT type on the given operand. static StatusOr<Shape> InferFftShape(const Shape& in, FftType fft_type, diff --git a/tensorflow/compiler/xla/service/shape_inference_test.cc b/tensorflow/compiler/xla/service/shape_inference_test.cc index cc92e58ef8..864ed43118 100644 --- a/tensorflow/compiler/xla/service/shape_inference_test.cc +++ b/tensorflow/compiler/xla/service/shape_inference_test.cc @@ -419,8 +419,8 @@ TEST_F(ShapeInferenceTest, Convolve) { dim1->set_padding_high(0); dim1->set_window_dilation(1); dim1->set_base_dilation(1); - auto inferred_status = - ShapeInference::InferConvolveShape(lhs_shape, rhs_shape, window, dnums); + auto inferred_status = ShapeInference::InferConvolveShape( + lhs_shape, rhs_shape, /*feature_group_count=*/1, window, dnums); ASSERT_IS_OK(inferred_status.status()); Shape inferred_shape = inferred_status.ValueOrDie(); ASSERT_TRUE(ShapeUtil::Equal(ShapeUtil::MakeShape(F32, {10, 12, 2, 3}), @@ -464,8 +464,8 @@ TEST_F(ShapeInferenceTest, ConvolveWithWindowDilation) { dim1->set_padding_high(1); dim1->set_window_dilation(2); dim1->set_base_dilation(1); - auto inferred_status = - ShapeInference::InferConvolveShape(lhs_shape, rhs_shape, window, dnums); + auto inferred_status = ShapeInference::InferConvolveShape( + lhs_shape, rhs_shape, /*feature_group_count=*/1, window, dnums); ASSERT_IS_OK(inferred_status.status()); Shape inferred_shape = inferred_status.ValueOrDie(); ASSERT_TRUE(ShapeUtil::Equal(ShapeUtil::MakeShape(F32, {10, 12, 31, 5}), @@ -509,8 +509,8 @@ TEST_F(ShapeInferenceTest, ConvolveWithBaseDilation) { dim1->set_padding_high(1); dim1->set_window_dilation(1); dim1->set_base_dilation(2); - auto inferred_status = - ShapeInference::InferConvolveShape(lhs_shape, rhs_shape, window, dnums); + auto inferred_status = ShapeInference::InferConvolveShape( + lhs_shape, rhs_shape, /*feature_group_count=*/1, window, dnums); ASSERT_IS_OK(inferred_status.status()); Shape inferred_shape = inferred_status.ValueOrDie(); ASSERT_TRUE(ShapeUtil::Equal(ShapeUtil::MakeShape(F32, {10, 12, 4, 9}), @@ -547,8 +547,8 @@ TEST_F(ShapeInferenceTest, ConvolveDimensionNumbersOverlapError) { dim1->set_stride(2); dim1->set_padding_low(1); dim1->set_padding_high(1); - auto inferred_status = - ShapeInference::InferConvolveShape(lhs_shape, rhs_shape, window, dnums); + auto inferred_status = ShapeInference::InferConvolveShape( + lhs_shape, rhs_shape, /*feature_group_count=*/1, window, dnums); ASSERT_FALSE(inferred_status.ok()); ASSERT_THAT(inferred_status.status().error_message(), HasSubstr("each dimension exactly once")); diff --git a/tensorflow/compiler/xla/service/transpose_folding.cc b/tensorflow/compiler/xla/service/transpose_folding.cc index 530f40e4b2..7c1f4b5cc6 100644 --- a/tensorflow/compiler/xla/service/transpose_folding.cc +++ b/tensorflow/compiler/xla/service/transpose_folding.cc @@ -108,8 +108,7 @@ Status FoldTransposeIntoDot(InstructionOperandsPair pair) { } std::unique_ptr<HloInstruction> new_dot = HloInstruction::CreateDot( - dot->shape(), new_lhs, new_rhs, new_dim_numbers); - new_dot->set_precision_config(dot->precision_config()); + dot->shape(), new_lhs, new_rhs, new_dim_numbers, dot->precision_config()); return dot->parent()->ReplaceWithNewInstruction(dot, std::move(new_dot)); } @@ -178,8 +177,8 @@ bool FoldTransposeIntoConvolution(InstructionOperandsPair pair) { } auto new_conv = HloInstruction::CreateConvolve( - convolution.shape(), new_lhs, new_rhs, convolution.window(), new_dnums); - new_conv->set_precision_config(convolution.precision_config()); + convolution.shape(), new_lhs, new_rhs, convolution.feature_group_count(), + convolution.window(), new_dnums, convolution.precision_config()); TF_CHECK_OK(convolution.parent()->ReplaceWithNewInstruction( &convolution, std::move(new_conv))); diff --git a/tensorflow/compiler/xla/service/transpose_folding_test.cc b/tensorflow/compiler/xla/service/transpose_folding_test.cc index 58f767e913..79b5c09abb 100644 --- a/tensorflow/compiler/xla/service/transpose_folding_test.cc +++ b/tensorflow/compiler/xla/service/transpose_folding_test.cc @@ -240,10 +240,12 @@ TEST_F(TransposeFoldingTest, FoldConvDimSwapTransposeRhs) { transpose_y->shape().dimensions(dnums.kernel_spatial_dimensions(i))); } StatusOr<Shape> conv_shape = ShapeInference::InferConvolveShape( - x->shape(), transpose_y->shape(), window, dnums); + x->shape(), transpose_y->shape(), /*feature_group_count=*/1, window, + dnums); EXPECT_IS_OK(conv_shape); HloInstruction* conv = builder.AddInstruction(HloInstruction::CreateConvolve( - conv_shape.ValueOrDie(), x, transpose_y, window, dnums)); + conv_shape.ValueOrDie(), x, transpose_y, + /*feature_group_count=*/1, window, dnums, DefaultPrecisionConfig(2))); auto module = CreateNewModule("test_module"); HloComputation* entry_computation = @@ -293,10 +295,12 @@ TEST_F(TransposeFoldingTest, FoldConvComplexTransposeRhs) { transpose_y->shape().dimensions(dnums.kernel_spatial_dimensions(i))); } StatusOr<Shape> conv_shape = ShapeInference::InferConvolveShape( - x->shape(), transpose_y->shape(), window, dnums); + x->shape(), transpose_y->shape(), /*feature_group_count=*/1, window, + dnums); EXPECT_IS_OK(conv_shape); HloInstruction* conv = builder.AddInstruction(HloInstruction::CreateConvolve( - conv_shape.ValueOrDie(), x, transpose_y, window, dnums)); + conv_shape.ValueOrDie(), x, transpose_y, + /*feature_group_count=*/1, window, dnums, DefaultPrecisionConfig(2))); auto module = CreateNewModule("test_module"); HloComputation* entry_computation = @@ -351,10 +355,12 @@ TEST_F(TransposeFoldingTest, FoldConvTransposeLhs) { dim->set_size(y->shape().dimensions(dnums.kernel_spatial_dimensions(i))); } StatusOr<Shape> conv_shape = ShapeInference::InferConvolveShape( - transpose_x->shape(), y->shape(), window, dnums); + transpose_x->shape(), y->shape(), /*feature_group_count=*/1, window, + dnums); EXPECT_IS_OK(conv_shape); HloInstruction* conv = builder.AddInstruction(HloInstruction::CreateConvolve( - conv_shape.ValueOrDie(), transpose_x, y, window, dnums)); + conv_shape.ValueOrDie(), transpose_x, y, + /*feature_group_count=*/1, window, dnums, DefaultPrecisionConfig(2))); auto module = CreateNewModule("test_module"); HloComputation* entry_computation = @@ -415,10 +421,12 @@ TEST_F(TransposeFoldingTest, FoldConvComplexTransposeLhs) { dim->set_size(y->shape().dimensions(dnums.kernel_spatial_dimensions(i))); } StatusOr<Shape> conv_shape = ShapeInference::InferConvolveShape( - transpose_x->shape(), y->shape(), window, dnums); + transpose_x->shape(), y->shape(), /*feature_group_count=*/1, window, + dnums); EXPECT_IS_OK(conv_shape); HloInstruction* conv = builder.AddInstruction(HloInstruction::CreateConvolve( - conv_shape.ValueOrDie(), transpose_x, y, window, dnums)); + conv_shape.ValueOrDie(), transpose_x, y, + /*feature_group_count=*/1, window, dnums, DefaultPrecisionConfig(2))); auto module = CreateNewModule("test_module"); HloComputation* entry_computation = diff --git a/tensorflow/compiler/xla/service/tuple_points_to_analysis_test.cc b/tensorflow/compiler/xla/service/tuple_points_to_analysis_test.cc index a32d1f9026..2b2a2eb42a 100644 --- a/tensorflow/compiler/xla/service/tuple_points_to_analysis_test.cc +++ b/tensorflow/compiler/xla/service/tuple_points_to_analysis_test.cc @@ -1064,8 +1064,11 @@ TEST_F(CanShareOperandBufferWithUserTest, FusedDotAdd) { DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); + PrecisionConfig precision_config; + precision_config.mutable_operand_precision()->Resize( + /*new_size=*/2, PrecisionConfig::DEFAULT); auto dot = builder.AddInstruction( - HloInstruction::CreateDot(data_shape, a, b, dot_dnums)); + HloInstruction::CreateDot(data_shape, a, b, dot_dnums, precision_config)); auto one = builder.AddInstruction( HloInstruction::CreateConstant(LiteralUtil::CreateR0<float>(1.0))); diff --git a/tensorflow/compiler/xla/service/while_loop_constant_sinking.cc b/tensorflow/compiler/xla/service/while_loop_constant_sinking.cc index aab1180662..56145822be 100644 --- a/tensorflow/compiler/xla/service/while_loop_constant_sinking.cc +++ b/tensorflow/compiler/xla/service/while_loop_constant_sinking.cc @@ -15,10 +15,10 @@ limitations under the License. #include "tensorflow/compiler/xla/service/while_loop_constant_sinking.h" #include "absl/algorithm/container.h" +#include "absl/container/inlined_vector.h" #include "tensorflow/compiler/xla/service/while_util.h" #include "tensorflow/compiler/xla/util.h" #include "tensorflow/core/lib/gtl/flatmap.h" -#include "tensorflow/core/lib/gtl/inlined_vector.h" namespace xla { diff --git a/tensorflow/compiler/xla/tests/hlo_test_base.cc b/tensorflow/compiler/xla/tests/hlo_test_base.cc index fc4c68246e..3df99aac7d 100644 --- a/tensorflow/compiler/xla/tests/hlo_test_base.cc +++ b/tensorflow/compiler/xla/tests/hlo_test_base.cc @@ -120,6 +120,14 @@ StatusOr<bool> HloTestBase::RunHloPass(HloPassInterface* hlo_pass, return status_or; } +/* static */ +PrecisionConfig HloTestBase::DefaultPrecisionConfig(int operands) { + PrecisionConfig precision_config; + precision_config.mutable_operand_precision()->Resize( + operands, PrecisionConfig::DEFAULT); + return precision_config; +} + DebugOptions HloTestBase::GetDebugOptionsForTest() { auto debug_options = legacy_flags::GetDebugOptionsFromFlags(); // TODO(b/38354253): Change tests to use Parameters instead of Constants. diff --git a/tensorflow/compiler/xla/tests/hlo_test_base.h b/tensorflow/compiler/xla/tests/hlo_test_base.h index 4c88257bb2..21d77c0cc4 100644 --- a/tensorflow/compiler/xla/tests/hlo_test_base.h +++ b/tensorflow/compiler/xla/tests/hlo_test_base.h @@ -80,6 +80,8 @@ class HloTestBase : public ::testing::Test { static StatusOr<bool> RunHloPass(HloPassInterface* hlo_pass, HloModule* module); + static PrecisionConfig DefaultPrecisionConfig(int operands); + protected: // This uses the interpreter backend as the reference backend and // automatically finds another supported backend as the test backend. If the diff --git a/tensorflow/compiler/xla/tests/multioutput_fusion_test.cc b/tensorflow/compiler/xla/tests/multioutput_fusion_test.cc index 05f90ba9fb..c5e0b9b097 100644 --- a/tensorflow/compiler/xla/tests/multioutput_fusion_test.cc +++ b/tensorflow/compiler/xla/tests/multioutput_fusion_test.cc @@ -47,7 +47,6 @@ limitations under the License. namespace xla { namespace { - class MultiOutputFusionTest : public HloTestBase { protected: MultiOutputFusionTest() { error_spec_ = ErrorSpec{0.0001, 1e-2}; } @@ -90,8 +89,8 @@ class MultiOutputFusionTest : public HloTestBase { DotDimensionNumbers dot_dnums; dot_dnums.add_lhs_contracting_dimensions(1); dot_dnums.add_rhs_contracting_dimensions(0); - HloInstruction* dot = builder.AddInstruction( - HloInstruction::CreateDot(elem_shape2, sub, add2, dot_dnums)); + HloInstruction* dot = builder.AddInstruction(HloInstruction::CreateDot( + elem_shape2, sub, add2, dot_dnums, DefaultPrecisionConfig(2))); auto computation = hlo_module->AddEntryComputation(builder.Build(dot)); if (manual_fusion) { @@ -154,7 +153,7 @@ class MultiOutputFusionTest : public HloTestBase { dot_dnums.add_rhs_contracting_dimensions(0); HloInstruction* dot = builder.AddInstruction(HloInstruction::CreateDot( ShapeUtil::MakeShapeWithDescendingLayout(F32, {1}), sub, reshape, - dot_dnums)); + dot_dnums, DefaultPrecisionConfig(2))); auto computation = hlo_module->AddEntryComputation(builder.Build(dot)); if (manual_fusion) { diff --git a/tensorflow/compiler/xla/tests/reduce_window_test.cc b/tensorflow/compiler/xla/tests/reduce_window_test.cc index 997880a018..a1001296a1 100644 --- a/tensorflow/compiler/xla/tests/reduce_window_test.cc +++ b/tensorflow/compiler/xla/tests/reduce_window_test.cc @@ -613,7 +613,7 @@ class R4ReduceWindowTest : public ReduceWindowTestBase, Array4D<float> input(param.base_bounds[0], param.base_bounds[1], param.base_bounds[2], param.base_bounds[3]); - input.FillIota(1); + input.FillRandom(0.1f, 0.1f); std::unique_ptr<Literal> input_literal = LiteralUtil::CreateR4FromArray4DWithLayout( input, LayoutUtil::MakeLayout(param.layout)); @@ -629,7 +629,14 @@ class R4ReduceWindowTest : public ReduceWindowTestBase, auto init_value = CreateConstantFromLiteral(*LiteralUtil::CreateR0(kInitValue), &b); CHECK(param.reducer == kAdd || param.reducer == kMax); - auto computation = param.reducer == kAdd + auto reducer = param.reducer; + if (use_bfloat16() && Product(param.window_bounds) > 128) { + // To avoid numerical issues, force the reducer to be kMax for large bf16 + // windows. + reducer = kMax; + } + + auto computation = reducer == kAdd ? CreateScalarAddComputation(FloatType(), &b) : CreateScalarMaxComputation(FloatType(), &b); ReduceWindowWithGeneralPadding( @@ -640,8 +647,8 @@ class R4ReduceWindowTest : public ReduceWindowTestBase, /*window_strides=*/param.strides, /*padding=*/padding); - CHECK(param.reducer == kAdd || param.reducer == kMax); - auto reduce_func = param.reducer == kAdd + CHECK(reducer == kAdd || reducer == kMax); + auto reduce_func = reducer == kAdd ? +[](float a, float b) { return a + b; } : +[](float a, float b) { return std::max(a, b); }; std::unique_ptr<Array4D<float>> expected = @@ -809,6 +816,22 @@ const R4ReduceWindowTestData kR4ReduceWindowTestValues[] = { /*pad_high=*/{1, 0, 0, 0}, /*layout=*/{3, 2, 1, 0}, /*reducer=*/kAdd}, + + R4ReduceWindowTestData{/*base_bounds=*/{8, 256, 256, 3}, + /*window_bounds=*/{1, 64, 64, 1}, + /*strides=*/{1, 64, 64, 1}, + /*pad_low=*/{0, 0, 0, 0}, + /*pad_high=*/{0, 0, 0, 0}, + /*layout=*/{3, 0, 2, 1}, + /*reducer=*/kAdd}, + + R4ReduceWindowTestData{/*base_bounds=*/{112, 112, 8, 64}, + /*window_bounds=*/{112, 112, 1, 8}, + /*strides=*/{112, 112, 1, 8}, + /*pad_low=*/{0, 0, 0, 0}, + /*pad_high=*/{0, 0, 0, 0}, + /*layout=*/{3, 2, 1, 0}, + /*reducer=*/kAdd}, }; INSTANTIATE_TEST_CASE_P( @@ -930,6 +953,27 @@ struct R3ReduceWindowTestData { {/*base_bounds=*/{6, 21, 3}, /*window_bounds=*/{2, 3, 2}, /*strides=*/{1, 2, 2}, /*layout=*/{1, 0, 2}, /*padding=*/Padding::kValid, /*reducer=*/Reducer::kAdd}, + {/*base_bounds=*/{95, 202, 251}, /*window_bounds=*/{95, 202, 251}, + /*strides=*/{1, 1, 1}, /*layout=*/{2, 1, 0}, + /*padding=*/Padding::kValid, /*reducer=*/Reducer::kAdd}, + {/*base_bounds=*/{999, 57, 3}, /*window_bounds=*/{999, 57, 3}, + /*strides=*/{1, 1, 1}, /*layout=*/{2, 1, 0}, + /*padding=*/Padding::kValid, /*reducer=*/Reducer::kAdd}, + {/*base_bounds=*/{178, 302, 64}, /*window_bounds=*/{178, 302, 64}, + /*strides=*/{1, 1, 1}, /*layout=*/{2, 1, 0}, + /*padding=*/Padding::kValid, /*reducer=*/Reducer::kAdd}, + {/*base_bounds=*/{63, 261, 257}, /*window_bounds=*/{63, 261, 257}, + /*strides=*/{1, 1, 1}, /*layout=*/{2, 1, 0}, + /*padding=*/Padding::kValid, /*reducer=*/Reducer::kAdd}, + {/*base_bounds=*/{10003, 10, 5}, /*window_bounds=*/{9999, 7, 3}, + /*strides=*/{1, 1, 1}, /*layout=*/{2, 1, 0}, + /*padding=*/Padding::kValid, /*reducer=*/Reducer::kAdd}, + {/*base_bounds=*/{9999, 1, 1}, /*window_bounds=*/{9999, 1, 1}, + /*strides=*/{1, 1, 1}, /*layout=*/{2, 1, 0}, + /*padding=*/Padding::kValid, /*reducer=*/Reducer::kAdd}, + {/*base_bounds=*/{10003, 10, 5}, /*window_bounds=*/{9999, 7, 3}, + /*strides=*/{2, 2, 2}, /*layout=*/{2, 1, 0}, + /*padding=*/Padding::kValid, /*reducer=*/Reducer::kAdd}, }; string R3ReduceWindowTestDataToString( @@ -956,35 +1000,42 @@ class R3ReduceWindowTest : public ReduceWindowTestBase, R3ReduceWindowTest() { set_use_bfloat16(::testing::get<1>(GetParam())); } }; -TEST_P(R3ReduceWindowTest, Add) { +TEST_P(R3ReduceWindowTest, DoIt) { XlaBuilder b(TestName()); const auto& param = ::testing::get<0>(GetParam()); - CHECK(param.reducer == kAdd); const float kInitValue = 0.0f; Array3D<float> input(param.base_bounds[0], param.base_bounds[1], - param.base_bounds[2], 1.0f); + param.base_bounds[2]); + input.FillRandom(0.1f, 0.1f); std::unique_ptr<Literal> input_literal = LiteralUtil::CreateR3FromArray3DWithLayout( input, LayoutUtil::MakeLayout(param.layout)); + auto reducer = param.reducer; + if (use_bfloat16()) { + input_literal = LiteralUtil::ConvertF32ToBF16(*input_literal); + if (Product(param.window_bounds) > 128) { + // To avoid numerical issues, force the reducer to be kMax for large bf16 + // windows. + reducer = kMax; + } + } - XlaOp parameter; - auto input_arg = CreateParameterAndTransferLiteral(0, *input_literal, "p0", - &b, ¶meter); + XlaOp parameter = Parameter(&b, 0, input_literal->shape(), "input"); auto init_value = CreateConstantFromLiteral(*LiteralUtil::CreateR0(kInitValue), &b); + + auto computation = reducer == kAdd + ? CreateScalarAddComputation(FloatType(), &b) + : CreateScalarMaxComputation(FloatType(), &b); + ReduceWindow(/*operand=*/parameter, /*init_value=*/init_value, - /*computation=*/CreateScalarAddComputation(FloatType(), &b), + /*computation=*/computation, /*window_dimensions=*/param.window_bounds, /*window_strides=*/param.strides, /*padding=*/param.padding); - auto expected = ReferenceUtil::ReduceWindow3DAdd( - /*operand=*/input, /*init=*/kInitValue, /*window=*/param.window_bounds, - /*stride=*/param.strides, /*padding=*/param.padding); - - ComputeAndCompareLiteral(&b, *LiteralUtil::CreateFromArray(*expected), - {input_arg.get()}, DefaultErrorSpec()); + ComputeAndCompare(&b, {std::move(*input_literal)}, DefaultErrorSpec()); } INSTANTIATE_TEST_CASE_P( @@ -1093,7 +1144,6 @@ class R2ReduceWindowTest : public ReduceWindowTestBase, void DoIt() { XlaBuilder b(TestName()); const auto& param = ::testing::get<0>(GetParam()); - CHECK(param.reducer == kAdd); const float kInitValue = 0.0f; Array2D<float> input(param.base_bounds[0], param.base_bounds[1], 1.0f); diff --git a/tensorflow/compiler/xla/tools/BUILD b/tensorflow/compiler/xla/tools/BUILD index 22c28a8f4c..3a086c66bb 100644 --- a/tensorflow/compiler/xla/tools/BUILD +++ b/tensorflow/compiler/xla/tools/BUILD @@ -24,6 +24,7 @@ tf_cc_binary( "//tensorflow/core:framework_internal", "//tensorflow/core:lib", "//tensorflow/core:lib_internal", + "@com_google_absl//absl/base", "@com_google_absl//absl/strings", ], ) diff --git a/tensorflow/compiler/xla/tools/hex_floats_to_packed_literal.cc b/tensorflow/compiler/xla/tools/hex_floats_to_packed_literal.cc index 75b63c3b84..23ce1d235b 100644 --- a/tensorflow/compiler/xla/tools/hex_floats_to_packed_literal.cc +++ b/tensorflow/compiler/xla/tools/hex_floats_to_packed_literal.cc @@ -17,9 +17,9 @@ limitations under the License. #include <string> #include <vector> +#include "absl/base/casts.h" #include "absl/strings/string_view.h" #include "tensorflow/compiler/xla/types.h" -#include "tensorflow/core/lib/core/casts.h" #include "tensorflow/core/lib/core/status.h" #include "tensorflow/core/lib/io/buffered_inputstream.h" #include "tensorflow/core/lib/io/random_inputstream.h" @@ -67,9 +67,8 @@ int main(int argc, char** argv) { floats.push_back(value); } - tensorflow::StringPiece content( // non-absl ok - tensorflow::bit_cast<const char*>(floats.data()), - floats.size() * sizeof(float)); + absl::string_view content(absl::bit_cast<const char*>(floats.data()), + floats.size() * sizeof(float)); TF_CHECK_OK(tensorflow::WriteStringToFile(tensorflow::Env::Default(), output_file, content)); return 0; diff --git a/tensorflow/compiler/xla/xla_data.proto b/tensorflow/compiler/xla/xla_data.proto index 8e43f275e1..dd329f1181 100644 --- a/tensorflow/compiler/xla/xla_data.proto +++ b/tensorflow/compiler/xla/xla_data.proto @@ -580,7 +580,7 @@ message SourceTarget { // Used to indicate the precision configuration. It has backend specific // meaning. -message PrecisionConfigProto { +message PrecisionConfig { enum Precision { DEFAULT = 0; HIGH = 1; diff --git a/tensorflow/compiler/xrt/BUILD b/tensorflow/compiler/xrt/BUILD index efbe980278..2ff97914f8 100644 --- a/tensorflow/compiler/xrt/BUILD +++ b/tensorflow/compiler/xrt/BUILD @@ -56,6 +56,7 @@ cc_library( "//tensorflow/core:lib_internal", "//tensorflow/stream_executor", "@com_google_absl//absl/memory", + "@com_google_absl//absl/strings", "@com_google_absl//absl/synchronization", ], ) diff --git a/tensorflow/compiler/xrt/kernels/BUILD b/tensorflow/compiler/xrt/kernels/BUILD index 68ba17a424..9e3d2454d1 100644 --- a/tensorflow/compiler/xrt/kernels/BUILD +++ b/tensorflow/compiler/xrt/kernels/BUILD @@ -46,19 +46,15 @@ cc_library( deps = [ ":xrt_state_ops", "//tensorflow/compiler/tf2xla:xla_compiler", - "//tensorflow/compiler/xla:literal", "//tensorflow/compiler/xla:shape_util", "//tensorflow/compiler/xla:status_macros", "//tensorflow/compiler/xla:statusor", "//tensorflow/compiler/xla:xla_data_proto", "//tensorflow/compiler/xla/client:client_library", - "//tensorflow/compiler/xla/client:compile_only_client", "//tensorflow/compiler/xla/client:local_client", "//tensorflow/compiler/xla/client:xla_computation", - "//tensorflow/compiler/xla/legacy_flags:debug_options_flags", "//tensorflow/compiler/xla/service:compiler", "//tensorflow/compiler/xla/service:computation_placer", - "//tensorflow/compiler/xla/service:hlo_proto", "//tensorflow/compiler/xrt:xrt_proto", "//tensorflow/compiler/xrt:xrt_utils", "//tensorflow/core:core_cpu_internal", @@ -67,6 +63,7 @@ cc_library( "//tensorflow/core:lib_internal", "//tensorflow/core:protos_all_cc", "//tensorflow/stream_executor:stream_executor_headers_lib", + "@com_google_absl//absl/strings", ], alwayslink = 1, ) diff --git a/tensorflow/compiler/xrt/kernels/xrt_compile_ops.cc b/tensorflow/compiler/xrt/kernels/xrt_compile_ops.cc index 5cf2bc8861..1d4f8d97f2 100644 --- a/tensorflow/compiler/xrt/kernels/xrt_compile_ops.cc +++ b/tensorflow/compiler/xrt/kernels/xrt_compile_ops.cc @@ -22,6 +22,7 @@ limitations under the License. #include <utility> #include <vector> +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/tf2xla/xla_op_registry.h" #include "tensorflow/compiler/xla/client/client_library.h" #include "tensorflow/compiler/xla/client/xla_computation.h" @@ -40,7 +41,6 @@ limitations under the License. #include "tensorflow/core/lib/core/refcount.h" #include "tensorflow/core/lib/core/status.h" #include "tensorflow/core/lib/strings/proto_serialization.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/fingerprint.h" #include "tensorflow/core/platform/types.h" @@ -70,7 +70,7 @@ Status CompilationCacheKey(const xrt::XLAComputation& computation, string serialized; TF_RET_CHECK(SerializeToStringDeterministic(computation, &serialized)); uint64 fingerprint = Fingerprint64(serialized); - *key = strings::StrCat(fingerprint); + *key = absl::StrCat(fingerprint); return Status::OK(); } diff --git a/tensorflow/compiler/xrt/xrt_state.cc b/tensorflow/compiler/xrt/xrt_state.cc index 911ac9a78b..2c3b07da58 100644 --- a/tensorflow/compiler/xrt/xrt_state.cc +++ b/tensorflow/compiler/xrt/xrt_state.cc @@ -24,6 +24,7 @@ limitations under the License. #include <utility> #include "absl/memory/memory.h" +#include "absl/strings/str_cat.h" #include "tensorflow/compiler/xla/literal.h" #include "tensorflow/compiler/xla/service/backend.h" #include "tensorflow/compiler/xla/shape_util.h" @@ -32,7 +33,6 @@ limitations under the License. #include "tensorflow/compiler/xla/xla_data.pb.h" #include "tensorflow/core/framework/resource_mgr.h" #include "tensorflow/core/lib/core/status.h" -#include "tensorflow/core/lib/strings/strcat.h" #include "tensorflow/core/platform/types.h" #include "tensorflow/stream_executor/stream_executor.h" @@ -201,14 +201,14 @@ const se::DeviceMemoryBase& XRTTupleAllocation::root_allocation() { /*static*/ Status XRTTupleAllocation::Lookup(ResourceMgr* rm, int64 key, XRTTupleAllocation** allocation) { - string key_string = strings::StrCat(key); + string key_string = absl::StrCat(key); TF_RETURN_IF_ERROR(rm->Lookup(kTupleContainer, key_string, allocation)); return Status::OK(); } /*static*/ Status XRTTupleAllocation::DeleteFromResourceManager(ResourceMgr* rm, int64 key) { - string key_string = strings::StrCat(key); + string key_string = absl::StrCat(key); return rm->Delete<XRTTupleAllocation>(kTupleContainer, key_string); } @@ -410,7 +410,7 @@ typedef XRTBufferAllocation* XRTBufferAllocationPtr; Status XRTTupleAllocation::Intern(ResourceMgr* rm, int64* key) { *key = get_uid(); - string key_string = strings::StrCat(*key); + string key_string = absl::StrCat(*key); return rm->Create(kTupleContainer, key_string, this); } diff --git a/tensorflow/contrib/BUILD b/tensorflow/contrib/BUILD index 66983801bf..798f499870 100644 --- a/tensorflow/contrib/BUILD +++ b/tensorflow/contrib/BUILD @@ -20,13 +20,7 @@ py_library( ), srcs_version = "PY2AND3", visibility = ["//visibility:public"], - deps = if_not_windows([ - # TODO(aaroey): tensorrt dependency has to appear before tflite so the - # build can resolve its flatbuffers symbols within the tensorrt library. - # This is an issue with the tensorrt static library and will be fixed by - # the next tensorrt release, so fix the order here after that. - "//tensorflow/contrib/tensorrt:init_py", # doesn't compile on windows - ]) + [ + deps = [ "//tensorflow/contrib/all_reduce", "//tensorflow/contrib/batching:batch_py", "//tensorflow/contrib/bayesflow:bayesflow_py", @@ -135,6 +129,7 @@ py_library( ]) + if_not_windows([ "//tensorflow/contrib/bigtable", # depends on bigtable "//tensorflow/contrib/cloud:cloud_py", # doesn't compile on Windows + "//tensorflow/contrib/tensorrt:init_py", # doesn't compile on windows "//tensorflow/contrib/ffmpeg:ffmpeg_ops_py", ]), ) diff --git a/tensorflow/contrib/__init__.py b/tensorflow/contrib/__init__.py index 5f477a79a3..9478e42b46 100644 --- a/tensorflow/contrib/__init__.py +++ b/tensorflow/contrib/__init__.py @@ -21,6 +21,14 @@ from __future__ import print_function import os +from tensorflow.python.tools import component_api_helper +component_api_helper.package_hook( + parent_package_str=( + "tensorflow.contrib"), + child_package_str=( + "tensorflow_estimator.contrib.estimator")) +del component_api_helper + # Add projects here, they will show up under tf.contrib. from tensorflow.contrib import autograph from tensorflow.contrib import batching diff --git a/tensorflow/contrib/autograph/converters/builtin_functions.py b/tensorflow/contrib/autograph/converters/builtin_functions.py index b26c52294c..29dce13999 100644 --- a/tensorflow/contrib/autograph/converters/builtin_functions.py +++ b/tensorflow/contrib/autograph/converters/builtin_functions.py @@ -21,6 +21,8 @@ from __future__ import print_function import gast from tensorflow.contrib.autograph.core import converter +from tensorflow.contrib.autograph.operators import py_builtins +from tensorflow.contrib.autograph.pyct import anno from tensorflow.contrib.autograph.pyct import templates @@ -31,41 +33,32 @@ class BuiltinFunctionTransformer(converter.Base): TF equivalent, like `len`. """ - def _convert_builtin(self, node): + def _convert_builtin(self, f, args, as_expression): template = """ - ag__.utils.dynamic_builtin(func, args) + ag__.func(args) """ - return templates.replace(template, func=node.func, args=node.args)[0].value - - def _convert_print(self, node): - template = """ - ag__.utils.dynamic_print(args) - """ - return templates.replace(template, args=node.args)[0].value + if as_expression: + return templates.replace_as_expression( + template, func=py_builtins.overload_of(f).__name__, args=args) + else: + return templates.replace( + template, func=py_builtins.overload_of(f).__name__, args=args) def visit_Call(self, node): - self.generic_visit(node) - # TODO(mdan): This won't work if the function was hidden. - # TODO(mdan): Rely on the live_val and use inspect_utils.is_builtin instead. - if (isinstance(node.func, gast.Name) and - node.func.id in ('len', 'range', 'xrange', 'float', 'int')): - return self._convert_builtin(node) - # Print needs to be handled separately because it can be read as statement. - if isinstance(node.func, gast.Name) and node.func.id == 'print': - return self._convert_print(node) + node = self.generic_visit(node) + if anno.hasanno(node.func, 'live_val'): + live_val = anno.getanno(node.func, 'live_val') + if live_val in py_builtins.SUPPORTED_BUILTINS: + node = self._convert_builtin(live_val, node.args, as_expression=True) return node def visit_Print(self, node): - self.generic_visit(node) + node = self.generic_visit(node) args = node.values # Following is the case when calling print(a, b) if len(args) == 1 and isinstance(args[0], gast.Tuple): args = args[0].elts - template = """ - fname(args) - """ - function_call = templates.replace(template, fname='print', args=args)[0] - return self.visit(function_call) + return self._convert_builtin(print, args, as_expression=False) def transform(node, ctx): diff --git a/tensorflow/contrib/autograph/converters/builtin_functions_test.py b/tensorflow/contrib/autograph/converters/builtin_functions_test.py index d0a0cbbeb6..3e3a04f38b 100644 --- a/tensorflow/contrib/autograph/converters/builtin_functions_test.py +++ b/tensorflow/contrib/autograph/converters/builtin_functions_test.py @@ -23,6 +23,7 @@ import six from tensorflow.contrib.autograph.converters import builtin_functions from tensorflow.contrib.autograph.core import converter_testing from tensorflow.python.framework import constant_op +from tensorflow.python.framework import dtypes from tensorflow.python.ops import array_ops from tensorflow.python.platform import test @@ -34,11 +35,11 @@ class BuiltinFunctionsTest(converter_testing.TestCase): def test_fn(a): return len(a) - with self.converted(test_fn, builtin_functions, {'len': len}, - array_ops.shape) as result: + with self.converted(test_fn, builtin_functions, {'len': len}) as result: with self.cached_session() as sess: - ops = result.test_fn(constant_op.constant([0, 0, 0])) - self.assertEqual(sess.run(ops), 3) + p = array_ops.placeholder(dtype=dtypes.int32, shape=None) + ops = result.test_fn(p) + self.assertEqual(sess.run(ops, {p: [0, 0, 0]}), 3) def test_print(self): diff --git a/tensorflow/contrib/autograph/examples/integration_tests/BUILD b/tensorflow/contrib/autograph/examples/integration_tests/BUILD index 6c281485b4..3630b41fc8 100644 --- a/tensorflow/contrib/autograph/examples/integration_tests/BUILD +++ b/tensorflow/contrib/autograph/examples/integration_tests/BUILD @@ -23,7 +23,6 @@ py_test( ], srcs_version = "PY2AND3", tags = ["no_windows"], - visibility = ["//visibility:public"], deps = [ "//tensorflow:tensorflow_py", ], diff --git a/tensorflow/contrib/autograph/impl/api.py b/tensorflow/contrib/autograph/impl/api.py index 276a387180..8b38d5d080 100644 --- a/tensorflow/contrib/autograph/impl/api.py +++ b/tensorflow/contrib/autograph/impl/api.py @@ -29,9 +29,9 @@ import six from tensorflow.contrib.autograph.core import config from tensorflow.contrib.autograph.core import converter from tensorflow.contrib.autograph.impl import conversion +from tensorflow.contrib.autograph.operators import py_builtins from tensorflow.contrib.autograph.pyct import compiler from tensorflow.contrib.autograph.pyct import inspect_utils -from tensorflow.contrib.autograph.utils import builtins from tensorflow.contrib.autograph.utils import py_func from tensorflow.python.platform import tf_logging as logging from tensorflow.python.util import tf_decorator @@ -150,7 +150,7 @@ def converted_call(f, recursive, verbose, force_conversion, arg_types, *args, unknown_arg_value = object() # Sentinel for arguments of unknown value if inspect_utils.isbuiltin(f): - return builtins.dynamic_builtin(f, *args, **kwargs) + return py_builtins.overload_of(f)(*args, **kwargs) if tf_inspect.isfunction(f) or tf_inspect.ismethod(f): # Regular functions diff --git a/tensorflow/contrib/autograph/operators/BUILD b/tensorflow/contrib/autograph/operators/BUILD index 332d5dab19..29759bad79 100644 --- a/tensorflow/contrib/autograph/operators/BUILD +++ b/tensorflow/contrib/autograph/operators/BUILD @@ -22,6 +22,7 @@ py_library( "__init__.py", "control_flow.py", "data_structures.py", + "py_builtins.py", "slices.py", ], srcs_version = "PY2AND3", @@ -62,6 +63,16 @@ py_test( ) py_test( + name = "py_builtins_test", + srcs = ["py_builtins_test.py"], + srcs_version = "PY2AND3", + deps = [ + ":operators", + "//tensorflow/python:client_testlib", + ], +) + +py_test( name = "slices_test", srcs = ["slices_test.py"], srcs_version = "PY2AND3", diff --git a/tensorflow/contrib/autograph/operators/__init__.py b/tensorflow/contrib/autograph/operators/__init__.py index 392cb60bcc..c4fbc260a2 100644 --- a/tensorflow/contrib/autograph/operators/__init__.py +++ b/tensorflow/contrib/autograph/operators/__init__.py @@ -45,6 +45,11 @@ from tensorflow.contrib.autograph.operators.data_structures import list_stack from tensorflow.contrib.autograph.operators.data_structures import ListPopOpts from tensorflow.contrib.autograph.operators.data_structures import ListStackOpts from tensorflow.contrib.autograph.operators.data_structures import new_list +from tensorflow.contrib.autograph.operators.py_builtins import float_ +from tensorflow.contrib.autograph.operators.py_builtins import int_ +from tensorflow.contrib.autograph.operators.py_builtins import len_ +from tensorflow.contrib.autograph.operators.py_builtins import print_ +from tensorflow.contrib.autograph.operators.py_builtins import range_ from tensorflow.contrib.autograph.operators.slices import get_item from tensorflow.contrib.autograph.operators.slices import GetItemOpts from tensorflow.contrib.autograph.operators.slices import set_item diff --git a/tensorflow/contrib/autograph/operators/control_flow.py b/tensorflow/contrib/autograph/operators/control_flow.py index 9909e52164..9a66a6bb60 100644 --- a/tensorflow/contrib/autograph/operators/control_flow.py +++ b/tensorflow/contrib/autograph/operators/control_flow.py @@ -18,7 +18,7 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function -from tensorflow.contrib.autograph.utils import builtins +from tensorflow.contrib.autograph.operators import py_builtins from tensorflow.python.data.ops import dataset_ops from tensorflow.python.framework import ops from tensorflow.python.framework import tensor_util @@ -82,8 +82,8 @@ def _py_for_stmt(iter_, extra_test, body, init_state): def _known_len_for_stmt(iter_, extra_test, body, init_state): - """Overload of for_stmt that iterates over objects that define a length.""" - n = builtins.dynamic_len(iter_) + """Overload of for_stmt that iterates over objects that admit a length.""" + n = py_builtins.len_(iter_) def while_body(iterate_index, *state): iterate = iter_[iterate_index] diff --git a/tensorflow/contrib/autograph/operators/py_builtins.py b/tensorflow/contrib/autograph/operators/py_builtins.py new file mode 100644 index 0000000000..c5730934e7 --- /dev/null +++ b/tensorflow/contrib/autograph/operators/py_builtins.py @@ -0,0 +1,225 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Operators corresponding to Python builtin functions. + +List of built-in functions: https://docs.python.org/3/library/functions.html +""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import six + +from tensorflow.contrib.autograph.utils import py_func +from tensorflow.contrib.autograph.utils import tensors +from tensorflow.python.framework import constant_op +from tensorflow.python.framework import dtypes +from tensorflow.python.framework import ops +from tensorflow.python.framework import tensor_util +from tensorflow.python.ops import array_ops +from tensorflow.python.ops import control_flow_ops +from tensorflow.python.ops import gen_parsing_ops +from tensorflow.python.ops import gen_string_ops +from tensorflow.python.ops import list_ops +from tensorflow.python.ops import math_ops + + +UNDEFINED = object() + + +def overload_of(f): + if f in SUPPORTED_BUILTINS: + return BUILTIN_FUINCTIONS_MAP[f.__name__] + return f + + +def abs_(x): + if tensor_util.is_tensor(x): + return _tf_abs(x) + return _py_abs(x) + + +def _tf_abs(x): + return math_ops.abs(x) + + +def _py_abs(x): + return abs(x) + + +def float_(x=0): + if tensor_util.is_tensor(x): + return _tf_float(x) + return _py_float(x) + + +def _tf_float(x): + # TODO(mdan): We shouldn't assume float32. + if x.dtype == dtypes.string: + return gen_parsing_ops.string_to_number(x, out_type=dtypes.float32) + return math_ops.cast(x, dtype=dtypes.float32) + + +def _py_float(x): + return float(x) + + +def int_(x=0, base=UNDEFINED): + if tensor_util.is_tensor(x): + return _tf_int(x, base) + return _py_int(x, base) + + +def _tf_int(x, base): + if base not in (10, UNDEFINED): + raise NotImplementedError('base {} not supported for int'.format(base)) + + # TODO(mdan): We shouldn't assume int32. + if x.dtype == dtypes.string: + return gen_parsing_ops.string_to_number(x, out_type=dtypes.int32) + return math_ops.cast(x, dtype=dtypes.int32) + + +def _py_int(x, base): + if base is UNDEFINED: + return int(x) + return int(x, base) + + +def len_(s): + if tensors.is_tensor_array(s): + return _tf_tensor_array_len(s) + elif tensors.is_tensor_list(s): + return _tf_tensor_list_len(s) + elif tensor_util.is_tensor(s): + return _tf_tensor_len(s) + return _py_len(s) + + +def _tf_tensor_array_len(s): + return s.size() + + +def _tf_tensor_list_len(s): + return list_ops.tensor_list_length(s) + + +def _tf_tensor_len(s): + """Overload of len_ for Tensor arguments.""" + # Statically shaped tensors: length is known ahead of time. + if s.shape.ndims and s.shape[0].value is not None: + return s.shape[0].value + + # Static shape of unknown dimensions: use dynamic shape but statically + # chech that it's a scalar. + shape = array_ops.shape(s) + + assert shape.shape, 'shape tensor of zero size? {}'.format(shape) + + if shape.shape[0] == 0: + raise ValueError( + 'len requires a non-scalar tensor, got one of shape {}'.format(shape)) + + if shape.shape[0].value is not None: + return array_ops.shape(s)[0] + + # Fully dynamic shape: use ops. + rank = array_ops.rank(s) + + def raise_zero_rank_error(): + msg = gen_string_ops.string_join( + ['len requires non-zero rank, got ', + gen_string_ops.as_string(rank)]) + with ops.control_dependencies([control_flow_ops.Assert(False, [msg])]): + return constant_op.constant(0, dtype=dtypes.int32) + + return control_flow_ops.cond(rank > 0, lambda: array_ops.shape(s)[0], + raise_zero_rank_error) + + +def _py_len(s): + return len(s) + + +def print_(*objects, **kwargs): + # Note: Python 2.6 doesn't support explicit keywords after starargs. + unknown_kwargs = tuple( + set(kwargs.keys()) - set(('sep', 'end', 'file', 'flush'))) + if unknown_kwargs: + raise ValueError('invalid keyword arguments: {}'.format(unknown_kwargs)) + + # TODO(mdan): use logging_ops.Print when py_func is not supported. + return _tf_py_func_print(objects, kwargs) + + +def _tf_py_func_print(objects, kwargs): + """Overload of print_ as a py_func implementation.""" + override_kwargs = {k: v for k, v in kwargs.items() if v is not UNDEFINED} + if 'flush' not in override_kwargs: + # Defaulting to flushing the console in graph mode, which helps reduce + # garbled output in IPython. + override_kwargs['flush'] = True + + def print_wrapper(*vals): + if six.PY3: + # TensorFlow doesn't seem to generate Unicode when passing strings to + # py_func. This causes the print to add a "b'" wrapper to the output, + # which is probably never what you want. + vals = tuple( + v.decode('utf-8') if isinstance(v, bytes) else v for v in vals) + six.print_(*vals, **override_kwargs) + + return py_func.wrap_py_func( + print_wrapper, None, objects, use_dummy_return=True) + + +def range_(start_or_stop, stop=UNDEFINED, step=UNDEFINED): + if any(tensor_util.is_tensor(s) for s in (start_or_stop, stop, step)): + return _tf_range(start_or_stop, stop, step) + return _py_range(start_or_stop, stop, step) + + +def _tf_range(start_or_stop, stop, step): + # TODO(mdan): We should optimize this when a full tensor is not required. + if step is not UNDEFINED: + return math_ops.range(start_or_stop, stop, step) + if stop is not UNDEFINED: + return math_ops.range(start_or_stop, stop) + return math_ops.range(start_or_stop) + + +def _py_range(start_or_stop, stop, step): + if step is not UNDEFINED: + return range(start_or_stop, stop, step) + if stop is not UNDEFINED: + return range(start_or_stop, stop) + return range(start_or_stop) + + +SUPPORTED_BUILTINS = set((abs, float, int, len, print, range)) + +if six.PY2: + SUPPORTED_BUILTINS.add(xrange) + +BUILTIN_FUINCTIONS_MAP = { + 'abs': abs_, + 'float': float_, + 'int': int_, + 'len': len_, + 'print': print_, + 'range': range_, + 'xrange': range_, +} diff --git a/tensorflow/contrib/autograph/operators/py_builtins_test.py b/tensorflow/contrib/autograph/operators/py_builtins_test.py new file mode 100644 index 0000000000..4073c51785 --- /dev/null +++ b/tensorflow/contrib/autograph/operators/py_builtins_test.py @@ -0,0 +1,131 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for py_builtins module.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import sys + +import six + +from tensorflow.contrib.autograph.operators import data_structures +from tensorflow.contrib.autograph.operators import py_builtins +from tensorflow.python.framework import constant_op +from tensorflow.python.framework import dtypes +from tensorflow.python.framework import errors_impl +from tensorflow.python.ops import array_ops +from tensorflow.python.ops import tensor_array_ops +from tensorflow.python.platform import test + + +class PyBuiltinsTest(test.TestCase): + + def test_abs(self): + self.assertEqual(py_builtins.abs_(-1), 1) + with self.test_session() as sess: + t = py_builtins.abs_(constant_op.constant(-1)) + self.assertEqual(sess.run(t), 1) + t = py_builtins.abs_(constant_op.constant([-1, 2, -3])) + self.assertAllEqual(sess.run(t), [1, 2, 3]) + + def test_float(self): + self.assertEqual(py_builtins.float_(10), 10.0) + self.assertEqual(py_builtins.float_('10.0'), 10.0) + with self.test_session() as sess: + t = py_builtins.float_(constant_op.constant(1, dtype=dtypes.int64)) + self.assertEqual(sess.run(t), 1.0) + st = py_builtins.float_(constant_op.constant('1.0')) + self.assertEqual(sess.run(st), 1.0) + + def test_int(self): + self.assertEqual(py_builtins.int_(10.0), 10) + self.assertEqual(py_builtins.int_('11', 2), 3) + with self.test_session() as sess: + t = py_builtins.int_(constant_op.constant(1, dtype=dtypes.float64)) + self.assertEqual(sess.run(t), 1) + st = py_builtins.int_(constant_op.constant('1')) + self.assertEqual(sess.run(st), 1) + st = py_builtins.int_(constant_op.constant('1'), 10) + self.assertEqual(sess.run(st), 1) + + def test_int_unsupported_base(self): + t = constant_op.constant(1, dtype=dtypes.float64) + with self.assertRaises(NotImplementedError): + py_builtins.int_(t, 2) + + def test_len(self): + self.assertEqual(py_builtins.len_([1, 2, 3]), 3) + with self.test_session() as sess: + t = py_builtins.len_(constant_op.constant([[1], [2], [3]])) + self.assertEqual(t, 3) + ta = py_builtins.len_(tensor_array_ops.TensorArray(dtypes.int32, size=5)) + self.assertEqual(sess.run(ta), 5) + tl = py_builtins.len_(data_structures.tf_tensor_list_new([3, 4, 5])) + self.assertEqual(sess.run(tl), 3) + + def test_len_scalar(self): + with self.assertRaises(ValueError): + py_builtins.len_(constant_op.constant(1)) + + def test_len_dynamic_shape(self): + with self.test_session() as sess: + p = array_ops.placeholder(dtype=dtypes.int32, shape=None) + t = py_builtins.len_(p) + self.assertEqual(sess.run(t, {p: [1, 2, 3]}), 3) + + with self.assertRaises(errors_impl.InvalidArgumentError): + t = py_builtins.len_(p) + sess.run(t, {p: 1}) + + def test_print_tensors(self): + try: + out_capturer = six.StringIO() + sys.stdout = out_capturer + with self.test_session() as sess: + sess.run(py_builtins.print_(constant_op.constant('test message'), 1)) + self.assertEqual(out_capturer.getvalue(), 'test message 1\n') + finally: + sys.stdout = sys.__stdout__ + + def test_print_complex(self): + try: + out_capturer = six.StringIO() + sys.stdout = out_capturer + with self.test_session() as sess: + sess.run( + py_builtins.print_(constant_op.constant('test message'), [1, 2])) + self.assertEqual(out_capturer.getvalue(), 'test message [1, 2]\n') + finally: + sys.stdout = sys.__stdout__ + + def test_range(self): + self.assertListEqual(list(py_builtins.range_(3)), [0, 1, 2]) + self.assertListEqual(list(py_builtins.range_(1, 3)), [1, 2]) + self.assertListEqual(list(py_builtins.range_(2, 0, -1)), [2, 1]) + + def test_range_tensor(self): + with self.test_session() as sess: + r = py_builtins.range_(constant_op.constant(3)) + self.assertAllEqual(sess.run(r), [0, 1, 2]) + r = py_builtins.range_(1, constant_op.constant(3)) + self.assertAllEqual(sess.run(r), [1, 2]) + r = py_builtins.range_(2, 0, constant_op.constant(-1)) + self.assertAllEqual(sess.run(r), [2, 1]) + + +if __name__ == '__main__': + test.main() diff --git a/tensorflow/contrib/autograph/utils/BUILD b/tensorflow/contrib/autograph/utils/BUILD index d2b399f19b..4504a5c7a3 100644 --- a/tensorflow/contrib/autograph/utils/BUILD +++ b/tensorflow/contrib/autograph/utils/BUILD @@ -20,12 +20,12 @@ py_library( name = "utils", srcs = [ "__init__.py", - "builtins.py", "context_managers.py", "misc.py", "multiple_dispatch.py", "py_func.py", "tensor_list.py", + "tensors.py", "testing.py", "type_check.py", ], @@ -42,17 +42,6 @@ py_library( ) py_test( - name = "builtins_test", - srcs = ["builtins_test.py"], - srcs_version = "PY2AND3", - tags = ["no_windows"], - deps = [ - ":utils", - "//tensorflow/python:client_testlib", - ], -) - -py_test( name = "context_managers_test", srcs = ["context_managers_test.py"], srcs_version = "PY2AND3", @@ -113,3 +102,13 @@ py_test( "//tensorflow/python:list_ops", ], ) + +py_test( + name = "tensors_test", + srcs = ["tensors_test.py"], + srcs_version = "PY2AND3", + deps = [ + ":utils", + "//tensorflow/python:client_testlib", + ], +) diff --git a/tensorflow/contrib/autograph/utils/__init__.py b/tensorflow/contrib/autograph/utils/__init__.py index 57b5f74741..38e0a0a8f0 100644 --- a/tensorflow/contrib/autograph/utils/__init__.py +++ b/tensorflow/contrib/autograph/utils/__init__.py @@ -18,9 +18,6 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function -from tensorflow.contrib.autograph.utils.builtins import dynamic_builtin -from tensorflow.contrib.autograph.utils.builtins import dynamic_print -from tensorflow.contrib.autograph.utils.builtins import dynamic_range from tensorflow.contrib.autograph.utils.context_managers import control_dependency_on_returns from tensorflow.contrib.autograph.utils.misc import alias_tensors from tensorflow.contrib.autograph.utils.multiple_dispatch import dynamic_is diff --git a/tensorflow/contrib/autograph/utils/builtins.py b/tensorflow/contrib/autograph/utils/builtins.py deleted file mode 100644 index 4dd440ef19..0000000000 --- a/tensorflow/contrib/autograph/utils/builtins.py +++ /dev/null @@ -1,143 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Builtin conversion utilities.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import sys - -import six - -from tensorflow.contrib.autograph.utils import py_func -from tensorflow.contrib.autograph.utils import type_check -from tensorflow.python.framework import dtypes -from tensorflow.python.framework import tensor_util -from tensorflow.python.ops import array_ops -from tensorflow.python.ops import list_ops -from tensorflow.python.ops import logging_ops -from tensorflow.python.ops import math_ops - - -def dynamic_builtin(f, *args, **kwargs): - """Converts a builtin function call inline.""" - if f is len: - return dynamic_len(*args, **kwargs) - if six.PY2 and f is xrange: - return dynamic_range(*args, **kwargs) - if f is range: - return dynamic_range(*args, **kwargs) - if f is int: - return dynamic_int(*args, **kwargs) - if f is float: - return dynamic_float(*args, **kwargs) - if f is abs: - return dynamic_abs(*args, **kwargs) - - raise NotImplementedError( - 'The "%s" builtin is not yet supported.' % f.__name__) - - -def dynamic_len(list_or_tensor): - """Implementation of len using dynamic dispatch.""" - if _is_tensor_list(list_or_tensor): - return list_ops.tensor_list_length(list_or_tensor) - elif tensor_util.is_tensor(list_or_tensor): - shape = list_or_tensor.shape - if not shape.ndims: - raise ValueError( - 'len requires non-zero rank for tensor "%s"' % list_or_tensor) - return array_ops.shape(list_or_tensor)[0] - return len(list_or_tensor) - - -def _is_tensor_list(list_or_tensor): - return (tensor_util.is_tensor(list_or_tensor) - and list_or_tensor.dtype == dtypes.variant) - - -def dynamic_int(num_or_tensor, **kwargs): - """Implementation of int() using dynamic dispatch.""" - if tensor_util.is_tensor(num_or_tensor): - return math_ops.cast(num_or_tensor, dtype=dtypes.int32, **kwargs) - return int(num_or_tensor) - - -def dynamic_float(num_or_tensor, **kwargs): - """Implementation of float() using dynamic dispatch.""" - if tensor_util.is_tensor(num_or_tensor): - return math_ops.cast(num_or_tensor, dtype=dtypes.float32, **kwargs) - return float(num_or_tensor) - - -def dynamic_abs(num_or_tensor, **kwargs): - if tensor_util.is_tensor(num_or_tensor): - return math_ops.abs(num_or_tensor, **kwargs) - else: - return abs(num_or_tensor, **kwargs) - - -def dynamic_range(start_or_stop, stop=None, step=None): - """Implementation of range using dynamic dispatch.""" - if type_check.is_tensor(start_or_stop, stop, step): - if step is not None: - return math_ops.range(start_or_stop, stop, step) - if stop is not None: - return math_ops.range(start_or_stop, stop) - return math_ops.range(start_or_stop) - - if step is not None: - return range(start_or_stop, stop, step) - elif stop is not None: - return range(start_or_stop, stop) - return range(start_or_stop) - - -def is_tf_print_compatible(value): - # TODO(mdan): Enable once we can reliably test this. - # This is currently disabled because we can't capture the output of - # op kernels from Python. - del value - return False - - -def dynamic_print(*values): - """Implementation of print using dynamic dispatch. - - The function attempts to use tf.Print if all the values are compatible. - Otherwise, it will fall back to py_func. - - Args: - *values: values to print - Returns: - A dummy value indicating the print completed. If tf. - """ - - if all(map(is_tf_print_compatible, values)): - return logging_ops.Print(1, values) - - def print_wrapper(*vals): - if six.PY3: - # TensorFlow doesn't seem to generate Unicode when passing strings to - # py_func. This causes the print to add a "b'" wrapper to the output, - # which is probably never what you want. - vals = tuple(v.decode() if isinstance(v, bytes) else v for v in vals) - print(*vals) - # The flush helps avoid garbled output in IPython. - sys.stdout.flush() - - return py_func.wrap_py_func( - print_wrapper, None, values, use_dummy_return=True) diff --git a/tensorflow/contrib/autograph/utils/builtins_test.py b/tensorflow/contrib/autograph/utils/builtins_test.py deleted file mode 100644 index b1cd5253bc..0000000000 --- a/tensorflow/contrib/autograph/utils/builtins_test.py +++ /dev/null @@ -1,145 +0,0 @@ -# Copyright 2017 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Tests for builtins module.""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import sys - -import six - -from tensorflow.contrib.autograph.utils import builtins -from tensorflow.python.framework import constant_op -from tensorflow.python.framework import dtypes -from tensorflow.python.platform import test - - -class BuiltinsTest(test.TestCase): - - def test_dynamic_len_tf_scalar(self): - a = constant_op.constant(1) - - with self.assertRaisesRegexp(ValueError, - 'len requires non-zero rank for tensor.*'): - with self.test_session() as sess: - sess.run(builtins.dynamic_builtin(len, a)) - - def test_dynamic_len_tf_array(self): - a = constant_op.constant([1, 2, 3]) - - with self.test_session() as sess: - self.assertEqual(3, sess.run(builtins.dynamic_builtin(len, a))) - - def test_dynamic_abs_tf_scalar(self): - a = constant_op.constant(-1) - - with self.test_session() as sess: - self.assertEqual(1, sess.run(builtins.dynamic_builtin(abs, a))) - - def test_dynamic_abs_tf_array(self): - a = constant_op.constant([-1, 2, -3]) - - with self.test_session() as sess: - self.assertListEqual([1, 2, 3], - list(sess.run(builtins.dynamic_builtin(abs, a)))) - - def test_dynamic_abs_py_scalar(self): - a = -1 - self.assertEqual(1, builtins.dynamic_builtin(abs, a)) - - def test_dynamic_len_tf_matrix(self): - a = constant_op.constant([[1, 2], [3, 4]]) - - with self.test_session() as sess: - self.assertEqual(2, sess.run(builtins.dynamic_builtin(len, a))) - - def test_dynamic_len_py_list(self): - a = [3] * 5 - - self.assertEqual(5, builtins.dynamic_builtin(len, a)) - - def test_dynamic_range_all_python(self): - self.assertListEqual(list(builtins.dynamic_builtin(range, 3)), [0, 1, 2]) - self.assertListEqual(list(builtins.dynamic_builtin(range, 1, 3)), [1, 2]) - self.assertListEqual( - list(builtins.dynamic_builtin(range, 2, 0, -1)), [2, 1]) - - def test_dynamic_range_tf(self): - with self.test_session() as sess: - self.assertAllEqual( - sess.run(builtins.dynamic_builtin(range, constant_op.constant(3))), - [0, 1, 2]) - self.assertAllEqual( - sess.run(builtins.dynamic_builtin(range, 1, constant_op.constant(3))), - [1, 2]) - self.assertAllEqual( - sess.run( - builtins.dynamic_builtin(range, 2, 0, constant_op.constant(-1))), - [2, 1]) - - def test_dynamic_range_detection(self): - def range(x): # pylint:disable=redefined-builtin - return x - - # Functions that just have the names of builtins are rejected. - with self.assertRaises(NotImplementedError): - self.assertEqual(builtins.dynamic_builtin(range, 1), 1) - if six.PY2: - self.assertListEqual( - list(builtins.dynamic_builtin(xrange, 3)), [0, 1, 2]) - self.assertListEqual( - list(builtins.dynamic_builtin(six.moves.range, 3)), [0, 1, 2]) - self.assertListEqual( - list(builtins.dynamic_builtin(six.moves.xrange, 3)), [0, 1, 2]) - - def test_casts(self): - i = constant_op.constant(2, dtype=dtypes.int32) - f = constant_op.constant(1.0, dtype=dtypes.float32) - - self.assertEqual(builtins.dynamic_builtin(int, i).dtype, dtypes.int32) - self.assertEqual(builtins.dynamic_builtin(int, f).dtype, dtypes.int32) - self.assertEqual(builtins.dynamic_builtin(float, i).dtype, dtypes.float32) - self.assertEqual(builtins.dynamic_builtin(float, f).dtype, dtypes.float32) - - self.assertEqual(builtins.dynamic_builtin(int, True), 1) - self.assertEqual(builtins.dynamic_builtin(int, False), 0) - self.assertEqual(builtins.dynamic_builtin(float, True), 1.0) - self.assertEqual(builtins.dynamic_builtin(float, False), 0.0) - - def test_dynamic_print_tf(self): - try: - out_capturer = six.StringIO() - sys.stdout = out_capturer - with self.test_session() as sess: - sess.run(builtins.dynamic_print('test message', 1)) - self.assertEqual(out_capturer.getvalue(), 'test message 1\n') - finally: - sys.stdout = sys.__stdout__ - - def test_dynamic_print_complex(self): - try: - out_capturer = six.StringIO() - sys.stdout = out_capturer - with self.test_session() as sess: - sess.run(builtins.dynamic_print('test message', [1, 2])) - self.assertEqual(out_capturer.getvalue(), 'test message [1, 2]\n') - finally: - sys.stdout = sys.__stdout__ - - -if __name__ == '__main__': - test.main() diff --git a/tensorflow/contrib/autograph/utils/tensors.py b/tensorflow/contrib/autograph/utils/tensors.py new file mode 100644 index 0000000000..fa5db81a71 --- /dev/null +++ b/tensorflow/contrib/autograph/utils/tensors.py @@ -0,0 +1,41 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""This module defines tensor utilities not found in TensorFlow. + +The reason these utilities are not defined in TensorFlow is because they may +not be not fully robust, although they work in the vast majority of cases. So +we define them here in order for their behavior to be consistently verified. +""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +from tensorflow.python.framework import dtypes +from tensorflow.python.framework import tensor_util +from tensorflow.python.ops import tensor_array_ops + + +def is_tensor_array(t): + return isinstance(t, tensor_array_ops.TensorArray) + + +def is_tensor_list(t): + # TODO(mdan): This is just a heuristic. + # With TF lacking support for templated types, this is unfortunately the + # closest we can get right now. A dedicated op ought to be possible to + # construct. + return (tensor_util.is_tensor(t) and t.dtype == dtypes.variant and + not t.shape.ndims) diff --git a/tensorflow/contrib/autograph/utils/tensors_test.py b/tensorflow/contrib/autograph/utils/tensors_test.py new file mode 100644 index 0000000000..e855e0b6cb --- /dev/null +++ b/tensorflow/contrib/autograph/utils/tensors_test.py @@ -0,0 +1,57 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for tensors module.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +from tensorflow.contrib.autograph.utils import tensors +from tensorflow.python.framework import constant_op +from tensorflow.python.framework import dtypes +from tensorflow.python.ops import list_ops +from tensorflow.python.ops import tensor_array_ops +from tensorflow.python.platform import test + + +class TensorsTest(test.TestCase): + + def _simple_tensor_array(self): + return tensor_array_ops.TensorArray(dtypes.int32, size=3) + + def _simple_tensor_list(self): + return list_ops.empty_tensor_list( + element_shape=constant_op.constant([1]), element_dtype=dtypes.int32) + + def _simple_list_of_tensors(self): + return [constant_op.constant(1), constant_op.constant(2)] + + def test_is_tensor_array(self): + self.assertTrue(tensors.is_tensor_array(self._simple_tensor_array())) + self.assertFalse(tensors.is_tensor_array(self._simple_tensor_list())) + self.assertFalse(tensors.is_tensor_array(constant_op.constant(1))) + self.assertFalse(tensors.is_tensor_array(self._simple_list_of_tensors())) + self.assertFalse(tensors.is_tensor_array(None)) + + def test_is_tensor_list(self): + self.assertFalse(tensors.is_tensor_list(self._simple_tensor_array())) + self.assertTrue(tensors.is_tensor_list(self._simple_tensor_list())) + self.assertFalse(tensors.is_tensor_list(constant_op.constant(1))) + self.assertFalse(tensors.is_tensor_list(self._simple_list_of_tensors())) + self.assertFalse(tensors.is_tensor_list(None)) + + +if __name__ == '__main__': + test.main() diff --git a/tensorflow/contrib/boosted_trees/lib/learner/batch/categorical_split_handler.py b/tensorflow/contrib/boosted_trees/lib/learner/batch/categorical_split_handler.py index e6407174b1..35d727482b 100644 --- a/tensorflow/contrib/boosted_trees/lib/learner/batch/categorical_split_handler.py +++ b/tensorflow/contrib/boosted_trees/lib/learner/batch/categorical_split_handler.py @@ -141,11 +141,18 @@ class EqualitySplitHandler(base_split_handler.BaseSplitHandler): # The bias is computed on gradients and hessians (and not # filtered_gradients) which have exactly one value per example, so we # don't double count a gradient in multivalent columns. + # Since unsorted_segment_sum can be numerically unstable, use 64bit + # operation. + gradients64 = math_ops.cast(gradients, dtypes.float64) + hessians64 = math_ops.cast(hessians, dtypes.float64) per_partition_gradients = math_ops.unsorted_segment_sum( - gradients, mapped_partitions, array_ops.size(unique_partitions)) + gradients64, mapped_partitions, array_ops.size(unique_partitions)) per_partition_hessians = math_ops.unsorted_segment_sum( - hessians, mapped_partitions, array_ops.size(unique_partitions)) - + hessians64, mapped_partitions, array_ops.size(unique_partitions)) + per_partition_gradients = math_ops.cast(per_partition_gradients, + dtypes.float32) + per_partition_hessians = math_ops.cast(per_partition_hessians, + dtypes.float32) # Prepend a bias feature per partition that accumulates the stats for all # examples in that partition. # Bias is added to the stats even if there are no examples with values in diff --git a/tensorflow/contrib/data/python/kernel_tests/BUILD b/tensorflow/contrib/data/python/kernel_tests/BUILD index b86a543fc3..34f594f741 100644 --- a/tensorflow/contrib/data/python/kernel_tests/BUILD +++ b/tensorflow/contrib/data/python/kernel_tests/BUILD @@ -293,6 +293,7 @@ py_test( "//tensorflow/python:client_testlib", "//tensorflow/python:errors", "//tensorflow/python/data/ops:dataset_ops", + "//third_party/py/numpy", "@absl_py//absl/testing:parameterized", ], ) diff --git a/tensorflow/contrib/data/python/kernel_tests/optimize_dataset_op_test.py b/tensorflow/contrib/data/python/kernel_tests/optimize_dataset_op_test.py index 446bf8d749..089717156c 100644 --- a/tensorflow/contrib/data/python/kernel_tests/optimize_dataset_op_test.py +++ b/tensorflow/contrib/data/python/kernel_tests/optimize_dataset_op_test.py @@ -18,10 +18,13 @@ from __future__ import division from __future__ import print_function from absl.testing import parameterized +import numpy as np from tensorflow.contrib.data.python.ops import optimization from tensorflow.python.data.ops import dataset_ops +from tensorflow.python.framework import dtypes from tensorflow.python.framework import errors +from tensorflow.python.ops import array_ops from tensorflow.python.ops import random_ops from tensorflow.python.platform import test @@ -62,7 +65,7 @@ class OptimizeDatasetTest(test.TestCase, parameterized.TestCase): "Asserted next 2 transformations but encountered only 1."): sess.run(get_next) - def testDefaultOptimizations(self): + def testOptimizationDefault(self): dataset = dataset_ops.Dataset.range(10).apply( optimization.assert_next( ["Map", "Batch"])).map(lambda x: x * x).batch(10).apply( @@ -75,7 +78,7 @@ class OptimizeDatasetTest(test.TestCase, parameterized.TestCase): with self.assertRaises(errors.OutOfRangeError): sess.run(get_next) - def testEmptyOptimizations(self): + def testOptimizationEmpty(self): dataset = dataset_ops.Dataset.range(10).apply( optimization.assert_next( ["Map", "Batch"])).map(lambda x: x * x).batch(10).apply( @@ -88,7 +91,7 @@ class OptimizeDatasetTest(test.TestCase, parameterized.TestCase): with self.assertRaises(errors.OutOfRangeError): sess.run(get_next) - def testOptimization(self): + def testOptimizationFusion(self): dataset = dataset_ops.Dataset.range(10).apply( optimization.assert_next( ["MapAndBatch"])).map(lambda x: x * x).batch(10).apply( @@ -101,11 +104,9 @@ class OptimizeDatasetTest(test.TestCase, parameterized.TestCase): with self.assertRaises(errors.OutOfRangeError): sess.run(get_next) - def testStatefulFunctionOptimization(self): - dataset = dataset_ops.Dataset.range(10).apply( - optimization.assert_next([ - "MapAndBatch" - ])).map(lambda _: random_ops.random_uniform([])).batch(10).apply( + def testOptimizationStatefulFunction(self): + dataset = dataset_ops.Dataset.range(10).map( + lambda _: random_ops.random_uniform([])).batch(10).apply( optimization.optimize(["map_and_batch_fusion"])) iterator = dataset.make_one_shot_iterator() get_next = iterator.get_next() @@ -113,6 +114,30 @@ class OptimizeDatasetTest(test.TestCase, parameterized.TestCase): with self.test_session() as sess: sess.run(get_next) + def testOptimizationLargeInputFromTensor(self): + input_t = array_ops.placeholder(dtypes.int32, (None, None, None)) + dataset = dataset_ops.Dataset.from_tensors(input_t).apply( + optimization.optimize()) + iterator = dataset.make_initializable_iterator() + init_op = iterator.initializer + get_next = iterator.get_next() + + with self.test_session() as sess: + sess.run(init_op, {input_t: np.ones([512, 1024, 1025], np.int32)}) + sess.run(get_next) + + def testOptimizationLargeInputFromTensorSlices(self): + input_t = array_ops.placeholder(dtypes.int32, (None, None, None, None)) + dataset = dataset_ops.Dataset.from_tensor_slices(input_t).apply( + optimization.optimize()) + iterator = dataset.make_initializable_iterator() + init_op = iterator.initializer + get_next = iterator.get_next() + + with self.test_session() as sess: + sess.run(init_op, {input_t: np.ones([1, 512, 1024, 1025], np.int32)}) + sess.run(get_next) + if __name__ == "__main__": test.main() diff --git a/tensorflow/contrib/data/python/ops/interleave_ops.py b/tensorflow/contrib/data/python/ops/interleave_ops.py index 38c0a09c33..92d4251a86 100644 --- a/tensorflow/contrib/data/python/ops/interleave_ops.py +++ b/tensorflow/contrib/data/python/ops/interleave_ops.py @@ -220,6 +220,7 @@ def sample_from_datasets(datasets, weights=None, seed=None): if weights is None: # Select inputs with uniform probability. logits = [[1.0] * num_datasets] + else: # Use the given `weights` as the probability of choosing the respective # input. @@ -245,8 +246,11 @@ def sample_from_datasets(datasets, weights=None, seed=None): return array_ops.squeeze( stateless.stateless_multinomial(logits, 1, seed=seed), axis=[0, 1]) - selector_input = random_ops.RandomDataset(seed).batch(2).map( - select_dataset_constant_logits) + selector_input = dataset_ops.MapDataset( + random_ops.RandomDataset(seed).batch(2), + select_dataset_constant_logits, + use_inter_op_parallelism=False) + else: # Use each element of the given `weights` dataset as the probability of # choosing the respective input. @@ -259,9 +263,12 @@ def sample_from_datasets(datasets, weights=None, seed=None): return array_ops.squeeze( stateless.stateless_multinomial(logits, 1, seed=seed), axis=[0, 1]) - selector_input = dataset_ops.Dataset.zip( - (logits_ds, random_ops.RandomDataset(seed).batch(2) - )).map(select_dataset_varying_logits) + logits_and_seeds = dataset_ops.Dataset.zip( + (logits_ds, random_ops.RandomDataset(seed).batch(2))) + selector_input = dataset_ops.MapDataset( + logits_and_seeds, + select_dataset_varying_logits, + use_inter_op_parallelism=False) return _DirectedInterleaveDataset(selector_input, datasets) diff --git a/tensorflow/contrib/data/python/ops/readers.py b/tensorflow/contrib/data/python/ops/readers.py index 7f09ba71dc..4c466781f7 100644 --- a/tensorflow/contrib/data/python/ops/readers.py +++ b/tensorflow/contrib/data/python/ops/readers.py @@ -499,7 +499,8 @@ def make_csv_dataset( # indefinitely, and all batches will be full-sized. dataset = dataset.batch(batch_size=batch_size, drop_remainder=num_epochs is None) - dataset = dataset.map(map_fn) + dataset = dataset_ops.MapDataset( + dataset, map_fn, use_inter_op_parallelism=False) dataset = dataset.prefetch(prefetch_buffer_size) return dataset @@ -778,7 +779,8 @@ def make_batched_features_dataset(file_pattern, # Extract values if the `Example` tensors are stored as key-value tuples. if dataset.output_types == (dtypes.string, dtypes.string): - dataset = dataset.map(lambda _, v: v) + dataset = dataset_ops.MapDataset( + dataset, lambda _, v: v, use_inter_op_parallelism=False) # Apply dataset repeat and shuffle transformations. dataset = _maybe_shuffle_and_repeat( diff --git a/tensorflow/contrib/distribute/BUILD b/tensorflow/contrib/distribute/BUILD index 02feeafb60..a87a5624c8 100644 --- a/tensorflow/contrib/distribute/BUILD +++ b/tensorflow/contrib/distribute/BUILD @@ -36,5 +36,6 @@ py_library( "//tensorflow/python:training", "//tensorflow/python:util", "//tensorflow/python/distribute:distribute_config", + "//tensorflow/python/distribute:distribute_coordinator", ], ) diff --git a/tensorflow/contrib/distribute/README.md b/tensorflow/contrib/distribute/README.md index ba92ea0b12..30e1992c01 100644 --- a/tensorflow/contrib/distribute/README.md +++ b/tensorflow/contrib/distribute/README.md @@ -12,26 +12,108 @@ models and training code with minimal changes to enable distributed training. Moreover, we've designed the API in such a way that it works with both eager and graph execution. -Currently we support one type of strategy, called -[`MirroredStrategy`](https://www.tensorflow.org/versions/master/api_docs/python/tf/contrib/distribute/MirroredStrategy). -It does in-graph replication with synchronous training +Currently we support several types of strategies: + +* [`MirroredStrategy`](https://www.tensorflow.org/versions/master/api_docs/python/tf/contrib/distribute/MirroredStrategy): +This does in-graph replication with synchronous training on many GPUs on one machine. Essentially, we create copies of all variables in the model's layers on each device. We then use all-reduce to combine gradients across the devices before applying them to the variables to keep them in sync. -In the future, we intend to support other kinds of training configurations such -as multi-node, synchronous, -[asynchronous](https://www.tensorflow.org/deploy/distributed#putting_it_all_together_example_trainer_program), -parameter servers and model parallelism. +* [`CollectiveAllReduceStrategy`](https://www.tensorflow.org/versions/master/api_docs/python/tf/contrib/distribute/CollectiveAllReduceStrategy): +This is a version of `MirroredStrategy` for multi-working training. It uses +a collective op to do all-reduce. This supports between-graph communication and +synchronization, and delegates the specifics of the all-reduce implementation to +the runtime (as opposed to encoding it in the graph). This allows it to perform +optimizations like batching and switch between plugins that support different +hardware or algorithms. In the future, this strategy will implement +fault-tolerance to allow training to continue when there is worker failure. + +* [`ParameterServerStrategy`](https://www.tensorflow.org/versions/master/api_docs/python/tf/contrib/distribute/ParameterServerStrategy): +This strategy supports using parameter servers either for multi-GPU local +training or asynchronous multi-machine training. When used to train locally, +variables are not mirrored, instead they placed on the CPU and operations are +replicated across all local GPUs. In a multi-machine setting, some are +designated as workers and some as parameter servers. Each variable is placed on +one parameter server. Computation operations are replicated across all GPUs of +the workers. + +## Multi-GPU Training + +## Example with Keras API + +Let's see how to scale to multiple GPUs on one machine using `MirroredStrategy` with [tf.keras] (https://www.tensorflow.org/guide/keras). + +Take a very simple model consisting of a single layer: + +```python +inputs = tf.keras.layers.Input(shape=(1,)) +predictions = tf.keras.layers.Dense(1)(inputs) +model = tf.keras.models.Model(inputs=inputs, outputs=predictions) +``` -## Example +Let's also define a simple input dataset for training this model. Note that currently we require using +[`tf.data.Dataset`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset) +with `DistributionStrategy`. + +```python +features = tf.data.Dataset.from_tensors([1.]).repeat(10000).batch(10) +labels = tf.data.Dataset.from_tensors([1.]).repeat(10000).batch(10) +train_dataset = tf.data.Dataset.zip((features, labels)) +``` -Let's demonstrate how to use this API with a simple example. We will use the -[`Estimator`](https://www.tensorflow.org/api_docs/python/tf/estimator/Estimator) -approach, and show you how to scale your model to run on multiple GPUs on one -machine using `MirroredStrategy`. -Let's consider a very simple model function which tries to learn a simple -function. +To distribute this Keras model on multiple GPUs using `MirroredStrategy` we +first instantiate a `MirroredStrategy` object. + +```python +distribution = tf.contrib.distribute.MirroredStrategy() +``` + +We then compile the Keras model and pass the `MirroredStrategy` object in the +`distribute` argument (apart from other usual arguments like `loss` and +`optimizer`). + +```python +model.compile(loss='mean_squared_error', + optimizer=tf.train.GradientDescentOptimizer(learning_rate=0.2), + distribute=strategy) +``` + +To train the model we call Keras `fit` API using the input dataset that we +created earlier, same as how we would in a non-distributed case. + +```python +model.fit(train_dataset, epochs=5, steps_per_epoch=10) +``` + +Similarly, we can also call `evaluate` and `predict` as before using appropriate +datasets. + +```python +model.evaluate(eval_dataset) +model.predict(predict_dataset) +``` + +That's all you need to train your model with Keras on multiple GPUs with +`MirroredStrategy`. It will take care of splitting up +the input dataset, replicating layers and variables on each device, and +combining and applying gradients. + +The model and input code does not have to change because we have changed the +underlying components of TensorFlow (such as +optimizer, batch norm and summaries) to become distribution-aware. +That means those components know how to +combine their state across devices. Further, saving and checkpointing works +seamlessly, so you can save with one or no distribution strategy and resume with +another. + + +## Example with Estimator API + +You can also use Distribution Strategy API with [`Estimator`](https://www.tensorflow.org/api_docs/python/tf/estimator/Estimator). Let's see a simple example of it's usage with `MirroredStrategy`. + + +Consider a very simple model function which tries to learn a simple function. ```python def model_fn(features, labels, mode): @@ -53,17 +135,14 @@ def model_fn(features, labels, mode): return tf.estimator.EstimatorSpec(mode, loss=loss, train_op=train_op) ``` -Let's also define a simple input function to feed data for training this model. -Note that we require using -[`tf.data.Dataset`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset) -with `DistributionStrategy`. +Again, let's define a simple input function to feed data for training this model. ```python def input_fn(): features = tf.data.Dataset.from_tensors([[1.]]).repeat(100) labels = tf.data.Dataset.from_tensors(1.).repeat(100) - return dataset_ops.Dataset.zip((features, labels)) + return tf.data.Dataset.zip((features, labels)) ``` Now that we have a model function and input function defined, we can define the @@ -80,20 +159,14 @@ distribution = tf.contrib.distribute.MirroredStrategy() config = tf.estimator.RunConfig(train_distribute=distribution) classifier = tf.estimator.Estimator(model_fn=model_fn, config=config) classifier.train(input_fn=input_fn) +classifier.evaluate(input_fn=input_fn) ``` That's it! This change will now configure estimator to run on all GPUs on your -machine, with the `MirroredStrategy` approach. It will take care of distributing -the input dataset, replicating layers and variables on each device, and -combining and applying gradients. +machine. -The model and input functions do not have to change because we have changed the -underlying components of TensorFlow (such as -optimizer, batch norm and summaries) to become distribution-aware. -That means those components know how to -combine their state across devices. Further, saving and checkpointing works -seamlessly, so you can save with one or no distribution strategy and resume with -another. + +## Customization and Performance Tips Above, we showed the easiest way to use [`MirroredStrategy`](https://www.tensorflow.org/versions/master/api_docs/python/tf/contrib/distribute/MirroredStrategy#__init__). There are few things you can customize in practice: @@ -103,8 +176,6 @@ of GPUs (using param `num_gpus`), in case you don't want auto detection. * You can specify various parameters for all reduce with the `cross_tower_ops` param, such as the all reduce algorithm to use, and gradient repacking. -## Performance Tips - We've tried to make it such that you get the best performance for your existing model. We also recommend you follow the tips from [Input Pipeline Performance Guide](https://www.tensorflow.org/performance/datasets_performance). @@ -113,15 +184,177 @@ and [`dataset.prefetch`](https://www.tensorflow.org/performance/datasets_perform in the input function gives a solid boost in performance. When using `dataset.prefetch`, use `buffer_size=None` to let it detect optimal buffer size. +## Multi-worker Training +### Overview + +For multi-worker training, no code change is required to the `Estimator` code. +You can run the same model code for all tasks in your cluster including +parameter servers and the evaluator. But you need to use +`tf.estimator.train_and_evaluator`, explicitly specify `num_gpus_per_workers` +for your strategy object, and set "TF\_CONFIG" environment variables for each +binary running in your cluster. We'll provide a Kubernetes template in the +[tensorflow/ecosystem](https://github.com/tensorflow/ecosystem) repo which sets +"TF\_CONFIG" for your training tasks. + +### TF\_CONFIG environment variable + +The "TF\_CONFIG" environment variables is a JSON string which specifies what +tasks constitute a cluster, their addresses and each task's role in the cluster. +One example of "TF\_CONFIG" is: + +```python +TF_CONFIG='{ + "cluster": { + "worker": ["host1:port", "host2:port", "host3:port"], + "ps": ["host4:port", "host5:port"] + }, + "task": {"type": "worker", "index": 1} +}' +``` + +This "TF\_CONFIG" specifies that there are three workers and two ps tasks in the +cluster along with their hosts and ports. The "task" part specifies that the +role of the current task in the cluster, worker 1. Valid roles in a cluster is +"chief", "worker", "ps" and "evaluator". There should be no "ps" job for +`CollectiveAllReduceStrategy` and `MirroredStrategy`. The "evaluator" job is +optional and can have at most one task. It does single machine evaluation and if +you don't want to do evaluation, you can pass in a dummy `input_fn` to the +`tf.estimator.EvalSpec` of `tf.estimator.train_and_evaluate`. + +### Dataset + +The `input_fn` you provide to estimator code is for one worker. So remember to +scale up your batch if you have multiple GPUs on each worker. + +The same `input_fn` will be used for all workers if you use +`CollectiveAllReduceStrategy` and `ParameterServerStrategy`. Therefore it is +important to shuffle your dataset in your `input_fn`. + +`MirroredStrategy` will insert a `tf.dataset.Dataset.shard` call in you +`input_fn`. As a result, each worker gets a fraction of your input data. + +### Performance Tips + +We have been actively working on multi-worker performance. Currently, prefer +`CollectiveAllReduceStrategy` for synchronous multi-worker training. + +### Example + +Let's use the same example for multi-worker. We'll start a cluster with 3 +workers doing synchronous all-reduce training. In the following code snippet, we +start multi-worker training using `tf.estimator.train_and_evaluate`: + + +```python +def model_main(): + estimator = ... + distribution = tf.contrib.distribute.CollectiveAllReduceStrategy( + num_gpus_per_worker=2) + config = tf.estimator.RunConfig(train_distribute=distribution) + train_spec = tf.estimator.TrainSpec(input_fn=input_fn) + eval_spec = tf.estimator.EvalSpec(input_fn=eval_input_fn) + tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec) +``` + + +**Note**: You don't have to set "TF\_CONFIG" manually if you use our provided +Kubernetes template. + +You'll then need 3 machines, find out their host addresses and one available +port on each machine. Then set "TF\_CONFIG" in each binary and run the above +model code. + +In your worker 0, run: + +```python +os.environ["TF_CONFIG"] = json.dumps({ + "cluster": { + "worker": ["host1:port", "host2:port", "host3:port"] + }, + "task": {"type": "worker", "index": 0} +}) + +# Call the model_main function defined above. +model_main() +``` + +In your worker 1, run: + +```python +os.environ["TF_CONFIG"] = json.dumps({ + "cluster": { + "worker": ["host1:port", "host2:port", "host3:port"] + }, + "task": {"type": "worker", "index": 1} +}) + +# Call the model_main function defined above. +model_main() +``` + +In your worker 2, run: + +```python +os.environ["TF_CONFIG"] = json.dumps({ + "cluster": { + "worker": ["host1:port", "host2:port", "host3:port"] + }, + "task": {"type": "worker", "index": 2} +}) + +# Call the model_main function defined above. +model_main() +``` + +Then you'll find your cluster has started training! You can inspect the logs of +workers or start a tensorboard. + +### Standalone client mode + +We have a new way to run distributed training. You can bring up standard +tensorflow servers in your cluster and run your model code anywhere such as on +your laptop. + +In the above example, instead of calling `model_main`, you can call +`tf.contrib.distribute.run_standard_tensorflow_server().join()`. This will bring +up a cluster running standard tensorflow servers which wait for your request to +start training. + +On your laptop, you can run + +```python +estimator = ... +distribution = tf.contrib.distribute.CollectiveAllReduceStrategy( + num_gpus_per_worker=2) +config = tf.estimator.RunConfig( + experimental_distribute=tf.contrib.distribute.DistributeConfig( + train_distribute=distribution, + remote_cluster={"worker": ["host1:port", "host2:port", "host3:port"]})) +train_spec = tf.estimator.TrainSpec(input_fn=input_fn) +eval_spec = tf.estimator.EvalSpec(input_fn=eval_input_fn) +tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec) +``` + +Then you will see the training logs on your laptop. You can terminate the +training by terminating your process on your laptop. You can also modify your +code and run a new model against the same cluster. + +We've been optimizing the performance of standalone client mode. If you notice +high latency between your laptop and your cluster, you can reduce that latency +by running your model binary in the cluster. + ## Caveats + This feature is in early stages and there are a lot of improvements forthcoming: * Summaries are only computed in the first tower in `MirroredStrategy`. -* Evaluation is not yet distributed. * Eager support is in the works; performance can be more challenging with eager execution. -* As mentioned earlier, multi-node and other distributed strategies will be -introduced in the future. +* We currently support the following predefined Keras callbacks: +`ModelCheckpointCallback`, `TensorBoardCallback`. We will soon be adding support for +some of the other callbacks such as `EarlyStopping`, `ReduceLROnPlateau`, etc. If you +create your own callback, you will not have access to all model properties and +validation data. * If you are [`batching`](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#batch) your input data, we will place one batch on each GPU in each step. So your effective batch size will be `num_gpus * batch_size`. Therefore, consider diff --git a/tensorflow/contrib/distribute/__init__.py b/tensorflow/contrib/distribute/__init__.py index bf763215ba..350f81f60f 100644 --- a/tensorflow/contrib/distribute/__init__.py +++ b/tensorflow/contrib/distribute/__init__.py @@ -28,6 +28,7 @@ from tensorflow.contrib.distribute.python.parameter_server_strategy import Param from tensorflow.contrib.distribute.python.step_fn import * from tensorflow.contrib.distribute.python.tpu_strategy import TPUStrategy from tensorflow.python.distribute.distribute_config import DistributeConfig +from tensorflow.python.distribute.distribute_coordinator import run_standard_tensorflow_server from tensorflow.python.training.distribute import * from tensorflow.python.training.distribution_strategy_context import * @@ -56,6 +57,7 @@ _allowed_symbols = [ 'get_tower_context', 'has_distribution_strategy', 'require_tower_context', + 'run_standard_tensorflow_server', 'UpdateContext', ] diff --git a/tensorflow/contrib/distribute/python/collective_all_reduce_strategy.py b/tensorflow/contrib/distribute/python/collective_all_reduce_strategy.py index ea81301bd9..77079d0df9 100644 --- a/tensorflow/contrib/distribute/python/collective_all_reduce_strategy.py +++ b/tensorflow/contrib/distribute/python/collective_all_reduce_strategy.py @@ -50,7 +50,8 @@ class CollectiveAllReduceStrategy(mirrored_strategy.MirroredStrategy): """Initializes the object. Args: - num_gpus_per_worker: number of local GPUs or GPUs per worker. + num_gpus_per_worker: number of local GPUs or GPUs per worker, the default + is 0 meaning CPU only. """ self._num_gpus_per_worker = num_gpus_per_worker self._initialize_local_worker(num_gpus_per_worker) @@ -228,6 +229,8 @@ class CollectiveAllReduceStrategy(mirrored_strategy.MirroredStrategy): if not session_config or not self._cluster_spec: return + session_config.isolate_session_state = True + assert self._task_type assert self._task_id is not None diff --git a/tensorflow/contrib/distribute/python/cross_tower_ops.py b/tensorflow/contrib/distribute/python/cross_tower_ops.py index 2219ab2c15..e08ba9c2a6 100644 --- a/tensorflow/contrib/distribute/python/cross_tower_ops.py +++ b/tensorflow/contrib/distribute/python/cross_tower_ops.py @@ -35,13 +35,13 @@ from tensorflow.python.training import device_util def check_destinations(destinations): - """Checks whether `destinations` is not None and not empty. + """Checks whether `destinations` is not empty. Args: destinations: a DistributedValues, Variable, string or a list of strings. Returns: - Boolean indicating whether `destinations` is not None and not empty. + Boolean which is True if `destinations` is not empty. """ # Calling bool() on a ResourceVariable is not allowed. if isinstance(destinations, resource_variable_ops.ResourceVariable): @@ -56,7 +56,7 @@ def validate_destinations(destinations): value_lib.AggregatingVariable, six.string_types, list)): raise ValueError("destinations must be one of a `DistributedValues` object," " a tf.Variable object, a device string, a list of device " - "strings or None") + "strings") if not check_destinations(destinations): raise ValueError("destinations can not be empty") @@ -131,8 +131,7 @@ def _devices_match(left, right): def _all_devices_match(value_destination_pairs): - if not all([d is None or _devices_match(v, d) - for v, d in value_destination_pairs]): + if not all([_devices_match(v, d) for v, d in value_destination_pairs]): return False if not all([_devices_match(v, value_destination_pairs[0][0]) for v, _ in value_destination_pairs[1:]]): @@ -189,7 +188,7 @@ class CrossTowerOps(object): def __init__(self): pass - def reduce(self, aggregation, per_device_value, destinations=None): + def reduce(self, aggregation, per_device_value, destinations): """Reduce `per_device_value` to `destinations`. It runs the reduction operation defined by `aggregation` and put the @@ -210,8 +209,7 @@ class CrossTowerOps(object): if not isinstance(per_device_value, value_lib.PerDevice): per_device_value = _make_tensor_into_per_device(per_device_value) - if destinations is not None: - validate_destinations(destinations) + validate_destinations(destinations) return self._reduce(aggregation, per_device_value, destinations) def batch_reduce(self, aggregation, value_destination_pairs): @@ -224,9 +222,7 @@ class CrossTowerOps(object): aggregation: Indicates how a variable will be aggregated. Accepted values are `tf.VariableAggregation.SUM`, `tf.VariableAggregation.MEAN`. value_destination_pairs: a list or a tuple of tuples of PerDevice objects - (or tensors with device set if there is one tower) and destinations. If - a destination is None, then the destinations are set to match the - devices of the input PerDevice object. + (or tensors with device set if there is one tower) and destinations. Returns: a list of Mirrored objects. @@ -242,8 +238,7 @@ class CrossTowerOps(object): value_destination_pairs) for _, d in value_destination_pairs: - if d is not None: - validate_destinations(d) + validate_destinations(d) return self._batch_reduce(aggregation, value_destination_pairs) @@ -573,7 +568,7 @@ class AllReduceCrossTowerOps(CrossTowerOps): def _reduce(self, aggregation, per_device_value, destinations): contains_indexed_slices = cross_tower_utils.contains_indexed_slices( per_device_value) - if ((destinations is None or _devices_match(per_device_value, destinations)) + if (_devices_match(per_device_value, destinations) and not context.executing_eagerly() and not contains_indexed_slices): return self._batch_all_reduce(aggregation, [per_device_value])[0] @@ -813,7 +808,7 @@ class CollectiveAllReduce(CrossTowerOps): "Eager execution is not supported for Collective All-Reduce") all_reduced = self._batch_all_reduce(aggregation, [per_device_value])[0] - if destinations is None or _devices_match(per_device_value, destinations): + if _devices_match(per_device_value, destinations): return all_reduced else: index = {} diff --git a/tensorflow/contrib/distribute/python/cross_tower_ops_test.py b/tensorflow/contrib/distribute/python/cross_tower_ops_test.py index 2ad91d56e9..490371477a 100644 --- a/tensorflow/contrib/distribute/python/cross_tower_ops_test.py +++ b/tensorflow/contrib/distribute/python/cross_tower_ops_test.py @@ -135,7 +135,7 @@ class CrossTowerOpsTestBase(test.TestCase, parameterized.TestCase): destination_list = devices all_destinations = [ - None, destination_mirrored, destination_different, destination_str, + destination_mirrored, destination_different, destination_str, destination_list ] @@ -146,24 +146,24 @@ class CrossTowerOpsTestBase(test.TestCase, parameterized.TestCase): vs.VariableAggregation.MEAN, per_device, destinations=destinations), - _fake_mirrored(mean, destinations or per_device)) + _fake_mirrored(mean, destinations)) self._assert_values_equal( cross_tower_ops.reduce( vs.VariableAggregation.MEAN, per_device_2, destinations=destinations), - _fake_mirrored(mean_2, destinations or per_device)) + _fake_mirrored(mean_2, destinations)) self._assert_values_equal( cross_tower_ops.reduce( vs.VariableAggregation.SUM, per_device, destinations=destinations), - _fake_mirrored(mean * len(devices), destinations or per_device)) + _fake_mirrored(mean * len(devices), destinations)) self._assert_values_equal( cross_tower_ops.reduce( vs.VariableAggregation.SUM, per_device_2, destinations=destinations), - _fake_mirrored(mean_2 * len(devices), destinations or per_device)) + _fake_mirrored(mean_2 * len(devices), destinations)) # test batch_reduce() for d1, d2 in itertools.product(all_destinations, all_destinations): @@ -171,25 +171,22 @@ class CrossTowerOpsTestBase(test.TestCase, parameterized.TestCase): cross_tower_ops.batch_reduce(vs.VariableAggregation.MEAN, [(per_device, d1), (per_device_2, d2)]), [ - _fake_mirrored(mean, d1 or per_device), - _fake_mirrored(mean_2, d2 or per_device_2) + _fake_mirrored(mean, d1), + _fake_mirrored(mean_2, d2) ]) self._assert_values_equal( cross_tower_ops.batch_reduce(vs.VariableAggregation.SUM, [(per_device, d1), (per_device_2, d2)]), [ - _fake_mirrored(mean * len(devices), d1 or per_device), - _fake_mirrored(mean_2 * len(devices), d2 or per_device_2) + _fake_mirrored(mean * len(devices), d1), + _fake_mirrored(mean_2 * len(devices), d2) ]) # test broadcast() for destinations in all_destinations: - if destinations is None: - continue - else: - self._assert_values_equal( - cross_tower_ops.broadcast(constant_op.constant(1.), destinations), - _fake_mirrored(1., destinations)) + self._assert_values_equal( + cross_tower_ops.broadcast(constant_op.constant(1.), destinations), + _fake_mirrored(1., destinations)) class SingleWorkerCrossTowerOpsTest(CrossTowerOpsTestBase): @@ -494,7 +491,7 @@ class MultiWorkerCollectiveAllReduceTest( destination_list = devices all_destinations = [ - destination_different, None, destination_mirrored, destination_str, + destination_different, destination_mirrored, destination_str, destination_list ] @@ -505,27 +502,27 @@ class MultiWorkerCollectiveAllReduceTest( vs.VariableAggregation.MEAN, per_device, destinations=destinations), - _fake_mirrored(mean, destinations or per_device), sess) + _fake_mirrored(mean, destinations), sess) self._assert_values_equal( collective_all_reduce.reduce( vs.VariableAggregation.MEAN, per_device_2, destinations=destinations), - _fake_mirrored(mean_2, destinations or per_device), sess) + _fake_mirrored(mean_2, destinations), sess) self._assert_values_equal( collective_all_reduce.reduce( vs.VariableAggregation.SUM, per_device, destinations=destinations), - _fake_mirrored(mean * len(devices) * num_workers, destinations or - per_device), sess) + _fake_mirrored(mean * len(devices) * num_workers, destinations), + sess) self._assert_values_equal( collective_all_reduce.reduce( vs.VariableAggregation.SUM, per_device_2, destinations=destinations), - _fake_mirrored(mean_2 * len(devices) * num_workers, destinations or - per_device), sess) + _fake_mirrored(mean_2 * len(devices) * num_workers, destinations), + sess) # test batch_reduce() for d1, d2 in itertools.product(all_destinations, all_destinations): @@ -534,18 +531,16 @@ class MultiWorkerCollectiveAllReduceTest( [(per_device, d1), (per_device_2, d2)]), [ - _fake_mirrored(mean, d1 or per_device), - _fake_mirrored(mean_2, d2 or per_device_2) + _fake_mirrored(mean, d1), + _fake_mirrored(mean_2, d2) ], sess) self._assert_values_equal( collective_all_reduce.batch_reduce(vs.VariableAggregation.SUM, [(per_device, d1), (per_device_2, d2)]), [ - _fake_mirrored(mean * len(devices) * num_workers, d1 or - per_device), - _fake_mirrored(mean_2 * len(devices) * num_workers, d2 or - per_device_2) + _fake_mirrored(mean * len(devices) * num_workers, d1), + _fake_mirrored(mean_2 * len(devices) * num_workers, d2) ], sess) return True diff --git a/tensorflow/contrib/distribute/python/examples/keras_mnist.py b/tensorflow/contrib/distribute/python/examples/keras_mnist.py index a20069c4fe..0495134636 100644 --- a/tensorflow/contrib/distribute/python/examples/keras_mnist.py +++ b/tensorflow/contrib/distribute/python/examples/keras_mnist.py @@ -58,13 +58,13 @@ def get_input_datasets(): train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train)) train_ds = train_ds.repeat() train_ds = train_ds.shuffle(100) - train_ds = train_ds.batch(64) + train_ds = train_ds.batch(64, drop_remainder=True) # eval dataset eval_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test)) eval_ds = eval_ds.repeat() eval_ds = eval_ds.shuffle(100) - eval_ds = eval_ds.batch(64) + eval_ds = eval_ds.batch(64, drop_remainder=True) return train_ds, eval_ds, input_shape diff --git a/tensorflow/contrib/distribute/python/input_ops.py b/tensorflow/contrib/distribute/python/input_ops.py index 1f24f62947..f07ec8234d 100644 --- a/tensorflow/contrib/distribute/python/input_ops.py +++ b/tensorflow/contrib/distribute/python/input_ops.py @@ -47,11 +47,8 @@ def auto_shard_dataset(dataset, num_shards, index): Returns: A modified `Dataset` obtained by updating the pipeline sharded by the - files. - - Raises: - NotImplementedError: If we cannot automatically determine a good way to - shard the input dataset. + files. The input dataset will be returned if we cannot automatically + determine a good way to shard the input dataset. """ # TODO(priyag): Clone datasets instead of updating in place, similar to the @@ -127,8 +124,10 @@ def auto_shard_dataset(dataset, num_shards, index): tf_logging.warn( "Could not find a standard reader in the input pipeline" "(one of TextLineDataset, TFRecordDataset, FixedLengthRecordDataset)." - "Falling back to sharding the dataset anyway. Please verify" - "correctness of auto-sharding for your input.") + "So auto-sharding is not done. Please verify correctness of " + "auto-sharding for your input.") + # TODO(yuefengz): maybe still shard it? + return dataset # TODO(priyag): What do we want to do if the number of filenames is # uneven in the number of shards? By default, this will just return as diff --git a/tensorflow/contrib/distribute/python/mirrored_strategy.py b/tensorflow/contrib/distribute/python/mirrored_strategy.py index d1235b7afb..0c6805d682 100644 --- a/tensorflow/contrib/distribute/python/mirrored_strategy.py +++ b/tensorflow/contrib/distribute/python/mirrored_strategy.py @@ -572,6 +572,10 @@ class MirroredStrategy(distribute_lib.DistributionStrategy): task_type=None, task_id=None): del task_type, task_id + + if session_config: + session_config.isolate_session_state = True + if cluster_spec: self._initialize_multi_worker(self._num_gpus, cluster_spec) diff --git a/tensorflow/contrib/distribute/python/one_device_strategy.py b/tensorflow/contrib/distribute/python/one_device_strategy.py index 68561b5bbf..23b220f64b 100644 --- a/tensorflow/contrib/distribute/python/one_device_strategy.py +++ b/tensorflow/contrib/distribute/python/one_device_strategy.py @@ -67,6 +67,7 @@ class OneDeviceStrategy(distribute_lib.DistributionStrategy): self._prefetch_on_device) def _broadcast(self, tensor, destinations): + del destinations return tensor # TODO(priyag): Deal with OutOfRange errors once b/111349762 is fixed. @@ -127,6 +128,7 @@ class OneDeviceStrategy(distribute_lib.DistributionStrategy): return values.MapOutput([fn(m, *args, **kwargs) for m in map_over]) def _reduce(self, aggregation, value, destinations): + del destinations if not isinstance(value, values.MapOutput): return value l = value.get() diff --git a/tensorflow/contrib/distribute/python/parameter_server_strategy.py b/tensorflow/contrib/distribute/python/parameter_server_strategy.py index 74a4984f4c..1125d027f6 100644 --- a/tensorflow/contrib/distribute/python/parameter_server_strategy.py +++ b/tensorflow/contrib/distribute/python/parameter_server_strategy.py @@ -83,19 +83,12 @@ class ParameterServerStrategy(distribute_lib.DistributionStrategy): create conflicts of device assignment. """ - def __init__(self, - num_gpus_per_worker=0, - cluster_spec=None, - task_type=None, - task_id=None): + def __init__(self, num_gpus_per_worker=0): """Initializes this strategy. Args: - num_gpus_per_worker: number of local GPUs or GPUs per worker. - cluster_spec: a dict, ClusterDef or ClusterSpec object specifying the - cluster configurations. - task_type: the current task type. - task_id: the current task id. + num_gpus_per_worker: number of local GPUs or GPUs per worker, the default + is 0 meaning CPU only. Raises: ValueError: if `cluster_spec` is given but `task_type` or `task_id` is @@ -103,11 +96,7 @@ class ParameterServerStrategy(distribute_lib.DistributionStrategy): """ super(ParameterServerStrategy, self).__init__() self._num_gpus_per_worker = num_gpus_per_worker - if cluster_spec: - self._initialize_multi_worker(num_gpus_per_worker, cluster_spec, - task_type, task_id) - else: - self._initialize_local(num_gpus_per_worker) + self._initialize_local(num_gpus_per_worker) # We typically don't need to do all-reduce in this strategy. self._cross_tower_ops = ( @@ -423,6 +412,8 @@ class ParameterServerStrategy(distribute_lib.DistributionStrategy): if not session_config or not self._cluster_spec: return + session_config.isolate_session_state = False + assert self._cluster_spec assert self._task_type assert self._task_id is not None diff --git a/tensorflow/contrib/distribute/python/strategy_test_lib.py b/tensorflow/contrib/distribute/python/strategy_test_lib.py index 6ee26e19ac..5d498fb629 100644 --- a/tensorflow/contrib/distribute/python/strategy_test_lib.py +++ b/tensorflow/contrib/distribute/python/strategy_test_lib.py @@ -190,7 +190,8 @@ class DistributionTestBase(test.TestCase): with d.scope(): map_in = [constant_op.constant(i) for i in range(10)] map_out = d.map(map_in, lambda x, y: x * y, 2) - observed = d.reduce(variable_scope.VariableAggregation.SUM, map_out) + observed = d.reduce(variable_scope.VariableAggregation.SUM, map_out, + "/device:CPU:0") expected = 90 # 2 * (0 + 1 + ... + 9) self.assertEqual(expected, observed.numpy()) diff --git a/tensorflow/contrib/distribute/python/tpu_strategy.py b/tensorflow/contrib/distribute/python/tpu_strategy.py index d0dbbd0da8..4fb70ec685 100644 --- a/tensorflow/contrib/distribute/python/tpu_strategy.py +++ b/tensorflow/contrib/distribute/python/tpu_strategy.py @@ -73,70 +73,98 @@ class TPUStrategy(one_device_strategy.OneDeviceStrategy): num_cores: Number of cores to use on the TPU. If None specified, then auto-detect the cores and topology of the TPU system. """ - # TODO(isaprykin): Generalize the defaults. They are currently tailored for - # the unit test. + # TODO(sourabhbajaj): OneDeviceStrategy should be initialized with the + # master node fetched from the cluster resolver. super(TPUStrategy, self).__init__('/device:CPU:0') self._tpu_cluster_resolver = tpu_cluster_resolver self._tpu_metadata = get_tpu_system_metadata(self._tpu_cluster_resolver) + # TODO(sourabhbajaj): Change this from num_cores to metadata_override self._num_cores_override = num_cores # TODO(sourabhbajaj): Remove this once performance of running one step # at a time is comparable to multiple steps. self.steps_per_run = steps_per_run - # TODO(frankchn): This should not be hardcoded here for pod purposes. - self._host = self.tpu_host_cpu_device(0) + def _get_enqueue_op_per_host(self, host_id, iterator, input_shapes, + iterations): + """Create an enqueue op for a single host identified using host_id. - def distribute_dataset(self, dataset_fn): - # TODO(priyag): Perhaps distribute across cores here. - return self._call_dataset_fn(dataset_fn) - - # TODO(priyag): Deal with OutOfRange errors once b/111349762 is fixed. - # TODO(sourabhbajaj): Remove the initial_loop_values parameter when we have - # a mechanism to infer the outputs of `fn`. Pending b/110550782. - def _run_steps_on_dataset(self, fn, iterator, iterations, - initial_loop_values=None): + The while_loop op returned will run `iterations` times and in each run + enqueue batches for each shard. - shapes = nest.flatten(iterator.output_shapes) - if any([not s.is_fully_defined() for s in shapes]): - raise ValueError( - 'TPU currently requires fully defined shapes. Either use ' - 'set_shape() on the input tensors or use ' - 'dataset.apply(map_and_batch(..., drop_remainder=True)).') - types = nest.flatten(iterator.output_types) + Args: + host_id: integer, id of the host to run the enqueue ops on. + iterator: `tf.data` iterator to read the input data. + input_shapes: shape of inputs to be enqueue on the queue. This is same as + the value of `nest.flatten(iterator.output_shapes)`. + iterations: integer, number of iterations to be run; determines the + number of batches to be enqueued. + + Returns: + while_loop_op running `iterations` times; in each run we enqueue a batch + on the infeed queue from the host with id `host_id` for each device shard. + """ + host = self.get_host_cpu_device(host_id) - def enqueue_ops_fn(): + def _infeed_enqueue_ops_fn(): """Enqueue ops for one iteration.""" control_deps = [] sharded_inputs = [] - # TODO(sourabhbajaj): Add support for TPU pods - with ops.device(self._host): - for _ in range(self.num_towers): + enqueue_ops = [] + + with ops.device(host): + for _ in range(self.num_towers_per_host): # Use control dependencies to ensure a deterministic ordering. with ops.control_dependencies(control_deps): inputs = nest.flatten(iterator.get_next()) control_deps.extend(inputs) sharded_inputs.append(inputs) - enqueue_ops = [] for core_id, shard_input in enumerate(sharded_inputs): enqueue_ops.append( tpu_ops.infeed_enqueue_tuple( - inputs=shard_input, shapes=shapes, device_ordinal=core_id)) + inputs=shard_input, + shapes=input_shapes, + device_ordinal=core_id)) return enqueue_ops def enqueue_ops_loop_body(i): - with ops.control_dependencies(enqueue_ops_fn()): + """Callable for the loop body of the while_loop instantiated below.""" + with ops.control_dependencies(_infeed_enqueue_ops_fn()): return i + 1 - with ops.device(self._host): - enqueue_ops = control_flow_ops.while_loop( + with ops.device(host): + enqueue_op_per_host = control_flow_ops.while_loop( lambda i: i < iterations, enqueue_ops_loop_body, [constant_op.constant(0)], parallel_iterations=1) + return enqueue_op_per_host + + def distribute_dataset(self, dataset_fn): + # TODO(priyag): Perhaps distribute across cores here. + return self._call_dataset_fn(dataset_fn) + + # TODO(priyag): Deal with OutOfRange errors once b/111349762 is fixed. + # TODO(sourabhbajaj): Remove the initial_loop_values parameter when we have + # a mechanism to infer the outputs of `fn`. Pending b/110550782. + def _run_steps_on_dataset(self, fn, iterator, iterations, + initial_loop_values=None): + + shapes = nest.flatten(iterator.output_shapes) + if any([not s.is_fully_defined() for s in shapes]): + raise ValueError( + 'TPU currently requires fully defined shapes. Either use ' + 'set_shape() on the input tensors or use ' + 'dataset.apply(map_and_batch(..., drop_remainder=True)).') + types = nest.flatten(iterator.output_types) + + enqueue_ops = [ + self._get_enqueue_op_per_host(host_id, iterator, shapes, iterations) + for host_id in range(self.num_hosts)] + def dequeue_fn(): dequeued = tpu_ops.infeed_dequeue_tuple(dtypes=types, shapes=shapes) return nest.pack_sequence_as(iterator.output_shapes, dequeued) @@ -147,6 +175,7 @@ class TPUStrategy(one_device_strategy.OneDeviceStrategy): initial_loop_values = nest.flatten(initial_loop_values) ctx = values.MultiStepContext() def run_fn(*args, **kwargs): + """Single step on the TPU device.""" del args, kwargs fn_inputs = dequeue_fn() if not isinstance(fn_inputs, tuple): @@ -250,7 +279,7 @@ class TPUStrategy(one_device_strategy.OneDeviceStrategy): devices = cross_tower_ops_lib.get_devices_from(destinations) if len(devices) == 1: assert device_util.canonicalize(devices[0]) == device_util.canonicalize( - self._host) + self.get_host_cpu_device(0)) else: raise ValueError('Multiple devices are not supported for TPUStrategy') @@ -270,8 +299,28 @@ class TPUStrategy(one_device_strategy.OneDeviceStrategy): def num_towers(self): return self._num_cores_override or self._tpu_metadata.num_cores - def tpu_host_cpu_device(self, host_id): + @property + def num_hosts(self): + return self._tpu_metadata.num_hosts + + @property + def num_towers_per_host(self): + return self._tpu_metadata.num_of_cores_per_host + + def get_host_cpu_device(self, host_id): if self._tpu_cluster_resolver.get_master() in ('', 'local'): return '/replica:0/task:0/device:CPU:0' - return '/job:%s/task:%d/device:CPU:0' % ('tpu_worker', host_id) + return '/job:tpu_worker/task:%d/device:CPU:0' % (host_id,) + + def configure(self, + session_config=None, + cluster_spec=None, + task_type=None, + task_id=None): + del cluster_spec, task_type, task_id + if session_config: + session_config.isolate_session_state = True + cluster_spec = self._tpu_cluster_resolver.cluster_spec() + if cluster_spec: + session_config.cluster_def.CopyFrom(cluster_spec.as_cluster_def()) diff --git a/tensorflow/contrib/distribute/python/values.py b/tensorflow/contrib/distribute/python/values.py index 479b7f39d6..fafa6384a1 100644 --- a/tensorflow/contrib/distribute/python/values.py +++ b/tensorflow/contrib/distribute/python/values.py @@ -340,10 +340,6 @@ class MirroredVariable(DistributedVariable, Mirrored, """Holds a map from device to variables whose values are kept in sync.""" def __init__(self, index, primary_var, aggregation): - # Use a weakref to make it easy to map from the contained values - # to the container without introducing a reference cycle. - for v in six.itervalues(index): - v._mirrored_container = weakref.ref(self) # pylint: disable=protected-access self._primary_var = primary_var self._aggregation = aggregation super(MirroredVariable, self).__init__(index) diff --git a/tensorflow/contrib/distribute/python/values_test.py b/tensorflow/contrib/distribute/python/values_test.py index 3602f4d128..15a85a28f5 100644 --- a/tensorflow/contrib/distribute/python/values_test.py +++ b/tensorflow/contrib/distribute/python/values_test.py @@ -521,6 +521,7 @@ class MultiWorkerDatasetTest(multi_worker_test_base.MultiWorkerTestBase): return worker_device_map, devices def testDataDistributionOneDevicePerWorker(self): + self.skipTest("Temporarily disabled.") worker_device_map, devices = self._cpu_devices() with context.graph_mode(): dataset_fn = lambda: dataset_ops.Dataset.range(8) @@ -528,6 +529,7 @@ class MultiWorkerDatasetTest(multi_worker_test_base.MultiWorkerTestBase): [[0, 1], [2, 3], [4, 5], [6, 7]]) def testDataDistributionTwoDevicePerWorker(self): + self.skipTest("Temporarily disabled.") if context.num_gpus() < 1: self.skipTest("A GPU is not available for this test.") worker_device_map, devices = self._cpu_and_one_gpu_devices() @@ -537,6 +539,7 @@ class MultiWorkerDatasetTest(multi_worker_test_base.MultiWorkerTestBase): [[0, 2, 1, 3], [4, 6, 5, 7]]) def testTupleDataset(self): + self.skipTest("Temporarily disabled.") worker_device_map, devices = self._cpu_devices() with context.graph_mode(): @@ -553,6 +556,7 @@ class MultiWorkerDatasetTest(multi_worker_test_base.MultiWorkerTestBase): expected_values) def testInitializableIterator(self): + self.skipTest("Temporarily disabled.") worker_device_map, devices = self._cpu_devices() with context.graph_mode(): dataset_fn = lambda: dataset_ops.Dataset.range(8) @@ -570,6 +574,7 @@ class MultiWorkerDatasetTest(multi_worker_test_base.MultiWorkerTestBase): [[0, 1], [2, 3], [4, 5], [6, 7]]) def testValueErrorForIterator(self): + self.skipTest("Temporarily disabled.") # Incompatiable arguments. with self.assertRaises(ValueError): values.MultiWorkerDataIterator({"w1": None}, {"w1": "d1", "w2": "d2"}) diff --git a/tensorflow/contrib/distributions/BUILD b/tensorflow/contrib/distributions/BUILD index a8d0d493ab..97c53ae2b9 100644 --- a/tensorflow/contrib/distributions/BUILD +++ b/tensorflow/contrib/distributions/BUILD @@ -445,7 +445,7 @@ cuda_py_test( cuda_py_test( name = "sinh_arcsinh_test", - size = "small", + size = "medium", srcs = ["python/kernel_tests/sinh_arcsinh_test.py"], additional_deps = [ ":distributions_py", diff --git a/tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb b/tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb index 315d7a4893..529c99b37c 100644 --- a/tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb +++ b/tensorflow/contrib/eager/python/examples/generative_examples/image_captioning_with_attention.ipynb @@ -66,7 +66,7 @@ "\n", "[Image Source](https://commons.wikimedia.org/wiki/Surfing#/media/File:Surfing_in_Hawaii.jpg), License: Public Domain\n", "\n", - "Our goal is generate a caption, such as \"a surfer riding on a wave\". Here, we'll use an attention based model. This enables us to see which parts of the image the model focuses on as it generates a caption.\n", + "Our goal is to generate a caption, such as \"a surfer riding on a wave\". Here, we'll use an attention-based model. This enables us to see which parts of the image the model focuses on as it generates a caption.\n", "\n", "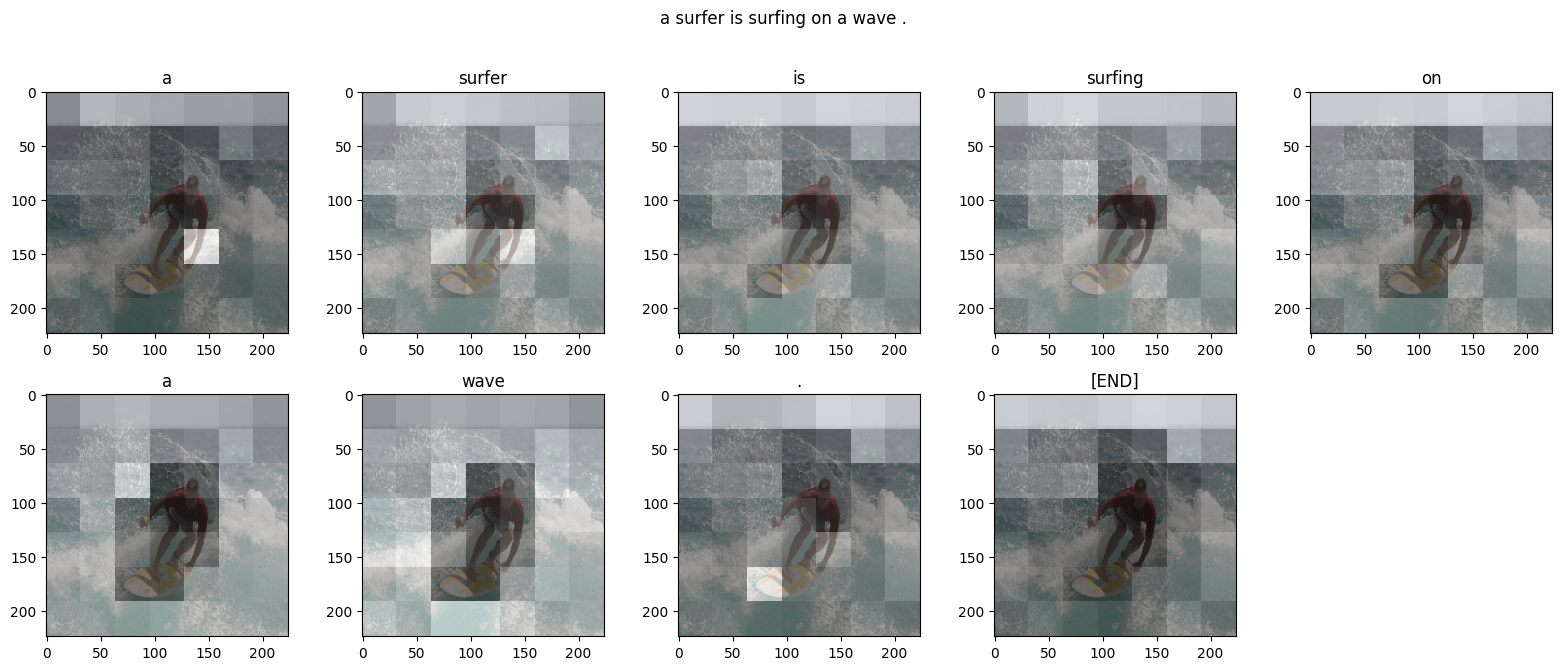\n", "\n", @@ -128,7 +128,7 @@ "source": [ "## Download and prepare the MS-COCO dataset\n", "\n", - "We will use the [MS-COCO dataset](http://cocodataset.org/#home) to train our model. This dataset contains >82,000 images, each of which has been annotated with at least 5 different captions. The code code below will download and extract the dataset automatically. \n", + "We will use the [MS-COCO dataset](http://cocodataset.org/#home) to train our model. This dataset contains >82,000 images, each of which has been annotated with at least 5 different captions. The code below will download and extract the dataset automatically. \n", "\n", "**Caution: large download ahead**. We'll use the training set, it's a 13GB file." ] diff --git a/tensorflow/contrib/eager/python/examples/pix2pix/pix2pix_eager.ipynb b/tensorflow/contrib/eager/python/examples/pix2pix/pix2pix_eager.ipynb index ee25d25b52..d60ee18586 100644 --- a/tensorflow/contrib/eager/python/examples/pix2pix/pix2pix_eager.ipynb +++ b/tensorflow/contrib/eager/python/examples/pix2pix/pix2pix_eager.ipynb @@ -147,11 +147,12 @@ " # random jittering\n", " \n", " # resizing to 286 x 286 x 3\n", - " # method = 2 indicates using \"ResizeMethod.NEAREST_NEIGHBOR\"\n", " input_image = tf.image.resize_images(input_image, [286, 286], \n", - " align_corners=True, method=2)\n", + " align_corners=True, \n", + " method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)\n", " real_image = tf.image.resize_images(real_image, [286, 286], \n", - " align_corners=True, method=2)\n", + " align_corners=True, \n", + " method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)\n", " \n", " # randomly cropping to 256 x 256 x 3\n", " stacked_image = tf.stack([input_image, real_image], axis=0)\n", diff --git a/tensorflow/contrib/eager/python/metrics_test.py b/tensorflow/contrib/eager/python/metrics_test.py index aa99616810..dcc7b71d79 100644 --- a/tensorflow/contrib/eager/python/metrics_test.py +++ b/tensorflow/contrib/eager/python/metrics_test.py @@ -25,11 +25,14 @@ from tensorflow.contrib.eager.python import metrics from tensorflow.contrib.summary import summary_test_util from tensorflow.python.eager import context from tensorflow.python.eager import test +from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes from tensorflow.python.framework import errors from tensorflow.python.framework import ops from tensorflow.python.framework import test_util from tensorflow.python.ops import array_ops +from tensorflow.python.ops import control_flow_ops +from tensorflow.python.ops import math_ops from tensorflow.python.ops import summary_ops_v2 as summary_ops from tensorflow.python.training import training_util from tensorflow.python.training.checkpointable import util as checkpointable_utils @@ -244,6 +247,48 @@ class MetricsTest(test.TestCase): value = m.value() self.assertEqual(self.evaluate(value), 2.5) + @test_util.run_in_graph_and_eager_modes + def testGraphAndEagerTensorGlobalVariables(self): + m = metrics.Mean(use_global_variables=True) + inputs = ops.convert_to_tensor([1.0, 2.0]) + accumulate = m(inputs) + result = m.result() + self.evaluate(m.init_variables()) + self.evaluate(accumulate) + self.assertEqual(self.evaluate(result), 1.5) + # Second init resets all the variables. + self.evaluate(m.init_variables()) + inputs = ops.convert_to_tensor([2.0, 3.0]) + self.evaluate(m(inputs)) + value = m.value() + self.assertEqual(self.evaluate(value), 2.5) + + @test_util.run_in_graph_and_eager_modes + def testGraphAndEagerTensorWhileLoopDoubleCall(self): + m = metrics.Mean() + init_value = constant_op.constant(1) + cond = lambda i: math_ops.less(i, 3) + def body(x): + with ops.control_dependencies([m(x)]): + return math_ops.add(x, 1) + accumulate = control_flow_ops.while_loop(cond, body, [init_value]) + + result = m.result() + self.evaluate(m.init_variables()) + self.evaluate(accumulate) + self.assertEqual(self.evaluate(result), 1.5) + # Second init resets all the variables. + self.evaluate(m.init_variables()) + inputs = ops.convert_to_tensor([2.0, 3.0]) + self.evaluate(m(inputs)) + if ops.context.executing_eagerly(): + self.evaluate(control_flow_ops.while_loop(cond, body, [init_value])) + else: + # Reuse the loop operators in graph mode + self.evaluate(accumulate) + value = m.value() + self.assertEqual(self.evaluate(value), 2.0) + def testTwoMeansGraph(self): # Verify two metrics with the same name in the same graph raises a # ValueError. diff --git a/tensorflow/contrib/factorization/python/ops/wals.py b/tensorflow/contrib/factorization/python/ops/wals.py index ca46c39baa..b82bf1188f 100644 --- a/tensorflow/contrib/factorization/python/ops/wals.py +++ b/tensorflow/contrib/factorization/python/ops/wals.py @@ -377,64 +377,68 @@ class WALSMatrixFactorization(estimator.Estimator): WALS (Weighted Alternating Least Squares) is an algorithm for weighted matrix factorization. It computes a low-rank approximation of a given sparse (n x m) - matrix A, by a product of two matrices, U * V^T, where U is a (n x k) matrix - and V is a (m x k) matrix. Here k is the rank of the approximation, also - called the embedding dimension. We refer to U as the row factors, and V as the - column factors. + matrix `A`, by a product of two matrices, `U * V^T`, where `U` is a (n x k) + matrix and `V` is a (m x k) matrix. Here k is the rank of the approximation, + also called the embedding dimension. We refer to `U` as the row factors, and + `V` as the column factors. See tensorflow/contrib/factorization/g3doc/wals.md for the precise problem formulation. - The training proceeds in sweeps: during a row_sweep, we fix V and solve for U. - During a column sweep, we fix U and solve for V. Each one of these problems is - an unconstrained quadratic minimization problem and can be solved exactly (it - can also be solved in mini-batches, since the solution decouples nicely). + The training proceeds in sweeps: during a row_sweep, we fix `V` and solve for + `U`. During a column sweep, we fix `U` and solve for `V`. Each one of these + problems is an unconstrained quadratic minimization problem and can be solved + exactly (it can also be solved in mini-batches, since the solution decouples + across rows of each matrix). The alternating between sweeps is achieved by using a hook during training, which is responsible for keeping track of the sweeps and running preparation ops at the beginning of each sweep. It also updates the global_step variable, which keeps track of the number of batches processed since the beginning of training. The current implementation assumes that the training is run on a single - machine, and will fail if config.num_worker_replicas is not equal to one. - Training is done by calling self.fit(input_fn=input_fn), where input_fn + machine, and will fail if `config.num_worker_replicas` is not equal to one. + Training is done by calling `self.fit(input_fn=input_fn)`, where `input_fn` provides two tensors: one for rows of the input matrix, and one for rows of the transposed input matrix (i.e. columns of the original matrix). Note that during a row sweep, only row batches are processed (ignoring column batches) and vice-versa. Also note that every row (respectively every column) of the input matrix must be processed at least once for the sweep to be considered complete. In - particular, training will not make progress if input_fn does not generate some - rows. - - For prediction, given a new set of input rows A' (e.g. new rows of the A - matrix), we compute a corresponding set of row factors U', such that U' * V^T - is a good approximation of A'. We call this operation a row projection. A - similar operation is defined for columns. - Projection is done by calling self.get_projections(input_fn=input_fn), where - input_fn satisfies the constraints given below. - - The input functions must satisfy the following constraints: Calling input_fn - must return a tuple (features, labels) where labels is None, and features is - a dict containing the following keys: + particular, training will not make progress if some rows are not generated by + the `input_fn`. + + For prediction, given a new set of input rows `A'`, we compute a corresponding + set of row factors `U'`, such that `U' * V^T` is a good approximation of `A'`. + We call this operation a row projection. A similar operation is defined for + columns. Projection is done by calling + `self.get_projections(input_fn=input_fn)`, where `input_fn` satisfies the + constraints given below. + + The input functions must satisfy the following constraints: Calling `input_fn` + must return a tuple `(features, labels)` where `labels` is None, and + `features` is a dict containing the following keys: + TRAIN: - - WALSMatrixFactorization.INPUT_ROWS: float32 SparseTensor (matrix). + * `WALSMatrixFactorization.INPUT_ROWS`: float32 SparseTensor (matrix). Rows of the input matrix to process (or to project). - - WALSMatrixFactorization.INPUT_COLS: float32 SparseTensor (matrix). + * `WALSMatrixFactorization.INPUT_COLS`: float32 SparseTensor (matrix). Columns of the input matrix to process (or to project), transposed. + INFER: - - WALSMatrixFactorization.INPUT_ROWS: float32 SparseTensor (matrix). + * `WALSMatrixFactorization.INPUT_ROWS`: float32 SparseTensor (matrix). Rows to project. - - WALSMatrixFactorization.INPUT_COLS: float32 SparseTensor (matrix). + * `WALSMatrixFactorization.INPUT_COLS`: float32 SparseTensor (matrix). Columns to project. - - WALSMatrixFactorization.PROJECT_ROW: Boolean Tensor. Whether to project + * `WALSMatrixFactorization.PROJECT_ROW`: Boolean Tensor. Whether to project the rows or columns. - - WALSMatrixFactorization.PROJECTION_WEIGHTS (Optional): float32 Tensor + * `WALSMatrixFactorization.PROJECTION_WEIGHTS` (Optional): float32 Tensor (vector). The weights to use in the projection. + EVAL: - - WALSMatrixFactorization.INPUT_ROWS: float32 SparseTensor (matrix). + * `WALSMatrixFactorization.INPUT_ROWS`: float32 SparseTensor (matrix). Rows to project. - - WALSMatrixFactorization.INPUT_COLS: float32 SparseTensor (matrix). + * `WALSMatrixFactorization.INPUT_COLS`: float32 SparseTensor (matrix). Columns to project. - - WALSMatrixFactorization.PROJECT_ROW: Boolean Tensor. Whether to project + * `WALSMatrixFactorization.PROJECT_ROW`: Boolean Tensor. Whether to project the rows or columns. """ # Keys to be used in model_fn @@ -469,7 +473,7 @@ class WALSMatrixFactorization(estimator.Estimator): max_sweeps=None, model_dir=None, config=None): - """Creates a model for matrix factorization using the WALS method. + r"""Creates a model for matrix factorization using the WALS method. Args: num_rows: Total number of rows for input matrix. diff --git a/tensorflow/contrib/factorization/python/ops/wals_test.py b/tensorflow/contrib/factorization/python/ops/wals_test.py index 36b483c6d7..31820a18b4 100644 --- a/tensorflow/contrib/factorization/python/ops/wals_test.py +++ b/tensorflow/contrib/factorization/python/ops/wals_test.py @@ -125,11 +125,13 @@ class WALSMatrixFactorizationTest(test.TestCase): nz_row_ids = np.arange(np.shape(np_matrix)[0]) nz_col_ids = np.arange(np.shape(np_matrix)[1]) - def extract_features(row_batch, col_batch, shape): + def extract_features(row_batch, col_batch, num_rows, num_cols): row_ids = row_batch[0] col_ids = col_batch[0] - rows = self.remap_sparse_tensor_rows(row_batch[1], row_ids, shape) - cols = self.remap_sparse_tensor_rows(col_batch[1], col_ids, shape) + rows = self.remap_sparse_tensor_rows( + row_batch[1], row_ids, shape=[num_rows, num_cols]) + cols = self.remap_sparse_tensor_rows( + col_batch[1], col_ids, shape=[num_cols, num_rows]) features = { wals_lib.WALSMatrixFactorization.INPUT_ROWS: rows, wals_lib.WALSMatrixFactorization.INPUT_COLS: cols, @@ -154,7 +156,7 @@ class WALSMatrixFactorizationTest(test.TestCase): capacity=10, enqueue_many=True) - features = extract_features(row_batch, col_batch, sp_mat.dense_shape) + features = extract_features(row_batch, col_batch, num_rows, num_cols) if mode == model_fn.ModeKeys.INFER or mode == model_fn.ModeKeys.EVAL: self.assertTrue( diff --git a/tensorflow/contrib/gan/python/estimator/python/gan_estimator_impl.py b/tensorflow/contrib/gan/python/estimator/python/gan_estimator_impl.py index ab9886580d..7243f150ce 100644 --- a/tensorflow/contrib/gan/python/estimator/python/gan_estimator_impl.py +++ b/tensorflow/contrib/gan/python/estimator/python/gan_estimator_impl.py @@ -184,7 +184,7 @@ class GANEstimator(estimator.Estimator): return _get_estimator_spec( mode, gan_model, generator_loss_fn, discriminator_loss_fn, get_eval_metric_ops_fn, generator_optimizer, discriminator_optimizer, - get_hooks_fn) + get_hooks_fn, use_loss_summaries) super(GANEstimator, self).__init__( model_fn=_model_fn, model_dir=model_dir, config=config) @@ -211,15 +211,17 @@ def _get_gan_model( def _get_estimator_spec( mode, gan_model, generator_loss_fn, discriminator_loss_fn, get_eval_metric_ops_fn, generator_optimizer, discriminator_optimizer, - get_hooks_fn=None): + get_hooks_fn=None, use_loss_summaries=True): """Get the EstimatorSpec for the current mode.""" if mode == model_fn_lib.ModeKeys.PREDICT: estimator_spec = model_fn_lib.EstimatorSpec( mode=mode, predictions=gan_model.generated_data) else: gan_loss = tfgan_tuples.GANLoss( - generator_loss=generator_loss_fn(gan_model), - discriminator_loss=discriminator_loss_fn(gan_model)) + generator_loss=generator_loss_fn( + gan_model, add_summaries=use_loss_summaries), + discriminator_loss=discriminator_loss_fn( + gan_model, add_summaries=use_loss_summaries)) if mode == model_fn_lib.ModeKeys.EVAL: estimator_spec = _get_eval_estimator_spec( gan_model, gan_loss, get_eval_metric_ops_fn) diff --git a/tensorflow/contrib/gan/python/estimator/python/gan_estimator_test.py b/tensorflow/contrib/gan/python/estimator/python/gan_estimator_test.py index 9ac9c6ca9c..83f8dd641f 100644 --- a/tensorflow/contrib/gan/python/estimator/python/gan_estimator_test.py +++ b/tensorflow/contrib/gan/python/estimator/python/gan_estimator_test.py @@ -116,7 +116,7 @@ def get_dummy_gan_model(): discriminator_fn=None) -def dummy_loss_fn(gan_model): +def dummy_loss_fn(gan_model, add_summaries=True): return math_ops.reduce_sum(gan_model.discriminator_real_outputs - gan_model.discriminator_gen_outputs) diff --git a/tensorflow/contrib/layers/python/layers/feature_column.py b/tensorflow/contrib/layers/python/layers/feature_column.py index 28d19a0445..53c8ae5d08 100644 --- a/tensorflow/contrib/layers/python/layers/feature_column.py +++ b/tensorflow/contrib/layers/python/layers/feature_column.py @@ -1100,9 +1100,9 @@ class _EmbeddingColumn( raise ValueError("Must specify both `ckpt_to_load_from` and " "`tensor_name_in_ckpt` or none of them.") if initializer is None: - logging.warn("The default stddev value of initializer will change from " - "\"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" after " - "2017/02/25.") + logging.warn("The default stddev value of initializer was changed from " + "\"1/sqrt(vocab_size)\" to \"1/sqrt(dimension)\" in core " + "implementation (tf.feature_column.embedding_column).") stddev = 1 / math.sqrt(sparse_id_column.length) initializer = init_ops.truncated_normal_initializer( mean=0.0, stddev=stddev) @@ -1501,8 +1501,6 @@ class _ScatteredEmbeddingColumn( raise ValueError("initializer must be callable if specified. " "column_name: {}".format(column_name)) if initializer is None: - logging.warn("The default stddev value of initializer will change from " - "\"0.1\" to \"1/sqrt(dimension)\" after 2017/02/25.") stddev = 0.1 initializer = init_ops.truncated_normal_initializer( mean=0.0, stddev=stddev) diff --git a/tensorflow/contrib/layers/python/layers/layers_test.py b/tensorflow/contrib/layers/python/layers/layers_test.py index eee90864b4..52c9c4f3be 100644 --- a/tensorflow/contrib/layers/python/layers/layers_test.py +++ b/tensorflow/contrib/layers/python/layers/layers_test.py @@ -1288,7 +1288,7 @@ class ConvolutionInPlaneTest(test.TestCase): result = sess.run(vert_gradients) expected = np.zeros((1, 9, 10, 1)) - self.assertAllEqual(result, expected) + self.assertAllClose(result, expected, rtol=1e-5, atol=1e-5) def testVertConvWithVaryingImage(self): image = np.asmatrix(('1.0 2.0 3.0;' '1.1 2.0 4.0;' '-4.3 0.0 8.9')) diff --git a/tensorflow/contrib/layers/python/layers/rev_block_lib.py b/tensorflow/contrib/layers/python/layers/rev_block_lib.py index b25f11b5a6..06da32072f 100644 --- a/tensorflow/contrib/layers/python/layers/rev_block_lib.py +++ b/tensorflow/contrib/layers/python/layers/rev_block_lib.py @@ -30,6 +30,7 @@ import functools import re import numpy as np +import six from six.moves import xrange # pylint: disable=redefined-builtin from tensorflow.contrib.framework.python import ops as contrib_framework_ops @@ -44,6 +45,7 @@ from tensorflow.python.ops import custom_gradient from tensorflow.python.ops import gradients_impl from tensorflow.python.ops import math_ops from tensorflow.python.ops import variable_scope +from tensorflow.python.ops import variables as variables_lib from tensorflow.python.platform import tf_logging as logging from tensorflow.python.util import nest from tensorflow.python.util import tf_inspect @@ -471,7 +473,8 @@ def recompute_grad(fn, use_data_dep=_USE_DEFAULT, tupleize_grads=False): Args: fn: a function that takes Tensors (all as positional arguments) and returns - a tuple of Tensors. + a tuple of Tensors. Note that `fn` should not close over any other + Tensors or Variables. use_data_dep: `bool`, if `True` will use a dummy data dependency to force the recompute to happen. If `False` will use a control dependency. By default will be `True` if in an XLA context and `False` otherwise. XLA @@ -485,7 +488,22 @@ def recompute_grad(fn, use_data_dep=_USE_DEFAULT, tupleize_grads=False): A wrapped fn that is identical to fn when called, but its activations will be discarded and recomputed on the backwards pass (i.e. on a call to tf.gradients). + + Raises: + ValueError: if `fn` closes over any Tensors or Variables. """ + # Check for closed-over Tensors/Variables + if fn.__code__.co_freevars: + closed_over_vars = dict(zip(fn.__code__.co_freevars, + [c.cell_contents for c in fn.__closure__])) + for var_name, value in six.iteritems(closed_over_vars): + if isinstance(value, (framework_ops.Tensor, variables_lib.Variable)): + raise ValueError( + "fn decorated with @recompute_grad closes over Tensor %s " + "(local variable name: %s). The decorated fn must not close over " + "Tensors or Variables because gradients will NOT be computed for " + "them through fn. To ensure correct gradients, make the " + "Tensor an input to fn." % (value.name, var_name)) @_safe_wraps(fn) def wrapped(*args): @@ -500,6 +518,62 @@ def _is_on_tpu(): return control_flow_util.GetContainingXLAContext(ctxt) is not None +def _recomputing_grad_fn(compute_fn, + original_args, + original_vars, + output_grads, + grad_fn_variables, + use_data_dep, + tupleize_grads, + arg_scope, + var_scope, + has_is_recompute_kwarg): + """Grad fn for recompute_grad.""" + variables = grad_fn_variables or [] + + # Identity ops around the inputs ensures correct gradient graph-walking. + inputs = [array_ops.identity(x) for x in list(original_args)] + + # Recompute outputs + # Use a control dependency to ensure that the recompute is not eliminated by + # CSE and that it happens on the backwards pass. + ctrl_dep_grads = [g for g in output_grads if g is not None] + with framework_ops.control_dependencies(ctrl_dep_grads): + if use_data_dep: + inputs = _force_data_dependency(output_grads, inputs) + # Re-enter scopes + with contrib_framework_ops.arg_scope(arg_scope): + with variable_scope.variable_scope(var_scope, reuse=True): + # Re-call the function and ensure that the touched variables are the + # same as in the first call. + with backprop.GradientTape() as tape: + fn_kwargs = {} + if has_is_recompute_kwarg: + fn_kwargs["is_recomputing"] = True + outputs = compute_fn(*inputs, **fn_kwargs) + recompute_vars = set(tape.watched_variables()) + if original_vars != recompute_vars: + raise ValueError(_WRONG_VARS_ERR) + + if not isinstance(outputs, (list, tuple)): + outputs = [outputs] + outputs = list(outputs) + + # Compute gradients + grads = gradients_impl.gradients(outputs, inputs + variables, + output_grads) + + if tupleize_grads: + if use_data_dep: + grads = _tuple_with_data_dep(grads) + else: + grads = control_flow_ops.tuple(grads) + + grad_inputs = grads[:len(inputs)] + grad_vars = grads[len(inputs):] + return grad_inputs, grad_vars + + def _recompute_grad(fn, args, use_data_dep=_USE_DEFAULT, tupleize_grads=False): """See recompute_grad.""" has_is_recompute_kwarg = "is_recomputing" in tf_inspect.getargspec(fn).args @@ -510,12 +584,16 @@ def _recompute_grad(fn, args, use_data_dep=_USE_DEFAULT, tupleize_grads=False): if use_data_dep_ == _USE_DEFAULT: use_data_dep_ = _is_on_tpu() + # Use custom_gradient and return a grad_fn that recomputes on the backwards + # pass. @custom_gradient.custom_gradient def fn_with_recompute(*args): """Wrapper for fn.""" - # Forward pass + # Capture the variable and arg scopes so we can re-enter them when + # recomputing. vs = variable_scope.get_variable_scope() arg_scope = contrib_framework_ops.current_arg_scope() + # Track all variables touched in the function. with backprop.GradientTape() as tape: fn_kwargs = {} if has_is_recompute_kwarg: @@ -523,46 +601,25 @@ def _recompute_grad(fn, args, use_data_dep=_USE_DEFAULT, tupleize_grads=False): outputs = fn(*args, **fn_kwargs) original_vars = set(tape.watched_variables()) - # Backward pass def _grad_fn(output_grads, variables=None): - """Recompute outputs for gradient computation.""" - variables = variables or [] + # Validate that custom_gradient passes the right variables into grad_fn. if original_vars: assert variables, ("Fn created variables but the variables were not " "passed to the gradient fn.") if set(variables) != original_vars: raise ValueError(_WRONG_VARS_ERR) - inputs = [array_ops.identity(x) for x in list(args)] - # Recompute outputs - with framework_ops.control_dependencies(output_grads): - if use_data_dep_: - inputs = _force_data_dependency(output_grads, inputs) - with contrib_framework_ops.arg_scope(arg_scope): - with variable_scope.variable_scope(vs, reuse=True): - with backprop.GradientTape() as tape: - fn_kwargs = {} - if has_is_recompute_kwarg: - fn_kwargs["is_recomputing"] = True - outputs = fn(*inputs, **fn_kwargs) - recompute_vars = set(tape.watched_variables()) - if original_vars != recompute_vars: - raise ValueError(_WRONG_VARS_ERR) - - if not isinstance(outputs, (list, tuple)): - outputs = [outputs] - outputs = list(outputs) - grads = gradients_impl.gradients(outputs, inputs + variables, - output_grads) - - if tupleize_grads: - if use_data_dep_: - grads = _tuple_with_data_dep(grads) - else: - grads = control_flow_ops.tuple(grads) - grad_inputs = grads[:len(inputs)] - grad_vars = grads[len(inputs):] - return grad_inputs, grad_vars + return _recomputing_grad_fn( + compute_fn=fn, + original_args=args, + original_vars=original_vars, + output_grads=output_grads, + grad_fn_variables=variables, + use_data_dep=use_data_dep_, + tupleize_grads=tupleize_grads, + arg_scope=arg_scope, + var_scope=vs, + has_is_recompute_kwarg=has_is_recompute_kwarg) # custom_gradient inspects the signature of the function to determine # whether the user expects variables passed in the grad_fn. If the function diff --git a/tensorflow/contrib/layers/python/layers/rev_block_lib_test.py b/tensorflow/contrib/layers/python/layers/rev_block_lib_test.py index d5971fb9d8..c34b5a8017 100644 --- a/tensorflow/contrib/layers/python/layers/rev_block_lib_test.py +++ b/tensorflow/contrib/layers/python/layers/rev_block_lib_test.py @@ -392,6 +392,16 @@ class RecomputeTest(test.TestCase): with self.test_session() as sess: sess.run(grads) + def testErrorOnClosedOverTensor(self): + x = random_ops.random_uniform((4, 8)) + y = random_ops.random_uniform((4, 8)) + z = x * y + + with self.assertRaisesWithPredicateMatch(ValueError, "closes over"): + @rev_block_lib.recompute_grad + def fn_with_capture(a): # pylint: disable=unused-variable + return a * z + if __name__ == "__main__": test.main() diff --git a/tensorflow/contrib/linear_optimizer/kernels/g3doc/readme.md b/tensorflow/contrib/linear_optimizer/kernels/g3doc/readme.md index a4f5086dde..5fe883d647 100644 --- a/tensorflow/contrib/linear_optimizer/kernels/g3doc/readme.md +++ b/tensorflow/contrib/linear_optimizer/kernels/g3doc/readme.md @@ -199,6 +199,46 @@ does. However, in practice, convergence with $$x_0 = 0$$ always happens (tested for a sample of generic values for the parameters). +### Poisson log loss + +Poisson log loss is defined as $$ \l(u) = e^u - uy $$ for label $$y \geq 0.$$ +Its dual is + +$$ \l^\star(v) = (y+v) (\log(y+v) - 1) $$ + +and is only defined for $$ y+v > 0 $$. We then have the constraint + +$$ y > \a+\d. $$ + +The dual is + +$$ D(\d) = -(y-\a-\d) (\log(y-\a-\d) - 1) - \bar{y} \d - \frac{A}{2} \d^2 $$ + +and its derivative is, + +$$ D'(\d) = \log(y-\a-\d) - \bar{y} - A\d $$ + +Similar to the logistic loss, we perform a change of variable to handle the +constraint on $$ \d $$ + +$$ y - (\a+\d) = e^x $$ + +After this change of variable, the goal is to find the zero of this function + +$$ H(x) = x - \bar{y} -A(y-\a-e^x) $$ + +whose first derivative is + +$$ H'(x) = 1+Ae^x $$ + +Since this function is always positive, $$H$$ is increasing and has a unique +zero. + +We can start Newton algorithm at $$\d=0$$ which corresponds to $$ x = +\log(y-\a)$$. As before the Newton step is given by + +$$x_{k+1} = x_k - \frac{H(x_k)}{H'(x_k)}. $$ + ### References [1] C. Ma et al., Adding vs. Averaging in Distributed Primal-Dual Optimization, diff --git a/tensorflow/contrib/linear_optimizer/python/kernel_tests/sdca_ops_test.py b/tensorflow/contrib/linear_optimizer/python/kernel_tests/sdca_ops_test.py index ef0e08a777..1d2db1cec8 100644 --- a/tensorflow/contrib/linear_optimizer/python/kernel_tests/sdca_ops_test.py +++ b/tensorflow/contrib/linear_optimizer/python/kernel_tests/sdca_ops_test.py @@ -1192,6 +1192,57 @@ class SdcaWithSmoothHingeLossTest(SdcaModelTest): self.assertAllClose(0.33, unregularized_loss.eval(), atol=0.02) self.assertAllClose(0.44, regularized_loss.eval(), atol=0.02) +class SdcaWithPoissonLossTest(SdcaModelTest): + """SDCA optimizer test class for poisson loss.""" + + def testSimple(self): + # Setup test data + example_protos = [ + make_example_proto({ + 'age': [0], + 'gender': [0] + }, 0), + make_example_proto({ + 'age': [1], + 'gender': [1] + }, 2), + ] + example_weights = [100.0, 100.0] + with self._single_threaded_test_session(): + examples = make_example_dict(example_protos, example_weights) + variables = make_variable_dict(1, 1) + options = dict( + symmetric_l2_regularization=1.0, + symmetric_l1_regularization=0, + loss_type='poisson_loss') + model = SdcaModel(examples, variables, options) + variables_lib.global_variables_initializer().run() + + # Before minimization, the weights default to zero. There is no loss due + # to regularization, only unregularized loss which is 1 for each example. + predictions = model.predictions(examples) + self.assertAllClose([1.0, 1.0], predictions.eval()) + unregularized_loss = model.unregularized_loss(examples) + regularized_loss = model.regularized_loss(examples) + approximate_duality_gap = model.approximate_duality_gap() + self.assertAllClose(1.0, unregularized_loss.eval()) + self.assertAllClose(1.0, regularized_loss.eval()) + + # There are 4 sparse weights: 2 for age (say w1, w2) and 2 for gender + # (say w3 and w4). The minimization leads to: + # w1=w3=-1.96487, argmin of 100*(exp(2*w)-2*w*0)+w**2. + # w2=w4=0.345708, argmin of 100*(exp(2*w)-2*w*2)+w**2. + # This gives an unregularized loss of .3167 and .3366 with regularization. + train_op = model.minimize() + for _ in range(_MAX_ITERATIONS): + train_op.run() + model.update_weights(train_op).run() + + self.assertAllClose([0.0196, 1.9965], predictions.eval(), atol=1e-4) + self.assertAllClose(0.3167, unregularized_loss.eval(), atol=1e-4) + self.assertAllClose(0.3366, regularized_loss.eval(), atol=1e-4) + self.assertAllClose(0., approximate_duality_gap.eval(), atol=1e-6) + class SdcaFprintTest(SdcaModelTest): """Tests for the SdcaFprint op. diff --git a/tensorflow/contrib/linear_optimizer/python/ops/sdca_ops.py b/tensorflow/contrib/linear_optimizer/python/ops/sdca_ops.py index 0047d5753a..14f59a3f64 100644 --- a/tensorflow/contrib/linear_optimizer/python/ops/sdca_ops.py +++ b/tensorflow/contrib/linear_optimizer/python/ops/sdca_ops.py @@ -35,6 +35,7 @@ from tensorflow.python.ops import math_ops from tensorflow.python.ops import nn_ops from tensorflow.python.ops import state_ops from tensorflow.python.ops import variables as var_ops +from tensorflow.python.ops.nn import log_poisson_loss from tensorflow.python.ops.nn import sigmoid_cross_entropy_with_logits from tensorflow.python.summary import summary @@ -51,6 +52,7 @@ class SdcaModel(object): * Squared loss * Hinge loss * Smooth hinge loss + * Poisson log loss This class defines an optimizer API to train a linear model. @@ -112,7 +114,7 @@ class SdcaModel(object): raise ValueError('examples, variables and options must all be specified.') supported_losses = ('logistic_loss', 'squared_loss', 'hinge_loss', - 'smooth_hinge_loss') + 'smooth_hinge_loss', 'poisson_loss') if options['loss_type'] not in supported_losses: raise ValueError('Unsupported loss_type: ', options['loss_type']) @@ -315,6 +317,7 @@ class SdcaModel(object): """Add operations to compute predictions by the model. If logistic_loss is being used, predicted probabilities are returned. + If poisson_loss is being used, predictions are exponentiated. Otherwise, (raw) linear predictions (w*x) are returned. Args: @@ -335,6 +338,10 @@ class SdcaModel(object): # Convert logits to probability for logistic loss predictions. with name_scope('sdca/logistic_prediction'): result = math_ops.sigmoid(result) + elif self._options['loss_type'] == 'poisson_loss': + # Exponeniate the prediction for poisson loss predictions. + with name_scope('sdca/poisson_prediction'): + result = math_ops.exp(result) return result def _get_partitioned_update_ops(self, @@ -624,6 +631,11 @@ class SdcaModel(object): logits=predictions), weights)) / math_ops.reduce_sum(weights) + if self._options['loss_type'] == 'poisson_loss': + return math_ops.reduce_sum(math_ops.multiply( + log_poisson_loss(targets=labels, log_input=predictions), + weights)) / math_ops.reduce_sum(weights) + if self._options['loss_type'] in ['hinge_loss', 'smooth_hinge_loss']: # hinge_loss = max{0, 1 - y_i w*x} where y_i \in {-1, 1}. So, we need to # first convert 0/1 labels into -1/1 labels. diff --git a/tensorflow/contrib/lite/RELEASE.md b/tensorflow/contrib/lite/RELEASE.md deleted file mode 100644 index 8fd63d5cee..0000000000 --- a/tensorflow/contrib/lite/RELEASE.md +++ /dev/null @@ -1,8 +0,0 @@ -# Release 0.1.7 - -* TensorFlow Lite 0.1.7 is based on tag `tflite-v0.1.7` (git commit - fa1db5eb0da85b5baccc2a46d534fdeb3bb473d0). -* To reproduce the iOS library, it's required to cherry pick git commit - f1f1d5172fe5bfeaeb2cf657ffc43ba744187bee to fix a dependency issue. -* The code is based on TensorFlow 1.8.0 release candidate and it's very close - to TensorFlow 1.8.0 release. diff --git a/tensorflow/contrib/lite/build_def.bzl b/tensorflow/contrib/lite/build_def.bzl index fc199f0a0e..0246e7fa30 100644 --- a/tensorflow/contrib/lite/build_def.bzl +++ b/tensorflow/contrib/lite/build_def.bzl @@ -57,6 +57,7 @@ def tflite_linkopts_unstripped(): "-Wl,--as-needed", # Don't link unused libs. ], "//tensorflow:darwin": [], + "//tensorflow:ios": [], "//tensorflow/contrib/lite:mips": [], "//tensorflow/contrib/lite:mips64": [], "//conditions:default": [ diff --git a/tensorflow/contrib/lite/examples/android/app/build.gradle b/tensorflow/contrib/lite/examples/android/app/build.gradle index eb7fd705e1..35e7887852 100644 --- a/tensorflow/contrib/lite/examples/android/app/build.gradle +++ b/tensorflow/contrib/lite/examples/android/app/build.gradle @@ -9,7 +9,6 @@ android { targetSdkVersion 26 versionCode 1 versionName "1.0" - testInstrumentationRunner "androidx.test.runner.AndroidJUnitRunner" // Remove this block. jackOptions { @@ -51,10 +50,5 @@ apply from: "download-models.gradle" dependencies { compile fileTree(dir: 'libs', include: ['*.jar']) - androidTestCompile('androidx.test.espresso:espresso-core:3.1.0-alpha3', { - exclude group: 'com.android.support', module: 'support-annotations' - }) compile 'org.tensorflow:tensorflow-lite:0.0.0-nightly' - - testCompile 'junit:junit:4.12' } diff --git a/tensorflow/contrib/lite/experimental/kernels/ctc_beam_search.h b/tensorflow/contrib/lite/experimental/kernels/ctc_beam_search.h index c658e43092..7c5099235a 100644 --- a/tensorflow/contrib/lite/experimental/kernels/ctc_beam_search.h +++ b/tensorflow/contrib/lite/experimental/kernels/ctc_beam_search.h @@ -257,6 +257,16 @@ void CTCBeamSearchDecoder<CTCBeamState, CTCBeamComparer>::Step( } else { max_coeff = raw_input.maxCoeff(); } + + // Get normalization term of softmax: log(sum(exp(logit[j]-max_coeff))). + float logsumexp = 0.0; + for (int j = 0; j < raw_input.size(); ++j) { + logsumexp += Eigen::numext::exp(raw_input(j) - max_coeff); + } + logsumexp = Eigen::numext::log(logsumexp); + // Final normalization offset to get correct log probabilities. + float norm_offset = max_coeff + logsumexp; + const float label_selection_input_min = (label_selection_margin_ >= 0) ? (max_coeff - label_selection_margin_) : -std::numeric_limits<float>::infinity(); @@ -288,10 +298,10 @@ void CTCBeamSearchDecoder<CTCBeamState, CTCBeamComparer>::Step( beam_scorer_->GetStateExpansionScore(b->state, previous)); } // Plabel(l=abc @ t=6) *= P(c @ 6) - b->newp.label += raw_input(b->label) - max_coeff; + b->newp.label += raw_input(b->label) - norm_offset; } // Pblank(l=abc @ t=6) = P(l=abc @ t=5) * P(- @ 6) - b->newp.blank = b->oldp.total + raw_input(blank_index_) - max_coeff; + b->newp.blank = b->oldp.total + raw_input(blank_index_) - norm_offset; // P(l=abc @ t=6) = Plabel(l=abc @ t=6) + Pblank(l=abc @ t=6) b->newp.total = LogSumExp(b->newp.blank, b->newp.label); @@ -326,6 +336,8 @@ void CTCBeamSearchDecoder<CTCBeamState, CTCBeamComparer>::Step( const float logit = top_k ? top_k_logits[ind] : raw_input(ind); // Perform label selection: if input for this label looks very // unpromising, never evaluate it with a scorer. + // We may compare logits instead of log probabilities, + // since the difference is the same in both cases. if (logit < label_selection_input_min) { continue; } @@ -339,7 +351,7 @@ void CTCBeamSearchDecoder<CTCBeamState, CTCBeamComparer>::Step( // Plabel(l=abcd @ t=6) = P(l=abc @ t=5) * P(d @ 6) beam_scorer_->ExpandState(b->state, b->label, &c.state, c.label); float previous = (c.label == b->label) ? b->oldp.blank : b->oldp.total; - c.newp.label = logit - max_coeff + + c.newp.label = logit - norm_offset + beam_scorer_->GetStateExpansionScore(c.state, previous); // P(l=abcd @ t=6) = Plabel(l=abcd @ t=6) c.newp.total = c.newp.label; diff --git a/tensorflow/contrib/lite/experimental/kernels/ctc_beam_search_decoder_test.cc b/tensorflow/contrib/lite/experimental/kernels/ctc_beam_search_decoder_test.cc index 32458305c4..aa42b495bd 100644 --- a/tensorflow/contrib/lite/experimental/kernels/ctc_beam_search_decoder_test.cc +++ b/tensorflow/contrib/lite/experimental/kernels/ctc_beam_search_decoder_test.cc @@ -117,7 +117,7 @@ TEST(CTCBeamSearchTest, SimpleTest) { EXPECT_THAT(decoded_outputs[2], ElementsAre(1, 1)); // Check log probabilities output. EXPECT_THAT(m.GetLogProbabilitiesOutput(), - ElementsAreArray(ArrayFloatNear({0.32134813}))); + ElementsAreArray(ArrayFloatNear({-0.357094}))); } TEST(CTCBeamSearchTest, MultiBatchTest) { @@ -148,9 +148,8 @@ TEST(CTCBeamSearchTest, MultiBatchTest) { EXPECT_THAT(decoded_outputs[1], ElementsAre(1, 0, 0, 0)); EXPECT_THAT(decoded_outputs[2], ElementsAre(3, 2)); // Check log probabilities output. - EXPECT_THAT( - m.GetLogProbabilitiesOutput(), - ElementsAreArray(ArrayFloatNear({0.46403232, 0.49500442, 0.40443572}))); + EXPECT_THAT(m.GetLogProbabilitiesOutput(), + ElementsAreArray(ArrayFloatNear({-1.88343, -1.41188, -1.20958}))); } TEST(CTCBeamSearchTest, MultiPathsTest) { @@ -188,8 +187,8 @@ TEST(CTCBeamSearchTest, MultiPathsTest) { EXPECT_THAT(decoded_outputs[5], ElementsAre(2, 2)); // Check log probabilities output. EXPECT_THAT(m.GetLogProbabilitiesOutput(), - ElementsAreArray(ArrayFloatNear( - {0.91318405, 0.9060272, 1.0780245, 0.64358956}))); + ElementsAreArray( + ArrayFloatNear({-2.65148, -2.65864, -2.17914, -2.61357}))); } TEST(CTCBeamSearchTest, NonEqualSequencesTest) { @@ -223,7 +222,7 @@ TEST(CTCBeamSearchTest, NonEqualSequencesTest) { EXPECT_THAT(decoded_outputs[2], ElementsAre(3, 1)); // Check log probabilities output. EXPECT_THAT(m.GetLogProbabilitiesOutput(), - ElementsAreArray(ArrayFloatNear({0., 1.0347567, 0.7833005}))); + ElementsAreArray(ArrayFloatNear({-0.97322, -1.16334, -2.15553}))); } } // namespace diff --git a/tensorflow/contrib/lite/g3doc/README.md b/tensorflow/contrib/lite/g3doc/README.md deleted file mode 100644 index e3db478481..0000000000 --- a/tensorflow/contrib/lite/g3doc/README.md +++ /dev/null @@ -1,4 +0,0 @@ -This is a *work-in-progress* TF Lite subsite for: -https://www.tensorflow.org/mobile - -DO NOT PUBLISH diff --git a/tensorflow/contrib/lite/g3doc/api_docs/python/index.md b/tensorflow/contrib/lite/g3doc/api_docs/python/index.md deleted file mode 100644 index 70031a3c3d..0000000000 --- a/tensorflow/contrib/lite/g3doc/api_docs/python/index.md +++ /dev/null @@ -1,10 +0,0 @@ -Project: /mobile/_project.yaml -Book: /mobile/_book.yaml -page_type: reference -<style> table img { max-width: 100%; } </style> -<script src="/_static/js/managed/mathjax/MathJax.js?config=TeX-AMS-MML_SVG"></script> - -<!-- DO NOT EDIT! Automatically generated file. --> -# All symbols in TensorFlow Lite - -TEMP PAGE diff --git a/tensorflow/contrib/lite/g3doc/apis.md b/tensorflow/contrib/lite/g3doc/apis.md index f255017ad9..69616c7b8a 100644 --- a/tensorflow/contrib/lite/g3doc/apis.md +++ b/tensorflow/contrib/lite/g3doc/apis.md @@ -37,7 +37,7 @@ float* output = interpreter->typed_output_tensor<float>(0); ``` ### Data Alignment -TensorFlow Lite data is usually aligned to 32-bit boundaries. It is recommended +TensorFlow Lite data is usually aligned to 16-byte boundaries. It is recommended that all data provided to TensorFlow Lite be aligned that way. ### Error Reporting @@ -112,7 +112,7 @@ below. It should be noted that: * Tensors are represented by integers, in order to avoid string comparisons (and any fixed dependency on string libraries). - * An interpreter must not be accessed from concurrent threads + * An interpreter must not be accessed from concurrent threads. * Memory allocation for input and output tensors must be triggered by calling AllocateTensors() right after resizing tensors. @@ -169,7 +169,7 @@ former provides error reporting facilities and access to global objects, including all the tensors. The latter allows implementations to access their inputs and outputs. -When the interpreter loads a model, it calls init() once for each node in the +When the interpreter loads a model, it calls `init()` once for each node in the graph. A given `init()` will be called more than once if the op is used multiple times in the graph. For custom ops a configuration buffer will be provided, containing a flexbuffer that maps parameter names to their values. @@ -210,8 +210,9 @@ namespace custom { Note that registration is not automatic and an explicit call to `Register_MY_CUSTOM_OP` should be made somewhere. While the standard -`:builtin_ops` takes care of the registration of builtins, custom ops will have -to be collected in separated custom libraries. +`BuiltinOpResolver` (available from the `:builtin_ops` target) takes care of the +registration of builtins, custom ops will have to be collected in separate +custom libraries. ### Customizing the kernel library @@ -232,7 +233,7 @@ class OpResolver { }; ``` -The regular usage will require the developer to use the `BuiltinOpResolver` and +Regular usage will require the developer to use the `BuiltinOpResolver` and write: ```c++ @@ -308,18 +309,25 @@ an `IllegalArgumentException` will be thrown. #### Inputs -Each input should be an array, a multi-dimensional array, or a `ByteBuffer` of -the supported primitive types. +Each input should be an array or multi-dimensional array of the supported +primitive types, or a raw `ByteBuffer` of the appropriate size. If the input is +an array or multi-dimensional array, the associated input tensor will be +implicitly resized to the array's dimensions at inference time. If the input is +a ByteBuffer, the caller should first manually resize the associated input +tensor (via `Interpreter.resizeInput()`) before running inference. -The use of `ByteBuffer` is preferred since it allows the `Interpreter` to avoid -unnecessary copies. Each `ByteBuffer` needs to be a direct byte buffer, and its -order must be `ByteOrder.nativeOrder()`. After it is used for a model inference, -it must remain unchanged until the model inference is finished. +When using 'ByteBuffer', prefer using direct byte buffers, as this allows the +`Interpreter` to avoid unnecessary copies. If the `ByteBuffer` is a direct byte +buffer, its order must be `ByteOrder.nativeOrder()`. After it is used for a +model inference, it must remain unchanged until the model inference is finished. #### Outputs -Each output should be an array, or a multi-dimensional array of the supported -primitive types. +Each output should be an array or multi-dimensional array of the supported +primitive types, or a ByteBuffer of the appropriate size. Note that some models +have dynamic outputs, where the shape of output tensors can vary depending on +the input. There's no straightforward way of handling this with the existing +Java inference API, but planned extensions will make this possible. #### Running Model Inference @@ -339,9 +347,10 @@ interpreter.runForMultipleInputsOutputs(inputs, map_of_indices_to_outputs); where each entry in `inputs` corresponds to an input tensor and `map_of_indices_to_outputs` maps indices of output tensors to the corresponding output data. In both cases the tensor indices should correspond to -the values given to the `TensorFlow Lite Optimized Converter` when the model was -created. Be aware that the order of tensors in `input` must match the order -given to the `TensorFlow Lite Optimized Converter`. +the values given to the [TensorFlow Lite Optimized Converter](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/lite/toco/g3doc/cmdline_examples.md) +when the model was created. Be aware that the order of tensors in `input` must +match the order given to the `TensorFlow Lite Optimized Converter`. + The Java API also provides convenient functions for app developers to get the index of any model input or output using a tensor name: diff --git a/tensorflow/contrib/lite/g3doc/ios.md b/tensorflow/contrib/lite/g3doc/ios.md index 5ff0412209..a83d2c8fec 100644 --- a/tensorflow/contrib/lite/g3doc/ios.md +++ b/tensorflow/contrib/lite/g3doc/ios.md @@ -36,7 +36,7 @@ brew link libtool Then you need to run a shell script to download the dependencies you need: ```bash -tensorflow/contrib/lite/download_dependencies.sh +tensorflow/contrib/lite/tools/make/download_dependencies.sh ``` This will fetch copies of libraries and data from the web and install them in @@ -46,14 +46,14 @@ With all of the dependencies set up, you can now build the library for all five supported architectures on iOS: ```bash -tensorflow/contrib/lite/build_ios_universal_lib.sh +tensorflow/contrib/lite/tools/make/build_ios_universal_lib.sh ``` Under the hood this uses a makefile in `tensorflow/contrib/lite` to build the different versions of the library, followed by a call to `lipo` to bundle them into a universal file containing armv7, armv7s, arm64, i386, and x86_64 architectures. The resulting library is in -`tensorflow/contrib/lite/gen/lib/libtensorflow-lite.a`. +`tensorflow/contrib/lite/tools/make/gen/lib/libtensorflow-lite.a`. If you get an error such as `no such file or directory: 'x86_64'` when running `build_ios_universal_lib.sh`: open Xcode > Preferences > Locations, and ensure diff --git a/tensorflow/contrib/lite/g3doc/rpi.md b/tensorflow/contrib/lite/g3doc/rpi.md index 8ed8640582..41a1892b6f 100644 --- a/tensorflow/contrib/lite/g3doc/rpi.md +++ b/tensorflow/contrib/lite/g3doc/rpi.md @@ -1,28 +1,36 @@ - # TensorFlow Lite for Raspberry Pi ## Cross compiling -### Installing toolchian -This has been tested on Ubuntu 16.04.3 64bit and Tensorflow devel docker image [tensorflow/tensorflow:nightly-devel](https://hub.docker.com/r/tensorflow/tensorflow/tags/). -To cross compiling TensorFlow Lite. First you should install the toolchain and libs. +### Installing the toolchain + +This has been tested on Ubuntu 16.04.3 64bit and Tensorflow devel docker image +[tensorflow/tensorflow:nightly-devel](https://hub.docker.com/r/tensorflow/tensorflow/tags/). + +To cross compile TensorFlow Lite, first install the toolchain and libs. + ```bash sudo apt-get update sudo apt-get install crossbuild-essential-armhf ``` -> If you are using docker, you may not use `sudo` + +> If you are using Docker, you may not use `sudo`. ### Building + Clone this Tensorflow repository, Run this script at the root of the repository to download all the dependencies: + > The Tensorflow repository is in `/tensorflow` if you are using `tensorflow/tensorflow:nightly-devel` docker image, just try it. + ```bash -./tensorflow/contrib/lite/download_dependencies.sh +./tensorflow/contrib/lite/tools/make/download_dependencies.sh ``` Note that you only need to do this once. You should then be able to compile: + ```bash -./tensorflow/contrib/lite/build_rpi_lib.sh +./tensorflow/contrib/lite/tools/make/build_rpi_lib.sh ``` This should compile a static library in: @@ -31,21 +39,23 @@ This should compile a static library in: ## Native compiling This has been tested on Raspberry Pi 3b, Raspbian GNU/Linux 9.1 (stretch), gcc version 6.3.0 20170516 (Raspbian 6.3.0-18+rpi1). -Log in to you RPI, install the toolchain. +Log in to you Raspberry Pi, install the toolchain. + ```bash sudo apt-get install build-essential ``` -First, clone this TensorFlow repository. Run this at the root of the repository: +First, clone the TensorFlow repository. Run this at the root of the repository: + ```bash -./tensorflow/contrib/lite/download_dependencies.sh +./tensorflow/contrib/lite/tools/make/download_dependencies.sh ``` Note that you only need to do this once. You should then be able to compile: ```bash -./tensorflow/contrib/lite/build_rpi_lib.sh +./tensorflow/contrib/lite/tools/make/build_rpi_lib.sh ``` This should compile a static library in: -`tensorflow/contrib/lite/gen/lib/rpi_armv7/libtensorflow-lite.a`. +`tensorflow/contrib/lite/tools/make/gen/lib/rpi_armv7/libtensorflow-lite.a`. diff --git a/tensorflow/contrib/lite/java/demo/app/build.gradle b/tensorflow/contrib/lite/java/demo/app/build.gradle index 92f04c651c..05301ebf88 100644 --- a/tensorflow/contrib/lite/java/demo/app/build.gradle +++ b/tensorflow/contrib/lite/java/demo/app/build.gradle @@ -10,7 +10,6 @@ android { targetSdkVersion 26 versionCode 1 versionName "1.0" - testInstrumentationRunner "androidx.test.runner.AndroidJUnitRunner" // Remove this block. jackOptions { @@ -44,9 +43,6 @@ repositories { dependencies { compile fileTree(dir: 'libs', include: ['*.jar']) - androidTestCompile('androidx.test.espresso:espresso-core:3.1.0-alpha3', { - exclude group: 'com.android.support', module: 'support-annotations' - }) compile 'com.android.support:appcompat-v7:25.2.0' compile 'com.android.support.constraint:constraint-layout:1.0.2' compile 'com.android.support:design:25.2.0' @@ -54,8 +50,6 @@ dependencies { compile 'com.android.support:support-v13:25.2.0' compile 'org.tensorflow:tensorflow-lite:0.0.0-nightly' - - testCompile 'junit:junit:4.12' } def modelDownloadUrl = "https://storage.googleapis.com/download.tensorflow.org/models/tflite/mobilenet_v1_224_android_quant_2017_11_08.zip" diff --git a/tensorflow/contrib/lite/java/ovic/demo/app/build.gradle b/tensorflow/contrib/lite/java/ovic/demo/app/build.gradle index 2a08608bbb..4f3a6cdb2f 100644 --- a/tensorflow/contrib/lite/java/ovic/demo/app/build.gradle +++ b/tensorflow/contrib/lite/java/ovic/demo/app/build.gradle @@ -9,7 +9,6 @@ android { targetSdkVersion 26 versionCode 1 versionName "1.0" - testInstrumentationRunner "androidx.test.runner.AndroidJUnitRunner" // Remove this block. jackOptions { @@ -43,9 +42,6 @@ repositories { dependencies { compile fileTree(dir: 'libs', include: ['*.jar']) - androidTestCompile('androidx.test.espresso:espresso-core:3.1.0-alpha3', { - exclude group: 'com.android.support', module: 'support-annotations' - }) compile 'com.android.support:appcompat-v7:25.2.0' compile 'com.android.support.constraint:constraint-layout:1.0.2' compile 'com.android.support:design:25.2.0' @@ -53,6 +49,4 @@ dependencies { compile 'com.android.support:support-v13:25.2.0' compile 'org.tensorflow:tensorflow-lite:+' - - testCompile 'junit:junit:4.12' } diff --git a/tensorflow/contrib/lite/kernels/BUILD b/tensorflow/contrib/lite/kernels/BUILD index 8287115f5c..b7c5cbf207 100644 --- a/tensorflow/contrib/lite/kernels/BUILD +++ b/tensorflow/contrib/lite/kernels/BUILD @@ -6,7 +6,7 @@ licenses(["notice"]) # Apache 2.0 load("//tensorflow/contrib/lite:build_def.bzl", "tflite_copts") load("//tensorflow/contrib/lite:special_rules.bzl", "tflite_portable_test_suite") -load("//tensorflow:tensorflow.bzl", "tf_cc_test") +load("//tensorflow:tensorflow.bzl", "tf_cc_test", "tf_opts_nortti_if_android") # Suppress warnings that are introduced by Eigen Tensor. EXTRA_EIGEN_COPTS = select({ @@ -147,7 +147,7 @@ tf_cc_test( ) cc_library( - name = "builtin_ops", + name = "builtin_op_kernels", srcs = [ "activations.cc", "add.cc", @@ -177,6 +177,7 @@ cc_library( "gather.cc", "hashtable_lookup.cc", "l2norm.cc", + "layer_norm_lstm.cc", "local_response_norm.cc", "logical.cc", "lsh_projection.cc", @@ -191,7 +192,7 @@ cc_library( "pooling.cc", "pow.cc", "reduce.cc", - "register.cc", + "relu1.cc", "reshape.cc", "resize_bilinear.cc", "select.cc", @@ -216,9 +217,9 @@ cc_library( ], hdrs = [ "padding.h", - "register.h", ], - copts = tflite_copts() + EXTRA_EIGEN_COPTS, + copts = tflite_copts() + tf_opts_nortti_if_android() + EXTRA_EIGEN_COPTS, + visibility = ["//visibility:private"], deps = [ ":activation_functor", ":eigen_support", @@ -242,6 +243,17 @@ cc_library( ], ) +cc_library( + name = "builtin_ops", + srcs = ["register.cc"], + hdrs = ["register.h"], + deps = [ + ":builtin_op_kernels", + "//tensorflow/contrib/lite:framework", + "//tensorflow/contrib/lite:util", + ], +) + tf_cc_test( name = "audio_spectrogram_test", size = "small", @@ -294,6 +306,23 @@ tf_cc_test( ) tf_cc_test( + name = "relu1_test", + size = "small", + srcs = ["relu1_test.cc"], + tags = [ + "no_oss", + "tflite_not_portable_ios", + ], + deps = [ + ":builtin_ops", + "//tensorflow/contrib/lite:framework", + "//tensorflow/contrib/lite/kernels:test_util", + "@com_google_googletest//:gtest", + "@flatbuffers", + ], +) + +tf_cc_test( name = "activations_test", size = "small", srcs = ["activations_test.cc"], @@ -904,6 +933,20 @@ tf_cc_test( ) tf_cc_test( + name = "layer_norm_lstm_test", + size = "small", + srcs = ["layer_norm_lstm_test.cc"], + tags = ["tflite_not_portable_ios"], + deps = [ + ":builtin_ops", + "//tensorflow/contrib/lite:framework", + "//tensorflow/contrib/lite/kernels:test_util", + "@com_google_googletest//:gtest", + "@flatbuffers", + ], +) + +tf_cc_test( name = "lstm_test", size = "small", srcs = ["lstm_test.cc"], diff --git a/tensorflow/contrib/lite/kernels/activations.cc b/tensorflow/contrib/lite/kernels/activations.cc index 9c891fe904..5cdd9fc94f 100644 --- a/tensorflow/contrib/lite/kernels/activations.cc +++ b/tensorflow/contrib/lite/kernels/activations.cc @@ -200,7 +200,7 @@ TfLiteStatus SoftmaxPrepare(TfLiteContext* context, TfLiteNode* node) { TF_LITE_ENSURE_EQ(context, input->type, output->type); const int num_dims = NumDimensions(input); - TF_LITE_ENSURE(context, num_dims == 1 || num_dims == 2 || num_dims == 4); + TF_LITE_ENSURE(context, num_dims >= 1 && num_dims <= 4); if (input->type == kTfLiteUInt8) { TF_LITE_ENSURE_EQ(context, output->params.zero_point, 0); @@ -453,6 +453,19 @@ void Softmax2DFloat(const TfLiteTensor* input, TfLiteTensor* output, Softmax(input->data.f, input_size, batch_size, params->beta, output->data.f); } +// Takes a 3D tensor and perform softmax along the last dimension. +void Softmax3DFloat(const TfLiteTensor* input, TfLiteTensor* output, + TfLiteSoftmaxParams* params) { + const int batch_size = input->dims->data[0]; + const int intermediate_size = input->dims->data[1]; + const int input_size = input->dims->data[2]; + optimized_ops::Softmax( + GetTensorData<float>(input), + GetTensorShape({batch_size, intermediate_size, 1, input_size}), + params->beta, GetTensorData<float>(output), + GetTensorShape({batch_size, intermediate_size, 1, input_size})); +} + void Softmax1DQuantized(const TfLiteTensor* input, TfLiteTensor* output, TfLiteSoftmaxParams* params, OpData* data) { // TODO(ahentz): this is arguably a dirty trick. Since the implementation @@ -480,6 +493,19 @@ void Softmax2DQuantized(const TfLiteTensor* input, TfLiteTensor* output, GetTensorShape({batch_size, 1, 1, input_size})); } +void Softmax3DQuantized(const TfLiteTensor* input, TfLiteTensor* output, + TfLiteSoftmaxParams* params, OpData* data) { + const int batch_size = input->dims->data[0]; + const int intermediate_size = input->dims->data[1]; + const int input_size = input->dims->data[2]; + optimized_ops::Softmax( + GetTensorData<uint8_t>(input), + GetTensorShape({batch_size, intermediate_size, 1, input_size}), + data->input_multiplier, data->input_left_shift, data->diff_min, + GetTensorData<uint8_t>(output), + GetTensorShape({batch_size, intermediate_size, 1, input_size})); +} + // Takes a 4D tensor and perform softmax along the forth dimension. void Softmax4DFloat(const TfLiteTensor* input, TfLiteTensor* output, TfLiteSoftmaxParams* params) { @@ -515,6 +541,10 @@ TfLiteStatus SoftmaxEval(TfLiteContext* context, TfLiteNode* node) { Softmax2DFloat(input, output, params); return kTfLiteOk; } + if (NumDimensions(input) == 3) { + Softmax3DFloat(input, output, params); + return kTfLiteOk; + } if (NumDimensions(input) == 4) { Softmax4DFloat(input, output, params); return kTfLiteOk; @@ -533,6 +563,10 @@ TfLiteStatus SoftmaxEval(TfLiteContext* context, TfLiteNode* node) { Softmax2DQuantized(input, output, params, data); return kTfLiteOk; } + if (NumDimensions(input) == 3) { + Softmax3DQuantized(input, output, params, data); + return kTfLiteOk; + } if (NumDimensions(input) == 4) { Softmax4DQuantized(input, output, params, data); return kTfLiteOk; diff --git a/tensorflow/contrib/lite/kernels/activations_test.cc b/tensorflow/contrib/lite/kernels/activations_test.cc index e577e3a762..9fa47e190a 100644 --- a/tensorflow/contrib/lite/kernels/activations_test.cc +++ b/tensorflow/contrib/lite/kernels/activations_test.cc @@ -339,6 +339,76 @@ TEST(QuantizedActivationsOpTest, Softmax4D) { kQuantizedTolerance))); } +TEST(FloatActivationsOpTest, Softmax3D) { + FloatActivationsOpModel m(0.1, + /*input=*/{TensorType_FLOAT32, {1, 2, 4}}); + m.SetInput({ + 0, -6, 2, 4, // depth = 0 + 3, -2, 10, 1, // depth = 1 + }); + m.Invoke(); + EXPECT_THAT(m.GetOutput(), ElementsAreArray(ArrayFloatNear({ + .23463, .12877, .28658, .35003, // + .22528, .13664, .45365, .18443, // + }))); + + // Same input, but a different shape. + FloatActivationsOpModel m2(0.1, + /*input=*/{TensorType_FLOAT32, {4, 1, 2}}); + m2.SetInput({ + 0, -6, // + 2, 4, // + 3, -2, // + 10, 1, // + }); + m2.Invoke(); + EXPECT_THAT(m2.GetOutput(), ElementsAreArray(ArrayFloatNear({ + 0.645656, 0.354344, // + 0.450166, 0.549834, // + 0.622459, 0.377541, // + 0.710949, 0.28905, // + }))); +} + +TEST(QuantizedActivationsOpTest, Softmax3D) { + QuantizedActivationsOpModel m( + 0.1, + /*input=*/{TensorType_UINT8, {1, 2, 4}, -10, 10}); + m.SetInput<uint8_t>({ + 0, -6, 2, 4, // depth = 0 + 3, -2, 10, 1, // depth = 1 + }); + m.Invoke(); + EXPECT_THAT(m.GetDequantizedOutput<uint8_t>(), + ElementsAreArray(ArrayFloatNear( + { + .23463, .12877, .28658, .35003, // + .22528, .13664, .45365, .18443, // + }, + kQuantizedTolerance))); + + // Same input, but a different shape. + QuantizedActivationsOpModel m2( + 0.1, + /*input=*/{TensorType_UINT8, {4, 1, 2}, -10, 10}); + m2.SetInput<uint8_t>({ + 0, -6, // + 2, 4, // + 3, -2, // + 10, 1, // + }); + m2.Invoke(); + EXPECT_THAT(m2.GetDequantizedOutput<uint8_t>(), + ElementsAreArray(ArrayFloatNear( + { + 0.645656, 0.354344, // + 0.450166, 0.549834, // + 0.622459, 0.377541, // + 0.710949, 0.28905, // + }, + kQuantizedTolerance))); +} + TEST(FloatActivationsOpTest, Softmax1D) { FloatActivationsOpModel m(0.1, /*input=*/{TensorType_FLOAT32, {8}}); diff --git a/tensorflow/contrib/lite/kernels/bidirectional_sequence_lstm.cc b/tensorflow/contrib/lite/kernels/bidirectional_sequence_lstm.cc index a11a59aa05..6b8ecdd5c3 100644 --- a/tensorflow/contrib/lite/kernels/bidirectional_sequence_lstm.cc +++ b/tensorflow/contrib/lite/kernels/bidirectional_sequence_lstm.cc @@ -94,18 +94,54 @@ constexpr int kBwProjectionWeightsTensor = 33; // Optional // Projection bias tensor of size {n_output} constexpr int kBwProjectionBiasTensor = 34; // Optional -// Output tensors. -constexpr int kFwOutputStateTensor = 0; -constexpr int kFwCellStateTensor = 1; -constexpr int kFwOutputTensor = 2; +// Stateful input tensors that are variables and will be modified by the Op. +// Activation state tensors of size {n_batch, n_output} +constexpr int kFwInputActivationStateTensor = 35; +// Cell state tensors of size {n_batch, n_cell} +constexpr int kFwInputCellStateTensor = 36; +// Activation state tensors of size {n_batch, n_output} +constexpr int kBwInputActivationStateTensor = 37; +// Cell state tensors of size {n_batch, n_cell} +constexpr int kBwInputCellStateTensor = 38; + +// Auxiliary input and weights when stacking. +constexpr int kAuxInputTensor = 39; // Optional +// Forward weights. +constexpr int kFwAuxInputToInputWeightsTensor = 40; // Optional +constexpr int kFwAuxInputToForgetWeightsTensor = 41; // Optional +constexpr int kFwAuxInputToCellWeightsTensor = 42; // Optional +constexpr int kFwAuxInputToOutputWeightsTensor = 43; // Optional +// Backward weights. +constexpr int kBwAuxInputToInputWeightsTensor = 44; // Optional +constexpr int kBwAuxInputToForgetWeightsTensor = 45; // Optional +constexpr int kBwAuxInputToCellWeightsTensor = 46; // Optional +constexpr int kBwAuxInputToOutputWeightsTensor = 47; // Optional -constexpr int kBwOutputStateTensor = 3; -constexpr int kBwCellStateTensor = 4; -constexpr int kBwOutputTensor = 5; +// Output tensors. +constexpr int kFwOutputTensor = 0; +constexpr int kBwOutputTensor = 1; + +// Temporary tensors. +enum TemporaryTensor { + // Scratch buffers for input, forget, etc. gates + kFwScratchBuffer = 0, + kBwScratchBuffer = 1, + // Quantized tensors needed for the hybrid kernel. + kInputQuantized = 2, + kAuxInputQuantized = 3, // Quantized tensor needed for auxiliary input. + kFwActivationStateQuantized = 4, + kBwActivationStateQuantized = 5, + kFwCellStateQuantized = 6, + kBwCellStateQuantized = 7, + kScalingFactors = 8, + kProductScalingFactors = 9, + kRecoveredCellWeights = 10, + kNumTemporaryTensors = 11 +}; void* Init(TfLiteContext* context, const char* buffer, size_t length) { auto* scratch_tensor_index = new int; - context->AddTensors(context, 2, scratch_tensor_index); + context->AddTensors(context, kNumTemporaryTensors, scratch_tensor_index); return scratch_tensor_index; } @@ -126,7 +162,7 @@ TfLiteStatus CheckLstmTensorDimensions( int input_gate_bias_tensor, int forget_gate_bias_tensor, int cell_gate_bias_tensor, int output_gate_bias_tensor, int projection_weights_tensor, int projection_bias_tensor) { - auto* params = reinterpret_cast<TfLiteLSTMParams*>(node->builtin_data); + const auto* params = reinterpret_cast<TfLiteLSTMParams*>(node->builtin_data); // Making sure clipping parameters have valid values. // == 0 means no clipping @@ -307,19 +343,20 @@ TfLiteStatus CheckInputTensorDimensions(TfLiteContext* context, return kTfLiteOk; } -// Resize the output, state and scratch tensors based on the sizes of the input +// Resize the output and scratch tensors based on the sizes of the input // tensors. Also check that the size of the input tensors match each other. TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { int* scratch_tensor_index = reinterpret_cast<int*>(node->user_data); // Check we have all the inputs and outputs we need. - TF_LITE_ENSURE_EQ(context, node->inputs->size, 35); - TF_LITE_ENSURE_EQ(context, node->outputs->size, 6); + TF_LITE_ENSURE_EQ(context, node->inputs->size, 48); + TF_LITE_ENSURE_EQ(context, node->outputs->size, 2); // Inferring batch size, number of outputs and sequence length and // number of cells from the input tensors. const TfLiteTensor* input = GetInput(context, node, kInputTensor); - TF_LITE_ENSURE(context, input->dims->size > 1); + TF_LITE_ENSURE_EQ(context, input->type, kTfLiteFloat32); + TF_LITE_ENSURE_EQ(context, input->dims->size, 3); const int max_time = input->dims->data[0]; const int n_batch = input->dims->data[1]; const int n_input = input->dims->data[2]; @@ -343,13 +380,63 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { context, CheckInputTensorDimensions(context, node, n_input, n_fw_output, n_fw_cell)); - // Get the pointer to output, state and scratch buffer tensors. - TfLiteTensor* fw_output = GetOutput(context, node, kFwOutputTensor); - TfLiteTensor* fw_output_state = - GetOutput(context, node, kFwOutputStateTensor); - TfLiteTensor* fw_cell_state = GetOutput(context, node, kFwCellStateTensor); + // Get (optional) auxiliary inputs and weights. + const TfLiteTensor* aux_input = + GetOptionalInputTensor(context, node, kAuxInputTensor); + const TfLiteTensor* fw_aux_input_to_input_weights = + GetOptionalInputTensor(context, node, kFwAuxInputToInputWeightsTensor); + const TfLiteTensor* fw_aux_input_to_forget_weights = + GetOptionalInputTensor(context, node, kFwAuxInputToForgetWeightsTensor); + const TfLiteTensor* fw_aux_input_to_cell_weights = + GetOptionalInputTensor(context, node, kFwAuxInputToCellWeightsTensor); + const TfLiteTensor* fw_aux_input_to_output_weights = + GetOptionalInputTensor(context, node, kFwAuxInputToOutputWeightsTensor); + const TfLiteTensor* bw_aux_input_to_input_weights = + GetOptionalInputTensor(context, node, kBwAuxInputToInputWeightsTensor); + const TfLiteTensor* bw_aux_input_to_forget_weights = + GetOptionalInputTensor(context, node, kBwAuxInputToForgetWeightsTensor); + const TfLiteTensor* bw_aux_input_to_cell_weights = + GetOptionalInputTensor(context, node, kBwAuxInputToCellWeightsTensor); + const TfLiteTensor* bw_aux_input_to_output_weights = + GetOptionalInputTensor(context, node, kBwAuxInputToOutputWeightsTensor); + + const bool aux_inputs_all_or_none = + ((aux_input != nullptr) && (fw_aux_input_to_cell_weights != nullptr) && + (fw_aux_input_to_forget_weights != nullptr) && + (fw_aux_input_to_output_weights != nullptr) && + (bw_aux_input_to_cell_weights != nullptr) && + (bw_aux_input_to_forget_weights != nullptr) && + (bw_aux_input_to_output_weights != nullptr)) || + ((fw_aux_input_to_cell_weights == nullptr) && + (fw_aux_input_to_forget_weights == nullptr) && + (fw_aux_input_to_output_weights == nullptr) && + (bw_aux_input_to_cell_weights == nullptr) && + (bw_aux_input_to_forget_weights == nullptr) && + (bw_aux_input_to_output_weights == nullptr)); + TF_LITE_ENSURE(context, aux_inputs_all_or_none); + const bool has_aux_input = (aux_input != nullptr); + + if (has_aux_input) { + // Check that aux_input has the same dimensions (except last) as the input. + TF_LITE_ASSERT_EQ(aux_input->dims->data[0], input->dims->data[0]); + TF_LITE_ASSERT_EQ(aux_input->dims->data[1], input->dims->data[1]); + } - // Resize the output, output_state and cell_state tensors. + // Get the pointer to output, activation_state and cell_state buffer tensors. + TfLiteTensor* fw_output = GetOutput(context, node, kFwOutputTensor); + TfLiteTensor* fw_activation_state = + GetVariableInput(context, node, kFwInputActivationStateTensor); + TfLiteTensor* fw_cell_state = + GetVariableInput(context, node, kFwInputCellStateTensor); + + // Check the shape of input state tensors. + // These tensor may be 1D or 2D. It's fine as long as the total size is + // correct. + TF_LITE_ENSURE_EQ(context, NumElements(fw_activation_state), + n_batch * n_fw_output); + TF_LITE_ENSURE_EQ(context, NumElements(fw_cell_state), n_batch * n_fw_cell); + + // Resize the output tensors. TfLiteIntArray* fw_output_size = TfLiteIntArrayCreate(3); fw_output_size->data[0] = max_time; fw_output_size->data[1] = n_batch; @@ -357,32 +444,28 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, fw_output, fw_output_size)); - TfLiteIntArray* fw_output_state_size = TfLiteIntArrayCreate(2); - fw_output_state_size->data[0] = n_batch; - fw_output_state_size->data[1] = n_fw_output; - TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, fw_output_state, - fw_output_state_size)); - - TfLiteIntArray* fw_cell_size = TfLiteIntArrayCreate(2); - fw_cell_size->data[0] = n_batch; - fw_cell_size->data[1] = n_fw_cell; - TF_LITE_ENSURE_OK( - context, context->ResizeTensor(context, fw_cell_state, fw_cell_size)); + // The weights are of consistent type, so it suffices to check one. + const bool is_hybrid_op = (fw_input_to_output_weights->type == kTfLiteUInt8); - // Create a scratch buffer tensor. TfLiteIntArrayFree(node->temporaries); - node->temporaries = TfLiteIntArrayCreate(2); - node->temporaries->data[0] = *scratch_tensor_index; - TfLiteTensor* fw_scratch_buffer = GetTemporary(context, node, /*index=*/0); + if (is_hybrid_op) { + node->temporaries = TfLiteIntArrayCreate(kNumTemporaryTensors); + } else { + node->temporaries = TfLiteIntArrayCreate(2); // the two scratch buffers. + } + // Create a scratch buffer tensor. + node->temporaries->data[kFwScratchBuffer] = *scratch_tensor_index; + TfLiteTensor* fw_scratch_buffer = + GetTemporary(context, node, kFwScratchBuffer); fw_scratch_buffer->type = input->type; fw_scratch_buffer->allocation_type = kTfLiteArenaRw; - // Mark state tensors as persistent tensors. - fw_output_state->allocation_type = kTfLiteArenaRwPersistent; - fw_cell_state->allocation_type = kTfLiteArenaRwPersistent; - const TfLiteTensor* fw_input_to_input_weights = GetOptionalInputTensor(context, node, kFwInputToInputWeightsTensor); + if (has_aux_input) { + TF_LITE_ENSURE_EQ(context, fw_aux_input_to_input_weights->dims->data[0], + fw_input_to_input_weights->dims->data[0]); + } const bool fw_use_cifg = (fw_input_to_input_weights == nullptr); TfLiteIntArray* fw_scratch_buffer_size = TfLiteIntArrayCreate(2); fw_scratch_buffer_size->data[0] = n_batch; @@ -415,13 +498,14 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { context, CheckInputTensorDimensions(context, node, n_input, n_bw_output, n_bw_cell)); - // Get the pointer to output, output_state and cell_state buffer tensors. + // Get the pointer to output, activation_state and cell_state buffer tensors. TfLiteTensor* bw_output = GetOutput(context, node, kBwOutputTensor); - TfLiteTensor* bw_output_state = - GetOutput(context, node, kBwOutputStateTensor); - TfLiteTensor* bw_cell_state = GetOutput(context, node, kBwCellStateTensor); + TfLiteTensor* bw_activation_state = + GetVariableInput(context, node, kBwInputActivationStateTensor); + TfLiteTensor* bw_cell_state = + GetVariableInput(context, node, kBwInputCellStateTensor); - // Resize the output, output_state and cell_state tensors. + // Resize the output tensors. TfLiteIntArray* bw_output_size = TfLiteIntArrayCreate(3); bw_output_size->data[0] = max_time; bw_output_size->data[1] = n_batch; @@ -429,30 +513,27 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, bw_output, bw_output_size)); - TfLiteIntArray* bw_output_state_size = TfLiteIntArrayCreate(2); - bw_output_state_size->data[0] = n_batch; - bw_output_state_size->data[1] = n_bw_output; - TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, bw_output_state, - bw_output_state_size)); - - TfLiteIntArray* bw_cell_size = TfLiteIntArrayCreate(2); - bw_cell_size->data[0] = n_batch; - bw_cell_size->data[1] = n_bw_cell; - TF_LITE_ENSURE_OK( - context, context->ResizeTensor(context, bw_cell_state, bw_cell_size)); + // Check the shape of input state tensors. + // These tensor may be 1D or 2D. It's fine as long as the total size is + // correct. + TF_LITE_ENSURE_EQ(context, NumElements(bw_activation_state), + n_batch * n_bw_output); + TF_LITE_ENSURE_EQ(context, NumElements(bw_cell_state), n_batch * n_bw_cell); // Create a scratch buffer tensor. - node->temporaries->data[1] = *(scratch_tensor_index) + 1; - TfLiteTensor* bw_scratch_buffer = GetTemporary(context, node, /*index=*/1); + node->temporaries->data[kBwScratchBuffer] = + *(scratch_tensor_index) + kBwScratchBuffer; + TfLiteTensor* bw_scratch_buffer = + GetTemporary(context, node, kBwScratchBuffer); bw_scratch_buffer->type = input->type; bw_scratch_buffer->allocation_type = kTfLiteArenaRw; - // Mark state tensors as persistent tensors. - bw_output_state->allocation_type = kTfLiteArenaRwPersistent; - bw_cell_state->allocation_type = kTfLiteArenaRwPersistent; - const TfLiteTensor* bw_input_to_input_weights = GetOptionalInputTensor(context, node, kBwInputToInputWeightsTensor); + if (has_aux_input) { + TF_LITE_ENSURE_EQ(context, bw_aux_input_to_input_weights->dims->data[0], + bw_input_to_input_weights->dims->data[0]); + } const bool bw_use_cifg = (bw_input_to_input_weights == nullptr); TfLiteIntArray* bw_scratch_buffer_size = TfLiteIntArrayCreate(2); bw_scratch_buffer_size->data[0] = n_batch; @@ -465,18 +546,528 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { } TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, bw_scratch_buffer, bw_scratch_buffer_size)); + if (is_hybrid_op) { + // Allocate temporary tensors to store quantized values of input, aux_input + // (if present), activation_state and cell_state tensors. + node->temporaries->data[kInputQuantized] = + *scratch_tensor_index + kInputQuantized; + TfLiteTensor* input_quantized = + GetTemporary(context, node, kInputQuantized); + input_quantized->type = kTfLiteUInt8; + input_quantized->allocation_type = kTfLiteArenaRw; + if (!TfLiteIntArrayEqual(input_quantized->dims, input->dims)) { + TfLiteIntArray* input_quantized_size = TfLiteIntArrayCopy(input->dims); + TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, input_quantized, + input_quantized_size)); + } + + if (has_aux_input) { + node->temporaries->data[kAuxInputQuantized] = + *scratch_tensor_index + kAuxInputQuantized; + TfLiteTensor* aux_input_quantized = + GetTemporary(context, node, kAuxInputQuantized); + aux_input_quantized->type = kTfLiteUInt8; + aux_input_quantized->allocation_type = kTfLiteArenaRw; + if (!TfLiteIntArrayEqual(aux_input_quantized->dims, aux_input->dims)) { + TfLiteIntArray* aux_input_quantized_size = + TfLiteIntArrayCopy(aux_input->dims); + TF_LITE_ENSURE_OK(context, + context->ResizeTensor(context, aux_input_quantized, + aux_input_quantized_size)); + } + } + + node->temporaries->data[kFwActivationStateQuantized] = + *scratch_tensor_index + kFwActivationStateQuantized; + TfLiteTensor* fw_activation_state_quantized = + GetTemporary(context, node, kFwActivationStateQuantized); + fw_activation_state_quantized->type = kTfLiteUInt8; + fw_activation_state_quantized->allocation_type = kTfLiteArenaRw; + if (!TfLiteIntArrayEqual(fw_activation_state_quantized->dims, + fw_activation_state->dims)) { + TfLiteIntArray* fw_activation_state_quantized_size = + TfLiteIntArrayCopy(fw_activation_state->dims); + TF_LITE_ENSURE_OK( + context, context->ResizeTensor(context, fw_activation_state_quantized, + fw_activation_state_quantized_size)); + } + node->temporaries->data[kBwActivationStateQuantized] = + *scratch_tensor_index + kBwActivationStateQuantized; + TfLiteTensor* bw_activation_state_quantized = + GetTemporary(context, node, kBwActivationStateQuantized); + bw_activation_state_quantized->type = kTfLiteUInt8; + bw_activation_state_quantized->allocation_type = kTfLiteArenaRw; + if (!TfLiteIntArrayEqual(bw_activation_state_quantized->dims, + bw_activation_state->dims)) { + TfLiteIntArray* bw_activation_state_quantized_size = + TfLiteIntArrayCopy(bw_activation_state->dims); + TF_LITE_ENSURE_OK( + context, context->ResizeTensor(context, bw_activation_state_quantized, + bw_activation_state_quantized_size)); + } + node->temporaries->data[kFwCellStateQuantized] = + *scratch_tensor_index + kFwCellStateQuantized; + TfLiteTensor* fw_cell_state_quantized = + GetTemporary(context, node, kFwCellStateQuantized); + fw_cell_state_quantized->type = kTfLiteUInt8; + fw_cell_state_quantized->allocation_type = kTfLiteArenaRw; + if (!TfLiteIntArrayEqual(fw_cell_state_quantized->dims, + fw_cell_state->dims)) { + TfLiteIntArray* fw_cell_state_quantized_size = + TfLiteIntArrayCopy(fw_cell_state->dims); + TF_LITE_ENSURE_OK(context, + context->ResizeTensor(context, fw_cell_state_quantized, + fw_cell_state_quantized_size)); + } + node->temporaries->data[kBwCellStateQuantized] = + *scratch_tensor_index + kBwCellStateQuantized; + TfLiteTensor* bw_cell_state_quantized = + GetTemporary(context, node, kBwCellStateQuantized); + bw_cell_state_quantized->type = kTfLiteUInt8; + bw_cell_state_quantized->allocation_type = kTfLiteArenaRw; + if (!TfLiteIntArrayEqual(bw_cell_state_quantized->dims, + bw_cell_state->dims)) { + TfLiteIntArray* bw_cell_state_quantized_size = + TfLiteIntArrayCopy(bw_cell_state->dims); + TF_LITE_ENSURE_OK(context, + context->ResizeTensor(context, bw_cell_state_quantized, + bw_cell_state_quantized_size)); + } + + // Allocate temporary tensors to store scaling factors and product scaling + // factors. The latter is a convenience storage which allows to quantize + // a vector once (which produces the scaling factors) and multiply it with + // different matrices (which requires multiplying the scaling factors with + // the scaling factor of the matrix). + node->temporaries->data[kScalingFactors] = + *scratch_tensor_index + kScalingFactors; + TfLiteTensor* scaling_factors = + GetTemporary(context, node, kScalingFactors); + scaling_factors->type = kTfLiteFloat32; + scaling_factors->allocation_type = kTfLiteArenaRw; + TfLiteIntArray* scaling_factors_size = TfLiteIntArrayCreate(1); + scaling_factors_size->data[0] = n_batch; + if (!TfLiteIntArrayEqual(scaling_factors->dims, scaling_factors_size)) { + TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, scaling_factors, + scaling_factors_size)); + } + node->temporaries->data[kProductScalingFactors] = + *scratch_tensor_index + kProductScalingFactors; + TfLiteTensor* prod_scaling_factors = + GetTemporary(context, node, kProductScalingFactors); + prod_scaling_factors->type = kTfLiteFloat32; + prod_scaling_factors->allocation_type = kTfLiteArenaRw; + TfLiteIntArray* prod_scaling_factors_size = TfLiteIntArrayCreate(1); + prod_scaling_factors_size->data[0] = n_batch; + if (!TfLiteIntArrayEqual(prod_scaling_factors->dims, + prod_scaling_factors_size)) { + TF_LITE_ENSURE_OK(context, + context->ResizeTensor(context, prod_scaling_factors, + prod_scaling_factors_size)); + } + + // Allocate a temporary tensor to store the recovered cell weights. Since + // this is used for diagonal matrices, only need to store n_cell values. + node->temporaries->data[kRecoveredCellWeights] = + *scratch_tensor_index + kRecoveredCellWeights; + TfLiteTensor* recovered_cell_weights = + GetTemporary(context, node, kRecoveredCellWeights); + recovered_cell_weights->type = kTfLiteFloat32; + recovered_cell_weights->allocation_type = kTfLiteArenaRw; + TfLiteIntArray* recovered_cell_weights_size = TfLiteIntArrayCreate(1); + recovered_cell_weights_size->data[0] = n_fw_cell; + if (!TfLiteIntArrayEqual(recovered_cell_weights->dims, + recovered_cell_weights_size)) { + TF_LITE_ENSURE_OK(context, + context->ResizeTensor(context, recovered_cell_weights, + recovered_cell_weights_size)); + } + } + return kTfLiteOk; +} + +TfLiteStatus EvalFloat( + const TfLiteTensor* input, const TfLiteTensor* input_to_input_weights, + const TfLiteTensor* input_to_forget_weights, + const TfLiteTensor* input_to_cell_weights, + const TfLiteTensor* input_to_output_weights, + const TfLiteTensor* recurrent_to_input_weights, + const TfLiteTensor* recurrent_to_forget_weights, + const TfLiteTensor* recurrent_to_cell_weights, + const TfLiteTensor* recurrent_to_output_weights, + const TfLiteTensor* cell_to_input_weights, + const TfLiteTensor* cell_to_forget_weights, + const TfLiteTensor* cell_to_output_weights, const TfLiteTensor* aux_input, + const TfLiteTensor* aux_input_to_input_weights, + const TfLiteTensor* aux_input_to_forget_weights, + const TfLiteTensor* aux_input_to_cell_weights, + const TfLiteTensor* aux_input_to_output_weights, + const TfLiteTensor* input_gate_bias, const TfLiteTensor* forget_gate_bias, + const TfLiteTensor* cell_bias, const TfLiteTensor* output_gate_bias, + const TfLiteTensor* projection_weights, const TfLiteTensor* projection_bias, + const TfLiteLSTMParams* params, bool forward_sequence, + TfLiteTensor* scratch_buffer, TfLiteTensor* activation_state, + TfLiteTensor* cell_state, TfLiteTensor* output) { + const int max_time = input->dims->data[0]; + const int n_batch = input->dims->data[1]; + const int n_input = input->dims->data[2]; + const int aux_input_size = (aux_input) ? aux_input->dims->data[2] : 0; + + // n_cell and n_output will be the same size when there is no projection. + const int n_cell = input_to_output_weights->dims->data[0]; + const int n_output = recurrent_to_output_weights->dims->data[1]; + + // Since we have already checked that weights are all there or none, we can + // check the existense of only one to the get the condition. + const bool use_cifg = (input_to_input_weights == nullptr); + const bool use_peephole = (cell_to_output_weights != nullptr); + + // Index the scratch buffers pointers to the global scratch buffer. + float* input_gate_scratch = nullptr; + float* cell_scratch = nullptr; + float* forget_gate_scratch = nullptr; + float* output_gate_scratch = nullptr; + if (use_cifg) { + cell_scratch = scratch_buffer->data.f; + forget_gate_scratch = scratch_buffer->data.f + n_cell * n_batch; + output_gate_scratch = scratch_buffer->data.f + 2 * n_cell * n_batch; + } else { + input_gate_scratch = scratch_buffer->data.f; + cell_scratch = scratch_buffer->data.f + n_cell * n_batch; + forget_gate_scratch = scratch_buffer->data.f + 2 * n_cell * n_batch; + output_gate_scratch = scratch_buffer->data.f + 3 * n_cell * n_batch; + } + + // Check optional tensors, the respective pointers can be null. + const float* input_to_input_weights_ptr = + (use_cifg) ? nullptr : input_to_input_weights->data.f; + const float* recurrent_to_input_weights_ptr = + (use_cifg) ? nullptr : recurrent_to_input_weights->data.f; + const float* input_gate_bias_ptr = + (use_cifg) ? nullptr : input_gate_bias->data.f; + const float* cell_to_input_weights_ptr = + (use_peephole && !use_cifg) ? cell_to_input_weights->data.f : nullptr; + const float* cell_to_forget_weights_ptr = + (use_peephole) ? cell_to_forget_weights->data.f : nullptr; + const float* cell_to_output_weights_ptr = + (use_peephole) ? cell_to_output_weights->data.f : nullptr; + const float* projection_weights_ptr = + (projection_weights == nullptr) ? nullptr : projection_weights->data.f; + const float* projection_bias_ptr = + (projection_bias == nullptr) ? nullptr : projection_bias->data.f; + + float* aux_input_ptr = nullptr; + float* aux_input_to_input_weights_ptr = nullptr; + float* aux_input_to_forget_weights_ptr = nullptr; + float* aux_input_to_cell_weights_ptr = nullptr; + float* aux_input_to_output_weights_ptr = nullptr; + if (aux_input_size > 0) { + aux_input_ptr = aux_input->data.f; + aux_input_to_input_weights_ptr = aux_input_to_input_weights->data.f; + aux_input_to_forget_weights_ptr = aux_input_to_forget_weights->data.f; + aux_input_to_cell_weights_ptr = aux_input_to_cell_weights->data.f; + aux_input_to_output_weights_ptr = aux_input_to_output_weights->data.f; + } + + // Loop through the sequence. + if (forward_sequence) { + for (int t = 0; t < max_time; t++) { + const float* input_ptr = input->data.f + t * n_batch * n_input; + float* output_ptr_time = output->data.f + t * n_batch * n_output; + + kernel_utils::LstmStepWithAuxInput( + input_ptr, input_to_input_weights_ptr, + input_to_forget_weights->data.f, input_to_cell_weights->data.f, + input_to_output_weights->data.f, aux_input_ptr, + aux_input_to_input_weights_ptr, aux_input_to_forget_weights_ptr, + aux_input_to_cell_weights_ptr, aux_input_to_output_weights_ptr, + recurrent_to_input_weights_ptr, recurrent_to_forget_weights->data.f, + recurrent_to_cell_weights->data.f, + recurrent_to_output_weights->data.f, cell_to_input_weights_ptr, + cell_to_forget_weights_ptr, cell_to_output_weights_ptr, + input_gate_bias_ptr, forget_gate_bias->data.f, cell_bias->data.f, + output_gate_bias->data.f, projection_weights_ptr, projection_bias_ptr, + params, n_batch, n_cell, n_input, aux_input_size, n_output, + activation_state->data.f, cell_state->data.f, input_gate_scratch, + forget_gate_scratch, cell_scratch, output_gate_scratch, + output_ptr_time); + } + } else { + // Loop through the sequence backwards. + for (int t = max_time - 1; t >= 0; t--) { + const float* input_ptr = input->data.f + t * n_batch * n_input; + float* output_ptr_time = output->data.f + t * n_batch * n_output; + + kernel_utils::LstmStepWithAuxInput( + input_ptr, input_to_input_weights_ptr, + input_to_forget_weights->data.f, input_to_cell_weights->data.f, + input_to_output_weights->data.f, aux_input_ptr, + aux_input_to_input_weights_ptr, aux_input_to_forget_weights_ptr, + aux_input_to_cell_weights_ptr, aux_input_to_output_weights_ptr, + recurrent_to_input_weights_ptr, recurrent_to_forget_weights->data.f, + recurrent_to_cell_weights->data.f, + recurrent_to_output_weights->data.f, cell_to_input_weights_ptr, + cell_to_forget_weights_ptr, cell_to_output_weights_ptr, + input_gate_bias_ptr, forget_gate_bias->data.f, cell_bias->data.f, + output_gate_bias->data.f, projection_weights_ptr, projection_bias_ptr, + params, n_batch, n_cell, n_input, aux_input_size, n_output, + activation_state->data.f, cell_state->data.f, input_gate_scratch, + forget_gate_scratch, cell_scratch, output_gate_scratch, + output_ptr_time); + } + } + return kTfLiteOk; +} + +TfLiteStatus EvalHybrid( + const TfLiteTensor* input, const TfLiteTensor* input_to_input_weights, + const TfLiteTensor* input_to_forget_weights, + const TfLiteTensor* input_to_cell_weights, + const TfLiteTensor* input_to_output_weights, + const TfLiteTensor* recurrent_to_input_weights, + const TfLiteTensor* recurrent_to_forget_weights, + const TfLiteTensor* recurrent_to_cell_weights, + const TfLiteTensor* recurrent_to_output_weights, + const TfLiteTensor* cell_to_input_weights, + const TfLiteTensor* cell_to_forget_weights, + const TfLiteTensor* cell_to_output_weights, const TfLiteTensor* aux_input, + const TfLiteTensor* aux_input_to_input_weights, + const TfLiteTensor* aux_input_to_forget_weights, + const TfLiteTensor* aux_input_to_cell_weights, + const TfLiteTensor* aux_input_to_output_weights, + const TfLiteTensor* input_gate_bias, const TfLiteTensor* forget_gate_bias, + const TfLiteTensor* cell_bias, const TfLiteTensor* output_gate_bias, + const TfLiteTensor* projection_weights, const TfLiteTensor* projection_bias, + const TfLiteLSTMParams* params, bool forward_sequence, + TfLiteTensor* scratch_buffer, TfLiteTensor* scaling_factors, + TfLiteTensor* prod_scaling_factors, TfLiteTensor* recovered_cell_weights, + TfLiteTensor* input_quantized, TfLiteTensor* aux_input_quantized, + TfLiteTensor* output_state_quantized, TfLiteTensor* cell_state_quantized, + TfLiteTensor* output_state, TfLiteTensor* cell_state, + TfLiteTensor* output) { + const int max_time = input->dims->data[0]; + const int n_batch = input->dims->data[1]; + const int n_input = input->dims->data[2]; + const int aux_input_size = (aux_input) ? aux_input->dims->data[2] : 0; + // n_cell and n_output will be the same size when there is no projection. + const int n_cell = input_to_output_weights->dims->data[0]; + const int n_output = recurrent_to_output_weights->dims->data[1]; + + // Since we have already checked that weights are all there or none, we can + // check the existence of only one to get the condition. + const bool use_cifg = (input_to_input_weights == nullptr); + const bool use_peephole = (cell_to_output_weights != nullptr); + + float* input_gate_scratch = nullptr; + float* cell_scratch = nullptr; + float* forget_gate_scratch = nullptr; + float* output_gate_scratch = nullptr; + if (use_cifg) { + cell_scratch = scratch_buffer->data.f; + forget_gate_scratch = scratch_buffer->data.f + n_cell * n_batch; + output_gate_scratch = scratch_buffer->data.f + 2 * n_cell * n_batch; + } else { + input_gate_scratch = scratch_buffer->data.f; + cell_scratch = scratch_buffer->data.f + n_cell * n_batch; + forget_gate_scratch = scratch_buffer->data.f + 2 * n_cell * n_batch; + output_gate_scratch = scratch_buffer->data.f + 3 * n_cell * n_batch; + } + + // Check optional tensors, the respective pointers can be null. + int8_t* input_to_input_weights_ptr = nullptr; + float input_to_input_weights_scale = 1.0f; + int8_t* recurrent_to_input_weights_ptr = nullptr; + float recurrent_to_input_weights_scale = 1.0f; + float* input_gate_bias_ptr = nullptr; + if (!use_cifg) { + input_to_input_weights_ptr = + reinterpret_cast<int8_t*>(input_to_input_weights->data.uint8); + recurrent_to_input_weights_ptr = + reinterpret_cast<int8_t*>(recurrent_to_input_weights->data.uint8); + input_gate_bias_ptr = input_gate_bias->data.f; + input_to_input_weights_scale = input_to_input_weights->params.scale; + recurrent_to_input_weights_scale = recurrent_to_input_weights->params.scale; + } + + int8_t* cell_to_input_weights_ptr = nullptr; + int8_t* cell_to_forget_weights_ptr = nullptr; + int8_t* cell_to_output_weights_ptr = nullptr; + float cell_to_input_weights_scale = 1.0f; + float cell_to_forget_weights_scale = 1.0f; + float cell_to_output_weights_scale = 1.0f; + if (use_peephole) { + if (!use_cifg) { + cell_to_input_weights_ptr = + reinterpret_cast<int8_t*>(cell_to_input_weights->data.uint8); + cell_to_input_weights_scale = cell_to_input_weights->params.scale; + } + cell_to_forget_weights_ptr = + reinterpret_cast<int8_t*>(cell_to_forget_weights->data.uint8); + cell_to_output_weights_ptr = + reinterpret_cast<int8_t*>(cell_to_output_weights->data.uint8); + cell_to_forget_weights_scale = cell_to_forget_weights->params.scale; + cell_to_output_weights_scale = cell_to_output_weights->params.scale; + } + + const int8_t* projection_weights_ptr = + (projection_weights == nullptr) + ? nullptr + : reinterpret_cast<int8_t*>(projection_weights->data.uint8); + const float projection_weights_scale = + (projection_weights == nullptr) ? 1.0f : projection_weights->params.scale; + const float* projection_bias_ptr = + (projection_bias == nullptr) ? nullptr : projection_bias->data.f; + + // Required tensors, pointers are non-null. + const int8_t* input_to_forget_weights_ptr = + reinterpret_cast<int8_t*>(input_to_forget_weights->data.uint8); + const float input_to_forget_weights_scale = + input_to_forget_weights->params.scale; + const int8_t* input_to_cell_weights_ptr = + reinterpret_cast<int8_t*>(input_to_cell_weights->data.uint8); + const float input_to_cell_weights_scale = input_to_cell_weights->params.scale; + const int8_t* input_to_output_weights_ptr = + reinterpret_cast<int8_t*>(input_to_output_weights->data.uint8); + const float input_to_output_weights_scale = + input_to_output_weights->params.scale; + const int8_t* recurrent_to_forget_weights_ptr = + reinterpret_cast<int8_t*>(recurrent_to_forget_weights->data.uint8); + const float recurrent_to_forget_weights_scale = + recurrent_to_forget_weights->params.scale; + const int8_t* recurrent_to_cell_weights_ptr = + reinterpret_cast<int8_t*>(recurrent_to_cell_weights->data.uint8); + const float recurrent_to_cell_weights_scale = + recurrent_to_cell_weights->params.scale; + const int8_t* recurrent_to_output_weights_ptr = + reinterpret_cast<int8_t*>(recurrent_to_output_weights->data.uint8); + const float recurrent_to_output_weights_scale = + recurrent_to_output_weights->params.scale; + const float* forget_gate_bias_ptr = forget_gate_bias->data.f; + const float* cell_bias_ptr = cell_bias->data.f; + const float* output_gate_bias_ptr = output_gate_bias->data.f; + + float* output_state_ptr = output_state->data.f; + float* cell_state_ptr = cell_state->data.f; + + // Temporary storage for quantized values and scaling factors. + int8_t* quantized_input_ptr = + reinterpret_cast<int8_t*>(input_quantized->data.uint8); + int8_t* quantized_aux_input_ptr = + (aux_input_quantized == nullptr) + ? nullptr + : reinterpret_cast<int8_t*>(aux_input_quantized->data.uint8); + int8_t* quantized_output_state_ptr = + reinterpret_cast<int8_t*>(output_state_quantized->data.uint8); + int8_t* quantized_cell_state_ptr = + reinterpret_cast<int8_t*>(cell_state_quantized->data.uint8); + float* scaling_factors_ptr = scaling_factors->data.f; + float* prod_scaling_factors_ptr = prod_scaling_factors->data.f; + float* recovered_cell_weights_ptr = recovered_cell_weights->data.f; + + // Auxiliary input and weights. + float* aux_input_ptr = nullptr; + int8_t* aux_input_to_input_weights_ptr = nullptr; + int8_t* aux_input_to_forget_weights_ptr = nullptr; + int8_t* aux_input_to_cell_weights_ptr = nullptr; + int8_t* aux_input_to_output_weights_ptr = nullptr; + float aux_input_to_input_weights_scale = 0.0f; + float aux_input_to_forget_weights_scale = 0.0f; + float aux_input_to_cell_weights_scale = 0.0f; + float aux_input_to_output_weights_scale = 0.0f; + if (aux_input_size > 0) { + aux_input_ptr = aux_input->data.f; + aux_input_to_input_weights_ptr = + reinterpret_cast<int8_t*>(aux_input_to_input_weights->data.uint8); + aux_input_to_forget_weights_ptr = + reinterpret_cast<int8_t*>(aux_input_to_forget_weights->data.uint8); + aux_input_to_cell_weights_ptr = + reinterpret_cast<int8_t*>(aux_input_to_cell_weights->data.uint8); + aux_input_to_output_weights_ptr = + reinterpret_cast<int8_t*>(aux_input_to_output_weights->data.uint8); + aux_input_to_input_weights_scale = aux_input_to_input_weights->params.scale; + aux_input_to_forget_weights_scale = + aux_input_to_forget_weights->params.scale; + aux_input_to_cell_weights_scale = aux_input_to_cell_weights->params.scale; + aux_input_to_output_weights_scale = + aux_input_to_output_weights->params.scale; + } + if (forward_sequence) { + // Feed the sequence into the LSTM step-by-step. + for (int t = 0; t < max_time; t++) { + const float* input_ptr = input->data.f + t * n_batch * n_input; + float* output_ptr = output->data.f + t * n_batch * n_output; + + kernel_utils::LstmStepWithAuxInput( + input_ptr, input_to_input_weights_ptr, input_to_input_weights_scale, + input_to_forget_weights_ptr, input_to_forget_weights_scale, + input_to_cell_weights_ptr, input_to_cell_weights_scale, + input_to_output_weights_ptr, input_to_output_weights_scale, + aux_input_ptr, aux_input_to_input_weights_ptr, + aux_input_to_input_weights_scale, aux_input_to_forget_weights_ptr, + aux_input_to_forget_weights_scale, aux_input_to_cell_weights_ptr, + aux_input_to_cell_weights_scale, aux_input_to_output_weights_ptr, + aux_input_to_output_weights_scale, recurrent_to_input_weights_ptr, + recurrent_to_input_weights_scale, recurrent_to_forget_weights_ptr, + recurrent_to_forget_weights_scale, recurrent_to_cell_weights_ptr, + recurrent_to_cell_weights_scale, recurrent_to_output_weights_ptr, + recurrent_to_output_weights_scale, cell_to_input_weights_ptr, + cell_to_input_weights_scale, cell_to_forget_weights_ptr, + cell_to_forget_weights_scale, cell_to_output_weights_ptr, + cell_to_output_weights_scale, input_gate_bias_ptr, + forget_gate_bias_ptr, cell_bias_ptr, output_gate_bias_ptr, + projection_weights_ptr, projection_weights_scale, projection_bias_ptr, + params, n_batch, n_cell, n_input, aux_input_size, n_output, + input_gate_scratch, forget_gate_scratch, cell_scratch, + output_gate_scratch, scaling_factors_ptr, prod_scaling_factors_ptr, + recovered_cell_weights_ptr, quantized_input_ptr, + quantized_aux_input_ptr, quantized_output_state_ptr, + quantized_cell_state_ptr, output_state_ptr, cell_state_ptr, + output_ptr); + } + } else { + // Loop through the sequence backwards. + for (int t = max_time - 1; t >= 0; t--) { + const float* input_ptr = input->data.f + t * n_batch * n_input; + float* output_ptr = output->data.f + t * n_batch * n_output; + + kernel_utils::LstmStepWithAuxInput( + input_ptr, input_to_input_weights_ptr, input_to_input_weights_scale, + input_to_forget_weights_ptr, input_to_forget_weights_scale, + input_to_cell_weights_ptr, input_to_cell_weights_scale, + input_to_output_weights_ptr, input_to_output_weights_scale, + aux_input_ptr, aux_input_to_input_weights_ptr, + aux_input_to_input_weights_scale, aux_input_to_forget_weights_ptr, + aux_input_to_forget_weights_scale, aux_input_to_cell_weights_ptr, + aux_input_to_cell_weights_scale, aux_input_to_output_weights_ptr, + aux_input_to_output_weights_scale, recurrent_to_input_weights_ptr, + recurrent_to_input_weights_scale, recurrent_to_forget_weights_ptr, + recurrent_to_forget_weights_scale, recurrent_to_cell_weights_ptr, + recurrent_to_cell_weights_scale, recurrent_to_output_weights_ptr, + recurrent_to_output_weights_scale, cell_to_input_weights_ptr, + cell_to_input_weights_scale, cell_to_forget_weights_ptr, + cell_to_forget_weights_scale, cell_to_output_weights_ptr, + cell_to_output_weights_scale, input_gate_bias_ptr, + forget_gate_bias_ptr, cell_bias_ptr, output_gate_bias_ptr, + projection_weights_ptr, projection_weights_scale, projection_bias_ptr, + params, n_batch, n_cell, n_input, aux_input_size, n_output, + input_gate_scratch, forget_gate_scratch, cell_scratch, + output_gate_scratch, scaling_factors_ptr, prod_scaling_factors_ptr, + recovered_cell_weights_ptr, quantized_input_ptr, + quantized_aux_input_ptr, quantized_output_state_ptr, + quantized_cell_state_ptr, output_state_ptr, cell_state_ptr, + output_ptr); + } + } + return kTfLiteOk; } // The LSTM Op engine. TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { - auto* params = reinterpret_cast<TfLiteLSTMParams*>(node->builtin_data); + const auto* params = reinterpret_cast<TfLiteLSTMParams*>(node->builtin_data); // Input tensor. const TfLiteTensor* input = GetInput(context, node, kInputTensor); - const int max_time = input->dims->data[0]; - const int n_batch = input->dims->data[1]; - const int n_input = input->dims->data[2]; // Tensors for the forward cell. const TfLiteTensor* fw_input_to_input_weights = @@ -518,9 +1109,10 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { const TfLiteTensor* fw_projection_bias = GetOptionalInputTensor(context, node, kFwProjectionBiasTensor); - TfLiteTensor* fw_output_state = - GetOutput(context, node, kFwOutputStateTensor); - TfLiteTensor* fw_cell_state = GetOutput(context, node, kFwCellStateTensor); + TfLiteTensor* fw_activation_state = + GetVariableInput(context, node, kFwInputActivationStateTensor); + TfLiteTensor* fw_cell_state = + GetVariableInput(context, node, kFwInputCellStateTensor); TfLiteTensor* fw_output = GetOutput(context, node, kFwOutputTensor); // Tensors for the backward cell. @@ -563,154 +1155,134 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { const TfLiteTensor* bw_projection_bias = GetOptionalInputTensor(context, node, kBwProjectionBiasTensor); - TfLiteTensor* bw_output_state = - GetOutput(context, node, kBwOutputStateTensor); - TfLiteTensor* bw_cell_state = GetOutput(context, node, kBwCellStateTensor); + // State tensors. + TfLiteTensor* bw_activation_state = + GetVariableInput(context, node, kBwInputActivationStateTensor); + TfLiteTensor* bw_cell_state = + GetVariableInput(context, node, kBwInputCellStateTensor); TfLiteTensor* bw_output = GetOutput(context, node, kBwOutputTensor); - // n_cell and n_output will be the same size when there is no projection. - const int n_fw_cell = fw_input_to_output_weights->dims->data[0]; - const int n_fw_output = fw_recurrent_to_output_weights->dims->data[1]; - - // Since we have already checked that weights are all there or none, we can - // check the existense of only one to the get the condition. - const bool fw_use_cifg = (fw_input_to_input_weights == nullptr); - const bool fw_use_peephole = (fw_cell_to_output_weights != nullptr); - - // Index the scratch buffers pointers to the global scratch buffer. + // Temporary tensors. TfLiteTensor* fw_scratch_buffer = - &context->tensors[node->temporaries->data[0]]; - float* fw_input_gate_scratch = nullptr; - float* fw_cell_scratch = nullptr; - float* fw_forget_gate_scratch = nullptr; - float* fw_output_gate_scratch = nullptr; - if (fw_use_cifg) { - fw_cell_scratch = fw_scratch_buffer->data.f; - fw_forget_gate_scratch = fw_scratch_buffer->data.f + n_fw_cell * n_batch; - fw_output_gate_scratch = - fw_scratch_buffer->data.f + 2 * n_fw_cell * n_batch; - } else { - fw_input_gate_scratch = fw_scratch_buffer->data.f; - fw_cell_scratch = fw_scratch_buffer->data.f + n_fw_cell * n_batch; - fw_forget_gate_scratch = - fw_scratch_buffer->data.f + 2 * n_fw_cell * n_batch; - fw_output_gate_scratch = - fw_scratch_buffer->data.f + 3 * n_fw_cell * n_batch; - } - - // Check optional tensors, the respective pointers can be null. - const float* fw_input_to_input_weights_ptr = - (fw_use_cifg) ? nullptr : fw_input_to_input_weights->data.f; - const float* fw_recurrent_to_input_weights_ptr = - (fw_use_cifg) ? nullptr : fw_recurrent_to_input_weights->data.f; - const float* fw_input_gate_bias_ptr = - (fw_use_cifg) ? nullptr : fw_input_gate_bias->data.f; - const float* fw_cell_to_input_weights_ptr = - (fw_use_peephole && !fw_use_cifg) ? fw_cell_to_input_weights->data.f - : nullptr; - const float* fw_cell_to_forget_weights_ptr = - (fw_use_peephole) ? fw_cell_to_forget_weights->data.f : nullptr; - const float* fw_cell_to_output_weights_ptr = - (fw_use_peephole) ? fw_cell_to_output_weights->data.f : nullptr; - const float* fw_projection_weights_ptr = (fw_projection_weights == nullptr) - ? nullptr - : fw_projection_weights->data.f; - const float* fw_projection_bias_ptr = - (fw_projection_bias == nullptr) ? nullptr : fw_projection_bias->data.f; - - // Loop through the sequence. - for (int t = 0; t < max_time; t++) { - const float* input_ptr_batch = input->data.f + t * n_batch * n_input; - float* output_ptr_time = fw_output->data.f + t * n_batch * n_fw_output; - - kernel_utils::LstmStep( - input_ptr_batch, fw_input_to_input_weights_ptr, - fw_input_to_forget_weights->data.f, fw_input_to_cell_weights->data.f, - fw_input_to_output_weights->data.f, fw_recurrent_to_input_weights_ptr, - fw_recurrent_to_forget_weights->data.f, - fw_recurrent_to_cell_weights->data.f, - fw_recurrent_to_output_weights->data.f, fw_cell_to_input_weights_ptr, - fw_cell_to_forget_weights_ptr, fw_cell_to_output_weights_ptr, - fw_input_gate_bias_ptr, fw_forget_gate_bias->data.f, - fw_cell_bias->data.f, fw_output_gate_bias->data.f, - fw_projection_weights_ptr, fw_projection_bias_ptr, params, n_batch, - n_fw_cell, n_input, n_fw_output, fw_output_state->data.f, - fw_cell_state->data.f, fw_input_gate_scratch, fw_forget_gate_scratch, - fw_cell_scratch, fw_output_gate_scratch, output_ptr_time); - } - - // n_cell and n_output will be the same size when there is no projection. - const int n_bw_cell = bw_input_to_output_weights->dims->data[0]; - const int n_bw_output = bw_recurrent_to_output_weights->dims->data[1]; - - // Since we have already checked that weights are all there or none, we can - // check the existense of only one to the get the condition. - const bool bw_use_cifg = (bw_input_to_input_weights == nullptr); - const bool bw_use_peephole = (bw_cell_to_output_weights != nullptr); - - // Index the scratch buffers pointers to the global scratch buffer. + GetTemporary(context, node, kFwScratchBuffer); TfLiteTensor* bw_scratch_buffer = - &context->tensors[node->temporaries->data[1]]; - float* bw_input_gate_scratch = nullptr; - float* bw_cell_scratch = nullptr; - float* bw_forget_gate_scratch = nullptr; - float* bw_output_gate_scratch = nullptr; - if (bw_use_cifg) { - bw_cell_scratch = bw_scratch_buffer->data.f; - bw_forget_gate_scratch = bw_scratch_buffer->data.f + n_bw_cell * n_batch; - bw_output_gate_scratch = - bw_scratch_buffer->data.f + 2 * n_bw_cell * n_batch; - } else { - bw_input_gate_scratch = bw_scratch_buffer->data.f; - bw_cell_scratch = bw_scratch_buffer->data.f + n_bw_cell * n_batch; - bw_forget_gate_scratch = - bw_scratch_buffer->data.f + 2 * n_bw_cell * n_batch; - bw_output_gate_scratch = - bw_scratch_buffer->data.f + 3 * n_bw_cell * n_batch; - } - - // Check optional tensors, the respective pointers can be null. - const float* bw_input_to_input_weights_ptr = - (bw_use_cifg) ? nullptr : bw_input_to_input_weights->data.f; - const float* bw_recurrent_to_input_weights_ptr = - (bw_use_cifg) ? nullptr : bw_recurrent_to_input_weights->data.f; - const float* bw_input_gate_bias_ptr = - (bw_use_cifg) ? nullptr : bw_input_gate_bias->data.f; - const float* bw_cell_to_input_weights_ptr = - (bw_use_peephole && !bw_use_cifg) ? bw_cell_to_input_weights->data.f - : nullptr; - const float* bw_cell_to_forget_weights_ptr = - (bw_use_peephole) ? bw_cell_to_forget_weights->data.f : nullptr; - const float* bw_cell_to_output_weights_ptr = - (bw_use_peephole) ? bw_cell_to_output_weights->data.f : nullptr; - const float* bw_projection_weights_ptr = (bw_projection_weights == nullptr) - ? nullptr - : bw_projection_weights->data.f; - const float* bw_projection_bias_ptr = - (bw_projection_bias == nullptr) ? nullptr : bw_projection_bias->data.f; - - // Loop through the sequence backwards. - for (int t = max_time - 1; t >= 0; t--) { - const float* input_ptr_batch = input->data.f + t * n_batch * n_input; - float* output_ptr_time = bw_output->data.f + t * n_batch * n_bw_output; - - kernel_utils::LstmStep( - input_ptr_batch, bw_input_to_input_weights_ptr, - bw_input_to_forget_weights->data.f, bw_input_to_cell_weights->data.f, - bw_input_to_output_weights->data.f, bw_recurrent_to_input_weights_ptr, - bw_recurrent_to_forget_weights->data.f, - bw_recurrent_to_cell_weights->data.f, - bw_recurrent_to_output_weights->data.f, bw_cell_to_input_weights_ptr, - bw_cell_to_forget_weights_ptr, bw_cell_to_output_weights_ptr, - bw_input_gate_bias_ptr, bw_forget_gate_bias->data.f, - bw_cell_bias->data.f, bw_output_gate_bias->data.f, - bw_projection_weights_ptr, bw_projection_bias_ptr, params, n_batch, - n_bw_cell, n_input, n_bw_output, bw_output_state->data.f, - bw_cell_state->data.f, bw_input_gate_scratch, bw_forget_gate_scratch, - bw_cell_scratch, bw_output_gate_scratch, output_ptr_time); + GetTemporary(context, node, kBwScratchBuffer); + + // (Optional) auxiliary inputs. + const TfLiteTensor* aux_input = + GetOptionalInputTensor(context, node, kAuxInputTensor); + const TfLiteTensor* fw_aux_input_to_input_weights = + GetOptionalInputTensor(context, node, kFwAuxInputToInputWeightsTensor); + const TfLiteTensor* fw_aux_input_to_forget_weights = + GetOptionalInputTensor(context, node, kFwAuxInputToForgetWeightsTensor); + const TfLiteTensor* fw_aux_input_to_cell_weights = + GetOptionalInputTensor(context, node, kFwAuxInputToCellWeightsTensor); + const TfLiteTensor* fw_aux_input_to_output_weights = + GetOptionalInputTensor(context, node, kFwAuxInputToOutputWeightsTensor); + const TfLiteTensor* bw_aux_input_to_input_weights = + GetOptionalInputTensor(context, node, kBwAuxInputToInputWeightsTensor); + const TfLiteTensor* bw_aux_input_to_forget_weights = + GetOptionalInputTensor(context, node, kBwAuxInputToForgetWeightsTensor); + const TfLiteTensor* bw_aux_input_to_cell_weights = + GetOptionalInputTensor(context, node, kBwAuxInputToCellWeightsTensor); + const TfLiteTensor* bw_aux_input_to_output_weights = + GetOptionalInputTensor(context, node, kBwAuxInputToOutputWeightsTensor); + + switch (fw_input_to_output_weights->type) { + case kTfLiteFloat32: { + TfLiteStatus fw_pass_status = EvalFloat( + input, fw_input_to_input_weights, fw_input_to_forget_weights, + fw_input_to_cell_weights, fw_input_to_output_weights, + fw_recurrent_to_input_weights, fw_recurrent_to_forget_weights, + fw_recurrent_to_cell_weights, fw_recurrent_to_output_weights, + fw_cell_to_input_weights, fw_cell_to_forget_weights, + fw_cell_to_output_weights, aux_input, fw_aux_input_to_input_weights, + fw_aux_input_to_forget_weights, fw_aux_input_to_cell_weights, + fw_aux_input_to_output_weights, fw_input_gate_bias, + fw_forget_gate_bias, fw_cell_bias, fw_output_gate_bias, + fw_projection_weights, fw_projection_bias, params, + /*forward_sequence=*/true, fw_scratch_buffer, fw_activation_state, + fw_cell_state, fw_output); + TF_LITE_ENSURE_OK(context, fw_pass_status); + + TfLiteStatus bw_pass_status = EvalFloat( + input, bw_input_to_input_weights, bw_input_to_forget_weights, + bw_input_to_cell_weights, bw_input_to_output_weights, + bw_recurrent_to_input_weights, bw_recurrent_to_forget_weights, + bw_recurrent_to_cell_weights, bw_recurrent_to_output_weights, + bw_cell_to_input_weights, bw_cell_to_forget_weights, + bw_cell_to_output_weights, aux_input, bw_aux_input_to_input_weights, + bw_aux_input_to_forget_weights, bw_aux_input_to_cell_weights, + bw_aux_input_to_output_weights, bw_input_gate_bias, + bw_forget_gate_bias, bw_cell_bias, bw_output_gate_bias, + bw_projection_weights, bw_projection_bias, params, + /*forward_sequence=*/false, bw_scratch_buffer, bw_activation_state, + bw_cell_state, bw_output); + TF_LITE_ENSURE_OK(context, bw_pass_status); + return kTfLiteOk; + } + case kTfLiteUInt8: { + TfLiteTensor* input_quantized = + GetTemporary(context, node, kInputQuantized); + TfLiteTensor* aux_input_quantized = + GetTemporary(context, node, kAuxInputQuantized); + TfLiteTensor* fw_activation_state_quantized = + GetTemporary(context, node, kFwActivationStateQuantized); + TfLiteTensor* bw_activation_state_quantized = + GetTemporary(context, node, kBwActivationStateQuantized); + TfLiteTensor* fw_cell_state_quantized = + GetTemporary(context, node, kFwCellStateQuantized); + TfLiteTensor* bw_cell_state_quantized = + GetTemporary(context, node, kBwCellStateQuantized); + TfLiteTensor* scaling_factors = + GetTemporary(context, node, kScalingFactors); + TfLiteTensor* prod_scaling_factors = + GetTemporary(context, node, kProductScalingFactors); + TfLiteTensor* recovered_cell_weights = + GetTemporary(context, node, kRecoveredCellWeights); + + TfLiteStatus fw_pass_status = EvalHybrid( + input, fw_input_to_input_weights, fw_input_to_forget_weights, + fw_input_to_cell_weights, fw_input_to_output_weights, + fw_recurrent_to_input_weights, fw_recurrent_to_forget_weights, + fw_recurrent_to_cell_weights, fw_recurrent_to_output_weights, + fw_cell_to_input_weights, fw_cell_to_forget_weights, + fw_cell_to_output_weights, aux_input, fw_aux_input_to_input_weights, + fw_aux_input_to_forget_weights, fw_aux_input_to_cell_weights, + fw_aux_input_to_output_weights, fw_input_gate_bias, + fw_forget_gate_bias, fw_cell_bias, fw_output_gate_bias, + fw_projection_weights, fw_projection_bias, params, + /*forward_sequence=*/true, fw_scratch_buffer, scaling_factors, + prod_scaling_factors, recovered_cell_weights, input_quantized, + aux_input_quantized, fw_activation_state_quantized, + fw_cell_state_quantized, fw_activation_state, fw_cell_state, + fw_output); + TF_LITE_ENSURE_OK(context, fw_pass_status); + + TfLiteStatus bw_pass_status = EvalHybrid( + input, bw_input_to_input_weights, bw_input_to_forget_weights, + bw_input_to_cell_weights, bw_input_to_output_weights, + bw_recurrent_to_input_weights, bw_recurrent_to_forget_weights, + bw_recurrent_to_cell_weights, bw_recurrent_to_output_weights, + bw_cell_to_input_weights, bw_cell_to_forget_weights, + bw_cell_to_output_weights, aux_input, fw_aux_input_to_input_weights, + fw_aux_input_to_forget_weights, fw_aux_input_to_cell_weights, + fw_aux_input_to_output_weights, bw_input_gate_bias, + bw_forget_gate_bias, bw_cell_bias, bw_output_gate_bias, + bw_projection_weights, bw_projection_bias, params, + /*forward_sequence=*/false, bw_scratch_buffer, scaling_factors, + prod_scaling_factors, recovered_cell_weights, input_quantized, + aux_input_quantized, bw_activation_state_quantized, + bw_cell_state_quantized, bw_activation_state, bw_cell_state, + bw_output); + TF_LITE_ENSURE_OK(context, bw_pass_status); + return kTfLiteOk; + } + default: + context->ReportError(context, "Type %d is not currently supported.", + fw_input_to_output_weights->type); + return kTfLiteError; } - - // Backward step. return kTfLiteOk; } diff --git a/tensorflow/contrib/lite/kernels/bidirectional_sequence_lstm_test.cc b/tensorflow/contrib/lite/kernels/bidirectional_sequence_lstm_test.cc index a18e1bce34..74ba8021c2 100644 --- a/tensorflow/contrib/lite/kernels/bidirectional_sequence_lstm_test.cc +++ b/tensorflow/contrib/lite/kernels/bidirectional_sequence_lstm_test.cc @@ -102,10 +102,6 @@ class BidirectionalLSTMOpModel : public SingleOpModel { fw_projection_bias_ = AddNullInput(); } - fw_output_state_ = AddOutput(TensorType_FLOAT32); - fw_cell_state_ = AddOutput(TensorType_FLOAT32); - fw_output_ = AddOutput(TensorType_FLOAT32); - if (use_cifg) { bw_input_to_input_weights_ = AddNullInput(); } else { @@ -161,10 +157,36 @@ class BidirectionalLSTMOpModel : public SingleOpModel { bw_projection_bias_ = AddNullInput(); } - bw_output_state_ = AddOutput(TensorType_FLOAT32); - bw_cell_state_ = AddOutput(TensorType_FLOAT32); + // Adding the 2 input state tensors. + fw_input_activation_state_ = + AddInput(TensorData{TensorType_FLOAT32, {n_fw_output_ * n_batch_}}, + /*is_variable=*/true); + fw_input_cell_state_ = + AddInput(TensorData{TensorType_FLOAT32, {n_fw_cell_ * n_batch_}}, + /*is_variable=*/true); + + // Adding the 2 input state tensors. + bw_input_activation_state_ = + AddInput(TensorData{TensorType_FLOAT32, {n_bw_output_ * n_batch_}}, + /*is_variable=*/true); + bw_input_cell_state_ = + AddInput(TensorData{TensorType_FLOAT32, {n_bw_cell_ * n_batch_}}, + /*is_variable=*/true); + + fw_output_ = AddOutput(TensorType_FLOAT32); + bw_output_ = AddOutput(TensorType_FLOAT32); + aux_input_ = AddNullInput(); + fw_aux_input_to_input_weights_ = AddNullInput(); + fw_aux_input_to_forget_weights_ = AddNullInput(); + fw_aux_input_to_cell_weights_ = AddNullInput(); + fw_aux_input_to_output_weights_ = AddNullInput(); + bw_aux_input_to_input_weights_ = AddNullInput(); + bw_aux_input_to_forget_weights_ = AddNullInput(); + bw_aux_input_to_cell_weights_ = AddNullInput(); + bw_aux_input_to_output_weights_ = AddNullInput(); + SetBuiltinOp(BuiltinOperator_BIDIRECTIONAL_SEQUENCE_LSTM, BuiltinOptions_LSTMOptions, CreateLSTMOptions(builder_, ActivationFunctionType_TANH, @@ -259,26 +281,6 @@ class BidirectionalLSTMOpModel : public SingleOpModel { PopulateTensor(bw_projection_bias_, f); } - void ResetFwOutputAndCellStates() { - const int zero_buffer_size = n_fw_cell_ * n_batch_; - std::unique_ptr<float[]> zero_buffer(new float[zero_buffer_size]); - memset(zero_buffer.get(), 0, zero_buffer_size * sizeof(float)); - PopulateTensor(fw_output_state_, 0, zero_buffer.get(), - zero_buffer.get() + zero_buffer_size); - PopulateTensor(fw_cell_state_, 0, zero_buffer.get(), - zero_buffer.get() + zero_buffer_size); - } - - void ResetBwOutputAndCellStates() { - const int zero_buffer_size = n_bw_cell_ * n_batch_; - std::unique_ptr<float[]> zero_buffer(new float[zero_buffer_size]); - memset(zero_buffer.get(), 0, zero_buffer_size * sizeof(float)); - PopulateTensor(bw_output_state_, 0, zero_buffer.get(), - zero_buffer.get() + zero_buffer_size); - PopulateTensor(bw_cell_state_, 0, zero_buffer.get(), - zero_buffer.get() + zero_buffer_size); - } - void SetInput(int offset, float* begin, float* end) { PopulateTensor(input_, offset, begin, end); } @@ -340,13 +342,23 @@ class BidirectionalLSTMOpModel : public SingleOpModel { int bw_projection_weights_; int bw_projection_bias_; - int fw_output_; - int fw_output_state_; - int fw_cell_state_; + int fw_input_activation_state_; + int fw_input_cell_state_; + int bw_input_activation_state_; + int bw_input_cell_state_; + int fw_output_; int bw_output_; - int bw_output_state_; - int bw_cell_state_; + + int aux_input_; + int fw_aux_input_to_input_weights_; + int fw_aux_input_to_forget_weights_; + int fw_aux_input_to_cell_weights_; + int fw_aux_input_to_output_weights_; + int bw_aux_input_to_input_weights_; + int bw_aux_input_to_forget_weights_; + int bw_aux_input_to_cell_weights_; + int bw_aux_input_to_output_weights_; int n_batch_; int n_input_; @@ -417,6 +429,22 @@ TEST(LSTMOpTest, BlackBoxTestNoCifgNoPeepholeNoProjectionNoClipping) { {0, 0}, // projection_weight tensor {0}, // projection_bias tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor + + {n_batch, sequence_length, 0}, // aux_input tensor + {n_cell, 0}, // aux_fw_input_to_input tensor + {n_cell, 0}, // aux_fw_input_to_forget tensor + {n_cell, 0}, // aux_fw_input_to_cell tensor + {n_cell, 0}, // aux_fw_input_to_output tensor + {n_cell, 0}, // aux_bw_input_to_input tensor + {n_cell, 0}, // aux_bw_input_to_forget tensor + {n_cell, 0}, // aux_bw_input_to_cell tensor + {n_cell, 0}, // aux_bw_input_to_output tensor }); lstm.SetInputToInputWeights({-0.45018822, -0.02338299, -0.0870589, @@ -474,10 +502,6 @@ TEST(LSTMOpTest, BlackBoxTestNoCifgNoPeepholeNoProjectionNoClipping) { -0.0332076, 0.123838, 0.309777, -0.17621, -0.0490733, 0.0739237, 0.067706, -0.0208124}; - // Resetting cell_state and output_state - lstm.ResetFwOutputAndCellStates(); - lstm.ResetBwOutputAndCellStates(); - float* batch0_start = lstm_input; float* batch0_end = batch0_start + lstm.num_inputs() * lstm.sequence_length(); @@ -500,34 +524,161 @@ TEST(LSTMOpTest, BlackBoxTestNoCifgNoPeepholeNoProjectionNoClipping) { bw_expected.insert(bw_expected.end(), bw_golden_start, bw_golden_end); EXPECT_THAT(lstm.GetBwOutput(), ElementsAreArray(ArrayFloatNear(bw_expected))); +} + +TEST(LSTMOpTest, BlackBoxTestNoCifgNoPeepholeNoProjectionNoClippingReverse) { + const int n_batch = 1; + const int n_input = 2; + // n_cell and n_output have the same size when there is no projection. + const int n_cell = 4; + const int n_output = 4; + const int sequence_length = 3; + + BidirectionalLSTMOpModel lstm( + n_batch, n_input, n_cell, n_output, sequence_length, /*use_cifg=*/false, + /*use_peephole=*/false, /*use_projection_weights=*/false, + /*use_projection_bias=*/false, /*cell_clip=*/0.0, /*proj_clip=*/0.0, + { + {sequence_length, n_batch, n_input}, // input tensor + + // Forward cell + {n_cell, n_input}, // input_to_input_weight tensor + {n_cell, n_input}, // input_to_forget_weight tensor + {n_cell, n_input}, // input_to_cell_weight tensor + {n_cell, n_input}, // input_to_output_weight tensor + + {n_cell, n_output}, // recurrent_to_input_weight tensor + {n_cell, n_output}, // recurrent_to_forget_weight tensor + {n_cell, n_output}, // recurrent_to_cell_weight tensor + {n_cell, n_output}, // recurrent_to_output_weight tensor + + {0}, // cell_to_input_weight tensor + {0}, // cell_to_forget_weight tensor + {0}, // cell_to_output_weight tensor + + {n_cell}, // input_gate_bias tensor + {n_cell}, // forget_gate_bias tensor + {n_cell}, // cell_bias tensor + {n_cell}, // output_gate_bias tensor + + {0, 0}, // projection_weight tensor + {0}, // projection_bias tensor + + // Backward cell + {n_cell, n_input}, // input_to_input_weight tensor + {n_cell, n_input}, // input_to_forget_weight tensor + {n_cell, n_input}, // input_to_cell_weight tensor + {n_cell, n_input}, // input_to_output_weight tensor + + {n_cell, n_output}, // recurrent_to_input_weight tensor + {n_cell, n_output}, // recurrent_to_forget_weight tensor + {n_cell, n_output}, // recurrent_to_cell_weight tensor + {n_cell, n_output}, // recurrent_to_output_weight tensor + + {0}, // cell_to_input_weight tensor + {0}, // cell_to_forget_weight tensor + {0}, // cell_to_output_weight tensor + + {n_cell}, // input_gate_bias tensor + {n_cell}, // forget_gate_bias tensor + {n_cell}, // cell_bias tensor + {n_cell}, // output_gate_bias tensor + + {0, 0}, // projection_weight tensor + {0}, // projection_bias tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor + + {n_batch, sequence_length, 0}, // aux_input tensor + {n_cell, 0}, // aux_fw_input_to_input tensor + {n_cell, 0}, // aux_fw_input_to_forget tensor + {n_cell, 0}, // aux_fw_input_to_cell tensor + {n_cell, 0}, // aux_fw_input_to_output tensor + {n_cell, 0}, // aux_bw_input_to_input tensor + {n_cell, 0}, // aux_bw_input_to_forget tensor + {n_cell, 0}, // aux_bw_input_to_cell tensor + {n_cell, 0}, // aux_bw_input_to_output tensor + }); + + lstm.SetInputToInputWeights({-0.45018822, -0.02338299, -0.0870589, + -0.34550029, 0.04266912, -0.15680569, + -0.34856534, 0.43890524}); + + lstm.SetInputToCellWeights({-0.50013041, 0.1370284, 0.11810488, 0.2013163, + -0.20583314, 0.44344562, 0.22077113, + -0.29909778}); + + lstm.SetInputToForgetWeights({0.09701663, 0.20334584, -0.50592935, + -0.31343272, -0.40032279, 0.44781327, + 0.01387155, -0.35593212}); + + lstm.SetInputToOutputWeights({-0.25065863, -0.28290087, 0.04613829, + 0.40525138, 0.44272184, 0.03897077, -0.1556896, + 0.19487578}); + + lstm.SetInputGateBias({0., 0., 0., 0.}); + + lstm.SetCellBias({0., 0., 0., 0.}); + + lstm.SetForgetGateBias({1., 1., 1., 1.}); + + lstm.SetOutputGateBias({0., 0., 0., 0.}); + + lstm.SetRecurrentToInputWeights( + {-0.0063535, -0.2042388, 0.31454784, -0.35746509, 0.28902304, 0.08183324, + -0.16555229, 0.02286911, -0.13566875, 0.03034258, 0.48091322, + -0.12528998, 0.24077177, -0.51332325, -0.33502164, 0.10629296}); + lstm.SetRecurrentToCellWeights( + {-0.3407414, 0.24443203, -0.2078532, 0.26320225, 0.05695659, -0.00123841, + -0.4744786, -0.35869038, -0.06418842, -0.13502428, -0.501764, 0.22830659, + -0.46367589, 0.26016325, -0.03894562, -0.16368064}); + + lstm.SetRecurrentToForgetWeights( + {-0.48684245, -0.06655136, 0.42224967, 0.2112639, 0.27654213, 0.20864892, + -0.07646349, 0.45877004, 0.00141793, -0.14609534, 0.36447752, 0.09196436, + 0.28053468, 0.01560611, -0.20127171, -0.01140004}); + + lstm.SetRecurrentToOutputWeights( + {0.43385774, -0.17194885, 0.2718237, 0.09215671, 0.24107647, -0.39835793, + 0.18212086, 0.01301402, 0.48572797, -0.50656658, 0.20047462, -0.20607421, + -0.51818722, -0.15390486, 0.0468148, 0.39922136}); + + // Input should have n_input * sequence_length many values. // Check reversed inputs. static float lstm_input_reversed[] = {1., 1., 3., 4., 2., 3.}; + static float lstm_fw_golden_output[] = { + -0.02973187, 0.1229473, 0.20885126, -0.15358765, + -0.03716109, 0.12507336, 0.41193449, -0.20860538, + -0.15053082, 0.09120187, 0.24278517, -0.12222792}; + static float lstm_bw_golden_output[] = { + -0.0806187, 0.139077, 0.400476, -0.197842, -0.0332076, 0.123838, + 0.309777, -0.17621, -0.0490733, 0.0739237, 0.067706, -0.0208124}; - // Resetting cell_state and output_state - lstm.ResetFwOutputAndCellStates(); - lstm.ResetBwOutputAndCellStates(); - - batch0_start = lstm_input_reversed; - batch0_end = batch0_start + lstm.num_inputs() * lstm.sequence_length(); + float* batch0_start = lstm_input_reversed; + float* batch0_end = batch0_start + lstm.num_inputs() * lstm.sequence_length(); lstm.SetInput(0, batch0_start, batch0_end); lstm.Invoke(); - fw_expected.clear(); + std::vector<float> fw_expected; for (int s = 0; s < lstm.sequence_length(); s++) { - fw_golden_start = lstm_fw_golden_output + s * lstm.num_fw_outputs(); - fw_golden_end = fw_golden_start + lstm.num_fw_outputs(); + float* fw_golden_start = lstm_fw_golden_output + s * lstm.num_fw_outputs(); + float* fw_golden_end = fw_golden_start + lstm.num_fw_outputs(); fw_expected.insert(fw_expected.begin(), fw_golden_start, fw_golden_end); } EXPECT_THAT(lstm.GetBwOutput(), ElementsAreArray(ArrayFloatNear(fw_expected))); - bw_expected.clear(); + std::vector<float> bw_expected; for (int s = 0; s < lstm.sequence_length(); s++) { - bw_golden_start = lstm_bw_golden_output + s * lstm.num_bw_outputs(); - bw_golden_end = bw_golden_start + lstm.num_bw_outputs(); + float* bw_golden_start = lstm_bw_golden_output + s * lstm.num_bw_outputs(); + float* bw_golden_end = bw_golden_start + lstm.num_bw_outputs(); bw_expected.insert(bw_expected.begin(), bw_golden_start, bw_golden_end); } EXPECT_THAT(lstm.GetFwOutput(), @@ -592,6 +743,22 @@ TEST(LSTMOpTest, BlackBoxTestWithCifgWithPeepholeNoProjectionNoClipping) { {0, 0}, // projection_weight tensor {0}, // projection_bias tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor + + {n_batch, sequence_length, 0}, // aux_input tensor + {n_cell, 0}, // aux_fw_input_to_input tensor + {n_cell, 0}, // aux_fw_input_to_forget tensor + {n_cell, 0}, // aux_fw_input_to_cell tensor + {n_cell, 0}, // aux_fw_input_to_output tensor + {n_cell, 0}, // aux_bw_input_to_input tensor + {n_cell, 0}, // aux_bw_input_to_forget tensor + {n_cell, 0}, // aux_bw_input_to_cell tensor + {n_cell, 0}, // aux_bw_input_to_output tensor }); lstm.SetInputToCellWeights({-0.49770179, -0.27711356, -0.09624726, 0.05100781, @@ -642,10 +809,6 @@ TEST(LSTMOpTest, BlackBoxTestWithCifgWithPeepholeNoProjectionNoClipping) { -0.401685, -0.0232794, 0.288642, -0.123074, -0.42915, -0.00871577, 0.20912, -0.103567, -0.166398, -0.00486649, 0.0697471, -0.0537578}; - // Resetting cell_state and output_state - lstm.ResetFwOutputAndCellStates(); - lstm.ResetBwOutputAndCellStates(); - float* batch0_start = lstm_input; float* batch0_end = batch0_start + lstm.num_inputs() * lstm.sequence_length(); @@ -668,34 +831,153 @@ TEST(LSTMOpTest, BlackBoxTestWithCifgWithPeepholeNoProjectionNoClipping) { bw_expected.insert(bw_expected.end(), bw_golden_start, bw_golden_end); EXPECT_THAT(lstm.GetBwOutput(), ElementsAreArray(ArrayFloatNear(bw_expected))); +} - // Check reversed inputs. - static float lstm_input_reversed[] = {1., 1., 3., 4., 2., 3.}; +TEST(LSTMOpTest, + BlackBoxTestWithCifgWithPeepholeNoProjectionNoClippingReversed) { + const int n_batch = 1; + const int n_input = 2; + // n_cell and n_output have the same size when there is no projection. + const int n_cell = 4; + const int n_output = 4; + const int sequence_length = 3; + + BidirectionalLSTMOpModel lstm( + n_batch, n_input, n_cell, n_output, sequence_length, /*use_cifg=*/true, + /*use_peephole=*/true, /*use_projection_weights=*/false, + /*use_projection_bias=*/false, /*cell_clip=*/0.0, /*proj_clip=*/0.0, + { + {sequence_length, n_batch, n_input}, // input tensor + + {0, 0}, // input_to_input_weight tensor + {n_cell, n_input}, // input_to_forget_weight tensor + {n_cell, n_input}, // input_to_cell_weight tensor + {n_cell, n_input}, // input_to_output_weight tensor + + {0, 0}, // recurrent_to_input_weight tensor + {n_cell, n_output}, // recurrent_to_forget_weight tensor + {n_cell, n_output}, // recurrent_to_cell_weight tensor + {n_cell, n_output}, // recurrent_to_output_weight tensor + + {0}, // cell_to_input_weight tensor + {n_cell}, // cell_to_forget_weight tensor + {n_cell}, // cell_to_output_weight tensor + + {0}, // input_gate_bias tensor + {n_cell}, // forget_gate_bias tensor + {n_cell}, // cell_bias tensor + {n_cell}, // output_gate_bias tensor + + {0, 0}, // projection_weight tensor + {0}, // projection_bias tensor + + {0, 0}, // input_to_input_weight tensor + {n_cell, n_input}, // input_to_forget_weight tensor + {n_cell, n_input}, // input_to_cell_weight tensor + {n_cell, n_input}, // input_to_output_weight tensor + + {0, 0}, // recurrent_to_input_weight tensor + {n_cell, n_output}, // recurrent_to_forget_weight tensor + {n_cell, n_output}, // recurrent_to_cell_weight tensor + {n_cell, n_output}, // recurrent_to_output_weight tensor + + {0}, // cell_to_input_weight tensor + {n_cell}, // cell_to_forget_weight tensor + {n_cell}, // cell_to_output_weight tensor - // Resetting cell_state and output_state - lstm.ResetFwOutputAndCellStates(); - lstm.ResetBwOutputAndCellStates(); + {0}, // input_gate_bias tensor + {n_cell}, // forget_gate_bias tensor + {n_cell}, // cell_bias tensor + {n_cell}, // output_gate_bias tensor + + {0, 0}, // projection_weight tensor + {0}, // projection_bias tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor + + {n_batch, sequence_length, 0}, // aux_input tensor + {n_cell, 0}, // aux_fw_input_to_input tensor + {n_cell, 0}, // aux_fw_input_to_forget tensor + {n_cell, 0}, // aux_fw_input_to_cell tensor + {n_cell, 0}, // aux_fw_input_to_output tensor + {n_cell, 0}, // aux_bw_input_to_input tensor + {n_cell, 0}, // aux_bw_input_to_forget tensor + {n_cell, 0}, // aux_bw_input_to_cell tensor + {n_cell, 0}, // aux_bw_input_to_output tensor + }); + + lstm.SetInputToCellWeights({-0.49770179, -0.27711356, -0.09624726, 0.05100781, + 0.04717243, 0.48944736, -0.38535351, + -0.17212132}); + + lstm.SetInputToForgetWeights({-0.55291498, -0.42866567, 0.13056988, + -0.3633365, -0.22755712, 0.28253698, 0.24407166, + 0.33826375}); + + lstm.SetInputToOutputWeights({0.10725588, -0.02335852, -0.55932593, + -0.09426838, -0.44257352, 0.54939759, + 0.01533556, 0.42751634}); + + lstm.SetCellBias({0., 0., 0., 0.}); + + lstm.SetForgetGateBias({1., 1., 1., 1.}); + + lstm.SetOutputGateBias({0., 0., 0., 0.}); + + lstm.SetRecurrentToCellWeights( + {0.54066205, -0.32668582, -0.43562764, -0.56094903, 0.42957711, + 0.01841056, -0.32764608, -0.33027974, -0.10826075, 0.20675004, + 0.19069612, -0.03026325, -0.54532051, 0.33003211, 0.44901288, + 0.21193194}); + + lstm.SetRecurrentToForgetWeights( + {-0.13832897, -0.0515101, -0.2359007, -0.16661474, -0.14340827, + 0.36986142, 0.23414481, 0.55899, 0.10798943, -0.41174671, 0.17751795, + -0.34484994, -0.35874045, -0.11352962, 0.27268326, 0.54058349}); + + lstm.SetRecurrentToOutputWeights( + {0.41613156, 0.42610586, -0.16495961, -0.5663873, 0.30579174, -0.05115908, + -0.33941799, 0.23364776, 0.11178309, 0.09481031, -0.26424935, 0.46261835, + 0.50248802, 0.26114327, -0.43736315, 0.33149987}); - batch0_start = lstm_input_reversed; - batch0_end = batch0_start + lstm.num_inputs() * lstm.sequence_length(); + lstm.SetCellToForgetWeights( + {0.47485286, -0.51955009, -0.24458408, 0.31544167}); + lstm.SetCellToOutputWeights( + {-0.17135078, 0.82760304, 0.85573703, -0.77109635}); + + static float lstm_input_reversed[] = {1., 1., 3., 4., 2., 3.}; + static float lstm_fw_golden_output[] = { + -0.36444446, -0.00352185, 0.12886585, -0.05163646, + -0.42312205, -0.01218222, 0.24201041, -0.08124574, + -0.358325, -0.04621704, 0.21641694, -0.06471302}; + static float lstm_bw_golden_output[] = { + -0.401685, -0.0232794, 0.288642, -0.123074, -0.42915, -0.00871577, + 0.20912, -0.103567, -0.166398, -0.00486649, 0.0697471, -0.0537578}; + + float* batch0_start = lstm_input_reversed; + float* batch0_end = batch0_start + lstm.num_inputs() * lstm.sequence_length(); lstm.SetInput(0, batch0_start, batch0_end); lstm.Invoke(); - fw_expected.clear(); + std::vector<float> fw_expected; for (int s = 0; s < lstm.sequence_length(); s++) { - fw_golden_start = lstm_fw_golden_output + s * lstm.num_fw_outputs(); - fw_golden_end = fw_golden_start + lstm.num_fw_outputs(); + float* fw_golden_start = lstm_fw_golden_output + s * lstm.num_fw_outputs(); + float* fw_golden_end = fw_golden_start + lstm.num_fw_outputs(); fw_expected.insert(fw_expected.begin(), fw_golden_start, fw_golden_end); } EXPECT_THAT(lstm.GetBwOutput(), ElementsAreArray(ArrayFloatNear(fw_expected))); - bw_expected.clear(); + std::vector<float> bw_expected; for (int s = 0; s < lstm.sequence_length(); s++) { - bw_golden_start = lstm_bw_golden_output + s * lstm.num_bw_outputs(); - bw_golden_end = bw_golden_start + lstm.num_bw_outputs(); + float* bw_golden_start = lstm_bw_golden_output + s * lstm.num_bw_outputs(); + float* bw_golden_end = bw_golden_start + lstm.num_bw_outputs(); bw_expected.insert(bw_expected.begin(), bw_golden_start, bw_golden_end); } EXPECT_THAT(lstm.GetFwOutput(), @@ -759,6 +1041,22 @@ TEST(LSTMOpTest, BlackBoxTestWithPeepholeWithProjectionNoClipping) { {n_output, n_cell}, // projection_weight tensor {0}, // projection_bias tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor + + {n_batch, sequence_length, 0}, // aux_input tensor + {n_cell, 0}, // aux_fw_input_to_input tensor + {n_cell, 0}, // aux_fw_input_to_forget tensor + {n_cell, 0}, // aux_fw_input_to_cell tensor + {n_cell, 0}, // aux_fw_input_to_output tensor + {n_cell, 0}, // aux_bw_input_to_input tensor + {n_cell, 0}, // aux_bw_input_to_forget tensor + {n_cell, 0}, // aux_bw_input_to_cell tensor + {n_cell, 0}, // aux_bw_input_to_output tensor }); lstm.SetInputToInputWeights( @@ -1343,10 +1641,6 @@ TEST(LSTMOpTest, BlackBoxTestWithPeepholeWithProjectionNoClipping) { 0.065133, 0.024321, 0.038473, 0.062438 }}; - // Resetting cell_state and output_state - lstm.ResetFwOutputAndCellStates(); - lstm.ResetBwOutputAndCellStates(); - for (int i = 0; i < lstm.sequence_length(); i++) { float* batch0_start = lstm_input[0] + i * lstm.num_inputs(); float* batch0_end = batch0_start + lstm.num_inputs(); diff --git a/tensorflow/contrib/lite/kernels/bidirectional_sequence_rnn.cc b/tensorflow/contrib/lite/kernels/bidirectional_sequence_rnn.cc index c65bc33d08..d988ef8b33 100644 --- a/tensorflow/contrib/lite/kernels/bidirectional_sequence_rnn.cc +++ b/tensorflow/contrib/lite/kernels/bidirectional_sequence_rnn.cc @@ -41,13 +41,27 @@ constexpr int kBwWeightsTensor = 5; constexpr int kBwRecurrentWeightsTensor = 6; constexpr int kBwBiasTensor = 7; constexpr int kBwHiddenStateTensor = 8; +// Auxiliary inputs. +constexpr int kAuxInputTensor = 9; // Optional. +constexpr int kFwAuxWeightsTensor = 10; // Optional. +constexpr int kBwAuxWeightsTensor = 11; // Optional. // Output tensors. constexpr int kFwOutputTensor = 0; constexpr int kBwOutputTensor = 1; +// Temporary tensors. +enum TemporaryTensor { + kInputQuantized = 0, + kFwHiddenStateQuantized = 1, + kBwHiddenStateQuantized = 2, + kScalingFactors = 3, + kAuxInputQuantized = 4, + kNumTemporaryTensors = 5 +}; + void* Init(TfLiteContext* context, const char* buffer, size_t length) { auto* scratch_tensor_index = new int; - context->AddTensors(context, /*tensors_to_add=*/3, scratch_tensor_index); + context->AddTensors(context, kNumTemporaryTensors, scratch_tensor_index); return scratch_tensor_index; } @@ -57,7 +71,7 @@ void Free(TfLiteContext* context, void* buffer) { TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { // Check we have all the inputs and outputs we need. - TF_LITE_ENSURE_EQ(context, node->inputs->size, 9); + TF_LITE_ENSURE_EQ(context, node->inputs->size, 12); TF_LITE_ENSURE_EQ(context, node->outputs->size, 2); const TfLiteTensor* input = GetInput(context, node, kInputTensor); @@ -76,6 +90,21 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { const TfLiteTensor* bw_hidden_state = GetInput(context, node, kBwHiddenStateTensor); + const TfLiteTensor* aux_input = + GetOptionalInputTensor(context, node, kAuxInputTensor); + const TfLiteTensor* fw_aux_input_weights = + GetOptionalInputTensor(context, node, kFwAuxWeightsTensor); + const TfLiteTensor* bw_aux_input_weights = + GetOptionalInputTensor(context, node, kBwAuxWeightsTensor); + + const bool aux_inputs_all_or_none = + ((aux_input != nullptr) && (fw_aux_input_weights != nullptr) && + (bw_aux_input_weights != nullptr)) || + ((aux_input == nullptr) && (fw_aux_input_weights == nullptr) && + (bw_aux_input_weights == nullptr)); + TF_LITE_ENSURE(context, aux_inputs_all_or_none); + const bool has_aux_input = (aux_input != nullptr); + // Check all the parameters of tensor match within themselves and match the // input configuration. TF_LITE_ENSURE_EQ(context, input->type, kTfLiteFloat32); @@ -99,6 +128,20 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { TF_LITE_ENSURE_EQ(context, bw_hidden_state->dims->data[0], batch_size); TF_LITE_ENSURE_EQ(context, bw_hidden_state->dims->data[1], bw_num_units); + if (has_aux_input) { + // Check that aux_input has the same dimensions (except last) as the input. + TF_LITE_ASSERT_EQ(aux_input->dims->data[0], input->dims->data[0]); + TF_LITE_ASSERT_EQ(aux_input->dims->data[1], input->dims->data[1]); + // Check that aux_input_weights has the same dimensions (except last) as + // the input_weights. + TF_LITE_ASSERT_EQ(fw_aux_input_weights->dims->data[0], fw_num_units); + TF_LITE_ASSERT_EQ(bw_aux_input_weights->dims->data[0], bw_num_units); + TF_LITE_ASSERT_EQ(aux_input->dims->data[2], + fw_aux_input_weights->dims->data[1]); + TF_LITE_ASSERT_EQ(aux_input->dims->data[2], + bw_aux_input_weights->dims->data[1]); + } + TfLiteTensor* fw_output = GetOutput(context, node, kFwOutputTensor); TfLiteTensor* bw_output = GetOutput(context, node, kBwOutputTensor); @@ -107,10 +150,19 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { if (is_hybrid_op) { int* scratch_tensor_index = reinterpret_cast<int*>(node->user_data); + TfLiteIntArrayFree(node->temporaries); - node->temporaries = TfLiteIntArrayCreate(2); - node->temporaries->data[0] = *scratch_tensor_index; - TfLiteTensor* input_quantized = GetTemporary(context, node, /*index=*/0); + if (has_aux_input) { + node->temporaries = TfLiteIntArrayCreate(kNumTemporaryTensors); + } else { + // No need to create a temporary tensor for the non-existent aux_input. + node->temporaries = TfLiteIntArrayCreate(kNumTemporaryTensors - 1); + } + + node->temporaries->data[kInputQuantized] = + *scratch_tensor_index + kInputQuantized; + TfLiteTensor* input_quantized = + GetTemporary(context, node, kInputQuantized); input_quantized->type = kTfLiteUInt8; input_quantized->allocation_type = kTfLiteArenaRw; if (!TfLiteIntArrayEqual(input_quantized->dims, input->dims)) { @@ -118,9 +170,11 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, input_quantized, input_quantized_size)); } - node->temporaries->data[1] = *scratch_tensor_index + 1; + + node->temporaries->data[kFwHiddenStateQuantized] = + *scratch_tensor_index + kFwHiddenStateQuantized; TfLiteTensor* fw_hidden_state_quantized = - GetTemporary(context, node, /*index=*/1); + GetTemporary(context, node, kFwHiddenStateQuantized); fw_hidden_state_quantized->type = kTfLiteUInt8; fw_hidden_state_quantized->allocation_type = kTfLiteArenaRw; if (!TfLiteIntArrayEqual(fw_hidden_state_quantized->dims, @@ -131,9 +185,11 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { context, context->ResizeTensor(context, fw_hidden_state_quantized, fw_hidden_state_quantized_size)); } - node->temporaries->data[2] = *scratch_tensor_index + 2; + + node->temporaries->data[kBwHiddenStateQuantized] = + *scratch_tensor_index + kBwHiddenStateQuantized; TfLiteTensor* bw_hidden_state_quantized = - GetTemporary(context, node, /*index=*/2); + GetTemporary(context, node, kBwHiddenStateQuantized); bw_hidden_state_quantized->type = kTfLiteUInt8; bw_hidden_state_quantized->allocation_type = kTfLiteArenaRw; if (!TfLiteIntArrayEqual(bw_hidden_state_quantized->dims, @@ -144,6 +200,36 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { context, context->ResizeTensor(context, bw_hidden_state_quantized, bw_hidden_state_quantized_size)); } + + // Allocate temporary tensors to store scaling factors of quantization. + node->temporaries->data[kScalingFactors] = + *scratch_tensor_index + kScalingFactors; + TfLiteTensor* scaling_factors = + GetTemporary(context, node, kScalingFactors); + scaling_factors->type = kTfLiteFloat32; + scaling_factors->allocation_type = kTfLiteArenaRw; + TfLiteIntArray* scaling_factors_size = TfLiteIntArrayCreate(1); + scaling_factors_size->data[0] = batch_size; + if (!TfLiteIntArrayEqual(scaling_factors->dims, scaling_factors_size)) { + TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, scaling_factors, + scaling_factors_size)); + } + + if (has_aux_input) { + node->temporaries->data[kAuxInputQuantized] = + *scratch_tensor_index + kAuxInputQuantized; + TfLiteTensor* aux_input_quantized = + GetTemporary(context, node, kAuxInputQuantized); + aux_input_quantized->type = kTfLiteUInt8; + aux_input_quantized->allocation_type = kTfLiteArenaRw; + if (!TfLiteIntArrayEqual(aux_input_quantized->dims, aux_input->dims)) { + TfLiteIntArray* aux_input_quantized_size = + TfLiteIntArrayCopy(aux_input->dims); + TF_LITE_ENSURE_OK(context, + context->ResizeTensor(context, aux_input_quantized, + aux_input_quantized_size)); + } + } } // Resize outputs. @@ -163,19 +249,20 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { return kTfLiteOk; } -TfLiteStatus EvalFloat(const TfLiteTensor* input, - const TfLiteTensor* fw_input_weights, - const TfLiteTensor* fw_recurrent_weights, - const TfLiteTensor* fw_bias, - const TfLiteTensor* bw_input_weights, - const TfLiteTensor* bw_recurrent_weights, - const TfLiteTensor* bw_bias, - const TfLiteSequenceRNNParams* params, - TfLiteTensor* fw_hidden_state, TfLiteTensor* fw_output, - TfLiteTensor* bw_hidden_state, TfLiteTensor* bw_output) { +TfLiteStatus EvalFloat( + const TfLiteTensor* input, const TfLiteTensor* fw_input_weights, + const TfLiteTensor* fw_recurrent_weights, const TfLiteTensor* fw_bias, + const TfLiteTensor* bw_input_weights, + const TfLiteTensor* bw_recurrent_weights, const TfLiteTensor* bw_bias, + const TfLiteTensor* aux_input, const TfLiteTensor* fw_aux_input_weights, + const TfLiteTensor* bw_aux_input_weights, + const TfLiteSequenceRNNParams* params, TfLiteTensor* fw_hidden_state, + TfLiteTensor* fw_output, TfLiteTensor* bw_hidden_state, + TfLiteTensor* bw_output) { const int batch_size = input->dims->data[0]; const int max_time = input->dims->data[1]; const int input_size = input->dims->data[2]; + const int aux_input_size = (aux_input) ? aux_input->dims->data[2] : 0; const int fw_num_units = fw_input_weights->dims->data[0]; const float* fw_bias_ptr = fw_bias->data.f; @@ -187,6 +274,13 @@ TfLiteStatus EvalFloat(const TfLiteTensor* input, const float* bw_input_weights_ptr = bw_input_weights->data.f; const float* bw_recurrent_weights_ptr = bw_recurrent_weights->data.f; + const float* fw_aux_input_weights_ptr = (fw_aux_input_weights != nullptr) + ? fw_aux_input_weights->data.f + : nullptr; + const float* bw_aux_input_weights_ptr = (bw_aux_input_weights != nullptr) + ? bw_aux_input_weights->data.f + : nullptr; + for (int b = 0; b < batch_size; b++) { // Forward cell. float* fw_hidden_state_ptr_batch = @@ -194,12 +288,17 @@ TfLiteStatus EvalFloat(const TfLiteTensor* input, for (int s = 0; s < max_time; s++) { const float* input_ptr_batch = input->data.f + b * input_size * max_time + s * input_size; + const float* aux_input_ptr_batch = + (aux_input != nullptr) + ? aux_input->data.f + b * input_size * max_time + s * input_size + : nullptr; float* output_ptr_batch = fw_output->data.f + b * fw_num_units * max_time + s * fw_num_units; kernel_utils::RnnBatchStep( - input_ptr_batch, fw_input_weights_ptr, fw_recurrent_weights_ptr, - fw_bias_ptr, input_size, fw_num_units, /*batch_size=*/1, + input_ptr_batch, fw_input_weights_ptr, aux_input_ptr_batch, + fw_aux_input_weights_ptr, fw_recurrent_weights_ptr, fw_bias_ptr, + input_size, aux_input_size, fw_num_units, /*batch_size=*/1, params->activation, fw_hidden_state_ptr_batch, output_ptr_batch); } // Backward cell. @@ -208,12 +307,17 @@ TfLiteStatus EvalFloat(const TfLiteTensor* input, for (int s = max_time - 1; s >= 0; s--) { const float* input_ptr_batch = input->data.f + b * input_size * max_time + s * input_size; + const float* aux_input_ptr_batch = + (aux_input != nullptr) + ? aux_input->data.f + b * input_size * max_time + s * input_size + : nullptr; float* output_ptr_batch = bw_output->data.f + b * bw_num_units * max_time + s * bw_num_units; kernel_utils::RnnBatchStep( - input_ptr_batch, bw_input_weights_ptr, bw_recurrent_weights_ptr, - bw_bias_ptr, input_size, bw_num_units, /*batch_size=*/1, + input_ptr_batch, bw_input_weights_ptr, aux_input_ptr_batch, + bw_aux_input_weights_ptr, bw_recurrent_weights_ptr, bw_bias_ptr, + input_size, aux_input_size, bw_num_units, /*batch_size=*/1, params->activation, bw_hidden_state_ptr_batch, output_ptr_batch); } } @@ -225,14 +329,17 @@ TfLiteStatus EvalHybrid( const TfLiteTensor* fw_recurrent_weights, const TfLiteTensor* fw_bias, const TfLiteTensor* bw_input_weights, const TfLiteTensor* bw_recurrent_weights, const TfLiteTensor* bw_bias, - const TfLiteSequenceRNNParams* params, TfLiteTensor* input_quantized, - TfLiteTensor* fw_hidden_state_quantized, TfLiteTensor* fw_scaling_factors, - TfLiteTensor* fw_hidden_state, TfLiteTensor* fw_output, - TfLiteTensor* bw_hidden_state_quantized, TfLiteTensor* bw_scaling_factors, + const TfLiteTensor* aux_input, const TfLiteTensor* aux_fw_input_weights, + const TfLiteTensor* aux_bw_input_weights, + const TfLiteSequenceRNNParams* params, TfLiteTensor* scaling_factors, + TfLiteTensor* input_quantized, TfLiteTensor* aux_input_quantized, + TfLiteTensor* fw_hidden_state_quantized, TfLiteTensor* fw_hidden_state, + TfLiteTensor* fw_output, TfLiteTensor* bw_hidden_state_quantized, TfLiteTensor* bw_hidden_state, TfLiteTensor* bw_output) { const int batch_size = input->dims->data[0]; const int max_time = input->dims->data[1]; const int input_size = input->dims->data[2]; + const int aux_input_size = (aux_input) ? aux_input->dims->data[2] : 0; const int fw_num_units = fw_input_weights->dims->data[0]; const float* fw_bias_ptr = fw_bias->data.f; @@ -252,6 +359,22 @@ TfLiteStatus EvalHybrid( reinterpret_cast<const int8_t*>(bw_recurrent_weights->data.uint8); float bw_recurrent_weights_scale = bw_recurrent_weights->params.scale; + // Set the auxiliary pointers and scales if needed. + int8_t* aux_fw_input_weights_ptr = nullptr; + float aux_fw_input_weights_scale = 0.0f; + int8_t* aux_bw_input_weights_ptr = nullptr; + float aux_bw_input_weights_scale = 0.0f; + int8_t* aux_quantized_input_ptr = nullptr; + if (aux_input_size > 0) { + aux_fw_input_weights_ptr = + reinterpret_cast<int8_t*>(aux_fw_input_weights->data.uint8); + aux_fw_input_weights_scale = aux_fw_input_weights->params.scale; + aux_bw_input_weights_ptr = + reinterpret_cast<int8_t*>(aux_bw_input_weights->data.uint8); + aux_bw_input_weights_scale = aux_bw_input_weights->params.scale; + aux_quantized_input_ptr = reinterpret_cast<int8_t*>(aux_input_quantized); + } + // Initialize temporary storage for quantized values. int8_t* quantized_input_ptr = reinterpret_cast<int8_t*>(input_quantized->data.uint8); @@ -259,8 +382,7 @@ TfLiteStatus EvalHybrid( reinterpret_cast<int8_t*>(fw_hidden_state_quantized->data.uint8); int8_t* bw_quantized_hidden_state_ptr = reinterpret_cast<int8_t*>(bw_hidden_state_quantized->data.uint8); - float* fw_scaling_factors_ptr = fw_scaling_factors->data.f; - float* bw_scaling_factors_ptr = bw_scaling_factors->data.f; + float* scaling_factors_ptr = scaling_factors->data.f; for (int b = 0; b < batch_size; b++) { // Forward cell. @@ -269,15 +391,22 @@ TfLiteStatus EvalHybrid( for (int s = 0; s < max_time; s++) { const float* input_ptr_batch = input->data.f + b * input_size * max_time + s * input_size; + const float* aux_input_ptr_batch = + (aux_input != nullptr) + ? aux_input->data.f + b * input_size * max_time + s * input_size + : nullptr; float* output_ptr_batch = fw_output->data.f + b * fw_num_units * max_time + s * fw_num_units; kernel_utils::RnnBatchStep( input_ptr_batch, fw_input_weights_ptr, fw_input_weights_scale, - fw_recurrent_weights_ptr, fw_recurrent_weights_scale, fw_bias_ptr, - input_size, fw_num_units, /*batch_size=*/1, params->activation, - quantized_input_ptr, fw_quantized_hidden_state_ptr, - fw_scaling_factors_ptr, fw_hidden_state_ptr_batch, output_ptr_batch); + aux_input_ptr_batch, aux_fw_input_weights_ptr, + aux_fw_input_weights_scale, fw_recurrent_weights_ptr, + fw_recurrent_weights_scale, fw_bias_ptr, input_size, aux_input_size, + fw_num_units, /*batch_size=*/1, params->activation, + quantized_input_ptr, aux_quantized_input_ptr, + fw_quantized_hidden_state_ptr, scaling_factors_ptr, + fw_hidden_state_ptr_batch, output_ptr_batch); } // Backward cell. float* bw_hidden_state_ptr_batch = @@ -285,15 +414,22 @@ TfLiteStatus EvalHybrid( for (int s = max_time - 1; s >= 0; s--) { const float* input_ptr_batch = input->data.f + b * input_size * max_time + s * input_size; + const float* aux_input_ptr_batch = + (aux_input != nullptr) + ? aux_input->data.f + b * input_size * max_time + s * input_size + : nullptr; float* output_ptr_batch = bw_output->data.f + b * bw_num_units * max_time + s * bw_num_units; kernel_utils::RnnBatchStep( input_ptr_batch, bw_input_weights_ptr, bw_input_weights_scale, - bw_recurrent_weights_ptr, bw_recurrent_weights_scale, bw_bias_ptr, - input_size, bw_num_units, /*batch_size=*/1, params->activation, - quantized_input_ptr, bw_quantized_hidden_state_ptr, - bw_scaling_factors_ptr, bw_hidden_state_ptr_batch, output_ptr_batch); + aux_input_ptr_batch, aux_bw_input_weights_ptr, + aux_bw_input_weights_scale, bw_recurrent_weights_ptr, + bw_recurrent_weights_scale, bw_bias_ptr, input_size, aux_input_size, + bw_num_units, /*batch_size=*/1, params->activation, + quantized_input_ptr, aux_quantized_input_ptr, + bw_quantized_hidden_state_ptr, scaling_factors_ptr, + bw_hidden_state_ptr_batch, output_ptr_batch); } } return kTfLiteOk; @@ -315,10 +451,18 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { GetInput(context, node, kBwRecurrentWeightsTensor); const TfLiteTensor* bw_bias = GetInput(context, node, kBwBiasTensor); + // Get auxiliary inputs. + const TfLiteTensor* aux_input = + GetOptionalInputTensor(context, node, kAuxInputTensor); + const TfLiteTensor* fw_aux_input_weights = + GetOptionalInputTensor(context, node, kFwAuxWeightsTensor); + const TfLiteTensor* bw_aux_input_weights = + GetOptionalInputTensor(context, node, kBwAuxWeightsTensor); + TfLiteTensor* fw_hidden_state = - const_cast<TfLiteTensor*>(GetInput(context, node, kFwHiddenStateTensor)); + GetVariableInput(context, node, kFwHiddenStateTensor); TfLiteTensor* bw_hidden_state = - const_cast<TfLiteTensor*>(GetInput(context, node, kBwHiddenStateTensor)); + GetVariableInput(context, node, kBwHiddenStateTensor); TfLiteTensor* fw_output = GetOutput(context, node, kFwOutputTensor); TfLiteTensor* bw_output = GetOutput(context, node, kBwOutputTensor); @@ -326,19 +470,30 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { switch (fw_input_weights->type) { case kTfLiteFloat32: return EvalFloat(input, fw_input_weights, fw_recurrent_weights, fw_bias, - bw_input_weights, bw_recurrent_weights, bw_bias, params, - fw_hidden_state, fw_output, bw_hidden_state, bw_output); + bw_input_weights, bw_recurrent_weights, bw_bias, + aux_input, fw_aux_input_weights, bw_aux_input_weights, + params, fw_hidden_state, fw_output, bw_hidden_state, + bw_output); case kTfLiteUInt8: { - TfLiteTensor* input_quantized = GetTemporary(context, node, 0); - TfLiteTensor* fw_hidden_state_quantized = GetTemporary(context, node, 1); - TfLiteTensor* bw_hidden_state_quantized = GetTemporary(context, node, 2); - TfLiteTensor* fw_scaling_factors = GetTemporary(context, node, 3); - TfLiteTensor* bw_scaling_factors = GetTemporary(context, node, 4); + TfLiteTensor* input_quantized = + GetTemporary(context, node, kInputQuantized); + TfLiteTensor* fw_hidden_state_quantized = + GetTemporary(context, node, kFwHiddenStateQuantized); + TfLiteTensor* bw_hidden_state_quantized = + GetTemporary(context, node, kBwHiddenStateQuantized); + TfLiteTensor* scaling_factors = + GetTemporary(context, node, kScalingFactors); + TfLiteTensor* aux_input_quantized = + (aux_input != nullptr) + ? GetTemporary(context, node, kAuxInputQuantized) + : nullptr; + return EvalHybrid(input, fw_input_weights, fw_recurrent_weights, fw_bias, - bw_input_weights, bw_recurrent_weights, bw_bias, params, - input_quantized, fw_hidden_state_quantized, - fw_scaling_factors, fw_hidden_state, fw_output, - bw_hidden_state_quantized, bw_scaling_factors, + bw_input_weights, bw_recurrent_weights, bw_bias, + aux_input, fw_aux_input_weights, bw_aux_input_weights, + params, scaling_factors, input_quantized, + aux_input_quantized, fw_hidden_state_quantized, + fw_hidden_state, fw_output, bw_hidden_state_quantized, bw_hidden_state, bw_output); } default: diff --git a/tensorflow/contrib/lite/kernels/bidirectional_sequence_rnn_test.cc b/tensorflow/contrib/lite/kernels/bidirectional_sequence_rnn_test.cc index 03236dbcdc..3e34ba6196 100644 --- a/tensorflow/contrib/lite/kernels/bidirectional_sequence_rnn_test.cc +++ b/tensorflow/contrib/lite/kernels/bidirectional_sequence_rnn_test.cc @@ -665,12 +665,18 @@ class BidirectionalRNNOpModel : public SingleOpModel { fw_recurrent_weights_ = AddInput(TensorType_FLOAT32); fw_bias_ = AddInput(TensorType_FLOAT32); fw_hidden_state_ = AddInput(TensorType_FLOAT32, true); - fw_output_ = AddOutput(TensorType_FLOAT32); bw_weights_ = AddInput(TensorType_FLOAT32); bw_recurrent_weights_ = AddInput(TensorType_FLOAT32); bw_bias_ = AddInput(TensorType_FLOAT32); bw_hidden_state_ = AddInput(TensorType_FLOAT32, true); + + aux_input_ = AddNullInput(); + aux_fw_weights_ = AddNullInput(); + aux_bw_weights_ = AddNullInput(); + + fw_output_ = AddOutput(TensorType_FLOAT32); bw_output_ = AddOutput(TensorType_FLOAT32); + SetBuiltinOp(BuiltinOperator_BIDIRECTIONAL_SEQUENCE_RNN, BuiltinOptions_SequenceRNNOptions, CreateSequenceRNNOptions(builder_, /*time_major=*/false, @@ -685,7 +691,10 @@ class BidirectionalRNNOpModel : public SingleOpModel { {bw_units_, input_size_}, // bw_weights {bw_units_, bw_units_}, // bw_recurrent_weights {bw_units_}, // bw_bias - {batches_, bw_units_} // bw_hidden_state + {batches_, bw_units_}, // bw_hidden_state + {batches_, sequence_len_, 0}, // aux_input + {fw_units_, 0}, // aux_fw_weights + {bw_units_, 0}, // aux_bw_weights }); } @@ -742,6 +751,9 @@ class BidirectionalRNNOpModel : public SingleOpModel { int bw_bias_; int bw_hidden_state_; int bw_output_; + int aux_input_; + int aux_fw_weights_; + int aux_bw_weights_; int batches_; int sequence_len_; diff --git a/tensorflow/contrib/lite/kernels/internal/kernel_utils.cc b/tensorflow/contrib/lite/kernels/internal/kernel_utils.cc index 88a0622286..b9dd40ddf9 100644 --- a/tensorflow/contrib/lite/kernels/internal/kernel_utils.cc +++ b/tensorflow/contrib/lite/kernels/internal/kernel_utils.cc @@ -26,6 +26,21 @@ void RnnBatchStep(const float* input_ptr_batch, const float* input_weights_ptr, int input_size, int num_units, int batch_size, TfLiteFusedActivation activation, float* hidden_state_ptr_batch, float* output_ptr_batch) { + RnnBatchStep(input_ptr_batch, input_weights_ptr, + /*aux_input_ptr_batch=*/nullptr, + /*aux_input_weights_ptr=*/nullptr, recurrent_weights_ptr, + bias_ptr, input_size, /*aux_input_size=*/0, num_units, + batch_size, activation, hidden_state_ptr_batch, + output_ptr_batch); +} + +void RnnBatchStep(const float* input_ptr_batch, const float* input_weights_ptr, + const float* aux_input_ptr_batch, + const float* aux_input_weights_ptr, + const float* recurrent_weights_ptr, const float* bias_ptr, + int input_size, int aux_input_size, int num_units, + int batch_size, TfLiteFusedActivation activation, + float* hidden_state_ptr_batch, float* output_ptr_batch) { // Output = bias tensor_utils::VectorBatchVectorAssign(bias_ptr, num_units, batch_size, output_ptr_batch); @@ -33,6 +48,12 @@ void RnnBatchStep(const float* input_ptr_batch, const float* input_weights_ptr, tensor_utils::MatrixBatchVectorMultiplyAccumulate( input_weights_ptr, num_units, input_size, input_ptr_batch, batch_size, output_ptr_batch, /*result_stride=*/1); + // Output += aux_input * aux_input_weights (if they are not empty). + if (aux_input_size > 0) { + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + aux_input_weights_ptr, num_units, aux_input_size, aux_input_ptr_batch, + batch_size, output_ptr_batch, /*result_stride=*/1); + } // Output += recurrent_weights * hidden_state tensor_utils::MatrixBatchVectorMultiplyAccumulate( recurrent_weights_ptr, num_units, num_units, hidden_state_ptr_batch, @@ -54,6 +75,28 @@ void RnnBatchStep(const float* input_ptr_batch, const int8_t* input_weights_ptr, int8_t* quantized_hidden_state_ptr_batch, float* scaling_factors, float* hidden_state_ptr_batch, float* output_ptr_batch) { + RnnBatchStep(input_ptr_batch, input_weights_ptr, input_weights_scale, + /*aux_input_ptr_batch=*/nullptr, + /*aux_input_weights_ptr=*/nullptr, + /*aux_input_weights_scale=*/0.0f, recurrent_weights_ptr, + recurrent_weights_scale, bias_ptr, input_size, + /*aux_input_size=*/0, num_units, batch_size, activation, + quantized_input_ptr_batch, + /*aux_quantized_input_ptr_batch=*/nullptr, + quantized_hidden_state_ptr_batch, scaling_factors, + hidden_state_ptr_batch, output_ptr_batch); +} + +void RnnBatchStep( + const float* input_ptr_batch, const int8_t* input_weights_ptr, + float input_weights_scale, const float* aux_input_ptr_batch, + const int8_t* aux_input_weights_ptr, float aux_input_weights_scale, + const int8_t* recurrent_weights_ptr, float recurrent_weights_scale, + const float* bias_ptr, int input_size, int aux_input_size, int num_units, + int batch_size, TfLiteFusedActivation activation, + int8_t* quantized_input_ptr_batch, int8_t* aux_quantized_input_ptr_batch, + int8_t* quantized_hidden_state_ptr_batch, float* scaling_factors, + float* hidden_state_ptr_batch, float* output_ptr_batch) { // Output = bias tensor_utils::VectorBatchVectorAssign(bias_ptr, num_units, batch_size, output_ptr_batch); @@ -80,6 +123,26 @@ void RnnBatchStep(const float* input_ptr_batch, const int8_t* input_weights_ptr, scaling_factors, batch_size, output_ptr_batch, /*result_stride=*/1); } + if (aux_input_ptr_batch && + !tensor_utils::IsZeroVector(aux_input_ptr_batch, + batch_size * aux_input_size)) { + float unused_min, unused_max; + for (int b = 0; b < batch_size; ++b) { + const int offset = b * aux_input_size; + tensor_utils::SymmetricQuantizeFloats( + aux_input_ptr_batch + offset, aux_input_size, + aux_quantized_input_ptr_batch + offset, &unused_min, &unused_max, + &scaling_factors[b]); + scaling_factors[b] *= aux_input_weights_scale; + } + + // Output += aux_input * aux_input_weights + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + aux_input_weights_ptr, num_units, aux_input_size, + aux_quantized_input_ptr_batch, scaling_factors, batch_size, + output_ptr_batch, /*result_stride=*/1); + } + // Save quantization and matmul computation for all zero input. if (!tensor_utils::IsZeroVector(hidden_state_ptr_batch, batch_size * num_units)) { @@ -140,9 +203,9 @@ void LstmStep( cell_to_input_weights_ptr, cell_to_forget_weights_ptr, cell_to_output_weights_ptr, input_gate_bias_ptr, forget_gate_bias_ptr, cell_bias_ptr, output_gate_bias_ptr, projection_weights_ptr, - projection_bias_ptr, params, n_batch, n_cell, n_input, n_output, - output_state_ptr, cell_state_ptr, input_gate_scratch, forget_gate_scratch, - cell_scratch, output_gate_scratch, output_ptr_batch); + projection_bias_ptr, params, n_batch, n_cell, n_input, /*n_aux_input=*/0, + n_output, output_state_ptr, cell_state_ptr, input_gate_scratch, + forget_gate_scratch, cell_scratch, output_gate_scratch, output_ptr_batch); } void LstmStepWithAuxInput( @@ -164,8 +227,8 @@ void LstmStepWithAuxInput( const float* forget_gate_bias_ptr, const float* cell_bias_ptr, const float* output_gate_bias_ptr, const float* projection_weights_ptr, const float* projection_bias_ptr, const TfLiteLSTMParams* params, - int n_batch, int n_cell, int n_input, int n_output, float* output_state_ptr, - float* cell_state_ptr, float* input_gate_scratch, + int n_batch, int n_cell, int n_input, int n_aux_input, int n_output, + float* output_state_ptr, float* cell_state_ptr, float* input_gate_scratch, float* forget_gate_scratch, float* cell_scratch, float* output_gate_scratch, float* output_ptr_batch) { // Since we have already checked that weights are all there or none, we can @@ -205,19 +268,20 @@ void LstmStepWithAuxInput( if (aux_input_ptr_batch != nullptr) { if (!use_cifg) { tensor_utils::MatrixBatchVectorMultiplyAccumulate( - aux_input_to_input_weights_ptr, n_cell, n_input, aux_input_ptr_batch, - n_batch, input_gate_scratch, /*result_stride=*/1); + aux_input_to_input_weights_ptr, n_cell, n_aux_input, + aux_input_ptr_batch, n_batch, input_gate_scratch, + /*result_stride=*/1); } tensor_utils::MatrixBatchVectorMultiplyAccumulate( - aux_input_to_forget_weights_ptr, n_cell, n_input, aux_input_ptr_batch, - n_batch, forget_gate_scratch, /*result_stride=*/1); + aux_input_to_forget_weights_ptr, n_cell, n_aux_input, + aux_input_ptr_batch, n_batch, forget_gate_scratch, /*result_stride=*/1); tensor_utils::MatrixBatchVectorMultiplyAccumulate( - aux_input_to_cell_weights_ptr, n_cell, n_input, aux_input_ptr_batch, + aux_input_to_cell_weights_ptr, n_cell, n_aux_input, aux_input_ptr_batch, n_batch, cell_scratch, /*result_stride=*/1); tensor_utils::MatrixBatchVectorMultiplyAccumulate( - aux_input_to_output_weights_ptr, n_cell, n_input, aux_input_ptr_batch, - n_batch, output_gate_scratch, /*result_stride=*/1); + aux_input_to_output_weights_ptr, n_cell, n_aux_input, + aux_input_ptr_batch, n_batch, output_gate_scratch, /*result_stride=*/1); } // For each batch and cell: compute recurrent_weight * output_state. @@ -369,10 +433,11 @@ void LstmStep( cell_to_output_weights_ptr, cell_to_output_weights_scale, input_gate_bias_ptr, forget_gate_bias_ptr, cell_bias_ptr, output_gate_bias_ptr, projection_weights_ptr, projection_weights_scale, - projection_bias_ptr, params, n_batch, n_cell, n_input, n_output, - input_gate_scratch, forget_gate_scratch, cell_scratch, - output_gate_scratch, scaling_factors, product_scaling_factors, - recovered_cell_weights, quantized_input_ptr_batch, + projection_bias_ptr, params, n_batch, n_cell, n_input, + /*n_aux_input=*/0, n_output, input_gate_scratch, forget_gate_scratch, + cell_scratch, output_gate_scratch, scaling_factors, + product_scaling_factors, recovered_cell_weights, + quantized_input_ptr_batch, /*quantized_aux_input_ptr_batch=*/nullptr, quantized_output_state_ptr, quantized_cell_state_ptr, output_state_ptr, cell_state_ptr, output_ptr_batch); @@ -413,8 +478,9 @@ void LstmStep( const float* output_gate_bias_ptr, const int8_t* projection_weights_ptr, float projection_weights_scale, const float* projection_bias_ptr, const TfLiteLSTMParams* params, int n_batch, int n_cell, int n_input, - int n_output, float* input_gate_scratch, float* forget_gate_scratch, - float* cell_scratch, float* output_gate_scratch, float* scaling_factors, + int n_aux_input, int n_output, float* input_gate_scratch, + float* forget_gate_scratch, float* cell_scratch, + float* output_gate_scratch, float* scaling_factors, float* product_scaling_factors, float* recovered_cell_weights, int8_t* quantized_input_ptr_batch, int8_t* quantized_aux_input_ptr_batch, diff --git a/tensorflow/contrib/lite/kernels/internal/kernel_utils.h b/tensorflow/contrib/lite/kernels/internal/kernel_utils.h index 599850db60..215ad04add 100644 --- a/tensorflow/contrib/lite/kernels/internal/kernel_utils.h +++ b/tensorflow/contrib/lite/kernels/internal/kernel_utils.h @@ -35,6 +35,15 @@ void RnnBatchStep(const float* input_ptr_batch, const float* input_weights_ptr, TfLiteFusedActivation activation, float* hidden_state_ptr_batch, float* output_ptr_batch); +// Same as above but includes an auxiliary input with the corresponding weights. +void RnnBatchStep(const float* input_ptr_batch, const float* input_weights_ptr, + const float* aux_input_ptr_batch, + const float* aux_input_weights_ptr, + const float* recurrent_weights_ptr, const float* bias_ptr, + int input_size, int aux_input_size, int num_units, + int batch_size, TfLiteFusedActivation activation, + float* hidden_state_ptr_batch, float* output_ptr_batch); + // Performs a quantized RNN batch inference step. Same as above, but for // quantization purposes, we also pass in quantized_hidden_state_ptr_batch and // quantized_input_ptr_batch pointers for temporary storage of the quantized @@ -56,6 +65,17 @@ void RnnBatchStep(const float* input_ptr_batch, const int8_t* input_weights_ptr, float* scaling_factors, float* hidden_state_ptr_batch, float* output_ptr_batch); +void RnnBatchStep( + const float* input_ptr_batch, const int8_t* input_weights_ptr, + float input_weights_scale, const float* aux_input_ptr_batch, + const int8_t* aux_input_weights_ptr, float aux_input_weights_scale, + const int8_t* recurrent_weights_ptr, float recurrent_weights_scale, + const float* bias_ptr, int input_size, int aux_input_size, int num_units, + int batch_size, TfLiteFusedActivation activation, + int8_t* quantized_input_ptr_batch, int8_t* aux_quantized_input_ptr_batch, + int8_t* quantized_hidden_state_ptr_batch, float* scaling_factors, + float* hidden_state_ptr_batch, float* output_ptr_batch); + // Performs an LSTM batch inference step for input specified by input_ptr_batch. // The LSTM cell is specified by the pointers to its weights (*_weights_ptr) and // biases (*_bias_ptr), and buffers (*_scratch), along with additional @@ -111,8 +131,8 @@ void LstmStepWithAuxInput( const float* forget_gate_bias_ptr, const float* cell_bias_ptr, const float* output_gate_bias_ptr, const float* projection_weights_ptr, const float* projection_bias_ptr, const TfLiteLSTMParams* params, - int n_batch, int n_cell, int n_input, int n_output, float* output_state_ptr, - float* cell_state_ptr, float* input_gate_scratch, + int n_batch, int n_cell, int n_input, int n_aux_input, int n_output, + float* output_state_ptr, float* cell_state_ptr, float* input_gate_scratch, float* forget_gate_scratch, float* cell_scratch, float* output_gate_scratch, float* output_ptr_batch); @@ -232,12 +252,13 @@ void LstmStepWithAuxInput( const float* output_gate_bias_ptr, const int8_t* projection_weights_ptr, float projection_weights_scale, const float* projection_bias_ptr, const TfLiteLSTMParams* params, int n_batch, int n_cell, int n_input, - int n_output, float* input_gate_scratch, float* forget_gate_scratch, - float* cell_scratch, float* output_gate_scratch, float* scaling_factors, - float* product_scaling_factors, float* recovered_cell_weights, - int8_t* quantized_input_ptr_batch, int8_t* quantized_aux_input_ptr_batch, - int8_t* quantized_output_state_ptr, int8_t* quantized_cell_state_ptr, - float* output_state_ptr, float* cell_state_ptr, float* output_ptr_batch); + int n_aux_input, int n_output, float* input_gate_scratch, + float* forget_gate_scratch, float* cell_scratch, float* output_gate_scratch, + float* scaling_factors, float* product_scaling_factors, + float* recovered_cell_weights, int8_t* quantized_input_ptr_batch, + int8_t* quantized_aux_input_ptr_batch, int8_t* quantized_output_state_ptr, + int8_t* quantized_cell_state_ptr, float* output_state_ptr, + float* cell_state_ptr, float* output_ptr_batch); } // namespace kernel_utils } // namespace tflite diff --git a/tensorflow/contrib/lite/kernels/internal/optimized/neon_tensor_utils.h b/tensorflow/contrib/lite/kernels/internal/optimized/neon_tensor_utils.h index e671624fe7..5ca1b4b76f 100644 --- a/tensorflow/contrib/lite/kernels/internal/optimized/neon_tensor_utils.h +++ b/tensorflow/contrib/lite/kernels/internal/optimized/neon_tensor_utils.h @@ -79,6 +79,11 @@ void BatchVectorBatchVectorDotProduct(const float* vector1, n_batch, result, result_stride); } +void VectorBatchVectorAdd(const float* vector, int v_size, int n_batch, + float* batch_vector) { + PortableVectorBatchVectorAdd(vector, v_size, n_batch, batch_vector); +} + void VectorBatchVectorAssign(const float* vector, int v_size, int n_batch, float* batch_vector) { PortableVectorBatchVectorAssign(vector, v_size, n_batch, batch_vector); @@ -138,6 +143,13 @@ void ReductionSumVector(const float* input_vector, float* output_vector, reduction_size); } +void MeanStddevNormalization(const float* input_vector, float* output_vector, + int v_size, int n_batch, + float normalization_epsilon) { + PortableMeanStddevNormalization(input_vector, output_vector, v_size, n_batch, + normalization_epsilon); +} + } // namespace tensor_utils } // namespace tflite diff --git a/tensorflow/contrib/lite/kernels/internal/optimized/optimized_ops.h b/tensorflow/contrib/lite/kernels/internal/optimized/optimized_ops.h index 70adffda3b..2c8e8f90e3 100644 --- a/tensorflow/contrib/lite/kernels/internal/optimized/optimized_ops.h +++ b/tensorflow/contrib/lite/kernels/internal/optimized/optimized_ops.h @@ -43,6 +43,14 @@ namespace optimized_ops { // Unoptimized reference ops: using reference_ops::ArgMax; using reference_ops::ArgMinMax; +using reference_ops::Broadcast4DSlowGreater; +using reference_ops::Broadcast4DSlowGreaterEqual; +using reference_ops::Broadcast4DSlowGreaterEqualWithScaling; +using reference_ops::Broadcast4DSlowGreaterWithScaling; +using reference_ops::Broadcast4DSlowLess; +using reference_ops::Broadcast4DSlowLessEqual; +using reference_ops::Broadcast4DSlowLessEqualWithScaling; +using reference_ops::Broadcast4DSlowLessWithScaling; using reference_ops::BroadcastAdd4DSlow; using reference_ops::BroadcastGreater; using reference_ops::BroadcastGreaterEqual; @@ -58,8 +66,12 @@ using reference_ops::FakeQuant; using reference_ops::Gather; using reference_ops::Greater; using reference_ops::GreaterEqual; +using reference_ops::GreaterEqualWithScaling; +using reference_ops::GreaterWithScaling; using reference_ops::Less; using reference_ops::LessEqual; +using reference_ops::LessEqualWithScaling; +using reference_ops::LessWithScaling; using reference_ops::Mean; using reference_ops::RankOneSelect; using reference_ops::Relu1; @@ -67,6 +79,7 @@ using reference_ops::Relu6; using reference_ops::ReluX; using reference_ops::Select; using reference_ops::SpaceToBatchND; +using reference_ops::Split; using reference_ops::StridedSlice; using reference_ops::Transpose; diff --git a/tensorflow/contrib/lite/kernels/internal/optimized/tensor_utils_impl.h b/tensorflow/contrib/lite/kernels/internal/optimized/tensor_utils_impl.h index 8664ebc4f6..7e53dc2fa2 100644 --- a/tensorflow/contrib/lite/kernels/internal/optimized/tensor_utils_impl.h +++ b/tensorflow/contrib/lite/kernels/internal/optimized/tensor_utils_impl.h @@ -117,6 +117,10 @@ void PortableClipVector(const float* vector, int v_size, float abs_limit, void NeonClipVector(const float* vector, int v_size, float abs_limit, float* result); +// Add another vector for each batch in the batch vector. +void PortableVectorBatchVectorAdd(const float* vector, int v_size, int n_batch, + float* batch_vector); + // Batch vector initialization with another vector. void PortableVectorBatchVectorAssign(const float* vector, int v_size, int n_batch, float* batch_vector); @@ -172,6 +176,10 @@ void PortableReductionSumVector(const float* input_vector, float* output_vector, void NeonReductionSumVector(const float* input_vector, float* output_vector, int output_size, int reduction_size); +void PortableMeanStddevNormalization(const float* input_vector, + float* output_vector, int v_size, + int n_batch, float normalization_epsilon); + } // namespace tensor_utils } // namespace tflite diff --git a/tensorflow/contrib/lite/kernels/internal/quantization_util.cc b/tensorflow/contrib/lite/kernels/internal/quantization_util.cc index f882f9910e..544ef16ce1 100644 --- a/tensorflow/contrib/lite/kernels/internal/quantization_util.cc +++ b/tensorflow/contrib/lite/kernels/internal/quantization_util.cc @@ -23,6 +23,32 @@ limitations under the License. namespace tflite { +namespace { +// These constants are used to manipulate the binary representation of doubles. +// Double-precision binary64 floating point format is: +// Bit | 63 | 62-52 | 51-0 | +// | Sign | Exponent | Fraction | +// To avoid 64-bit integers as much as possible, I break this into high and +// low 32-bit chunks. High is: +// Bit | 31 | 30-20 | 19-0 | +// | Sign | Exponent | High Fraction | +// Low is: +// Bit | 31-0 | +// | Low Fraction | +// We then access the components through logical bit-wise operations to +// extract the parts needed, with the positions and masks derived from the +// layout shown above. +constexpr uint64_t kSignMask = 0x8000000000000000LL; +constexpr uint64_t kExponentMask = 0x7ff0000000000000LL; +constexpr int32_t kExponentShift = 52; +constexpr int32_t kExponentBias = 1023; +constexpr uint32_t kExponentIsBadNum = 0x7ff; +constexpr uint64_t kFractionMask = 0x000fffffffc00000LL; +constexpr uint32_t kFractionShift = 22; +constexpr uint32_t kFractionRoundingMask = 0x003fffff; +constexpr uint32_t kFractionRoundingThreshold = 0x00200000; +} // namespace + void QuantizeMultiplier(double double_multiplier, int32_t* quantized_multiplier, int* shift) { if (double_multiplier == 0.) { @@ -30,8 +56,16 @@ void QuantizeMultiplier(double double_multiplier, int32_t* quantized_multiplier, *shift = 0; return; } +#ifdef TFLITE_EMULATE_FLOAT + // If we're trying to avoid the use of floating-point instructions (for + // example on microcontrollers) then use an alternative implementation + // that only requires integer and bitwise operations. To enable this, you + // need to set the define during the build process for your platform. + int64_t q_fixed = IntegerFrExp(double_multiplier, shift); +#else // TFLITE_EMULATE_FLOAT const double q = std::frexp(double_multiplier, shift); auto q_fixed = static_cast<int64_t>(TfLiteRound(q * (1ll << 31))); +#endif // TFLITE_EMULATE_FLOAT TFLITE_CHECK(q_fixed <= (1ll << 31)); if (q_fixed == (1ll << 31)) { q_fixed /= 2; @@ -60,6 +94,163 @@ void QuantizeMultiplierSmallerThanOneExp(double double_multiplier, *left_shift = shift; } +int64_t IntegerFrExp(double input, int* shift) { + // Make sure our assumptions about the double layout hold. + TFLITE_CHECK_EQ(8, sizeof(double)); + + // We want to access the bits of the input double value directly, which is + // tricky to do safely, so use a union to handle the casting. + union { + double double_value; + uint64_t double_as_uint; + } cast_union; + cast_union.double_value = input; + const uint64_t u = cast_union.double_as_uint; + + // If the bitfield is all zeros apart from the sign bit, this is a normalized + // zero value, so return standard values for this special case. + if ((u & ~kSignMask) == 0) { + *shift = 0; + return 0; + } + + // Deal with NaNs and Infs, which are always indicated with a fixed pattern in + // the exponent, and distinguished by whether the fractions are zero or + // non-zero. + const uint32_t exponent_part = ((u & kExponentMask) >> kExponentShift); + if (exponent_part == kExponentIsBadNum) { + *shift = std::numeric_limits<int>::max(); + if (u & kFractionMask) { + // NaN, so just return zero (with the exponent set to INT_MAX). + return 0; + } else { + // Infinity, so return +/- INT_MAX. + if (u & kSignMask) { + return std::numeric_limits<int64_t>::min(); + } else { + return std::numeric_limits<int64_t>::max(); + } + } + } + + // The shift is fairly easy to extract from the high bits of the double value, + // just by masking it out and applying a bias. The std::frexp() implementation + // always returns values between 0.5 and 1.0 though, whereas the exponent + // assumes 1.0 to 2.0 is the standard range, so I add on one to match that + // interface. + *shift = (exponent_part - kExponentBias) + 1; + + // There's an implicit high bit in the double format definition, so make sure + // we include that at the top, and then reconstruct the rest of the fractional + // value from the remaining fragments. + int64_t fraction = 0x40000000 + ((u & kFractionMask) >> kFractionShift); + + // We're cutting off some bits at the bottom, so to exactly match the standard + // frexp implementation here we'll apply rounding by adding one to the least + // significant bit of the result if the discarded portion is over half of the + // maximum. + if ((u & kFractionRoundingMask) > kFractionRoundingThreshold) { + fraction += 1; + } + // Negate the fraction if the sign bit was set. + if (u & kSignMask) { + fraction *= -1; + } + + return fraction; +} + +double DoubleFromFractionAndShift(int64_t fraction, int shift) { + union { + double double_value; + uint64_t double_as_uint; + } result; + + // Detect NaNs and infinities. + if (shift == std::numeric_limits<int>::max()) { + if (fraction == 0) { + return NAN; + } else if (fraction > 0) { + return INFINITY; + } else { + return -INFINITY; + } + } + + // Return a normalized zero for a zero fraction. + if (fraction == 0) { + result.double_as_uint = 0; + return result.double_value; + } + + bool is_negative = (fraction < 0); + int64_t encoded_fraction = is_negative ? -fraction : fraction; + int64_t encoded_shift = (shift - 1); + while (encoded_fraction < 0x40000000) { + encoded_fraction *= 2; + encoded_shift -= 1; + } + while (encoded_fraction > 0x80000000) { + encoded_fraction /= 2; + encoded_shift += 1; + } + encoded_fraction -= 0x40000000; + if (encoded_shift < -1022) { + encoded_shift = -1023; + } else if (encoded_shift > 1022) { + encoded_shift = 1023; + } + encoded_shift += kExponentBias; + uint64_t encoded_sign = is_negative ? kSignMask : 0; + result.double_as_uint = encoded_sign | (encoded_shift << kExponentShift) | + (encoded_fraction << kFractionShift); + return result.double_value; +} + +double IntegerDoubleMultiply(double a, double b) { + int a_shift; + const int64_t a_fraction = IntegerFrExp(a, &a_shift); + int b_shift; + const int64_t b_fraction = IntegerFrExp(b, &b_shift); + // Detect NaNs and infinities. + if (a_shift == std::numeric_limits<int>::max() || + (b_shift == std::numeric_limits<int>::max())) { + return NAN; + } + const int result_shift = a_shift + b_shift + 1; + const int64_t result_fraction = (a_fraction * b_fraction) >> 32; + return DoubleFromFractionAndShift(result_fraction, result_shift); +} + +int IntegerDoubleCompare(double a, double b) { + int a_shift; + const int64_t a_fraction = IntegerFrExp(a, &a_shift); + int b_shift; + const int64_t b_fraction = IntegerFrExp(b, &b_shift); + + // Detect NaNs and infinities. + if (a_shift == std::numeric_limits<int>::max() || + (b_shift == std::numeric_limits<int>::max())) { + return 1; + } + + if ((a_fraction == 0) && (b_fraction < 0)) { + return 1; + } else if ((a_fraction < 0) && (b_fraction == 0)) { + return -1; + } else if (a_shift < b_shift) { + return -1; + } else if (a_shift > b_shift) { + return 1; + } else if (a_fraction < b_fraction) { + return -1; + } else if (a_fraction > b_fraction) { + return 1; + } else { + return 0; + } +} + void PreprocessSoftmaxScaling(double beta, double input_scale, int input_integer_bits, int32_t* quantized_multiplier, int* left_shift) { @@ -72,8 +263,20 @@ void PreprocessSoftmaxScaling(double beta, double input_scale, // result is double equivalent of Q0.31 (actually with more precision). Thus // this generates a Q(input_integer_bits).(31-input_integer_bits) // representation. +#ifdef TFLITE_EMULATE_FLOAT + const double input_beta = IntegerDoubleMultiply(beta, input_scale); + int shift; + int64_t fraction = IntegerFrExp(input_beta, &shift); + shift += (31 - input_integer_bits); + double input_beta_real_multiplier = + DoubleFromFractionAndShift(fraction, shift); + if (IntegerDoubleCompare(input_beta_real_multiplier, (1ll << 31) - 1.0) > 0) { + input_beta_real_multiplier = (1ll << 31) - 1.0; + } +#else // TFLITE_EMULATE_FLOAT const double input_beta_real_multiplier = std::min( beta * input_scale * (1 << (31 - input_integer_bits)), (1ll << 31) - 1.0); +#endif // TFLITE_EMULATE_FLOAT QuantizeMultiplierGreaterThanOne(input_beta_real_multiplier, quantized_multiplier, left_shift); @@ -97,6 +300,12 @@ void PreprocessLogSoftmaxScalingExp(double beta, double input_scale, } int CalculateInputRadius(int input_integer_bits, int input_left_shift) { +#ifdef TFLITE_EMULATE_FLOAT + int64_t result = (1 << input_integer_bits) - 1; + result <<= (31 - input_integer_bits); + result >>= input_left_shift; + return result; +#else // TFLITE_EMULATE_FLOAT const double max_input_rescaled = 1.0 * ((1 << input_integer_bits) - 1) * (1ll << (31 - input_integer_bits)) / (1ll << input_left_shift); @@ -104,6 +313,7 @@ int CalculateInputRadius(int input_integer_bits, int input_left_shift) { // After scaling the difference, the result would be at the maximum. Thus we // must ensure that our value has lower magnitude. return static_cast<int>(std::floor(max_input_rescaled)); +#endif // TFLITE_EMULATE_FLOAT } void NudgeQuantizationRange(const float min, const float max, diff --git a/tensorflow/contrib/lite/kernels/internal/quantization_util.h b/tensorflow/contrib/lite/kernels/internal/quantization_util.h index 9ee4a47fbb..d74a1bac97 100644 --- a/tensorflow/contrib/lite/kernels/internal/quantization_util.h +++ b/tensorflow/contrib/lite/kernels/internal/quantization_util.h @@ -195,6 +195,44 @@ void QuantizeMultiplierGreaterThanOne(double double_multiplier, void QuantizeMultiplier(double double_multiplier, int32_t* quantized_multiplier, int* shift); +// Splits a double input value into a returned fraction, and a shift value from +// the exponent, using only bitwise and integer operations to support +// microcontrollers and other environments without floating-point support. +// +// This is designed to be a replacement for how std::frexp() is used within the +// QuantizeMultiplier() function, and so has a different signature than the +// standard version, returning a 64-bit integer rather than a double. This +// result has a maximum value of 1<<31, with the fraction expressed as a +// proportion of that maximum. +// +// std::frexp() returns NaNs and infinities unmodified, but since we're +// returning integers that can't represent those values, instead we return +// a shift of std::numeric_limits<int>::max() for all bad numbers, with an int64 +// result of 0 for NaNs, std:numeric_limits<int64_t>::max() for +INFINITY, and +// std::numeric_limits<int64_t>::min() for -INFINITY. Denormalized inputs will +// result in return values that end up truncating some bits at the end, +// reflecting the loss of precision inherent in denormalization. +int64_t IntegerFrExp(double input, int* shift); + +// Converts an integer fraction in the format produced by IntegerFrExp (where +// 0x40000000 is 1.0) and an exponent shift (between -1022 and +1022) into an +// IEEE binary64 double format result. The implementation uses only integer and +// bitwise operators, so no floating point hardware support or emulation is +// needed. This is here so quantized operations can run non-time-critical +// preparation calculations on microcontrollers and other platforms without +// float support. +double DoubleFromFractionAndShift(int64_t fraction, int shift); + +// Performs a multiplication of two numbers in double format, using only integer +// and bitwise instructions. This is aimed at supporting housekeeping functions +// for quantized operations on microcontrollers without floating-point hardware. +double IntegerDoubleMultiply(double a, double b); + +// Returns -1 if a is less than b, 0 if a and b are equal, and +1 if a is +// greater than b. It is implemented using only integer and logical instructions +// so that it can be easily run on microcontrollers for quantized operations. +int IntegerDoubleCompare(double a, double b); + // This first creates a multiplier in a double equivalent of // Q(input_integer_bits).(31-input_integer_bits) representation, with extra // precision in the double's fractional bits. It then splits the result into diff --git a/tensorflow/contrib/lite/kernels/internal/quantization_util_test.cc b/tensorflow/contrib/lite/kernels/internal/quantization_util_test.cc index 00fc3e91dc..14281f25c6 100644 --- a/tensorflow/contrib/lite/kernels/internal/quantization_util_test.cc +++ b/tensorflow/contrib/lite/kernels/internal/quantization_util_test.cc @@ -191,6 +191,139 @@ TEST(QuantizationUtilTest, ChooseQuantizationParamsZeroPointOnMaxBoundary) { EXPECT_EQ(qp.zero_point, 255); } +TEST(QuantizationUtilTest, IntegerFrExp) { + int shift; + int64_t result = IntegerFrExp(0.0, &shift); + EXPECT_EQ(0, result); + EXPECT_EQ(0, shift); + + result = IntegerFrExp(1.0, &shift); + EXPECT_NEAR(0x40000000, result, 1); + EXPECT_EQ(1, shift); + + result = IntegerFrExp(0.25, &shift); + EXPECT_NEAR(0x40000000, result, 1); + EXPECT_EQ(-1, shift); + + result = IntegerFrExp(-1.0, &shift); + EXPECT_NEAR(-(1 << 30), result, 1); + EXPECT_EQ(1, shift); + + result = IntegerFrExp(123.45, &shift); + EXPECT_NEAR(2071147315, result, 1); + EXPECT_EQ(7, shift); + + result = IntegerFrExp(NAN, &shift); + EXPECT_NEAR(0, result, 1); + EXPECT_EQ(0x7fffffff, shift); + + result = IntegerFrExp(INFINITY, &shift); + EXPECT_NEAR(std::numeric_limits<int64_t>::max(), result, 1); + EXPECT_EQ(0x7fffffff, shift); + + result = IntegerFrExp(-INFINITY, &shift); + EXPECT_NEAR(std::numeric_limits<int64_t>::min(), result, 1); + EXPECT_EQ(0x7fffffff, shift); +} + +TEST(QuantizationUtilTest, IntegerFrExpVersusDouble) { + int shift; + int32_t result = IntegerFrExp(0.0, &shift); + EXPECT_EQ(result, 0); + EXPECT_EQ(shift, 0); + + int double_shift; + double double_result = std::frexp(0.0, &double_shift); + EXPECT_EQ(double_result, 0); + EXPECT_EQ(double_shift, 0); + + result = IntegerFrExp(1.0, &shift); + EXPECT_NEAR(result, 0x40000000, 1); + EXPECT_EQ(shift, 1); + double_result = std::frexp(1.0, &double_shift); + EXPECT_NEAR(double_result, 0.5, 1e-5); + EXPECT_EQ(double_shift, 1); + + result = IntegerFrExp(0.25, &shift); + EXPECT_NEAR(result, 0x40000000, 1); + EXPECT_EQ(shift, -1); + double_result = std::frexp(0.25, &double_shift); + EXPECT_NEAR(double_result, 0.5, 1e-5); + EXPECT_EQ(double_shift, -1); + + result = IntegerFrExp(-1.0, &shift); + EXPECT_NEAR(result, -(1 << 30), 1); + EXPECT_EQ(shift, 1); + double_result = std::frexp(-1.0, &double_shift); + EXPECT_NEAR(double_result, -0.5, 1e-5); + EXPECT_EQ(double_shift, 1); + + result = IntegerFrExp(123.45, &shift); + EXPECT_NEAR(result, (0.964453 * (1L << 31)), 1000); + EXPECT_EQ(shift, 7); + double_result = std::frexp(123.45, &double_shift); + EXPECT_NEAR(double_result, 0.964453, 1e-5); + EXPECT_EQ(double_shift, 7); +} + +TEST(QuantizationUtilTest, DoubleFromFractionAndShift) { + double result = DoubleFromFractionAndShift(0, 0); + EXPECT_EQ(0, result); + + result = DoubleFromFractionAndShift(0x40000000, 1); + EXPECT_NEAR(1.0, result, 1e-5); + + result = DoubleFromFractionAndShift(0x40000000, 2); + EXPECT_NEAR(2.0, result, 1e-5); + + int shift; + int64_t fraction = IntegerFrExp(3.0, &shift); + result = DoubleFromFractionAndShift(fraction, shift); + EXPECT_NEAR(3.0, result, 1e-5); + + fraction = IntegerFrExp(123.45, &shift); + result = DoubleFromFractionAndShift(fraction, shift); + EXPECT_NEAR(123.45, result, 1e-5); + + fraction = IntegerFrExp(-23.232323, &shift); + result = DoubleFromFractionAndShift(fraction, shift); + EXPECT_NEAR(-23.232323, result, 1e-5); + + fraction = IntegerFrExp(NAN, &shift); + result = DoubleFromFractionAndShift(fraction, shift); + EXPECT_TRUE(std::isnan(result)); + + fraction = IntegerFrExp(INFINITY, &shift); + result = DoubleFromFractionAndShift(fraction, shift); + EXPECT_FALSE(std::isfinite(result)); +} + +TEST(QuantizationUtilTest, IntegerDoubleMultiply) { + EXPECT_NEAR(1.0, IntegerDoubleMultiply(1.0, 1.0), 1e-5); + EXPECT_NEAR(2.0, IntegerDoubleMultiply(1.0, 2.0), 1e-5); + EXPECT_NEAR(2.0, IntegerDoubleMultiply(2.0, 1.0), 1e-5); + EXPECT_NEAR(4.0, IntegerDoubleMultiply(2.0, 2.0), 1e-5); + EXPECT_NEAR(0.5, IntegerDoubleMultiply(1.0, 0.5), 1e-5); + EXPECT_NEAR(0.25, IntegerDoubleMultiply(0.5, 0.5), 1e-5); + EXPECT_NEAR(-1.0, IntegerDoubleMultiply(1.0, -1.0), 1e-5); + EXPECT_NEAR(-1.0, IntegerDoubleMultiply(-1.0, 1.0), 1e-5); + EXPECT_NEAR(1.0, IntegerDoubleMultiply(-1.0, -1.0), 1e-5); + EXPECT_NEAR(15000000.0, IntegerDoubleMultiply(3000.0, 5000.0), 1e-5); + EXPECT_TRUE(std::isnan(IntegerDoubleMultiply(NAN, 5000.0))); + EXPECT_TRUE(std::isnan(IntegerDoubleMultiply(3000.0, NAN))); +} + +TEST(QuantizationUtilTest, IntegerDoubleCompare) { + EXPECT_EQ(-1, IntegerDoubleCompare(0.0, 1.0)); + EXPECT_EQ(1, IntegerDoubleCompare(1.0, 0.0)); + EXPECT_EQ(0, IntegerDoubleCompare(1.0, 1.0)); + EXPECT_EQ(0, IntegerDoubleCompare(0.0, 0.0)); + EXPECT_EQ(-1, IntegerDoubleCompare(-10.0, 10.0)); + EXPECT_EQ(1, IntegerDoubleCompare(123.45, 10.0)); + EXPECT_EQ(1, IntegerDoubleCompare(NAN, INFINITY)); + EXPECT_EQ(1, IntegerDoubleCompare(INFINITY, NAN)); +} + #ifdef GTEST_HAS_DEATH_TEST TEST(QuantizationUtilTest, ChooseQuantizationParamsInvalidRange) { EXPECT_DEATH(ChooseQuantizationParams<uint8>(10.0, -30.0), ""); diff --git a/tensorflow/contrib/lite/kernels/internal/reference/portable_tensor_utils.cc b/tensorflow/contrib/lite/kernels/internal/reference/portable_tensor_utils.cc index e79e75a898..2a30910c3f 100644 --- a/tensorflow/contrib/lite/kernels/internal/reference/portable_tensor_utils.cc +++ b/tensorflow/contrib/lite/kernels/internal/reference/portable_tensor_utils.cc @@ -173,6 +173,16 @@ void PortableVectorBatchVectorCwiseProductAccumulate(const float* vector, } } +void PortableVectorBatchVectorAdd(const float* vector, int v_size, int n_batch, + float* batch_vector) { + for (int b = 0; b < n_batch; b++) { + for (int i = 0; i < v_size; ++i) { + batch_vector[i] += vector[i]; + } + batch_vector += v_size; + } +} + void PortableVectorBatchVectorAssign(const float* vector, int v_size, int n_batch, float* batch_vector) { for (int b = 0; b < n_batch; b++) { @@ -243,5 +253,31 @@ void PortableReductionSumVector(const float* input_vector, float* output_vector, } } +void PortableMeanStddevNormalization(const float* input_vector, + float* output_vector, int v_size, + int n_batch, float normalization_epsilon) { + for (int batch = 0; batch < n_batch; ++batch) { + float sum = 0.0f; + float sum_sq = 0.0f; + for (int i = 0; i < v_size; ++i) { + sum += input_vector[i]; + sum_sq += input_vector[i] * input_vector[i]; + } + const float mean = sum / v_size; + float stddev_inv = 0.0f; + const float variance = sum_sq / v_size - mean * mean; + if (variance == 0) { + stddev_inv = 1.0f / sqrt(normalization_epsilon); + } else { + stddev_inv = 1.0f / sqrt(variance); + } + for (int i = 0; i < v_size; ++i) { + output_vector[i] = (input_vector[i] - mean) * stddev_inv; + } + input_vector += v_size; + output_vector += v_size; + } +} + } // namespace tensor_utils } // namespace tflite diff --git a/tensorflow/contrib/lite/kernels/internal/reference/portable_tensor_utils.h b/tensorflow/contrib/lite/kernels/internal/reference/portable_tensor_utils.h index 3829be0c5e..f5b3a84f07 100644 --- a/tensorflow/contrib/lite/kernels/internal/reference/portable_tensor_utils.h +++ b/tensorflow/contrib/lite/kernels/internal/reference/portable_tensor_utils.h @@ -87,6 +87,10 @@ void PortableVectorBatchVectorCwiseProductAccumulate(const float* vector, void PortableVectorBatchVectorAssign(const float* vector, int v_size, int n_batch, float* batch_vector); +// Add another vector for each batch in the batch vector. +void PortableVectorBatchVectorAdd(const float* vector, int v_size, int n_batch, + float* batch_vector); + // Apply sigmoid to elements of a vector. void PortableApplySigmoidToVector(const float* vector, int v_size, float* result); @@ -125,6 +129,12 @@ void PortableVectorShiftLeft(float* vector, int v_size, float shift_value); void PortableReductionSumVector(const float* input_vector, float* output_vector, int output_size, int reduction_size); +// Layer norm for each batch. +// normalization_epsilon is added to avoid divergence. +void PortableMeanStddevNormalization(const float* input_vector, + float* output_vector, int v_size, + int n_batch, float normalization_epsilon); + float Clip(float f, float abs_limit) { return PortableClip(f, abs_limit); } bool IsZeroVector(const float* vector, int v_size) { @@ -193,6 +203,11 @@ void BatchVectorBatchVectorDotProduct(const float* vector1, result, result_stride); } +void VectorBatchVectorAdd(const float* vector, int v_size, int n_batch, + float* batch_vector) { + PortableVectorBatchVectorAdd(vector, v_size, n_batch, batch_vector); +} + void VectorBatchVectorAssign(const float* vector, int v_size, int n_batch, float* batch_vector) { PortableVectorBatchVectorAssign(vector, v_size, n_batch, batch_vector); @@ -240,6 +255,13 @@ void ReductionSumVector(const float* input_vector, float* output_vector, reduction_size); } +void MeanStddevNormalization(const float* input_vector, float* output_vector, + int v_size, int n_batch, + float normalization_epsilon) { + PortableMeanStddevNormalization(input_vector, output_vector, v_size, n_batch, + normalization_epsilon); +} + } // namespace tensor_utils } // namespace tflite diff --git a/tensorflow/contrib/lite/kernels/internal/reference/reference_ops.h b/tensorflow/contrib/lite/kernels/internal/reference/reference_ops.h index 62f7ade7d5..00f9616cc2 100644 --- a/tensorflow/contrib/lite/kernels/internal/reference/reference_ops.h +++ b/tensorflow/contrib/lite/kernels/internal/reference/reference_ops.h @@ -2524,32 +2524,69 @@ void LstmCell(const uint8* input_data_uint8, const Dims<4>& input_dims, } template <typename Scalar> +void Split(const SplitParams& params, const RuntimeShape& input_shape, + const Scalar* input_data, const RuntimeShape* const* output_shapes, + Scalar* const* output_data) { + const int concat_dimensions = input_shape.DimensionsCount(); + int axis = params.axis < 0 ? params.axis + concat_dimensions : params.axis; + int outputs_count = params.num_split; + TFLITE_DCHECK_LT(axis, concat_dimensions); + + int64_t concat_size = 0; + for (int i = 0; i < outputs_count; i++) { + TFLITE_DCHECK_EQ(output_shapes[i]->DimensionsCount(), concat_dimensions); + for (int j = 0; j < concat_dimensions; j++) { + if (j != axis) { + MatchingDim(*output_shapes[i], j, input_shape, j); + } + } + concat_size += output_shapes[i]->Dims(axis); + } + TFLITE_DCHECK_EQ(concat_size, input_shape.Dims(axis)); + int64_t outer_size = 1; + for (int i = 0; i < axis; ++i) { + outer_size *= input_shape.Dims(i); + } + // For all output arrays, + // FlatSize() = outer_size * Dims(axis) * base_inner_size; + int64_t base_inner_size = 1; + for (int i = axis + 1; i < concat_dimensions; ++i) { + base_inner_size *= input_shape.Dims(i); + } + + const Scalar* input_ptr = input_data; + for (int k = 0; k < outer_size; k++) { + for (int i = 0; i < outputs_count; ++i) { + const int copy_size = output_shapes[i]->Dims(axis) * base_inner_size; + memcpy(output_data[i] + k * copy_size, input_ptr, + copy_size * sizeof(Scalar)); + input_ptr += copy_size; + } + } +} + +// TODO(b/80418076): Move to legacy ops file, update invocations. +// Legacy Dims<4>. +template <typename Scalar> void TensorFlowSplit(const Scalar* input_data, const Dims<4>& input_dims, int axis, int outputs_count, Scalar* const* output_data, const Dims<4>* const* output_dims) { - const int batches = ArraySize(*output_dims[0], 3); - const int height = ArraySize(*output_dims[0], 2); - const int width = ArraySize(*output_dims[0], 1); - const int depth = ArraySize(*output_dims[0], 0); - - const int slice_size = ArraySize(*output_dims[0], axis); - + std::vector<RuntimeShape> output_shapes(outputs_count); + std::vector<const RuntimeShape*> output_shapes_indirect(outputs_count); for (int i = 0; i < outputs_count; ++i) { - int offset = i * slice_size * input_dims.strides[axis]; - for (int b = 0; b < batches; ++b) { - for (int y = 0; y < height; ++y) { - for (int x = 0; x < width; ++x) { - for (int c = 0; c < depth; ++c) { - auto out = Offset(*output_dims[i], c, x, y, b); - auto in = Offset(input_dims, c, x, y, b); - output_data[i][out] = input_data[offset + in]; - } - } - } - } + ShapeFromDims(*output_dims[i], &output_shapes[i]); + output_shapes_indirect[i] = &output_shapes[i]; } + tflite::SplitParams op_params; + op_params.axis = 3 - axis; + op_params.num_split = outputs_count; + + Split(op_params, DimsToShape(input_dims), input_data, + output_shapes_indirect.data(), output_data); } +// TODO(b/80418076): Move to legacy ops file, update invocations. +// Legacy Dims<4>. template <FusedActivationFunctionType Ac, typename Scalar> void TensorFlowSplit(const Scalar* input_data, const Dims<4>& input_dims, int outputs_count, Scalar* const* output_data, @@ -2560,9 +2597,8 @@ void TensorFlowSplit(const Scalar* input_data, const Dims<4>& input_dims, /* height = */ MatchingArraySize(*output_dims[i], 2, input_dims, 2); /* width = */ MatchingArraySize(*output_dims[i], 1, input_dims, 1); } - // for now we dont have a model with a TensorFlowSplit - // with fused activation function. - TFLITE_DCHECK(Ac == FusedActivationFunctionType::kNone); + // For now we don't have a model with a Split with fused activation. + TFLITE_DCHECK_EQ(Ac, FusedActivationFunctionType::kNone); TensorFlowSplit(input_data, input_dims, /*axis=*/0, outputs_count, output_data, output_dims); @@ -3416,23 +3452,55 @@ inline void Floor(const RuntimeShape& input_shape, const float* input_data, } template <typename T> -inline void Gather(const T* input_data, const Dims<4>& input_dims, - int input_rank, const int32* coords_data, - const Dims<4>& coords_dims, T* output_data, - const Dims<4>& output_dims) { - TFLITE_DCHECK(coords_dims.sizes[0] == output_dims.sizes[input_rank - 1]); - int stride = input_dims.strides[input_rank - 1]; +inline void Gather(const tflite::GatherParams& op_params, + const RuntimeShape& input_shape, const T* input_data, + const RuntimeShape& coords_shape, const int32* coords_data, + const RuntimeShape& output_shape, T* output_data) { + // TODO(b/80418076): Enable these checks when moving legacy ops to + // legacy_reference_ops. + // + // TFLITE_DCHECK_EQ(coords_shape.DimensionsCount(), 1); + const int input_rank = op_params.input_rank; + const int gather_dimensions = output_shape.DimensionsCount(); + TFLITE_DCHECK_LE(input_shape.DimensionsCount(), gather_dimensions); + const int axis = gather_dimensions - input_rank; + TFLITE_DCHECK_LT(axis, gather_dimensions); + TFLITE_DCHECK_GE(axis, 0); + const int coords_count = coords_shape.FlatSize(); + TFLITE_DCHECK_EQ(coords_count, output_shape.Dims(axis)); + + int64_t stride = 1; + for (int i = axis + 1; i < gather_dimensions; ++i) { + stride *= input_shape.Dims(i); + } T* out = output_data; - for (int i = 0; i < coords_dims.sizes[0]; i++) { + for (int i = 0; i < coords_count; ++i) { TFLITE_DCHECK_GE(coords_data[i], 0); - TFLITE_DCHECK_LT(coords_data[i], input_dims.sizes[input_rank - 1]); + TFLITE_DCHECK_LT(coords_data[i], input_shape.Dims(axis)); const T* in = input_data + coords_data[i] * stride; memcpy(out, in, sizeof(T) * stride); out += stride; } } +// TODO(b/80418076): Move to legacy ops file, update invocations. +// Legacy Dims<4> version. +// When moving legacy ops to legacy_reference_ops, replace content with looser +// implementation. +template <typename T> +inline void Gather(const T* input_data, const Dims<4>& input_dims, + int input_rank, const int32* coords_data, + const Dims<4>& coords_dims, T* output_data, + const Dims<4>& output_dims) { + tflite::GatherParams op_params; + op_params.input_rank = input_rank; + + Gather(op_params, DimsToShape(input_dims), input_data, + DimsToShape(coords_dims), coords_data, DimsToShape(output_dims), + output_data); +} + template <typename T> inline void ResizeBilinear(const tflite::ResizeBilinearParams& op_params, const RuntimeShape& unextended_input_shape, @@ -4301,9 +4369,10 @@ template <typename T> using ComparisonFn = bool (*)(T, T); template <typename T, ComparisonFn<T> F> -inline void Comparison(const RuntimeShape& input1_shape, const T* input1_data, - const RuntimeShape& input2_shape, const T* input2_data, - const RuntimeShape& output_shape, bool* output_data) { +inline void ComparisonImpl( + const ComparisonParams& op_params, const RuntimeShape& input1_shape, + const T* input1_data, const RuntimeShape& input2_shape, + const T* input2_data, const RuntimeShape& output_shape, bool* output_data) { const int64_t flatsize = MatchingFlatSize(input1_shape, input2_shape, output_shape); for (int64_t i = 0; i < flatsize; ++i) { @@ -4311,25 +4380,45 @@ inline void Comparison(const RuntimeShape& input1_shape, const T* input1_data, } } +template <ComparisonFn<float> F> +inline void Comparison(const ComparisonParams& op_params, + const RuntimeShape& input1_shape, + const float* input1_data, + const RuntimeShape& input2_shape, + const float* input2_data, + const RuntimeShape& output_shape, bool* output_data) { + ComparisonImpl<float, F>(op_params, input1_shape, input1_data, input2_shape, + input2_data, output_shape, output_data); +} + +// TODO(b/80418076): Move to legacy ops file, update invocations. +// Legacy. template <typename T, ComparisonFn<T> F> inline void Comparison(const T* input1_data, const Dims<4>& input1_dims, const T* input2_data, const Dims<4>& input2_dims, bool* output_data, const Dims<4>& output_dims) { - Comparison<T, F>(DimsToShape(input1_dims), input1_data, - DimsToShape(input2_dims), input2_data, - DimsToShape(output_dims), output_data); + ComparisonParams op_params; + // No parameters needed. + ComparisonImpl<T, F>(op_params, DimsToShape(input1_dims), input1_data, + DimsToShape(input2_dims), input2_data, + DimsToShape(output_dims), output_data); } template <typename T, ComparisonFn<int32> F> -inline void Comparison(int left_shift, const T* input1_data, - const Dims<4>& input1_dims, int32 input1_offset, - int32 input1_multiplier, int input1_shift, - const T* input2_data, const Dims<4>& input2_dims, - int32 input2_offset, int32 input2_multiplier, - int input2_shift, bool* output_data, - const Dims<4>& output_dims) { +inline void ComparisonWithScaling( + const ComparisonParams& op_params, const RuntimeShape& input1_shape, + const T* input1_data, const RuntimeShape& input2_shape, + const T* input2_data, const RuntimeShape& output_shape, bool* output_data) { + int left_shift = op_params.left_shift; + int32 input1_offset = op_params.input1_offset; + int32 input1_multiplier = op_params.input1_multiplier; + int input1_shift = op_params.input1_shift; + int32 input2_offset = op_params.input2_offset; + int32 input2_multiplier = op_params.input2_multiplier; + int input2_shift = op_params.input2_shift; + const int64_t flatsize = - MatchingFlatSize(input1_dims, input2_dims, output_dims); + MatchingFlatSize(input1_shape, input2_shape, output_shape); for (int64_t i = 0; i < flatsize; ++i) { const int32 input1_val = input1_offset + input1_data[i]; const int32 input2_val = input2_offset + input2_data[i]; @@ -4337,68 +4426,140 @@ inline void Comparison(int left_shift, const T* input1_data, const int32 shifted_input2_val = input2_val * (1 << left_shift); const int32 scaled_input1_val = MultiplyByQuantizedMultiplierSmallerThanOneExp( - shifted_input1_val, input1_multiplier, - kReverseShift * input1_shift); + shifted_input1_val, input1_multiplier, input1_shift); const int32 scaled_input2_val = MultiplyByQuantizedMultiplierSmallerThanOneExp( - shifted_input2_val, input2_multiplier, - kReverseShift * input2_shift); + shifted_input2_val, input2_multiplier, input2_shift); output_data[i] = F(scaled_input1_val, scaled_input2_val); } } +// TODO(b/80418076): Move to legacy ops file, update invocations. +// Legacy. +template <typename T, ComparisonFn<int32> F> +inline void Comparison(int left_shift, const T* input1_data, + const Dims<4>& input1_dims, int32 input1_offset, + int32 input1_multiplier, int input1_shift, + const T* input2_data, const Dims<4>& input2_dims, + int32 input2_offset, int32 input2_multiplier, + int input2_shift, bool* output_data, + const Dims<4>& output_dims) { + tflite::ComparisonParams op_params; + op_params.left_shift = left_shift; + op_params.input1_offset = input1_offset; + op_params.input1_multiplier = input1_multiplier; + op_params.input1_shift = kReverseShift * input1_shift; + op_params.input2_offset = input2_offset; + op_params.input2_multiplier = input2_multiplier; + op_params.input2_shift = kReverseShift * input2_shift; + + ComparisonWithScaling<T, F>(op_params, DimsToShape(input1_dims), input1_data, + DimsToShape(input2_dims), input2_data, + DimsToShape(output_dims), output_data); +} + template <typename T, ComparisonFn<T> F> -inline void BroadcastComparison(const T* input1_data, - const Dims<4>& input1_dims, - const T* input2_data, - const Dims<4>& input2_dims, bool* output_data, - const Dims<4>& output_dims) { +inline void BroadcastComparison4DSlowImpl( + const ComparisonParams& op_params, + const RuntimeShape& unextended_input1_shape, const T* input1_data, + const RuntimeShape& unextended_input2_shape, const T* input2_data, + const RuntimeShape& unextended_output_shape, bool* output_data) { + gemmlowp::ScopedProfilingLabel label("BroadcastComparison4DSlow"); + TFLITE_DCHECK_LE(unextended_input1_shape.DimensionsCount(), 4); + TFLITE_DCHECK_LE(unextended_input2_shape.DimensionsCount(), 4); + TFLITE_DCHECK_LE(unextended_output_shape.DimensionsCount(), 4); + RuntimeShape output_shape = + RuntimeShape::ExtendedShape(4, unextended_output_shape); + NdArrayDesc<4> desc1; NdArrayDesc<4> desc2; - NdArrayDescsForElementwiseBroadcast(input1_dims, input2_dims, &desc1, &desc2); - for (int b = 0; b < ArraySize(output_dims, 3); ++b) { - for (int y = 0; y < ArraySize(output_dims, 2); ++y) { - for (int x = 0; x < ArraySize(output_dims, 1); ++x) { - for (int c = 0; c < ArraySize(output_dims, 0); ++c) { - output_data[Offset(output_dims, c, x, y, b)] = - F(input1_data[SubscriptToIndex(desc1, c, x, y, b)], - input2_data[SubscriptToIndex(desc2, c, x, y, b)]); + NdArrayDescsForElementwiseBroadcast(unextended_input1_shape, + unextended_input2_shape, &desc1, &desc2); + + for (int b = 0; b < output_shape.Dims(0); ++b) { + for (int y = 0; y < output_shape.Dims(1); ++y) { + for (int x = 0; x < output_shape.Dims(2); ++x) { + for (int c = 0; c < output_shape.Dims(3); ++c) { + output_data[Offset(output_shape, b, y, x, c)] = + F(input1_data[SubscriptToIndex(desc1, b, y, x, c)], + input2_data[SubscriptToIndex(desc2, b, y, x, c)]); } } } } } +template <ComparisonFn<float> F> +inline void BroadcastComparison4DSlow(const ComparisonParams& op_params, + const RuntimeShape& input1_shape, + const float* input1_data, + const RuntimeShape& input2_shape, + const float* input2_data, + const RuntimeShape& output_shape, + bool* output_data) { + BroadcastComparison4DSlowImpl<float, F>(op_params, input1_shape, input1_data, + input2_shape, input2_data, + output_shape, output_data); +} -template <typename T, ComparisonFn<int32> F> -inline void BroadcastComparison(int left_shift, const T* input1_data, - const Dims<4>& input1_dims, int32 input1_offset, - int32 input1_multiplier, int input1_shift, +// TODO(b/80418076): Move to legacy ops file, update invocations. +// Legacy. +template <typename T, ComparisonFn<T> F> +inline void BroadcastComparison(const T* input1_data, + const Dims<4>& input1_dims, const T* input2_data, - const Dims<4>& input2_dims, int32 input2_offset, - int32 input2_multiplier, int input2_shift, - bool* output_data, const Dims<4>& output_dims) { + const Dims<4>& input2_dims, bool* output_data, + const Dims<4>& output_dims) { + ComparisonParams op_params; + // No parameters needed. + BroadcastComparison4DSlowImpl<T, F>(op_params, DimsToShape(input1_dims), + input1_data, DimsToShape(input2_dims), + input2_data, DimsToShape(output_dims), + output_data); +} + +template <typename T, ComparisonFn<int32> F> +inline void BroadcastComparison4DSlowWithScaling( + const ComparisonParams& op_params, + const RuntimeShape& unextended_input1_shape, const T* input1_data, + const RuntimeShape& unextended_input2_shape, const T* input2_data, + const RuntimeShape& unextended_output_shape, bool* output_data) { + gemmlowp::ScopedProfilingLabel label("BroadcastComparison4DSlowWithScaling"); + TFLITE_DCHECK_LE(unextended_input1_shape.DimensionsCount(), 4); + TFLITE_DCHECK_LE(unextended_input2_shape.DimensionsCount(), 4); + TFLITE_DCHECK_LE(unextended_output_shape.DimensionsCount(), 4); + RuntimeShape output_shape = + RuntimeShape::ExtendedShape(4, unextended_output_shape); + NdArrayDesc<4> desc1; NdArrayDesc<4> desc2; - NdArrayDescsForElementwiseBroadcast(input1_dims, input2_dims, &desc1, &desc2); - for (int b = 0; b < ArraySize(output_dims, 3); ++b) { - for (int y = 0; y < ArraySize(output_dims, 2); ++y) { - for (int x = 0; x < ArraySize(output_dims, 1); ++x) { - for (int c = 0; c < ArraySize(output_dims, 0); ++c) { + NdArrayDescsForElementwiseBroadcast(unextended_input1_shape, + unextended_input2_shape, &desc1, &desc2); + + int left_shift = op_params.left_shift; + int32 input1_offset = op_params.input1_offset; + int32 input1_multiplier = op_params.input1_multiplier; + int input1_shift = op_params.input1_shift; + int32 input2_offset = op_params.input2_offset; + int32 input2_multiplier = op_params.input2_multiplier; + int input2_shift = op_params.input2_shift; + + for (int b = 0; b < output_shape.Dims(0); ++b) { + for (int y = 0; y < output_shape.Dims(1); ++y) { + for (int x = 0; x < output_shape.Dims(2); ++x) { + for (int c = 0; c < output_shape.Dims(3); ++c) { const int32 input1_val = - input1_offset + input1_data[SubscriptToIndex(desc1, c, x, y, b)]; + input1_offset + input1_data[SubscriptToIndex(desc1, b, y, x, c)]; const int32 input2_val = - input2_offset + input2_data[SubscriptToIndex(desc2, c, x, y, b)]; + input2_offset + input2_data[SubscriptToIndex(desc2, b, y, x, c)]; const int32 shifted_input1_val = input1_val * (1 << left_shift); const int32 shifted_input2_val = input2_val * (1 << left_shift); const int32 scaled_input1_val = MultiplyByQuantizedMultiplierSmallerThanOneExp( - shifted_input1_val, input1_multiplier, - kReverseShift * input1_shift); + shifted_input1_val, input1_multiplier, input1_shift); const int32 scaled_input2_val = MultiplyByQuantizedMultiplierSmallerThanOneExp( - shifted_input2_val, input2_multiplier, - kReverseShift * input2_shift); - output_data[Offset(output_dims, c, x, y, b)] = + shifted_input2_val, input2_multiplier, input2_shift); + output_data[Offset(output_shape, b, y, x, c)] = F(scaled_input1_val, scaled_input2_val); } } @@ -4406,51 +4567,117 @@ inline void BroadcastComparison(int left_shift, const T* input1_data, } } -#define TFLITE_COMPARISON_OP(name) \ - template <typename T> \ - inline void name(const T* input1_data, const Dims<4>& input1_dims, \ - const T* input2_data, const Dims<4>& input2_dims, \ - bool* output_data, const Dims<4>& output_dims) { \ - gemmlowp::ScopedProfilingLabel label(#name); \ - Comparison<T, name##Fn>(input1_data, input1_dims, input2_data, \ - input2_dims, output_data, output_dims); \ - } \ - template <typename T> \ - inline void name( \ - int left_shift, const T* input1_data, const Dims<4>& input1_dims, \ - int32 input1_offset, int32 input1_multiplier, int input1_shift, \ - const T* input2_data, const Dims<4>& input2_dims, int32 input2_offset, \ - int32 input2_multiplier, int input2_shift, bool* output_data, \ - const Dims<4>& output_dims) { \ - gemmlowp::ScopedProfilingLabel label(#name "/8bit"); \ - Comparison<T, name##Fn>(left_shift, input1_data, input1_dims, \ - input1_offset, input1_multiplier, input1_shift, \ - input2_data, input2_dims, input2_offset, \ - input2_multiplier, input2_shift, output_data, \ - output_dims); \ - } \ - template <typename T> \ - inline void Broadcast##name( \ - const T* input1_data, const Dims<4>& input1_dims, const T* input2_data, \ - const Dims<4>& input2_dims, bool* output_data, \ - const Dims<4>& output_dims) { \ - gemmlowp::ScopedProfilingLabel label("Broadcast" #name); \ - BroadcastComparison<T, name##Fn>(input1_data, input1_dims, input2_data, \ - input2_dims, output_data, output_dims); \ - } \ - template <typename T> \ - inline void Broadcast##name( \ - int left_shift, const T* input1_data, const Dims<4>& input1_dims, \ - int32 input1_offset, int32 input1_multiplier, int input1_shift, \ - const T* input2_data, const Dims<4>& input2_dims, int32 input2_offset, \ - int32 input2_multiplier, int input2_shift, bool* output_data, \ - const Dims<4>& output_dims) { \ - gemmlowp::ScopedProfilingLabel label("Broadcast" #name "/8bit"); \ - BroadcastComparison<T, name##Fn>(left_shift, input1_data, input1_dims, \ - input1_offset, input1_multiplier, \ - input1_shift, input2_data, input2_dims, \ - input2_offset, input2_multiplier, \ - input2_shift, output_data, output_dims); \ +// TODO(b/80418076): Move to legacy ops file, update invocations. +// Legacy. +template <typename T, ComparisonFn<int32> F> +inline void BroadcastComparison(int left_shift, const T* input1_data, + const Dims<4>& input1_dims, int32 input1_offset, + int32 input1_multiplier, int input1_shift, + const T* input2_data, + const Dims<4>& input2_dims, int32 input2_offset, + int32 input2_multiplier, int input2_shift, + bool* output_data, const Dims<4>& output_dims) { + ComparisonParams op_params; + + op_params.left_shift = left_shift; + op_params.input1_offset = input1_offset; + op_params.input1_multiplier = input1_multiplier; + op_params.input1_shift = kReverseShift * input1_shift; + op_params.input2_offset = input2_offset; + op_params.input2_multiplier = input2_multiplier; + op_params.input2_shift = kReverseShift * input2_shift; + + BroadcastComparison4DSlowWithScaling<T, F>( + op_params, DimsToShape(input1_dims), input1_data, + DimsToShape(input2_dims), input2_data, DimsToShape(output_dims), + output_data); +} + +#define TFLITE_COMPARISON_OP(name) \ + template <typename T> \ + inline void name(const T* input1_data, const Dims<4>& input1_dims, \ + const T* input2_data, const Dims<4>& input2_dims, \ + bool* output_data, const Dims<4>& output_dims) { \ + gemmlowp::ScopedProfilingLabel label(#name); \ + Comparison<T, name##Fn>(input1_data, input1_dims, input2_data, \ + input2_dims, output_data, output_dims); \ + } \ + template <typename T> \ + inline void name( \ + int left_shift, const T* input1_data, const Dims<4>& input1_dims, \ + int32 input1_offset, int32 input1_multiplier, int input1_shift, \ + const T* input2_data, const Dims<4>& input2_dims, int32 input2_offset, \ + int32 input2_multiplier, int input2_shift, bool* output_data, \ + const Dims<4>& output_dims) { \ + gemmlowp::ScopedProfilingLabel label(#name "/8bit"); \ + Comparison<T, name##Fn>(left_shift, input1_data, input1_dims, \ + input1_offset, input1_multiplier, input1_shift, \ + input2_data, input2_dims, input2_offset, \ + input2_multiplier, input2_shift, output_data, \ + output_dims); \ + } \ + template <typename T> \ + inline void Broadcast##name( \ + const T* input1_data, const Dims<4>& input1_dims, const T* input2_data, \ + const Dims<4>& input2_dims, bool* output_data, \ + const Dims<4>& output_dims) { \ + gemmlowp::ScopedProfilingLabel label("Broadcast" #name); \ + BroadcastComparison<T, name##Fn>(input1_data, input1_dims, input2_data, \ + input2_dims, output_data, output_dims); \ + } \ + template <typename T> \ + inline void Broadcast##name( \ + int left_shift, const T* input1_data, const Dims<4>& input1_dims, \ + int32 input1_offset, int32 input1_multiplier, int input1_shift, \ + const T* input2_data, const Dims<4>& input2_dims, int32 input2_offset, \ + int32 input2_multiplier, int input2_shift, bool* output_data, \ + const Dims<4>& output_dims) { \ + gemmlowp::ScopedProfilingLabel label("Broadcast" #name "/8bit"); \ + BroadcastComparison<T, name##Fn>(left_shift, input1_data, input1_dims, \ + input1_offset, input1_multiplier, \ + input1_shift, input2_data, input2_dims, \ + input2_offset, input2_multiplier, \ + input2_shift, output_data, output_dims); \ + } \ + inline void name(const ComparisonParams& op_params, \ + const RuntimeShape& input1_shape, const float* input1_data, \ + const RuntimeShape& input2_shape, const float* input2_data, \ + const RuntimeShape& output_shape, bool* output_data) { \ + gemmlowp::ScopedProfilingLabel label(#name); \ + Comparison<name##Fn>(op_params, input1_shape, input1_data, input2_shape, \ + input2_data, output_shape, output_data); \ + } \ + template <typename T> \ + inline void name##WithScaling( \ + const ComparisonParams& op_params, const RuntimeShape& input1_shape, \ + const T* input1_data, const RuntimeShape& input2_shape, \ + const T* input2_data, const RuntimeShape& output_shape, \ + bool* output_data) { \ + gemmlowp::ScopedProfilingLabel label(#name "/8bit"); \ + ComparisonWithScaling<T, name##Fn>(op_params, input1_shape, input1_data, \ + input2_shape, input2_data, \ + output_shape, output_data); \ + } \ + inline void Broadcast4DSlow##name( \ + const ComparisonParams& op_params, const RuntimeShape& input1_shape, \ + const float* input1_data, const RuntimeShape& input2_shape, \ + const float* input2_data, const RuntimeShape& output_shape, \ + bool* output_data) { \ + gemmlowp::ScopedProfilingLabel label("Broadcast" #name); \ + BroadcastComparison4DSlow<name##Fn>(op_params, input1_shape, input1_data, \ + input2_shape, input2_data, \ + output_shape, output_data); \ + } \ + template <typename T> \ + inline void Broadcast4DSlow##name##WithScaling( \ + const ComparisonParams& op_params, const RuntimeShape& input1_shape, \ + const T* input1_data, const RuntimeShape& input2_shape, \ + const T* input2_data, const RuntimeShape& output_shape, \ + bool* output_data) { \ + gemmlowp::ScopedProfilingLabel label("Broadcast" #name "/8bit"); \ + BroadcastComparison4DSlowWithScaling<T, name##Fn>( \ + op_params, input1_shape, input1_data, input2_shape, input2_data, \ + output_shape, output_data); \ } TFLITE_COMPARISON_OP(Equal); TFLITE_COMPARISON_OP(NotEqual); diff --git a/tensorflow/contrib/lite/kernels/internal/tensor_utils.h b/tensorflow/contrib/lite/kernels/internal/tensor_utils.h index 748356d1bd..1439bf8c37 100644 --- a/tensorflow/contrib/lite/kernels/internal/tensor_utils.h +++ b/tensorflow/contrib/lite/kernels/internal/tensor_utils.h @@ -113,6 +113,10 @@ void VectorBatchVectorCwiseProductAccumulate(const float* vector, int v_size, const float* batch_vector, int n_batch, float* result); +// Add another vector for each batch in the batch vector. +void VectorBatchVectorAdd(const float* vector, int v_size, int n_batch, + float* batch_vector); + // Batch vector initialization with another vector. void VectorBatchVectorAssign(const float* vector, int v_size, int n_batch, float* batch_vector); @@ -152,6 +156,12 @@ void VectorShiftLeft(float* vector, int v_size, float shift_value); // added to get one element of output. void ReductionSumVector(const float* input_vector, float* output_vector, int output_size, int reduction_size); + +// Layer norm for each batch. +// normalization_epsilon is added to avoid divergence. +void MeanStddevNormalization(const float* input_vector, float* output_vector, + int v_size, int n_batch, + float normalization_epsilon); } // namespace tensor_utils } // namespace tflite diff --git a/tensorflow/contrib/lite/kernels/internal/tensor_utils_test.cc b/tensorflow/contrib/lite/kernels/internal/tensor_utils_test.cc index 240fb64ca3..dad924fc28 100644 --- a/tensorflow/contrib/lite/kernels/internal/tensor_utils_test.cc +++ b/tensorflow/contrib/lite/kernels/internal/tensor_utils_test.cc @@ -496,6 +496,16 @@ TEST(uKernels, VectorVectorCwiseProductAccumulateTest) { {1.0, 1.05, 1.1, 1.15, 1.2, 1.25, 1.3, 1.35, 1.4, 1.45}))); } +TEST(uKernels, VectorBatchVectorAddTest) { + constexpr int kVectorSize = 3; + constexpr int kBatchSize = 2; + static float input[kVectorSize] = {0.0, -0.5, 1.0}; + std::vector<float> output = {1.0, 2.0, 3.0, 4.0, 5.0, 6.0}; + VectorBatchVectorAdd(input, kVectorSize, kBatchSize, output.data()); + EXPECT_THAT(output, + testing::ElementsAreArray({1.0, 1.5, 4.0, 4.0, 4.5, 7.0})); +} + TEST(uKernels, VectorBatchVectorAssignTest) { constexpr int kVectorSize = 5; constexpr int kBatchSize = 3; @@ -712,5 +722,85 @@ TEST(uKernels, ReductionSumVectorTest) { EXPECT_THAT(result2, ElementsAreArray(ArrayFloatNear({1.0, 3.5}))); } +TEST(uKernels, MeanStddevNormalizationNoneZeroInput) { + constexpr int kVectorSize = 4; + constexpr int kBatchSize = 2; + constexpr float kNormalizationEpsilon = 1e-8; + + // None-zero input. + static float input[kVectorSize * kBatchSize] = { + 0.1, 0.2, 0.3, 0.4, // batch 0 + 0.9, 1.0, 1.1, 1.2, // batch 1 + }; + std::vector<float> output(kVectorSize * kBatchSize); + MeanStddevNormalization(input, output.data(), kVectorSize, kBatchSize, + kNormalizationEpsilon); + const std::vector<float> expected_output = { + -1.34164071, -0.447213531, 0.44721365, 1.34164071, // batch 0 + -1.34163153, -0.447210163, 0.447211236, 1.3416326, // batch 1 + }; + EXPECT_THAT(output, testing::ElementsAreArray(expected_output)); +} + +TEST(uKernels, MeanStddevNormalizationAllZeroInput) { + constexpr int kVectorSize = 4; + constexpr int kBatchSize = 2; + constexpr float kNormalizationEpsilon = 1e-8; + + // Zero input. + static float input[kVectorSize * kBatchSize] = { + 0.0, 0.0, 0.0, 0.0, // batch 0 + 0.0, 0.0, 0.0, 0.0, // batch 1 + }; + std::vector<float> output(kVectorSize * kBatchSize); + MeanStddevNormalization(input, output.data(), kVectorSize, kBatchSize, + kNormalizationEpsilon); + const std::vector<float> expected_output = { + 0.0, 0.0, 0.0, 0.0, // batch 0 + 0.0, 0.0, 0.0, 0.0, // batch 1 + }; + EXPECT_THAT(output, testing::ElementsAreArray(expected_output)); +} + +TEST(uKernels, MeanStddevNormalizationMixed) { + constexpr int kVectorSize = 4; + constexpr int kBatchSize = 2; + constexpr float kNormalizationEpsilon = 1e-8; + + // Mix of zero and non-zero input. + static float input[kVectorSize * kBatchSize] = { + 0.0, 0.0, 0.0, 0.0, // batch 0 + 0.1, 0.2, 0.3, 0.4, // batch 1 + }; + std::vector<float> output(kVectorSize * kBatchSize); + MeanStddevNormalization(input, output.data(), kVectorSize, kBatchSize, + kNormalizationEpsilon); + const std::vector<float> expected_output = { + 0.0, 0.0, 0.0, 0.0, // batch 0 + -1.34164071, -0.447213531, 0.44721365, 1.34164071, // batch 1 + }; + EXPECT_THAT(output, testing::ElementsAreArray(expected_output)); +} + +TEST(uKernels, MeanStddevNormalizationSmallValue) { + constexpr int kVectorSize = 4; + constexpr int kBatchSize = 2; + constexpr float kNormalizationEpsilon = 1e-8; + + // Mix of zero and non-zero input. + static float input[kVectorSize * kBatchSize] = { + 3e-5, -7e-6, -9e-5, 1e-6, // batch 0 + 4e-5, 9e-6, 2e-4, 0.0, // batch 1 + }; + std::vector<float> output(kVectorSize * kBatchSize); + MeanStddevNormalization(input, output.data(), kVectorSize, kBatchSize, + kNormalizationEpsilon); + const std::vector<float> expected_output = { + 1.04231524, 0.212946132, -1.64753067, 0.392269224, // batch 0 + -0.275023013, -0.658201098, 1.70267045, -0.769446373, // batch 1 + }; + EXPECT_THAT(output, testing::ElementsAreArray(expected_output)); +} + } // namespace tensor_utils } // namespace tflite diff --git a/tensorflow/contrib/lite/kernels/internal/types.h b/tensorflow/contrib/lite/kernels/internal/types.h index 3b296f024f..9f6e74a267 100644 --- a/tensorflow/contrib/lite/kernels/internal/types.h +++ b/tensorflow/contrib/lite/kernels/internal/types.h @@ -720,12 +720,12 @@ struct ConcatenationParams { struct ComparisonParams { // uint8 inference params. int left_shift; - int32 input0_offset; - int32 input0_multiplier; - int input0_shift; int32 input1_offset; int32 input1_multiplier; int input1_shift; + int32 input2_offset; + int32 input2_multiplier; + int input2_shift; // Shape dependent / common to inference types. bool is_broadcast; }; @@ -889,6 +889,7 @@ struct SplitParams { // Graphs that split into, say, 2000 nodes are encountered. The indices in // OperatorEdges are of type uint16. uint16 num_split; + int16 axis; }; struct SqueezeParams { diff --git a/tensorflow/contrib/lite/kernels/layer_norm_lstm.cc b/tensorflow/contrib/lite/kernels/layer_norm_lstm.cc new file mode 100644 index 0000000000..1bbea67b93 --- /dev/null +++ b/tensorflow/contrib/lite/kernels/layer_norm_lstm.cc @@ -0,0 +1,1316 @@ +/* Copyright 2017 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +// Layer Normalization LSTM op that applies normalization by mean and standard +// deviation to the activation of the LSTM layers. Please see +// https://arxiv.org/abs/1607.06450 for details. +#include "flatbuffers/flexbuffers.h" // flatbuffers +#include "tensorflow/contrib/lite/context.h" +#include "tensorflow/contrib/lite/kernels/internal/tensor_utils.h" +#include "tensorflow/contrib/lite/kernels/kernel_util.h" + +namespace tflite { +namespace ops { +namespace custom { +namespace layer_norm_lstm { + +// Struct to hold Layer Norm LSTM option data. +struct OpData { + TfLiteFusedActivation activation; + float cell_clip; + float proj_clip; + int scratch_tensor_index; +}; + +// Input Tensors of size {n_batch, n_input} +constexpr int kInputTensor = 0; + +// Input weight tensors of size: {n_cell, n_input} +constexpr int kInputToInputWeightsTensor = 1; // Optional +constexpr int kInputToForgetWeightsTensor = 2; +constexpr int kInputToCellWeightsTensor = 3; +constexpr int kInputToOutputWeightsTensor = 4; + +// Recurrent weight tensors of size {n_cell, n_output} +constexpr int kRecurrentToInputWeightsTensor = 5; // Optional +constexpr int kRecurrentToForgetWeightsTensor = 6; +constexpr int kRecurrentToCellWeightsTensor = 7; +constexpr int kRecurrentToOutputWeightsTensor = 8; + +// Peephole weights tensors of size {n_cell}, representing a diagonal matrix. +constexpr int kCellToInputWeightsTensor = 9; // Optional +constexpr int kCellToForgetWeightsTensor = 10; // Optional +constexpr int kCellToOutputWeightsTensor = 11; // Optional + +// Layer norm weights tensors of size {n_cell}, representing a diagonal matrix. +constexpr int kInputLayerNormWeightsTensor = 12; +constexpr int kForgetLayerNormWeightsTensor = 13; +constexpr int kCellLayerNormWeightsTensor = 14; +constexpr int kOutputLayerNormWeightsTensor = 15; + +// Gates bias tensors of size {n_cell} +constexpr int kInputGateBiasTensor = 16; // Optional +constexpr int kForgetGateBiasTensor = 17; +constexpr int kCellGateBiasTensor = 18; +constexpr int kOutputGateBiasTensor = 19; + +// Projection weight tensor of size {n_output, n_cell} +constexpr int kProjectionWeightsTensor = 20; // Optional +// Projection bias tensor of size {n_output} +constexpr int kProjectionBiasTensor = 21; // Optional + +// State tensors. +constexpr int kInputActivationStateTensor = 22; +constexpr int kInputCellStateTensor = 23; + +// Output tensor. +constexpr int kOutputTensor = 0; + +// Total number of scratch tensors for hybrid Op. +constexpr int kTensorsToAdd = 7; + +// Small float to avoid divergence during calculation of deviation. +const float kLayerNormEpsilon = 1e-8; + +void* Init(TfLiteContext* context, const char* buffer, size_t length) { + auto* data = new OpData; + + // Turn custom option data into flexbuffer map format. + const uint8_t* buffer_t = reinterpret_cast<const uint8_t*>(buffer); + const flexbuffers::Map& m = flexbuffers::GetRoot(buffer_t, length).AsMap(); + + // Get activation function, cell_clip and proj_clip from the flexbuffer. + // TODO(b/113824099): make activation more generic. + assert(m["fused_activation_function"].ToString() == "TANH"); + data->activation = kTfLiteActTanh; + data->cell_clip = m["cell_clip"].AsFloat(); + data->proj_clip = m["proj_clip"].AsFloat(); + + // Populate scratch_tensor_index. + context->AddTensors(context, /*tensors_to_add=*/kTensorsToAdd, + &data->scratch_tensor_index); + return data; +} + +// Check that input tensor dimensions matches with each other. +TfLiteStatus CheckInputTensorDimensions(TfLiteContext* context, + TfLiteNode* node, int n_input, + int n_output, int n_cell) { + const OpData* op_data = reinterpret_cast<OpData*>(node->user_data); + + // Making sure clipping parameters have valid values. + // == 0 means no clipping + // > 0 means clipping + TF_LITE_ENSURE(context, op_data->cell_clip >= 0); + TF_LITE_ENSURE(context, op_data->proj_clip >= 0); + + const TfLiteTensor* input_to_input_weights = + GetOptionalInputTensor(context, node, kInputToInputWeightsTensor); + if (input_to_input_weights != nullptr) { + TF_LITE_ENSURE_EQ(context, input_to_input_weights->dims->size, 2); + TF_LITE_ENSURE_EQ(context, input_to_input_weights->dims->data[0], n_cell); + TF_LITE_ENSURE_EQ(context, input_to_input_weights->dims->data[1], n_input); + } + + const TfLiteTensor* input_to_forget_weights = + GetInput(context, node, kInputToForgetWeightsTensor); + TF_LITE_ENSURE_EQ(context, input_to_forget_weights->dims->size, 2); + TF_LITE_ENSURE_EQ(context, input_to_forget_weights->dims->data[0], n_cell); + TF_LITE_ENSURE_EQ(context, input_to_forget_weights->dims->data[1], n_input); + + const TfLiteTensor* input_to_cell_weights = + GetInput(context, node, kInputToCellWeightsTensor); + TF_LITE_ENSURE_EQ(context, input_to_cell_weights->dims->size, 2); + TF_LITE_ENSURE_EQ(context, input_to_cell_weights->dims->data[0], n_cell); + TF_LITE_ENSURE_EQ(context, input_to_cell_weights->dims->data[1], n_input); + + const TfLiteTensor* recurrent_to_input_weights = + GetOptionalInputTensor(context, node, kRecurrentToInputWeightsTensor); + if (recurrent_to_input_weights != nullptr) { + TF_LITE_ENSURE_EQ(context, recurrent_to_input_weights->dims->size, 2); + TF_LITE_ENSURE_EQ(context, recurrent_to_input_weights->dims->data[0], + n_cell); + TF_LITE_ENSURE_EQ(context, recurrent_to_input_weights->dims->data[1], + n_output); + } + + const TfLiteTensor* recurrent_to_forget_weights = + GetInput(context, node, kRecurrentToForgetWeightsTensor); + TF_LITE_ENSURE_EQ(context, recurrent_to_forget_weights->dims->size, 2); + TF_LITE_ENSURE_EQ(context, recurrent_to_forget_weights->dims->data[0], + n_cell); + TF_LITE_ENSURE_EQ(context, recurrent_to_forget_weights->dims->data[1], + n_output); + + const TfLiteTensor* recurrent_to_cell_weights = + GetInput(context, node, kRecurrentToCellWeightsTensor); + TF_LITE_ENSURE_EQ(context, recurrent_to_cell_weights->dims->size, 2); + TF_LITE_ENSURE_EQ(context, recurrent_to_cell_weights->dims->data[0], n_cell); + TF_LITE_ENSURE_EQ(context, recurrent_to_cell_weights->dims->data[1], + n_output); + + // We make sure the input-gate's parameters are either both present (regular + // LSTM) or not at all (CIFG-LSTM). + const bool cifg_weights_all_or_none = + ((input_to_input_weights != nullptr) && + (recurrent_to_input_weights != nullptr)) || + ((input_to_input_weights == nullptr) && + (recurrent_to_input_weights == nullptr)); + TF_LITE_ENSURE(context, cifg_weights_all_or_none == true); + + const TfLiteTensor* cell_to_input_weights = + GetOptionalInputTensor(context, node, kCellToInputWeightsTensor); + if (cell_to_input_weights) { + TF_LITE_ENSURE_EQ(context, cell_to_input_weights->dims->size, 1); + TF_LITE_ENSURE_EQ(context, cell_to_input_weights->dims->data[0], n_cell); + } + + const TfLiteTensor* cell_to_forget_weights = + GetOptionalInputTensor(context, node, kCellToForgetWeightsTensor); + if (cell_to_forget_weights) { + TF_LITE_ENSURE_EQ(context, cell_to_forget_weights->dims->size, 1); + TF_LITE_ENSURE_EQ(context, cell_to_forget_weights->dims->data[0], n_cell); + } + + const TfLiteTensor* cell_to_output_weights = + GetOptionalInputTensor(context, node, kCellToOutputWeightsTensor); + if (cell_to_output_weights) { + TF_LITE_ENSURE_EQ(context, cell_to_output_weights->dims->size, 1); + TF_LITE_ENSURE_EQ(context, cell_to_output_weights->dims->data[0], n_cell); + } + + // Making sure the peephole weights are there all or none. + const bool use_cifg = (input_to_input_weights == nullptr); + const bool peephole_weights_all_or_none = + ((cell_to_input_weights != nullptr || use_cifg) && + (cell_to_forget_weights != nullptr) && + (cell_to_output_weights != nullptr)) || + ((cell_to_input_weights == nullptr) && + (cell_to_forget_weights == nullptr) && + (cell_to_output_weights == nullptr)); + TF_LITE_ENSURE(context, peephole_weights_all_or_none == true); + + // Making sure layer norm weights are not null and have the right dimension. + const TfLiteTensor* input_layer_norm_weights = + GetInput(context, node, kInputLayerNormWeightsTensor); + TF_LITE_ENSURE(context, input_layer_norm_weights != nullptr); + TF_LITE_ENSURE_EQ(context, input_layer_norm_weights->dims->size, 1); + TF_LITE_ENSURE_EQ(context, input_layer_norm_weights->dims->data[0], n_cell); + + const TfLiteTensor* forget_layer_norm_weights = + GetInput(context, node, kForgetLayerNormWeightsTensor); + TF_LITE_ENSURE(context, forget_layer_norm_weights != nullptr); + TF_LITE_ENSURE_EQ(context, forget_layer_norm_weights->dims->size, 1); + TF_LITE_ENSURE_EQ(context, forget_layer_norm_weights->dims->data[0], n_cell); + + const TfLiteTensor* cell_layer_norm_weights = + GetInput(context, node, kCellLayerNormWeightsTensor); + TF_LITE_ENSURE(context, cell_layer_norm_weights != nullptr); + TF_LITE_ENSURE_EQ(context, cell_layer_norm_weights->dims->size, 1); + TF_LITE_ENSURE_EQ(context, cell_layer_norm_weights->dims->data[0], n_cell); + + const TfLiteTensor* output_layer_norm_weights = + GetInput(context, node, kOutputLayerNormWeightsTensor); + TF_LITE_ENSURE(context, output_layer_norm_weights != nullptr); + TF_LITE_ENSURE_EQ(context, output_layer_norm_weights->dims->size, 1); + TF_LITE_ENSURE_EQ(context, output_layer_norm_weights->dims->data[0], n_cell); + + // Make sure the input gate bias is present only when not a CIFG-LSTM. + const TfLiteTensor* input_gate_bias = + GetOptionalInputTensor(context, node, kInputGateBiasTensor); + if (use_cifg) { + TF_LITE_ENSURE_EQ(context, input_gate_bias, nullptr); + } else { + TF_LITE_ENSURE_EQ(context, input_gate_bias->dims->size, 1); + TF_LITE_ENSURE_EQ(context, input_gate_bias->dims->data[0], n_cell); + } + + const TfLiteTensor* forget_gate_bias = + GetInput(context, node, kForgetGateBiasTensor); + TF_LITE_ENSURE_EQ(context, forget_gate_bias->dims->size, 1); + TF_LITE_ENSURE_EQ(context, forget_gate_bias->dims->data[0], n_cell); + + const TfLiteTensor* cell_bias = GetInput(context, node, kCellGateBiasTensor); + TF_LITE_ENSURE_EQ(context, cell_bias->dims->size, 1); + TF_LITE_ENSURE_EQ(context, cell_bias->dims->data[0], n_cell); + + const TfLiteTensor* output_gate_bias = + GetInput(context, node, kOutputGateBiasTensor); + TF_LITE_ENSURE_EQ(context, output_gate_bias->dims->size, 1); + TF_LITE_ENSURE_EQ(context, output_gate_bias->dims->data[0], n_cell); + + const TfLiteTensor* projection_weights = + GetOptionalInputTensor(context, node, kProjectionWeightsTensor); + if (projection_weights != nullptr) { + TF_LITE_ENSURE_EQ(context, projection_weights->dims->size, 2); + TF_LITE_ENSURE_EQ(context, projection_weights->dims->data[0], n_output); + TF_LITE_ENSURE_EQ(context, projection_weights->dims->data[1], n_cell); + } + + const TfLiteTensor* projection_bias = + GetOptionalInputTensor(context, node, kProjectionBiasTensor); + if (projection_bias != nullptr) { + TF_LITE_ENSURE_EQ(context, projection_bias->dims->size, 1); + TF_LITE_ENSURE_EQ(context, projection_bias->dims->data[0], n_output); + } + + // Making sure the projection tensors are consistent: + // 1) If projection weight is not present, then projection bias should not be + // present. + // 2) If projection weight is present, then projection bias is optional. + const bool projection_tensors_consistent = + ((projection_weights != nullptr) || (projection_bias == nullptr)); + TF_LITE_ENSURE(context, projection_tensors_consistent == true); + + return kTfLiteOk; +} + +// Resize the output, state tensors based on the sizes of the input tensors. +// Allocate a temporary scratch tensor. Also check that the sizes of the input +// tensors match each other. +TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { + OpData* op_data = reinterpret_cast<OpData*>(node->user_data); + TF_LITE_ENSURE_EQ(context, node->inputs->size, 24); + TF_LITE_ENSURE_EQ(context, node->outputs->size, 1); + + // Inferring batch size, number of outputs and number of cells from the + // input tensors. + const TfLiteTensor* input = GetInput(context, node, kInputTensor); + TF_LITE_ENSURE_EQ(context, input->type, kTfLiteFloat32); + TF_LITE_ENSURE(context, input->dims->size > 1); + const int n_batch = input->dims->data[0]; + const int n_input = input->dims->data[1]; + + const TfLiteTensor* input_to_output_weights = + GetInput(context, node, kInputToOutputWeightsTensor); + const int n_cell = input_to_output_weights->dims->data[0]; + TF_LITE_ENSURE_EQ(context, input_to_output_weights->dims->size, 2); + TF_LITE_ENSURE_EQ(context, input_to_output_weights->dims->data[1], n_input); + + const TfLiteTensor* recurrent_to_output_weights = + GetInput(context, node, kRecurrentToOutputWeightsTensor); + TF_LITE_ENSURE_EQ(context, recurrent_to_output_weights->dims->size, 2); + TF_LITE_ENSURE_EQ(context, recurrent_to_output_weights->dims->data[0], + n_cell); + const int n_output = recurrent_to_output_weights->dims->data[1]; + + // Check that input tensor dimensions matches with each other. + TF_LITE_ENSURE_OK(context, CheckInputTensorDimensions(context, node, n_input, + n_output, n_cell)); + + // Get the pointer to output, activation_state and cell_state tensors. + TfLiteTensor* output = GetOutput(context, node, kOutputTensor); + + const TfLiteTensor* activation_state = + GetInput(context, node, kInputActivationStateTensor); + const TfLiteTensor* cell_state = + GetInput(context, node, kInputCellStateTensor); + + // Check the shape of input state tensors. + // These tensor may be 1D or 2D. It's fine as long as the total size is + // correct. + TF_LITE_ENSURE_EQ(context, NumElements(activation_state), n_batch * n_output); + TF_LITE_ENSURE_EQ(context, NumElements(cell_state), n_batch * n_cell); + // Resize the output tensors. + TfLiteIntArray* output_size = TfLiteIntArrayCreate(2); + output_size->data[0] = n_batch; + output_size->data[1] = n_output; + TF_LITE_ENSURE_OK(context, + context->ResizeTensor(context, output, output_size)); + + // The weights are of consistent type, so it suffices to check one. + const bool is_hybrid_op = (input_to_output_weights->type == kTfLiteUInt8 && + input->type == kTfLiteFloat32); + + TfLiteIntArrayFree(node->temporaries); + if (is_hybrid_op) { + node->temporaries = TfLiteIntArrayCreate(7); + } else { + node->temporaries = TfLiteIntArrayCreate(1); + } + node->temporaries->data[0] = op_data->scratch_tensor_index; + + // Create a scratch buffer tensor. + TfLiteTensor* scratch_buffer = GetTemporary(context, node, /*index=*/0); + scratch_buffer->type = input->type; + scratch_buffer->allocation_type = kTfLiteArenaRw; + + const TfLiteTensor* input_to_input_weights = + GetOptionalInputTensor(context, node, kInputToInputWeightsTensor); + const bool use_cifg = (input_to_input_weights == nullptr); + TfLiteIntArray* scratch_buffer_size = TfLiteIntArrayCreate(2); + scratch_buffer_size->data[0] = n_batch; + if (use_cifg) { + // Reserving space for Cell, Forget, Output gates + scratch_buffer_size->data[1] = n_cell * 3; + } else { + // Reserving space for Input, Cell, Forget, Output gates + scratch_buffer_size->data[1] = n_cell * 4; + } + TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, scratch_buffer, + scratch_buffer_size)); + + if (is_hybrid_op) { + // Allocate temporary tensors to store quantized values of input, + // activation_state and cell_state tensors. + node->temporaries->data[1] = op_data->scratch_tensor_index + 1; + TfLiteTensor* input_quantized = GetTemporary(context, node, /*index=*/1); + input_quantized->type = kTfLiteUInt8; + input_quantized->allocation_type = kTfLiteArenaRw; + if (!TfLiteIntArrayEqual(input_quantized->dims, input->dims)) { + TfLiteIntArray* input_quantized_size = TfLiteIntArrayCopy(input->dims); + TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, input_quantized, + input_quantized_size)); + } + node->temporaries->data[2] = op_data->scratch_tensor_index + 2; + TfLiteTensor* activation_state_quantized = + GetTemporary(context, node, /*index=*/2); + activation_state_quantized->type = kTfLiteUInt8; + activation_state_quantized->allocation_type = kTfLiteArenaRw; + if (!TfLiteIntArrayEqual(activation_state_quantized->dims, + activation_state->dims)) { + TfLiteIntArray* activation_state_quantized_size = + TfLiteIntArrayCopy(activation_state->dims); + TF_LITE_ENSURE_OK( + context, context->ResizeTensor(context, activation_state_quantized, + activation_state_quantized_size)); + } + node->temporaries->data[3] = op_data->scratch_tensor_index + 3; + TfLiteTensor* cell_state_quantized = + GetTemporary(context, node, /*index=*/3); + cell_state_quantized->type = kTfLiteUInt8; + cell_state_quantized->allocation_type = kTfLiteArenaRw; + if (!TfLiteIntArrayEqual(cell_state_quantized->dims, cell_state->dims)) { + TfLiteIntArray* cell_state_quantized_size = + TfLiteIntArrayCopy(cell_state->dims); + TF_LITE_ENSURE_OK(context, + context->ResizeTensor(context, cell_state_quantized, + cell_state_quantized_size)); + } + + // Allocate temporary tensors to store scaling factors and product scaling + // factors. The latter is a convenience storage which allows to quantize + // a vector once (which produces the scaling factors) and multiply it with + // different matrices (which requires multiplying the scaling factors with + // the scaling factor of the matrix). + node->temporaries->data[4] = op_data->scratch_tensor_index + 4; + TfLiteTensor* scaling_factors = GetTemporary(context, node, /*index=*/4); + scaling_factors->type = kTfLiteFloat32; + scaling_factors->allocation_type = kTfLiteArenaRw; + TfLiteIntArray* scaling_factors_size = TfLiteIntArrayCreate(1); + scaling_factors_size->data[0] = n_batch; + if (!TfLiteIntArrayEqual(scaling_factors->dims, scaling_factors_size)) { + TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, scaling_factors, + scaling_factors_size)); + } + node->temporaries->data[5] = op_data->scratch_tensor_index + 5; + TfLiteTensor* prod_scaling_factors = + GetTemporary(context, node, /*index=*/5); + prod_scaling_factors->type = kTfLiteFloat32; + prod_scaling_factors->allocation_type = kTfLiteArenaRw; + TfLiteIntArray* prod_scaling_factors_size = TfLiteIntArrayCreate(1); + prod_scaling_factors_size->data[0] = n_batch; + if (!TfLiteIntArrayEqual(prod_scaling_factors->dims, + prod_scaling_factors_size)) { + TF_LITE_ENSURE_OK(context, + context->ResizeTensor(context, prod_scaling_factors, + prod_scaling_factors_size)); + } + + // Allocate a temporary tensor to store the recovered weights. Since + // this is used for diagonal matrices, only need to store n_cell values. + node->temporaries->data[6] = op_data->scratch_tensor_index + 6; + TfLiteTensor* recovered_weights = GetTemporary(context, node, /*index=*/6); + recovered_weights->type = kTfLiteFloat32; + recovered_weights->allocation_type = kTfLiteArenaRw; + TfLiteIntArray* recovered_weights_size = TfLiteIntArrayCreate(1); + recovered_weights_size->data[0] = n_cell; + if (!TfLiteIntArrayEqual(recovered_weights->dims, recovered_weights_size)) { + TF_LITE_ENSURE_OK(context, + context->ResizeTensor(context, recovered_weights, + recovered_weights_size)); + } + } + return kTfLiteOk; +} + +void LayerNormLstmStep( + const float* input_ptr_batch, const float* input_to_input_weights_ptr, + const float* input_to_forget_weights_ptr, + const float* input_to_cell_weights_ptr, + const float* input_to_output_weights_ptr, + const float* recurrent_to_input_weights_ptr, + const float* recurrent_to_forget_weights_ptr, + const float* recurrent_to_cell_weights_ptr, + const float* recurrent_to_output_weights_ptr, + const float* cell_to_input_weights_ptr, + const float* cell_to_forget_weights_ptr, + const float* cell_to_output_weights_ptr, + const float* input_layer_norm_weight_ptr, + const float* forget_layer_norm_weight_ptr, + const float* cell_layer_norm_weight_ptr, + const float* output_layer_norm_weight_ptr, const float* input_gate_bias_ptr, + const float* forget_gate_bias_ptr, const float* cell_bias_ptr, + const float* output_gate_bias_ptr, const float* projection_weights_ptr, + const float* projection_bias_ptr, float cell_clip, float proj_clip, + const TfLiteFusedActivation& activation, int n_batch, int n_cell, + int n_input, int n_output, float* output_state_ptr, float* cell_state_ptr, + float* input_gate_scratch, float* forget_gate_scratch, float* cell_scratch, + float* output_gate_scratch, float* output_ptr_batch) { + // Since we have already checked that weights are all there or none, we can + // check the existense of only one to the get the condition. + const bool use_cifg = (input_to_input_weights_ptr == nullptr); + const bool use_peephole = (cell_to_output_weights_ptr != nullptr); + + // Initialize scratch buffers with 0. + if (!use_cifg) { + tensor_utils::ZeroVector(input_gate_scratch, n_cell * n_batch); + } + tensor_utils::ZeroVector(forget_gate_scratch, n_cell * n_batch); + tensor_utils::ZeroVector(cell_scratch, n_cell * n_batch); + tensor_utils::ZeroVector(output_gate_scratch, n_cell * n_batch); + + // For each batch and cell: compute input_weight * input. + if (!use_cifg) { + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + input_to_input_weights_ptr, n_cell, n_input, input_ptr_batch, n_batch, + input_gate_scratch, /*result_stride=*/1); + } + + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + input_to_forget_weights_ptr, n_cell, n_input, input_ptr_batch, n_batch, + forget_gate_scratch, /*result_stride=*/1); + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + input_to_cell_weights_ptr, n_cell, n_input, input_ptr_batch, n_batch, + cell_scratch, /*result_stride=*/1); + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + input_to_output_weights_ptr, n_cell, n_input, input_ptr_batch, n_batch, + output_gate_scratch, /*result_stride=*/1); + + // For each batch and cell: compute recurrent_weight * output_state. + if (!use_cifg) { + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + recurrent_to_input_weights_ptr, n_cell, n_output, output_state_ptr, + n_batch, input_gate_scratch, /*result_stride=*/1); + } + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + recurrent_to_forget_weights_ptr, n_cell, n_output, output_state_ptr, + n_batch, forget_gate_scratch, + /*result_stride=*/1); + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + recurrent_to_cell_weights_ptr, n_cell, n_output, output_state_ptr, + n_batch, cell_scratch, /*result_stride=*/1); + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + recurrent_to_output_weights_ptr, n_cell, n_output, output_state_ptr, + n_batch, output_gate_scratch, + /*result_stride=*/1); + + // For each batch and cell: update input gate. + if (!use_cifg) { + if (use_peephole) { + tensor_utils::VectorBatchVectorCwiseProductAccumulate( + cell_to_input_weights_ptr, n_cell, cell_state_ptr, n_batch, + input_gate_scratch); + } + tensor_utils::MeanStddevNormalization(input_gate_scratch, + input_gate_scratch, n_cell, n_batch, + kLayerNormEpsilon); + tensor_utils::VectorBatchVectorCwiseProduct(input_layer_norm_weight_ptr, + n_cell, input_gate_scratch, + n_batch, input_gate_scratch); + tensor_utils::VectorBatchVectorAdd(input_gate_bias_ptr, n_cell, n_batch, + input_gate_scratch); + tensor_utils::ApplySigmoidToVector(input_gate_scratch, n_cell * n_batch, + input_gate_scratch); + } + + // For each batch and cell: update forget gate. + if (use_peephole) { + tensor_utils::VectorBatchVectorCwiseProductAccumulate( + cell_to_forget_weights_ptr, n_cell, cell_state_ptr, n_batch, + forget_gate_scratch); + } + tensor_utils::MeanStddevNormalization(forget_gate_scratch, + forget_gate_scratch, n_cell, n_batch, + kLayerNormEpsilon); + tensor_utils::VectorBatchVectorCwiseProduct(forget_layer_norm_weight_ptr, + n_cell, forget_gate_scratch, + n_batch, forget_gate_scratch); + tensor_utils::VectorBatchVectorAdd(forget_gate_bias_ptr, n_cell, n_batch, + forget_gate_scratch); + tensor_utils::ApplySigmoidToVector(forget_gate_scratch, n_cell * n_batch, + forget_gate_scratch); + + // For each batch and cell: update the cell. + tensor_utils::MeanStddevNormalization(cell_scratch, cell_scratch, n_cell, + n_batch, kLayerNormEpsilon); + tensor_utils::VectorBatchVectorCwiseProduct( + cell_layer_norm_weight_ptr, n_cell, cell_scratch, n_batch, cell_scratch); + tensor_utils::VectorBatchVectorAdd(cell_bias_ptr, n_cell, n_batch, + cell_scratch); + tensor_utils::VectorVectorCwiseProduct(forget_gate_scratch, cell_state_ptr, + n_batch * n_cell, cell_state_ptr); + tensor_utils::ApplyActivationToVector(cell_scratch, n_batch * n_cell, + activation, cell_scratch); + if (use_cifg) { + tensor_utils::Sub1Vector(forget_gate_scratch, n_batch * n_cell, + forget_gate_scratch); + tensor_utils::VectorVectorCwiseProductAccumulate( + cell_scratch, forget_gate_scratch, n_batch * n_cell, cell_state_ptr); + } else { + tensor_utils::VectorVectorCwiseProductAccumulate( + cell_scratch, input_gate_scratch, n_batch * n_cell, cell_state_ptr); + } + if (cell_clip > 0.0) { + tensor_utils::ClipVector(cell_state_ptr, n_batch * n_cell, cell_clip, + cell_state_ptr); + } + + // For each batch and cell: update the output gate. + if (use_peephole) { + tensor_utils::VectorBatchVectorCwiseProductAccumulate( + cell_to_output_weights_ptr, n_cell, cell_state_ptr, n_batch, + output_gate_scratch); + } + tensor_utils::MeanStddevNormalization(output_gate_scratch, + output_gate_scratch, n_cell, n_batch, + kLayerNormEpsilon); + tensor_utils::VectorBatchVectorCwiseProduct(output_layer_norm_weight_ptr, + n_cell, output_gate_scratch, + n_batch, output_gate_scratch); + tensor_utils::VectorBatchVectorAdd(output_gate_bias_ptr, n_cell, n_batch, + output_gate_scratch); + tensor_utils::ApplySigmoidToVector(output_gate_scratch, n_batch * n_cell, + output_gate_scratch); + tensor_utils::ApplyActivationToVector(cell_state_ptr, n_batch * n_cell, + activation, cell_scratch); + tensor_utils::VectorVectorCwiseProduct(output_gate_scratch, cell_scratch, + n_batch * n_cell, output_gate_scratch); + + // For each batch: update the projection and output_state. + const bool use_projection_weight = (projection_weights_ptr != nullptr); + const bool use_projection_bias = (projection_bias_ptr != nullptr); + if (use_projection_weight) { + if (use_projection_bias) { + tensor_utils::VectorBatchVectorAssign(projection_bias_ptr, n_output, + n_batch, output_ptr_batch); + } else { + tensor_utils::ZeroVector(output_ptr_batch, n_batch * n_output); + } + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + projection_weights_ptr, n_output, n_cell, output_gate_scratch, n_batch, + output_ptr_batch, /*result_stride=*/1); + if (proj_clip > 0.0) { + tensor_utils::ClipVector(output_ptr_batch, n_batch * n_output, proj_clip, + output_ptr_batch); + } + } else { + tensor_utils::CopyVector(output_gate_scratch, n_batch * n_output, + output_ptr_batch); + } + tensor_utils::CopyVector(output_ptr_batch, n_batch * n_output, + output_state_ptr); +} + +void LayerNormLstmStep( + const float* input_ptr_batch, const int8_t* input_to_input_weights_ptr, + float input_to_input_weights_scale, + const int8_t* input_to_forget_weights_ptr, + float input_to_forget_weights_scale, + const int8_t* input_to_cell_weights_ptr, float input_to_cell_weights_scale, + const int8_t* input_to_output_weights_ptr, + float input_to_output_weights_scale, + const int8_t* recurrent_to_input_weights_ptr, + float recurrent_to_input_weights_scale, + const int8_t* recurrent_to_forget_weights_ptr, + float recurrent_to_forget_weights_scale, + const int8_t* recurrent_to_cell_weights_ptr, + float recurrent_to_cell_weights_scale, + const int8_t* recurrent_to_output_weights_ptr, + float recurrent_to_output_weights_scale, + const int8_t* cell_to_input_weights_ptr, float cell_to_input_weights_scale, + const int8_t* cell_to_forget_weights_ptr, + float cell_to_forget_weights_scale, + const int8_t* cell_to_output_weights_ptr, + float cell_to_output_weights_scale, + const float* input_layer_norm_weight_ptr, + const float* forget_layer_norm_weight_ptr, + const float* cell_layer_norm_weight_ptr, + const float* output_layer_norm_weight_ptr, const float* input_gate_bias_ptr, + const float* forget_gate_bias_ptr, const float* cell_bias_ptr, + const float* output_gate_bias_ptr, const int8_t* projection_weights_ptr, + float projection_weights_scale, const float* projection_bias_ptr, + float cell_clip, float proj_clip, const TfLiteFusedActivation& activation, + int n_batch, int n_cell, int n_input, int n_output, + float* input_gate_scratch, float* forget_gate_scratch, float* cell_scratch, + float* output_gate_scratch, float* scaling_factors, + float* product_scaling_factors, float* recovered_weights, + int8_t* quantized_input_ptr_batch, int8_t* quantized_output_state_ptr, + int8_t* quantized_cell_state_ptr, float* output_state_ptr, + float* cell_state_ptr, float* output_ptr_batch) { + // Since we have already checked that weights are all there or none, we can + // check the existense of only one to the get the condition. + const bool use_cifg = (input_to_input_weights_ptr == nullptr); + const bool use_peephole = (cell_to_output_weights_ptr != nullptr); + + // Initialize scratch buffers with 0. + if (!use_cifg) { + tensor_utils::ZeroVector(input_gate_scratch, n_cell * n_batch); + } + tensor_utils::ZeroVector(forget_gate_scratch, n_cell * n_batch); + tensor_utils::ZeroVector(cell_scratch, n_cell * n_batch); + tensor_utils::ZeroVector(output_gate_scratch, n_cell * n_batch); + + if (!tensor_utils::IsZeroVector(input_ptr_batch, n_batch * n_input)) { + // Save quantization and matmul computation for all zero input. + float unused_min, unused_max; + for (int b = 0; b < n_batch; ++b) { + const int offset = b * n_input; + tensor_utils::SymmetricQuantizeFloats( + input_ptr_batch + offset, n_input, quantized_input_ptr_batch + offset, + &unused_min, &unused_max, &scaling_factors[b]); + } + // For each batch and cell: compute input_weight * input. + if (!use_cifg) { + for (int b = 0; b < n_batch; ++b) { + product_scaling_factors[b] = + scaling_factors[b] * input_to_input_weights_scale; + } + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + input_to_input_weights_ptr, n_cell, n_input, + quantized_input_ptr_batch, product_scaling_factors, n_batch, + input_gate_scratch, /*result_stride=*/1); + } + + for (int b = 0; b < n_batch; ++b) { + product_scaling_factors[b] = + scaling_factors[b] * input_to_forget_weights_scale; + } + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + input_to_forget_weights_ptr, n_cell, n_input, quantized_input_ptr_batch, + product_scaling_factors, n_batch, forget_gate_scratch, + /*result_stride=*/1); + + for (int b = 0; b < n_batch; ++b) { + product_scaling_factors[b] = + scaling_factors[b] * input_to_cell_weights_scale; + } + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + input_to_cell_weights_ptr, n_cell, n_input, quantized_input_ptr_batch, + product_scaling_factors, n_batch, cell_scratch, /*result_stride=*/1); + + for (int b = 0; b < n_batch; ++b) { + product_scaling_factors[b] = + scaling_factors[b] * input_to_output_weights_scale; + } + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + input_to_output_weights_ptr, n_cell, n_input, quantized_input_ptr_batch, + product_scaling_factors, n_batch, output_gate_scratch, + /*result_stride=*/1); + } + + if (!tensor_utils::IsZeroVector(output_state_ptr, n_batch * n_output)) { + // Save quantization and matmul computation for all zero input. + float unused_min, unused_max; + for (int b = 0; b < n_batch; ++b) { + const int offset = b * n_output; + tensor_utils::SymmetricQuantizeFloats(output_state_ptr + offset, n_output, + quantized_output_state_ptr + offset, + &unused_min, &unused_max, + &scaling_factors[b]); + } + // For each batch and cell: compute recurrent_weight * output_state. + if (!use_cifg) { + for (int b = 0; b < n_batch; ++b) { + product_scaling_factors[b] = + scaling_factors[b] * recurrent_to_input_weights_scale; + } + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + recurrent_to_input_weights_ptr, n_cell, n_output, + quantized_output_state_ptr, product_scaling_factors, n_batch, + input_gate_scratch, /*result_stride=*/1); + } + + for (int b = 0; b < n_batch; ++b) { + product_scaling_factors[b] = + scaling_factors[b] * recurrent_to_forget_weights_scale; + } + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + recurrent_to_forget_weights_ptr, n_cell, n_output, + quantized_output_state_ptr, product_scaling_factors, n_batch, + forget_gate_scratch, /*result_stride=*/1); + + for (int b = 0; b < n_batch; ++b) { + product_scaling_factors[b] = + scaling_factors[b] * recurrent_to_cell_weights_scale; + } + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + recurrent_to_cell_weights_ptr, n_cell, n_output, + quantized_output_state_ptr, product_scaling_factors, n_batch, + cell_scratch, /*result_stride=*/1); + + for (int b = 0; b < n_batch; ++b) { + product_scaling_factors[b] = + scaling_factors[b] * recurrent_to_output_weights_scale; + } + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + recurrent_to_output_weights_ptr, n_cell, n_output, + quantized_output_state_ptr, product_scaling_factors, n_batch, + output_gate_scratch, /*result_stride=*/1); + } + + // Save quantization and matmul computation for all zero input. + bool is_cell_state_all_zeros = + tensor_utils::IsZeroVector(cell_state_ptr, n_batch * n_cell); + + // For each batch and cell: update input gate. + if (!use_cifg) { + if (use_peephole && !is_cell_state_all_zeros) { + tensor_utils::VectorScalarMultiply(cell_to_input_weights_ptr, n_cell, + cell_to_input_weights_scale, + recovered_weights); + tensor_utils::VectorBatchVectorCwiseProductAccumulate( + recovered_weights, n_cell, cell_state_ptr, n_batch, + input_gate_scratch); + } + tensor_utils::MeanStddevNormalization(input_gate_scratch, + input_gate_scratch, n_cell, n_batch, + kLayerNormEpsilon); + tensor_utils::VectorBatchVectorCwiseProduct(input_layer_norm_weight_ptr, + n_cell, input_gate_scratch, + n_batch, input_gate_scratch); + tensor_utils::VectorBatchVectorAdd(input_gate_bias_ptr, n_cell, n_batch, + input_gate_scratch); + tensor_utils::ApplySigmoidToVector(input_gate_scratch, n_cell * n_batch, + input_gate_scratch); + } + + // For each batch and cell: update forget gate. + if (use_peephole && !is_cell_state_all_zeros) { + tensor_utils::VectorScalarMultiply(cell_to_forget_weights_ptr, n_cell, + cell_to_forget_weights_scale, + recovered_weights); + tensor_utils::VectorBatchVectorCwiseProductAccumulate( + recovered_weights, n_cell, cell_state_ptr, n_batch, + forget_gate_scratch); + } + tensor_utils::MeanStddevNormalization(forget_gate_scratch, + forget_gate_scratch, n_cell, n_batch, + kLayerNormEpsilon); + tensor_utils::VectorBatchVectorCwiseProduct(forget_layer_norm_weight_ptr, + n_cell, forget_gate_scratch, + n_batch, forget_gate_scratch); + tensor_utils::VectorBatchVectorAdd(forget_gate_bias_ptr, n_cell, n_batch, + forget_gate_scratch); + tensor_utils::ApplySigmoidToVector(forget_gate_scratch, n_cell * n_batch, + forget_gate_scratch); + + // For each batch and cell: update the cell. + tensor_utils::MeanStddevNormalization(cell_scratch, cell_scratch, n_cell, + n_batch, kLayerNormEpsilon); + tensor_utils::VectorBatchVectorCwiseProduct( + cell_layer_norm_weight_ptr, n_cell, cell_scratch, n_batch, cell_scratch); + tensor_utils::VectorBatchVectorAdd(cell_bias_ptr, n_cell, n_batch, + cell_scratch); + tensor_utils::VectorVectorCwiseProduct(forget_gate_scratch, cell_state_ptr, + n_batch * n_cell, cell_state_ptr); + tensor_utils::ApplyActivationToVector(cell_scratch, n_batch * n_cell, + activation, cell_scratch); + if (use_cifg) { + tensor_utils::Sub1Vector(forget_gate_scratch, n_batch * n_cell, + forget_gate_scratch); + tensor_utils::VectorVectorCwiseProductAccumulate( + cell_scratch, forget_gate_scratch, n_batch * n_cell, cell_state_ptr); + } else { + tensor_utils::VectorVectorCwiseProductAccumulate( + cell_scratch, input_gate_scratch, n_batch * n_cell, cell_state_ptr); + } + if (cell_clip > 0.0) { + tensor_utils::ClipVector(cell_state_ptr, n_batch * n_cell, cell_clip, + cell_state_ptr); + } + + is_cell_state_all_zeros = + tensor_utils::IsZeroVector(cell_state_ptr, n_batch * n_cell); + // For each batch and cell: update the output gate. + if (use_peephole && !is_cell_state_all_zeros) { + tensor_utils::VectorScalarMultiply(cell_to_output_weights_ptr, n_cell, + cell_to_output_weights_scale, + recovered_weights); + tensor_utils::VectorBatchVectorCwiseProductAccumulate( + recovered_weights, n_cell, cell_state_ptr, n_batch, + output_gate_scratch); + } + tensor_utils::MeanStddevNormalization(output_gate_scratch, + output_gate_scratch, n_cell, n_batch, + kLayerNormEpsilon); + tensor_utils::VectorBatchVectorCwiseProduct(output_layer_norm_weight_ptr, + n_cell, output_gate_scratch, + n_batch, output_gate_scratch); + tensor_utils::VectorBatchVectorAdd(output_gate_bias_ptr, n_cell, n_batch, + output_gate_scratch); + tensor_utils::ApplySigmoidToVector(output_gate_scratch, n_batch * n_cell, + output_gate_scratch); + tensor_utils::ApplyActivationToVector(cell_state_ptr, n_batch * n_cell, + activation, cell_scratch); + tensor_utils::VectorVectorCwiseProduct(output_gate_scratch, cell_scratch, + n_batch * n_cell, output_gate_scratch); + + // For each batch: update the projection and output_state. + const bool use_projection_weight = (projection_weights_ptr != nullptr); + const bool use_projection_bias = (projection_bias_ptr != nullptr); + if (use_projection_weight) { + if (use_projection_bias) { + tensor_utils::VectorBatchVectorAssign(projection_bias_ptr, n_output, + n_batch, output_ptr_batch); + } else { + tensor_utils::ZeroVector(output_ptr_batch, n_batch * n_output); + } + if (!tensor_utils::IsZeroVector(output_gate_scratch, n_batch * n_cell)) { + // Save quantization and matmul computation for all zero input. + float unused_min, unused_max; + for (int b = 0; b < n_batch; ++b) { + const int offset = b * n_cell; + tensor_utils::SymmetricQuantizeFloats( + output_gate_scratch + offset, n_cell, + quantized_cell_state_ptr + offset, &unused_min, &unused_max, + &scaling_factors[b]); + } + for (int b = 0; b < n_batch; ++b) { + product_scaling_factors[b] = + scaling_factors[b] * projection_weights_scale; + } + tensor_utils::MatrixBatchVectorMultiplyAccumulate( + projection_weights_ptr, n_output, n_cell, quantized_cell_state_ptr, + product_scaling_factors, n_batch, output_ptr_batch, + /*result_stride=*/1); + } + if (proj_clip > 0.0) { + tensor_utils::ClipVector(output_ptr_batch, n_batch * n_output, proj_clip, + output_ptr_batch); + } + } else { + tensor_utils::CopyVector(output_gate_scratch, n_batch * n_output, + output_ptr_batch); + } + tensor_utils::CopyVector(output_ptr_batch, n_batch * n_output, + output_state_ptr); +} + +// The LayerNormLSTM Op engine. +TfLiteStatus EvalFloat( + const TfLiteTensor* input, const TfLiteTensor* input_to_input_weights, + const TfLiteTensor* input_to_forget_weights, + const TfLiteTensor* input_to_cell_weights, + const TfLiteTensor* input_to_output_weights, + const TfLiteTensor* recurrent_to_input_weights, + const TfLiteTensor* recurrent_to_forget_weights, + const TfLiteTensor* recurrent_to_cell_weights, + const TfLiteTensor* recurrent_to_output_weights, + const TfLiteTensor* cell_to_input_weights, + const TfLiteTensor* cell_to_forget_weights, + const TfLiteTensor* cell_to_output_weights, + const TfLiteTensor* input_layer_norm_weights, + const TfLiteTensor* forget_layer_norm_weights, + const TfLiteTensor* cell_layer_norm_weights, + const TfLiteTensor* output_layer_norm_weights, + const TfLiteTensor* input_gate_bias, const TfLiteTensor* forget_gate_bias, + const TfLiteTensor* cell_bias, const TfLiteTensor* output_gate_bias, + const TfLiteTensor* projection_weights, const TfLiteTensor* projection_bias, + float cell_clip, float proj_clip, const TfLiteFusedActivation& activation, + TfLiteTensor* scratch_buffer, TfLiteTensor* activation_state, + TfLiteTensor* cell_state, TfLiteTensor* output) { + const int n_batch = input->dims->data[0]; + const int n_input = input->dims->data[1]; + // n_cell and n_output will be the same size when there is no projection. + const int n_cell = input_to_output_weights->dims->data[0]; + const int n_output = recurrent_to_output_weights->dims->data[1]; + + // Since we have already checked that weights are all there or none, we can + // check the existence of only one to get the condition. + const bool use_cifg = (input_to_input_weights == nullptr); + const bool use_peephole = (cell_to_output_weights != nullptr); + + float* input_gate_scratch = nullptr; + float* cell_scratch = nullptr; + float* forget_gate_scratch = nullptr; + float* output_gate_scratch = nullptr; + if (use_cifg) { + cell_scratch = scratch_buffer->data.f; + forget_gate_scratch = scratch_buffer->data.f + n_cell * n_batch; + output_gate_scratch = scratch_buffer->data.f + 2 * n_cell * n_batch; + } else { + input_gate_scratch = scratch_buffer->data.f; + cell_scratch = scratch_buffer->data.f + n_cell * n_batch; + forget_gate_scratch = scratch_buffer->data.f + 2 * n_cell * n_batch; + output_gate_scratch = scratch_buffer->data.f + 3 * n_cell * n_batch; + } + + // Check optional tensors, the respective pointers can be null. + const float* input_to_input_weights_ptr = + (use_cifg) ? nullptr : input_to_input_weights->data.f; + const float* recurrent_to_input_weights_ptr = + (use_cifg) ? nullptr : recurrent_to_input_weights->data.f; + const float* input_gate_bias_ptr = + (use_cifg) ? nullptr : input_gate_bias->data.f; + const float* cell_to_input_weights_ptr = + (use_peephole && !use_cifg) ? cell_to_input_weights->data.f : nullptr; + const float* cell_to_forget_weights_ptr = + (use_peephole) ? cell_to_forget_weights->data.f : nullptr; + const float* cell_to_output_weights_ptr = + (use_peephole) ? cell_to_output_weights->data.f : nullptr; + const float* projection_weights_ptr = + (projection_weights == nullptr) ? nullptr : projection_weights->data.f; + const float* projection_bias_ptr = + (projection_bias == nullptr) ? nullptr : projection_bias->data.f; + + // Required tensors, pointers are non-null. + const float* input_ptr_batch = input->data.f; + const float* input_to_forget_weights_ptr = input_to_forget_weights->data.f; + const float* input_to_cell_weights_ptr = input_to_cell_weights->data.f; + const float* input_to_output_weights_ptr = input_to_output_weights->data.f; + const float* recurrent_to_forget_weights_ptr = + recurrent_to_forget_weights->data.f; + const float* recurrent_to_cell_weights_ptr = + recurrent_to_cell_weights->data.f; + const float* recurrent_to_output_weights_ptr = + recurrent_to_output_weights->data.f; + const float* input_layer_norm_weight_ptr = input_layer_norm_weights->data.f; + const float* forget_layer_norm_weight_ptr = forget_layer_norm_weights->data.f; + const float* cell_layer_norm_weight_ptr = cell_layer_norm_weights->data.f; + const float* output_layer_norm_weight_ptr = output_layer_norm_weights->data.f; + const float* forget_gate_bias_ptr = forget_gate_bias->data.f; + const float* cell_bias_ptr = cell_bias->data.f; + const float* output_gate_bias_ptr = output_gate_bias->data.f; + + float* activation_state_ptr = activation_state->data.f; + float* cell_state_ptr = cell_state->data.f; + float* output_ptr_batch = output->data.f; + + LayerNormLstmStep( + input_ptr_batch, input_to_input_weights_ptr, input_to_forget_weights_ptr, + input_to_cell_weights_ptr, input_to_output_weights_ptr, + recurrent_to_input_weights_ptr, recurrent_to_forget_weights_ptr, + recurrent_to_cell_weights_ptr, recurrent_to_output_weights_ptr, + cell_to_input_weights_ptr, cell_to_forget_weights_ptr, + cell_to_output_weights_ptr, input_layer_norm_weight_ptr, + forget_layer_norm_weight_ptr, cell_layer_norm_weight_ptr, + output_layer_norm_weight_ptr, input_gate_bias_ptr, forget_gate_bias_ptr, + cell_bias_ptr, output_gate_bias_ptr, projection_weights_ptr, + projection_bias_ptr, cell_clip, proj_clip, activation, n_batch, n_cell, + n_input, n_output, activation_state_ptr, cell_state_ptr, + input_gate_scratch, forget_gate_scratch, cell_scratch, + output_gate_scratch, output_ptr_batch); + + return kTfLiteOk; +} + +TfLiteStatus EvalHybrid( + const TfLiteTensor* input, const TfLiteTensor* input_to_input_weights, + const TfLiteTensor* input_to_forget_weights, + const TfLiteTensor* input_to_cell_weights, + const TfLiteTensor* input_to_output_weights, + const TfLiteTensor* recurrent_to_input_weights, + const TfLiteTensor* recurrent_to_forget_weights, + const TfLiteTensor* recurrent_to_cell_weights, + const TfLiteTensor* recurrent_to_output_weights, + const TfLiteTensor* cell_to_input_weights, + const TfLiteTensor* cell_to_forget_weights, + const TfLiteTensor* cell_to_output_weights, + const TfLiteTensor* input_layer_norm_weights, + const TfLiteTensor* forget_layer_norm_weights, + const TfLiteTensor* cell_layer_norm_weights, + const TfLiteTensor* output_layer_norm_weights, + const TfLiteTensor* input_gate_bias, const TfLiteTensor* forget_gate_bias, + const TfLiteTensor* cell_bias, const TfLiteTensor* output_gate_bias, + const TfLiteTensor* projection_weights, const TfLiteTensor* projection_bias, + float cell_clip, float proj_clip, const TfLiteFusedActivation& activation, + TfLiteTensor* scratch_buffer, TfLiteTensor* scaling_factors, + TfLiteTensor* prod_scaling_factors, TfLiteTensor* recovered_weights, + TfLiteTensor* input_quantized, TfLiteTensor* activation_state_quantized, + TfLiteTensor* cell_state_quantized, TfLiteTensor* activation_state, + TfLiteTensor* cell_state, TfLiteTensor* output) { + const int n_batch = input->dims->data[0]; + const int n_input = input->dims->data[1]; + // n_cell and n_output will be the same size when there is no projection. + const int n_cell = input_to_output_weights->dims->data[0]; + const int n_output = recurrent_to_output_weights->dims->data[1]; + + // Since we have already checked that weights are all there or none, we can + // check the existence of only one to get the condition. + const bool use_cifg = (input_to_input_weights == nullptr); + const bool use_peephole = (cell_to_output_weights != nullptr); + + float* input_gate_scratch = nullptr; + float* cell_scratch = nullptr; + float* forget_gate_scratch = nullptr; + float* output_gate_scratch = nullptr; + if (use_cifg) { + cell_scratch = scratch_buffer->data.f; + forget_gate_scratch = scratch_buffer->data.f + n_cell * n_batch; + output_gate_scratch = scratch_buffer->data.f + 2 * n_cell * n_batch; + } else { + input_gate_scratch = scratch_buffer->data.f; + cell_scratch = scratch_buffer->data.f + n_cell * n_batch; + forget_gate_scratch = scratch_buffer->data.f + 2 * n_cell * n_batch; + output_gate_scratch = scratch_buffer->data.f + 3 * n_cell * n_batch; + } + + // Check optional tensors, the respective pointers can be null. + int8_t* input_to_input_weights_ptr = nullptr; + float input_to_input_weights_scale = 1.0f; + int8_t* recurrent_to_input_weights_ptr = nullptr; + float recurrent_to_input_weights_scale = 1.0f; + float* input_gate_bias_ptr = nullptr; + if (!use_cifg) { + input_to_input_weights_ptr = + reinterpret_cast<int8_t*>(input_to_input_weights->data.uint8); + recurrent_to_input_weights_ptr = + reinterpret_cast<int8_t*>(recurrent_to_input_weights->data.uint8); + input_gate_bias_ptr = input_gate_bias->data.f; + input_to_input_weights_scale = input_to_input_weights->params.scale; + recurrent_to_input_weights_scale = recurrent_to_input_weights->params.scale; + } + + int8_t* cell_to_input_weights_ptr = nullptr; + int8_t* cell_to_forget_weights_ptr = nullptr; + int8_t* cell_to_output_weights_ptr = nullptr; + float cell_to_input_weights_scale = 1.0f; + float cell_to_forget_weights_scale = 1.0f; + float cell_to_output_weights_scale = 1.0f; + if (use_peephole) { + if (!use_cifg) { + cell_to_input_weights_ptr = + reinterpret_cast<int8_t*>(cell_to_input_weights->data.uint8); + cell_to_input_weights_scale = cell_to_input_weights->params.scale; + } + cell_to_forget_weights_ptr = + reinterpret_cast<int8_t*>(cell_to_forget_weights->data.uint8); + cell_to_output_weights_ptr = + reinterpret_cast<int8_t*>(cell_to_output_weights->data.uint8); + cell_to_forget_weights_scale = cell_to_forget_weights->params.scale; + cell_to_output_weights_scale = cell_to_output_weights->params.scale; + } + + const int8_t* projection_weights_ptr = + (projection_weights == nullptr) + ? nullptr + : reinterpret_cast<int8_t*>(projection_weights->data.uint8); + const float projection_weights_scale = + (projection_weights == nullptr) ? 1.0f : projection_weights->params.scale; + const float* projection_bias_ptr = + (projection_bias == nullptr) ? nullptr : projection_bias->data.f; + + // Required tensors, pointers are non-null. + const float* input_ptr_batch = input->data.f; + const int8_t* input_to_forget_weights_ptr = + reinterpret_cast<int8_t*>(input_to_forget_weights->data.uint8); + const float input_to_forget_weights_scale = + input_to_forget_weights->params.scale; + const int8_t* input_to_cell_weights_ptr = + reinterpret_cast<int8_t*>(input_to_cell_weights->data.uint8); + const float input_to_cell_weights_scale = input_to_cell_weights->params.scale; + const int8_t* input_to_output_weights_ptr = + reinterpret_cast<int8_t*>(input_to_output_weights->data.uint8); + const float input_to_output_weights_scale = + input_to_output_weights->params.scale; + const int8_t* recurrent_to_forget_weights_ptr = + reinterpret_cast<int8_t*>(recurrent_to_forget_weights->data.uint8); + const float recurrent_to_forget_weights_scale = + recurrent_to_forget_weights->params.scale; + const int8_t* recurrent_to_cell_weights_ptr = + reinterpret_cast<int8_t*>(recurrent_to_cell_weights->data.uint8); + const float recurrent_to_cell_weights_scale = + recurrent_to_cell_weights->params.scale; + const int8_t* recurrent_to_output_weights_ptr = + reinterpret_cast<int8_t*>(recurrent_to_output_weights->data.uint8); + const float recurrent_to_output_weights_scale = + recurrent_to_output_weights->params.scale; + const float* input_layer_norm_weight_ptr = input_layer_norm_weights->data.f; + const float* forget_layer_norm_weight_ptr = forget_layer_norm_weights->data.f; + const float* cell_layer_norm_weight_ptr = cell_layer_norm_weights->data.f; + const float* output_layer_norm_weight_ptr = output_layer_norm_weights->data.f; + const float* forget_gate_bias_ptr = forget_gate_bias->data.f; + const float* cell_bias_ptr = cell_bias->data.f; + const float* output_gate_bias_ptr = output_gate_bias->data.f; + + float* activation_state_ptr = activation_state->data.f; + float* cell_state_ptr = cell_state->data.f; + float* output_ptr_batch = output->data.f; + + // Temporary storage for quantized values and scaling factors. + int8_t* quantized_input_ptr = + reinterpret_cast<int8_t*>(input_quantized->data.uint8); + int8_t* quantized_activation_state_ptr = + reinterpret_cast<int8_t*>(activation_state_quantized->data.uint8); + int8_t* quantized_cell_state_ptr = + reinterpret_cast<int8_t*>(cell_state_quantized->data.uint8); + float* scaling_factors_ptr = scaling_factors->data.f; + float* prod_scaling_factors_ptr = prod_scaling_factors->data.f; + float* recovered_weights_ptr = recovered_weights->data.f; + + LayerNormLstmStep( + input_ptr_batch, input_to_input_weights_ptr, input_to_input_weights_scale, + input_to_forget_weights_ptr, input_to_forget_weights_scale, + input_to_cell_weights_ptr, input_to_cell_weights_scale, + input_to_output_weights_ptr, input_to_output_weights_scale, + recurrent_to_input_weights_ptr, recurrent_to_input_weights_scale, + recurrent_to_forget_weights_ptr, recurrent_to_forget_weights_scale, + recurrent_to_cell_weights_ptr, recurrent_to_cell_weights_scale, + recurrent_to_output_weights_ptr, recurrent_to_output_weights_scale, + cell_to_input_weights_ptr, cell_to_input_weights_scale, + cell_to_forget_weights_ptr, cell_to_forget_weights_scale, + cell_to_output_weights_ptr, cell_to_output_weights_scale, + input_layer_norm_weight_ptr, forget_layer_norm_weight_ptr, + cell_layer_norm_weight_ptr, output_layer_norm_weight_ptr, + input_gate_bias_ptr, forget_gate_bias_ptr, cell_bias_ptr, + output_gate_bias_ptr, projection_weights_ptr, projection_weights_scale, + projection_bias_ptr, cell_clip, proj_clip, activation, n_batch, n_cell, + n_input, n_output, input_gate_scratch, forget_gate_scratch, cell_scratch, + output_gate_scratch, scaling_factors_ptr, prod_scaling_factors_ptr, + recovered_weights_ptr, quantized_input_ptr, + quantized_activation_state_ptr, quantized_cell_state_ptr, + activation_state_ptr, cell_state_ptr, output_ptr_batch); + + return kTfLiteOk; +} + +TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { + const OpData* op_data = reinterpret_cast<OpData*>(node->user_data); + + const TfLiteTensor* input = GetInput(context, node, kInputTensor); + + const TfLiteTensor* input_to_input_weights = + GetOptionalInputTensor(context, node, kInputToInputWeightsTensor); + const TfLiteTensor* input_to_forget_weights = + GetInput(context, node, kInputToForgetWeightsTensor); + const TfLiteTensor* input_to_cell_weights = + GetInput(context, node, kInputToCellWeightsTensor); + const TfLiteTensor* input_to_output_weights = + GetInput(context, node, kInputToOutputWeightsTensor); + + const TfLiteTensor* recurrent_to_input_weights = + GetOptionalInputTensor(context, node, kRecurrentToInputWeightsTensor); + const TfLiteTensor* recurrent_to_forget_weights = + GetInput(context, node, kRecurrentToForgetWeightsTensor); + const TfLiteTensor* recurrent_to_cell_weights = + GetInput(context, node, kRecurrentToCellWeightsTensor); + const TfLiteTensor* recurrent_to_output_weights = + GetInput(context, node, kRecurrentToOutputWeightsTensor); + + const TfLiteTensor* cell_to_input_weights = + GetOptionalInputTensor(context, node, kCellToInputWeightsTensor); + const TfLiteTensor* cell_to_forget_weights = + GetOptionalInputTensor(context, node, kCellToForgetWeightsTensor); + const TfLiteTensor* cell_to_output_weights = + GetOptionalInputTensor(context, node, kCellToOutputWeightsTensor); + + const TfLiteTensor* input_layer_norm_weights = + GetInput(context, node, kInputLayerNormWeightsTensor); + const TfLiteTensor* forget_layer_norm_weights = + GetInput(context, node, kForgetLayerNormWeightsTensor); + const TfLiteTensor* cell_layer_norm_weights = + GetInput(context, node, kCellLayerNormWeightsTensor); + const TfLiteTensor* output_layer_norm_weights = + GetInput(context, node, kOutputLayerNormWeightsTensor); + + const TfLiteTensor* input_gate_bias = + GetOptionalInputTensor(context, node, kInputGateBiasTensor); + const TfLiteTensor* forget_gate_bias = + GetInput(context, node, kForgetGateBiasTensor); + const TfLiteTensor* cell_bias = GetInput(context, node, kCellGateBiasTensor); + const TfLiteTensor* output_gate_bias = + GetInput(context, node, kOutputGateBiasTensor); + + const TfLiteTensor* projection_weights = + GetOptionalInputTensor(context, node, kProjectionWeightsTensor); + const TfLiteTensor* projection_bias = + GetOptionalInputTensor(context, node, kProjectionBiasTensor); + + // Index the scratch buffers pointers to the global scratch buffer. + TfLiteTensor* scratch_buffer = GetTemporary(context, node, /*index=*/0); + + TfLiteTensor* activation_state = + &context->tensors[node->inputs->data[kInputActivationStateTensor]]; + TfLiteTensor* cell_state = + &context->tensors[node->inputs->data[kInputCellStateTensor]]; + + TfLiteTensor* output = GetOutput(context, node, kOutputTensor); + + switch (input_to_output_weights->type) { + case kTfLiteFloat32: { + return EvalFloat(input, input_to_input_weights, input_to_forget_weights, + input_to_cell_weights, input_to_output_weights, + recurrent_to_input_weights, recurrent_to_forget_weights, + recurrent_to_cell_weights, recurrent_to_output_weights, + cell_to_input_weights, cell_to_forget_weights, + cell_to_output_weights, input_layer_norm_weights, + forget_layer_norm_weights, cell_layer_norm_weights, + output_layer_norm_weights, input_gate_bias, + forget_gate_bias, cell_bias, output_gate_bias, + projection_weights, projection_bias, op_data->cell_clip, + op_data->proj_clip, op_data->activation, scratch_buffer, + activation_state, cell_state, output); + } + case kTfLiteUInt8: { + TfLiteTensor* input_quantized = GetTemporary(context, node, /*index=*/1); + TfLiteTensor* activation_state_quantized = + GetTemporary(context, node, /*index=*/2); + TfLiteTensor* cell_state_quantized = + GetTemporary(context, node, /*index=*/3); + TfLiteTensor* scaling_factors = GetTemporary(context, node, /*index=*/4); + TfLiteTensor* prod_scaling_factors = + GetTemporary(context, node, /*index=*/5); + TfLiteTensor* recovered_weights = + GetTemporary(context, node, /*index=*/6); + return EvalHybrid( + input, input_to_input_weights, input_to_forget_weights, + input_to_cell_weights, input_to_output_weights, + recurrent_to_input_weights, recurrent_to_forget_weights, + recurrent_to_cell_weights, recurrent_to_output_weights, + cell_to_input_weights, cell_to_forget_weights, cell_to_output_weights, + input_layer_norm_weights, forget_layer_norm_weights, + cell_layer_norm_weights, output_layer_norm_weights, input_gate_bias, + forget_gate_bias, cell_bias, output_gate_bias, projection_weights, + projection_bias, op_data->cell_clip, op_data->proj_clip, + op_data->activation, scratch_buffer, scaling_factors, + prod_scaling_factors, recovered_weights, input_quantized, + activation_state_quantized, cell_state_quantized, activation_state, + cell_state, output); + } + default: + context->ReportError(context, "Type %d is not currently supported.", + input_to_output_weights->type); + return kTfLiteError; + } + return kTfLiteOk; +} + +void Free(TfLiteContext* context, void* buffer) { + delete reinterpret_cast<OpData*>(buffer); +} + +} // namespace layer_norm_lstm + +TfLiteRegistration* Register_LAYER_NORM_LSTM() { + static TfLiteRegistration r = {layer_norm_lstm::Init, layer_norm_lstm::Free, + layer_norm_lstm::Prepare, + layer_norm_lstm::Eval}; + return &r; +} + +} // namespace custom +} // namespace ops +} // namespace tflite diff --git a/tensorflow/contrib/lite/kernels/layer_norm_lstm_test.cc b/tensorflow/contrib/lite/kernels/layer_norm_lstm_test.cc new file mode 100644 index 0000000000..abc229f85a --- /dev/null +++ b/tensorflow/contrib/lite/kernels/layer_norm_lstm_test.cc @@ -0,0 +1,664 @@ +/* Copyright 2017 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ +// Unit test for TFLite Layer Norm LSTM op. + +#include <memory> +#include <vector> + +#include <gmock/gmock.h> +#include <gtest/gtest.h> +#include "flatbuffers/flexbuffers.h" // flatbuffers +#include "tensorflow/contrib/lite/interpreter.h" +#include "tensorflow/contrib/lite/kernels/register.h" +#include "tensorflow/contrib/lite/kernels/test_util.h" +#include "tensorflow/contrib/lite/model.h" + +namespace tflite { +namespace ops { +namespace custom { + +TfLiteRegistration* Register_LAYER_NORM_LSTM(); + +namespace { + +using ::testing::ElementsAreArray; + +class LayerNormLSTMOpModel : public SingleOpModel { + public: + LayerNormLSTMOpModel(int n_batch, int n_input, int n_cell, int n_output, + bool use_cifg, bool use_peephole, + bool use_projection_weights, bool use_projection_bias, + float cell_clip, float proj_clip, + const std::vector<std::vector<int>>& input_shapes, + const TensorType& weight_type = TensorType_FLOAT32) + : n_batch_(n_batch), + n_input_(n_input), + n_cell_(n_cell), + n_output_(n_output) { + input_ = AddInput(TensorType_FLOAT32); + + if (use_cifg) { + input_to_input_weights_ = AddNullInput(); + } else { + input_to_input_weights_ = AddInput(weight_type); + } + + input_to_forget_weights_ = AddInput(weight_type); + input_to_cell_weights_ = AddInput(weight_type); + input_to_output_weights_ = AddInput(weight_type); + + if (use_cifg) { + recurrent_to_input_weights_ = AddNullInput(); + } else { + recurrent_to_input_weights_ = AddInput(weight_type); + } + + recurrent_to_forget_weights_ = AddInput(weight_type); + recurrent_to_cell_weights_ = AddInput(weight_type); + recurrent_to_output_weights_ = AddInput(weight_type); + + if (use_peephole) { + if (use_cifg) { + cell_to_input_weights_ = AddNullInput(); + } else { + cell_to_input_weights_ = AddInput(weight_type); + } + cell_to_forget_weights_ = AddInput(weight_type); + cell_to_output_weights_ = AddInput(weight_type); + } else { + cell_to_input_weights_ = AddNullInput(); + cell_to_forget_weights_ = AddNullInput(); + cell_to_output_weights_ = AddNullInput(); + } + + input_layer_norm_weights_ = AddInput(TensorType_FLOAT32); + forget_layer_norm_weights_ = AddInput(TensorType_FLOAT32); + cell_layer_norm_weights_ = AddInput(TensorType_FLOAT32); + output_layer_norm_weights_ = AddInput(TensorType_FLOAT32); + + if (use_cifg) { + input_gate_bias_ = AddNullInput(); + } else { + input_gate_bias_ = AddInput(TensorType_FLOAT32); + } + forget_gate_bias_ = AddInput(TensorType_FLOAT32); + cell_bias_ = AddInput(TensorType_FLOAT32); + output_gate_bias_ = AddInput(TensorType_FLOAT32); + + if (use_projection_weights) { + projection_weights_ = AddInput(weight_type); + if (use_projection_bias) { + projection_bias_ = AddInput(TensorType_FLOAT32); + } else { + projection_bias_ = AddNullInput(); + } + } else { + projection_weights_ = AddNullInput(); + projection_bias_ = AddNullInput(); + } + + // Adding the 2 state tensors. + output_state_ = + AddInput(TensorData{TensorType_FLOAT32, {n_output_ * n_batch_}}, true); + cell_state_ = + AddInput(TensorData{TensorType_FLOAT32, {n_cell_ * n_batch_}}, true); + + output_ = AddOutput(TensorType_FLOAT32); + + // Set up and pass in custom options using flexbuffer. + flexbuffers::Builder fbb; + fbb.Map([&]() { + fbb.Int("cell_clip", cell_clip); + fbb.Int("proj_clip", proj_clip); + fbb.String("fused_activation_function", "TANH"); + }); + fbb.Finish(); + SetCustomOp("LAYER_NORM_LSTM", fbb.GetBuffer(), Register_LAYER_NORM_LSTM); + BuildInterpreter(input_shapes); + } + + void SetInputToInputWeights(std::initializer_list<float> f) { + PopulateTensor(input_to_input_weights_, f); + } + + void SetInputToForgetWeights(std::initializer_list<float> f) { + PopulateTensor(input_to_forget_weights_, f); + } + + void SetInputToCellWeights(std::initializer_list<float> f) { + PopulateTensor(input_to_cell_weights_, f); + } + + void SetInputToOutputWeights(std::initializer_list<float> f) { + PopulateTensor(input_to_output_weights_, f); + } + + void SetRecurrentToInputWeights(std::initializer_list<float> f) { + PopulateTensor(recurrent_to_input_weights_, f); + } + + void SetRecurrentToForgetWeights(std::initializer_list<float> f) { + PopulateTensor(recurrent_to_forget_weights_, f); + } + + void SetRecurrentToCellWeights(std::initializer_list<float> f) { + PopulateTensor(recurrent_to_cell_weights_, f); + } + + void SetRecurrentToOutputWeights(std::initializer_list<float> f) { + PopulateTensor(recurrent_to_output_weights_, f); + } + + void SetCellToInputWeights(std::initializer_list<float> f) { + PopulateTensor(cell_to_input_weights_, f); + } + + void SetCellToForgetWeights(std::initializer_list<float> f) { + PopulateTensor(cell_to_forget_weights_, f); + } + + void SetCellToOutputWeights(std::initializer_list<float> f) { + PopulateTensor(cell_to_output_weights_, f); + } + + void SetInputLayerNormWeights(std::initializer_list<float> f) { + PopulateTensor(input_layer_norm_weights_, f); + } + + void SetForgetLayerNormWeights(std::initializer_list<float> f) { + PopulateTensor(forget_layer_norm_weights_, f); + } + + void SetCellLayerNormWeights(std::initializer_list<float> f) { + PopulateTensor(cell_layer_norm_weights_, f); + } + + void SetOutputLayerNormWeights(std::initializer_list<float> f) { + PopulateTensor(output_layer_norm_weights_, f); + } + + void SetInputGateBias(std::initializer_list<float> f) { + PopulateTensor(input_gate_bias_, f); + } + + void SetForgetGateBias(std::initializer_list<float> f) { + PopulateTensor(forget_gate_bias_, f); + } + + void SetCellBias(std::initializer_list<float> f) { + PopulateTensor(cell_bias_, f); + } + + void SetOutputGateBias(std::initializer_list<float> f) { + PopulateTensor(output_gate_bias_, f); + } + + void SetProjectionWeights(std::initializer_list<float> f) { + PopulateTensor(projection_weights_, f); + } + + void SetProjectionBias(std::initializer_list<float> f) { + PopulateTensor(projection_bias_, f); + } + + void SetInput(int offset, const float* begin, const float* end) { + PopulateTensor(input_, offset, const_cast<float*>(begin), + const_cast<float*>(end)); + } + + std::vector<float> GetOutput() { return ExtractVector<float>(output_); } + + int num_inputs() { return n_input_; } + int num_outputs() { return n_output_; } + int num_cells() { return n_cell_; } + int num_batches() { return n_batch_; } + + protected: + int input_; + int input_to_input_weights_; + int input_to_forget_weights_; + int input_to_cell_weights_; + int input_to_output_weights_; + + int recurrent_to_input_weights_; + int recurrent_to_forget_weights_; + int recurrent_to_cell_weights_; + int recurrent_to_output_weights_; + + int cell_to_input_weights_; + int cell_to_forget_weights_; + int cell_to_output_weights_; + + int input_layer_norm_weights_; + int forget_layer_norm_weights_; + int cell_layer_norm_weights_; + int output_layer_norm_weights_; + + int input_gate_bias_; + int forget_gate_bias_; + int cell_bias_; + int output_gate_bias_; + + int projection_weights_; + int projection_bias_; + + int output_state_; + int cell_state_; + + int output_; + + int n_batch_; + int n_input_; + int n_cell_; + int n_output_; +}; + +class HybridLayerNormLSTMOpModel : public LayerNormLSTMOpModel { + public: + HybridLayerNormLSTMOpModel(int n_batch, int n_input, int n_cell, int n_output, + bool use_cifg, bool use_peephole, + bool use_projection_weights, + bool use_projection_bias, float cell_clip, + float proj_clip, + const std::vector<std::vector<int>>& input_shapes) + : LayerNormLSTMOpModel(n_batch, n_input, n_cell, n_output, use_cifg, + use_peephole, use_projection_weights, + use_projection_bias, cell_clip, proj_clip, + input_shapes, TensorType_UINT8) {} + + void SetInputToInputWeights(std::initializer_list<float> f) { + SymmetricQuantizeAndPopulate(input_to_input_weights_, f); + } + + void SetInputToForgetWeights(std::initializer_list<float> f) { + SymmetricQuantizeAndPopulate(input_to_forget_weights_, f); + } + + void SetInputToCellWeights(std::initializer_list<float> f) { + SymmetricQuantizeAndPopulate(input_to_cell_weights_, f); + } + + void SetInputToOutputWeights(std::initializer_list<float> f) { + SymmetricQuantizeAndPopulate(input_to_output_weights_, f); + } + + void SetRecurrentToInputWeights(std::initializer_list<float> f) { + SymmetricQuantizeAndPopulate(recurrent_to_input_weights_, f); + } + + void SetRecurrentToForgetWeights(std::initializer_list<float> f) { + SymmetricQuantizeAndPopulate(recurrent_to_forget_weights_, f); + } + + void SetRecurrentToCellWeights(std::initializer_list<float> f) { + SymmetricQuantizeAndPopulate(recurrent_to_cell_weights_, f); + } + + void SetRecurrentToOutputWeights(std::initializer_list<float> f) { + SymmetricQuantizeAndPopulate(recurrent_to_output_weights_, f); + } + + void SetCellToInputWeights(std::initializer_list<float> f) { + SymmetricQuantizeAndPopulate(cell_to_input_weights_, f); + } + + void SetCellToForgetWeights(std::initializer_list<float> f) { + SymmetricQuantizeAndPopulate(cell_to_forget_weights_, f); + } + + void SetCellToOutputWeights(std::initializer_list<float> f) { + SymmetricQuantizeAndPopulate(cell_to_output_weights_, f); + } + + void SetInputLayerNormWeights(std::initializer_list<float> f) { + PopulateTensor(input_layer_norm_weights_, f); + } + + void SetForgetLayerNormWeights(std::initializer_list<float> f) { + PopulateTensor(forget_layer_norm_weights_, f); + } + + void SetCellLayerNormWeights(std::initializer_list<float> f) { + PopulateTensor(cell_layer_norm_weights_, f); + } + + void SetOutputLayerNormWeights(std::initializer_list<float> f) { + PopulateTensor(output_layer_norm_weights_, f); + } + + void SetProjectionWeights(std::initializer_list<float> f) { + SymmetricQuantizeAndPopulate(projection_weights_, f); + } +}; + +class BaseLayerNormLstmTest : public ::testing::Test { + protected: + // Weights of the Layer Norm LSTM model. Some are optional. + std::initializer_list<float> input_to_input_weights_; + std::initializer_list<float> input_to_cell_weights_; + std::initializer_list<float> input_to_forget_weights_; + std::initializer_list<float> input_to_output_weights_; + std::initializer_list<float> input_gate_bias_; + std::initializer_list<float> cell_gate_bias_; + std::initializer_list<float> forget_gate_bias_; + std::initializer_list<float> output_gate_bias_; + std::initializer_list<float> recurrent_to_input_weights_; + std::initializer_list<float> recurrent_to_cell_weights_; + std::initializer_list<float> recurrent_to_forget_weights_; + std::initializer_list<float> recurrent_to_output_weights_; + std::initializer_list<float> cell_to_input_weights_; + std::initializer_list<float> cell_to_forget_weights_; + std::initializer_list<float> cell_to_output_weights_; + std::initializer_list<float> input_layer_norm_weights_; + std::initializer_list<float> forget_layer_norm_weights_; + std::initializer_list<float> cell_layer_norm_weights_; + std::initializer_list<float> output_layer_norm_weights_; + std::initializer_list<float> projection_weights_; + + // Layer Norm LSTM input is stored as num_batch x num_inputs vector. + std::vector<std::vector<float>> layer_norm_lstm_input_; + + // Compares output up to tolerance to the result of the layer_norm_lstm given + // the input. + void VerifyGoldens(const std::vector<std::vector<float>>& input, + const std::vector<std::vector<float>>& output, + LayerNormLSTMOpModel* layer_norm_lstm, + float tolerance = 1e-5) { + const int num_batches = input.size(); + EXPECT_GT(num_batches, 0); + const int num_inputs = layer_norm_lstm->num_inputs(); + EXPECT_GT(num_inputs, 0); + const int input_sequence_size = input[0].size() / num_inputs; + EXPECT_GT(input_sequence_size, 0); + for (int i = 0; i < input_sequence_size; ++i) { + for (int b = 0; b < num_batches; ++b) { + const float* batch_start = input[b].data() + i * num_inputs; + const float* batch_end = batch_start + num_inputs; + + layer_norm_lstm->SetInput(b * layer_norm_lstm->num_inputs(), + batch_start, batch_end); + } + + layer_norm_lstm->Invoke(); + + const int num_outputs = layer_norm_lstm->num_outputs(); + std::vector<float> expected; + for (int b = 0; b < num_batches; ++b) { + const float* golden_start_batch = output[b].data() + i * num_outputs; + const float* golden_end_batch = golden_start_batch + num_outputs; + expected.insert(expected.end(), golden_start_batch, golden_end_batch); + } + EXPECT_THAT(layer_norm_lstm->GetOutput(), + ElementsAreArray(ArrayFloatNear(expected, tolerance))); + } + } +}; + +class NoCifgPeepholeProjectionNoClippingLayerNormLstmTest + : public BaseLayerNormLstmTest { + void SetUp() override { + input_to_input_weights_ = {0.5, 0.6, 0.7, -0.8, -0.9, 0.1, 0.2, + 0.3, -0.4, 0.5, -0.8, 0.7, -0.6, 0.5, + -0.4, -0.5, -0.4, -0.3, -0.2, -0.1}; + + input_to_forget_weights_ = {-0.6, -0.1, 0.3, 0.2, 0.9, -0.5, -0.2, + -0.4, 0.3, -0.8, -0.4, 0.3, -0.5, -0.4, + -0.6, 0.3, -0.4, -0.6, -0.5, -0.5}; + + input_to_cell_weights_ = {-0.4, -0.3, -0.2, -0.1, -0.5, 0.5, -0.2, + -0.3, -0.2, -0.6, 0.6, -0.1, -0.4, -0.3, + -0.7, 0.7, -0.9, -0.5, 0.8, 0.6}; + + input_to_output_weights_ = {-0.8, -0.4, -0.2, -0.9, -0.1, -0.7, 0.3, + -0.3, -0.8, -0.2, 0.6, -0.2, 0.4, -0.7, + -0.3, -0.5, 0.1, 0.5, -0.6, -0.4}; + + input_gate_bias_ = {0.03, 0.15, 0.22, 0.38}; + + forget_gate_bias_ = {0.1, -0.3, -0.2, 0.1}; + + cell_gate_bias_ = {-0.05, 0.72, 0.25, 0.08}; + + output_gate_bias_ = {0.05, -0.01, 0.2, 0.1}; + + recurrent_to_input_weights_ = {-0.2, -0.3, 0.4, 0.1, -0.5, 0.9, + -0.2, -0.3, -0.7, 0.05, -0.2, -0.6}; + + recurrent_to_cell_weights_ = {-0.3, 0.2, 0.1, -0.3, 0.8, -0.08, + -0.2, 0.3, 0.8, -0.6, -0.1, 0.2}; + + recurrent_to_forget_weights_ = {-0.5, -0.3, -0.5, -0.2, 0.6, 0.4, + 0.9, 0.3, -0.1, 0.2, 0.5, 0.2}; + + recurrent_to_output_weights_ = {0.3, -0.1, 0.1, -0.2, -0.5, -0.7, + -0.2, -0.6, -0.1, -0.4, -0.7, -0.2}; + + cell_to_input_weights_ = {0.05, 0.1, 0.25, 0.15}; + + cell_to_forget_weights_ = {-0.02, -0.15, -0.25, -0.03}; + + cell_to_output_weights_ = {0.1, -0.1, -0.5, 0.05}; + + input_layer_norm_weights_ = {0.1, 0.2, 0.3, 0.5}; + forget_layer_norm_weights_ = {0.2, 0.2, 0.4, 0.3}; + cell_layer_norm_weights_ = {0.7, 0.2, 0.3, 0.8}; + output_layer_norm_weights_ = {0.6, 0.2, 0.2, 0.5}; + + projection_weights_ = {-0.1, 0.2, 0.01, -0.2, 0.1, 0.5, + 0.3, 0.08, 0.07, 0.2, -0.4, 0.2}; + + layer_norm_lstm_input_ = { + {// Batch0: 3 (input_sequence_size) * 5 (n_input) + 0.7, 0.8, 0.1, 0.2, 0.3, // seq 0 + 0.8, 0.1, 0.2, 0.4, 0.5, // seq 1 + 0.2, 0.7, 0.7, 0.1, 0.7}, // seq 2 + + {// Batch1: 3 (input_sequence_size) * 5 (n_input) + 0.3, 0.2, 0.9, 0.8, 0.1, // seq 0 + 0.1, 0.5, 0.2, 0.4, 0.2, // seq 1 + 0.6, 0.9, 0.2, 0.5, 0.7}, // seq 2 + }; + } +}; + +TEST_F(NoCifgPeepholeProjectionNoClippingLayerNormLstmTest, + LayerNormLstmBlackBoxTest) { + const int n_batch = 2; + const int n_input = 5; + const int n_cell = 4; + const int n_output = 3; + const float ceil_clip = 0.0; + const float proj_clip = 0.0; + + LayerNormLSTMOpModel layer_norm_lstm( + n_batch, n_input, n_cell, n_output, + /*use_cifg=*/false, /*use_peephole=*/true, + /*use_projection_weights=*/true, + /*use_projection_bias=*/false, ceil_clip, proj_clip, + { + {n_batch, n_input}, // input tensor + + {n_cell, n_input}, // input_to_input_weight tensor + {n_cell, n_input}, // input_to_forget_weight tensor + {n_cell, n_input}, // input_to_cell_weight tensor + {n_cell, n_input}, // input_to_output_weight tensor + + {n_cell, n_output}, // recurrent_to_input_weight tensor + {n_cell, n_output}, // recurrent_to_forget_weight tensor + {n_cell, n_output}, // recurrent_to_cell_weight tensor + {n_cell, n_output}, // recurrent_to_output_weight tensor + + {n_cell}, // cell_to_input_weight tensor + {n_cell}, // cell_to_forget_weight tensor + {n_cell}, // cell_to_output_weight tensor + + {n_cell}, // input_layer_norm_weight tensor + {n_cell}, // forget_layer_norm_weight tensor + {n_cell}, // cell_layer_norm_weight tensor + {n_cell}, // output_layer_norm_weight tensor + + {n_cell}, // input_gate_bias tensor + {n_cell}, // forget_gate_bias tensor + {n_cell}, // cell_bias tensor + {n_cell}, // output_gate_bias tensor + + {n_output, n_cell}, // projection_weight tensor + {0}, // projection_bias tensor + }); + + layer_norm_lstm.SetInputToInputWeights(input_to_input_weights_); + layer_norm_lstm.SetInputToCellWeights(input_to_cell_weights_); + layer_norm_lstm.SetInputToForgetWeights(input_to_forget_weights_); + layer_norm_lstm.SetInputToOutputWeights(input_to_output_weights_); + + layer_norm_lstm.SetInputGateBias(input_gate_bias_); + layer_norm_lstm.SetCellBias(cell_gate_bias_); + layer_norm_lstm.SetForgetGateBias(forget_gate_bias_); + layer_norm_lstm.SetOutputGateBias(output_gate_bias_); + + layer_norm_lstm.SetRecurrentToInputWeights(recurrent_to_input_weights_); + layer_norm_lstm.SetRecurrentToCellWeights(recurrent_to_cell_weights_); + layer_norm_lstm.SetRecurrentToForgetWeights(recurrent_to_forget_weights_); + layer_norm_lstm.SetRecurrentToOutputWeights(recurrent_to_output_weights_); + + layer_norm_lstm.SetCellToInputWeights(cell_to_input_weights_); + layer_norm_lstm.SetCellToForgetWeights(cell_to_forget_weights_); + layer_norm_lstm.SetCellToOutputWeights(cell_to_output_weights_); + + layer_norm_lstm.SetInputLayerNormWeights(input_layer_norm_weights_); + layer_norm_lstm.SetForgetLayerNormWeights(forget_layer_norm_weights_); + layer_norm_lstm.SetCellLayerNormWeights(cell_layer_norm_weights_); + layer_norm_lstm.SetOutputLayerNormWeights(output_layer_norm_weights_); + + layer_norm_lstm.SetProjectionWeights(projection_weights_); + + // Verify the final output. + const std::vector<std::vector<float>> layer_norm_lstm_golden_output = { + { + // Batch0: 3 (input_sequence_size) * 3 (n_output) + 0.0244077, 0.128027, -0.00170918, // seq 0 + 0.0137642, 0.140751, 0.0395835, // seq 1 + -0.00459231, 0.155278, 0.0837377, // seq 2 + }, + { + // Batch1: 3 (input_sequence_size) * 3 (n_output) + -0.00692428, 0.0848741, 0.063445, // seq 0 + -0.00403912, 0.139963, 0.072681, // seq 1 + 0.00752706, 0.161903, 0.0561371, // seq 2 + }}; + + VerifyGoldens(layer_norm_lstm_input_, layer_norm_lstm_golden_output, + &layer_norm_lstm); +} + +TEST_F(NoCifgPeepholeProjectionNoClippingLayerNormLstmTest, + HybridLayerNormLstmBlackBoxTest) { + const int n_batch = 2; + const int n_input = 5; + const int n_cell = 4; + const int n_output = 3; + const float ceil_clip = 0.0; + const float proj_clip = 0.0; + + HybridLayerNormLSTMOpModel layer_norm_lstm( + n_batch, n_input, n_cell, n_output, + /*use_cifg=*/false, /*use_peephole=*/true, + /*use_projection_weights=*/true, + /*use_projection_bias=*/false, ceil_clip, proj_clip, + { + {n_batch, n_input}, // input tensor + + {n_cell, n_input}, // input_to_input_weight tensor + {n_cell, n_input}, // input_to_forget_weight tensor + {n_cell, n_input}, // input_to_cell_weight tensor + {n_cell, n_input}, // input_to_output_weight tensor + + {n_cell, n_output}, // recurrent_to_input_weight tensor + {n_cell, n_output}, // recurrent_to_forget_weight tensor + {n_cell, n_output}, // recurrent_to_cell_weight tensor + {n_cell, n_output}, // recurrent_to_output_weight tensor + + {n_cell}, // cell_to_input_weight tensor + {n_cell}, // cell_to_forget_weight tensor + {n_cell}, // cell_to_output_weight tensor + + {n_cell}, // input_layer_norm_weight tensor + {n_cell}, // forget_layer_norm_weight tensor + {n_cell}, // cell_layer_norm_weight tensor + {n_cell}, // output_layer_norm_weight tensor + + {n_cell}, // input_gate_bias tensor + {n_cell}, // forget_gate_bias tensor + {n_cell}, // cell_bias tensor + {n_cell}, // output_gate_bias tensor + + {n_output, n_cell}, // projection_weight tensor + {0}, // projection_bias tensor + }); + + layer_norm_lstm.SetInputToInputWeights(input_to_input_weights_); + layer_norm_lstm.SetInputToCellWeights(input_to_cell_weights_); + layer_norm_lstm.SetInputToForgetWeights(input_to_forget_weights_); + layer_norm_lstm.SetInputToOutputWeights(input_to_output_weights_); + + layer_norm_lstm.SetInputGateBias(input_gate_bias_); + layer_norm_lstm.SetCellBias(cell_gate_bias_); + layer_norm_lstm.SetForgetGateBias(forget_gate_bias_); + layer_norm_lstm.SetOutputGateBias(output_gate_bias_); + + layer_norm_lstm.SetRecurrentToInputWeights(recurrent_to_input_weights_); + layer_norm_lstm.SetRecurrentToCellWeights(recurrent_to_cell_weights_); + layer_norm_lstm.SetRecurrentToForgetWeights(recurrent_to_forget_weights_); + layer_norm_lstm.SetRecurrentToOutputWeights(recurrent_to_output_weights_); + + layer_norm_lstm.SetCellToInputWeights(cell_to_input_weights_); + layer_norm_lstm.SetCellToForgetWeights(cell_to_forget_weights_); + layer_norm_lstm.SetCellToOutputWeights(cell_to_output_weights_); + + layer_norm_lstm.SetInputLayerNormWeights(input_layer_norm_weights_); + layer_norm_lstm.SetForgetLayerNormWeights(forget_layer_norm_weights_); + layer_norm_lstm.SetCellLayerNormWeights(cell_layer_norm_weights_); + layer_norm_lstm.SetOutputLayerNormWeights(output_layer_norm_weights_); + + layer_norm_lstm.SetProjectionWeights(projection_weights_); + + const std::vector<std::vector<float>> layer_norm_lstm_golden_output = { + { + // Batch0: 3 (input_sequence_size) * 3 (n_output) + 0.0244576, 0.127847, -0.00181765, // seq 0 + 0.0137518, 0.140892, 0.0402234, // seq 1 + -0.0048839, 0.155096, 0.0840309, // seq 2 + }, + { + // Batch1: 3 (input_sequence_size) * 3 (n_output) + -0.00728636, 0.0843957, 0.0634786, // seq 0 + -0.00448382, 0.139278, 0.0737372, // seq 1 + 0.00734616, 0.161793, 0.0560238, // seq 2 + }}; + + VerifyGoldens(layer_norm_lstm_input_, layer_norm_lstm_golden_output, + &layer_norm_lstm); +} + +} // namespace +} // namespace custom +} // namespace ops +} // namespace tflite + +int main(int argc, char** argv) { + ::tflite::LogToStderr(); + ::testing::InitGoogleTest(&argc, argv); + return RUN_ALL_TESTS(); +} diff --git a/tensorflow/contrib/lite/kernels/pad.cc b/tensorflow/contrib/lite/kernels/pad.cc index 55bcf3b533..3bce05353d 100644 --- a/tensorflow/contrib/lite/kernels/pad.cc +++ b/tensorflow/contrib/lite/kernels/pad.cc @@ -92,8 +92,8 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { op_context.constant_values->type); } - // TODO(nupurgarg): Our current implementations rely on the inputs being 4D. - TF_LITE_ENSURE_EQ(context, op_context.dims, 4); + // TODO(nupurgarg): Current implementations rely on the inputs being <= 4D. + TF_LITE_ENSURE(context, op_context.dims <= 4); // Exit early if paddings is a non-const tensor. Set output tensor to // dynamic so output size can be determined in Eval. @@ -134,21 +134,21 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { after_padding.push_back(paddings_data[idx * 2 + 1]); } -#define TF_LITE_PAD(type, scalar, pad_value) \ - TF_LITE_ENSURE_EQ(context, before_padding.size(), 4); \ - TF_LITE_ENSURE_EQ(context, after_padding.size(), 4); \ - tflite::PadParams op_params; \ - op_params.left_padding_count = 4; \ - op_params.right_padding_count = 4; \ - for (int i = 0; i < 4; ++i) { \ - op_params.left_padding[i] = before_padding[3 - i]; \ - op_params.right_padding[i] = after_padding[3 - i]; \ - } \ - const scalar pad_value_copy = pad_value; \ - \ - type::Pad(op_params, GetTensorShape(op_context.input), \ - GetTensorData<scalar>(op_context.input), &pad_value_copy, \ - GetTensorShape(op_context.output), \ +#define TF_LITE_PAD(type, scalar, pad_value) \ + TF_LITE_ENSURE(context, before_padding.size() <= 4); \ + TF_LITE_ENSURE(context, after_padding.size() <= 4); \ + tflite::PadParams op_params; \ + op_params.left_padding_count = before_padding.size(); \ + op_params.right_padding_count = after_padding.size(); \ + for (int i = 0; i < op_context.dims; ++i) { \ + op_params.left_padding[i] = before_padding[op_context.dims - 1 - i]; \ + op_params.right_padding[i] = after_padding[op_context.dims - 1 - i]; \ + } \ + const scalar pad_value_copy = pad_value; \ + \ + type::Pad(op_params, GetTensorShape(op_context.input), \ + GetTensorData<scalar>(op_context.input), &pad_value_copy, \ + GetTensorShape(op_context.output), \ GetTensorData<scalar>(op_context.output)) switch (op_context.input->type) { case kTfLiteFloat32: { diff --git a/tensorflow/contrib/lite/kernels/pad_test.cc b/tensorflow/contrib/lite/kernels/pad_test.cc index f8b9064fbb..f663899713 100644 --- a/tensorflow/contrib/lite/kernels/pad_test.cc +++ b/tensorflow/contrib/lite/kernels/pad_test.cc @@ -193,7 +193,7 @@ TEST(PadOpTest, TooManyDimensions) { PadOpConstModel({TensorType_FLOAT32, {1, 2, 3, 4, 5, 6, 7, 8, 9}}, {9, 2}, {1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 6, 6, 7, 7, 8, 8, 9, 9}, {TensorType_FLOAT32}), - "dims != 4"); + "dims <= 4"); } TEST(PadOpTest, UnequalDimensions) { @@ -221,6 +221,15 @@ TEST(PadOpTest, SimpleConstTest) { EXPECT_THAT(m.GetOutputShape(), ElementsAreArray({1, 4, 4, 1})); } +TEST(PadOpTest, SimpleConst1DTest) { + PadOpConstModel m({TensorType_FLOAT32, {2}}, {1, 2}, {1, 2}, + {TensorType_FLOAT32}); + m.SetInput({2, 3}); + m.Invoke(); + EXPECT_THAT(m.GetOutput(), ElementsAreArray({0, 2, 3, 0, 0})); + EXPECT_THAT(m.GetOutputShape(), ElementsAreArray({5})); +} + TEST(PadOpTest, SimpleDynamicTest) { PadOpDynamicModel m({TensorType_FLOAT32, {1, 2, 2, 1}}, {4, 2}, {TensorType_FLOAT32}); @@ -334,7 +343,7 @@ TEST(PadV2OpTest, TooManyDimensions) { {TensorType_FLOAT32, {1, 2, 3, 4, 5, 6, 7, 8, 9}}, {9, 2}, {1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 6, 6, 7, 7, 8, 8, 9, 9}, 0.0, {TensorType_FLOAT32}), - "dims != 4"); + "dims <= 4"); } TEST(PadV2OpTest, UnequalDimensions) { diff --git a/tensorflow/contrib/lite/kernels/register.cc b/tensorflow/contrib/lite/kernels/register.cc index 7b859dc332..c66959fdf4 100644 --- a/tensorflow/contrib/lite/kernels/register.cc +++ b/tensorflow/contrib/lite/kernels/register.cc @@ -22,8 +22,10 @@ namespace ops { namespace custom { TfLiteRegistration* Register_AUDIO_SPECTROGRAM(); +TfLiteRegistration* Register_LAYER_NORM_LSTM(); TfLiteRegistration* Register_MFCC(); TfLiteRegistration* Register_DETECTION_POSTPROCESS(); +TfLiteRegistration* Register_RELU_1(); } // namespace custom @@ -247,6 +249,8 @@ BuiltinOpResolver::BuiltinOpResolver() { AddCustom("Mfcc", tflite::ops::custom::Register_MFCC()); AddCustom("AudioSpectrogram", tflite::ops::custom::Register_AUDIO_SPECTROGRAM()); + AddCustom("LayerNormLstm", tflite::ops::custom::Register_LAYER_NORM_LSTM()); + AddCustom("Relu1", tflite::ops::custom::Register_RELU_1()); AddCustom("TFLite_Detection_PostProcess", tflite::ops::custom::Register_DETECTION_POSTPROCESS()); } diff --git a/tensorflow/contrib/lite/kernels/relu1.cc b/tensorflow/contrib/lite/kernels/relu1.cc new file mode 100644 index 0000000000..abafee2d57 --- /dev/null +++ b/tensorflow/contrib/lite/kernels/relu1.cc @@ -0,0 +1,59 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ +#include "tensorflow/contrib/lite/context.h" +#include "tensorflow/contrib/lite/kernels/internal/tensor.h" +#include "tensorflow/contrib/lite/kernels/kernel_util.h" + +namespace tflite { +namespace ops { +namespace custom { +namespace relu1 { + +TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { + TF_LITE_ENSURE_EQ(context, NumInputs(node), 1); + TF_LITE_ENSURE_EQ(context, NumOutputs(node), 1); + const TfLiteTensor* input = GetInput(context, node, 0); + TF_LITE_ENSURE_EQ(context, input->type, kTfLiteFloat32); + TfLiteTensor* output = GetOutput(context, node, 0); + output->type = input->type; + return context->ResizeTensor(context, output, + TfLiteIntArrayCopy(input->dims)); +} + +// This is derived from lite/kernels/activations.cc. +TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { + const TfLiteTensor* input = GetInput(context, node, 0); + TfLiteTensor* output = GetOutput(context, node, 0); + const int elements = NumElements(input); + const float* in = input->data.f; + const float* in_end = in + elements; + float* out = output->data.f; + for (; in < in_end; ++in, ++out) { + *out = std::min(std::max(0.f, *in), 1.f); + } + return kTfLiteOk; +} + +} // namespace relu1 + +TfLiteRegistration* Register_RELU_1() { + static TfLiteRegistration r = {/*init=*/nullptr, /*free=*/nullptr, + relu1::Prepare, relu1::Eval}; + return &r; +} + +} // namespace custom +} // namespace ops +} // namespace tflite diff --git a/tensorflow/contrib/lite/kernels/relu1_test.cc b/tensorflow/contrib/lite/kernels/relu1_test.cc new file mode 100644 index 0000000000..c1e0149c20 --- /dev/null +++ b/tensorflow/contrib/lite/kernels/relu1_test.cc @@ -0,0 +1,79 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ +#include <gtest/gtest.h> +#include "flatbuffers/flexbuffers.h" // flatbuffers +#include "tensorflow/contrib/lite/kernels/register.h" +#include "tensorflow/contrib/lite/kernels/test_util.h" + +namespace tflite { +namespace ops { +namespace custom { + +TfLiteRegistration* Register_RELU_1(); + +namespace { + +using ::testing::ElementsAreArray; + +class BaseActivationsOpModel : public SingleOpModel { + public: + explicit BaseActivationsOpModel(const TensorData& input) { + input_ = AddInput(input); + output_ = AddOutput({input.type, {}}); + flexbuffers::Builder fbb; + fbb.Map([&]() {}); + fbb.Finish(); + SetCustomOp("RELU_1", fbb.GetBuffer(), Register_RELU_1); + BuildInterpreter({GetShape(input_)}); + } + + protected: + int input_; + int output_; +}; + +class FloatActivationsOpModel : public BaseActivationsOpModel { + public: + using BaseActivationsOpModel::BaseActivationsOpModel; + + void SetInput(std::initializer_list<float> data) { + PopulateTensor(input_, data); + } + std::vector<float> GetOutput() { return ExtractVector<float>(output_); } +}; + +TEST(FloatActivationsOpTest, Relu1) { + FloatActivationsOpModel m(/*input=*/{TensorType_FLOAT32, {1, 2, 4, 1}}); + m.SetInput({ + 0.0, -0.6, 0.2, -0.4, // + 0.3, -2.0, 1.1, -0.1, // + }); + m.Invoke(); + EXPECT_THAT(m.GetOutput(), ElementsAreArray({ + 0.0, 0.0, 0.2, 0.0, // + 0.3, 0.0, 1.0, 0.0, // + })); +} + +} // namespace +} // namespace custom +} // namespace ops +} // namespace tflite + +int main(int argc, char** argv) { + ::tflite::LogToStderr(); + ::testing::InitGoogleTest(&argc, argv); + return RUN_ALL_TESTS(); +} diff --git a/tensorflow/contrib/lite/kernels/unidirectional_sequence_lstm.cc b/tensorflow/contrib/lite/kernels/unidirectional_sequence_lstm.cc index 0acd705950..c678f14930 100644 --- a/tensorflow/contrib/lite/kernels/unidirectional_sequence_lstm.cc +++ b/tensorflow/contrib/lite/kernels/unidirectional_sequence_lstm.cc @@ -64,10 +64,14 @@ constexpr int kProjectionWeightsTensor = 16; // Optional // Projection bias tensor of size {n_output} constexpr int kProjectionBiasTensor = 17; // Optional +// Stateful input tensors that are variables and will be modified by the Op. +// Activation state tensor of size {n_batch, n_output} +constexpr int kInputActivationStateTensor = 18; +// Cell state tensor of size {n_batch, n_cell} +constexpr int kInputCellStateTensor = 19; + // Output tensors. -constexpr int kOutputStateTensor = 0; -constexpr int kCellStateTensor = 1; -constexpr int kOutputTensor = 2; +constexpr int kOutputTensor = 0; // Temporary tensors enum TemporaryTensor { @@ -82,7 +86,7 @@ enum TemporaryTensor { }; void* Init(TfLiteContext* context, const char* buffer, size_t length) { - auto* scratch_tensor_index = new int; + auto* scratch_tensor_index = new int(); context->AddTensors(context, kNumTemporaryTensors, scratch_tensor_index); return scratch_tensor_index; } @@ -247,8 +251,8 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { int* scratch_tensor_index = reinterpret_cast<int*>(node->user_data); // Check we have all the inputs and outputs we need. - TF_LITE_ENSURE_EQ(context, node->inputs->size, 18); - TF_LITE_ENSURE_EQ(context, node->outputs->size, 3); + TF_LITE_ENSURE_EQ(context, node->inputs->size, 20); + TF_LITE_ENSURE_EQ(context, node->outputs->size, 1); // Inferring batch size, number of outputs and sequence length and // number of cells from the input tensors. @@ -276,12 +280,21 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { TF_LITE_ENSURE_OK(context, CheckInputTensorDimensions(context, node, n_input, n_output, n_cell)); - // Get the pointer to output, output_state and cell_state buffer tensors. + // Get the pointer to output, activation_state and cell_state buffer tensors. TfLiteTensor* output = GetOutput(context, node, kOutputTensor); - TfLiteTensor* output_state = GetOutput(context, node, kOutputStateTensor); - TfLiteTensor* cell_state = GetOutput(context, node, kCellStateTensor); - // Resize the output, output_state and cell_state tensors. + TfLiteTensor* activation_state = + GetVariableInput(context, node, kInputActivationStateTensor); + TfLiteTensor* cell_state = + GetVariableInput(context, node, kInputCellStateTensor); + + // Check the shape of input state tensors. + // These tensor may be 1D or 2D. It's fine as long as the total size is + // correct. + TF_LITE_ENSURE_EQ(context, NumElements(activation_state), n_batch * n_output); + TF_LITE_ENSURE_EQ(context, NumElements(cell_state), n_batch * n_cell); + + // Resize the output tensors. TfLiteIntArray* output_size = TfLiteIntArrayCreate(3); output_size->data[0] = max_time; output_size->data[1] = n_batch; @@ -289,22 +302,6 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { TF_LITE_ENSURE_OK(context, context->ResizeTensor(context, output, output_size)); - TfLiteIntArray* output_state_size = TfLiteIntArrayCreate(2); - output_state_size->data[0] = n_batch; - output_state_size->data[1] = n_output; - TF_LITE_ENSURE_OK( - context, context->ResizeTensor(context, output_state, output_state_size)); - - TfLiteIntArray* cell_size = TfLiteIntArrayCreate(2); - cell_size->data[0] = n_batch; - cell_size->data[1] = n_cell; - TF_LITE_ENSURE_OK(context, - context->ResizeTensor(context, cell_state, cell_size)); - - // Mark state tensors as persistent tensors. - output_state->allocation_type = kTfLiteArenaRwPersistent; - cell_state->allocation_type = kTfLiteArenaRwPersistent; - // The weights are of consistent type, so it suffices to check one. // TODO(mirkov): create a utility/macro for this check, so all Ops can use it. const bool is_hybrid_op = (input_to_output_weights->type == kTfLiteUInt8 && @@ -340,7 +337,7 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { if (is_hybrid_op) { // Allocate temporary tensors to store quantized values of input, - // output_state and cell_state tensors. + // activation_state and cell_state tensors. node->temporaries->data[kInputQuantized] = *scratch_tensor_index + kInputQuantized; TfLiteTensor* input_quantized = @@ -354,17 +351,17 @@ TfLiteStatus Prepare(TfLiteContext* context, TfLiteNode* node) { } node->temporaries->data[kOutputStateQuantized] = *scratch_tensor_index + kOutputStateQuantized; - TfLiteTensor* output_state_quantized = + TfLiteTensor* activation_state_quantized = GetTemporary(context, node, kOutputStateQuantized); - output_state_quantized->type = kTfLiteUInt8; - output_state_quantized->allocation_type = kTfLiteArenaRw; - if (!TfLiteIntArrayEqual(output_state_quantized->dims, - output_state->dims)) { - TfLiteIntArray* output_state_quantized_size = - TfLiteIntArrayCopy(output_state->dims); - TF_LITE_ENSURE_OK(context, - context->ResizeTensor(context, output_state_quantized, - output_state_quantized_size)); + activation_state_quantized->type = kTfLiteUInt8; + activation_state_quantized->allocation_type = kTfLiteArenaRw; + if (!TfLiteIntArrayEqual(activation_state_quantized->dims, + activation_state->dims)) { + TfLiteIntArray* activation_state_quantized_size = + TfLiteIntArrayCopy(activation_state->dims); + TF_LITE_ENSURE_OK( + context, context->ResizeTensor(context, activation_state_quantized, + activation_state_quantized_size)); } node->temporaries->data[kCellStateQuantized] = *scratch_tensor_index + kCellStateQuantized; @@ -449,7 +446,7 @@ TfLiteStatus EvalFloat( const TfLiteTensor* cell_bias, const TfLiteTensor* output_gate_bias, const TfLiteTensor* projection_weights, const TfLiteTensor* projection_bias, const TfLiteLSTMParams* params, TfLiteTensor* scratch_buffer, - TfLiteTensor* output_state, TfLiteTensor* cell_state, + TfLiteTensor* activation_state, TfLiteTensor* cell_state, TfLiteTensor* output) { const int max_time = input->dims->data[0]; const int n_batch = input->dims->data[1]; @@ -510,7 +507,7 @@ TfLiteStatus EvalFloat( const float* cell_bias_ptr = cell_bias->data.f; const float* output_gate_bias_ptr = output_gate_bias->data.f; - float* output_state_ptr = output_state->data.f; + float* activation_state_ptr = activation_state->data.f; float* cell_state_ptr = cell_state->data.f; // Feed the sequence into the LSTM step-by-step. @@ -527,7 +524,7 @@ TfLiteStatus EvalFloat( cell_to_forget_weights_ptr, cell_to_output_weights_ptr, input_gate_bias_ptr, forget_gate_bias_ptr, cell_bias_ptr, output_gate_bias_ptr, projection_weights_ptr, projection_bias_ptr, - params, n_batch, n_cell, n_input, n_output, output_state_ptr, + params, n_batch, n_cell, n_input, n_output, activation_state_ptr, cell_state_ptr, input_gate_scratch, forget_gate_scratch, cell_scratch, output_gate_scratch, output_ptr_batch); } @@ -552,9 +549,9 @@ TfLiteStatus EvalHybrid( const TfLiteLSTMParams* params, TfLiteTensor* scratch_buffer, TfLiteTensor* scaling_factors, TfLiteTensor* prod_scaling_factors, TfLiteTensor* recovered_cell_weights, TfLiteTensor* input_quantized, - TfLiteTensor* output_state_quantized, TfLiteTensor* cell_state_quantized, - TfLiteTensor* output_state, TfLiteTensor* cell_state, - TfLiteTensor* output) { + TfLiteTensor* activation_state_quantized, + TfLiteTensor* cell_state_quantized, TfLiteTensor* activation_state, + TfLiteTensor* cell_state, TfLiteTensor* output) { const int max_time = input->dims->data[0]; const int n_batch = input->dims->data[1]; const int n_input = input->dims->data[2]; @@ -655,14 +652,14 @@ TfLiteStatus EvalHybrid( const float* cell_bias_ptr = cell_bias->data.f; const float* output_gate_bias_ptr = output_gate_bias->data.f; - float* output_state_ptr = output_state->data.f; + float* activation_state_ptr = activation_state->data.f; float* cell_state_ptr = cell_state->data.f; // Temporary storage for quantized values and scaling factors. int8_t* quantized_input_ptr = reinterpret_cast<int8_t*>(input_quantized->data.uint8); - int8_t* quantized_output_state_ptr = - reinterpret_cast<int8_t*>(output_state_quantized->data.uint8); + int8_t* quantized_activation_state_ptr = + reinterpret_cast<int8_t*>(activation_state_quantized->data.uint8); int8_t* quantized_cell_state_ptr = reinterpret_cast<int8_t*>(cell_state_quantized->data.uint8); float* scaling_factors_ptr = scaling_factors->data.f; @@ -692,8 +689,8 @@ TfLiteStatus EvalHybrid( n_input, n_output, input_gate_scratch, forget_gate_scratch, cell_scratch, output_gate_scratch, scaling_factors_ptr, prod_scaling_factors_ptr, recovered_cell_weights_ptr, - quantized_input_ptr, quantized_output_state_ptr, - quantized_cell_state_ptr, output_state_ptr, cell_state_ptr, + quantized_input_ptr, quantized_activation_state_ptr, + quantized_cell_state_ptr, activation_state_ptr, cell_state_ptr, output_ptr_batch); } return kTfLiteOk; @@ -744,8 +741,11 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { // Index the scratch buffers pointers to the global scratch buffer. TfLiteTensor* scratch_buffer = GetTemporary(context, node, /*index=*/0); - TfLiteTensor* output_state = GetOutput(context, node, kOutputStateTensor); - TfLiteTensor* cell_state = GetOutput(context, node, kCellStateTensor); + TfLiteTensor* activation_state = + GetVariableInput(context, node, kInputActivationStateTensor); + TfLiteTensor* cell_state = + GetVariableInput(context, node, kInputCellStateTensor); + TfLiteTensor* output = GetOutput(context, node, kOutputTensor); switch (input_to_output_weights->type) { @@ -758,11 +758,11 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { cell_to_output_weights, input_gate_bias, forget_gate_bias, cell_bias, output_gate_bias, projection_weights, projection_bias, params, - scratch_buffer, output_state, cell_state, output); + scratch_buffer, activation_state, cell_state, output); } case kTfLiteUInt8: { TfLiteTensor* input_quantized = GetTemporary(context, node, /*index=*/1); - TfLiteTensor* output_state_quantized = + TfLiteTensor* activation_state_quantized = GetTemporary(context, node, /*index=*/2); TfLiteTensor* cell_state_quantized = GetTemporary(context, node, /*index=*/3); @@ -780,8 +780,8 @@ TfLiteStatus Eval(TfLiteContext* context, TfLiteNode* node) { input_gate_bias, forget_gate_bias, cell_bias, output_gate_bias, projection_weights, projection_bias, params, scratch_buffer, scaling_factors, prod_scaling_factors, recovered_cell_weights, - input_quantized, output_state_quantized, cell_state_quantized, - output_state, cell_state, output); + input_quantized, activation_state_quantized, cell_state_quantized, + activation_state, cell_state, output); } default: context->ReportError(context, "Type %d is not currently supported.", diff --git a/tensorflow/contrib/lite/kernels/unidirectional_sequence_lstm_test.cc b/tensorflow/contrib/lite/kernels/unidirectional_sequence_lstm_test.cc index de38bdef6f..cd3aac0532 100644 --- a/tensorflow/contrib/lite/kernels/unidirectional_sequence_lstm_test.cc +++ b/tensorflow/contrib/lite/kernels/unidirectional_sequence_lstm_test.cc @@ -100,8 +100,14 @@ class UnidirectionalLSTMOpModel : public SingleOpModel { projection_bias_ = AddNullInput(); } - output_state_ = AddOutput(TensorType_FLOAT32); - cell_state_ = AddOutput(TensorType_FLOAT32); + // Adding the 2 input state tensors. + input_activation_state_ = + AddInput(TensorData{TensorType_FLOAT32, {n_output_ * n_batch_}}, + /*is_variable=*/true); + input_cell_state_ = + AddInput(TensorData{TensorType_FLOAT32, {n_cell_ * n_batch_}}, + /*is_variable=*/true); + output_ = AddOutput(TensorType_FLOAT32); SetBuiltinOp(BuiltinOperator_UNIDIRECTIONAL_SEQUENCE_LSTM, @@ -180,22 +186,6 @@ class UnidirectionalLSTMOpModel : public SingleOpModel { PopulateTensor(projection_bias_, f); } - void ResetOutputState() { - const int zero_buffer_size = n_cell_ * n_batch_; - std::unique_ptr<float[]> zero_buffer(new float[zero_buffer_size]); - memset(zero_buffer.get(), 0, zero_buffer_size * sizeof(float)); - PopulateTensor(output_state_, 0, zero_buffer.get(), - zero_buffer.get() + zero_buffer_size); - } - - void ResetCellState() { - const int zero_buffer_size = n_cell_ * n_batch_; - std::unique_ptr<float[]> zero_buffer(new float[zero_buffer_size]); - memset(zero_buffer.get(), 0, zero_buffer_size * sizeof(float)); - PopulateTensor(cell_state_, 0, zero_buffer.get(), - zero_buffer.get() + zero_buffer_size); - } - void SetInput(int offset, const float* begin, const float* end) { PopulateTensor(input_, offset, const_cast<float*>(begin), const_cast<float*>(end)); @@ -233,9 +223,10 @@ class UnidirectionalLSTMOpModel : public SingleOpModel { int projection_weights_; int projection_bias_; + int input_activation_state_; + int input_cell_state_; + int output_; - int output_state_; - int cell_state_; int n_batch_; int n_input_; @@ -458,6 +449,9 @@ TEST_F(NoCifgNoPeepholeNoProjectionNoClippingLstmTest, LstmBlackBoxTest) { {0, 0}, // projection_weight tensor {0}, // projection_bias tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor }); lstm.SetInputToInputWeights(input_to_input_weights_); @@ -475,10 +469,6 @@ TEST_F(NoCifgNoPeepholeNoProjectionNoClippingLstmTest, LstmBlackBoxTest) { lstm.SetRecurrentToForgetWeights(recurrent_to_forget_weights_); lstm.SetRecurrentToOutputWeights(recurrent_to_output_weights_); - // Resetting cell_state and output_state - lstm.ResetCellState(); - lstm.ResetOutputState(); - VerifyGoldens(lstm_input_, lstm_golden_output_, &lstm); } @@ -519,6 +509,9 @@ TEST_F(NoCifgNoPeepholeNoProjectionNoClippingLstmTest, HybridLstmBlackBoxTest) { {0, 0}, // projection_weight tensor {0}, // projection_bias tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor }); lstm.SetInputToInputWeights(input_to_input_weights_); @@ -536,10 +529,6 @@ TEST_F(NoCifgNoPeepholeNoProjectionNoClippingLstmTest, HybridLstmBlackBoxTest) { lstm.SetRecurrentToForgetWeights(recurrent_to_forget_weights_); lstm.SetRecurrentToOutputWeights(recurrent_to_output_weights_); - // Resetting cell_state and output_state - lstm.ResetCellState(); - lstm.ResetOutputState(); - VerifyGoldens(lstm_input_, lstm_golden_output_, &lstm, /*tolerance=*/0.0157651); } @@ -629,6 +618,9 @@ TEST_F(CifgPeepholeNoProjectionNoClippingLstmTest, LstmBlackBoxTest) { {0, 0}, // projection_weight tensor {0}, // projection_bias tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor }); lstm.SetInputToCellWeights(input_to_cell_weights_); @@ -646,10 +638,6 @@ TEST_F(CifgPeepholeNoProjectionNoClippingLstmTest, LstmBlackBoxTest) { lstm.SetCellToForgetWeights(cell_to_forget_weights_); lstm.SetCellToOutputWeights(cell_to_output_weights_); - // Resetting cell_state and output_state - lstm.ResetCellState(); - lstm.ResetOutputState(); - VerifyGoldens(lstm_input_, lstm_golden_output_, &lstm); } @@ -691,6 +679,9 @@ TEST_F(CifgPeepholeNoProjectionNoClippingLstmTest, HybridLstmBlackBoxTest) { {0, 0}, // projection_weight tensor {0}, // projection_bias tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor }); lstm.SetInputToCellWeights(input_to_cell_weights_); @@ -708,10 +699,6 @@ TEST_F(CifgPeepholeNoProjectionNoClippingLstmTest, HybridLstmBlackBoxTest) { lstm.SetCellToForgetWeights(cell_to_forget_weights_); lstm.SetCellToOutputWeights(cell_to_output_weights_); - // Resetting cell_state and output_state - lstm.ResetCellState(); - lstm.ResetOutputState(); - VerifyGoldens(lstm_input_, lstm_golden_output_, &lstm, /*tolerance=*/0.03573); } @@ -1351,6 +1338,9 @@ TEST_F(NoCifgPeepholeProjectionClippingLstmTest, LstmBlackBoxTest) { {n_output, n_cell}, // projection_weight tensor {0}, // projection_bias tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor }); lstm.SetInputToInputWeights(input_to_input_weights_); @@ -1374,10 +1364,6 @@ TEST_F(NoCifgPeepholeProjectionClippingLstmTest, LstmBlackBoxTest) { lstm.SetProjectionWeights(projection_weights_); - // Resetting cell_state and output_state - lstm.ResetCellState(); - lstm.ResetOutputState(); - VerifyGoldens(lstm_input_, lstm_golden_output_, &lstm); } @@ -1418,6 +1404,9 @@ TEST_F(NoCifgPeepholeProjectionClippingLstmTest, HybridLstmBlackBoxTest) { {n_output, n_cell}, // projection_weight tensor {0}, // projection_bias tensor + + {n_batch, n_output}, // activation_state tensor + {n_batch, n_cell}, // cell_state tensor }); lstm.SetInputToInputWeights(input_to_input_weights_); @@ -1441,10 +1430,6 @@ TEST_F(NoCifgPeepholeProjectionClippingLstmTest, HybridLstmBlackBoxTest) { lstm.SetProjectionWeights(projection_weights_); - // Resetting cell_state and output_state - lstm.ResetCellState(); - lstm.ResetOutputState(); - VerifyGoldens(lstm_input_, lstm_golden_output_, &lstm, /*tolerance=*/0.00467); } diff --git a/tensorflow/contrib/lite/nnapi_delegate.cc b/tensorflow/contrib/lite/nnapi_delegate.cc index 602f3ee5d2..484842713d 100644 --- a/tensorflow/contrib/lite/nnapi_delegate.cc +++ b/tensorflow/contrib/lite/nnapi_delegate.cc @@ -64,6 +64,14 @@ void logError(const char* format, ...) { __LINE__); \ } +#define RETURN_ERROR_IF_TFLITE_FAILED(x) \ + if (x != kTfLiteOk) { \ + logError( \ + "Returning error since TFLite returned failure nnapi_delegate.cc:%d.", \ + __LINE__); \ + return kTfLiteError; \ + } + #define RETURN_ERROR_IF_NN_FAILED(x) \ if (x != ANEURALNETWORKS_NO_ERROR) { \ logError( \ @@ -299,17 +307,21 @@ TfLiteStatus AddOpsAndParams( }; auto check_and_add_activation = [&add_scalar_int32](int activation) { if (activation > kTfLiteActRelu6) { - FATAL("NNAPI only supports RELU, RELU1 and RELU6 activations"); + logError("NNAPI only supports RELU, RELU1 and RELU6 activations"); + return kTfLiteError; } add_scalar_int32(activation); + return kTfLiteOk; }; auto add_add_params = [&add_scalar_int32](void* data) { auto* builtin = reinterpret_cast<TfLiteAddParams*>(data); if (builtin->activation > kTfLiteActRelu6) { - FATAL("NNAPI only supports RELU, RELU1 and RELU6 activations"); + logError("NNAPI only supports RELU, RELU1 and RELU6 activations"); + return kTfLiteError; } add_scalar_int32(builtin->activation); + return kTfLiteOk; }; auto add_pooling_params = [&add_scalar_int32, @@ -320,7 +332,7 @@ TfLiteStatus AddOpsAndParams( add_scalar_int32(builtin->stride_height); add_scalar_int32(builtin->filter_width); add_scalar_int32(builtin->filter_height); - check_and_add_activation(builtin->activation); + return check_and_add_activation(builtin->activation); }; auto add_convolution_params = [&add_scalar_int32, @@ -329,7 +341,7 @@ TfLiteStatus AddOpsAndParams( add_scalar_int32(builtin->padding); add_scalar_int32(builtin->stride_width); add_scalar_int32(builtin->stride_height); - check_and_add_activation(builtin->activation); + return check_and_add_activation(builtin->activation); }; auto add_depthwise_conv_params = [&add_scalar_int32, @@ -339,20 +351,22 @@ TfLiteStatus AddOpsAndParams( add_scalar_int32(builtin->stride_width); add_scalar_int32(builtin->stride_height); add_scalar_int32(builtin->depth_multiplier); - check_and_add_activation(builtin->activation); + return check_and_add_activation(builtin->activation); }; auto add_fully_connected_params = [&check_and_add_activation](void* data) { auto builtin = reinterpret_cast<TfLiteFullyConnectedParams*>(data); - check_and_add_activation(builtin->activation); + return check_and_add_activation(builtin->activation); }; auto add_concatenation_params = [&add_scalar_int32](void* data) { auto builtin = reinterpret_cast<TfLiteConcatenationParams*>(data); add_scalar_int32(builtin->axis); if (builtin->activation != kTfLiteActNone) { - FATAL("Concatenation does not support fused activation in NNAPI"); + logError("Concatenation does not support fused activation in NNAPI"); + return kTfLiteError; } + return kTfLiteOk; }; auto add_softmax_params = [&add_scalar_float32](void* data) { @@ -433,22 +447,22 @@ TfLiteStatus AddOpsAndParams( switch (builtin) { case tflite::BuiltinOperator_ADD: nn_op_type = ANEURALNETWORKS_ADD; - add_add_params(node.builtin_data); + RETURN_ERROR_IF_TFLITE_FAILED(add_add_params(node.builtin_data)); break; case tflite::BuiltinOperator_MUL: nn_op_type = ANEURALNETWORKS_MUL; - add_add_params(node.builtin_data); + RETURN_ERROR_IF_TFLITE_FAILED(add_add_params(node.builtin_data)); break; case tflite::BuiltinOperator_AVERAGE_POOL_2D: - add_pooling_params(node.builtin_data); + RETURN_ERROR_IF_TFLITE_FAILED(add_pooling_params(node.builtin_data)); nn_op_type = ANEURALNETWORKS_AVERAGE_POOL_2D; break; case tflite::BuiltinOperator_MAX_POOL_2D: - add_pooling_params(node.builtin_data); + RETURN_ERROR_IF_TFLITE_FAILED(add_pooling_params(node.builtin_data)); nn_op_type = ANEURALNETWORKS_MAX_POOL_2D; break; case tflite::BuiltinOperator_L2_POOL_2D: - add_pooling_params(node.builtin_data); + RETURN_ERROR_IF_TFLITE_FAILED(add_pooling_params(node.builtin_data)); nn_op_type = ANEURALNETWORKS_L2_POOL_2D; break; case tflite::BuiltinOperator_CONV_2D: { @@ -459,7 +473,8 @@ TfLiteStatus AddOpsAndParams( return kTfLiteError; } } - add_convolution_params(node.builtin_data); + RETURN_ERROR_IF_TFLITE_FAILED( + add_convolution_params(node.builtin_data)); nn_op_type = ANEURALNETWORKS_CONV_2D; break; case tflite::BuiltinOperator_RELU: @@ -478,11 +493,13 @@ TfLiteStatus AddOpsAndParams( nn_op_type = ANEURALNETWORKS_LOGISTIC; break; case tflite::BuiltinOperator_DEPTHWISE_CONV_2D: - add_depthwise_conv_params(node.builtin_data); + RETURN_ERROR_IF_TFLITE_FAILED( + add_depthwise_conv_params(node.builtin_data)); nn_op_type = ANEURALNETWORKS_DEPTHWISE_CONV_2D; break; case tflite::BuiltinOperator_CONCATENATION: - add_concatenation_params(node.builtin_data); + RETURN_ERROR_IF_TFLITE_FAILED( + add_concatenation_params(node.builtin_data)); nn_op_type = ANEURALNETWORKS_CONCATENATION; break; case tflite::BuiltinOperator_SOFTMAX: @@ -490,7 +507,8 @@ TfLiteStatus AddOpsAndParams( nn_op_type = ANEURALNETWORKS_SOFTMAX; break; case tflite::BuiltinOperator_FULLY_CONNECTED: - add_fully_connected_params(node.builtin_data); + RETURN_ERROR_IF_TFLITE_FAILED( + add_fully_connected_params(node.builtin_data)); nn_op_type = ANEURALNETWORKS_FULLY_CONNECTED; break; case tflite::BuiltinOperator_RESHAPE: @@ -544,14 +562,14 @@ TfLiteStatus AddOpsAndParams( case tflite::BuiltinOperator_DIV: nnapi_version = 11; // require NNAPI 1.1 nn_op_type = ANEURALNETWORKS_DIV; - check_and_add_activation( - reinterpret_cast<TfLiteDivParams*>(node.builtin_data)->activation); + RETURN_ERROR_IF_TFLITE_FAILED(check_and_add_activation( + reinterpret_cast<TfLiteDivParams*>(node.builtin_data)->activation)); break; case tflite::BuiltinOperator_SUB: nnapi_version = 11; // require NNAPI 1.1 nn_op_type = ANEURALNETWORKS_SUB; - check_and_add_activation( - reinterpret_cast<TfLiteSubParams*>(node.builtin_data)->activation); + RETURN_ERROR_IF_TFLITE_FAILED(check_and_add_activation( + reinterpret_cast<TfLiteSubParams*>(node.builtin_data)->activation)); break; case tflite::BuiltinOperator_SQUEEZE: nnapi_version = 11; // requires NNAPI 1.1 @@ -664,7 +682,8 @@ TfLiteStatus AddOpsAndParams( } if (nnapi_version == 11 && GetAndroidSdkVersionCached() < 28) { - FATAL("Op %d needs NNAPI1.1", builtin); + logError("Op %d needs NNAPI1.1", builtin); + return kTfLiteError; } // Add the operation. @@ -712,9 +731,9 @@ TfLiteStatus NNAPIDelegate::BuildGraph(Interpreter* interpreter) { interpreter->outputs().size()); uint32_t next_id = 0; - RETURN_ERROR_IF_NN_FAILED(addTensorOperands( + RETURN_ERROR_IF_TFLITE_FAILED(addTensorOperands( interpreter, nn_model_, &next_id, &tensor_id_to_nnapi_id)); - RETURN_ERROR_IF_NN_FAILED( + RETURN_ERROR_IF_TFLITE_FAILED( AddOpsAndParams(interpreter, nn_model_, next_id, &model_states_inputs_, &model_states_outputs_, tensor_id_to_nnapi_id)); diff --git a/tensorflow/contrib/lite/python/convert.py b/tensorflow/contrib/lite/python/convert.py index 69a3d562b3..1c5516ae7c 100644 --- a/tensorflow/contrib/lite/python/convert.py +++ b/tensorflow/contrib/lite/python/convert.py @@ -126,7 +126,7 @@ def build_toco_convert_protos(input_tensors, reorder_across_fake_quant=False, allow_custom_ops=False, change_concat_input_ranges=False, - quantize_weights=False, + post_training_quantize=False, dump_graphviz_dir=None, dump_graphviz_video=False): """Builds protocol buffers describing a conversion of a model using TOCO. @@ -173,9 +173,9 @@ def build_toco_convert_protos(input_tensors, change_concat_input_ranges: Boolean to change behavior of min/max ranges for inputs and outputs of the concat operator for quantized models. Changes the ranges of concat operator overlap when true. (default False) - quantize_weights: Boolean indicating whether to store weights as quantized - weights followed by dequantize operations. Computation is still done in - float, but reduces model size (at the cost of accuracy and latency). + post_training_quantize: Boolean indicating whether to quantize the weights + of the converted float model. Model size will be reduced and there will be + latency improvements (at the cost of accuracy). (default False) dump_graphviz_dir: Full filepath of folder to dump the graphs at various stages of processing GraphViz .dot files. Preferred over @@ -204,7 +204,7 @@ def build_toco_convert_protos(input_tensors, toco.drop_control_dependency = drop_control_dependency toco.reorder_across_fake_quant = reorder_across_fake_quant toco.allow_custom_ops = allow_custom_ops - toco.quantize_weights = quantize_weights + toco.post_training_quantize = post_training_quantize if default_ranges_stats: toco.default_ranges_min = default_ranges_stats[0] toco.default_ranges_max = default_ranges_stats[1] diff --git a/tensorflow/contrib/lite/python/lite.py b/tensorflow/contrib/lite/python/lite.py index 80cbb12825..2de97fec86 100644 --- a/tensorflow/contrib/lite/python/lite.py +++ b/tensorflow/contrib/lite/python/lite.py @@ -102,9 +102,9 @@ class TocoConverter(object): created for any op that is unknown. The developer will need to provide these to the TensorFlow Lite runtime with a custom resolver. (default False) - quantize_weights: Boolean indicating whether to store weights as quantized - weights followed by dequantize operations. Computation is still done in - float, but reduces model size (at the cost of accuracy and latency). + post_training_quantize: Boolean indicating whether to quantize the weights + of the converted float model. Model size will be reduced and there will be + latency improvements (at the cost of accuracy). (default False) dump_graphviz_dir: Full filepath of folder to dump the graphs at various stages of processing GraphViz .dot files. Preferred over @@ -175,7 +175,7 @@ class TocoConverter(object): self.reorder_across_fake_quant = False self.change_concat_input_ranges = False self.allow_custom_ops = False - self.quantize_weights = False + self.post_training_quantize = False self.dump_graphviz_dir = None self.dump_graphviz_video = False @@ -425,7 +425,7 @@ class TocoConverter(object): "reorder_across_fake_quant": self.reorder_across_fake_quant, "change_concat_input_ranges": self.change_concat_input_ranges, "allow_custom_ops": self.allow_custom_ops, - "quantize_weights": self.quantize_weights, + "post_training_quantize": self.post_training_quantize, "dump_graphviz_dir": self.dump_graphviz_dir, "dump_graphviz_video": self.dump_graphviz_video } diff --git a/tensorflow/contrib/lite/python/lite_test.py b/tensorflow/contrib/lite/python/lite_test.py index d004c3ecca..1c94ba605a 100644 --- a/tensorflow/contrib/lite/python/lite_test.py +++ b/tensorflow/contrib/lite/python/lite_test.py @@ -372,7 +372,7 @@ class FromSessionTest(test_util.TensorFlowTestCase): self.assertTrue(([1, 16, 16, 3] == output_details[0]['shape']).all()) self.assertTrue(output_details[0]['quantization'][0] > 0) # scale - def testQuantizeWeights(self): + def testPostTrainingQuantize(self): np.random.seed(0) # We need the tensor to have more than 1024 elements for quantize_weights # to kick in. Thus, the [33, 33] shape. @@ -393,14 +393,14 @@ class FromSessionTest(test_util.TensorFlowTestCase): self.assertTrue(float_tflite) # Convert quantized weights model. - quantized_weights_converter = lite.TocoConverter.from_session( + quantized_converter = lite.TocoConverter.from_session( sess, [in_tensor_1], [out_tensor]) - quantized_weights_converter.quantize_weights = True - quantized_weights_tflite = quantized_weights_converter.convert() - self.assertTrue(quantized_weights_tflite) + quantized_converter.post_training_quantize = True + quantized_tflite = quantized_converter.convert() + self.assertTrue(quantized_tflite) # Ensure that the quantized weights tflite model is smaller. - self.assertTrue(len(quantized_weights_tflite) < len(float_tflite)) + self.assertTrue(len(quantized_tflite) < len(float_tflite)) class FromFrozenGraphFile(test_util.TensorFlowTestCase): diff --git a/tensorflow/contrib/lite/python/tflite_convert.py b/tensorflow/contrib/lite/python/tflite_convert.py index dc078ffd21..cc08ed3fe9 100644 --- a/tensorflow/contrib/lite/python/tflite_convert.py +++ b/tensorflow/contrib/lite/python/tflite_convert.py @@ -142,11 +142,14 @@ def _convert_model(flags): flags.change_concat_input_ranges == "TRUE") if flags.allow_custom_ops: converter.allow_custom_ops = flags.allow_custom_ops - if flags.quantize_weights: + + if flags.post_training_quantize: + converter.post_training_quantize = flags.post_training_quantize if flags.inference_type == lite_constants.QUANTIZED_UINT8: - raise ValueError("--quantized_weights is not supported with " - "--inference_type=QUANTIZED_UINT8") - converter.quantize_weights = flags.quantize_weights + print("--post_training_quantize quantizes a graph of inference_type " + "FLOAT. Overriding inference type QUANTIZED_UINT8 to FLOAT.") + converter.inference_type = lite_constants.FLOAT + if flags.dump_graphviz_dir: converter.dump_graphviz_dir = flags.dump_graphviz_dir if flags.dump_graphviz_video: @@ -318,12 +321,20 @@ def run_main(_): help=("Default value for max bound of min/max range values used for all " "arrays without a specified range, Intended for experimenting with " "quantization via \"dummy quantization\". (default None)")) + # quantize_weights is DEPRECATED. parser.add_argument( "--quantize_weights", + dest="post_training_quantize", + action="store_true", + help=argparse.SUPPRESS) + parser.add_argument( + "--post_training_quantize", + dest="post_training_quantize", action="store_true", - help=("Store float weights as quantized weights followed by dequantize " - "operations. Inference is still done in FLOAT, but reduces model " - "size (at the cost of accuracy and latency).")) + help=( + "Boolean indicating whether to quantize the weights of the " + "converted float model. Model size will be reduced and there will " + "be latency improvements (at the cost of accuracy). (default False)")) # Graph manipulation flags. parser.add_argument( diff --git a/tensorflow/contrib/lite/testing/generate_examples.py b/tensorflow/contrib/lite/testing/generate_examples.py index 57134ccd15..32f02a4f6c 100644 --- a/tensorflow/contrib/lite/testing/generate_examples.py +++ b/tensorflow/contrib/lite/testing/generate_examples.py @@ -1679,6 +1679,7 @@ def make_pad_tests(zip_path): # TODO(nupurgarg): Add test for tf.uint8. test_parameters = [ + # 4D: { "dtype": [tf.int32, tf.int64, tf.float32], "input_shape": [[1, 1, 2, 1], [2, 1, 1, 1]], @@ -1686,13 +1687,20 @@ def make_pad_tests(zip_path): [0, 0], [2, 3]]], "constant_paddings": [True, False], }, - # Non-4D use case. + # 2D: { "dtype": [tf.int32, tf.int64, tf.float32], - "input_shape": [[1, 2], [0, 1, 2]], + "input_shape": [[1, 2]], "paddings": [[[0, 1], [2, 3]]], "constant_paddings": [True, False], }, + # 1D: + { + "dtype": [tf.int32], + "input_shape": [[1]], + "paddings": [[[1, 2]]], + "constant_paddings": [False], + }, ] def build_graph(parameters): @@ -1730,6 +1738,7 @@ def make_padv2_tests(zip_path): # TODO(nupurgarg): Add test for tf.uint8. test_parameters = [ + # 4D: { "dtype": [tf.int32, tf.int64, tf.float32], "input_shape": [[1, 1, 2, 1], [2, 1, 1, 1]], @@ -1738,14 +1747,22 @@ def make_padv2_tests(zip_path): "constant_paddings": [True, False], "constant_values": [0, 2], }, - # Non-4D use case. + # 2D: { "dtype": [tf.int32, tf.int64, tf.float32], - "input_shape": [[1, 2], [0, 1, 2]], + "input_shape": [[1, 2]], "paddings": [[[0, 1], [2, 3]]], "constant_paddings": [True, False], "constant_values": [0, 2], }, + # 1D: + { + "dtype": [tf.int32], + "input_shape": [[1]], + "paddings": [[[0, 1]]], + "constant_paddings": [False], + "constant_values": [0, 2], + }, ] def build_graph(parameters): diff --git a/tensorflow/contrib/lite/testing/generated_examples_zip_test.cc b/tensorflow/contrib/lite/testing/generated_examples_zip_test.cc index 37c7ae0e1c..349aa5a3b4 100644 --- a/tensorflow/contrib/lite/testing/generated_examples_zip_test.cc +++ b/tensorflow/contrib/lite/testing/generated_examples_zip_test.cc @@ -58,12 +58,6 @@ tensorflow::Env* env = tensorflow::Env::Default(); // Key is a substring of the test name and value is a bug number. // TODO(ahentz): make sure we clean this list up frequently. std::map<string, string> kBrokenTests = { - // Pad and PadV2 only supports 4D tensors. - {R"(^\/pad.*,input_shape=\[.,.\],paddings=\[\[.,.\],\[.,.\]\])", - "70527055"}, - {R"(^\/padv2.*,input_shape=\[.,.\],paddings=\[\[.,.\],\[.,.\]\])", - "70527055"}, - // L2Norm only supports tensors with 4D or fewer. {R"(^\/l2norm_dim=.*,epsilon=.*,input_shape=\[.,.,.,.,.*\])", "67963684"}, diff --git a/tensorflow/contrib/lite/toco/args.h b/tensorflow/contrib/lite/toco/args.h index aef35ad490..f14dbc258b 100644 --- a/tensorflow/contrib/lite/toco/args.h +++ b/tensorflow/contrib/lite/toco/args.h @@ -236,8 +236,9 @@ struct ParsedTocoFlags { Arg<bool> drop_fake_quant = Arg<bool>(false); Arg<bool> reorder_across_fake_quant = Arg<bool>(false); Arg<bool> allow_custom_ops = Arg<bool>(false); - Arg<bool> quantize_weights = Arg<bool>(false); + Arg<bool> post_training_quantize = Arg<bool>(false); // Deprecated flags + Arg<bool> quantize_weights = Arg<bool>(false); Arg<string> input_type; Arg<string> input_types; Arg<bool> debug_disable_recurrent_cell_fusion = Arg<bool>(false); @@ -246,6 +247,10 @@ struct ParsedTocoFlags { Arg<bool> allow_nudging_weights_to_use_fast_gemm_kernel = Arg<bool>(false); Arg<int64> dedupe_array_min_size_bytes = Arg<int64>(64); Arg<bool> split_tflite_lstm_inputs = Arg<bool>(true); + // WARNING: Experimental interface, subject to change + Arg<bool> allow_eager_ops = Arg<bool>(false); + // WARNING: Experimental interface, subject to change + Arg<bool> force_eager_ops = Arg<bool>(false); }; } // namespace toco diff --git a/tensorflow/contrib/lite/toco/export_tensorflow.cc b/tensorflow/contrib/lite/toco/export_tensorflow.cc index 6fdf47dedc..b52a79282c 100644 --- a/tensorflow/contrib/lite/toco/export_tensorflow.cc +++ b/tensorflow/contrib/lite/toco/export_tensorflow.cc @@ -1701,9 +1701,11 @@ void ConvertReduceOperator(const Model& model, const T& src_op, *new_op->add_input() = src_op.inputs[0]; *new_op->add_input() = src_op.inputs[1]; - const tensorflow::DataType params_type = - GetTensorFlowDataType(model, src_op.inputs[0]); - (*new_op->mutable_attr())["T"].set_type(params_type); + if (src_op.type != OperatorType::kAny) { + const tensorflow::DataType params_type = + GetTensorFlowDataType(model, src_op.inputs[0]); + (*new_op->mutable_attr())["T"].set_type(params_type); + } const tensorflow::DataType indices_type = GetTensorFlowDataType(model, src_op.inputs[1]); (*new_op->mutable_attr())["Tidx"].set_type(indices_type); diff --git a/tensorflow/contrib/lite/toco/g3doc/cmdline_examples.md b/tensorflow/contrib/lite/toco/g3doc/cmdline_examples.md index 4bf47aa3c4..84680b968e 100644 --- a/tensorflow/contrib/lite/toco/g3doc/cmdline_examples.md +++ b/tensorflow/contrib/lite/toco/g3doc/cmdline_examples.md @@ -24,8 +24,8 @@ Table of contents: * [Multiple output arrays](#multiple-output-arrays) * [Specifying subgraphs](#specifying-subgraphs) * [Graph visualizations](#graph-visualizations) - * [Using --output_format=GRAPHVIZ_DOT](#using-output-formatgraphviz-dot) - * [Using --dump_graphviz](#using-dump-graphviz) + * [Using --output_format=GRAPHVIZ_DOT](#using-output-format-graphviz-dot) + * [Using --dump_graphviz_dir](#using-dump-graphviz-dir) * [Graph "video" logging](#graph-video-logging) * [Legend for the graph visualizations](#graphviz-legend) @@ -247,17 +247,17 @@ function tends to get fused). ## Graph visualizations -TOCO can export a graph to the GraphViz Dot format for easy visualization via +TOCO can export a graph to the Graphviz Dot format for easy visualization via either the `--output_format` flag or the `--dump_graphviz_dir` flag. The subsections below outline the use cases for each. -### Using `--output_format=GRAPHVIZ_DOT` +### Using `--output_format=GRAPHVIZ_DOT` <a name="using-output-format-graphviz-dot"></a> -The first way to get a graphviz rendering is to pass `GRAPHVIZ_DOT` into +The first way to get a Graphviz rendering is to pass `GRAPHVIZ_DOT` into `--output_format`. This results in a plausible visualization of the graph. This -reduces the requirements that exist during conversion between other input and -output formats. This may be useful if conversion from TENSORFLOW_GRAPHDEF to -TFLITE is failing. +reduces the requirements that exist during conversion from a TensorFlow GraphDef +to a TensorFlow Lite FlatBuffer. This may be useful if the conversion to TFLite +is failing. ``` curl https://storage.googleapis.com/download.tensorflow.org/models/mobilenet_v1_0.50_128_frozen.tgz \ @@ -287,10 +287,10 @@ google-chrome /tmp/foo.dot.pdf Example PDF files are viewable online in the next section. -### Using `--dump_graphviz` +### Using `--dump_graphviz_dir` -The second way to get a graphviz rendering is to pass the `--dump_graphviz_dir` -flag, specifying a destination directory to dump GraphViz rendering to. Unlike +The second way to get a Graphviz rendering is to pass the `--dump_graphviz_dir` +flag, specifying a destination directory to dump Graphviz rendering to. Unlike the previous approach, this one retains the original output format. This provides a visualization of the actual graph resulting from a specific conversion process. diff --git a/tensorflow/contrib/lite/toco/g3doc/cmdline_reference.md b/tensorflow/contrib/lite/toco/g3doc/cmdline_reference.md index 76862970c8..00bc8d4ccb 100644 --- a/tensorflow/contrib/lite/toco/g3doc/cmdline_reference.md +++ b/tensorflow/contrib/lite/toco/g3doc/cmdline_reference.md @@ -38,7 +38,7 @@ files. The flag `--output_file` is always required. Additionally, either of TFLite specific transformations. Therefore, the resulting visualization may not reflect the final set of graph transformations. To get a final visualization with all graph - transformations use `--dump_graphviz` instead. + transformations use `--dump_graphviz_dir` instead. The following flags specify optional parameters when using SavedModels. @@ -149,10 +149,10 @@ have. true, custom ops are created for any op that is unknown. The developer will need to provide these to the TensorFlow Lite runtime with a custom resolver. -* `--quantize_weights`. Type: boolean. Default: False. Indicates whether to - store weights as quantized weights followed by dequantize operations. - Computation is still done in float, but reduces model size (at the cost of - accuracy and latency). +* `--post_training_quantize`. Type: boolean. Default: False. Boolean + indicating whether to quantize the weights of the converted float model. + Model size will be reduced and there will be latency improvements (at the + cost of accuracy). ## Logging flags diff --git a/tensorflow/contrib/lite/toco/g3doc/python_api.md b/tensorflow/contrib/lite/toco/g3doc/python_api.md index 3799eac0a1..51f808d4f0 100644 --- a/tensorflow/contrib/lite/toco/g3doc/python_api.md +++ b/tensorflow/contrib/lite/toco/g3doc/python_api.md @@ -70,6 +70,7 @@ val = img + var out = tf.identity(val, name="out") with tf.Session() as sess: + sess.run(tf.global_variables_initializer()) converter = tf.contrib.lite.TocoConverter.from_session(sess, [img], [out]) tflite_model = converter.convert() open("converted_model.tflite", "wb").write(tflite_model) diff --git a/tensorflow/contrib/lite/toco/graph_transformations/graph_transformations.h b/tensorflow/contrib/lite/toco/graph_transformations/graph_transformations.h index 34945ecc45..fdd0632451 100644 --- a/tensorflow/contrib/lite/toco/graph_transformations/graph_transformations.h +++ b/tensorflow/contrib/lite/toco/graph_transformations/graph_transformations.h @@ -177,9 +177,10 @@ DECLARE_GRAPH_TRANSFORMATION(ResolveSpaceToBatchNDAttributes) DECLARE_GRAPH_TRANSFORMATION(ResolveBatchToSpaceNDAttributes) DECLARE_GRAPH_TRANSFORMATION(ResolvePadAttributes) DECLARE_GRAPH_TRANSFORMATION(ResolvePadV2Attributes) -DECLARE_GRAPH_TRANSFORMATION(ResolveStridedSliceAttributes) -DECLARE_GRAPH_TRANSFORMATION(ResolveSliceAttributes) DECLARE_GRAPH_TRANSFORMATION(ResolveReduceAttributes) +DECLARE_GRAPH_TRANSFORMATION(ResolveReshapeAttributes) +DECLARE_GRAPH_TRANSFORMATION(ResolveSliceAttributes) +DECLARE_GRAPH_TRANSFORMATION(ResolveStridedSliceAttributes) DECLARE_GRAPH_TRANSFORMATION(ResolveTransposeAttributes) DECLARE_GRAPH_TRANSFORMATION(ResolveConstantPack) DECLARE_GRAPH_TRANSFORMATION(ResolveConstantRandomUniform) @@ -216,12 +217,6 @@ class PropagateDefaultMinMax : public GraphTransformation { std::vector<std::pair<ArrayDataType, MinMax>> type_ranges_; }; -class ResolveReshapeAttributes : public GraphTransformation { - public: - bool Run(Model* model, std::size_t op_index) override; - const char* Name() const override { return "ResolveReshapeAttributes"; } -}; - class RemoveTrivialReshape : public GraphTransformation { public: bool Run(Model* model, std::size_t op_index) override; diff --git a/tensorflow/contrib/lite/toco/graph_transformations/hardcode_min_max.cc b/tensorflow/contrib/lite/toco/graph_transformations/hardcode_min_max.cc index 502de88f7c..3114fa93e8 100644 --- a/tensorflow/contrib/lite/toco/graph_transformations/hardcode_min_max.cc +++ b/tensorflow/contrib/lite/toco/graph_transformations/hardcode_min_max.cc @@ -63,6 +63,25 @@ bool HardcodeMinMaxForL2Normalization(Model* model, Operator* op) { return true; } +bool HardcodeInputMinMaxFromOutput(Model* model, Operator* op) { + auto& input = model->GetArray(op->inputs[0]); + if (input.minmax) { + const auto* minmax = input.minmax.get(); + if (minmax) { + return false; + } + } + auto& output = model->GetArray(op->outputs[0]); + if (output.minmax) { + const auto* minmax = model->GetArray(op->outputs[0]).minmax.get(); + if (minmax) { + input.GetOrCreateMinMax() = *minmax; + return true; + } + } + return false; +} + bool HardcodeMinMaxForConcatenation(Model* model, Operator* op) { // Do not early return if the output already has min/max: // we may still need to adjust the inputs min/max. @@ -366,6 +385,16 @@ bool HardcodeMinMax::Run(Model* model, std::size_t op_index) { changed = HardcodeMinMaxForL2Normalization(model, op); break; + case OperatorType::kRelu: + // For any normalization other than batch norm, the quantizations ranges + // before and after relu are expected to be known. Having a quantization + // op before relu would reduce the number of bits of precision for the + // activation in half. So we deduce the range before relu from that after + // the relu. This would eliminate the need for two fake quantization nodes + // and would not reduce the bits of precision available for activation. + changed = HardcodeInputMinMaxFromOutput(model, op); + break; + case OperatorType::kConcatenation: changed = HardcodeMinMaxForConcatenation(model, op); break; diff --git a/tensorflow/contrib/lite/toco/graph_transformations/propagate_fixed_sizes.cc b/tensorflow/contrib/lite/toco/graph_transformations/propagate_fixed_sizes.cc index 28effc2a67..c25be078ff 100644 --- a/tensorflow/contrib/lite/toco/graph_transformations/propagate_fixed_sizes.cc +++ b/tensorflow/contrib/lite/toco/graph_transformations/propagate_fixed_sizes.cc @@ -561,26 +561,38 @@ void ProcessTensorFlowReductionOperator(Model* model, Operator* op) { const bool keep_dims = KeepDims(*op); if (op->inputs.size() == 2) { // There is a reduction_indices input. - const auto& reduction_array = model->GetArray(op->inputs[1]); - if (!reduction_array.buffer) { + const auto& reduction_indices_array = model->GetArray(op->inputs[1]); + if (!reduction_indices_array.buffer) { return; } - CHECK(reduction_array.buffer->type == ArrayDataType::kInt32); - const auto& reduction_array_vals = - reduction_array.GetBuffer<ArrayDataType::kInt32>().data; - auto& output_dims = *output_array.mutable_shape()->mutable_dims(); - output_dims.clear(); - for (int i = 0; i < input_shape.dimensions_count(); i++) { - bool is_reduction_dim = false; - for (int r : reduction_array_vals) { - if (i == r) { - is_reduction_dim = true; - } + CHECK(reduction_indices_array.buffer->type == ArrayDataType::kInt32); + + int input_rank = input_shape.dimensions_count(); + std::set<int32> true_indices; + const auto& reduction_indices = + reduction_indices_array.GetBuffer<ArrayDataType::kInt32>().data; + for (int i = 0; i < reduction_indices.size(); ++i) { + const int32 reduction_index = reduction_indices[i]; + if (reduction_index < -input_rank || reduction_index >= input_rank) { + CHECK(false) << "Invalid reduction dimension " << reduction_index + << " for input with " << input_rank << " dimensions"; + } + int32 wrapped_index = reduction_index; + if (wrapped_index < 0) { + wrapped_index += input_rank; } - if (!is_reduction_dim) { - output_dims.push_back(input_shape.dims(i)); - } else if (keep_dims) { - output_dims.push_back(1); + true_indices.insert(wrapped_index); + } + + auto* mutable_dims = output_array.mutable_shape()->mutable_dims(); + mutable_dims->clear(); + for (int i = 0; i < input_rank; ++i) { + if (true_indices.count(i) > 0) { + if (keep_dims) { + mutable_dims->emplace_back(1); + } + } else { + mutable_dims->emplace_back(input_shape.dims(i)); } } } else { diff --git a/tensorflow/contrib/lite/toco/graph_transformations/resolve_reduce_attributes.cc b/tensorflow/contrib/lite/toco/graph_transformations/resolve_reduce_attributes.cc index 7d456af2fb..73198ac7c0 100644 --- a/tensorflow/contrib/lite/toco/graph_transformations/resolve_reduce_attributes.cc +++ b/tensorflow/contrib/lite/toco/graph_transformations/resolve_reduce_attributes.cc @@ -52,6 +52,8 @@ bool ResolveReduceAttributes::Run(Model* model, std::size_t op_index) { return ResolveAttributes(model, static_cast<TensorFlowMinOperator*>(op)); case OperatorType::kReduceMax: return ResolveAttributes(model, static_cast<TensorFlowMaxOperator*>(op)); + case OperatorType::kAny: + return ResolveAttributes(model, static_cast<TensorFlowMaxOperator*>(op)); default: return false; } diff --git a/tensorflow/contrib/lite/toco/import_tensorflow.cc b/tensorflow/contrib/lite/toco/import_tensorflow.cc index cb6da21039..9bc23c4b3c 100644 --- a/tensorflow/contrib/lite/toco/import_tensorflow.cc +++ b/tensorflow/contrib/lite/toco/import_tensorflow.cc @@ -2061,8 +2061,14 @@ std::unique_ptr<Model> ImportTensorFlowGraphDef( } Model* model = new Model; - const internal::ConverterMapType& converter_map = - internal::GetTensorFlowNodeConverterMap(); + internal::ConverterMapType converter_map; + + // This is used for the TFLite "Full Eager Mode" conversion. All the ops are + // imported as `TensorFlowUnsupportedOperator`, and later all these ops are + // converted to TFLite Eager ops. + if (!tf_import_flags.import_all_ops_as_unsupported) { + converter_map = internal::GetTensorFlowNodeConverterMap(); + } for (auto node : inlined_graph.node()) { StripZeroOutputIndexFromInputs(&node); diff --git a/tensorflow/contrib/lite/toco/import_tensorflow.h b/tensorflow/contrib/lite/toco/import_tensorflow.h index 2177872334..7db23f2d44 100644 --- a/tensorflow/contrib/lite/toco/import_tensorflow.h +++ b/tensorflow/contrib/lite/toco/import_tensorflow.h @@ -27,6 +27,11 @@ struct TensorFlowImportFlags { // If true, control dependencies will be dropped immediately // during the import of the TensorFlow GraphDef. bool drop_control_dependency = false; + + // Do not recognize any op and import all ops as + // `TensorFlowUnsupportedOperator`. This is used to populated with the + // `force_eager_ops` flag. + bool import_all_ops_as_unsupported = false; }; std::unique_ptr<Model> ImportTensorFlowGraphDef( diff --git a/tensorflow/contrib/lite/toco/model.h b/tensorflow/contrib/lite/toco/model.h index fa1c459f0e..2e100e37f6 100644 --- a/tensorflow/contrib/lite/toco/model.h +++ b/tensorflow/contrib/lite/toco/model.h @@ -1768,6 +1768,7 @@ struct PowOperator : Operator { // // Inputs: // Inputs[0]: required: A boolean input tensor. +// Inputs[1]: required: reduction_indices. // // TensorFlow equivalent: tf.reduce_any. struct TensorFlowAnyOperator : Operator { diff --git a/tensorflow/contrib/lite/toco/tflite/export.cc b/tensorflow/contrib/lite/toco/tflite/export.cc index a27d00eb77..fee10b1dff 100644 --- a/tensorflow/contrib/lite/toco/tflite/export.cc +++ b/tensorflow/contrib/lite/toco/tflite/export.cc @@ -49,12 +49,21 @@ namespace { details::OperatorKey GetOperatorKey( const ::toco::Operator& op, - const std::map<OperatorType, std::unique_ptr<BaseOperator>>& ops_by_type) { + const std::map<OperatorType, std::unique_ptr<BaseOperator>>& ops_by_type, + bool allow_eager_ops) { string custom_code; if (op.type == OperatorType::kUnsupported) { const TensorFlowUnsupportedOperator& unsupported_op = static_cast<const TensorFlowUnsupportedOperator&>(op); - custom_code = unsupported_op.tensorflow_op; + + // TODO(b/113715895): When `allow_eager_ops` is on, for now there's no way + // to populate a regular custom op. We need to find a way to fix this. + if (allow_eager_ops) { + custom_code = string(::tflite::kEagerCustomCodePrefix) + + unsupported_op.tensorflow_op; + } else { + custom_code = unsupported_op.tensorflow_op; + } } int version = 1; if (ops_by_type.count(op.type) != 0) { @@ -91,11 +100,12 @@ void LoadTensorsMap(const Model& model, TensorsMap* tensors_map) { void LoadOperatorsMap( const Model& model, OperatorsMap* operators_map, - const std::map<OperatorType, std::unique_ptr<BaseOperator>>& ops_by_type) { + const std::map<OperatorType, std::unique_ptr<BaseOperator>>& ops_by_type, + bool allow_eager_ops) { // First find a list of unique operator types. std::set<OperatorKey> keys; for (const auto& op : model.operators) { - keys.insert(GetOperatorKey(*op, ops_by_type)); + keys.insert(GetOperatorKey(*op, ops_by_type, allow_eager_ops)); } // Now assign indices to them and fill in the map. int index = 0; @@ -189,7 +199,7 @@ Offset<Vector<Offset<OperatorCode>>> ExportOperatorCodes( const Model& model, const std::map<OperatorType, std::unique_ptr<BaseOperator>>& ops_by_type, const details::OperatorsMap& operators_map, FlatBufferBuilder* builder, - std::set<string>* error_summary) { + std::set<string>* error_summary, const ExportParams& params) { // Map from operator name to TF Lite enum value, for all builtins. std::map<string, BuiltinOperator> builtin_ops; for (int i = BuiltinOperator_MIN; i <= BuiltinOperator_MAX; ++i) { @@ -205,7 +215,8 @@ Offset<Vector<Offset<OperatorCode>>> ExportOperatorCodes( std::map<int, Offset<OperatorCode>> ordered_opcodes; for (const auto& op : model.operators) { - const details::OperatorKey operator_key = GetOperatorKey(*op, ops_by_type); + const details::OperatorKey operator_key = + GetOperatorKey(*op, ops_by_type, params.allow_eager_ops); int op_index = operators_map.at(operator_key); int op_version = operator_key.version; @@ -252,7 +263,7 @@ Offset<Vector<Offset<Operator>>> ExportOperators( const std::map<OperatorType, std::unique_ptr<BaseOperator>>& ops_by_type, const details::OperatorsMap& operators_map, const details::TensorsMap& tensors_map, FlatBufferBuilder* builder, - std::set<int32_t>* variable_tensor_indices) { + std::set<int32_t>* variable_tensor_indices, const ExportParams& params) { variable_tensor_indices->clear(); // The operators are in execution order, so we just follow tf.mini order. @@ -269,7 +280,8 @@ Offset<Vector<Offset<Operator>>> ExportOperators( outputs.push_back(tensors_map.at(output)); } - int op_index = operators_map.at(GetOperatorKey(*op, ops_by_type)); + int op_index = operators_map.at( + GetOperatorKey(*op, ops_by_type, params.allow_eager_ops)); auto tflite_op_it = ops_by_type.find(op->type); BaseOperator* tflite_op = tflite_op_it == ops_by_type.end() @@ -320,16 +332,15 @@ Offset<Vector<Offset<Buffer>>> ExportBuffers( return builder->CreateVector(buffer_vector); } -void Export(const Model& model, bool allow_custom_ops, bool quantize_weights, - string* output_file_contents) { - const auto ops_by_type = BuildOperatorByTypeMap(); - Export(model, allow_custom_ops, quantize_weights, output_file_contents, - ops_by_type); +void Export(const Model& model, string* output_file_contents, + const ExportParams& params) { + const auto ops_by_type = BuildOperatorByTypeMap(params.allow_eager_ops); + Export(model, output_file_contents, params, ops_by_type); } void Export( - const Model& model, bool allow_custom_ops, bool quantize_weights, - string* output_file_contents, + const Model& model, string* output_file_contents, + const ExportParams& params, const std::map<OperatorType, std::unique_ptr<BaseOperator>>& ops_by_type) { flatbuffers::FlatBufferBuilder builder(/*initial_size=*/10240); @@ -337,7 +348,8 @@ void Export( details::LoadTensorsMap(model, &tensors_map); details::OperatorsMap operators_map; - details::LoadOperatorsMap(model, &operators_map, ops_by_type); + details::LoadOperatorsMap(model, &operators_map, ops_by_type, + params.allow_eager_ops); std::vector<const Array*> buffers_to_write; Array empty_array; @@ -345,7 +357,7 @@ void Export( std::set<string> error_summary; auto op_codes = ExportOperatorCodes(model, ops_by_type, operators_map, - &builder, &error_summary); + &builder, &error_summary, params); for (const auto& op : model.operators) { if (op->type == OperatorType::kFakeQuant) { @@ -355,7 +367,7 @@ void Export( "for --std_values and --mean_values."; } } - if (!allow_custom_ops && !error_summary.empty()) { + if (!params.allow_custom_ops && !error_summary.empty()) { // Remove ExpandDims and ReorderAxes from unimplemented list unless they // compose the list. Both ops are removed during graph transformations. // However, if an op is unimplemented earlier in the model, the graph @@ -376,14 +388,14 @@ void Export( "the standard TensorFlow Lite runtime. If you have a custom " "implementation for them you can disable this error with " "--allow_custom_ops, or by setting allow_custom_ops=True " - "when calling tf.contrib.lite.toco_convert(). Here is a list " + "when calling tf.contrib.lite.TocoConverter(). Here is a list " "of operators for which you will need custom implementations: " << absl::StrJoin(error_summary_final, ", ") << "."; } std::set<int32_t> variable_tensor_indices; auto ops = ExportOperators(model, ops_by_type, operators_map, tensors_map, - &builder, &variable_tensor_indices); + &builder, &variable_tensor_indices, params); auto tensors = ExportTensors(model, tensors_map, &builder, &buffers_to_write, variable_tensor_indices); @@ -402,7 +414,7 @@ void Export( builder.CreateVector(subgraphs), description, buffers); ::tflite::FinishModelBuffer(builder, new_model_location); - if (quantize_weights) { + if (params.quantize_weights) { // Call the quantize_weights tool. LOG(INFO) << "Quantizing TFLite model after conversion to flatbuffer. " "dump_graphviz will only output the model before this " diff --git a/tensorflow/contrib/lite/toco/tflite/export.h b/tensorflow/contrib/lite/toco/tflite/export.h index 915d5dd3d6..b070a38768 100644 --- a/tensorflow/contrib/lite/toco/tflite/export.h +++ b/tensorflow/contrib/lite/toco/tflite/export.h @@ -23,22 +23,54 @@ namespace toco { namespace tflite { +// The parameters for exporting a TFLite model. +struct ExportParams { + bool allow_custom_ops = false; + bool allow_eager_ops = false; + bool quantize_weights = false; +}; + // Transform the given tf.mini model into a TF Lite flatbuffer and deposit the // result in the given string. -void Export(const Model& model, bool allow_custom_ops, bool quantize_weights, - string* output_file_contents); +void Export(const Model& model, string* output_file_contents, + const ExportParams& params); + +// Export API with custom TFLite operator mapping. +void Export( + const Model& model, string* output_file_contents, + const ExportParams& params, + const std::map<OperatorType, std::unique_ptr<BaseOperator>>& ops_by_type); -// This if backward-compatibility. +// This is for backward-compatibility. // TODO(ycling): Remove the deprecated entry functions. -inline void Export(const Model& model, string* output_file_contents) { - Export(model, true, false, output_file_contents); +inline void Export(const Model& model, bool allow_custom_ops, + bool quantize_weights, string* output_file_contents) { + ExportParams params; + params.allow_custom_ops = allow_custom_ops; + params.quantize_weights = quantize_weights; + Export(model, output_file_contents, params); } -// Export API with custom TFLite operator mapping. -void Export( +// This is for backward-compatibility. +// TODO(ycling): Remove the deprecated entry functions. +inline void Export( const Model& model, bool allow_custom_ops, bool quantize_weights, string* output_file_contents, - const std::map<OperatorType, std::unique_ptr<BaseOperator>>& ops_by_type); + const std::map<OperatorType, std::unique_ptr<BaseOperator>>& ops_by_type) { + ExportParams params; + params.allow_custom_ops = allow_custom_ops; + params.quantize_weights = quantize_weights; + Export(model, output_file_contents, params, ops_by_type); +} + +// This is for backward-compatibility. +// TODO(ycling): Remove the deprecated entry functions. +inline void Export(const Model& model, string* output_file_contents) { + ExportParams params; + params.allow_custom_ops = true; + Export(model, output_file_contents, params); + Export(model, true, false, output_file_contents); +} namespace details { @@ -88,7 +120,8 @@ using OperatorsMap = std::unordered_map<OperatorKey, int, OperatorKey::Hash>; void LoadTensorsMap(const Model& model, TensorsMap* tensors_map); void LoadOperatorsMap( const Model& model, OperatorsMap* operators_map, - const std::map<OperatorType, std::unique_ptr<BaseOperator>>& ops_by_type); + const std::map<OperatorType, std::unique_ptr<BaseOperator>>& ops_by_type, + bool allow_eager_ops); } // namespace details } // namespace tflite diff --git a/tensorflow/contrib/lite/toco/tflite/export_test.cc b/tensorflow/contrib/lite/toco/tflite/export_test.cc index 4994ea30de..8d4d197c46 100644 --- a/tensorflow/contrib/lite/toco/tflite/export_test.cc +++ b/tensorflow/contrib/lite/toco/tflite/export_test.cc @@ -105,7 +105,8 @@ TEST_F(ExportTest, LoadOperatorsMap) { details::OperatorsMap operators; const auto ops_by_type = BuildOperatorByTypeMap(); - details::LoadOperatorsMap(input_model_, &operators, ops_by_type); + // TODO(ycling): Add a test for allow_eager_ops. + details::LoadOperatorsMap(input_model_, &operators, ops_by_type, false); EXPECT_EQ(0, operators[details::OperatorKey(OperatorType::kAdd, "", 1)]); EXPECT_EQ(1, operators[details::OperatorKey(OperatorType::kConv, "", 1)]); EXPECT_EQ(2, operators[details::OperatorKey(OperatorType::kSub, "", 1)]); @@ -253,7 +254,7 @@ TEST_F(VersionedOpExportTest, LoadOperatorsMapWithOpV1) { details::OperatorsMap operators; const auto ops_by_type = BuildFakeOperatorByTypeMap(); - details::LoadOperatorsMap(input_model_, &operators, ops_by_type); + details::LoadOperatorsMap(input_model_, &operators, ops_by_type, false); EXPECT_EQ(1, operators.size()); EXPECT_EQ(0, operators.at(details::OperatorKey(OperatorType::kConv, "", 1))); @@ -264,7 +265,7 @@ TEST_F(VersionedOpExportTest, LoadOperatorsMapWithOpV2) { details::OperatorsMap operators; const auto ops_by_type = BuildFakeOperatorByTypeMap(); - details::LoadOperatorsMap(input_model_, &operators, ops_by_type); + details::LoadOperatorsMap(input_model_, &operators, ops_by_type, false); EXPECT_EQ(1, operators.size()); EXPECT_EQ(0, operators.at(details::OperatorKey(OperatorType::kConv, "", 2))); @@ -276,7 +277,7 @@ TEST_F(VersionedOpExportTest, LoadOperatorsMapWithBothVersions) { details::OperatorsMap operators; const auto ops_by_type = BuildFakeOperatorByTypeMap(); - details::LoadOperatorsMap(input_model_, &operators, ops_by_type); + details::LoadOperatorsMap(input_model_, &operators, ops_by_type, false); EXPECT_EQ(2, operators.size()); EXPECT_EQ(0, operators.at(details::OperatorKey(OperatorType::kConv, "", 1))); diff --git a/tensorflow/contrib/lite/toco/tflite/operator.cc b/tensorflow/contrib/lite/toco/tflite/operator.cc index a314c8d53a..eb0f7c443a 100644 --- a/tensorflow/contrib/lite/toco/tflite/operator.cc +++ b/tensorflow/contrib/lite/toco/tflite/operator.cc @@ -1149,7 +1149,9 @@ class Unpack : public BuiltinOperator<UnpackOperator, ::tflite::UnpackOptions, class TensorFlowUnsupported : public BaseOperator { public: - using BaseOperator::BaseOperator; + TensorFlowUnsupported(const string& name, OperatorType type, + bool allow_eager_ops) + : BaseOperator(name, type), allow_eager_ops_(allow_eager_ops) {} Options Serialize(const Operator& op, flatbuffers::FlatBufferBuilder* builder) const override { @@ -1165,6 +1167,9 @@ class TensorFlowUnsupported : public BaseOperator { std::unique_ptr<Operator> Deserialize( const BuiltinOptions* builtin_options, const CustomOptions* custom_options) const override { + // Deserializing Eager ops doesn't work now. + // TODO(ycling): Revisit and decide if we should fix the flow for importing + // TFLite models with Eager ops. auto op = absl::make_unique<TensorFlowUnsupportedOperator>(); if (custom_options) { auto flexbuffer_map = @@ -1185,6 +1190,16 @@ class TensorFlowUnsupported : public BaseOperator { return std::unique_ptr<flexbuffers::Builder>(); } + if (allow_eager_ops_) { + fbb->Vector([&]() { + fbb->String(node_def.op()); + fbb->String(op.tensorflow_node_def); + }); + fbb->Finish(); + LOG(INFO) << "Writing eager op: " << node_def.op(); + return std::unique_ptr<flexbuffers::Builder>(fbb.release()); + } + bool has_valid_attr = false; size_t map_start = fbb->StartMap(); for (const auto& pair : node_def.attr()) { @@ -1285,11 +1300,15 @@ class TensorFlowUnsupported : public BaseOperator { // custom ops. return 1; } + + private: + const bool allow_eager_ops_; }; namespace { // Build a vector containing all the known operators. -std::vector<std::unique_ptr<BaseOperator>> BuildOperatorList() { +std::vector<std::unique_ptr<BaseOperator>> BuildOperatorList( + bool allow_eager_ops = false) { std::vector<std::unique_ptr<BaseOperator>> ops; using tensorflow::MakeUnique; // Builtin Operators. @@ -1400,8 +1419,8 @@ std::vector<std::unique_ptr<BaseOperator>> BuildOperatorList() { MakeUnique<DepthToSpace>("DEPTH_TO_SPACE", OperatorType::kDepthToSpace)); ops.push_back(MakeUnique<CTCBeamSearchDecoder>( "CTC_BEAM_SEARCH_DECODER", OperatorType::kCTCBeamSearchDecoder)); - ops.push_back(MakeUnique<TensorFlowUnsupported>("TENSORFLOW_UNSUPPORTED", - OperatorType::kUnsupported)); + ops.push_back(MakeUnique<TensorFlowUnsupported>( + "TENSORFLOW_UNSUPPORTED", OperatorType::kUnsupported, allow_eager_ops)); // There operators are supported by Toco, but not by TF Lite, and has no // attributes. @@ -1474,10 +1493,12 @@ std::vector<std::unique_ptr<BaseOperator>> BuildOperatorList() { } } // namespace -std::map<OperatorType, std::unique_ptr<BaseOperator>> BuildOperatorByTypeMap() { +std::map<OperatorType, std::unique_ptr<BaseOperator>> BuildOperatorByTypeMap( + bool allow_eager_ops) { std::map<OperatorType, std::unique_ptr<BaseOperator>> result; - std::vector<std::unique_ptr<BaseOperator>> ops = BuildOperatorList(); + std::vector<std::unique_ptr<BaseOperator>> ops = + BuildOperatorList(allow_eager_ops); for (auto& op : ops) { result[op->type()] = std::move(op); } @@ -1485,10 +1506,12 @@ std::map<OperatorType, std::unique_ptr<BaseOperator>> BuildOperatorByTypeMap() { return result; } -std::map<string, std::unique_ptr<BaseOperator>> BuildOperatorByNameMap() { +std::map<string, std::unique_ptr<BaseOperator>> BuildOperatorByNameMap( + bool allow_eager_ops) { std::map<string, std::unique_ptr<BaseOperator>> result; - std::vector<std::unique_ptr<BaseOperator>> ops = BuildOperatorList(); + std::vector<std::unique_ptr<BaseOperator>> ops = + BuildOperatorList(allow_eager_ops); for (auto& op : ops) { result[op->name()] = std::move(op); } diff --git a/tensorflow/contrib/lite/toco/tflite/operator.h b/tensorflow/contrib/lite/toco/tflite/operator.h index d9ea23edf2..702fb28ea6 100644 --- a/tensorflow/contrib/lite/toco/tflite/operator.h +++ b/tensorflow/contrib/lite/toco/tflite/operator.h @@ -26,11 +26,15 @@ namespace tflite { class BaseOperator; // Return a map contained all know TF Lite Operators, keyed by their names. -std::map<string, std::unique_ptr<BaseOperator>> BuildOperatorByNameMap(); +// TODO(ycling): The pattern to propagate parameters (e.g. allow_eager_ops) +// is ugly here. Consider refactoring. +std::map<string, std::unique_ptr<BaseOperator>> BuildOperatorByNameMap( + bool allow_eager_ops = false); // Return a map contained all know TF Lite Operators, keyed by the type of // their tf.mini counterparts. -std::map<OperatorType, std::unique_ptr<BaseOperator>> BuildOperatorByTypeMap(); +std::map<OperatorType, std::unique_ptr<BaseOperator>> BuildOperatorByTypeMap( + bool allow_eager_ops = false); // These are the flatbuffer types for custom and builtin options. using CustomOptions = flatbuffers::Vector<uint8_t>; diff --git a/tensorflow/contrib/lite/toco/toco_cmdline_flags.cc b/tensorflow/contrib/lite/toco/toco_cmdline_flags.cc index c6d0a03452..b6aebc0470 100644 --- a/tensorflow/contrib/lite/toco/toco_cmdline_flags.cc +++ b/tensorflow/contrib/lite/toco/toco_cmdline_flags.cc @@ -160,10 +160,18 @@ bool ParseTocoFlagsFromCommandLineFlags( "Ignored if the output format is not TFLite."), Flag("quantize_weights", parsed_flags.quantize_weights.bind(), parsed_flags.quantize_weights.default_value(), - "Store weights as quantized weights followed by dequantize " - "operations. Computation is still done in float, but reduces model " - "size (at the cost of accuracy and latency)."), - }; + "Deprecated. Please use --post_training_quantize instead."), + Flag("post_training_quantize", parsed_flags.post_training_quantize.bind(), + parsed_flags.post_training_quantize.default_value(), + "Boolean indicating whether to quantize the weights of the " + "converted float model. Model size will be reduced and there will " + "be latency improvements (at the cost of accuracy)."), + // WARNING: Experimental interface, subject to change + Flag("allow_eager_ops", parsed_flags.allow_eager_ops.bind(), + parsed_flags.allow_eager_ops.default_value(), ""), + // WARNING: Experimental interface, subject to change + Flag("force_eager_ops", parsed_flags.force_eager_ops.bind(), + parsed_flags.force_eager_ops.default_value(), "")}; bool asked_for_help = *argc == 2 && (!strcmp(argv[1], "--help") || !strcmp(argv[1], "-help")); if (asked_for_help) { @@ -257,6 +265,17 @@ void ReadTocoFlagsFromCommandLineFlags(const ParsedTocoFlags& parsed_toco_flags, READ_TOCO_FLAG(dedupe_array_min_size_bytes, FlagRequirement::kNone); READ_TOCO_FLAG(split_tflite_lstm_inputs, FlagRequirement::kNone); READ_TOCO_FLAG(quantize_weights, FlagRequirement::kNone); + READ_TOCO_FLAG(post_training_quantize, FlagRequirement::kNone); + READ_TOCO_FLAG(allow_eager_ops, FlagRequirement::kNone); + READ_TOCO_FLAG(force_eager_ops, FlagRequirement::kNone); + + if (parsed_toco_flags.force_eager_ops.value() && + !parsed_toco_flags.allow_eager_ops.value()) { + // TODO(ycling): Consider to enforce `allow_eager_ops` when + // `force_eager_ops` is true. + LOG(WARNING) << "--force_eager_ops should always be used with " + "--allow_eager_ops."; + } // Deprecated flag handling. if (parsed_toco_flags.input_type.specified()) { @@ -291,9 +310,19 @@ void ReadTocoFlagsFromCommandLineFlags(const ParsedTocoFlags& parsed_toco_flags, toco_flags->set_inference_input_type(input_type); } if (parsed_toco_flags.quantize_weights.value()) { - QCHECK_NE(toco_flags->inference_type(), IODataType::QUANTIZED_UINT8) - << "quantize_weights is not supported with inference_type " - "QUANTIZED_UINT8."; + LOG(WARNING) + << "--quantize_weights is deprecated. Falling back to " + "--post_training_quantize. Please switch --post_training_quantize."; + toco_flags->set_post_training_quantize( + parsed_toco_flags.quantize_weights.value()); + } + if (parsed_toco_flags.quantize_weights.value()) { + if (toco_flags->inference_type() == IODataType::QUANTIZED_UINT8) { + LOG(WARNING) + << "--post_training_quantize quantizes a graph of inference_type " + "FLOAT. Overriding inference type QUANTIZED_UINT8 to FLOAT."; + toco_flags->set_inference_type(IODataType::FLOAT); + } } #undef READ_TOCO_FLAG diff --git a/tensorflow/contrib/lite/toco/toco_flags.proto b/tensorflow/contrib/lite/toco/toco_flags.proto index b4a9870d58..53d60fed05 100644 --- a/tensorflow/contrib/lite/toco/toco_flags.proto +++ b/tensorflow/contrib/lite/toco/toco_flags.proto @@ -37,7 +37,7 @@ enum FileFormat { // of as properties of models, instead describing how models are to be // processed in the context of the present tooling job. // -// Next ID to use: 26. +// Next ID to use: 29. message TocoFlags { // Input file format optional FileFormat input_format = 1; @@ -173,6 +173,7 @@ message TocoFlags { // Store weights as quantized weights followed by dequantize operations. // Computation is still done in float, but reduces model size (at the cost of // accuracy and latency). + // DEPRECATED: Please use post_training_quantize instead. optional bool quantize_weights = 20 [default = false]; // Full filepath of folder to dump the graphs at various stages of processing @@ -183,4 +184,22 @@ message TocoFlags { // Boolean indicating whether to dump the graph after every graph // transformation. optional bool dump_graphviz_include_video = 25; + + // Boolean indicating whether to quantize the weights of the converted float + // model. Model size will be reduced and there will be latency improvements + // (at the cost of accuracy). + optional bool post_training_quantize = 26 [default = false]; + + // When enabled, unsupported ops will be converted to TFLite Eager ops. + // TODO(ycling): Consider to rename the following 2 flags and don't call it + // "Eager". + // `allow_eager_ops` should always be used with `allow_custom_ops`. + // WARNING: Experimental interface, subject to change + optional bool allow_eager_ops = 27 [default = false]; + + // When enabled, all TensorFlow ops will be converted to TFLite Eager + // ops directly. This will force `allow_eager_ops` to true. + // `force_eager_ops` should always be used with `allow_eager_ops`. + // WARNING: Experimental interface, subject to change + optional bool force_eager_ops = 28 [default = false]; } diff --git a/tensorflow/contrib/lite/toco/toco_tooling.cc b/tensorflow/contrib/lite/toco/toco_tooling.cc index 243d0dabdb..a7c17156b1 100644 --- a/tensorflow/contrib/lite/toco/toco_tooling.cc +++ b/tensorflow/contrib/lite/toco/toco_tooling.cc @@ -197,6 +197,10 @@ std::unique_ptr<Model> Import(const TocoFlags& toco_flags, toco_flags.has_drop_control_dependency() ? toco_flags.drop_control_dependency() : (toco_flags.output_format() != TENSORFLOW_GRAPHDEF); + + tf_import_flags.import_all_ops_as_unsupported = + toco_flags.force_eager_ops(); + model = ImportTensorFlowGraphDef(model_flags, tf_import_flags, input_file_contents); break; @@ -397,10 +401,21 @@ void Export(const TocoFlags& toco_flags, const Model& model, case TENSORFLOW_GRAPHDEF: ExportTensorFlowGraphDef(model, output_file_contents); break; - case TFLITE: - toco::tflite::Export(model, allow_custom_ops, - toco_flags.quantize_weights(), output_file_contents); - break; + case TFLITE: { + toco::tflite::ExportParams params; + + // Always allow custom ops when eager ops are allowed. + if (toco_flags.force_eager_ops() || toco_flags.allow_eager_ops()) { + params.allow_eager_ops = true; + params.allow_custom_ops = true; + } else if (allow_custom_ops) { + params.allow_custom_ops = true; + } + + params.quantize_weights = toco_flags.post_training_quantize(); + + toco::tflite::Export(model, output_file_contents, params); + } break; case GRAPHVIZ_DOT: DumpGraphviz(model, output_file_contents); break; diff --git a/tensorflow/contrib/lite/tools/accuracy/BUILD b/tensorflow/contrib/lite/tools/accuracy/BUILD index 74f101c573..1b60d6a60d 100644 --- a/tensorflow/contrib/lite/tools/accuracy/BUILD +++ b/tensorflow/contrib/lite/tools/accuracy/BUILD @@ -45,7 +45,10 @@ tf_cc_test( data = ["//tensorflow/contrib/lite:testdata/multi_add.bin"], linkopts = common_linkopts, linkstatic = 1, - tags = ["tflite_not_portable_ios"], + tags = [ + "tflite_not_portable_android", + "tflite_not_portable_ios", + ], deps = [ ":utils", "@com_google_googletest//:gtest", diff --git a/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_model_evaluator.cc b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_model_evaluator.cc index 1731d2ade6..63616fc3b4 100644 --- a/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_model_evaluator.cc +++ b/tensorflow/contrib/lite/tools/accuracy/ilsvrc/imagenet_model_evaluator.cc @@ -327,7 +327,8 @@ Status ImagenetModelEvaluator::EvaluateModel() const { const auto& image_label = img_labels[i]; const uint64_t shard_id = i + 1; shard_id_image_count_map[shard_id] = image_label.size(); - auto func = [&]() { + auto func = [shard_id, &image_label, &model_labels, this, &observer, &eval, + &counter]() { TF_CHECK_OK(EvaluateModelForShard(shard_id, image_label, model_labels, model_info_, params_, &observer, &eval)); diff --git a/tensorflow/contrib/lite/tools/benchmark/README.md b/tensorflow/contrib/lite/tools/benchmark/README.md index f1e257ad10..8d997639fb 100644 --- a/tensorflow/contrib/lite/tools/benchmark/README.md +++ b/tensorflow/contrib/lite/tools/benchmark/README.md @@ -9,7 +9,7 @@ of runs. Aggregrate latency statistics are reported after running the benchmark. The instructions below are for running the binary on Desktop and Android, for iOS please use the -[iOS benchmark app] (https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/lite/tools/benchmark/ios). +[iOS benchmark app](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/lite/tools/benchmark/ios). ## Parameters @@ -17,11 +17,6 @@ The binary takes the following required parameters: * `graph`: `string` \ The path to the TFLite model file. -* `input_layer`: `string` \ - The name of the input layer, this is typically the first layer of the model. -* `input_layer_shape`: `string` \ - The shape of the input layer. This is a comma separated string of the shape - of tensor of input layer. and the following optional parameters: @@ -29,11 +24,13 @@ and the following optional parameters: The number of threads to use for running TFLite interpreter. * `warmup_runs`: `int` (default=1) \ The number of warmup runs to do before starting the benchmark. +* `num_runs`: `int` (default=50) \ + The number of runs. Increase this to reduce variance. * `run_delay`: `float` (default=-1.0) \ The delay in seconds between subsequent benchmark runs. Non-positive values mean use no delay. * `use_nnapi`: `bool` (default=false) \ - Whether to use [Android NNAPI] (https://developer.android.com/ndk/guides/neuralnetworks/). + Whether to use [Android NNAPI](https://developer.android.com/ndk/guides/neuralnetworks/). This API is available on recent Android devices. ## To build/install/run @@ -75,8 +72,6 @@ adb push mobilenet_quant_v1_224.tflite /data/local/tmp ``` adb shell /data/local/tmp/benchmark_model \ --graph=/data/local/tmp/mobilenet_quant_v1_224.tflite \ - --input_layer="input" \ - --input_layer_shape="1,224,224,3" \ --num_threads=4 ``` @@ -93,13 +88,10 @@ For example: ``` bazel-bin/tensorflow/contrib/lite/tools/benchmark/benchmark_model \ --graph=mobilenet_quant_v1_224.tflite \ - --input_layer="Placeholder" \ - --input_layer_shape="1,224,224,3" \ --num_threads=4 ``` -The MobileNet graph used as an example here may be downloaded from -https://storage.googleapis.com/download.tensorflow.org/models/tflite/mobilenet_v1_224_android_quant_2017_11_08.zip +The MobileNet graph used as an example here may be downloaded from [here](https://storage.googleapis.com/download.tensorflow.org/models/tflite/mobilenet_v1_224_android_quant_2017_11_08.zip). ## Reducing variance between runs on Android. @@ -117,8 +109,6 @@ can use the following command: ``` adb shell taskset f0 /data/local/tmp/benchmark_model \ --graph=/data/local/tmp/mobilenet_quant_v1_224.tflite \ - --input_layer="input" \ - --input_layer_shape="1,224,224,3" \ --num_threads=1 ``` @@ -205,5 +195,3 @@ Memory (bytes): count=0 Average inference timings in us: Warmup: 83235, Init: 38467, no stats: 79760.9 ``` - - diff --git a/tensorflow/contrib/lite/tools/benchmark/ios/README.md b/tensorflow/contrib/lite/tools/benchmark/ios/README.md index c8d3307e29..46144f7bf8 100644 --- a/tensorflow/contrib/lite/tools/benchmark/ios/README.md +++ b/tensorflow/contrib/lite/tools/benchmark/ios/README.md @@ -17,8 +17,8 @@ Mobilenet_1.0_224 model ## To build/install/run -- Follow instructions at [iOS build for TFLite] -(https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/lite/g3doc/ios.md) +- Follow instructions at +[iOS build for TFLite](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/lite/g3doc/ios.md) to build TFLite. Running diff --git a/tensorflow/contrib/lite/tools/optimize/g3doc/quantize_weights.md b/tensorflow/contrib/lite/tools/optimize/g3doc/quantize_weights.md new file mode 100644 index 0000000000..93fe576583 --- /dev/null +++ b/tensorflow/contrib/lite/tools/optimize/g3doc/quantize_weights.md @@ -0,0 +1,70 @@ +# TFLite Quantize Weights Tool + +## Recommended usage + +The Quantize Weights transformation is integrated with +[tflite_convert](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/lite/toco/g3doc/cmdline_reference.md#transformation-flags). + +The recommended way of invoking this tool is by simply adding the +`--post_training_quantize` flag to your original tflite_convert invocation. For +example, + +``` +tflite_convert \ + --output_file=/tmp/foo.tflite \ + --saved_model_dir=/tmp/saved_model \ + --post_training_quantize +``` + +## Overview + +The Quantize Weights tool provides a simple way to quantize the weights for a +float TFLite model. + +TODO(raghuramank): Add link to weight quantization tutorial. + +### Size reduction + +float32 weights will be converted to 8 bit integers. This results in a model +that is around 1/4th the size of the original model. + +### Latency reduction + +TFLite also has "hybrid" kernels implemented for many operations. These "hybrid" +kernels take 8 bit integer weights and float inputs, dynamically quantize the +inputs tensor (based on the input tensor's min and max elements), and does +computations using the 8 bit integer values. This results in a 2-4x reduction in +latency for "hybrid" kernels. In this mode the inference type is still FLOAT +since the inputs and output to each operation is still float. + +For operations that do not yet have "hybrid" kernels implemented, we introduce a +Dequantize operation after 8 bit integer weights. These convert weights back to +float32 during inference to allow original float32 kernels to run. Since we +cache dequantized results, the result of each of this dequantized path will be +on-par with the original float model. + +TODO(yunluli): Fill in latency results from latency experiments. + +### Accuracy + +Since this technique quantizes weights after the model has already been trained, +there can be accuracy drops depending on the model. For common CNN networks, the +observed accuracy drops are small and can be seen below. + +TODO(yunluli): Fill in accuracy results from accuracy experiments. + +## Direct usage + +One can also invoke the Quantize Weights directly via C++ if they have a float +`::tflite::Model` that they want to convert. They must provide a +`flatbuffers::FlatBufferBuilder` which owns the underlying buffer of the created +model. Here is an example invocation: + +``` +::tflite::Model* input_model = ...; +flatbuffers::FlatBufferBuilder builder; +TfLiteStatus status = ::tflite::optimize::QuantizeWeights(&builder, input_model); +CHECK(status, kTfLiteStatusOk); +const uint8_t* buffer = builder->GetBufferPointer(); +tflite::Model* output_model = ::tflite::GetModel(buffer); +``` diff --git a/tensorflow/contrib/lite/tools/optimize/quantize_weights.cc b/tensorflow/contrib/lite/tools/optimize/quantize_weights.cc index ec9fb04bf7..692efb9029 100644 --- a/tensorflow/contrib/lite/tools/optimize/quantize_weights.cc +++ b/tensorflow/contrib/lite/tools/optimize/quantize_weights.cc @@ -42,10 +42,9 @@ typedef struct { bool eval_hybrid; } TensorInfo; -// The minimum number of elements a weights array must have to be quantized -// by this transformation. -// TODO(suharshs): Make this configurable. -const int kWeightsMinSize = 1024; +// The default minimum number of elements a weights array must have to be +// quantized by this transformation. +const int kWeightsMinNumElementsDefault = 1024; // Nudge min and max so that floating point 0 falls exactly on a quantized // value, returning the nudges scale and zero_point. @@ -158,39 +157,51 @@ bool IsHybridEvaluationOp(const OperatorT* op, const BuiltinOperator& op_code) { // Returns a vector of TensorInfos for each input tensor of op that should be // quantized. -std::vector<TensorInfo> GetQuantizableTensorsFromOperator(const ModelT* model, - const OperatorT* op) { +std::vector<TensorInfo> GetQuantizableTensorsFromOperator( + const ModelT* model, const OperatorT* op, uint64_t weights_min_num_elements, + bool use_hybrid_evaluation) { SubGraphT* subgraph = model->subgraphs.at(0).get(); const BuiltinOperator op_code = model->operator_codes[op->opcode_index]->builtin_code; std::vector<TensorInfo> tensor_infos; - bool eval_hybrid = IsHybridEvaluationOp(op, op_code); + bool eval_hybrid = use_hybrid_evaluation && IsHybridEvaluationOp(op, op_code); std::vector<int32_t> op_input_indices = GetWeightInputIndices(op_code); for (const int32_t op_input_idx : op_input_indices) { int32_t tensor_idx = op->inputs[op_input_idx]; - // TODO(suharshs): Support shared weights, i.e. If two tensors share the - // same weight array, things may break. (i.e. SSD object detection) - if (CountTensorConsumers(model, subgraph, tensor_idx) != 1) { - LOG(INFO) << "Skipping quantization of tensor that is shared between " - "multiple multiple operations."; + if (tensor_idx == -1) { + LOG(INFO) << "Skipping optional tensor input " << op_input_idx + << " of operation " << EnumNameBuiltinOperator(op_code); continue; } TensorT* tensor = subgraph->tensors[tensor_idx].get(); + // TODO(suharshs): Support shared weights, i.e. If two tensors share the + // same weight array, things may break. (i.e. SSD object detection) + if (!eval_hybrid && + CountTensorConsumers(model, subgraph, tensor_idx) != 1) { + LOG(INFO) << "Skipping quantization of tensor " << tensor->name + << " that is shared between multiple multiple operations."; + continue; + } if (tensor->type != TensorType_FLOAT32) { - LOG(INFO) << "Skipping quantization of tensor that is not type float."; + LOG(INFO) << "Skipping quantization of tensor " << tensor->name + << " that is not type float."; continue; } const uint64_t num_elements = NumElements(tensor); - if (num_elements < kWeightsMinSize) { - LOG(INFO) << "Skipping quantization of tensor because it has fewer than " - << kWeightsMinSize << " elements (" << num_elements << ")."; + if (num_elements < weights_min_num_elements) { + LOG(INFO) << "Skipping quantization of tensor " << tensor->name + << " because it has fewer than " << weights_min_num_elements + << " elements (" << num_elements << ")."; + // If one of the weights isn't quantized, then we cannot use the hybrid + // kernel for this operation, since it expects everything to be quantized. + eval_hybrid = false; continue; } @@ -212,11 +223,16 @@ TfLiteStatus AsymmetricQuantizeTensor(ModelT* model, TensorT* tensor) { BufferT* buffer = model->buffers[tensor->buffer].get(); float* float_data = reinterpret_cast<float*>(buffer->data.data()); const uint64_t num_elements = NumElements(tensor); - LOG(INFO) << "Quantizing tensor with " << num_elements << " elements."; + LOG(INFO) << "Quantizing tensor " << tensor->name << " with " << num_elements + << " elements for float evaluation."; // Compute the quantization params. float min_value = *std::min_element(float_data, float_data + num_elements); float max_value = *std::max_element(float_data, float_data + num_elements); + + if (tensor->quantization == nullptr) { + tensor->quantization = absl::make_unique<QuantizationParametersT>(); + } GetAsymmetricQuantizationParams(min_value, max_value, 0, 255, tensor->quantization.get()); @@ -251,7 +267,8 @@ TfLiteStatus SymmetricQuantizeTensor(ModelT* model, TensorT* tensor) { BufferT* buffer = model->buffers[tensor->buffer].get(); float* float_data = reinterpret_cast<float*>(buffer->data.data()); const uint64_t num_elements = NumElements(tensor); - LOG(INFO) << "Quantizing tensor with " << num_elements << " elements."; + LOG(INFO) << "Quantizing tensor " << tensor->name << " with " << num_elements + << " elements for hybrid evaluation."; std::vector<int8_t> quantized_buffer; quantized_buffer.resize(num_elements); @@ -260,6 +277,10 @@ TfLiteStatus SymmetricQuantizeTensor(ModelT* model, TensorT* tensor) { tensor_utils::SymmetricQuantizeFloats(float_data, num_elements, quantized_buffer.data(), &min_value, &max_value, &scaling_factor); + + if (tensor->quantization == nullptr) { + tensor->quantization = absl::make_unique<QuantizationParametersT>(); + } tensor->quantization->scale = std::vector<float>(1, scaling_factor); tensor->quantization->zero_point = std::vector<int64_t>(1, 0); @@ -311,11 +332,10 @@ void MakeTensor(const string& name, const std::vector<int32_t>& shape, tensor->reset(tensor_raw); } -} // namespace - -TfLiteStatus QuantizeWeights(flatbuffers::FlatBufferBuilder* builder, - const Model* input_model, - bool use_hybrid_evaluation) { +TfLiteStatus QuantizeWeightsInternal(flatbuffers::FlatBufferBuilder* builder, + const Model* input_model, + bool use_hybrid_evaluation, + uint64_t weights_min_num_elements) { std::unique_ptr<ModelT> model; model.reset(input_model->UnPack()); @@ -332,11 +352,11 @@ TfLiteStatus QuantizeWeights(flatbuffers::FlatBufferBuilder* builder, for (int i = 0; i < subgraph->operators.size(); ++i) { OperatorT* op = subgraph->operators[i].get(); - std::vector<TensorInfo> tensor_infos = - GetQuantizableTensorsFromOperator(model.get(), op); + std::vector<TensorInfo> tensor_infos = GetQuantizableTensorsFromOperator( + model.get(), op, weights_min_num_elements, use_hybrid_evaluation); for (const TensorInfo& tensor_info : tensor_infos) { - if (use_hybrid_evaluation && tensor_info.eval_hybrid) { + if (tensor_info.eval_hybrid) { // Quantize the tensor. TF_LITE_ENSURE_STATUS( SymmetricQuantizeTensor(model.get(), tensor_info.tensor)); @@ -379,9 +399,32 @@ TfLiteStatus QuantizeWeights(flatbuffers::FlatBufferBuilder* builder, return kTfLiteOk; } +} // namespace + +namespace internal { +TfLiteStatus QuantizeWeights(flatbuffers::FlatBufferBuilder* builder, + const Model* input_model, + bool use_hybrid_evaluation) { + // By default we require that only weights with more than + // kWeightsMinSizeDefault elements are quantized. + return QuantizeWeightsInternal(builder, input_model, use_hybrid_evaluation, + kWeightsMinNumElementsDefault); +} +} // namespace internal + +TfLiteStatus QuantizeWeights(flatbuffers::FlatBufferBuilder* builder, + const Model* input_model, + uint64_t weights_min_num_elements) { + return QuantizeWeightsInternal(builder, input_model, true, + weights_min_num_elements); +} + TfLiteStatus QuantizeWeights(flatbuffers::FlatBufferBuilder* builder, const Model* input_model) { - return QuantizeWeights(builder, input_model, true); + // By default we require that only weights with more than + // kWeightsMinSizeDefault elements are quantized. + return QuantizeWeightsInternal(builder, input_model, true, + kWeightsMinNumElementsDefault); } } // namespace optimize diff --git a/tensorflow/contrib/lite/tools/optimize/quantize_weights.h b/tensorflow/contrib/lite/tools/optimize/quantize_weights.h index 3743c0ce53..706f10b87b 100644 --- a/tensorflow/contrib/lite/tools/optimize/quantize_weights.h +++ b/tensorflow/contrib/lite/tools/optimize/quantize_weights.h @@ -25,6 +25,8 @@ namespace tflite { namespace optimize { // Quantizes input_model and populates the provided builder with the new model. +// By default only weights tensors weight more than 1024 elements will be +// quantized. // // A tflite::Model can be obtained from the builder with: // const uint8_t* buffer = builder->GetBufferPointer(); @@ -32,11 +34,22 @@ namespace optimize { TfLiteStatus QuantizeWeights(flatbuffers::FlatBufferBuilder* builder, const Model* input_model); -// Same as above, but if use_hybrid_evaluation is false, will disable using -// hybrid eval for operations that support it. +// Same as above, but only weights with greater than or equal +// weights_min_num_elements elements will be quantized. +TfLiteStatus QuantizeWeights(flatbuffers::FlatBufferBuilder* builder, + const Model* input_model, + uint64_t weights_min_num_elements); + +namespace internal { +// If use_hybrid_evaluation is false, will disable using hybrid eval for +// operations that support it. +// +// We use this internal QuantizeWeights call to test models with hybrid +// evaluation disabled. TfLiteStatus QuantizeWeights(flatbuffers::FlatBufferBuilder* builder, const Model* input_model, bool use_hybrid_evaluation); +} // namespace internal } // namespace optimize } // namespace tflite diff --git a/tensorflow/contrib/lite/tools/optimize/quantize_weights_test.cc b/tensorflow/contrib/lite/tools/optimize/quantize_weights_test.cc index efaf9929e9..387b3471c2 100644 --- a/tensorflow/contrib/lite/tools/optimize/quantize_weights_test.cc +++ b/tensorflow/contrib/lite/tools/optimize/quantize_weights_test.cc @@ -76,7 +76,8 @@ class QuantizeWeightsTest : public ::testing::Test { void CheckWeights(const Model* input_model_packed, const Model* output_model_packed, - bool use_hybrid_evaluation) { + bool use_hybrid_evaluation, + uint64_t weights_min_num_elements = 1024) { std::unique_ptr<ModelT> input_model; input_model.reset(input_model_packed->UnPack()); @@ -113,8 +114,9 @@ class QuantizeWeightsTest : public ::testing::Test { int tensor_size = GetElementsNum(tensor); // If the tensor_size is less than 1024 we expect the tensor to remain // unquantized. - if (tensor_size < 1024) { - ASSERT_TRUE(tensor->type == TensorType_FLOAT32) << tensor->name; + if (tensor_size < weights_min_num_elements) { + ASSERT_TRUE(tensor->type == TensorType_FLOAT32) + << tensor->name << " of type " << tensor->type; const OperatorT* preceding_op = GetOpWithOutput(subgraph, tensor_idx); // The weight tensor should not come from a dequantize op. ASSERT_TRUE(preceding_op == nullptr); @@ -183,7 +185,7 @@ TEST_F(QuantizeWeightsTest, SimpleTestWithoutHybrid) { flatbuffers::FlatBufferBuilder builder; // Disable hybrid evaluation. - EXPECT_EQ(QuantizeWeights(&builder, input_model, false), kTfLiteOk); + EXPECT_EQ(internal::QuantizeWeights(&builder, input_model, false), kTfLiteOk); const uint8_t* buffer = builder.GetBufferPointer(); const Model* output_model = GetModel(buffer); @@ -191,6 +193,26 @@ TEST_F(QuantizeWeightsTest, SimpleTestWithoutHybrid) { CheckWeights(input_model, output_model, false); } +TEST_F(QuantizeWeightsTest, SimpleTestWithWeightsMinNumElements) { + string model_path = + "third_party/tensorflow/contrib/lite/tools/optimize/testdata/" + "mobilenet_v1_0.25_128.tflite"; + std::unique_ptr<FlatBufferModel> input_fb = + FlatBufferModel::BuildFromFile(model_path.data()); + const Model* input_model = input_fb->GetModel(); + + flatbuffers::FlatBufferBuilder builder; + // Make weights_min_size sufficiently large such that no quantization should + // happen, i.e. the original model is the same size as the old one. + const uint64_t kWeightsMinNumElements = 1000000; + EXPECT_EQ(QuantizeWeights(&builder, input_model, kWeightsMinNumElements), + kTfLiteOk); + + const uint8_t* buffer = builder.GetBufferPointer(); + const Model* output_model = GetModel(buffer); + CheckWeights(input_model, output_model, true, kWeightsMinNumElements); +} + // TODO(suharshs): Add tests that run the resulting model. } // namespace diff --git a/tensorflow/contrib/opt/BUILD b/tensorflow/contrib/opt/BUILD index 5319a8b655..93e589907e 100644 --- a/tensorflow/contrib/opt/BUILD +++ b/tensorflow/contrib/opt/BUILD @@ -22,6 +22,7 @@ py_library( "python/training/ggt.py", "python/training/lars_optimizer.py", "python/training/lazy_adam_optimizer.py", + "python/training/matrix_functions.py", "python/training/model_average_optimizer.py", "python/training/moving_average_optimizer.py", "python/training/multitask_optimizer_wrapper.py", @@ -381,3 +382,18 @@ py_test( "@six_archive//:six", ], ) + +py_test( + name = "matrix_functions_test", + srcs = ["python/training/matrix_functions_test.py"], + srcs_version = "PY2AND3", + deps = [ + ":opt_py", + "//tensorflow/python:client", + "//tensorflow/python:client_testlib", + "//tensorflow/python:dtypes", + "//tensorflow/python:variables", + "//third_party/py/numpy", + "@six_archive//:six", + ], +) diff --git a/tensorflow/contrib/opt/python/training/elastic_average_optimizer.py b/tensorflow/contrib/opt/python/training/elastic_average_optimizer.py index bbafd59aae..6c203e5519 100644 --- a/tensorflow/contrib/opt/python/training/elastic_average_optimizer.py +++ b/tensorflow/contrib/opt/python/training/elastic_average_optimizer.py @@ -128,12 +128,14 @@ class ElasticAverageCustomGetter(object): = list(global_center_variable)[i] return local_var else: - return getter( - name, - trainable=trainable, - collections=collections, - *args, - **kwargs) + kwargs['trainable'] = trainable + kwargs['collections'] = collections + if ops.GraphKeys.LOCAL_VARIABLES in collections: + with ops.device(self._worker_device): + return getter(name, *args, **kwargs) + else: + return getter(name, *args, **kwargs) + class ElasticAverageOptimizer(optimizer.Optimizer): diff --git a/tensorflow/contrib/opt/python/training/lazy_adam_optimizer.py b/tensorflow/contrib/opt/python/training/lazy_adam_optimizer.py index 72117c1e81..f026f437dc 100644 --- a/tensorflow/contrib/opt/python/training/lazy_adam_optimizer.py +++ b/tensorflow/contrib/opt/python/training/lazy_adam_optimizer.py @@ -25,9 +25,11 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function +from tensorflow.python.framework import ops from tensorflow.python.ops import array_ops from tensorflow.python.ops import control_flow_ops from tensorflow.python.ops import math_ops +from tensorflow.python.ops import resource_variable_ops from tensorflow.python.ops import state_ops from tensorflow.python.training import adam @@ -46,7 +48,12 @@ class LazyAdamOptimizer(adam.AdamOptimizer): may lead to different empirical results. """ - def _apply_sparse(self, grad, var): + def _apply_sparse_shared(self, + grad, + var, + indices, + scatter_update, + scatter_sub): beta1_power, beta2_power = self._get_beta_accumulators() beta1_power = math_ops.cast(beta1_power, var.dtype.base_dtype) beta2_power = math_ops.cast(beta2_power, var.dtype.base_dtype) @@ -58,23 +65,51 @@ class LazyAdamOptimizer(adam.AdamOptimizer): # \\(m := beta1 * m + (1 - beta1) * g_t\\) m = self.get_slot(var, "m") - m_t = state_ops.scatter_update(m, grad.indices, - beta1_t * array_ops.gather(m, grad.indices) + - (1 - beta1_t) * grad.values, - use_locking=self._use_locking) + m_t = scatter_update(m, indices, + beta1_t * array_ops.gather(m, indices) + + (1 - beta1_t) * grad) # \\(v := beta2 * v + (1 - beta2) * (g_t * g_t)\\) v = self.get_slot(var, "v") - v_t = state_ops.scatter_update(v, grad.indices, - beta2_t * array_ops.gather(v, grad.indices) + - (1 - beta2_t) * math_ops.square(grad.values), - use_locking=self._use_locking) + v_t = scatter_update(v, indices, + beta2_t * array_ops.gather(v, indices) + + (1 - beta2_t) * math_ops.square(grad)) # \\(variable -= learning_rate * m_t / (epsilon_t + sqrt(v_t))\\) - m_t_slice = array_ops.gather(m_t, grad.indices) - v_t_slice = array_ops.gather(v_t, grad.indices) + m_t_slice = array_ops.gather(m_t, indices) + v_t_slice = array_ops.gather(v_t, indices) denominator_slice = math_ops.sqrt(v_t_slice) + epsilon_t - var_update = state_ops.scatter_sub(var, grad.indices, - lr * m_t_slice / denominator_slice, - use_locking=self._use_locking) + var_update = scatter_sub(var, indices, + lr * m_t_slice / denominator_slice) return control_flow_ops.group(var_update, m_t, v_t) + + def _apply_sparse(self, grad, var): + return self._apply_sparse_shared( + grad.values, var, grad.indices, + self._scatter_update, + self._scatter_sub) + + def _resource_apply_sparse(self, grad, var, indices): + return self._apply_sparse_shared( + grad, var, indices, + self._resource_scatter_update, + self._resource_scatter_sub) + + # Utility functions for updating resource or non-resource variables. + def _scatter_update(self, x, i, v): + return state_ops.scatter_update( + x, i, v, use_locking=self._use_locking) + + def _scatter_sub(self, x, i, v): + return state_ops.scatter_sub( + x, i, v, use_locking=self._use_locking) + + def _resource_scatter_update(self, x, i, v): + update_op = resource_variable_ops.resource_scatter_update(x.handle, i, v) + with ops.control_dependencies([update_op]): + return x.value() + + def _resource_scatter_sub(self, x, i, v): + sub_op = resource_variable_ops.resource_scatter_sub(x.handle, i, v) + with ops.control_dependencies([sub_op]): + return x.value() diff --git a/tensorflow/contrib/opt/python/training/lazy_adam_optimizer_test.py b/tensorflow/contrib/opt/python/training/lazy_adam_optimizer_test.py index dc4c462ce4..d3e9e89502 100644 --- a/tensorflow/contrib/opt/python/training/lazy_adam_optimizer_test.py +++ b/tensorflow/contrib/opt/python/training/lazy_adam_optimizer_test.py @@ -27,6 +27,7 @@ from tensorflow.python.framework import dtypes from tensorflow.python.framework import ops from tensorflow.python.ops import array_ops from tensorflow.python.ops import math_ops +from tensorflow.python.ops import resource_variable_ops from tensorflow.python.ops import variables from tensorflow.python.platform import test @@ -51,7 +52,7 @@ def adam_update_numpy(param, class AdamOptimizerTest(test.TestCase): - def testSparse(self): + def doTestSparse(self, use_resource=False): for dtype in [dtypes.half, dtypes.float32, dtypes.float64]: with self.cached_session(): # Initialize variables for numpy implementation. @@ -61,8 +62,12 @@ class AdamOptimizerTest(test.TestCase): var1_np = np.array([3.0, 4.0], dtype=dtype.as_numpy_dtype) grads1_np = np.array([0.01, 0.01], dtype=dtype.as_numpy_dtype) - var0 = variables.Variable(var0_np) - var1 = variables.Variable(var1_np) + if use_resource: + var0 = resource_variable_ops.ResourceVariable(var0_np) + var1 = resource_variable_ops.ResourceVariable(var1_np) + else: + var0 = variables.Variable(var0_np) + var1 = variables.Variable(var1_np) grads0_np_indices = np.array([0, 1], dtype=np.int32) grads0 = ops.IndexedSlices( constant_op.constant(grads0_np), @@ -94,6 +99,12 @@ class AdamOptimizerTest(test.TestCase): self.assertAllCloseAccordingToType(var0_np, var0.eval()) self.assertAllCloseAccordingToType(var1_np, var1.eval()) + def testSparse(self): + self.doTestSparse(use_resource=False) + + def testResourceSparse(self): + self.doTestSparse(use_resource=True) + def testSparseDevicePlacement(self): for index_dtype in [dtypes.int32, dtypes.int64]: with self.test_session(force_gpu=test.is_gpu_available()): diff --git a/tensorflow/contrib/opt/python/training/matrix_functions.py b/tensorflow/contrib/opt/python/training/matrix_functions.py new file mode 100644 index 0000000000..baab577638 --- /dev/null +++ b/tensorflow/contrib/opt/python/training/matrix_functions.py @@ -0,0 +1,155 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Matrix functions contains iterative methods for M^p.""" +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +from tensorflow.python.ops import control_flow_ops +from tensorflow.python.ops import linalg_ops +from tensorflow.python.ops import math_ops + + +def matrix_square_root(mat_a, mat_a_size, iter_count=100, ridge_epsilon=1e-4): + """Iterative method to get matrix square root. + + Stable iterations for the matrix square root, Nicholas J. Higham + + Page 231, Eq 2.6b + http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.6.8799&rep=rep1&type=pdf + + Args: + mat_a: the symmetric PSD matrix whose matrix square root be computed + mat_a_size: size of mat_a. + iter_count: Maximum number of iterations. + ridge_epsilon: Ridge epsilon added to make the matrix positive definite. + + Returns: + mat_a^0.5 + """ + + def _iter_condition(i, unused_mat_y, unused_old_mat_y, unused_mat_z, + unused_old_mat_z, err, old_err): + # This method require that we check for divergence every step. + return math_ops.logical_and(i < iter_count, err < old_err) + + def _iter_body(i, mat_y, unused_old_mat_y, mat_z, unused_old_mat_z, err, + unused_old_err): + current_iterate = 0.5 * (3.0 * identity - math_ops.matmul(mat_z, mat_y)) + current_mat_y = math_ops.matmul(mat_y, current_iterate) + current_mat_z = math_ops.matmul(current_iterate, mat_z) + # Compute the error in approximation. + mat_sqrt_a = current_mat_y * math_ops.sqrt(norm) + mat_a_approx = math_ops.matmul(mat_sqrt_a, mat_sqrt_a) + residual = mat_a - mat_a_approx + current_err = math_ops.sqrt(math_ops.reduce_sum(residual * residual)) / norm + return i + 1, current_mat_y, mat_y, current_mat_z, mat_z, current_err, err + + identity = linalg_ops.eye(math_ops.to_int32(mat_a_size)) + mat_a = mat_a + ridge_epsilon * identity + norm = math_ops.sqrt(math_ops.reduce_sum(mat_a * mat_a)) + mat_init_y = mat_a / norm + mat_init_z = identity + init_err = norm + + _, _, prev_mat_y, _, _, _, _ = control_flow_ops.while_loop( + _iter_condition, _iter_body, [ + 0, mat_init_y, mat_init_y, mat_init_z, mat_init_z, init_err, + init_err + 1.0 + ]) + return prev_mat_y * math_ops.sqrt(norm) + + +def matrix_inverse_pth_root(mat_g, + mat_g_size, + alpha, + iter_count=100, + epsilon=1e-6, + ridge_epsilon=1e-6): + """Computes mat_g^alpha, where alpha = -1/p, p a positive integer. + + We use an iterative Schur-Newton method from equation 3.2 on page 9 of: + + A Schur-Newton Method for the Matrix p-th Root and its Inverse + by Chun-Hua Guo and Nicholas J. Higham + SIAM Journal on Matrix Analysis and Applications, + 2006, Vol. 28, No. 3 : pp. 788-804 + https://pdfs.semanticscholar.org/0abe/7f77433cf5908bfe2b79aa91af881da83858.pdf + + Args: + mat_g: the symmetric PSD matrix whose power it to be computed + mat_g_size: size of mat_g. + alpha: exponent, must be -1/p for p a positive integer. + iter_count: Maximum number of iterations. + epsilon: accuracy indicator, useful for early termination. + ridge_epsilon: Ridge epsilon added to make the matrix positive definite. + + Returns: + mat_g^alpha + """ + + identity = linalg_ops.eye(math_ops.to_int32(mat_g_size)) + + def mat_power(mat_m, p): + """Computes mat_m^p, for p a positive integer. + + Power p is known at graph compile time, so no need for loop and cond. + Args: + mat_m: a square matrix + p: a positive integer + + Returns: + mat_m^p + """ + assert p == int(p) and p > 0 + power = None + while p > 0: + if p % 2 == 1: + power = math_ops.matmul(mat_m, power) if power is not None else mat_m + p //= 2 + mat_m = math_ops.matmul(mat_m, mat_m) + return power + + def _iter_condition(i, mat_m, _): + return math_ops.logical_and( + i < iter_count, + math_ops.reduce_max(math_ops.abs(mat_m - identity)) > epsilon) + + def _iter_body(i, mat_m, mat_x): + mat_m_i = (1 - alpha) * identity + alpha * mat_m + return (i + 1, math_ops.matmul(mat_power(mat_m_i, -1.0 / alpha), mat_m), + math_ops.matmul(mat_x, mat_m_i)) + + if mat_g_size == 1: + mat_h = math_ops.pow(mat_g + ridge_epsilon, alpha) + else: + damped_mat_g = mat_g + ridge_epsilon * identity + z = (1 - 1 / alpha) / (2 * linalg_ops.norm(damped_mat_g)) + # The best value for z is + # (1 - 1/alpha) * (c_max^{-alpha} - c_min^{-alpha}) / + # (c_max^{1-alpha} - c_min^{1-alpha}) + # where c_max and c_min are the largest and smallest singular values of + # damped_mat_g. + # The above estimate assumes that c_max > c_min * 2^p. (p = -1/alpha) + # Can replace above line by the one below, but it is less accurate, + # hence needs more iterations to converge. + # z = (1 - 1/alpha) / math_ops.trace(damped_mat_g) + # If we want the method to always converge, use z = 1 / norm(damped_mat_g) + # or z = 1 / math_ops.trace(damped_mat_g), but these can result in many + # extra iterations. + _, _, mat_h = control_flow_ops.while_loop( + _iter_condition, _iter_body, + [0, damped_mat_g * z, identity * math_ops.pow(z, -alpha)]) + return mat_h diff --git a/tensorflow/contrib/opt/python/training/matrix_functions_test.py b/tensorflow/contrib/opt/python/training/matrix_functions_test.py new file mode 100644 index 0000000000..518fa38233 --- /dev/null +++ b/tensorflow/contrib/opt/python/training/matrix_functions_test.py @@ -0,0 +1,63 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Functional tests for Matrix functions.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import numpy as np + +from tensorflow.contrib.opt.python.training import matrix_functions +from tensorflow.python.platform import test + +TOLERANCE = 1e-3 + + +def np_power(mat_g, alpha): + """Computes mat_g^alpha for a square symmetric matrix mat_g.""" + + mat_u, diag_d, mat_v = np.linalg.svd(mat_g) + diag_d = np.power(diag_d, alpha) + return np.dot(np.dot(mat_u, np.diag(diag_d)), mat_v) + + +class MatrixFunctionTests(test.TestCase): + + def testMatrixSquareRootFunction(self): + """Tests for matrix square roots.""" + + size = 20 + mat_a = np.random.rand(size, size) + mat = np.dot(mat_a, mat_a.T) + expected_mat = np_power(mat, 0.5) + mat_root = matrix_functions.matrix_square_root(mat, size) + self.assertAllCloseAccordingToType( + expected_mat, mat_root, atol=TOLERANCE, rtol=TOLERANCE) + + def testMatrixInversePthRootFunction(self): + """Tests for matrix inverse pth roots.""" + + size = 20 + mat_a = np.random.rand(size, size) + mat = np.dot(mat_a, mat_a.T) + expected_mat = np_power(mat, -0.125) + mat_root = matrix_functions.matrix_inverse_pth_root(mat, size, -0.125) + self.assertAllCloseAccordingToType( + expected_mat, mat_root, atol=TOLERANCE, rtol=TOLERANCE) + + +if __name__ == '__main__': + test.main() diff --git a/tensorflow/contrib/opt/python/training/model_average_optimizer.py b/tensorflow/contrib/opt/python/training/model_average_optimizer.py index b6b10e500b..746df77ba2 100644 --- a/tensorflow/contrib/opt/python/training/model_average_optimizer.py +++ b/tensorflow/contrib/opt/python/training/model_average_optimizer.py @@ -89,7 +89,13 @@ class ModelAverageCustomGetter(object): self._local_2_global[local_var] = global_variable return local_var else: - return getter(name, trainable, collections, *args, **kwargs) + kwargs['trainable'] = trainable + kwargs['collections'] = collections + if ops.GraphKeys.LOCAL_VARIABLES in collections: + with ops.device(self._worker_device): + return getter(name, *args, **kwargs) + else: + return getter(name, *args, **kwargs) class ModelAverageOptimizer(optimizer.Optimizer): diff --git a/tensorflow/contrib/opt/python/training/model_average_optimizer_test.py b/tensorflow/contrib/opt/python/training/model_average_optimizer_test.py index 3acd940268..b1fc50a21f 100644 --- a/tensorflow/contrib/opt/python/training/model_average_optimizer_test.py +++ b/tensorflow/contrib/opt/python/training/model_average_optimizer_test.py @@ -80,28 +80,28 @@ def _get_workers(num_workers, steps, workers): var_0 = variable_scope.get_variable(initializer=0.0, name="v0") var_1 = variable_scope.get_variable(initializer=1.0, name="v1") - with ops.device("/job:worker/task:" + str(worker_id)): - if worker_id == 0: - grads_0 = constant_op.constant(-1.0) - grads_1 = constant_op.constant(-1.0) - else: - grads_0 = constant_op.constant(-2.0) - grads_1 = constant_op.constant(-2.0) - sgd_opt = gradient_descent.GradientDescentOptimizer(1.0) - opt = model_average_optimizer.ModelAverageOptimizer( - opt=sgd_opt, - num_worker=num_workers, - ma_custom_getter=ma_coustom, - is_chief=is_chief, - interval_steps=steps) - train_op = [ - opt.apply_gradients([[grads_0, var_0], [grads_1, var_1]], - global_step) - ] - easgd_hook = opt.make_session_run_hook() + with ops.device("/job:worker/task:" + str(worker_id)): + if worker_id == 0: + grads_0 = constant_op.constant(-1.0) + grads_1 = constant_op.constant(-1.0) + else: + grads_0 = constant_op.constant(-2.0) + grads_1 = constant_op.constant(-2.0) + sgd_opt = gradient_descent.GradientDescentOptimizer(1.0) + opt = model_average_optimizer.ModelAverageOptimizer( + opt=sgd_opt, + num_worker=num_workers, + ma_custom_getter=ma_coustom, + is_chief=is_chief, + interval_steps=steps) + train_op = [ + opt.apply_gradients([[grads_0, var_0], [grads_1, var_1]], + global_step) + ] + ma_hook = opt.make_session_run_hook() # Creates MonitoredSession sess = training.MonitoredTrainingSession( - workers[worker_id].target, hooks=[easgd_hook]) + workers[worker_id].target, hooks=[ma_hook]) sessions.append(sess) graphs.append(graph) diff --git a/tensorflow/contrib/opt/python/training/shampoo.py b/tensorflow/contrib/opt/python/training/shampoo.py index 294627f42a..f161521b97 100644 --- a/tensorflow/contrib/opt/python/training/shampoo.py +++ b/tensorflow/contrib/opt/python/training/shampoo.py @@ -23,6 +23,7 @@ from __future__ import division from __future__ import print_function import numpy as np +from tensorflow.contrib.opt.python.training import matrix_functions from tensorflow.python.framework import ops from tensorflow.python.ops import array_ops from tensorflow.python.ops import control_flow_ops @@ -76,7 +77,7 @@ class ShampooOptimizer(optimizer.Optimizer): learning_rate=1.0, svd_interval=1, precond_update_interval=1, - epsilon=0.1, + epsilon=1e-4, alpha=0.5, use_iterative_root=False, use_locking=False, @@ -255,81 +256,18 @@ class ShampooOptimizer(optimizer.Optimizer): def _compute_power_iter(self, var, mat_g, mat_g_size, alpha, mat_h_slot_name, iter_count=100, epsilon=1e-6): - """Computes mat_g^alpha, where alpha = -1/p, p a positive integer. + """Computes mat_g^alpha, where alpha = -1/p, p a positive integer.""" + + mat_g_sqrt = matrix_functions.matrix_square_root(mat_g, mat_g_size, + iter_count, self._epsilon) + mat_h = matrix_functions.matrix_inverse_pth_root( + mat_g_sqrt, + mat_g_size, + 2 * alpha, + iter_count, + epsilon, + ridge_epsilon=0.0) - We use an iterative Schur-Newton method from equation 3.2 on page 9 of: - - A Schur-Newton Method for the Matrix p-th Root and its Inverse - by Chun-Hua Guo and Nicholas J. Higham - SIAM Journal on Matrix Analysis and Applications, - 2006, Vol. 28, No. 3 : pp. 788-804 - https://pdfs.semanticscholar.org/0abe/7f77433cf5908bfe2b79aa91af881da83858.pdf - - Args: - var: the variable we are updating. - mat_g: the symmetric PSD matrix whose power it to be computed - mat_g_size: size of mat_g. - alpha: exponent, must be -1/p for p a positive integer. - mat_h_slot_name: name of slot to store the power, if needed. - iter_count: Maximum number of iterations. - epsilon: accuracy indicator, useful for early termination. - - Returns: - mat_g^alpha - """ - - identity = linalg_ops.eye(math_ops.to_int32(mat_g_size)) - - def MatPower(mat_m, p): - """Computes mat_m^p, for p a positive integer. - - Power p is known at graph compile time, so no need for loop and cond. - Args: - mat_m: a square matrix - p: a positive integer - - Returns: - mat_m^p - """ - assert p == int(p) and p > 0 - power = None - while p > 0: - if p % 2 == 1: - power = math_ops.matmul(mat_m, power) if power is not None else mat_m - p //= 2 - mat_m = math_ops.matmul(mat_m, mat_m) - return power - - def IterCondition(i, mat_m, _): - return math_ops.logical_and( - i < iter_count, - math_ops.reduce_max(math_ops.abs(mat_m - identity)) > epsilon) - - def IterBody(i, mat_m, mat_x): - mat_m_i = (1 - alpha) * identity + alpha * mat_m - return (i + 1, math_ops.matmul(MatPower(mat_m_i, -1.0/alpha), mat_m), - math_ops.matmul(mat_x, mat_m_i)) - - if mat_g_size == 1: - mat_h = math_ops.pow(mat_g + self._epsilon, alpha) - else: - damped_mat_g = mat_g + self._epsilon * identity - z = (1 - 1 / alpha) / (2 * linalg_ops.norm(damped_mat_g)) - # The best value for z is - # (1 - 1/alpha) * (c_max^{-alpha} - c_min^{-alpha}) / - # (c_max^{1-alpha} - c_min^{1-alpha}) - # where c_max and c_min are the largest and smallest singular values of - # damped_mat_g. - # The above estimate assumes that c_max > c_min * 2^p. (p = -1/alpha) - # Can replace above line by the one below, but it is less accurate, - # hence needs more iterations to converge. - # z = (1 - 1/alpha) / math_ops.trace(damped_mat_g) - # If we want the method to always converge, use z = 1 / norm(damped_mat_g) - # or z = 1 / math_ops.trace(damped_mat_g), but these can result in many - # extra iterations. - _, _, mat_h = control_flow_ops.while_loop( - IterCondition, IterBody, - [0, damped_mat_g * z, identity * math_ops.pow(z, -alpha)]) if mat_h_slot_name is not None: return state_ops.assign(self.get_slot(var, mat_h_slot_name), mat_h) return mat_h @@ -422,6 +360,8 @@ class ShampooOptimizer(optimizer.Optimizer): mat_gbar_weight_t * precond_update_interval, i), lambda: mat_g) + mat_g_updated = mat_g_updated / float(shape[i].value) + if self._svd_interval == 1: mat_h = self._compute_power(var, mat_g_updated, shape[i], neg_alpha) else: @@ -443,7 +383,13 @@ class ShampooOptimizer(optimizer.Optimizer): name="precond_" + str(i)) else: # Tensor size is too large -- perform diagonal Shampoo update - grad_outer = math_ops.reduce_sum(grad * grad, axis=axes) + # Only normalize non-vector cases. + if axes: + normalizer = 1.0 if indices is not None else float(shape[i].value) + grad_outer = math_ops.reduce_sum(grad * grad, axis=axes) / normalizer + else: + grad_outer = grad * grad + if i == 0 and indices is not None: assert self._mat_gbar_decay == 1.0 mat_g_updated = state_ops.scatter_add(mat_g, indices, diff --git a/tensorflow/contrib/opt/python/training/shampoo_test.py b/tensorflow/contrib/opt/python/training/shampoo_test.py index b3688ab181..05bcf2cfa3 100644 --- a/tensorflow/contrib/opt/python/training/shampoo_test.py +++ b/tensorflow/contrib/opt/python/training/shampoo_test.py @@ -31,6 +31,7 @@ from tensorflow.python.ops import variables from tensorflow.python.platform import test TOLERANCE = 1e-3 +RIDGE_EPSILON = 1e-4 def np_power(mat_g, alpha): @@ -77,8 +78,8 @@ class ShampooTest(test.TestCase, parameterized.TestCase): # let up compute this in numpy # Update rule is var = var - lr * mat_g^{-0.5} * grad # lr = 1 - mat_g = np.outer(grad_np, grad_np) - mat_h = np_power(mat_g + 0.1 * np.eye(size), -0.5) + mat_g = np.outer(grad_np, grad_np) / grad_np.shape[0] + mat_h = np_power(mat_g + RIDGE_EPSILON * np.eye(size), -0.5) new_val_np = init_var_np - np.dot(mat_h, grad_np) self.assertAllCloseAccordingToType(new_val_np, new_val, @@ -88,8 +89,8 @@ class ShampooTest(test.TestCase, parameterized.TestCase): update_2.run() new_val = sess.run(var) - mat_g += np.outer(grad_np_2, grad_np_2) - mat_h = np_power(mat_g + 0.1 * np.eye(size), -0.5) + mat_g += np.outer(grad_np_2, grad_np_2) / grad_np.shape[0] + mat_h = np_power(mat_g + RIDGE_EPSILON * np.eye(size), -0.5) new_val_np -= np.dot(mat_h, grad_np_2) self.assertAllCloseAccordingToType(new_val_np, new_val, @@ -128,10 +129,10 @@ class ShampooTest(test.TestCase, parameterized.TestCase): # let up compute this in numpy # Update rule is var = var - lr * mat_g1^{-0.25} * grad * mat_g2^{-0.25} # lr = 1 - mat_g1 = np.dot(grad_np, grad_np.transpose()) - mat_left = np_power(mat_g1 + 0.1 * np.eye(size[0]), -0.25) - mat_g2 = np.dot(grad_np.transpose(), grad_np) - mat_right = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.25) + mat_g1 = np.dot(grad_np, grad_np.transpose()) / grad_np.shape[0] + mat_left = np_power(mat_g1 + RIDGE_EPSILON * np.eye(size[0]), -0.25) + mat_g2 = np.dot(grad_np.transpose(), grad_np) / grad_np.shape[1] + mat_right = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), -0.25) new_val_np = init_var_np - np.dot(np.dot(mat_left, grad_np), mat_right) self.assertAllCloseAccordingToType(new_val_np, new_val, @@ -141,10 +142,10 @@ class ShampooTest(test.TestCase, parameterized.TestCase): update_2.run() new_val = sess.run(var) - mat_g1 += np.dot(grad_np_2, grad_np_2.transpose()) - mat_left = np_power(mat_g1 + 0.1 * np.eye(size[0]), -0.25) - mat_g2 += np.dot(grad_np_2.transpose(), grad_np_2) - mat_right = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.25) + mat_g1 += np.dot(grad_np_2, grad_np_2.transpose()) / grad_np_2.shape[0] + mat_left = np_power(mat_g1 + RIDGE_EPSILON * np.eye(size[0]), -0.25) + mat_g2 += np.dot(grad_np_2.transpose(), grad_np_2) / grad_np_2.shape[1] + mat_right = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), -0.25) new_val_np -= np.dot(np.dot(mat_left, grad_np_2), mat_right) self.assertAllCloseAccordingToType(new_val_np, new_val, @@ -188,12 +189,18 @@ class ShampooTest(test.TestCase, parameterized.TestCase): # let up compute this in numpy # Update rule is var = var - lr * Prod_i mat_g_i^{-0.5/3} grad # lr = 1 - mat_g1 = np.tensordot(grad_np, grad_np, axes=([1, 2], [1, 2])) - mat_g1_a = np_power(mat_g1 + 0.1 * np.eye(size[0]), -0.5/3.0) - mat_g2 = np.tensordot(grad_np, grad_np, axes=([0, 2], [0, 2])) - mat_g2_a = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.5/3.0) - mat_g3 = np.tensordot(grad_np, grad_np, axes=([0, 1], [0, 1])) - mat_g3_a = np_power(mat_g3 + 0.1 * np.eye(size[2]), -0.5/3.0) + mat_g1 = ( + np.tensordot(grad_np, grad_np, axes=([1, 2], [1, 2])) / + grad_np.shape[0]) + mat_g1_a = np_power(mat_g1 + RIDGE_EPSILON * np.eye(size[0]), -0.5 / 3.0) + mat_g2 = ( + np.tensordot(grad_np, grad_np, axes=([0, 2], [0, 2])) / + grad_np.shape[1]) + mat_g2_a = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), -0.5 / 3.0) + mat_g3 = ( + np.tensordot(grad_np, grad_np, axes=([0, 1], [0, 1])) / + grad_np.shape[2]) + mat_g3_a = np_power(mat_g3 + RIDGE_EPSILON * np.eye(size[2]), -0.5 / 3.0) precond_grad = np.tensordot(grad_np, mat_g1_a, axes=([0], [0])) precond_grad = np.tensordot(precond_grad, mat_g2_a, axes=([0], [0])) @@ -207,12 +214,18 @@ class ShampooTest(test.TestCase, parameterized.TestCase): update_2.run() new_val = sess.run(var) - mat_g1 += np.tensordot(grad_np_2, grad_np_2, axes=([1, 2], [1, 2])) - mat_g1_a = np_power(mat_g1 + 0.1 * np.eye(size[0]), -0.5/3.0) - mat_g2 += np.tensordot(grad_np_2, grad_np_2, axes=([0, 2], [0, 2])) - mat_g2_a = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.5/3.0) - mat_g3 += np.tensordot(grad_np_2, grad_np_2, axes=([0, 1], [0, 1])) - mat_g3_a = np_power(mat_g3 + 0.1 * np.eye(size[2]), -0.5/3.0) + mat_g1 += ( + np.tensordot(grad_np_2, grad_np_2, axes=([1, 2], [1, 2])) / + grad_np_2.shape[0]) + mat_g1_a = np_power(mat_g1 + RIDGE_EPSILON * np.eye(size[0]), -0.5 / 3.0) + mat_g2 += ( + np.tensordot(grad_np_2, grad_np_2, axes=([0, 2], [0, 2])) / + grad_np_2.shape[1]) + mat_g2_a = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), -0.5 / 3.0) + mat_g3 += ( + np.tensordot(grad_np_2, grad_np_2, axes=([0, 1], [0, 1])) / + grad_np_2.shape[2]) + mat_g3_a = np_power(mat_g3 + RIDGE_EPSILON * np.eye(size[2]), -0.5 / 3.0) precond_grad = np.tensordot(grad_np_2, mat_g1_a, axes=([0], [0])) precond_grad = np.tensordot(precond_grad, mat_g2_a, axes=([0], [0])) @@ -265,19 +278,21 @@ class ShampooTest(test.TestCase, parameterized.TestCase): # let up compute this in numpy # Update rule is var = var - lr * gg^{-0.5} * grad # lr = 1 - mat_g = grad_np * grad_np + 0.1 - new_val_np = init_var_np - np.power(mat_g, -0.5) * grad_np - - self.assertAllCloseAccordingToType(new_val_np, new_val) + mat_g = (grad_np * grad_np) + new_val_np = init_var_np - np.power(mat_g + RIDGE_EPSILON, -0.5) * grad_np + self.assertAllCloseAccordingToType( + new_val_np, new_val, atol=TOLERANCE, rtol=TOLERANCE) # Run another step of Shampoo update_2.run() new_val = sess.run(var) - mat_g += grad_np_2 * grad_np_2 - new_val_np -= np.power(mat_g, -0.5) * grad_np_2 + mat_g += (grad_np_2 * grad_np_2) + new_val_np -= np.power(mat_g + RIDGE_EPSILON, -0.5) * grad_np_2 + + self.assertAllCloseAccordingToType( + new_val_np, new_val, atol=TOLERANCE, rtol=TOLERANCE) - self.assertAllCloseAccordingToType(new_val_np, new_val) @parameterized.named_parameters(('Var', False), ('ResourceVar', True)) def testLargeMatrix(self, use_resource_var): @@ -322,10 +337,11 @@ class ShampooTest(test.TestCase, parameterized.TestCase): # with broadcasting # lr = 1 - mat_g1 = np.sum(grad_np * grad_np, axis=1, keepdims=True) - mat_left = np.power(mat_g1 + 0.1, -0.25) - mat_g2 = np.dot(grad_np.transpose(), grad_np) - mat_right = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.25) + mat_g1 = np.sum( + grad_np * grad_np, axis=1, keepdims=True) / grad_np.shape[0] + mat_left = np.power(mat_g1 + RIDGE_EPSILON, -0.25) + mat_g2 = np.dot(grad_np.transpose(), grad_np) / grad_np.shape[1] + mat_right = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), -0.25) new_val_np = init_var_np - np.dot(grad_np * mat_left, mat_right) self.assertAllCloseAccordingToType(new_val_np, new_val, @@ -335,10 +351,11 @@ class ShampooTest(test.TestCase, parameterized.TestCase): update_2.run() new_val = sess.run(var) - mat_g1 += np.sum(grad_np_2 * grad_np_2, axis=1, keepdims=True) - mat_left = np.power(mat_g1 + 0.1, -0.25) - mat_g2 += np.dot(grad_np_2.transpose(), grad_np_2) - mat_right = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.25) + mat_g1 += np.sum( + grad_np_2 * grad_np_2, axis=1, keepdims=True) / grad_np_2.shape[0] + mat_left = np.power(mat_g1 + RIDGE_EPSILON, -0.25) + mat_g2 += np.dot(grad_np_2.transpose(), grad_np_2) / grad_np_2.shape[1] + mat_right = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), -0.25) new_val_np -= np.dot(grad_np_2 * mat_left, mat_right) self.assertAllCloseAccordingToType(new_val_np, new_val, @@ -405,9 +422,9 @@ class ShampooTest(test.TestCase, parameterized.TestCase): mat_g1 = np.sum(grad_np * grad_np, axis=1, keepdims=True) mat_g1_acc = np.zeros((size[0], 1)) mat_g1_acc[grad_indices] += mat_g1 - mat_left = np.power(mat_g1 + 0.1, -0.25) - mat_g2 = np.dot(grad_np.transpose(), grad_np) - mat_right = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.25) + mat_left = np.power(mat_g1 + RIDGE_EPSILON, -0.25) + mat_g2 = np.dot(grad_np.transpose(), grad_np) / grad_np.shape[1] + mat_right = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), -0.25) new_val_np = init_var_np new_val_np[grad_indices, :] -= np.dot(grad_np * mat_left, mat_right) @@ -420,9 +437,9 @@ class ShampooTest(test.TestCase, parameterized.TestCase): mat_g1 = np.sum(grad_np_2 * grad_np_2, axis=1, keepdims=True) mat_g1_acc[grad_indices_2] += mat_g1 - mat_left = np.power(mat_g1_acc[grad_indices_2] + 0.1, -0.25) - mat_g2 += np.dot(grad_np_2.transpose(), grad_np_2) - mat_right = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.25) + mat_left = np.power(mat_g1_acc[grad_indices_2] + RIDGE_EPSILON, -0.25) + mat_g2 += np.dot(grad_np_2.transpose(), grad_np_2) / grad_np_2.shape[1] + mat_right = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), -0.25) new_val_np[grad_indices_2, :] -= np.dot(grad_np_2 * mat_left, mat_right) self.assertAllCloseAccordingToType(new_val_np, new_val, @@ -474,12 +491,15 @@ class ShampooTest(test.TestCase, parameterized.TestCase): grad_dense = np.zeros_like(init_var_np) grad_dense[grad_indices] = grad_np - mat_g1 = np.tensordot(grad_dense, grad_dense, axes=([1, 2], [1, 2])) - mat_g1_a = np_power(mat_g1 + 0.1 * np.eye(size[0]), -0.5/3.0) - mat_g2 = np.tensordot(grad_dense, grad_dense, axes=([0, 2], [0, 2])) - mat_g2_a = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.5/3.0) - mat_g3 = np.tensordot(grad_dense, grad_dense, axes=([0, 1], [0, 1])) - mat_g3_a = np_power(mat_g3 + 0.1 * np.eye(size[2]), -0.5/3.0) + mat_g1 = np.tensordot( + grad_dense, grad_dense, axes=([1, 2], [1, 2])) / grad_dense.shape[0] + mat_g1_a = np_power(mat_g1 + RIDGE_EPSILON * np.eye(size[0]), -0.5 / 3.0) + mat_g2 = np.tensordot( + grad_dense, grad_dense, axes=([0, 2], [0, 2])) / grad_dense.shape[1] + mat_g2_a = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), -0.5 / 3.0) + mat_g3 = np.tensordot( + grad_dense, grad_dense, axes=([0, 1], [0, 1])) / grad_dense.shape[2] + mat_g3_a = np_power(mat_g3 + RIDGE_EPSILON * np.eye(size[2]), -0.5 / 3.0) precond_grad = np.tensordot(grad_dense, mat_g1_a, axes=([0], [0])) precond_grad = np.tensordot(precond_grad, mat_g2_a, axes=([0], [0])) @@ -536,12 +556,15 @@ class ShampooTest(test.TestCase, parameterized.TestCase): # let up compute this in numpy # Update rule is var = var - lr * Prod_i mat_g_i^{-0.5/3} grad # lr = 1 - mat_g1 = np.tensordot(grad_np, grad_np, axes=([1, 2], [1, 2])) - mat_g1_a = np_power(mat_g1 + 0.1 * np.eye(size[0]), -0.5/3.0) - mat_g2 = np.tensordot(grad_np, grad_np, axes=([0, 2], [0, 2])) - mat_g2_a = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.5/3.0) - mat_g3 = np.tensordot(grad_np, grad_np, axes=([0, 1], [0, 1])) - mat_g3_a = np_power(mat_g3 + 0.1 * np.eye(size[2]), -0.5/3.0) + mat_g1 = np.tensordot( + grad_np, grad_np, axes=([1, 2], [1, 2])) / grad_np.shape[0] + mat_g1_a = np_power(mat_g1 + RIDGE_EPSILON * np.eye(size[0]), -0.5 / 3.0) + mat_g2 = np.tensordot( + grad_np, grad_np, axes=([0, 2], [0, 2])) / grad_np.shape[1] + mat_g2_a = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), -0.5 / 3.0) + mat_g3 = np.tensordot( + grad_np, grad_np, axes=([0, 1], [0, 1])) / grad_np.shape[2] + mat_g3_a = np_power(mat_g3 + RIDGE_EPSILON * np.eye(size[2]), -0.5 / 3.0) gbar_np = gbar_weight * grad_np precond_grad = np.tensordot(gbar_np, mat_g1_a, axes=([0], [0])) @@ -556,12 +579,15 @@ class ShampooTest(test.TestCase, parameterized.TestCase): update_2.run() new_val = sess.run(var) - mat_g1 += np.tensordot(grad_np_2, grad_np_2, axes=([1, 2], [1, 2])) - mat_g1_a = np_power(mat_g1 + 0.1 * np.eye(size[0]), -0.5/3.0) - mat_g2 += np.tensordot(grad_np_2, grad_np_2, axes=([0, 2], [0, 2])) - mat_g2_a = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.5/3.0) - mat_g3 += np.tensordot(grad_np_2, grad_np_2, axes=([0, 1], [0, 1])) - mat_g3_a = np_power(mat_g3 + 0.1 * np.eye(size[2]), -0.5/3.0) + mat_g1 += np.tensordot( + grad_np_2, grad_np_2, axes=([1, 2], [1, 2])) / grad_np_2.shape[0] + mat_g1_a = np_power(mat_g1 + RIDGE_EPSILON * np.eye(size[0]), -0.5 / 3.0) + mat_g2 += np.tensordot( + grad_np_2, grad_np_2, axes=([0, 2], [0, 2])) / grad_np_2.shape[1] + mat_g2_a = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), -0.5 / 3.0) + mat_g3 += np.tensordot( + grad_np_2, grad_np_2, axes=([0, 1], [0, 1])) / grad_np_2.shape[2] + mat_g3_a = np_power(mat_g3 + RIDGE_EPSILON * np.eye(size[2]), -0.5 / 3.0) gbar_np_2 = gbar_decay * gbar_np + gbar_weight * grad_np_2 precond_grad = np.tensordot(gbar_np_2, mat_g1_a, axes=([0], [0])) @@ -626,13 +652,19 @@ class ShampooTest(test.TestCase, parameterized.TestCase): # let up compute this in numpy # Update rule is var = var - lr * Prod_i mat_g_i^{-0.5/3} grad # lr = 1 - mat_g1 += np.tensordot(grad_np[i], grad_np[i], axes=([1, 2], [1, 2])) - mat_g2 += np.tensordot(grad_np[i], grad_np[i], axes=([0, 2], [0, 2])) - mat_g3 += np.tensordot(grad_np[i], grad_np[i], axes=([0, 1], [0, 1])) + mat_g1 += np.tensordot( + grad_np[i], grad_np[i], axes=([1, 2], [1, 2])) / grad_np[i].shape[0] + mat_g2 += np.tensordot( + grad_np[i], grad_np[i], axes=([0, 2], [0, 2])) / grad_np[i].shape[1] + mat_g3 += np.tensordot( + grad_np[i], grad_np[i], axes=([0, 1], [0, 1])) / grad_np[i].shape[2] if (i + 1) % svd_interval == 0: - mat_g1_a = np_power(mat_g1 + 0.1 * np.eye(size[0]), -0.5/3.0) - mat_g2_a = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.5/3.0) - mat_g3_a = np_power(mat_g3 + 0.1 * np.eye(size[2]), -0.5/3.0) + mat_g1_a = np_power(mat_g1 + RIDGE_EPSILON * np.eye(size[0]), + -0.5 / 3.0) + mat_g2_a = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), + -0.5 / 3.0) + mat_g3_a = np_power(mat_g3 + RIDGE_EPSILON * np.eye(size[2]), + -0.5 / 3.0) precond_grad = np.tensordot(grad_np[i], mat_g1_a, axes=([0], [0])) precond_grad = np.tensordot(precond_grad, mat_g2_a, axes=([0], [0])) @@ -700,17 +732,23 @@ class ShampooTest(test.TestCase, parameterized.TestCase): # Update rule is var = var - lr * Prod_i mat_g_i^{-0.5/3} grad # lr = 1 if (i + 1) % precond_update_interval == 0: - mat_g1 += (np.tensordot(grad_np[i], grad_np[i], axes=([1, 2], [1, 2])) - * precond_update_interval) - mat_g2 += (np.tensordot(grad_np[i], grad_np[i], axes=([0, 2], [0, 2])) - * precond_update_interval) - mat_g3 += (np.tensordot(grad_np[i], grad_np[i], axes=([0, 1], [0, 1])) - * precond_update_interval) + mat_g1 += ( + np.tensordot(grad_np[i], grad_np[i], axes=([1, 2], [1, 2])) / + grad_np[i].shape[0] * precond_update_interval) + mat_g2 += ( + np.tensordot(grad_np[i], grad_np[i], axes=([0, 2], [0, 2])) / + grad_np[i].shape[1] * precond_update_interval) + mat_g3 += ( + np.tensordot(grad_np[i], grad_np[i], axes=([0, 1], [0, 1])) / + grad_np[i].shape[2] * precond_update_interval) if (i + 1) % svd_interval == 0: - mat_g1_a = np_power(mat_g1 + 0.1 * np.eye(size[0]), -0.5/3.0) - mat_g2_a = np_power(mat_g2 + 0.1 * np.eye(size[1]), -0.5/3.0) - mat_g3_a = np_power(mat_g3 + 0.1 * np.eye(size[2]), -0.5/3.0) + mat_g1_a = np_power(mat_g1 + RIDGE_EPSILON * np.eye(size[0]), + -0.5 / 3.0) + mat_g2_a = np_power(mat_g2 + RIDGE_EPSILON * np.eye(size[1]), + -0.5 / 3.0) + mat_g3_a = np_power(mat_g3 + RIDGE_EPSILON * np.eye(size[2]), + -0.5 / 3.0) precond_grad = np.tensordot(grad_np[i], mat_g1_a, axes=([0], [0])) precond_grad = np.tensordot(precond_grad, mat_g2_a, axes=([0], [0])) diff --git a/tensorflow/contrib/opt/python/training/weight_decay_optimizers.py b/tensorflow/contrib/opt/python/training/weight_decay_optimizers.py index 29acfc602e..200b0d2008 100644 --- a/tensorflow/contrib/opt/python/training/weight_decay_optimizers.py +++ b/tensorflow/contrib/opt/python/training/weight_decay_optimizers.py @@ -18,6 +18,7 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function +from tensorflow.contrib.opt.python.training import shampoo from tensorflow.python.framework import ops from tensorflow.python.ops import control_flow_ops from tensorflow.python.ops import resource_variable_ops @@ -361,3 +362,74 @@ class AdamWOptimizer(DecoupledWeightDecayExtension, adam.AdamOptimizer): super(AdamWOptimizer, self).__init__( weight_decay, learning_rate=learning_rate, beta1=beta1, beta2=beta2, epsilon=epsilon, use_locking=use_locking, name=name) + + +@tf_export("contrib.opt.ShampooWOptimizer") +class ShampooWOptimizer(DecoupledWeightDecayExtension, + shampoo.ShampooOptimizer): + """Optimizer that implements the Shampoo algorithm with weight decay. + + For further information see the documentation of the Shampoo Optimizer. + """ + + def __init__(self, + weight_decay, + global_step, + max_matrix_size=768, + gbar_decay=0.0, + gbar_weight=1.0, + mat_gbar_decay=1.0, + mat_gbar_weight=1.0, + learning_rate=1.0, + svd_interval=1, + precond_update_interval=1, + epsilon=1e-4, + alpha=0.5, + use_iterative_root=False, + use_locking=False, + name="ShampooW"): + """Construct a new ShampooW optimizer. + + For further information see the documentation of the Shampoo Optimizer. + + Args: + weight_decay: A `Tensor` or a floating point value. The weight decay. + global_step: tensorflow variable indicating the step. + max_matrix_size: We do not perform SVD for matrices larger than this. + gbar_decay: + gbar_weight: Used to update gbar: gbar[t] = gbar_decay[t] * gbar[t-1] + + gbar_weight[t] * g[t] + mat_gbar_decay: + mat_gbar_weight: Used to update mat_gbar: mat_gbar_j[t] = + mat_gbar_decay[t] * mat_gbar_j[t-1] + mat_gbar_weight[t] * gg_j[t] + learning_rate: Similar to SGD + svd_interval: We should do SVD after this many steps. Default = 1, i.e. + every step. Usually 20 leads to no loss of accuracy, and 50 or 100 is + also OK. May also want more often early, + and less often later - set in caller as for example: + "svd_interval = lambda(T): tf.cond( + T < 2000, lambda: 20.0, lambda: 1000.0)" + precond_update_interval: We should update the preconditioners after this + many steps. Default = 1. Usually less than svd_interval. + epsilon: epsilon * I_n is added to each mat_gbar_j for stability + alpha: total power of the preconditioners. + use_iterative_root: should the optimizer use SVD (faster) or the iterative + root method (for TPU) for finding the roots of PSD matrices. + use_locking: If `True` use locks for update operations. + name: name of optimizer. + """ + super(ShampooWOptimizer, self).__init__( + weight_decay, + global_step=global_step, + max_matrix_size=max_matrix_size, + gbar_decay=gbar_decay, + gbar_weight=gbar_weight, + mat_gbar_decay=mat_gbar_weight, + learning_rate=learning_rate, + svd_interval=svd_interval, + precond_update_interval=precond_update_interval, + epsilon=epsilon, + alpha=alpha, + use_iterative_root=use_iterative_root, + use_locking=use_locking, + name=name) diff --git a/tensorflow/contrib/rnn/python/kernel_tests/core_rnn_cell_test.py b/tensorflow/contrib/rnn/python/kernel_tests/core_rnn_cell_test.py index 15ce9d1ce7..be0306cb07 100644 --- a/tensorflow/contrib/rnn/python/kernel_tests/core_rnn_cell_test.py +++ b/tensorflow/contrib/rnn/python/kernel_tests/core_rnn_cell_test.py @@ -48,7 +48,7 @@ Linear = core_rnn_cell._Linear # pylint: disable=invalid-name class RNNCellTest(test.TestCase): def testLinear(self): - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope( "root", initializer=init_ops.constant_initializer(1.0)): x = array_ops.zeros([1, 2]) @@ -69,7 +69,7 @@ class RNNCellTest(test.TestCase): self.assertEqual(len(variables_lib.trainable_variables()), 2) def testBasicRNNCell(self): - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope( "root", initializer=init_ops.constant_initializer(0.5)): x = array_ops.zeros([1, 2]) @@ -89,7 +89,7 @@ class RNNCellTest(test.TestCase): self.assertEqual(res[0].shape, (1, 2)) def testBasicRNNCellNotTrainable(self): - with self.test_session() as sess: + with self.cached_session() as sess: def not_trainable_getter(getter, *args, **kwargs): kwargs["trainable"] = False @@ -116,7 +116,7 @@ class RNNCellTest(test.TestCase): self.assertEqual(res[0].shape, (1, 2)) def testIndRNNCell(self): - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope( "root", initializer=init_ops.constant_initializer(0.5)): x = array_ops.zeros([1, 2]) @@ -137,7 +137,7 @@ class RNNCellTest(test.TestCase): self.assertEqual(res[0].shape, (1, 2)) def testGRUCell(self): - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope( "root", initializer=init_ops.constant_initializer(0.5)): x = array_ops.zeros([1, 2]) @@ -165,7 +165,7 @@ class RNNCellTest(test.TestCase): self.assertAllClose(res[0], [[0.156736, 0.156736]]) def testIndyGRUCell(self): - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope( "root", initializer=init_ops.constant_initializer(0.5)): x = array_ops.zeros([1, 2]) @@ -193,7 +193,7 @@ class RNNCellTest(test.TestCase): self.assertAllClose(res[0], [[0.155127, 0.157328]]) def testSRUCell(self): - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope( "root", initializer=init_ops.constant_initializer(0.5)): x = array_ops.zeros([1, 2]) @@ -208,7 +208,7 @@ class RNNCellTest(test.TestCase): self.assertAllClose(res[0], [[0.509682, 0.509682]]) def testSRUCellWithDiffSize(self): - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope( "root", initializer=init_ops.constant_initializer(0.5)): x = array_ops.zeros([1, 3]) @@ -288,7 +288,7 @@ class RNNCellTest(test.TestCase): def testBasicLSTMCellDimension0Error(self): """Tests that dimension 0 in both(x and m) shape must be equal.""" - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope( "root", initializer=init_ops.constant_initializer(0.5)): num_units = 2 @@ -309,7 +309,7 @@ class RNNCellTest(test.TestCase): def testBasicLSTMCellStateSizeError(self): """Tests that state_size must be num_units * 2.""" - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope( "root", initializer=init_ops.constant_initializer(0.5)): num_units = 2 @@ -329,7 +329,7 @@ class RNNCellTest(test.TestCase): }) def testBasicLSTMCellStateTupleType(self): - with self.test_session(): + with self.cached_session(): with variable_scope.variable_scope( "root", initializer=init_ops.constant_initializer(0.5)): x = array_ops.zeros([1, 2]) @@ -360,7 +360,7 @@ class RNNCellTest(test.TestCase): self.assertTrue(isinstance(out_m1, rnn_cell_impl.LSTMStateTuple)) def testBasicLSTMCellWithStateTuple(self): - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope( "root", initializer=init_ops.constant_initializer(0.5)): x = array_ops.zeros([1, 2]) @@ -459,7 +459,7 @@ class RNNCellTest(test.TestCase): self.assertEqual(len(res), 2) def testLSTMCell(self): - with self.test_session() as sess: + with self.cached_session() as sess: num_units = 8 num_proj = 6 state_size = num_units + num_proj @@ -494,7 +494,7 @@ class RNNCellTest(test.TestCase): float(np.linalg.norm((res[1][0, :] - res[1][i, :]))) > 1e-6) def testLSTMCellVariables(self): - with self.test_session(): + with self.cached_session(): num_units = 8 num_proj = 6 state_size = num_units + num_proj @@ -517,7 +517,7 @@ class RNNCellTest(test.TestCase): "root/lstm_cell/projection/kernel") def testLSTMCellLayerNorm(self): - with self.test_session() as sess: + with self.cached_session() as sess: num_units = 2 num_proj = 3 batch_size = 1 @@ -562,22 +562,21 @@ class RNNCellTest(test.TestCase): rnn_cell_impl.DropoutWrapper, rnn_cell_impl.ResidualWrapper, lambda cell: rnn_cell_impl.MultiRNNCell([cell])]: - with self.test_session(): - cell = rnn_cell_impl.BasicRNNCell(1) - wrapper = wrapper_type(cell) - wrapper(array_ops.ones([1, 1]), - state=wrapper.zero_state(batch_size=1, dtype=dtypes.float32)) - self.evaluate([v.initializer for v in cell.variables]) - checkpoint = checkpointable_utils.Checkpoint(wrapper=wrapper) - prefix = os.path.join(self.get_temp_dir(), "ckpt") - self.evaluate(cell._bias.assign([40.])) - save_path = checkpoint.save(prefix) - self.evaluate(cell._bias.assign([0.])) - checkpoint.restore(save_path).assert_consumed().run_restore_ops() - self.assertAllEqual([40.], self.evaluate(cell._bias)) + cell = rnn_cell_impl.BasicRNNCell(1) + wrapper = wrapper_type(cell) + wrapper(array_ops.ones([1, 1]), + state=wrapper.zero_state(batch_size=1, dtype=dtypes.float32)) + self.evaluate([v.initializer for v in cell.variables]) + checkpoint = checkpointable_utils.Checkpoint(wrapper=wrapper) + prefix = os.path.join(self.get_temp_dir(), "ckpt") + self.evaluate(cell._bias.assign([40.])) + save_path = checkpoint.save(prefix) + self.evaluate(cell._bias.assign([0.])) + checkpoint.restore(save_path).assert_consumed().run_restore_ops() + self.assertAllEqual([40.], self.evaluate(cell._bias)) def testOutputProjectionWrapper(self): - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope( "root", initializer=init_ops.constant_initializer(0.5)): x = array_ops.zeros([1, 3]) @@ -594,7 +593,7 @@ class RNNCellTest(test.TestCase): self.assertAllClose(res[0], [[0.231907, 0.231907]]) def testInputProjectionWrapper(self): - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope( "root", initializer=init_ops.constant_initializer(0.5)): x = array_ops.zeros([1, 2]) @@ -612,7 +611,7 @@ class RNNCellTest(test.TestCase): self.assertAllClose(res[0], [[0.154605, 0.154605, 0.154605]]) def testResidualWrapper(self): - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope( "root", initializer=init_ops.constant_initializer(0.5)): x = array_ops.zeros([1, 3]) @@ -638,7 +637,7 @@ class RNNCellTest(test.TestCase): self.assertAllClose(res[2], res[3]) def testResidualWrapperWithSlice(self): - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope( "root", initializer=init_ops.constant_initializer(0.5)): x = array_ops.zeros([1, 5]) @@ -716,7 +715,7 @@ class RNNCellTest(test.TestCase): self.assertTrue([s for s in gpu_stats if "gru_cell" in s.node_name]) def testEmbeddingWrapper(self): - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope( "root", initializer=init_ops.constant_initializer(0.5)): x = array_ops.zeros([1, 1], dtype=dtypes.int32) @@ -735,7 +734,7 @@ class RNNCellTest(test.TestCase): self.assertAllClose(res[0], [[0.17139, 0.17139]]) def testEmbeddingWrapperWithDynamicRnn(self): - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope("root"): inputs = ops.convert_to_tensor([[[0], [0]]], dtype=dtypes.int64) input_lengths = ops.convert_to_tensor([2], dtype=dtypes.int64) @@ -753,7 +752,7 @@ class RNNCellTest(test.TestCase): sess.run(outputs) def testMultiRNNCell(self): - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope( "root", initializer=init_ops.constant_initializer(0.5)): x = array_ops.zeros([1, 2]) @@ -770,7 +769,7 @@ class RNNCellTest(test.TestCase): self.assertAllClose(res, [[0.175991, 0.175991, 0.13248, 0.13248]]) def testMultiRNNCellWithStateTuple(self): - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope( "root", initializer=init_ops.constant_initializer(0.5)): x = array_ops.zeros([1, 2]) @@ -809,7 +808,7 @@ class DropoutWrapperTest(test.TestCase): time_steps=None, parallel_iterations=None, **kwargs): - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope( "root", initializer=init_ops.constant_initializer(0.5)): if batch_size is None and time_steps is None: diff --git a/tensorflow/contrib/saved_model/BUILD b/tensorflow/contrib/saved_model/BUILD index e7eb4ac563..b897224c6d 100644 --- a/tensorflow/contrib/saved_model/BUILD +++ b/tensorflow/contrib/saved_model/BUILD @@ -36,6 +36,7 @@ py_library( srcs_version = "PY2AND3", visibility = ["//visibility:public"], deps = [ + ":keras_saved_model", "//tensorflow/core:protos_all_py", "//tensorflow/python:framework_ops", "//tensorflow/python:lib", @@ -101,23 +102,33 @@ py_library( tags = ["no_windows"], visibility = ["//visibility:public"], deps = [ + "//tensorflow/python:array_ops", + "//tensorflow/python:framework_ops", "//tensorflow/python:lib", + "//tensorflow/python:metrics", + "//tensorflow/python:platform", + "//tensorflow/python:saver", "//tensorflow/python:util", + "//tensorflow/python/estimator", + "//tensorflow/python/estimator:export", + "//tensorflow/python/estimator:keras", + "//tensorflow/python/estimator:model_fn", "//tensorflow/python/keras:engine", - "//tensorflow/python/saved_model:constants", + "//tensorflow/python/saved_model", ], ) py_test( name = "keras_saved_model_test", - size = "small", + size = "medium", srcs = ["python/saved_model/keras_saved_model_test.py"], srcs_version = "PY2AND3", deps = [ - ":saved_model_py", + ":keras_saved_model", "//tensorflow/python:client_testlib", "//tensorflow/python:training", "//tensorflow/python/keras", "//third_party/py/numpy", + "@absl_py//absl/testing:parameterized", ], ) diff --git a/tensorflow/contrib/saved_model/__init__.py b/tensorflow/contrib/saved_model/__init__.py index 95e1a8967b..074dc655ac 100644 --- a/tensorflow/contrib/saved_model/__init__.py +++ b/tensorflow/contrib/saved_model/__init__.py @@ -26,10 +26,13 @@ from __future__ import print_function # pylint: disable=unused-import,wildcard-import,line-too-long from tensorflow.contrib.saved_model.python.saved_model.keras_saved_model import * from tensorflow.contrib.saved_model.python.saved_model.signature_def_utils import * -# pylint: enable=unused-import,widcard-import,line-too-long +# pylint: enable=unused-import,wildcard-import,line-too-long from tensorflow.python.util.all_util import remove_undocumented -_allowed_symbols = ["get_signature_def_by_key", "load_model", "save_model"] +_allowed_symbols = [ + "get_signature_def_by_key", + "load_keras_model", + "save_keras_model"] remove_undocumented(__name__, _allowed_symbols) diff --git a/tensorflow/contrib/saved_model/cc/saved_model/BUILD b/tensorflow/contrib/saved_model/cc/saved_model/BUILD index 3c616c555b..ea4d41d43b 100644 --- a/tensorflow/contrib/saved_model/cc/saved_model/BUILD +++ b/tensorflow/contrib/saved_model/cc/saved_model/BUILD @@ -30,6 +30,7 @@ cc_library( hdrs = ["signature_def_utils.h"], visibility = ["//visibility:public"], deps = [ + "//tensorflow/cc/saved_model:signature_constants", "//tensorflow/core:framework", "//tensorflow/core:lib", "//tensorflow/core:lib_proto_parsing", @@ -42,6 +43,7 @@ tf_cc_test( srcs = ["signature_def_utils_test.cc"], deps = [ ":signature_def_utils", + "//tensorflow/cc/saved_model:signature_constants", "//tensorflow/core:framework", "//tensorflow/core:lib", "//tensorflow/core:lib_proto_parsing", diff --git a/tensorflow/contrib/saved_model/cc/saved_model/signature_def_utils.cc b/tensorflow/contrib/saved_model/cc/saved_model/signature_def_utils.cc index a45908d272..e87e497e5f 100644 --- a/tensorflow/contrib/saved_model/cc/saved_model/signature_def_utils.cc +++ b/tensorflow/contrib/saved_model/cc/saved_model/signature_def_utils.cc @@ -15,6 +15,8 @@ limitations under the License. #include "tensorflow/contrib/saved_model/cc/saved_model/signature_def_utils.h" +#include "tensorflow/cc/saved_model/signature_constants.h" +#include "tensorflow/core/framework/types.pb.h" #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/platform/protobuf.h" @@ -33,6 +35,79 @@ Status FindInProtobufMap(StringPiece description, *value = &it->second; return Status::OK(); } + +// Looks up the TensorInfo for the given key in the given map and verifies that +// its datatype matches the given correct datatype. +bool VerifyTensorInfoForKeyInMap(const protobuf::Map<string, TensorInfo>& map, + const string& key, DataType correct_dtype) { + const TensorInfo* tensor_info; + const Status& status = FindInProtobufMap("", map, key, &tensor_info); + if (!status.ok()) { + return false; + } + if (tensor_info->dtype() != correct_dtype) { + return false; + } + return true; +} + +bool IsValidPredictSignature(const SignatureDef& signature_def) { + if (signature_def.method_name() != kPredictMethodName) { + return false; + } + if (signature_def.inputs().empty()) { + return false; + } + if (signature_def.outputs().empty()) { + return false; + } + return true; +} + +bool IsValidRegressionSignature(const SignatureDef& signature_def) { + if (signature_def.method_name() != kRegressMethodName) { + return false; + } + if (!VerifyTensorInfoForKeyInMap(signature_def.inputs(), kRegressInputs, + DT_STRING)) { + return false; + } + if (!VerifyTensorInfoForKeyInMap(signature_def.outputs(), kRegressOutputs, + DT_FLOAT)) { + return false; + } + return true; +} + +bool IsValidClassificationSignature(const SignatureDef& signature_def) { + if (signature_def.method_name() != kClassifyMethodName) { + return false; + } + if (!VerifyTensorInfoForKeyInMap(signature_def.inputs(), kClassifyInputs, + DT_STRING)) { + return false; + } + if (signature_def.outputs().empty()) { + return false; + } + for (auto const& output : signature_def.outputs()) { + const string& key = output.first; + const TensorInfo& tensor_info = output.second; + if (key == kClassifyOutputClasses) { + if (tensor_info.dtype() != DT_STRING) { + return false; + } + } else if (key == kClassifyOutputScores) { + if (tensor_info.dtype() != DT_FLOAT) { + return false; + } + } else { + return false; + } + } + return true; +} + } // namespace Status FindSignatureDefByKey(const MetaGraphDef& meta_graph_def, @@ -74,4 +149,10 @@ Status FindOutputTensorNameByKey(const SignatureDef& signature_def, return Status::OK(); } +bool IsValidSignature(const SignatureDef& signature_def) { + return IsValidClassificationSignature(signature_def) || + IsValidRegressionSignature(signature_def) || + IsValidPredictSignature(signature_def); +} + } // namespace tensorflow diff --git a/tensorflow/contrib/saved_model/cc/saved_model/signature_def_utils.h b/tensorflow/contrib/saved_model/cc/saved_model/signature_def_utils.h index b732cdd41e..bb24faa989 100644 --- a/tensorflow/contrib/saved_model/cc/saved_model/signature_def_utils.h +++ b/tensorflow/contrib/saved_model/cc/saved_model/signature_def_utils.h @@ -64,6 +64,9 @@ Status FindInputTensorNameByKey(const SignatureDef& signature_def, Status FindOutputTensorNameByKey(const SignatureDef& signature_def, const string& tensor_info_key, string* name); +// Determine whether a SignatureDef can be served by TensorFlow Serving. +bool IsValidSignature(const SignatureDef& signature_def); + } // namespace tensorflow #endif // TENSORFLOW_CONTRIB_SAVED_MODEL_CC_SAVED_MODEL_SIGNATURE_DEF_UTILS_H_ diff --git a/tensorflow/contrib/saved_model/cc/saved_model/signature_def_utils_test.cc b/tensorflow/contrib/saved_model/cc/saved_model/signature_def_utils_test.cc index a063e95696..c743112ce0 100644 --- a/tensorflow/contrib/saved_model/cc/saved_model/signature_def_utils_test.cc +++ b/tensorflow/contrib/saved_model/cc/saved_model/signature_def_utils_test.cc @@ -15,6 +15,7 @@ limitations under the License. #include "tensorflow/contrib/saved_model/cc/saved_model/signature_def_utils.h" +#include "tensorflow/cc/saved_model/signature_constants.h" #include "tensorflow/core/framework/tensor.h" #include "tensorflow/core/lib/core/status_test_util.h" #include "tensorflow/core/platform/test.h" @@ -22,7 +23,7 @@ limitations under the License. namespace tensorflow { -class SignatureDefUtilsTest : public ::testing::Test { +class FindByKeyTest : public ::testing::Test { protected: MetaGraphDef MakeSampleMetaGraphDef() { MetaGraphDef result; @@ -32,13 +33,23 @@ class SignatureDefUtilsTest : public ::testing::Test { return result; } + void SetInputNameForKey(const string& key, const string& name, + SignatureDef* signature_def) { + (*signature_def->mutable_inputs())[key].set_name(name); + } + + void SetOutputNameForKey(const string& key, const string& name, + SignatureDef* signature_def) { + (*signature_def->mutable_outputs())[key].set_name(name); + } + SignatureDef MakeSampleSignatureDef() { SignatureDef result; result.set_method_name(kMethodName); - (*result.mutable_inputs())[kInput1Key].set_name(kInput1Name); - (*result.mutable_inputs())[kInput2Key].set_name(kInput2Name); - (*result.mutable_outputs())[kOutput1Key].set_name(kOutput1Name); - (*result.mutable_outputs())[kOutput2Key].set_name(kOutput2Name); + SetInputNameForKey(kInput1Key, kInput1Name, &result); + SetInputNameForKey(kInput2Key, kInput2Name, &result); + SetOutputNameForKey(kOutput1Key, kOutput1Name, &result); + SetOutputNameForKey(kOutput2Key, kOutput2Name, &result); return result; } @@ -54,7 +65,7 @@ class SignatureDefUtilsTest : public ::testing::Test { const string kOutput2Name = "output_two"; }; -TEST_F(SignatureDefUtilsTest, FindSignatureDefByKey) { +TEST_F(FindByKeyTest, FindSignatureDefByKey) { const MetaGraphDef meta_graph_def = MakeSampleMetaGraphDef(); const SignatureDef* signature_def; // Succeeds for an existing signature. @@ -67,7 +78,7 @@ TEST_F(SignatureDefUtilsTest, FindSignatureDefByKey) { .ok()); } -TEST_F(SignatureDefUtilsTest, FindInputTensorNameByKey) { +TEST_F(FindByKeyTest, FindInputTensorNameByKey) { const SignatureDef signature_def = MakeSampleSignatureDef(); string name; // Succeeds for an existing input. @@ -78,7 +89,7 @@ TEST_F(SignatureDefUtilsTest, FindInputTensorNameByKey) { FindInputTensorNameByKey(signature_def, "nonexistent", &name).ok()); } -TEST_F(SignatureDefUtilsTest, FindOutputTensorNameByKey) { +TEST_F(FindByKeyTest, FindOutputTensorNameByKey) { const SignatureDef signature_def = MakeSampleSignatureDef(); string name; // Succeeds for an existing output. @@ -89,4 +100,100 @@ TEST_F(SignatureDefUtilsTest, FindOutputTensorNameByKey) { FindOutputTensorNameByKey(signature_def, "nonexistent", &name).ok()); } +class IsValidSignatureTest : public ::testing::Test { + protected: + void SetInputDataTypeForKey(const string& key, DataType dtype) { + (*signature_def_.mutable_inputs())[key].set_dtype(dtype); + } + + void SetOutputDataTypeForKey(const string& key, DataType dtype) { + (*signature_def_.mutable_outputs())[key].set_dtype(dtype); + } + + void EraseOutputKey(const string& key) { + (*signature_def_.mutable_outputs()).erase(key); + } + + void ExpectInvalidSignature() { + EXPECT_FALSE(IsValidSignature(signature_def_)); + } + + void ExpectValidSignature() { EXPECT_TRUE(IsValidSignature(signature_def_)); } + + SignatureDef signature_def_; +}; + +TEST_F(IsValidSignatureTest, IsValidPredictSignature) { + signature_def_.set_method_name("not_kPredictMethodName"); + // Incorrect method name + ExpectInvalidSignature(); + + signature_def_.set_method_name(kPredictMethodName); + // No inputs + ExpectInvalidSignature(); + + SetInputDataTypeForKey(kPredictInputs, DT_STRING); + // No outputs + ExpectInvalidSignature(); + + SetOutputDataTypeForKey(kPredictOutputs, DT_STRING); + ExpectValidSignature(); +} + +TEST_F(IsValidSignatureTest, IsValidRegressionSignature) { + signature_def_.set_method_name("not_kRegressMethodName"); + // Incorrect method name + ExpectInvalidSignature(); + + signature_def_.set_method_name(kRegressMethodName); + // No inputs + ExpectInvalidSignature(); + + SetInputDataTypeForKey(kRegressInputs, DT_STRING); + // No outputs + ExpectInvalidSignature(); + + SetOutputDataTypeForKey(kRegressOutputs, DT_STRING); + // Incorrect data type + ExpectInvalidSignature(); + + SetOutputDataTypeForKey(kRegressOutputs, DT_FLOAT); + ExpectValidSignature(); +} + +TEST_F(IsValidSignatureTest, IsValidClassificationSignature) { + signature_def_.set_method_name("not_kClassifyMethodName"); + // Incorrect method name + ExpectInvalidSignature(); + + signature_def_.set_method_name(kClassifyMethodName); + // No inputs + ExpectInvalidSignature(); + + SetInputDataTypeForKey(kClassifyInputs, DT_STRING); + // No outputs + ExpectInvalidSignature(); + + SetOutputDataTypeForKey("invalidKey", DT_FLOAT); + // Invalid key + ExpectInvalidSignature(); + + EraseOutputKey("invalidKey"); + SetOutputDataTypeForKey(kClassifyOutputClasses, DT_FLOAT); + // Invalid dtype for classes + ExpectInvalidSignature(); + + SetOutputDataTypeForKey(kClassifyOutputClasses, DT_STRING); + // Valid without scores + ExpectValidSignature(); + + SetOutputDataTypeForKey(kClassifyOutputScores, DT_STRING); + // Invalid dtype for scores + ExpectInvalidSignature(); + + SetOutputDataTypeForKey(kClassifyOutputScores, DT_FLOAT); + // Valid with both classes and scores + ExpectValidSignature(); +} + } // namespace tensorflow diff --git a/tensorflow/contrib/saved_model/python/saved_model/keras_saved_model.py b/tensorflow/contrib/saved_model/python/saved_model/keras_saved_model.py index e2a969f053..2c5c8c4afd 100644 --- a/tensorflow/contrib/saved_model/python/saved_model/keras_saved_model.py +++ b/tensorflow/contrib/saved_model/python/saved_model/keras_saved_model.py @@ -20,28 +20,69 @@ from __future__ import print_function import os +from tensorflow.python.client import session +from tensorflow.python.estimator import keras as estimator_keras_util +from tensorflow.python.estimator import model_fn as model_fn_lib +from tensorflow.python.estimator.export import export as export_helpers +from tensorflow.python.framework import errors +from tensorflow.python.framework import ops +from tensorflow.python.keras import backend as K +from tensorflow.python.keras import models as models_lib +from tensorflow.python.keras import optimizers from tensorflow.python.keras.models import model_from_json from tensorflow.python.lib.io import file_io +from tensorflow.python.ops import variables +from tensorflow.python.platform import gfile +from tensorflow.python.platform import tf_logging as logging +from tensorflow.python.saved_model import builder as saved_model_builder from tensorflow.python.saved_model import constants +from tensorflow.python.saved_model import utils_impl as saved_model_utils +from tensorflow.python.training import saver as saver_lib +from tensorflow.python.training.checkpointable import util as checkpointable_utils from tensorflow.python.util import compat -def save_model(model, saved_model_path): +def save_keras_model( + model, saved_model_path, custom_objects=None, as_text=None): """Save a `tf.keras.Model` into Tensorflow SavedModel format. - `save_model` generates such files/folders under the `saved_model_path` folder: + `save_model` generates new files/folders under the `saved_model_path` folder: 1) an asset folder containing the json string of the model's - configuration(topology). + configuration (topology). 2) a checkpoint containing the model weights. + 3) a saved_model.pb file containing the model's MetaGraphs. The prediction + graph is always exported. The evaluaton and training graphs are exported + if the following conditions are met: + - Evaluation: model loss is defined. + - Training: model is compiled with an optimizer defined under `tf.train`. + This is because `tf.keras.optimizers.Optimizer` instances cannot be + saved to checkpoints. - Note that subclassed models can not be saved via this function, unless you - provide an implementation for get_config() and from_config(). - Also note that `tf.keras.optimizers.Optimizer` instances can not currently be - saved to checkpoints. Use optimizers from `tf.train`. + Model Requirements: + - Model must be a sequential model or functional model. Subclassed models can + not be saved via this function, unless you provide an implementation for + get_config() and from_config(). + - All variables must be saveable by the model. In general, this condition is + met through the use of layers defined in the keras library. However, + there is currently a bug with variables created in Lambda layer functions + not being saved correctly (see + https://github.com/keras-team/keras/issues/9740). + + Note that each mode is exported in separate graphs, so different modes do not + share variables. To use the train graph with evaluation or prediction graphs, + create a new checkpoint if variable values have been updated. Args: model: A `tf.keras.Model` to be saved. saved_model_path: a string specifying the path to the SavedModel directory. + The SavedModel will be saved to a timestamped folder created within this + directory. + custom_objects: Optional dictionary mapping string names to custom classes + or functions (e.g. custom loss functions). + as_text: whether to write the `SavedModel` proto in text format. + + Returns: + String path to the SavedModel folder, a subdirectory of `saved_model_path`. Raises: NotImplementedError: If the passed in model is a subclassed model. @@ -49,35 +90,200 @@ def save_model(model, saved_model_path): if not model._is_graph_network: raise NotImplementedError - # save model configuration as a json string under assets folder. - model_json = model.to_json() - assets_destination_dir = os.path.join( - compat.as_bytes(saved_model_path), - compat.as_bytes(constants.ASSETS_DIRECTORY)) + export_dir = export_helpers.get_timestamped_export_dir(saved_model_path) + temp_export_dir = export_helpers.get_temp_export_dir(export_dir) + + builder = saved_model_builder.SavedModelBuilder(temp_export_dir) + + # Manually save variables to export them in an object-based checkpoint. This + # skips the `builder.add_meta_graph_and_variables()` step, which saves a + # named-based checkpoint. + # TODO(b/113134168): Add fn to Builder to save with object-based saver. + # TODO(b/113178242): This should only export the model json structure. Only + # one save is needed once the weights can be copied from the model to clone. + checkpoint_path = _export_model_json_and_variables(model, temp_export_dir) + + # Export each mode. Use ModeKeys enums defined for `Estimator` to ensure that + # Keras models and `Estimator`s are exported with the same format. + # Every time a mode is exported, the code checks to see if new variables have + # been created (e.g. optimizer slot variables). If that is the case, the + # checkpoint is re-saved to include the new variables. + export_args = {'builder': builder, + 'model': model, + 'custom_objects': custom_objects, + 'checkpoint_path': checkpoint_path} + + has_saved_vars = False + if model.optimizer: + if isinstance(model.optimizer, optimizers.TFOptimizer): + _export_mode(model_fn_lib.ModeKeys.TRAIN, has_saved_vars, **export_args) + has_saved_vars = True + _export_mode(model_fn_lib.ModeKeys.EVAL, has_saved_vars, **export_args) + else: + logging.warning( + 'Model was compiled with an optimizer, but the optimizer is not from ' + '`tf.train` (e.g. `tf.train.AdagradOptimizer`). Only the serving ' + 'graph was exported. The train and evaluate graphs were not added to ' + 'the SavedModel.') + _export_mode(model_fn_lib.ModeKeys.PREDICT, has_saved_vars, **export_args) + + builder.save(as_text) + + gfile.Rename(temp_export_dir, export_dir) + return export_dir - if not file_io.file_exists(assets_destination_dir): - file_io.recursive_create_dir(assets_destination_dir) +def _export_model_json_and_variables(model, saved_model_path): + """Save model variables and json structure into SavedModel subdirectories.""" + # Save model configuration as a json string under assets folder. + model_json = model.to_json() model_json_filepath = os.path.join( - compat.as_bytes(assets_destination_dir), - compat.as_bytes(constants.SAVED_MODEL_FILENAME_JSON)) + saved_model_utils.get_or_create_assets_dir(saved_model_path), + compat.as_text(constants.SAVED_MODEL_FILENAME_JSON)) file_io.write_string_to_file(model_json_filepath, model_json) - # save model weights in checkpoint format. - checkpoint_destination_dir = os.path.join( - compat.as_bytes(saved_model_path), - compat.as_bytes(constants.VARIABLES_DIRECTORY)) + # Save model weights in checkpoint format under variables folder. + saved_model_utils.get_or_create_variables_dir(saved_model_path) + checkpoint_prefix = saved_model_utils.get_variables_path(saved_model_path) + model.save_weights(checkpoint_prefix, save_format='tf', overwrite=True) + return checkpoint_prefix - if not file_io.file_exists(checkpoint_destination_dir): - file_io.recursive_create_dir(checkpoint_destination_dir) - checkpoint_prefix = os.path.join( - compat.as_text(checkpoint_destination_dir), - compat.as_text(constants.VARIABLES_FILENAME)) - model.save_weights(checkpoint_prefix, save_format='tf', overwrite=True) +def _get_var_list(model): + """Return list of all checkpointed saveable objects in the model.""" + return checkpointable_utils.named_saveables(model) + + +def _export_mode( + mode, has_saved_vars, builder, model, custom_objects, checkpoint_path): + """Export a model, and optionally save new vars from the clone model. + + Args: + mode: A `tf.estimator.ModeKeys` string. + has_saved_vars: A `boolean` indicating whether the SavedModel has already + exported variables. + builder: A `SavedModelBuilder` object. + model: A `tf.keras.Model` object. + custom_objects: A dictionary mapping string names to custom classes + or functions. + checkpoint_path: String path to checkpoint. + + Raises: + ValueError: If the train/eval mode is being exported, but the model does + not have an optimizer. + """ + compile_clone = (mode != model_fn_lib.ModeKeys.PREDICT) + if compile_clone and not model.optimizer: + raise ValueError( + 'Model does not have an optimizer. Cannot export mode %s' % mode) + + model_graph = ops.get_default_graph() + with ops.Graph().as_default() as g: + + K.set_learning_phase(mode == model_fn_lib.ModeKeys.TRAIN) + + # Clone the model into blank graph. This will create placeholders for inputs + # and targets. + clone = models_lib.clone_and_build_model( + model, custom_objects=custom_objects, compile_clone=compile_clone) + + # Make sure that iterations variable is added to the global step collection, + # to ensure that, when the SavedModel graph is loaded, the iterations + # variable is returned by `tf.train.get_global_step()`. This is required for + # compatibility with the SavedModelEstimator. + if compile_clone: + g.add_to_collection(ops.GraphKeys.GLOBAL_STEP, clone.optimizer.iterations) + + # Extract update and train ops from train/test/predict functions. + if mode == model_fn_lib.ModeKeys.TRAIN: + clone._make_train_function() + builder._add_train_op(clone.train_function.updates_op) + elif mode == model_fn_lib.ModeKeys.EVAL: + clone._make_test_function() + else: + clone._make_predict_function() + g.get_collection_ref(ops.GraphKeys.UPDATE_OPS).extend(clone.state_updates) + + clone_var_list = checkpointable_utils.named_saveables(clone) + + with session.Session().as_default(): + if has_saved_vars: + # Confirm all variables in the clone have an entry in the checkpoint. + status = clone.load_weights(checkpoint_path) + status.assert_existing_objects_matched() + else: + # Confirm that variables between the clone and model match up exactly, + # not counting optimizer objects. Optimizer objects are ignored because + # if the model has not trained, the slot variables will not have been + # created yet. + # TODO(b/113179535): Replace with checkpointable equivalence. + _assert_same_non_optimizer_objects(model, model_graph, clone, g) + + # TODO(b/113178242): Use value transfer for checkpointable objects. + clone.load_weights(checkpoint_path) + + # Add graph and variables to SavedModel. + # TODO(b/113134168): Switch to add_meta_graph_and_variables. + clone.save_weights(checkpoint_path, save_format='tf', overwrite=True) + builder._has_saved_variables = True + + # Add graph to the SavedModel builder. + builder.add_meta_graph( + model_fn_lib.EXPORT_TAG_MAP[mode], + signature_def_map=_create_signature_def_map(clone, mode), + saver=saver_lib.Saver(clone_var_list), + main_op=variables.local_variables_initializer()) + return None + + +def _create_signature_def_map(model, mode): + """Create a SignatureDef map from a Keras model.""" + inputs_dict = {name: x for name, x in zip(model.input_names, model.inputs)} + if model.optimizer: + targets_dict = {x.name.split(':')[0]: x + for x in model.targets if x is not None} + inputs_dict.update(targets_dict) + outputs_dict = {name: x + for name, x in zip(model.output_names, model.outputs)} + export_outputs = model_fn_lib.export_outputs_for_mode( + mode, + predictions=outputs_dict, + loss=model.total_loss if model.optimizer else None, + metrics=estimator_keras_util._convert_keras_metrics_to_estimator(model)) + return export_helpers.build_all_signature_defs( + inputs_dict, + export_outputs=export_outputs, + serving_only=(mode == model_fn_lib.ModeKeys.PREDICT)) + + +def _assert_same_non_optimizer_objects(model, model_graph, clone, clone_graph): + """Assert model and clone contain the same checkpointable objects.""" + + def get_non_optimizer_objects(m, g): + """Gather set of model and optimizer checkpointable objects.""" + # Set default graph because optimizer.variables() returns optimizer + # variables defined in the default graph. + with g.as_default(): + all_objects = set(checkpointable_utils.list_objects(m)) + optimizer_and_variables = set() + for obj in all_objects: + if isinstance(obj, optimizers.TFOptimizer): + optimizer_and_variables.update(checkpointable_utils.list_objects(obj)) + optimizer_and_variables.update(set(obj.optimizer.variables())) + return all_objects - optimizer_and_variables + + model_objects = get_non_optimizer_objects(model, model_graph) + clone_objects = get_non_optimizer_objects(clone, clone_graph) + + if len(model_objects) != len(clone_objects): + raise errors.InternalError( + None, None, + 'Model and clone must use the same variables.' + '\n\tModel variables: %s\n\t Clone variables: %s' + % (model_objects, clone_objects)) -def load_model(saved_model_path): +def load_keras_model(saved_model_path): """Load a keras.Model from SavedModel. load_model reinstantiates model state by: diff --git a/tensorflow/contrib/saved_model/python/saved_model/keras_saved_model_test.py b/tensorflow/contrib/saved_model/python/saved_model/keras_saved_model_test.py index 107ae1b07b..8a0dbef788 100644 --- a/tensorflow/contrib/saved_model/python/saved_model/keras_saved_model_test.py +++ b/tensorflow/contrib/saved_model/python/saved_model/keras_saved_model_test.py @@ -20,18 +20,35 @@ from __future__ import print_function import os import shutil + +from absl.testing import parameterized import numpy as np from tensorflow.contrib.saved_model.python.saved_model import keras_saved_model from tensorflow.python import keras +from tensorflow.python.client import session +from tensorflow.python.eager import context +from tensorflow.python.estimator import model_fn as model_fn_lib +from tensorflow.python.framework import errors +from tensorflow.python.framework import ops from tensorflow.python.framework import test_util from tensorflow.python.keras.engine import training +from tensorflow.python.keras.utils import tf_utils +from tensorflow.python.ops import array_ops from tensorflow.python.platform import test +from tensorflow.python.saved_model import constants +from tensorflow.python.saved_model import loader_impl +from tensorflow.python.saved_model import signature_constants from tensorflow.python.training import training as training_module class TestModelSavingandLoading(test.TestCase): + def _save_model_dir(self, dirname='saved_model'): + temp_dir = self.get_temp_dir() + self.addCleanup(shutil.rmtree, temp_dir, ignore_errors=True) + return os.path.join(temp_dir, dirname) + def test_saving_sequential_model(self): with self.test_session(): model = keras.models.Sequential() @@ -48,13 +65,11 @@ class TestModelSavingandLoading(test.TestCase): model.train_on_batch(x, y) ref_y = model.predict(x) - temp_dir = self.get_temp_dir() - self.addCleanup(shutil.rmtree, temp_dir) - temp_saved_model = os.path.join(temp_dir, 'saved_model') - keras_saved_model.save_model(model, temp_saved_model) + temp_saved_model = self._save_model_dir() + output_path = keras_saved_model.save_keras_model(model, temp_saved_model) - loaded_model = keras_saved_model.load_model(temp_saved_model) + loaded_model = keras_saved_model.load_keras_model(output_path) y = loaded_model.predict(x) self.assertAllClose(ref_y, y, atol=1e-05) @@ -69,12 +84,9 @@ class TestModelSavingandLoading(test.TestCase): x = np.random.random((1, 3)) ref_y = model.predict(x) - temp_dir = self.get_temp_dir() - self.addCleanup(shutil.rmtree, temp_dir) - - temp_saved_model = os.path.join(temp_dir, 'saved_model') - keras_saved_model.save_model(model, temp_saved_model) - loaded_model = keras_saved_model.load_model(temp_saved_model) + temp_saved_model = self._save_model_dir() + output_path = keras_saved_model.save_keras_model(model, temp_saved_model) + loaded_model = keras_saved_model.load_keras_model(output_path) y = loaded_model.predict(x) self.assertAllClose(ref_y, y, atol=1e-05) @@ -95,12 +107,10 @@ class TestModelSavingandLoading(test.TestCase): model.train_on_batch(x, y) ref_y = model.predict(x) - temp_dir = self.get_temp_dir() - self.addCleanup(shutil.rmtree, temp_dir) - temp_saved_model = os.path.join(temp_dir, 'saved_model') - keras_saved_model.save_model(model, temp_saved_model) - loaded_model = keras_saved_model.load_model(temp_saved_model) + temp_saved_model = self._save_model_dir() + output_path = keras_saved_model.save_keras_model(model, temp_saved_model) + loaded_model = keras_saved_model.load_keras_model(output_path) y = loaded_model.predict(x) self.assertAllClose(ref_y, y, atol=1e-05) @@ -118,12 +128,10 @@ class TestModelSavingandLoading(test.TestCase): y = np.random.random((1, 3)) ref_y = model.predict(x) - temp_dir = self.get_temp_dir() - self.addCleanup(shutil.rmtree, temp_dir) - temp_saved_model = os.path.join(temp_dir, 'saved_model') - keras_saved_model.save_model(model, temp_saved_model) - loaded_model = keras_saved_model.load_model(temp_saved_model) + temp_saved_model = self._save_model_dir() + output_path = keras_saved_model.save_keras_model(model, temp_saved_model) + loaded_model = keras_saved_model.load_keras_model(output_path) y = loaded_model.predict(x) self.assertAllClose(ref_y, y, atol=1e-05) @@ -142,14 +150,13 @@ class TestModelSavingandLoading(test.TestCase): x = np.random.random((1, 3)) y = np.random.random((1, 3)) model.train_on_batch(x, y) + model.train_on_batch(x, y) ref_y = model.predict(x) - temp_dir = self.get_temp_dir() - self.addCleanup(shutil.rmtree, temp_dir) - temp_saved_model = os.path.join(temp_dir, 'saved_model') - keras_saved_model.save_model(model, temp_saved_model) - loaded_model = keras_saved_model.load_model(temp_saved_model) + temp_saved_model = self._save_model_dir() + output_path = keras_saved_model.save_keras_model(model, temp_saved_model) + loaded_model = keras_saved_model.load_keras_model(output_path) loaded_model.compile( loss='mse', optimizer=training_module.RMSPropOptimizer(0.1), @@ -170,8 +177,10 @@ class TestModelSavingandLoading(test.TestCase): self.assertAllClose(ref_y, y, atol=1e-05) # test saving/loading again - keras_saved_model.save_model(loaded_model, temp_saved_model) - loaded_model = keras_saved_model.load_model(temp_saved_model) + temp_saved_model2 = self._save_model_dir('saved_model_2') + output_path2 = keras_saved_model.save_keras_model( + loaded_model, temp_saved_model2) + loaded_model = keras_saved_model.load_keras_model(output_path2) y = loaded_model.predict(x) self.assertAllClose(ref_y, y, atol=1e-05) @@ -190,11 +199,231 @@ class TestModelSavingandLoading(test.TestCase): return self.layer2(self.layer1(inp)) model = SubclassedModel() - temp_dir = self.get_temp_dir() - self.addCleanup(shutil.rmtree, temp_dir) - temp_saved_model = os.path.join(temp_dir, 'saved_model') + + temp_saved_model = self._save_model_dir() with self.assertRaises(NotImplementedError): - keras_saved_model.save_model(model, temp_saved_model) + keras_saved_model.save_keras_model(model, temp_saved_model) + + +class LayerWithLearningPhase(keras.engine.base_layer.Layer): + + def call(self, x): + phase = keras.backend.learning_phase() + output = tf_utils.smart_cond( + phase, lambda: x * 0, lambda: array_ops.identity(x)) + if not context.executing_eagerly(): + output._uses_learning_phase = True # pylint: disable=protected-access + return output + + def compute_output_shape(self, input_shape): + return input_shape + + +def functional_model(uses_learning_phase): + inputs = keras.layers.Input(shape=(3,)) + x = keras.layers.Dense(2)(inputs) + x = keras.layers.Dense(3)(x) + if uses_learning_phase: + x = LayerWithLearningPhase()(x) + return keras.models.Model(inputs, x) + + +def sequential_model(uses_learning_phase): + model = keras.models.Sequential() + model.add(keras.layers.Dense(2, input_shape=(3,))) + model.add(keras.layers.Dense(3)) + if uses_learning_phase: + model.add(LayerWithLearningPhase()) + return model + + +def load_model(sess, path, mode): + tags = model_fn_lib.EXPORT_TAG_MAP[mode] + sig_def_key = (signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY + if mode == model_fn_lib.ModeKeys.PREDICT else mode) + meta_graph_def = loader_impl.load(sess, tags, path) + inputs = { + k: sess.graph.get_tensor_by_name(v.name) + for k, v in meta_graph_def.signature_def[sig_def_key].inputs.items()} + outputs = { + k: sess.graph.get_tensor_by_name(v.name) + for k, v in meta_graph_def.signature_def[sig_def_key].outputs.items()} + return inputs, outputs + + +@test_util.run_all_in_graph_and_eager_modes +class TestModelSavedModelExport(test.TestCase, parameterized.TestCase): + + def _save_model_dir(self, dirname='saved_model'): + temp_dir = self.get_temp_dir() + self.addCleanup(shutil.rmtree, temp_dir, ignore_errors=True) + return os.path.join(temp_dir, dirname) + + @parameterized.parameters( + (functional_model, True, training_module.AdadeltaOptimizer(), True), + (functional_model, True, training_module.AdadeltaOptimizer(), False), + (functional_model, False, None, False), + (sequential_model, True, training_module.AdadeltaOptimizer(), True), + (sequential_model, True, training_module.AdadeltaOptimizer(), False), + (sequential_model, False, None, False)) + def testSaveAndLoadSavedModelExport( + self, model_builder, uses_learning_phase, optimizer, train_before_export): + saved_model_path = self._save_model_dir() + with self.test_session(graph=ops.Graph()): + input_arr = np.random.random((1, 3)) + target_arr = np.random.random((1, 3)) + + model = model_builder(uses_learning_phase) + if optimizer is not None: + model.compile( + loss='mse', + optimizer=optimizer, + metrics=['mae']) + if train_before_export: + model.train_on_batch(input_arr, target_arr) + + ref_loss, ref_mae = model.evaluate(input_arr, target_arr) + + ref_predict = model.predict(input_arr) + + # Export SavedModel + output_path = keras_saved_model.save_keras_model(model, saved_model_path) + + input_name = model.input_names[0] + output_name = model.output_names[0] + target_name = output_name + '_target' + + # Load predict graph, and test predictions + with session.Session(graph=ops.Graph()) as sess: + inputs, outputs = load_model(sess, output_path, + model_fn_lib.ModeKeys.PREDICT) + + predictions = sess.run(outputs[output_name], + {inputs[input_name]: input_arr}) + self.assertAllClose(ref_predict, predictions, atol=1e-05) + + if optimizer: + # Load eval graph, and test predictions, loss and metric values + with session.Session(graph=ops.Graph()) as sess: + inputs, outputs = load_model(sess, output_path, + model_fn_lib.ModeKeys.EVAL) + + eval_results = sess.run(outputs, {inputs[input_name]: input_arr, + inputs[target_name]: target_arr}) + + self.assertEqual(int(train_before_export), + sess.run(training_module.get_global_step())) + self.assertAllClose(ref_loss, eval_results['loss'], atol=1e-05) + self.assertAllClose( + ref_mae, eval_results['metrics/mae/update_op'], atol=1e-05) + self.assertAllClose( + ref_predict, eval_results['predictions/' + output_name], atol=1e-05) + + # Load train graph, and check for the train op, and prediction values + with session.Session(graph=ops.Graph()) as sess: + inputs, outputs = load_model(sess, output_path, + model_fn_lib.ModeKeys.TRAIN) + self.assertEqual(int(train_before_export), + sess.run(training_module.get_global_step())) + self.assertIn('loss', outputs) + self.assertIn('metrics/mae/update_op', outputs) + self.assertIn('metrics/mae/value', outputs) + self.assertIn('predictions/' + output_name, outputs) + + # Train for a step + train_op = ops.get_collection(constants.TRAIN_OP_KEY) + train_outputs, _ = sess.run( + [outputs, train_op], {inputs[input_name]: input_arr, + inputs[target_name]: target_arr}) + self.assertEqual(int(train_before_export) + 1, + sess.run(training_module.get_global_step())) + + if uses_learning_phase: + self.assertAllClose( + [[0, 0, 0]], train_outputs['predictions/' + output_name], + atol=1e-05) + else: + self.assertNotAllClose( + [[0, 0, 0]], train_outputs['predictions/' + output_name], + atol=1e-05) + + def testSaveAndLoadSavedModelWithCustomObject(self): + saved_model_path = self._save_model_dir() + with session.Session(graph=ops.Graph()) as sess: + def relu6(x): + return keras.backend.relu(x, max_value=6) + inputs = keras.layers.Input(shape=(1,)) + outputs = keras.layers.Activation(relu6)(inputs) + model = keras.models.Model(inputs, outputs) + output_path = keras_saved_model.save_keras_model( + model, saved_model_path, custom_objects={'relu6': relu6}) + with session.Session(graph=ops.Graph()) as sess: + inputs, outputs = load_model(sess, output_path, + model_fn_lib.ModeKeys.PREDICT) + input_name = model.input_names[0] + output_name = model.output_names[0] + predictions = sess.run( + outputs[output_name], {inputs[input_name]: [[7], [-3], [4]]}) + self.assertAllEqual([[6], [0], [4]], predictions) + + def testAssertModelCloneSameObjectsIgnoreOptimizer(self): + input_arr = np.random.random((1, 3)) + target_arr = np.random.random((1, 3)) + + model_graph = ops.Graph() + clone_graph = ops.Graph() + + # Create two models with the same layers but different optimizers. + with session.Session(graph=model_graph): + inputs = keras.layers.Input(shape=(3,)) + x = keras.layers.Dense(2)(inputs) + x = keras.layers.Dense(3)(x) + model = keras.models.Model(inputs, x) + + model.compile(loss='mse', optimizer=training_module.AdadeltaOptimizer()) + model.train_on_batch(input_arr, target_arr) + + with session.Session(graph=clone_graph): + inputs = keras.layers.Input(shape=(3,)) + x = keras.layers.Dense(2)(inputs) + x = keras.layers.Dense(3)(x) + clone = keras.models.Model(inputs, x) + clone.compile(loss='mse', optimizer=keras.optimizers.RMSprop(lr=0.0001)) + clone.train_on_batch(input_arr, target_arr) + + keras_saved_model._assert_same_non_optimizer_objects( + model, model_graph, clone, clone_graph) + + def testAssertModelCloneSameObjectsThrowError(self): + input_arr = np.random.random((1, 3)) + target_arr = np.random.random((1, 3)) + + model_graph = ops.Graph() + clone_graph = ops.Graph() + + # Create two models with the same layers but different optimizers. + with session.Session(graph=model_graph): + inputs = keras.layers.Input(shape=(3,)) + x = keras.layers.Dense(2)(inputs) + x = keras.layers.Dense(3)(x) + model = keras.models.Model(inputs, x) + + model.compile(loss='mse', optimizer=training_module.AdadeltaOptimizer()) + model.train_on_batch(input_arr, target_arr) + + with session.Session(graph=clone_graph): + inputs = keras.layers.Input(shape=(3,)) + x = keras.layers.Dense(2)(inputs) + x = keras.layers.Dense(4)(x) + x = keras.layers.Dense(3)(x) + clone = keras.models.Model(inputs, x) + clone.compile(loss='mse', optimizer=keras.optimizers.RMSprop(lr=0.0001)) + clone.train_on_batch(input_arr, target_arr) + + with self.assertRaisesRegexp( + errors.InternalError, 'Model and clone must use the same variables.'): + keras_saved_model._assert_same_non_optimizer_objects( + model, model_graph, clone, clone_graph) if __name__ == '__main__': diff --git a/tensorflow/contrib/tensor_forest/BUILD b/tensorflow/contrib/tensor_forest/BUILD index 652f709fe2..00c855daa3 100644 --- a/tensorflow/contrib/tensor_forest/BUILD +++ b/tensorflow/contrib/tensor_forest/BUILD @@ -462,7 +462,10 @@ py_test( size = "small", srcs = ["python/kernel_tests/scatter_add_ndim_op_test.py"], srcs_version = "PY2AND3", - tags = ["no_pip_gpu"], + tags = [ + "no_gpu", + "no_pip_gpu", + ], deps = [ ":tensor_forest_ops_py", "//tensorflow/python:framework_test_lib", diff --git a/tensorflow/contrib/tpu/BUILD b/tensorflow/contrib/tpu/BUILD index a9e338ee59..298ffc1ded 100644 --- a/tensorflow/contrib/tpu/BUILD +++ b/tensorflow/contrib/tpu/BUILD @@ -167,6 +167,7 @@ py_library( name = "keras_support", srcs = [ "python/tpu/keras_support.py", + "python/tpu/keras_tpu_variables.py", ], srcs_version = "PY2AND3", visibility = [ diff --git a/tensorflow/contrib/tpu/profiler/tf_op_stats.proto b/tensorflow/contrib/tpu/profiler/tf_op_stats.proto index 2b13343efa..f88dc51636 100644 --- a/tensorflow/contrib/tpu/profiler/tf_op_stats.proto +++ b/tensorflow/contrib/tpu/profiler/tf_op_stats.proto @@ -79,12 +79,15 @@ message StepInfoResult { // The step duration in picoseconds. optional uint64 duration_ps = 2; // The infeed duration in picoseconds. - // Can turn into a map if we want a variable number of ops. optional uint64 infeed_duration_ps = 3; + // The outfeed duration in picoseconds. + optional uint64 host_outfeed_ps = 8; // The start time of this step in picoseconds. optional uint64 begin_ps = 4; // The waiting time within this step in picoseconds. optional uint64 wait_duration_ps = 5; + // The unit b outfeed duration in picoseconds. + optional uint64 unit_b_outfeed_ps = 9; // The time spent on cross-replica-sum in picoseconds. optional uint64 crs_duration_ps = 6; // Percentage of unit b time spent on infeed. diff --git a/tensorflow/contrib/tpu/proto/optimization_parameters.proto b/tensorflow/contrib/tpu/proto/optimization_parameters.proto index bf807af68b..cbf6809257 100644 --- a/tensorflow/contrib/tpu/proto/optimization_parameters.proto +++ b/tensorflow/contrib/tpu/proto/optimization_parameters.proto @@ -18,8 +18,10 @@ message DynamicLearningRate { message LearningRate { oneof learning_rate { float constant = 1; - DynamicLearningRate dynamic = 2; + // DynamicLearningRate dynamic = 2; -- disabled while code is being + // rewritten. } + reserved 2; } message AdagradParameters { diff --git a/tensorflow/contrib/tpu/python/tpu/keras_support.py b/tensorflow/contrib/tpu/python/tpu/keras_support.py index dbf5c66c9e..dd7f8b678f 100644 --- a/tensorflow/contrib/tpu/python/tpu/keras_support.py +++ b/tensorflow/contrib/tpu/python/tpu/keras_support.py @@ -58,6 +58,7 @@ from tensorflow.contrib.cluster_resolver.python.training import tpu_cluster_reso from tensorflow.contrib.framework.python.framework import experimental from tensorflow.contrib.tpu.proto import compilation_result_pb2 as tpu_compilation_result from tensorflow.contrib.tpu.python.ops import tpu_ops +from tensorflow.contrib.tpu.python.tpu import keras_tpu_variables from tensorflow.contrib.tpu.python.tpu import tpu from tensorflow.contrib.tpu.python.tpu import tpu_function from tensorflow.contrib.tpu.python.tpu import tpu_optimizer @@ -65,16 +66,24 @@ from tensorflow.contrib.tpu.python.tpu import tpu_system_metadata as tpu_system_ from tensorflow.core.protobuf import config_pb2 from tensorflow.python.client import session as tf_session from tensorflow.python.data.ops import dataset_ops +from tensorflow.python.data.ops import iterator_ops +from tensorflow.python.eager import context from tensorflow.python.estimator import model_fn as model_fn_lib from tensorflow.python.framework import dtypes +from tensorflow.python.framework import errors from tensorflow.python.framework import ops from tensorflow.python.framework import tensor_shape from tensorflow.python.framework import tensor_spec from tensorflow.python.keras import backend as K +from tensorflow.python.keras import callbacks as cbks from tensorflow.python.keras import models from tensorflow.python.keras import optimizers as keras_optimizers from tensorflow.python.keras.engine import base_layer +from tensorflow.python.keras.engine import training_arrays +from tensorflow.python.keras.engine import training_utils from tensorflow.python.keras.layers import embeddings +from tensorflow.python.keras.utils.generic_utils import make_batches +from tensorflow.python.keras.utils.generic_utils import slice_arrays from tensorflow.python.ops import array_ops from tensorflow.python.ops import gen_linalg_ops from tensorflow.python.ops import math_ops @@ -96,9 +105,9 @@ def tpu_session(cluster_resolver): if cluster_spec: config.cluster_def.CopyFrom(cluster_spec.as_cluster_def()) + logging.info('Connecting to: %s', master) graph = ops.Graph() session = tf_session.Session(graph=graph, target=master, config=config) - with graph.as_default(): session.run(tpu.initialize_system()) @@ -109,6 +118,11 @@ def tpu_session(cluster_resolver): def reset_tpu_sessions(): _SESSIONS.clear() +try: + from scipy.sparse import issparse # pylint: disable=g-import-not-at-top +except ImportError: + issparse = None + def get_tpu_system_metadata(tpu_cluster_resolver): """Retrieves TPU system metadata given a TPUClusterResolver.""" @@ -147,14 +161,50 @@ class TPUDistributionStrategy(object): if tpu_cluster_resolver is None: tpu_cluster_resolver = tpu_cluster_resolver_lib.TPUClusterResolver('') - num_cores = (1 if using_single_core else - get_tpu_system_metadata(tpu_cluster_resolver).num_cores) - + metadata = get_tpu_system_metadata(tpu_cluster_resolver) + self._tpu_metadata = metadata self._tpu_cluster_resolver = tpu_cluster_resolver + self._num_cores = 1 if using_single_core else metadata.num_cores + + # Walk device list to identify TPU worker for enqueue/dequeue operations. + worker_re = re.compile('/job:([^/]+)') + for device in metadata.devices: + if 'TPU:0' in device.name: + self._worker_name = worker_re.search(device.name).group(1) + break + + def _make_assignment_for_model(self, cpu_model): + """Makes a `TPUAssignment` for the passed in `cpu_model`.""" + num_cores = self._num_cores + if num_cores > 1 and cpu_model.stateful: + logging.warning( + 'Model replication does not currently support stateful models. ' + 'Degrading to a single core.') + num_cores = 1 + + return TPUAssignment( + worker_name=self._worker_name, num_cores=num_cores) + + +class TPUAssignment(object): + """This is object holding TPU resources assignment for the concrete model. + + `TPUDistributionStrategy` is responsible to create the instance of + `TPUAssignment`, so, it can dynamically adjust the `num_cores` to use based on + model and input batch sizes. + """ + + def __init__(self, worker_name, num_cores): + self._worker_name = worker_name self._num_cores = num_cores @property + def worker_name(self): + return self._worker_name + + @property def num_towers(self): + # TODO(xiejw): Support automatically assign num_cores based on inputs. return self._num_cores @@ -475,8 +525,8 @@ class TPUNumpyInfeedManager(TPUInfeedManager): infeed_dict[tensor] = value return infeed_dict - def __init__(self, distribution_strategy): - self._strategy = distribution_strategy + def __init__(self, tpu_assignment): + self._tpu_assignment = tpu_assignment def _split_tensors(self, inputs): """Split input data across shards. @@ -489,16 +539,16 @@ class TPUNumpyInfeedManager(TPUInfeedManager): Returns: List of lists containing the input to feed to each TPU shard. """ - if self._strategy.num_towers == 1: + if self._tpu_assignment.num_towers == 1: return [inputs] batch_size = inputs[0].shape[0] - assert batch_size % self._strategy.num_towers == 0, ( - 'batch_size must be divisible by strategy.num_towers (%s vs %s)' % - (batch_size, self._strategy.num_towers)) - shard_size = batch_size // self._strategy.num_towers + assert batch_size % self._tpu_assignment.num_towers == 0, ( + 'batch_size must be divisible by the number of TPU cores in use (%s ' + 'vs %s)' % (batch_size, self._tpu_assignment.num_towers)) + shard_size = batch_size // self._tpu_assignment.num_towers input_list = [] - for index in range(self._strategy.num_towers): + for index in range(self._tpu_assignment.num_towers): shard_inputs = [ x[index * shard_size:(index + 1) * shard_size] for x in inputs ] @@ -513,8 +563,9 @@ class TPUNumpyInfeedManager(TPUInfeedManager): infeed_op = [] shard_infeed_tensors = [] - for shard_id in range(self._strategy.num_towers): - with ops.device('/device:CPU:0'): + for shard_id in range(self._tpu_assignment.num_towers): + with ops.device( + '/job:%s/device:CPU:0' % self._tpu_assignment.worker_name): infeed_tensors = [] with ops.device('/device:TPU:%d' % shard_id): for spec in input_specs: @@ -553,30 +604,31 @@ class TPUDatasetInfeedManager(TPUInfeedManager): # TODO(saeta): Verify tpu_model_op is as expected! return {} - def __init__(self, dataset, distribution_strategy, tpu_session): + # pylint: disable=redefined-outer-name + def __init__(self, dataset, tpu_assignment, tpu_session): """Constructs a TPUDatasetInfeedManager. Must be called within a `KerasTPUModel.tpu_session` context! Args: dataset: A `tf.data.Dataset` to infeed. - distribution_strategy: The `TPUDistributionStrategy` used to configure the + tpu_assignment: The `TPUAssignment` used to configure the Keras TPU model. tpu_session: The `tf.Session` object used for running the TPU model. """ self._verify_dataset_shape(dataset) self._dataset = dataset - self._strategy = distribution_strategy + self._tpu_assignment = tpu_assignment dummy_x_shape = dataset.output_shapes[0].as_list() - dummy_x_shape[0] *= distribution_strategy.num_towers + dummy_x_shape[0] *= tpu_assignment.num_towers dummy_y_shape = dataset.output_shapes[1].as_list() - dummy_y_shape[0] *= distribution_strategy.num_towers + dummy_y_shape[0] *= tpu_assignment.num_towers self._iterator = dataset.make_initializable_iterator() tpu_session.run(self._iterator.initializer) self._get_next_ops = [] ctrl_deps = [] - for i in range(distribution_strategy.num_towers): + for i in range(tpu_assignment.num_towers): with ops.control_dependencies(ctrl_deps): # Ensure deterministic # TODO(saeta): Ensure correct placement! get_next_op = self._iterator.get_next() @@ -656,10 +708,11 @@ class TPUDatasetInfeedManager(TPUInfeedManager): def build_infeed_from_input_specs(self, input_specs, execution_mode): shard_infeed_tensors = self._get_next_ops - assert len(shard_infeed_tensors) == self._strategy.num_towers + assert len(shard_infeed_tensors) == self._tpu_assignment.num_towers infeed_ops = [] - for shard_id in range(self._strategy.num_towers): - with ops.device('/device:CPU:0'): + for shard_id in range(self._tpu_assignment.num_towers): + with ops.device( + '/job:%s/device:CPU:0' % self._tpu_assignment.worker_name): infeed_ops.append( tpu_ops.infeed_enqueue_tuple( shard_infeed_tensors[shard_id], @@ -682,10 +735,10 @@ class TPUFunction(object): instead of being injected as `feed_dict` items or fetches. """ - def __init__(self, model, execution_mode, strategy): + def __init__(self, model, execution_mode, tpu_assignment): self.model = model self.execution_mode = execution_mode - self._strategy = strategy + self._tpu_assignment = tpu_assignment self._compilation_cache = {} self._cloned_model = None @@ -737,8 +790,8 @@ class TPUFunction(object): # Clone our CPU model, running within the TPU device context. with TPURewriteContext(tpu_input_map): with variable_scope.variable_scope('tpu_model_%s' % id(self.model)): - # TODO(power): Replicate variables. - with ops.device('/device:TPU:0'): + with keras_tpu_variables.replicated_scope( + self._tpu_assignment.num_towers): self._cloned_model = models.clone_model(self.model) # Create a copy of the optimizer for this graph. @@ -808,7 +861,7 @@ class TPUFunction(object): # `execute op` replicates `_model_fn` `num_replicas` times, with each shard # running on a different logical core. compile_op, execute_op = tpu.split_compile_and_replicate( - _model_fn, inputs=[[]] * self._strategy.num_towers) + _model_fn, inputs=[[]] * self._tpu_assignment.num_towers) # Generate CPU side operations to enqueue features/labels and dequeue # outputs from the model call. @@ -816,8 +869,9 @@ class TPUFunction(object): input_specs, self.execution_mode) # Build output ops. outfeed_op = [] - for shard_id in range(self._strategy.num_towers): - with ops.device('/device:CPU:0'): + for shard_id in range(self._tpu_assignment.num_towers): + with ops.device( + '/job:%s/device:CPU:0' % self._tpu_assignment.worker_name): outfeed_op.extend( tpu_ops.outfeed_dequeue_tuple( dtypes=[spec.dtype for spec in self._outfeed_spec], @@ -835,7 +889,7 @@ class TPUFunction(object): def _test_model_compiles(self, tpu_model_ops): """Verifies that the given TPUModelOp can be compiled via XLA.""" logging.info('Started compiling') - start_time = time.clock() + start_time = time.time() result = K.get_session().run(tpu_model_ops.compile_op) proto = tpu_compilation_result.CompilationResultProto() @@ -844,38 +898,52 @@ class TPUFunction(object): raise RuntimeError('Compilation failed: {}'.format( proto.status_error_message)) - end_time = time.clock() + end_time = time.time() logging.info('Finished compiling. Time elapsed: %s secs', end_time - start_time) - def __call__(self, inputs): - assert isinstance(inputs, list) + def _lookup_infeed_manager(self, inputs): + """Return an existing manager, or construct a new InfeedManager for inputs. + + _lookup_infeed_manager will return an existing InfeedManager if one has been + previously assigned for this model and input. If not, it will construct a + new TPUNumpyInfeedManager. + + Args: + inputs: A NumPy input to the model. + + Returns: + A `TPUInfeedManager` object to manage infeeds for this input. + """ + if inputs is None: + return None - infeed_manager = None for x, mgr in self.model._numpy_to_infeed_manager_list: if inputs[0] is x: - infeed_manager = mgr - break - if infeed_manager is None: - infeed_manager = TPUNumpyInfeedManager(self.model._strategy) + return mgr + return TPUNumpyInfeedManager(self.model._tpu_assignment) - # Strip sample weight from inputs - if (self.execution_mode == model_fn_lib.ModeKeys.TRAIN or - self.execution_mode == model_fn_lib.ModeKeys.EVAL): - input_tensors = self.model._feed_inputs + self.model._feed_targets - inputs = inputs[:len(input_tensors)] - else: - input_tensors = self.model._feed_inputs + def _tpu_model_ops_for_input_specs(self, input_specs, infeed_manager): + """Looks up the corresponding `TPUModelOp` for a given `input_specs`. - infeed_instance = infeed_manager.make_infeed_instance(inputs) - del inputs # To avoid accident usage. - input_specs = infeed_instance.make_input_specs(input_tensors) + It instantiates a new copy of the model for each unique input shape. + + Args: + input_specs: The specification of the inputs to train on. + infeed_manager: The infeed manager responsible for feeding in data. + + Returns: + A `TPUModelOp` instance that can be used to execute a step of the model. + """ + if input_specs is None or infeed_manager is None: + # Note: this condition is possible during the prologue or epilogue of the + # pipelined loop. + return None # XLA requires every operation in the graph has a fixed shape. To # handle varying batch sizes we recompile a new sub-graph for each # unique input shape. shape_key = tuple([tuple(spec.shape.as_list()) for spec in input_specs]) - if shape_key not in self._compilation_cache: with self.model.tpu_session(): logging.info('New input shapes; (re-)compiling: mode=%s, %s', @@ -885,24 +953,47 @@ class TPUFunction(object): self._compilation_cache[shape_key] = new_tpu_model_ops self._test_model_compiles(new_tpu_model_ops) - # Initialize our TPU weights on the first compile. - self.model._initialize_weights(self._cloned_model) - tpu_model_ops = self._compilation_cache[shape_key] + return self._compilation_cache[shape_key] - infeed_dict = infeed_instance.make_feed_dict(tpu_model_ops) + def _construct_input_tensors_and_inputs(self, inputs): + """Returns input tensors and numpy array inputs corresponding to `inputs`. - with self.model.tpu_session() as session: - _, _, outfeed_outputs = session.run([ - tpu_model_ops.infeed_op, tpu_model_ops.execute_op, - tpu_model_ops.outfeed_op - ], infeed_dict) + Args: + inputs: NumPy inputs. - # TODO(xiejw): Decide how to reduce outputs, or just discard all but first. + Returns: + A tuple of `input_tensors`, and `inputs`. + """ + if inputs is None: + # Note: this condition is possible during the prologue or epilogue of the + # pipelined loop. + return None, None + # Strip sample weight from inputs + if (self.execution_mode == model_fn_lib.ModeKeys.TRAIN or + self.execution_mode == model_fn_lib.ModeKeys.EVAL): + input_tensors = self.model._feed_inputs + self.model._feed_targets + inputs = inputs[:len(input_tensors)] + return input_tensors, inputs + else: + input_tensors = self.model._feed_inputs + return input_tensors, inputs + + def _process_outputs(self, outfeed_outputs): + """Processes the outputs of a model function execution. + + Args: + outfeed_outputs: The sharded outputs of the TPU computation. + + Returns: + The aggregated outputs of the TPU computation to be used in the rest of + the model execution. + """ + # TODO(xiejw): Decide how to reduce outputs, or discard all but first. if self.execution_mode == model_fn_lib.ModeKeys.PREDICT: outputs = [[]] * len(self._outfeed_spec) outputs_per_replica = len(self._outfeed_spec) - for i in range(self._strategy.num_towers): + for i in range(self._tpu_assignment.num_towers): output_group = outfeed_outputs[i * outputs_per_replica:(i + 1) * outputs_per_replica] for j in range(outputs_per_replica): @@ -910,7 +1001,139 @@ class TPUFunction(object): return [np.concatenate(group) for group in outputs] else: - return outfeed_outputs[:len(outfeed_outputs) // self._strategy.num_towers] + return outfeed_outputs[:len(outfeed_outputs) // + self._tpu_assignment.num_towers] + + def __call__(self, inputs): + """__call__ executes the function on the computational hardware. + + It handles executing infeed, and preprocessing in addition to executing the + model on the TPU hardware. + + Note: `__call__` has a sibling method `pipeline_run` which performs the same + operations, but with software pipelining. + + Args: + inputs: The inputs to use to train. + + Returns: + The output of the computation for the given mode it is executed in. + + Raises: + RuntimeError: If there is an inappropriate use of the function. + """ + assert isinstance(inputs, list) + + infeed_manager = self._lookup_infeed_manager(inputs) + input_tensors, inputs = self._construct_input_tensors_and_inputs(inputs) + infeed_instance = infeed_manager.make_infeed_instance(inputs) + del inputs # To avoid accident usage. + input_specs = infeed_instance.make_input_specs(input_tensors) + tpu_model_ops = self._tpu_model_ops_for_input_specs(input_specs, + infeed_manager) + infeed_dict = infeed_instance.make_feed_dict(tpu_model_ops) + + # Initialize our TPU weights on the first compile. + self.model._initialize_weights(self._cloned_model) + + with self.model.tpu_session() as session: + _, _, outfeed_outputs = session.run([ + tpu_model_ops.infeed_op, tpu_model_ops.execute_op, + tpu_model_ops.outfeed_op + ], infeed_dict) + return self._process_outputs(outfeed_outputs) + + def pipeline_run(self, cur_step_inputs, next_step_inputs): + """pipeline_run executes the function on the computational hardware. + + pipeline_run performs the same computation as __call__, however it runs the + infeed in a software pipelined fashion compared to the on-device execution. + + Note: it is the responsibility of the caller to call `pipeline_run` in the + following sequence: + - Once with `cur_step_inputs=None` and `next_step_inputs=list(...)` + - `n` times with `cur_step_inputs` and `next_step_inputs` as `list`s + - Once with `cur_step_inputs=list(...)` and `next_step_inputs=None` + Additionally, it is the responsibility of the caller to pass + `next_step_inputs` as `cur_step_inputs` on the next invocation of + `pipeline_run`. + + Args: + cur_step_inputs: The current step's inputs. + next_step_inputs: The next step's inputs. + + Returns: + The output of the computation for the given mode it is executed in. + + Raises: + RuntimeError: If there is an inappropriate use of the function. + """ + # Software pipelined case. + next_step_infeed_manager = self._lookup_infeed_manager(next_step_inputs) + cur_step_infeed_manager = self._lookup_infeed_manager(cur_step_inputs) + + if (next_step_infeed_manager is not None + and cur_step_infeed_manager is not None): + assert type(next_step_infeed_manager) is type(cur_step_infeed_manager) + + next_input_tensors, next_step_inputs = ( + self._construct_input_tensors_and_inputs(next_step_inputs)) + cur_input_tensors, cur_step_inputs = ( + self._construct_input_tensors_and_inputs(cur_step_inputs)) + + cur_infeed_instance = None + if cur_step_infeed_manager: + cur_infeed_instance = cur_step_infeed_manager.make_infeed_instance( + cur_step_inputs) + next_infeed_instance = None + if next_step_infeed_manager: + next_infeed_instance = next_step_infeed_manager.make_infeed_instance( + next_step_inputs) + + del cur_step_inputs # Avoid accidental re-use. + del next_step_inputs # Avoid accidental re-use. + + cur_tpu_model_ops = None + next_tpu_model_ops = None + infeed_dict = None + + if cur_infeed_instance and cur_input_tensors and cur_step_infeed_manager: + cur_input_specs = cur_infeed_instance.make_input_specs( + cur_input_tensors) + cur_tpu_model_ops = self._tpu_model_ops_for_input_specs( + cur_input_specs, cur_step_infeed_manager) + + if (next_infeed_instance + and next_input_tensors + and next_step_infeed_manager): + next_input_specs = next_infeed_instance.make_input_specs( + next_input_tensors) + next_tpu_model_ops = self._tpu_model_ops_for_input_specs( + next_input_specs, next_step_infeed_manager) + infeed_dict = next_infeed_instance.make_feed_dict(next_tpu_model_ops) + + # Initialize our TPU weights on the first compile. + self.model._initialize_weights(self._cloned_model) + + if next_tpu_model_ops and cur_tpu_model_ops: + with self.model.tpu_session() as session: + _, _, outfeed_outputs = session.run([ + next_tpu_model_ops.infeed_op, cur_tpu_model_ops.execute_op, + cur_tpu_model_ops.outfeed_op + ], infeed_dict) + return self._process_outputs(outfeed_outputs) + if cur_tpu_model_ops: + with self.model.tpu_session() as session: + _, outfeed_outputs = session.run([ + cur_tpu_model_ops.execute_op, cur_tpu_model_ops.outfeed_op]) + return self._process_outputs(outfeed_outputs) + if next_tpu_model_ops: + with self.model.tpu_session() as session: + session.run(next_tpu_model_ops.infeed_op, infeed_dict) + return None + raise RuntimeError('Internal error: both current & next tpu_model_ops ' + 'were None') + class KerasTPUModel(models.Model): @@ -931,16 +1154,15 @@ class KerasTPUModel(models.Model): self.predict_function = None self.test_function = None self.train_function = None - self._strategy = strategy - cluster_resolver = self._strategy._tpu_cluster_resolver + cluster_resolver = strategy._tpu_cluster_resolver self._tpu_name_or_address = cluster_resolver.get_master() self._cpu_model = cpu_model + self._tpu_assignment = strategy._make_assignment_for_model(cpu_model) self._tpu_model = None self._tpu_weights_initialized = False self._session = tpu_session(cluster_resolver) - self._graph = self._session.graph # If the input CPU model has already been compiled, compile our TPU model # immediately. @@ -959,7 +1181,7 @@ class KerasTPUModel(models.Model): return { 'cpu_model': self._cpu_model, 'tpu_name_or_address': self._tpu_name_or_address, - 'strategy': self._strategy, + 'tpu_assignment': self._tpu_assignment, } def compile(self, @@ -1003,6 +1225,10 @@ class KerasTPUModel(models.Model): steps_per_epoch=None, validation_steps=None, **kwargs): + if context.executing_eagerly(): + raise EnvironmentError('KerasTPUModel currently does not support eager ' + 'mode.') + assert not self._numpy_to_infeed_manager_list # Ensure empty. infeed_managers = [] # Managers to clean up at the end of the fit call. @@ -1015,7 +1241,8 @@ class KerasTPUModel(models.Model): 'https://github.com/tensorflow/tpu/tree/master/models/experimental' '/keras') if callable(x): - with self.tpu_session() as sess: + with self.tpu_session() as sess,\ + ops.device('/job:%s/device:CPU:0' % self._tpu_assignment.worker_name): dataset = x() if steps_per_epoch is None: raise ValueError('When using tf.data as input to a model, you ' @@ -1023,7 +1250,8 @@ class KerasTPUModel(models.Model): if y is not None: raise ValueError('When using tf.data as input to a model, y must be ' 'None') - infeed_manager = TPUDatasetInfeedManager(dataset, self._strategy, sess) + infeed_manager = TPUDatasetInfeedManager(dataset, self._tpu_assignment, + sess) # Use dummy numpy inputs for the rest of Keras' shape checking. We # intercept them when building the model. x = infeed_manager.dummy_x @@ -1044,7 +1272,8 @@ class KerasTPUModel(models.Model): if validation_steps is None: raise ValueError('When using tf.data as validation for a model, you ' 'should specify the validation_steps argument.') - infeed_manager = TPUDatasetInfeedManager(dataset, self._strategy, sess) + infeed_manager = TPUDatasetInfeedManager(dataset, self._tpu_assignment, + sess) # Use dummy numpy inputs for the rest of Keras' shape checking. We # intercept them when building the model. val_x = infeed_manager.dummy_x @@ -1054,7 +1283,28 @@ class KerasTPUModel(models.Model): self._numpy_to_infeed_manager_list = infeed_managers try: - return super(KerasTPUModel, self).fit( + if not kwargs.get('_pipeline', True): + logging.info( + 'Running non-pipelined training loop (`_pipeline=%s`).', + kwargs['_pipeline']) + kwargs.pop('_pipeline') + return super(KerasTPUModel, self).fit( + x, + y, + batch_size, + epochs, + verbose, + callbacks, + validation_split, + validation_data, + shuffle, + class_weight, + sample_weight, + initial_epoch, + steps_per_epoch, + validation_steps, + **kwargs) + return self._pipeline_fit( x, y, batch_size, @@ -1073,23 +1323,479 @@ class KerasTPUModel(models.Model): finally: self._numpy_to_infeed_manager_list = [] + def evaluate(self, + x=None, + y=None, + batch_size=None, + verbose=1, + sample_weight=None, + steps=None): + assert not self._numpy_to_infeed_manager_list # Ensure empty. + + infeed_managers = [] # Managers to clean up at the end of the fit call. + if isinstance(x, dataset_ops.Dataset): + # TODO(b/111413240): Support taking a tf.data.Dataset directly. + raise ValueError( + 'Taking a Dataset directly is not yet supported. Please ' + 'wrap your dataset construction code in a function and ' + 'pass that to fit instead. For examples, see: ' + 'https://github.com/tensorflow/tpu/tree/master/models/experimental' + '/keras') + if callable(x): + with self.tpu_session() as sess: + dataset = x() + if steps is None: + raise ValueError('When using tf.data as input to a model, you ' + 'should specify the steps argument.') + if y is not None: + raise ValueError('When using tf.data as input to a model, y must be ' + 'None') + infeed_manager = TPUDatasetInfeedManager(dataset, self._tpu_assignment, + sess) + # Use dummy numpy inputs for the rest of Keras' shape checking. We + # intercept them when building the model. + x = infeed_manager.dummy_x + y = infeed_manager.dummy_y + infeed_managers.append((x, infeed_manager)) + + self._numpy_to_infeed_manager_list = infeed_managers + try: + return super(KerasTPUModel, self).evaluate( + x, + y, + batch_size, + verbose, + sample_weight, + steps) + finally: + self._numpy_to_infeed_manager_list = [] + + def _pipeline_fit(self, + x, + y, + batch_size, + epochs, + verbose, + callbacks, + validation_split, + validation_data, + shuffle, + class_weight, + sample_weight, + initial_epoch, + steps_per_epoch, + validation_steps, + **kwargs): + # Similar to super.fit(...), but modified to support software pipelining. + + # Backwards compatibility + if batch_size is None and steps_per_epoch is None: + batch_size = 32 + # Legacy support + if 'nb_epoch' in kwargs: + logging.warning('The `nb_epoch` argument in `fit` has been renamed ' + '`epochs`.') + epochs = kwargs.pop('nb_epoch') + if kwargs: + raise TypeError('Unrecognized keyword arguments: ' + str(kwargs)) + + # Validate and standardize user data + x, y, sample_weights = self._standardize_user_data( + x, + y, + sample_weight=sample_weight, + class_weight=class_weight, + batch_size=batch_size, + check_steps=True, + steps_name='steps_per_epoch', + steps=steps_per_epoch, + validation_split=validation_split) + + # Prepare validation data + val_x, val_y, val_sample_weights = self._prepare_validation_data( + validation_data, + validation_split, + validation_steps, + x, + y, + sample_weights, + batch_size) + self._pipeline_fit_loop( + x, + y, + sample_weights=sample_weights, + batch_size=batch_size, + epochs=epochs, + verbose=verbose, + callbacks=callbacks, + val_inputs=val_x, + val_targets=val_y, + val_sample_weights=val_sample_weights, + shuffle=shuffle, + initial_epoch=initial_epoch, + steps_per_epoch=steps_per_epoch, + validation_steps=validation_steps) + + def _pipeline_fit_loop(self, + inputs, + targets, + sample_weights, + batch_size, + epochs, + verbose, + callbacks, + val_inputs, + val_targets, + val_sample_weights, + shuffle, + initial_epoch, + steps_per_epoch, + validation_steps): + self._make_train_function() + sample_weights = sample_weights or [] + val_sample_weights = val_sample_weights or [] + if self.uses_learning_phase and not isinstance(K.learning_phase(), int): + ins = inputs + targets + sample_weights + [1] + else: + ins = inputs + targets + sample_weights + + do_validation = False + if val_inputs: + do_validation = True + if (steps_per_epoch is None and verbose and inputs and + hasattr(inputs[0], 'shape') and hasattr(val_inputs[0], 'shape')): + print('Train on %d samples, validate on %d samples' % + (inputs[0].shape[0], val_inputs[0].shape[0])) + + if validation_steps: + do_validation = True + if steps_per_epoch is None: + raise ValueError('Can only use `validation_steps` when doing step-wise ' + 'training, i.e. `steps_per_epoch` must be set.') + + num_training_samples = training_utils.check_num_samples( + ins, batch_size, steps_per_epoch, 'steps_per_epoch') + count_mode = 'steps' if steps_per_epoch else 'samples' + callbacks = cbks.configure_callbacks( + callbacks, + self, + do_validation=do_validation, + val_inputs=val_inputs, + val_targets=val_targets, + val_sample_weights=val_sample_weights, + batch_size=batch_size, + epochs=epochs, + steps_per_epoch=steps_per_epoch, + samples=num_training_samples, + validation_steps=validation_steps, + verbose=verbose, + count_mode=count_mode) + + if num_training_samples is not None: + index_array = np.arange(num_training_samples) + + # To prevent a slowdown, we find beforehand the arrays that need conversion. + feed = self._feed_inputs + self._feed_targets + self._feed_sample_weights + indices_for_conversion_to_dense = [] + for i in range(len(feed)): + if issparse is not None and issparse(ins[i]) and not K.is_sparse(feed[i]): + indices_for_conversion_to_dense.append(i) + + callbacks.on_train_begin() + for epoch in range(initial_epoch, epochs): + # Reset stateful metrics + for m in self.stateful_metric_functions: + m.reset_states() + # Update callbacks + callbacks.on_epoch_begin(epoch) + epoch_logs = {} + if steps_per_epoch is not None: + # Step-wise fit loop. + self._pipeline_fit_loop_step_wise( + ins=ins, + callbacks=callbacks, + steps_per_epoch=steps_per_epoch, + epochs=epochs, + do_validation=do_validation, + val_inputs=val_inputs, + val_targets=val_targets, + val_sample_weights=val_sample_weights, + validation_steps=validation_steps, + epoch_logs=epoch_logs) + else: + # Sample-wise fit loop. + self._pipeline_fit_loop_sample_wise( + ins=ins, + callbacks=callbacks, + index_array=index_array, + shuffle=shuffle, + batch_size=batch_size, + num_training_samples=num_training_samples, + indices_for_conversion_to_dense=indices_for_conversion_to_dense, + do_validation=do_validation, + val_inputs=val_inputs, + val_targets=val_targets, + val_sample_weights=val_sample_weights, + validation_steps=validation_steps, + epoch_logs=epoch_logs) + + callbacks.on_epoch_end(epoch, epoch_logs) + if callbacks.model.stop_training: + break + callbacks.on_train_end() + return self.history + + def _pipeline_fit_loop_sample_wise(self, + ins, + callbacks, + index_array, + shuffle, + batch_size, + num_training_samples, + indices_for_conversion_to_dense, + do_validation, + val_inputs, + val_targets, + val_sample_weights, + validation_steps, + epoch_logs): + f = self.train_function + if shuffle == 'batch': + index_array = training_utils.batch_shuffle(index_array, batch_size) + elif shuffle: + np.random.shuffle(index_array) + batches = make_batches(num_training_samples, batch_size) + + ins_last_batch = None + last_batch_logs = None + batch_index = 0 + + for batch_index, (batch_start, batch_end) in enumerate(batches): + batch_ids = index_array[batch_start:batch_end] + try: + if isinstance(ins[-1], int): + # Do not slice the training phase flag. + ins_batch = slice_arrays(ins[:-1], batch_ids) + [ins[-1]] + else: + ins_batch = slice_arrays(ins, batch_ids) + except TypeError: + raise TypeError('TypeError while preparing batch. If using HDF5 ' + 'input data, pass shuffle="batch".') + + # Pipeline batch logs + next_batch_logs = {} + next_batch_logs['batch'] = batch_index + next_batch_logs['size'] = len(batch_ids) + if batch_index > 0: + # Callbacks operate one step behind in software pipeline. + callbacks.on_batch_begin(batch_index - 1, last_batch_logs) + for i in indices_for_conversion_to_dense: + ins_batch[i] = ins_batch[i].toarray() + + outs = f.pipeline_run(cur_step_inputs=ins_last_batch, + next_step_inputs=ins_batch) + ins_last_batch = ins_batch + + if batch_index == 0: + assert outs is None + else: + if not isinstance(outs, list): + outs = [outs] + for l, o in zip(self.metrics_names, outs): + last_batch_logs[l] = o # pylint: disable=unsupported-assignment-operation + callbacks.on_batch_end(batch_index - 1, last_batch_logs) + if callbacks.model.stop_training: + return + last_batch_logs = next_batch_logs + + # Final batch + callbacks.on_batch_begin(batch_index, last_batch_logs) + outs = f.pipeline_run(cur_step_inputs=ins_last_batch, next_step_inputs=None) + if not isinstance(outs, list): + outs = [outs] + for l, o in zip(self.metrics_names, outs): + last_batch_logs[l] = o + callbacks.on_batch_end(batch_index, last_batch_logs) + if callbacks.model.stop_training: + return + + if do_validation: + val_outs = training_arrays.test_loop( + self, + val_inputs, + val_targets, + sample_weights=val_sample_weights, + batch_size=batch_size, + steps=validation_steps, + verbose=0) + if not isinstance(val_outs, list): + val_outs = [val_outs] + # Same labels assumed. + for l, o in zip(self.metrics_names, val_outs): + epoch_logs['val_' + l] = o + + def _pipeline_fit_loop_step_wise(self, + ins, + callbacks, + steps_per_epoch, + epochs, + do_validation, + val_inputs, + val_targets, + val_sample_weights, + validation_steps, + epoch_logs): + f = self.train_function + + # Loop prologue + try: + outs = f.pipeline_run(cur_step_inputs=None, next_step_inputs=ins) + assert outs is None # Function shouldn't return anything! + except errors.OutOfRangeError: + logging.warning('Your dataset iterator ran out of data on the first step ' + 'of the epoch, preventing further training. Check to ' + 'make sure your paths are correct and you have ' + 'permissions to read the files. Skipping validation') + + for step_index in range(steps_per_epoch - 1): + batch_logs = {'batch': step_index, 'size': 1} + callbacks.on_batch_begin(step_index, batch_logs) + try: + if step_index < steps_per_epoch - 1: + next_step_inputs = ins + else: + next_step_inputs = None + outs = f.pipeline_run(cur_step_inputs=ins, + next_step_inputs=next_step_inputs) + except errors.OutOfRangeError: + logging.warning('Your dataset iterator ran out of data; ' + 'interrupting training. Make sure that your ' + 'dataset can generate at least `steps_per_batch * ' + 'epochs` batches (in this case, %d batches). You ' + 'may need to use the repeat() function when ' + 'building your dataset.' % steps_per_epoch * epochs) + break + + if not isinstance(outs, list): + outs = [outs] + for l, o in zip(self.metrics_names, outs): + batch_logs[l] = o + + callbacks.on_batch_end(step_index, batch_logs) + if callbacks.model.stop_training: + break + + if do_validation: + val_outs = training_arrays.test_loop(self, + val_inputs, + val_targets, + sample_weights=val_sample_weights, + steps=validation_steps, + verbose=0) + if not isinstance(val_outs, list): + val_outs = [val_outs] + # Same labels assumed. + for l, o in zip(self.metrics_names, val_outs): + epoch_logs['val_' + l] = o + + def _prepare_validation_data(self, + validation_data, + validation_split, + validation_steps, + x, + y, + sample_weights, + batch_size): + """Prepares the validation dataset. + + Args: + validation_data: The validation data (if provided) + validation_split: The validation split (if provided) + validation_steps: The validation steps (if provided) + x: The main training data x (if provided) + y: The main training data y (if provided) + sample_weights: The sample weights (if provided) + batch_size: The training batch size (if provided) + + Returns: + A 3-tuple of (val_x, val_y, val_sample_weights). + + Raises: + ValueError: If the provided arguments are not compatible with + `KerasTPUModel`. + """ + # Note: this is similar to a section of $tf/python/keras/engine/training.py + # It differns in that tf.data objects are not allowed to be passed directly. + # Additionally, it handles validating shapes & types appropriately for use + # in TPUs. + if validation_data: + if (isinstance(validation_data, iterator_ops.Iterator) or + isinstance(validation_data, iterator_ops.EagerIterator) or + isinstance(validation_data, dataset_ops.Dataset)): + raise ValueError('KerasTPUModel cannot handle a Dataset or Iterator ' + 'for validation_data. Please instead pass a function ' + 'that returns a `tf.data.Dataset`.') + if len(validation_data) == 2: + val_x, val_y = validation_data # pylint: disable=unpacking-non-sequence + val_sample_weight = None + elif len(validation_data) == 3: + val_x, val_y, val_sample_weight = validation_data # pylint: disable=unpacking-non-sequence + else: + raise ValueError('When passing a `validation_data` argument, it must ' + 'contain either 2 items (x_val, y_val), or 3 items ' + '(x_val, y_val, val_sample_weights). However we ' + 'received `validation_data=%s`' % validation_data) + val_x, val_y, val_sample_weights = self._standardize_user_data( + val_x, + val_y, + sample_weight=val_sample_weight, + batch_size=batch_size, + steps=validation_steps) + elif validation_split and 0. < validation_split < 1.: + if training_utils.has_symbolic_tensors(x): + raise ValueError('If your data is in the form of symbolic tensors, you ' + 'cannot use `validation_split`.') + if hasattr(x[0], 'shape'): + split_at = int(x[0].shape[0] * (1. - validation_split)) + else: + split_at = int(len(x[0]) * (1. - validation_split)) + + x, val_x = (slice_arrays(x, 0, split_at), slice_arrays(x, split_at)) + y, val_y = (slice_arrays(y, 0, split_at), slice_arrays(y, split_at)) + sample_weights, val_sample_weights = (slice_arrays( + sample_weights, 0, split_at), slice_arrays(sample_weights, split_at)) + elif validation_steps: + val_x = [] + val_y = [] + val_sample_weights = [] + else: + val_x = None + val_y = None + val_sample_weights = None + + return val_x, val_y, val_sample_weights + def _make_train_function(self): if not self.train_function: self.train_function = TPUFunction( - self, model_fn_lib.ModeKeys.TRAIN, strategy=self._strategy) + self, + model_fn_lib.ModeKeys.TRAIN, + tpu_assignment=self._tpu_assignment) return self.train_function def _make_test_function(self): if not self.test_function: self.test_function = TPUFunction( - self, model_fn_lib.ModeKeys.EVAL, strategy=self._strategy) + self, model_fn_lib.ModeKeys.EVAL, tpu_assignment=self._tpu_assignment) return self.test_function def _make_predict_function(self): if not self.predict_function: self.predict_function = TPUFunction( - self, model_fn_lib.ModeKeys.PREDICT, strategy=self._strategy) + self, + model_fn_lib.ModeKeys.PREDICT, + tpu_assignment=self._tpu_assignment) return self.predict_function def _initialize_weights(self, cloned_model): @@ -1143,7 +1849,7 @@ class KerasTPUModel(models.Model): @contextlib.contextmanager def tpu_session(self): """Yields a TPU session and sets it as the default Keras session.""" - with self._graph.as_default(): + with self._session.graph.as_default(): default_session = K.get_session() # N.B. We have to call `K.set_session()` AND set our session as the # TF default. `K.get_session()` surprisingly does not return the value @@ -1161,6 +1867,7 @@ class KerasTPUModel(models.Model): self._session.close() +# pylint: disable=bad-continuation def _validate_shapes(model): """Validate that all layers in `model` have constant shape.""" for layer in model.layers: @@ -1188,10 +1895,13 @@ Layer: %(layer)s Input shape: %(input_shape)s Output shape: %(output_shape)s """ % { - 'layer': layer, - 'input_shape': layer.input_shape, - 'output_shape': layer.output_shape - }) + 'layer': layer, + 'input_shape': layer.input_shape, + 'output_shape': layer.output_shape + }) + + +# pylint: enable=bad-continuation @experimental diff --git a/tensorflow/contrib/tpu/python/tpu/keras_tpu_variables.py b/tensorflow/contrib/tpu/python/tpu/keras_tpu_variables.py new file mode 100644 index 0000000000..a423aeace7 --- /dev/null +++ b/tensorflow/contrib/tpu/python/tpu/keras_tpu_variables.py @@ -0,0 +1,289 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Distributed variable implementation for TPUs. + +N.B. This is an experimental feature that should only be used for Keras support. + +It is unsupported and will be removed in favor of Distribution Strategy soon. +""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import contextlib + +from tensorflow.python.client import session as session_lib +from tensorflow.python.framework import ops +from tensorflow.python.ops import control_flow_ops +from tensorflow.python.ops import gen_resource_variable_ops +from tensorflow.python.ops import variable_scope +from tensorflow.python.platform import tf_logging as logging + + +@contextlib.contextmanager +def _handle_graph(handle): + with handle.graph.as_default(): + yield + + +def _enclosing_tpu_context(): + # pylint: disable=protected-access + context = ops.get_default_graph()._get_control_flow_context() + # pylint: enable=protected-access + while context is not None and not isinstance( + context, control_flow_ops.XLAControlFlowContext): + context = context.outer_context + return context + + +class ReplicatedVariable(object): + """A replicated variable for use on TPUs. + + When accessed inside a tpu.replicate() context, this variable acts as if it + is a single variable whose handle is a replicated input to the computation. + + Outside a tpu.replicate() context currently this object has pretty murky + semantics, especially with respect to things such as + * initialization + * colocation. + """ + + def __init__(self, name, variables): + self._name = name + self._primary_var = variables[0] + self._vars = variables + self._cached_value = None + self._dtype = variables[0].dtype + + @property + def handle(self): + tpu_context = _enclosing_tpu_context() + if tpu_context is None: + return self._primary_var.handle + + return tpu_context.get_replicated_var_handle(self) + + @contextlib.contextmanager + def _assign_dependencies(self): + """Makes assignments depend on the cached value, if any. + + This prevents undefined behavior with reads not ordered wrt writes. + + Yields: + None. + """ + if self._cached_value is not None: + with ops.control_dependencies([self._cached_value]): + yield + else: + yield + + @property + def initializer(self): + return control_flow_ops.group([v.initializer for v in self._vars]) + + @property + def graph(self): + return self._primary_var.graph + + @property + def _shared_name(self): + return self._common_name + + @property + def _unique_id(self): + return self._primary_var._unique_id # pylint: disable=protected-access + + @property + def name(self): + return self._name + + @property + def dtype(self): + return self._primary_var.dtype + + @property + def shape(self): + return self._primary_var.shape + + def get_shape(self): + return self._primary_var.get_shape() + + def to_proto(self, export_scope=None): + return self._primary_var.to_proto(export_scope=export_scope) + + @property + def constraint(self): + return None + + @property + def op(self): + return self.get().op + + @property + def is_tensor_like(self): + return True + + def _read_variable_op(self): + if _enclosing_tpu_context() is None: + return self._primary_var.read_value() + v = gen_resource_variable_ops.read_variable_op(self.handle, self._dtype) + return v + + def read_value(self): + return self._read_variable_op() + + def is_initialized(self, name=None): + return self._vars[0].is_initialized(name=name) + + def __getitem__(self, *args): + return self.read_value().__getitem__(*args) + + def assign(self, value, use_locking=None, name=None, read_value=False): + """Assign `value` to all replicas. + + Outside of the tpu.rewrite context, assign explicitly to all replicas. + Inside of the tpu.rewrite context, assigns to the local replica. + + Arguments: + value: Tensor to assign + use_locking: ignored + name: ignored + read_value: return the value from the assignment + Returns: + Assignment operation, or new value of the variable if `read_value` is True + """ + del use_locking + if _enclosing_tpu_context() is None: + assign_ops = [] + with self._assign_dependencies(): + for var in self._vars: + assign_ops.append(var.assign(value, use_locking=None, name=name)) + + if read_value: + with ops.control_dependencies(assign_ops): + return self.read_value() + else: + return control_flow_ops.group(assign_ops) + + with _handle_graph(self.handle), self._assign_dependencies(): + value_tensor = ops.convert_to_tensor(value, dtype=self.dtype) + assign_op = gen_resource_variable_ops.assign_variable_op( + self.handle, value_tensor, name=name) + if read_value: + return self._read_variable_op() + return assign_op + + def assign_add(self, delta, use_locking=None, name=None, read_value=True): + del use_locking + with _handle_graph(self.handle), self._assign_dependencies(): + assign_add_op = gen_resource_variable_ops.assign_add_variable_op( + self.handle, + ops.convert_to_tensor(delta, dtype=self.dtype), + name=name) + if read_value: + return self._read_variable_op() + return assign_add_op + + def assign_sub(self, delta, use_locking=None, name=None, read_value=True): + del use_locking + with _handle_graph(self.handle), self._assign_dependencies(): + assign_sub_op = gen_resource_variable_ops.assign_sub_variable_op( + self.handle, + ops.convert_to_tensor(delta, dtype=self.dtype), + name=name) + if read_value: + return self._read_variable_op() + return assign_sub_op + + def get(self): + return self._primary_var + + def _should_act_as_resource_variable(self): + """Pass resource_variable_ops.is_resource_variable check.""" + pass + + def _dense_var_to_tensor(self, dtype=None, name=None, as_ref=False): + """Converts a variable to a tensor.""" + # pylint: disable=protected-access + if _enclosing_tpu_context() is None: + return self._primary_var._dense_var_to_tensor(dtype, name, as_ref) + # pylint: enable=protected-access + if dtype is not None and dtype != self.dtype: + return NotImplemented + if as_ref: + return self.handle + else: + return self.read_value() + + +# Register a conversion function which reads the value of the variable, +# allowing instances of the class to be used as tensors. +def _tensor_conversion(var, dtype=None, name=None, as_ref=False): + return var._dense_var_to_tensor(dtype=dtype, name=name, as_ref=as_ref) # pylint: disable=protected-access + + +def replicated_fetch_function(var): + # pylint: disable=protected-access + return ([var._dense_var_to_tensor()], lambda v: v[0]) + # pylint: enable=protected-access + + +ops.register_tensor_conversion_function(ReplicatedVariable, _tensor_conversion) +ops.register_dense_tensor_like_type(ReplicatedVariable) +session_lib.register_session_run_conversion_functions( + ReplicatedVariable, replicated_fetch_function) + + +def replicated_scope(num_replicas): + """Variable scope for constructing replicated variables.""" + + def _replicated_variable_getter(getter, name, *args, **kwargs): + """Getter that constructs replicated variables.""" + collections = kwargs.pop("collections", None) + if collections is None: + collections = [ops.GraphKeys.GLOBAL_VARIABLES] + kwargs["collections"] = [] + + logging.info("Constructing replicated variable %s", name) + variables = [] + index = {} + for i in range(num_replicas): + replica_name = "{}/{}".format(name, i) + with ops.device("device:TPU:{}".format(i)): + v = getter(*args, name=replica_name, **kwargs) + variables.append(v) + index[i] = v + result = ReplicatedVariable(name, variables) + + g = ops.get_default_graph() + # If "trainable" is True, next_creator() will add the member variables + # to the TRAINABLE_VARIABLES collection, so we manually remove + # them and replace with the MirroredVariable. We can't set + # "trainable" to False for next_creator() since that causes functions + # like implicit_gradients to skip those variables. + if kwargs.get("trainable", True): + collections.append(ops.GraphKeys.TRAINABLE_VARIABLES) + l = g.get_collection_ref(ops.GraphKeys.TRAINABLE_VARIABLES) + for v in index.values(): + if v in l: + l.remove(v) + g.add_to_collections(collections, result) + + return result + + return variable_scope.variable_scope( + "", custom_getter=_replicated_variable_getter) diff --git a/tensorflow/core/BUILD b/tensorflow/core/BUILD index 84b11024fd..c06fea130f 100644 --- a/tensorflow/core/BUILD +++ b/tensorflow/core/BUILD @@ -695,7 +695,9 @@ cc_library( visibility = ["//visibility:public"], deps = [ ":lib_internal", + "@com_google_absl//absl/container:inlined_vector", "@com_google_absl//absl/strings", + "@com_google_absl//absl/types:optional", ], ) @@ -872,7 +874,6 @@ tf_cuda_library( "util/sparse/sparse_tensor.h", "util/stat_summarizer.h", "util/stat_summarizer_options.h", - "util/status_util.h", "util/stream_executor_util.h", "util/strided_slice_op.h", "util/tensor_format.h", @@ -939,15 +940,6 @@ cc_library( ) cc_library( - name = "status_util", - hdrs = ["util/status_util.h"], - deps = [ - ":graph", - ":lib", - ], -) - -cc_library( name = "reader_base", srcs = ["framework/reader_base.cc"], hdrs = ["framework/reader_base.h"], @@ -3229,12 +3221,10 @@ tf_cc_tests( "lib/gtl/edit_distance_test.cc", "lib/gtl/flatmap_test.cc", "lib/gtl/flatset_test.cc", - "lib/gtl/inlined_vector_test.cc", "lib/gtl/int_type_test.cc", "lib/gtl/iterator_range_test.cc", "lib/gtl/manual_constructor_test.cc", "lib/gtl/map_util_test.cc", - "lib/gtl/optional_test.cc", "lib/gtl/top_n_test.cc", "lib/hash/crc32c_test.cc", "lib/hash/hash_test.cc", @@ -3560,7 +3550,6 @@ tf_cc_tests( "util/semver_test.cc", "util/sparse/sparse_tensor_test.cc", "util/stat_summarizer_test.cc", - "util/status_util_test.cc", "util/tensor_format_test.cc", "util/tensor_slice_reader_test.cc", "util/tensor_slice_set_test.cc", @@ -3585,7 +3574,6 @@ tf_cc_tests( ":ops", ":protos_all_cc", ":protos_test_cc", - ":status_util", ":test", ":test_main", ":testlib", @@ -4078,6 +4066,7 @@ tf_cuda_cc_test( ":testlib", "//third_party/eigen3", "//tensorflow/cc:cc_ops", + "//tensorflow/core/kernels:collective_ops", "//tensorflow/core/kernels:control_flow_ops", "//tensorflow/core/kernels:cwise_op", "//tensorflow/core/kernels:dense_update_ops", @@ -4119,6 +4108,7 @@ tf_cc_test( "//tensorflow/cc:cc_ops", # Link with support for TensorFlow Debugger (tfdbg). "//tensorflow/core/debug", + "//tensorflow/core/kernels:collective_ops", "//tensorflow/core/kernels:control_flow_ops", "//tensorflow/core/kernels:cwise_op", "//tensorflow/core/kernels:dense_update_ops", diff --git a/tensorflow/core/api_def/base_api/api_def_StridedSlice.pbtxt b/tensorflow/core/api_def/base_api/api_def_StridedSlice.pbtxt index 8d6fc04847..9a89a4e8e7 100644 --- a/tensorflow/core/api_def/base_api/api_def_StridedSlice.pbtxt +++ b/tensorflow/core/api_def/base_api/api_def_StridedSlice.pbtxt @@ -32,7 +32,7 @@ END description: <<END a bitmask where a bit i being 1 means to ignore the begin value and instead use the largest interval possible. At runtime -begin[i] will be replaced with `[0, n-1) if `stride[i] > 0` or +begin[i] will be replaced with `[0, n-1)` if `stride[i] > 0` or `[-1, n-1]` if `stride[i] < 0` END } diff --git a/tensorflow/core/common_runtime/bfc_allocator.cc b/tensorflow/core/common_runtime/bfc_allocator.cc index 3bf0532491..84c6285bbe 100644 --- a/tensorflow/core/common_runtime/bfc_allocator.cc +++ b/tensorflow/core/common_runtime/bfc_allocator.cc @@ -596,7 +596,7 @@ string BFCAllocator::RenderOccupancy() { region_offset += region.memory_size(); } - return std::string(rendered, resolution); + return string(rendered, resolution); } void BFCAllocator::DumpMemoryLog(size_t num_bytes) { diff --git a/tensorflow/core/common_runtime/direct_session.cc b/tensorflow/core/common_runtime/direct_session.cc index bf1d78ec65..eb388202fa 100644 --- a/tensorflow/core/common_runtime/direct_session.cc +++ b/tensorflow/core/common_runtime/direct_session.cc @@ -451,8 +451,22 @@ Status DirectSession::RunInternal(int64 step_id, const RunOptions& run_options, RunState run_state(step_id, &devices_); run_state.rendez = new IntraProcessRendezvous(device_mgr_.get()); #ifndef __ANDROID__ - // Set up for collectives if the RunOption declares a key. - if (run_options.experimental().collective_graph_key() > 0) { + // Set up for collectives if ExecutorsAndKeys declares a key. + if (executors_and_keys->collective_graph_key != + BuildGraphOptions::kNoCollectiveGraphKey) { + if (run_options.experimental().collective_graph_key() != + BuildGraphOptions::kNoCollectiveGraphKey) { + // If a collective_graph_key was specified in run_options, ensure that it + // matches what came out of GraphExecutionState::BuildGraph(). + if (run_options.experimental().collective_graph_key() != + executors_and_keys->collective_graph_key) { + return errors::Internal( + "collective_graph_key in RunOptions ", + run_options.experimental().collective_graph_key(), + " should match collective_graph_key from optimized graph ", + executors_and_keys->collective_graph_key); + } + } if (!collective_executor_mgr_) { std::unique_ptr<DeviceResolverInterface> drl( new DeviceResolverLocal(device_mgr_.get())); @@ -678,10 +692,16 @@ Status DirectSession::Run(const RunOptions& run_options, // Check if we already have an executor for these arguments. ExecutorsAndKeys* executors_and_keys; RunStateArgs run_state_args(run_options.debug_options()); + run_state_args.collective_graph_key = + run_options.experimental().collective_graph_key(); TF_RETURN_IF_ERROR(GetOrCreateExecutors(input_tensor_names, output_names, target_nodes, &executors_and_keys, &run_state_args)); + { + mutex_lock l(collective_graph_key_lock_); + collective_graph_key_ = executors_and_keys->collective_graph_key; + } // Configure a call frame for the step, which we use to feed and // fetch values to and from the executors. @@ -1116,6 +1136,8 @@ Status DirectSession::CreateExecutors( BuildGraphOptions options; options.callable_options = callable_options; options.use_function_convention = !run_state_args->is_partial_run; + options.collective_graph_key = + callable_options.run_options().experimental().collective_graph_key(); std::unique_ptr<FunctionInfo> func_info(new FunctionInfo); std::unique_ptr<ExecutorsAndKeys> ek(new ExecutorsAndKeys); @@ -1123,9 +1145,9 @@ Status DirectSession::CreateExecutors( ek->callable_options = callable_options; std::unordered_map<string, std::unique_ptr<Graph>> graphs; - TF_RETURN_IF_ERROR(CreateGraphs(options, &graphs, &func_info->flib_def, - run_state_args, &ek->input_types, - &ek->output_types)); + TF_RETURN_IF_ERROR(CreateGraphs( + options, &graphs, &func_info->flib_def, run_state_args, &ek->input_types, + &ek->output_types, &ek->collective_graph_key)); if (run_state_args->is_partial_run) { ek->graph = std::move(run_state_args->graph); @@ -1353,6 +1375,9 @@ Status DirectSession::GetOrCreateExecutors( } *callable_options.mutable_run_options()->mutable_debug_options() = run_state_args->debug_options; + callable_options.mutable_run_options() + ->mutable_experimental() + ->set_collective_graph_key(run_state_args->collective_graph_key); std::unique_ptr<ExecutorsAndKeys> ek; std::unique_ptr<FunctionInfo> func_info; TF_RETURN_IF_ERROR( @@ -1379,7 +1404,7 @@ Status DirectSession::CreateGraphs( std::unordered_map<string, std::unique_ptr<Graph>>* outputs, std::unique_ptr<FunctionLibraryDefinition>* flib_def, RunStateArgs* run_state_args, DataTypeVector* input_types, - DataTypeVector* output_types) { + DataTypeVector* output_types, int64* collective_graph_key) { mutex_lock l(graph_def_lock_); std::unique_ptr<ClientGraph> client_graph; @@ -1403,6 +1428,7 @@ Status DirectSession::CreateGraphs( TF_RETURN_IF_ERROR( execution_state->BuildGraph(subgraph_options, &client_graph)); } + *collective_graph_key = client_graph->collective_graph_key; if (subgraph_options.callable_options.feed_size() != client_graph->feed_types.size()) { diff --git a/tensorflow/core/common_runtime/direct_session.h b/tensorflow/core/common_runtime/direct_session.h index 55a6fbce6d..c2cf3c7fd7 100644 --- a/tensorflow/core/common_runtime/direct_session.h +++ b/tensorflow/core/common_runtime/direct_session.h @@ -117,6 +117,9 @@ class DirectSession : public Session { ::tensorflow::Status ReleaseCallable(CallableHandle handle) override; private: + // For access to collective_graph_key_. + friend class DirectSessionCollectiveTest; + // We create one executor and its dependent library runtime for // every partition. struct PerPartitionExecutorsAndLib { @@ -150,6 +153,8 @@ class DirectSession : public Session { DataTypeVector output_types; CallableOptions callable_options; + + int64 collective_graph_key = BuildGraphOptions::kNoCollectiveGraphKey; }; // A FunctionInfo object is created for every unique set of feeds/fetches. @@ -203,6 +208,7 @@ class DirectSession : public Session { string handle; std::unique_ptr<Graph> graph; const DebugOptions& debug_options; + int64 collective_graph_key = BuildGraphOptions::kNoCollectiveGraphKey; }; // Initializes the base execution state given the 'graph', @@ -234,7 +240,7 @@ class DirectSession : public Session { std::unordered_map<string, std::unique_ptr<Graph>>* outputs, std::unique_ptr<FunctionLibraryDefinition>* flib_def, RunStateArgs* run_state_args, DataTypeVector* input_types, - DataTypeVector* output_types); + DataTypeVector* output_types, int64* collective_graph_key); ::tensorflow::Status RunInternal(int64 step_id, const RunOptions& run_options, CallFrameInterface* call_frame, @@ -391,6 +397,10 @@ class DirectSession : public Session { Executor::Args::NodeOutputsCallback node_outputs_callback_ = nullptr; + // For testing collective graph key generation. + mutex collective_graph_key_lock_; + int64 collective_graph_key_ GUARDED_BY(collective_graph_key_lock_) = -1; + TF_DISALLOW_COPY_AND_ASSIGN(DirectSession); // EXPERIMENTAL: debugger (tfdbg) related diff --git a/tensorflow/core/common_runtime/direct_session_test.cc b/tensorflow/core/common_runtime/direct_session_test.cc index 4b51b20bb1..3f2355e530 100644 --- a/tensorflow/core/common_runtime/direct_session_test.cc +++ b/tensorflow/core/common_runtime/direct_session_test.cc @@ -2218,4 +2218,121 @@ BENCHMARK(BM_FeedFetch)->Arg(1)->Arg(2)->Arg(5)->Arg(10); BENCHMARK(BM_FeedFetchCallable)->Arg(1)->Arg(2)->Arg(5)->Arg(10); } // namespace + +class DirectSessionCollectiveTest : public ::testing::Test { + public: + // Creates a graph with CollectiveOps inside functions and runs it. Returns + // the generated collective_graph_key. + Status RunGraphWithCollectiveFunctions(bool add_unused_function, + int64* collective_graph_key) { + GraphDef g = CreateGraph(add_unused_function); + const Tensor t1 = + test::AsTensor<float>({0.1, 1.1, 2.1, 3.1, 4.1, 5.1, 6.1, 7.1}); + const Tensor t2 = + test::AsTensor<float>({0.3, 1.3, 2.3, 3.3, 4.3, 5.3, 6.3, 7.3}); + auto session = CreateSession(); + TF_RETURN_IF_ERROR(session->Create(g)); + std::vector<Tensor> outputs; + TF_RETURN_IF_ERROR( + session->Run({{"input1:0", t1}, {"input2:0", t2}}, {}, + {"collective_call1:0", "collective_call2:0"}, &outputs)); + DirectSession* direct_session = static_cast<DirectSession*>(session.get()); + { + mutex_lock l(direct_session->collective_graph_key_lock_); + *collective_graph_key = direct_session->collective_graph_key_; + } + return Status::OK(); + } + + private: + // Creates a function with name `function_name` and a single CollectiveReduce + // node with instance key set as `instance_key`. + FunctionDef CollectiveFunction(const string& function_name, + int instance_key) { + return FunctionDefHelper::Define( + // Function name + function_name, + // In def + {"arg:float"}, + // Out def + {"reduce:float"}, + // Attr def + {}, + // Node def + {{ + {"reduce"}, + "CollectiveReduce", + {"arg"}, + {{"group_size", 2}, + {"group_key", 1}, + {"instance_key", instance_key}, + {"subdiv_offsets", gtl::ArraySlice<int32>({0})}, + {"merge_op", "Add"}, + {"final_op", "Div"}, + {"T", DT_FLOAT}}, + }}); + } + + // Creates a GraphDef that adds two CollectiveFunctions, one each on CPU0 and + // CPU1, with instance_key 1, and appropriate placeholder inputs. If + // `add_unused_function` is true, adds another CollectiveFunction with + // instance_key 2 that is not invoked in the graph. + GraphDef CreateGraph(bool add_unused_function) { + GraphDef g; + FunctionDef collective_function = + CollectiveFunction("CollectiveFunction1", 1); + FunctionDefLibrary* lib = g.mutable_library(); + *lib->add_function() = collective_function; + if (add_unused_function) { + FunctionDef unused_function = + CollectiveFunction("CollectiveFunction2", 2); + *lib->add_function() = unused_function; + } + + // Inputs. + AttrValue dtype_attr; + SetAttrValue(DT_FLOAT, &dtype_attr); + NodeDef input1; + input1.set_name("input1"); + input1.set_op("Placeholder"); + input1.mutable_attr()->insert({"dtype", dtype_attr}); + NodeDef input2; + input2.set_name("input2"); + input2.set_op("Placeholder"); + input2.mutable_attr()->insert({"dtype", dtype_attr}); + + // CollectiveReduce on CPU0 with instance_key 1. + NodeDef collective_call1; + collective_call1.set_name("collective_call1"); + collective_call1.set_op("CollectiveFunction1"); + collective_call1.add_input("input1"); + collective_call1.set_device("/job:localhost/replica:0/task:0/device:CPU:0"); + // CollectiveReduce on CPU1 with instance_key 1. + NodeDef collective_call2; + collective_call2.set_name("collective_call2"); + collective_call2.set_op("CollectiveFunction1"); + collective_call2.add_input("input2"); + collective_call1.set_device("/job:localhost/replica:0/task:0/device:CPU:1"); + + *g.add_node() = input1; + *g.add_node() = input2; + *g.add_node() = collective_call1; + *g.add_node() = collective_call2; + + return g; + } +}; + +#ifndef GOOGLE_CUDA +// TODO(ayushd): enable this test for GPU builds. +TEST_F(DirectSessionCollectiveTest, + TestCollectiveGraphKeyUsesOnlyCalledFunctions) { + int64 key1; + TF_ASSERT_OK(RunGraphWithCollectiveFunctions(false, &key1)); + int64 key2; + TF_ASSERT_OK(RunGraphWithCollectiveFunctions(true, &key2)); + ASSERT_EQ(key1, key2); +} +#endif + } // namespace tensorflow diff --git a/tensorflow/core/common_runtime/eager/context.cc b/tensorflow/core/common_runtime/eager/context.cc index 39a3b49cd1..879a794368 100644 --- a/tensorflow/core/common_runtime/eager/context.cc +++ b/tensorflow/core/common_runtime/eager/context.cc @@ -36,22 +36,34 @@ bool ReadBoolFromEnvVar(StringPiece env_var_name, bool default_val) { EagerContext::EagerContext(const SessionOptions& opts, ContextDevicePlacementPolicy default_policy, - bool async, std::unique_ptr<DeviceMgr> device_mgr, + bool async, + std::unique_ptr<const DeviceMgr> device_mgr, Rendezvous* rendezvous) + : EagerContext(opts, default_policy, async, device_mgr.release(), + /*device_mgr_owned*/ true, rendezvous) {} + +EagerContext::EagerContext(const SessionOptions& opts, + ContextDevicePlacementPolicy default_policy, + bool async, const DeviceMgr* device_mgr, + bool device_mgr_owned, Rendezvous* rendezvous) : policy_(default_policy), - local_device_manager_(std::move(device_mgr)), - local_unowned_device_manager_(nullptr), - devices_(local_device_manager_->ListDevices()), + devices_(device_mgr->ListDevices()), rendezvous_(rendezvous), thread_pool_(NewThreadPoolFromSessionOptions(opts)), pflr_(new ProcessFunctionLibraryRuntime( - local_device_manager_.get(), opts.env, TF_GRAPH_DEF_VERSION, - &func_lib_def_, {}, thread_pool_.get())), + device_mgr, opts.env, TF_GRAPH_DEF_VERSION, &func_lib_def_, {}, + thread_pool_.get())), log_device_placement_(opts.config.log_device_placement()), num_active_steps_(0), async_default_(async), env_(opts.env), use_send_tensor_rpc_(false) { + if (device_mgr_owned) { + local_device_manager_.reset(device_mgr); + local_unowned_device_manager_ = nullptr; + } else { + local_unowned_device_manager_ = device_mgr; + } InitDeviceMapAndAsync(); if (opts.config.inter_op_parallelism_threads() > 0) { runner_ = [this](std::function<void()> closure) { diff --git a/tensorflow/core/common_runtime/eager/context.h b/tensorflow/core/common_runtime/eager/context.h index 3c95ac590d..eb6eb0d55a 100644 --- a/tensorflow/core/common_runtime/eager/context.h +++ b/tensorflow/core/common_runtime/eager/context.h @@ -65,10 +65,17 @@ enum ContextDevicePlacementPolicy { class EagerContext { public: - explicit EagerContext(const SessionOptions& opts, - ContextDevicePlacementPolicy default_policy, bool async, - std::unique_ptr<DeviceMgr> device_mgr, - Rendezvous* rendezvous); + // TODO: remove this constructor once we migrate all callers to the next one. + EagerContext(const SessionOptions& opts, + ContextDevicePlacementPolicy default_policy, bool async, + std::unique_ptr<const DeviceMgr> device_mgr, + Rendezvous* rendezvous); + + EagerContext(const SessionOptions& opts, + ContextDevicePlacementPolicy default_policy, bool async, + const DeviceMgr* device_mgr, bool device_mgr_owned, + Rendezvous* rendezvous); + ~EagerContext(); // Returns the function library runtime for the given device. @@ -207,8 +214,8 @@ class EagerContext { thread_local_policies_ GUARDED_BY(policy_map_mu_); // Only one of the below is set. - std::unique_ptr<DeviceMgr> local_device_manager_; - DeviceMgr* local_unowned_device_manager_; + std::unique_ptr<const DeviceMgr> local_device_manager_; + const DeviceMgr* local_unowned_device_manager_; std::unique_ptr<DeviceMgr> remote_device_manager_; // Devices owned by device_manager diff --git a/tensorflow/core/common_runtime/executor.cc b/tensorflow/core/common_runtime/executor.cc index 02193dae5a..84865397bc 100644 --- a/tensorflow/core/common_runtime/executor.cc +++ b/tensorflow/core/common_runtime/executor.cc @@ -1482,6 +1482,7 @@ void ExecutorState::RunAsync(Executor::DoneCallback done) { const Status fill_status = device->FillContextMap(graph, &device_context_map_); if (!fill_status.ok()) { + delete this; done(fill_status); return; } @@ -1492,6 +1493,7 @@ void ExecutorState::RunAsync(Executor::DoneCallback done) { ready.push_back(TaggedNode{n, root_frame_, 0, false}); } if (ready.empty()) { + delete this; done(Status::OK()); } else { num_outstanding_ops_ = ready.size(); @@ -2419,8 +2421,7 @@ void ExecutorState::DeleteFrame(FrameState* frame, TaggedNodeSeq* ready) { } if (dst_ready) { if (IsControlTrigger(dst_node)) dst_dead = false; - ready->push_back( - TaggedNode(dst_node, parent_frame, parent_iter, dst_dead)); + ready->emplace_back(dst_node, parent_frame, parent_iter, dst_dead); parent_iter_state->outstanding_ops++; } } @@ -2544,7 +2545,7 @@ void ExecutorState::FrameState::ActivateNodes(const NodeItem* item, // Add dst to the ready queue if it's ready if (dst_ready) { if (dst_item->is_control_trigger) dst_dead = false; - ready->push_back(TaggedNode(dst_item->node, this, iter, dst_dead)); + ready->emplace_back(dst_item->node, this, iter, dst_dead); iter_state->outstanding_ops++; } } diff --git a/tensorflow/core/common_runtime/graph_execution_state.cc b/tensorflow/core/common_runtime/graph_execution_state.cc index 346befc255..7f260b3139 100644 --- a/tensorflow/core/common_runtime/graph_execution_state.cc +++ b/tensorflow/core/common_runtime/graph_execution_state.cc @@ -16,6 +16,7 @@ limitations under the License. #include "tensorflow/core/common_runtime/graph_execution_state.h" #include <memory> +#include <set> #include <string> #include <unordered_set> #include <utility> @@ -727,12 +728,50 @@ Status GraphExecutionState::BuildGraph(const BuildGraphOptions& options, TF_RETURN_IF_ERROR(OptimizationPassRegistry::Global()->RunGrouping( OptimizationPassRegistry::POST_REWRITE_FOR_EXEC, optimization_options)); + int64 collective_graph_key = options.collective_graph_key; + if (collective_graph_key == BuildGraphOptions::kNoCollectiveGraphKey) { + // BuildGraphOptions does not specify a collective_graph_key. Check all + // nodes in the Graph and FunctionLibraryDefinition for collective ops and + // if found, initialize a collective_graph_key as a hash of the ordered set + // of instance keys. + std::set<int32> instance_key_set; + for (Node* node : optimized_graph->nodes()) { + if (node->IsCollective()) { + int32 instance_key; + TF_RETURN_IF_ERROR( + GetNodeAttr(node->attrs(), "instance_key", &instance_key)); + instance_key_set.emplace(instance_key); + } else { + const FunctionDef* fdef = optimized_flib->Find(node->def().op()); + if (fdef != nullptr) { + for (const NodeDef& ndef : fdef->node_def()) { + if (ndef.op() == "CollectiveReduce" || + ndef.op() == "CollectiveBcastSend" || + ndef.op() == "CollectiveBcastRecv") { + int32 instance_key; + TF_RETURN_IF_ERROR( + GetNodeAttr(ndef, "instance_key", &instance_key)); + instance_key_set.emplace(instance_key); + } + } + } + } + } + if (!instance_key_set.empty()) { + uint64 hash = 0x8774aa605c729c72ULL; + for (int32 instance_key : instance_key_set) { + hash = Hash64Combine(instance_key, hash); + } + collective_graph_key = hash; + } + } + // Copy the extracted graph in order to make its node ids dense, // since the local CostModel used to record its stats is sized by // the largest node id. std::unique_ptr<ClientGraph> dense_copy( new ClientGraph(std::move(optimized_flib), rewrite_metadata.feed_types, - rewrite_metadata.fetch_types)); + rewrite_metadata.fetch_types, collective_graph_key)); CopyGraph(*optimized_graph, &dense_copy->graph); // TODO(vrv): We should check invariants of the graph here. diff --git a/tensorflow/core/common_runtime/graph_execution_state.h b/tensorflow/core/common_runtime/graph_execution_state.h index d44a24c87b..9cabe478a6 100644 --- a/tensorflow/core/common_runtime/graph_execution_state.h +++ b/tensorflow/core/common_runtime/graph_execution_state.h @@ -50,17 +50,20 @@ struct GraphExecutionStateOptions { // BuildGraphOptions. struct ClientGraph { explicit ClientGraph(std::unique_ptr<FunctionLibraryDefinition> flib, - DataTypeVector feed_types, DataTypeVector fetch_types) + DataTypeVector feed_types, DataTypeVector fetch_types, + int64 collective_graph_key) : flib_def(std::move(flib)), graph(flib_def.get()), feed_types(std::move(feed_types)), - fetch_types(std::move(fetch_types)) {} + fetch_types(std::move(fetch_types)), + collective_graph_key(collective_graph_key) {} // Each client-graph gets its own function library since optimization passes // post rewrite for execution might want to introduce new functions. std::unique_ptr<FunctionLibraryDefinition> flib_def; Graph graph; DataTypeVector feed_types; DataTypeVector fetch_types; + int64 collective_graph_key; }; // GraphExecutionState is responsible for generating an diff --git a/tensorflow/core/common_runtime/graph_runner.cc b/tensorflow/core/common_runtime/graph_runner.cc index 0a1797fa19..f9aef3af70 100644 --- a/tensorflow/core/common_runtime/graph_runner.cc +++ b/tensorflow/core/common_runtime/graph_runner.cc @@ -56,7 +56,7 @@ class SimpleRendezvous : public Rendezvous { } mutex_lock l(mu_); - string edge_name = std::string(parsed.edge_name); + string edge_name(parsed.edge_name); if (table_.count(edge_name) > 0) { return errors::Internal("Send of an already sent tensor"); } @@ -69,7 +69,7 @@ class SimpleRendezvous : public Rendezvous { Tensor tensor; Status status = Status::OK(); { - string key = std::string(parsed.edge_name); + string key(parsed.edge_name); mutex_lock l(mu_); if (table_.count(key) <= 0) { status = errors::Internal("Did not find key ", key); diff --git a/tensorflow/core/common_runtime/placer.cc b/tensorflow/core/common_runtime/placer.cc index d581f45a90..3b59995433 100644 --- a/tensorflow/core/common_runtime/placer.cc +++ b/tensorflow/core/common_runtime/placer.cc @@ -30,7 +30,6 @@ limitations under the License. #include "tensorflow/core/lib/core/errors.h" #include "tensorflow/core/lib/core/stringpiece.h" #include "tensorflow/core/lib/strings/str_util.h" -#include "tensorflow/core/util/status_util.h" namespace tensorflow { @@ -255,9 +254,11 @@ class ColocationGraph { old_root_member.device_name, allow_soft_placement_); if (!s.ok()) { - return errors::InvalidArgument("Cannot colocate nodes '", x.name(), - "' and '", y.name(), ": ", - s.error_message()); + return errors::InvalidArgument( + "Cannot colocate nodes ", + errors::FormatColocationNodeForError(x.name()), " and ", + errors::FormatColocationNodeForError(y.name()), ": ", + s.error_message()); } // Ensure that the common root has at least one supported device @@ -268,8 +269,10 @@ class ColocationGraph { old_root_member.supported_device_types); if (new_root_member.supported_device_types.empty()) { return errors::InvalidArgument( - "Cannot colocate nodes '", x.name(), "' and '", y.name(), - "' because no device type supports both of those nodes and the " + "Cannot colocate nodes ", + errors::FormatColocationNodeForError(x.name()), " and ", + errors::FormatColocationNodeForError(y.name()), + " because no device type supports both of those nodes and the " "other nodes colocated with them.", DebugInfo(x_root), DebugInfo(y_root)); } @@ -377,8 +380,9 @@ class ColocationGraph { // merged set device is different, so print both. return errors::InvalidArgument( "Could not satisfy explicit device specification '", - node->requested_device(), - "' because the node was colocated with a group of nodes that " + node->requested_device(), "' because the node ", + errors::FormatColocationNodeForError(node->name()), + " was colocated with a group of nodes that ", "required incompatible device '", DeviceNameUtils::ParsedNameToString( members_[node_root].device_name), @@ -810,10 +814,10 @@ Status Placer::Run() { std::vector<Device*>* devices; Status status = colocation_graph.GetDevicesForNode(node, &devices); if (!status.ok()) { - return AttachDef(errors::InvalidArgument( - "Cannot assign a device for operation ", - RichNodeName(node), ": ", status.error_message()), - *node); + return AttachDef( + errors::InvalidArgument("Cannot assign a device for operation ", + node->name(), ": ", status.error_message()), + *node); } // Returns the first device in sorted devices list so we will always @@ -857,10 +861,10 @@ Status Placer::Run() { std::vector<Device*>* devices; Status status = colocation_graph.GetDevicesForNode(node, &devices); if (!status.ok()) { - return AttachDef(errors::InvalidArgument( - "Cannot assign a device for operation ", - RichNodeName(node), ": ", status.error_message()), - *node); + return AttachDef( + errors::InvalidArgument("Cannot assign a device for operation ", + node->name(), ": ", status.error_message()), + *node); } int assigned_device = -1; @@ -926,22 +930,4 @@ void Placer::LogDeviceAssignment(const Node* node) const { } } -bool Placer::ClientHandlesErrorFormatting() const { - return options_ != nullptr && - options_->config.experimental().client_handles_error_formatting(); -} - -// Returns the node name in single quotes. If the client handles formatted -// errors, appends a formatting tag which the client will reformat into, for -// example, " (defined at filename:123)". -string Placer::RichNodeName(const Node* node) const { - string quoted_name = strings::StrCat("'", node->name(), "'"); - if (ClientHandlesErrorFormatting()) { - string file_and_line = error_format_tag(*node, "${defined_at}"); - return strings::StrCat(quoted_name, file_and_line); - } else { - return quoted_name; - } -} - } // namespace tensorflow diff --git a/tensorflow/core/common_runtime/placer.h b/tensorflow/core/common_runtime/placer.h index cefcdd25db..f97ffe7372 100644 --- a/tensorflow/core/common_runtime/placer.h +++ b/tensorflow/core/common_runtime/placer.h @@ -87,8 +87,6 @@ class Placer { // placement if the SessionOptions entry in 'options_' requests it. void AssignAndLog(int assigned_device, Node* node) const; void LogDeviceAssignment(const Node* node) const; - bool ClientHandlesErrorFormatting() const; - string RichNodeName(const Node* node) const; Graph* const graph_; // Not owned. const DeviceSet* const devices_; // Not owned. diff --git a/tensorflow/core/common_runtime/placer_test.cc b/tensorflow/core/common_runtime/placer_test.cc index 87f2f2ceb9..9b8a95e3b6 100644 --- a/tensorflow/core/common_runtime/placer_test.cc +++ b/tensorflow/core/common_runtime/placer_test.cc @@ -800,11 +800,11 @@ TEST_F(PlacerTest, TestInvalidMultipleColocationGroups) { } Status s = Place(&g); - EXPECT_TRUE( - str_util::StrContains(s.error_message(), - "Cannot colocate nodes 'foo' and 'in' because no " - "device type supports both of those nodes and the " - "other nodes colocated with them")); + EXPECT_TRUE(str_util::StrContains( + s.error_message(), + "Cannot colocate nodes {{colocation_node foo}} and " + "{{colocation_node in}} because no device type supports both of those " + "nodes and the other nodes colocated with them")); } TEST_F(PlacerTest, TestColocationGroupWithReferenceConnections) { @@ -867,9 +867,9 @@ TEST_F(PlacerTest, TestColocationGroupWithUnsatisfiableReferenceConnections) { Status s = Place(&g); EXPECT_TRUE(str_util::StrContains( s.error_message(), - "Cannot colocate nodes 'var3' and 'assign3' because no " - "device type supports both of those nodes and the other " - "nodes colocated with them.")); + "Cannot colocate nodes {{colocation_node var3}} and {{colocation_node " + "assign3}} because no device type supports both of those nodes and the " + "other nodes colocated with them.")); } TEST_F(PlacerTest, TestColocationAndReferenceConnections) { @@ -1154,36 +1154,12 @@ TEST_F(PlacerTest, TestNonexistentGpuNoAllowSoftPlacementFormatTag) { } SessionOptions options; - options.config.mutable_experimental()->set_client_handles_error_formatting( - true); Status s = Place(&g, &options); EXPECT_EQ(error::INVALID_ARGUMENT, s.code()); LOG(WARNING) << s.error_message(); EXPECT_TRUE(str_util::StrContains(s.error_message(), - "Cannot assign a device for operation 'in'" - "^^node:in:${defined_at}^^")); -} - -// Test that the "Cannot assign a device" error message does not contain a -// format tag when not it shouldn't -TEST_F(PlacerTest, TestNonexistentGpuNoAllowSoftPlacementNoFormatTag) { - Graph g(OpRegistry::Global()); - { // Scope for temporary variables used to construct g. - GraphDefBuilder b(GraphDefBuilder::kFailImmediately); - ops::SourceOp("TestDevice", - b.opts().WithName("in").WithDevice("/device:fakegpu:11")); - TF_EXPECT_OK(BuildGraph(b, &g)); - } - - SessionOptions options; - options.config.mutable_experimental()->set_client_handles_error_formatting( - false); - Status s = Place(&g, &options); - EXPECT_EQ(error::INVALID_ARGUMENT, s.code()); - EXPECT_TRUE(str_util::StrContains( - s.error_message(), "Cannot assign a device for operation 'in'")); - EXPECT_FALSE(str_util::StrContains( - s.error_message(), "'in' (defined at ^^node:in:${file}:${line}^^)")); + "Cannot assign a device for operation in")); + EXPECT_TRUE(str_util::StrContains(s.error_message(), "{{node in}}")); } // Test that placement fails when a node requests an explicit device that is not @@ -1289,8 +1265,9 @@ TEST_F(PlacerTest, TestUnsatisfiableConstraintWithReferenceConnections) { Status s = Place(&g); EXPECT_EQ(error::INVALID_ARGUMENT, s.code()); - EXPECT_TRUE(str_util::StrContains( - s.error_message(), "Cannot colocate nodes 'var' and 'assign'")); + EXPECT_TRUE(str_util::StrContains(s.error_message(), + "Cannot colocate nodes {{colocation_node " + "var}} and {{colocation_node assign}}")); } // Test that a generator node follows its consumers (where there are several diff --git a/tensorflow/core/common_runtime/pool_allocator.cc b/tensorflow/core/common_runtime/pool_allocator.cc index 10a24ed14c..fdad8de8d6 100644 --- a/tensorflow/core/common_runtime/pool_allocator.cc +++ b/tensorflow/core/common_runtime/pool_allocator.cc @@ -26,6 +26,7 @@ limitations under the License. #include "tensorflow/core/lib/strings/numbers.h" #include "tensorflow/core/platform/logging.h" +#include "tensorflow/core/platform/mem.h" #include "tensorflow/core/platform/mutex.h" #include "tensorflow/core/platform/types.h" diff --git a/tensorflow/core/common_runtime/session_state.cc b/tensorflow/core/common_runtime/session_state.cc index 65ff356e73..5b1915755d 100644 --- a/tensorflow/core/common_runtime/session_state.cc +++ b/tensorflow/core/common_runtime/session_state.cc @@ -70,7 +70,7 @@ Status TensorStore::SaveTensors(const std::vector<string>& output_names, // Save only the tensors in output_names in the session. for (const string& name : output_names) { TensorId id(ParseTensorName(name)); - const string& op_name = std::string(id.first); + const string op_name(id.first); auto it = tensors_.find(op_name); if (it != tensors_.end()) { // Save the tensor to the session state. diff --git a/tensorflow/core/common_runtime/step_stats_collector.cc b/tensorflow/core/common_runtime/step_stats_collector.cc index 9c2510e6a9..836cb8ed14 100644 --- a/tensorflow/core/common_runtime/step_stats_collector.cc +++ b/tensorflow/core/common_runtime/step_stats_collector.cc @@ -176,7 +176,7 @@ static int ExtractGpuWithStreamAll(string device_name) { } else { // Convert the captured string into an integer. But first we need to put // the digits back in order - string ordered_capture = std::string(capture); + string ordered_capture(capture); std::reverse(ordered_capture.begin(), ordered_capture.end()); int gpu_id; CHECK(strings::safe_strto32(ordered_capture, &gpu_id)); @@ -205,7 +205,7 @@ static int ExtractGpuWithoutStream(string device_name) { } else { // Convert the captured string into an integer. But first we need to put // the digits back in order - string ordered_capture = std::string(capture); + string ordered_capture(capture); std::reverse(ordered_capture.begin(), ordered_capture.end()); int gpu_id; CHECK(strings::safe_strto32(ordered_capture, &gpu_id)); @@ -252,7 +252,7 @@ void StepStatsCollector::BuildCostModel( for (auto& itr : per_device_stats) { const StringPiece device_name = itr.first; - const int gpu_id = ExtractGpuWithoutStream(std::string(device_name)); + const int gpu_id = ExtractGpuWithoutStream(string(device_name)); if (gpu_id >= 0) { // Reference the gpu hardware stats in addition to the regular stats // for this gpu device if they're available. diff --git a/tensorflow/core/distributed_runtime/master_session.cc b/tensorflow/core/distributed_runtime/master_session.cc index abd07e37b7..8e9eec1ed9 100644 --- a/tensorflow/core/distributed_runtime/master_session.cc +++ b/tensorflow/core/distributed_runtime/master_session.cc @@ -449,7 +449,7 @@ Status MasterSession::ReffedClientGraph::DoRegisterPartitions( *c->req.mutable_graph_options() = session_opts_.config.graph_options(); *c->req.mutable_debug_options() = callable_opts_.run_options().debug_options(); - c->req.set_collective_graph_key(bg_opts_.collective_graph_key); + c->req.set_collective_graph_key(client_graph()->collective_graph_key); VLOG(2) << "Register " << c->req.graph_def().DebugString(); auto cb = [c, &done](const Status& s) { c->status = s; @@ -1111,10 +1111,6 @@ uint64 HashBuildGraphOptions(const BuildGraphOptions& opts) { h = Hash64(watch_summary.c_str(), watch_summary.size(), h); } - if (opts.collective_graph_key != BuildGraphOptions::kNoCollectiveGraphKey) { - h = Hash64Combine(opts.collective_graph_key, h); - } - return h; } @@ -1788,10 +1784,10 @@ Status MasterSession::PostRunCleanup(MasterSession::ReffedClientGraph* rcg, Status s = run_status; if (s.ok()) { pss->end_micros = Env::Default()->NowMicros(); - if (rcg->build_graph_options().collective_graph_key != + if (rcg->client_graph()->collective_graph_key != BuildGraphOptions::kNoCollectiveGraphKey) { env_->collective_executor_mgr->RetireStepId( - rcg->build_graph_options().collective_graph_key, step_id); + rcg->client_graph()->collective_graph_key, step_id); } // Schedule post-processing and cleanup to be done asynchronously. rcg->ProcessStats(step_id, pss, ph.get(), run_options, out_run_metadata); @@ -1850,7 +1846,7 @@ Status MasterSession::DoRunWithLocalExecution( // Keeps the highest 8 bits 0x01: we reserve some bits of the // step_id for future use. - uint64 step_id = NewStepId(bgopts.collective_graph_key); + uint64 step_id = NewStepId(rcg->client_graph()->collective_graph_key); TRACEPRINTF("stepid %llu", step_id); std::unique_ptr<ProfileHandler> ph; @@ -1914,8 +1910,7 @@ Status MasterSession::DoRunCallable(CallOptions* opts, ReffedClientGraph* rcg, // Prepare. int64 count = rcg->get_and_increment_execution_count(); - const uint64 step_id = - NewStepId(rcg->build_graph_options().collective_graph_key); + const uint64 step_id = NewStepId(rcg->client_graph()->collective_graph_key); TRACEPRINTF("stepid %llu", step_id); const RunOptions& run_options = rcg->callable_options().run_options(); diff --git a/tensorflow/core/framework/dataset.cc b/tensorflow/core/framework/dataset.cc index b0b27ce94f..9ffd8e1ee0 100644 --- a/tensorflow/core/framework/dataset.cc +++ b/tensorflow/core/framework/dataset.cc @@ -179,6 +179,13 @@ Status GraphDefBuilderWrapper::AddFunction(SerializationContext* ctx, return Status::OK(); } +void GraphDefBuilderWrapper::AddPlaceholderInternal(const Tensor& val, + Node** output) { + *output = ops::SourceOp( + "Placeholder", + b_->opts().WithAttr("dtype", val.dtype()).WithAttr("shape", val.shape())); +} + void GraphDefBuilderWrapper::AddTensorInternal(const Tensor& val, Node** output) { *output = ops::SourceOp( diff --git a/tensorflow/core/framework/dataset.h b/tensorflow/core/framework/dataset.h index e06ca68bca..04865a1d4f 100644 --- a/tensorflow/core/framework/dataset.h +++ b/tensorflow/core/framework/dataset.h @@ -110,10 +110,11 @@ class GraphDefBuilderWrapper { return Status::OK(); } - // Adds a Const node with Tensor value to the Graph. + // Adds a `Const` node for the given tensor value to the graph. + // // `*output` contains a pointer to the output `Node`. It is guaranteed to be - // non-null if the method returns with an OK status. - // The returned Node pointer is owned by the backing Graph of GraphDefBuilder. + // non-null if the method returns with an OK status. The returned `Node` + // pointer is owned by the backing graph of `GraphDefBuilder`. Status AddTensor(const Tensor& val, Node** output) { AddTensorInternal(val, output); if (*output == nullptr) { @@ -122,6 +123,20 @@ class GraphDefBuilderWrapper { return Status::OK(); } + // Adds a `Placeholder` node for the given tensor value to the graph. + // + // `*output` contains a pointer to the output `Node`. It is guaranteed to be + // non-null if the method returns with an OK status. The returned `Node` + // pointer is owned by the backing graph of `GraphDefBuilder`. + Status AddPlaceholder(const Tensor& val, Node** output) { + AddPlaceholderInternal(val, output); + if (*output == nullptr) { + return errors::Internal( + "AddPlaceholder: Failed to build Placeholder op."); + } + return Status::OK(); + } + Status AddDataset(const DatasetBase* dataset, const std::vector<Node*>& inputs, Node** output) { return AddDataset(dataset, inputs, {}, output); @@ -168,6 +183,7 @@ class GraphDefBuilderWrapper { } private: + void AddPlaceholderInternal(const Tensor& val, Node** output); void AddTensorInternal(const Tensor& val, Node** output); Status EnsureFunctionIsStateless(const FunctionLibraryDefinition& flib_def, @@ -334,7 +350,8 @@ class SerializationContext { public: struct Params { bool allow_stateful_functions = false; - const FunctionLibraryDefinition* flib_def; // Not owned. + const FunctionLibraryDefinition* flib_def = nullptr; // Not owned. + std::vector<std::pair<string, Tensor>>* input_list = nullptr; // Not owned. }; explicit SerializationContext(Params params) : params_(std::move(params)) {} @@ -343,6 +360,10 @@ class SerializationContext { const FunctionLibraryDefinition& flib_def() { return *params_.flib_def; } + std::vector<std::pair<string, Tensor>>* input_list() { + return params_.input_list; + } + private: Params params_; diff --git a/tensorflow/core/graph/testlib.cc b/tensorflow/core/graph/testlib.cc index ea7788f654..0a38aa1c91 100644 --- a/tensorflow/core/graph/testlib.cc +++ b/tensorflow/core/graph/testlib.cc @@ -485,6 +485,33 @@ Node* DiagPart(Graph* g, Node* in, DataType type) { return ret; } +Node* CheckNumerics(Graph* g, Node* in, const string& message) { + Node* ret; + TF_CHECK_OK(NodeBuilder(g->NewName("n"), "CheckNumerics") + .Input(in) + .Attr("message", message) + .Finalize(g, &ret)); + return ret; +} + +Node* Arg(Graph* g, int64 index, DataType type) { + Node* ret; + TF_CHECK_OK(NodeBuilder(g->NewName("n"), "_Arg") + .Attr("T", type) + .Attr("index", index) + .Finalize(g, &ret)); + return ret; +} + +Node* Retval(Graph* g, int64 index, Node* in) { + Node* ret; + TF_CHECK_OK(NodeBuilder(g->NewName("n"), "_Retval") + .Input(in) + .Attr("index", index) + .Finalize(g, &ret)); + return ret; +} + void ToGraphDef(Graph* g, GraphDef* gdef) { g->ToGraphDef(gdef); } } // end namespace graph diff --git a/tensorflow/core/graph/testlib.h b/tensorflow/core/graph/testlib.h index 8585b35a19..bd0284d43a 100644 --- a/tensorflow/core/graph/testlib.h +++ b/tensorflow/core/graph/testlib.h @@ -209,6 +209,15 @@ Node* Diag(Graph* g, Node* in, DataType type); // Add a DiagPart node in "g". Node* DiagPart(Graph* g, Node* in, DataType type); +// Add a CheckNumerics node in "g". +Node* CheckNumerics(Graph* g, Node* in, const string& message); + +// Add an _Arg node in "g". +Node* Arg(Graph* g, int64 index, DataType type); + +// Add a _Retval node in "g". +Node* Retval(Graph* g, int64 index, Node* in); + } // end namespace graph } // end namespace test } // end namespace tensorflow diff --git a/tensorflow/core/grappler/graph_analyzer/graph_analyzer.h b/tensorflow/core/grappler/graph_analyzer/graph_analyzer.h index 26d38a4931..97626346c7 100644 --- a/tensorflow/core/grappler/graph_analyzer/graph_analyzer.h +++ b/tensorflow/core/grappler/graph_analyzer/graph_analyzer.h @@ -138,7 +138,7 @@ class GraphAnalyzer { // The entries are owned by collation_map_, so must be removed from // ordered_collation_ before removing them from collation_map_. struct ReverseLessByCount { - bool operator()(CollationEntry* left, CollationEntry* right) { + bool operator()(CollationEntry* left, CollationEntry* right) const { return left->count > right->count; // Reverse order. } }; diff --git a/tensorflow/core/grappler/op_types.cc b/tensorflow/core/grappler/op_types.cc index 653b088b1d..e78239bd43 100644 --- a/tensorflow/core/grappler/op_types.cc +++ b/tensorflow/core/grappler/op_types.cc @@ -135,16 +135,37 @@ bool IsDequeueOp(const NodeDef& node) { bool IsDiv(const NodeDef& node) { return node.op() == "Div"; } -bool IsElementWiseMonotonic(const NodeDef& node) { - static const std::unordered_set<string>* element_wise_monotonic_ops = +// Returns true if node represents a unary elementwise function that is +// monotonic. If *is_non_decreasing is true, the function is non-decreasing, +// e.g. sqrt, exp. *is_non_decreasing is false, the function is non-increasing, +// e.g. inv. +bool IsElementWiseMonotonic(const NodeDef& node, bool* is_non_decreasing) { + static const std::unordered_set<string>* monotonic_non_decreasing_ops = CHECK_NOTNULL((new std::unordered_set<string>{ - "Relu", - "Relu6", - "Sigmoid", - "Sqrt", - "Tanh", + "Asinh", "Atanh", "Ceil", "Elu", "Erf", "Exp", "Expm1", + "Floor", "Log", "Log1p", "Relu", "Relu", "Relu6", "Rint", + "Selu", "Sigmoid", "Sign", "Sinh", "Sqrt", "Tanh", + })); + static const std::unordered_set<string>* monotonic_non_increasing_ops = + CHECK_NOTNULL((new std::unordered_set<string>{ + "Inv", + "Reciprocal", + "Erfc", + "Rsqrt", + "Neg", })); - return element_wise_monotonic_ops->count(node.op()) > 0; + if (monotonic_non_decreasing_ops->count(node.op()) > 0) { + if (is_non_decreasing) { + *is_non_decreasing = true; + } + return true; + } else if (monotonic_non_increasing_ops->count(node.op()) > 0) { + if (is_non_decreasing) { + *is_non_decreasing = false; + } + return true; + } + return false; } bool IsEluGrad(const NodeDef& node) { return node.op() == "EluGrad"; } diff --git a/tensorflow/core/grappler/op_types.h b/tensorflow/core/grappler/op_types.h index 94439265c9..25ab6b65ac 100644 --- a/tensorflow/core/grappler/op_types.h +++ b/tensorflow/core/grappler/op_types.h @@ -55,7 +55,7 @@ bool IsDepthwiseConv2dNativeBackpropFilter(const NodeDef& node); bool IsDepthwiseConv2dNativeBackpropInput(const NodeDef& node); bool IsDequeueOp(const NodeDef& node); bool IsDiv(const NodeDef& node); -bool IsElementWiseMonotonic(const NodeDef& node); +bool IsElementWiseMonotonic(const NodeDef& node, bool* is_non_decreasing); bool IsEluGrad(const NodeDef& node); bool IsEnter(const NodeDef& node); bool IsEqual(const NodeDef& node); diff --git a/tensorflow/core/grappler/optimizers/BUILD b/tensorflow/core/grappler/optimizers/BUILD index 70ad9f9a9b..a24004dc16 100644 --- a/tensorflow/core/grappler/optimizers/BUILD +++ b/tensorflow/core/grappler/optimizers/BUILD @@ -110,12 +110,13 @@ cc_library( ], ) -tf_cuda_cc_test( +tf_cc_test( name = "constant_folding_test", srcs = ["constant_folding_test.cc"], - tags = ["requires-gpu-sm35"], + shard_count = 5, deps = [ ":constant_folding", + ":dependency_optimizer", "//tensorflow/cc:cc_ops", "//tensorflow/cc:cc_ops_internal", "//tensorflow/core:all_kernels", diff --git a/tensorflow/core/grappler/optimizers/arithmetic_optimizer.cc b/tensorflow/core/grappler/optimizers/arithmetic_optimizer.cc index 4fed88d536..65947ddce5 100644 --- a/tensorflow/core/grappler/optimizers/arithmetic_optimizer.cc +++ b/tensorflow/core/grappler/optimizers/arithmetic_optimizer.cc @@ -2706,8 +2706,9 @@ class OptimizeMaxOrMinOfMonotonicStage : public ArithmeticOptimizerStage { // 0. inner_function is not in the preserve set, // 1. inner_function's Op is element-wise monotonic // 2. inner_function's output is not being consumed elsewhere. + bool is_non_decreasing = false; if (!IsInPreserveSet(*inner_function) && - IsElementWiseMonotonic(*inner_function) && + IsElementWiseMonotonic(*inner_function, &is_non_decreasing) && ctx().node_map->GetOutputs(inner_function->name()).size() == 1) { // Swap the first inputs of the inner function Op & the reduction Op. NodeDef* inner_input; @@ -2719,7 +2720,12 @@ class OptimizeMaxOrMinOfMonotonicStage : public ArithmeticOptimizerStage { UpdateConsumers(reduction_node, inner_function->name()); ctx().node_map->UpdateInput(inner_function->name(), inner_input->name(), reduction_node->name()); - + if (!is_non_decreasing) { + // Flip Min<->Max if the function is non-increasing, e.g. + // Max(Neg(x)) = Neg(Min(x)). + const string opposite = IsMax(*reduction_node) ? "Min" : "Max"; + reduction_node->set_op(opposite); + } AddToOptimizationQueue(reduction_node); AddToOptimizationQueue(inner_function); AddToOptimizationQueue(inner_input); diff --git a/tensorflow/core/grappler/optimizers/arithmetic_optimizer.h b/tensorflow/core/grappler/optimizers/arithmetic_optimizer.h index 551c3652bf..d457eb6d21 100644 --- a/tensorflow/core/grappler/optimizers/arithmetic_optimizer.h +++ b/tensorflow/core/grappler/optimizers/arithmetic_optimizer.h @@ -61,7 +61,7 @@ class ArithmeticOptimizer : public GraphOptimizer { bool fold_multiply_into_conv = true; bool fold_transpose_into_matmul = true; bool hoist_common_factor_out_of_aggregation = true; - bool hoist_cwise_unary_chains = false; + bool hoist_cwise_unary_chains = true; bool minimize_broadcasts = true; bool optimize_max_or_min_of_monotonic = true; bool remove_idempotent = true; diff --git a/tensorflow/core/grappler/optimizers/arithmetic_optimizer_test.cc b/tensorflow/core/grappler/optimizers/arithmetic_optimizer_test.cc index bfccc0affd..39517edc06 100644 --- a/tensorflow/core/grappler/optimizers/arithmetic_optimizer_test.cc +++ b/tensorflow/core/grappler/optimizers/arithmetic_optimizer_test.cc @@ -3248,6 +3248,48 @@ TEST_F(ArithmeticOptimizerTest, VerifyGraphsMatch(item.graph, output, __LINE__); } +TEST_F(ArithmeticOptimizerTest, + OptimizeMaxOrMinOfMonotonicElementWiseNonIncreasing) { + tensorflow::Scope s = tensorflow::Scope::NewRootScope(); + auto x = ops::Const(s.WithOpName("x"), {1.0f, 2.0f}, {1, 2}); + Output neg = ops::Neg(s.WithOpName("neg"), x); + Output reduce_max = ops::Max(s.WithOpName("reduce_max"), neg, {0}); + Output final_out = ops::Identity(s.WithOpName("final_out"), reduce_max); + + GrapplerItem item; + item.fetch = {"final_out"}; + TF_CHECK_OK(s.ToGraphDef(&item.graph)); + auto tensors_expected = EvaluateNodes(item.graph, item.fetch); + EXPECT_EQ(1, tensors_expected.size()); + + GraphDef output; + ArithmeticOptimizer optimizer; + EnableOnlyOptimizeMaxOrMinOfMonotonic(&optimizer); + OptimizeAndPrune(&optimizer, &item, &output); + auto tensors = EvaluateNodes(output, item.fetch); + EXPECT_EQ(1, tensors.size()); + + test::ExpectTensorNear<float>(tensors_expected[0], tensors[0], 1e-6); + EXPECT_EQ(item.graph.node_size(), output.node_size()); + // Check if the inputs are switched + int required_node_count = 0; + for (int i = 0; i < output.node_size(); ++i) { + const NodeDef& node = output.node(i); + if (node.name() == "neg") { + EXPECT_EQ("Neg", node.op()); + EXPECT_EQ(1, node.input_size()); + EXPECT_EQ("reduce_max", node.input(0)); + ++required_node_count; + } else if (node.name() == "reduce_max") { + EXPECT_EQ("Min", node.op()); + EXPECT_EQ(2, node.input_size()); + EXPECT_EQ("x", node.input(0)); + ++required_node_count; + } + } + EXPECT_EQ(2, required_node_count); +} + TEST_F(ArithmeticOptimizerTest, UnaryOpsComposition) { tensorflow::Scope s = tensorflow::Scope::NewRootScope(); diff --git a/tensorflow/core/grappler/optimizers/constant_folding.cc b/tensorflow/core/grappler/optimizers/constant_folding.cc index 815bd23307..99737a71eb 100644 --- a/tensorflow/core/grappler/optimizers/constant_folding.cc +++ b/tensorflow/core/grappler/optimizers/constant_folding.cc @@ -136,6 +136,27 @@ bool MaybeRemoveControlInput(const string& old_input, NodeDef* node, return removed_input; } +bool GetConcatAxis(const GraphProperties& properties, NodeDef* node, + int* axis) { + if (node->op() != "ConcatV2" || + properties.GetInputProperties(node->name()).empty()) { + return false; + } + const auto& axis_input = properties.GetInputProperties(node->name()).back(); + if (!TensorShape::IsValid(axis_input.shape()) || !axis_input.has_value()) { + return false; + } + + Tensor axis_tensor(axis_input.dtype(), axis_input.shape()); + if (!axis_tensor.FromProto(axis_input.value())) { + return false; + } + *axis = axis_input.dtype() == DT_INT64 + ? static_cast<int>(axis_tensor.scalar<int64>()()) + : axis_tensor.scalar<int32>()(); + return true; +} + } // namespace ConstantFolding::ConstantFolding(RewriterConfig::Toggle opt_level, @@ -852,19 +873,7 @@ DataType GetDataTypeFromNodeOrProps(const NodeDef& node, } return dtype; } -bool IsValidConstShapeForNCHW(const TensorShapeProto& shape) { - if (shape.dim_size() != 4) { - return false; - } - int num_dim_larger_than_one = 0; - for (const auto& dim : shape.dim()) { - if (dim.size() > 1) ++num_dim_larger_than_one; - } - return num_dim_larger_than_one <= 1; -} -const string& GetShape(const NodeDef& node) { - return node.attr().at("data_format").s(); -} + } // namespace // static @@ -1711,7 +1720,7 @@ Status ConstantFolding::SimplifyNode(bool use_shape_info, NodeDef* node, return Status::OK(); } - if (MulConvPushDown(*properties, optimized_graph, node)) { + if (MulConvPushDown(node, *properties)) { graph_modified_ = true; return Status::OK(); } @@ -1731,6 +1740,11 @@ Status ConstantFolding::SimplifyNode(bool use_shape_info, NodeDef* node, return Status::OK(); } + if (MergeConcat(*properties, use_shape_info, optimized_graph, node)) { + graph_modified_ = true; + return Status::OK(); + } + return Status::OK(); } @@ -2553,9 +2567,8 @@ bool ConstantFolding::ConstantPushDown(NodeDef* node) { return false; } -bool ConstantFolding::MulConvPushDown(const GraphProperties& properties, - GraphDef* optimized_graph, - NodeDef* node) { +bool ConstantFolding::MulConvPushDown(NodeDef* node, + const GraphProperties& properties) { // Push down multiplication on ConvND. // * ConvND // / \ / \ @@ -2631,14 +2644,12 @@ bool ConstantFolding::MulConvPushDown(const GraphProperties& properties, } const auto& const_shape = const_props[0].shape(); - if (GetShape(*conv_node) == "NHWC") { - TensorShapeProto new_filter_shape; - if (!ShapeAfterBroadcast(filter_shape, const_shape, &new_filter_shape)) { - return false; - } - if (!ShapesSymbolicallyEqual(filter_shape, new_filter_shape)) { - return false; - } + TensorShapeProto new_filter_shape; + if (!ShapeAfterBroadcast(filter_shape, const_shape, &new_filter_shape)) { + return false; + } + if (!ShapesSymbolicallyEqual(filter_shape, new_filter_shape)) { + return false; } string mul_new_name = @@ -2672,69 +2683,6 @@ bool ConstantFolding::MulConvPushDown(const GraphProperties& properties, } node_map_->AddNode(mul_new_name, node); - if (GetShape(*conv_node) == "NCHW") { - if (const_node->attr().at("value").tensor().tensor_shape().dim_size() <= - 1) { - // Broadcast should work for scalar or 1D. No need to reshape. - return true; - } - if (!IsValidConstShapeForNCHW( - const_node->attr().at("value").tensor().tensor_shape())) { - return false; - } - // Adds Const node for Reshape. - auto* shape_const_node = optimized_graph->add_node(); - const string shape_const_node_name = - OptimizedNodeName(*const_node, "_new_shape"); - shape_const_node->set_name(shape_const_node_name); - shape_const_node->set_op("Const"); - shape_const_node->set_device(const_node->device()); - (*shape_const_node->mutable_attr())["dtype"].set_type(DT_INT32); - Tensor t(DT_INT32, {4}); - t.flat<int32>()(0) = 1; - t.flat<int32>()(1) = 1; - t.flat<int32>()(2) = 1; - t.flat<int32>()(3) = const_node->attr() - .at("value") - .tensor() - .tensor_shape() - .dim(1) // IsValidConstShapeForNCHW guarantees - // dim 1 is the dim to reshape - .size(); - t.AsProtoTensorContent( - (*shape_const_node->mutable_attr())["value"].mutable_tensor()); - node_map_->AddNode(shape_const_node_name, shape_const_node); - - // Adds Reshape node. - auto* reshape_node = optimized_graph->add_node(); - const string reshape_node_name = - OptimizedNodeName(*const_node, "_reshape"); - reshape_node->set_op("Reshape"); - reshape_node->set_name(reshape_node_name); - reshape_node->set_device(const_node->device()); - (*reshape_node->mutable_attr())["T"].set_type( - const_node->attr().at("dtype").type()); - (*reshape_node->mutable_attr())["Tshape"].set_type(DT_INT32); - node_map_->AddNode(reshape_node_name, reshape_node); - - // const_node -> reshape_node - node_map_->RemoveOutput(const_node->name(), node->name()); - *reshape_node->add_input() = const_node->name(); - node_map_->AddOutput(const_node->name(), reshape_node_name); - - // shape_const_node -> reshape_node - *reshape_node->add_input() = shape_const_node_name; - node_map_->AddOutput(shape_const_node_name, reshape_node_name); - - // reshape_node -> node (Mul) - node_map_->AddOutput(reshape_node_name, node->name()); - if (left_child_is_constant) { - node->set_input(0, reshape_node_name); - } else { - node->set_input(1, reshape_node_name); - } - } - return true; } return false; @@ -2988,6 +2936,55 @@ bool ConstantFolding::PartialConcatConstFolding(GraphDef* optimized_graph, return false; } +bool ConstantFolding::MergeConcat(const GraphProperties& properties, + bool use_shape_info, + GraphDef* optimized_graph, NodeDef* node) { + // We only optimize for ConcatV2. + int axis; + if (!use_shape_info || !GetConcatAxis(properties, node, &axis) || + nodes_to_preserve_.find(node->name()) != nodes_to_preserve_.end() || + node_map_->GetOutputs(node->name()).size() != 1) { + return false; + } + + NodeDef* parent = *node_map_->GetOutputs(node->name()).begin(); + int parent_axis; + if (!GetConcatAxis(properties, parent, &parent_axis) || axis != parent_axis) { + return false; + } + + const int index = NumNonControlInputs(*node) - 1; + auto inputs = parent->input(); + parent->clear_input(); + for (int i = 0; i < inputs.size(); ++i) { + if (IsSameInput(inputs.Get(i), node->name())) { + for (int j = 0; j < node->input_size(); ++j) { + if (j < index) { + // Input tensors (non axis), add to input list of parent. + parent->add_input(node->input(j)); + node_map_->RemoveOutput(node->input(j), node->name()); + node_map_->AddOutput(node->input(j), parent->name()); + } + // Skip j == index, which means axis tensor. + if (j > index) { + // Control Dependencies, push back to inputs so they can be forwarded + // to parent. + *inputs.Add() = node->input(j); + } + } + } else { + parent->add_input(inputs.Get(i)); + } + } + node->clear_input(); + node->set_op("NoOp"); + node->clear_attr(); + node_map_->RemoveNode(node->name()); + (*parent->mutable_attr())["N"].set_i(NumNonControlInputs(*parent) - 1); + + return true; +} + Status ConstantFolding::RunOptimizationPass(Cluster* cluster, const GrapplerItem& item, GraphDef* optimized_graph) { diff --git a/tensorflow/core/grappler/optimizers/constant_folding.h b/tensorflow/core/grappler/optimizers/constant_folding.h index 051dfb681e..8593b3e0b8 100644 --- a/tensorflow/core/grappler/optimizers/constant_folding.h +++ b/tensorflow/core/grappler/optimizers/constant_folding.h @@ -125,8 +125,7 @@ class ConstantFolding : public GraphOptimizer { // Aggregate constants present around a conv operator. Returns true if the // transformation was applied successfully. - bool MulConvPushDown(const GraphProperties& properties, - GraphDef* optimized_graph, NodeDef* node); + bool MulConvPushDown(NodeDef* node, const GraphProperties& properties); // Strength reduces floating point division by a constant Div(x, const) to // multiplication by the reciprocal Mul(x, Reciprocal(const)). @@ -210,6 +209,10 @@ class ConstantFolding : public GraphOptimizer { // Removes Split or SplitV node if possible. bool RemoveSplitOrSplitV(const GraphProperties& properties, GraphDef* optimized_graph, NodeDef* node); + + bool MergeConcat(const GraphProperties& properties, bool use_shape_info, + GraphDef* optimized_graph, NodeDef* node); + // Points to an externally provided device or to owned_device_; RewriterConfig::Toggle opt_level_; DeviceBase* cpu_device_; diff --git a/tensorflow/core/grappler/optimizers/constant_folding_test.cc b/tensorflow/core/grappler/optimizers/constant_folding_test.cc index 0683572dcc..2a19b3f95a 100644 --- a/tensorflow/core/grappler/optimizers/constant_folding_test.cc +++ b/tensorflow/core/grappler/optimizers/constant_folding_test.cc @@ -240,7 +240,7 @@ TEST_F(ConstantFoldingTest, AddTree) { } } -TEST_F(ConstantFoldingTest, ConvPushDownTestNHWC) { +TEST_F(ConstantFoldingTest, ConvPushDownTest) { // Tests if the following rewrite is performed: // // * Conv2D @@ -2030,6 +2030,130 @@ TEST_F(ConstantFoldingTest, TileWithMultipliesBeingOne) { CompareGraphs(want, got); } +TEST_F(ConstantFoldingTest, MergeConcat) { + tensorflow::Scope scope = tensorflow::Scope::NewRootScope(); + + Output in1 = ops::Variable(scope.WithOpName("in1"), {4, 6}, DT_FLOAT); + Output in2 = ops::Variable(scope.WithOpName("in2"), {4, 6}, DT_FLOAT); + Output in3 = ops::Variable(scope.WithOpName("in3"), {4, 6}, DT_FLOAT); + Output axis = ops::Const(scope.WithOpName("axis"), 0, {}); + + ops::Concat c1(scope.WithOpName("c1"), {in1, in2}, axis); + ops::Concat c2(scope.WithOpName("c2"), {Output(c1), in3}, axis); + + GrapplerItem item; + item.fetch = {"c2"}; + TF_CHECK_OK(scope.ToGraphDef(&item.graph)); + + ConstantFolding optimizer(nullptr /* cpu_device */); + GraphDef got; + Status status = optimizer.Optimize(nullptr, item, &got); + TF_EXPECT_OK(status); + + GraphDef want; + AddNode("in1", "VariableV2", {}, {}, &want); + AddNode("in2", "VariableV2", {}, {}, &want); + AddNode("in3", "VariableV2", {}, {}, &want); + AddNode("axis", "Const", {}, {}, &want); + AddNode("c2", "ConcatV2", {"in1", "in2", "in3", "axis"}, {}, &want); + + CompareGraphs(want, got); +} + +TEST_F(ConstantFoldingTest, MergeConcat_SameInput) { + tensorflow::Scope scope = tensorflow::Scope::NewRootScope(); + + Output in1 = ops::Variable(scope.WithOpName("in1"), {4, 6}, DT_FLOAT); + Output in2 = ops::Variable(scope.WithOpName("in2"), {4, 6}, DT_FLOAT); + Output in3 = ops::Variable(scope.WithOpName("in3"), {4, 6}, DT_FLOAT); + Output axis = ops::Const(scope.WithOpName("axis"), 0, {}); + + ops::Concat c1(scope.WithOpName("c1"), {in1, in2}, axis); + ops::Concat c2(scope.WithOpName("c2"), {Output(c1), in3, Output(c1)}, axis); + + GrapplerItem item; + item.fetch = {"c2"}; + TF_CHECK_OK(scope.ToGraphDef(&item.graph)); + + ConstantFolding optimizer(nullptr /* cpu_device */); + GraphDef got; + Status status = optimizer.Optimize(nullptr, item, &got); + TF_EXPECT_OK(status); + + GraphDef want; + AddNode("in1", "VariableV2", {}, {}, &want); + AddNode("in2", "VariableV2", {}, {}, &want); + AddNode("in3", "VariableV2", {}, {}, &want); + AddNode("axis", "Const", {}, {}, &want); + AddNode("c2", "ConcatV2", {"in1", "in2", "in3", "in1", "in2", "axis"}, {}, + &want); + + CompareGraphs(want, got); +} + +TEST_F(ConstantFoldingTest, MergeConcat_ConcatWithConst) { + tensorflow::Scope scope = tensorflow::Scope::NewRootScope(); + + Output in1 = ops::Variable(scope.WithOpName("in1"), {2, 6}, DT_FLOAT); + Output in2 = ops::Variable(scope.WithOpName("in2"), {}, DT_FLOAT); + Output in3 = ops::Variable(scope.WithOpName("in3"), {4, 6}, DT_FLOAT); + Output axis = ops::Const(scope.WithOpName("axis"), 0, {}); + + ops::Concat c1(scope.WithOpName("c1"), {in1, in2}, axis); + ops::Concat c2(scope.WithOpName("c2"), {Output(c1), in3}, axis); + + GrapplerItem item; + item.fetch = {"c2"}; + TF_CHECK_OK(scope.ToGraphDef(&item.graph)); + + ConstantFolding optimizer(nullptr /* cpu_device */); + GraphDef got; + Status status = optimizer.Optimize(nullptr, item, &got); + TF_EXPECT_OK(status); + + GraphDef want; + AddNode("in1", "VariableV2", {}, {}, &want); + AddNode("in2", "VariableV2", {}, {}, &want); + AddNode("in3", "VariableV2", {}, {}, &want); + AddNode("axis", "Const", {}, {}, &want); + AddNode("c2", "ConcatV2", {"in1", "in2", "in3", "axis"}, {}, &want); + + CompareGraphs(want, got); +} + +TEST_F(ConstantFoldingTest, MergeConcat_AxisMismatch) { + tensorflow::Scope scope = tensorflow::Scope::NewRootScope(); + + Output in1 = ops::Variable(scope.WithOpName("in1"), {2, 5}, DT_FLOAT); + Output in2 = ops::Variable(scope.WithOpName("in2"), {}, DT_FLOAT); + Output in3 = ops::Variable(scope.WithOpName("in3"), {4, 6}, DT_FLOAT); + Output axis1 = ops::Const(scope.WithOpName("axis1"), 0, {}); + Output axis2 = ops::Const(scope.WithOpName("axis2"), 1, {}); + + ops::Concat c1(scope.WithOpName("c1"), {in1, in2}, axis2); + ops::Concat c2(scope.WithOpName("c2"), {Output(c1), in3}, axis1); + + GrapplerItem item; + item.fetch = {"c2"}; + TF_CHECK_OK(scope.ToGraphDef(&item.graph)); + + ConstantFolding optimizer(nullptr /* cpu_device */); + GraphDef got; + Status status = optimizer.Optimize(nullptr, item, &got); + TF_EXPECT_OK(status); + + GraphDef want; + AddNode("in1", "VariableV2", {}, {}, &want); + AddNode("in2", "VariableV2", {}, {}, &want); + AddNode("in3", "VariableV2", {}, {}, &want); + AddNode("axis1", "Const", {}, {}, &want); + AddNode("axis2", "Const", {}, {}, &want); + AddNode("c1", "ConcatV2", {"in1", "in2", "axis2"}, {}, &want); + AddNode("c2", "ConcatV2", {"c1", "in3", "axis1"}, {}, &want); + + CompareGraphs(want, got); +} + TEST_F(ConstantFoldingTest, PaddingWithZeroSize) { tensorflow::Scope scope = tensorflow::Scope::NewRootScope(); @@ -3080,110 +3204,6 @@ TEST_F(ConstantFoldingTest, FoldingPreservesDenormalFlushing) { test::ExpectTensorEqual<float>(tensors_expected[0], tensors[0]); } -#if GOOGLE_CUDA -TEST_F(ConstantFoldingTest, ConvPushDownTestNCHW) { - // Tests if the following rewrite is performed: - // - // * Conv2D - // / \ / \ - // c Conv2D --> x (c * filter) - // / \ - // x filter - tensorflow::Scope s = tensorflow::Scope::NewRootScope(); - - int input_channel = 1; - int output_channel = 2; - int filter_size = 1; - - TensorShape filter_shape( - {filter_size, filter_size, input_channel, output_channel}); - - // Filter shape: [1, 1, 1, 2] - // Filter for output channel 0 = {2.f} - // Filter for output channel 1 = {-2.f} - // clang-format off - Output filter = - ops::Const(s.WithOpName("filter"), { - { - {{2.f, -2.f}} - } - }); - // clang-format on - - int batch_size = 1; - int matrix_size = 3; - // input shape: [1,1,3,3] - TensorShape input_shape( - {batch_size, input_channel, matrix_size, matrix_size}); - Output input = ops::Placeholder(s.WithOpName("x"), DT_FLOAT, - ops::Placeholder::Shape(input_shape)); - - Output conv = ops::Conv2D(s.WithOpName("conv"), input, filter, {1, 1, 1, 1}, - "VALID", ops::Conv2D::DataFormat("NCHW")); - Output c = ops::Const(s.WithOpName("c"), 2.0f, /* shape */ {1, 2, 1, 1}); - Output mul = ops::Mul(s.WithOpName("mul"), c, conv); - - GrapplerItem item; - TF_CHECK_OK(s.ToGraphDef(&item.graph)); - - ConstantFolding fold(nullptr); - GraphDef output; - Status status = fold.Optimize(nullptr, item, &output); - TF_EXPECT_OK(status); - - // Here only op/IO are checked. The values are verified by EvaluateNodes - // below. - int found = 0; - for (const auto& node : output.node()) { - if (node.name() == "mul") { - ++found; - EXPECT_EQ("Conv2D", node.op()); - EXPECT_EQ(2, node.input_size()); - EXPECT_EQ("x", node.input(0)); - EXPECT_EQ("conv/merged_input", node.input(1)); - } else if (node.name() == "conv/merged_input") { - ++found; - EXPECT_EQ("Const", node.op()); - EXPECT_EQ(0, node.input_size()); - } - } - EXPECT_EQ(2, found); - - // Check that const folded multiplication node has the expected value. - std::vector<string> fetch = {"mul"}; - // Input shape (NCHW) is [1,1,3,3], filter is [1,1,1,2] output shape should be - // (NCHW) [1,2,3,3] - ::tensorflow::Input::Initializer x{ - { - { - {1.f, 2.f, 3.f}, // H = 0 - {4.f, 5.f, 6.f}, // H = 1 - {7.f, 8.f, 9.f} // H = 2 - } // C = 0 - } // N = 0 - }; - - // |1,2,3| - // conv( |4,5,6|, // input - // |7,8,9| - // [[[2,-2]]]) // filter - // * [1,2,1,1] // mul by const - // = - // [ - // |4, 8, 12| - // |16,20,24| ==> output channel 0 - // |28,32,36| - // - // | -4, -8,-12| - // |-16,-20,-24| ==> output channel 1 - // |-28,-32,-36| - // ] - auto actual = EvaluateNodes(output, fetch, {{"x", x.tensor}}); - auto expected = EvaluateNodes(item.graph, fetch, {{"x", x.tensor}}); - test::ExpectTensorEqual<float>(expected[0], actual[0]); -} -#endif - } // namespace } // namespace grappler } // namespace tensorflow diff --git a/tensorflow/core/grappler/optimizers/memory_optimizer.cc b/tensorflow/core/grappler/optimizers/memory_optimizer.cc index 91794cefe5..c775a26914 100644 --- a/tensorflow/core/grappler/optimizers/memory_optimizer.cc +++ b/tensorflow/core/grappler/optimizers/memory_optimizer.cc @@ -1071,11 +1071,13 @@ static bool IdentifySwappingCandidates( // ensure that swapping the tensor back in won't recreate the memory // bottleneck. Last but not least, we want the tensor to have as few // remaining uses as possible. + // + // Note that we must perform the arithmetic inexactly as "double", since + // the values do not fit into any integral type. mem_info.fitness = - MathUtil::IPow((earliest_use - peak_time).count(), 2); - mem_info.fitness /= MathUtil::IPow(mem_info.uses_left.size(), 2); - mem_info.fitness += - MathUtil::IPow((allocation_time - peak_time).count(), 2); + MathUtil::IPow<double>((earliest_use - peak_time).count(), 2) / + MathUtil::IPow<double>(mem_info.uses_left.size(), 2) + + MathUtil::IPow<double>((allocation_time - peak_time).count(), 2); mem_info.fitness = -mem_info.fitness; mem_state.push_back(mem_info); } diff --git a/tensorflow/core/grappler/utils/functions.cc b/tensorflow/core/grappler/utils/functions.cc index a2c363ea6e..a428aea7f5 100644 --- a/tensorflow/core/grappler/utils/functions.cc +++ b/tensorflow/core/grappler/utils/functions.cc @@ -304,21 +304,21 @@ Status GrapplerFunctionItemInstantiation::GetArgType( } GrapplerFunctionItem::GrapplerFunctionItem( - const string& func_name, const string& description, - const AttrValueMap& func_attr, - const std::vector<InputArgExpansion>& input_arg_expansions, - const std::vector<OutputArgExpansion>& output_arg_expansions, - const std::vector<string>& keep_nodes, const int graph_def_version, - bool is_stateful, GraphDef&& function_body) - : description_(description), - func_attr_(func_attr), - input_arg_expansions_(input_arg_expansions), - output_arg_expansions_(output_arg_expansions), + string func_name, string description, AttrValueMap func_attr, + std::vector<InputArgExpansion> input_arg_expansions, + std::vector<OutputArgExpansion> output_arg_expansions, + std::vector<string> keep_nodes, const int graph_def_version, + const bool is_stateful, GraphDef&& function_body) + : description_(std::move(description)), + func_attr_(std::move(func_attr)), + input_arg_expansions_(std::move(input_arg_expansions)), + output_arg_expansions_(std::move(output_arg_expansions)), is_stateful_(is_stateful) { - id = func_name; - keep_ops = keep_nodes; - // Swap the graph body. - graph.Swap(&function_body); + // Move assign GrapplerItem members. + keep_ops = std::move(keep_nodes); + id = std::move(func_name); + graph = std::move(function_body); + graph.mutable_versions()->set_producer(graph_def_version); // Fill the feed nodes with input placeholders. for (const InputArgExpansion& input_arg : input_arg_expansions_) { @@ -598,8 +598,8 @@ Status MakeGrapplerFunctionItem(const FunctionDef& func, *item = GrapplerFunctionItem( /*func_name=*/signature.name(), /*description=*/signature.description(), /*func_attr=*/AttrValueMap(func.attr().begin(), func.attr().end()), - inputs, outputs, keep_nodes, graph_def_version, is_stateful, - std::move(function_body)); + std::move(inputs), std::move(outputs), std::move(keep_nodes), + graph_def_version, is_stateful, std::move(function_body)); return Status::OK(); } diff --git a/tensorflow/core/grappler/utils/functions.h b/tensorflow/core/grappler/utils/functions.h index 61588ceb83..733caf325f 100644 --- a/tensorflow/core/grappler/utils/functions.h +++ b/tensorflow/core/grappler/utils/functions.h @@ -136,13 +136,12 @@ class GrapplerFunctionItemInstantiation { class GrapplerFunctionItem : public GrapplerItem { public: GrapplerFunctionItem() = default; - GrapplerFunctionItem( - const string& func_name, const string& description, - const AttrValueMap& func_attr, - const std::vector<InputArgExpansion>& input_arg_expansions, - const std::vector<OutputArgExpansion>& output_arg_expansions, - const std::vector<string>& keep_nodes, const int versions, - bool is_stateful, GraphDef&& function_body); + GrapplerFunctionItem(string func_name, string description, + AttrValueMap func_attr, + std::vector<InputArgExpansion> input_arg_expansions, + std::vector<OutputArgExpansion> output_arg_expansions, + std::vector<string> keep_nodes, int graph_def_version, + bool is_stateful, GraphDef&& function_body); const string& description() const; diff --git a/tensorflow/core/kernels/BUILD b/tensorflow/core/kernels/BUILD index 633fe9ab77..25063ac823 100644 --- a/tensorflow/core/kernels/BUILD +++ b/tensorflow/core/kernels/BUILD @@ -2296,6 +2296,31 @@ tf_cc_tests( ], ) +cc_library( + name = "eigen_benchmark", + testonly = 1, + hdrs = [ + "eigen_benchmark.h", + ":eigen_helpers", + ], + deps = [ + "//tensorflow/core:framework", + "//third_party/eigen3", + ], +) + +tf_cc_test( + name = "eigen_benchmark_cpu_test", + srcs = ["eigen_benchmark_cpu_test.cc"], + deps = [ + ":eigen_benchmark", + ":eigen_helpers", + "//tensorflow/core:test", + "//tensorflow/core:test_main", + "//third_party/eigen3", + ], +) + tf_cc_tests( name = "basic_ops_benchmark_test", size = "small", @@ -4196,6 +4221,7 @@ cc_library( "hinge-loss.h", "logistic-loss.h", "loss.h", + "poisson-loss.h", "smooth-hinge-loss.h", "squared-loss.h", ], diff --git a/tensorflow/core/kernels/data/BUILD b/tensorflow/core/kernels/data/BUILD index 8d867455e7..3a1ac73f64 100644 --- a/tensorflow/core/kernels/data/BUILD +++ b/tensorflow/core/kernels/data/BUILD @@ -51,6 +51,7 @@ cc_library( hdrs = ["captured_function.h"], deps = [ ":dataset", + ":single_threaded_executor", "//tensorflow/core:core_cpu_internal", "//tensorflow/core:framework", "//tensorflow/core:lib", @@ -61,6 +62,42 @@ cc_library( ) cc_library( + name = "single_threaded_executor", + srcs = ["single_threaded_executor.cc"], + hdrs = ["single_threaded_executor.h"], + deps = [ + "//tensorflow/core:core_cpu", + "//tensorflow/core:core_cpu_internal", + "//tensorflow/core:lib", + ], + alwayslink = 1, +) + +tf_cc_test( + name = "single_threaded_executor_test", + srcs = ["single_threaded_executor_test.cc"], + deps = [ + ":single_threaded_executor", + "//tensorflow/core:core_cpu", + "//tensorflow/core:core_cpu_internal", + "//tensorflow/core:framework", + "//tensorflow/core:framework_internal", + "//tensorflow/core:lib", + "//tensorflow/core:lib_internal", + "//tensorflow/core:protos_all_cc", + "//tensorflow/core:test", + "//tensorflow/core:test_main", + "//tensorflow/core:testlib", + "//tensorflow/core/kernels:array", + "//tensorflow/core/kernels:control_flow_ops", + "//tensorflow/core/kernels:function_ops", + "//tensorflow/core/kernels:math", + "//tensorflow/core/kernels:random_ops", + "//tensorflow/core/kernels:state", + ], +) + +cc_library( name = "window_dataset", srcs = ["window_dataset.cc"], hdrs = ["window_dataset.h"], @@ -481,8 +518,7 @@ tf_kernel_library( ":dataset", "//tensorflow/core:dataset_ops_op_lib", "//tensorflow/core:framework", - "//tensorflow/core:lib", - "//tensorflow/core:lib_internal", + "//tensorflow/core:graph", ], ) @@ -505,8 +541,7 @@ tf_kernel_library( ":dataset", "//tensorflow/core:dataset_ops_op_lib", "//tensorflow/core:framework", - "//tensorflow/core:lib", - "//tensorflow/core:lib_internal", + "//tensorflow/core:graph", ], ) diff --git a/tensorflow/core/kernels/data/captured_function.cc b/tensorflow/core/kernels/data/captured_function.cc index abdf6ee4e8..186740c2ac 100644 --- a/tensorflow/core/kernels/data/captured_function.cc +++ b/tensorflow/core/kernels/data/captured_function.cc @@ -28,7 +28,16 @@ namespace tensorflow { Status CapturedFunction::Create( const NameAttrList& func, std::vector<Tensor> captured_inputs, std::unique_ptr<CapturedFunction>* out_function) { - out_function->reset(new CapturedFunction(func, std::move(captured_inputs))); + return Create(func, std::move(captured_inputs), true, out_function); +} + +/* static */ +Status CapturedFunction::Create( + const NameAttrList& func, std::vector<Tensor> captured_inputs, + bool use_inter_op_parallelism, + std::unique_ptr<CapturedFunction>* out_function) { + out_function->reset(new CapturedFunction(func, std::move(captured_inputs), + use_inter_op_parallelism)); return Status::OK(); } @@ -272,6 +281,9 @@ Status CapturedFunction::Instantiate(IteratorContext* ctx) { inst_opts.overlay_lib = ctx->function_library().get(); inst_opts.state_handle = std::to_string(random::New64()); inst_opts.create_kernels_eagerly = true; + if (!use_inter_op_parallelism_) { + inst_opts.executor_type = "SINGLE_THREADED_EXECUTOR"; + } Status s = (lib_->Instantiate(func_.name(), AttrSlice(&func_.attr()), inst_opts, &f_handle_)); TF_RETURN_IF_ERROR(s); @@ -398,10 +410,12 @@ void CapturedFunction::RunAsync(IteratorContext* ctx, } CapturedFunction::CapturedFunction(const NameAttrList& func, - std::vector<Tensor> captured_inputs) + std::vector<Tensor> captured_inputs, + bool use_inter_op_parallelism) : func_(func), lib_(nullptr), f_handle_(kInvalidHandle), - captured_inputs_(std::move(captured_inputs)) {} + captured_inputs_(std::move(captured_inputs)), + use_inter_op_parallelism_(use_inter_op_parallelism) {} } // namespace tensorflow diff --git a/tensorflow/core/kernels/data/captured_function.h b/tensorflow/core/kernels/data/captured_function.h index c95f2b1c01..9526da22d1 100644 --- a/tensorflow/core/kernels/data/captured_function.h +++ b/tensorflow/core/kernels/data/captured_function.h @@ -48,6 +48,15 @@ class CapturedFunction { std::vector<Tensor> captured_inputs, std::unique_ptr<CapturedFunction>* out_function); + // Creates a new instance from a list of named attributes and captured inputs. + // + // If `use_inter_op_parallelism` is false, the runtime may use an executor + // that is optimized for small functions. + static Status Create(const NameAttrList& func, + std::vector<Tensor> captured_inputs, + bool use_inter_op_parallelism, + std::unique_ptr<CapturedFunction>* out_function); + // Creates a new instance using a list of named attributes, fetching captured // inputs from a context argument. static Status Create(const NameAttrList& func, OpKernelContext* ctx, @@ -114,7 +123,8 @@ class CapturedFunction { private: CapturedFunction(const NameAttrList& func, - std::vector<Tensor> captured_inputs); + std::vector<Tensor> captured_inputs, + bool use_inter_op_parallelism); Status GetHandle(IteratorContext* ctx, FunctionLibraryRuntime::Handle* out_handle); @@ -126,6 +136,7 @@ class CapturedFunction { const std::vector<Tensor> captured_inputs_; DataTypeSlice ret_types_; std::function<void(std::function<void()>)> captured_runner_ = nullptr; + const bool use_inter_op_parallelism_; TF_DISALLOW_COPY_AND_ASSIGN(CapturedFunction); }; diff --git a/tensorflow/core/kernels/data/map_dataset_op.cc b/tensorflow/core/kernels/data/map_dataset_op.cc index 7f8182d917..6c45fcafcc 100644 --- a/tensorflow/core/kernels/data/map_dataset_op.cc +++ b/tensorflow/core/kernels/data/map_dataset_op.cc @@ -34,6 +34,8 @@ class MapDatasetOp : public UnaryDatasetOpKernel { OP_REQUIRES_OK(ctx, ctx->GetAttr("f", &func_)); OP_REQUIRES_OK(ctx, ctx->GetAttr("output_types", &output_types_)); OP_REQUIRES_OK(ctx, ctx->GetAttr("output_shapes", &output_shapes_)); + OP_REQUIRES_OK(ctx, ctx->GetAttr("use_inter_op_parallelism", + &use_inter_op_parallelism_)); } void MakeDataset(OpKernelContext* ctx, DatasetBase* input, @@ -48,7 +50,8 @@ class MapDatasetOp : public UnaryDatasetOpKernel { std::unique_ptr<CapturedFunction> captured_func; OP_REQUIRES_OK(ctx, CapturedFunction::Create( - func_, std::move(other_arguments), &captured_func)); + func_, std::move(other_arguments), + use_inter_op_parallelism_, &captured_func)); *output = new Dataset(ctx, input, func_, std::move(captured_func), output_types_, output_shapes_); @@ -187,6 +190,7 @@ class MapDatasetOp : public UnaryDatasetOpKernel { DataTypeVector output_types_; std::vector<PartialTensorShape> output_shapes_; NameAttrList func_; + bool use_inter_op_parallelism_; }; REGISTER_KERNEL_BUILDER(Name("MapDataset").Device(DEVICE_CPU), MapDatasetOp); diff --git a/tensorflow/core/kernels/data/optimize_dataset_op.cc b/tensorflow/core/kernels/data/optimize_dataset_op.cc index 831e7252da..6263dc3cf8 100644 --- a/tensorflow/core/kernels/data/optimize_dataset_op.cc +++ b/tensorflow/core/kernels/data/optimize_dataset_op.cc @@ -92,8 +92,10 @@ class OptimizeDatasetOp : public UnaryDatasetOpKernel { DatasetGraphDefBuilder db(&b); Node* input_node = nullptr; SerializationContext::Params params; + std::vector<std::pair<string, Tensor>> input_list; params.allow_stateful_functions = true; params.flib_def = ctx->function_library()->GetFunctionLibraryDefinition(); + params.input_list = &input_list; SerializationContext serialization_ctx(params); TF_RETURN_IF_ERROR( db.AddInputDataset(&serialization_ctx, input_, &input_node)); @@ -118,7 +120,7 @@ class OptimizeDatasetOp : public UnaryDatasetOpKernel { GraphRunner graph_runner(ctx->function_library()->device()); TF_RETURN_IF_ERROR( - graph_runner.Run(&graph, lib_, {}, {output_node}, &outputs)); + graph_runner.Run(&graph, lib_, input_list, {output_node}, &outputs)); TF_RETURN_IF_ERROR( GetDatasetFromVariantTensor(outputs[0], &optimized_input_)); optimized_input_->Ref(); diff --git a/tensorflow/core/kernels/data/single_threaded_executor.cc b/tensorflow/core/kernels/data/single_threaded_executor.cc new file mode 100644 index 0000000000..e785b8b4d5 --- /dev/null +++ b/tensorflow/core/kernels/data/single_threaded_executor.cc @@ -0,0 +1,378 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/core/kernels/data/single_threaded_executor.h" + +#include "tensorflow/core/common_runtime/executor.h" +#include "tensorflow/core/common_runtime/executor_factory.h" +#include "tensorflow/core/graph/algorithm.h" +#include "tensorflow/core/lib/core/errors.h" +#include "tensorflow/core/lib/core/status.h" + +namespace tensorflow { +namespace { + +typedef gtl::InlinedVector<TensorValue, 4> TensorValueVec; +typedef gtl::InlinedVector<DeviceContext*, 4> DeviceContextVec; +typedef gtl::InlinedVector<AllocatorAttributes, 4> AllocatorAttributeVec; + +class SingleThreadedExecutorImpl : public Executor { + public: + explicit SingleThreadedExecutorImpl(const LocalExecutorParams& params) + : params_(params) {} + + ~SingleThreadedExecutorImpl() override { + for (const KernelState& kernel_state : kernels_) { + params_.delete_kernel(kernel_state.kernel); + } + } + + Status Initialize(const Graph& graph) { + // Topologicially sort `graph` to get a sequence of OpKernels. + std::vector<Node*> ordered_nodes; + ordered_nodes.reserve(graph.num_nodes()); + GetReversePostOrder(graph, &ordered_nodes); + + if (ordered_nodes.size() != graph.num_nodes()) { + return errors::InvalidArgument("Graph had ", graph.num_nodes(), + " but reverse post-order had ", + ordered_nodes.size()); + } + + kernels_.resize(ordered_nodes.size()); + + std::unordered_map<Node*, size_t> node_to_index_map; + + // Create the kernel and input-related structures for each node in `graph`. + for (size_t i = 0; i < ordered_nodes.size(); ++i) { + Node* n = ordered_nodes[i]; + node_to_index_map[n] = i; + + for (DataType dt : n->output_types()) { + if (IsRefType(dt)) { + return errors::Unimplemented( + "Single-threaded executor does not support reference-typed " + "edges."); + } + } + + if (n->IsControlFlow()) { + return errors::Unimplemented( + "Single-threaded executor does not support control flow."); + } + if (n->IsSend() || n->IsHostSend() || n->IsRecv() || n->IsHostRecv()) { + return errors::Unimplemented( + "Single-threaded executor does not support partitioned graphs."); + } + if (n->IsCollective()) { + return errors::Unimplemented( + "Single-threaded executor does not support collective ops."); + } + + KernelState& kernel_state = kernels_[i]; + TF_RETURN_IF_ERROR(params_.create_kernel(n->def(), &kernel_state.kernel)); + kernel_state.num_inputs = n->num_inputs(); + kernel_state.num_outputs = n->num_outputs(); + + if (i == 0) { + kernel_state.input_start_index = 0; + } else { + const KernelState& previous_kernel_state = kernels_[i - 1]; + kernel_state.input_start_index = + previous_kernel_state.input_start_index + + previous_kernel_state.num_inputs; + } + } + + // Build the mapping from each node output to the input slot for the + // corresponding destination node. + for (size_t i = 0; i < ordered_nodes.size(); ++i) { + Node* n = ordered_nodes[i]; + KernelState& kernel_state = kernels_[i]; + kernel_state.output_locations.resize(kernel_state.num_outputs); + for (const Edge* e : n->out_edges()) { + if (!e->IsControlEdge()) { + kernel_state.output_locations[e->src_output()].push_back( + kernels_[node_to_index_map[e->dst()]].input_start_index + + e->dst_input()); + } + } + + // Compute allocator attributes for each node output, and corresponding + // node input. + kernel_state.output_alloc_attrs.resize(kernel_state.num_outputs); + AllocatorAttributes* attrs = kernel_state.output_alloc_attrs.data(); + + OpKernel* op_kernel = kernel_state.kernel; + for (int out = 0; out < n->num_outputs(); out++) { + DCHECK_LT(out, op_kernel->output_memory_types().size()); + bool on_host = op_kernel->output_memory_types()[out] == HOST_MEMORY; + if (on_host) { + AllocatorAttributes h; + h.set_on_host(on_host); + attrs[out].Merge(h); + } + } + } + + if (!kernels_.empty()) { + const KernelState& last_kernel_state = kernels_.back(); + total_num_inputs_ = + last_kernel_state.input_start_index + last_kernel_state.num_inputs; + input_alloc_attrs_.resize(total_num_inputs_); + for (size_t i = 0; i < ordered_nodes.size(); ++i) { + for (size_t j = 0; j < kernels_[i].output_locations.size(); ++j) { + for (size_t output_location : kernels_[i].output_locations[j]) { + input_alloc_attrs_[output_location] = + kernels_[i].output_alloc_attrs[j]; + } + } + } + } else { + total_num_inputs_ = 0; + } + return Status::OK(); + } + + // TODO(mrry): Consider specializing the implementation of Executor::Run() + // instead, to avoid unnecessary atomic operations in the callback when + // running synchronously. + void RunAsync(const Args& args, DoneCallback done) override { + // The inputs to each kernel are stored contiguously in `inputs`. + // + // We use `kernels_[i].input_start_index` and `kernels_[i].num_inputs` to + // determine the range of elements in this vector that correspond to + // the inputs of `kernels_[i]`. + // + // This vector has the following layout: + // + // * Kernel 0, input 0. + // * Kernel 0, input 1. + // * ... + // * Kernel 0, input `kernels_[0].num_inputs - 1`. + // * Kernel 1, input 0. + // * ... + // * Kernel 1, input `kernels_[1].num_inputs - 1`. + // * ... + // * Kernel `kernels_.size() - 1`, input 0. + // * ... + // * Kernel `kernels_.size() - 1`, input `kernels_.back().num_inputs - 1`. + // + // Note that kernels with zero inputs do not correspond to any elements in + // this vector. + // + // We use `ManualConstructor<Tensor>` to avoid the overhead of + // default-constructing an invalid `Tensor` for each slot at the beginning + // of execution: + // * Elements are initialized when the outputs of a kernel execution are + // propagated to the inputs of kernels that depend on them. + // * The elements corresponding to the inputs for kernel `i` are destroyed + // after kernel `i` executes. + // * In an error case (see below), we use the connectivity information in + // `KernelState::output_locations` to determine which locations have been + // initialized, and manually destroy them. + std::vector<ManualConstructor<Tensor>> inputs(total_num_inputs_); + + // TODO(mrry): Can we avoid copying into these vectors? Consider modifying + // OpKernelContext to take the TensorValueVec as a pointer into `inputs`. + TensorValueVec node_inputs; + DeviceContextVec input_device_contexts; + AllocatorAttributeVec input_alloc_attrs; + + // Prepare the parameters that will be the same for all kernels. + OpKernelContext::Params params; + params.step_id = args.step_id; + Device* device = params_.device; + params.device = device; + params.log_memory = false; // TODO(mrry): Too severe? + params.record_tensor_accesses = false; // TODO(mrry): Too severe? + params.rendezvous = args.rendezvous; + params.session_state = args.session_state; + params.tensor_store = args.tensor_store; + params.cancellation_manager = args.cancellation_manager; + // TODO(mrry): ArgOp is a relatively expensive OpKernel due to the Tensor + // allocations that it performs. Consider specializing its handling in the + // executor. + params.call_frame = args.call_frame; + params.function_library = params_.function_library; + params.resource_manager = device->resource_manager(); + params.step_container = args.step_container; + params.slice_reader_cache = nullptr; // TODO(mrry): Too severe? + params.inputs = &node_inputs; + params.input_device_contexts = &input_device_contexts; + params.input_alloc_attrs = &input_alloc_attrs; + + Args::Runner runner_copy = args.runner; + params.runner = &runner_copy; + params.stats_collector = args.stats_collector; + + // NOTE(mrry): We are assuming that the graph is loopless and condless. + params.frame_iter = FrameAndIter(0, 0); + params.is_input_dead = false; + + // TODO(mrry): Add non-default device context inference. + params.op_device_context = nullptr; + // TODO(mrry): Consider implementing forwarding. + params.forward_from_array = nullptr; + + // Execute the kernels one-at-a-time in topological order. + for (size_t i = 0; i < kernels_.size(); ++i) { + const KernelState& kernel_state = kernels_[i]; + + // Prepare the per-kernel parameters. + const size_t input_start_index = kernel_state.input_start_index; + const size_t num_inputs = kernel_state.num_inputs; + const size_t num_outputs = kernel_state.num_outputs; + + node_inputs.clear(); + node_inputs.resize(num_inputs); + input_alloc_attrs.clear(); + input_alloc_attrs.resize(num_inputs); + for (size_t j = 0; j < num_inputs; ++j) { + auto t = inputs[input_start_index + j].get(); + node_inputs[j].tensor = t; + input_alloc_attrs[j] = input_alloc_attrs_[input_start_index + j]; + } + params.op_kernel = kernel_state.kernel; + input_device_contexts.clear(); + input_device_contexts.resize(num_inputs); + params.output_attr_array = kernel_state.output_alloc_attrs.data(); + OpKernelContext ctx(¶ms, num_outputs); + + // Actually execute the kernel. + device->Compute(kernel_state.kernel, &ctx); + + if (!ctx.status().ok()) { + // On failure, we must manually free all intermediate tensors. We have + // already freed all the inputs for kernels up to (but not including) + // the `i`th kernel. We scan through the previously executed kernels and + // destroy any tensors that were destined to be the input for a kernel + // that has not yet executed. + for (size_t j = 0; j < i; ++j) { + const KernelState& executed_kernel_state = kernels_[j]; + for (size_t k = 0; k < executed_kernel_state.num_outputs; ++k) { + for (size_t output_location : + executed_kernel_state.output_locations[k]) { + if (output_location >= input_start_index) { + // Only destroy an output location if it is an input to an + // operation that has not yet executed. + inputs[output_location].Destroy(); + } + } + } + } + done(ctx.status()); + return; + } + + // Free the inputs to the current kernel. + for (size_t j = 0; j < num_inputs; ++j) { + inputs[input_start_index + j].Destroy(); + } + + // Forward the outputs of the kernel to the inputs of subsequent kernels. + for (size_t j = 0; j < num_outputs; ++j) { + TensorValue val = ctx.release_output(j); + // TODO(mrry): Consider flattening the `output_locations` vector + // to improve the cache-friendliness of this loop. + for (size_t output_location : kernel_state.output_locations[j]) { + // TODO(mrry): Validate that the types match the expected values or + // ensure that the necessary validation has already happened. + inputs[output_location].Init(*val.tensor); + } + delete val.tensor; + } + } + done(Status::OK()); + } + + private: + const LocalExecutorParams params_; + + // All following members are read-only after Initialize(). + + // The sum of the number of inputs for each node in the graph. This determines + // the length of the flat `inputs` vector. See comment at the beginning of + // `RunAsync()` for details. + size_t total_num_inputs_; + + // Represents cached graph structure state for each kernel. + struct KernelState { + // The kernel object. Not owned. + // + // This pointer is managed by `params_.create_kernel()` and + // `params_.delete_kernel()`. + OpKernel* kernel; + + // These fields determine the range of elements in `inputs` that corresponds + // to the inputs of `kernel`. + size_t input_start_index; + size_t num_inputs; + + size_t num_outputs; + + // For the `j`th output of `kernel`, `output_locations[j]` contains the + // locations in the flat `inputs` vector to which that output must be + // copied. See comment at the beginning of `RunAsync()` for details. + std::vector<std::vector<size_t>> + output_locations; // Length = `num_outputs`. + + // Memory space information for each output of `kernel`. + std::vector<AllocatorAttributes> + output_alloc_attrs; // Length = `num_outputs`. + }; + std::vector<KernelState> kernels_; + + // Memory space information for each input. This information is stored in the + // same order as the flat `inputs` vector. See comment at the beginning of + // `RunAsync()` for details. + std::vector<AllocatorAttributes> + input_alloc_attrs_; // Length = `total_num_inputs_`. +}; + +class SingleThreadedExecutorRegistrar { + public: + SingleThreadedExecutorRegistrar() { + ExecutorFactory::Register("SINGLE_THREADED_EXECUTOR", new Factory()); + } + + private: + class Factory : public ExecutorFactory { + Status NewExecutor(const LocalExecutorParams& params, + std::unique_ptr<const Graph> graph, + std::unique_ptr<Executor>* out_executor) override { + Executor* ret; + TF_RETURN_IF_ERROR( + NewSingleThreadedExecutor(params, std::move(graph), &ret)); + out_executor->reset(ret); + return Status::OK(); + } + }; +}; +static SingleThreadedExecutorRegistrar registrar; + +} // namespace + +Status NewSingleThreadedExecutor(const LocalExecutorParams& params, + std::unique_ptr<const Graph> graph, + Executor** executor) { + std::unique_ptr<SingleThreadedExecutorImpl> impl( + new SingleThreadedExecutorImpl(params)); + TF_RETURN_IF_ERROR(impl->Initialize(*graph)); + *executor = impl.release(); + return Status::OK(); +} + +} // namespace tensorflow diff --git a/tensorflow/core/kernels/data/single_threaded_executor.h b/tensorflow/core/kernels/data/single_threaded_executor.h new file mode 100644 index 0000000000..15836b24c9 --- /dev/null +++ b/tensorflow/core/kernels/data/single_threaded_executor.h @@ -0,0 +1,60 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CORE_KERNELS_DATA_SINGLE_THREADED_EXECUTOR_H_ +#define TENSORFLOW_CORE_KERNELS_DATA_SINGLE_THREADED_EXECUTOR_H_ + +#include "tensorflow/core/common_runtime/executor.h" + +namespace tensorflow { + +// Creates a new `Executor` for executing `graph` synchronously on the caller +// thread. +// +// NOTE(mrry): The returned executor is optimized to impose low overhead on +// graphs that perform a small amount of work (e.g. <15us of work per graph on +// present architectures). It eschews concurrency, because issuing work to +// multiple threads can dominate the cost of executing small ops synchronously, +// and because contention in the executor data structures can reduce throughput +// (in terms of ops executed per unit time). +// +// However, the current implementation has the following limitations: +// +// 1. Reference-typed tensors are not supported and will not be supported in +// future. +// 2. Graphs with control flow (containing "Switch" and "Merge" nodes) are not +// currently supported. The current plan is to extend support to "functional" +// control flow after the TensorFlow APIs transition to building graphs in +// that form (e.g. `tf.cond_v2()`). +// 3. Partitioned graphs (containing "_Recv" nodes) are not currently supported. +// The present implementation executes kernels one at a time in topological +// order, and cannot currently distinguish between disconnected subgraphs +// that are logically connected by subgraphs on a different device. +// 4. Memory logging is not currently supported. +// 5. Allocation forwarding is not currently supported. +// 6. Non-default device contexts are not currently supported. In effect, this +// limits the executor to CPU devices. +// 7. Ops that rely on `OpKernelContext::slice_reader_cache()` being non-null +// are not currently supported. +// +// The single-threaded executor is primarily suitable for executing simple +// TensorFlow functions, such as one might find in a `tf.data` pipeline. +Status NewSingleThreadedExecutor(const LocalExecutorParams& params, + std::unique_ptr<const Graph> graph, + Executor** executor); + +} // namespace tensorflow + +#endif // TENSORFLOW_CORE_KERNELS_DATA_SINGLE_THREADED_EXECUTOR_H_ diff --git a/tensorflow/core/kernels/data/single_threaded_executor_test.cc b/tensorflow/core/kernels/data/single_threaded_executor_test.cc new file mode 100644 index 0000000000..f8b5769197 --- /dev/null +++ b/tensorflow/core/kernels/data/single_threaded_executor_test.cc @@ -0,0 +1,330 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#include "tensorflow/core/kernels/data/single_threaded_executor.h" + +#include <algorithm> + +#include "tensorflow/core/common_runtime/device.h" +#include "tensorflow/core/common_runtime/device_factory.h" +#include "tensorflow/core/common_runtime/executor.h" +#include "tensorflow/core/common_runtime/kernel_benchmark_testlib.h" +#include "tensorflow/core/common_runtime/process_util.h" +#include "tensorflow/core/framework/op.h" +#include "tensorflow/core/framework/rendezvous.h" +#include "tensorflow/core/framework/versions.pb.h" +#include "tensorflow/core/graph/algorithm.h" +#include "tensorflow/core/graph/graph_constructor.h" +#include "tensorflow/core/lib/core/status_test_util.h" +#include "tensorflow/core/lib/random/simple_philox.h" +#include "tensorflow/core/lib/strings/strcat.h" +#include "tensorflow/core/platform/logging.h" +#include "tensorflow/core/platform/test.h" +#include "tensorflow/core/platform/test_benchmark.h" +#include "tensorflow/core/platform/tracing.h" +#include "tensorflow/core/public/session_options.h" + +namespace tensorflow { +namespace { + +class ExecutorTest : public ::testing::Test { + protected: + ExecutorTest() + : device_(DeviceFactory::NewDevice("CPU", {}, + "/job:localhost/replica:0/task:0")) {} + + ~ExecutorTest() override { + // There should always be exactly one Ref left on the Rendezvous + // when the test completes. + CHECK(rendez_->Unref()); + delete exec_; + delete device_; + } + + // Resets executor_ with a new executor based on a graph 'gdef'. + void Create(std::unique_ptr<const Graph> graph) { + const int version = graph->versions().producer(); + LocalExecutorParams params; + params.device = device_; + params.create_kernel = [this, version](const NodeDef& ndef, + OpKernel** kernel) { + return CreateNonCachedKernel(device_, nullptr, ndef, version, kernel); + }; + params.delete_kernel = [](OpKernel* kernel) { + DeleteNonCachedKernel(kernel); + }; + delete exec_; + TF_CHECK_OK(NewSingleThreadedExecutor(params, std::move(graph), &exec_)); + runner_ = [](std::function<void()> fn) { fn(); }; + rendez_ = NewLocalRendezvous(); + } + + Status Run(Rendezvous* rendez) { + Executor::Args args; + args.rendezvous = rendez; + args.runner = runner_; + return exec_->Run(args); + } + + Status Run(CallFrameInterface* call_frame) { + Executor::Args args; + args.call_frame = call_frame; + args.runner = runner_; + return exec_->Run(args); + } + + Device* device_ = nullptr; + Executor* exec_ = nullptr; + Executor::Args::Runner runner_; + Rendezvous* rendez_ = nullptr; +}; + +// A float val -> Tensor<float> +Tensor V(const float val) { + Tensor tensor(DT_FLOAT, TensorShape({})); + tensor.scalar<float>()() = val; + return tensor; +} + +// A int32 val -> Tensor<int32> +Tensor VI(const int32 val) { + Tensor tensor(DT_INT32, TensorShape({})); + tensor.scalar<int32>()() = val; + return tensor; +} + +// A bool val -> Tensor<bool> +Tensor VB(const bool val) { + Tensor tensor(DT_BOOL, TensorShape({})); + tensor.scalar<bool>()() = val; + return tensor; +} + +// A double val -> Tensor<double> +Tensor VD(const double val) { + Tensor tensor(DT_DOUBLE, TensorShape({})); + tensor.scalar<double>()() = val; + return tensor; +} + +// Tensor<float> -> a float val. +float V(const Tensor& tensor) { + CHECK_EQ(tensor.dtype(), DT_FLOAT); + CHECK(TensorShapeUtils::IsScalar(tensor.shape())); + return tensor.scalar<float>()(); +} + +Rendezvous::ParsedKey Key(const string& sender, const uint64 incarnation, + const string& receiver, const string& name) { + Rendezvous::ParsedKey result; + TF_CHECK_OK( + Rendezvous::ParseKey(Rendezvous::CreateKey(sender, incarnation, receiver, + name, FrameAndIter(0, 0)), + &result)); + return result; +} + +TEST_F(ExecutorTest, SimpleAdd) { + // c = a + b + std::unique_ptr<Graph> g(new Graph(OpRegistry::Global())); + auto in0 = test::graph::Arg(g.get(), 0, DT_FLOAT); + auto in1 = test::graph::Arg(g.get(), 0, DT_FLOAT); + auto tmp = test::graph::Add(g.get(), in0, in1); + test::graph::Retval(g.get(), 0, tmp); + FixupSourceAndSinkEdges(g.get()); + Create(std::move(g)); + FunctionCallFrame call_frame({DT_FLOAT, DT_FLOAT}, {DT_FLOAT}); + TF_ASSERT_OK(call_frame.SetArgs({V(1.0), V(1.0)})); + TF_ASSERT_OK(Run(&call_frame)); + std::vector<Tensor> retvals; + TF_ASSERT_OK(call_frame.ConsumeRetvals(&retvals, false)); + EXPECT_EQ(2.0, V(retvals[0])); // out = 1.0 + 1.0 = 2.0 +} + +TEST_F(ExecutorTest, SelfAdd) { + // v0 <- a + // v1 = v0 + v0 + // v2 = v1 + v1 + // ... ... + // v10 = v9 + v9 + // + // b <- v10 + // All nodes are executed by one thread. + std::unique_ptr<Graph> g(new Graph(OpRegistry::Global())); + auto v = test::graph::Arg(g.get(), 0, DT_FLOAT); + const int N = 10; + for (int i = 1; i <= N; ++i) { + v = test::graph::Add(g.get(), v, v); + } + // out <- v10 + test::graph::Retval(g.get(), 0, v); + FixupSourceAndSinkEdges(g.get()); + Create(std::move(g)); + FunctionCallFrame call_frame({DT_FLOAT}, {DT_FLOAT}); + // a = 1.0 + TF_ASSERT_OK(call_frame.SetArgs({V(1.0)})); + TF_ASSERT_OK(Run(&call_frame)); + std::vector<Tensor> retvals; + TF_ASSERT_OK(call_frame.ConsumeRetvals(&retvals, false)); + EXPECT_EQ(1024.0, V(retvals[0])); // b=v10=2*v9=4*v8=...=1024*a=1024.0 +} + +// Builds a graph which adds N copies of one variable "in". I.e., +// a + a + a + ... + a +// The returned graph is parenthesized ramdonly. I.e., +// a + ((a + a) + a) +// (a + a) + (a + a) +// ((a + a) + a) + a +// are all possibly generated. +void BuildTree(int N, Graph* g) { + CHECK_GT(N, 1); + // A single input node "in". + auto in = test::graph::Arg(g, 0, DT_FLOAT); + std::vector<Node*> nodes; + int i = 0; + // Duplicate "in" N times. Each copies is named as l0, l1, l2, .... + for (; i < N; ++i) { + nodes.push_back(test::graph::Identity(g, in, 0)); + } + random::PhiloxRandom philox(0, 17); + random::SimplePhilox rnd(&philox); + while (nodes.size() > 1) { + // Randomly pick two from nodes and add them. The resulting node + // is named lik n10, n11, .... and is put back into "nodes". + int x = rnd.Uniform(nodes.size()); + auto in0 = nodes[x]; + nodes[x] = nodes.back(); + nodes.resize(nodes.size() - 1); + x = rnd.Uniform(nodes.size()); + auto in1 = nodes[x]; + // node = in0 + in1. + nodes[x] = test::graph::Add(g, in0, in1); + } + // The final output node "out". + test::graph::Retval(g, 0, nodes.back()); + FixupSourceAndSinkEdges(g); +} + +TEST_F(ExecutorTest, RandomTree) { + std::unique_ptr<Graph> g(new Graph(OpRegistry::Global())); + BuildTree(4096, g.get()); + Create(std::move(g)); + FunctionCallFrame call_frame({DT_FLOAT}, {DT_FLOAT}); + TF_ASSERT_OK(call_frame.SetArgs({V(1.0)})); + TF_ASSERT_OK(Run(&call_frame)); + std::vector<Tensor> retvals; + TF_ASSERT_OK(call_frame.ConsumeRetvals(&retvals, false)); + EXPECT_EQ(4096.0, V(retvals[0])); +} + +TEST_F(ExecutorTest, OpError) { + std::unique_ptr<Graph> g(new Graph(OpRegistry::Global())); + auto zero = test::graph::Constant(g.get(), V(0.0)); + auto inf = test::graph::Unary(g.get(), "Reciprocal", zero); + auto check = test::graph::CheckNumerics(g.get(), inf, "message"); + auto two = test::graph::Constant(g.get(), V(2.0)); + test::graph::Binary(g.get(), "Mul", check, two); + FixupSourceAndSinkEdges(g.get()); + Create(std::move(g)); + FunctionCallFrame call_frame({}, {}); + // Fails due to invalid dtype. + EXPECT_TRUE(errors::IsInvalidArgument(Run(&call_frame))); +} + +static void BM_executor(int iters, int width, int depth) { +#ifdef PLATFORM_GOOGLE + BenchmarkUseRealTime(); +#endif // PLATFORM_GOOGLE + Graph* g = new Graph(OpRegistry::Global()); + random::PhiloxRandom philox(1729, 17); + random::SimplePhilox rand(&philox); + uint64 cur = 0; + uint32 r = 1 + rand.Rand32() % width; + std::vector<Node*> ready_nodes; + for (int i = 0; i < r; ++i) { + ready_nodes.push_back(test::graph::NoOp(g, {})); + ++cur; + } + for (int i = 0; i < depth; ++i) { + std::random_shuffle(ready_nodes.begin(), ready_nodes.end()); + r = 1 + rand.Rand32() % (ready_nodes.size()); + std::vector<Node*> control_inputs; + for (int j = 0; j < r; ++j) { + control_inputs.push_back(ready_nodes.back()); + ready_nodes.pop_back(); + } + Node* n = test::graph::NoOp(g, control_inputs); + ++cur; + r = 1 + rand.Rand32() % width; + for (int j = 0; j < r; ++j) { + ready_nodes.push_back(test::graph::NoOp(g, {n})); + ++cur; + } + } + FixupSourceAndSinkEdges(g); +#ifdef PLATFORM_GOOGLE + SetBenchmarkLabel(strings::StrCat("Nodes = ", cur)); + SetBenchmarkItemsProcessed(cur * static_cast<int64>(iters)); +#endif // PLATFORM_GOOGLE + test::Benchmark("cpu", g, nullptr, nullptr, nullptr, + "SINGLE_THREADED_EXECUTOR") + .Run(iters); +} + +// Tall skinny graphs +BENCHMARK(BM_executor)->ArgPair(16, 1024); +BENCHMARK(BM_executor)->ArgPair(32, 8192); + +// Short fat graphs +BENCHMARK(BM_executor)->ArgPair(1024, 16); +BENCHMARK(BM_executor)->ArgPair(8192, 32); + +// Tall fat graph +BENCHMARK(BM_executor)->ArgPair(1024, 1024); + +// TODO(mrry): This benchmark currently crashes with a use-after free, because +// test::Benchmark::RunWithArgs() assumes that the executor will take ownership +// of the given graph, *and* keep its nodes (`x`, `y` and `z`) alive for the +// duration of the benchmark. Since the single threaded executor does not retain +// a copy of the graph, this fails. +// +// TODO(mrry): Add support for Arg/Retval "function call convention" in +// `test::Benchmark::RunWithArgs()`. +#if 0 +#define ALICE "/job:j/replica:0/task:0/cpu:0" +#define BOB "/job:j/replica:0/task:0/gpu:0" + +static void BM_FeedInputFetchOutput(int iters) { + Graph* g = new Graph(OpRegistry::Global()); + // z = x + y: x and y are provided as benchmark inputs. z is the + // output of the benchmark. Conceptually, the caller is ALICE, the + // benchmark is BOB. + Node* x = test::graph::Recv(g, "x", "float", ALICE, 1, BOB); + Node* y = test::graph::Recv(g, "y", "float", ALICE, 1, BOB); + Node* sum = test::graph::Add(g, x, y); + Node* z = test::graph::Send(g, sum, "z", BOB, 1, ALICE); + FixupSourceAndSinkEdges(g); + Tensor val(DT_FLOAT, TensorShape({})); + val.scalar<float>()() = 3.14; + SetBenchmarkItemsProcessed(static_cast<int64>(iters)); + test::Benchmark("cpu", g, nullptr, nullptr, nullptr, + "SINGLE_THREADED_EXECUTOR") + .RunWithArgs({{x, val}, {y, val}}, {z}, iters); +} +BENCHMARK(BM_FeedInputFetchOutput); +#endif + +} // namespace +} // namespace tensorflow diff --git a/tensorflow/core/kernels/data/tensor_dataset_op.cc b/tensorflow/core/kernels/data/tensor_dataset_op.cc index fc21c3235a..1192fafc4c 100644 --- a/tensorflow/core/kernels/data/tensor_dataset_op.cc +++ b/tensorflow/core/kernels/data/tensor_dataset_op.cc @@ -14,6 +14,7 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/core/framework/partial_tensor_shape.h" #include "tensorflow/core/framework/tensor.h" +#include "tensorflow/core/graph/graph.h" #include "tensorflow/core/kernels/data/dataset.h" namespace tensorflow { @@ -28,8 +29,6 @@ class TensorDatasetOp : public DatasetOpKernel { explicit TensorDatasetOp(OpKernelConstruction* ctx) : DatasetOpKernel(ctx) {} void MakeDataset(OpKernelContext* ctx, DatasetBase** output) override { - // Create a new TensorDatasetOp::Dataset, insert it in the step - // container, and return it as the output. OpInputList inputs; OP_REQUIRES_OK(ctx, ctx->input_list("components", &inputs)); // TODO(mrry): Validate that the shapes of the "components" tensors match @@ -74,7 +73,13 @@ class TensorDatasetOp : public DatasetOpKernel { components.reserve(tensors_.size()); for (const Tensor& t : tensors_) { Node* node; - TF_RETURN_IF_ERROR(b->AddTensor(t, &node)); + std::vector<std::pair<string, Tensor>>* input_list = ctx->input_list(); + if (input_list) { + TF_RETURN_IF_ERROR(b->AddPlaceholder(t, &node)); + input_list->emplace_back(node->name(), t); + } else { + TF_RETURN_IF_ERROR(b->AddTensor(t, &node)); + } components.emplace_back(node); } AttrValue dtypes; diff --git a/tensorflow/core/kernels/data/tensor_slice_dataset_op.cc b/tensorflow/core/kernels/data/tensor_slice_dataset_op.cc index 5b051e0e08..dc32cd23e5 100644 --- a/tensorflow/core/kernels/data/tensor_slice_dataset_op.cc +++ b/tensorflow/core/kernels/data/tensor_slice_dataset_op.cc @@ -14,6 +14,7 @@ limitations under the License. ==============================================================================*/ #include "tensorflow/core/framework/partial_tensor_shape.h" #include "tensorflow/core/framework/tensor.h" +#include "tensorflow/core/graph/graph.h" #include "tensorflow/core/kernels/data/dataset.h" #include "tensorflow/core/util/batch_util.h" @@ -30,8 +31,6 @@ class TensorSliceDatasetOp : public DatasetOpKernel { : DatasetOpKernel(ctx) {} void MakeDataset(OpKernelContext* ctx, DatasetBase** output) override { - // Create a new TensorDatasetOp::Dataset, insert it in the step - // container, and return it as the output. OpInputList inputs; OP_REQUIRES_OK(ctx, ctx->input_list("components", &inputs)); std::vector<Tensor> components; @@ -93,7 +92,13 @@ class TensorSliceDatasetOp : public DatasetOpKernel { components.reserve(tensors_.size()); for (const Tensor& t : tensors_) { Node* node; - TF_RETURN_IF_ERROR(b->AddTensor(t, &node)); + std::vector<std::pair<string, Tensor>>* input_list = ctx->input_list(); + if (input_list) { + TF_RETURN_IF_ERROR(b->AddPlaceholder(t, &node)); + input_list->emplace_back(node->name(), t); + } else { + TF_RETURN_IF_ERROR(b->AddTensor(t, &node)); + } components.emplace_back(node); } AttrValue dtypes; diff --git a/tensorflow/core/kernels/debug_ops.h b/tensorflow/core/kernels/debug_ops.h index 33ed5522d0..d705e82b0d 100644 --- a/tensorflow/core/kernels/debug_ops.h +++ b/tensorflow/core/kernels/debug_ops.h @@ -255,7 +255,7 @@ class DebugNanCountOp : public BaseDebugOp { TensorShape shape({1}); OP_REQUIRES_OK(context, context->allocate_output(0, shape, &output_tensor)); output_tensor->vec<int64>()(0) = nan_count; - PublishTensor(*output_tensor); + OP_REQUIRES_OK(context, PublishTensor(*output_tensor)); } }; @@ -380,7 +380,7 @@ class DebugNumericSummaryOp : public BaseDebugOp { bool mute = mute_if_healthy_ && nan_count == 0 && negative_inf_count == 0 && positive_inf_count == 0; if (!mute) { - PublishTensor(*output_tensor); + OP_REQUIRES_OK(context, PublishTensor(*output_tensor)); } } diff --git a/tensorflow/core/kernels/eigen_backward_cuboid_convolutions.h b/tensorflow/core/kernels/eigen_backward_cuboid_convolutions.h index e13e548f86..27918b410b 100644 --- a/tensorflow/core/kernels/eigen_backward_cuboid_convolutions.h +++ b/tensorflow/core/kernels/eigen_backward_cuboid_convolutions.h @@ -51,14 +51,18 @@ EIGEN_ALWAYS_INLINE static const typename internal::conditional< internal::traits<OutputBackward>::NumDimensions>, const TensorContractionOp< const array< - IndexPair<typename internal::traits<OutputBackward>::Index>, 2>, - const TensorReshapingOp< + IndexPair<typename internal::traits<OutputBackward>::Index>, 1>, + const Eigen::TensorForcedEvalOp<const TensorReshapingOp< const DSizes<typename internal::traits<OutputBackward>::Index, - 3>, - const TensorReverseOp<const array<bool, 5>, const Kernel> >, + 2>, + const TensorShufflingOp< + const array< + typename internal::traits<OutputBackward>::Index, 5>, + const TensorReverseOp<const Eigen::array<bool, 5>, + const Kernel> > > >, const TensorReshapingOp< const DSizes<typename internal::traits<OutputBackward>::Index, - 3>, + 2>, const TensorVolumePatchOp<Dynamic, Dynamic, Dynamic, const OutputBackward> > > >, TensorReshapingOp< @@ -66,24 +70,27 @@ EIGEN_ALWAYS_INLINE static const typename internal::conditional< internal::traits<OutputBackward>::NumDimensions>, const TensorContractionOp< const array< - IndexPair<typename internal::traits<OutputBackward>::Index>, 2>, + IndexPair<typename internal::traits<OutputBackward>::Index>, 1>, const TensorReshapingOp< const DSizes<typename internal::traits<OutputBackward>::Index, - 3>, + 2>, const TensorVolumePatchOp<Dynamic, Dynamic, Dynamic, const OutputBackward> >, - const TensorReshapingOp< + const Eigen::TensorForcedEvalOp<const TensorReshapingOp< const DSizes<typename internal::traits<OutputBackward>::Index, - 3>, - const TensorReverseOp<const array<bool, 5>, - const Kernel> > > > >::type + 2>, + const TensorShufflingOp< + const array< + typename internal::traits<OutputBackward>::Index, 5>, + const TensorReverseOp<const Eigen::array<bool, 5>, + const Kernel> > > > > > >::type CuboidConvolutionBackwardInput( const Kernel& kernel, const OutputBackward& output_backward, typename internal::traits<OutputBackward>::Index inputPlanes, typename internal::traits<OutputBackward>::Index inputRows, typename internal::traits<OutputBackward>::Index inputCols, - const DenseIndex stridePlanes = 1, const DenseIndex strideRows = 1, - const DenseIndex strideCols = 1) { + const DenseIndex plane_stride = 1, const DenseIndex row_stride = 1, + const DenseIndex col_stride = 1) { typedef typename internal::traits<OutputBackward>::Index TensorIndex; const TensorRef<const Tensor<typename internal::traits<Kernel>::Scalar, internal::traits<Kernel>::NumDimensions, @@ -125,58 +132,45 @@ CuboidConvolutionBackwardInput( const TensorIndex outputCols = isColMajor ? out.dimensions()[3] : out.dimensions()[NumDims - 4]; - TensorIndex forward_pad_z, forward_pad_y, forward_pad_x; - const TensorIndex size_z = - Eigen::divup(inputPlanes, static_cast<TensorIndex>(stridePlanes)); - const TensorIndex size_y = - Eigen::divup(inputRows, static_cast<TensorIndex>(strideRows)); - const TensorIndex size_x = - Eigen::divup(inputCols, static_cast<TensorIndex>(strideCols)); - - // Infer padding type. - if (size_z == outputPlanes && size_y == outputRows && size_x == outputCols) { - // SAME padding. - const TensorIndex dz = numext::maxi<TensorIndex>( - 0, (size_z - 1) * stridePlanes + kernelPlanes - inputPlanes); - const TensorIndex dy = numext::maxi<TensorIndex>( - 0, (size_y - 1) * strideRows + kernelRows - inputRows); - const TensorIndex dx = numext::maxi<TensorIndex>( - 0, (size_x - 1) * strideCols + kernelCols - inputCols); - - forward_pad_z = dz / 2; - forward_pad_y = dy / 2; - forward_pad_x = dx / 2; - } else { - // VALID padding. - forward_pad_z = 0; - forward_pad_y = 0; - forward_pad_x = 0; - } - const TensorIndex padding_ztop = kernelPlanes - 1 - forward_pad_z; - const TensorIndex padding_top = kernelRows - 1 - forward_pad_y; - const TensorIndex padding_left = kernelCols - 1 - forward_pad_x; - - const TensorIndex padding_zbottom = inputPlanes + kernelPlanes - 1 - - (outputPlanes - 1) * stridePlanes - 1 - - padding_ztop; - const TensorIndex padding_bottom = inputRows + kernelRows - 1 - - (outputRows - 1) * strideRows - 1 - - padding_top; - const TensorIndex padding_right = inputCols + kernelCols - 1 - - (outputCols - 1) * strideCols - 1 - - padding_left; - - eigen_assert(padding_ztop >= 0); - eigen_assert(padding_zbottom >= 0); + // TODO(ezhulenev): Add support for inflated strides. Without inflated strides + // effective kernel planes/rows/cols are always the same as the kernel itself + // (see eigen_spatial_convolutions for details). + const TensorIndex kernelPlanesEff = kernelPlanes; + const TensorIndex kernelRowsEff = kernelRows; + const TensorIndex kernelColsEff = kernelCols; + + // Computing the forward padding. + const TensorIndex forward_pad_top_z = numext::maxi<Index>( + 0, + ((outputPlanes - 1) * plane_stride + kernelPlanesEff - inputPlanes) / 2); + const TensorIndex forward_pad_top = numext::maxi<Index>( + 0, ((outputRows - 1) * row_stride + kernelRowsEff - inputRows) / 2); + const TensorIndex forward_pad_left = numext::maxi<Index>( + 0, ((outputCols - 1) * col_stride + kernelColsEff - inputCols) / 2); + + const TensorIndex padding_top_z = kernelPlanesEff - 1 - forward_pad_top_z; + const TensorIndex padding_top = kernelRowsEff - 1 - forward_pad_top; + const TensorIndex padding_left = kernelColsEff - 1 - forward_pad_left; + + const TensorIndex padding_bottom_z = inputPlanes - + (outputPlanes - 1) * plane_stride - 2 - + padding_top_z + kernelPlanesEff; + const TensorIndex padding_bottom = inputRows - (outputRows - 1) * row_stride - + 2 - padding_top + kernelRowsEff; + const TensorIndex padding_right = inputCols - (outputCols - 1) * col_stride - + 2 - padding_left + kernelColsEff; + + eigen_assert(padding_top_z >= 0); eigen_assert(padding_top >= 0); eigen_assert(padding_left >= 0); + eigen_assert(padding_bottom_z >= 0); eigen_assert(padding_bottom >= 0); eigen_assert(padding_right >= 0); - // The kernel has dimensions filters X channels X patch_planes X patch_rows X - // patch_cols. + // The kernel has dimensions : + // filters x channels x patch_planes x patch_rows x patch_cols. // We need to reverse the kernel along the spatial dimensions. - array<bool, 5> kernel_reverse; + Eigen::array<bool, 5> kernel_reverse; if (isColMajor) { kernel_reverse[0] = false; kernel_reverse[1] = false; @@ -191,15 +185,35 @@ CuboidConvolutionBackwardInput( kernel_reverse[4] = false; } - DSizes<TensorIndex, 3> kernel_dims; + // Reorder the dimensions to: + // filters x patch_planes x patch_rows x patch_cols x channels + array<TensorIndex, 5> kernel_shuffle; if (isColMajor) { - kernel_dims[0] = kernelFilters; - kernel_dims[1] = kernelChannels; - kernel_dims[2] = kernelRows * kernelCols * kernelPlanes; + // From: filters x channels x planes x rows x cols + // To: filters x planes x rows x cols x channels + kernel_shuffle[0] = 0; + kernel_shuffle[1] = 2; + kernel_shuffle[2] = 3; + kernel_shuffle[3] = 4; + kernel_shuffle[4] = 1; } else { - kernel_dims[0] = kernelRows * kernelCols * kernelPlanes; + // From: cols x rows x planes x channels x filters + // To: channels x cols x rows x planes x filters + kernel_shuffle[0] = 3; + kernel_shuffle[1] = 0; + kernel_shuffle[2] = 1; + kernel_shuffle[3] = 2; + kernel_shuffle[4] = 4; + } + + // Collapse the dims + DSizes<TensorIndex, 2> kernel_dims; + if (isColMajor) { + kernel_dims[0] = kernelFilters * kernelPlanes * kernelRows * kernelCols; kernel_dims[1] = kernelChannels; - kernel_dims[2] = kernelFilters; + } else { + kernel_dims[1] = kernelFilters * kernelPlanes * kernelRows * kernelCols; + kernel_dims[0] = kernelChannels; } // The output_backward has dimensions out_depth X out_planes X out_rows X @@ -208,36 +222,32 @@ CuboidConvolutionBackwardInput( // dimensions: // out_depth X (patch_planes * patch_rows * patch_cols) X (input_planes * // input_rows * input_cols * OTHERS) - DSizes<TensorIndex, 3> pre_contract_dims; + DSizes<TensorIndex, 2> pre_contract_dims; if (isColMajor) { - pre_contract_dims[0] = kernelFilters; - pre_contract_dims[1] = kernelRows * kernelCols * kernelPlanes; - pre_contract_dims[2] = inputRows * inputCols * inputPlanes; + pre_contract_dims[0] = + kernelFilters * kernelPlanes * kernelRows * kernelCols; + pre_contract_dims[1] = inputPlanes * inputRows * inputCols; for (int i = 4; i < NumDims; ++i) { - pre_contract_dims[2] *= out.dimension(i); + pre_contract_dims[1] *= out.dimension(i); } } else { - pre_contract_dims[2] = kernelFilters; - pre_contract_dims[1] = kernelRows * kernelCols * kernelPlanes; - pre_contract_dims[0] = inputRows * inputCols * inputPlanes; + pre_contract_dims[1] = + kernelFilters * kernelPlanes * kernelRows * kernelCols; + pre_contract_dims[0] = inputPlanes * inputRows * inputCols; for (int i = 0; i < NumDims - 4; ++i) { pre_contract_dims[0] *= out.dimension(i); } } - // We will contract along dimensions (0, 2) in kernel and (0, 1) in - // output_backward, if this is col-major, and - // dimensions (0, 2) in kernel and (1, 2) in output_backward, if this - // row-major. - array<IndexPair<TensorIndex>, 2> contract_dims; + // We will contract along the fused dimension that contains the kernelFilters, + // kernelPlanes, kernelRows and kernelCols. + array<IndexPair<TensorIndex>, 1> contract_dims; if (isColMajor) { // col-major: kernel.contract(output.patches) contract_dims[0] = IndexPair<TensorIndex>(0, 0); - contract_dims[1] = IndexPair<TensorIndex>(2, 1); } else { // row-major: output.patches.contract(kernel) - contract_dims[0] = IndexPair<TensorIndex>(1, 0); - contract_dims[1] = IndexPair<TensorIndex>(2, 2); + contract_dims[0] = IndexPair<TensorIndex>(1, 1); } // Post contraction, the dimensions of the input_backprop is @@ -261,40 +271,31 @@ CuboidConvolutionBackwardInput( } } - DSizes<TensorIndex, NumDims> strides; - for (int i = 0; i < NumDims; i++) { - strides[i] = 1; - } - if (isColMajor) { - strides[1] = stridePlanes; - strides[2] = strideRows; - strides[3] = strideCols; - } else { - strides[NumDims - 2] = stridePlanes; - strides[NumDims - 3] = strideRows; - strides[NumDims - 4] = strideCols; - } - return choose( Cond<internal::traits<OutputBackward>::Layout == ColMajor>(), kernel.reverse(kernel_reverse) + .shuffle(kernel_shuffle) .reshape(kernel_dims) + .eval() .contract(output_backward .extract_volume_patches( kernelPlanes, kernelRows, kernelCols, 1, 1, 1, - stridePlanes, strideRows, strideCols, padding_ztop, - padding_zbottom, padding_top, padding_bottom, + plane_stride, row_stride, col_stride, padding_top_z, + padding_bottom_z, padding_top, padding_bottom, padding_left, padding_right) .reshape(pre_contract_dims), contract_dims) .reshape(post_contract_dims), output_backward .extract_volume_patches(kernelPlanes, kernelRows, kernelCols, 1, 1, 1, - stridePlanes, strideRows, strideCols, - padding_ztop, padding_zbottom, padding_top, + plane_stride, row_stride, col_stride, + padding_top_z, padding_bottom_z, padding_top, padding_bottom, padding_left, padding_right) .reshape(pre_contract_dims) - .contract(kernel.reverse(kernel_reverse).reshape(kernel_dims), + .contract(kernel.reverse(kernel_reverse) + .shuffle(kernel_shuffle) + .reshape(kernel_dims) + .eval(), contract_dims) .reshape(post_contract_dims)); } @@ -323,47 +324,34 @@ CuboidConvolutionBackwardInput( template <typename OutputBackward, typename Input> EIGEN_ALWAYS_INLINE static const typename internal::conditional< internal::traits<OutputBackward>::Layout == ColMajor, - const TensorShufflingOp< - const array<typename internal::traits<OutputBackward>::Index, 5>, - const TensorReverseOp< - const array<bool, 5>, + TensorReshapingOp< + const DSizes<typename internal::traits<Input>::Index, 5>, + const TensorContractionOp< + const array<IndexPair<typename internal::traits<Input>::Index>, 1>, const TensorReshapingOp< - const DSizes<typename internal::traits<OutputBackward>::Index, - 5>, - const TensorContractionOp< - const array< - IndexPair<typename internal::traits<Input>::Index>, 2>, - const TensorReshapingOp< - const DSizes<typename internal::traits<Input>::Index, - 3>, - const Input>, - const TensorReshapingOp< - const DSizes< - typename internal::traits<OutputBackward>::Index, - 4>, - const TensorVolumePatchOp< - Dynamic, Dynamic, Dynamic, - const OutputBackward> > > > > >, - const TensorShufflingOp< - const array<typename internal::traits<OutputBackward>::Index, 5>, - const TensorReverseOp< - const array<bool, 5>, + const DSizes<typename internal::traits<Input>::Index, 2>, + const OutputBackward>, + const TensorShufflingOp< + const array<typename internal::traits<OutputBackward>::Index, + 2>, + const TensorReshapingOp< + const DSizes<typename internal::traits<Input>::Index, 2>, + const TensorVolumePatchOp<Dynamic, Dynamic, Dynamic, + const Input> > > > >, + TensorReshapingOp< + const DSizes<typename internal::traits<Input>::Index, 5>, + const TensorContractionOp< + const array<IndexPair<typename internal::traits<Input>::Index>, 1>, + const TensorShufflingOp< + const array<typename internal::traits<OutputBackward>::Index, + 2>, + const TensorReshapingOp< + const DSizes<typename internal::traits<Input>::Index, 2>, + const TensorVolumePatchOp<Dynamic, Dynamic, Dynamic, + const Input> > >, const TensorReshapingOp< - const DSizes<typename internal::traits<OutputBackward>::Index, - 5>, - const TensorContractionOp< - const array< - IndexPair<typename internal::traits<Input>::Index>, 2>, - const TensorReshapingOp< - const DSizes< - typename internal::traits<OutputBackward>::Index, - 4>, - const TensorVolumePatchOp<Dynamic, Dynamic, Dynamic, - const OutputBackward> >, - const TensorReshapingOp< - const DSizes<typename internal::traits<Input>::Index, - 3>, - const Input> > > > > >::type + const DSizes<typename internal::traits<Input>::Index, 2>, + const OutputBackward> > > >::type CuboidConvolutionBackwardKernel( const Input& input, const OutputBackward& output_backward, typename internal::traits<Input>::Index kernelPlanes, @@ -406,213 +394,114 @@ CuboidConvolutionBackwardKernel( const TensorIndex outputCols = isColMajor ? out.dimension(3) : out.dimension(NumDims - 4); + // Number of filters. This is the same as the output depth. const TensorIndex kernelFilters = isColMajor ? out.dimension(0) : out.dimension(NumDims - 1); + // Number of channels. This is the same as the input depth. const TensorIndex kernelChannels = isColMajor ? in.dimension(0) : in.dimension(NumDims - 1); - TensorIndex forward_pad_z, forward_pad_y, forward_pad_x; - const TensorIndex size_z = - Eigen::divup(inputPlanes, static_cast<TensorIndex>(stridePlanes)); - const TensorIndex size_y = - Eigen::divup(inputRows, static_cast<TensorIndex>(strideRows)); - const TensorIndex size_x = - Eigen::divup(inputCols, static_cast<TensorIndex>(strideCols)); - - // Infer padding type. - if (size_z == outputPlanes && size_y == outputRows && size_x == outputCols) { - // SAME padding. - const TensorIndex dz = numext::maxi<TensorIndex>( - 0, (size_z - 1) * stridePlanes + kernelPlanes - inputPlanes); - const TensorIndex dy = numext::maxi<TensorIndex>( - 0, (size_y - 1) * strideRows + kernelRows - inputRows); - const TensorIndex dx = numext::maxi<TensorIndex>( - 0, (size_x - 1) * strideCols + kernelCols - inputCols); - - forward_pad_z = dz / 2; - forward_pad_y = dy / 2; - forward_pad_x = dx / 2; - } else { - // VALID padding. - forward_pad_z = 0; - forward_pad_y = 0; - forward_pad_x = 0; - } - - const TensorIndex padding_ztop = kernelPlanes - 1 - forward_pad_z; - const TensorIndex padding_top = kernelRows - 1 - forward_pad_y; - const TensorIndex padding_left = kernelCols - 1 - forward_pad_x; - - const TensorIndex padding_zbottom = inputPlanes + kernelPlanes - 1 - - (outputPlanes - 1) * stridePlanes - 1 - - padding_ztop; - const TensorIndex padding_bottom = inputRows + kernelRows - 1 - - (outputRows - 1) * strideRows - 1 - - padding_top; - const TensorIndex padding_right = inputCols + kernelCols - 1 - - (outputCols - 1) * strideCols - 1 - - padding_left; - - eigen_assert(padding_ztop >= 0); - eigen_assert(padding_zbottom >= 0); - eigen_assert(padding_top >= 0); - eigen_assert(padding_left >= 0); - eigen_assert(padding_bottom >= 0); - eigen_assert(padding_right >= 0); - - // The output_backward has dimensions out_depth X out_plaens X out_rows X - // out_cols X OTHERS - // When we extract the image patches from output_backward (with input as the - // kernel), it will have dimensions - // (out_depth) X (input_planes * input_rows * input_cols) X (kernel_planes * - // kernel_rows * kernel_cols) X OTHERS - DSizes<TensorIndex, 4> pre_contract_dims; + // TODO(ezhulenev): Add support for inflated strides. Without inflated strides + // effective kernel planes/rows/cols are always the same as the kernel itself + // (see eigen_spatial_convolutions for details). + const TensorIndex kernelPlanesEff = kernelPlanes; + const TensorIndex kernelRowsEff = kernelRows; + const TensorIndex kernelColsEff = kernelCols; + + const TensorIndex padPlanes = numext::maxi<Index>( + 0, (outputPlanes - 1) * stridePlanes + kernelPlanesEff - inputPlanes); + const TensorIndex padRows = numext::maxi<Index>( + 0, (outputRows - 1) * strideRows + kernelRowsEff - inputRows); + const TensorIndex padCols = numext::maxi<Index>( + 0, (outputCols - 1) * strideCols + kernelColsEff - inputCols); + + const TensorIndex padding_top_z = padPlanes / 2; + const TensorIndex padding_bottom_z = padPlanes - padding_top_z; + const TensorIndex padding_top = padRows / 2; + const TensorIndex padding_bottom = padRows - padding_top; + const TensorIndex padding_left = padCols / 2; + const TensorIndex padding_right = padCols - padding_left; + + // Reshaped output_backward before contraction. + DSizes<TensorIndex, 2> output_dims; if (isColMajor) { - pre_contract_dims[0] = kernelFilters; - pre_contract_dims[1] = inputRows * inputCols * inputPlanes; - pre_contract_dims[2] = kernelRows * kernelCols * kernelPlanes; - pre_contract_dims[3] = 1; + output_dims[0] = kernelFilters; + output_dims[1] = outputPlanes * outputRows * outputCols; for (int i = 4; i < NumDims; ++i) { - pre_contract_dims[3] *= out.dimension(i); + output_dims[1] *= out.dimension(i); } } else { - pre_contract_dims[3] = kernelFilters; - pre_contract_dims[2] = inputRows * inputCols * inputPlanes; - pre_contract_dims[1] = kernelRows * kernelCols * kernelPlanes; - pre_contract_dims[0] = 1; + output_dims[1] = kernelFilters; + output_dims[0] = outputCols * outputRows * outputPlanes; for (int i = 0; i < NumDims - 4; ++i) { - pre_contract_dims[0] *= out.dimension(i); + output_dims[0] *= out.dimension(i); } } - // The input has dimensions in_depth X (input_planes * input_rows * - // input_cols) X OTHERS - DSizes<TensorIndex, 3> input_dims; + // Reshaped extract_volume_patches(in) + DSizes<TensorIndex, 2> pre_contract_dims; if (isColMajor) { - input_dims[0] = kernelChannels; - input_dims[1] = inputRows * inputCols * inputPlanes; - input_dims[2] = 1; + pre_contract_dims[0] = + kernelChannels * kernelPlanes * kernelRows * kernelCols; + pre_contract_dims[1] = outputPlanes * outputRows * outputCols; for (int i = 4; i < NumDims; ++i) { - input_dims[2] *= in.dimension(i); + pre_contract_dims[1] *= in.dimension(i); } - eigen_assert(input_dims[2] == pre_contract_dims[3]); + eigen_assert(output_dims[1] == pre_contract_dims[1]); } else { - input_dims[2] = kernelChannels; - input_dims[1] = inputRows * inputCols * inputPlanes; - input_dims[0] = 1; + pre_contract_dims[1] = + kernelCols * kernelRows * kernelPlanes * kernelChannels; + pre_contract_dims[0] = outputCols * outputRows * outputPlanes; for (int i = 0; i < NumDims - 4; ++i) { - input_dims[0] *= in.dimension(i); + pre_contract_dims[0] *= in.dimension(i); } - eigen_assert(input_dims[0] == pre_contract_dims[0]); + eigen_assert(output_dims[0] == pre_contract_dims[0]); } - // We will contract along dimensions (1, 2) in and (1, 3) in out, if - // this is col-major. - // For row-major, it's dimensions (0, 1) in and (0, 2) in out. - array<IndexPair<TensorIndex>, 2> contract_dims; - if (isColMajor) { - // col-major: in.contract(output.patches) - contract_dims[0] = IndexPair<TensorIndex>(1, 1); - contract_dims[1] = IndexPair<TensorIndex>(2, 3); - } else { - // row-major: output.patches.contract(in) - contract_dims[0] = IndexPair<TensorIndex>(0, 0); - contract_dims[1] = IndexPair<TensorIndex>(2, 1); - } + array<TensorIndex, 2> shuffle_dims; + shuffle_dims[0] = 1; + shuffle_dims[1] = 0; - // After the contraction, the kernel will have dimension - // in_depth X out_depth X kernel_patches X kernel_rows X kernel_cols - // We will need to shuffle the first two dimensions and reverse the spatial - // dimensions. - // The end shape is: - // out_depth X in_shape X kernel_planes X kernel_rows X kernel_cols + array<IndexPair<TensorIndex>, 1> contract_dims; + contract_dims[0] = IndexPair<TensorIndex>(1, 0); - // This is the shape of the kernel *before* the shuffling. DSizes<TensorIndex, 5> kernel_dims; if (isColMajor) { - kernel_dims[0] = kernelChannels; - kernel_dims[1] = kernelFilters; + kernel_dims[0] = kernelFilters; + kernel_dims[1] = kernelChannels; kernel_dims[2] = kernelPlanes; kernel_dims[3] = kernelRows; kernel_dims[4] = kernelCols; } else { - kernel_dims[0] = kernelCols; - kernel_dims[1] = kernelRows; + kernel_dims[4] = kernelFilters; + kernel_dims[3] = kernelChannels; kernel_dims[2] = kernelPlanes; - kernel_dims[3] = kernelFilters; - kernel_dims[4] = kernelChannels; - } - - // Flip filters and channels. - array<TensorIndex, 5> kernel_shuffle; - if (isColMajor) { - kernel_shuffle[0] = 1; - kernel_shuffle[1] = 0; - kernel_shuffle[2] = 2; - kernel_shuffle[3] = 3; - kernel_shuffle[4] = 4; - } else { - kernel_shuffle[0] = 0; - kernel_shuffle[1] = 1; - kernel_shuffle[2] = 2; - kernel_shuffle[3] = 4; - kernel_shuffle[4] = 3; - } - - // Reverse the spatial dimensions. - array<bool, 5> kernel_reverse; - if (isColMajor) { - kernel_reverse[0] = false; - kernel_reverse[1] = false; - kernel_reverse[2] = true; - kernel_reverse[3] = true; - kernel_reverse[4] = true; - } else { - kernel_reverse[0] = true; - kernel_reverse[1] = true; - kernel_reverse[2] = true; - kernel_reverse[3] = false; - kernel_reverse[4] = false; + kernel_dims[1] = kernelRows; + kernel_dims[0] = kernelCols; } - DSizes<TensorIndex, NumDims> strides; - for (int i = 0; i < NumDims; i++) { - strides[i] = 1; - } - if (isColMajor) { - strides[1] = stridePlanes; - strides[2] = strideRows; - strides[3] = strideCols; - } else { - strides[NumDims - 2] = stridePlanes; - strides[NumDims - 3] = strideRows; - strides[NumDims - 4] = strideCols; - } return choose( Cond<internal::traits<Input>::Layout == ColMajor>(), - input.reshape(input_dims) - .contract(output_backward + output_backward.reshape(output_dims) + .contract(input .extract_volume_patches( - inputPlanes, inputRows, inputCols, 1, 1, 1, - stridePlanes, strideRows, strideCols, - - padding_ztop, padding_zbottom, padding_top, - padding_bottom, padding_left, padding_right) - .reshape(pre_contract_dims), + kernelPlanes, kernelRows, kernelCols, stridePlanes, + strideRows, strideCols, 1, 1, 1, padding_top_z, + padding_bottom_z, padding_top, padding_bottom, + padding_left, padding_right) + .reshape(pre_contract_dims) + .shuffle(shuffle_dims), contract_dims) - .reshape(kernel_dims) - .reverse(kernel_reverse) - .shuffle(kernel_shuffle), - output_backward - .extract_volume_patches(inputPlanes, inputRows, inputCols, 1, 1, 1, - stridePlanes, strideRows, strideCols, - padding_ztop, padding_zbottom, padding_top, + .reshape(kernel_dims), + input + .extract_volume_patches(kernelPlanes, kernelRows, kernelCols, + stridePlanes, strideRows, strideCols, 1, 1, 1, + padding_top_z, padding_bottom_z, padding_top, padding_bottom, padding_left, padding_right) .reshape(pre_contract_dims) - .contract(input.reshape(input_dims), contract_dims) - .reshape(kernel_dims) - .reverse(kernel_reverse) - .shuffle(kernel_shuffle)); + .shuffle(shuffle_dims) + .contract(output_backward.reshape(output_dims), contract_dims) + .reshape(kernel_dims)); } } // end namespace Eigen diff --git a/tensorflow/core/kernels/eigen_backward_spatial_convolutions.h b/tensorflow/core/kernels/eigen_backward_spatial_convolutions.h index cb0a76dac4..8d06107553 100644 --- a/tensorflow/core/kernels/eigen_backward_spatial_convolutions.h +++ b/tensorflow/core/kernels/eigen_backward_spatial_convolutions.h @@ -189,14 +189,19 @@ SpatialConvolutionBackwardInput( } #endif - // Reorder the dimensions to filters X patch_rows X patch_cols X channels + // Reorder the dimensions to: + // filters x patch_rows x patch_cols x channels array<TensorIndex, 4> kernel_shuffle; if (isColMajor) { + // From: filters x channels x rows x cols + // To: filters x rows x cols x channels kernel_shuffle[0] = 0; kernel_shuffle[1] = 2; kernel_shuffle[2] = 3; kernel_shuffle[3] = 1; } else { + // From: cols x rows x channels x filters + // To: channels x cols x rows x filters kernel_shuffle[0] = 2; kernel_shuffle[1] = 0; kernel_shuffle[2] = 1; diff --git a/tensorflow/core/kernels/eigen_benchmark.h b/tensorflow/core/kernels/eigen_benchmark.h new file mode 100644 index 0000000000..87e41b89b3 --- /dev/null +++ b/tensorflow/core/kernels/eigen_benchmark.h @@ -0,0 +1,304 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CORE_KERNELS_EIGEN_BENCHMARK_H_ +#define TENSORFLOW_CORE_KERNELS_EIGEN_BENCHMARK_H_ + +#include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" +#include "tensorflow/core/framework/tensor_types.h" +#include "tensorflow/core/kernels/eigen_backward_cuboid_convolutions.h" +#include "tensorflow/core/kernels/eigen_backward_spatial_convolutions.h" +#include "tensorflow/core/kernels/eigen_cuboid_convolution.h" +#include "tensorflow/core/kernels/eigen_spatial_convolutions.h" +#include "tensorflow/core/platform/test_benchmark.h" + +using ::tensorflow::TTypes; + +template <typename Scalar, typename Device> +class SpatialConvolutionBenchmarksSuite { + public: + using Input = TTypes<float, 4>::ConstTensor; + using Filter = TTypes<float, 4>::ConstTensor; + using Output = TTypes<float, 4>::Tensor; + + using Dimensions = Eigen::DSizes<Eigen::Index, 4>; + + SpatialConvolutionBenchmarksSuite(int iters, Device& device) + : iters_(iters), device_(device) {} + + Eigen::Index BufferSize(const Dimensions& dims) { + return dims.TotalSize() * sizeof(Scalar); + } + + void SpatialConvolution(Dimensions input_dims, Dimensions filter_dims) { + Dimensions output_dims(input_dims[0], // batch + input_dims[1], // input_height + input_dims[2], // input_width + filter_dims[3]); // filter_count + + Scalar* input_data = + static_cast<Scalar*>(device_.allocate(BufferSize(input_dims))); + Scalar* filter_data = + static_cast<Scalar*>(device_.allocate(BufferSize(filter_dims))); + Scalar* output_data = + static_cast<Scalar*>(device_.allocate(BufferSize(output_dims))); + + device_.memset(input_data, 123, BufferSize(input_dims)); + device_.memset(filter_data, 123, BufferSize(filter_dims)); + + Input input(input_data, input_dims); + Filter filter(filter_data, filter_dims); + Output output(output_data, output_dims); + + ::tensorflow::testing::StartTiming(); + for (int i = 0; i < iters_; ++i) { + output.device(device_) = Eigen::SpatialConvolution(input, filter); + tensorflow::testing::DoNotOptimize(output); + } + ::tensorflow::testing::StopTiming(); + + device_.deallocate(input_data); + device_.deallocate(filter_data); + device_.deallocate(output_data); + } + + void SpatialConvolutionBackwardInput(Dimensions input_dims, + Dimensions filter_dims) { + using OutputBackward = TTypes<float, 4>::ConstTensor; + using InputBackward = TTypes<float, 4>::Tensor; + + Dimensions output_dims(input_dims[0], // batch + input_dims[1], // input_height + input_dims[2], // input_width + filter_dims[3]); // filter_count + + // Assuming that the convolution had SAME padding. + Eigen::Index input_rows = input_dims[1]; + Eigen::Index input_cols = input_dims[2]; + + Scalar* filter_data = + static_cast<Scalar*>(device_.allocate(BufferSize(filter_dims))); + Scalar* output_backward_data = + static_cast<Scalar*>(device_.allocate(BufferSize(output_dims))); + Scalar* input_backward_data = + static_cast<Scalar*>(device_.allocate(BufferSize(input_dims))); + + device_.memset(filter_data, 123, BufferSize(filter_dims)); + device_.memset(output_backward_data, 123, BufferSize(output_dims)); + + Filter filter(filter_data, filter_dims); + OutputBackward output_backward(output_backward_data, output_dims); + InputBackward input_backward(input_backward_data, input_dims); + + ::tensorflow::testing::StartTiming(); + for (int i = 0; i < iters_; ++i) { + input_backward.device(device_) = Eigen::SpatialConvolutionBackwardInput( + filter, output_backward, input_rows, input_cols); + tensorflow::testing::DoNotOptimize(input_backward); + } + ::tensorflow::testing::StopTiming(); + + device_.deallocate(filter_data); + device_.deallocate(output_backward_data); + device_.deallocate(input_backward_data); + } + + void SpatialConvolutionBackwardKernel(Dimensions input_dims, + Dimensions filter_dims) { + using OutputBackward = TTypes<float, 4>::ConstTensor; + using FilterBackward = TTypes<float, 4>::Tensor; + + Dimensions output_dims(input_dims[0], // batch + input_dims[1], // input_height + input_dims[2], // input_width + filter_dims[3]); // filter_count + + // Assuming that the convolution had SAME padding. + Eigen::Index filter_rows = filter_dims[0]; + Eigen::Index filter_cols = filter_dims[1]; + + Scalar* input_data = + static_cast<Scalar*>(device_.allocate(BufferSize(input_dims))); + Scalar* output_backward_data = + static_cast<Scalar*>(device_.allocate(BufferSize(output_dims))); + Scalar* filter_backward_data = + static_cast<Scalar*>(device_.allocate(BufferSize(filter_dims))); + + device_.memset(input_data, 123, BufferSize(input_dims)); + device_.memset(output_backward_data, 123, BufferSize(output_dims)); + + Input input(input_data, input_dims); + OutputBackward output_backward(output_backward_data, input_dims); + FilterBackward filter_backward(filter_backward_data, filter_dims); + + ::tensorflow::testing::StartTiming(); + for (int i = 0; i < iters_; ++i) { + filter_backward.device(device_) = Eigen::SpatialConvolutionBackwardKernel( + input, output_backward, filter_rows, filter_cols); + tensorflow::testing::DoNotOptimize(filter_backward); + } + ::tensorflow::testing::StopTiming(); + + device_.deallocate(input_data); + device_.deallocate(output_backward_data); + device_.deallocate(filter_backward_data); + } + + private: + int iters_; + Device& device_; +}; + +template <typename Scalar, typename Device> +class CuboidConvolutionBenchmarksSuite { + public: + using Input = TTypes<float, 5>::ConstTensor; + using Filter = TTypes<float, 5>::ConstTensor; + using Output = TTypes<float, 5>::Tensor; + + using Dimensions = Eigen::DSizes<Eigen::Index, 5>; + + CuboidConvolutionBenchmarksSuite(int iters, Device& device) + : iters_(iters), device_(device) {} + + Eigen::Index BufferSize(const Dimensions& dims) { + return dims.TotalSize() * sizeof(Scalar); + } + + void CuboidConvolution(Dimensions input_dims, Dimensions filter_dims) { + Dimensions output_dims(input_dims[0], // batch + input_dims[1], // input_height + input_dims[2], // input_width + input_dims[3], // input_planes + filter_dims[4]); // filter_count + + Scalar* input_data = + static_cast<Scalar*>(device_.allocate(BufferSize(input_dims))); + Scalar* filter_data = + static_cast<Scalar*>(device_.allocate(BufferSize(filter_dims))); + Scalar* output_data = + static_cast<Scalar*>(device_.allocate(BufferSize(output_dims))); + + device_.memset(input_data, 123, BufferSize(input_dims)); + device_.memset(filter_data, 123, BufferSize(filter_dims)); + + Input input(input_data, input_dims); + Filter filter(filter_data, filter_dims); + Output output(output_data, output_dims); + + ::tensorflow::testing::StartTiming(); + for (int i = 0; i < iters_; ++i) { + output.device(device_) = Eigen::CuboidConvolution(input, filter); + tensorflow::testing::DoNotOptimize(output); + } + ::tensorflow::testing::StopTiming(); + + device_.deallocate(input_data); + device_.deallocate(filter_data); + device_.deallocate(output_data); + } + + void CuboidConvolutionBackwardInput(Dimensions input_dims, + Dimensions filter_dims) { + Dimensions output_dims(input_dims[0], // batch + input_dims[1], // input_height + input_dims[2], // input_width + input_dims[3], // input_planes + filter_dims[4]); // filter_count + + using OutputBackward = TTypes<float, 5>::ConstTensor; + using InputBackward = TTypes<float, 5>::Tensor; + + // Assuming that the convolution had SAME padding. + Eigen::Index input_rows = input_dims[1]; + Eigen::Index input_cols = input_dims[2]; + Eigen::Index input_planes = input_dims[3]; + + Scalar* filter_data = + static_cast<Scalar*>(device_.allocate(BufferSize(filter_dims))); + Scalar* output_backward_data = + static_cast<Scalar*>(device_.allocate(BufferSize(output_dims))); + Scalar* input_backward_data = + static_cast<Scalar*>(device_.allocate(BufferSize(input_dims))); + + device_.memset(filter_data, 123, BufferSize(filter_dims)); + device_.memset(output_backward_data, 123, BufferSize(output_dims)); + + Filter filter(filter_data, filter_dims); + OutputBackward output_backward(output_backward_data, output_dims); + InputBackward input_backward(input_backward_data, input_dims); + + ::tensorflow::testing::StartTiming(); + for (int i = 0; i < iters_; ++i) { + input_backward.device(device_) = Eigen::CuboidConvolutionBackwardInput( + filter, output_backward, input_planes, input_rows, input_cols); + tensorflow::testing::DoNotOptimize(input_backward); + } + ::tensorflow::testing::StopTiming(); + + device_.deallocate(filter_data); + device_.deallocate(output_backward_data); + device_.deallocate(input_backward_data); + } + + void CuboidConvolutionBackwardKernel(Dimensions input_dims, + Dimensions filter_dims) { + using OutputBackward = TTypes<float, 5>::ConstTensor; + using FilterBackward = TTypes<float, 5>::Tensor; + + Dimensions output_dims(input_dims[0], // batch + input_dims[1], // input_height + input_dims[2], // input_width + input_dims[3], // input_planes + filter_dims[4]); // filter_count + + // Assuming that the convolution had SAME padding. + Eigen::Index filter_rows = filter_dims[0]; + Eigen::Index filter_cols = filter_dims[1]; + Eigen::Index filter_planes = filter_dims[2]; + + Scalar* input_data = + static_cast<Scalar*>(device_.allocate(BufferSize(input_dims))); + Scalar* output_backward_data = + static_cast<Scalar*>(device_.allocate(BufferSize(output_dims))); + Scalar* filter_backward_data = + static_cast<Scalar*>(device_.allocate(BufferSize(filter_dims))); + + device_.memset(input_data, 123, BufferSize(input_dims)); + device_.memset(output_backward_data, 123, BufferSize(output_dims)); + + Input input(input_data, input_dims); + OutputBackward output_backward(output_backward_data, output_dims); + FilterBackward filter_backward(filter_backward_data, filter_dims); + + ::tensorflow::testing::StartTiming(); + for (int i = 0; i < iters_; ++i) { + filter_backward.device(device_) = Eigen::CuboidConvolutionBackwardKernel( + input, output_backward, filter_planes, filter_rows, filter_cols); + tensorflow::testing::DoNotOptimize(filter_backward); + } + ::tensorflow::testing::StopTiming(); + + device_.deallocate(input_data); + device_.deallocate(output_backward_data); + device_.deallocate(filter_backward_data); + } + + private: + int iters_; + Device& device_; +}; + +#endif // TENSORFLOW_CORE_KERNELS_EIGEN_BENCHMARK_H_ diff --git a/tensorflow/core/kernels/eigen_benchmark_cpu_test.cc b/tensorflow/core/kernels/eigen_benchmark_cpu_test.cc new file mode 100644 index 0000000000..7c2bbb8148 --- /dev/null +++ b/tensorflow/core/kernels/eigen_benchmark_cpu_test.cc @@ -0,0 +1,411 @@ +/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENTE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONT OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ +#define EIGEN_USE_CUSTOM_THREAD_POOL +#define EIGEN_USE_THREADS + +#include "third_party/eigen3/unsupported/Eigen/CXX11/Tensor" +#include "tensorflow/core/kernels/eigen_benchmark.h" +#include "tensorflow/core/platform/test_benchmark.h" + +#define CREATE_THREAD_POOL(threads) \ + Eigen::ThreadPool tp(threads); \ + Eigen::ThreadPoolDevice device(&tp, threads) + +// -------------------------------------------------------------------------- // +// Spatial Convolutions // +// -------------------------------------------------------------------------- // + +void SpatialConvolution(int iters, int num_threads, + /* Input dimensions: */ + int input_batches, int input_height, int input_width, + int input_depth, + /* Filter (kernel) dimensions: */ + int filter_count, int filter_height, int filter_width) { + ::tensorflow::testing::StopTiming(); + + CREATE_THREAD_POOL(num_threads); + + using Benchmark = + SpatialConvolutionBenchmarksSuite<float, Eigen::ThreadPoolDevice>; + auto benchmark = Benchmark(iters, device); + + typename Benchmark::Dimensions input_dims(input_batches, input_height, + input_width, input_depth); + typename Benchmark::Dimensions filter_dims(filter_height, filter_width, + input_depth, filter_count); + + benchmark.SpatialConvolution(input_dims, filter_dims); + + auto output_size = input_dims.TotalSize(); + auto flops = output_size * (input_depth * filter_height * filter_width); + ::tensorflow::testing::ItemsProcessed(flops * iters); +} + +void SpatialConvolutionBackwardInput(int iters, int num_threads, + /* Input dimensions: */ + int input_batches, int input_height, + int input_width, int input_depth, + /* Filter (kernel) dimensions: */ + int filter_count, int filter_height, + int filter_width) { + ::tensorflow::testing::StopTiming(); + + CREATE_THREAD_POOL(num_threads); + + using Benchmark = + SpatialConvolutionBenchmarksSuite<float, Eigen::ThreadPoolDevice>; + auto benchmark = Benchmark(iters, device); + + typename Benchmark::Dimensions input_dims(input_batches, input_height, + input_width, input_depth); + typename Benchmark::Dimensions filter_dims(filter_height, filter_width, + input_depth, filter_count); + + benchmark.SpatialConvolutionBackwardInput(input_dims, filter_dims); + + auto output_size = input_dims.TotalSize(); + auto flops = output_size * (input_depth * filter_height * filter_width); + ::tensorflow::testing::ItemsProcessed(flops * iters); +} + +void SpatialConvolutionBackwardKernel(int iters, int num_threads, + /* Input dimensions: */ + int input_batches, int input_height, + int input_width, int input_depth, + /* Filter (kernel) dimensions: */ + int filter_count, int filter_height, + int filter_width) { + ::tensorflow::testing::StopTiming(); + + CREATE_THREAD_POOL(num_threads); + + using Benchmark = + SpatialConvolutionBenchmarksSuite<float, Eigen::ThreadPoolDevice>; + auto benchmark = Benchmark(iters, device); + + typename Benchmark::Dimensions input_dims(input_batches, input_height, + input_width, input_depth); + typename Benchmark::Dimensions filter_dims(filter_height, filter_width, + input_depth, filter_count); + + benchmark.SpatialConvolutionBackwardKernel(input_dims, filter_dims); + + auto filter_size = filter_dims.TotalSize(); + auto flops = filter_size * (input_batches * input_height * input_width); + ::tensorflow::testing::ItemsProcessed(flops * iters); +} + +// Macro arguments names: --------------------------------------------------- // +// NT: num threads +// N: batch size +// H: height +// W: width +// C: channels +// FC: filter count +// FH: filter height +// FW: filter width + +#define BM_SPATIAL_NAME(prefix, NT, N, H, W, C, FC, FH, FW) \ + BM_##prefix##_CPU_##NT##T_in_##N##_##H##_##W##_##C##_f_##FC##_##FH##_##FW + +#define BM_SpatialConvolution(NT, N, H, W, C, FC, FH, FW, LABEL) \ + static void BM_SPATIAL_NAME(SpatialConvolution, NT, N, H, W, C, FC, FH, \ + FW)(int iters) { \ + ::tensorflow::testing::SetLabel(LABEL); \ + SpatialConvolution(iters, NT, N, H, W, C, FC, FH, FW); \ + } \ + BENCHMARK(BM_SPATIAL_NAME(SpatialConvolution, NT, N, H, W, C, FC, FH, FW)) + +#define BM_SpatialConvolutionBwdInput(NT, N, H, W, C, FC, FH, FW, LABEL) \ + static void BM_SPATIAL_NAME(SpatialConvolutionBwdInput, NT, N, H, W, C, FC, \ + FH, FW)(int iters) { \ + ::tensorflow::testing::SetLabel(LABEL); \ + SpatialConvolutionBackwardInput(iters, NT, N, H, W, C, FC, FH, FW); \ + } \ + BENCHMARK( \ + BM_SPATIAL_NAME(SpatialConvolutionBwdInput, NT, N, H, W, C, FC, FH, FW)) + +#define BM_SpatialConvolutionBwdKernel(NT, N, H, W, C, FC, FH, FW, LABEL) \ + static void BM_SPATIAL_NAME(SpatialConvolutionBwdKernel, NT, N, H, W, C, FC, \ + FH, FW)(int iters) { \ + ::tensorflow::testing::SetLabel(LABEL); \ + SpatialConvolutionBackwardKernel(iters, NT, N, H, W, C, FC, FH, FW); \ + } \ + BENCHMARK(BM_SPATIAL_NAME(SpatialConvolutionBwdKernel, NT, N, H, W, C, FC, \ + FH, FW)) + +#define BM_SpatialConvolutions(N, H, W, C, FC, FH, FW, LABEL) \ + BM_SpatialConvolution(2, N, H, W, C, FC, FH, FW, LABEL); \ + BM_SpatialConvolution(4, N, H, W, C, FC, FH, FW, LABEL); \ + BM_SpatialConvolution(8, N, H, W, C, FC, FH, FW, LABEL); \ + BM_SpatialConvolution(16, N, H, W, C, FC, FH, FW, LABEL); + +#define BM_SpatialConvolutionsBwdInput(N, H, W, C, FC, FH, FW, LABEL) \ + BM_SpatialConvolutionBwdInput(2, N, H, W, C, FC, FH, FW, LABEL); \ + BM_SpatialConvolutionBwdInput(4, N, H, W, C, FC, FH, FW, LABEL); \ + BM_SpatialConvolutionBwdInput(8, N, H, W, C, FC, FH, FW, LABEL); \ + BM_SpatialConvolutionBwdInput(16, N, H, W, C, FC, FH, FW, LABEL); + +#define BM_SpatialConvolutionsBwdKernel(N, H, W, C, FC, FH, FW, LABEL) \ + BM_SpatialConvolutionBwdKernel(2, N, H, W, C, FC, FH, FW, LABEL); \ + BM_SpatialConvolutionBwdKernel(4, N, H, W, C, FC, FH, FW, LABEL); \ + BM_SpatialConvolutionBwdKernel(8, N, H, W, C, FC, FH, FW, LABEL); \ + BM_SpatialConvolutionBwdKernel(16, N, H, W, C, FC, FH, FW, LABEL); + +// ImageNet Forward Convolutions -------------------------------------------- // + +BM_SpatialConvolutions(32, // batch size + 56, 56, 64, // input: height, width, depth + 192, 3, 3, // filter: count, height, width + "conv2_00"); + +BM_SpatialConvolutions(32, 28, 28, 96, 128, 3, 3, "conv3a_00_3x3"); +BM_SpatialConvolutions(32, 28, 28, 16, 32, 5, 5, "conv3a_00_5x5"); +BM_SpatialConvolutions(32, 28, 28, 128, 192, 3, 3, "conv3_00_3x3"); +BM_SpatialConvolutions(32, 28, 28, 32, 96, 5, 5, "conv3_00_5x5"); +BM_SpatialConvolutions(32, 14, 14, 96, 204, 3, 3, "conv4a_00_3x3"); +BM_SpatialConvolutions(32, 14, 14, 16, 48, 5, 5, "conv4a_00_5x5"); +BM_SpatialConvolutions(32, 14, 14, 112, 224, 3, 3, "conv4b_00_3x3"); +BM_SpatialConvolutions(32, 14, 14, 24, 64, 5, 5, + "conv4b_00_5x5 / conv4c_00_5x5"); +BM_SpatialConvolutions(32, 14, 14, 128, 256, 3, 3, "conv4c_00_3x3"); +BM_SpatialConvolutions(32, 14, 14, 144, 288, 3, 3, "conv4d_00_3x3"); +BM_SpatialConvolutions(32, 14, 14, 32, 64, 5, 5, "conv4d_00_5x5"); +BM_SpatialConvolutions(32, 14, 14, 160, 320, 3, 3, "conv4_00_3x3"); +BM_SpatialConvolutions(32, 14, 14, 32, 128, 5, 5, "conv4_00_5x5"); +BM_SpatialConvolutions(32, 7, 7, 160, 320, 3, 3, "conv5a_00_3x3"); +BM_SpatialConvolutions(32, 7, 7, 48, 128, 5, 5, "conv5a_00_5x5 / conv5_00_5x5"); +BM_SpatialConvolutions(32, 7, 7, 192, 384, 3, 3, "conv5_00_3x3"); + +// Benchmarks from https://github.com/soumith/convnet-benchmarks +BM_SpatialConvolutions(128, 128, 128, 3, 96, 11, 11, "convnet-layer1"); +BM_SpatialConvolutions(128, 64, 64, 64, 128, 9, 9, "convnet-layer2"); +BM_SpatialConvolutions(128, 32, 32, 128, 128, 9, 9, "convnet-layer3"); +BM_SpatialConvolutions(128, 16, 16, 128, 128, 7, 7, "convnet-layer4"); +BM_SpatialConvolutions(128, 13, 13, 384, 384, 3, 3, "convnet-layer5"); + +// ImageNet BackwardInput Convolutions -------------------------------------- // + +BM_SpatialConvolutionsBwdInput(32, 56, 56, 64, 192, 3, 3, "conv2_00"); +BM_SpatialConvolutionsBwdInput(32, 28, 28, 96, 128, 3, 3, "conv3a_00_3x3"); +BM_SpatialConvolutionsBwdInput(32, 28, 28, 16, 32, 5, 5, "conv3a_00_5x5"); +BM_SpatialConvolutionsBwdInput(32, 28, 28, 128, 192, 3, 3, "conv3_00_3x3"); +BM_SpatialConvolutionsBwdInput(32, 28, 28, 32, 96, 5, 5, "conv3_00_5x5"); +BM_SpatialConvolutionsBwdInput(32, 14, 14, 96, 204, 3, 3, "conv4a_00_3x3"); +BM_SpatialConvolutionsBwdInput(32, 14, 14, 16, 48, 5, 5, "conv4a_00_5x5"); +BM_SpatialConvolutionsBwdInput(32, 14, 14, 112, 224, 3, 3, "conv4b_00_3x3"); +BM_SpatialConvolutionsBwdInput(32, 14, 14, 24, 64, 5, 5, + "conv4b_00_5x5 / conv4c_00_5x5"); +BM_SpatialConvolutionsBwdInput(32, 14, 14, 128, 256, 3, 3, "conv4c_00_3x3"); +BM_SpatialConvolutionsBwdInput(32, 14, 14, 144, 288, 3, 3, "conv4d_00_3x3"); +BM_SpatialConvolutionsBwdInput(32, 14, 14, 32, 64, 5, 5, "conv4d_00_5x5"); +BM_SpatialConvolutionsBwdInput(32, 14, 14, 160, 320, 3, 3, "conv4_00_3x3"); +BM_SpatialConvolutionsBwdInput(32, 14, 14, 32, 128, 5, 5, "conv4_00_5x5"); +BM_SpatialConvolutionsBwdInput(32, 7, 7, 160, 320, 3, 3, "conv5a_00_3x3"); +BM_SpatialConvolutionsBwdInput(32, 7, 7, 48, 128, 5, 5, + "conv5a_00_5x5 / conv5_00_5x5"); +BM_SpatialConvolutionsBwdInput(32, 7, 7, 192, 384, 3, 3, "conv5_00_3x3"); + +// ImageNet BackwardKernel Convolutions ------------------------------------- // + +BM_SpatialConvolutionsBwdKernel(32, 56, 56, 64, 192, 3, 3, "conv2_00"); +BM_SpatialConvolutionsBwdKernel(32, 28, 28, 96, 128, 3, 3, "conv3a_00_3x3"); +BM_SpatialConvolutionsBwdKernel(32, 28, 28, 16, 32, 5, 5, "conv3a_00_5x5"); +BM_SpatialConvolutionsBwdKernel(32, 28, 28, 128, 192, 3, 3, "conv3_00_3x3"); +BM_SpatialConvolutionsBwdKernel(32, 28, 28, 32, 96, 5, 5, "conv3_00_5x5"); +BM_SpatialConvolutionsBwdKernel(32, 14, 14, 96, 204, 3, 3, "conv4a_00_3x3"); +BM_SpatialConvolutionsBwdKernel(32, 14, 14, 16, 48, 5, 5, "conv4a_00_5x5"); +BM_SpatialConvolutionsBwdKernel(32, 14, 14, 112, 224, 3, 3, "conv4b_00_3x3"); +BM_SpatialConvolutionsBwdKernel(32, 14, 14, 24, 64, 5, 5, + "conv4b_00_5x5 / conv4c_00_5x5"); +BM_SpatialConvolutionsBwdKernel(32, 14, 14, 128, 256, 3, 3, "conv4c_00_3x3"); +BM_SpatialConvolutionsBwdKernel(32, 14, 14, 144, 288, 3, 3, "conv4d_00_3x3"); +BM_SpatialConvolutionsBwdKernel(32, 14, 14, 32, 64, 5, 5, "conv4d_00_5x5"); +BM_SpatialConvolutionsBwdKernel(32, 14, 14, 160, 320, 3, 3, "conv4_00_3x3"); +BM_SpatialConvolutionsBwdKernel(32, 14, 14, 32, 128, 5, 5, "conv4_00_5x5"); +BM_SpatialConvolutionsBwdKernel(32, 7, 7, 160, 320, 3, 3, "conv5a_00_3x3"); +BM_SpatialConvolutionsBwdKernel(32, 7, 7, 48, 128, 5, 5, + "conv5a_00_5x5 / conv5_00_5x5"); +BM_SpatialConvolutionsBwdKernel(32, 7, 7, 192, 384, 3, 3, "conv5_00_3x3"); + +// -------------------------------------------------------------------------- // +// Cuboid Convolutions // +// -------------------------------------------------------------------------- // + +void CuboidConvolution(int iters, int num_threads, + /* Input dimensions: */ + int input_batches, int input_height, int input_width, + int input_planes, int input_depth, + /* Filter (kernel) dimensions: */ + int filter_count, int filter_height, int filter_width, + int filter_planes) { + ::tensorflow::testing::StopTiming(); + + CREATE_THREAD_POOL(num_threads); + + using Benchmark = + CuboidConvolutionBenchmarksSuite<float, Eigen::ThreadPoolDevice>; + auto benchmark = Benchmark(iters, device); + + typename Benchmark::Dimensions input_dims( + input_batches, input_height, input_width, input_planes, input_depth); + typename Benchmark::Dimensions filter_dims( + filter_height, filter_width, filter_planes, input_depth, filter_count); + + benchmark.CuboidConvolution(input_dims, filter_dims); + + auto output_size = input_dims.TotalSize(); + auto flops = output_size * + (input_depth * filter_height * filter_width * filter_planes); + ::tensorflow::testing::ItemsProcessed(flops * iters); +} + +void CuboidConvolutionBackwardInput(int iters, int num_threads, + /* Input dimensions: */ + int input_batches, int input_height, + int input_width, int input_planes, + int input_depth, + /* Filter (kernel) dimensions: */ + int filter_count, int filter_height, + int filter_width, int filter_planes) { + ::tensorflow::testing::StopTiming(); + + CREATE_THREAD_POOL(num_threads); + + using Benchmark = + CuboidConvolutionBenchmarksSuite<float, Eigen::ThreadPoolDevice>; + auto benchmark = Benchmark(iters, device); + + typename Benchmark::Dimensions input_dims( + input_batches, input_height, input_width, input_planes, input_depth); + typename Benchmark::Dimensions filter_dims( + filter_height, filter_width, filter_planes, input_depth, filter_count); + + benchmark.CuboidConvolutionBackwardInput(input_dims, filter_dims); + + auto output_size = input_dims.TotalSize(); + auto flops = output_size * + (input_depth * filter_height * filter_width * filter_planes); + ::tensorflow::testing::ItemsProcessed(flops * iters); +} + +void CuboidConvolutionBackwardKernel(int iters, int num_threads, + /* Input dimensions: */ + int input_batches, int input_height, + int input_width, int input_planes, + int input_depth, + /* Filter (kernel) dimensions: */ + int filter_count, int filter_height, + int filter_width, int filter_planes) { + ::tensorflow::testing::StopTiming(); + + CREATE_THREAD_POOL(num_threads); + + using Benchmark = + CuboidConvolutionBenchmarksSuite<float, Eigen::ThreadPoolDevice>; + auto benchmark = Benchmark(iters, device); + + typename Benchmark::Dimensions input_dims( + input_batches, input_height, input_width, input_planes, input_depth); + typename Benchmark::Dimensions filter_dims( + filter_height, filter_width, filter_planes, input_depth, filter_count); + + benchmark.CuboidConvolutionBackwardKernel(input_dims, filter_dims); + + auto filter_size = filter_dims.TotalSize(); + auto flops = + filter_size * (input_batches * input_height * input_width * input_planes); + ::tensorflow::testing::ItemsProcessed(flops * iters); +} + +// Macro arguments names: --------------------------------------------------- // +// NT: num threads +// N: batch size +// H: height +// W: width +// P: panes +// C: channels +// FC: filter count +// FH: filter height +// FW: filter width +// FP: filter panes + +#define BM_CONCAT(a, b) a##b + +#define BM_CUBOID_NAME(p, NT, N, H, W, P, C, FC, FH, FW, FP) \ + BM_CONCAT(BM_##p##_CPU_##NT##T_in_##N##_##H##_##W##_##P##_##C, \ + _f_##FC##_##FH##_##FW##_##FP) + +#define BM_CuboidConvolution(NT, N, H, W, P, C, FC, FH, FW, FP, LABEL) \ + static void BM_CUBOID_NAME(CuboidConvolution, NT, N, H, W, P, C, FC, FH, FW, \ + FP)(int iters) { \ + ::tensorflow::testing::SetLabel(LABEL); \ + CuboidConvolution(iters, NT, N, H, W, P, C, FC, FH, FW, FP); \ + } \ + BENCHMARK( \ + BM_CUBOID_NAME(CuboidConvolution, NT, N, H, W, P, C, FC, FH, FW, FP)) + +#define BM_CuboidConvolutionBwdInput(NT, N, H, W, P, C, FC, FH, FW, FP, LABEL) \ + static void BM_CUBOID_NAME(CuboidConvolutionBwdInput, NT, N, H, W, P, C, FC, \ + FH, FW, FP)(int iters) { \ + ::tensorflow::testing::SetLabel(LABEL); \ + CuboidConvolutionBackwardInput(iters, NT, N, H, W, P, C, FC, FH, FW, FP); \ + } \ + BENCHMARK(BM_CUBOID_NAME(CuboidConvolutionBwdInput, NT, N, H, W, P, C, FC, \ + FH, FW, FP)) + +#define BM_CuboidConvolutionBwdKernel(NT, N, H, W, P, C, FC, FH, FW, FP, \ + LABEL) \ + static void BM_CUBOID_NAME(CuboidConvolutionBwdKernel, NT, N, H, W, P, C, \ + FC, FH, FW, FP)(int iters) { \ + ::tensorflow::testing::SetLabel(LABEL); \ + CuboidConvolutionBackwardKernel(iters, NT, N, H, W, P, C, FC, FH, FW, FP); \ + } \ + BENCHMARK(BM_CUBOID_NAME(CuboidConvolutionBwdKernel, NT, N, H, W, P, C, FC, \ + FH, FW, FP)) + +#define BM_CuboidConvolutions(N, H, W, P, C, FC, FH, FW, FP, LABEL) \ + BM_CuboidConvolution(2, N, H, W, P, C, FC, FH, FW, FP, LABEL); \ + BM_CuboidConvolution(4, N, H, W, P, C, FC, FH, FW, FP, LABEL); \ + BM_CuboidConvolution(8, N, H, W, P, C, FC, FH, FW, FP, LABEL); \ + BM_CuboidConvolution(16, N, H, W, P, C, FC, FH, FW, FP, LABEL); + +#define BM_CuboidConvolutionsBwdInput(N, H, W, P, C, FC, FH, FW, FP, LABEL) \ + BM_CuboidConvolutionBwdInput(2, N, H, W, P, C, FC, FH, FW, FP, LABEL); \ + BM_CuboidConvolutionBwdInput(4, N, H, W, P, C, FC, FH, FW, FP, LABEL); \ + BM_CuboidConvolutionBwdInput(8, N, H, W, P, C, FC, FH, FW, FP, LABEL); \ + BM_CuboidConvolutionBwdInput(16, N, H, W, P, C, FC, FH, FW, FP, LABEL); + +#define BM_CuboidConvolutionsBwdKernel(N, H, W, P, C, FC, FH, FW, FP, LABEL) \ + BM_CuboidConvolutionBwdKernel(2, N, H, W, P, C, FC, FH, FW, FP, LABEL); \ + BM_CuboidConvolutionBwdKernel(4, N, H, W, P, C, FC, FH, FW, FP, LABEL); \ + BM_CuboidConvolutionBwdKernel(8, N, H, W, P, C, FC, FH, FW, FP, LABEL); \ + BM_CuboidConvolutionBwdKernel(16, N, H, W, P, C, FC, FH, FW, FP, LABEL); + +// Random Cuboid Convolutions ----------------------------------------------- // +// TODO(ezhulenev): find representative dims for cuboid convolutions (find +// models using Conv3D ops). + +BM_CuboidConvolutions(8, // batch size + 25, 25, 25, 4, // input: height, width, panes, depth + 16, 5, 5, 5, // filter: count, height, width, panes + "conv3d_depth4"); +BM_CuboidConvolutions(8, 25, 25, 25, 8, 16, 5, 5, 5, "conv3d_depth8"); + +BM_CuboidConvolutionsBwdInput(8, 25, 25, 25, 4, 16, 5, 5, 5, "conv3d_depth4"); +BM_CuboidConvolutionsBwdInput(8, 25, 25, 25, 8, 16, 5, 5, 5, "conv3d_depth8"); + +BM_CuboidConvolutionsBwdKernel(8, 25, 25, 25, 4, 16, 5, 5, 5, "conv3d_depth4"); +BM_CuboidConvolutionsBwdKernel(8, 25, 25, 25, 8, 16, 5, 5, 5, "conv3d_depth8"); diff --git a/tensorflow/core/kernels/gather_nd_op_cpu_impl.h b/tensorflow/core/kernels/gather_nd_op_cpu_impl.h index ad0112e6cb..277ee2be02 100644 --- a/tensorflow/core/kernels/gather_nd_op_cpu_impl.h +++ b/tensorflow/core/kernels/gather_nd_op_cpu_impl.h @@ -113,10 +113,25 @@ struct GatherNdSlice<CPUDevice, T, Index, IXDIM> { #endif generator::GatherNdSliceGenerator<T, Index, IXDIM> gather_nd_generator( slice_size, Tindices, Tparams, Tout, &error_loc); + +#ifdef INTEL_MKL +// Eigen implementation below is not highly performant. gather_nd_generator +// does not seem to be called in parallel, leading to very poor performance. +// Additionally, since it uses scalar (Tscratch) to invoke 'generate', it +// needs to go through redundant operations like 'reshape', 'broadcast' and +// 'sum'. OpenMP loop below essentially does same thing as Eigen code, but +// is considerably more efficient. +#pragma omp parallel for + for (Eigen::DenseIndex i = 0; i < batch_size; i++) { + const Eigen::array<Eigen::DenseIndex, 1> loc{i}; + gather_nd_generator(loc); + } +#else // INTEL_MKL Tscratch.device(d) = Tscratch.reshape(reshape_dims) .broadcast(broadcast_dims) .generate(gather_nd_generator) .sum(); +#endif // error_loc() returns -1 if there's no out-of-bounds index, // otherwise it returns the location of an OOB index in Tindices. diff --git a/tensorflow/core/kernels/gpu_utils.h b/tensorflow/core/kernels/gpu_utils.h index c7dbefa0b4..86146f75f4 100644 --- a/tensorflow/core/kernels/gpu_utils.h +++ b/tensorflow/core/kernels/gpu_utils.h @@ -123,8 +123,7 @@ class AutoTuneMap { string GetActionSummary(StringPiece action, const Parameters& params, const Config& config) { return strings::Printf("autotune_map %s %s: %s -> (%s)", name_.c_str(), - std::string(action).c_str(), - params.ToString().c_str(), + string(action).c_str(), params.ToString().c_str(), config.ToString().c_str()); } diff --git a/tensorflow/core/kernels/list_kernels.h b/tensorflow/core/kernels/list_kernels.h index 066a1d603b..72581c9293 100644 --- a/tensorflow/core/kernels/list_kernels.h +++ b/tensorflow/core/kernels/list_kernels.h @@ -374,7 +374,12 @@ Status TensorListZerosLike(OpKernelContext* c, const TensorList& x, y->tensors.reserve(x.tensors.size()); for (const Tensor& t : x.tensors) { Tensor out_tensor; - TF_RETURN_IF_ERROR(c->allocate_temp(t.dtype(), t.shape(), &out_tensor)); + AllocatorAttributes attr; + if (t.dtype() == DT_VARIANT) { + attr.set_on_host(true); + } + TF_RETURN_IF_ERROR( + c->allocate_temp(t.dtype(), t.shape(), &out_tensor, attr)); switch (out_tensor.dtype()) { #define DTYPE_CASE(dtype) \ case DataTypeToEnum<dtype>::value: \ @@ -385,6 +390,20 @@ Status TensorListZerosLike(OpKernelContext* c, const TensorList& x, TF_CALL_POD_TYPES(DTYPE_CASE) #undef DTYPE_CASE + + case DataTypeToEnum<Variant>::value: { + const TensorList* inner_x = t.scalar<Variant>()().get<TensorList>(); + if (inner_x == nullptr) { + return errors::InvalidArgument("Input handle is not a list. Saw: '", + t.scalar<Variant>()().DebugString(), + "'"); + } + TensorList inner_y; + TF_RETURN_IF_ERROR(TensorListZerosLike<Device>(c, *inner_x, &inner_y)); + out_tensor.scalar<Variant>()() = std::move(inner_y); + break; + } + default: return errors::InvalidArgument( "Trying to compute zeros_like for unsupported dtype ", diff --git a/tensorflow/core/kernels/logistic-loss.h b/tensorflow/core/kernels/logistic-loss.h index b43902e0b9..9198a98e47 100644 --- a/tensorflow/core/kernels/logistic-loss.h +++ b/tensorflow/core/kernels/logistic-loss.h @@ -86,7 +86,7 @@ class LogisticLossUpdater : public DualLossUpdater { } else { inverse_exp_term = 1 / (1 + exp(label * wx)); } - return inverse_exp_term * label * example_weight; + return -inverse_exp_term * label * example_weight; } // The smoothness constant is 4 since the derivative of logistic loss, which diff --git a/tensorflow/core/kernels/loss_test.cc b/tensorflow/core/kernels/loss_test.cc index 460d65c5c2..9209ed2ab7 100644 --- a/tensorflow/core/kernels/loss_test.cc +++ b/tensorflow/core/kernels/loss_test.cc @@ -17,6 +17,7 @@ limitations under the License. #include "tensorflow/core/kernels/hinge-loss.h" #include "tensorflow/core/kernels/logistic-loss.h" +#include "tensorflow/core/kernels/poisson-loss.h" #include "tensorflow/core/kernels/smooth-hinge-loss.h" #include "tensorflow/core/kernels/squared-loss.h" #include "tensorflow/core/lib/core/errors.h" @@ -30,6 +31,24 @@ namespace { // TODO(sibyl-Aix6ihai): add a test to show the improvements of the Newton // modification detailed in readme.md +// This test checks that the dual value after update is optimal. +// At the optimum the dual value should be the opposite of the primal gradient. +// This does not hold at a point where the primal is not differentiable. +void TestComputeUpdatedDual(const DualLossUpdater &loss_updater, + const int num_loss_partitions, const double label, + const double example_weight, + const double current_dual, const double wx, + const double weighted_example_norm) { + double new_dual = loss_updater.ComputeUpdatedDual( + num_loss_partitions, label, example_weight, current_dual, wx, + weighted_example_norm); + // The primal gradient needs to be computed after the weight update. + double new_wx = wx + (new_dual - current_dual) * num_loss_partitions * + weighted_example_norm * example_weight; + EXPECT_NEAR(new_dual, -loss_updater.PrimalLossDerivative(new_wx, label, 1.0), + 1e-5); +} + TEST(LogisticLoss, ComputePrimalLoss) { LogisticLossUpdater loss_updater; EXPECT_NEAR(0.693147, @@ -65,19 +84,12 @@ TEST(LogisticLoss, ComputeDualLoss) { TEST(LogisticLoss, ComputeUpdatedDual) { LogisticLossUpdater loss_updater; - EXPECT_NEAR(0.479, - loss_updater.ComputeUpdatedDual( - 1 /* num partitions */, 1.0 /* label */, - 1.0 /* example weight */, 0.5 /* current_dual */, - 0.3 /* wx */, 10.0 /* weighted_example_norm */), - 1e-3); - - EXPECT_NEAR(-0.031, - loss_updater.ComputeUpdatedDual( - 2 /* num partitions */, -1.0 /* label */, - 1.0 /* example weight */, 0.1 /* current_dual */, - -0.8 /* wx */, 10.0 /* weighted_example_norm */), - 1e-3); + TestComputeUpdatedDual(loss_updater, 1 /* num partitions */, 1.0 /* label */, + 1.0 /* example weight */, 0.5 /* current_dual */, + 0.3 /* wx */, 10.0 /* weighted_example_norm */); + TestComputeUpdatedDual(loss_updater, 2 /* num partitions */, -1.0 /* label */, + 1.0 /* example weight */, 0.1 /* current_dual */, + -0.8 /* wx */, 10.0 /* weighted_example_norm */); } TEST(SquaredLoss, ComputePrimalLoss) { @@ -126,19 +138,12 @@ TEST(SquaredLoss, ComputeDualLoss) { TEST(SquaredLoss, ComputeUpdatedDual) { SquaredLossUpdater loss_updater; - EXPECT_NEAR(0.336, - loss_updater.ComputeUpdatedDual( - 1 /* num partitions */, 1.0 /* label */, - 1.0 /* example weight */, 0.3 /* current_dual */, - 0.3 /* wx */, 10.0 /* weighted_example_norm */), - 1e-3); - - EXPECT_NEAR(-0.427, - loss_updater.ComputeUpdatedDual( - 5 /* num partitions */, -1.0 /* label */, - 1.0 /* example weight */, -0.4 /* current_dual */, - 0.8 /* wx */, 10.0 /* weighted_example_norm */), - 1e-3); + TestComputeUpdatedDual(loss_updater, 1 /* num partitions */, 1.0 /* label */, + 1.0 /* example weight */, 0.3 /* current_dual */, + 0.3 /* wx */, 10.0 /* weighted_example_norm */); + TestComputeUpdatedDual(loss_updater, 5 /* num partitions */, -1.0 /* label */, + 1.0 /* example weight */, -0.4 /* current_dual */, + 0.8 /* wx */, 10.0 /* weighted_example_norm */); } TEST(HingeLoss, ComputePrimalLoss) { @@ -207,48 +212,27 @@ TEST(HingeLoss, ConvertLabel) { TEST(HingeLoss, ComputeUpdatedDual) { HingeLossUpdater loss_updater; - // When label=1.0, example_weight=1.0, current_dual=0.5, wx=0.3 and - // weighted_example_norm=100.0, it turns out that the optimal value to update - // the dual to is 0.507 which is within the permitted range and thus should be - // the value returned. + // For the two tests belows, y*wx=1 after the update which is a + // non-differetiable point of the hinge loss and TestComputeUpdatedDual + // cannot be used. Check value of the dual variable instead. EXPECT_NEAR(0.507, loss_updater.ComputeUpdatedDual( 1 /* num partitions */, 1.0 /* label */, 1.0 /* example weight */, 0.5 /* current_dual */, 0.3 /* wx */, 100.0 /* weighted_example_norm */), 1e-3); - // When label=-1.0, example_weight=1.0, current_dual=0.4, wx=0.6, - // weighted_example_norm=10.0 and num_loss_partitions=10, it turns out that - // the optimal value to update the dual to is 0.384 which is within the - // permitted range and thus should be the value returned. EXPECT_NEAR(-0.416, loss_updater.ComputeUpdatedDual( 10 /* num partitions */, -1.0 /* label */, 1.0 /* example weight */, -0.4 /* current_dual */, 0.6 /* wx */, 10.0 /* weighted_example_norm */), 1e-3); - // When label=1.0, example_weight=1.0, current_dual=-0.5, wx=0.3 and - // weighted_example_norm=10.0, it turns out that the optimal value to update - // the dual to is -0.43. However, this is outside the allowed [0.0, 1.0] range - // and hence the closest permitted value (0.0) should be returned instead. - EXPECT_NEAR(0.0, - loss_updater.ComputeUpdatedDual( - 1 /* num partitions */, 1.0 /* label */, - 1.0 /* example weight */, -0.5 /* current_dual */, - 0.3 /* wx */, 10.0 /* weighted_example_norm */), - 1e-3); - - // When label=-1.0, example_weight=2.0, current_dual=-1.0, wx=0.3 and - // weighted_example_norm=10.0, it turns out that the optimal value to update - // the dual to is -1.065. However, this is outside the allowed [-1.0, 0.0] - // range and hence the closest permitted value (-1.0) should be returned - // instead. - EXPECT_NEAR(-1.0, - loss_updater.ComputeUpdatedDual( - 1 /* num partitions */, -1.0 /* label */, - 2.0 /* example weight */, -1.0 /* current_dual */, - 0.3 /* wx */, 10.0 /* weighted_example_norm */), - 1e-3); + TestComputeUpdatedDual(loss_updater, 1 /* num partitions */, 1.0 /* label */, + 1.0 /* example weight */, -0.5 /* current_dual */, + 0.3 /* wx */, 10.0 /* weighted_example_norm */); + TestComputeUpdatedDual(loss_updater, 1 /* num partitions */, -1.0 /* label */, + 2.0 /* example weight */, -1.0 /* current_dual */, + 0.3 /* wx */, 10.0 /* weighted_example_norm */); } TEST(SmoothHingeLoss, ComputePrimalLoss) { @@ -297,19 +281,75 @@ TEST(SmoothHingeLoss, ComputeDualLoss) { TEST(SmoothHingeLoss, ComputeUpdatedDual) { SmoothHingeLossUpdater loss_updater; - EXPECT_NEAR(0.336, - loss_updater.ComputeUpdatedDual( - 1 /* num partitions */, 1.0 /* label */, - 1.0 /* example weight */, 0.3 /* current_dual */, - 0.3 /* wx */, 10.0 /* weighted_example_norm */), - 1e-3); + TestComputeUpdatedDual(loss_updater, 1 /* num partitions */, 1.0 /* label */, + 1.0 /* example weight */, 0.3 /* current_dual */, + 0.3 /* wx */, 10.0 /* weighted_example_norm */); + TestComputeUpdatedDual(loss_updater, 5 /* num partitions */, -1.0 /* label */, + 1.0 /* example weight */, -0.4 /* current_dual */, + 0.8 /* wx */, 10.0 /* weighted_example_norm */); +} - EXPECT_NEAR(-0.427, - loss_updater.ComputeUpdatedDual( - 5 /* num partitions */, -1.0 /* label */, - 1.0 /* example weight */, -0.4 /* current_dual */, - 0.8 /* wx */, 10.0 /* weighted_example_norm */), +TEST(PoissonLoss, ComputePrimalLoss) { + PoissonLossUpdater loss_updater; + EXPECT_NEAR(1.0, + loss_updater.ComputePrimalLoss(0.0 /* wx */, 3.0 /* label */, + 1.0 /* example weight */), 1e-3); + EXPECT_NEAR(21996.0, + loss_updater.ComputePrimalLoss(10.0 /* wx */, 3.0 /* label */, + 1.0 /* example weight */), + 1.0); + EXPECT_NEAR(0.606, + loss_updater.ComputePrimalLoss(-0.5 /* wx */, 0.0 /* label */, + 1.0 /* example weight */), + 1e-3); + EXPECT_NEAR(6.64, + loss_updater.ComputePrimalLoss(1.2 /* wx */, 0.0 /* label */, + 2.0 /* example weight */), + 1e-2); +} + +TEST(PoissonLoss, ComputeDualLoss) { + PoissonLossUpdater loss_updater; + // Dual is undefined. + EXPECT_NEAR( + std::numeric_limits<double>::max(), + loss_updater.ComputeDualLoss(1.0 /* current dual */, 0.0 /* label */, + 1.0 /* example weight */), + 1e-3); + EXPECT_NEAR( + 0.0, + loss_updater.ComputeDualLoss(0.0 /* current dual */, 0.0 /* label */, + 3.0 /* example weight */), + 1e-3); + EXPECT_NEAR( + -0.847, + loss_updater.ComputeDualLoss(1.5 /* current dual */, 2.0 /* label */, + 1.0 /* example weight */), + 1e-3); + EXPECT_NEAR( + -2.675, + loss_updater.ComputeDualLoss(0.5 /* current dual */, 2.0 /* label */, + 3.0 /* example weight */), + 1e-3); +} + +TEST(PoissonLoss, ConvertLabel) { + PoissonLossUpdater loss_updater; + float example_label = -1.0; + // Negative label should throw an error. + Status status = loss_updater.ConvertLabel(&example_label); + EXPECT_FALSE(status.ok()); +} + +TEST(PoissonLoss, ComputeUpdatedDual) { + PoissonLossUpdater loss_updater; + TestComputeUpdatedDual(loss_updater, 1 /* num partitions */, 2.0 /* label */, + 1.0 /* example weight */, 0.5 /* current_dual */, + 0.3 /* wx */, 10.0 /* weighted_example_norm */); + TestComputeUpdatedDual(loss_updater, 2 /* num partitions */, 0.0 /* label */, + 1.0 /* example weight */, 0.0 /* current_dual */, + -0.8 /* wx */, 10.0 /* weighted_example_norm */); } } // namespace diff --git a/tensorflow/core/kernels/merge_v2_checkpoints_op_test.cc b/tensorflow/core/kernels/merge_v2_checkpoints_op_test.cc index 10e468ce46..693ed8a8f0 100644 --- a/tensorflow/core/kernels/merge_v2_checkpoints_op_test.cc +++ b/tensorflow/core/kernels/merge_v2_checkpoints_op_test.cc @@ -114,9 +114,7 @@ class MergeV2CheckpointsOpTest : public OpsTestBase { // Exercises "delete_old_dirs". for (int i = 0; i < 2; ++i) { int directory_found = - Env::Default() - ->IsDirectory(std::string(io::Dirname(prefixes[i]))) - .code(); + Env::Default()->IsDirectory(string(io::Dirname(prefixes[i]))).code(); if (delete_old_dirs) { EXPECT_EQ(error::NOT_FOUND, directory_found); } else { diff --git a/tensorflow/core/kernels/mkl_conv_grad_filter_ops.cc b/tensorflow/core/kernels/mkl_conv_grad_filter_ops.cc index afbfaa83f3..52157ed5fb 100644 --- a/tensorflow/core/kernels/mkl_conv_grad_filter_ops.cc +++ b/tensorflow/core/kernels/mkl_conv_grad_filter_ops.cc @@ -300,19 +300,24 @@ template <typename T> class MklConvBwdFilterPrimitiveFactory : public MklPrimitiveFactory<T> { public: static MklConvBwdFilterPrimitive<T>* Get( - const MklConvBwdFilterParams& convBwdFilterDims) { + const MklConvBwdFilterParams& convBwdFilterDims, bool do_not_cache) { MklConvBwdFilterPrimitive<T>* conv_bwd_filter = nullptr; - // look into the pool for reusable primitive - conv_bwd_filter = dynamic_cast<MklConvBwdFilterPrimitive<T>*>( + if (do_not_cache) { /* Create new primitive always */ + conv_bwd_filter = new MklConvBwdFilterPrimitive<T>(convBwdFilterDims); + } else { + // look into the pool for reusable primitive + conv_bwd_filter = dynamic_cast<MklConvBwdFilterPrimitive<T>*> ( MklConvBwdFilterPrimitiveFactory<T>::GetInstance().GetConvBwdFilter( convBwdFilterDims)); - if (conv_bwd_filter == nullptr) { - conv_bwd_filter = new MklConvBwdFilterPrimitive<T>(convBwdFilterDims); - MklConvBwdFilterPrimitiveFactory<T>::GetInstance().SetConvBwdFilter( - convBwdFilterDims, conv_bwd_filter); + if (conv_bwd_filter == nullptr) { + conv_bwd_filter = new MklConvBwdFilterPrimitive<T>(convBwdFilterDims); + MklConvBwdFilterPrimitiveFactory<T>::GetInstance().SetConvBwdFilter( + convBwdFilterDims, conv_bwd_filter); + } } + return conv_bwd_filter; } @@ -845,8 +850,13 @@ class MklConvCustomBackpropFilterOp MklConvBwdFilterParams convBwdFilterDims(fwd_src_dims, fwd_filter_dims, diff_bias_dims, diff_dst_dims, strides, dilations, padding_left, padding_right, TFPaddingToMklDnnPadding(this->padding_)); - conv_bwd_filter = - MklConvBwdFilterPrimitiveFactory<T>::Get(convBwdFilterDims); + + // MKL DNN allocates large buffers when a conv gradient filter primtive is + // created. So we don't cache conv backward primitives when the env + // variable TF_MKL_OPTIMIZE_PRIMITVE_MEMUSE is set to true. + bool do_not_cache = MklPrimitiveFactory<T>::IsPrimitiveMemOptEnabled(); + conv_bwd_filter = MklConvBwdFilterPrimitiveFactory<T>::Get( + convBwdFilterDims, do_not_cache); auto bwd_filter_pd = conv_bwd_filter->GetPrimitiveDesc(); // allocate output tensors: diff_fitler and diff_bias (w bias) @@ -938,6 +948,9 @@ class MklConvCustomBackpropFilterOp if (diff_filter_reorder_required) { diff_filter.InsertReorderToUserMem(); } + + // delete primitive since it is not cached. + if (do_not_cache) delete conv_bwd_filter; } catch (mkldnn::error& e) { string error_msg = "Status: " + std::to_string(e.status) + ", message: " + string(e.message) + ", in file " + diff --git a/tensorflow/core/kernels/mkl_conv_grad_input_ops.cc b/tensorflow/core/kernels/mkl_conv_grad_input_ops.cc index b5a98301e2..c38c9cc27c 100644 --- a/tensorflow/core/kernels/mkl_conv_grad_input_ops.cc +++ b/tensorflow/core/kernels/mkl_conv_grad_input_ops.cc @@ -174,7 +174,6 @@ class MklConvBwdInputPrimitive : public MklPrimitive { } }; - void Setup(const MklConvBwdInputParams& convBwdInputDims) { // create memory descriptors for convolution data w/ no specified format context_.diff_src_md.reset(new memory::desc( @@ -242,19 +241,23 @@ class MklConvBwdInputPrimitiveFactory : public MklPrimitiveFactory<T> { public: static MklConvBwdInputPrimitive<T>* Get( - const MklConvBwdInputParams& convBwdInputDims) { + const MklConvBwdInputParams& convBwdInputDims, bool do_not_cache) { MklConvBwdInputPrimitive<T>* conv_bwd_input = nullptr; - // look into the pool for reusable primitive - conv_bwd_input = dynamic_cast<MklConvBwdInputPrimitive<T>*>( - MklConvBwdInputPrimitiveFactory<T>::GetInstance().GetConvBwdInput( - convBwdInputDims)); - - if (conv_bwd_input == nullptr) { + if (do_not_cache) { /* Always allocate primitive */ conv_bwd_input = new MklConvBwdInputPrimitive<T>(convBwdInputDims); - MklConvBwdInputPrimitiveFactory<T>::GetInstance().SetConvBwdInput( - convBwdInputDims, conv_bwd_input); + } else { + // look into the pool for reusable primitive + conv_bwd_input = dynamic_cast<MklConvBwdInputPrimitive<T>*>( + MklConvBwdInputPrimitiveFactory<T>::GetInstance().GetConvBwdInput( + convBwdInputDims)); + if (conv_bwd_input == nullptr) { + conv_bwd_input = new MklConvBwdInputPrimitive<T>(convBwdInputDims); + MklConvBwdInputPrimitiveFactory<T>::GetInstance().SetConvBwdInput( + convBwdInputDims, conv_bwd_input); + } } + return conv_bwd_input; } @@ -708,8 +711,18 @@ class MklConvCustomBackpropInputOp : public MklConvBackpropCommonOp<Device, T> { MklConvBwdInputParams convBwdInputDims(fwd_src_dims, fwd_filter_dims, diff_dst_dims, strides, dilations, padding_left, padding_right, TFPaddingToMklDnnPadding(this->padding_)); - conv_bwd_input = - MklConvBwdInputPrimitiveFactory<T>::Get(convBwdInputDims); + + // We don't cache those primitves if the env variable + // TF_MKL_OPTIMIZE_PRIMITVE_MEMUSE is true and if primitve descriptor + // includes potentialy large buffers. MKL DNN allocates buffers + // in the following cases + // 1. Legacy CPU without AVX512/AVX2, or + // 2. 1x1 convolution with stride != 1 + bool do_not_cache = MklPrimitiveFactory<T>::IsPrimitiveMemOptEnabled() && + (MklPrimitiveFactory<T>::IsLegacyPlatform() || + IsConv1x1StrideNot1(fwd_filter_dims, strides)); + conv_bwd_input = MklConvBwdInputPrimitiveFactory<T>::Get(convBwdInputDims, + do_not_cache); auto bwd_input_pd = conv_bwd_input->GetPrimitiveDesc(); // allocate output tensor @@ -755,6 +768,11 @@ class MklConvCustomBackpropInputOp : public MklConvBackpropCommonOp<Device, T> { // execute convolution input bwd conv_bwd_input->Execute(diff_src_data, filter_data, diff_dst_data); + + // delete primitive since it is not cached. + if (do_not_cache) { + delete conv_bwd_input; + } } catch (mkldnn::error& e) { string error_msg = "Status: " + std::to_string(e.status) + ", message: " + string(e.message) + ", in file " + diff --git a/tensorflow/core/kernels/mkl_conv_ops.cc b/tensorflow/core/kernels/mkl_conv_ops.cc index c6295c7280..9b10c3f3d6 100644 --- a/tensorflow/core/kernels/mkl_conv_ops.cc +++ b/tensorflow/core/kernels/mkl_conv_ops.cc @@ -271,18 +271,23 @@ class MklConvFwdPrimitive : public MklPrimitive { template <typename T> class MklConvFwdPrimitiveFactory : public MklPrimitiveFactory<T> { public: - static MklConvFwdPrimitive<T>* Get(const MklConvFwdParams& convFwdDims) { + static MklConvFwdPrimitive<T>* Get(const MklConvFwdParams& convFwdDims, + bool do_not_cache) { MklConvFwdPrimitive<T>* conv_fwd = nullptr; - // try to find a suitable one in pool - conv_fwd = dynamic_cast<MklConvFwdPrimitive<T>*>( - MklConvFwdPrimitiveFactory<T>::GetInstance().GetConvFwd(convFwdDims)); - - if (conv_fwd == nullptr) { + if (do_not_cache) { /* Always create new primitive */ conv_fwd = new MklConvFwdPrimitive<T>(convFwdDims); - MklConvFwdPrimitiveFactory<T>::GetInstance().SetConvFwd(convFwdDims, - conv_fwd); + } else { + // try to find a suitable one in pool + conv_fwd = dynamic_cast<MklConvFwdPrimitive<T>*>( + MklConvFwdPrimitiveFactory<T>::GetInstance().GetConvFwd(convFwdDims)); + if (conv_fwd == nullptr) { + conv_fwd = new MklConvFwdPrimitive<T>(convFwdDims); + MklConvFwdPrimitiveFactory<T>::GetInstance().SetConvFwd(convFwdDims, + conv_fwd); + } } + return conv_fwd; } @@ -894,6 +899,17 @@ class MklConvOp : public OpKernel { // MKLDNN dilation starts from 0. for (int i = 0; i < dilations.size(); i++) dilations[i] -= 1; + // In some cases, primitve descriptor includes potentialy large buffers, + // we don't cache those primitves if the env variable + // TF_MKL_OPTIMIZE_PRIMITVE_MEMUSE is true. MKL DNN allocates buffers + // in the following cases + // 1. Legacy CPU without AVX512/AVX2, or + // 2. 1x1 convolution with stride != 1 + bool do_not_cache = MklPrimitiveFactory<T>::IsPrimitiveMemOptEnabled() && + (src_dims[MklDnnDims::Dim_N] > kSmallBatchSize) && + (MklPrimitiveFactory<T>::IsLegacyPlatform() || + IsConv1x1StrideNot1(filter_dims, strides)); + // get a conv2d fwd from primitive pool MklConvFwdPrimitive<T>* conv_fwd = nullptr; if (biasEnabled) { @@ -902,12 +918,14 @@ class MklConvOp : public OpKernel { MklConvFwdParams convFwdDims(src_dims, filter_dims, bias_dims, dst_dims_mkl_order, strides, dilations, padding_left, padding_right); - conv_fwd = MklConvFwdPrimitiveFactory<T>::Get(convFwdDims); + conv_fwd = MklConvFwdPrimitiveFactory<T>::Get( + convFwdDims, do_not_cache); } else { MklConvFwdParams convFwdDims(src_dims, filter_dims, NONE_DIMS, dst_dims_mkl_order, strides, dilations, padding_left, padding_right); - conv_fwd = MklConvFwdPrimitiveFactory<T>::Get(convFwdDims); + conv_fwd = MklConvFwdPrimitiveFactory<T>::Get( + convFwdDims, do_not_cache); } // allocate output tensors output_tensor and filter_out_tensor @@ -952,6 +970,9 @@ class MklConvOp : public OpKernel { } else { conv_fwd->Execute(src_data, filter_data, dst_data); } + + // delete primitive since it is not cached. + if (do_not_cache) delete conv_fwd; } catch (mkldnn::error &e) { string error_msg = tensorflow::strings::StrCat( "Status: ", e.status, ", message: ", string(e.message), ", in file ", diff --git a/tensorflow/core/kernels/mkl_softmax_op.cc b/tensorflow/core/kernels/mkl_softmax_op.cc index 8bde966be9..04d8a1bdeb 100644 --- a/tensorflow/core/kernels/mkl_softmax_op.cc +++ b/tensorflow/core/kernels/mkl_softmax_op.cc @@ -50,6 +50,7 @@ class MklSoftmaxOp : public OpKernel { // src_tensor now points to the 0-th input of global data struct "context" size_t src_idx = 0; const Tensor& src_tensor = MklGetInput(context, src_idx); + const int input_dims = src_tensor.dims(); // Add: get MklShape MklDnnShape src_mkl_shape; @@ -62,7 +63,32 @@ class MklSoftmaxOp : public OpKernel { : src_tensor.shape(); auto src_dims = TFShapeToMklDnnDims(src_tf_shape); auto output_dims = src_dims; - + memory::format layout_type; + // In MKL, data format passed to mkl softmax op depends on dimension of the input tensor. + // Here "x" data format in MKL is used for 1 dim tensor, "nc" for 2 dim tensor, + // "tnc" for 3 dim tensor, "nchw" for 4 dim tensor, and "ncdhw" for 5 dim tensor. + // Each of the simbols has the following meaning: + // n = batch, c = channels, t = sequence lenght, h = height, + // w = width, d = depth + switch (input_dims) { + case 1: + layout_type = memory::format::x; + break; + case 2: + layout_type = memory::format::nc; + break; + case 3: + layout_type = memory::format::tnc; + break; + case 4: + layout_type = memory::format::nchw; + break; + case 5: + layout_type = memory::format::ncdhw; + break; + default: + OP_REQUIRES_OK(context, errors::Aborted("Input dims must be <= 5 and >=1")); + } // Create softmax memory for src, dst: both are defined in mkl_util.h, // they are wrapper MklDnnData<T> src(&cpu_engine); @@ -75,7 +101,7 @@ class MklSoftmaxOp : public OpKernel { auto src_md = src_mkl_shape.IsMklTensor() ? src_mkl_shape.GetMklLayout() - : memory::desc(src_dims, MklDnnType<T>(), memory::format::nc); + : memory::desc(src_dims, MklDnnType<T>(), layout_type); // src: setting memory descriptor and op memory descriptor // Basically following two functions maps the TF "src_tensor" to mkl @@ -84,10 +110,11 @@ class MklSoftmaxOp : public OpKernel { // data format is "nc" for src and dst; since the src and dst buffer is // always in 2D shape src.SetUsrMem(src_md, &src_tensor); - src.SetOpMemDesc(src_dims, memory::format::nc); + src.SetOpMemDesc(src_dims, layout_type); // creating a memory descriptor - int axis = 1; // axis to which softmax will be applied + // passing outermost dim as default axis, where the softmax is applied + int axis = input_dims - 1; auto softmax_fwd_desc = softmax_forward::desc(prop_kind::forward_scoring, src.GetOpMemDesc(), axis); auto softmax_fwd_pd = @@ -107,7 +134,7 @@ class MklSoftmaxOp : public OpKernel { output_mkl_shape.SetMklLayout(&dst_pd); output_mkl_shape.SetElemType(MklDnnType<T>()); output_mkl_shape.SetTfLayout(output_dims.size(), output_dims, - memory::format::nc); + layout_type); output_tf_shape.AddDim((dst_pd.get_size() / sizeof(T))); } else { // then output is also TF shape output_mkl_shape.SetMklTensor(false); diff --git a/tensorflow/core/kernels/poisson-loss.h b/tensorflow/core/kernels/poisson-loss.h new file mode 100644 index 0000000000..f91244454e --- /dev/null +++ b/tensorflow/core/kernels/poisson-loss.h @@ -0,0 +1,109 @@ +/* Copyright 2016 The TensorFlow Authors. All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +#ifndef TENSORFLOW_CORE_KERNELS_POISSON_LOSS_H_ +#define TENSORFLOW_CORE_KERNELS_POISSON_LOSS_H_ + +#include <cmath> + +#include "tensorflow/core/kernels/loss.h" +#include "tensorflow/core/lib/core/errors.h" + +namespace tensorflow { + +class PoissonLossUpdater : public DualLossUpdater { + public: + // Update is found by a Newton algorithm (see readme.md). + double ComputeUpdatedDual(const int num_loss_partitions, const double label, + const double example_weight, + const double current_dual, const double wx, + const double weighted_example_norm) const final { + // Newton algorithm converges quadratically so 10 steps will be largely + // enough to achieve a very good precision + static const int newton_total_steps = 10; + // Initialize the Newton optimization at x such that + // exp(x) = label - current_dual + const double y_minus_a = label - current_dual; + double x = (y_minus_a > 0) ? log(y_minus_a) : 0; + for (int i = 0; i < newton_total_steps; ++i) { + x = NewtonStep(x, num_loss_partitions, label, wx, example_weight, + weighted_example_norm, current_dual); + } + return label - exp(x); + } + + // Dual of poisson loss function. + // https://en.wikipedia.org/wiki/Convex_conjugate + double ComputeDualLoss(const double current_dual, const double example_label, + const double example_weight) const final { + // Dual of the poisson loss function is + // (y-a)*(log(y-a)-1), where a is the dual variable. + // It is defined only for a<y. + const double y_minus_a = example_label - current_dual; + if (y_minus_a == 0.0) { + // (y-a)*(log(y-a)-1) approaches 0 as y-a approaches 0. + return 0.0; + } + if (y_minus_a < 0.0) { + return std::numeric_limits<double>::max(); + } + return y_minus_a * (log(y_minus_a) - 1) * example_weight; + } + + double ComputePrimalLoss(const double wx, const double example_label, + const double example_weight) const final { + return (exp(wx) - wx * example_label) * example_weight; + } + + double PrimalLossDerivative(const double wx, const double label, + const double example_weight) const final { + return (exp(wx) - label) * example_weight; + } + + // TODO(chapelle): We need to introduce a maximum_prediction parameter, + // expose that parameter to the user and have this method return + // 1.0/maximum_prediction. + // Setting this at 1 for now, it only impacts the adaptive sampling. + double SmoothnessConstant() const final { return 1; } + + Status ConvertLabel(float* const example_label) const final { + if (*example_label < 0.0) { + return errors::InvalidArgument( + "Only non-negative labels can be used with the Poisson log loss. " + "Found example with label: ", *example_label); + } + return Status::OK(); + } + + private: + // One Newton step (see readme.md). + double NewtonStep(const double x, const int num_loss_partitions, + const double label, const double wx, + const double example_weight, + const double weighted_example_norm, + const double current_dual) const { + const double expx = exp(x); + const double numerator = + x - wx - num_loss_partitions * weighted_example_norm * + example_weight * (label - current_dual - expx); + const double denominator = + 1 + num_loss_partitions * weighted_example_norm * example_weight * expx; + return x - numerator / denominator; + } +}; + +} // namespace tensorflow + +#endif // TENSORFLOW_CORE_KERNELS_LOGISTIC_LOSS_H_ diff --git a/tensorflow/core/kernels/qr_op_complex128.cc b/tensorflow/core/kernels/qr_op_complex128.cc index d8d589f5aa..8a3e3dc0a9 100644 --- a/tensorflow/core/kernels/qr_op_complex128.cc +++ b/tensorflow/core/kernels/qr_op_complex128.cc @@ -24,7 +24,13 @@ REGISTER_LINALG_OP("Qr", (QrOp<complex128>), complex128); // cuSolver affecting older hardware. The cuSolver team is tracking the issue // (https://partners.nvidia.com/bug/viewbug/2171459) and we will re-enable // this feature when a fix is available. -// REGISTER_LINALG_OP_GPU("Qr", (QrOpGpu<complex128>), complex128); +REGISTER_KERNEL_BUILDER(Name("Qr") + .Device(DEVICE_GPU) + .TypeConstraint<complex128>("T") + .HostMemory("input") + .HostMemory("q") + .HostMemory("r"), + QrOp<complex128>); #endif } // namespace tensorflow diff --git a/tensorflow/core/kernels/qr_op_double.cc b/tensorflow/core/kernels/qr_op_double.cc index 63f2e03b3b..05537a0eaa 100644 --- a/tensorflow/core/kernels/qr_op_double.cc +++ b/tensorflow/core/kernels/qr_op_double.cc @@ -24,7 +24,13 @@ REGISTER_LINALG_OP("Qr", (QrOp<double>), double); // cuSolver affecting older hardware. The cuSolver team is tracking the issue // (https://partners.nvidia.com/bug/viewbug/2171459) and we will re-enable // this feature when a fix is available. -// REGISTER_LINALG_OP_GPU("Qr", (QrOpGpu<double>), double); +REGISTER_KERNEL_BUILDER(Name("Qr") + .Device(DEVICE_GPU) + .TypeConstraint<double>("T") + .HostMemory("input") + .HostMemory("q") + .HostMemory("r"), + QrOp<double>); #endif } // namespace tensorflow diff --git a/tensorflow/core/kernels/qr_op_float.cc b/tensorflow/core/kernels/qr_op_float.cc index 0b1a0aaa76..6aebd98186 100644 --- a/tensorflow/core/kernels/qr_op_float.cc +++ b/tensorflow/core/kernels/qr_op_float.cc @@ -24,7 +24,13 @@ REGISTER_LINALG_OP("Qr", (QrOp<float>), float); // cuSolver affecting older hardware. The cuSolver team is tracking the issue // (https://partners.nvidia.com/bug/viewbug/2171459) and we will re-enable // this feature when a fix is available. -// REGISTER_LINALG_OP_GPU("Qr", (QrOpGpu<float>), float); +REGISTER_KERNEL_BUILDER(Name("Qr") + .Device(DEVICE_GPU) + .TypeConstraint<float>("T") + .HostMemory("input") + .HostMemory("q") + .HostMemory("r"), + QrOp<float>); #endif } // namespace tensorflow diff --git a/tensorflow/core/kernels/remote_fused_graph_execute_utils.cc b/tensorflow/core/kernels/remote_fused_graph_execute_utils.cc index 194a711d98..26f107f940 100644 --- a/tensorflow/core/kernels/remote_fused_graph_execute_utils.cc +++ b/tensorflow/core/kernels/remote_fused_graph_execute_utils.cc @@ -47,7 +47,7 @@ std::unordered_set<string> BuildNodeSetFromNodeNamesAndPorts( std::unordered_set<string> retval; for (const string& node_name_and_port : node_names_and_ports) { const TensorId tid = ParseTensorName(node_name_and_port); - retval.emplace(std::string(tid.first)); + retval.emplace(tid.first); } return retval; } @@ -64,7 +64,7 @@ Node* FindMutableNodeByName(const string& name, Graph* graph) { const NodeDef* FindNodeDefByName(const string& input, const GraphDef& graph_def) { const TensorId tid = ParseTensorName(input); - const string name = std::string(tid.first); + const string name = string(tid.first); for (const NodeDef& node_def : graph_def.node()) { if (node_def.name() == name) { return &node_def; @@ -423,7 +423,7 @@ RemoteFusedGraphExecuteUtils::AddOutputTensorShapeTypeByTensorShapeMap( std::vector<DataType> data_types; std::vector<TensorShape> shapes; const TensorId tid = ParseTensorName(name_and_port); - const string node_name = std::string(tid.first); + const string node_name(tid.first); const int port = tid.second; const NodeDef* node_def = FindNodeDefByName(node_name, graph_def); CHECK_NOTNULL(node_def); @@ -522,8 +522,7 @@ RemoteFusedGraphExecuteUtils::GetTensorShapeType( const TensorShapeMap& tensor_shape_map, const string& node_name) { if (node_name.find(':') != string::npos) { const TensorId tid = ParseTensorName(node_name); - return GetTensorShapeType(tensor_shape_map, std::string(tid.first), - tid.second); + return GetTensorShapeType(tensor_shape_map, string(tid.first), tid.second); } else { return GetTensorShapeType(tensor_shape_map, node_name, 0); } @@ -570,7 +569,7 @@ RemoteFusedGraphExecuteUtils::BuildRemoteGraphInputsAndOutputsFromProto( const TensorId tid = ParseTensorName(name); CHECK_EQ(tensor_shape_map->count(name), 0); tensor_shape_map->emplace( - std::string(tid.first), + string(tid.first), std::make_pair(tid.second, std::make_pair(tensor.dtype(), tensor.shape()))); } @@ -692,7 +691,7 @@ RemoteFusedGraphExecuteUtils::BuildRemoteFusedGraphExecuteOpNode( std::vector<NodeBuilder::NodeOut> node_out_list; for (const string& input : inputs) { const TensorId tid = ParseTensorName(input); - Node* node = FindMutableNodeByName(std::string(tid.first), graph); + Node* node = FindMutableNodeByName(string(tid.first), graph); CHECK_NOTNULL(node); node_out_list.emplace_back(node, tid.second); } @@ -848,7 +847,7 @@ RemoteFusedGraphExecuteUtils::BuildRemoteFusedGraphExecuteOpNode( for (const string& subgraph_input : std::get<1>(cluster)) { const TensorId tid = ParseTensorName(subgraph_input); - const string subgraph_input_name = std::string(tid.first); + const string subgraph_input_name(tid.first); const int subgraph_input_port = tid.second; const NodeDef* node_def = FindNodeDefByName(subgraph_input_name, graph_def); CHECK_NOTNULL(node_def); @@ -895,7 +894,7 @@ RemoteFusedGraphExecuteUtils::BuildRemoteFusedGraphExecuteOpNode( std::deque<const Node*> queue; for (const string& output : border_outputs) { const TensorId tid = ParseTensorName(output); - const string& output_node_name = std::string(tid.first); + const string output_node_name(tid.first); for (const Node* node : graph.nodes()) { if (output_node_name == node->name()) { queue.push_back(node); @@ -975,7 +974,7 @@ RemoteFusedGraphExecuteUtils::BuildRemoteFusedGraphExecuteOpNode( for (int j = 0; j < border_outputs.size(); ++j) { const string& output = border_outputs.at(j); const TensorId tid = ParseTensorName(output); - const string output_name = std::string(tid.first); + const string output_name(tid.first); Node* src_node = edge->src(); if (src_node != nullptr && src_node->name() == output_name && edge->src_output() == tid.second) { @@ -995,12 +994,11 @@ RemoteFusedGraphExecuteUtils::BuildRemoteFusedGraphExecuteOpNode( // RemoteFusedGraphExecuteOpNode for (const string& output : outputs) { const TensorId output_tid = ParseTensorName(output); - const string output_name = std::string(output_tid.first); + const string output_name(output_tid.first); for (size_t i = 0; i < border_outputs.size(); ++i) { const TensorId subgraph_output_tid = ParseTensorName(border_outputs.at(i)); - const string& subgraph_output_name = - std::string(subgraph_output_tid.first); + const string subgraph_output_name(subgraph_output_tid.first); if (output_name == subgraph_output_name) { LOG(INFO) << "As graph output and subgraph output are same, " << "the graph output node is replaced by identity node"; @@ -1435,7 +1433,7 @@ RemoteFusedGraphExecuteUtils::BuildNodeMapFromOpsDefinitions( GraphDef* graph_def) { const TensorId tid = ParseTensorName(input); CHECK_EQ(0, tid.second); - const string node_name = std::string(tid.first); + const string node_name(tid.first); for (NodeDef& node : *graph_def->mutable_node()) { if (node.name() != node_name) { continue; diff --git a/tensorflow/core/kernels/save_restore_tensor.cc b/tensorflow/core/kernels/save_restore_tensor.cc index e335e38bdc..82546d581a 100644 --- a/tensorflow/core/kernels/save_restore_tensor.cc +++ b/tensorflow/core/kernels/save_restore_tensor.cc @@ -161,9 +161,12 @@ void RestoreTensor(OpKernelContext* context, // If we cannot find a cached reader we will allocate our own. std::unique_ptr<checkpoint::TensorSliceReader> allocated_reader; - const checkpoint::TensorSliceReader* reader = - context->slice_reader_cache()->GetReader(file_pattern, open_func, - preferred_shard); + const checkpoint::TensorSliceReader* reader = nullptr; + + if (context->slice_reader_cache()) { + reader = context->slice_reader_cache()->GetReader(file_pattern, open_func, + preferred_shard); + } if (!reader) { allocated_reader.reset(new checkpoint::TensorSliceReader( file_pattern, open_func, preferred_shard)); diff --git a/tensorflow/core/kernels/save_restore_v2_ops.cc b/tensorflow/core/kernels/save_restore_v2_ops.cc index ab4de6c815..180eb3ca34 100644 --- a/tensorflow/core/kernels/save_restore_v2_ops.cc +++ b/tensorflow/core/kernels/save_restore_v2_ops.cc @@ -220,9 +220,9 @@ class MergeV2Checkpoints : public OpKernel { context, tensorflow::MergeBundles(env, input_prefixes, merged_prefix)); if (delete_old_dirs_) { - const string& merged_dir = std::string(io::Dirname(merged_prefix)); + const string merged_dir(io::Dirname(merged_prefix)); for (const string& input_prefix : input_prefixes) { - const string& dirname = std::string(io::Dirname(input_prefix)); + const string dirname(io::Dirname(input_prefix)); if (dirname == merged_dir) continue; Status status = env->DeleteDir(dirname); // For sharded save, only the first delete will go through and all diff --git a/tensorflow/core/kernels/sdca_internal.cc b/tensorflow/core/kernels/sdca_internal.cc index 1c071d3d41..a8e9b3261c 100644 --- a/tensorflow/core/kernels/sdca_internal.cc +++ b/tensorflow/core/kernels/sdca_internal.cc @@ -251,7 +251,7 @@ Status Examples::SampleAdaptiveProbabilities( num_weight_vectors); const double kappa = example_state_data(example_id, 0) + loss_updater->PrimalLossDerivative( - example_statistics.wx[0], label, example_weight); + example_statistics.wx[0], label, 1.0); probabilities_[example_id] = example_weight * sqrt(examples_[example_id].squared_norm_ + regularization.symmetric_l2() * diff --git a/tensorflow/core/kernels/sdca_ops.cc b/tensorflow/core/kernels/sdca_ops.cc index 05c835ebc4..3bd4168dc7 100644 --- a/tensorflow/core/kernels/sdca_ops.cc +++ b/tensorflow/core/kernels/sdca_ops.cc @@ -38,6 +38,7 @@ limitations under the License. #include "tensorflow/core/kernels/hinge-loss.h" #include "tensorflow/core/kernels/logistic-loss.h" #include "tensorflow/core/kernels/loss.h" +#include "tensorflow/core/kernels/poisson-loss.h" #include "tensorflow/core/kernels/sdca_internal.h" #include "tensorflow/core/kernels/smooth-hinge-loss.h" #include "tensorflow/core/kernels/squared-loss.h" @@ -75,6 +76,8 @@ struct ComputeOptions { loss_updater.reset(new HingeLossUpdater); } else if (loss_type == "smooth_hinge_loss") { loss_updater.reset(new SmoothHingeLossUpdater); + } else if (loss_type == "poisson_loss") { + loss_updater.reset(new PoissonLossUpdater); } else { OP_REQUIRES( context, false, diff --git a/tensorflow/core/kernels/string_strip_op.cc b/tensorflow/core/kernels/string_strip_op.cc index 2aeafa28c4..544dca96ba 100644 --- a/tensorflow/core/kernels/string_strip_op.cc +++ b/tensorflow/core/kernels/string_strip_op.cc @@ -43,7 +43,7 @@ class StringStripOp : public OpKernel { for (int64 i = 0; i < input.size(); ++i) { StringPiece entry(input(i)); str_util::RemoveWhitespaceContext(&entry); - output(i) = std::string(entry); + output(i) = string(entry); } } }; diff --git a/tensorflow/core/kernels/tensor_array_ops.cc b/tensorflow/core/kernels/tensor_array_ops.cc index 632b65e9b6..2ec2651c04 100644 --- a/tensorflow/core/kernels/tensor_array_ops.cc +++ b/tensorflow/core/kernels/tensor_array_ops.cc @@ -297,7 +297,7 @@ class TensorArrayGradOp : public TensorArrayCreationOp { resource.name()); } tensor_array_name = - std::string(StringPiece(resource.name()).substr(container.size())); + string(StringPiece(resource.name()).substr(container.size())); } auto output_handle = tensor_array_output_handle->flat<string>(); diff --git a/tensorflow/core/kernels/whole_file_read_ops.cc b/tensorflow/core/kernels/whole_file_read_ops.cc index ed2bf3e8e2..1bf46b5e46 100644 --- a/tensorflow/core/kernels/whole_file_read_ops.cc +++ b/tensorflow/core/kernels/whole_file_read_ops.cc @@ -134,7 +134,7 @@ class WriteFileOp : public OpKernel { "Contents tensor must be scalar, but had shape: ", contents_input->shape().DebugString())); const string& filename = filename_input->scalar<string>()(); - const string dir = std::string(io::Dirname(filename)); + const string dir(io::Dirname(filename)); if (!context->env()->FileExists(dir).ok()) { OP_REQUIRES_OK(context, context->env()->RecursivelyCreateDir(dir)); } diff --git a/tensorflow/core/lib/core/errors.h b/tensorflow/core/lib/core/errors.h index 49a8a4dbd4..d5cbe6c616 100644 --- a/tensorflow/core/lib/core/errors.h +++ b/tensorflow/core/lib/core/errors.h @@ -131,11 +131,23 @@ inline string FormatNodeNameForError(const string& name) { // LINT.ThenChange(//tensorflow/python/client/session.py) template <typename T> string FormatNodeNamesForError(const T& names) { - ::tensorflow::str_util::Formatter<string> f( - [](string* output, const string& s) { + return ::tensorflow::str_util::Join( + names, ", ", [](string* output, const string& s) { ::tensorflow::strings::StrAppend(output, FormatNodeNameForError(s)); }); - return ::tensorflow::str_util::Join(names, ", ", f); +} +// LINT.IfChange +inline string FormatColocationNodeForError(const string& name) { + return strings::StrCat("{{colocation_node ", name, "}}"); +} +// LINT.ThenChange(//tensorflow/python/framework/error_interpolation.py) +template <typename T> +string FormatColocationNodeForError(const T& names) { + return ::tensorflow::str_util::Join( + names, ", ", [](string* output, const string& s) { + ::tensorflow::strings::StrAppend(output, + FormatColocationNodeForError(s)); + }); } // The CanonicalCode() for non-errors. diff --git a/tensorflow/core/lib/gtl/inlined_vector.h b/tensorflow/core/lib/gtl/inlined_vector.h index c18dc9ad1a..2d622dc229 100644 --- a/tensorflow/core/lib/gtl/inlined_vector.h +++ b/tensorflow/core/lib/gtl/inlined_vector.h @@ -13,674 +13,19 @@ See the License for the specific language governing permissions and limitations under the License. ==============================================================================*/ -// An InlinedVector<T,N,A> is like a std::vector<T,A>, except that storage -// for sequences of length <= N are provided inline without requiring -// any heap allocation. Typically N is very small (e.g., 4) so that -// sequences that are expected to be short do not require allocations. -// -// Only some of the std::vector<> operations are currently implemented. -// Other operations may be added as needed to facilitate migrating -// code that uses std::vector<> to InlinedVector<>. -// -// NOTE: If you want an inlined version to replace use of a -// std::vector<bool>, consider using util::bitmap::InlinedBitVector<NBITS> -// in util/bitmap/inlined_bitvector.h -// -// TODO(billydonahue): change size_t to size_type where appropriate. - #ifndef TENSORFLOW_CORE_LIB_GTL_INLINED_VECTOR_H_ #define TENSORFLOW_CORE_LIB_GTL_INLINED_VECTOR_H_ -#include <stddef.h> -#include <stdlib.h> -#include <string.h> -#include <sys/types.h> -#include <algorithm> -#include <cstddef> -#include <iterator> -#include <memory> -#include <type_traits> -#include <vector> - -#include "tensorflow/core/lib/gtl/manual_constructor.h" -#include "tensorflow/core/platform/byte_order.h" -#include "tensorflow/core/platform/logging.h" -#include "tensorflow/core/platform/mem.h" +#include "absl/container/inlined_vector.h" +// TODO(kramerb): This is kept only because lots of targets transitively depend +// on it. Remove all targets' dependencies. +#include "tensorflow/core/platform/macros.h" #include "tensorflow/core/platform/types.h" -#include <initializer_list> // NOLINT(build/include_order) - namespace tensorflow { namespace gtl { -template <typename T, int N> -class InlinedVector { - public: - typedef T value_type; - typedef T* pointer; - typedef const T* const_pointer; - typedef T& reference; - typedef const T& const_reference; - typedef size_t size_type; - typedef std::ptrdiff_t difference_type; - typedef pointer iterator; - typedef const_pointer const_iterator; - - // Create an empty vector - InlinedVector(); - - // Create a vector with n copies of value_type(). - explicit InlinedVector(size_t n); - - // Create a vector with n copies of elem - InlinedVector(size_t n, const value_type& elem); - - // Create and initialize with the elements [range_start .. range_end). - // The unused enable_if argument restricts this constructor so that it is - // elided when value_type is an integral type. This prevents ambiguous - // interpretation between a call to this constructor with two integral - // arguments and a call to the preceding (n, elem) constructor. - template <typename InputIterator> - InlinedVector( - InputIterator range_start, InputIterator range_end, - typename std::enable_if<!std::is_integral<InputIterator>::value>::type* = - NULL) { - InitRep(); - AppendRange(range_start, range_end); - } - - InlinedVector(std::initializer_list<value_type> init) { - InitRep(); - AppendRange(init.begin(), init.end()); - } - - InlinedVector(const InlinedVector& v); - - ~InlinedVector() { clear(); } - - InlinedVector& operator=(const InlinedVector& v) { - // Optimized to avoid reallocation. - // Prefer reassignment to copy construction for elements. - const size_t s = size(); - const size_t vs = v.size(); - if (s < vs) { // grow - reserve(vs); - if (s) std::copy(v.begin(), v.begin() + s, begin()); - std::copy(v.begin() + s, v.end(), std::back_inserter(*this)); - } else { // maybe shrink - erase(begin() + vs, end()); - std::copy(v.begin(), v.end(), begin()); - } - return *this; - } - - size_t size() const { return size_internal(); } - - bool empty() const { return (size() == 0); } - - // Return number of elements that can be stored in vector - // without requiring a reallocation of underlying memory - size_t capacity() const { - if (is_inline()) { - return kFit; - } else { - return static_cast<size_t>(1) << u_.data[kSize - 2]; - } - } - - // Return a pointer to the underlying array. - // Only result[0,size()-1] are defined. - pointer data() { - if (is_inline()) { - return reinterpret_cast<T*>(u_.data); - } else { - return outofline_pointer(); - } - } - const_pointer data() const { - return const_cast<InlinedVector<T, N>*>(this)->data(); - } - - // Remove all elements - void clear() { - DiscardStorage(); - u_.data[kSize - 1] = 0; - } - - // Return the ith element - // REQUIRES: 0 <= i < size() - const value_type& at(size_t i) const { - DCHECK_LT(i, size()); - return data()[i]; - } - const value_type& operator[](size_t i) const { - DCHECK_LT(i, size()); - return data()[i]; - } - - // Return a non-const reference to the ith element - // REQUIRES: 0 <= i < size() - value_type& at(size_t i) { - DCHECK_LT(i, size()); - return data()[i]; - } - value_type& operator[](size_t i) { - DCHECK_LT(i, size()); - return data()[i]; - } - - value_type& back() { - DCHECK(!empty()); - return at(size() - 1); - } - - const value_type& back() const { - DCHECK(!empty()); - return at(size() - 1); - } - - value_type& front() { - DCHECK(!empty()); - return at(0); - } - - const value_type& front() const { - DCHECK(!empty()); - return at(0); - } - - // Append a T constructed with args to the vector. - // Increases size() by one. - // Amortized complexity: O(1) - // Worst-case complexity: O(size()) - template <typename... Args> - void emplace_back(Args&&... args) { - size_t s = size(); - DCHECK_LE(s, capacity()); - if (s < capacity()) { - new (data() + s) T(std::forward<Args>(args)...); - set_size_internal(s + 1); - } else { - EmplaceBackSlow(std::forward<Args>(args)...); - } - } - - // Append t to the vector. - // Increases size() by one. - // Amortized complexity: O(1) - // Worst-case complexity: O(size()) - void push_back(const value_type& t) { emplace_back(t); } - void push_back(value_type&& t) { emplace_back(std::move(t)); } - - inline void pop_back() { - DCHECK(!empty()); - const size_t s = size(); - Destroy(data() + s - 1, 1); - set_size_internal(s - 1); - } - - // Resizes the vector to contain "n" elements. - // If "n" is smaller than the initial size, extra elements are destroyed. - // If "n" is larger than the initial size, enough copies of "elem" - // are appended to increase the size to "n". If "elem" is omitted, - // new elements are value-initialized. - void resize(size_t n) { Resize<ValueInit>(n, nullptr); } - void resize(size_t n, const value_type& elem) { Resize<Fill>(n, &elem); } - - iterator begin() { return data(); } - const_iterator begin() const { return data(); } - - iterator end() { return data() + size(); } - const_iterator end() const { return data() + size(); } - - iterator insert(iterator pos, const value_type& v); - - iterator erase(iterator pos) { - DCHECK_LT(pos, end()); - DCHECK_GE(pos, begin()); - std::copy(pos + 1, end(), pos); - pop_back(); - return pos; - } - - iterator erase(iterator first, iterator last); - - // Enlarges the underlying representation so it can hold at least - // "n" elements without reallocation. - // Does not change size() or the actual contents of the vector. - void reserve(size_t n) { - if (n > capacity()) { - // Make room for new elements - Grow<Move>(n); - } - } - - // Swap the contents of *this with other. - // REQUIRES: value_type is swappable and copyable. - void swap(InlinedVector& other); - - private: - // Representation can either be inlined or out-of-line. - // In either case, at least sizeof(void*) + 8 bytes are available. - // - // Inlined: - // Last byte holds the length. - // First (length*sizeof(T)) bytes stores the elements. - // Outlined: - // Last byte holds kSentinel. - // Second-last byte holds lg(capacity) - // Preceding 6 bytes hold size. - // First sizeof(T*) bytes hold pointer. - - // Compute rep size. - static const size_t kSizeUnaligned = N * sizeof(T) + 1; // Room for tag - static const size_t kSize = ((kSizeUnaligned + 15) / 16) * 16; // Align - - // See how many fit T we can fit inside kSize, but no more than 254 - // since 255 is used as sentinel tag for out-of-line allocation. - static const unsigned int kSentinel = 255; - static const size_t kFit1 = (kSize - 1) / sizeof(T); - static const size_t kFit = (kFit1 >= kSentinel) ? (kSentinel - 1) : kFit1; - - union { - unsigned char data[kSize]; - // Force data to be aligned enough for a pointer. - T* unused_aligner; - } u_; - - inline void InitRep() { u_.data[kSize - 1] = 0; } - inline bool is_inline() const { return u_.data[kSize - 1] != kSentinel; } - - inline T* outofline_pointer() const { - T* ptr; - memcpy(&ptr, &u_.data[0], sizeof(ptr)); - return ptr; - } - - inline void set_outofline_pointer(T* p) { - memcpy(&u_.data[0], &p, sizeof(p)); - } - - inline uint64_t outofline_word() const { - uint64_t word; - memcpy(&word, &u_.data[kSize - 8], sizeof(word)); - return word; - } - - inline void set_outofline_word(uint64_t w) { - memcpy(&u_.data[kSize - 8], &w, sizeof(w)); - } - - inline size_t size_internal() const { - uint8_t s = static_cast<uint8_t>(u_.data[kSize - 1]); - if (s != kSentinel) { - return static_cast<size_t>(s); - } else { - const uint64_t word = outofline_word(); - if (port::kLittleEndian) { - // The sentinel and capacity bits are most-significant bits in word. - return static_cast<size_t>(word & 0xffffffffffffull); - } else { - // The sentinel and capacity bits are least-significant bits in word. - return static_cast<size_t>(word >> 16); - } - } - } - - void set_size_internal(size_t n) { - if (is_inline()) { - DCHECK_LT(n, kSentinel); - u_.data[kSize - 1] = static_cast<unsigned char>(n); - } else { - uint64_t word; - if (port::kLittleEndian) { - // The sentinel and capacity bits are most-significant bits in word. - word = (static_cast<uint64_t>(n) | - (static_cast<uint64_t>(u_.data[kSize - 2]) << 48) | - (static_cast<uint64_t>(kSentinel) << 56)); - } else { - // The sentinel and capacity bits are least-significant bits in word. - word = ((static_cast<uint64_t>(n) << 16) | - (static_cast<uint64_t>(u_.data[kSize - 2]) << 8) | - (static_cast<uint64_t>(kSentinel))); - } - set_outofline_word(word); - DCHECK_EQ(u_.data[kSize - 1], kSentinel) << n; - } - } - - void DiscardStorage() { - T* base = data(); - size_t n = size(); - Destroy(base, n); - if (!is_inline()) { - port::Free(base); - } - } - - template <typename... Args> - void EmplaceBackSlow(Args&&... args) { - const size_t s = size(); - DCHECK_EQ(s, capacity()); - Grow<Move, Construct>(s + 1, std::forward<Args>(args)...); - set_size_internal(s + 1); - } - - // Movers for Grow - // Does nothing. - static void Nop(T* src, size_t n, T* dst) {} - - // Moves srcs[0,n-1] contents to dst[0,n-1]. - static void Move(T* src, size_t n, T* dst) { - for (size_t i = 0; i < n; i++) { - new (dst + i) T(std::move(*(src + i))); - } - } - - // Initializers for Resize. - // Initializes dst[0,n-1] with empty constructor. - static void ValueInit(const T*, size_t n, T* dst) { - for (size_t i = 0; i < n; i++) { - new (dst + i) T(); - } - } - - // Initializes dst[0,n-1] with copies of *src. - static void Fill(const T* src, size_t n, T* dst) { - for (size_t i = 0; i < n; i++) { - new (dst + i) T(*src); - } - } - - void Destroy(T* src, int n) { - if (!std::is_trivially_destructible<T>::value) { - for (int i = 0; i < n; i++) { - (src + i)->~T(); - } - } - } - - // Initialization methods for Grow. - // 1) Leave uninitialized memory. - struct Uninitialized { - void operator()(T*) const {} - }; - // 2) Construct a T with args at not-yet-initialized memory pointed by dst. - struct Construct { - template <class... Args> - void operator()(T* dst, Args&&... args) const { - new (dst) T(std::forward<Args>(args)...); - } - }; - - // Grow so that capacity >= n. Uses Mover to move existing elements - // to new buffer, and possibly initialize the new element according - // to InitType. - // We pass the InitType and Mover as template arguments so that - // this code compiles even if T does not support copying or default - // construction. - template <void(Mover)(T*, size_t, T*), class InitType = Uninitialized, - class... Args> - void Grow(size_t n, Args&&... args) { - size_t s = size(); - DCHECK_LE(s, capacity()); - - // Compute new capacity by repeatedly doubling current capacity - size_t target = 1; - size_t target_lg = 0; - while (target < kFit || target < n) { - // TODO(psrc): Check and avoid overflow? - target_lg++; - target <<= 1; - } - - T* src = data(); - T* dst = static_cast<T*>(port::Malloc(target * sizeof(T))); - - // Need to copy elem before discarding src since it might alias src. - InitType{}(dst + s, std::forward<Args>(args)...); - Mover(src, s, dst); - DiscardStorage(); - - u_.data[kSize - 1] = kSentinel; - u_.data[kSize - 2] = static_cast<unsigned char>(target_lg); - set_size_internal(s); - DCHECK_EQ(capacity(), target); - set_outofline_pointer(dst); - } - - // Resize to size n. Any new elements are initialized by passing - // elem and the destination to Initializer. We pass the Initializer - // as a template argument so that this code compiles even if T does - // not support copying. - template <void(Initializer)(const T*, size_t, T*)> - void Resize(size_t n, const T* elem) { - size_t s = size(); - if (n <= s) { - Destroy(data() + n, s - n); - set_size_internal(n); - return; - } - reserve(n); - DCHECK_GE(capacity(), n); - set_size_internal(n); - Initializer(elem, n - s, data() + s); - } - - template <typename Iter> - void AppendRange(Iter first, Iter last, std::input_iterator_tag); - - // Faster path for forward iterators. - template <typename Iter> - void AppendRange(Iter first, Iter last, std::forward_iterator_tag); - - template <typename Iter> - void AppendRange(Iter first, Iter last); -}; - -// Provide linkage for constants. -template <typename T, int N> -const size_t InlinedVector<T, N>::kSizeUnaligned; -template <typename T, int N> -const size_t InlinedVector<T, N>::kSize; -template <typename T, int N> -const unsigned int InlinedVector<T, N>::kSentinel; -template <typename T, int N> -const size_t InlinedVector<T, N>::kFit1; -template <typename T, int N> -const size_t InlinedVector<T, N>::kFit; - -template <typename T, int N> -inline void swap(InlinedVector<T, N>& a, InlinedVector<T, N>& b) { - a.swap(b); -} - -template <typename T, int N> -inline bool operator==(const InlinedVector<T, N>& a, - const InlinedVector<T, N>& b) { - return a.size() == b.size() && std::equal(a.begin(), a.end(), b.begin()); -} - -template <typename T, int N> -inline bool operator!=(const InlinedVector<T, N>& a, - const InlinedVector<T, N>& b) { - return !(a == b); -} - -template <typename T, int N> -inline bool operator<(const InlinedVector<T, N>& a, - const InlinedVector<T, N>& b) { - return std::lexicographical_compare(a.begin(), a.end(), b.begin(), b.end()); -} - -template <typename T, int N> -inline bool operator>(const InlinedVector<T, N>& a, - const InlinedVector<T, N>& b) { - return b < a; -} - -template <typename T, int N> -inline bool operator<=(const InlinedVector<T, N>& a, - const InlinedVector<T, N>& b) { - return !(b < a); -} - -template <typename T, int N> -inline bool operator>=(const InlinedVector<T, N>& a, - const InlinedVector<T, N>& b) { - return !(a < b); -} - -// ======================================== -// Implementation - -template <typename T, int N> -inline InlinedVector<T, N>::InlinedVector() { - InitRep(); -} - -template <typename T, int N> -inline InlinedVector<T, N>::InlinedVector(size_t n) { - InitRep(); - if (n > capacity()) { - Grow<Nop>(n); // Must use Nop in case T is not copyable - } - set_size_internal(n); - ValueInit(nullptr, n, data()); -} - -template <typename T, int N> -inline InlinedVector<T, N>::InlinedVector(size_t n, const value_type& elem) { - InitRep(); - if (n > capacity()) { - Grow<Nop>(n); // Can use Nop since we know we have nothing to copy - } - set_size_internal(n); - Fill(&elem, n, data()); -} - -template <typename T, int N> -inline InlinedVector<T, N>::InlinedVector(const InlinedVector& v) { - InitRep(); - *this = v; -} - -template <typename T, int N> -typename InlinedVector<T, N>::iterator InlinedVector<T, N>::insert( - iterator pos, const value_type& v) { - DCHECK_GE(pos, begin()); - DCHECK_LE(pos, end()); - if (pos == end()) { - push_back(v); - return end() - 1; - } - size_t s = size(); - size_t idx = std::distance(begin(), pos); - if (s == capacity()) { - Grow<Move>(s + 1); - } - CHECK_LT(s, capacity()); - pos = begin() + idx; // Reset 'pos' into a post-enlarge iterator. - Fill(data() + s - 1, 1, data() + s); // data[s] = data[s-1] - std::copy_backward(pos, data() + s - 1, data() + s); - *pos = v; - - set_size_internal(s + 1); - return pos; -} - -template <typename T, int N> -typename InlinedVector<T, N>::iterator InlinedVector<T, N>::erase( - iterator first, iterator last) { - DCHECK_LE(begin(), first); - DCHECK_LE(first, last); - DCHECK_LE(last, end()); - - size_t s = size(); - ptrdiff_t erase_gap = std::distance(first, last); - std::copy(last, data() + s, first); - Destroy(data() + s - erase_gap, erase_gap); - set_size_internal(s - erase_gap); - return first; -} - -template <typename T, int N> -void InlinedVector<T, N>::swap(InlinedVector& other) { - using std::swap; // Augment ADL with std::swap. - if (&other == this) { - return; - } - - InlinedVector* a = this; - InlinedVector* b = &other; - - const bool a_inline = a->is_inline(); - const bool b_inline = b->is_inline(); - - if (!a_inline && !b_inline) { - // Just swap the top-level representations. - T* aptr = a->outofline_pointer(); - T* bptr = b->outofline_pointer(); - a->set_outofline_pointer(bptr); - b->set_outofline_pointer(aptr); - - uint64_t aword = a->outofline_word(); - uint64_t bword = b->outofline_word(); - a->set_outofline_word(bword); - b->set_outofline_word(aword); - return; - } - - // Make a the larger of the two to reduce number of cases. - size_t a_size = a->size(); - size_t b_size = b->size(); - if (a->size() < b->size()) { - swap(a, b); - swap(a_size, b_size); - } - DCHECK_GE(a_size, b_size); - - if (b->capacity() < a_size) { - b->Grow<Move>(a_size); - } - - // One is inline and one is not. - // 'a' is larger. Swap the elements up to the smaller array size. - std::swap_ranges(a->data(), a->data() + b_size, b->data()); - std::uninitialized_copy(a->data() + b_size, a->data() + a_size, - b->data() + b_size); - Destroy(a->data() + b_size, a_size - b_size); - a->set_size_internal(b_size); - b->set_size_internal(a_size); - DCHECK_EQ(b->size(), a_size); - DCHECK_EQ(a->size(), b_size); -} - -template <typename T, int N> -template <typename Iter> -inline void InlinedVector<T, N>::AppendRange(Iter first, Iter last, - std::input_iterator_tag) { - std::copy(first, last, std::back_inserter(*this)); -} - -template <typename T, int N> -template <typename Iter> -inline void InlinedVector<T, N>::AppendRange(Iter first, Iter last, - std::forward_iterator_tag) { - typedef typename std::iterator_traits<Iter>::difference_type Length; - Length length = std::distance(first, last); - size_t s = size(); - reserve(s + length); - std::uninitialized_copy_n(first, length, data() + s); - set_size_internal(s + length); -} - -template <typename T, int N> -template <typename Iter> -inline void InlinedVector<T, N>::AppendRange(Iter first, Iter last) { - typedef typename std::iterator_traits<Iter>::iterator_category IterTag; - AppendRange(first, last, IterTag()); -} +using absl::InlinedVector; } // namespace gtl } // namespace tensorflow diff --git a/tensorflow/core/lib/gtl/inlined_vector_test.cc b/tensorflow/core/lib/gtl/inlined_vector_test.cc deleted file mode 100644 index 2721885c4a..0000000000 --- a/tensorflow/core/lib/gtl/inlined_vector_test.cc +++ /dev/null @@ -1,898 +0,0 @@ -/* Copyright 2015 The TensorFlow Authors. All Rights Reserved. - -Licensed under the Apache License, Version 2.0 (the "License"); -you may not use this file except in compliance with the License. -You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - -Unless required by applicable law or agreed to in writing, software -distributed under the License is distributed on an "AS IS" BASIS, -WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -See the License for the specific language governing permissions and -limitations under the License. -==============================================================================*/ - -#include "tensorflow/core/lib/gtl/inlined_vector.h" - -#include <list> -#include <memory> -#include <string> -#include <vector> - -#include "tensorflow/core/platform/logging.h" -#include "tensorflow/core/platform/macros.h" -#include "tensorflow/core/platform/test.h" -#include "tensorflow/core/platform/test_benchmark.h" -#include "tensorflow/core/platform/types.h" - -namespace tensorflow { - -typedef tensorflow::gtl::InlinedVector<int, 8> IntVec; - -// A type that counts number of live occurrences of the type -static int64 instances = 0; -class Instance { - public: - int value_; - explicit Instance(int x) : value_(x) { instances++; } - Instance(const Instance& x) : value_(x.value_) { instances++; } - ~Instance() { instances--; } - - friend inline void swap(Instance& a, Instance& b) { - using std::swap; - swap(a.value_, b.value_); - } - - friend std::ostream& operator<<(std::ostream& o, const Instance& v) { - return o << "[value:" << v.value_ << "]"; - } -}; - -typedef tensorflow::gtl::InlinedVector<Instance, 8> InstanceVec; - -// A simple reference counted class to make sure that the proper elements are -// destroyed in the erase(begin, end) test. -class RefCounted { - public: - RefCounted(int value, int* count) : value_(value), count_(count) { Ref(); } - - RefCounted(const RefCounted& v) : value_(v.value_), count_(v.count_) { - VLOG(5) << "[RefCounted: copy" - << " from count @" << v.count_ << "]"; - Ref(); - } - - ~RefCounted() { - Unref(); - count_ = nullptr; - } - - friend void swap(RefCounted& a, RefCounted& b) { - using std::swap; - swap(a.value_, b.value_); - swap(a.count_, b.count_); - } - - RefCounted& operator=(RefCounted v) { - using std::swap; - swap(*this, v); - return *this; - } - - void Ref() const { - CHECK(count_ != nullptr); - ++(*count_); - VLOG(5) << "[Ref: refcount " << *count_ << " on count @" << count_ << "]"; - } - - void Unref() const { - --(*count_); - CHECK_GE(*count_, 0); - VLOG(5) << "[Unref: refcount " << *count_ << " on count @" << count_ << "]"; - } - - int count() const { return *count_; } - - friend std::ostream& operator<<(std::ostream& o, const RefCounted& v) { - return o << "[value:" << v.value_ << ", count:" << *v.count_ << "]"; - } - - int value_; - int* count_; -}; - -typedef tensorflow::gtl::InlinedVector<RefCounted, 8> RefCountedVec; - -// A class with a vtable pointer -class Dynamic { - public: - virtual ~Dynamic() {} - - friend std::ostream& operator<<(std::ostream& o, const Dynamic& v) { - return o << "[Dynamic]"; - } -}; - -typedef tensorflow::gtl::InlinedVector<Dynamic, 8> DynamicVec; - -// Append 0..len-1 to *v -static void Fill(IntVec* v, int len, int offset = 0) { - for (int i = 0; i < len; i++) { - v->push_back(i + offset); - } -} - -static IntVec Fill(int len, int offset = 0) { - IntVec v; - Fill(&v, len, offset); - return v; -} - -TEST(IntVec, SimpleOps) { - for (int len = 0; len < 20; len++) { - IntVec v; - const IntVec& cv = v; // const alias - - Fill(&v, len); - EXPECT_EQ(len, v.size()); - EXPECT_LE(len, v.capacity()); - - for (int i = 0; i < len; i++) { - EXPECT_EQ(i, v[i]); - } - EXPECT_EQ(v.begin(), v.data()); - EXPECT_EQ(cv.begin(), cv.data()); - - int counter = 0; - for (IntVec::iterator iter = v.begin(); iter != v.end(); ++iter) { - EXPECT_EQ(counter, *iter); - counter++; - } - EXPECT_EQ(counter, len); - - counter = 0; - for (IntVec::const_iterator iter = v.begin(); iter != v.end(); ++iter) { - EXPECT_EQ(counter, *iter); - counter++; - } - EXPECT_EQ(counter, len); - - if (len > 0) { - EXPECT_EQ(0, v.front()); - EXPECT_EQ(len - 1, v.back()); - v.pop_back(); - EXPECT_EQ(len - 1, v.size()); - for (size_t i = 0; i < v.size(); ++i) { - EXPECT_EQ(i, v[i]); - } - } - } -} - -TEST(IntVec, Erase) { - for (int len = 1; len < 20; len++) { - for (int i = 0; i < len; ++i) { - IntVec v; - Fill(&v, len); - v.erase(v.begin() + i); - EXPECT_EQ(len - 1, v.size()); - for (int j = 0; j < i; ++j) { - EXPECT_EQ(j, v[j]); - } - for (int j = i; j < len - 1; ++j) { - EXPECT_EQ(j + 1, v[j]); - } - } - } -} - -// At the end of this test loop, the elements between [erase_begin, erase_end) -// should have reference counts == 0, and all others elements should have -// reference counts == 1. -TEST(RefCountedVec, EraseBeginEnd) { - for (int len = 1; len < 20; ++len) { - for (int erase_begin = 0; erase_begin < len; ++erase_begin) { - for (int erase_end = erase_begin; erase_end <= len; ++erase_end) { - std::vector<int> counts(len, 0); - RefCountedVec v; - for (int i = 0; i < len; ++i) { - v.push_back(RefCounted(i, &counts[i])); - } - - int erase_len = erase_end - erase_begin; - - v.erase(v.begin() + erase_begin, v.begin() + erase_end); - - EXPECT_EQ(len - erase_len, v.size()); - - // Check the elements before the first element erased. - for (int i = 0; i < erase_begin; ++i) { - EXPECT_EQ(i, v[i].value_); - } - - // Check the elements after the first element erased. - for (size_t i = erase_begin; i < v.size(); ++i) { - EXPECT_EQ(i + erase_len, v[i].value_); - } - - // Check that the elements at the beginning are preserved. - for (int i = 0; i < erase_begin; ++i) { - EXPECT_EQ(1, counts[i]); - } - - // Check that the erased elements are destroyed - for (int i = erase_begin; i < erase_end; ++i) { - EXPECT_EQ(0, counts[i]); - } - - // Check that the elements at the end are preserved. - for (int i = erase_end; i < len; ++i) { - EXPECT_EQ(1, counts[i]); - } - } - } - } -} - -struct NoDefaultCtor { - explicit NoDefaultCtor(int) {} -}; -struct NoCopy { - NoCopy() {} - NoCopy(const NoCopy&) = delete; -}; -struct NoAssign { - NoAssign() {} - NoAssign& operator=(const NoAssign&) = delete; -}; -struct MoveOnly { - MoveOnly() {} - MoveOnly(MoveOnly&&) = default; - MoveOnly& operator=(MoveOnly&&) = default; -}; -TEST(InlinedVectorTest, NoDefaultCtor) { - tensorflow::gtl::InlinedVector<NoDefaultCtor, 1> v(10, NoDefaultCtor(2)); - (void)v; -} -TEST(InlinedVectorTest, NoCopy) { - tensorflow::gtl::InlinedVector<NoCopy, 1> v(10); - (void)v; -} -TEST(InlinedVectorTest, NoAssign) { - tensorflow::gtl::InlinedVector<NoAssign, 1> v(10); - (void)v; -} -TEST(InlinedVectorTest, MoveOnly) { - gtl::InlinedVector<MoveOnly, 2> v; - v.push_back(MoveOnly{}); - v.push_back(MoveOnly{}); - v.push_back(MoveOnly{}); -} - -TEST(IntVec, Insert) { - for (int len = 0; len < 20; len++) { - for (int pos = 0; pos <= len; pos++) { - IntVec v; - Fill(&v, len); - v.insert(v.begin() + pos, 9999); - EXPECT_EQ(v.size(), len + 1); - for (int i = 0; i < pos; i++) { - EXPECT_EQ(v[i], i); - } - EXPECT_EQ(v[pos], 9999); - for (size_t i = pos + 1; i < v.size(); i++) { - EXPECT_EQ(v[i], i - 1); - } - } - } -} - -TEST(RefCountedVec, InsertConstructorDestructor) { - // Make sure the proper construction/destruction happen during insert - // operations. - for (int len = 0; len < 20; len++) { - SCOPED_TRACE(len); - for (int pos = 0; pos <= len; pos++) { - SCOPED_TRACE(pos); - std::vector<int> counts(len, 0); - int inserted_count = 0; - RefCountedVec v; - for (int i = 0; i < len; ++i) { - SCOPED_TRACE(i); - v.push_back(RefCounted(i, &counts[i])); - } - - for (auto elem : counts) { - EXPECT_EQ(1, elem); - } - - RefCounted insert_element(9999, &inserted_count); - EXPECT_EQ(1, inserted_count); - v.insert(v.begin() + pos, insert_element); - EXPECT_EQ(2, inserted_count); - // Check that the elements at the end are preserved. - for (auto elem : counts) { - EXPECT_EQ(1, elem); - } - EXPECT_EQ(2, inserted_count); - } - } -} - -TEST(IntVec, Resize) { - for (int len = 0; len < 20; len++) { - IntVec v; - Fill(&v, len); - - // Try resizing up and down by k elements - static const int kResizeElem = 1000000; - for (int k = 0; k < 10; k++) { - // Enlarging resize - v.resize(len + k, kResizeElem); - EXPECT_EQ(len + k, v.size()); - EXPECT_LE(len + k, v.capacity()); - for (int i = 0; i < len + k; i++) { - if (i < len) { - EXPECT_EQ(i, v[i]); - } else { - EXPECT_EQ(kResizeElem, v[i]); - } - } - - // Shrinking resize - v.resize(len, kResizeElem); - EXPECT_EQ(len, v.size()); - EXPECT_LE(len, v.capacity()); - for (int i = 0; i < len; i++) { - EXPECT_EQ(i, v[i]); - } - } - } -} - -TEST(IntVec, InitWithLength) { - for (int len = 0; len < 20; len++) { - IntVec v(len, 7); - EXPECT_EQ(len, v.size()); - EXPECT_LE(len, v.capacity()); - for (int i = 0; i < len; i++) { - EXPECT_EQ(7, v[i]); - } - } -} - -TEST(IntVec, CopyConstructorAndAssignment) { - for (int len = 0; len < 20; len++) { - IntVec v; - Fill(&v, len); - EXPECT_EQ(len, v.size()); - EXPECT_LE(len, v.capacity()); - - IntVec v2(v); - EXPECT_EQ(v, v2); - - for (int start_len = 0; start_len < 20; start_len++) { - IntVec v3; - Fill(&v3, start_len, 99); // Add dummy elements that should go away - v3 = v; - EXPECT_EQ(v, v3); - } - } -} - -TEST(OverheadTest, Storage) { - // Check for size overhead. - using tensorflow::gtl::InlinedVector; - EXPECT_EQ(2 * sizeof(int*), sizeof(InlinedVector<int*, 1>)); - EXPECT_EQ(4 * sizeof(int*), sizeof(InlinedVector<int*, 2>)); - EXPECT_EQ(4 * sizeof(int*), sizeof(InlinedVector<int*, 3>)); - EXPECT_EQ(6 * sizeof(int*), sizeof(InlinedVector<int*, 4>)); - - EXPECT_EQ(2 * sizeof(char*), sizeof(InlinedVector<char, 1>)); - EXPECT_EQ(2 * sizeof(char*), sizeof(InlinedVector<char, 2>)); - EXPECT_EQ(2 * sizeof(char*), sizeof(InlinedVector<char, 3>)); - EXPECT_EQ(2 * sizeof(char*), - sizeof(InlinedVector<char, 2 * sizeof(char*) - 1>)); - EXPECT_EQ(4 * sizeof(char*), sizeof(InlinedVector<char, 2 * sizeof(char*)>)); -} - -TEST(IntVec, Clear) { - for (int len = 0; len < 20; len++) { - SCOPED_TRACE(len); - IntVec v; - Fill(&v, len); - v.clear(); - EXPECT_EQ(0, v.size()); - EXPECT_EQ(v.begin(), v.end()); - } -} - -TEST(IntVec, Reserve) { - for (size_t len = 0; len < 20; len++) { - IntVec v; - Fill(&v, len); - - for (size_t newlen = 0; newlen < 100; newlen++) { - const int* start_rep = v.data(); - v.reserve(newlen); - const int* final_rep = v.data(); - if (newlen <= len) { - EXPECT_EQ(start_rep, final_rep); - } - EXPECT_LE(newlen, v.capacity()); - - // Filling up to newlen should not change rep - while (v.size() < newlen) { - v.push_back(0); - } - EXPECT_EQ(final_rep, v.data()); - } - } -} - -template <typename T> -static std::vector<typename T::value_type> Vec(const T& src) { - std::vector<typename T::value_type> result; - for (const auto& elem : src) { - result.push_back(elem); - } - return result; -} - -TEST(IntVec, SelfRefPushBack) { - std::vector<string> std_v; - tensorflow::gtl::InlinedVector<string, 4> v; - const string s = "A quite long string to ensure heap."; - std_v.push_back(s); - v.push_back(s); - for (int i = 0; i < 20; ++i) { - EXPECT_EQ(std_v, Vec(v)); - - v.push_back(v.back()); - std_v.push_back(std_v.back()); - } - EXPECT_EQ(std_v, Vec(v)); -} - -TEST(IntVec, SelfRefPushBackWithMove) { - std::vector<string> std_v; - gtl::InlinedVector<string, 4> v; - const string s = "A quite long string to ensure heap."; - std_v.push_back(s); - v.push_back(s); - for (int i = 0; i < 20; ++i) { - EXPECT_EQ(v.back(), std_v.back()); - - v.push_back(std::move(v.back())); - std_v.push_back(std::move(std_v.back())); - } - EXPECT_EQ(v.back(), std_v.back()); -} - -TEST(IntVec, Swap) { - for (int l1 = 0; l1 < 20; l1++) { - SCOPED_TRACE(l1); - for (int l2 = 0; l2 < 20; l2++) { - SCOPED_TRACE(l2); - IntVec a = Fill(l1, 0); - IntVec b = Fill(l2, 100); - { - using std::swap; - swap(a, b); - } - EXPECT_EQ(l1, b.size()); - EXPECT_EQ(l2, a.size()); - for (int i = 0; i < l1; i++) { - SCOPED_TRACE(i); - EXPECT_EQ(i, b[i]); - } - for (int i = 0; i < l2; i++) { - SCOPED_TRACE(i); - EXPECT_EQ(100 + i, a[i]); - } - } - } -} - -TEST(InstanceVec, Swap) { - for (int l1 = 0; l1 < 20; l1++) { - for (int l2 = 0; l2 < 20; l2++) { - InstanceVec a, b; - for (int i = 0; i < l1; i++) a.push_back(Instance(i)); - for (int i = 0; i < l2; i++) b.push_back(Instance(100 + i)); - EXPECT_EQ(l1 + l2, instances); - { - using std::swap; - swap(a, b); - } - EXPECT_EQ(l1 + l2, instances); - EXPECT_EQ(l1, b.size()); - EXPECT_EQ(l2, a.size()); - for (int i = 0; i < l1; i++) { - EXPECT_EQ(i, b[i].value_); - } - for (int i = 0; i < l2; i++) { - EXPECT_EQ(100 + i, a[i].value_); - } - } - } -} - -TEST(IntVec, EqualAndNotEqual) { - IntVec a, b; - EXPECT_TRUE(a == b); - EXPECT_FALSE(a != b); - - a.push_back(3); - EXPECT_FALSE(a == b); - EXPECT_TRUE(a != b); - - b.push_back(3); - EXPECT_TRUE(a == b); - EXPECT_FALSE(a != b); - - b.push_back(7); - EXPECT_FALSE(a == b); - EXPECT_TRUE(a != b); - - a.push_back(6); - EXPECT_FALSE(a == b); - EXPECT_TRUE(a != b); - - a.clear(); - b.clear(); - for (int i = 0; i < 100; i++) { - a.push_back(i); - b.push_back(i); - EXPECT_TRUE(a == b); - EXPECT_FALSE(a != b); - - b[i] = b[i] + 1; - EXPECT_FALSE(a == b); - EXPECT_TRUE(a != b); - - b[i] = b[i] - 1; // Back to before - EXPECT_TRUE(a == b); - EXPECT_FALSE(a != b); - } -} - -TEST(IntVec, RelationalOps) { - IntVec a, b; - EXPECT_FALSE(a < b); - EXPECT_FALSE(b < a); - EXPECT_FALSE(a > b); - EXPECT_FALSE(b > a); - EXPECT_TRUE(a <= b); - EXPECT_TRUE(b <= a); - EXPECT_TRUE(a >= b); - EXPECT_TRUE(b >= a); - b.push_back(3); - EXPECT_TRUE(a < b); - EXPECT_FALSE(b < a); - EXPECT_FALSE(a > b); - EXPECT_TRUE(b > a); - EXPECT_TRUE(a <= b); - EXPECT_FALSE(b <= a); - EXPECT_FALSE(a >= b); - EXPECT_TRUE(b >= a); -} - -TEST(InstanceVec, CountConstructorsDestructors) { - const int start = instances; - for (int len = 0; len < 20; len++) { - InstanceVec v; - for (int i = 0; i < len; i++) { - v.push_back(Instance(i)); - } - EXPECT_EQ(start + len, instances); - - { // Copy constructor should create 'len' more instances. - InstanceVec v_copy(v); - EXPECT_EQ(start + len + len, instances); - } - EXPECT_EQ(start + len, instances); - - // Enlarging resize() must construct some objects - v.resize(len + 10, Instance(100)); - EXPECT_EQ(start + len + 10, instances); - - // Shrinking resize() must destroy some objects - v.resize(len, Instance(100)); - EXPECT_EQ(start + len, instances); - - // reserve() must not increase the number of initialized objects - v.reserve(len + 1000); - EXPECT_EQ(start + len, instances); - - // pop_back() and erase() must destroy one object - if (len > 0) { - v.pop_back(); - EXPECT_EQ(start + len - 1, instances); - if (!v.empty()) { - v.erase(v.begin()); - EXPECT_EQ(start + len - 2, instances); - } - } - } - EXPECT_EQ(start, instances); -} - -TEST(InstanceVec, CountConstructorsDestructorsOnAssignment) { - const int start = instances; - for (int len = 0; len < 20; len++) { - for (int longorshort = 0; longorshort <= 1; ++longorshort) { - InstanceVec longer, shorter; - for (int i = 0; i < len; i++) { - longer.push_back(Instance(i)); - shorter.push_back(Instance(i)); - } - longer.push_back(Instance(len)); - EXPECT_EQ(start + len + len + 1, instances); - - if (longorshort) { - shorter = longer; - EXPECT_EQ(start + (len + 1) + (len + 1), instances); - } else { - longer = shorter; - EXPECT_EQ(start + len + len, instances); - } - } - } - EXPECT_EQ(start, instances); -} - -TEST(RangedConstructor, SimpleType) { - std::vector<int> source_v = {4, 5, 6, 7}; - // First try to fit in inline backing - tensorflow::gtl::InlinedVector<int, 4> v(source_v.begin(), source_v.end()); - tensorflow::gtl::InlinedVector<int, 4> empty4; - EXPECT_EQ(4, v.size()); - EXPECT_EQ(empty4.capacity(), v.capacity()); // Must still be inline - EXPECT_EQ(4, v[0]); - EXPECT_EQ(5, v[1]); - EXPECT_EQ(6, v[2]); - EXPECT_EQ(7, v[3]); - - // Now, force a re-allocate - tensorflow::gtl::InlinedVector<int, 2> realloc_v(source_v.begin(), - source_v.end()); - tensorflow::gtl::InlinedVector<int, 2> empty2; - EXPECT_EQ(4, realloc_v.size()); - EXPECT_LT(empty2.capacity(), realloc_v.capacity()); - EXPECT_EQ(4, realloc_v[0]); - EXPECT_EQ(5, realloc_v[1]); - EXPECT_EQ(6, realloc_v[2]); - EXPECT_EQ(7, realloc_v[3]); -} - -TEST(RangedConstructor, ComplexType) { - // We also use a list here to pass a different flavor of iterator (e.g. not - // random-access). - std::list<Instance> source_v = {Instance(0)}; - - // First try to fit in inline backing - tensorflow::gtl::InlinedVector<Instance, 1> v(source_v.begin(), - source_v.end()); - tensorflow::gtl::InlinedVector<Instance, 1> empty1; - EXPECT_EQ(1, v.size()); - EXPECT_EQ(empty1.capacity(), v.capacity()); // Must still be inline - EXPECT_EQ(0, v[0].value_); - - std::list<Instance> source_v2 = {Instance(0), Instance(1), Instance(2), - Instance(3)}; - // Now, force a re-allocate - tensorflow::gtl::InlinedVector<Instance, 1> realloc_v(source_v2.begin(), - source_v2.end()); - EXPECT_EQ(4, realloc_v.size()); - EXPECT_LT(empty1.capacity(), realloc_v.capacity()); - EXPECT_EQ(0, realloc_v[0].value_); - EXPECT_EQ(1, realloc_v[1].value_); - EXPECT_EQ(2, realloc_v[2].value_); - EXPECT_EQ(3, realloc_v[3].value_); -} - -TEST(RangedConstructor, ElementsAreConstructed) { - std::vector<string> source_v = {"cat", "dog"}; - - // Force expansion and re-allocation of v. Ensures that when the vector is - // expanded that new elements are constructed. - tensorflow::gtl::InlinedVector<string, 1> v(source_v.begin(), source_v.end()); - EXPECT_EQ("cat", v[0]); - EXPECT_EQ("dog", v[1]); -} - -TEST(InitializerListConstructor, SimpleTypeWithInlineBacking) { - auto vec = tensorflow::gtl::InlinedVector<int, 3>{4, 5, 6}; - EXPECT_EQ(3, vec.size()); - EXPECT_EQ(3, vec.capacity()); - EXPECT_EQ(4, vec[0]); - EXPECT_EQ(5, vec[1]); - EXPECT_EQ(6, vec[2]); -} - -TEST(InitializerListConstructor, SimpleTypeWithReallocationRequired) { - auto vec = tensorflow::gtl::InlinedVector<int, 2>{4, 5, 6}; - EXPECT_EQ(3, vec.size()); - EXPECT_LE(3, vec.capacity()); - EXPECT_EQ(4, vec[0]); - EXPECT_EQ(5, vec[1]); - EXPECT_EQ(6, vec[2]); -} - -TEST(InitializerListConstructor, DisparateTypesInList) { - EXPECT_EQ((std::vector<int>{-7, 8}), - Vec(tensorflow::gtl::InlinedVector<int, 2>{-7, 8ULL})); - - EXPECT_EQ( - (std::vector<string>{"foo", "bar"}), - Vec(tensorflow::gtl::InlinedVector<string, 2>{"foo", string("bar")})); -} - -TEST(InitializerListConstructor, ComplexTypeWithInlineBacking) { - tensorflow::gtl::InlinedVector<Instance, 1> empty; - auto vec = tensorflow::gtl::InlinedVector<Instance, 1>{Instance(0)}; - EXPECT_EQ(1, vec.size()); - EXPECT_EQ(empty.capacity(), vec.capacity()); - EXPECT_EQ(0, vec[0].value_); -} - -TEST(InitializerListConstructor, ComplexTypeWithReallocationRequired) { - auto vec = - tensorflow::gtl::InlinedVector<Instance, 1>{Instance(0), Instance(1)}; - EXPECT_EQ(2, vec.size()); - EXPECT_LE(2, vec.capacity()); - EXPECT_EQ(0, vec[0].value_); - EXPECT_EQ(1, vec[1].value_); -} - -TEST(DynamicVec, DynamicVecCompiles) { - DynamicVec v; - (void)v; -} - -static void BM_InlinedVectorFill(int iters, int len) { - for (int i = 0; i < iters; i++) { - IntVec v; - for (int j = 0; j < len; j++) { - v.push_back(j); - } - } - testing::BytesProcessed((int64{iters} * len) * sizeof(int)); -} -BENCHMARK(BM_InlinedVectorFill)->Range(0, 1024); - -static void BM_InlinedVectorFillRange(int iters, int len) { - std::unique_ptr<int[]> ia(new int[len]); - for (int j = 0; j < len; j++) { - ia[j] = j; - } - for (int i = 0; i < iters; i++) { - IntVec TF_ATTRIBUTE_UNUSED v(ia.get(), ia.get() + len); - } - testing::BytesProcessed((int64{iters} * len) * sizeof(int)); -} -BENCHMARK(BM_InlinedVectorFillRange)->Range(0, 1024); - -static void BM_StdVectorFill(int iters, int len) { - for (int i = 0; i < iters; i++) { - std::vector<int> v; - v.reserve(len); - for (int j = 0; j < len; j++) { - v.push_back(j); - } - } - testing::BytesProcessed((int64{iters} * len) * sizeof(int)); -} -BENCHMARK(BM_StdVectorFill)->Range(0, 1024); - -bool StringRepresentedInline(string s) { - const char* chars = s.data(); - string s1 = std::move(s); - return s1.data() != chars; -} - -static void BM_InlinedVectorFillString(int iters, int len) { - string strings[4] = {"a quite long string", "another long string", - "012345678901234567", "to cause allocation"}; - for (int i = 0; i < iters; i++) { - gtl::InlinedVector<string, 8> v; - for (int j = 0; j < len; j++) { - v.push_back(strings[j & 3]); - } - } - testing::ItemsProcessed(int64{iters} * len); -} -BENCHMARK(BM_InlinedVectorFillString)->Range(0, 1024); - -static void BM_StdVectorFillString(int iters, int len) { - string strings[4] = {"a quite long string", "another long string", - "012345678901234567", "to cause allocation"}; - for (int i = 0; i < iters; i++) { - std::vector<string> v; - v.reserve(len); - for (int j = 0; j < len; j++) { - v.push_back(strings[j & 3]); - } - } - testing::ItemsProcessed(int64{iters} * len); - // The purpose of the benchmark is to verify that inlined vector is - // efficient when moving is more efficient than copying. To do so, we - // use strings that are larger than the small string optimization. - CHECK(!StringRepresentedInline(strings[0])); -} -BENCHMARK(BM_StdVectorFillString)->Range(0, 1024); - -namespace { -struct Buffer { // some arbitrary structure for benchmarking. - char* base; - int length; - int capacity; - void* user_data; -}; -} // anonymous namespace - -static void BM_InlinedVectorTenAssignments(int iters, int len) { - typedef tensorflow::gtl::InlinedVector<Buffer, 2> BufferVec; - - BufferVec src; - src.resize(len); - - iters *= 10; - BufferVec dst; - for (int i = 0; i < iters; i++) { - dst = src; - } -} -BENCHMARK(BM_InlinedVectorTenAssignments) - ->Arg(0) - ->Arg(1) - ->Arg(2) - ->Arg(3) - ->Arg(4) - ->Arg(20); - -static void BM_CreateFromInitializerList(int iters) { - for (; iters > 0; iters--) { - tensorflow::gtl::InlinedVector<int, 4> x{1, 2, 3}; - (void)x[0]; - } -} -BENCHMARK(BM_CreateFromInitializerList); - -namespace { - -struct LargeSwappable { - LargeSwappable() : d_(1024, 17) {} - ~LargeSwappable() {} - LargeSwappable(const LargeSwappable& o) : d_(o.d_) {} - - friend void swap(LargeSwappable& a, LargeSwappable& b) { - using std::swap; - swap(a.d_, b.d_); - } - - LargeSwappable& operator=(LargeSwappable o) { - using std::swap; - swap(*this, o); - return *this; - } - - std::vector<int> d_; -}; - -} // namespace - -static void BM_LargeSwappableElements(int iters, int len) { - typedef tensorflow::gtl::InlinedVector<LargeSwappable, 32> Vec; - Vec a(len); - Vec b; - while (--iters >= 0) { - using std::swap; - swap(a, b); - } -} -BENCHMARK(BM_LargeSwappableElements)->Range(0, 1024); - -} // namespace tensorflow diff --git a/tensorflow/core/lib/gtl/optional.cc b/tensorflow/core/lib/gtl/optional.cc deleted file mode 100644 index 8dea073788..0000000000 --- a/tensorflow/core/lib/gtl/optional.cc +++ /dev/null @@ -1,25 +0,0 @@ -/* Copyright 2017 The TensorFlow Authors. All Rights Reserved. - -Licensed under the Apache License, Version 2.0 (the "License"); -you may not use this file except in compliance with the License. -You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - -Unless required by applicable law or agreed to in writing, software -distributed under the License is distributed on an "AS IS" BASIS, -WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -See the License for the specific language governing permissions and -limitations under the License. -==============================================================================*/ - -#include "tensorflow/core/lib/gtl/optional.h" - -namespace tensorflow { -namespace gtl { - -nullopt_t::init_t nullopt_t::init; -extern const nullopt_t nullopt{nullopt_t::init}; - -} // namespace gtl -} // namespace tensorflow diff --git a/tensorflow/core/lib/gtl/optional.h b/tensorflow/core/lib/gtl/optional.h index 7ad916ad3d..238aa18e1e 100644 --- a/tensorflow/core/lib/gtl/optional.h +++ b/tensorflow/core/lib/gtl/optional.h @@ -16,861 +16,18 @@ limitations under the License. #ifndef TENSORFLOW_CORE_LIB_GTL_OPTIONAL_H_ #define TENSORFLOW_CORE_LIB_GTL_OPTIONAL_H_ -#include <assert.h> -#include <functional> -#include <initializer_list> -#include <type_traits> -#include <utility> - -#include "tensorflow/core/platform/logging.h" +#include "absl/types/optional.h" namespace tensorflow { namespace gtl { -// A value of type gtl::optional<T> holds either a value of T or an -// "empty" value. When it holds a value of T, it stores it as a direct -// subobject, so sizeof(optional<T>) is approximately sizeof(T)+1. The interface -// is based on the upcoming std::optional<T>, and gtl::optional<T> is -// designed to be cheaply drop-in replaceable by std::optional<T>, once it is -// rolled out. -// -// This implementation is based on the specification in the latest draft as of -// 2017-01-05, section 20.6. -// -// Differences between gtl::optional<T> and std::optional<T> include: -// - constexpr not used for nonconst member functions. -// (dependency on some differences between C++11 and C++14.) -// - nullopt and in_place are not constexpr. We need the inline variable -// support in C++17 for external linkage. -// - CHECK instead of throwing std::bad_optional_access. -// - optional::swap() and swap() relies on std::is_(nothrow_)swappable -// which is introduced in C++17. So we assume is_swappable is always true -// and is_nothrow_swappable is same as std::is_trivial. -// - make_optional cannot be constexpr due to absence of guaranteed copy -// elision. -// -// Synopsis: -// -// #include "tensorflow/core/lib/gtl/optional.h" -// -// tensorflow::gtl::optional<string> f() { -// string result; -// if (...) { -// ... -// result = ...; -// return result; -// } else { -// ... -// return tensorflow::gtl::nullopt; -// } -// } -// -// int main() { -// tensorflow::gtl::optional<string> optstr = f(); -// if (optstr) { -// // non-empty -// print(optstr.value()); -// } else { -// // empty -// error(); -// } -// } -template <typename T> -class optional; - -// The tag constant `in_place` is used as the first parameter of an optional<T> -// constructor to indicate that the remaining arguments should be forwarded -// to the underlying T constructor. -struct in_place_t {}; -extern const in_place_t in_place; - -// The tag constant `nullopt` is used to indicate an empty optional<T> in -// certain functions, such as construction or assignment. -struct nullopt_t { - struct init_t {}; - static init_t init; - // It must not be default-constructible to avoid ambiguity for opt = {}. - // Note the non-const reference, it is to eliminate ambiguity for code like: - // struct S { int value; }; - // - // void Test() { - // optional<S> opt; - // opt = {{}}; - // } - explicit constexpr nullopt_t(init_t& /*unused*/) {} // NOLINT -}; -extern const nullopt_t nullopt; - -namespace internal_optional { - -// define forward locally because std::forward is not constexpr until C++14 -template <typename T> -constexpr T&& forward(typename std::remove_reference<T>::type& - t) noexcept { // NOLINT(runtime/references) - return static_cast<T&&>(t); -} - -struct empty_struct {}; -// This class stores the data in optional<T>. -// It is specialized based on whether T is trivially destructible. -// This is the specialization for non trivially destructible type. -template <typename T, bool = std::is_trivially_destructible<T>::value> -class optional_data_dtor_base { - protected: - // Whether there is data or not. - bool engaged_; - // data storage - union { - empty_struct dummy_; - T data_; - }; - - void destruct() noexcept { - if (engaged_) { - data_.~T(); - engaged_ = false; - } - } - - // dummy_ must be initialized for constexpr constructor - constexpr optional_data_dtor_base() noexcept : engaged_(false), dummy_{} {} - - template <typename... Args> - constexpr explicit optional_data_dtor_base(in_place_t, Args&&... args) - : engaged_(true), data_(internal_optional::forward<Args>(args)...) {} - - ~optional_data_dtor_base() { destruct(); } -}; - -// Specialization for trivially destructible type. -template <typename T> -class optional_data_dtor_base<T, true> { - protected: - // Whether there is data or not. - bool engaged_; - // data storage - union { - empty_struct dummy_; - T data_; - }; - void destruct() noexcept { engaged_ = false; } - - // dummy_ must be initialized for constexpr constructor - constexpr optional_data_dtor_base() noexcept : engaged_(false), dummy_{} {} - - template <typename... Args> - constexpr explicit optional_data_dtor_base(in_place_t, Args&&... args) - : engaged_(true), data_(internal_optional::forward<Args>(args)...) {} - - ~optional_data_dtor_base() = default; -}; - -template <typename T> -class optional_data : public optional_data_dtor_base<T> { - protected: - using base = optional_data_dtor_base<T>; - using base::base; - - T* pointer() { return &this->data_; } - - constexpr const T* pointer() const { return &this->data_; } - - template <typename... Args> - void construct(Args&&... args) { - new (pointer()) T(std::forward<Args>(args)...); - this->engaged_ = true; - } - - template <typename U> - void assign(U&& u) { - if (this->engaged_) { - this->data_ = std::forward<U>(u); - } else { - construct(std::forward<U>(u)); - } - } - - optional_data() = default; - - optional_data(const optional_data& rhs) { - if (rhs.engaged_) { - construct(rhs.data_); - } - } - - optional_data(optional_data&& rhs) noexcept( - std::is_nothrow_move_constructible<T>::value) { - if (rhs.engaged_) { - construct(std::move(rhs.data_)); - } - } - - optional_data& operator=(const optional_data& rhs) { - if (rhs.engaged_) { - assign(rhs.data_); - } else { - this->destruct(); - } - return *this; - } - - optional_data& operator=(optional_data&& rhs) noexcept( - std::is_nothrow_move_assignable<T>::value&& - std::is_nothrow_move_constructible<T>::value) { - if (rhs.engaged_) { - assign(std::move(rhs.data_)); - } else { - this->destruct(); - } - return *this; - } -}; - -// ordered by level of restriction, from low to high. -// copyable implies movable. -enum class copy_traits { copyable = 0, movable = 1, non_movable = 2 }; - -// base class for enabling/disabling copy/move constructor. -template <copy_traits> -class optional_ctor_base; - -template <> -class optional_ctor_base<copy_traits::copyable> { - public: - constexpr optional_ctor_base() = default; - optional_ctor_base(const optional_ctor_base&) = default; - optional_ctor_base(optional_ctor_base&&) = default; - optional_ctor_base& operator=(const optional_ctor_base&) = default; - optional_ctor_base& operator=(optional_ctor_base&&) = default; -}; - -template <> -class optional_ctor_base<copy_traits::movable> { - public: - constexpr optional_ctor_base() = default; - optional_ctor_base(const optional_ctor_base&) = delete; - optional_ctor_base(optional_ctor_base&&) = default; - optional_ctor_base& operator=(const optional_ctor_base&) = default; - optional_ctor_base& operator=(optional_ctor_base&&) = default; -}; - -template <> -class optional_ctor_base<copy_traits::non_movable> { - public: - constexpr optional_ctor_base() = default; - optional_ctor_base(const optional_ctor_base&) = delete; - optional_ctor_base(optional_ctor_base&&) = delete; - optional_ctor_base& operator=(const optional_ctor_base&) = default; - optional_ctor_base& operator=(optional_ctor_base&&) = default; -}; - -// base class for enabling/disabling copy/move assignment. -template <copy_traits> -class optional_assign_base; - -template <> -class optional_assign_base<copy_traits::copyable> { - public: - constexpr optional_assign_base() = default; - optional_assign_base(const optional_assign_base&) = default; - optional_assign_base(optional_assign_base&&) = default; - optional_assign_base& operator=(const optional_assign_base&) = default; - optional_assign_base& operator=(optional_assign_base&&) = default; -}; - -template <> -class optional_assign_base<copy_traits::movable> { - public: - constexpr optional_assign_base() = default; - optional_assign_base(const optional_assign_base&) = default; - optional_assign_base(optional_assign_base&&) = default; - optional_assign_base& operator=(const optional_assign_base&) = delete; - optional_assign_base& operator=(optional_assign_base&&) = default; -}; - -template <> -class optional_assign_base<copy_traits::non_movable> { - public: - constexpr optional_assign_base() = default; - optional_assign_base(const optional_assign_base&) = default; - optional_assign_base(optional_assign_base&&) = default; - optional_assign_base& operator=(const optional_assign_base&) = delete; - optional_assign_base& operator=(optional_assign_base&&) = delete; -}; - +// Deprecated: please use absl::optional directly. +using absl::make_optional; +using absl::nullopt; template <typename T> -constexpr copy_traits get_ctor_copy_traits() { - return std::is_copy_constructible<T>::value - ? copy_traits::copyable - : std::is_move_constructible<T>::value ? copy_traits::movable - : copy_traits::non_movable; -} - -template <typename T> -constexpr copy_traits get_assign_copy_traits() { - return std::is_copy_assignable<T>::value && - std::is_copy_constructible<T>::value - ? copy_traits::copyable - : std::is_move_assignable<T>::value && - std::is_move_constructible<T>::value - ? copy_traits::movable - : copy_traits::non_movable; -} - -// Whether T is constructible or convertible from optional<U>. -template <typename T, typename U> -struct is_constructible_convertible_from_optional - : std::integral_constant< - bool, std::is_constructible<T, optional<U>&>::value || - std::is_constructible<T, optional<U>&&>::value || - std::is_constructible<T, const optional<U>&>::value || - std::is_constructible<T, const optional<U>&&>::value || - std::is_convertible<optional<U>&, T>::value || - std::is_convertible<optional<U>&&, T>::value || - std::is_convertible<const optional<U>&, T>::value || - std::is_convertible<const optional<U>&&, T>::value> {}; - -// Whether T is constructible or convertible or assignable from optional<U>. -template <typename T, typename U> -struct is_constructible_convertible_assignable_from_optional - : std::integral_constant< - bool, is_constructible_convertible_from_optional<T, U>::value || - std::is_assignable<T&, optional<U>&>::value || - std::is_assignable<T&, optional<U>&&>::value || - std::is_assignable<T&, const optional<U>&>::value || - std::is_assignable<T&, const optional<U>&&>::value> {}; - -} // namespace internal_optional - -template <typename T> -class optional : private internal_optional::optional_data<T>, - private internal_optional::optional_ctor_base< - internal_optional::get_ctor_copy_traits<T>()>, - private internal_optional::optional_assign_base< - internal_optional::get_assign_copy_traits<T>()> { - using data_base = internal_optional::optional_data<T>; - - public: - typedef T value_type; - - // [optional.ctor], constructors - - // A default constructed optional holds the empty value, NOT a default - // constructed T. - constexpr optional() noexcept {} - - // An optional initialized with `nullopt` holds the empty value. - constexpr optional(nullopt_t) noexcept {} // NOLINT(runtime/explicit) - - // Copy constructor, standard semantics. - optional(const optional& src) = default; - - // Move constructor, standard semantics. - optional(optional&& src) = default; - - // optional<T>(in_place, arg1, arg2, arg3) constructs a non-empty optional - // with an in-place constructed value of T(arg1,arg2,arg3). - // TODO(b/34201852): Add std::is_constructible<T, Args&&...> SFINAE. - template <typename... Args> - constexpr explicit optional(in_place_t, Args&&... args) - : data_base(in_place_t(), internal_optional::forward<Args>(args)...) {} - - // optional<T>(in_place, {arg1, arg2, arg3}) constructs a non-empty optional - // with an in-place list-initialized value of T({arg1, arg2, arg3}). - template <typename U, typename... Args, - typename = typename std::enable_if<std::is_constructible< - T, std::initializer_list<U>&, Args&&...>::value>::type> - constexpr explicit optional(in_place_t, std::initializer_list<U> il, - Args&&... args) - : data_base(in_place_t(), il, internal_optional::forward<Args>(args)...) { - } - - template < - typename U = T, - typename std::enable_if< - std::is_constructible<T, U&&>::value && - !std::is_same<in_place_t, typename std::decay<U>::type>::value && - !std::is_same<optional<T>, typename std::decay<U>::type>::value && - std::is_convertible<U&&, T>::value, - bool>::type = false> - constexpr optional(U&& v) // NOLINT - : data_base(in_place_t(), internal_optional::forward<U>(v)) {} - - template < - typename U = T, - typename std::enable_if< - std::is_constructible<T, U&&>::value && - !std::is_same<in_place_t, typename std::decay<U>::type>::value && - !std::is_same<optional<T>, typename std::decay<U>::type>::value && - !std::is_convertible<U&&, T>::value, - bool>::type = false> - explicit constexpr optional(U&& v) - : data_base(in_place_t(), internal_optional::forward<U>(v)) {} - - // Converting copy constructor (implicit) - template < - typename U, - typename std::enable_if< - std::is_constructible<T, const U&>::value && - !internal_optional::is_constructible_convertible_from_optional< - T, U>::value && - std::is_convertible<const U&, T>::value, - bool>::type = false> - optional(const optional<U>& rhs) { // NOLINT - if (rhs) { - this->construct(*rhs); - } - } - - // Converting copy constructor (explicit) - template < - typename U, - typename std::enable_if< - std::is_constructible<T, const U&>::value && - !internal_optional::is_constructible_convertible_from_optional< - T, U>::value && - !std::is_convertible<const U&, T>::value, - bool>::type = false> - explicit optional(const optional<U>& rhs) { - if (rhs) { - this->construct(*rhs); - } - } - - // Converting move constructor (implicit) - template < - typename U, - typename std::enable_if< - std::is_constructible<T, U&&>::value && - !internal_optional::is_constructible_convertible_from_optional< - T, U>::value && - std::is_convertible<U&&, T>::value, - bool>::type = false> - optional(optional<U>&& rhs) { // NOLINT - if (rhs) { - this->construct(std::move(*rhs)); - } - } - - // Converting move constructor (explicit) - template < - typename U, - typename std::enable_if< - std::is_constructible<T, U&&>::value && - !internal_optional::is_constructible_convertible_from_optional< - T, U>::value && - !std::is_convertible<U&&, T>::value, - bool>::type = false> - explicit optional(optional<U>&& rhs) { - if (rhs) { - this->construct(std::move(*rhs)); - } - } - - // [optional.dtor], destructor, trivial if T is trivially destructible. - ~optional() = default; - - // [optional.assign], assignment - - // Assignment from nullopt: opt = nullopt - optional& operator=(nullopt_t) noexcept { - this->destruct(); - return *this; - } - - // Copy assignment, standard semantics. - optional& operator=(const optional& src) = default; - - // Move assignment, standard semantics. - optional& operator=(optional&& src) = default; - - // Value assignment - template < - typename U = T, - typename = typename std::enable_if< - !std::is_same<optional<T>, typename std::decay<U>::type>::value && - (!std::is_scalar<T>::value || - !std::is_same<T, typename std::decay<U>::type>::value) && - std::is_constructible<T, U>::value && - std::is_assignable<T&, U>::value>::type> - optional& operator=(U&& v) { - this->assign(std::forward<U>(v)); - return *this; - } - - template <typename U, - typename = typename std::enable_if< - std::is_constructible<T, const U&>::value && - std::is_assignable<T&, const U&>::value && - !internal_optional:: - is_constructible_convertible_assignable_from_optional< - T, U>::value>::type> - optional& operator=(const optional<U>& rhs) { - if (rhs) { - this->assign(*rhs); - } else { - this->destruct(); - } - return *this; - } - - template <typename U, - typename = typename std::enable_if< - std::is_constructible<T, U>::value && - std::is_assignable<T&, U>::value && - !internal_optional:: - is_constructible_convertible_assignable_from_optional< - T, U>::value>::type> - optional& operator=(optional<U>&& rhs) { - if (rhs) { - this->assign(std::move(*rhs)); - } else { - this->destruct(); - } - return *this; - } - - // [optional.mod], modifiers - // Destroys the inner T value if one is present. - void reset() noexcept { this->destruct(); } - - // Emplace reconstruction. (Re)constructs the underlying T in-place with the - // given arguments forwarded: - // - // optional<Foo> opt; - // opt.emplace(arg1,arg2,arg3); (Constructs Foo(arg1,arg2,arg3)) - // - // If the optional is non-empty, and the `args` refer to subobjects of the - // current object, then behavior is undefined. This is because the current - // object will be destructed before the new object is constructed with `args`. - // - template <typename... Args, - typename = typename std::enable_if< - std::is_constructible<T, Args&&...>::value>::type> - void emplace(Args&&... args) { - this->destruct(); - this->construct(std::forward<Args>(args)...); - } - - // Emplace reconstruction with initializer-list. See immediately above. - template <class U, class... Args, - typename = typename std::enable_if<std::is_constructible< - T, std::initializer_list<U>&, Args&&...>::value>::type> - void emplace(std::initializer_list<U> il, Args&&... args) { - this->destruct(); - this->construct(il, std::forward<Args>(args)...); - } - - // [optional.swap], swap - // Swap, standard semantics. - void swap(optional& rhs) noexcept( - std::is_nothrow_move_constructible<T>::value&& - std::is_trivial<T>::value) { - if (*this) { - if (rhs) { - using std::swap; - swap(**this, *rhs); - } else { - rhs.construct(std::move(**this)); - this->destruct(); - } - } else { - if (rhs) { - this->construct(std::move(*rhs)); - rhs.destruct(); - } else { - // no effect (swap(disengaged, disengaged)) - } - } - } - - // [optional.observe], observers - // You may use `*opt`, and `opt->m`, to access the underlying T value and T's - // member `m`, respectively. If the optional is empty, behavior is - // undefined. - constexpr const T* operator->() const { return this->pointer(); } - T* operator->() { - assert(this->engaged_); - return this->pointer(); - } - constexpr const T& operator*() const& { return reference(); } - T& operator*() & { - assert(this->engaged_); - return reference(); - } - constexpr const T&& operator*() const&& { return std::move(reference()); } - T&& operator*() && { - assert(this->engaged_); - return std::move(reference()); - } - - // In a bool context an optional<T> will return false if and only if it is - // empty. - // - // if (opt) { - // // do something with opt.value(); - // } else { - // // opt is empty - // } - // - constexpr explicit operator bool() const noexcept { return this->engaged_; } - - // Returns false if and only if *this is empty. - constexpr bool has_value() const noexcept { return this->engaged_; } - - // Use `opt.value()` to get a reference to underlying value. The constness - // and lvalue/rvalue-ness of `opt` is preserved to the view of the T - // subobject. - const T& value() const& { - CHECK(*this) << "Bad optional access"; - return reference(); - } - T& value() & { - CHECK(*this) << "Bad optional access"; - return reference(); - } - T&& value() && { // NOLINT(build/c++11) - CHECK(*this) << "Bad optional access"; - return std::move(reference()); - } - const T&& value() const&& { // NOLINT(build/c++11) - CHECK(*this) << "Bad optional access"; - return std::move(reference()); - } - - // Use `opt.value_or(val)` to get either the value of T or the given default - // `val` in the empty case. - template <class U> - constexpr T value_or(U&& v) const& { - return static_cast<bool>(*this) ? **this - : static_cast<T>(std::forward<U>(v)); - } - template <class U> - T value_or(U&& v) && { // NOLINT(build/c++11) - return static_cast<bool>(*this) ? std::move(**this) - : static_cast<T>(std::forward<U>(v)); - } - - private: - // Private accessors for internal storage viewed as reference to T. - constexpr const T& reference() const { return *this->pointer(); } - T& reference() { return *(this->pointer()); } - - // T constraint checks. You can't have an optional of nullopt_t, in_place_t - // or a reference. - static_assert( - !std::is_same<nullopt_t, typename std::remove_cv<T>::type>::value, - "optional<nullopt_t> is not allowed."); - static_assert( - !std::is_same<in_place_t, typename std::remove_cv<T>::type>::value, - "optional<in_place_t> is not allowed."); - static_assert(!std::is_reference<T>::value, - "optional<reference> is not allowed."); -}; - -// [optional.specalg] -// Swap, standard semantics. -// This function shall not participate in overload resolution unless -// is_move_constructible_v<T> is true and is_swappable_v<T> is true. -// NOTE: we assume is_swappable is always true. There will be a compiling error -// if T is actually not Swappable. -template <typename T, - typename std::enable_if<std::is_move_constructible<T>::value, - bool>::type = false> -void swap(optional<T>& a, optional<T>& b) noexcept(noexcept(a.swap(b))) { - a.swap(b); -} - -// NOTE: make_optional cannot be constexpr in C++11 because the copy/move -// constructor is not constexpr and we don't have guaranteed copy elision -// util C++17. But they are still declared constexpr for consistency with -// the standard. - -// make_optional(v) creates a non-empty optional<T> where the type T is deduced -// from v. Can also be explicitly instantiated as make_optional<T>(v). -template <typename T> -constexpr optional<typename std::decay<T>::type> make_optional(T&& v) { - return optional<typename std::decay<T>::type>(std::forward<T>(v)); -} - -template <typename T, typename... Args> -constexpr optional<T> make_optional(Args&&... args) { - return optional<T>(in_place_t(), internal_optional::forward<Args>(args)...); -} - -template <typename T, typename U, typename... Args> -constexpr optional<T> make_optional(std::initializer_list<U> il, - Args&&... args) { - return optional<T>(in_place_t(), il, - internal_optional::forward<Args>(args)...); -} - -// Relational operators. Empty optionals are considered equal to each -// other and less than non-empty optionals. Supports relations between -// optional<T> and optional<T>, between optional<T> and T, and between -// optional<T> and nullopt. -// Note: We're careful to support T having non-bool relationals. - -// Relational operators [optional.relops] -// The C++17 (N4606) "Returns:" statements are translated into code -// in an obvious way here, and the original text retained as function docs. -// Returns: If bool(x) != bool(y), false; otherwise if bool(x) == false, true; -// otherwise *x == *y. -template <class T> -constexpr bool operator==(const optional<T>& x, const optional<T>& y) { - return static_cast<bool>(x) != static_cast<bool>(y) - ? false - : static_cast<bool>(x) == false ? true : *x == *y; -} -// Returns: If bool(x) != bool(y), true; otherwise, if bool(x) == false, false; -// otherwise *x != *y. -template <class T> -constexpr bool operator!=(const optional<T>& x, const optional<T>& y) { - return static_cast<bool>(x) != static_cast<bool>(y) - ? true - : static_cast<bool>(x) == false ? false : *x != *y; -} -// Returns: If !y, false; otherwise, if !x, true; otherwise *x < *y. -template <class T> -constexpr bool operator<(const optional<T>& x, const optional<T>& y) { - return !y ? false : !x ? true : *x < *y; -} -// Returns: If !x, false; otherwise, if !y, true; otherwise *x > *y. -template <class T> -constexpr bool operator>(const optional<T>& x, const optional<T>& y) { - return !x ? false : !y ? true : *x > *y; -} -// Returns: If !x, true; otherwise, if !y, false; otherwise *x <= *y. -template <class T> -constexpr bool operator<=(const optional<T>& x, const optional<T>& y) { - return !x ? true : !y ? false : *x <= *y; -} -// Returns: If !y, true; otherwise, if !x, false; otherwise *x >= *y. -template <class T> -constexpr bool operator>=(const optional<T>& x, const optional<T>& y) { - return !y ? true : !x ? false : *x >= *y; -} - -// Comparison with nullopt [optional.nullops] -// The C++17 (N4606) "Returns:" statements are used directly here. -template <class T> -constexpr bool operator==(const optional<T>& x, nullopt_t) noexcept { - return !x; -} -template <class T> -constexpr bool operator==(nullopt_t, const optional<T>& x) noexcept { - return !x; -} -template <class T> -constexpr bool operator!=(const optional<T>& x, nullopt_t) noexcept { - return static_cast<bool>(x); -} -template <class T> -constexpr bool operator!=(nullopt_t, const optional<T>& x) noexcept { - return static_cast<bool>(x); -} -template <class T> -constexpr bool operator<(const optional<T>& x, nullopt_t) noexcept { - return false; -} -template <class T> -constexpr bool operator<(nullopt_t, const optional<T>& x) noexcept { - return static_cast<bool>(x); -} -template <class T> -constexpr bool operator<=(const optional<T>& x, nullopt_t) noexcept { - return !x; -} -template <class T> -constexpr bool operator<=(nullopt_t, const optional<T>& x) noexcept { - return true; -} -template <class T> -constexpr bool operator>(const optional<T>& x, nullopt_t) noexcept { - return static_cast<bool>(x); -} -template <class T> -constexpr bool operator>(nullopt_t, const optional<T>& x) noexcept { - return false; -} -template <class T> -constexpr bool operator>=(const optional<T>& x, nullopt_t) noexcept { - return true; -} -template <class T> -constexpr bool operator>=(nullopt_t, const optional<T>& x) noexcept { - return !x; -} - -// Comparison with T [optional.comp_with_t] -// The C++17 (N4606) "Equivalent to:" statements are used directly here. -template <class T> -constexpr bool operator==(const optional<T>& x, const T& v) { - return static_cast<bool>(x) ? *x == v : false; -} -template <class T> -constexpr bool operator==(const T& v, const optional<T>& x) { - return static_cast<bool>(x) ? v == *x : false; -} -template <class T> -constexpr bool operator!=(const optional<T>& x, const T& v) { - return static_cast<bool>(x) ? *x != v : true; -} -template <class T> -constexpr bool operator!=(const T& v, const optional<T>& x) { - return static_cast<bool>(x) ? v != *x : true; -} -template <class T> -constexpr bool operator<(const optional<T>& x, const T& v) { - return static_cast<bool>(x) ? *x < v : true; -} -template <class T> -constexpr bool operator<(const T& v, const optional<T>& x) { - return static_cast<bool>(x) ? v < *x : false; -} -template <class T> -constexpr bool operator<=(const optional<T>& x, const T& v) { - return static_cast<bool>(x) ? *x <= v : true; -} -template <class T> -constexpr bool operator<=(const T& v, const optional<T>& x) { - return static_cast<bool>(x) ? v <= *x : false; -} -template <class T> -constexpr bool operator>(const optional<T>& x, const T& v) { - return static_cast<bool>(x) ? *x > v : false; -} -template <class T> -constexpr bool operator>(const T& v, const optional<T>& x) { - return static_cast<bool>(x) ? v > *x : true; -} -template <class T> -constexpr bool operator>=(const optional<T>& x, const T& v) { - return static_cast<bool>(x) ? *x >= v : false; -} -template <class T> -constexpr bool operator>=(const T& v, const optional<T>& x) { - return static_cast<bool>(x) ? v >= *x : true; -} +using optional = absl::optional<T>; } // namespace gtl } // namespace tensorflow -namespace std { - -// Normally std::hash specializations are not recommended in tensorflow code, -// but we allow this as it is following a standard library component. -template <class T> -struct hash<::tensorflow::gtl::optional<T>> { - size_t operator()(const ::tensorflow::gtl::optional<T>& opt) const { - if (opt) { - return hash<T>()(*opt); - } else { - return static_cast<size_t>(0x297814aaad196e6dULL); - } - } -}; - -} // namespace std - #endif // TENSORFLOW_CORE_LIB_GTL_OPTIONAL_H_ diff --git a/tensorflow/core/lib/gtl/optional_test.cc b/tensorflow/core/lib/gtl/optional_test.cc deleted file mode 100644 index 12b5bbc60b..0000000000 --- a/tensorflow/core/lib/gtl/optional_test.cc +++ /dev/null @@ -1,1098 +0,0 @@ -/* Copyright 2017 The TensorFlow Authors. All Rights Reserved. - -Licensed under the Apache License, Version 2.0 (the "License"); -you may not use this file except in compliance with the License. -You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - -Unless required by applicable law or agreed to in writing, software -distributed under the License is distributed on an "AS IS" BASIS, -WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -See the License for the specific language governing permissions and -limitations under the License. -==============================================================================*/ - -#include "tensorflow/core/lib/gtl/optional.h" - -#include <string> -#include <utility> - -#include "tensorflow/core/platform/test.h" -#include "tensorflow/core/platform/types.h" - -namespace tensorflow { -namespace { - -using tensorflow::gtl::in_place; -using tensorflow::gtl::in_place_t; -using tensorflow::gtl::make_optional; -using tensorflow::gtl::nullopt; -using tensorflow::gtl::nullopt_t; -using tensorflow::gtl::optional; - -template <typename T> -string TypeQuals(T&) { - return "&"; -} -template <typename T> -string TypeQuals(T&&) { - return "&&"; -} -template <typename T> -string TypeQuals(const T&) { - return "c&"; -} -template <typename T> -string TypeQuals(const T&&) { - return "c&&"; -} - -struct StructorListener { - int construct0 = 0; - int construct1 = 0; - int construct2 = 0; - int listinit = 0; - int copy = 0; - int move = 0; - int copy_assign = 0; - int move_assign = 0; - int destruct = 0; -}; - -struct Listenable { - static StructorListener* listener; - - Listenable() { ++listener->construct0; } - Listenable(int /*unused*/) { ++listener->construct1; } // NOLINT - Listenable(int /*unused*/, int /*unused*/) { ++listener->construct2; } - Listenable(std::initializer_list<int> /*unused*/) { ++listener->listinit; } - Listenable(const Listenable& /*unused*/) { ++listener->copy; } - Listenable(Listenable&& /*unused*/) { ++listener->move; } // NOLINT - Listenable& operator=(const Listenable& /*unused*/) { - ++listener->copy_assign; - return *this; - } - Listenable& operator=(Listenable&& /*unused*/) { // NOLINT - ++listener->move_assign; - return *this; - } - ~Listenable() { ++listener->destruct; } -}; - -StructorListener* Listenable::listener = nullptr; - -// clang on macos -- even the latest major version at time of writing (8.x) -- -// does not like much of our constexpr business. clang < 3.0 also has trouble. -#if defined(__clang__) && defined(__APPLE__) -#define SKIP_CONSTEXPR_TEST_DUE_TO_CLANG_BUG -#endif - -struct ConstexprType { - constexpr ConstexprType() : x(0) {} - constexpr explicit ConstexprType(int i) : x(i) {} -#ifndef SKIP_CONSTEXPR_TEST_DUE_TO_CLANG_BUG - constexpr ConstexprType(std::initializer_list<int> il) : x(il.size()) {} -#endif - constexpr ConstexprType(const char* s) : x(-1) {} // NOLINT - int x; -}; - -struct Copyable { - Copyable() {} - Copyable(const Copyable&) {} - Copyable& operator=(const Copyable&) { return *this; } -}; - -struct MoveableThrow { - MoveableThrow() {} - MoveableThrow(MoveableThrow&&) {} - MoveableThrow& operator=(MoveableThrow&&) { return *this; } -}; - -struct MoveableNoThrow { - MoveableNoThrow() {} - MoveableNoThrow(MoveableNoThrow&&) noexcept {} - MoveableNoThrow& operator=(MoveableNoThrow&&) noexcept { return *this; } -}; - -struct NonMovable { - NonMovable() {} - NonMovable(const NonMovable&) = delete; - NonMovable& operator=(const NonMovable&) = delete; - NonMovable(NonMovable&&) = delete; - NonMovable& operator=(NonMovable&&) = delete; -}; - -TEST(optionalTest, DefaultConstructor) { - optional<int> empty; - EXPECT_FALSE(!!empty); - constexpr optional<int> cempty; - static_assert(!cempty.has_value(), ""); - EXPECT_TRUE(std::is_nothrow_default_constructible<optional<int>>::value); -} - -TEST(optionalTest, NullOptConstructor) { - optional<int> empty(nullopt); - EXPECT_FALSE(!!empty); - // Creating a temporary nullopt_t object instead of using nullopt because - // nullopt cannot be constexpr and have external linkage at the same time. - constexpr optional<int> cempty{nullopt_t(nullopt_t::init)}; - static_assert(!cempty.has_value(), ""); - EXPECT_TRUE((std::is_nothrow_constructible<optional<int>, nullopt_t>::value)); -} - -TEST(optionalTest, CopyConstructor) { - optional<int> empty, opt42 = 42; - optional<int> empty_copy(empty); - EXPECT_FALSE(!!empty_copy); - optional<int> opt42_copy(opt42); - EXPECT_TRUE(!!opt42_copy); - EXPECT_EQ(42, opt42_copy); - // test copyablility - EXPECT_TRUE(std::is_copy_constructible<optional<int>>::value); - EXPECT_TRUE(std::is_copy_constructible<optional<Copyable>>::value); - EXPECT_FALSE(std::is_copy_constructible<optional<MoveableThrow>>::value); - EXPECT_FALSE(std::is_copy_constructible<optional<MoveableNoThrow>>::value); - EXPECT_FALSE(std::is_copy_constructible<optional<NonMovable>>::value); -} - -TEST(optionalTest, MoveConstructor) { - optional<int> empty, opt42 = 42; - optional<int> empty_move(std::move(empty)); - EXPECT_FALSE(!!empty_move); - optional<int> opt42_move(std::move(opt42)); - EXPECT_TRUE(!!opt42_move); - EXPECT_EQ(42, opt42_move); - // test movability - EXPECT_TRUE(std::is_move_constructible<optional<int>>::value); - EXPECT_TRUE(std::is_move_constructible<optional<Copyable>>::value); - EXPECT_TRUE(std::is_move_constructible<optional<MoveableThrow>>::value); - EXPECT_TRUE(std::is_move_constructible<optional<MoveableNoThrow>>::value); - EXPECT_FALSE(std::is_move_constructible<optional<NonMovable>>::value); - // test noexcept - EXPECT_TRUE(std::is_nothrow_move_constructible<optional<int>>::value); - EXPECT_FALSE( - std::is_nothrow_move_constructible<optional<MoveableThrow>>::value); - EXPECT_TRUE( - std::is_nothrow_move_constructible<optional<MoveableNoThrow>>::value); -} - -TEST(optionalTest, Destructor) { - struct Trivial {}; - - struct NonTrivial { - ~NonTrivial() {} - }; - - EXPECT_TRUE(std::is_trivially_destructible<optional<int>>::value); - EXPECT_TRUE(std::is_trivially_destructible<optional<Trivial>>::value); - EXPECT_FALSE(std::is_trivially_destructible<optional<NonTrivial>>::value); -} - -TEST(optionalTest, InPlaceConstructor) { - constexpr optional<ConstexprType> opt0{in_place_t()}; - static_assert(opt0, ""); - static_assert(opt0->x == 0, ""); - constexpr optional<ConstexprType> opt1{in_place_t(), 1}; - static_assert(opt1, ""); - static_assert(opt1->x == 1, ""); -#ifndef SKIP_CONSTEXPR_TEST_DUE_TO_CLANG_BUG - constexpr optional<ConstexprType> opt2{in_place_t(), {1, 2}}; - static_assert(opt2, ""); - static_assert(opt2->x == 2, ""); -#endif - - // TODO(b/34201852): uncomment these when std::is_constructible<T, Args&&...> - // SFINAE is added to optional::optional(in_place_t, Args&&...). - // struct I { - // I(in_place_t); - // }; - - // EXPECT_FALSE((std::is_constructible<optional<I>, in_place_t>::value)); - // EXPECT_FALSE((std::is_constructible<optional<I>, const - // in_place_t&>::value)); -} - -// template<U=T> optional(U&&); -TEST(optionalTest, ValueConstructor) { - constexpr optional<int> opt0(0); - static_assert(opt0, ""); - static_assert(*opt0 == 0, ""); - EXPECT_TRUE((std::is_convertible<int, optional<int>>::value)); - // Copy initialization ( = "abc") won't work due to optional(optional&&) - // is not constexpr. Use list initialization instead. This invokes - // optional<ConstexprType>::optional<U>(U&&), with U = const char (&) [4], - // which direct-initializes the ConstexprType value held by the optional - // via ConstexprType::ConstexprType(const char*). - constexpr optional<ConstexprType> opt1 = {"abc"}; - static_assert(opt1, ""); - static_assert(-1 == opt1->x, ""); - EXPECT_TRUE( - (std::is_convertible<const char*, optional<ConstexprType>>::value)); - // direct initialization - constexpr optional<ConstexprType> opt2{2}; - static_assert(opt2, ""); - static_assert(2 == opt2->x, ""); - EXPECT_FALSE((std::is_convertible<int, optional<ConstexprType>>::value)); - - // this invokes optional<int>::optional(int&&) - // NOTE: this has different behavior than assignment, e.g. - // "opt3 = {};" clears the optional rather than setting the value to 0 - constexpr optional<int> opt3({}); - static_assert(opt3, ""); - static_assert(*opt3 == 0, ""); - - // this invokes the move constructor with a default constructed optional - // because non-template function is a better match than template function. - optional<ConstexprType> opt4({}); - EXPECT_FALSE(!!opt4); -} - -struct Implicit {}; - -struct Explicit {}; - -struct Convert { - Convert(const Implicit&) // NOLINT(runtime/explicit) - : implicit(true), move(false) {} - Convert(Implicit&&) // NOLINT(runtime/explicit) - : implicit(true), move(true) {} - explicit Convert(const Explicit&) : implicit(false), move(false) {} - explicit Convert(Explicit&&) : implicit(false), move(true) {} - - bool implicit; - bool move; -}; - -struct ConvertFromOptional { - ConvertFromOptional(const Implicit&) // NOLINT(runtime/explicit) - : implicit(true), move(false), from_optional(false) {} - ConvertFromOptional(Implicit&&) // NOLINT(runtime/explicit) - : implicit(true), move(true), from_optional(false) {} - ConvertFromOptional(const optional<Implicit>&) // NOLINT(runtime/explicit) - : implicit(true), move(false), from_optional(true) {} - ConvertFromOptional(optional<Implicit>&&) // NOLINT(runtime/explicit) - : implicit(true), move(true), from_optional(true) {} - explicit ConvertFromOptional(const Explicit&) - : implicit(false), move(false), from_optional(false) {} - explicit ConvertFromOptional(Explicit&&) - : implicit(false), move(true), from_optional(false) {} - explicit ConvertFromOptional(const optional<Explicit>&) - : implicit(false), move(false), from_optional(true) {} - explicit ConvertFromOptional(optional<Explicit>&&) - : implicit(false), move(true), from_optional(true) {} - - bool implicit; - bool move; - bool from_optional; -}; - -TEST(optionalTest, ConvertingConstructor) { - optional<Implicit> i_empty; - optional<Implicit> i(in_place); - optional<Explicit> e_empty; - optional<Explicit> e(in_place); - { - // implicitly constructing optional<Convert> from optional<Implicit> - optional<Convert> empty = i_empty; - EXPECT_FALSE(!!empty); - optional<Convert> opt_copy = i; - EXPECT_TRUE(!!opt_copy); - EXPECT_TRUE(opt_copy->implicit); - EXPECT_FALSE(opt_copy->move); - optional<Convert> opt_move = optional<Implicit>(in_place); - EXPECT_TRUE(!!opt_move); - EXPECT_TRUE(opt_move->implicit); - EXPECT_TRUE(opt_move->move); - } - { - // explicitly constructing optional<Convert> from optional<Explicit> - optional<Convert> empty(e_empty); - EXPECT_FALSE(!!empty); - optional<Convert> opt_copy(e); - EXPECT_TRUE(!!opt_copy); - EXPECT_FALSE(opt_copy->implicit); - EXPECT_FALSE(opt_copy->move); - EXPECT_FALSE((std::is_convertible<const optional<Explicit>&, - optional<Convert>>::value)); - optional<Convert> opt_move{optional<Explicit>(in_place)}; - EXPECT_TRUE(!!opt_move); - EXPECT_FALSE(opt_move->implicit); - EXPECT_TRUE(opt_move->move); - EXPECT_FALSE( - (std::is_convertible<optional<Explicit>&&, optional<Convert>>::value)); - } - { - // implicitly constructing optional<ConvertFromOptional> from - // optional<Implicit> via ConvertFromOptional(optional<Implicit>&&) - // check that ConvertFromOptional(Implicit&&) is NOT called - static_assert( - gtl::internal_optional::is_constructible_convertible_from_optional< - ConvertFromOptional, Implicit>::value, - ""); - optional<ConvertFromOptional> opt0 = i_empty; - EXPECT_TRUE(!!opt0); - EXPECT_TRUE(opt0->implicit); - EXPECT_FALSE(opt0->move); - EXPECT_TRUE(opt0->from_optional); - optional<ConvertFromOptional> opt1 = optional<Implicit>(); - EXPECT_TRUE(!!opt1); - EXPECT_TRUE(opt1->implicit); - EXPECT_TRUE(opt1->move); - EXPECT_TRUE(opt1->from_optional); - } - { - // implicitly constructing optional<ConvertFromOptional> from - // optional<Explicit> via ConvertFromOptional(optional<Explicit>&&) - // check that ConvertFromOptional(Explicit&&) is NOT called - optional<ConvertFromOptional> opt0(e_empty); - EXPECT_TRUE(!!opt0); - EXPECT_FALSE(opt0->implicit); - EXPECT_FALSE(opt0->move); - EXPECT_TRUE(opt0->from_optional); - EXPECT_FALSE((std::is_convertible<const optional<Explicit>&, - optional<ConvertFromOptional>>::value)); - optional<ConvertFromOptional> opt1{optional<Explicit>()}; - EXPECT_TRUE(!!opt1); - EXPECT_FALSE(opt1->implicit); - EXPECT_TRUE(opt1->move); - EXPECT_TRUE(opt1->from_optional); - EXPECT_FALSE((std::is_convertible<optional<Explicit>&&, - optional<ConvertFromOptional>>::value)); - } -} - -TEST(optionalTest, StructorBasic) { - StructorListener listener; - Listenable::listener = &listener; - { - optional<Listenable> empty; - EXPECT_FALSE(!!empty); - optional<Listenable> opt0(in_place); - EXPECT_TRUE(!!opt0); - optional<Listenable> opt1(in_place, 1); - EXPECT_TRUE(!!opt1); - optional<Listenable> opt2(in_place, 1, 2); - EXPECT_TRUE(!!opt2); - } - EXPECT_EQ(1, listener.construct0); - EXPECT_EQ(1, listener.construct1); - EXPECT_EQ(1, listener.construct2); - EXPECT_EQ(3, listener.destruct); -} - -TEST(optionalTest, CopyMoveStructor) { - StructorListener listener; - Listenable::listener = &listener; - optional<Listenable> original(in_place); - EXPECT_EQ(1, listener.construct0); - EXPECT_EQ(0, listener.copy); - EXPECT_EQ(0, listener.move); - optional<Listenable> copy(original); - EXPECT_EQ(1, listener.construct0); - EXPECT_EQ(1, listener.copy); - EXPECT_EQ(0, listener.move); - optional<Listenable> move(std::move(original)); - EXPECT_EQ(1, listener.construct0); - EXPECT_EQ(1, listener.copy); - EXPECT_EQ(1, listener.move); -} - -TEST(optionalTest, ListInit) { - StructorListener listener; - Listenable::listener = &listener; - optional<Listenable> listinit1(in_place, {1}); - optional<Listenable> listinit2(in_place, {1, 2}); - EXPECT_EQ(2, listener.listinit); -} - -TEST(optionalTest, AssignFromNullopt) { - optional<int> opt(1); - opt = nullopt; - EXPECT_FALSE(!!opt); - - StructorListener listener; - Listenable::listener = &listener; - optional<Listenable> opt1(in_place); - opt1 = nullopt; - EXPECT_FALSE(opt1); - EXPECT_EQ(1, listener.construct0); - EXPECT_EQ(1, listener.destruct); - - EXPECT_TRUE((std::is_nothrow_assignable<optional<int>, nullopt_t>::value)); - EXPECT_TRUE( - (std::is_nothrow_assignable<optional<Listenable>, nullopt_t>::value)); -} - -TEST(optionalTest, CopyAssignment) { - const optional<int> empty, opt1 = 1, opt2 = 2; - optional<int> empty_to_opt1, opt1_to_opt2, opt2_to_empty; - - EXPECT_FALSE(!!empty_to_opt1); - empty_to_opt1 = empty; - EXPECT_FALSE(!!empty_to_opt1); - empty_to_opt1 = opt1; - EXPECT_TRUE(!!empty_to_opt1); - EXPECT_EQ(1, empty_to_opt1.value()); - - EXPECT_FALSE(!!opt1_to_opt2); - opt1_to_opt2 = opt1; - EXPECT_TRUE(!!opt1_to_opt2); - EXPECT_EQ(1, opt1_to_opt2.value()); - opt1_to_opt2 = opt2; - EXPECT_TRUE(!!opt1_to_opt2); - EXPECT_EQ(2, opt1_to_opt2.value()); - - EXPECT_FALSE(!!opt2_to_empty); - opt2_to_empty = opt2; - EXPECT_TRUE(!!opt2_to_empty); - EXPECT_EQ(2, opt2_to_empty.value()); - opt2_to_empty = empty; - EXPECT_FALSE(!!opt2_to_empty); - - EXPECT_TRUE(std::is_copy_assignable<optional<Copyable>>::value); - EXPECT_FALSE(std::is_copy_assignable<optional<MoveableThrow>>::value); - EXPECT_FALSE(std::is_copy_assignable<optional<MoveableNoThrow>>::value); - EXPECT_FALSE(std::is_copy_assignable<optional<NonMovable>>::value); -} - -TEST(optionalTest, MoveAssignment) { - StructorListener listener; - Listenable::listener = &listener; - - optional<Listenable> empty1, empty2, set1(in_place), set2(in_place); - EXPECT_EQ(2, listener.construct0); - optional<Listenable> empty_to_empty, empty_to_set, set_to_empty(in_place), - set_to_set(in_place); - EXPECT_EQ(4, listener.construct0); - empty_to_empty = std::move(empty1); - empty_to_set = std::move(set1); - set_to_empty = std::move(empty2); - set_to_set = std::move(set2); - EXPECT_EQ(0, listener.copy); - EXPECT_EQ(1, listener.move); - EXPECT_EQ(1, listener.destruct); - EXPECT_EQ(1, listener.move_assign); - - EXPECT_TRUE(std::is_move_assignable<optional<Copyable>>::value); - EXPECT_TRUE(std::is_move_assignable<optional<MoveableThrow>>::value); - EXPECT_TRUE(std::is_move_assignable<optional<MoveableNoThrow>>::value); - EXPECT_FALSE(std::is_move_assignable<optional<NonMovable>>::value); - - EXPECT_FALSE(std::is_nothrow_move_assignable<optional<MoveableThrow>>::value); - EXPECT_TRUE( - std::is_nothrow_move_assignable<optional<MoveableNoThrow>>::value); -} - -struct NoConvertToOptional { - // disable implicit conversion from const NoConvertToOptional& - // to optional<NoConvertToOptional>. - NoConvertToOptional(const NoConvertToOptional&) = delete; -}; - -struct CopyConvert { - CopyConvert(const NoConvertToOptional&); - CopyConvert& operator=(const CopyConvert&) = delete; - CopyConvert& operator=(const NoConvertToOptional&); -}; - -struct CopyConvertFromOptional { - CopyConvertFromOptional(const NoConvertToOptional&); - CopyConvertFromOptional(const optional<NoConvertToOptional>&); - CopyConvertFromOptional& operator=(const CopyConvertFromOptional&) = delete; - CopyConvertFromOptional& operator=(const NoConvertToOptional&); - CopyConvertFromOptional& operator=(const optional<NoConvertToOptional>&); -}; - -struct MoveConvert { - MoveConvert(NoConvertToOptional&&); - MoveConvert& operator=(const MoveConvert&) = delete; - MoveConvert& operator=(NoConvertToOptional&&); -}; - -struct MoveConvertFromOptional { - MoveConvertFromOptional(NoConvertToOptional&&); - MoveConvertFromOptional(optional<NoConvertToOptional>&&); - MoveConvertFromOptional& operator=(const MoveConvertFromOptional&) = delete; - MoveConvertFromOptional& operator=(NoConvertToOptional&&); - MoveConvertFromOptional& operator=(optional<NoConvertToOptional>&&); -}; - -// template <class U = T> optional<T>& operator=(U&& v); -TEST(optionalTest, ValueAssignment) { - optional<int> opt; - EXPECT_FALSE(!!opt); - opt = 42; - EXPECT_TRUE(!!opt); - EXPECT_EQ(42, opt.value()); - opt = nullopt; - EXPECT_FALSE(!!opt); - opt = 42; - EXPECT_TRUE(!!opt); - EXPECT_EQ(42, opt.value()); - opt = 43; - EXPECT_TRUE(!!opt); - EXPECT_EQ(43, opt.value()); - opt = {}; // this should clear optional - EXPECT_FALSE(!!opt); - - opt = {44}; - EXPECT_TRUE(!!opt); - EXPECT_EQ(44, opt.value()); - - // U = const NoConvertToOptional& - EXPECT_TRUE((std::is_assignable<optional<CopyConvert>&, - const NoConvertToOptional&>::value)); - // U = const optional<NoConvertToOptional>& - EXPECT_TRUE((std::is_assignable<optional<CopyConvertFromOptional>&, - const NoConvertToOptional&>::value)); - // U = const NoConvertToOptional& triggers SFINAE because - // std::is_constructible_v<MoveConvert, const NoConvertToOptional&> is false - EXPECT_FALSE((std::is_assignable<optional<MoveConvert>&, - const NoConvertToOptional&>::value)); - // U = NoConvertToOptional - EXPECT_TRUE((std::is_assignable<optional<MoveConvert>&, - NoConvertToOptional&&>::value)); - // U = const NoConvertToOptional& triggers SFINAE because - // std::is_constructible_v<MoveConvertFromOptional, const - // NoConvertToOptional&> is false - EXPECT_FALSE((std::is_assignable<optional<MoveConvertFromOptional>&, - const NoConvertToOptional&>::value)); - // U = NoConvertToOptional - EXPECT_TRUE((std::is_assignable<optional<MoveConvertFromOptional>&, - NoConvertToOptional&&>::value)); - // U = const optional<NoConvertToOptional>& - EXPECT_TRUE( - (std::is_assignable<optional<CopyConvertFromOptional>&, - const optional<NoConvertToOptional>&>::value)); - // U = optional<NoConvertToOptional> - EXPECT_TRUE((std::is_assignable<optional<MoveConvertFromOptional>&, - optional<NoConvertToOptional>&&>::value)); -} - -// template <class U> optional<T>& operator=(const optional<U>& rhs); -// template <class U> optional<T>& operator=(optional<U>&& rhs); -TEST(optionalTest, ConvertingAssignment) { - optional<int> opt_i; - optional<char> opt_c('c'); - opt_i = opt_c; - EXPECT_TRUE(!!opt_i); - EXPECT_EQ(*opt_c, *opt_i); - opt_i = optional<char>(); - EXPECT_FALSE(!!opt_i); - opt_i = optional<char>('d'); - EXPECT_TRUE(!!opt_i); - EXPECT_EQ('d', *opt_i); - - optional<string> opt_str; - optional<const char*> opt_cstr("abc"); - opt_str = opt_cstr; - EXPECT_TRUE(!!opt_str); - EXPECT_EQ(string("abc"), *opt_str); - opt_str = optional<const char*>(); - EXPECT_FALSE(!!opt_str); - opt_str = optional<const char*>("def"); - EXPECT_TRUE(!!opt_str); - EXPECT_EQ(string("def"), *opt_str); - - // operator=(const optional<U>&) with U = NoConvertToOptional - EXPECT_TRUE( - (std::is_assignable<optional<CopyConvert>, - const optional<NoConvertToOptional>&>::value)); - // operator=(const optional<U>&) with U = NoConvertToOptional - // triggers SFINAE because - // std::is_constructible_v<MoveConvert, const NoConvertToOptional&> is false - EXPECT_FALSE( - (std::is_assignable<optional<MoveConvert>&, - const optional<NoConvertToOptional>&>::value)); - // operator=(optional<U>&&) with U = NoConvertToOptional - EXPECT_TRUE((std::is_assignable<optional<MoveConvert>&, - optional<NoConvertToOptional>&&>::value)); - // operator=(const optional<U>&) with U = NoConvertToOptional triggers SFINAE - // because std::is_constructible_v<MoveConvertFromOptional, - // const NoConvertToOptional&> is false. - // operator=(U&&) with U = const optional<NoConverToOptional>& triggers SFINAE - // because std::is_constructible<MoveConvertFromOptional, - // optional<NoConvertToOptional>&&> is true. - EXPECT_FALSE( - (std::is_assignable<optional<MoveConvertFromOptional>&, - const optional<NoConvertToOptional>&>::value)); -} - -TEST(optionalTest, ResetAndHasValue) { - StructorListener listener; - Listenable::listener = &listener; - optional<Listenable> opt; - EXPECT_FALSE(!!opt); - EXPECT_FALSE(opt.has_value()); - opt.emplace(); - EXPECT_TRUE(!!opt); - EXPECT_TRUE(opt.has_value()); - opt.reset(); - EXPECT_FALSE(!!opt); - EXPECT_FALSE(opt.has_value()); - EXPECT_EQ(1, listener.destruct); - opt.reset(); - EXPECT_FALSE(!!opt); - EXPECT_FALSE(opt.has_value()); - - constexpr optional<int> empty; - static_assert(!empty.has_value(), ""); - constexpr optional<int> nonempty(1); - static_assert(nonempty.has_value(), ""); -} - -TEST(optionalTest, Emplace) { - StructorListener listener; - Listenable::listener = &listener; - optional<Listenable> opt; - EXPECT_FALSE(!!opt); - opt.emplace(1); - EXPECT_TRUE(!!opt); - opt.emplace(1, 2); - EXPECT_EQ(1, listener.construct1); - EXPECT_EQ(1, listener.construct2); - EXPECT_EQ(1, listener.destruct); -} - -TEST(optionalTest, ListEmplace) { - StructorListener listener; - Listenable::listener = &listener; - optional<Listenable> opt; - EXPECT_FALSE(!!opt); - opt.emplace({1}); - EXPECT_TRUE(!!opt); - opt.emplace({1, 2}); - EXPECT_EQ(2, listener.listinit); - EXPECT_EQ(1, listener.destruct); -} - -TEST(optionalTest, Swap) { - optional<int> opt_empty, opt1 = 1, opt2 = 2; - EXPECT_FALSE(!!opt_empty); - EXPECT_TRUE(!!opt1); - EXPECT_EQ(1, opt1.value()); - EXPECT_TRUE(!!opt2); - EXPECT_EQ(2, opt2.value()); - swap(opt_empty, opt1); - EXPECT_FALSE(!!opt1); - EXPECT_TRUE(!!opt_empty); - EXPECT_EQ(1, opt_empty.value()); - EXPECT_TRUE(!!opt2); - EXPECT_EQ(2, opt2.value()); - swap(opt_empty, opt1); - EXPECT_FALSE(!!opt_empty); - EXPECT_TRUE(!!opt1); - EXPECT_EQ(1, opt1.value()); - EXPECT_TRUE(!!opt2); - EXPECT_EQ(2, opt2.value()); - swap(opt1, opt2); - EXPECT_FALSE(!!opt_empty); - EXPECT_TRUE(!!opt1); - EXPECT_EQ(2, opt1.value()); - EXPECT_TRUE(!!opt2); - EXPECT_EQ(1, opt2.value()); - - EXPECT_TRUE(noexcept(opt1.swap(opt2))); - EXPECT_TRUE(noexcept(swap(opt1, opt2))); -} - -TEST(optionalTest, PointerStuff) { - optional<string> opt(in_place, "foo"); - EXPECT_EQ("foo", *opt); - const auto& opt_const = opt; - EXPECT_EQ("foo", *opt_const); - EXPECT_EQ(opt->size(), 3); - EXPECT_EQ(opt_const->size(), 3); - - constexpr optional<ConstexprType> opt1(1); - static_assert(opt1->x == 1, ""); -} - -// gcc has a bug pre 4.9 where it doesn't do correct overload resolution -// between rvalue reference qualified member methods. Skip that test to make -// the build green again when using the old compiler. -#if defined(__GNUC__) && !defined(__clang__) -#if __GNUC__ < 4 || (__GNUC__ == 4 && __GNUC_MINOR__ < 9) -#define SKIP_OVERLOAD_TEST_DUE_TO_GCC_BUG -#endif -#endif - -TEST(optionalTest, Value) { - using O = optional<string>; - using CO = const optional<string>; - O lvalue(in_place, "lvalue"); - CO clvalue(in_place, "clvalue"); - EXPECT_EQ("lvalue", lvalue.value()); - EXPECT_EQ("clvalue", clvalue.value()); - EXPECT_EQ("xvalue", O(in_place, "xvalue").value()); -#ifndef SKIP_OVERLOAD_TEST_DUE_TO_GCC_BUG - EXPECT_EQ("cxvalue", CO(in_place, "cxvalue").value()); - EXPECT_EQ("&", TypeQuals(lvalue.value())); - EXPECT_EQ("c&", TypeQuals(clvalue.value())); - EXPECT_EQ("&&", TypeQuals(O(in_place, "xvalue").value())); - EXPECT_EQ("c&&", TypeQuals(CO(in_place, "cxvalue").value())); -#endif -} - -TEST(optionalTest, DerefOperator) { - using O = optional<string>; - using CO = const optional<string>; - O lvalue(in_place, "lvalue"); - CO clvalue(in_place, "clvalue"); - EXPECT_EQ("lvalue", *lvalue); - EXPECT_EQ("clvalue", *clvalue); - EXPECT_EQ("xvalue", *O(in_place, "xvalue")); -#ifndef SKIP_OVERLOAD_TEST_DUE_TO_GCC_BUG - EXPECT_EQ("cxvalue", *CO(in_place, "cxvalue")); - EXPECT_EQ("&", TypeQuals(*lvalue)); - EXPECT_EQ("c&", TypeQuals(*clvalue)); - EXPECT_EQ("&&", TypeQuals(*O(in_place, "xvalue"))); - EXPECT_EQ("c&&", TypeQuals(*CO(in_place, "cxvalue"))); -#endif - - constexpr optional<int> opt1(1); - static_assert(*opt1 == 1, ""); - -#if !defined(SKIP_CONSTEXPR_TEST_DUE_TO_CLANG_BUG) && \ - !defined(SKIP_OVERLOAD_TEST_DUE_TO_GCC_BUG) - using COI = const optional<int>; - static_assert(*COI(2) == 2, ""); -#endif -} - -TEST(optionalTest, ValueOr) { - optional<double> opt_empty, opt_set = 1.2; - EXPECT_EQ(42.0, opt_empty.value_or(42)); - EXPECT_EQ(1.2, opt_set.value_or(42)); - EXPECT_EQ(42.0, optional<double>().value_or(42)); - EXPECT_EQ(1.2, optional<double>(1.2).value_or(42)); - -#ifndef SKIP_CONSTEXPR_TEST_DUE_TO_CLANG_BUG - constexpr optional<double> copt_empty; - static_assert(42.0 == copt_empty.value_or(42), ""); - - constexpr optional<double> copt_set = {1.2}; - static_assert(1.2 == copt_set.value_or(42), ""); - - using COD = const optional<double>; - static_assert(42.0 == COD().value_or(42), ""); - static_assert(1.2 == COD(1.2).value_or(42), ""); -#endif -} - -// make_optional cannot be constexpr until C++17 -TEST(optionalTest, make_optional) { - auto opt_int = make_optional(42); - EXPECT_TRUE((std::is_same<decltype(opt_int), optional<int>>::value)); - EXPECT_EQ(42, opt_int); - - StructorListener listener; - Listenable::listener = &listener; - - optional<Listenable> opt0 = make_optional<Listenable>(); - EXPECT_EQ(1, listener.construct0); - optional<Listenable> opt1 = make_optional<Listenable>(1); - EXPECT_EQ(1, listener.construct1); - optional<Listenable> opt2 = make_optional<Listenable>(1, 2); - EXPECT_EQ(1, listener.construct2); - optional<Listenable> opt3 = make_optional<Listenable>({1}); - optional<Listenable> opt4 = make_optional<Listenable>({1, 2}); - EXPECT_EQ(2, listener.listinit); -} - -TEST(optionalTest, Comparisons) { - optional<int> ae, be, a2 = 2, b2 = 2, a4 = 4, b4 = 4; - -#define optionalTest_Comparisons_EXPECT_LESS(x, y) \ - EXPECT_FALSE((x) == (y)); \ - EXPECT_TRUE((x) != (y)); \ - EXPECT_TRUE((x) < (y)); \ - EXPECT_FALSE((x) > (y)); \ - EXPECT_TRUE((x) <= (y)); \ - EXPECT_FALSE((x) >= (y)); - -#define optionalTest_Comparisons_EXPECT_SAME(x, y) \ - EXPECT_TRUE((x) == (y)); \ - EXPECT_FALSE((x) != (y)); \ - EXPECT_FALSE((x) < (y)); \ - EXPECT_FALSE((x) > (y)); \ - EXPECT_TRUE((x) <= (y)); \ - EXPECT_TRUE((x) >= (y)); - -#define optionalTest_Comparisons_EXPECT_GREATER(x, y) \ - EXPECT_FALSE((x) == (y)); \ - EXPECT_TRUE((x) != (y)); \ - EXPECT_FALSE((x) < (y)); \ - EXPECT_TRUE((x) > (y)); \ - EXPECT_FALSE((x) <= (y)); \ - EXPECT_TRUE((x) >= (y)); - - // LHS: nullopt, ae, a2, 3, a4 - // RHS: nullopt, be, b2, 3, b4 - - // optionalTest_Comparisons_EXPECT_NOT_TO_WORK(nullopt,nullopt); - optionalTest_Comparisons_EXPECT_SAME(nullopt, be); - optionalTest_Comparisons_EXPECT_LESS(nullopt, b2); - // optionalTest_Comparisons_EXPECT_NOT_TO_WORK(nullopt,3); - optionalTest_Comparisons_EXPECT_LESS(nullopt, b4); - - optionalTest_Comparisons_EXPECT_SAME(ae, nullopt); - optionalTest_Comparisons_EXPECT_SAME(ae, be); - optionalTest_Comparisons_EXPECT_LESS(ae, b2); - optionalTest_Comparisons_EXPECT_LESS(ae, 3); - optionalTest_Comparisons_EXPECT_LESS(ae, b4); - - optionalTest_Comparisons_EXPECT_GREATER(a2, nullopt); - optionalTest_Comparisons_EXPECT_GREATER(a2, be); - optionalTest_Comparisons_EXPECT_SAME(a2, b2); - optionalTest_Comparisons_EXPECT_LESS(a2, 3); - optionalTest_Comparisons_EXPECT_LESS(a2, b4); - - // optionalTest_Comparisons_EXPECT_NOT_TO_WORK(3,nullopt); - optionalTest_Comparisons_EXPECT_GREATER(3, be); - optionalTest_Comparisons_EXPECT_GREATER(3, b2); - optionalTest_Comparisons_EXPECT_SAME(3, 3); - optionalTest_Comparisons_EXPECT_LESS(3, b4); - - optionalTest_Comparisons_EXPECT_GREATER(a4, nullopt); - optionalTest_Comparisons_EXPECT_GREATER(a4, be); - optionalTest_Comparisons_EXPECT_GREATER(a4, b2); - optionalTest_Comparisons_EXPECT_GREATER(a4, 3); - optionalTest_Comparisons_EXPECT_SAME(a4, b4); -} - -TEST(optionalTest, SwapRegression) { - StructorListener listener; - Listenable::listener = &listener; - - { - optional<Listenable> a; - optional<Listenable> b(in_place); - a.swap(b); - } - - EXPECT_EQ(1, listener.construct0); - EXPECT_EQ(1, listener.move); - EXPECT_EQ(2, listener.destruct); - - { - optional<Listenable> a(in_place); - optional<Listenable> b; - a.swap(b); - } - - EXPECT_EQ(2, listener.construct0); - EXPECT_EQ(2, listener.move); - EXPECT_EQ(4, listener.destruct); -} - -TEST(optionalTest, BigStringLeakCheck) { - constexpr size_t n = 1 << 16; - - using OS = optional<string>; - - OS a; - OS b = nullopt; - OS c = string(n, 'c'); - string sd(n, 'd'); - OS d = sd; - OS e(in_place, n, 'e'); - OS f; - f.emplace(n, 'f'); - - OS ca(a); - OS cb(b); - OS cc(c); - OS cd(d); - OS ce(e); - - OS oa; - OS ob = nullopt; - OS oc = string(n, 'c'); - string sod(n, 'd'); - OS od = sod; - OS oe(in_place, n, 'e'); - OS of; - of.emplace(n, 'f'); - - OS ma(std::move(oa)); - OS mb(std::move(ob)); - OS mc(std::move(oc)); - OS md(std::move(od)); - OS me(std::move(oe)); - OS mf(std::move(of)); - - OS aa1; - OS ab1 = nullopt; - OS ac1 = string(n, 'c'); - string sad1(n, 'd'); - OS ad1 = sad1; - OS ae1(in_place, n, 'e'); - OS af1; - af1.emplace(n, 'f'); - - OS aa2; - OS ab2 = nullopt; - OS ac2 = string(n, 'c'); - string sad2(n, 'd'); - OS ad2 = sad2; - OS ae2(in_place, n, 'e'); - OS af2; - af2.emplace(n, 'f'); - - aa1 = af2; - ab1 = ae2; - ac1 = ad2; - ad1 = ac2; - ae1 = ab2; - af1 = aa2; - - OS aa3; - OS ab3 = nullopt; - OS ac3 = string(n, 'c'); - string sad3(n, 'd'); - OS ad3 = sad3; - OS ae3(in_place, n, 'e'); - OS af3; - af3.emplace(n, 'f'); - - aa3 = nullopt; - ab3 = nullopt; - ac3 = nullopt; - ad3 = nullopt; - ae3 = nullopt; - af3 = nullopt; - - OS aa4; - OS ab4 = nullopt; - OS ac4 = string(n, 'c'); - string sad4(n, 'd'); - OS ad4 = sad4; - OS ae4(in_place, n, 'e'); - OS af4; - af4.emplace(n, 'f'); - - aa4 = OS(in_place, n, 'a'); - ab4 = OS(in_place, n, 'b'); - ac4 = OS(in_place, n, 'c'); - ad4 = OS(in_place, n, 'd'); - ae4 = OS(in_place, n, 'e'); - af4 = OS(in_place, n, 'f'); - - OS aa5; - OS ab5 = nullopt; - OS ac5 = string(n, 'c'); - string sad5(n, 'd'); - OS ad5 = sad5; - OS ae5(in_place, n, 'e'); - OS af5; - af5.emplace(n, 'f'); - - string saa5(n, 'a'); - string sab5(n, 'a'); - string sac5(n, 'a'); - string sad52(n, 'a'); - string sae5(n, 'a'); - string saf5(n, 'a'); - - aa5 = saa5; - ab5 = sab5; - ac5 = sac5; - ad5 = sad52; - ae5 = sae5; - af5 = saf5; - - OS aa6; - OS ab6 = nullopt; - OS ac6 = string(n, 'c'); - string sad6(n, 'd'); - OS ad6 = sad6; - OS ae6(in_place, n, 'e'); - OS af6; - af6.emplace(n, 'f'); - - aa6 = string(n, 'a'); - ab6 = string(n, 'b'); - ac6 = string(n, 'c'); - ad6 = string(n, 'd'); - ae6 = string(n, 'e'); - af6 = string(n, 'f'); - - OS aa7; - OS ab7 = nullopt; - OS ac7 = string(n, 'c'); - string sad7(n, 'd'); - OS ad7 = sad7; - OS ae7(in_place, n, 'e'); - OS af7; - af7.emplace(n, 'f'); - - aa7.emplace(n, 'A'); - ab7.emplace(n, 'B'); - ac7.emplace(n, 'C'); - ad7.emplace(n, 'D'); - ae7.emplace(n, 'E'); - af7.emplace(n, 'F'); -} - -TEST(optionalTest, MoveAssignRegression) { - StructorListener listener; - Listenable::listener = &listener; - - { - optional<Listenable> a; - Listenable b; - a = std::move(b); - } - - EXPECT_EQ(1, listener.construct0); - EXPECT_EQ(1, listener.move); - EXPECT_EQ(2, listener.destruct); -} - -TEST(optionalTest, ValueType) { - EXPECT_TRUE((std::is_same<optional<int>::value_type, int>::value)); - EXPECT_TRUE((std::is_same<optional<string>::value_type, string>::value)); - EXPECT_FALSE((std::is_same<optional<int>::value_type, nullopt_t>::value)); -} - -TEST(optionalTest, Hash) { - std::hash<optional<int>> hash; - std::set<size_t> hashcodes; - hashcodes.insert(hash(nullopt)); - for (int i = 0; i < 100; ++i) { - hashcodes.insert(hash(i)); - } - EXPECT_GT(hashcodes.size(), 90); -} - -struct MoveMeNoThrow { - MoveMeNoThrow() : x(0) {} - MoveMeNoThrow(const MoveMeNoThrow& other) : x(other.x) { - LOG(FATAL) << "Should not be called."; - } - MoveMeNoThrow(MoveMeNoThrow&& other) noexcept : x(other.x) {} - int x; -}; - -struct MoveMeThrow { - MoveMeThrow() : x(0) {} - MoveMeThrow(const MoveMeThrow& other) : x(other.x) {} - MoveMeThrow(MoveMeThrow&& other) : x(other.x) {} - int x; -}; - -TEST(optionalTest, NoExcept) { - static_assert( - std::is_nothrow_move_constructible<optional<MoveMeNoThrow>>::value, ""); - static_assert( - !std::is_nothrow_move_constructible<optional<MoveMeThrow>>::value, ""); - std::vector<optional<MoveMeNoThrow>> v; - v.reserve(10); - for (int i = 0; i < 10; ++i) v.emplace_back(); -} - -} // namespace -} // namespace tensorflow diff --git a/tensorflow/core/ops/compat/ops_history.v1.pbtxt b/tensorflow/core/ops/compat/ops_history.v1.pbtxt index b2456bed3f..9836f784ab 100644 --- a/tensorflow/core/ops/compat/ops_history.v1.pbtxt +++ b/tensorflow/core/ops/compat/ops_history.v1.pbtxt @@ -29381,6 +29381,49 @@ op { } } op { + name: "MapDataset" + input_arg { + name: "input_dataset" + type: DT_VARIANT + } + input_arg { + name: "other_arguments" + type_list_attr: "Targuments" + } + output_arg { + name: "handle" + type: DT_VARIANT + } + attr { + name: "f" + type: "func" + } + attr { + name: "Targuments" + type: "list(type)" + has_minimum: true + } + attr { + name: "output_types" + type: "list(type)" + has_minimum: true + minimum: 1 + } + attr { + name: "output_shapes" + type: "list(shape)" + has_minimum: true + minimum: 1 + } + attr { + name: "use_inter_op_parallelism" + type: "bool" + default_value { + b: true + } + } +} +op { name: "MapDefun" input_arg { name: "arguments" @@ -37397,6 +37440,201 @@ op { } } op { + name: "ParseSequenceExample" + input_arg { + name: "serialized" + type: DT_STRING + } + input_arg { + name: "debug_name" + type: DT_STRING + } + input_arg { + name: "context_dense_defaults" + type_list_attr: "Tcontext_dense" + } + output_arg { + name: "context_sparse_indices" + type: DT_INT64 + number_attr: "Ncontext_sparse" + } + output_arg { + name: "context_sparse_values" + type_list_attr: "context_sparse_types" + } + output_arg { + name: "context_sparse_shapes" + type: DT_INT64 + number_attr: "Ncontext_sparse" + } + output_arg { + name: "context_dense_values" + type_list_attr: "Tcontext_dense" + } + output_arg { + name: "feature_list_sparse_indices" + type: DT_INT64 + number_attr: "Nfeature_list_sparse" + } + output_arg { + name: "feature_list_sparse_values" + type_list_attr: "feature_list_sparse_types" + } + output_arg { + name: "feature_list_sparse_shapes" + type: DT_INT64 + number_attr: "Nfeature_list_sparse" + } + output_arg { + name: "feature_list_dense_values" + type_list_attr: "feature_list_dense_types" + } + output_arg { + name: "feature_list_dense_lengths" + type: DT_INT64 + number_attr: "Nfeature_list_dense" + } + attr { + name: "feature_list_dense_missing_assumed_empty" + type: "list(string)" + has_minimum: true + } + attr { + name: "context_sparse_keys" + type: "list(string)" + has_minimum: true + } + attr { + name: "context_dense_keys" + type: "list(string)" + has_minimum: true + } + attr { + name: "feature_list_sparse_keys" + type: "list(string)" + has_minimum: true + } + attr { + name: "feature_list_dense_keys" + type: "list(string)" + has_minimum: true + } + attr { + name: "Ncontext_sparse" + type: "int" + default_value { + i: 0 + } + has_minimum: true + } + attr { + name: "Ncontext_dense" + type: "int" + default_value { + i: 0 + } + has_minimum: true + } + attr { + name: "Nfeature_list_sparse" + type: "int" + default_value { + i: 0 + } + has_minimum: true + } + attr { + name: "Nfeature_list_dense" + type: "int" + default_value { + i: 0 + } + has_minimum: true + } + attr { + name: "context_sparse_types" + type: "list(type)" + default_value { + list { + } + } + has_minimum: true + allowed_values { + list { + type: DT_FLOAT + type: DT_INT64 + type: DT_STRING + } + } + } + attr { + name: "Tcontext_dense" + type: "list(type)" + default_value { + list { + } + } + has_minimum: true + allowed_values { + list { + type: DT_FLOAT + type: DT_INT64 + type: DT_STRING + } + } + } + attr { + name: "feature_list_dense_types" + type: "list(type)" + default_value { + list { + } + } + has_minimum: true + allowed_values { + list { + type: DT_FLOAT + type: DT_INT64 + type: DT_STRING + } + } + } + attr { + name: "context_dense_shapes" + type: "list(shape)" + default_value { + list { + } + } + has_minimum: true + } + attr { + name: "feature_list_sparse_types" + type: "list(type)" + default_value { + list { + } + } + has_minimum: true + allowed_values { + list { + type: DT_FLOAT + type: DT_INT64 + type: DT_STRING + } + } + } + attr { + name: "feature_list_dense_shapes" + type: "list(shape)" + default_value { + list { + } + } + has_minimum: true + } +} +op { name: "ParseSingleExample" input_arg { name: "serialized" @@ -56470,6 +56708,125 @@ op { } } op { + name: "SdcaOptimizer" + input_arg { + name: "sparse_example_indices" + type: DT_INT64 + number_attr: "num_sparse_features" + } + input_arg { + name: "sparse_feature_indices" + type: DT_INT64 + number_attr: "num_sparse_features" + } + input_arg { + name: "sparse_feature_values" + type: DT_FLOAT + number_attr: "num_sparse_features_with_values" + } + input_arg { + name: "dense_features" + type: DT_FLOAT + number_attr: "num_dense_features" + } + input_arg { + name: "example_weights" + type: DT_FLOAT + } + input_arg { + name: "example_labels" + type: DT_FLOAT + } + input_arg { + name: "sparse_indices" + type: DT_INT64 + number_attr: "num_sparse_features" + } + input_arg { + name: "sparse_weights" + type: DT_FLOAT + number_attr: "num_sparse_features" + } + input_arg { + name: "dense_weights" + type: DT_FLOAT + number_attr: "num_dense_features" + } + input_arg { + name: "example_state_data" + type: DT_FLOAT + } + output_arg { + name: "out_example_state_data" + type: DT_FLOAT + } + output_arg { + name: "out_delta_sparse_weights" + type: DT_FLOAT + number_attr: "num_sparse_features" + } + output_arg { + name: "out_delta_dense_weights" + type: DT_FLOAT + number_attr: "num_dense_features" + } + attr { + name: "loss_type" + type: "string" + allowed_values { + list { + s: "logistic_loss" + s: "squared_loss" + s: "hinge_loss" + s: "smooth_hinge_loss" + s: "poisson_loss" + } + } + } + attr { + name: "adaptative" + type: "bool" + default_value { + b: false + } + } + attr { + name: "num_sparse_features" + type: "int" + has_minimum: true + } + attr { + name: "num_sparse_features_with_values" + type: "int" + has_minimum: true + } + attr { + name: "num_dense_features" + type: "int" + has_minimum: true + } + attr { + name: "l1" + type: "float" + } + attr { + name: "l2" + type: "float" + } + attr { + name: "num_loss_partitions" + type: "int" + has_minimum: true + minimum: 1 + } + attr { + name: "num_inner_iterations" + type: "int" + has_minimum: true + minimum: 1 + } +} +op { name: "SdcaShrinkL1" input_arg { name: "weights" diff --git a/tensorflow/core/ops/dataset_ops.cc b/tensorflow/core/ops/dataset_ops.cc index f03639e833..1a5ad8f421 100644 --- a/tensorflow/core/ops/dataset_ops.cc +++ b/tensorflow/core/ops/dataset_ops.cc @@ -198,6 +198,7 @@ REGISTER_OP("MapDataset") .Attr("Targuments: list(type) >= 0") .Attr("output_types: list(type) >= 1") .Attr("output_shapes: list(shape) >= 1") + .Attr("use_inter_op_parallelism: bool = true") .SetShapeFn(shape_inference::ScalarShape); REGISTER_OP("ParallelMapDataset") diff --git a/tensorflow/core/ops/ops.pbtxt b/tensorflow/core/ops/ops.pbtxt index 397a890e07..28b25fdeae 100644 --- a/tensorflow/core/ops/ops.pbtxt +++ b/tensorflow/core/ops/ops.pbtxt @@ -14542,6 +14542,13 @@ op { has_minimum: true minimum: 1 } + attr { + name: "use_inter_op_parallelism" + type: "bool" + default_value { + b: true + } + } } op { name: "MapDefun" @@ -18448,6 +18455,201 @@ op { } } op { + name: "ParseSequenceExample" + input_arg { + name: "serialized" + type: DT_STRING + } + input_arg { + name: "debug_name" + type: DT_STRING + } + input_arg { + name: "context_dense_defaults" + type_list_attr: "Tcontext_dense" + } + output_arg { + name: "context_sparse_indices" + type: DT_INT64 + number_attr: "Ncontext_sparse" + } + output_arg { + name: "context_sparse_values" + type_list_attr: "context_sparse_types" + } + output_arg { + name: "context_sparse_shapes" + type: DT_INT64 + number_attr: "Ncontext_sparse" + } + output_arg { + name: "context_dense_values" + type_list_attr: "Tcontext_dense" + } + output_arg { + name: "feature_list_sparse_indices" + type: DT_INT64 + number_attr: "Nfeature_list_sparse" + } + output_arg { + name: "feature_list_sparse_values" + type_list_attr: "feature_list_sparse_types" + } + output_arg { + name: "feature_list_sparse_shapes" + type: DT_INT64 + number_attr: "Nfeature_list_sparse" + } + output_arg { + name: "feature_list_dense_values" + type_list_attr: "feature_list_dense_types" + } + output_arg { + name: "feature_list_dense_lengths" + type: DT_INT64 + number_attr: "Nfeature_list_dense" + } + attr { + name: "feature_list_dense_missing_assumed_empty" + type: "list(string)" + has_minimum: true + } + attr { + name: "context_sparse_keys" + type: "list(string)" + has_minimum: true + } + attr { + name: "context_dense_keys" + type: "list(string)" + has_minimum: true + } + attr { + name: "feature_list_sparse_keys" + type: "list(string)" + has_minimum: true + } + attr { + name: "feature_list_dense_keys" + type: "list(string)" + has_minimum: true + } + attr { + name: "Ncontext_sparse" + type: "int" + default_value { + i: 0 + } + has_minimum: true + } + attr { + name: "Ncontext_dense" + type: "int" + default_value { + i: 0 + } + has_minimum: true + } + attr { + name: "Nfeature_list_sparse" + type: "int" + default_value { + i: 0 + } + has_minimum: true + } + attr { + name: "Nfeature_list_dense" + type: "int" + default_value { + i: 0 + } + has_minimum: true + } + attr { + name: "context_sparse_types" + type: "list(type)" + default_value { + list { + } + } + has_minimum: true + allowed_values { + list { + type: DT_FLOAT + type: DT_INT64 + type: DT_STRING + } + } + } + attr { + name: "Tcontext_dense" + type: "list(type)" + default_value { + list { + } + } + has_minimum: true + allowed_values { + list { + type: DT_FLOAT + type: DT_INT64 + type: DT_STRING + } + } + } + attr { + name: "feature_list_dense_types" + type: "list(type)" + default_value { + list { + } + } + has_minimum: true + allowed_values { + list { + type: DT_FLOAT + type: DT_INT64 + type: DT_STRING + } + } + } + attr { + name: "context_dense_shapes" + type: "list(shape)" + default_value { + list { + } + } + has_minimum: true + } + attr { + name: "feature_list_sparse_types" + type: "list(type)" + default_value { + list { + } + } + has_minimum: true + allowed_values { + list { + type: DT_FLOAT + type: DT_INT64 + type: DT_STRING + } + } + } + attr { + name: "feature_list_dense_shapes" + type: "list(shape)" + default_value { + list { + } + } + has_minimum: true + } +} +op { name: "ParseSingleExample" input_arg { name: "serialized" @@ -26782,6 +26984,7 @@ op { s: "squared_loss" s: "hinge_loss" s: "smooth_hinge_loss" + s: "poisson_loss" } } } diff --git a/tensorflow/core/ops/sdca_ops.cc b/tensorflow/core/ops/sdca_ops.cc index 4025070adb..fdf53a55dd 100644 --- a/tensorflow/core/ops/sdca_ops.cc +++ b/tensorflow/core/ops/sdca_ops.cc @@ -41,7 +41,7 @@ static Status ApplySdcaOptimizerShapeFn(InferenceContext* c) { REGISTER_OP("SdcaOptimizer") .Attr( "loss_type: {'logistic_loss', 'squared_loss', 'hinge_loss'," - "'smooth_hinge_loss'}") + "'smooth_hinge_loss', 'poisson_loss'}") .Attr("adaptative : bool=false") .Attr("num_sparse_features: int >= 0") .Attr("num_sparse_features_with_values: int >= 0") diff --git a/tensorflow/core/platform/cloud/curl_http_request.cc b/tensorflow/core/platform/cloud/curl_http_request.cc index a1be4aacce..5e1eabee5b 100644 --- a/tensorflow/core/platform/cloud/curl_http_request.cc +++ b/tensorflow/core/platform/cloud/curl_http_request.cc @@ -394,9 +394,9 @@ size_t CurlHttpRequest::HeaderCallback(const void* ptr, size_t size, .StopCapture() .OneLiteral(": ") .GetResult(&value, &name)) { - string str_value = std::string(value); + string str_value(value); str_util::StripTrailingWhitespace(&str_value); - that->response_headers_[std::string(name)] = str_value; + that->response_headers_[string(name)] = str_value; } return size * nmemb; } diff --git a/tensorflow/core/platform/cloud/gcs_file_system.cc b/tensorflow/core/platform/cloud/gcs_file_system.cc index 9d33787bd5..8f959c018e 100644 --- a/tensorflow/core/platform/cloud/gcs_file_system.cc +++ b/tensorflow/core/platform/cloud/gcs_file_system.cc @@ -179,13 +179,13 @@ Status ParseGcsPath(StringPiece fname, bool empty_object_ok, string* bucket, return errors::InvalidArgument("GCS path doesn't start with 'gs://': ", fname); } - *bucket = std::string(bucketp); + *bucket = string(bucketp); if (bucket->empty() || *bucket == ".") { return errors::InvalidArgument("GCS path doesn't contain a bucket name: ", fname); } str_util::ConsumePrefix(&objectp, "/"); - *object = std::string(objectp); + *object = string(objectp); if (!empty_object_ok && object->empty()) { return errors::InvalidArgument("GCS path doesn't contain an object name: ", fname); @@ -224,7 +224,7 @@ std::set<string> AddAllSubpaths(const std::vector<string>& paths) { for (const string& path : paths) { StringPiece subpath = io::Dirname(path); while (!subpath.empty()) { - result.emplace(std::string(subpath)); + result.emplace(string(subpath)); subpath = io::Dirname(subpath); } } @@ -723,7 +723,7 @@ GcsFileSystem::GcsFileSystem() { if (!header_name.empty() && !header_value.empty()) { additional_header_.reset(new std::pair<const string, const string>( - std::string(header_name), std::string(header_value))); + string(header_name), string(header_value))); VLOG(1) << "GCS additional header ENABLED. " << "Name: " << additional_header_->first << ", " @@ -1229,7 +1229,7 @@ Status GcsFileSystem::GetMatchingPaths(const string& pattern, // Find the fixed prefix by looking for the first wildcard. const string& fixed_prefix = pattern.substr(0, pattern.find_first_of("*?[\\")); - const string& dir = std::string(io::Dirname(fixed_prefix)); + const string dir(io::Dirname(fixed_prefix)); if (dir.empty()) { return errors::InvalidArgument( "A GCS pattern doesn't have a bucket name: ", pattern); @@ -1326,7 +1326,7 @@ Status GcsFileSystem::GetChildrenBounded(const string& dirname, " doesn't match the prefix ", object_prefix)); } if (!relative_path.empty() || include_self_directory_marker) { - result->emplace_back(std::string(relative_path)); + result->emplace_back(relative_path); } if (++retrieved_results >= max_results) { return Status::OK(); @@ -1354,7 +1354,7 @@ Status GcsFileSystem::GetChildrenBounded(const string& dirname, "Unexpected response: the returned folder name ", prefix_str, " doesn't match the prefix ", object_prefix); } - result->emplace_back(std::string(relative_path)); + result->emplace_back(relative_path); if (++retrieved_results >= max_results) { return Status::OK(); } diff --git a/tensorflow/core/platform/cloud/oauth_client.cc b/tensorflow/core/platform/cloud/oauth_client.cc index ee6ba7b041..9b85cae9b9 100644 --- a/tensorflow/core/platform/cloud/oauth_client.cc +++ b/tensorflow/core/platform/cloud/oauth_client.cc @@ -216,7 +216,7 @@ Status OAuthClient::GetTokenFromServiceAccountJson( // Send the request to the Google OAuth 2.0 server to get the token. std::unique_ptr<HttpRequest> request(http_request_factory_->Create()); std::vector<char> response_buffer; - request->SetUri(std::string(oauth_server_uri)); + request->SetUri(string(oauth_server_uri)); request->SetPostFromBuffer(request_body.c_str(), request_body.size()); request->SetResultBuffer(&response_buffer); TF_RETURN_IF_ERROR(request->Send()); @@ -248,7 +248,7 @@ Status OAuthClient::GetTokenFromRefreshTokenJson( std::unique_ptr<HttpRequest> request(http_request_factory_->Create()); std::vector<char> response_buffer; - request->SetUri(std::string(oauth_server_uri)); + request->SetUri(string(oauth_server_uri)); request->SetPostFromBuffer(request_body.c_str(), request_body.size()); request->SetResultBuffer(&response_buffer); TF_RETURN_IF_ERROR(request->Send()); diff --git a/tensorflow/core/platform/cloud/oauth_client_test.cc b/tensorflow/core/platform/cloud/oauth_client_test.cc index 4ffa72288b..1cd0641cd3 100644 --- a/tensorflow/core/platform/cloud/oauth_client_test.cc +++ b/tensorflow/core/platform/cloud/oauth_client_test.cc @@ -126,9 +126,9 @@ TEST(OAuthClientTest, GetTokenFromServiceAccountJson) { EXPECT_EQ("urn%3Aietf%3Aparams%3Aoauth%3Agrant-type%3Ajwt-bearer", grant_type); - int last_dot = std::string(assertion).find_last_of("."); - string header_dot_claim = std::string(assertion.substr(0, last_dot)); - string signature_encoded = std::string(assertion.substr(last_dot + 1)); + int last_dot = assertion.rfind('.'); + string header_dot_claim(assertion.substr(0, last_dot)); + string signature_encoded(assertion.substr(last_dot + 1)); // Check that 'signature' signs 'header_dot_claim'. diff --git a/tensorflow/core/platform/default/build_config.bzl b/tensorflow/core/platform/default/build_config.bzl index 0411a8c4f9..bb841aeab7 100644 --- a/tensorflow/core/platform/default/build_config.bzl +++ b/tensorflow/core/platform/default/build_config.bzl @@ -625,7 +625,9 @@ def tf_additional_lib_deps(): """Additional dependencies needed to build TF libraries.""" return [ "@com_google_absl//absl/base:base", + "@com_google_absl//absl/container:inlined_vector", "@com_google_absl//absl/types:span", + "@com_google_absl//absl/types:optional", ] + if_static( ["@nsync//:nsync_cpp"], ["@nsync//:nsync_headers"], diff --git a/tensorflow/core/protobuf/config.proto b/tensorflow/core/protobuf/config.proto index da3a99565e..625d5649e6 100644 --- a/tensorflow/core/protobuf/config.proto +++ b/tensorflow/core/protobuf/config.proto @@ -390,9 +390,12 @@ message ConfigProto { message Experimental { // Task name for group resolution. string collective_group_leader = 1; - // Whether the client will format templated errors. For example, the string: - // "The node was defined on ^^node:Foo:${file}:${line}^^". - bool client_handles_error_formatting = 2; + + // We removed the flag client_handles_error_formatting. Marking the tag + // number as reserved. + // TODO(shikharagarwal): Should we just remove this tag so that it can be + // used in future for other purpose? + reserved 2; // Which executor to use, the default executor will be used // if it is an empty string or "DEFAULT" diff --git a/tensorflow/core/util/mkl_util.h b/tensorflow/core/util/mkl_util.h index 6474319370..680211edff 100644 --- a/tensorflow/core/util/mkl_util.h +++ b/tensorflow/core/util/mkl_util.h @@ -17,6 +17,7 @@ limitations under the License. #define TENSORFLOW_CORE_UTIL_MKL_UTIL_H_ #ifdef INTEL_MKL +#include <string> #include <memory> #include <unordered_map> #include <utility> @@ -56,6 +57,7 @@ limitations under the License. #include "tensorflow/core/platform/macros.h" #include "tensorflow/core/util/padding.h" #include "tensorflow/core/util/tensor_format.h" +#include "tensorflow/core/util/env_var.h" #ifndef INTEL_MKL_ML_ONLY #include "mkldnn.hpp" @@ -102,6 +104,8 @@ typedef enum { Dim3d_I = 1 } MklDnnDims3D; +static const int kSmallBatchSize = 32; + #ifdef INTEL_MKL_ML_ONLY class MklShape { public: @@ -2000,7 +2004,9 @@ const mkldnn::memory::dims NONE_DIMS = {}; template <typename T> class MklPrimitiveFactory { public: - MklPrimitiveFactory() {} + MklPrimitiveFactory() { + } + ~MklPrimitiveFactory() {} MklPrimitive* GetOp(const string& key) { @@ -2023,6 +2029,22 @@ class MklPrimitiveFactory { map[key] = op; } + /// Function to decide whether HW has AVX512 or AVX2 + /// For those legacy device(w/o AVX512 and AVX2), + /// MKL-DNN GEMM will be used. + static inline bool IsLegacyPlatform() { + return (!port::TestCPUFeature(port::CPUFeature::AVX512F) + && !port::TestCPUFeature(port::CPUFeature::AVX2)); + } + + /// Fuction to check whether primitive memory optimization is enabled + static inline bool IsPrimitiveMemOptEnabled() { + bool is_primitive_mem_opt_enabled = true; + TF_CHECK_OK(ReadBoolFromEnvVar("TF_MKL_OPTIMIZE_PRIMITVE_MEMUSE", true, + &is_primitive_mem_opt_enabled)); + return is_primitive_mem_opt_enabled; + } + private: static inline std::unordered_map<string, MklPrimitive*>& GetHashMap() { static thread_local std::unordered_map<string, MklPrimitive*> map_; @@ -2060,7 +2082,7 @@ class FactoryKeyCreator { const char delimiter = 'x'; const int kMaxKeyLength = 256; void Append(StringPiece s) { - key_.append(s.ToString()); + key_.append(string(s)); key_.append(1, delimiter); } }; @@ -2099,7 +2121,7 @@ class MklReorderPrimitive : public MklPrimitive { context_.dst_mem->set_data_handle(to->get_data_handle()); } - private: + private: struct ReorderContext { std::shared_ptr<mkldnn::memory> src_mem; std::shared_ptr<mkldnn::memory> dst_mem; @@ -2141,7 +2163,7 @@ class MklReorderPrimitiveFactory : public MklPrimitiveFactory<T> { return instance_; } - private: + private: MklReorderPrimitiveFactory() {} ~MklReorderPrimitiveFactory() {} @@ -2186,6 +2208,15 @@ inline primitive FindOrCreateReorder(const memory* from, const memory* to) { return *reorder_prim->GetPrimitive(); } +// utility function to determine if it is conv 1x1 and stride != 1 +// for purpose of temporarily disabling primitive reuse +inline bool IsConv1x1StrideNot1(memory::dims filter_dims, memory::dims strides) { + if (filter_dims.size() != 4 || strides.size() != 2) return false; + + return ((filter_dims[2] == 1) && (filter_dims[3] == 1) && + ((strides[0] != 1) || (strides[1] != 1))); +} + #endif // INTEL_MKL_DNN } // namespace tensorflow diff --git a/tensorflow/core/util/status_util.h b/tensorflow/core/util/status_util.h deleted file mode 100644 index ea92f61dce..0000000000 --- a/tensorflow/core/util/status_util.h +++ /dev/null @@ -1,36 +0,0 @@ -/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. - -Licensed under the Apache License, Version 2.0 (the "License"); -you may not use this file except in compliance with the License. -You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - -Unless required by applicable law or agreed to in writing, software -distributed under the License is distributed on an "AS IS" BASIS, -WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -See the License for the specific language governing permissions and -limitations under the License. -==============================================================================*/ - -#ifndef TENSORFLOW_CORE_UTIL_STATUS_UTIL_H_ -#define TENSORFLOW_CORE_UTIL_STATUS_UTIL_H_ - -#include "tensorflow/core/graph/graph.h" -#include "tensorflow/core/lib/strings/strcat.h" - -namespace tensorflow { - -// Creates a tag to be used in an exception error message. This can be parsed by -// the Python layer and replaced with information about the node. -// -// For example, error_format_tag(node, "${file}") returns -// "^^node:NODE_NAME:${line}^^" which would be rewritten by the Python layer as -// e.g. "file/where/node/was/created.py". -inline string error_format_tag(const Node& node, const string& format) { - return strings::StrCat("^^node:", node.name(), ":", format, "^^"); -} - -} // namespace tensorflow - -#endif // TENSORFLOW_CORE_UTIL_STATUS_UTIL_H_ diff --git a/tensorflow/core/util/status_util_test.cc b/tensorflow/core/util/status_util_test.cc deleted file mode 100644 index 1f06004db2..0000000000 --- a/tensorflow/core/util/status_util_test.cc +++ /dev/null @@ -1,36 +0,0 @@ -/* Copyright 2018 The TensorFlow Authors. All Rights Reserved. - -Licensed under the Apache License, Version 2.0 (the "License"); -you may not use this file except in compliance with the License. -You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - -Unless required by applicable law or agreed to in writing, software -distributed under the License is distributed on an "AS IS" BASIS, -WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -See the License for the specific language governing permissions and -limitations under the License. -==============================================================================*/ - -#include "tensorflow/core/util/status_util.h" - -#include "tensorflow/core/graph/graph_constructor.h" -#include "tensorflow/core/graph/node_builder.h" -#include "tensorflow/core/lib/core/status_test_util.h" -#include "tensorflow/core/platform/test.h" - -namespace tensorflow { -namespace { - -TEST(TestStatusUtil, ErrorFormatTagForNode) { - Graph graph(OpRegistry::Global()); - Node* node; - TF_CHECK_OK(NodeBuilder("Foo", "NoOp").Finalize(&graph, &node)); - EXPECT_EQ(error_format_tag(*node, "${line}"), "^^node:Foo:${line}^^"); - EXPECT_EQ(error_format_tag(*node, "${file}:${line}"), - "^^node:Foo:${file}:${line}^^"); -} - -} // namespace -} // namespace tensorflow diff --git a/tensorflow/python/BUILD b/tensorflow/python/BUILD index 5af6437c56..e6169e9e80 100644 --- a/tensorflow/python/BUILD +++ b/tensorflow/python/BUILD @@ -2090,6 +2090,18 @@ py_library( srcs = [ "ops/custom_gradient.py", "ops/gradients.py", + ], + srcs_version = "PY2AND3", + deps = [ + ":gradients_impl", + "//tensorflow/python/eager:function", + "//tensorflow/python/eager:tape", + ], +) + +py_library( + name = "gradients_impl", + srcs = [ "ops/gradients_impl.py", ], srcs_version = "PY2AND3", diff --git a/tensorflow/python/__init__.py b/tensorflow/python/__init__.py index a2ab63bb48..4921ecc43c 100644 --- a/tensorflow/python/__init__.py +++ b/tensorflow/python/__init__.py @@ -48,6 +48,13 @@ import numpy as np from tensorflow.python import pywrap_tensorflow +from tensorflow.python.tools import component_api_helper +component_api_helper.package_hook( + parent_package_str='tensorflow.python', + child_package_str=( + 'tensorflow_estimator.python.estimator')) +del component_api_helper + # Protocol buffers from tensorflow.core.framework.graph_pb2 import * from tensorflow.core.framework.node_def_pb2 import * diff --git a/tensorflow/python/client/session.py b/tensorflow/python/client/session.py index 1841dd998b..ae0ad27f15 100644 --- a/tensorflow/python/client/session.py +++ b/tensorflow/python/client/session.py @@ -1132,7 +1132,7 @@ class BaseSession(SessionInterface): for details of the allowable fetch types. feed_list: (Optional.) A list of `feed_dict` keys. See `tf.Session.run` for details of the allowable feed key types. - accept_options: (Optional.) Iff `True`, the returned `Callable` will be + accept_options: (Optional.) If `True`, the returned `Callable` will be able to accept `tf.RunOptions` and `tf.RunMetadata` as optional keyword arguments `options` and `run_metadata`, respectively, with the same syntax and semantics as `tf.Session.run`, which is useful @@ -1302,9 +1302,7 @@ class BaseSession(SessionInterface): node_def = op.node_def except KeyError: pass - if (self._config is not None and - self._config.experimental.client_handles_error_formatting): - message = error_interpolation.interpolate(message, self._graph) + message = error_interpolation.interpolate(message, self._graph) raise type(e)(node_def, op, message) def _extend_graph(self): diff --git a/tensorflow/python/client/session_test.py b/tensorflow/python/client/session_test.py index 052be68385..f87a96e547 100644 --- a/tensorflow/python/client/session_test.py +++ b/tensorflow/python/client/session_test.py @@ -49,6 +49,8 @@ from tensorflow.python.ops import array_ops from tensorflow.python.ops import control_flow_ops from tensorflow.python.ops import data_flow_ops from tensorflow.python.ops import gen_control_flow_ops +# Import gradients to resolve circular imports +from tensorflow.python.ops import gradients # pylint: disable=unused-import from tensorflow.python.ops import gradients_impl from tensorflow.python.ops import math_ops # Import resource_variable_ops for the variables-to-tensor implicit conversion. diff --git a/tensorflow/python/compat/compat.py b/tensorflow/python/compat/compat.py index d31aeae4a3..586f4c6936 100644 --- a/tensorflow/python/compat/compat.py +++ b/tensorflow/python/compat/compat.py @@ -26,7 +26,7 @@ import datetime from tensorflow.python.util import tf_contextlib from tensorflow.python.util.tf_export import tf_export -_FORWARD_COMPATIBILITY_HORIZON = datetime.date(2018, 8, 31) +_FORWARD_COMPATIBILITY_HORIZON = datetime.date(2018, 9, 5) @tf_export("compat.forward_compatible") diff --git a/tensorflow/python/data/kernel_tests/iterator_ops_test.py b/tensorflow/python/data/kernel_tests/iterator_ops_test.py index b0414ad655..671e5d4812 100644 --- a/tensorflow/python/data/kernel_tests/iterator_ops_test.py +++ b/tensorflow/python/data/kernel_tests/iterator_ops_test.py @@ -91,7 +91,7 @@ class IteratorTest(test.TestCase): self.assertEqual([c.shape[1:] for c in components], [t.shape for t in get_next]) - with self.test_session() as sess: + with self.cached_session() as sess: for _ in range(14): for i in range(7): result = sess.run(get_next) @@ -117,7 +117,7 @@ class IteratorTest(test.TestCase): self.assertEqual([c.shape[1:] for c in components], [t.shape for t in get_next]) - with self.test_session() as sess: + with self.cached_session() as sess: for _ in range(14): for i in range(7): result = sess.run(get_next) @@ -208,7 +208,7 @@ class IteratorTest(test.TestCase): iterator = dataset.make_one_shot_iterator() next_element = iterator.get_next() - with self.test_session() as sess: + with self.cached_session() as sess: with self.assertRaisesRegexp(errors.InvalidArgumentError, "oops"): sess.run(next_element) @@ -216,7 +216,7 @@ class IteratorTest(test.TestCase): with self.assertRaisesRegexp(errors.InvalidArgumentError, "oops"): sess.run(next_element) - with self.test_session() as sess: + with self.cached_session() as sess: def consumer_thread(): with self.assertRaisesRegexp(errors.InvalidArgumentError, "oops"): @@ -287,7 +287,7 @@ class IteratorTest(test.TestCase): .make_initializable_iterator()) get_next = iterator.get_next() - with self.test_session() as sess: + with self.cached_session() as sess: with self.assertRaisesRegexp(errors.FailedPreconditionError, "iterator has not been initialized"): sess.run(get_next) @@ -308,7 +308,7 @@ class IteratorTest(test.TestCase): self.assertEqual(dataset_4.output_types, iterator.output_types) self.assertEqual([None], iterator.output_shapes.as_list()) - with self.test_session() as sess: + with self.cached_session() as sess: # The iterator is initially uninitialized. with self.assertRaises(errors.FailedPreconditionError): sess.run(get_next) @@ -380,7 +380,7 @@ class IteratorTest(test.TestCase): self.assertEqual(dataset_4.output_types, feedable_iterator.output_types) self.assertEqual([], feedable_iterator.output_shapes) - with self.test_session() as sess: + with self.cached_session() as sess: iterator_3_handle = sess.run(iterator_3.string_handle()) iterator_4_handle = sess.run(iterator_4.string_handle()) @@ -436,7 +436,7 @@ class IteratorTest(test.TestCase): self.assertEqual(dataset_4.output_types, feedable_iterator.output_types) self.assertEqual([], feedable_iterator.output_shapes) - with self.test_session() as sess: + with self.cached_session() as sess: iterator_3_handle = sess.run(iterator_3.string_handle()) iterator_4_handle = sess.run(iterator_4.string_handle()) @@ -524,7 +524,7 @@ class IteratorTest(test.TestCase): feedable_int_any = iterator_ops.Iterator.from_string_handle( handle_placeholder, dtypes.int32) - with self.test_session() as sess: + with self.cached_session() as sess: handle_int_scalar = sess.run( dataset_int_scalar.make_one_shot_iterator().string_handle()) handle_float_vector = sess.run( @@ -687,7 +687,7 @@ class IteratorTest(test.TestCase): f=_remote_fn, target=target_placeholder) - with self.test_session() as sess: + with self.cached_session() as sess: elem = sess.run( remote_op, feed_dict={ @@ -803,16 +803,15 @@ class IteratorCheckpointingTest(test.TestCase): get_next = iterator.get_next if context.executing_eagerly( ) else functools.partial(self.evaluate, iterator.get_next()) checkpoint = checkpointable_utils.Checkpoint(iterator=iterator) - with self.test_session() as sess: - self.assertAllEqual([1, 4], get_next()) - save_path = checkpoint.save(checkpoint_prefix) - self.assertAllEqual([9, 16], get_next()) - self.assertAllEqual([25, 36], get_next()) - checkpoint.restore(save_path).run_restore_ops(sess) - self.assertAllEqual([9, 16], get_next()) - self.assertAllEqual([25, 36], get_next()) - with self.assertRaises(errors.OutOfRangeError): - get_next() + self.assertAllEqual([1, 4], get_next()) + save_path = checkpoint.save(checkpoint_prefix) + self.assertAllEqual([9, 16], get_next()) + self.assertAllEqual([25, 36], get_next()) + checkpoint.restore(save_path).run_restore_ops() + self.assertAllEqual([9, 16], get_next()) + self.assertAllEqual([25, 36], get_next()) + with self.assertRaises(errors.OutOfRangeError): + get_next() @test_util.run_in_graph_and_eager_modes def testSaveRestoreMultipleIterator(self): @@ -833,19 +832,18 @@ class IteratorCheckpointingTest(test.TestCase): ) else functools.partial(self.evaluate, iterator_3.get_next()) checkpoint = checkpointable_utils.Checkpoint( iterator_1=iterator_1, iterator_2=iterator_2, iterator_3=iterator_3) - with self.test_session() as sess: - self.assertAllEqual([1, 4], get_next_1()) - self.assertAllEqual(0, get_next_3()) - self.assertAllEqual(1, get_next_3()) - self.assertAllEqual(2, get_next_3()) - save_path = checkpoint.save(checkpoint_prefix) - self.assertAllEqual([1, 4], get_next_2()) - self.assertAllEqual([9, 16], get_next_2()) - self.assertAllEqual(3, get_next_3()) - checkpoint.restore(save_path).run_restore_ops(sess) - self.assertAllEqual([9, 16], get_next_1()) - self.assertAllEqual([1, 4], get_next_2()) - self.assertAllEqual(3, get_next_3()) + self.assertAllEqual([1, 4], get_next_1()) + self.assertAllEqual(0, get_next_3()) + self.assertAllEqual(1, get_next_3()) + self.assertAllEqual(2, get_next_3()) + save_path = checkpoint.save(checkpoint_prefix) + self.assertAllEqual([1, 4], get_next_2()) + self.assertAllEqual([9, 16], get_next_2()) + self.assertAllEqual(3, get_next_3()) + checkpoint.restore(save_path).run_restore_ops() + self.assertAllEqual([9, 16], get_next_1()) + self.assertAllEqual([1, 4], get_next_2()) + self.assertAllEqual(3, get_next_3()) @test_util.run_in_graph_and_eager_modes def testRestoreExhaustedIterator(self): @@ -856,17 +854,16 @@ class IteratorCheckpointingTest(test.TestCase): get_next = iterator.get_next if context.executing_eagerly( ) else functools.partial(self.evaluate, iterator.get_next()) checkpoint = checkpointable_utils.Checkpoint(iterator=iterator) - with self.test_session() as sess: - self.assertAllEqual(0, get_next()) - self.assertAllEqual(1, get_next()) - save_path = checkpoint.save(checkpoint_prefix) - self.assertAllEqual(2, get_next()) - checkpoint.restore(save_path).run_restore_ops(sess) - self.assertAllEqual(2, get_next()) - save_path = checkpoint.save(checkpoint_prefix) - checkpoint.restore(save_path).run_restore_ops(sess) - with self.assertRaises(errors.OutOfRangeError): - get_next() + self.assertAllEqual(0, get_next()) + self.assertAllEqual(1, get_next()) + save_path = checkpoint.save(checkpoint_prefix) + self.assertAllEqual(2, get_next()) + checkpoint.restore(save_path).run_restore_ops() + self.assertAllEqual(2, get_next()) + save_path = checkpoint.save(checkpoint_prefix) + checkpoint.restore(save_path).run_restore_ops() + with self.assertRaises(errors.OutOfRangeError): + get_next() def testRestoreInReconstructedIteratorInitializable(self): checkpoint_directory = self.get_temp_dir() @@ -876,7 +873,7 @@ class IteratorCheckpointingTest(test.TestCase): get_next = iterator.get_next() checkpoint = checkpointable_utils.Checkpoint(iterator=iterator) for i in range(5): - with self.test_session() as sess: + with self.cached_session() as sess: checkpoint.restore(checkpoint_management.latest_checkpoint( checkpoint_directory)).initialize_or_restore(sess) for j in range(2): diff --git a/tensorflow/python/data/kernel_tests/map_dataset_op_test.py b/tensorflow/python/data/kernel_tests/map_dataset_op_test.py index 52b4320bf1..df2c9b170a 100644 --- a/tensorflow/python/data/kernel_tests/map_dataset_op_test.py +++ b/tensorflow/python/data/kernel_tests/map_dataset_op_test.py @@ -711,57 +711,74 @@ class MapDatasetBenchmark(test.Benchmark): def benchmarkChainOfMaps(self): chain_lengths = [0, 1, 2, 5, 10, 20, 50] for chain_length in chain_lengths: - with ops.Graph().as_default(): - dataset = dataset_ops.Dataset.from_tensors(0).repeat(None) - for _ in range(chain_length): - dataset = dataset.map(lambda x: x) - iterator = dataset.make_one_shot_iterator() - next_element = iterator.get_next() - - with session.Session() as sess: - for _ in range(5): - sess.run(next_element.op) - deltas = [] - for _ in range(100): - start = time.time() - for _ in range(100): + for use_inter_op_parallelism in [False, True]: + with ops.Graph().as_default(): + dataset = dataset_ops.Dataset.from_tensors(0).repeat(None) + for _ in range(chain_length): + dataset = dataset_ops.MapDataset( + dataset, + lambda x: x, + use_inter_op_parallelism=use_inter_op_parallelism) + iterator = dataset.make_one_shot_iterator() + next_element = iterator.get_next() + + with session.Session() as sess: + for _ in range(5): sess.run(next_element.op) - end = time.time() - deltas.append(end - start) - - median_wall_time = np.median(deltas) / 100 - print("Map dataset chain length: %d Median wall time: %f" - % (chain_length, median_wall_time)) - self.report_benchmark( - iters=1000, wall_time=median_wall_time, - name="benchmark_map_dataset_chain_latency_%d" % chain_length) + deltas = [] + for _ in range(100): + start = time.time() + for _ in range(100): + sess.run(next_element.op) + end = time.time() + deltas.append(end - start) + + median_wall_time = np.median(deltas) / 100 + print("Map dataset chain length%s: %d Median wall time: %f" % + (" (single threaded mode)" if not use_inter_op_parallelism + else "", chain_length, median_wall_time)) + self.report_benchmark( + iters=1000, + wall_time=median_wall_time, + name="benchmark_map_dataset_chain_latency_%d%s" % + (chain_length, "_single_threaded" + if not use_inter_op_parallelism else "")) def benchmarkMapFanOut(self): fan_outs = [1, 2, 5, 10, 20, 50, 100] for fan_out in fan_outs: - with ops.Graph().as_default(): - dataset = dataset_ops.Dataset.from_tensors( - tuple(0 for _ in range(fan_out))).repeat(None).map(lambda *xs: xs) - iterator = dataset.make_one_shot_iterator() - next_element = iterator.get_next() - - with session.Session() as sess: - for _ in range(5): - sess.run(next_element[0].op) - deltas = [] - for _ in range(100): - start = time.time() - for _ in range(100): + for use_inter_op_parallelism in [False, True]: + with ops.Graph().as_default(): + dataset = dataset_ops.Dataset.from_tensors( + tuple(0 for _ in range(fan_out))).repeat(None) + dataset = dataset_ops.MapDataset( + dataset, + lambda *xs: xs, + use_inter_op_parallelism=use_inter_op_parallelism) + iterator = dataset.make_one_shot_iterator() + next_element = iterator.get_next() + + with session.Session() as sess: + for _ in range(5): sess.run(next_element[0].op) - end = time.time() - deltas.append(end - start) - - median_wall_time = np.median(deltas) / 100 - print("Map dataset fan out: %d Median wall time: %f" - % (fan_out, median_wall_time)) - self.report_benchmark( - iters=1000, wall_time=median_wall_time, - name="benchmark_map_dataset_fan_out_%d" % fan_out) + deltas = [] + for _ in range(100): + start = time.time() + for _ in range(100): + sess.run(next_element[0].op) + end = time.time() + deltas.append(end - start) + + median_wall_time = np.median(deltas) / 100 + print("Map dataset fan out%s: %d Median wall time: %f" % + (" (single threaded mode)" if not use_inter_op_parallelism + else "", fan_out, median_wall_time)) + self.report_benchmark( + iters=1000, + wall_time=median_wall_time, + name="benchmark_map_dataset_fan_out_%d%s" % + (fan_out, "_single_threaded" + if not use_inter_op_parallelism else "")) if __name__ == "__main__": diff --git a/tensorflow/python/data/ops/dataset_ops.py b/tensorflow/python/data/ops/dataset_ops.py index 8c37b1871b..6205ee392e 100644 --- a/tensorflow/python/data/ops/dataset_ops.py +++ b/tensorflow/python/data/ops/dataset_ops.py @@ -2207,10 +2207,11 @@ def _warn_if_collections(transformation_name): class MapDataset(Dataset): """A `Dataset` that maps a function over elements in its input.""" - def __init__(self, input_dataset, map_func): + def __init__(self, input_dataset, map_func, use_inter_op_parallelism=True): """See `Dataset.map()` for details.""" super(MapDataset, self).__init__() self._input_dataset = input_dataset + self._use_inter_op_parallelism = use_inter_op_parallelism wrapped_func = StructuredFunctionWrapper( map_func, "Dataset.map()", input_dataset) @@ -2225,6 +2226,7 @@ class MapDataset(Dataset): input_t, self._map_func.captured_inputs, f=self._map_func, + use_inter_op_parallelism=self._use_inter_op_parallelism, **flat_structure(self)) @property diff --git a/tensorflow/python/distribute/distribute_coordinator.py b/tensorflow/python/distribute/distribute_coordinator.py index d9f78150b9..bd3562f1ff 100644 --- a/tensorflow/python/distribute/distribute_coordinator.py +++ b/tensorflow/python/distribute/distribute_coordinator.py @@ -501,6 +501,79 @@ def _configure_session_config_for_std_servers( del session_config.device_filters[:] +def run_standard_tensorflow_server(session_config=None): + """Starts a standard TensorFlow server. + + This method parses configurations from "TF_CONFIG" environment variable and + starts a TensorFlow server. The "TF_CONFIG" is typically a json string and + must have information of the cluster and the role of the server in the + cluster. One example is: + + TF_CONFIG='{ + "cluster": { + "worker": ["host1:2222", "host2:2222", "host3:2222"], + "ps": ["host4:2222", "host5:2222"] + }, + "task": {"type": "worker", "index": 1} + }' + + This "TF_CONFIG" specifies there are 3 workers and 2 ps tasks in the cluster + and the current role is worker 1. + + Valid task types are "chief", "worker", "ps" and "evaluator" and you can have + at most one "chief" and at most one "evaluator". + + An optional key-value can be specified is "rpc_layer". The default value is + "grpc". + + Args: + session_config: an optional `tf.ConfigProto` object. Users can pass in + the session config object to configure server-local devices. + + Returns: + a `tf.train.Server` object which has already been started. + + Raises: + ValueError: if the "TF_CONFIG" environment is not complete. + """ + tf_config = json.loads(os.environ.get("TF_CONFIG", "{}")) + if "cluster" not in tf_config: + raise ValueError("\"cluster\" is not found in TF_CONFIG.") + cluster_spec = multi_worker_util.normalize_cluster_spec(tf_config["cluster"]) + if "task" not in tf_config: + raise ValueError("\"task\" is not found in TF_CONFIG.") + task_env = tf_config["task"] + if "type" not in task_env: + raise ValueError( + "\"task_type\" is not found in the `task` part of TF_CONFIG.") + task_type = task_env["type"] + task_id = int(task_env.get("index", 0)) + + rpc_layer = tf_config.get("rpc_layer", "grpc") + + session_config = session_config or config_pb2.ConfigProto() + # Set the collective group leader for collective ops to initialize collective + # ops when server starts. + if "chief" in cluster_spec.jobs: + session_config.experimental.collective_group_leader = ( + "/job:chief/replica:0/task:0") + else: + if "worker" not in cluster_spec.jobs: + raise ValueError( + "You must have `chief` or `worker` jobs in the `cluster_spec`.") + session_config.experimental.collective_group_leader = ( + "/job:worker/replica:0/task:0") + + server = _run_std_server( + cluster_spec=cluster_spec, + task_type=task_type, + task_id=task_id, + session_config=session_config, + rpc_layer=rpc_layer) + server.start() + return server + + # TODO(yuefengz): propagate cluster_spec in the STANDALONE_CLIENT mode. # TODO(yuefengz): we may need a smart way to figure out whether the current task # is the special task when we support cluster_spec propagation. diff --git a/tensorflow/python/distribute/distribute_coordinator_test.py b/tensorflow/python/distribute/distribute_coordinator_test.py index ac5dd569ed..b07308a1b5 100644 --- a/tensorflow/python/distribute/distribute_coordinator_test.py +++ b/tensorflow/python/distribute/distribute_coordinator_test.py @@ -23,19 +23,18 @@ import copy import json import os import sys -import time import threading +import time import six -# pylint: disable=invalid-name _portpicker_import_error = None try: import portpicker # pylint: disable=g-import-not-at-top -except ImportError as _error: +except ImportError as _error: # pylint: disable=invalid-name _portpicker_import_error = _error portpicker = None -# pylint: enable=invalid-name +# pylint: disable=g-import-not-at-top from tensorflow.core.protobuf import config_pb2 from tensorflow.python.client import session from tensorflow.python.distribute import distribute_coordinator @@ -144,6 +143,10 @@ class MockServer(object): def __init__(self): self._joined = False + self._started = False + + def start(self): + self._started = True def join(self): assert not self._joined @@ -153,6 +156,10 @@ class MockServer(object): def joined(self): return self._joined + @property + def started(self): + return self._started + class DistributeCoordinatorTestBase(test.TestCase): @@ -161,6 +168,7 @@ class DistributeCoordinatorTestBase(test.TestCase): # We have to create a global in-process cluster because once an in-process # tensorflow server is created, there is no way to terminate it. Please see # multi_worker_test_base.py for more details. + # TODO(yuefengz): use the utitliy from multi_worker_test_base. cls._workers, cls._ps = test_util.create_local_cluster( NUM_WORKERS, num_ps=NUM_PS) cls._cluster_spec = { @@ -185,6 +193,7 @@ class DistributeCoordinatorTestBase(test.TestCase): with session.Session(graph=None, config=config, target=target) as sess: yield sess + # TODO(yuefengz): use the utitliy from multi_worker_test_base. def _create_cluster_spec(self, has_chief=False, num_workers=1, @@ -886,6 +895,38 @@ class StrategyConfigureTest(test.TestCase): self.assertEqual(self._inter_op_parallelism_threads, 2) +class RunStandardTensorflowServerTest(test.TestCase): + + def test_std_server_arguments(self): + cs = {"worker": ["fake_worker"], "ps": ["fake_ps"]} + tf_config = {"cluster": cs, "task": {"type": "ps", "id": 0}} + + def _mock_run_std_server(cluster_spec=None, + task_type=None, + task_id=None, + session_config=None, + rpc_layer=None): + self.assertEqual(cluster_spec.as_dict(), cs) + self.assertEqual(task_type, "ps") + self.assertEqual(task_id, 0) + self.assertEqual(session_config.experimental.collective_group_leader, + "/job:worker/replica:0/task:0") + self.assertEqual(session_config.intra_op_parallelism_threads, 1) + self.assertEqual(rpc_layer, "grpc") + + return MockServer() + + with test.mock.patch.dict( + "os.environ", + {"TF_CONFIG": json.dumps(tf_config)}), test.mock.patch.object( + distribute_coordinator, "_run_std_server", _mock_run_std_server): + session_config = config_pb2.ConfigProto() + session_config.intra_op_parallelism_threads = 1 + mock_server = distribute_coordinator.run_standard_tensorflow_server( + session_config) + self.assertTrue(mock_server.started) + + if __name__ == "__main__": # TODO(yuefengz): find a smart way to terminite std server threads. with test.mock.patch.object(sys, "exit", os._exit): diff --git a/tensorflow/python/eager/BUILD b/tensorflow/python/eager/BUILD index 6f48d38b58..85da1baaf0 100644 --- a/tensorflow/python/eager/BUILD +++ b/tensorflow/python/eager/BUILD @@ -241,7 +241,7 @@ py_library( "//tensorflow/python:dtypes", "//tensorflow/python:errors", "//tensorflow/python:framework_ops", - "//tensorflow/python:gradients", + "//tensorflow/python:gradients_impl", "//tensorflow/python:graph_to_function_def", "//tensorflow/python:util", "//tensorflow/python/eager:context", diff --git a/tensorflow/python/eager/backprop.py b/tensorflow/python/eager/backprop.py index 7978383e55..9891068056 100644 --- a/tensorflow/python/eager/backprop.py +++ b/tensorflow/python/eager/backprop.py @@ -522,7 +522,7 @@ def make_vjp(f, params=None, persistent=True): args = _ensure_unique_tensor_objects(parameter_positions, args) for i in parameter_positions: sources.append(args[i]) - tape.watch(args[i]) + tape.watch(this_tape, args[i]) result = f(*args) if result is None: raise ValueError("Cannot differentiate a function that returns None; " @@ -748,7 +748,7 @@ class GradientTape(object): tensor: a Tensor or list of Tensors. """ for t in nest.flatten(tensor): - tape.watch(_handle_or_self(t)) + tape.watch(self._tape, _handle_or_self(t)) @tf_contextlib.contextmanager def stop_recording(self): diff --git a/tensorflow/python/eager/backprop_test.py b/tensorflow/python/eager/backprop_test.py index 45f2d0d6ac..6673178ee7 100644 --- a/tensorflow/python/eager/backprop_test.py +++ b/tensorflow/python/eager/backprop_test.py @@ -64,7 +64,7 @@ class BackpropTest(test.TestCase): grad = backprop.gradients_function(fn, [0])(var)[0] grad = self.evaluate(ops.convert_to_tensor(grad)) - with context.graph_mode(), self.test_session(): + with context.graph_mode(): tf_var = array_ops.constant(var_np, dtypes.float32) tf_ind1 = array_ops.constant([0, 1]) tf_ind2 = array_ops.constant([2, 3]) @@ -79,7 +79,7 @@ class BackpropTest(test.TestCase): tf_dense_grad = math_ops.unsorted_segment_sum( tf_grad.values, tf_grad.indices, tf_grad.dense_shape[0]) - self.assertAllClose(grad, tf_dense_grad.eval()) + self.assertAllClose(grad, self.evaluate(tf_dense_grad)) def testImplicitGradWithResourceVariable(self): x = resource_variable_ops.ResourceVariable( @@ -198,7 +198,7 @@ class BackpropTest(test.TestCase): grad = backprop.implicit_grad(f)()[0][0] opt = training.GradientDescentOptimizer(lrn_rate) - with context.graph_mode(), self.test_session(): + with context.graph_mode(), self.cached_session(): tf_x = array_ops.ones((batch_size), dtypes.int64) # TODO(ashankar,apassos): Change to ResourceVariable. tf_embedding = variables.Variable( @@ -313,6 +313,24 @@ class BackpropTest(test.TestCase): grad = backprop.gradients_function(second, [0])(f)[0] self.assertAllEqual([[0.0]], grad) + @test_util.run_in_graph_and_eager_modes + def testWatchingIsTapeLocal(self): + x1 = resource_variable_ops.ResourceVariable(2.0, trainable=False) + x2 = resource_variable_ops.ResourceVariable(2.0, trainable=False) + + with backprop.GradientTape() as tape1: + with backprop.GradientTape() as tape2: + tape1.watch(x1) + tape2.watch([x1, x2]) + y = x1 ** 3 + z = x2 ** 2 + dy, dz = tape2.gradient([y, z], [x1, x2]) + d2y, d2z = tape1.gradient([dy, dz], [x1, x2]) + + self.evaluate([x1.initializer, x2.initializer]) + self.assertEqual(self.evaluate(d2y), 12.0) + self.assertIsNone(d2z) + @test_util.assert_no_new_tensors def testMakeVJP(self): @@ -923,7 +941,7 @@ class BackpropTest(test.TestCase): def testZerosCacheDoesntLeakAcrossGraphs(self): with context.graph_mode(): def get_grad(): - with ops.Graph().as_default(), self.test_session(): + with ops.Graph().as_default(), self.cached_session(): t = constant_op.constant(1, dtype=dtypes.float32, shape=(10, 4)) x = constant_op.constant(2, dtype=dtypes.float32, shape=(10, 4)) with backprop.GradientTape() as tape: diff --git a/tensorflow/python/eager/function.py b/tensorflow/python/eager/function.py index 6c87dccaf1..b57979b484 100644 --- a/tensorflow/python/eager/function.py +++ b/tensorflow/python/eager/function.py @@ -55,6 +55,9 @@ from tensorflow.python.util import tf_inspect # (function -> gradients_impl -> control_flow_ops -> cond_v2_impl). cond_v2_impl._function = sys.modules[__name__] # pylint: disable=protected-access +# This is to avoid a circular dependency with gradients_impl +gradients_impl._function = sys.modules[__name__] # pylint: disable=protected-access + def create_substitute_placeholder(value, name, dtype=None): """Creates a placeholder for `value` and propagates shape info to it.""" diff --git a/tensorflow/python/eager/pywrap_tfe.h b/tensorflow/python/eager/pywrap_tfe.h index 823c4078b8..16f8c3c917 100755 --- a/tensorflow/python/eager/pywrap_tfe.h +++ b/tensorflow/python/eager/pywrap_tfe.h @@ -138,7 +138,7 @@ void TFE_Py_TapeSetAdd(PyObject* tape); PyObject* TFE_Py_TapeSetIsEmpty(); PyObject* TFE_Py_TapeSetShouldRecord(PyObject* tensors); -void TFE_Py_TapeSetWatch(PyObject* tensor); +void TFE_Py_TapeWatch(PyObject* tape, PyObject* tensor); void TFE_Py_TapeSetDeleteTrace(tensorflow::int64 tensor_id); // Stops any gradient recording on the current thread. diff --git a/tensorflow/python/eager/pywrap_tfe_src.cc b/tensorflow/python/eager/pywrap_tfe_src.cc index 71ab3e1404..0a33a04dcb 100644 --- a/tensorflow/python/eager/pywrap_tfe_src.cc +++ b/tensorflow/python/eager/pywrap_tfe_src.cc @@ -1154,7 +1154,7 @@ PyObject* TFE_Py_TapeSetShouldRecord(PyObject* tensors) { Py_RETURN_FALSE; } -void TFE_Py_TapeSetWatch(PyObject* tensor) { +void TFE_Py_TapeWatch(PyObject* tape, PyObject* tensor) { if (*ThreadTapeIsStopped()) { return; } @@ -1162,9 +1162,7 @@ void TFE_Py_TapeSetWatch(PyObject* tensor) { if (PyErr_Occurred()) { return; } - for (TFE_Py_Tape* tape : *GetTapeSet()) { - tape->tape->Watch(tensor_id); - } + reinterpret_cast<TFE_Py_Tape*>(tape)->tape->Watch(tensor_id); } static tensorflow::eager::TapeTensor TapeTensorFromTensor(PyObject* tensor) { diff --git a/tensorflow/python/eager/tape.py b/tensorflow/python/eager/tape.py index caa217b70c..6eb62afec4 100644 --- a/tensorflow/python/eager/tape.py +++ b/tensorflow/python/eager/tape.py @@ -44,13 +44,9 @@ def push_tape(tape): pywrap_tensorflow.TFE_Py_TapeSetAdd(tape._tape) # pylint: disable=protected-access -def watch(tensor): - """Marks this tensor to be watched by all tapes in the stack. - - Args: - tensor: tensor to be watched. - """ - pywrap_tensorflow.TFE_Py_TapeSetWatch(tensor) +def watch(tape, tensor): + """Marks this tensor to be watched by the given tape.""" + pywrap_tensorflow.TFE_Py_TapeWatch(tape._tape, tensor) # pylint: disable=protected-access def watch_variable(variable): diff --git a/tensorflow/python/eager/tensor_test.py b/tensorflow/python/eager/tensor_test.py index 871136e2c8..32742a9b96 100644 --- a/tensorflow/python/eager/tensor_test.py +++ b/tensorflow/python/eager/tensor_test.py @@ -295,6 +295,7 @@ class TFETensorUtilTest(test_util.TensorFlowTestCase): def testFloatTensor(self): self.assertEqual(dtypes.float64, _create_tensor(np.float64()).dtype) self.assertEqual(dtypes.float32, _create_tensor(np.float32()).dtype) + self.assertEqual(dtypes.float16, _create_tensor(np.float16()).dtype) self.assertEqual(dtypes.float32, _create_tensor(0.0).dtype) def testSliceDimOutOfRange(self): diff --git a/tensorflow/python/estimator/BUILD b/tensorflow/python/estimator/BUILD index 9fce172bee..f6ef6d8dcb 100644 --- a/tensorflow/python/estimator/BUILD +++ b/tensorflow/python/estimator/BUILD @@ -684,8 +684,10 @@ py_test( shard_count = 4, srcs_version = "PY2AND3", tags = [ + "manual", # b/112769036, b/113907597 + "no_oss", # b/112769036, b/113907597 "no_windows", - "notsan", + "notsan", # b/67510291 ], deps = [ ":keras", diff --git a/tensorflow/python/estimator/canned/dnn.py b/tensorflow/python/estimator/canned/dnn.py index c08cf61220..1c0c4581c0 100644 --- a/tensorflow/python/estimator/canned/dnn.py +++ b/tensorflow/python/estimator/canned/dnn.py @@ -142,7 +142,7 @@ def _dnn_model_fn(features, dropout=None, input_layer_partitioner=None, config=None, - tpu_estimator_spec=False, + use_tpu=False, batch_norm=False): """Deep Neural Net model_fn. @@ -164,8 +164,8 @@ def _dnn_model_fn(features, input_layer_partitioner: Partitioner for input layer. Defaults to `min_max_variable_partitioner` with `min_slice_size` 64 << 20. config: `RunConfig` object to configure the runtime settings. - tpu_estimator_spec: Whether to return a `_TPUEstimatorSpec` or - or `model_fn.EstimatorSpec` instance. + use_tpu: Whether to make a DNN model able to run on TPU. Will make function + return a `_TPUEstimatorSpec` instance and disable variable partitioning. batch_norm: Whether to use batch normalization after each hidden layer. Returns: @@ -182,13 +182,15 @@ def _dnn_model_fn(features, optimizer, learning_rate=_LEARNING_RATE) num_ps_replicas = config.num_ps_replicas if config else 0 - partitioner = partitioned_variables.min_max_variable_partitioner( - max_partitions=num_ps_replicas) + partitioner = (None if use_tpu else + partitioned_variables.min_max_variable_partitioner( + max_partitions=num_ps_replicas)) with variable_scope.variable_scope( 'dnn', values=tuple(six.itervalues(features)), partitioner=partitioner): input_layer_partitioner = input_layer_partitioner or ( + None if use_tpu else partitioned_variables.min_max_variable_partitioner( max_partitions=num_ps_replicas, min_slice_size=64 << 20)) @@ -203,7 +205,7 @@ def _dnn_model_fn(features, batch_norm=batch_norm) logits = logit_fn(features=features, mode=mode) - if tpu_estimator_spec: + if use_tpu: return head._create_tpu_estimator_spec( # pylint: disable=protected-access features=features, mode=mode, diff --git a/tensorflow/python/estimator/estimator.py b/tensorflow/python/estimator/estimator.py index 44a60495d8..e44a69b374 100644 --- a/tensorflow/python/estimator/estimator.py +++ b/tensorflow/python/estimator/estimator.py @@ -35,7 +35,6 @@ from tensorflow.python.estimator import model_fn as model_fn_lib from tensorflow.python.estimator import run_config from tensorflow.python.estimator import util as estimator_util from tensorflow.python.estimator.export import export as export_helpers -from tensorflow.python.estimator.export import export_output from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes from tensorflow.python.framework import errors @@ -46,7 +45,6 @@ from tensorflow.python.keras import metrics from tensorflow.python.ops import array_ops from tensorflow.python.ops import control_flow_ops from tensorflow.python.ops import metrics as metrics_lib -from tensorflow.python.ops import resources from tensorflow.python.ops import variables from tensorflow.python.platform import gfile from tensorflow.python.platform import tf_logging as logging @@ -958,7 +956,12 @@ class Estimator(object): mode=mode, config=self.config) - export_outputs = self._get_export_outputs_for_spec(estimator_spec) + export_outputs = model_fn_lib.export_outputs_for_mode( + mode=estimator_spec.mode, + serving_export_outputs=estimator_spec.export_outputs, + predictions=estimator_spec.predictions, + loss=estimator_spec.loss, + metrics=estimator_spec.eval_metric_ops) # Build the SignatureDefs from receivers and all outputs signature_def_map = export_helpers.build_all_signature_defs( @@ -1015,45 +1018,6 @@ class Estimator(object): else: builder.add_meta_graph(**meta_graph_kwargs) - def _get_export_outputs_for_spec(self, estimator_spec): - """Given an `EstimatorSpec`, determine what our export outputs should be. - - `EstimatorSpecs` contains `export_outputs` that are used for serving, but - for - training and eval graphs, we must wrap the tensors of interest in - appropriate `tf.estimator.export.ExportOutput` objects. - - Args: - estimator_spec: `tf.estimator.EstimatorSpec` object that will be exported. - - Returns: - a dict mapping `export_output_name` to `tf.estimator.export.ExportOutput` - object. - - Raises: - ValueError: if an appropriate `ExportOutput` cannot be found for the - passed `EstimatorSpec.mode` - """ - mode = estimator_spec.mode - if mode == model_fn_lib.ModeKeys.PREDICT: - outputs = estimator_spec.export_outputs - else: - if mode == model_fn_lib.ModeKeys.TRAIN: - output_class = export_output.TrainOutput - elif mode == model_fn_lib.ModeKeys.EVAL: - output_class = export_output.EvalOutput - else: - raise ValueError( - 'Export output type not found for mode: {}'.format(mode)) - - export_out = output_class( - loss=estimator_spec.loss, - predictions=estimator_spec.predictions, - metrics=estimator_spec.eval_metric_ops) - outputs = {mode: export_out} - - return outputs - def _get_features_from_input_fn(self, input_fn, mode): """Extracts the `features` from return values of `input_fn`.""" result = self._call_input_fn(input_fn, mode) @@ -1644,21 +1608,6 @@ def maybe_overwrite_model_dir_and_session_config(config, model_dir): return config -def create_per_tower_ready_op(scaffold): - """Create a `tf.train.Scaffold.ready_op` inside a tower.""" - if scaffold.ready_op: - return scaffold.ready_op - - def default_ready_op(): - return array_ops.concat([ - variables.report_uninitialized_variables(), - resources.report_uninitialized_resources() - ], 0) - - return monitored_session.Scaffold.get_or_default( - 'ready_op', ops.GraphKeys.READY_OP, default_ready_op) - - def create_per_tower_ready_for_local_init_op(scaffold): """Create a `tf.train.Scaffold.ready_for_local_init_op` inside a tower.""" if scaffold.ready_for_local_init_op: @@ -1708,11 +1657,9 @@ def _combine_distributed_scaffold(grouped_scaffold, distribution): return value[0] ready_op = distribution.call_for_each_tower( - create_per_tower_ready_op, grouped_scaffold) + lambda scaffold: scaffold.ready_op, grouped_scaffold) if ready_op is not None: ready_op = _unwrap_and_concat(ready_op) - else: - ready_op = None ready_for_local_init_op = distribution.call_for_each_tower( create_per_tower_ready_for_local_init_op, grouped_scaffold) diff --git a/tensorflow/python/estimator/keras.py b/tensorflow/python/estimator/keras.py index 6361c6acc1..6b2765be82 100644 --- a/tensorflow/python/estimator/keras.py +++ b/tensorflow/python/estimator/keras.py @@ -182,10 +182,58 @@ def _clone_and_build_model(mode, K.set_learning_phase(mode == model_fn_lib.ModeKeys.TRAIN) input_tensors, target_tensors = _convert_estimator_io_to_keras( keras_model, features, labels) - return models.clone_and_build_model( + + compile_clone = (mode != model_fn_lib.ModeKeys.PREDICT) + + global_step = None + if compile_clone: + # Set iterations to the global step created by tf.train.create_global_step() + # which is automatically run in the estimator framework. + global_step = training_util.get_or_create_global_step() + K.track_variable(global_step) + + clone = models.clone_and_build_model( keras_model, input_tensors, target_tensors, custom_objects, - compile_clone=(mode != model_fn_lib.ModeKeys.PREDICT), - in_place_reset=(not keras_model._is_graph_network)) + compile_clone=compile_clone, + in_place_reset=(not keras_model._is_graph_network), + optimizer_iterations=global_step) + + return clone + + +def _convert_keras_metrics_to_estimator(model): + """Convert metrics from a Keras model to ops used by the Estimator framework. + + Args: + model: A `tf.keras.Model` object. + + Returns: + Dictionary mapping metric names to tuples of (value, update) ops. May return + `None` if the model does not contain any metrics. + """ + if not getattr(model, 'metrics', None): + return None + + # TODO(psv/fchollet): support stateful metrics + eval_metric_ops = {} + # When each metric maps to an output + if isinstance(model.metrics, dict): + for i, output_name in enumerate(model.metrics.keys()): + metric_name = model.metrics[output_name] + if callable(metric_name): + metric_name = metric_name.__name__ + # When some outputs use the same metric + if list(model.metrics.values()).count(metric_name) > 1: + metric_name += '_' + output_name + eval_metric_ops[metric_name] = metrics_module.mean( + model.metrics_tensors[i - len(model.metrics)]) + else: + for i, metric_name in enumerate(model.metrics): + if callable(metric_name): + metric_name = metric_name.__name__ + eval_metric_ops[metric_name] = metrics_module.mean( + model.metrics_tensors[i]) + return eval_metric_ops def _create_keras_model_fn(keras_model, custom_objects=None): @@ -237,26 +285,7 @@ def _create_keras_model_fn(keras_model, custom_objects=None): model._make_test_function() # pylint: disable=protected-access loss = model.total_loss - if model.metrics: - # TODO(psv/fchollet): support stateful metrics - eval_metric_ops = {} - # When each metric maps to an output - if isinstance(model.metrics, dict): - for i, output_name in enumerate(model.metrics.keys()): - metric_name = model.metrics[output_name] - if callable(metric_name): - metric_name = metric_name.__name__ - # When some outputs use the same metric - if list(model.metrics.values()).count(metric_name) > 1: - metric_name += '_' + output_name - eval_metric_ops[metric_name] = metrics_module.mean( - model.metrics_tensors[i - len(model.metrics)]) - else: - for i, metric_name in enumerate(model.metrics): - if callable(metric_name): - metric_name = metric_name.__name__ - eval_metric_ops[metric_name] = metrics_module.mean( - model.metrics_tensors[i]) + eval_metric_ops = _convert_keras_metrics_to_estimator(model) # Set train_op only during train. if mode is model_fn_lib.ModeKeys.TRAIN: diff --git a/tensorflow/python/estimator/model_fn.py b/tensorflow/python/estimator/model_fn.py index fd2787aeaf..439cc2e3a4 100644 --- a/tensorflow/python/estimator/model_fn.py +++ b/tensorflow/python/estimator/model_fn.py @@ -142,7 +142,7 @@ class EstimatorSpec( prediction. predictions: Predictions `Tensor` or dict of `Tensor`. loss: Training loss `Tensor`. Must be either scalar, or with shape `[1]`. - train_op: Op to run one training step. + train_op: Op for the training step. eval_metric_ops: Dict of metric results keyed by name. The values of the dict can be one of the following: (1) instance of `Metric` class. @@ -475,3 +475,44 @@ def _check_is_tensor(x, tensor_name): if not isinstance(x, ops.Tensor): raise TypeError('{} must be Tensor, given: {}'.format(tensor_name, x)) return x + + +def export_outputs_for_mode( + mode, serving_export_outputs=None, predictions=None, loss=None, + metrics=None): + """Util function for constructing a `ExportOutput` dict given a mode. + + The returned dict can be directly passed to `build_all_signature_defs` helper + function as the `export_outputs` argument, used for generating a SignatureDef + map. + + Args: + mode: A `ModeKeys` specifying the mode. + serving_export_outputs: Describes the output signatures to be exported to + `SavedModel` and used during serving. Should be a dict or None. + predictions: A dict of Tensors or single Tensor representing model + predictions. This argument is only used if serving_export_outputs is not + set. + loss: A dict of Tensors or single Tensor representing calculated loss. + metrics: A dict of (metric_value, update_op) tuples, or a single tuple. + metric_value must be a Tensor, and update_op must be a Tensor or Op + + Returns: + Dictionary mapping the a key to an `tf.estimator.export.ExportOutput` object + The key is the expected SignatureDef key for the mode. + + Raises: + ValueError: if an appropriate ExportOutput cannot be found for the mode. + """ + # TODO(b/113185250): move all model export helper functions into an util file. + if mode == ModeKeys.PREDICT: + return _get_export_outputs(serving_export_outputs, predictions) + elif mode == ModeKeys.TRAIN: + return {mode: export_output_lib.TrainOutput( + loss=loss, predictions=predictions, metrics=metrics)} + elif mode == ModeKeys.EVAL: + return {mode: export_output_lib.EvalOutput( + loss=loss, predictions=predictions, metrics=metrics)} + else: + raise ValueError( + 'Export output type not found for mode: {}'.format(mode)) diff --git a/tensorflow/python/framework/error_interpolation.py b/tensorflow/python/framework/error_interpolation.py index 6e844e14b9..46bda2e621 100644 --- a/tensorflow/python/framework/error_interpolation.py +++ b/tensorflow/python/framework/error_interpolation.py @@ -15,7 +15,7 @@ """Function for interpolating formatted errors from the TensorFlow runtime. Exposes the function `interpolate` to interpolate messages with tags of the form -^^type:name:format^^. +{{type name}}. """ from __future__ import absolute_import @@ -26,21 +26,17 @@ import collections import itertools import os import re -import string import six from tensorflow.python.util import tf_stack - _NAME_REGEX = r"[A-Za-z0-9.][A-Za-z0-9_.\-/]*?" -_FORMAT_REGEX = r"[A-Za-z0-9_.\-/${}:]+" -_TAG_REGEX = r"\^\^({name}):({name}):({fmt})\^\^".format( - name=_NAME_REGEX, fmt=_FORMAT_REGEX) +_TAG_REGEX = r"{{{{({name}) ({name})}}}}".format(name=_NAME_REGEX) _INTERPOLATION_REGEX = r"^(.*?)({tag})".format(tag=_TAG_REGEX) _INTERPOLATION_PATTERN = re.compile(_INTERPOLATION_REGEX) -_ParseTag = collections.namedtuple("_ParseTag", ["type", "name", "format"]) +_ParseTag = collections.namedtuple("_ParseTag", ["type", "name"]) _BAD_FILE_SUBSTRINGS = [ os.path.join("tensorflow", "python"), @@ -52,16 +48,9 @@ def _parse_message(message): """Parses the message. Splits the message into separators and tags. Tags are named tuples - representing the string ^^type:name:format^^ and they are separated by - separators. For example, in - "123^^node:Foo:${file}^^456^^node:Bar:${line}^^789", there are two tags and - three separators. The separators are the numeric characters. - - Supported tags after node:<node_name> - file: Replaced with the filename in which the node was defined. - line: Replaced by the line number at which the node was defined. - colocations: Replaced by a multi-line message describing the file and - line numbers at which this node was colocated with other nodes. + representing the string {{type name}} and they are separated by + separators. For example, in "123{{node Foo}}456{{node Bar}}789", there are + two tags and three separators. The separators are the numeric characters. Args: message: String to parse @@ -69,8 +58,8 @@ def _parse_message(message): Returns: (list of separator strings, list of _ParseTags). - For example, if message is "123^^node:Foo:${file}^^456" then this function - returns (["123", "456"], [_ParseTag("node", "Foo", "${file}")]) + For example, if message is "123{{node Foo}}456" then this function + returns (["123", "456"], [_ParseTag("node", "Foo")]) """ seps = [] tags = [] @@ -79,7 +68,7 @@ def _parse_message(message): match = re.match(_INTERPOLATION_PATTERN, message[pos:]) if match: seps.append(match.group(1)) - tags.append(_ParseTag(match.group(3), match.group(4), match.group(5))) + tags.append(_ParseTag(match.group(3), match.group(4))) pos += match.end() else: break @@ -111,12 +100,12 @@ def _compute_device_summary_from_list(name, device_assignment_list, prefix=""): return prefix + message str_list = [] - str_list.append("%sDevice assignments active during op '%s' creation:" - % (prefix, name)) + str_list.append( + "%sDevice assignments active during op '%s' creation:" % (prefix, name)) for traceable_obj in device_assignment_list: - location_summary = "<{file}:{line}>".format(file=traceable_obj.filename, - line=traceable_obj.lineno) + location_summary = "<{file}:{line}>".format( + file=traceable_obj.filename, line=traceable_obj.lineno) subs = { "prefix": prefix, "indent": " ", @@ -160,12 +149,12 @@ def _compute_colocation_summary_from_dict(name, colocation_dict, prefix=""): return prefix + message str_list = [] - str_list.append("%sNode-device colocations active during op '%s' creation:" - % (prefix, name)) + str_list.append("%sNode-device colocations active during op '%s' creation:" % + (prefix, name)) for coloc_name, location in colocation_dict.items(): - location_summary = "<{file}:{line}>".format(file=location.filename, - line=location.lineno) + location_summary = "<{file}:{line}>".format( + file=location.filename, line=location.lineno) subs = { "prefix": prefix, "indent": " ", @@ -180,8 +169,10 @@ def _compute_colocation_summary_from_dict(name, colocation_dict, prefix=""): def _compute_colocation_summary_from_op(op, prefix=""): """Fetch colocation file, line, and nesting and return a summary string.""" - return _compute_colocation_summary_from_dict( - op.name, op._colocation_dict, prefix) # pylint: disable=protected-access + # pylint: disable=protected-access + return _compute_colocation_summary_from_dict(op.name, op._colocation_dict, + prefix) + # pylint: enable=protected-access def _find_index_of_defining_frame_for_op(op): @@ -276,7 +267,7 @@ def compute_field_dict(op): def interpolate(error_message, graph): """Interpolates an error message. - The error message can contain tags of the form ^^type:name:format^^ which will + The error message can contain tags of the form ^^type:name^^ which will be replaced. Args: @@ -285,29 +276,29 @@ def interpolate(error_message, graph): message. Returns: - The string with tags of the form ^^type:name:format^^ interpolated. + The string with tags of the form {{type name}} interpolated. """ seps, tags = _parse_message(error_message) + subs = [] + end_msg = "" - node_name_to_substitution_dict = {} - for name in [t.name for t in tags]: - if name in node_name_to_substitution_dict: - continue + for t in tags: try: - op = graph.get_operation_by_name(name) + op = graph.get_operation_by_name(t.name) except KeyError: op = None + msg = "{{%s %s}}" % (t.type, t.name) if op is not None: field_dict = compute_field_dict(op) - else: - msg = "<NA>" - field_dict = collections.defaultdict(lambda s=msg: s) - node_name_to_substitution_dict[name] = field_dict - - subs = [ - string.Template(tag.format).safe_substitute( - node_name_to_substitution_dict[tag.name]) for tag in tags - ] + if t.type == "node": + msg = "node %s%s " % (t.name, field_dict["defined_at"]) + elif t.type == "colocation_node": + msg = "node %s%s having device %s " % (t.name, field_dict["defined_at"], + field_dict["devices"]) + end_msg += "\n\n" + field_dict["devs_and_colocs"] + subs.append(msg) + subs.append(end_msg) + return "".join( itertools.chain(*six.moves.zip_longest(seps, subs, fillvalue=""))) diff --git a/tensorflow/python/framework/error_interpolation_test.py b/tensorflow/python/framework/error_interpolation_test.py index 0427156b2b..d312b825d2 100644 --- a/tensorflow/python/framework/error_interpolation_test.py +++ b/tensorflow/python/framework/error_interpolation_test.py @@ -50,9 +50,9 @@ def _modify_op_stack_with_filenames(op, num_user_frames, user_filename, stack = [] for idx in range(0, num_outer_frames): stack.append(op._traceback[idx]) - for idx in range(len(stack), len(stack)+num_user_frames): + for idx in range(len(stack), len(stack) + num_user_frames): stack.append(_make_frame_with_filename(op, idx, user_filename % idx)) - for idx in range(len(stack), len(stack)+num_inner_tf_frames): + for idx in range(len(stack), len(stack) + num_inner_tf_frames): stack.append(_make_frame_with_filename(op, idx, tf_filename % idx)) op._traceback = stack @@ -62,13 +62,11 @@ class ComputeDeviceSummaryFromOpTest(test.TestCase): def testCorrectFormatWithActiveDeviceAssignments(self): assignments = [] assignments.append( - traceable_stack.TraceableObject("/cpu:0", - filename="hope.py", - lineno=24)) + traceable_stack.TraceableObject( + "/cpu:0", filename="hope.py", lineno=24)) assignments.append( - traceable_stack.TraceableObject("/gpu:2", - filename="please.py", - lineno=42)) + traceable_stack.TraceableObject( + "/gpu:2", filename="please.py", lineno=42)) summary = error_interpolation._compute_device_summary_from_list( "nodename", assignments, prefix=" ") @@ -90,12 +88,10 @@ class ComputeDeviceSummaryFromOpTest(test.TestCase): class ComputeColocationSummaryFromOpTest(test.TestCase): def testCorrectFormatWithActiveColocations(self): - t_obj_1 = traceable_stack.TraceableObject(None, - filename="test_1.py", - lineno=27) - t_obj_2 = traceable_stack.TraceableObject(None, - filename="test_2.py", - lineno=38) + t_obj_1 = traceable_stack.TraceableObject( + None, filename="test_1.py", lineno=27) + t_obj_2 = traceable_stack.TraceableObject( + None, filename="test_2.py", lineno=38) colocation_dict = { "test_node_1": t_obj_1, "test_node_2": t_obj_2, @@ -140,10 +136,11 @@ class InterpolateFilenamesAndLineNumbersTest(test.TestCase): def testFindIndexOfDefiningFrameForOp(self): local_op = constant_op.constant(42).op user_filename = "hope.py" - _modify_op_stack_with_filenames(local_op, - num_user_frames=3, - user_filename=user_filename, - num_inner_tf_frames=5) + _modify_op_stack_with_filenames( + local_op, + num_user_frames=3, + user_filename=user_filename, + num_inner_tf_frames=5) idx = error_interpolation._find_index_of_defining_frame_for_op(local_op) # Expected frame is 6th from the end because there are 5 inner frames witih # TF filenames. @@ -155,44 +152,39 @@ class InterpolateFilenamesAndLineNumbersTest(test.TestCase): # Truncate stack to known length. local_op._traceback = local_op._traceback[:7] # Ensure all frames look like TF frames. - _modify_op_stack_with_filenames(local_op, - num_user_frames=0, - user_filename="user_file.py", - num_inner_tf_frames=7) + _modify_op_stack_with_filenames( + local_op, + num_user_frames=0, + user_filename="user_file.py", + num_inner_tf_frames=7) idx = error_interpolation._find_index_of_defining_frame_for_op(local_op) self.assertEqual(0, idx) def testNothingToDo(self): normal_string = "This is just a normal string" - interpolated_string = error_interpolation.interpolate(normal_string, - self.graph) + interpolated_string = error_interpolation.interpolate( + normal_string, self.graph) self.assertEqual(interpolated_string, normal_string) - def testOneTag(self): - one_tag_string = "^^node:Two:${file}^^" - interpolated_string = error_interpolation.interpolate(one_tag_string, - self.graph) - self.assertTrue(interpolated_string.endswith("constant_op.py"), - "interpolated_string '%s' did not end with constant_op.py" - % interpolated_string) - def testOneTagWithAFakeNameResultsInPlaceholders(self): - one_tag_string = "^^node:MinusOne:${file}^^" - interpolated_string = error_interpolation.interpolate(one_tag_string, - self.graph) - self.assertEqual("<NA>", interpolated_string) + one_tag_string = "{{node MinusOne}}" + interpolated_string = error_interpolation.interpolate( + one_tag_string, self.graph) + self.assertEqual(one_tag_string, interpolated_string) def testTwoTagsNoSeps(self): - two_tags_no_seps = "^^node:One:${file}^^^^node:Three:${line}^^" - interpolated_string = error_interpolation.interpolate(two_tags_no_seps, - self.graph) - self.assertRegexpMatches(interpolated_string, "constant_op.py[0-9]+") + two_tags_no_seps = "{{node One}}{{node Three}}" + interpolated_string = error_interpolation.interpolate( + two_tags_no_seps, self.graph) + self.assertRegexpMatches(interpolated_string, + "constant_op.py:[0-9]+.*constant_op.py:[0-9]+") def testTwoTagsWithSeps(self): - two_tags_with_seps = ";;;^^node:Two:${file}^^,,,^^node:Three:${line}^^;;;" - interpolated_string = error_interpolation.interpolate(two_tags_with_seps, - self.graph) - expected_regex = "^;;;.*constant_op.py,,,[0-9]*;;;$" + two_tags_with_seps = ";;;{{node Two}},,,{{node Three}};;;" + interpolated_string = error_interpolation.interpolate( + two_tags_with_seps, self.graph) + expected_regex = ( + r"^;;;.*constant_op.py:[0-9]+\) ,,,.*constant_op.py:[0-9]*\) ;;;$") self.assertRegexpMatches(interpolated_string, expected_regex) @@ -214,30 +206,26 @@ class InterpolateDeviceSummaryTest(test.TestCase): self.graph = self.three.graph def testNodeZeroHasNoDeviceSummaryInfo(self): - message = "^^node:zero:${devices}^^" + message = "{{colocation_node zero}}" result = error_interpolation.interpolate(message, self.graph) self.assertIn("No device assignments were active", result) def testNodeOneHasExactlyOneInterpolatedDevice(self): - message = "^^node:one:${devices}^^" + message = "{{colocation_node one}}" result = error_interpolation.interpolate(message, self.graph) - num_devices = result.count("tf.device") - self.assertEqual(1, num_devices) - self.assertIn("tf.device(/cpu)", result) + self.assertEqual(2, result.count("tf.device(/cpu)")) def testNodeTwoHasTwoInterpolatedDevice(self): - message = "^^node:two:${devices}^^" + message = "{{colocation_node two}}" result = error_interpolation.interpolate(message, self.graph) - num_devices = result.count("tf.device") - self.assertEqual(2, num_devices) - self.assertIn("tf.device(/cpu)", result) - self.assertIn("tf.device(/cpu:0)", result) + self.assertEqual(2, result.count("tf.device(/cpu)")) + self.assertEqual(2, result.count("tf.device(/cpu:0)")) def testNodeThreeHasFancyFunctionDisplayNameForInterpolatedDevice(self): - message = "^^node:three:${devices}^^" + message = "{{colocation_node three}}" result = error_interpolation.interpolate(message, self.graph) num_devices = result.count("tf.device") - self.assertEqual(1, num_devices) + self.assertEqual(2, num_devices) name_re = r"_fancy_device_function<.*error_interpolation_test.py, [0-9]+>" expected_re = r"with tf.device\(.*%s\)" % name_re self.assertRegexpMatches(result, expected_re) @@ -268,27 +256,26 @@ class InterpolateColocationSummaryTest(test.TestCase): self.graph = node_three.graph def testNodeThreeHasColocationInterpolation(self): - message = "^^node:Three_with_one:${colocations}^^" + message = "{{colocation_node Three_with_one}}" result = error_interpolation.interpolate(message, self.graph) self.assertIn("colocate_with(One)", result) def testNodeFourHasColocationInterpolationForNodeThreeOnly(self): - message = "^^node:Four_with_three:${colocations}^^" + message = "{{colocation_node Four_with_three}}" result = error_interpolation.interpolate(message, self.graph) self.assertIn("colocate_with(Three_with_one)", result) self.assertNotIn( "One", result, - "Node One should not appear in Four_with_three's summary:\n%s" - % result) + "Node One should not appear in Four_with_three's summary:\n%s" % result) def testNodeFiveHasColocationInterpolationForNodeOneAndTwo(self): - message = "^^node:Five_with_one_with_two:${colocations}^^" + message = "{{colocation_node Five_with_one_with_two}}" result = error_interpolation.interpolate(message, self.graph) self.assertIn("colocate_with(One)", result) self.assertIn("colocate_with(Two)", result) def testColocationInterpolationForNodeLackingColocation(self): - message = "^^node:One:${colocations}^^" + message = "{{colocation_node One}}" result = error_interpolation.interpolate(message, self.graph) self.assertIn("No node-device colocations", result) self.assertNotIn("Two", result) diff --git a/tensorflow/python/framework/errors_impl.py b/tensorflow/python/framework/errors_impl.py index 9f973de400..5af71f2cfb 100644 --- a/tensorflow/python/framework/errors_impl.py +++ b/tensorflow/python/framework/errors_impl.py @@ -25,6 +25,7 @@ from tensorflow.core.lib.core import error_codes_pb2 from tensorflow.python import pywrap_tensorflow as c_api from tensorflow.python.framework import c_api_util from tensorflow.python.util import compat +from tensorflow.python.util import tf_inspect from tensorflow.python.util.tf_export import tf_export @@ -47,11 +48,17 @@ class OpError(Exception): error_code: The `error_codes_pb2.Code` describing the error. """ super(OpError, self).__init__() - self._message = message self._node_def = node_def self._op = op + self._message = message self._error_code = error_code + def __reduce__(self): + # Allow the subclasses to accept less arguments in their __init__. + init_argspec = tf_inspect.getargspec(self.__class__.__init__) + args = tuple(getattr(self, arg) for arg in init_argspec.args[1:]) + return self.__class__, args + @property def message(self): """The error message that describes the error.""" diff --git a/tensorflow/python/framework/errors_test.py b/tensorflow/python/framework/errors_test.py index 62f8ab030c..574b126cae 100644 --- a/tensorflow/python/framework/errors_test.py +++ b/tensorflow/python/framework/errors_test.py @@ -19,6 +19,7 @@ from __future__ import division from __future__ import print_function import gc +import pickle import warnings from tensorflow.core.lib.core import error_codes_pb2 @@ -107,6 +108,34 @@ class ErrorsTest(test.TestCase): gc.collect() self.assertEqual(0, self._CountReferences(c_api_util.ScopedTFStatus)) + def testPickleable(self): + for error_code in [ + errors.CANCELLED, + errors.UNKNOWN, + errors.INVALID_ARGUMENT, + errors.DEADLINE_EXCEEDED, + errors.NOT_FOUND, + errors.ALREADY_EXISTS, + errors.PERMISSION_DENIED, + errors.UNAUTHENTICATED, + errors.RESOURCE_EXHAUSTED, + errors.FAILED_PRECONDITION, + errors.ABORTED, + errors.OUT_OF_RANGE, + errors.UNIMPLEMENTED, + errors.INTERNAL, + errors.UNAVAILABLE, + errors.DATA_LOSS, + ]: + # pylint: disable=protected-access + exc = errors_impl._make_specific_exception(None, None, None, error_code) + # pylint: enable=protected-access + unpickled = pickle.loads(pickle.dumps(exc)) + self.assertEqual(exc.node_def, unpickled.node_def) + self.assertEqual(exc.op, unpickled.op) + self.assertEqual(exc.message, unpickled.message) + self.assertEqual(exc.error_code, unpickled.error_code) + if __name__ == "__main__": test.main() diff --git a/tensorflow/python/framework/tensor_util.py b/tensorflow/python/framework/tensor_util.py index b14290c203..26170b000d 100644 --- a/tensorflow/python/framework/tensor_util.py +++ b/tensorflow/python/framework/tensor_util.py @@ -367,7 +367,7 @@ def make_tensor_proto(values, dtype=None, shape=None, verify_shape=False): A `TensorProto`. Depending on the type, it may contain data in the "tensor_content" attribute, which is not directly useful to Python programs. To access the values you should convert the proto back to a numpy ndarray - with `tensor_util.MakeNdarray(proto)`. + with `tf.make_ndarray(proto)`. If `values` is a `TensorProto`, it is immediately returned; `dtype` and `shape` are ignored. diff --git a/tensorflow/python/framework/test_util.py b/tensorflow/python/framework/test_util.py index b5388ad0b2..0925598e33 100644 --- a/tensorflow/python/framework/test_util.py +++ b/tensorflow/python/framework/test_util.py @@ -535,15 +535,16 @@ def assert_no_new_tensors(f): tensors_before = set( id(obj) for obj in gc.get_objects() if _is_tensorflow_object(obj)) - if context.executing_eagerly(): - f(self, **kwargs) - ops.reset_default_graph() - else: - # Run the test in a new graph so that collections get cleared when it's - # done, but inherit the graph key so optimizers behave. - outside_graph_key = ops.get_default_graph()._graph_key - with ops.Graph().as_default(): - ops.get_default_graph()._graph_key = outside_graph_key + outside_executed_eagerly = context.executing_eagerly() + # Run the test in a new graph so that collections get cleared when it's + # done, but inherit the graph key so optimizers behave. + outside_graph_key = ops.get_default_graph()._graph_key + with ops.Graph().as_default(): + ops.get_default_graph()._graph_key = outside_graph_key + if outside_executed_eagerly: + with context.eager_mode(): + f(self, **kwargs) + else: f(self, **kwargs) # Make an effort to clear caches, which would otherwise look like leaked # Tensors. @@ -1072,13 +1073,9 @@ class TensorFlowTestCase(googletest.TestCase): if context.executing_eagerly(): yield None else: - sess = self._create_session(graph, config, use_gpu, force_gpu) - with self._constrain_devices_and_set_default( - sess, use_gpu, force_gpu) as constrained_sess: - # We need to do this to make sure the session closes, otherwise, even - # if the user does with self.session():, it will not close the session. - with constrained_sess: - yield constrained_sess + with self._create_session(graph, config, force_gpu) as sess: + with self._constrain_devices_and_set_default(sess, use_gpu, force_gpu): + yield sess @contextlib.contextmanager def cached_session(self, @@ -1126,10 +1123,11 @@ class TensorFlowTestCase(googletest.TestCase): if context.executing_eagerly(): yield None else: - with self._get_cached_session( - graph, config, use_gpu, force_gpu, - crash_if_inconsistent_args=True) as sess: - yield sess + sess = self._get_cached_session( + graph, config, force_gpu, crash_if_inconsistent_args=True) + with self._constrain_devices_and_set_default(sess, use_gpu, + force_gpu) as cached: + yield cached @contextlib.contextmanager def test_session(self, @@ -1145,10 +1143,11 @@ class TensorFlowTestCase(googletest.TestCase): yield None else: if graph is None: - with self._get_cached_session( - graph, config, use_gpu, force_gpu, - crash_if_inconsistent_args=False) as sess: - yield sess + sess = self._get_cached_session( + graph, config, force_gpu, crash_if_inconsistent_args=False) + with self._constrain_devices_and_set_default(sess, use_gpu, + force_gpu) as cached: + yield cached else: with self.session(graph, config, use_gpu, force_gpu) as sess: yield sess @@ -1834,91 +1833,69 @@ class TensorFlowTestCase(googletest.TestCase): with sess.graph.device("/cpu:0"): yield sess - def _create_session(self, graph, config, use_gpu, force_gpu): + def _create_session(self, graph, config, force_gpu): """See session() for details.""" - if context.executing_eagerly(): - return None - else: + def prepare_config(config): + """Returns a config for sessions. - def prepare_config(config): - """Returns a config for sessions. - - Args: - config: An optional config_pb2.ConfigProto to use to configure the - session. - Returns: - A config_pb2.ConfigProto object. - """ - if config is None: - config = config_pb2.ConfigProto() - config.allow_soft_placement = not force_gpu - config.gpu_options.per_process_gpu_memory_fraction = 0.3 - elif force_gpu and config.allow_soft_placement: - config = config_pb2.ConfigProto().CopyFrom(config) - config.allow_soft_placement = False - # Don't perform optimizations for tests so we don't inadvertently run - # gpu ops on cpu - config.graph_options.optimizer_options.opt_level = -1 - config.graph_options.rewrite_options.constant_folding = ( - rewriter_config_pb2.RewriterConfig.OFF) - config.graph_options.rewrite_options.arithmetic_optimization = ( - rewriter_config_pb2.RewriterConfig.OFF) - return config - - return ErrorLoggingSession(graph=graph, config=prepare_config(config)) + Args: + config: An optional config_pb2.ConfigProto to use to configure the + session. + + Returns: + A config_pb2.ConfigProto object. + """ + if config is None: + config = config_pb2.ConfigProto() + config.allow_soft_placement = not force_gpu + config.gpu_options.per_process_gpu_memory_fraction = 0.3 + elif force_gpu and config.allow_soft_placement: + config = config_pb2.ConfigProto().CopyFrom(config) + config.allow_soft_placement = False + # Don't perform optimizations for tests so we don't inadvertently run + # gpu ops on cpu + config.graph_options.optimizer_options.opt_level = -1 + config.graph_options.rewrite_options.constant_folding = ( + rewriter_config_pb2.RewriterConfig.OFF) + config.graph_options.rewrite_options.arithmetic_optimization = ( + rewriter_config_pb2.RewriterConfig.OFF) + return config + + return ErrorLoggingSession(graph=graph, config=prepare_config(config)) - @contextlib.contextmanager def _get_cached_session(self, graph=None, config=None, - use_gpu=False, force_gpu=False, crash_if_inconsistent_args=True): """See cached_session() for documentation.""" - if context.executing_eagerly(): - yield None + if self._cached_session is None: + sess = self._create_session( + graph=graph, config=config, force_gpu=force_gpu) + self._cached_session = sess + self._cached_graph = graph + self._cached_config = config + self._cached_force_gpu = force_gpu + return sess else: - if self._cached_session is None: - sess = self._create_session( - graph=graph, config=config, use_gpu=use_gpu, force_gpu=force_gpu) - self._cached_session = sess - self._cached_graph = graph - self._cached_config = config - self._cached_use_gpu = use_gpu - self._cached_force_gpu = force_gpu - with self._constrain_devices_and_set_default( - sess, use_gpu, force_gpu) as constrained_sess: - yield constrained_sess - else: - if crash_if_inconsistent_args and self._cached_graph is not graph: - raise ValueError("The graph used to get the cached session is " - "different than the one that was used to create the " - "session. Maybe create a new session with " - "self.session()") - if crash_if_inconsistent_args and self._cached_config is not config: - raise ValueError("The config used to get the cached session is " - "different than the one that was used to create the " - "session. Maybe create a new session with " - "self.session()") - if crash_if_inconsistent_args and self._cached_use_gpu is not use_gpu: - raise ValueError( - "The use_gpu value used to get the cached session is " - "different than the one that was used to create the " - "session. Maybe create a new session with " - "self.session()") - if crash_if_inconsistent_args and (self._cached_force_gpu is - not force_gpu): - raise ValueError( - "The force_gpu value used to get the cached session is " - "different than the one that was used to create the " - "session. Maybe create a new session with " - "self.session()") - # If you modify this logic, make sure to modify it in _create_session - # as well. - sess = self._cached_session - with self._constrain_devices_and_set_default( - sess, use_gpu, force_gpu) as constrained_sess: - yield constrained_sess + if crash_if_inconsistent_args and self._cached_graph is not graph: + raise ValueError("The graph used to get the cached session is " + "different than the one that was used to create the " + "session. Maybe create a new session with " + "self.session()") + if crash_if_inconsistent_args and self._cached_config is not config: + raise ValueError("The config used to get the cached session is " + "different than the one that was used to create the " + "session. Maybe create a new session with " + "self.session()") + if crash_if_inconsistent_args and (self._cached_force_gpu is + not force_gpu): + raise ValueError( + "The force_gpu value used to get the cached session is " + "different than the one that was used to create the " + "session. Maybe create a new session with " + "self.session()") + return self._cached_session @tf_export("test.create_local_cluster") diff --git a/tensorflow/python/framework/test_util_test.py b/tensorflow/python/framework/test_util_test.py index a0939f98b2..c4f8fa9108 100644 --- a/tensorflow/python/framework/test_util_test.py +++ b/tensorflow/python/framework/test_util_test.py @@ -71,9 +71,6 @@ class TestUtilTest(test_util.TensorFlowTestCase): with self.cached_session(graph=ops.Graph()) as sess2: pass with self.assertRaises(ValueError): - with self.cached_session(use_gpu=True) as sess2: - pass - with self.assertRaises(ValueError): with self.cached_session(force_gpu=True) as sess2: pass # We make sure that test_session will cache the session even after the diff --git a/tensorflow/python/keras/backend.py b/tensorflow/python/keras/backend.py index b52ab7f05c..7768caeaf0 100644 --- a/tensorflow/python/keras/backend.py +++ b/tensorflow/python/keras/backend.py @@ -443,13 +443,7 @@ def get_session(): session = default_session else: if _SESSION is None: - if not os.environ.get('OMP_NUM_THREADS'): - config = config_pb2.ConfigProto(allow_soft_placement=True) - else: - num_thread = int(os.environ.get('OMP_NUM_THREADS')) - config = config_pb2.ConfigProto( - intra_op_parallelism_threads=num_thread, allow_soft_placement=True) - _SESSION = session_module.Session(config=config) + _SESSION = session_module.Session(config=get_default_session_config()) session = _SESSION if not _MANUAL_VAR_INIT: with session.graph.as_default(): @@ -468,6 +462,16 @@ def set_session(session): _SESSION = session +def get_default_session_config(): + if not os.environ.get('OMP_NUM_THREADS'): + config = config_pb2.ConfigProto(allow_soft_placement=True) + else: + num_thread = int(os.environ.get('OMP_NUM_THREADS')) + config = config_pb2.ConfigProto( + intra_op_parallelism_threads=num_thread, allow_soft_placement=True) + return config + + # DEVICE MANIPULATION diff --git a/tensorflow/python/keras/engine/distributed_training_utils.py b/tensorflow/python/keras/engine/distributed_training_utils.py index fcb073322c..c1c4970025 100644 --- a/tensorflow/python/keras/engine/distributed_training_utils.py +++ b/tensorflow/python/keras/engine/distributed_training_utils.py @@ -17,8 +17,9 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function +from tensorflow.python.client import session as session_module from tensorflow.python.framework import tensor_util -from tensorflow.python.keras import backend +from tensorflow.python.keras import backend as K from tensorflow.python.keras import callbacks from tensorflow.python.platform import tf_logging as logging from tensorflow.python.training import distribute as distribute_lib @@ -46,7 +47,7 @@ def set_weights(distribution_strategy, dist_model, weights): assign_ops.append(distribution_strategy.unwrap(sw.assign(w))) weights = weights[num_param:] - backend.get_session().run(assign_ops) + K.get_session().run(assign_ops) def unwrap_values(distribution_strategy, grouped_inputs, grouped_outputs, @@ -269,3 +270,20 @@ def validate_all_tensor_shapes(x, x_values): if x_shape != x_values[i].get_shape().as_list(): raise ValueError('Input tensor shapes do not match for distributed tensor' ' inputs {}'.format(x)) + + +def configure_and_create_session(distribution_strategy): + """Configure session config and create a session with it.""" + # TODO(priyag): Throw error if a session already exists. + session_config = K.get_default_session_config() + distribution_strategy.configure(session_config) + + if distribution_strategy.__class__.__name__ == 'TPUStrategy': + # TODO(priyag): Remove this workaround when Distributed Coordinator is + # integrated with keras and we can create a session from there. + master = distribution_strategy._tpu_cluster_resolver.master() # pylint: disable=protected-access + session = session_module.Session(config=session_config, target=master) + else: + session = session_module.Session(config=session_config) + + K.set_session(session) diff --git a/tensorflow/python/keras/engine/network.py b/tensorflow/python/keras/engine/network.py index cd74e36e68..f8c23ed124 100644 --- a/tensorflow/python/keras/engine/network.py +++ b/tensorflow/python/keras/engine/network.py @@ -1355,7 +1355,9 @@ class Network(base_layer.Layer): ``` """ if not self._is_graph_network: - raise NotImplementedError + raise NotImplementedError( + 'Currently `save` requires model to be a graph network. Consider ' + 'using `save_weights`, in order to save the weights of the model.') from tensorflow.python.keras.models import save_model # pylint: disable=g-import-not-at-top save_model(self, filepath, overwrite, include_optimizer) diff --git a/tensorflow/python/keras/engine/training.py b/tensorflow/python/keras/engine/training.py index 85d25411b4..966b446f22 100644 --- a/tensorflow/python/keras/engine/training.py +++ b/tensorflow/python/keras/engine/training.py @@ -405,20 +405,9 @@ class Model(Network): # Set DistributionStrategy specific parameters. self._distribution_strategy = distribute if self._distribution_strategy is not None: - self._grouped_model = self._compile_distributed_model( + self._grouped_model = None + distributed_training_utils.configure_and_create_session( self._distribution_strategy) - with self._distribution_strategy.scope(): - first_replicated_model = self._distribution_strategy.unwrap( - self._grouped_model)[0] - # If the specified metrics in `compile` are stateful, raise an error - # since we currently don't support stateful metrics. - if first_replicated_model.stateful_metric_names: - raise NotImplementedError('Stateful metrics are not supported with ' - 'DistributionStrategy.') - - # We initialize the callback model with the first replicated model. - self._replicated_model = DistributedCallbackModel(first_replicated_model) - self._replicated_model.set_original_model(self) if not self.built: # Model is not compilable because it does not know its number of inputs # and outputs, nor their shapes and names. We will compile after the first @@ -636,6 +625,12 @@ class Model(Network): skip_target_indices=skip_target_indices, sample_weights=self.sample_weights) + # If using distribution strategy and stateful_metrics, raise an error + # since we currently don't support stateful metrics. + if self._distribution_strategy is not None and self.stateful_metric_names: + raise NotImplementedError('Stateful metrics are not supported with ' + 'DistributionStrategy.') + # Prepare gradient updates and state updates. self.total_loss = total_loss @@ -652,19 +647,6 @@ class Model(Network): trainable_weights = self.trainable_weights self._collected_trainable_weights = trainable_weights - def _compile_distributed_model(self, distribution_strategy): - # TODO(anjalisridhar): Can we move the clone_and_build_model to outside the - # model? - def _clone_model_per_tower(model): - new_model = training_distributed.clone_and_build_model(model) - return new_model - - with distribution_strategy.scope(): - # Create a copy of this model on each of the devices. - grouped_models = distribution_strategy.call_for_each_tower( - _clone_model_per_tower, self) - return grouped_models - def _check_trainable_weights_consistency(self): """Check trainable weights count consistency. @@ -790,10 +772,7 @@ class Model(Network): Fraction of the training data to be used as validation data. Returns: - A tuple of 3 lists: input arrays, target arrays, sample-weight arrays. - If the model's input and targets are symbolic, these lists are empty - (since the model takes no user-provided data, instead the data comes - from the symbolic inputs/targets). + Iterator for reading the dataset `x`. Raises: ValueError: In case of invalid user-provided data. @@ -828,30 +807,7 @@ class Model(Network): training_utils.validate_iterator_input(x, y, sample_weight, validation_split) - # x an y may be PerDevice objects with an input and output tensor - # corresponding to each device. For example, x could be - # PerDevice:{device: get_next tensor,...}. - next_element = iterator.get_next() - - if not isinstance(next_element, (list, tuple)) or len(next_element) != 2: - raise ValueError('Please provide model inputs as a list or tuple of 2 ' - 'elements: input and target pair. ' - 'Received %s' % next_element) - x, y = next_element - # Validate that all the elements in x and y are of the same type and shape. - # We can then pass the first element of x and y to `_standardize_weights` - # below and be confident of the output. We need to reopen the scope since - # we unwrap values when we validate x and y. - with self._distribution_strategy.scope(): - x_values, y_values = distributed_training_utils.\ - validate_distributed_dataset_inputs(self._distribution_strategy, x, y) - - _, _, sample_weights = self._standardize_weights(x_values, - y_values, - sample_weight, - class_weight, - batch_size) - return x, y, sample_weights + return iterator def _standardize_user_data(self, x, @@ -916,7 +872,7 @@ class Model(Network): RuntimeError: If the model was never compiled. """ if self._distribution_strategy: - return self._distribution_standardize_user_data( + iterator = self._distribution_standardize_user_data( x, y, sample_weight=sample_weight, @@ -926,6 +882,7 @@ class Model(Network): steps_name=steps_name, steps=steps, validation_split=validation_split) + return iterator, None, None if isinstance(x, dataset_ops.Dataset): if context.executing_eagerly(): @@ -982,6 +939,7 @@ class Model(Network): def _standardize_weights(self, x, y, sample_weight=None, class_weight=None, batch_size=None,): + # TODO(sourabhbajaj): Split input validation from weight standardization. if sample_weight is not None and class_weight is not None: logging.warning( 'Received both a `sample_weight` and `class_weight` argument. ' @@ -1566,12 +1524,11 @@ class Model(Network): validation_steps=validation_steps) elif self._distribution_strategy: return training_distributed.fit_loop( - self, x, y, + self, x, epochs=epochs, verbose=verbose, callbacks=callbacks, - val_inputs=val_x, - val_targets=val_y, + val_iterator=val_x, initial_epoch=initial_epoch, steps_per_epoch=steps_per_epoch, validation_steps=validation_steps) @@ -1677,8 +1634,7 @@ class Model(Network): elif self._distribution_strategy: return training_distributed.test_loop( self, - inputs=x, - targets=y, + iterator=x, verbose=verbose, steps=steps) else: @@ -2188,6 +2144,13 @@ class Model(Network): return self.callback_model return self + def _make_callback_model(self): + first_replicated_model = self._distribution_strategy.unwrap( + self._grouped_model)[0] + # We initialize the callback model with the first replicated model. + self._replicated_model = DistributedCallbackModel(first_replicated_model) + self._replicated_model.set_original_model(self) + class DistributedCallbackModel(Model): """Model that is used for callbacks with DistributionStrategy.""" @@ -2225,6 +2188,6 @@ class DistributedCallbackModel(Model): # Whitelisted atttributes of the model that can be accessed by the user # during a callback. if item not in ['_setattr_tracking']: - logging.warning('You are accessing attribute ' + item + 'of the' - 'DistributedCallbackModel that may not have been set' + logging.warning('You are accessing attribute ' + item + 'of the ' + 'DistributedCallbackModel that may not have been set ' 'correctly.') diff --git a/tensorflow/python/keras/engine/training_distributed.py b/tensorflow/python/keras/engine/training_distributed.py index 85f1d6299f..e440e02bfb 100644 --- a/tensorflow/python/keras/engine/training_distributed.py +++ b/tensorflow/python/keras/engine/training_distributed.py @@ -19,24 +19,25 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function import numpy as np +from tensorflow.python.framework import constant_op from tensorflow.python.framework import errors from tensorflow.python.keras import backend as K from tensorflow.python.keras import callbacks as cbks from tensorflow.python.keras import optimizers from tensorflow.python.keras.engine import distributed_training_utils from tensorflow.python.keras.utils.generic_utils import Progbar +from tensorflow.python.ops import array_ops from tensorflow.python.platform import tf_logging as logging +from tensorflow.python.training import distribute as distribute_lib def fit_loop( model, - inputs, - targets, + iterator, epochs=100, verbose=1, callbacks=None, - val_inputs=None, - val_targets=None, + val_iterator=None, initial_epoch=0, steps_per_epoch=None, validation_steps=None): @@ -44,13 +45,11 @@ def fit_loop( Arguments: model: Keras Model instance. - inputs: List of input arrays. - targets: List of target arrays. + iterator: Iterator for input data. epochs: Number of times to iterate over the data verbose: Verbosity mode, 0, 1 or 2 callbacks: List of callbacks to be called during training - val_inputs: List of input arrays. - val_targets: List of target arrays. + val_iterator: Iterator for validation data. initial_epoch: Epoch at which to start training (useful for resuming a previous training run) steps_per_epoch: Total number of steps (batches of samples) @@ -67,6 +66,15 @@ def fit_loop( ValueError: in case of invalid arguments. """ current_strategy = model._distribution_strategy + + # TODO(priyag, sourabhbajaj): Remove this when the codepaths are merged. + if current_strategy.__class__.__name__ == 'TPUStrategy': + return _experimental_fit_loop( + model, iterator, epochs, initial_epoch, steps_per_epoch) + + clone_model_on_towers( + model, current_strategy, make_callback_model=True) + def _per_device_train_function(model): model._make_train_function() return (model.train_function.inputs, @@ -74,6 +82,7 @@ def fit_loop( model.train_function.updates_op, model.train_function.session_kwargs) + inputs, targets = _get_input_from_iterator(iterator, model) with current_strategy.scope(): # Create train ops on each of the devices when we call # `_per_device_train_function`. @@ -115,11 +124,6 @@ def fit_loop( do_validation = False if validation_steps: do_validation = True - if steps_per_epoch is None: - raise ValueError('Can only use `validation_steps` ' - 'when doing step-wise ' - 'training, i.e. `steps_per_epoch` ' - 'must be set.') # Copy the weights from the original model to each of the replicated models. orig_model_weights = model.get_weights() @@ -139,45 +143,46 @@ def fit_loop( verbose=verbose) out_labels = model.metrics_names or [] callbacks.on_train_begin() + + assert steps_per_epoch is not None + for epoch in range(initial_epoch, epochs): callbacks.on_epoch_begin(epoch) - if steps_per_epoch is not None: - epoch_logs = {} - for step_index in range(steps_per_epoch): - batch_logs = {'batch': step_index, 'size': 1} - callbacks.on_batch_begin(step_index, batch_logs) - try: - outs = distributed_train_function(ins) - except errors.OutOfRangeError: - logging.warning('Your dataset iterator ran out of data; ' - 'interrupting training. Make sure that your dataset ' - 'can generate at least `steps_per_epoch * epochs` ' - 'batches (in this case, %d batches).' % - steps_per_epoch * epochs) - break - - if not isinstance(outs, list): - outs = [outs] - - outs = _aggregate_metrics_across_towers( - current_strategy.num_towers, out_labels, outs) - for l, o in zip(out_labels, outs): - batch_logs[l] = o - callbacks.on_batch_end(step_index, batch_logs) - if callbacks.model.stop_training: - break - if do_validation: - val_outs = test_loop( - model, - val_inputs, - val_targets, - steps=validation_steps, - verbose=0) - if not isinstance(val_outs, list): - val_outs = [val_outs] - # Same labels assumed. - for l, o in zip(out_labels, val_outs): - epoch_logs['val_' + l] = o + epoch_logs = {} + for step_index in range(steps_per_epoch): + batch_logs = {'batch': step_index, 'size': 1} + callbacks.on_batch_begin(step_index, batch_logs) + try: + outs = distributed_train_function(ins) + except errors.OutOfRangeError: + logging.warning('Your dataset iterator ran out of data; ' + 'interrupting training. Make sure that your dataset ' + 'can generate at least `steps_per_epoch * epochs` ' + 'batches (in this case, %d batches).' % + steps_per_epoch * epochs) + break + + if not isinstance(outs, list): + outs = [outs] + + outs = _aggregate_metrics_across_towers( + current_strategy.num_towers, out_labels, outs) + for l, o in zip(out_labels, outs): + batch_logs[l] = o + callbacks.on_batch_end(step_index, batch_logs) + if callbacks.model.stop_training: + break + if do_validation: + val_outs = test_loop( + model, + val_iterator, + steps=validation_steps, + verbose=0) + if not isinstance(val_outs, list): + val_outs = [val_outs] + # Same labels assumed. + for l, o in zip(out_labels, val_outs): + epoch_logs['val_' + l] = o callbacks.on_epoch_end(epoch, epoch_logs) if callbacks.model.stop_training: @@ -192,13 +197,145 @@ def fit_loop( return model.history -def test_loop(model, inputs, targets, verbose=0, steps=None): +def _experimental_fit_loop( + model, + iterator, + epochs=100, + initial_epoch=0, + steps_per_epoch=None): + """fit function when using TPU DistributionStrategy for training. + + Arguments: + model: Keras Model instance. + iterator: Iterator that returns inputs and targets + epochs: Number of times to iterate over the data + initial_epoch: Epoch at which to start training + (useful for resuming a previous training run) + steps_per_epoch: Total number of steps (batches of samples) + before declaring one epoch finished and starting the + next epoch. Ignored with the default value of `None`. + + Returns: + Returns `None`. + + Raises: + ValueError: in case of invalid arguments. + """ + current_strategy = model._distribution_strategy + + # TODO(priyag): Add validation that shapes are fully defined for TPU case. + + # TODO(priyag, sourabhbajaj): This should be moved into a callback instead. + K.get_session().run(current_strategy.initialize()) + + def _per_device_train_function(model): + model._make_train_function() + return (model.train_function.inputs, + model.train_function.outputs, + model.train_function.updates_op, + model.train_function.session_kwargs) + + # TODO(priyag, sourabhbajaj): This should likely not be hardcoded here. + K.set_learning_phase(1) + + def step_fn(ctx, inputs, targets): + """Clones the model and calls make_train_function.""" + # TODO(priyag, sourabhbajaj): Should cache this keyed on input shapes. + clone_model_on_towers( + model, + current_strategy, + make_callback_model=True, + inputs=inputs, + targets=targets) + + (grouped_inputs, grouped_outputs, grouped_updates, + grouped_session_args) = current_strategy.call_for_each_tower( + _per_device_train_function, model._grouped_model) + (all_inputs, all_outputs, all_updates, + all_session_args) = distributed_training_utils.unwrap_values( + current_strategy, grouped_inputs, grouped_outputs, + grouped_updates, grouped_session_args, with_loss_tensor=True) + combined_fn = K.Function( + all_inputs, all_outputs, + updates=all_updates, + name='distributed_train_function', + **all_session_args) + + # TODO(priyag, sourabhbajaj): Perhaps the aggregation type needs to be + # something else for different outputs. + out_labels = model.metrics_names or [] + for label, output in zip(out_labels, combined_fn.outputs): + ctx.set_last_step_output(label, output, + aggregation=distribute_lib.get_loss_reduction()) + + # TODO(priyag, sourabhbajaj): Ignoring these things from the combined_fn: + # feed_dict, session kwargs, run options, run_metadata for now. These should + # be handled appropriately + return combined_fn.updates_op + + # Add initial dummy values for loss and other metric tensors. + initial_loop_values = {} + initial_loop_values['loss'] = constant_op.constant(1e7) + for name, tensor in zip(model.metrics_names[1:], model.metrics_tensors): + initial_loop_values[name] = array_ops.zeros(tensor.shape, tensor.dtype) + + with current_strategy.scope(): + # TODO(priyag, sourabhbajaj): Adjust steps_per_run appropriately based on + # steps_per_epoch and number of epochs. + ctx = current_strategy.run_steps_on_dataset( + step_fn, iterator, iterations=current_strategy.steps_per_run, + initial_loop_values=initial_loop_values) + + train_op = ctx.run_op + output_tensors = ctx.last_step_outputs + + # Copy the weights from the original model to each of the replicated models. + orig_model_weights = model.get_weights() + with current_strategy.scope(): + distributed_model = current_strategy.unwrap(model._grouped_model)[0] + distributed_training_utils.set_weights( + current_strategy, distributed_model, orig_model_weights) + + assert steps_per_epoch is not None + + # TODO(priyag, sourabhbajaj): Add callbacks support. + # TODO(priyag, sourabhbajaj): Add validation. + for epoch in range(initial_epoch, epochs): + for step_index in range( + 0, steps_per_epoch, current_strategy.steps_per_run): + try: + _, outs = K.get_session().run([train_op, output_tensors]) + # TODO(priyag, sourabhbajaj): Remove this logging in favor of proper + # summaries through callbacks. + print('Epoch: {}, step_index: {}, loss: {}'.format( + epoch, step_index, outs['loss'])) + for label, out in outs.items(): + print(label, ': ', out) + except errors.OutOfRangeError: + logging.warning('Your dataset iterator ran out of data; ' + 'interrupting training. Make sure that your dataset ' + 'can generate at least `steps_per_epoch * epochs` ' + 'batches (in this case, %d batches).' % + steps_per_epoch * epochs) + break + + # Copy the weights back from the replicated model to the original model. + with current_strategy.scope(): + updated_weights = current_strategy.unwrap( + model._grouped_model)[0].get_weights() + model.set_weights(updated_weights) + + K.get_session().run(current_strategy.finalize()) + + # TODO(priyag, sourabhbajaj): Return history. + + +def test_loop(model, iterator, verbose=0, steps=None): """evaluate method to validate a model that uses DistributionStrategy. Arguments: model: Keras Model instance. - inputs: List of input arrays. - targets: List of target arrays. + iterator: Iterator for input data. verbose: verbosity mode. steps: Total number of steps (batches of samples) before declaring predictions finished. @@ -211,6 +348,9 @@ def test_loop(model, inputs, targets, verbose=0, steps=None): the display labels for the scalar outputs. """ current_strategy = model._distribution_strategy + + clone_model_on_towers(model, current_strategy) + def _per_device_test_function(model): model._make_test_function() return (model.test_function.inputs, @@ -218,6 +358,7 @@ def test_loop(model, inputs, targets, verbose=0, steps=None): model.test_function.updates_op, model.test_function.session_kwargs) + inputs, targets = _get_input_from_iterator(iterator, model) with current_strategy.scope(): (grouped_inputs, grouped_outputs, grouped_updates, grouped_session_args) = current_strategy.call_for_each_tower( @@ -284,12 +425,12 @@ def test_loop(model, inputs, targets, verbose=0, steps=None): return outs -def predict_loop(model, inputs, verbose=0, steps=None): +def predict_loop(model, iterator, verbose=0, steps=None): """Abstract method to loop over some data in batches. Arguments: model: Keras Model instance. - inputs: list of tensors to be fed to `f`. + iterator: Iterator for input data. verbose: verbosity mode. steps: Total number of steps (batches of samples) before declaring `_predict_loop` finished. @@ -301,6 +442,9 @@ def predict_loop(model, inputs, verbose=0, steps=None): (if the model has multiple outputs). """ current_strategy = model._distribution_strategy + + clone_model_on_towers(model, current_strategy) + def _per_device_predict_function(model): model._make_predict_function() return (model.predict_function.inputs, @@ -308,6 +452,7 @@ def predict_loop(model, inputs, verbose=0, steps=None): model.predict_function.updates_op, model.predict_function.session_kwargs) + inputs, _ = _get_input_from_iterator(iterator, model) with current_strategy.scope(): (grouped_inputs, grouped_outputs, grouped_updates, grouped_session_args) = current_strategy.call_for_each_tower( @@ -366,12 +511,12 @@ def predict_loop(model, inputs, verbose=0, steps=None): ] -def clone_and_build_model(model): +def _clone_and_build_model(model, inputs=None, targets=None): """Clone and build the given keras_model.""" # We need to set the import here since we run into a circular dependency # error. from tensorflow.python.keras import models # pylint: disable=g-import-not-at-top - cloned_model = models.clone_model(model, input_tensors=None) + cloned_model = models.clone_model(model, input_tensors=inputs) # Compile and build model. if isinstance(model.optimizer, optimizers.TFOptimizer): @@ -380,16 +525,33 @@ def clone_and_build_model(model): optimizer_config = model.optimizer.get_config() optimizer = model.optimizer.__class__.from_config(optimizer_config) + # TODO(priyag): Is there a cleaner way to do this? The API doc suggests a + # single tensor should be OK but it throws an error in that case. + if (targets is not None and not isinstance(targets, list) and + not isinstance(targets, dict)): + targets = [targets] cloned_model.compile( optimizer, model.loss, metrics=model.metrics, loss_weights=model.loss_weights, sample_weight_mode=model.sample_weight_mode, - weighted_metrics=model.weighted_metrics) + weighted_metrics=model.weighted_metrics, + target_tensors=targets) return cloned_model +def clone_model_on_towers( + model, strategy, make_callback_model=False, inputs=None, targets=None): + """Create a cloned model on each tower, unless already created.""" + if not model._grouped_model: + with strategy.scope(): + model._grouped_model = strategy.call_for_each_tower( + _clone_and_build_model, model, inputs, targets) + if make_callback_model: + model._make_callback_model() + + def _aggregate_metrics_across_towers(num_devices, out_labels, outs): """Aggregate metrics values across all towers. @@ -419,3 +581,25 @@ def _aggregate_metrics_across_towers(num_devices, out_labels, outs): merged_output.append(m) current_index += num_devices return merged_output + + +def _get_input_from_iterator(iterator, model): + """Get elements from the iterator and verify the input shape and type.""" + next_element = iterator.get_next() + # TODO(anjalisridhar): Support predict input correctly as it will not contain + # targets, only inputs. + if not isinstance(next_element, (list, tuple)) or len(next_element) != 2: + raise ValueError('Please provide model inputs as a list or tuple of 2 ' + 'elements: input and target pair. ' + 'Received %s' % next_element) + + x, y = next_element + # Validate that all the elements in x and y are of the same type and shape. + # We can then pass the first element of x and y to `_standardize_weights` + # below and be confident of the output. + x_values, y_values = distributed_training_utils.\ + validate_distributed_dataset_inputs(model._distribution_strategy, x, y) + # TODO(sourabhbajaj): Add support for sample weights in distribution + # strategy. + model._standardize_weights(x_values, y_values) + return x, y diff --git a/tensorflow/python/keras/initializers.py b/tensorflow/python/keras/initializers.py index 2f12fae8f9..cac78c44ca 100644 --- a/tensorflow/python/keras/initializers.py +++ b/tensorflow/python/keras/initializers.py @@ -27,8 +27,8 @@ from tensorflow.python.keras.utils.generic_utils import serialize_keras_object # These imports are brought in so that keras.initializers.deserialize # has them available in module_objects. from tensorflow.python.ops.init_ops import Constant -from tensorflow.python.ops.init_ops import glorot_normal_initializer -from tensorflow.python.ops.init_ops import glorot_uniform_initializer +from tensorflow.python.ops.init_ops import GlorotNormal +from tensorflow.python.ops.init_ops import GlorotUniform from tensorflow.python.ops.init_ops import he_normal # pylint: disable=unused-import from tensorflow.python.ops.init_ops import he_uniform # pylint: disable=unused-import from tensorflow.python.ops.init_ops import Identity @@ -126,8 +126,8 @@ normal = random_normal = RandomNormal truncated_normal = TruncatedNormal identity = Identity orthogonal = Orthogonal -glorot_normal = glorot_normal_initializer -glorot_uniform = glorot_uniform_initializer +glorot_normal = GlorotNormal +glorot_uniform = GlorotUniform # Utility functions diff --git a/tensorflow/python/keras/models.py b/tensorflow/python/keras/models.py index 39b6042597..c3b7301eba 100644 --- a/tensorflow/python/keras/models.py +++ b/tensorflow/python/keras/models.py @@ -30,7 +30,6 @@ from tensorflow.python.keras.engine.input_layer import InputLayer from tensorflow.python.keras.engine.network import Network from tensorflow.python.keras.utils import generic_utils from tensorflow.python.keras.utils.generic_utils import CustomObjectScope -from tensorflow.python.training import training_util from tensorflow.python.training.checkpointable import base as checkpointable from tensorflow.python.training.checkpointable import data_structures from tensorflow.python.util.tf_export import tf_export @@ -394,10 +393,11 @@ def in_place_subclassed_model_state_restoration(model): def clone_and_build_model( model, input_tensors=None, target_tensors=None, custom_objects=None, - compile_clone=True, in_place_reset=False): + compile_clone=True, in_place_reset=False, optimizer_iterations=None): """Clone a `Model` and build/compile it with the same settings used before. - This function should be run in the same graph as the model. + This function can be be run in the same graph or in a separate graph from the + model. When using a separate graph, `in_place_reset` must be `False`. Args: model: `tf.keras.Model` object. Can be Functional, Sequential, or @@ -414,6 +414,10 @@ def clone_and_build_model( this argument must be set to `True` (default `False`). To restore the original model, use the function `in_place_subclassed_model_state_restoration(model)`. + optimizer_iterations: An iterations variable to pass to the optimizer if + the model uses a TFOptimizer, and if the clone is compiled. This is used + when a Keras model is cloned into an Estimator model function, because + Estimators create their own global step variable. Returns: Clone of the model. @@ -448,14 +452,12 @@ def clone_and_build_model( clone.build() elif model.optimizer: if isinstance(model.optimizer, optimizers.TFOptimizer): - optimizer = model.optimizer + optimizer = optimizers.TFOptimizer( + model.optimizer.optimizer, optimizer_iterations) K.track_tf_optimizer(optimizer) else: optimizer_config = model.optimizer.get_config() optimizer = model.optimizer.__class__.from_config(optimizer_config) - global_step = training_util.get_or_create_global_step() - K.track_variable(global_step) - optimizer.iterations = global_step clone.compile( optimizer, diff --git a/tensorflow/python/keras/optimizers.py b/tensorflow/python/keras/optimizers.py index 2ce79285db..ab13e5c632 100644 --- a/tensorflow/python/keras/optimizers.py +++ b/tensorflow/python/keras/optimizers.py @@ -692,11 +692,15 @@ class TFOptimizer(Optimizer, checkpointable.CheckpointableBase): """Wrapper class for native TensorFlow optimizers. """ - def __init__(self, optimizer): # pylint: disable=super-init-not-called + def __init__(self, optimizer, iterations=None): # pylint: disable=super-init-not-called self.optimizer = optimizer self._track_checkpointable(optimizer, name='optimizer') - with K.name_scope(self.__class__.__name__): - self.iterations = K.variable(0, dtype='int64', name='iterations') + if iterations is None: + with K.name_scope(self.__class__.__name__): + self.iterations = K.variable(0, dtype='int64', name='iterations') + else: + self.iterations = iterations + self._track_checkpointable(self.iterations, name='global_step') def apply_gradients(self, grads): self.optimizer.apply_gradients(grads, global_step=self.iterations) diff --git a/tensorflow/python/kernel_tests/check_ops_test.py b/tensorflow/python/kernel_tests/check_ops_test.py index 05f998d0d2..680d0c97cc 100644 --- a/tensorflow/python/kernel_tests/check_ops_test.py +++ b/tensorflow/python/kernel_tests/check_ops_test.py @@ -116,7 +116,7 @@ class AssertEqualTest(test.TestCase): check_ops.assert_equal(static_big, static_small, message="fail") def test_raises_when_greater_dynamic(self): - with self.test_session(): + with self.cached_session(): small = array_ops.placeholder(dtypes.int32, name="small") big = array_ops.placeholder(dtypes.int32, name="big") with ops.control_dependencies( @@ -194,7 +194,7 @@ First 2 elements of y: check_ops.assert_equal(static_big, static_small, message="fail") def test_raises_when_less_dynamic(self): - with self.test_session(): + with self.cached_session(): small = array_ops.placeholder(dtypes.int32, name="small") big = array_ops.placeholder(dtypes.int32, name="big") with ops.control_dependencies([check_ops.assert_equal(small, big)]): @@ -271,30 +271,28 @@ class AssertNoneEqualTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def test_raises_when_not_equal_but_non_broadcastable_shapes(self): - with self.test_session(): - small = constant_op.constant([1, 1, 1], name="small") - big = constant_op.constant([10, 10], name="big") - # The exception in eager and non-eager mode is different because - # eager mode relies on shape check done as part of the C++ op, while - # graph mode does shape checks when creating the `Operation` instance. - with self.assertRaisesRegexp( - (ValueError, errors.InvalidArgumentError), - (r"Incompatible shapes: \[3\] vs. \[2\]|" - r"Dimensions must be equal, but are 3 and 2")): - with ops.control_dependencies( - [check_ops.assert_none_equal(small, big)]): - out = array_ops.identity(small) - self.evaluate(out) + small = constant_op.constant([1, 1, 1], name="small") + big = constant_op.constant([10, 10], name="big") + # The exception in eager and non-eager mode is different because + # eager mode relies on shape check done as part of the C++ op, while + # graph mode does shape checks when creating the `Operation` instance. + with self.assertRaisesRegexp( + (ValueError, errors.InvalidArgumentError), + (r"Incompatible shapes: \[3\] vs. \[2\]|" + r"Dimensions must be equal, but are 3 and 2")): + with ops.control_dependencies( + [check_ops.assert_none_equal(small, big)]): + out = array_ops.identity(small) + self.evaluate(out) @test_util.run_in_graph_and_eager_modes def test_doesnt_raise_when_both_empty(self): - with self.test_session(): - larry = constant_op.constant([]) - curly = constant_op.constant([]) - with ops.control_dependencies( - [check_ops.assert_none_equal(larry, curly)]): - out = array_ops.identity(larry) - self.evaluate(out) + larry = constant_op.constant([]) + curly = constant_op.constant([]) + with ops.control_dependencies( + [check_ops.assert_none_equal(larry, curly)]): + out = array_ops.identity(larry) + self.evaluate(out) def test_returns_none_with_eager(self): with context.eager_mode(): @@ -905,7 +903,7 @@ class AssertRankTest(test.TestCase): self.evaluate(array_ops.identity(tensor)) def test_rank_zero_tensor_raises_if_rank_too_small_dynamic_rank(self): - with self.test_session(): + with self.cached_session(): tensor = array_ops.placeholder(dtypes.float32, name="my_tensor") desired_rank = 1 with ops.control_dependencies( @@ -923,7 +921,7 @@ class AssertRankTest(test.TestCase): self.evaluate(array_ops.identity(tensor)) def test_rank_zero_tensor_doesnt_raise_if_rank_just_right_dynamic_rank(self): - with self.test_session(): + with self.cached_session(): tensor = array_ops.placeholder(dtypes.float32, name="my_tensor") desired_rank = 0 with ops.control_dependencies( @@ -940,7 +938,7 @@ class AssertRankTest(test.TestCase): self.evaluate(array_ops.identity(tensor)) def test_rank_one_tensor_raises_if_rank_too_large_dynamic_rank(self): - with self.test_session(): + with self.cached_session(): tensor = array_ops.placeholder(dtypes.float32, name="my_tensor") desired_rank = 0 with ops.control_dependencies( @@ -957,7 +955,7 @@ class AssertRankTest(test.TestCase): self.evaluate(array_ops.identity(tensor)) def test_rank_one_tensor_doesnt_raise_if_rank_just_right_dynamic_rank(self): - with self.test_session(): + with self.cached_session(): tensor = array_ops.placeholder(dtypes.float32, name="my_tensor") desired_rank = 1 with ops.control_dependencies( @@ -974,7 +972,7 @@ class AssertRankTest(test.TestCase): self.evaluate(array_ops.identity(tensor)) def test_rank_one_tensor_raises_if_rank_too_small_dynamic_rank(self): - with self.test_session(): + with self.cached_session(): tensor = array_ops.placeholder(dtypes.float32, name="my_tensor") desired_rank = 2 with ops.control_dependencies( @@ -989,7 +987,7 @@ class AssertRankTest(test.TestCase): check_ops.assert_rank(tensor, np.array([], dtype=np.int32)) def test_raises_if_rank_is_not_scalar_dynamic(self): - with self.test_session(): + with self.cached_session(): tensor = constant_op.constant( [1, 2], dtype=dtypes.float32, name="my_tensor") rank_tensor = array_ops.placeholder(dtypes.int32, name="rank_tensor") @@ -1006,7 +1004,7 @@ class AssertRankTest(test.TestCase): check_ops.assert_rank(tensor, .5) def test_raises_if_rank_is_not_integer_dynamic(self): - with self.test_session(): + with self.cached_session(): tensor = constant_op.constant( [1, 2], dtype=dtypes.float32, name="my_tensor") rank_tensor = array_ops.placeholder(dtypes.float32, name="rank_tensor") @@ -1029,7 +1027,7 @@ class AssertRankInTest(test.TestCase): self.evaluate(array_ops.identity(tensor_rank0)) def test_rank_zero_tensor_raises_if_rank_mismatch_dynamic_rank(self): - with self.test_session(): + with self.cached_session(): tensor_rank0 = array_ops.placeholder(dtypes.float32, name="my_tensor") with ops.control_dependencies([ check_ops.assert_rank_in(tensor_rank0, (1, 2), message="fail")]): @@ -1045,7 +1043,7 @@ class AssertRankInTest(test.TestCase): self.evaluate(array_ops.identity(tensor_rank0)) def test_rank_zero_tensor_doesnt_raise_if_rank_matches_dynamic_rank(self): - with self.test_session(): + with self.cached_session(): tensor_rank0 = array_ops.placeholder(dtypes.float32, name="my_tensor") for desired_ranks in ((0, 1, 2), (1, 0, 2), (1, 2, 0)): with ops.control_dependencies([ @@ -1061,7 +1059,7 @@ class AssertRankInTest(test.TestCase): self.evaluate(array_ops.identity(tensor_rank1)) def test_rank_one_tensor_doesnt_raise_if_rank_matches_dynamic_rank(self): - with self.test_session(): + with self.cached_session(): tensor_rank1 = array_ops.placeholder(dtypes.float32, name="my_tensor") for desired_ranks in ((0, 1, 2), (1, 0, 2), (1, 2, 0)): with ops.control_dependencies([ @@ -1079,7 +1077,7 @@ class AssertRankInTest(test.TestCase): self.evaluate(array_ops.identity(tensor_rank1)) def test_rank_one_tensor_raises_if_rank_mismatches_dynamic_rank(self): - with self.test_session(): + with self.cached_session(): tensor_rank1 = array_ops.placeholder(dtypes.float32, name="my_tensor") with ops.control_dependencies([ check_ops.assert_rank_in(tensor_rank1, (0, 2))]): @@ -1098,7 +1096,7 @@ class AssertRankInTest(test.TestCase): check_ops.assert_rank_in(tensor, desired_ranks) def test_raises_if_rank_is_not_scalar_dynamic(self): - with self.test_session(): + with self.cached_session(): tensor = constant_op.constant( (42, 43), dtype=dtypes.float32, name="my_tensor") desired_ranks = ( @@ -1120,7 +1118,7 @@ class AssertRankInTest(test.TestCase): check_ops.assert_rank_in(tensor, (1, .5,)) def test_raises_if_rank_is_not_integer_dynamic(self): - with self.test_session(): + with self.cached_session(): tensor = constant_op.constant( (42, 43), dtype=dtypes.float32, name="my_tensor") rank_tensor = array_ops.placeholder(dtypes.float32, name="rank_tensor") @@ -1143,7 +1141,7 @@ class AssertRankAtLeastTest(test.TestCase): self.evaluate(array_ops.identity(tensor)) def test_rank_zero_tensor_raises_if_rank_too_small_dynamic_rank(self): - with self.test_session(): + with self.cached_session(): tensor = array_ops.placeholder(dtypes.float32, name="my_tensor") desired_rank = 1 with ops.control_dependencies( @@ -1160,7 +1158,7 @@ class AssertRankAtLeastTest(test.TestCase): self.evaluate(array_ops.identity(tensor)) def test_rank_zero_tensor_doesnt_raise_if_rank_just_right_dynamic_rank(self): - with self.test_session(): + with self.cached_session(): tensor = array_ops.placeholder(dtypes.float32, name="my_tensor") desired_rank = 0 with ops.control_dependencies( @@ -1176,7 +1174,7 @@ class AssertRankAtLeastTest(test.TestCase): self.evaluate(array_ops.identity(tensor)) def test_rank_one_ten_doesnt_raise_if_rank_too_large_dynamic_rank(self): - with self.test_session(): + with self.cached_session(): tensor = array_ops.placeholder(dtypes.float32, name="my_tensor") desired_rank = 0 with ops.control_dependencies( @@ -1192,7 +1190,7 @@ class AssertRankAtLeastTest(test.TestCase): self.evaluate(array_ops.identity(tensor)) def test_rank_one_tensor_doesnt_raise_if_rank_just_right_dynamic_rank(self): - with self.test_session(): + with self.cached_session(): tensor = array_ops.placeholder(dtypes.float32, name="my_tensor") desired_rank = 1 with ops.control_dependencies( @@ -1209,7 +1207,7 @@ class AssertRankAtLeastTest(test.TestCase): self.evaluate(array_ops.identity(tensor)) def test_rank_one_tensor_raises_if_rank_too_small_dynamic_rank(self): - with self.test_session(): + with self.cached_session(): tensor = array_ops.placeholder(dtypes.float32, name="my_tensor") desired_rank = 2 with ops.control_dependencies( diff --git a/tensorflow/python/kernel_tests/distributions/bernoulli_test.py b/tensorflow/python/kernel_tests/distributions/bernoulli_test.py index 9ad77a54cb..26d013bccb 100644 --- a/tensorflow/python/kernel_tests/distributions/bernoulli_test.py +++ b/tensorflow/python/kernel_tests/distributions/bernoulli_test.py @@ -62,59 +62,50 @@ class BernoulliTest(test.TestCase): def testP(self): p = [0.2, 0.4] dist = bernoulli.Bernoulli(probs=p) - with self.test_session(): - self.assertAllClose(p, self.evaluate(dist.probs)) + self.assertAllClose(p, self.evaluate(dist.probs)) @test_util.run_in_graph_and_eager_modes def testLogits(self): logits = [-42., 42.] dist = bernoulli.Bernoulli(logits=logits) - with self.test_session(): - self.assertAllClose(logits, self.evaluate(dist.logits)) + self.assertAllClose(logits, self.evaluate(dist.logits)) if not special: return - with self.test_session(): - self.assertAllClose(special.expit(logits), self.evaluate(dist.probs)) + self.assertAllClose(special.expit(logits), self.evaluate(dist.probs)) p = [0.01, 0.99, 0.42] dist = bernoulli.Bernoulli(probs=p) - with self.test_session(): - self.assertAllClose(special.logit(p), self.evaluate(dist.logits)) + self.assertAllClose(special.logit(p), self.evaluate(dist.logits)) @test_util.run_in_graph_and_eager_modes def testInvalidP(self): invalid_ps = [1.01, 2.] for p in invalid_ps: - with self.test_session(): - with self.assertRaisesOpError("probs has components greater than 1"): - dist = bernoulli.Bernoulli(probs=p, validate_args=True) - self.evaluate(dist.probs) + with self.assertRaisesOpError("probs has components greater than 1"): + dist = bernoulli.Bernoulli(probs=p, validate_args=True) + self.evaluate(dist.probs) invalid_ps = [-0.01, -3.] for p in invalid_ps: - with self.test_session(): - with self.assertRaisesOpError("Condition x >= 0"): - dist = bernoulli.Bernoulli(probs=p, validate_args=True) - self.evaluate(dist.probs) + with self.assertRaisesOpError("Condition x >= 0"): + dist = bernoulli.Bernoulli(probs=p, validate_args=True) + self.evaluate(dist.probs) valid_ps = [0.0, 0.5, 1.0] for p in valid_ps: - with self.test_session(): - dist = bernoulli.Bernoulli(probs=p) - self.assertEqual(p, self.evaluate(dist.probs)) # Should not fail + dist = bernoulli.Bernoulli(probs=p) + self.assertEqual(p, self.evaluate(dist.probs)) # Should not fail @test_util.run_in_graph_and_eager_modes def testShapes(self): - with self.test_session(): - for batch_shape in ([], [1], [2, 3, 4]): - dist = make_bernoulli(batch_shape) - self.assertAllEqual(batch_shape, dist.batch_shape.as_list()) - self.assertAllEqual(batch_shape, - self.evaluate(dist.batch_shape_tensor())) - self.assertAllEqual([], dist.event_shape.as_list()) - self.assertAllEqual([], self.evaluate(dist.event_shape_tensor())) + for batch_shape in ([], [1], [2, 3, 4]): + dist = make_bernoulli(batch_shape) + self.assertAllEqual(batch_shape, dist.batch_shape.as_list()) + self.assertAllEqual(batch_shape, self.evaluate(dist.batch_shape_tensor())) + self.assertAllEqual([], dist.event_shape.as_list()) + self.assertAllEqual([], self.evaluate(dist.event_shape_tensor())) @test_util.run_in_graph_and_eager_modes def testDtype(self): @@ -137,31 +128,29 @@ class BernoulliTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def _testPmf(self, **kwargs): dist = bernoulli.Bernoulli(**kwargs) - with self.test_session(): - # pylint: disable=bad-continuation - xs = [ - 0, - [1], - [1, 0], - [[1, 0]], - [[1, 0], [1, 1]], - ] - expected_pmfs = [ - [[0.8, 0.6], [0.7, 0.4]], - [[0.2, 0.4], [0.3, 0.6]], - [[0.2, 0.6], [0.3, 0.4]], - [[0.2, 0.6], [0.3, 0.4]], - [[0.2, 0.6], [0.3, 0.6]], - ] - # pylint: enable=bad-continuation - - for x, expected_pmf in zip(xs, expected_pmfs): - self.assertAllClose(self.evaluate(dist.prob(x)), expected_pmf) - self.assertAllClose( - self.evaluate(dist.log_prob(x)), np.log(expected_pmf)) + # pylint: disable=bad-continuation + xs = [ + 0, + [1], + [1, 0], + [[1, 0]], + [[1, 0], [1, 1]], + ] + expected_pmfs = [ + [[0.8, 0.6], [0.7, 0.4]], + [[0.2, 0.4], [0.3, 0.6]], + [[0.2, 0.6], [0.3, 0.4]], + [[0.2, 0.6], [0.3, 0.4]], + [[0.2, 0.6], [0.3, 0.6]], + ] + # pylint: enable=bad-continuation + + for x, expected_pmf in zip(xs, expected_pmfs): + self.assertAllClose(self.evaluate(dist.prob(x)), expected_pmf) + self.assertAllClose(self.evaluate(dist.log_prob(x)), np.log(expected_pmf)) def testPmfCorrectBroadcastDynamicShape(self): - with self.test_session(): + with self.cached_session(): p = array_ops.placeholder(dtype=dtypes.float32) dist = bernoulli.Bernoulli(probs=p) event1 = [1, 0, 1] @@ -178,12 +167,11 @@ class BernoulliTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def testPmfInvalid(self): p = [0.1, 0.2, 0.7] - with self.test_session(): - dist = bernoulli.Bernoulli(probs=p, validate_args=True) - with self.assertRaisesOpError("must be non-negative."): - self.evaluate(dist.prob([1, 1, -1])) - with self.assertRaisesOpError("Elements cannot exceed 1."): - self.evaluate(dist.prob([2, 0, 1])) + dist = bernoulli.Bernoulli(probs=p, validate_args=True) + with self.assertRaisesOpError("must be non-negative."): + self.evaluate(dist.prob([1, 1, -1])) + with self.assertRaisesOpError("Elements cannot exceed 1."): + self.evaluate(dist.prob([2, 0, 1])) @test_util.run_in_graph_and_eager_modes def testPmfWithP(self): @@ -194,7 +182,7 @@ class BernoulliTest(test.TestCase): self._testPmf(logits=special.logit(p)) def testBroadcasting(self): - with self.test_session(): + with self.cached_session(): p = array_ops.placeholder(dtypes.float32) dist = bernoulli.Bernoulli(probs=p) self.assertAllClose(np.log(0.5), dist.log_prob(1).eval({p: 0.5})) @@ -208,70 +196,63 @@ class BernoulliTest(test.TestCase): })) def testPmfShapes(self): - with self.test_session(): + with self.cached_session(): p = array_ops.placeholder(dtypes.float32, shape=[None, 1]) dist = bernoulli.Bernoulli(probs=p) self.assertEqual(2, len(dist.log_prob(1).eval({p: [[0.5], [0.5]]}).shape)) - with self.test_session(): dist = bernoulli.Bernoulli(probs=0.5) self.assertEqual(2, len(self.evaluate(dist.log_prob([[1], [1]])).shape)) - with self.test_session(): dist = bernoulli.Bernoulli(probs=0.5) self.assertEqual((), dist.log_prob(1).get_shape()) self.assertEqual((1), dist.log_prob([1]).get_shape()) self.assertEqual((2, 1), dist.log_prob([[1], [1]]).get_shape()) - with self.test_session(): dist = bernoulli.Bernoulli(probs=[[0.5], [0.5]]) self.assertEqual((2, 1), dist.log_prob(1).get_shape()) @test_util.run_in_graph_and_eager_modes def testBoundaryConditions(self): - with self.test_session(): - dist = bernoulli.Bernoulli(probs=1.0) - self.assertAllClose(np.nan, self.evaluate(dist.log_prob(0))) - self.assertAllClose([np.nan], [self.evaluate(dist.log_prob(1))]) + dist = bernoulli.Bernoulli(probs=1.0) + self.assertAllClose(np.nan, self.evaluate(dist.log_prob(0))) + self.assertAllClose([np.nan], [self.evaluate(dist.log_prob(1))]) @test_util.run_in_graph_and_eager_modes def testEntropyNoBatch(self): p = 0.2 dist = bernoulli.Bernoulli(probs=p) - with self.test_session(): - self.assertAllClose(self.evaluate(dist.entropy()), entropy(p)) + self.assertAllClose(self.evaluate(dist.entropy()), entropy(p)) @test_util.run_in_graph_and_eager_modes def testEntropyWithBatch(self): p = [[0.1, 0.7], [0.2, 0.6]] dist = bernoulli.Bernoulli(probs=p, validate_args=False) - with self.test_session(): - self.assertAllClose( - self.evaluate(dist.entropy()), - [[entropy(0.1), entropy(0.7)], [entropy(0.2), - entropy(0.6)]]) + self.assertAllClose( + self.evaluate(dist.entropy()), + [[entropy(0.1), entropy(0.7)], [entropy(0.2), + entropy(0.6)]]) @test_util.run_in_graph_and_eager_modes def testSampleN(self): - with self.test_session(): - p = [0.2, 0.6] - dist = bernoulli.Bernoulli(probs=p) - n = 100000 - samples = dist.sample(n) - samples.set_shape([n, 2]) - self.assertEqual(samples.dtype, dtypes.int32) - sample_values = self.evaluate(samples) - self.assertTrue(np.all(sample_values >= 0)) - self.assertTrue(np.all(sample_values <= 1)) - # Note that the standard error for the sample mean is ~ sqrt(p * (1 - p) / - # n). This means that the tolerance is very sensitive to the value of p - # as well as n. - self.assertAllClose(p, np.mean(sample_values, axis=0), atol=1e-2) - self.assertEqual(set([0, 1]), set(sample_values.flatten())) - # In this test we're just interested in verifying there isn't a crash - # owing to mismatched types. b/30940152 - dist = bernoulli.Bernoulli(np.log([.2, .4])) - self.assertAllEqual((1, 2), dist.sample(1, seed=42).get_shape().as_list()) + p = [0.2, 0.6] + dist = bernoulli.Bernoulli(probs=p) + n = 100000 + samples = dist.sample(n) + samples.set_shape([n, 2]) + self.assertEqual(samples.dtype, dtypes.int32) + sample_values = self.evaluate(samples) + self.assertTrue(np.all(sample_values >= 0)) + self.assertTrue(np.all(sample_values <= 1)) + # Note that the standard error for the sample mean is ~ sqrt(p * (1 - p) / + # n). This means that the tolerance is very sensitive to the value of p + # as well as n. + self.assertAllClose(p, np.mean(sample_values, axis=0), atol=1e-2) + self.assertEqual(set([0, 1]), set(sample_values.flatten())) + # In this test we're just interested in verifying there isn't a crash + # owing to mismatched types. b/30940152 + dist = bernoulli.Bernoulli(np.log([.2, .4])) + self.assertAllEqual((1, 2), dist.sample(1, seed=42).get_shape().as_list()) @test_util.run_in_graph_and_eager_modes def testNotReparameterized(self): @@ -284,7 +265,7 @@ class BernoulliTest(test.TestCase): self.assertIsNone(grad_p) def testSampleActsLikeSampleN(self): - with self.test_session() as sess: + with self.cached_session() as sess: p = [0.2, 0.6] dist = bernoulli.Bernoulli(probs=p) n = 1000 @@ -299,27 +280,24 @@ class BernoulliTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def testMean(self): - with self.test_session(): - p = np.array([[0.2, 0.7], [0.5, 0.4]], dtype=np.float32) - dist = bernoulli.Bernoulli(probs=p) - self.assertAllEqual(self.evaluate(dist.mean()), p) + p = np.array([[0.2, 0.7], [0.5, 0.4]], dtype=np.float32) + dist = bernoulli.Bernoulli(probs=p) + self.assertAllEqual(self.evaluate(dist.mean()), p) @test_util.run_in_graph_and_eager_modes def testVarianceAndStd(self): var = lambda p: p * (1. - p) - with self.test_session(): - p = [[0.2, 0.7], [0.5, 0.4]] - dist = bernoulli.Bernoulli(probs=p) - self.assertAllClose( - self.evaluate(dist.variance()), - np.array( - [[var(0.2), var(0.7)], [var(0.5), var(0.4)]], dtype=np.float32)) - self.assertAllClose( - self.evaluate(dist.stddev()), - np.array( - [[np.sqrt(var(0.2)), np.sqrt(var(0.7))], - [np.sqrt(var(0.5)), np.sqrt(var(0.4))]], - dtype=np.float32)) + p = [[0.2, 0.7], [0.5, 0.4]] + dist = bernoulli.Bernoulli(probs=p) + self.assertAllClose( + self.evaluate(dist.variance()), + np.array([[var(0.2), var(0.7)], [var(0.5), var(0.4)]], + dtype=np.float32)) + self.assertAllClose( + self.evaluate(dist.stddev()), + np.array([[np.sqrt(var(0.2)), np.sqrt(var(0.7))], + [np.sqrt(var(0.5)), np.sqrt(var(0.4))]], + dtype=np.float32)) @test_util.run_in_graph_and_eager_modes def testBernoulliBernoulliKL(self): diff --git a/tensorflow/python/kernel_tests/distributions/beta_test.py b/tensorflow/python/kernel_tests/distributions/beta_test.py index 36f3ffc333..d580a415dd 100644 --- a/tensorflow/python/kernel_tests/distributions/beta_test.py +++ b/tensorflow/python/kernel_tests/distributions/beta_test.py @@ -20,7 +20,6 @@ import importlib import numpy as np -from tensorflow.python.client import session from tensorflow.python.eager import backprop from tensorflow.python.framework import constant_op from tensorflow.python.framework import random_seed @@ -51,237 +50,215 @@ stats = try_import("scipy.stats") class BetaTest(test.TestCase): def testSimpleShapes(self): - with self.test_session(): - a = np.random.rand(3) - b = np.random.rand(3) - dist = beta_lib.Beta(a, b) - self.assertAllEqual([], self.evaluate(dist.event_shape_tensor())) - self.assertAllEqual([3], self.evaluate(dist.batch_shape_tensor())) - self.assertEqual(tensor_shape.TensorShape([]), dist.event_shape) - self.assertEqual(tensor_shape.TensorShape([3]), dist.batch_shape) + a = np.random.rand(3) + b = np.random.rand(3) + dist = beta_lib.Beta(a, b) + self.assertAllEqual([], self.evaluate(dist.event_shape_tensor())) + self.assertAllEqual([3], self.evaluate(dist.batch_shape_tensor())) + self.assertEqual(tensor_shape.TensorShape([]), dist.event_shape) + self.assertEqual(tensor_shape.TensorShape([3]), dist.batch_shape) def testComplexShapes(self): - with self.test_session(): - a = np.random.rand(3, 2, 2) - b = np.random.rand(3, 2, 2) - dist = beta_lib.Beta(a, b) - self.assertAllEqual([], self.evaluate(dist.event_shape_tensor())) - self.assertAllEqual([3, 2, 2], self.evaluate(dist.batch_shape_tensor())) - self.assertEqual(tensor_shape.TensorShape([]), dist.event_shape) - self.assertEqual( - tensor_shape.TensorShape([3, 2, 2]), dist.batch_shape) + a = np.random.rand(3, 2, 2) + b = np.random.rand(3, 2, 2) + dist = beta_lib.Beta(a, b) + self.assertAllEqual([], self.evaluate(dist.event_shape_tensor())) + self.assertAllEqual([3, 2, 2], self.evaluate(dist.batch_shape_tensor())) + self.assertEqual(tensor_shape.TensorShape([]), dist.event_shape) + self.assertEqual(tensor_shape.TensorShape([3, 2, 2]), dist.batch_shape) def testComplexShapesBroadcast(self): - with self.test_session(): - a = np.random.rand(3, 2, 2) - b = np.random.rand(2, 2) - dist = beta_lib.Beta(a, b) - self.assertAllEqual([], self.evaluate(dist.event_shape_tensor())) - self.assertAllEqual([3, 2, 2], self.evaluate(dist.batch_shape_tensor())) - self.assertEqual(tensor_shape.TensorShape([]), dist.event_shape) - self.assertEqual( - tensor_shape.TensorShape([3, 2, 2]), dist.batch_shape) + a = np.random.rand(3, 2, 2) + b = np.random.rand(2, 2) + dist = beta_lib.Beta(a, b) + self.assertAllEqual([], self.evaluate(dist.event_shape_tensor())) + self.assertAllEqual([3, 2, 2], self.evaluate(dist.batch_shape_tensor())) + self.assertEqual(tensor_shape.TensorShape([]), dist.event_shape) + self.assertEqual(tensor_shape.TensorShape([3, 2, 2]), dist.batch_shape) def testAlphaProperty(self): a = [[1., 2, 3]] b = [[2., 4, 3]] - with self.test_session(): - dist = beta_lib.Beta(a, b) - self.assertEqual([1, 3], dist.concentration1.get_shape()) - self.assertAllClose(a, self.evaluate(dist.concentration1)) + dist = beta_lib.Beta(a, b) + self.assertEqual([1, 3], dist.concentration1.get_shape()) + self.assertAllClose(a, self.evaluate(dist.concentration1)) def testBetaProperty(self): a = [[1., 2, 3]] b = [[2., 4, 3]] - with self.test_session(): - dist = beta_lib.Beta(a, b) - self.assertEqual([1, 3], dist.concentration0.get_shape()) - self.assertAllClose(b, self.evaluate(dist.concentration0)) + dist = beta_lib.Beta(a, b) + self.assertEqual([1, 3], dist.concentration0.get_shape()) + self.assertAllClose(b, self.evaluate(dist.concentration0)) def testPdfXProper(self): a = [[1., 2, 3]] b = [[2., 4, 3]] - with self.test_session(): - dist = beta_lib.Beta(a, b, validate_args=True) - self.evaluate(dist.prob([.1, .3, .6])) - self.evaluate(dist.prob([.2, .3, .5])) - # Either condition can trigger. - with self.assertRaisesOpError("sample must be positive"): - self.evaluate(dist.prob([-1., 0.1, 0.5])) - with self.assertRaisesOpError("sample must be positive"): - self.evaluate(dist.prob([0., 0.1, 0.5])) - with self.assertRaisesOpError("sample must be less than `1`"): - self.evaluate(dist.prob([.1, .2, 1.2])) - with self.assertRaisesOpError("sample must be less than `1`"): - self.evaluate(dist.prob([.1, .2, 1.0])) + dist = beta_lib.Beta(a, b, validate_args=True) + self.evaluate(dist.prob([.1, .3, .6])) + self.evaluate(dist.prob([.2, .3, .5])) + # Either condition can trigger. + with self.assertRaisesOpError("sample must be positive"): + self.evaluate(dist.prob([-1., 0.1, 0.5])) + with self.assertRaisesOpError("sample must be positive"): + self.evaluate(dist.prob([0., 0.1, 0.5])) + with self.assertRaisesOpError("sample must be less than `1`"): + self.evaluate(dist.prob([.1, .2, 1.2])) + with self.assertRaisesOpError("sample must be less than `1`"): + self.evaluate(dist.prob([.1, .2, 1.0])) def testPdfTwoBatches(self): - with self.test_session(): - a = [1., 2] - b = [1., 2] - x = [.5, .5] - dist = beta_lib.Beta(a, b) - pdf = dist.prob(x) - self.assertAllClose([1., 3. / 2], self.evaluate(pdf)) - self.assertEqual((2,), pdf.get_shape()) + a = [1., 2] + b = [1., 2] + x = [.5, .5] + dist = beta_lib.Beta(a, b) + pdf = dist.prob(x) + self.assertAllClose([1., 3. / 2], self.evaluate(pdf)) + self.assertEqual((2,), pdf.get_shape()) def testPdfTwoBatchesNontrivialX(self): - with self.test_session(): - a = [1., 2] - b = [1., 2] - x = [.3, .7] - dist = beta_lib.Beta(a, b) - pdf = dist.prob(x) - self.assertAllClose([1, 63. / 50], self.evaluate(pdf)) - self.assertEqual((2,), pdf.get_shape()) + a = [1., 2] + b = [1., 2] + x = [.3, .7] + dist = beta_lib.Beta(a, b) + pdf = dist.prob(x) + self.assertAllClose([1, 63. / 50], self.evaluate(pdf)) + self.assertEqual((2,), pdf.get_shape()) def testPdfUniformZeroBatch(self): - with self.test_session(): - # This is equivalent to a uniform distribution - a = 1. - b = 1. - x = np.array([.1, .2, .3, .5, .8], dtype=np.float32) - dist = beta_lib.Beta(a, b) - pdf = dist.prob(x) - self.assertAllClose([1.] * 5, self.evaluate(pdf)) - self.assertEqual((5,), pdf.get_shape()) + # This is equivalent to a uniform distribution + a = 1. + b = 1. + x = np.array([.1, .2, .3, .5, .8], dtype=np.float32) + dist = beta_lib.Beta(a, b) + pdf = dist.prob(x) + self.assertAllClose([1.] * 5, self.evaluate(pdf)) + self.assertEqual((5,), pdf.get_shape()) def testPdfAlphaStretchedInBroadcastWhenSameRank(self): - with self.test_session(): - a = [[1., 2]] - b = [[1., 2]] - x = [[.5, .5], [.3, .7]] - dist = beta_lib.Beta(a, b) - pdf = dist.prob(x) - self.assertAllClose([[1., 3. / 2], [1., 63. / 50]], self.evaluate(pdf)) - self.assertEqual((2, 2), pdf.get_shape()) + a = [[1., 2]] + b = [[1., 2]] + x = [[.5, .5], [.3, .7]] + dist = beta_lib.Beta(a, b) + pdf = dist.prob(x) + self.assertAllClose([[1., 3. / 2], [1., 63. / 50]], self.evaluate(pdf)) + self.assertEqual((2, 2), pdf.get_shape()) def testPdfAlphaStretchedInBroadcastWhenLowerRank(self): - with self.test_session(): - a = [1., 2] - b = [1., 2] - x = [[.5, .5], [.2, .8]] - pdf = beta_lib.Beta(a, b).prob(x) - self.assertAllClose([[1., 3. / 2], [1., 24. / 25]], self.evaluate(pdf)) - self.assertEqual((2, 2), pdf.get_shape()) + a = [1., 2] + b = [1., 2] + x = [[.5, .5], [.2, .8]] + pdf = beta_lib.Beta(a, b).prob(x) + self.assertAllClose([[1., 3. / 2], [1., 24. / 25]], self.evaluate(pdf)) + self.assertEqual((2, 2), pdf.get_shape()) def testPdfXStretchedInBroadcastWhenSameRank(self): - with self.test_session(): - a = [[1., 2], [2., 3]] - b = [[1., 2], [2., 3]] - x = [[.5, .5]] - pdf = beta_lib.Beta(a, b).prob(x) - self.assertAllClose([[1., 3. / 2], [3. / 2, 15. / 8]], self.evaluate(pdf)) - self.assertEqual((2, 2), pdf.get_shape()) + a = [[1., 2], [2., 3]] + b = [[1., 2], [2., 3]] + x = [[.5, .5]] + pdf = beta_lib.Beta(a, b).prob(x) + self.assertAllClose([[1., 3. / 2], [3. / 2, 15. / 8]], self.evaluate(pdf)) + self.assertEqual((2, 2), pdf.get_shape()) def testPdfXStretchedInBroadcastWhenLowerRank(self): - with self.test_session(): - a = [[1., 2], [2., 3]] - b = [[1., 2], [2., 3]] - x = [.5, .5] - pdf = beta_lib.Beta(a, b).prob(x) - self.assertAllClose([[1., 3. / 2], [3. / 2, 15. / 8]], self.evaluate(pdf)) - self.assertEqual((2, 2), pdf.get_shape()) + a = [[1., 2], [2., 3]] + b = [[1., 2], [2., 3]] + x = [.5, .5] + pdf = beta_lib.Beta(a, b).prob(x) + self.assertAllClose([[1., 3. / 2], [3. / 2, 15. / 8]], self.evaluate(pdf)) + self.assertEqual((2, 2), pdf.get_shape()) def testBetaMean(self): - with session.Session(): - a = [1., 2, 3] - b = [2., 4, 1.2] - dist = beta_lib.Beta(a, b) - self.assertEqual(dist.mean().get_shape(), (3,)) - if not stats: - return - expected_mean = stats.beta.mean(a, b) - self.assertAllClose(expected_mean, self.evaluate(dist.mean())) + a = [1., 2, 3] + b = [2., 4, 1.2] + dist = beta_lib.Beta(a, b) + self.assertEqual(dist.mean().get_shape(), (3,)) + if not stats: + return + expected_mean = stats.beta.mean(a, b) + self.assertAllClose(expected_mean, self.evaluate(dist.mean())) def testBetaVariance(self): - with session.Session(): - a = [1., 2, 3] - b = [2., 4, 1.2] - dist = beta_lib.Beta(a, b) - self.assertEqual(dist.variance().get_shape(), (3,)) - if not stats: - return - expected_variance = stats.beta.var(a, b) - self.assertAllClose(expected_variance, self.evaluate(dist.variance())) + a = [1., 2, 3] + b = [2., 4, 1.2] + dist = beta_lib.Beta(a, b) + self.assertEqual(dist.variance().get_shape(), (3,)) + if not stats: + return + expected_variance = stats.beta.var(a, b) + self.assertAllClose(expected_variance, self.evaluate(dist.variance())) def testBetaMode(self): - with session.Session(): - a = np.array([1.1, 2, 3]) - b = np.array([2., 4, 1.2]) - expected_mode = (a - 1) / (a + b - 2) - dist = beta_lib.Beta(a, b) - self.assertEqual(dist.mode().get_shape(), (3,)) - self.assertAllClose(expected_mode, self.evaluate(dist.mode())) + a = np.array([1.1, 2, 3]) + b = np.array([2., 4, 1.2]) + expected_mode = (a - 1) / (a + b - 2) + dist = beta_lib.Beta(a, b) + self.assertEqual(dist.mode().get_shape(), (3,)) + self.assertAllClose(expected_mode, self.evaluate(dist.mode())) def testBetaModeInvalid(self): - with session.Session(): - a = np.array([1., 2, 3]) - b = np.array([2., 4, 1.2]) - dist = beta_lib.Beta(a, b, allow_nan_stats=False) - with self.assertRaisesOpError("Condition x < y.*"): - self.evaluate(dist.mode()) - - a = np.array([2., 2, 3]) - b = np.array([1., 4, 1.2]) - dist = beta_lib.Beta(a, b, allow_nan_stats=False) - with self.assertRaisesOpError("Condition x < y.*"): - self.evaluate(dist.mode()) + a = np.array([1., 2, 3]) + b = np.array([2., 4, 1.2]) + dist = beta_lib.Beta(a, b, allow_nan_stats=False) + with self.assertRaisesOpError("Condition x < y.*"): + self.evaluate(dist.mode()) + + a = np.array([2., 2, 3]) + b = np.array([1., 4, 1.2]) + dist = beta_lib.Beta(a, b, allow_nan_stats=False) + with self.assertRaisesOpError("Condition x < y.*"): + self.evaluate(dist.mode()) def testBetaModeEnableAllowNanStats(self): - with session.Session(): - a = np.array([1., 2, 3]) - b = np.array([2., 4, 1.2]) - dist = beta_lib.Beta(a, b, allow_nan_stats=True) + a = np.array([1., 2, 3]) + b = np.array([2., 4, 1.2]) + dist = beta_lib.Beta(a, b, allow_nan_stats=True) - expected_mode = (a - 1) / (a + b - 2) - expected_mode[0] = np.nan - self.assertEqual((3,), dist.mode().get_shape()) - self.assertAllClose(expected_mode, self.evaluate(dist.mode())) + expected_mode = (a - 1) / (a + b - 2) + expected_mode[0] = np.nan + self.assertEqual((3,), dist.mode().get_shape()) + self.assertAllClose(expected_mode, self.evaluate(dist.mode())) - a = np.array([2., 2, 3]) - b = np.array([1., 4, 1.2]) - dist = beta_lib.Beta(a, b, allow_nan_stats=True) + a = np.array([2., 2, 3]) + b = np.array([1., 4, 1.2]) + dist = beta_lib.Beta(a, b, allow_nan_stats=True) - expected_mode = (a - 1) / (a + b - 2) - expected_mode[0] = np.nan - self.assertEqual((3,), dist.mode().get_shape()) - self.assertAllClose(expected_mode, self.evaluate(dist.mode())) + expected_mode = (a - 1) / (a + b - 2) + expected_mode[0] = np.nan + self.assertEqual((3,), dist.mode().get_shape()) + self.assertAllClose(expected_mode, self.evaluate(dist.mode())) def testBetaEntropy(self): - with session.Session(): - a = [1., 2, 3] - b = [2., 4, 1.2] - dist = beta_lib.Beta(a, b) - self.assertEqual(dist.entropy().get_shape(), (3,)) - if not stats: - return - expected_entropy = stats.beta.entropy(a, b) - self.assertAllClose(expected_entropy, self.evaluate(dist.entropy())) + a = [1., 2, 3] + b = [2., 4, 1.2] + dist = beta_lib.Beta(a, b) + self.assertEqual(dist.entropy().get_shape(), (3,)) + if not stats: + return + expected_entropy = stats.beta.entropy(a, b) + self.assertAllClose(expected_entropy, self.evaluate(dist.entropy())) def testBetaSample(self): - with self.test_session(): - a = 1. - b = 2. - beta = beta_lib.Beta(a, b) - n = constant_op.constant(100000) - samples = beta.sample(n) - sample_values = self.evaluate(samples) - self.assertEqual(sample_values.shape, (100000,)) - self.assertFalse(np.any(sample_values < 0.0)) - if not stats: - return - self.assertLess( - stats.kstest( - # Beta is a univariate distribution. - sample_values, - stats.beta(a=1., b=2.).cdf)[0], - 0.01) - # The standard error of the sample mean is 1 / (sqrt(18 * n)) - self.assertAllClose( - sample_values.mean(axis=0), stats.beta.mean(a, b), atol=1e-2) - self.assertAllClose( - np.cov(sample_values, rowvar=0), stats.beta.var(a, b), atol=1e-1) + a = 1. + b = 2. + beta = beta_lib.Beta(a, b) + n = constant_op.constant(100000) + samples = beta.sample(n) + sample_values = self.evaluate(samples) + self.assertEqual(sample_values.shape, (100000,)) + self.assertFalse(np.any(sample_values < 0.0)) + if not stats: + return + self.assertLess( + stats.kstest( + # Beta is a univariate distribution. + sample_values, + stats.beta(a=1., b=2.).cdf)[0], + 0.01) + # The standard error of the sample mean is 1 / (sqrt(18 * n)) + self.assertAllClose( + sample_values.mean(axis=0), stats.beta.mean(a, b), atol=1e-2) + self.assertAllClose( + np.cov(sample_values, rowvar=0), stats.beta.var(a, b), atol=1e-1) def testBetaFullyReparameterized(self): a = constant_op.constant(1.0) @@ -297,78 +274,71 @@ class BetaTest(test.TestCase): # Test that sampling with the same seed twice gives the same results. def testBetaSampleMultipleTimes(self): - with self.test_session(): - a_val = 1. - b_val = 2. - n_val = 100 + a_val = 1. + b_val = 2. + n_val = 100 - random_seed.set_random_seed(654321) - beta1 = beta_lib.Beta(concentration1=a_val, - concentration0=b_val, - name="beta1") - samples1 = self.evaluate(beta1.sample(n_val, seed=123456)) + random_seed.set_random_seed(654321) + beta1 = beta_lib.Beta( + concentration1=a_val, concentration0=b_val, name="beta1") + samples1 = self.evaluate(beta1.sample(n_val, seed=123456)) - random_seed.set_random_seed(654321) - beta2 = beta_lib.Beta(concentration1=a_val, - concentration0=b_val, - name="beta2") - samples2 = self.evaluate(beta2.sample(n_val, seed=123456)) + random_seed.set_random_seed(654321) + beta2 = beta_lib.Beta( + concentration1=a_val, concentration0=b_val, name="beta2") + samples2 = self.evaluate(beta2.sample(n_val, seed=123456)) - self.assertAllClose(samples1, samples2) + self.assertAllClose(samples1, samples2) def testBetaSampleMultidimensional(self): - with self.test_session(): - a = np.random.rand(3, 2, 2).astype(np.float32) - b = np.random.rand(3, 2, 2).astype(np.float32) - beta = beta_lib.Beta(a, b) - n = constant_op.constant(100000) - samples = beta.sample(n) - sample_values = self.evaluate(samples) - self.assertEqual(sample_values.shape, (100000, 3, 2, 2)) - self.assertFalse(np.any(sample_values < 0.0)) - if not stats: - return - self.assertAllClose( - sample_values[:, 1, :].mean(axis=0), - stats.beta.mean(a, b)[1, :], - atol=1e-1) + a = np.random.rand(3, 2, 2).astype(np.float32) + b = np.random.rand(3, 2, 2).astype(np.float32) + beta = beta_lib.Beta(a, b) + n = constant_op.constant(100000) + samples = beta.sample(n) + sample_values = self.evaluate(samples) + self.assertEqual(sample_values.shape, (100000, 3, 2, 2)) + self.assertFalse(np.any(sample_values < 0.0)) + if not stats: + return + self.assertAllClose( + sample_values[:, 1, :].mean(axis=0), + stats.beta.mean(a, b)[1, :], + atol=1e-1) def testBetaCdf(self): - with self.test_session(): - shape = (30, 40, 50) - for dt in (np.float32, np.float64): - a = 10. * np.random.random(shape).astype(dt) - b = 10. * np.random.random(shape).astype(dt) - x = np.random.random(shape).astype(dt) - actual = self.evaluate(beta_lib.Beta(a, b).cdf(x)) - self.assertAllEqual(np.ones(shape, dtype=np.bool), 0. <= x) - self.assertAllEqual(np.ones(shape, dtype=np.bool), 1. >= x) - if not stats: - return - self.assertAllClose(stats.beta.cdf(x, a, b), actual, rtol=1e-4, atol=0) + shape = (30, 40, 50) + for dt in (np.float32, np.float64): + a = 10. * np.random.random(shape).astype(dt) + b = 10. * np.random.random(shape).astype(dt) + x = np.random.random(shape).astype(dt) + actual = self.evaluate(beta_lib.Beta(a, b).cdf(x)) + self.assertAllEqual(np.ones(shape, dtype=np.bool), 0. <= x) + self.assertAllEqual(np.ones(shape, dtype=np.bool), 1. >= x) + if not stats: + return + self.assertAllClose(stats.beta.cdf(x, a, b), actual, rtol=1e-4, atol=0) def testBetaLogCdf(self): - with self.test_session(): - shape = (30, 40, 50) - for dt in (np.float32, np.float64): - a = 10. * np.random.random(shape).astype(dt) - b = 10. * np.random.random(shape).astype(dt) - x = np.random.random(shape).astype(dt) - actual = self.evaluate(math_ops.exp(beta_lib.Beta(a, b).log_cdf(x))) - self.assertAllEqual(np.ones(shape, dtype=np.bool), 0. <= x) - self.assertAllEqual(np.ones(shape, dtype=np.bool), 1. >= x) - if not stats: - return - self.assertAllClose(stats.beta.cdf(x, a, b), actual, rtol=1e-4, atol=0) + shape = (30, 40, 50) + for dt in (np.float32, np.float64): + a = 10. * np.random.random(shape).astype(dt) + b = 10. * np.random.random(shape).astype(dt) + x = np.random.random(shape).astype(dt) + actual = self.evaluate(math_ops.exp(beta_lib.Beta(a, b).log_cdf(x))) + self.assertAllEqual(np.ones(shape, dtype=np.bool), 0. <= x) + self.assertAllEqual(np.ones(shape, dtype=np.bool), 1. >= x) + if not stats: + return + self.assertAllClose(stats.beta.cdf(x, a, b), actual, rtol=1e-4, atol=0) def testBetaWithSoftplusConcentration(self): - with self.test_session(): - a, b = -4.2, -9.1 - dist = beta_lib.BetaWithSoftplusConcentration(a, b) - self.assertAllClose( - self.evaluate(nn_ops.softplus(a)), self.evaluate(dist.concentration1)) - self.assertAllClose( - self.evaluate(nn_ops.softplus(b)), self.evaluate(dist.concentration0)) + a, b = -4.2, -9.1 + dist = beta_lib.BetaWithSoftplusConcentration(a, b) + self.assertAllClose( + self.evaluate(nn_ops.softplus(a)), self.evaluate(dist.concentration1)) + self.assertAllClose( + self.evaluate(nn_ops.softplus(b)), self.evaluate(dist.concentration0)) def testBetaBetaKL(self): for shape in [(10,), (4, 5)]: diff --git a/tensorflow/python/kernel_tests/distributions/bijector_test.py b/tensorflow/python/kernel_tests/distributions/bijector_test.py index 8b11556330..e20f59f48a 100644 --- a/tensorflow/python/kernel_tests/distributions/bijector_test.py +++ b/tensorflow/python/kernel_tests/distributions/bijector_test.py @@ -36,11 +36,10 @@ class BaseBijectorTest(test.TestCase): """Tests properties of the Bijector base-class.""" def testIsAbstract(self): - with self.test_session(): - with self.assertRaisesRegexp(TypeError, - ("Can't instantiate abstract class Bijector " - "with abstract methods __init__")): - bijector.Bijector() # pylint: disable=abstract-class-instantiated + with self.assertRaisesRegexp(TypeError, + ("Can't instantiate abstract class Bijector " + "with abstract methods __init__")): + bijector.Bijector() # pylint: disable=abstract-class-instantiated def testDefaults(self): class _BareBonesBijector(bijector.Bijector): @@ -136,7 +135,7 @@ class BijectorTestEventNdims(test.TestCase): def testBijectorDynamicEventNdims(self): bij = BrokenBijector(validate_args=True) event_ndims = array_ops.placeholder(dtype=np.int32, shape=None) - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("Expected scalar"): bij.forward_log_det_jacobian(1., event_ndims=event_ndims).eval({ event_ndims: (1, 2)}) @@ -308,7 +307,7 @@ class BijectorReduceEventDimsTest(test.TestCase): event_ndims = array_ops.placeholder(dtype=np.int32, shape=[]) bij = ExpOnlyJacobian(forward_min_event_ndims=1) bij.inverse_log_det_jacobian(x, event_ndims=event_ndims) - with self.test_session() as sess: + with self.cached_session() as sess: ildj = sess.run(bij.inverse_log_det_jacobian(x, event_ndims=event_ndims), feed_dict={event_ndims: 1}) self.assertAllClose(-np.log(x_), ildj) diff --git a/tensorflow/python/kernel_tests/distributions/dirichlet_test.py b/tensorflow/python/kernel_tests/distributions/dirichlet_test.py index 67ed0447ed..cace5b3ba2 100644 --- a/tensorflow/python/kernel_tests/distributions/dirichlet_test.py +++ b/tensorflow/python/kernel_tests/distributions/dirichlet_test.py @@ -49,115 +49,102 @@ stats = try_import("scipy.stats") class DirichletTest(test.TestCase): def testSimpleShapes(self): - with self.test_session(): - alpha = np.random.rand(3) - dist = dirichlet_lib.Dirichlet(alpha) - self.assertEqual(3, self.evaluate(dist.event_shape_tensor())) - self.assertAllEqual([], self.evaluate(dist.batch_shape_tensor())) - self.assertEqual(tensor_shape.TensorShape([3]), dist.event_shape) - self.assertEqual(tensor_shape.TensorShape([]), dist.batch_shape) + alpha = np.random.rand(3) + dist = dirichlet_lib.Dirichlet(alpha) + self.assertEqual(3, self.evaluate(dist.event_shape_tensor())) + self.assertAllEqual([], self.evaluate(dist.batch_shape_tensor())) + self.assertEqual(tensor_shape.TensorShape([3]), dist.event_shape) + self.assertEqual(tensor_shape.TensorShape([]), dist.batch_shape) def testComplexShapes(self): - with self.test_session(): - alpha = np.random.rand(3, 2, 2) - dist = dirichlet_lib.Dirichlet(alpha) - self.assertEqual(2, self.evaluate(dist.event_shape_tensor())) - self.assertAllEqual([3, 2], self.evaluate(dist.batch_shape_tensor())) - self.assertEqual(tensor_shape.TensorShape([2]), dist.event_shape) - self.assertEqual(tensor_shape.TensorShape([3, 2]), dist.batch_shape) + alpha = np.random.rand(3, 2, 2) + dist = dirichlet_lib.Dirichlet(alpha) + self.assertEqual(2, self.evaluate(dist.event_shape_tensor())) + self.assertAllEqual([3, 2], self.evaluate(dist.batch_shape_tensor())) + self.assertEqual(tensor_shape.TensorShape([2]), dist.event_shape) + self.assertEqual(tensor_shape.TensorShape([3, 2]), dist.batch_shape) def testConcentrationProperty(self): alpha = [[1., 2, 3]] - with self.test_session(): - dist = dirichlet_lib.Dirichlet(alpha) - self.assertEqual([1, 3], dist.concentration.get_shape()) - self.assertAllClose(alpha, self.evaluate(dist.concentration)) + dist = dirichlet_lib.Dirichlet(alpha) + self.assertEqual([1, 3], dist.concentration.get_shape()) + self.assertAllClose(alpha, self.evaluate(dist.concentration)) def testPdfXProper(self): alpha = [[1., 2, 3]] - with self.test_session(): - dist = dirichlet_lib.Dirichlet(alpha, validate_args=True) - self.evaluate(dist.prob([.1, .3, .6])) - self.evaluate(dist.prob([.2, .3, .5])) - # Either condition can trigger. - with self.assertRaisesOpError("samples must be positive"): - self.evaluate(dist.prob([-1., 1.5, 0.5])) - with self.assertRaisesOpError("samples must be positive"): - self.evaluate(dist.prob([0., .1, .9])) - with self.assertRaisesOpError( - "sample last-dimension must sum to `1`"): - self.evaluate(dist.prob([.1, .2, .8])) + dist = dirichlet_lib.Dirichlet(alpha, validate_args=True) + self.evaluate(dist.prob([.1, .3, .6])) + self.evaluate(dist.prob([.2, .3, .5])) + # Either condition can trigger. + with self.assertRaisesOpError("samples must be positive"): + self.evaluate(dist.prob([-1., 1.5, 0.5])) + with self.assertRaisesOpError("samples must be positive"): + self.evaluate(dist.prob([0., .1, .9])) + with self.assertRaisesOpError("sample last-dimension must sum to `1`"): + self.evaluate(dist.prob([.1, .2, .8])) def testPdfZeroBatches(self): - with self.test_session(): - alpha = [1., 2] - x = [.5, .5] - dist = dirichlet_lib.Dirichlet(alpha) - pdf = dist.prob(x) - self.assertAllClose(1., self.evaluate(pdf)) - self.assertEqual((), pdf.get_shape()) + alpha = [1., 2] + x = [.5, .5] + dist = dirichlet_lib.Dirichlet(alpha) + pdf = dist.prob(x) + self.assertAllClose(1., self.evaluate(pdf)) + self.assertEqual((), pdf.get_shape()) def testPdfZeroBatchesNontrivialX(self): - with self.test_session(): - alpha = [1., 2] - x = [.3, .7] - dist = dirichlet_lib.Dirichlet(alpha) - pdf = dist.prob(x) - self.assertAllClose(7. / 5, self.evaluate(pdf)) - self.assertEqual((), pdf.get_shape()) + alpha = [1., 2] + x = [.3, .7] + dist = dirichlet_lib.Dirichlet(alpha) + pdf = dist.prob(x) + self.assertAllClose(7. / 5, self.evaluate(pdf)) + self.assertEqual((), pdf.get_shape()) def testPdfUniformZeroBatches(self): - with self.test_session(): - # Corresponds to a uniform distribution - alpha = [1., 1, 1] - x = [[.2, .5, .3], [.3, .4, .3]] - dist = dirichlet_lib.Dirichlet(alpha) - pdf = dist.prob(x) - self.assertAllClose([2., 2.], self.evaluate(pdf)) - self.assertEqual((2), pdf.get_shape()) + # Corresponds to a uniform distribution + alpha = [1., 1, 1] + x = [[.2, .5, .3], [.3, .4, .3]] + dist = dirichlet_lib.Dirichlet(alpha) + pdf = dist.prob(x) + self.assertAllClose([2., 2.], self.evaluate(pdf)) + self.assertEqual((2), pdf.get_shape()) def testPdfAlphaStretchedInBroadcastWhenSameRank(self): - with self.test_session(): - alpha = [[1., 2]] - x = [[.5, .5], [.3, .7]] - dist = dirichlet_lib.Dirichlet(alpha) - pdf = dist.prob(x) - self.assertAllClose([1., 7. / 5], self.evaluate(pdf)) - self.assertEqual((2), pdf.get_shape()) + alpha = [[1., 2]] + x = [[.5, .5], [.3, .7]] + dist = dirichlet_lib.Dirichlet(alpha) + pdf = dist.prob(x) + self.assertAllClose([1., 7. / 5], self.evaluate(pdf)) + self.assertEqual((2), pdf.get_shape()) def testPdfAlphaStretchedInBroadcastWhenLowerRank(self): - with self.test_session(): - alpha = [1., 2] - x = [[.5, .5], [.2, .8]] - pdf = dirichlet_lib.Dirichlet(alpha).prob(x) - self.assertAllClose([1., 8. / 5], self.evaluate(pdf)) - self.assertEqual((2), pdf.get_shape()) + alpha = [1., 2] + x = [[.5, .5], [.2, .8]] + pdf = dirichlet_lib.Dirichlet(alpha).prob(x) + self.assertAllClose([1., 8. / 5], self.evaluate(pdf)) + self.assertEqual((2), pdf.get_shape()) def testPdfXStretchedInBroadcastWhenSameRank(self): - with self.test_session(): - alpha = [[1., 2], [2., 3]] - x = [[.5, .5]] - pdf = dirichlet_lib.Dirichlet(alpha).prob(x) - self.assertAllClose([1., 3. / 2], self.evaluate(pdf)) - self.assertEqual((2), pdf.get_shape()) + alpha = [[1., 2], [2., 3]] + x = [[.5, .5]] + pdf = dirichlet_lib.Dirichlet(alpha).prob(x) + self.assertAllClose([1., 3. / 2], self.evaluate(pdf)) + self.assertEqual((2), pdf.get_shape()) def testPdfXStretchedInBroadcastWhenLowerRank(self): - with self.test_session(): - alpha = [[1., 2], [2., 3]] - x = [.5, .5] - pdf = dirichlet_lib.Dirichlet(alpha).prob(x) - self.assertAllClose([1., 3. / 2], self.evaluate(pdf)) - self.assertEqual((2), pdf.get_shape()) + alpha = [[1., 2], [2., 3]] + x = [.5, .5] + pdf = dirichlet_lib.Dirichlet(alpha).prob(x) + self.assertAllClose([1., 3. / 2], self.evaluate(pdf)) + self.assertEqual((2), pdf.get_shape()) def testMean(self): - with self.test_session(): - alpha = [1., 2, 3] - dirichlet = dirichlet_lib.Dirichlet(concentration=alpha) - self.assertEqual(dirichlet.mean().get_shape(), [3]) - if not stats: - return - expected_mean = stats.dirichlet.mean(alpha) - self.assertAllClose(self.evaluate(dirichlet.mean()), expected_mean) + alpha = [1., 2, 3] + dirichlet = dirichlet_lib.Dirichlet(concentration=alpha) + self.assertEqual(dirichlet.mean().get_shape(), [3]) + if not stats: + return + expected_mean = stats.dirichlet.mean(alpha) + self.assertAllClose(self.evaluate(dirichlet.mean()), expected_mean) def testCovarianceFromSampling(self): alpha = np.array([[1., 2, 3], @@ -197,73 +184,66 @@ class DirichletTest(test.TestCase): self.assertAllClose(sample_stddev_, analytic_stddev, atol=0.02, rtol=0.) def testVariance(self): - with self.test_session(): - alpha = [1., 2, 3] - denominator = np.sum(alpha)**2 * (np.sum(alpha) + 1) - dirichlet = dirichlet_lib.Dirichlet(concentration=alpha) - self.assertEqual(dirichlet.covariance().get_shape(), (3, 3)) - if not stats: - return - expected_covariance = np.diag(stats.dirichlet.var(alpha)) - expected_covariance += [[0., -2, -3], [-2, 0, -6], - [-3, -6, 0]] / denominator - self.assertAllClose( - self.evaluate(dirichlet.covariance()), expected_covariance) + alpha = [1., 2, 3] + denominator = np.sum(alpha)**2 * (np.sum(alpha) + 1) + dirichlet = dirichlet_lib.Dirichlet(concentration=alpha) + self.assertEqual(dirichlet.covariance().get_shape(), (3, 3)) + if not stats: + return + expected_covariance = np.diag(stats.dirichlet.var(alpha)) + expected_covariance += [[0., -2, -3], [-2, 0, -6], [-3, -6, 0] + ] / denominator + self.assertAllClose( + self.evaluate(dirichlet.covariance()), expected_covariance) def testMode(self): - with self.test_session(): - alpha = np.array([1.1, 2, 3]) - expected_mode = (alpha - 1) / (np.sum(alpha) - 3) - dirichlet = dirichlet_lib.Dirichlet(concentration=alpha) - self.assertEqual(dirichlet.mode().get_shape(), [3]) - self.assertAllClose(self.evaluate(dirichlet.mode()), expected_mode) + alpha = np.array([1.1, 2, 3]) + expected_mode = (alpha - 1) / (np.sum(alpha) - 3) + dirichlet = dirichlet_lib.Dirichlet(concentration=alpha) + self.assertEqual(dirichlet.mode().get_shape(), [3]) + self.assertAllClose(self.evaluate(dirichlet.mode()), expected_mode) def testModeInvalid(self): - with self.test_session(): - alpha = np.array([1., 2, 3]) - dirichlet = dirichlet_lib.Dirichlet(concentration=alpha, - allow_nan_stats=False) - with self.assertRaisesOpError("Condition x < y.*"): - self.evaluate(dirichlet.mode()) + alpha = np.array([1., 2, 3]) + dirichlet = dirichlet_lib.Dirichlet( + concentration=alpha, allow_nan_stats=False) + with self.assertRaisesOpError("Condition x < y.*"): + self.evaluate(dirichlet.mode()) def testModeEnableAllowNanStats(self): - with self.test_session(): - alpha = np.array([1., 2, 3]) - dirichlet = dirichlet_lib.Dirichlet(concentration=alpha, - allow_nan_stats=True) - expected_mode = np.zeros_like(alpha) + np.nan + alpha = np.array([1., 2, 3]) + dirichlet = dirichlet_lib.Dirichlet( + concentration=alpha, allow_nan_stats=True) + expected_mode = np.zeros_like(alpha) + np.nan - self.assertEqual(dirichlet.mode().get_shape(), [3]) - self.assertAllClose(self.evaluate(dirichlet.mode()), expected_mode) + self.assertEqual(dirichlet.mode().get_shape(), [3]) + self.assertAllClose(self.evaluate(dirichlet.mode()), expected_mode) def testEntropy(self): - with self.test_session(): - alpha = [1., 2, 3] - dirichlet = dirichlet_lib.Dirichlet(concentration=alpha) - self.assertEqual(dirichlet.entropy().get_shape(), ()) - if not stats: - return - expected_entropy = stats.dirichlet.entropy(alpha) - self.assertAllClose(self.evaluate(dirichlet.entropy()), expected_entropy) + alpha = [1., 2, 3] + dirichlet = dirichlet_lib.Dirichlet(concentration=alpha) + self.assertEqual(dirichlet.entropy().get_shape(), ()) + if not stats: + return + expected_entropy = stats.dirichlet.entropy(alpha) + self.assertAllClose(self.evaluate(dirichlet.entropy()), expected_entropy) def testSample(self): - with self.test_session(): - alpha = [1., 2] - dirichlet = dirichlet_lib.Dirichlet(alpha) - n = constant_op.constant(100000) - samples = dirichlet.sample(n) - sample_values = self.evaluate(samples) - self.assertEqual(sample_values.shape, (100000, 2)) - self.assertTrue(np.all(sample_values > 0.0)) - if not stats: - return - self.assertLess( - stats.kstest( - # Beta is a univariate distribution. - sample_values[:, 0], - stats.beta( - a=1., b=2.).cdf)[0], - 0.01) + alpha = [1., 2] + dirichlet = dirichlet_lib.Dirichlet(alpha) + n = constant_op.constant(100000) + samples = dirichlet.sample(n) + sample_values = self.evaluate(samples) + self.assertEqual(sample_values.shape, (100000, 2)) + self.assertTrue(np.all(sample_values > 0.0)) + if not stats: + return + self.assertLess( + stats.kstest( + # Beta is a univariate distribution. + sample_values[:, 0], + stats.beta(a=1., b=2.).cdf)[0], + 0.01) def testDirichletFullyReparameterized(self): alpha = constant_op.constant([1.0, 2.0, 3.0]) diff --git a/tensorflow/python/kernel_tests/distributions/exponential_test.py b/tensorflow/python/kernel_tests/distributions/exponential_test.py index 850da3e969..27d1291912 100644 --- a/tensorflow/python/kernel_tests/distributions/exponential_test.py +++ b/tensorflow/python/kernel_tests/distributions/exponential_test.py @@ -22,7 +22,6 @@ import importlib import numpy as np -from tensorflow.python.client import session from tensorflow.python.eager import backprop from tensorflow.python.framework import constant_op from tensorflow.python.framework import test_util @@ -48,121 +47,108 @@ stats = try_import("scipy.stats") class ExponentialTest(test.TestCase): def testExponentialLogPDF(self): - with session.Session(): - batch_size = 6 - lam = constant_op.constant([2.0] * batch_size) - lam_v = 2.0 - x = np.array([2.5, 2.5, 4.0, 0.1, 1.0, 2.0], dtype=np.float32) - exponential = exponential_lib.Exponential(rate=lam) + batch_size = 6 + lam = constant_op.constant([2.0] * batch_size) + lam_v = 2.0 + x = np.array([2.5, 2.5, 4.0, 0.1, 1.0, 2.0], dtype=np.float32) + exponential = exponential_lib.Exponential(rate=lam) - log_pdf = exponential.log_prob(x) - self.assertEqual(log_pdf.get_shape(), (6,)) + log_pdf = exponential.log_prob(x) + self.assertEqual(log_pdf.get_shape(), (6,)) - pdf = exponential.prob(x) - self.assertEqual(pdf.get_shape(), (6,)) + pdf = exponential.prob(x) + self.assertEqual(pdf.get_shape(), (6,)) - if not stats: - return - expected_log_pdf = stats.expon.logpdf(x, scale=1 / lam_v) - self.assertAllClose(self.evaluate(log_pdf), expected_log_pdf) - self.assertAllClose(self.evaluate(pdf), np.exp(expected_log_pdf)) + if not stats: + return + expected_log_pdf = stats.expon.logpdf(x, scale=1 / lam_v) + self.assertAllClose(self.evaluate(log_pdf), expected_log_pdf) + self.assertAllClose(self.evaluate(pdf), np.exp(expected_log_pdf)) def testExponentialCDF(self): - with session.Session(): - batch_size = 6 - lam = constant_op.constant([2.0] * batch_size) - lam_v = 2.0 - x = np.array([2.5, 2.5, 4.0, 0.1, 1.0, 2.0], dtype=np.float32) + batch_size = 6 + lam = constant_op.constant([2.0] * batch_size) + lam_v = 2.0 + x = np.array([2.5, 2.5, 4.0, 0.1, 1.0, 2.0], dtype=np.float32) - exponential = exponential_lib.Exponential(rate=lam) + exponential = exponential_lib.Exponential(rate=lam) - cdf = exponential.cdf(x) - self.assertEqual(cdf.get_shape(), (6,)) + cdf = exponential.cdf(x) + self.assertEqual(cdf.get_shape(), (6,)) - if not stats: - return - expected_cdf = stats.expon.cdf(x, scale=1 / lam_v) - self.assertAllClose(self.evaluate(cdf), expected_cdf) + if not stats: + return + expected_cdf = stats.expon.cdf(x, scale=1 / lam_v) + self.assertAllClose(self.evaluate(cdf), expected_cdf) def testExponentialMean(self): - with session.Session(): - lam_v = np.array([1.0, 4.0, 2.5]) - exponential = exponential_lib.Exponential(rate=lam_v) - self.assertEqual(exponential.mean().get_shape(), (3,)) - if not stats: - return - expected_mean = stats.expon.mean(scale=1 / lam_v) - self.assertAllClose(self.evaluate(exponential.mean()), expected_mean) + lam_v = np.array([1.0, 4.0, 2.5]) + exponential = exponential_lib.Exponential(rate=lam_v) + self.assertEqual(exponential.mean().get_shape(), (3,)) + if not stats: + return + expected_mean = stats.expon.mean(scale=1 / lam_v) + self.assertAllClose(self.evaluate(exponential.mean()), expected_mean) def testExponentialVariance(self): - with session.Session(): - lam_v = np.array([1.0, 4.0, 2.5]) - exponential = exponential_lib.Exponential(rate=lam_v) - self.assertEqual(exponential.variance().get_shape(), (3,)) - if not stats: - return - expected_variance = stats.expon.var(scale=1 / lam_v) - self.assertAllClose( - self.evaluate(exponential.variance()), expected_variance) + lam_v = np.array([1.0, 4.0, 2.5]) + exponential = exponential_lib.Exponential(rate=lam_v) + self.assertEqual(exponential.variance().get_shape(), (3,)) + if not stats: + return + expected_variance = stats.expon.var(scale=1 / lam_v) + self.assertAllClose( + self.evaluate(exponential.variance()), expected_variance) def testExponentialEntropy(self): - with session.Session(): - lam_v = np.array([1.0, 4.0, 2.5]) - exponential = exponential_lib.Exponential(rate=lam_v) - self.assertEqual(exponential.entropy().get_shape(), (3,)) - if not stats: - return - expected_entropy = stats.expon.entropy(scale=1 / lam_v) - self.assertAllClose( - self.evaluate(exponential.entropy()), expected_entropy) + lam_v = np.array([1.0, 4.0, 2.5]) + exponential = exponential_lib.Exponential(rate=lam_v) + self.assertEqual(exponential.entropy().get_shape(), (3,)) + if not stats: + return + expected_entropy = stats.expon.entropy(scale=1 / lam_v) + self.assertAllClose(self.evaluate(exponential.entropy()), expected_entropy) def testExponentialSample(self): - with self.test_session(): - lam = constant_op.constant([3.0, 4.0]) - lam_v = [3.0, 4.0] - n = constant_op.constant(100000) - exponential = exponential_lib.Exponential(rate=lam) - - samples = exponential.sample(n, seed=137) - sample_values = self.evaluate(samples) - self.assertEqual(sample_values.shape, (100000, 2)) - self.assertFalse(np.any(sample_values < 0.0)) - if not stats: - return - for i in range(2): - self.assertLess( - stats.kstest( - sample_values[:, i], stats.expon(scale=1.0 / lam_v[i]).cdf)[0], - 0.01) + lam = constant_op.constant([3.0, 4.0]) + lam_v = [3.0, 4.0] + n = constant_op.constant(100000) + exponential = exponential_lib.Exponential(rate=lam) + + samples = exponential.sample(n, seed=137) + sample_values = self.evaluate(samples) + self.assertEqual(sample_values.shape, (100000, 2)) + self.assertFalse(np.any(sample_values < 0.0)) + if not stats: + return + for i in range(2): + self.assertLess( + stats.kstest(sample_values[:, i], + stats.expon(scale=1.0 / lam_v[i]).cdf)[0], 0.01) def testExponentialSampleMultiDimensional(self): - with self.test_session(): - batch_size = 2 - lam_v = [3.0, 22.0] - lam = constant_op.constant([lam_v] * batch_size) + batch_size = 2 + lam_v = [3.0, 22.0] + lam = constant_op.constant([lam_v] * batch_size) - exponential = exponential_lib.Exponential(rate=lam) + exponential = exponential_lib.Exponential(rate=lam) + + n = 100000 + samples = exponential.sample(n, seed=138) + self.assertEqual(samples.get_shape(), (n, batch_size, 2)) + + sample_values = self.evaluate(samples) - n = 100000 - samples = exponential.sample(n, seed=138) - self.assertEqual(samples.get_shape(), (n, batch_size, 2)) - - sample_values = self.evaluate(samples) - - self.assertFalse(np.any(sample_values < 0.0)) - if not stats: - return - for i in range(2): - self.assertLess( - stats.kstest( - sample_values[:, 0, i], - stats.expon(scale=1.0 / lam_v[i]).cdf)[0], - 0.01) - self.assertLess( - stats.kstest( - sample_values[:, 1, i], - stats.expon(scale=1.0 / lam_v[i]).cdf)[0], - 0.01) + self.assertFalse(np.any(sample_values < 0.0)) + if not stats: + return + for i in range(2): + self.assertLess( + stats.kstest(sample_values[:, 0, i], + stats.expon(scale=1.0 / lam_v[i]).cdf)[0], 0.01) + self.assertLess( + stats.kstest(sample_values[:, 1, i], + stats.expon(scale=1.0 / lam_v[i]).cdf)[0], 0.01) def testFullyReparameterized(self): lam = constant_op.constant([0.1, 1.0]) @@ -174,11 +160,10 @@ class ExponentialTest(test.TestCase): self.assertIsNotNone(grad_lam) def testExponentialWithSoftplusRate(self): - with self.test_session(): - lam = [-2.2, -3.4] - exponential = exponential_lib.ExponentialWithSoftplusRate(rate=lam) - self.assertAllClose( - self.evaluate(nn_ops.softplus(lam)), self.evaluate(exponential.rate)) + lam = [-2.2, -3.4] + exponential = exponential_lib.ExponentialWithSoftplusRate(rate=lam) + self.assertAllClose( + self.evaluate(nn_ops.softplus(lam)), self.evaluate(exponential.rate)) if __name__ == "__main__": diff --git a/tensorflow/python/kernel_tests/distributions/gamma_test.py b/tensorflow/python/kernel_tests/distributions/gamma_test.py index 297e20264c..4eff40b029 100644 --- a/tensorflow/python/kernel_tests/distributions/gamma_test.py +++ b/tensorflow/python/kernel_tests/distributions/gamma_test.py @@ -50,221 +50,203 @@ stats = try_import("scipy.stats") class GammaTest(test.TestCase): def testGammaShape(self): - with self.test_session(): - alpha = constant_op.constant([3.0] * 5) - beta = constant_op.constant(11.0) - gamma = gamma_lib.Gamma(concentration=alpha, rate=beta) + alpha = constant_op.constant([3.0] * 5) + beta = constant_op.constant(11.0) + gamma = gamma_lib.Gamma(concentration=alpha, rate=beta) - self.assertEqual(self.evaluate(gamma.batch_shape_tensor()), (5,)) - self.assertEqual(gamma.batch_shape, tensor_shape.TensorShape([5])) - self.assertAllEqual(self.evaluate(gamma.event_shape_tensor()), []) - self.assertEqual(gamma.event_shape, tensor_shape.TensorShape([])) + self.assertEqual(self.evaluate(gamma.batch_shape_tensor()), (5,)) + self.assertEqual(gamma.batch_shape, tensor_shape.TensorShape([5])) + self.assertAllEqual(self.evaluate(gamma.event_shape_tensor()), []) + self.assertEqual(gamma.event_shape, tensor_shape.TensorShape([])) def testGammaLogPDF(self): - with self.test_session(): - batch_size = 6 - alpha = constant_op.constant([2.0] * batch_size) - beta = constant_op.constant([3.0] * batch_size) - alpha_v = 2.0 - beta_v = 3.0 - x = np.array([2.5, 2.5, 4.0, 0.1, 1.0, 2.0], dtype=np.float32) - gamma = gamma_lib.Gamma(concentration=alpha, rate=beta) - log_pdf = gamma.log_prob(x) - self.assertEqual(log_pdf.get_shape(), (6,)) - pdf = gamma.prob(x) - self.assertEqual(pdf.get_shape(), (6,)) - if not stats: - return - expected_log_pdf = stats.gamma.logpdf(x, alpha_v, scale=1 / beta_v) - self.assertAllClose(self.evaluate(log_pdf), expected_log_pdf) - self.assertAllClose(self.evaluate(pdf), np.exp(expected_log_pdf)) + batch_size = 6 + alpha = constant_op.constant([2.0] * batch_size) + beta = constant_op.constant([3.0] * batch_size) + alpha_v = 2.0 + beta_v = 3.0 + x = np.array([2.5, 2.5, 4.0, 0.1, 1.0, 2.0], dtype=np.float32) + gamma = gamma_lib.Gamma(concentration=alpha, rate=beta) + log_pdf = gamma.log_prob(x) + self.assertEqual(log_pdf.get_shape(), (6,)) + pdf = gamma.prob(x) + self.assertEqual(pdf.get_shape(), (6,)) + if not stats: + return + expected_log_pdf = stats.gamma.logpdf(x, alpha_v, scale=1 / beta_v) + self.assertAllClose(self.evaluate(log_pdf), expected_log_pdf) + self.assertAllClose(self.evaluate(pdf), np.exp(expected_log_pdf)) def testGammaLogPDFMultidimensional(self): - with self.test_session(): - batch_size = 6 - alpha = constant_op.constant([[2.0, 4.0]] * batch_size) - beta = constant_op.constant([[3.0, 4.0]] * batch_size) - alpha_v = np.array([2.0, 4.0]) - beta_v = np.array([3.0, 4.0]) - x = np.array([[2.5, 2.5, 4.0, 0.1, 1.0, 2.0]], dtype=np.float32).T - gamma = gamma_lib.Gamma(concentration=alpha, rate=beta) - log_pdf = gamma.log_prob(x) - log_pdf_values = self.evaluate(log_pdf) - self.assertEqual(log_pdf.get_shape(), (6, 2)) - pdf = gamma.prob(x) - pdf_values = self.evaluate(pdf) - self.assertEqual(pdf.get_shape(), (6, 2)) - if not stats: - return - expected_log_pdf = stats.gamma.logpdf(x, alpha_v, scale=1 / beta_v) - self.assertAllClose(log_pdf_values, expected_log_pdf) - self.assertAllClose(pdf_values, np.exp(expected_log_pdf)) + batch_size = 6 + alpha = constant_op.constant([[2.0, 4.0]] * batch_size) + beta = constant_op.constant([[3.0, 4.0]] * batch_size) + alpha_v = np.array([2.0, 4.0]) + beta_v = np.array([3.0, 4.0]) + x = np.array([[2.5, 2.5, 4.0, 0.1, 1.0, 2.0]], dtype=np.float32).T + gamma = gamma_lib.Gamma(concentration=alpha, rate=beta) + log_pdf = gamma.log_prob(x) + log_pdf_values = self.evaluate(log_pdf) + self.assertEqual(log_pdf.get_shape(), (6, 2)) + pdf = gamma.prob(x) + pdf_values = self.evaluate(pdf) + self.assertEqual(pdf.get_shape(), (6, 2)) + if not stats: + return + expected_log_pdf = stats.gamma.logpdf(x, alpha_v, scale=1 / beta_v) + self.assertAllClose(log_pdf_values, expected_log_pdf) + self.assertAllClose(pdf_values, np.exp(expected_log_pdf)) def testGammaLogPDFMultidimensionalBroadcasting(self): - with self.test_session(): - batch_size = 6 - alpha = constant_op.constant([[2.0, 4.0]] * batch_size) - beta = constant_op.constant(3.0) - alpha_v = np.array([2.0, 4.0]) - beta_v = 3.0 - x = np.array([[2.5, 2.5, 4.0, 0.1, 1.0, 2.0]], dtype=np.float32).T - gamma = gamma_lib.Gamma(concentration=alpha, rate=beta) - log_pdf = gamma.log_prob(x) - log_pdf_values = self.evaluate(log_pdf) - self.assertEqual(log_pdf.get_shape(), (6, 2)) - pdf = gamma.prob(x) - pdf_values = self.evaluate(pdf) - self.assertEqual(pdf.get_shape(), (6, 2)) - - if not stats: - return - expected_log_pdf = stats.gamma.logpdf(x, alpha_v, scale=1 / beta_v) - self.assertAllClose(log_pdf_values, expected_log_pdf) - self.assertAllClose(pdf_values, np.exp(expected_log_pdf)) + batch_size = 6 + alpha = constant_op.constant([[2.0, 4.0]] * batch_size) + beta = constant_op.constant(3.0) + alpha_v = np.array([2.0, 4.0]) + beta_v = 3.0 + x = np.array([[2.5, 2.5, 4.0, 0.1, 1.0, 2.0]], dtype=np.float32).T + gamma = gamma_lib.Gamma(concentration=alpha, rate=beta) + log_pdf = gamma.log_prob(x) + log_pdf_values = self.evaluate(log_pdf) + self.assertEqual(log_pdf.get_shape(), (6, 2)) + pdf = gamma.prob(x) + pdf_values = self.evaluate(pdf) + self.assertEqual(pdf.get_shape(), (6, 2)) - def testGammaCDF(self): - with self.test_session(): - batch_size = 6 - alpha = constant_op.constant([2.0] * batch_size) - beta = constant_op.constant([3.0] * batch_size) - alpha_v = 2.0 - beta_v = 3.0 - x = np.array([2.5, 2.5, 4.0, 0.1, 1.0, 2.0], dtype=np.float32) + if not stats: + return + expected_log_pdf = stats.gamma.logpdf(x, alpha_v, scale=1 / beta_v) + self.assertAllClose(log_pdf_values, expected_log_pdf) + self.assertAllClose(pdf_values, np.exp(expected_log_pdf)) - gamma = gamma_lib.Gamma(concentration=alpha, rate=beta) - cdf = gamma.cdf(x) - self.assertEqual(cdf.get_shape(), (6,)) - if not stats: - return - expected_cdf = stats.gamma.cdf(x, alpha_v, scale=1 / beta_v) - self.assertAllClose(self.evaluate(cdf), expected_cdf) + def testGammaCDF(self): + batch_size = 6 + alpha = constant_op.constant([2.0] * batch_size) + beta = constant_op.constant([3.0] * batch_size) + alpha_v = 2.0 + beta_v = 3.0 + x = np.array([2.5, 2.5, 4.0, 0.1, 1.0, 2.0], dtype=np.float32) + + gamma = gamma_lib.Gamma(concentration=alpha, rate=beta) + cdf = gamma.cdf(x) + self.assertEqual(cdf.get_shape(), (6,)) + if not stats: + return + expected_cdf = stats.gamma.cdf(x, alpha_v, scale=1 / beta_v) + self.assertAllClose(self.evaluate(cdf), expected_cdf) def testGammaMean(self): - with self.test_session(): - alpha_v = np.array([1.0, 3.0, 2.5]) - beta_v = np.array([1.0, 4.0, 5.0]) - gamma = gamma_lib.Gamma(concentration=alpha_v, rate=beta_v) - self.assertEqual(gamma.mean().get_shape(), (3,)) - if not stats: - return - expected_means = stats.gamma.mean(alpha_v, scale=1 / beta_v) - self.assertAllClose(self.evaluate(gamma.mean()), expected_means) + alpha_v = np.array([1.0, 3.0, 2.5]) + beta_v = np.array([1.0, 4.0, 5.0]) + gamma = gamma_lib.Gamma(concentration=alpha_v, rate=beta_v) + self.assertEqual(gamma.mean().get_shape(), (3,)) + if not stats: + return + expected_means = stats.gamma.mean(alpha_v, scale=1 / beta_v) + self.assertAllClose(self.evaluate(gamma.mean()), expected_means) def testGammaModeAllowNanStatsIsFalseWorksWhenAllBatchMembersAreDefined(self): - with self.test_session(): - alpha_v = np.array([5.5, 3.0, 2.5]) - beta_v = np.array([1.0, 4.0, 5.0]) - gamma = gamma_lib.Gamma(concentration=alpha_v, rate=beta_v) - expected_modes = (alpha_v - 1) / beta_v - self.assertEqual(gamma.mode().get_shape(), (3,)) - self.assertAllClose(self.evaluate(gamma.mode()), expected_modes) + alpha_v = np.array([5.5, 3.0, 2.5]) + beta_v = np.array([1.0, 4.0, 5.0]) + gamma = gamma_lib.Gamma(concentration=alpha_v, rate=beta_v) + expected_modes = (alpha_v - 1) / beta_v + self.assertEqual(gamma.mode().get_shape(), (3,)) + self.assertAllClose(self.evaluate(gamma.mode()), expected_modes) def testGammaModeAllowNanStatsFalseRaisesForUndefinedBatchMembers(self): - with self.test_session(): - # Mode will not be defined for the first entry. - alpha_v = np.array([0.5, 3.0, 2.5]) - beta_v = np.array([1.0, 4.0, 5.0]) - gamma = gamma_lib.Gamma(concentration=alpha_v, - rate=beta_v, - allow_nan_stats=False) - with self.assertRaisesOpError("x < y"): - self.evaluate(gamma.mode()) + # Mode will not be defined for the first entry. + alpha_v = np.array([0.5, 3.0, 2.5]) + beta_v = np.array([1.0, 4.0, 5.0]) + gamma = gamma_lib.Gamma( + concentration=alpha_v, rate=beta_v, allow_nan_stats=False) + with self.assertRaisesOpError("x < y"): + self.evaluate(gamma.mode()) def testGammaModeAllowNanStatsIsTrueReturnsNaNforUndefinedBatchMembers(self): - with self.test_session(): - # Mode will not be defined for the first entry. - alpha_v = np.array([0.5, 3.0, 2.5]) - beta_v = np.array([1.0, 4.0, 5.0]) - gamma = gamma_lib.Gamma(concentration=alpha_v, - rate=beta_v, - allow_nan_stats=True) - expected_modes = (alpha_v - 1) / beta_v - expected_modes[0] = np.nan - self.assertEqual(gamma.mode().get_shape(), (3,)) - self.assertAllClose(self.evaluate(gamma.mode()), expected_modes) + # Mode will not be defined for the first entry. + alpha_v = np.array([0.5, 3.0, 2.5]) + beta_v = np.array([1.0, 4.0, 5.0]) + gamma = gamma_lib.Gamma( + concentration=alpha_v, rate=beta_v, allow_nan_stats=True) + expected_modes = (alpha_v - 1) / beta_v + expected_modes[0] = np.nan + self.assertEqual(gamma.mode().get_shape(), (3,)) + self.assertAllClose(self.evaluate(gamma.mode()), expected_modes) def testGammaVariance(self): - with self.test_session(): - alpha_v = np.array([1.0, 3.0, 2.5]) - beta_v = np.array([1.0, 4.0, 5.0]) - gamma = gamma_lib.Gamma(concentration=alpha_v, rate=beta_v) - self.assertEqual(gamma.variance().get_shape(), (3,)) - if not stats: - return - expected_variances = stats.gamma.var(alpha_v, scale=1 / beta_v) - self.assertAllClose(self.evaluate(gamma.variance()), expected_variances) + alpha_v = np.array([1.0, 3.0, 2.5]) + beta_v = np.array([1.0, 4.0, 5.0]) + gamma = gamma_lib.Gamma(concentration=alpha_v, rate=beta_v) + self.assertEqual(gamma.variance().get_shape(), (3,)) + if not stats: + return + expected_variances = stats.gamma.var(alpha_v, scale=1 / beta_v) + self.assertAllClose(self.evaluate(gamma.variance()), expected_variances) def testGammaStd(self): - with self.test_session(): - alpha_v = np.array([1.0, 3.0, 2.5]) - beta_v = np.array([1.0, 4.0, 5.0]) - gamma = gamma_lib.Gamma(concentration=alpha_v, rate=beta_v) - self.assertEqual(gamma.stddev().get_shape(), (3,)) - if not stats: - return - expected_stddev = stats.gamma.std(alpha_v, scale=1. / beta_v) - self.assertAllClose(self.evaluate(gamma.stddev()), expected_stddev) + alpha_v = np.array([1.0, 3.0, 2.5]) + beta_v = np.array([1.0, 4.0, 5.0]) + gamma = gamma_lib.Gamma(concentration=alpha_v, rate=beta_v) + self.assertEqual(gamma.stddev().get_shape(), (3,)) + if not stats: + return + expected_stddev = stats.gamma.std(alpha_v, scale=1. / beta_v) + self.assertAllClose(self.evaluate(gamma.stddev()), expected_stddev) def testGammaEntropy(self): - with self.test_session(): - alpha_v = np.array([1.0, 3.0, 2.5]) - beta_v = np.array([1.0, 4.0, 5.0]) - gamma = gamma_lib.Gamma(concentration=alpha_v, rate=beta_v) - self.assertEqual(gamma.entropy().get_shape(), (3,)) - if not stats: - return - expected_entropy = stats.gamma.entropy(alpha_v, scale=1 / beta_v) - self.assertAllClose(self.evaluate(gamma.entropy()), expected_entropy) + alpha_v = np.array([1.0, 3.0, 2.5]) + beta_v = np.array([1.0, 4.0, 5.0]) + gamma = gamma_lib.Gamma(concentration=alpha_v, rate=beta_v) + self.assertEqual(gamma.entropy().get_shape(), (3,)) + if not stats: + return + expected_entropy = stats.gamma.entropy(alpha_v, scale=1 / beta_v) + self.assertAllClose(self.evaluate(gamma.entropy()), expected_entropy) def testGammaSampleSmallAlpha(self): - with self.test_session(): - alpha_v = 0.05 - beta_v = 1.0 - alpha = constant_op.constant(alpha_v) - beta = constant_op.constant(beta_v) - n = 100000 - gamma = gamma_lib.Gamma(concentration=alpha, rate=beta) - samples = gamma.sample(n, seed=137) - sample_values = self.evaluate(samples) - self.assertEqual(samples.get_shape(), (n,)) - self.assertEqual(sample_values.shape, (n,)) - self.assertTrue(self._kstest(alpha_v, beta_v, sample_values)) - if not stats: - return - self.assertAllClose( - sample_values.mean(), - stats.gamma.mean( - alpha_v, scale=1 / beta_v), - atol=.01) - self.assertAllClose( - sample_values.var(), - stats.gamma.var(alpha_v, scale=1 / beta_v), - atol=.15) + alpha_v = 0.05 + beta_v = 1.0 + alpha = constant_op.constant(alpha_v) + beta = constant_op.constant(beta_v) + n = 100000 + gamma = gamma_lib.Gamma(concentration=alpha, rate=beta) + samples = gamma.sample(n, seed=137) + sample_values = self.evaluate(samples) + self.assertEqual(samples.get_shape(), (n,)) + self.assertEqual(sample_values.shape, (n,)) + self.assertTrue(self._kstest(alpha_v, beta_v, sample_values)) + if not stats: + return + self.assertAllClose( + sample_values.mean(), + stats.gamma.mean(alpha_v, scale=1 / beta_v), + atol=.01) + self.assertAllClose( + sample_values.var(), + stats.gamma.var(alpha_v, scale=1 / beta_v), + atol=.15) def testGammaSample(self): - with self.test_session(): - alpha_v = 4.0 - beta_v = 3.0 - alpha = constant_op.constant(alpha_v) - beta = constant_op.constant(beta_v) - n = 100000 - gamma = gamma_lib.Gamma(concentration=alpha, rate=beta) - samples = gamma.sample(n, seed=137) - sample_values = self.evaluate(samples) - self.assertEqual(samples.get_shape(), (n,)) - self.assertEqual(sample_values.shape, (n,)) - self.assertTrue(self._kstest(alpha_v, beta_v, sample_values)) - if not stats: - return - self.assertAllClose( - sample_values.mean(), - stats.gamma.mean( - alpha_v, scale=1 / beta_v), - atol=.01) - self.assertAllClose( - sample_values.var(), - stats.gamma.var(alpha_v, scale=1 / beta_v), - atol=.15) + alpha_v = 4.0 + beta_v = 3.0 + alpha = constant_op.constant(alpha_v) + beta = constant_op.constant(beta_v) + n = 100000 + gamma = gamma_lib.Gamma(concentration=alpha, rate=beta) + samples = gamma.sample(n, seed=137) + sample_values = self.evaluate(samples) + self.assertEqual(samples.get_shape(), (n,)) + self.assertEqual(sample_values.shape, (n,)) + self.assertTrue(self._kstest(alpha_v, beta_v, sample_values)) + if not stats: + return + self.assertAllClose( + sample_values.mean(), + stats.gamma.mean(alpha_v, scale=1 / beta_v), + atol=.01) + self.assertAllClose( + sample_values.var(), + stats.gamma.var(alpha_v, scale=1 / beta_v), + atol=.15) def testGammaFullyReparameterized(self): alpha = constant_op.constant(4.0) @@ -279,37 +261,37 @@ class GammaTest(test.TestCase): self.assertIsNotNone(grad_beta) def testGammaSampleMultiDimensional(self): - with self.test_session(): - alpha_v = np.array([np.arange(1, 101, dtype=np.float32)]) # 1 x 100 - beta_v = np.array([np.arange(1, 11, dtype=np.float32)]).T # 10 x 1 - gamma = gamma_lib.Gamma(concentration=alpha_v, rate=beta_v) - n = 10000 - samples = gamma.sample(n, seed=137) - sample_values = self.evaluate(samples) - self.assertEqual(samples.get_shape(), (n, 10, 100)) - self.assertEqual(sample_values.shape, (n, 10, 100)) - zeros = np.zeros_like(alpha_v + beta_v) # 10 x 100 - alpha_bc = alpha_v + zeros - beta_bc = beta_v + zeros - if not stats: - return - self.assertAllClose( - sample_values.mean(axis=0), - stats.gamma.mean( - alpha_bc, scale=1 / beta_bc), - atol=0., rtol=.05) - self.assertAllClose( - sample_values.var(axis=0), - stats.gamma.var(alpha_bc, scale=1 / beta_bc), - atol=10.0, rtol=0.) - fails = 0 - trials = 0 - for ai, a in enumerate(np.reshape(alpha_v, [-1])): - for bi, b in enumerate(np.reshape(beta_v, [-1])): - s = sample_values[:, bi, ai] - trials += 1 - fails += 0 if self._kstest(a, b, s) else 1 - self.assertLess(fails, trials * 0.03) + alpha_v = np.array([np.arange(1, 101, dtype=np.float32)]) # 1 x 100 + beta_v = np.array([np.arange(1, 11, dtype=np.float32)]).T # 10 x 1 + gamma = gamma_lib.Gamma(concentration=alpha_v, rate=beta_v) + n = 10000 + samples = gamma.sample(n, seed=137) + sample_values = self.evaluate(samples) + self.assertEqual(samples.get_shape(), (n, 10, 100)) + self.assertEqual(sample_values.shape, (n, 10, 100)) + zeros = np.zeros_like(alpha_v + beta_v) # 10 x 100 + alpha_bc = alpha_v + zeros + beta_bc = beta_v + zeros + if not stats: + return + self.assertAllClose( + sample_values.mean(axis=0), + stats.gamma.mean(alpha_bc, scale=1 / beta_bc), + atol=0., + rtol=.05) + self.assertAllClose( + sample_values.var(axis=0), + stats.gamma.var(alpha_bc, scale=1 / beta_bc), + atol=10.0, + rtol=0.) + fails = 0 + trials = 0 + for ai, a in enumerate(np.reshape(alpha_v, [-1])): + for bi, b in enumerate(np.reshape(beta_v, [-1])): + s = sample_values[:, bi, ai] + trials += 1 + fails += 0 if self._kstest(a, b, s) else 1 + self.assertLess(fails, trials * 0.03) def _kstest(self, alpha, beta, samples): # Uses the Kolmogorov-Smirnov test for goodness of fit. @@ -320,30 +302,29 @@ class GammaTest(test.TestCase): return ks < 0.02 def testGammaPdfOfSampleMultiDims(self): - with self.test_session(): - gamma = gamma_lib.Gamma(concentration=[7., 11.], rate=[[5.], [6.]]) - num = 50000 - samples = gamma.sample(num, seed=137) - pdfs = gamma.prob(samples) - sample_vals, pdf_vals = self.evaluate([samples, pdfs]) - self.assertEqual(samples.get_shape(), (num, 2, 2)) - self.assertEqual(pdfs.get_shape(), (num, 2, 2)) - self._assertIntegral(sample_vals[:, 0, 0], pdf_vals[:, 0, 0], err=0.02) - self._assertIntegral(sample_vals[:, 0, 1], pdf_vals[:, 0, 1], err=0.02) - self._assertIntegral(sample_vals[:, 1, 0], pdf_vals[:, 1, 0], err=0.02) - self._assertIntegral(sample_vals[:, 1, 1], pdf_vals[:, 1, 1], err=0.02) - if not stats: - return - self.assertAllClose( - stats.gamma.mean( - [[7., 11.], [7., 11.]], scale=1 / np.array([[5., 5.], [6., 6.]])), - sample_vals.mean(axis=0), - atol=.1) - self.assertAllClose( - stats.gamma.var([[7., 11.], [7., 11.]], - scale=1 / np.array([[5., 5.], [6., 6.]])), - sample_vals.var(axis=0), - atol=.1) + gamma = gamma_lib.Gamma(concentration=[7., 11.], rate=[[5.], [6.]]) + num = 50000 + samples = gamma.sample(num, seed=137) + pdfs = gamma.prob(samples) + sample_vals, pdf_vals = self.evaluate([samples, pdfs]) + self.assertEqual(samples.get_shape(), (num, 2, 2)) + self.assertEqual(pdfs.get_shape(), (num, 2, 2)) + self._assertIntegral(sample_vals[:, 0, 0], pdf_vals[:, 0, 0], err=0.02) + self._assertIntegral(sample_vals[:, 0, 1], pdf_vals[:, 0, 1], err=0.02) + self._assertIntegral(sample_vals[:, 1, 0], pdf_vals[:, 1, 0], err=0.02) + self._assertIntegral(sample_vals[:, 1, 1], pdf_vals[:, 1, 1], err=0.02) + if not stats: + return + self.assertAllClose( + stats.gamma.mean([[7., 11.], [7., 11.]], + scale=1 / np.array([[5., 5.], [6., 6.]])), + sample_vals.mean(axis=0), + atol=.1) + self.assertAllClose( + stats.gamma.var([[7., 11.], [7., 11.]], + scale=1 / np.array([[5., 5.], [6., 6.]])), + sample_vals.var(axis=0), + atol=.1) def _assertIntegral(self, sample_vals, pdf_vals, err=1e-3): s_p = zip(sample_vals, pdf_vals) @@ -356,32 +337,29 @@ class GammaTest(test.TestCase): self.assertNear(1., total, err=err) def testGammaNonPositiveInitializationParamsRaises(self): - with self.test_session(): - alpha_v = constant_op.constant(0.0, name="alpha") - beta_v = constant_op.constant(1.0, name="beta") - with self.assertRaisesOpError("x > 0"): - gamma = gamma_lib.Gamma(concentration=alpha_v, - rate=beta_v, - validate_args=True) - self.evaluate(gamma.mean()) - alpha_v = constant_op.constant(1.0, name="alpha") - beta_v = constant_op.constant(0.0, name="beta") - with self.assertRaisesOpError("x > 0"): - gamma = gamma_lib.Gamma(concentration=alpha_v, - rate=beta_v, - validate_args=True) - self.evaluate(gamma.mean()) + alpha_v = constant_op.constant(0.0, name="alpha") + beta_v = constant_op.constant(1.0, name="beta") + with self.assertRaisesOpError("x > 0"): + gamma = gamma_lib.Gamma( + concentration=alpha_v, rate=beta_v, validate_args=True) + self.evaluate(gamma.mean()) + alpha_v = constant_op.constant(1.0, name="alpha") + beta_v = constant_op.constant(0.0, name="beta") + with self.assertRaisesOpError("x > 0"): + gamma = gamma_lib.Gamma( + concentration=alpha_v, rate=beta_v, validate_args=True) + self.evaluate(gamma.mean()) def testGammaWithSoftplusConcentrationRate(self): - with self.test_session(): - alpha_v = constant_op.constant([0.0, -2.1], name="alpha") - beta_v = constant_op.constant([1.0, -3.6], name="beta") - gamma = gamma_lib.GammaWithSoftplusConcentrationRate( - concentration=alpha_v, rate=beta_v) - self.assertAllEqual(self.evaluate(nn_ops.softplus(alpha_v)), - self.evaluate(gamma.concentration)) - self.assertAllEqual(self.evaluate(nn_ops.softplus(beta_v)), - self.evaluate(gamma.rate)) + alpha_v = constant_op.constant([0.0, -2.1], name="alpha") + beta_v = constant_op.constant([1.0, -3.6], name="beta") + gamma = gamma_lib.GammaWithSoftplusConcentrationRate( + concentration=alpha_v, rate=beta_v) + self.assertAllEqual( + self.evaluate(nn_ops.softplus(alpha_v)), + self.evaluate(gamma.concentration)) + self.assertAllEqual( + self.evaluate(nn_ops.softplus(beta_v)), self.evaluate(gamma.rate)) def testGammaGammaKL(self): alpha0 = np.array([3.]) @@ -391,15 +369,14 @@ class GammaTest(test.TestCase): beta1 = np.array([0.5, 1., 1.5, 2., 2.5, 3.]) # Build graph. - with self.test_session(): - g0 = gamma_lib.Gamma(concentration=alpha0, rate=beta0) - g1 = gamma_lib.Gamma(concentration=alpha1, rate=beta1) - x = g0.sample(int(1e4), seed=0) - kl_sample = math_ops.reduce_mean(g0.log_prob(x) - g1.log_prob(x), 0) - kl_actual = kullback_leibler.kl_divergence(g0, g1) - - # Execute graph. - [kl_sample_, kl_actual_] = self.evaluate([kl_sample, kl_actual]) + g0 = gamma_lib.Gamma(concentration=alpha0, rate=beta0) + g1 = gamma_lib.Gamma(concentration=alpha1, rate=beta1) + x = g0.sample(int(1e4), seed=0) + kl_sample = math_ops.reduce_mean(g0.log_prob(x) - g1.log_prob(x), 0) + kl_actual = kullback_leibler.kl_divergence(g0, g1) + + # Execute graph. + [kl_sample_, kl_actual_] = self.evaluate([kl_sample, kl_actual]) self.assertEqual(beta0.shape, kl_actual.get_shape()) diff --git a/tensorflow/python/kernel_tests/distributions/laplace_test.py b/tensorflow/python/kernel_tests/distributions/laplace_test.py index 24b243f647..630c2cb424 100644 --- a/tensorflow/python/kernel_tests/distributions/laplace_test.py +++ b/tensorflow/python/kernel_tests/distributions/laplace_test.py @@ -21,7 +21,6 @@ import importlib import numpy as np -from tensorflow.python.client import session from tensorflow.python.eager import backprop from tensorflow.python.framework import constant_op from tensorflow.python.framework import tensor_shape @@ -49,212 +48,198 @@ stats = try_import("scipy.stats") class LaplaceTest(test.TestCase): def testLaplaceShape(self): - with self.test_session(): - loc = constant_op.constant([3.0] * 5) - scale = constant_op.constant(11.0) - laplace = laplace_lib.Laplace(loc=loc, scale=scale) + loc = constant_op.constant([3.0] * 5) + scale = constant_op.constant(11.0) + laplace = laplace_lib.Laplace(loc=loc, scale=scale) - self.assertEqual(self.evaluate(laplace.batch_shape_tensor()), (5,)) - self.assertEqual(laplace.batch_shape, tensor_shape.TensorShape([5])) - self.assertAllEqual(self.evaluate(laplace.event_shape_tensor()), []) - self.assertEqual(laplace.event_shape, tensor_shape.TensorShape([])) + self.assertEqual(self.evaluate(laplace.batch_shape_tensor()), (5,)) + self.assertEqual(laplace.batch_shape, tensor_shape.TensorShape([5])) + self.assertAllEqual(self.evaluate(laplace.event_shape_tensor()), []) + self.assertEqual(laplace.event_shape, tensor_shape.TensorShape([])) def testLaplaceLogPDF(self): - with self.test_session(): - batch_size = 6 - loc = constant_op.constant([2.0] * batch_size) - scale = constant_op.constant([3.0] * batch_size) - loc_v = 2.0 - scale_v = 3.0 - x = np.array([2.5, 2.5, 4.0, 0.1, 1.0, 2.0], dtype=np.float32) - laplace = laplace_lib.Laplace(loc=loc, scale=scale) - log_pdf = laplace.log_prob(x) - self.assertEqual(log_pdf.get_shape(), (6,)) - if not stats: - return - expected_log_pdf = stats.laplace.logpdf(x, loc_v, scale=scale_v) - self.assertAllClose(self.evaluate(log_pdf), expected_log_pdf) + batch_size = 6 + loc = constant_op.constant([2.0] * batch_size) + scale = constant_op.constant([3.0] * batch_size) + loc_v = 2.0 + scale_v = 3.0 + x = np.array([2.5, 2.5, 4.0, 0.1, 1.0, 2.0], dtype=np.float32) + laplace = laplace_lib.Laplace(loc=loc, scale=scale) + log_pdf = laplace.log_prob(x) + self.assertEqual(log_pdf.get_shape(), (6,)) + if not stats: + return + expected_log_pdf = stats.laplace.logpdf(x, loc_v, scale=scale_v) + self.assertAllClose(self.evaluate(log_pdf), expected_log_pdf) - pdf = laplace.prob(x) - self.assertEqual(pdf.get_shape(), (6,)) - self.assertAllClose(self.evaluate(pdf), np.exp(expected_log_pdf)) + pdf = laplace.prob(x) + self.assertEqual(pdf.get_shape(), (6,)) + self.assertAllClose(self.evaluate(pdf), np.exp(expected_log_pdf)) def testLaplaceLogPDFMultidimensional(self): - with self.test_session(): - batch_size = 6 - loc = constant_op.constant([[2.0, 4.0]] * batch_size) - scale = constant_op.constant([[3.0, 4.0]] * batch_size) - loc_v = np.array([2.0, 4.0]) - scale_v = np.array([3.0, 4.0]) - x = np.array([[2.5, 2.5, 4.0, 0.1, 1.0, 2.0]], dtype=np.float32).T - laplace = laplace_lib.Laplace(loc=loc, scale=scale) - log_pdf = laplace.log_prob(x) - log_pdf_values = self.evaluate(log_pdf) - self.assertEqual(log_pdf.get_shape(), (6, 2)) - - pdf = laplace.prob(x) - pdf_values = self.evaluate(pdf) - self.assertEqual(pdf.get_shape(), (6, 2)) - if not stats: - return - expected_log_pdf = stats.laplace.logpdf(x, loc_v, scale=scale_v) - self.assertAllClose(log_pdf_values, expected_log_pdf) - self.assertAllClose(pdf_values, np.exp(expected_log_pdf)) + batch_size = 6 + loc = constant_op.constant([[2.0, 4.0]] * batch_size) + scale = constant_op.constant([[3.0, 4.0]] * batch_size) + loc_v = np.array([2.0, 4.0]) + scale_v = np.array([3.0, 4.0]) + x = np.array([[2.5, 2.5, 4.0, 0.1, 1.0, 2.0]], dtype=np.float32).T + laplace = laplace_lib.Laplace(loc=loc, scale=scale) + log_pdf = laplace.log_prob(x) + log_pdf_values = self.evaluate(log_pdf) + self.assertEqual(log_pdf.get_shape(), (6, 2)) + + pdf = laplace.prob(x) + pdf_values = self.evaluate(pdf) + self.assertEqual(pdf.get_shape(), (6, 2)) + if not stats: + return + expected_log_pdf = stats.laplace.logpdf(x, loc_v, scale=scale_v) + self.assertAllClose(log_pdf_values, expected_log_pdf) + self.assertAllClose(pdf_values, np.exp(expected_log_pdf)) def testLaplaceLogPDFMultidimensionalBroadcasting(self): - with self.test_session(): - batch_size = 6 - loc = constant_op.constant([[2.0, 4.0]] * batch_size) - scale = constant_op.constant(3.0) - loc_v = np.array([2.0, 4.0]) - scale_v = 3.0 - x = np.array([[2.5, 2.5, 4.0, 0.1, 1.0, 2.0]], dtype=np.float32).T - laplace = laplace_lib.Laplace(loc=loc, scale=scale) - log_pdf = laplace.log_prob(x) - log_pdf_values = self.evaluate(log_pdf) - self.assertEqual(log_pdf.get_shape(), (6, 2)) - - pdf = laplace.prob(x) - pdf_values = self.evaluate(pdf) - self.assertEqual(pdf.get_shape(), (6, 2)) - if not stats: - return - expected_log_pdf = stats.laplace.logpdf(x, loc_v, scale=scale_v) - self.assertAllClose(log_pdf_values, expected_log_pdf) - self.assertAllClose(pdf_values, np.exp(expected_log_pdf)) + batch_size = 6 + loc = constant_op.constant([[2.0, 4.0]] * batch_size) + scale = constant_op.constant(3.0) + loc_v = np.array([2.0, 4.0]) + scale_v = 3.0 + x = np.array([[2.5, 2.5, 4.0, 0.1, 1.0, 2.0]], dtype=np.float32).T + laplace = laplace_lib.Laplace(loc=loc, scale=scale) + log_pdf = laplace.log_prob(x) + log_pdf_values = self.evaluate(log_pdf) + self.assertEqual(log_pdf.get_shape(), (6, 2)) + + pdf = laplace.prob(x) + pdf_values = self.evaluate(pdf) + self.assertEqual(pdf.get_shape(), (6, 2)) + if not stats: + return + expected_log_pdf = stats.laplace.logpdf(x, loc_v, scale=scale_v) + self.assertAllClose(log_pdf_values, expected_log_pdf) + self.assertAllClose(pdf_values, np.exp(expected_log_pdf)) def testLaplaceCDF(self): - with self.test_session(): - batch_size = 6 - loc = constant_op.constant([2.0] * batch_size) - scale = constant_op.constant([3.0] * batch_size) - loc_v = 2.0 - scale_v = 3.0 - x = np.array([2.5, 2.5, 4.0, 0.1, 1.0, 2.0], dtype=np.float32) + batch_size = 6 + loc = constant_op.constant([2.0] * batch_size) + scale = constant_op.constant([3.0] * batch_size) + loc_v = 2.0 + scale_v = 3.0 + x = np.array([2.5, 2.5, 4.0, 0.1, 1.0, 2.0], dtype=np.float32) - laplace = laplace_lib.Laplace(loc=loc, scale=scale) + laplace = laplace_lib.Laplace(loc=loc, scale=scale) - cdf = laplace.cdf(x) - self.assertEqual(cdf.get_shape(), (6,)) - if not stats: - return - expected_cdf = stats.laplace.cdf(x, loc_v, scale=scale_v) - self.assertAllClose(self.evaluate(cdf), expected_cdf) + cdf = laplace.cdf(x) + self.assertEqual(cdf.get_shape(), (6,)) + if not stats: + return + expected_cdf = stats.laplace.cdf(x, loc_v, scale=scale_v) + self.assertAllClose(self.evaluate(cdf), expected_cdf) def testLaplaceLogCDF(self): - with self.test_session(): - batch_size = 6 - loc = constant_op.constant([2.0] * batch_size) - scale = constant_op.constant([3.0] * batch_size) - loc_v = 2.0 - scale_v = 3.0 - x = np.array([-2.5, 2.5, -4.0, 0.1, 1.0, 2.0], dtype=np.float32) + batch_size = 6 + loc = constant_op.constant([2.0] * batch_size) + scale = constant_op.constant([3.0] * batch_size) + loc_v = 2.0 + scale_v = 3.0 + x = np.array([-2.5, 2.5, -4.0, 0.1, 1.0, 2.0], dtype=np.float32) - laplace = laplace_lib.Laplace(loc=loc, scale=scale) + laplace = laplace_lib.Laplace(loc=loc, scale=scale) - cdf = laplace.log_cdf(x) - self.assertEqual(cdf.get_shape(), (6,)) - if not stats: - return - expected_cdf = stats.laplace.logcdf(x, loc_v, scale=scale_v) - self.assertAllClose(self.evaluate(cdf), expected_cdf) + cdf = laplace.log_cdf(x) + self.assertEqual(cdf.get_shape(), (6,)) + if not stats: + return + expected_cdf = stats.laplace.logcdf(x, loc_v, scale=scale_v) + self.assertAllClose(self.evaluate(cdf), expected_cdf) def testLaplaceLogSurvivalFunction(self): - with self.test_session(): - batch_size = 6 - loc = constant_op.constant([2.0] * batch_size) - scale = constant_op.constant([3.0] * batch_size) - loc_v = 2.0 - scale_v = 3.0 - x = np.array([-2.5, 2.5, -4.0, 0.1, 1.0, 2.0], dtype=np.float32) + batch_size = 6 + loc = constant_op.constant([2.0] * batch_size) + scale = constant_op.constant([3.0] * batch_size) + loc_v = 2.0 + scale_v = 3.0 + x = np.array([-2.5, 2.5, -4.0, 0.1, 1.0, 2.0], dtype=np.float32) - laplace = laplace_lib.Laplace(loc=loc, scale=scale) + laplace = laplace_lib.Laplace(loc=loc, scale=scale) - sf = laplace.log_survival_function(x) - self.assertEqual(sf.get_shape(), (6,)) - if not stats: - return - expected_sf = stats.laplace.logsf(x, loc_v, scale=scale_v) - self.assertAllClose(self.evaluate(sf), expected_sf) + sf = laplace.log_survival_function(x) + self.assertEqual(sf.get_shape(), (6,)) + if not stats: + return + expected_sf = stats.laplace.logsf(x, loc_v, scale=scale_v) + self.assertAllClose(self.evaluate(sf), expected_sf) def testLaplaceMean(self): - with self.test_session(): - loc_v = np.array([1.0, 3.0, 2.5]) - scale_v = np.array([1.0, 4.0, 5.0]) - laplace = laplace_lib.Laplace(loc=loc_v, scale=scale_v) - self.assertEqual(laplace.mean().get_shape(), (3,)) - if not stats: - return - expected_means = stats.laplace.mean(loc_v, scale=scale_v) - self.assertAllClose(self.evaluate(laplace.mean()), expected_means) + loc_v = np.array([1.0, 3.0, 2.5]) + scale_v = np.array([1.0, 4.0, 5.0]) + laplace = laplace_lib.Laplace(loc=loc_v, scale=scale_v) + self.assertEqual(laplace.mean().get_shape(), (3,)) + if not stats: + return + expected_means = stats.laplace.mean(loc_v, scale=scale_v) + self.assertAllClose(self.evaluate(laplace.mean()), expected_means) def testLaplaceMode(self): - with self.test_session(): - loc_v = np.array([0.5, 3.0, 2.5]) - scale_v = np.array([1.0, 4.0, 5.0]) - laplace = laplace_lib.Laplace(loc=loc_v, scale=scale_v) - self.assertEqual(laplace.mode().get_shape(), (3,)) - self.assertAllClose(self.evaluate(laplace.mode()), loc_v) + loc_v = np.array([0.5, 3.0, 2.5]) + scale_v = np.array([1.0, 4.0, 5.0]) + laplace = laplace_lib.Laplace(loc=loc_v, scale=scale_v) + self.assertEqual(laplace.mode().get_shape(), (3,)) + self.assertAllClose(self.evaluate(laplace.mode()), loc_v) def testLaplaceVariance(self): - with self.test_session(): - loc_v = np.array([1.0, 3.0, 2.5]) - scale_v = np.array([1.0, 4.0, 5.0]) - laplace = laplace_lib.Laplace(loc=loc_v, scale=scale_v) - self.assertEqual(laplace.variance().get_shape(), (3,)) - if not stats: - return - expected_variances = stats.laplace.var(loc_v, scale=scale_v) - self.assertAllClose(self.evaluate(laplace.variance()), expected_variances) + loc_v = np.array([1.0, 3.0, 2.5]) + scale_v = np.array([1.0, 4.0, 5.0]) + laplace = laplace_lib.Laplace(loc=loc_v, scale=scale_v) + self.assertEqual(laplace.variance().get_shape(), (3,)) + if not stats: + return + expected_variances = stats.laplace.var(loc_v, scale=scale_v) + self.assertAllClose(self.evaluate(laplace.variance()), expected_variances) def testLaplaceStd(self): - with self.test_session(): - loc_v = np.array([1.0, 3.0, 2.5]) - scale_v = np.array([1.0, 4.0, 5.0]) - laplace = laplace_lib.Laplace(loc=loc_v, scale=scale_v) - self.assertEqual(laplace.stddev().get_shape(), (3,)) - if not stats: - return - expected_stddev = stats.laplace.std(loc_v, scale=scale_v) - self.assertAllClose(self.evaluate(laplace.stddev()), expected_stddev) + loc_v = np.array([1.0, 3.0, 2.5]) + scale_v = np.array([1.0, 4.0, 5.0]) + laplace = laplace_lib.Laplace(loc=loc_v, scale=scale_v) + self.assertEqual(laplace.stddev().get_shape(), (3,)) + if not stats: + return + expected_stddev = stats.laplace.std(loc_v, scale=scale_v) + self.assertAllClose(self.evaluate(laplace.stddev()), expected_stddev) def testLaplaceEntropy(self): - with self.test_session(): - loc_v = np.array([1.0, 3.0, 2.5]) - scale_v = np.array([1.0, 4.0, 5.0]) - laplace = laplace_lib.Laplace(loc=loc_v, scale=scale_v) - self.assertEqual(laplace.entropy().get_shape(), (3,)) - if not stats: - return - expected_entropy = stats.laplace.entropy(loc_v, scale=scale_v) - self.assertAllClose(self.evaluate(laplace.entropy()), expected_entropy) + loc_v = np.array([1.0, 3.0, 2.5]) + scale_v = np.array([1.0, 4.0, 5.0]) + laplace = laplace_lib.Laplace(loc=loc_v, scale=scale_v) + self.assertEqual(laplace.entropy().get_shape(), (3,)) + if not stats: + return + expected_entropy = stats.laplace.entropy(loc_v, scale=scale_v) + self.assertAllClose(self.evaluate(laplace.entropy()), expected_entropy) def testLaplaceSample(self): - with session.Session(): - loc_v = 4.0 - scale_v = 3.0 - loc = constant_op.constant(loc_v) - scale = constant_op.constant(scale_v) - n = 100000 - laplace = laplace_lib.Laplace(loc=loc, scale=scale) - samples = laplace.sample(n, seed=137) - sample_values = self.evaluate(samples) - self.assertEqual(samples.get_shape(), (n,)) - self.assertEqual(sample_values.shape, (n,)) - if not stats: - return - self.assertAllClose( - sample_values.mean(), - stats.laplace.mean( - loc_v, scale=scale_v), - rtol=0.05, - atol=0.) - self.assertAllClose( - sample_values.var(), - stats.laplace.var(loc_v, scale=scale_v), - rtol=0.05, - atol=0.) - self.assertTrue(self._kstest(loc_v, scale_v, sample_values)) + loc_v = 4.0 + scale_v = 3.0 + loc = constant_op.constant(loc_v) + scale = constant_op.constant(scale_v) + n = 100000 + laplace = laplace_lib.Laplace(loc=loc, scale=scale) + samples = laplace.sample(n, seed=137) + sample_values = self.evaluate(samples) + self.assertEqual(samples.get_shape(), (n,)) + self.assertEqual(sample_values.shape, (n,)) + if not stats: + return + self.assertAllClose( + sample_values.mean(), + stats.laplace.mean(loc_v, scale=scale_v), + rtol=0.05, + atol=0.) + self.assertAllClose( + sample_values.var(), + stats.laplace.var(loc_v, scale=scale_v), + rtol=0.05, + atol=0.) + self.assertTrue(self._kstest(loc_v, scale_v, sample_values)) def testLaplaceFullyReparameterized(self): loc = constant_op.constant(4.0) @@ -269,39 +254,37 @@ class LaplaceTest(test.TestCase): self.assertIsNotNone(grad_scale) def testLaplaceSampleMultiDimensional(self): - with session.Session(): - loc_v = np.array([np.arange(1, 101, dtype=np.float32)]) # 1 x 100 - scale_v = np.array([np.arange(1, 11, dtype=np.float32)]).T # 10 x 1 - laplace = laplace_lib.Laplace(loc=loc_v, scale=scale_v) - n = 10000 - samples = laplace.sample(n, seed=137) - sample_values = self.evaluate(samples) - self.assertEqual(samples.get_shape(), (n, 10, 100)) - self.assertEqual(sample_values.shape, (n, 10, 100)) - zeros = np.zeros_like(loc_v + scale_v) # 10 x 100 - loc_bc = loc_v + zeros - scale_bc = scale_v + zeros - if not stats: - return - self.assertAllClose( - sample_values.mean(axis=0), - stats.laplace.mean( - loc_bc, scale=scale_bc), - rtol=0.35, - atol=0.) - self.assertAllClose( - sample_values.var(axis=0), - stats.laplace.var(loc_bc, scale=scale_bc), - rtol=0.10, - atol=0.) - fails = 0 - trials = 0 - for ai, a in enumerate(np.reshape(loc_v, [-1])): - for bi, b in enumerate(np.reshape(scale_v, [-1])): - s = sample_values[:, bi, ai] - trials += 1 - fails += 0 if self._kstest(a, b, s) else 1 - self.assertLess(fails, trials * 0.03) + loc_v = np.array([np.arange(1, 101, dtype=np.float32)]) # 1 x 100 + scale_v = np.array([np.arange(1, 11, dtype=np.float32)]).T # 10 x 1 + laplace = laplace_lib.Laplace(loc=loc_v, scale=scale_v) + n = 10000 + samples = laplace.sample(n, seed=137) + sample_values = self.evaluate(samples) + self.assertEqual(samples.get_shape(), (n, 10, 100)) + self.assertEqual(sample_values.shape, (n, 10, 100)) + zeros = np.zeros_like(loc_v + scale_v) # 10 x 100 + loc_bc = loc_v + zeros + scale_bc = scale_v + zeros + if not stats: + return + self.assertAllClose( + sample_values.mean(axis=0), + stats.laplace.mean(loc_bc, scale=scale_bc), + rtol=0.35, + atol=0.) + self.assertAllClose( + sample_values.var(axis=0), + stats.laplace.var(loc_bc, scale=scale_bc), + rtol=0.10, + atol=0.) + fails = 0 + trials = 0 + for ai, a in enumerate(np.reshape(loc_v, [-1])): + for bi, b in enumerate(np.reshape(scale_v, [-1])): + s = sample_values[:, bi, ai] + trials += 1 + fails += 0 if self._kstest(a, b, s) else 1 + self.assertLess(fails, trials * 0.03) def _kstest(self, loc, scale, samples): # Uses the Kolmogorov-Smirnov test for goodness of fit. @@ -349,30 +332,26 @@ class LaplaceTest(test.TestCase): self.assertNear(1., total, err=err) def testLaplaceNonPositiveInitializationParamsRaises(self): - with self.test_session(): - loc_v = constant_op.constant(0.0, name="loc") - scale_v = constant_op.constant(-1.0, name="scale") - with self.assertRaisesOpError( - "Condition x > 0 did not hold element-wise"): - laplace = laplace_lib.Laplace( - loc=loc_v, scale=scale_v, validate_args=True) - self.evaluate(laplace.mean()) - loc_v = constant_op.constant(1.0, name="loc") - scale_v = constant_op.constant(0.0, name="scale") - with self.assertRaisesOpError( - "Condition x > 0 did not hold element-wise"): - laplace = laplace_lib.Laplace( - loc=loc_v, scale=scale_v, validate_args=True) - self.evaluate(laplace.mean()) + loc_v = constant_op.constant(0.0, name="loc") + scale_v = constant_op.constant(-1.0, name="scale") + with self.assertRaisesOpError("Condition x > 0 did not hold element-wise"): + laplace = laplace_lib.Laplace( + loc=loc_v, scale=scale_v, validate_args=True) + self.evaluate(laplace.mean()) + loc_v = constant_op.constant(1.0, name="loc") + scale_v = constant_op.constant(0.0, name="scale") + with self.assertRaisesOpError("Condition x > 0 did not hold element-wise"): + laplace = laplace_lib.Laplace( + loc=loc_v, scale=scale_v, validate_args=True) + self.evaluate(laplace.mean()) def testLaplaceWithSoftplusScale(self): - with self.test_session(): - loc_v = constant_op.constant([0.0, 1.0], name="loc") - scale_v = constant_op.constant([-1.0, 2.0], name="scale") - laplace = laplace_lib.LaplaceWithSoftplusScale(loc=loc_v, scale=scale_v) - self.assertAllClose( - self.evaluate(nn_ops.softplus(scale_v)), self.evaluate(laplace.scale)) - self.assertAllClose(self.evaluate(loc_v), self.evaluate(laplace.loc)) + loc_v = constant_op.constant([0.0, 1.0], name="loc") + scale_v = constant_op.constant([-1.0, 2.0], name="scale") + laplace = laplace_lib.LaplaceWithSoftplusScale(loc=loc_v, scale=scale_v) + self.assertAllClose( + self.evaluate(nn_ops.softplus(scale_v)), self.evaluate(laplace.scale)) + self.assertAllClose(self.evaluate(loc_v), self.evaluate(laplace.loc)) if __name__ == "__main__": diff --git a/tensorflow/python/kernel_tests/distributions/normal_test.py b/tensorflow/python/kernel_tests/distributions/normal_test.py index 7ff48c0c10..de73a40b23 100644 --- a/tensorflow/python/kernel_tests/distributions/normal_test.py +++ b/tensorflow/python/kernel_tests/distributions/normal_test.py @@ -61,16 +61,15 @@ class NormalTest(test.TestCase): self.assertAllEqual(all_true, is_finite) def _testParamShapes(self, sample_shape, expected): - with self.test_session(): - param_shapes = normal_lib.Normal.param_shapes(sample_shape) - mu_shape, sigma_shape = param_shapes["loc"], param_shapes["scale"] - self.assertAllEqual(expected, self.evaluate(mu_shape)) - self.assertAllEqual(expected, self.evaluate(sigma_shape)) - mu = array_ops.zeros(mu_shape) - sigma = array_ops.ones(sigma_shape) - self.assertAllEqual( - expected, - self.evaluate(array_ops.shape(normal_lib.Normal(mu, sigma).sample()))) + param_shapes = normal_lib.Normal.param_shapes(sample_shape) + mu_shape, sigma_shape = param_shapes["loc"], param_shapes["scale"] + self.assertAllEqual(expected, self.evaluate(mu_shape)) + self.assertAllEqual(expected, self.evaluate(sigma_shape)) + mu = array_ops.zeros(mu_shape) + sigma = array_ops.ones(sigma_shape) + self.assertAllEqual( + expected, + self.evaluate(array_ops.shape(normal_lib.Normal(mu, sigma).sample()))) def _testParamStaticShapes(self, sample_shape, expected): param_shapes = normal_lib.Normal.param_static_shapes(sample_shape) @@ -91,156 +90,150 @@ class NormalTest(test.TestCase): self._testParamStaticShapes( tensor_shape.TensorShape(sample_shape), sample_shape) - @test_util.run_in_graph_and_eager_modes + @test_util.run_in_graph_and_eager_modes(assert_no_eager_garbage=True) def testNormalWithSoftplusScale(self): - with self.test_session(): - mu = array_ops.zeros((10, 3)) - rho = array_ops.ones((10, 3)) * -2. - normal = normal_lib.NormalWithSoftplusScale(loc=mu, scale=rho) - self.assertAllEqual(self.evaluate(mu), self.evaluate(normal.loc)) - self.assertAllEqual( - self.evaluate(nn_ops.softplus(rho)), self.evaluate(normal.scale)) + mu = array_ops.zeros((10, 3)) + rho = array_ops.ones((10, 3)) * -2. + normal = normal_lib.NormalWithSoftplusScale(loc=mu, scale=rho) + self.assertAllEqual(self.evaluate(mu), self.evaluate(normal.loc)) + self.assertAllEqual( + self.evaluate(nn_ops.softplus(rho)), self.evaluate(normal.scale)) @test_util.run_in_graph_and_eager_modes def testNormalLogPDF(self): - with self.test_session(): - batch_size = 6 - mu = constant_op.constant([3.0] * batch_size) - sigma = constant_op.constant([math.sqrt(10.0)] * batch_size) - x = np.array([-2.5, 2.5, 4.0, 0.0, -1.0, 2.0], dtype=np.float32) - normal = normal_lib.Normal(loc=mu, scale=sigma) - - log_pdf = normal.log_prob(x) - self.assertAllEqual( - self.evaluate(normal.batch_shape_tensor()), log_pdf.get_shape()) - self.assertAllEqual( - self.evaluate(normal.batch_shape_tensor()), - self.evaluate(log_pdf).shape) - self.assertAllEqual(normal.batch_shape, log_pdf.get_shape()) - self.assertAllEqual(normal.batch_shape, self.evaluate(log_pdf).shape) + batch_size = 6 + mu = constant_op.constant([3.0] * batch_size) + sigma = constant_op.constant([math.sqrt(10.0)] * batch_size) + x = np.array([-2.5, 2.5, 4.0, 0.0, -1.0, 2.0], dtype=np.float32) + normal = normal_lib.Normal(loc=mu, scale=sigma) - pdf = normal.prob(x) - self.assertAllEqual( - self.evaluate(normal.batch_shape_tensor()), pdf.get_shape()) - self.assertAllEqual( - self.evaluate(normal.batch_shape_tensor()), - self.evaluate(pdf).shape) - self.assertAllEqual(normal.batch_shape, pdf.get_shape()) - self.assertAllEqual(normal.batch_shape, self.evaluate(pdf).shape) - - if not stats: - return - expected_log_pdf = stats.norm(self.evaluate(mu), - self.evaluate(sigma)).logpdf(x) - self.assertAllClose(expected_log_pdf, self.evaluate(log_pdf)) - self.assertAllClose(np.exp(expected_log_pdf), self.evaluate(pdf)) + log_pdf = normal.log_prob(x) + self.assertAllEqual( + self.evaluate(normal.batch_shape_tensor()), log_pdf.get_shape()) + self.assertAllEqual( + self.evaluate(normal.batch_shape_tensor()), + self.evaluate(log_pdf).shape) + self.assertAllEqual(normal.batch_shape, log_pdf.get_shape()) + self.assertAllEqual(normal.batch_shape, self.evaluate(log_pdf).shape) + + pdf = normal.prob(x) + self.assertAllEqual( + self.evaluate(normal.batch_shape_tensor()), pdf.get_shape()) + self.assertAllEqual( + self.evaluate(normal.batch_shape_tensor()), + self.evaluate(pdf).shape) + self.assertAllEqual(normal.batch_shape, pdf.get_shape()) + self.assertAllEqual(normal.batch_shape, self.evaluate(pdf).shape) + + if not stats: + return + expected_log_pdf = stats.norm(self.evaluate(mu), + self.evaluate(sigma)).logpdf(x) + self.assertAllClose(expected_log_pdf, self.evaluate(log_pdf)) + self.assertAllClose(np.exp(expected_log_pdf), self.evaluate(pdf)) @test_util.run_in_graph_and_eager_modes def testNormalLogPDFMultidimensional(self): - with self.test_session(): - batch_size = 6 - mu = constant_op.constant([[3.0, -3.0]] * batch_size) - sigma = constant_op.constant([[math.sqrt(10.0), math.sqrt(15.0)]] * - batch_size) - x = np.array([[-2.5, 2.5, 4.0, 0.0, -1.0, 2.0]], dtype=np.float32).T - normal = normal_lib.Normal(loc=mu, scale=sigma) - - log_pdf = normal.log_prob(x) - log_pdf_values = self.evaluate(log_pdf) - self.assertEqual(log_pdf.get_shape(), (6, 2)) - self.assertAllEqual( - self.evaluate(normal.batch_shape_tensor()), log_pdf.get_shape()) - self.assertAllEqual( - self.evaluate(normal.batch_shape_tensor()), - self.evaluate(log_pdf).shape) - self.assertAllEqual(normal.batch_shape, log_pdf.get_shape()) - self.assertAllEqual(normal.batch_shape, self.evaluate(log_pdf).shape) - - pdf = normal.prob(x) - pdf_values = self.evaluate(pdf) - self.assertEqual(pdf.get_shape(), (6, 2)) - self.assertAllEqual( - self.evaluate(normal.batch_shape_tensor()), pdf.get_shape()) - self.assertAllEqual( - self.evaluate(normal.batch_shape_tensor()), pdf_values.shape) - self.assertAllEqual(normal.batch_shape, pdf.get_shape()) - self.assertAllEqual(normal.batch_shape, pdf_values.shape) + batch_size = 6 + mu = constant_op.constant([[3.0, -3.0]] * batch_size) + sigma = constant_op.constant( + [[math.sqrt(10.0), math.sqrt(15.0)]] * batch_size) + x = np.array([[-2.5, 2.5, 4.0, 0.0, -1.0, 2.0]], dtype=np.float32).T + normal = normal_lib.Normal(loc=mu, scale=sigma) - if not stats: - return - expected_log_pdf = stats.norm(self.evaluate(mu), - self.evaluate(sigma)).logpdf(x) - self.assertAllClose(expected_log_pdf, log_pdf_values) - self.assertAllClose(np.exp(expected_log_pdf), pdf_values) + log_pdf = normal.log_prob(x) + log_pdf_values = self.evaluate(log_pdf) + self.assertEqual(log_pdf.get_shape(), (6, 2)) + self.assertAllEqual( + self.evaluate(normal.batch_shape_tensor()), log_pdf.get_shape()) + self.assertAllEqual( + self.evaluate(normal.batch_shape_tensor()), + self.evaluate(log_pdf).shape) + self.assertAllEqual(normal.batch_shape, log_pdf.get_shape()) + self.assertAllEqual(normal.batch_shape, self.evaluate(log_pdf).shape) + + pdf = normal.prob(x) + pdf_values = self.evaluate(pdf) + self.assertEqual(pdf.get_shape(), (6, 2)) + self.assertAllEqual( + self.evaluate(normal.batch_shape_tensor()), pdf.get_shape()) + self.assertAllEqual( + self.evaluate(normal.batch_shape_tensor()), pdf_values.shape) + self.assertAllEqual(normal.batch_shape, pdf.get_shape()) + self.assertAllEqual(normal.batch_shape, pdf_values.shape) + + if not stats: + return + expected_log_pdf = stats.norm(self.evaluate(mu), + self.evaluate(sigma)).logpdf(x) + self.assertAllClose(expected_log_pdf, log_pdf_values) + self.assertAllClose(np.exp(expected_log_pdf), pdf_values) @test_util.run_in_graph_and_eager_modes def testNormalCDF(self): - with self.test_session(): - batch_size = 50 - mu = self._rng.randn(batch_size) - sigma = self._rng.rand(batch_size) + 1.0 - x = np.linspace(-8.0, 8.0, batch_size).astype(np.float64) + batch_size = 50 + mu = self._rng.randn(batch_size) + sigma = self._rng.rand(batch_size) + 1.0 + x = np.linspace(-8.0, 8.0, batch_size).astype(np.float64) - normal = normal_lib.Normal(loc=mu, scale=sigma) - cdf = normal.cdf(x) - self.assertAllEqual( - self.evaluate(normal.batch_shape_tensor()), cdf.get_shape()) - self.assertAllEqual( - self.evaluate(normal.batch_shape_tensor()), - self.evaluate(cdf).shape) - self.assertAllEqual(normal.batch_shape, cdf.get_shape()) - self.assertAllEqual(normal.batch_shape, self.evaluate(cdf).shape) - if not stats: - return - expected_cdf = stats.norm(mu, sigma).cdf(x) - self.assertAllClose(expected_cdf, self.evaluate(cdf), atol=0) + normal = normal_lib.Normal(loc=mu, scale=sigma) + cdf = normal.cdf(x) + self.assertAllEqual( + self.evaluate(normal.batch_shape_tensor()), cdf.get_shape()) + self.assertAllEqual( + self.evaluate(normal.batch_shape_tensor()), + self.evaluate(cdf).shape) + self.assertAllEqual(normal.batch_shape, cdf.get_shape()) + self.assertAllEqual(normal.batch_shape, self.evaluate(cdf).shape) + if not stats: + return + expected_cdf = stats.norm(mu, sigma).cdf(x) + self.assertAllClose(expected_cdf, self.evaluate(cdf), atol=0) @test_util.run_in_graph_and_eager_modes def testNormalSurvivalFunction(self): - with self.test_session(): - batch_size = 50 - mu = self._rng.randn(batch_size) - sigma = self._rng.rand(batch_size) + 1.0 - x = np.linspace(-8.0, 8.0, batch_size).astype(np.float64) + batch_size = 50 + mu = self._rng.randn(batch_size) + sigma = self._rng.rand(batch_size) + 1.0 + x = np.linspace(-8.0, 8.0, batch_size).astype(np.float64) - normal = normal_lib.Normal(loc=mu, scale=sigma) + normal = normal_lib.Normal(loc=mu, scale=sigma) - sf = normal.survival_function(x) - self.assertAllEqual( - self.evaluate(normal.batch_shape_tensor()), sf.get_shape()) - self.assertAllEqual( - self.evaluate(normal.batch_shape_tensor()), - self.evaluate(sf).shape) - self.assertAllEqual(normal.batch_shape, sf.get_shape()) - self.assertAllEqual(normal.batch_shape, self.evaluate(sf).shape) - if not stats: - return - expected_sf = stats.norm(mu, sigma).sf(x) - self.assertAllClose(expected_sf, self.evaluate(sf), atol=0) + sf = normal.survival_function(x) + self.assertAllEqual( + self.evaluate(normal.batch_shape_tensor()), sf.get_shape()) + self.assertAllEqual( + self.evaluate(normal.batch_shape_tensor()), + self.evaluate(sf).shape) + self.assertAllEqual(normal.batch_shape, sf.get_shape()) + self.assertAllEqual(normal.batch_shape, self.evaluate(sf).shape) + if not stats: + return + expected_sf = stats.norm(mu, sigma).sf(x) + self.assertAllClose(expected_sf, self.evaluate(sf), atol=0) @test_util.run_in_graph_and_eager_modes def testNormalLogCDF(self): - with self.test_session(): - batch_size = 50 - mu = self._rng.randn(batch_size) - sigma = self._rng.rand(batch_size) + 1.0 - x = np.linspace(-100.0, 10.0, batch_size).astype(np.float64) + batch_size = 50 + mu = self._rng.randn(batch_size) + sigma = self._rng.rand(batch_size) + 1.0 + x = np.linspace(-100.0, 10.0, batch_size).astype(np.float64) - normal = normal_lib.Normal(loc=mu, scale=sigma) + normal = normal_lib.Normal(loc=mu, scale=sigma) - cdf = normal.log_cdf(x) - self.assertAllEqual( - self.evaluate(normal.batch_shape_tensor()), cdf.get_shape()) - self.assertAllEqual( - self.evaluate(normal.batch_shape_tensor()), - self.evaluate(cdf).shape) - self.assertAllEqual(normal.batch_shape, cdf.get_shape()) - self.assertAllEqual(normal.batch_shape, self.evaluate(cdf).shape) + cdf = normal.log_cdf(x) + self.assertAllEqual( + self.evaluate(normal.batch_shape_tensor()), cdf.get_shape()) + self.assertAllEqual( + self.evaluate(normal.batch_shape_tensor()), + self.evaluate(cdf).shape) + self.assertAllEqual(normal.batch_shape, cdf.get_shape()) + self.assertAllEqual(normal.batch_shape, self.evaluate(cdf).shape) - if not stats: - return - expected_cdf = stats.norm(mu, sigma).logcdf(x) - self.assertAllClose(expected_cdf, self.evaluate(cdf), atol=0, rtol=1e-3) + if not stats: + return + expected_cdf = stats.norm(mu, sigma).logcdf(x) + self.assertAllClose(expected_cdf, self.evaluate(cdf), atol=0, rtol=1e-3) def testFiniteGradientAtDifficultPoints(self): for dtype in [np.float32, np.float64]: @@ -256,7 +249,7 @@ class NormalTest(test.TestCase): ]: value = func(x) grads = gradients_impl.gradients(value, [mu, sigma]) - with self.test_session(graph=g): + with self.session(graph=g): variables.global_variables_initializer().run() self.assertAllFinite(value) self.assertAllFinite(grads[0]) @@ -264,112 +257,106 @@ class NormalTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def testNormalLogSurvivalFunction(self): - with self.test_session(): - batch_size = 50 - mu = self._rng.randn(batch_size) - sigma = self._rng.rand(batch_size) + 1.0 - x = np.linspace(-10.0, 100.0, batch_size).astype(np.float64) + batch_size = 50 + mu = self._rng.randn(batch_size) + sigma = self._rng.rand(batch_size) + 1.0 + x = np.linspace(-10.0, 100.0, batch_size).astype(np.float64) - normal = normal_lib.Normal(loc=mu, scale=sigma) + normal = normal_lib.Normal(loc=mu, scale=sigma) - sf = normal.log_survival_function(x) - self.assertAllEqual( - self.evaluate(normal.batch_shape_tensor()), sf.get_shape()) - self.assertAllEqual( - self.evaluate(normal.batch_shape_tensor()), - self.evaluate(sf).shape) - self.assertAllEqual(normal.batch_shape, sf.get_shape()) - self.assertAllEqual(normal.batch_shape, self.evaluate(sf).shape) + sf = normal.log_survival_function(x) + self.assertAllEqual( + self.evaluate(normal.batch_shape_tensor()), sf.get_shape()) + self.assertAllEqual( + self.evaluate(normal.batch_shape_tensor()), + self.evaluate(sf).shape) + self.assertAllEqual(normal.batch_shape, sf.get_shape()) + self.assertAllEqual(normal.batch_shape, self.evaluate(sf).shape) - if not stats: - return - expected_sf = stats.norm(mu, sigma).logsf(x) - self.assertAllClose(expected_sf, self.evaluate(sf), atol=0, rtol=1e-5) + if not stats: + return + expected_sf = stats.norm(mu, sigma).logsf(x) + self.assertAllClose(expected_sf, self.evaluate(sf), atol=0, rtol=1e-5) @test_util.run_in_graph_and_eager_modes def testNormalEntropyWithScalarInputs(self): # Scipy.stats.norm cannot deal with the shapes in the other test. - with self.test_session(): - mu_v = 2.34 - sigma_v = 4.56 - normal = normal_lib.Normal(loc=mu_v, scale=sigma_v) - - entropy = normal.entropy() - self.assertAllEqual( - self.evaluate(normal.batch_shape_tensor()), entropy.get_shape()) - self.assertAllEqual( - self.evaluate(normal.batch_shape_tensor()), - self.evaluate(entropy).shape) - self.assertAllEqual(normal.batch_shape, entropy.get_shape()) - self.assertAllEqual(normal.batch_shape, self.evaluate(entropy).shape) - # scipy.stats.norm cannot deal with these shapes. - if not stats: - return - expected_entropy = stats.norm(mu_v, sigma_v).entropy() - self.assertAllClose(expected_entropy, self.evaluate(entropy)) + mu_v = 2.34 + sigma_v = 4.56 + normal = normal_lib.Normal(loc=mu_v, scale=sigma_v) + + entropy = normal.entropy() + self.assertAllEqual( + self.evaluate(normal.batch_shape_tensor()), entropy.get_shape()) + self.assertAllEqual( + self.evaluate(normal.batch_shape_tensor()), + self.evaluate(entropy).shape) + self.assertAllEqual(normal.batch_shape, entropy.get_shape()) + self.assertAllEqual(normal.batch_shape, self.evaluate(entropy).shape) + # scipy.stats.norm cannot deal with these shapes. + if not stats: + return + expected_entropy = stats.norm(mu_v, sigma_v).entropy() + self.assertAllClose(expected_entropy, self.evaluate(entropy)) @test_util.run_in_graph_and_eager_modes def testNormalEntropy(self): - with self.test_session(): - mu_v = np.array([1.0, 1.0, 1.0]) - sigma_v = np.array([[1.0, 2.0, 3.0]]).T - normal = normal_lib.Normal(loc=mu_v, scale=sigma_v) - - # scipy.stats.norm cannot deal with these shapes. - sigma_broadcast = mu_v * sigma_v - expected_entropy = 0.5 * np.log(2 * np.pi * np.exp(1) * sigma_broadcast** - 2) - entropy = normal.entropy() - np.testing.assert_allclose(expected_entropy, self.evaluate(entropy)) - self.assertAllEqual( - self.evaluate(normal.batch_shape_tensor()), entropy.get_shape()) - self.assertAllEqual( - self.evaluate(normal.batch_shape_tensor()), - self.evaluate(entropy).shape) - self.assertAllEqual(normal.batch_shape, entropy.get_shape()) - self.assertAllEqual(normal.batch_shape, self.evaluate(entropy).shape) - - @test_util.run_in_graph_and_eager_modes + mu_v = np.array([1.0, 1.0, 1.0]) + sigma_v = np.array([[1.0, 2.0, 3.0]]).T + normal = normal_lib.Normal(loc=mu_v, scale=sigma_v) + + # scipy.stats.norm cannot deal with these shapes. + sigma_broadcast = mu_v * sigma_v + expected_entropy = 0.5 * np.log(2 * np.pi * np.exp(1) * sigma_broadcast**2) + entropy = normal.entropy() + np.testing.assert_allclose(expected_entropy, self.evaluate(entropy)) + self.assertAllEqual( + self.evaluate(normal.batch_shape_tensor()), entropy.get_shape()) + self.assertAllEqual( + self.evaluate(normal.batch_shape_tensor()), + self.evaluate(entropy).shape) + self.assertAllEqual(normal.batch_shape, entropy.get_shape()) + self.assertAllEqual(normal.batch_shape, self.evaluate(entropy).shape) + + @test_util.run_in_graph_and_eager_modes(assert_no_eager_garbage=True) def testNormalMeanAndMode(self): - with self.test_session(): - # Mu will be broadcast to [7, 7, 7]. - mu = [7.] - sigma = [11., 12., 13.] + # Mu will be broadcast to [7, 7, 7]. + mu = [7.] + sigma = [11., 12., 13.] - normal = normal_lib.Normal(loc=mu, scale=sigma) + normal = normal_lib.Normal(loc=mu, scale=sigma) - self.assertAllEqual((3,), normal.mean().get_shape()) - self.assertAllEqual([7., 7, 7], self.evaluate(normal.mean())) + self.assertAllEqual((3,), normal.mean().get_shape()) + self.assertAllEqual([7., 7, 7], self.evaluate(normal.mean())) - self.assertAllEqual((3,), normal.mode().get_shape()) - self.assertAllEqual([7., 7, 7], self.evaluate(normal.mode())) + self.assertAllEqual((3,), normal.mode().get_shape()) + self.assertAllEqual([7., 7, 7], self.evaluate(normal.mode())) @test_util.run_in_graph_and_eager_modes def testNormalQuantile(self): - with self.test_session(): - batch_size = 52 - mu = self._rng.randn(batch_size) - sigma = self._rng.rand(batch_size) + 1.0 - p = np.linspace(0., 1.0, batch_size - 2).astype(np.float64) - # Quantile performs piecewise rational approximation so adding some - # special input values to make sure we hit all the pieces. - p = np.hstack((p, np.exp(-33), 1. - np.exp(-33))) + batch_size = 52 + mu = self._rng.randn(batch_size) + sigma = self._rng.rand(batch_size) + 1.0 + p = np.linspace(0., 1.0, batch_size - 2).astype(np.float64) + # Quantile performs piecewise rational approximation so adding some + # special input values to make sure we hit all the pieces. + p = np.hstack((p, np.exp(-33), 1. - np.exp(-33))) - normal = normal_lib.Normal(loc=mu, scale=sigma) - x = normal.quantile(p) + normal = normal_lib.Normal(loc=mu, scale=sigma) + x = normal.quantile(p) - self.assertAllEqual( - self.evaluate(normal.batch_shape_tensor()), x.get_shape()) - self.assertAllEqual( - self.evaluate(normal.batch_shape_tensor()), - self.evaluate(x).shape) - self.assertAllEqual(normal.batch_shape, x.get_shape()) - self.assertAllEqual(normal.batch_shape, self.evaluate(x).shape) + self.assertAllEqual( + self.evaluate(normal.batch_shape_tensor()), x.get_shape()) + self.assertAllEqual( + self.evaluate(normal.batch_shape_tensor()), + self.evaluate(x).shape) + self.assertAllEqual(normal.batch_shape, x.get_shape()) + self.assertAllEqual(normal.batch_shape, self.evaluate(x).shape) - if not stats: - return - expected_x = stats.norm(mu, sigma).ppf(p) - self.assertAllClose(expected_x, self.evaluate(x), atol=0.) + if not stats: + return + expected_x = stats.norm(mu, sigma).ppf(p) + self.assertAllClose(expected_x, self.evaluate(x), atol=0.) def _baseQuantileFiniteGradientAtDifficultPoints(self, dtype): g = ops.Graph() @@ -385,7 +372,7 @@ class NormalTest(test.TestCase): value = dist.quantile(p) grads = gradients_impl.gradients(value, [mu, p]) - with self.test_session(graph=g): + with self.cached_session(graph=g): variables.global_variables_initializer().run() self.assertAllFinite(grads[0]) self.assertAllFinite(grads[1]) @@ -398,61 +385,58 @@ class NormalTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def testNormalVariance(self): - with self.test_session(): - # sigma will be broadcast to [7, 7, 7] - mu = [1., 2., 3.] - sigma = [7.] + # sigma will be broadcast to [7, 7, 7] + mu = [1., 2., 3.] + sigma = [7.] - normal = normal_lib.Normal(loc=mu, scale=sigma) + normal = normal_lib.Normal(loc=mu, scale=sigma) - self.assertAllEqual((3,), normal.variance().get_shape()) - self.assertAllEqual([49., 49, 49], self.evaluate(normal.variance())) + self.assertAllEqual((3,), normal.variance().get_shape()) + self.assertAllEqual([49., 49, 49], self.evaluate(normal.variance())) @test_util.run_in_graph_and_eager_modes def testNormalStandardDeviation(self): - with self.test_session(): - # sigma will be broadcast to [7, 7, 7] - mu = [1., 2., 3.] - sigma = [7.] + # sigma will be broadcast to [7, 7, 7] + mu = [1., 2., 3.] + sigma = [7.] - normal = normal_lib.Normal(loc=mu, scale=sigma) + normal = normal_lib.Normal(loc=mu, scale=sigma) - self.assertAllEqual((3,), normal.stddev().get_shape()) - self.assertAllEqual([7., 7, 7], self.evaluate(normal.stddev())) + self.assertAllEqual((3,), normal.stddev().get_shape()) + self.assertAllEqual([7., 7, 7], self.evaluate(normal.stddev())) @test_util.run_in_graph_and_eager_modes def testNormalSample(self): - with self.test_session(): - mu = constant_op.constant(3.0) - sigma = constant_op.constant(math.sqrt(3.0)) - mu_v = 3.0 - sigma_v = np.sqrt(3.0) - n = constant_op.constant(100000) - normal = normal_lib.Normal(loc=mu, scale=sigma) - samples = normal.sample(n) - sample_values = self.evaluate(samples) - # Note that the standard error for the sample mean is ~ sigma / sqrt(n). - # The sample variance similarly is dependent on sigma and n. - # Thus, the tolerances below are very sensitive to number of samples - # as well as the variances chosen. - self.assertEqual(sample_values.shape, (100000,)) - self.assertAllClose(sample_values.mean(), mu_v, atol=1e-1) - self.assertAllClose(sample_values.std(), sigma_v, atol=1e-1) - - expected_samples_shape = tensor_shape.TensorShape( - [self.evaluate(n)]).concatenate( - tensor_shape.TensorShape( - self.evaluate(normal.batch_shape_tensor()))) - - self.assertAllEqual(expected_samples_shape, samples.get_shape()) - self.assertAllEqual(expected_samples_shape, sample_values.shape) - - expected_samples_shape = ( - tensor_shape.TensorShape([self.evaluate(n)]).concatenate( - normal.batch_shape)) - - self.assertAllEqual(expected_samples_shape, samples.get_shape()) - self.assertAllEqual(expected_samples_shape, sample_values.shape) + mu = constant_op.constant(3.0) + sigma = constant_op.constant(math.sqrt(3.0)) + mu_v = 3.0 + sigma_v = np.sqrt(3.0) + n = constant_op.constant(100000) + normal = normal_lib.Normal(loc=mu, scale=sigma) + samples = normal.sample(n) + sample_values = self.evaluate(samples) + # Note that the standard error for the sample mean is ~ sigma / sqrt(n). + # The sample variance similarly is dependent on sigma and n. + # Thus, the tolerances below are very sensitive to number of samples + # as well as the variances chosen. + self.assertEqual(sample_values.shape, (100000,)) + self.assertAllClose(sample_values.mean(), mu_v, atol=1e-1) + self.assertAllClose(sample_values.std(), sigma_v, atol=1e-1) + + expected_samples_shape = tensor_shape.TensorShape( + [self.evaluate(n)]).concatenate( + tensor_shape.TensorShape( + self.evaluate(normal.batch_shape_tensor()))) + + self.assertAllEqual(expected_samples_shape, samples.get_shape()) + self.assertAllEqual(expected_samples_shape, sample_values.shape) + + expected_samples_shape = ( + tensor_shape.TensorShape([self.evaluate(n)]).concatenate( + normal.batch_shape)) + + self.assertAllEqual(expected_samples_shape, samples.get_shape()) + self.assertAllEqual(expected_samples_shape, sample_values.shape) def testNormalFullyReparameterized(self): mu = constant_op.constant(4.0) @@ -468,66 +452,63 @@ class NormalTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def testNormalSampleMultiDimensional(self): - with self.test_session(): - batch_size = 2 - mu = constant_op.constant([[3.0, -3.0]] * batch_size) - sigma = constant_op.constant([[math.sqrt(2.0), math.sqrt(3.0)]] * - batch_size) - mu_v = [3.0, -3.0] - sigma_v = [np.sqrt(2.0), np.sqrt(3.0)] - n = constant_op.constant(100000) - normal = normal_lib.Normal(loc=mu, scale=sigma) - samples = normal.sample(n) - sample_values = self.evaluate(samples) - # Note that the standard error for the sample mean is ~ sigma / sqrt(n). - # The sample variance similarly is dependent on sigma and n. - # Thus, the tolerances below are very sensitive to number of samples - # as well as the variances chosen. - self.assertEqual(samples.get_shape(), (100000, batch_size, 2)) - self.assertAllClose(sample_values[:, 0, 0].mean(), mu_v[0], atol=1e-1) - self.assertAllClose(sample_values[:, 0, 0].std(), sigma_v[0], atol=1e-1) - self.assertAllClose(sample_values[:, 0, 1].mean(), mu_v[1], atol=1e-1) - self.assertAllClose(sample_values[:, 0, 1].std(), sigma_v[1], atol=1e-1) - - expected_samples_shape = tensor_shape.TensorShape( - [self.evaluate(n)]).concatenate( - tensor_shape.TensorShape( - self.evaluate(normal.batch_shape_tensor()))) - self.assertAllEqual(expected_samples_shape, samples.get_shape()) - self.assertAllEqual(expected_samples_shape, sample_values.shape) - - expected_samples_shape = ( - tensor_shape.TensorShape([self.evaluate(n)]).concatenate( - normal.batch_shape)) - self.assertAllEqual(expected_samples_shape, samples.get_shape()) - self.assertAllEqual(expected_samples_shape, sample_values.shape) + batch_size = 2 + mu = constant_op.constant([[3.0, -3.0]] * batch_size) + sigma = constant_op.constant( + [[math.sqrt(2.0), math.sqrt(3.0)]] * batch_size) + mu_v = [3.0, -3.0] + sigma_v = [np.sqrt(2.0), np.sqrt(3.0)] + n = constant_op.constant(100000) + normal = normal_lib.Normal(loc=mu, scale=sigma) + samples = normal.sample(n) + sample_values = self.evaluate(samples) + # Note that the standard error for the sample mean is ~ sigma / sqrt(n). + # The sample variance similarly is dependent on sigma and n. + # Thus, the tolerances below are very sensitive to number of samples + # as well as the variances chosen. + self.assertEqual(samples.get_shape(), (100000, batch_size, 2)) + self.assertAllClose(sample_values[:, 0, 0].mean(), mu_v[0], atol=1e-1) + self.assertAllClose(sample_values[:, 0, 0].std(), sigma_v[0], atol=1e-1) + self.assertAllClose(sample_values[:, 0, 1].mean(), mu_v[1], atol=1e-1) + self.assertAllClose(sample_values[:, 0, 1].std(), sigma_v[1], atol=1e-1) + + expected_samples_shape = tensor_shape.TensorShape( + [self.evaluate(n)]).concatenate( + tensor_shape.TensorShape( + self.evaluate(normal.batch_shape_tensor()))) + self.assertAllEqual(expected_samples_shape, samples.get_shape()) + self.assertAllEqual(expected_samples_shape, sample_values.shape) + + expected_samples_shape = ( + tensor_shape.TensorShape([self.evaluate(n)]).concatenate( + normal.batch_shape)) + self.assertAllEqual(expected_samples_shape, samples.get_shape()) + self.assertAllEqual(expected_samples_shape, sample_values.shape) @test_util.run_in_graph_and_eager_modes def testNegativeSigmaFails(self): - with self.test_session(): - with self.assertRaisesOpError("Condition x > 0 did not hold"): - normal = normal_lib.Normal( - loc=[1.], scale=[-5.], validate_args=True, name="G") - self.evaluate(normal.mean()) + with self.assertRaisesOpError("Condition x > 0 did not hold"): + normal = normal_lib.Normal( + loc=[1.], scale=[-5.], validate_args=True, name="G") + self.evaluate(normal.mean()) @test_util.run_in_graph_and_eager_modes def testNormalShape(self): - with self.test_session(): - mu = constant_op.constant([-3.0] * 5) - sigma = constant_op.constant(11.0) - normal = normal_lib.Normal(loc=mu, scale=sigma) + mu = constant_op.constant([-3.0] * 5) + sigma = constant_op.constant(11.0) + normal = normal_lib.Normal(loc=mu, scale=sigma) - self.assertEqual(self.evaluate(normal.batch_shape_tensor()), [5]) - self.assertEqual(normal.batch_shape, tensor_shape.TensorShape([5])) - self.assertAllEqual(self.evaluate(normal.event_shape_tensor()), []) - self.assertEqual(normal.event_shape, tensor_shape.TensorShape([])) + self.assertEqual(self.evaluate(normal.batch_shape_tensor()), [5]) + self.assertEqual(normal.batch_shape, tensor_shape.TensorShape([5])) + self.assertAllEqual(self.evaluate(normal.event_shape_tensor()), []) + self.assertEqual(normal.event_shape, tensor_shape.TensorShape([])) def testNormalShapeWithPlaceholders(self): mu = array_ops.placeholder(dtype=dtypes.float32) sigma = array_ops.placeholder(dtype=dtypes.float32) normal = normal_lib.Normal(loc=mu, scale=sigma) - with self.test_session() as sess: + with self.cached_session() as sess: # get_batch_shape should return an "<unknown>" tensor. self.assertEqual(normal.batch_shape, tensor_shape.TensorShape(None)) self.assertEqual(normal.event_shape, ()) diff --git a/tensorflow/python/kernel_tests/distributions/special_math_test.py b/tensorflow/python/kernel_tests/distributions/special_math_test.py index a634194ce5..cc43e12168 100644 --- a/tensorflow/python/kernel_tests/distributions/special_math_test.py +++ b/tensorflow/python/kernel_tests/distributions/special_math_test.py @@ -92,22 +92,21 @@ class NdtriTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def testNdtri(self): """Verifies that ndtri computation is correct.""" - with self.test_session(): - if not special: - return + if not special: + return - p = np.linspace(0., 1.0, 50).astype(np.float64) - # Quantile performs piecewise rational approximation so adding some - # special input values to make sure we hit all the pieces. - p = np.hstack((p, np.exp(-32), 1. - np.exp(-32), - np.exp(-2), 1. - np.exp(-2))) - expected_x = special.ndtri(p) - x = special_math.ndtri(p) - self.assertAllClose(expected_x, self.evaluate(x), atol=0.) + p = np.linspace(0., 1.0, 50).astype(np.float64) + # Quantile performs piecewise rational approximation so adding some + # special input values to make sure we hit all the pieces. + p = np.hstack((p, np.exp(-32), 1. - np.exp(-32), np.exp(-2), + 1. - np.exp(-2))) + expected_x = special.ndtri(p) + x = special_math.ndtri(p) + self.assertAllClose(expected_x, self.evaluate(x), atol=0.) def testNdtriDynamicShape(self): """Verifies that ndtri computation is correct.""" - with self.test_session() as sess: + with self.cached_session() as sess: if not special: return @@ -286,7 +285,7 @@ class NdtrGradientTest(test.TestCase): def _test_grad_accuracy(self, dtype, grid_spec, error_spec): raw_grid = _make_grid(dtype, grid_spec) grid = ops.convert_to_tensor(raw_grid) - with self.test_session(): + with self.cached_session(): fn = sm.log_ndtr if self._use_log else sm.ndtr # If there are N points in the grid, @@ -355,7 +354,7 @@ class LogNdtrGradientTest(NdtrGradientTest): class ErfInvTest(test.TestCase): def testErfInvValues(self): - with self.test_session(): + with self.cached_session(): if not special: return @@ -366,7 +365,7 @@ class ErfInvTest(test.TestCase): self.assertAllClose(expected_x, x.eval(), atol=0.) def testErfInvIntegerInput(self): - with self.test_session(): + with self.cached_session(): with self.assertRaises(TypeError): x = np.array([1, 2, 3]).astype(np.int32) @@ -397,7 +396,7 @@ class LogCDFLaplaceTest(test.TestCase): self.assertAllEqual(np.ones_like(x, dtype=np.bool), x) def _test_grid_log(self, dtype, scipy_dtype, grid_spec, error_spec): - with self.test_session(): + with self.cached_session(): grid = _make_grid(dtype, grid_spec) actual = sm.log_cdf_laplace(grid).eval() @@ -439,7 +438,7 @@ class LogCDFLaplaceTest(test.TestCase): ErrorSpec(rtol=0.05, atol=0)) def test_float32_extreme_values_result_and_gradient_finite_and_nonzero(self): - with self.test_session() as sess: + with self.cached_session() as sess: # On the lower branch, log_cdf_laplace(x) = x, so we know this will be # fine, but test to -200 anyways. grid = _make_grid( @@ -458,7 +457,7 @@ class LogCDFLaplaceTest(test.TestCase): self.assertFalse(np.any(grad_ == 0)) def test_float64_extreme_values_result_and_gradient_finite_and_nonzero(self): - with self.test_session() as sess: + with self.cached_session() as sess: # On the lower branch, log_cdf_laplace(x) = x, so we know this will be # fine, but test to -200 anyways. grid = _make_grid( diff --git a/tensorflow/python/kernel_tests/distributions/student_t_test.py b/tensorflow/python/kernel_tests/distributions/student_t_test.py index 05590542ef..b34b538160 100644 --- a/tensorflow/python/kernel_tests/distributions/student_t_test.py +++ b/tensorflow/python/kernel_tests/distributions/student_t_test.py @@ -50,100 +50,96 @@ stats = try_import("scipy.stats") class StudentTTest(test.TestCase): def testStudentPDFAndLogPDF(self): - with self.test_session(): - batch_size = 6 - df = constant_op.constant([3.] * batch_size) - mu = constant_op.constant([7.] * batch_size) - sigma = constant_op.constant([8.] * batch_size) - df_v = 3. - mu_v = 7. - sigma_v = 8. - t = np.array([-2.5, 2.5, 8., 0., -1., 2.], dtype=np.float32) - student = student_t.StudentT(df, loc=mu, scale=-sigma) - - log_pdf = student.log_prob(t) - self.assertEquals(log_pdf.get_shape(), (6,)) - log_pdf_values = self.evaluate(log_pdf) - pdf = student.prob(t) - self.assertEquals(pdf.get_shape(), (6,)) - pdf_values = self.evaluate(pdf) - - if not stats: - return - - expected_log_pdf = stats.t.logpdf(t, df_v, loc=mu_v, scale=sigma_v) - expected_pdf = stats.t.pdf(t, df_v, loc=mu_v, scale=sigma_v) - self.assertAllClose(expected_log_pdf, log_pdf_values) - self.assertAllClose(np.log(expected_pdf), log_pdf_values) - self.assertAllClose(expected_pdf, pdf_values) - self.assertAllClose(np.exp(expected_log_pdf), pdf_values) + batch_size = 6 + df = constant_op.constant([3.] * batch_size) + mu = constant_op.constant([7.] * batch_size) + sigma = constant_op.constant([8.] * batch_size) + df_v = 3. + mu_v = 7. + sigma_v = 8. + t = np.array([-2.5, 2.5, 8., 0., -1., 2.], dtype=np.float32) + student = student_t.StudentT(df, loc=mu, scale=-sigma) + + log_pdf = student.log_prob(t) + self.assertEquals(log_pdf.get_shape(), (6,)) + log_pdf_values = self.evaluate(log_pdf) + pdf = student.prob(t) + self.assertEquals(pdf.get_shape(), (6,)) + pdf_values = self.evaluate(pdf) + + if not stats: + return + + expected_log_pdf = stats.t.logpdf(t, df_v, loc=mu_v, scale=sigma_v) + expected_pdf = stats.t.pdf(t, df_v, loc=mu_v, scale=sigma_v) + self.assertAllClose(expected_log_pdf, log_pdf_values) + self.assertAllClose(np.log(expected_pdf), log_pdf_values) + self.assertAllClose(expected_pdf, pdf_values) + self.assertAllClose(np.exp(expected_log_pdf), pdf_values) def testStudentLogPDFMultidimensional(self): - with self.test_session(): - batch_size = 6 - df = constant_op.constant([[1.5, 7.2]] * batch_size) - mu = constant_op.constant([[3., -3.]] * batch_size) - sigma = constant_op.constant([[-math.sqrt(10.), math.sqrt(15.)]] * - batch_size) - df_v = np.array([1.5, 7.2]) - mu_v = np.array([3., -3.]) - sigma_v = np.array([np.sqrt(10.), np.sqrt(15.)]) - t = np.array([[-2.5, 2.5, 4., 0., -1., 2.]], dtype=np.float32).T - student = student_t.StudentT(df, loc=mu, scale=sigma) - log_pdf = student.log_prob(t) - log_pdf_values = self.evaluate(log_pdf) - self.assertEqual(log_pdf.get_shape(), (6, 2)) - pdf = student.prob(t) - pdf_values = self.evaluate(pdf) - self.assertEqual(pdf.get_shape(), (6, 2)) - - if not stats: - return - expected_log_pdf = stats.t.logpdf(t, df_v, loc=mu_v, scale=sigma_v) - expected_pdf = stats.t.pdf(t, df_v, loc=mu_v, scale=sigma_v) - self.assertAllClose(expected_log_pdf, log_pdf_values) - self.assertAllClose(np.log(expected_pdf), log_pdf_values) - self.assertAllClose(expected_pdf, pdf_values) - self.assertAllClose(np.exp(expected_log_pdf), pdf_values) + batch_size = 6 + df = constant_op.constant([[1.5, 7.2]] * batch_size) + mu = constant_op.constant([[3., -3.]] * batch_size) + sigma = constant_op.constant( + [[-math.sqrt(10.), math.sqrt(15.)]] * batch_size) + df_v = np.array([1.5, 7.2]) + mu_v = np.array([3., -3.]) + sigma_v = np.array([np.sqrt(10.), np.sqrt(15.)]) + t = np.array([[-2.5, 2.5, 4., 0., -1., 2.]], dtype=np.float32).T + student = student_t.StudentT(df, loc=mu, scale=sigma) + log_pdf = student.log_prob(t) + log_pdf_values = self.evaluate(log_pdf) + self.assertEqual(log_pdf.get_shape(), (6, 2)) + pdf = student.prob(t) + pdf_values = self.evaluate(pdf) + self.assertEqual(pdf.get_shape(), (6, 2)) + + if not stats: + return + expected_log_pdf = stats.t.logpdf(t, df_v, loc=mu_v, scale=sigma_v) + expected_pdf = stats.t.pdf(t, df_v, loc=mu_v, scale=sigma_v) + self.assertAllClose(expected_log_pdf, log_pdf_values) + self.assertAllClose(np.log(expected_pdf), log_pdf_values) + self.assertAllClose(expected_pdf, pdf_values) + self.assertAllClose(np.exp(expected_log_pdf), pdf_values) def testStudentCDFAndLogCDF(self): - with self.test_session(): - batch_size = 6 - df = constant_op.constant([3.] * batch_size) - mu = constant_op.constant([7.] * batch_size) - sigma = constant_op.constant([-8.] * batch_size) - df_v = 3. - mu_v = 7. - sigma_v = 8. - t = np.array([-2.5, 2.5, 8., 0., -1., 2.], dtype=np.float32) - student = student_t.StudentT(df, loc=mu, scale=sigma) - - log_cdf = student.log_cdf(t) - self.assertEquals(log_cdf.get_shape(), (6,)) - log_cdf_values = self.evaluate(log_cdf) - cdf = student.cdf(t) - self.assertEquals(cdf.get_shape(), (6,)) - cdf_values = self.evaluate(cdf) - - if not stats: - return - expected_log_cdf = stats.t.logcdf(t, df_v, loc=mu_v, scale=sigma_v) - expected_cdf = stats.t.cdf(t, df_v, loc=mu_v, scale=sigma_v) - self.assertAllClose(expected_log_cdf, log_cdf_values, atol=0., rtol=1e-5) - self.assertAllClose( - np.log(expected_cdf), log_cdf_values, atol=0., rtol=1e-5) - self.assertAllClose(expected_cdf, cdf_values, atol=0., rtol=1e-5) - self.assertAllClose( - np.exp(expected_log_cdf), cdf_values, atol=0., rtol=1e-5) + batch_size = 6 + df = constant_op.constant([3.] * batch_size) + mu = constant_op.constant([7.] * batch_size) + sigma = constant_op.constant([-8.] * batch_size) + df_v = 3. + mu_v = 7. + sigma_v = 8. + t = np.array([-2.5, 2.5, 8., 0., -1., 2.], dtype=np.float32) + student = student_t.StudentT(df, loc=mu, scale=sigma) + + log_cdf = student.log_cdf(t) + self.assertEquals(log_cdf.get_shape(), (6,)) + log_cdf_values = self.evaluate(log_cdf) + cdf = student.cdf(t) + self.assertEquals(cdf.get_shape(), (6,)) + cdf_values = self.evaluate(cdf) + + if not stats: + return + expected_log_cdf = stats.t.logcdf(t, df_v, loc=mu_v, scale=sigma_v) + expected_cdf = stats.t.cdf(t, df_v, loc=mu_v, scale=sigma_v) + self.assertAllClose(expected_log_cdf, log_cdf_values, atol=0., rtol=1e-5) + self.assertAllClose( + np.log(expected_cdf), log_cdf_values, atol=0., rtol=1e-5) + self.assertAllClose(expected_cdf, cdf_values, atol=0., rtol=1e-5) + self.assertAllClose( + np.exp(expected_log_cdf), cdf_values, atol=0., rtol=1e-5) def testStudentEntropy(self): df_v = np.array([[2., 3., 7.]]) # 1x3 mu_v = np.array([[1., -1, 0]]) # 1x3 sigma_v = np.array([[1., -2., 3.]]).T # transposed => 3x1 - with self.test_session(): - student = student_t.StudentT(df=df_v, loc=mu_v, scale=sigma_v) - ent = student.entropy() - ent_values = self.evaluate(ent) + student = student_t.StudentT(df=df_v, loc=mu_v, scale=sigma_v) + ent = student.entropy() + ent_values = self.evaluate(ent) # Help scipy broadcast to 3x3 ones = np.array([[1, 1, 1]]) @@ -160,90 +156,81 @@ class StudentTTest(test.TestCase): self.assertAllClose(expected_entropy, ent_values) def testStudentSample(self): - with self.test_session(): - df = constant_op.constant(4.) - mu = constant_op.constant(3.) - sigma = constant_op.constant(-math.sqrt(10.)) - df_v = 4. - mu_v = 3. - sigma_v = np.sqrt(10.) - n = constant_op.constant(200000) - student = student_t.StudentT(df=df, loc=mu, scale=sigma) - samples = student.sample(n, seed=123456) - sample_values = self.evaluate(samples) - n_val = 200000 - self.assertEqual(sample_values.shape, (n_val,)) - self.assertAllClose(sample_values.mean(), mu_v, rtol=0.1, atol=0) - self.assertAllClose( - sample_values.var(), - sigma_v**2 * df_v / (df_v - 2), - rtol=0.1, - atol=0) - self._checkKLApprox(df_v, mu_v, sigma_v, sample_values) + df = constant_op.constant(4.) + mu = constant_op.constant(3.) + sigma = constant_op.constant(-math.sqrt(10.)) + df_v = 4. + mu_v = 3. + sigma_v = np.sqrt(10.) + n = constant_op.constant(200000) + student = student_t.StudentT(df=df, loc=mu, scale=sigma) + samples = student.sample(n, seed=123456) + sample_values = self.evaluate(samples) + n_val = 200000 + self.assertEqual(sample_values.shape, (n_val,)) + self.assertAllClose(sample_values.mean(), mu_v, rtol=0.1, atol=0) + self.assertAllClose( + sample_values.var(), sigma_v**2 * df_v / (df_v - 2), rtol=0.1, atol=0) + self._checkKLApprox(df_v, mu_v, sigma_v, sample_values) # Test that sampling with the same seed twice gives the same results. def testStudentSampleMultipleTimes(self): - with self.test_session(): - df = constant_op.constant(4.) - mu = constant_op.constant(3.) - sigma = constant_op.constant(math.sqrt(10.)) - n = constant_op.constant(100) + df = constant_op.constant(4.) + mu = constant_op.constant(3.) + sigma = constant_op.constant(math.sqrt(10.)) + n = constant_op.constant(100) - random_seed.set_random_seed(654321) - student = student_t.StudentT( - df=df, loc=mu, scale=sigma, name="student_t1") - samples1 = self.evaluate(student.sample(n, seed=123456)) + random_seed.set_random_seed(654321) + student = student_t.StudentT(df=df, loc=mu, scale=sigma, name="student_t1") + samples1 = self.evaluate(student.sample(n, seed=123456)) - random_seed.set_random_seed(654321) - student2 = student_t.StudentT( - df=df, loc=mu, scale=sigma, name="student_t2") - samples2 = self.evaluate(student2.sample(n, seed=123456)) + random_seed.set_random_seed(654321) + student2 = student_t.StudentT(df=df, loc=mu, scale=sigma, name="student_t2") + samples2 = self.evaluate(student2.sample(n, seed=123456)) - self.assertAllClose(samples1, samples2) + self.assertAllClose(samples1, samples2) def testStudentSampleSmallDfNoNan(self): - with self.test_session(): - df_v = [1e-1, 1e-5, 1e-10, 1e-20] - df = constant_op.constant(df_v) - n = constant_op.constant(200000) - student = student_t.StudentT(df=df, loc=1., scale=1.) - samples = student.sample(n, seed=123456) - sample_values = self.evaluate(samples) - n_val = 200000 - self.assertEqual(sample_values.shape, (n_val, 4)) - self.assertTrue(np.all(np.logical_not(np.isnan(sample_values)))) + df_v = [1e-1, 1e-5, 1e-10, 1e-20] + df = constant_op.constant(df_v) + n = constant_op.constant(200000) + student = student_t.StudentT(df=df, loc=1., scale=1.) + samples = student.sample(n, seed=123456) + sample_values = self.evaluate(samples) + n_val = 200000 + self.assertEqual(sample_values.shape, (n_val, 4)) + self.assertTrue(np.all(np.logical_not(np.isnan(sample_values)))) def testStudentSampleMultiDimensional(self): - with self.test_session(): - batch_size = 7 - df = constant_op.constant([[5., 7.]] * batch_size) - mu = constant_op.constant([[3., -3.]] * batch_size) - sigma = constant_op.constant([[math.sqrt(10.), math.sqrt(15.)]] * - batch_size) - df_v = [5., 7.] - mu_v = [3., -3.] - sigma_v = [np.sqrt(10.), np.sqrt(15.)] - n = constant_op.constant(200000) - student = student_t.StudentT(df=df, loc=mu, scale=sigma) - samples = student.sample(n, seed=123456) - sample_values = self.evaluate(samples) - self.assertEqual(samples.get_shape(), (200000, batch_size, 2)) - self.assertAllClose( - sample_values[:, 0, 0].mean(), mu_v[0], rtol=0.1, atol=0) - self.assertAllClose( - sample_values[:, 0, 0].var(), - sigma_v[0]**2 * df_v[0] / (df_v[0] - 2), - rtol=0.2, - atol=0) - self._checkKLApprox(df_v[0], mu_v[0], sigma_v[0], sample_values[:, 0, 0]) - self.assertAllClose( - sample_values[:, 0, 1].mean(), mu_v[1], rtol=0.1, atol=0) - self.assertAllClose( - sample_values[:, 0, 1].var(), - sigma_v[1]**2 * df_v[1] / (df_v[1] - 2), - rtol=0.2, - atol=0) - self._checkKLApprox(df_v[1], mu_v[1], sigma_v[1], sample_values[:, 0, 1]) + batch_size = 7 + df = constant_op.constant([[5., 7.]] * batch_size) + mu = constant_op.constant([[3., -3.]] * batch_size) + sigma = constant_op.constant( + [[math.sqrt(10.), math.sqrt(15.)]] * batch_size) + df_v = [5., 7.] + mu_v = [3., -3.] + sigma_v = [np.sqrt(10.), np.sqrt(15.)] + n = constant_op.constant(200000) + student = student_t.StudentT(df=df, loc=mu, scale=sigma) + samples = student.sample(n, seed=123456) + sample_values = self.evaluate(samples) + self.assertEqual(samples.get_shape(), (200000, batch_size, 2)) + self.assertAllClose( + sample_values[:, 0, 0].mean(), mu_v[0], rtol=0.1, atol=0) + self.assertAllClose( + sample_values[:, 0, 0].var(), + sigma_v[0]**2 * df_v[0] / (df_v[0] - 2), + rtol=0.2, + atol=0) + self._checkKLApprox(df_v[0], mu_v[0], sigma_v[0], sample_values[:, 0, 0]) + self.assertAllClose( + sample_values[:, 0, 1].mean(), mu_v[1], rtol=0.1, atol=0) + self.assertAllClose( + sample_values[:, 0, 1].var(), + sigma_v[1]**2 * df_v[1] / (df_v[1] - 2), + rtol=0.2, + atol=0) + self._checkKLApprox(df_v[1], mu_v[1], sigma_v[1], sample_values[:, 0, 1]) def _checkKLApprox(self, df, mu, sigma, samples): n = samples.size @@ -325,114 +312,102 @@ class StudentTTest(test.TestCase): _check2d_rows(student_t.StudentT(df=7., loc=3., scale=[[2.], [3.], [4.]])) def testMeanAllowNanStatsIsFalseWorksWhenAllBatchMembersAreDefined(self): - with self.test_session(): - mu = [1., 3.3, 4.4] - student = student_t.StudentT(df=[3., 5., 7.], loc=mu, scale=[3., 2., 1.]) - mean = self.evaluate(student.mean()) - self.assertAllClose([1., 3.3, 4.4], mean) + mu = [1., 3.3, 4.4] + student = student_t.StudentT(df=[3., 5., 7.], loc=mu, scale=[3., 2., 1.]) + mean = self.evaluate(student.mean()) + self.assertAllClose([1., 3.3, 4.4], mean) def testMeanAllowNanStatsIsFalseRaisesWhenBatchMemberIsUndefined(self): - with self.test_session(): - mu = [1., 3.3, 4.4] - student = student_t.StudentT( - df=[0.5, 5., 7.], loc=mu, scale=[3., 2., 1.], - allow_nan_stats=False) - with self.assertRaisesOpError("x < y"): - self.evaluate(student.mean()) + mu = [1., 3.3, 4.4] + student = student_t.StudentT( + df=[0.5, 5., 7.], loc=mu, scale=[3., 2., 1.], allow_nan_stats=False) + with self.assertRaisesOpError("x < y"): + self.evaluate(student.mean()) def testMeanAllowNanStatsIsTrueReturnsNaNForUndefinedBatchMembers(self): - with self.test_session(): - mu = [-2, 0., 1., 3.3, 4.4] - sigma = [5., 4., 3., 2., 1.] - student = student_t.StudentT( - df=[0.5, 1., 3., 5., 7.], loc=mu, scale=sigma, - allow_nan_stats=True) - mean = self.evaluate(student.mean()) - self.assertAllClose([np.nan, np.nan, 1., 3.3, 4.4], mean) + mu = [-2, 0., 1., 3.3, 4.4] + sigma = [5., 4., 3., 2., 1.] + student = student_t.StudentT( + df=[0.5, 1., 3., 5., 7.], loc=mu, scale=sigma, allow_nan_stats=True) + mean = self.evaluate(student.mean()) + self.assertAllClose([np.nan, np.nan, 1., 3.3, 4.4], mean) def testVarianceAllowNanStatsTrueReturnsNaNforUndefinedBatchMembers(self): - with self.test_session(): - # df = 0.5 ==> undefined mean ==> undefined variance. - # df = 1.5 ==> infinite variance. - df = [0.5, 1.5, 3., 5., 7.] - mu = [-2, 0., 1., 3.3, 4.4] - sigma = [5., 4., 3., 2., 1.] - student = student_t.StudentT( - df=df, loc=mu, scale=sigma, allow_nan_stats=True) - var = self.evaluate(student.variance()) - ## scipy uses inf for variance when the mean is undefined. When mean is - # undefined we say variance is undefined as well. So test the first - # member of var, making sure it is NaN, then replace with inf and compare - # to scipy. - self.assertTrue(np.isnan(var[0])) - var[0] = np.inf - - if not stats: - return - expected_var = [ - stats.t.var(d, loc=m, scale=s) for (d, m, s) in zip(df, mu, sigma) - ] - self.assertAllClose(expected_var, var) + # df = 0.5 ==> undefined mean ==> undefined variance. + # df = 1.5 ==> infinite variance. + df = [0.5, 1.5, 3., 5., 7.] + mu = [-2, 0., 1., 3.3, 4.4] + sigma = [5., 4., 3., 2., 1.] + student = student_t.StudentT( + df=df, loc=mu, scale=sigma, allow_nan_stats=True) + var = self.evaluate(student.variance()) + ## scipy uses inf for variance when the mean is undefined. When mean is + # undefined we say variance is undefined as well. So test the first + # member of var, making sure it is NaN, then replace with inf and compare + # to scipy. + self.assertTrue(np.isnan(var[0])) + var[0] = np.inf + + if not stats: + return + expected_var = [ + stats.t.var(d, loc=m, scale=s) for (d, m, s) in zip(df, mu, sigma) + ] + self.assertAllClose(expected_var, var) def testVarianceAllowNanStatsFalseGivesCorrectValueForDefinedBatchMembers( self): - with self.test_session(): - # df = 1.5 ==> infinite variance. - df = [1.5, 3., 5., 7.] - mu = [0., 1., 3.3, 4.4] - sigma = [4., 3., 2., 1.] - student = student_t.StudentT(df=df, loc=mu, scale=sigma) - var = self.evaluate(student.variance()) + # df = 1.5 ==> infinite variance. + df = [1.5, 3., 5., 7.] + mu = [0., 1., 3.3, 4.4] + sigma = [4., 3., 2., 1.] + student = student_t.StudentT(df=df, loc=mu, scale=sigma) + var = self.evaluate(student.variance()) - if not stats: - return - expected_var = [ - stats.t.var(d, loc=m, scale=s) for (d, m, s) in zip(df, mu, sigma) - ] - self.assertAllClose(expected_var, var) + if not stats: + return + expected_var = [ + stats.t.var(d, loc=m, scale=s) for (d, m, s) in zip(df, mu, sigma) + ] + self.assertAllClose(expected_var, var) def testVarianceAllowNanStatsFalseRaisesForUndefinedBatchMembers(self): - with self.test_session(): - # df <= 1 ==> variance not defined - student = student_t.StudentT( - df=1., loc=0., scale=1., allow_nan_stats=False) - with self.assertRaisesOpError("x < y"): - self.evaluate(student.variance()) + # df <= 1 ==> variance not defined + student = student_t.StudentT(df=1., loc=0., scale=1., allow_nan_stats=False) + with self.assertRaisesOpError("x < y"): + self.evaluate(student.variance()) - with self.test_session(): - # df <= 1 ==> variance not defined - student = student_t.StudentT( - df=0.5, loc=0., scale=1., allow_nan_stats=False) - with self.assertRaisesOpError("x < y"): - self.evaluate(student.variance()) + # df <= 1 ==> variance not defined + student = student_t.StudentT( + df=0.5, loc=0., scale=1., allow_nan_stats=False) + with self.assertRaisesOpError("x < y"): + self.evaluate(student.variance()) def testStd(self): - with self.test_session(): - # Defined for all batch members. - df = [3.5, 5., 3., 5., 7.] - mu = [-2.2] - sigma = [5., 4., 3., 2., 1.] - student = student_t.StudentT(df=df, loc=mu, scale=sigma) - # Test broadcast of mu across shape of df/sigma - stddev = self.evaluate(student.stddev()) - mu *= len(df) + # Defined for all batch members. + df = [3.5, 5., 3., 5., 7.] + mu = [-2.2] + sigma = [5., 4., 3., 2., 1.] + student = student_t.StudentT(df=df, loc=mu, scale=sigma) + # Test broadcast of mu across shape of df/sigma + stddev = self.evaluate(student.stddev()) + mu *= len(df) - if not stats: - return - expected_stddev = [ - stats.t.std(d, loc=m, scale=s) for (d, m, s) in zip(df, mu, sigma) - ] - self.assertAllClose(expected_stddev, stddev) + if not stats: + return + expected_stddev = [ + stats.t.std(d, loc=m, scale=s) for (d, m, s) in zip(df, mu, sigma) + ] + self.assertAllClose(expected_stddev, stddev) def testMode(self): - with self.test_session(): - df = [0.5, 1., 3] - mu = [-1, 0., 1] - sigma = [5., 4., 3.] - student = student_t.StudentT(df=df, loc=mu, scale=sigma) - # Test broadcast of mu across shape of df/sigma - mode = self.evaluate(student.mode()) - self.assertAllClose([-1., 0, 1], mode) + df = [0.5, 1., 3] + mu = [-1, 0., 1] + sigma = [5., 4., 3.] + student = student_t.StudentT(df=df, loc=mu, scale=sigma) + # Test broadcast of mu across shape of df/sigma + mode = self.evaluate(student.mode()) + self.assertAllClose([-1., 0, 1], mode) def testPdfOfSample(self): student = student_t.StudentT(df=3., loc=np.pi, scale=1.) @@ -510,25 +485,23 @@ class StudentTTest(test.TestCase): self.assertNear(1., total, err=err) def testNegativeDofFails(self): - with self.test_session(): - with self.assertRaisesOpError(r"Condition x > 0 did not hold"): - student = student_t.StudentT( - df=[2, -5.], loc=0., scale=1., validate_args=True, name="S") - self.evaluate(student.mean()) + with self.assertRaisesOpError(r"Condition x > 0 did not hold"): + student = student_t.StudentT( + df=[2, -5.], loc=0., scale=1., validate_args=True, name="S") + self.evaluate(student.mean()) def testStudentTWithAbsDfSoftplusScale(self): - with self.test_session(): - df = constant_op.constant([-3.2, -4.6]) - mu = constant_op.constant([-4.2, 3.4]) - sigma = constant_op.constant([-6.4, -8.8]) - student = student_t.StudentTWithAbsDfSoftplusScale( - df=df, loc=mu, scale=sigma) - self.assertAllClose( - math_ops.floor(self.evaluate(math_ops.abs(df))), - self.evaluate(student.df)) - self.assertAllClose(self.evaluate(mu), self.evaluate(student.loc)) - self.assertAllClose( - self.evaluate(nn_ops.softplus(sigma)), self.evaluate(student.scale)) + df = constant_op.constant([-3.2, -4.6]) + mu = constant_op.constant([-4.2, 3.4]) + sigma = constant_op.constant([-6.4, -8.8]) + student = student_t.StudentTWithAbsDfSoftplusScale( + df=df, loc=mu, scale=sigma) + self.assertAllClose( + math_ops.floor(self.evaluate(math_ops.abs(df))), + self.evaluate(student.df)) + self.assertAllClose(self.evaluate(mu), self.evaluate(student.loc)) + self.assertAllClose( + self.evaluate(nn_ops.softplus(sigma)), self.evaluate(student.scale)) if __name__ == "__main__": diff --git a/tensorflow/python/kernel_tests/distributions/uniform_test.py b/tensorflow/python/kernel_tests/distributions/uniform_test.py index bc9c267b9a..9cdcd369c1 100644 --- a/tensorflow/python/kernel_tests/distributions/uniform_test.py +++ b/tensorflow/python/kernel_tests/distributions/uniform_test.py @@ -50,255 +50,239 @@ class UniformTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def testUniformRange(self): - with self.test_session(): - a = 3.0 - b = 10.0 - uniform = uniform_lib.Uniform(low=a, high=b) - self.assertAllClose(a, self.evaluate(uniform.low)) - self.assertAllClose(b, self.evaluate(uniform.high)) - self.assertAllClose(b - a, self.evaluate(uniform.range())) + a = 3.0 + b = 10.0 + uniform = uniform_lib.Uniform(low=a, high=b) + self.assertAllClose(a, self.evaluate(uniform.low)) + self.assertAllClose(b, self.evaluate(uniform.high)) + self.assertAllClose(b - a, self.evaluate(uniform.range())) @test_util.run_in_graph_and_eager_modes def testUniformPDF(self): - with self.test_session(): - a = constant_op.constant([-3.0] * 5 + [15.0]) - b = constant_op.constant([11.0] * 5 + [20.0]) - uniform = uniform_lib.Uniform(low=a, high=b) + a = constant_op.constant([-3.0] * 5 + [15.0]) + b = constant_op.constant([11.0] * 5 + [20.0]) + uniform = uniform_lib.Uniform(low=a, high=b) - a_v = -3.0 - b_v = 11.0 - x = np.array([-10.5, 4.0, 0.0, 10.99, 11.3, 17.0], dtype=np.float32) + a_v = -3.0 + b_v = 11.0 + x = np.array([-10.5, 4.0, 0.0, 10.99, 11.3, 17.0], dtype=np.float32) - def _expected_pdf(): - pdf = np.zeros_like(x) + 1.0 / (b_v - a_v) - pdf[x > b_v] = 0.0 - pdf[x < a_v] = 0.0 - pdf[5] = 1.0 / (20.0 - 15.0) - return pdf + def _expected_pdf(): + pdf = np.zeros_like(x) + 1.0 / (b_v - a_v) + pdf[x > b_v] = 0.0 + pdf[x < a_v] = 0.0 + pdf[5] = 1.0 / (20.0 - 15.0) + return pdf - expected_pdf = _expected_pdf() + expected_pdf = _expected_pdf() - pdf = uniform.prob(x) - self.assertAllClose(expected_pdf, self.evaluate(pdf)) + pdf = uniform.prob(x) + self.assertAllClose(expected_pdf, self.evaluate(pdf)) - log_pdf = uniform.log_prob(x) - self.assertAllClose(np.log(expected_pdf), self.evaluate(log_pdf)) + log_pdf = uniform.log_prob(x) + self.assertAllClose(np.log(expected_pdf), self.evaluate(log_pdf)) @test_util.run_in_graph_and_eager_modes def testUniformShape(self): - with self.test_session(): - a = constant_op.constant([-3.0] * 5) - b = constant_op.constant(11.0) - uniform = uniform_lib.Uniform(low=a, high=b) + a = constant_op.constant([-3.0] * 5) + b = constant_op.constant(11.0) + uniform = uniform_lib.Uniform(low=a, high=b) - self.assertEqual(self.evaluate(uniform.batch_shape_tensor()), (5,)) - self.assertEqual(uniform.batch_shape, tensor_shape.TensorShape([5])) - self.assertAllEqual(self.evaluate(uniform.event_shape_tensor()), []) - self.assertEqual(uniform.event_shape, tensor_shape.TensorShape([])) + self.assertEqual(self.evaluate(uniform.batch_shape_tensor()), (5,)) + self.assertEqual(uniform.batch_shape, tensor_shape.TensorShape([5])) + self.assertAllEqual(self.evaluate(uniform.event_shape_tensor()), []) + self.assertEqual(uniform.event_shape, tensor_shape.TensorShape([])) @test_util.run_in_graph_and_eager_modes def testUniformPDFWithScalarEndpoint(self): - with self.test_session(): - a = constant_op.constant([0.0, 5.0]) - b = constant_op.constant(10.0) - uniform = uniform_lib.Uniform(low=a, high=b) + a = constant_op.constant([0.0, 5.0]) + b = constant_op.constant(10.0) + uniform = uniform_lib.Uniform(low=a, high=b) - x = np.array([0.0, 8.0], dtype=np.float32) - expected_pdf = np.array([1.0 / (10.0 - 0.0), 1.0 / (10.0 - 5.0)]) + x = np.array([0.0, 8.0], dtype=np.float32) + expected_pdf = np.array([1.0 / (10.0 - 0.0), 1.0 / (10.0 - 5.0)]) - pdf = uniform.prob(x) - self.assertAllClose(expected_pdf, self.evaluate(pdf)) + pdf = uniform.prob(x) + self.assertAllClose(expected_pdf, self.evaluate(pdf)) @test_util.run_in_graph_and_eager_modes def testUniformCDF(self): - with self.test_session(): - batch_size = 6 - a = constant_op.constant([1.0] * batch_size) - b = constant_op.constant([11.0] * batch_size) - a_v = 1.0 - b_v = 11.0 - x = np.array([-2.5, 2.5, 4.0, 0.0, 10.99, 12.0], dtype=np.float32) + batch_size = 6 + a = constant_op.constant([1.0] * batch_size) + b = constant_op.constant([11.0] * batch_size) + a_v = 1.0 + b_v = 11.0 + x = np.array([-2.5, 2.5, 4.0, 0.0, 10.99, 12.0], dtype=np.float32) - uniform = uniform_lib.Uniform(low=a, high=b) + uniform = uniform_lib.Uniform(low=a, high=b) - def _expected_cdf(): - cdf = (x - a_v) / (b_v - a_v) - cdf[x >= b_v] = 1 - cdf[x < a_v] = 0 - return cdf + def _expected_cdf(): + cdf = (x - a_v) / (b_v - a_v) + cdf[x >= b_v] = 1 + cdf[x < a_v] = 0 + return cdf - cdf = uniform.cdf(x) - self.assertAllClose(_expected_cdf(), self.evaluate(cdf)) + cdf = uniform.cdf(x) + self.assertAllClose(_expected_cdf(), self.evaluate(cdf)) - log_cdf = uniform.log_cdf(x) - self.assertAllClose(np.log(_expected_cdf()), self.evaluate(log_cdf)) + log_cdf = uniform.log_cdf(x) + self.assertAllClose(np.log(_expected_cdf()), self.evaluate(log_cdf)) @test_util.run_in_graph_and_eager_modes def testUniformEntropy(self): - with self.test_session(): - a_v = np.array([1.0, 1.0, 1.0]) - b_v = np.array([[1.5, 2.0, 3.0]]) - uniform = uniform_lib.Uniform(low=a_v, high=b_v) + a_v = np.array([1.0, 1.0, 1.0]) + b_v = np.array([[1.5, 2.0, 3.0]]) + uniform = uniform_lib.Uniform(low=a_v, high=b_v) - expected_entropy = np.log(b_v - a_v) - self.assertAllClose(expected_entropy, self.evaluate(uniform.entropy())) + expected_entropy = np.log(b_v - a_v) + self.assertAllClose(expected_entropy, self.evaluate(uniform.entropy())) @test_util.run_in_graph_and_eager_modes def testUniformAssertMaxGtMin(self): - with self.test_session(): - a_v = np.array([1.0, 1.0, 1.0], dtype=np.float32) - b_v = np.array([1.0, 2.0, 3.0], dtype=np.float32) + a_v = np.array([1.0, 1.0, 1.0], dtype=np.float32) + b_v = np.array([1.0, 2.0, 3.0], dtype=np.float32) - with self.assertRaisesWithPredicateMatch(errors.InvalidArgumentError, - "x < y"): - uniform = uniform_lib.Uniform(low=a_v, high=b_v, validate_args=True) - self.evaluate(uniform.low) + with self.assertRaisesWithPredicateMatch(errors.InvalidArgumentError, + "x < y"): + uniform = uniform_lib.Uniform(low=a_v, high=b_v, validate_args=True) + self.evaluate(uniform.low) @test_util.run_in_graph_and_eager_modes def testUniformSample(self): - with self.test_session(): - a = constant_op.constant([3.0, 4.0]) - b = constant_op.constant(13.0) - a1_v = 3.0 - a2_v = 4.0 - b_v = 13.0 - n = constant_op.constant(100000) - uniform = uniform_lib.Uniform(low=a, high=b) - - samples = uniform.sample(n, seed=137) - sample_values = self.evaluate(samples) - self.assertEqual(sample_values.shape, (100000, 2)) - self.assertAllClose( - sample_values[::, 0].mean(), (b_v + a1_v) / 2, atol=1e-1, rtol=0.) - self.assertAllClose( - sample_values[::, 1].mean(), (b_v + a2_v) / 2, atol=1e-1, rtol=0.) - self.assertFalse( - np.any(sample_values[::, 0] < a1_v) or np.any(sample_values >= b_v)) - self.assertFalse( - np.any(sample_values[::, 1] < a2_v) or np.any(sample_values >= b_v)) + a = constant_op.constant([3.0, 4.0]) + b = constant_op.constant(13.0) + a1_v = 3.0 + a2_v = 4.0 + b_v = 13.0 + n = constant_op.constant(100000) + uniform = uniform_lib.Uniform(low=a, high=b) + + samples = uniform.sample(n, seed=137) + sample_values = self.evaluate(samples) + self.assertEqual(sample_values.shape, (100000, 2)) + self.assertAllClose( + sample_values[::, 0].mean(), (b_v + a1_v) / 2, atol=1e-1, rtol=0.) + self.assertAllClose( + sample_values[::, 1].mean(), (b_v + a2_v) / 2, atol=1e-1, rtol=0.) + self.assertFalse( + np.any(sample_values[::, 0] < a1_v) or np.any(sample_values >= b_v)) + self.assertFalse( + np.any(sample_values[::, 1] < a2_v) or np.any(sample_values >= b_v)) @test_util.run_in_graph_and_eager_modes def _testUniformSampleMultiDimensional(self): # DISABLED: Please enable this test once b/issues/30149644 is resolved. - with self.test_session(): - batch_size = 2 - a_v = [3.0, 22.0] - b_v = [13.0, 35.0] - a = constant_op.constant([a_v] * batch_size) - b = constant_op.constant([b_v] * batch_size) - - uniform = uniform_lib.Uniform(low=a, high=b) - - n_v = 100000 - n = constant_op.constant(n_v) - samples = uniform.sample(n) - self.assertEqual(samples.get_shape(), (n_v, batch_size, 2)) - - sample_values = self.evaluate(samples) - - self.assertFalse( - np.any(sample_values[:, 0, 0] < a_v[0]) or - np.any(sample_values[:, 0, 0] >= b_v[0])) - self.assertFalse( - np.any(sample_values[:, 0, 1] < a_v[1]) or - np.any(sample_values[:, 0, 1] >= b_v[1])) - - self.assertAllClose( - sample_values[:, 0, 0].mean(), (a_v[0] + b_v[0]) / 2, atol=1e-2) - self.assertAllClose( - sample_values[:, 0, 1].mean(), (a_v[1] + b_v[1]) / 2, atol=1e-2) + batch_size = 2 + a_v = [3.0, 22.0] + b_v = [13.0, 35.0] + a = constant_op.constant([a_v] * batch_size) + b = constant_op.constant([b_v] * batch_size) + + uniform = uniform_lib.Uniform(low=a, high=b) + + n_v = 100000 + n = constant_op.constant(n_v) + samples = uniform.sample(n) + self.assertEqual(samples.get_shape(), (n_v, batch_size, 2)) + + sample_values = self.evaluate(samples) + + self.assertFalse( + np.any(sample_values[:, 0, 0] < a_v[0]) or + np.any(sample_values[:, 0, 0] >= b_v[0])) + self.assertFalse( + np.any(sample_values[:, 0, 1] < a_v[1]) or + np.any(sample_values[:, 0, 1] >= b_v[1])) + + self.assertAllClose( + sample_values[:, 0, 0].mean(), (a_v[0] + b_v[0]) / 2, atol=1e-2) + self.assertAllClose( + sample_values[:, 0, 1].mean(), (a_v[1] + b_v[1]) / 2, atol=1e-2) @test_util.run_in_graph_and_eager_modes def testUniformMean(self): - with self.test_session(): - a = 10.0 - b = 100.0 - uniform = uniform_lib.Uniform(low=a, high=b) - if not stats: - return - s_uniform = stats.uniform(loc=a, scale=b - a) - self.assertAllClose(self.evaluate(uniform.mean()), s_uniform.mean()) + a = 10.0 + b = 100.0 + uniform = uniform_lib.Uniform(low=a, high=b) + if not stats: + return + s_uniform = stats.uniform(loc=a, scale=b - a) + self.assertAllClose(self.evaluate(uniform.mean()), s_uniform.mean()) @test_util.run_in_graph_and_eager_modes def testUniformVariance(self): - with self.test_session(): - a = 10.0 - b = 100.0 - uniform = uniform_lib.Uniform(low=a, high=b) - if not stats: - return - s_uniform = stats.uniform(loc=a, scale=b - a) - self.assertAllClose(self.evaluate(uniform.variance()), s_uniform.var()) + a = 10.0 + b = 100.0 + uniform = uniform_lib.Uniform(low=a, high=b) + if not stats: + return + s_uniform = stats.uniform(loc=a, scale=b - a) + self.assertAllClose(self.evaluate(uniform.variance()), s_uniform.var()) @test_util.run_in_graph_and_eager_modes def testUniformStd(self): - with self.test_session(): - a = 10.0 - b = 100.0 - uniform = uniform_lib.Uniform(low=a, high=b) - if not stats: - return - s_uniform = stats.uniform(loc=a, scale=b - a) - self.assertAllClose(self.evaluate(uniform.stddev()), s_uniform.std()) + a = 10.0 + b = 100.0 + uniform = uniform_lib.Uniform(low=a, high=b) + if not stats: + return + s_uniform = stats.uniform(loc=a, scale=b - a) + self.assertAllClose(self.evaluate(uniform.stddev()), s_uniform.std()) @test_util.run_in_graph_and_eager_modes def testUniformNans(self): - with self.test_session(): - a = 10.0 - b = [11.0, 100.0] - uniform = uniform_lib.Uniform(low=a, high=b) + a = 10.0 + b = [11.0, 100.0] + uniform = uniform_lib.Uniform(low=a, high=b) - no_nans = constant_op.constant(1.0) - nans = constant_op.constant(0.0) / constant_op.constant(0.0) - self.assertTrue(self.evaluate(math_ops.is_nan(nans))) - with_nans = array_ops.stack([no_nans, nans]) + no_nans = constant_op.constant(1.0) + nans = constant_op.constant(0.0) / constant_op.constant(0.0) + self.assertTrue(self.evaluate(math_ops.is_nan(nans))) + with_nans = array_ops.stack([no_nans, nans]) - pdf = uniform.prob(with_nans) + pdf = uniform.prob(with_nans) - is_nan = self.evaluate(math_ops.is_nan(pdf)) - self.assertFalse(is_nan[0]) - self.assertTrue(is_nan[1]) + is_nan = self.evaluate(math_ops.is_nan(pdf)) + self.assertFalse(is_nan[0]) + self.assertTrue(is_nan[1]) @test_util.run_in_graph_and_eager_modes def testUniformSamplePdf(self): - with self.test_session(): - a = 10.0 - b = [11.0, 100.0] - uniform = uniform_lib.Uniform(a, b) - self.assertTrue( - self.evaluate( - math_ops.reduce_all(uniform.prob(uniform.sample(10)) > 0))) + a = 10.0 + b = [11.0, 100.0] + uniform = uniform_lib.Uniform(a, b) + self.assertTrue( + self.evaluate( + math_ops.reduce_all(uniform.prob(uniform.sample(10)) > 0))) @test_util.run_in_graph_and_eager_modes def testUniformBroadcasting(self): - with self.test_session(): - a = 10.0 - b = [11.0, 20.0] - uniform = uniform_lib.Uniform(a, b) + a = 10.0 + b = [11.0, 20.0] + uniform = uniform_lib.Uniform(a, b) - pdf = uniform.prob([[10.5, 11.5], [9.0, 19.0], [10.5, 21.0]]) - expected_pdf = np.array([[1.0, 0.1], [0.0, 0.1], [1.0, 0.0]]) - self.assertAllClose(expected_pdf, self.evaluate(pdf)) + pdf = uniform.prob([[10.5, 11.5], [9.0, 19.0], [10.5, 21.0]]) + expected_pdf = np.array([[1.0, 0.1], [0.0, 0.1], [1.0, 0.0]]) + self.assertAllClose(expected_pdf, self.evaluate(pdf)) @test_util.run_in_graph_and_eager_modes def testUniformSampleWithShape(self): - with self.test_session(): - a = 10.0 - b = [11.0, 20.0] - uniform = uniform_lib.Uniform(a, b) - - pdf = uniform.prob(uniform.sample((2, 3))) - # pylint: disable=bad-continuation - expected_pdf = [ - [[1.0, 0.1], [1.0, 0.1], [1.0, 0.1]], - [[1.0, 0.1], [1.0, 0.1], [1.0, 0.1]], - ] - # pylint: enable=bad-continuation - self.assertAllClose(expected_pdf, self.evaluate(pdf)) - - pdf = uniform.prob(uniform.sample()) - expected_pdf = [1.0, 0.1] - self.assertAllClose(expected_pdf, self.evaluate(pdf)) + a = 10.0 + b = [11.0, 20.0] + uniform = uniform_lib.Uniform(a, b) + + pdf = uniform.prob(uniform.sample((2, 3))) + # pylint: disable=bad-continuation + expected_pdf = [ + [[1.0, 0.1], [1.0, 0.1], [1.0, 0.1]], + [[1.0, 0.1], [1.0, 0.1], [1.0, 0.1]], + ] + # pylint: enable=bad-continuation + self.assertAllClose(expected_pdf, self.evaluate(pdf)) + + pdf = uniform.prob(uniform.sample()) + expected_pdf = [1.0, 0.1] + self.assertAllClose(expected_pdf, self.evaluate(pdf)) def testFullyReparameterized(self): a = constant_op.constant(0.1) diff --git a/tensorflow/python/kernel_tests/distributions/util_test.py b/tensorflow/python/kernel_tests/distributions/util_test.py index 61faa8466e..27d652c2c6 100644 --- a/tensorflow/python/kernel_tests/distributions/util_test.py +++ b/tensorflow/python/kernel_tests/distributions/util_test.py @@ -69,7 +69,7 @@ class AssertCloseTest(test.TestCase): w = array_ops.placeholder(dtypes.float32) feed_dict = {x: [1., 5, 10, 15, 20], y: [1.1, 5, 10, 15, 20], z: [1.0001, 5, 10, 15, 20], w: [1e-8, 5, 10, 15, 20]} - with self.test_session(): + with self.cached_session(): with ops.control_dependencies([du.assert_integer_form(x)]): array_ops.identity(x).eval(feed_dict=feed_dict) @@ -122,58 +122,52 @@ class GetLogitsAndProbsTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def testImproperArguments(self): - with self.test_session(): - with self.assertRaises(ValueError): - du.get_logits_and_probs(logits=None, probs=None) + with self.assertRaises(ValueError): + du.get_logits_and_probs(logits=None, probs=None) - with self.assertRaises(ValueError): - du.get_logits_and_probs(logits=[0.1], probs=[0.1]) + with self.assertRaises(ValueError): + du.get_logits_and_probs(logits=[0.1], probs=[0.1]) @test_util.run_in_graph_and_eager_modes def testLogits(self): p = np.array([0.01, 0.2, 0.5, 0.7, .99], dtype=np.float32) logits = _logit(p) - with self.test_session(): - new_logits, new_p = du.get_logits_and_probs( - logits=logits, validate_args=True) + new_logits, new_p = du.get_logits_and_probs( + logits=logits, validate_args=True) - self.assertAllClose(p, self.evaluate(new_p), rtol=1e-5, atol=0.) - self.assertAllClose(logits, self.evaluate(new_logits), rtol=1e-5, atol=0.) + self.assertAllClose(p, self.evaluate(new_p), rtol=1e-5, atol=0.) + self.assertAllClose(logits, self.evaluate(new_logits), rtol=1e-5, atol=0.) @test_util.run_in_graph_and_eager_modes def testLogitsMultidimensional(self): p = np.array([0.2, 0.3, 0.5], dtype=np.float32) logits = np.log(p) - with self.test_session(): - new_logits, new_p = du.get_logits_and_probs( - logits=logits, multidimensional=True, validate_args=True) + new_logits, new_p = du.get_logits_and_probs( + logits=logits, multidimensional=True, validate_args=True) - self.assertAllClose(self.evaluate(new_p), p) - self.assertAllClose(self.evaluate(new_logits), logits) + self.assertAllClose(self.evaluate(new_p), p) + self.assertAllClose(self.evaluate(new_logits), logits) @test_util.run_in_graph_and_eager_modes def testProbability(self): p = np.array([0.01, 0.2, 0.5, 0.7, .99], dtype=np.float32) - with self.test_session(): - new_logits, new_p = du.get_logits_and_probs( - probs=p, validate_args=True) + new_logits, new_p = du.get_logits_and_probs(probs=p, validate_args=True) - self.assertAllClose(_logit(p), self.evaluate(new_logits)) - self.assertAllClose(p, self.evaluate(new_p)) + self.assertAllClose(_logit(p), self.evaluate(new_logits)) + self.assertAllClose(p, self.evaluate(new_p)) @test_util.run_in_graph_and_eager_modes def testProbabilityMultidimensional(self): p = np.array([[0.3, 0.4, 0.3], [0.1, 0.5, 0.4]], dtype=np.float32) - with self.test_session(): - new_logits, new_p = du.get_logits_and_probs( - probs=p, multidimensional=True, validate_args=True) + new_logits, new_p = du.get_logits_and_probs( + probs=p, multidimensional=True, validate_args=True) - self.assertAllClose(np.log(p), self.evaluate(new_logits)) - self.assertAllClose(p, self.evaluate(new_p)) + self.assertAllClose(np.log(p), self.evaluate(new_logits)) + self.assertAllClose(p, self.evaluate(new_p)) @test_util.run_in_graph_and_eager_modes def testProbabilityValidateArgs(self): @@ -183,29 +177,23 @@ class GetLogitsAndProbsTest(test.TestCase): # Component greater than 1. p3 = [2, 0.2, 0.5, 0.3, .2] - with self.test_session(): - _, prob = du.get_logits_and_probs( - probs=p, validate_args=True) - self.evaluate(prob) - - with self.assertRaisesOpError("Condition x >= 0"): - _, prob = du.get_logits_and_probs( - probs=p2, validate_args=True) - self.evaluate(prob) + _, prob = du.get_logits_and_probs(probs=p, validate_args=True) + self.evaluate(prob) - _, prob = du.get_logits_and_probs( - probs=p2, validate_args=False) + with self.assertRaisesOpError("Condition x >= 0"): + _, prob = du.get_logits_and_probs(probs=p2, validate_args=True) self.evaluate(prob) - with self.assertRaisesOpError("probs has components greater than 1"): - _, prob = du.get_logits_and_probs( - probs=p3, validate_args=True) - self.evaluate(prob) + _, prob = du.get_logits_and_probs(probs=p2, validate_args=False) + self.evaluate(prob) - _, prob = du.get_logits_and_probs( - probs=p3, validate_args=False) + with self.assertRaisesOpError("probs has components greater than 1"): + _, prob = du.get_logits_and_probs(probs=p3, validate_args=True) self.evaluate(prob) + _, prob = du.get_logits_and_probs(probs=p3, validate_args=False) + self.evaluate(prob) + @test_util.run_in_graph_and_eager_modes def testProbabilityValidateArgsMultidimensional(self): p = np.array([[0.3, 0.4, 0.3], [0.1, 0.5, 0.4]], dtype=np.float32) @@ -216,41 +204,39 @@ class GetLogitsAndProbsTest(test.TestCase): # Does not sum to 1. p4 = np.array([[1.1, 0.3, 0.4], [0.1, 0.5, 0.4]], dtype=np.float32) - with self.test_session(): - _, prob = du.get_logits_and_probs( - probs=p, multidimensional=True) - self.evaluate(prob) - - with self.assertRaisesOpError("Condition x >= 0"): - _, prob = du.get_logits_and_probs( - probs=p2, multidimensional=True, validate_args=True) - self.evaluate(prob) + _, prob = du.get_logits_and_probs(probs=p, multidimensional=True) + self.evaluate(prob) + with self.assertRaisesOpError("Condition x >= 0"): _, prob = du.get_logits_and_probs( - probs=p2, multidimensional=True, validate_args=False) + probs=p2, multidimensional=True, validate_args=True) self.evaluate(prob) - with self.assertRaisesOpError( - "(probs has components greater than 1|probs does not sum to 1)"): - _, prob = du.get_logits_and_probs( - probs=p3, multidimensional=True, validate_args=True) - self.evaluate(prob) + _, prob = du.get_logits_and_probs( + probs=p2, multidimensional=True, validate_args=False) + self.evaluate(prob) + with self.assertRaisesOpError( + "(probs has components greater than 1|probs does not sum to 1)"): _, prob = du.get_logits_and_probs( - probs=p3, multidimensional=True, validate_args=False) + probs=p3, multidimensional=True, validate_args=True) self.evaluate(prob) - with self.assertRaisesOpError("probs does not sum to 1"): - _, prob = du.get_logits_and_probs( - probs=p4, multidimensional=True, validate_args=True) - self.evaluate(prob) + _, prob = du.get_logits_and_probs( + probs=p3, multidimensional=True, validate_args=False) + self.evaluate(prob) + with self.assertRaisesOpError("probs does not sum to 1"): _, prob = du.get_logits_and_probs( - probs=p4, multidimensional=True, validate_args=False) + probs=p4, multidimensional=True, validate_args=True) self.evaluate(prob) + _, prob = du.get_logits_and_probs( + probs=p4, multidimensional=True, validate_args=False) + self.evaluate(prob) + def testProbsMultidimShape(self): - with self.test_session(): + with self.cached_session(): with self.assertRaises(ValueError): p = array_ops.ones([int(2**11+1)], dtype=np.float16) du.get_logits_and_probs( @@ -264,7 +250,7 @@ class GetLogitsAndProbsTest(test.TestCase): prob.eval(feed_dict={p: np.ones([int(2**11+1)])}) def testLogitsMultidimShape(self): - with self.test_session(): + with self.cached_session(): with self.assertRaises(ValueError): l = array_ops.ones([int(2**11+1)], dtype=np.float16) du.get_logits_and_probs( @@ -281,7 +267,7 @@ class GetLogitsAndProbsTest(test.TestCase): class EmbedCheckCategoricalEventShapeTest(test.TestCase): def testTooSmall(self): - with self.test_session(): + with self.cached_session(): with self.assertRaises(ValueError): param = array_ops.ones([1], dtype=np.float16) checked_param = du.embed_check_categorical_event_shape( @@ -295,7 +281,7 @@ class EmbedCheckCategoricalEventShapeTest(test.TestCase): checked_param.eval(feed_dict={param: np.ones([1])}) def testTooLarge(self): - with self.test_session(): + with self.cached_session(): with self.assertRaises(ValueError): param = array_ops.ones([int(2**11+1)], dtype=dtypes.float16) checked_param = du.embed_check_categorical_event_shape( @@ -310,18 +296,17 @@ class EmbedCheckCategoricalEventShapeTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def testUnsupportedDtype(self): - with self.test_session(): - param = ops.convert_to_tensor( - np.ones([2**11 + 1]).astype(dtypes.qint16.as_numpy_dtype), - dtype=dtypes.qint16) - with self.assertRaises(TypeError): - du.embed_check_categorical_event_shape(param) + param = ops.convert_to_tensor( + np.ones([2**11 + 1]).astype(dtypes.qint16.as_numpy_dtype), + dtype=dtypes.qint16) + with self.assertRaises(TypeError): + du.embed_check_categorical_event_shape(param) class EmbedCheckIntegerCastingClosedTest(test.TestCase): def testCorrectlyAssertsNonnegative(self): - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("Elements must be non-negative"): x = array_ops.placeholder(dtype=dtypes.float16) x_checked = du.embed_check_integer_casting_closed( @@ -329,7 +314,7 @@ class EmbedCheckIntegerCastingClosedTest(test.TestCase): x_checked.eval(feed_dict={x: np.array([1, -1], dtype=np.float16)}) def testCorrectlyAssersIntegerForm(self): - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("Elements must be int16-equivalent."): x = array_ops.placeholder(dtype=dtypes.float16) x_checked = du.embed_check_integer_casting_closed( @@ -337,7 +322,7 @@ class EmbedCheckIntegerCastingClosedTest(test.TestCase): x_checked.eval(feed_dict={x: np.array([1, 1.5], dtype=np.float16)}) def testCorrectlyAssertsLargestPossibleInteger(self): - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("Elements cannot exceed 32767."): x = array_ops.placeholder(dtype=dtypes.int32) x_checked = du.embed_check_integer_casting_closed( @@ -345,7 +330,7 @@ class EmbedCheckIntegerCastingClosedTest(test.TestCase): x_checked.eval(feed_dict={x: np.array([1, 2**15], dtype=np.int32)}) def testCorrectlyAssertsSmallestPossibleInteger(self): - with self.test_session(): + with self.cached_session(): with self.assertRaisesOpError("Elements cannot be smaller than 0."): x = array_ops.placeholder(dtype=dtypes.int32) x_checked = du.embed_check_integer_casting_closed( @@ -365,29 +350,27 @@ class LogCombinationsTest(test.TestCase): log_combs = np.log(special.binom(n, k)) - with self.test_session(): - n = np.array(n, dtype=np.float32) - counts = [[1., 1], [2., 3], [4., 8], [11, 4]] - log_binom = du.log_combinations(n, counts) - self.assertEqual([4], log_binom.get_shape()) - self.assertAllClose(log_combs, self.evaluate(log_binom)) + n = np.array(n, dtype=np.float32) + counts = [[1., 1], [2., 3], [4., 8], [11, 4]] + log_binom = du.log_combinations(n, counts) + self.assertEqual([4], log_binom.get_shape()) + self.assertAllClose(log_combs, self.evaluate(log_binom)) def testLogCombinationsShape(self): # Shape [2, 2] n = [[2, 5], [12, 15]] - with self.test_session(): - n = np.array(n, dtype=np.float32) - # Shape [2, 2, 4] - counts = [[[1., 1, 0, 0], [2., 2, 1, 0]], [[4., 4, 1, 3], [10, 1, 1, 4]]] - log_binom = du.log_combinations(n, counts) - self.assertEqual([2, 2], log_binom.get_shape()) + n = np.array(n, dtype=np.float32) + # Shape [2, 2, 4] + counts = [[[1., 1, 0, 0], [2., 2, 1, 0]], [[4., 4, 1, 3], [10, 1, 1, 4]]] + log_binom = du.log_combinations(n, counts) + self.assertEqual([2, 2], log_binom.get_shape()) class DynamicShapeTest(test.TestCase): def testSameDynamicShape(self): - with self.test_session(): + with self.cached_session(): scalar = constant_op.constant(2.0) scalar1 = array_ops.placeholder(dtype=dtypes.float32) @@ -497,22 +480,21 @@ class RotateTransposeTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def testRollStatic(self): - with self.test_session(): - if context.executing_eagerly(): - error_message = r"Attempt to convert a value \(None\)" - else: - error_message = "None values not supported." - with self.assertRaisesRegexp(ValueError, error_message): - du.rotate_transpose(None, 1) - for x in (np.ones(1), np.ones((2, 1)), np.ones((3, 2, 1))): - for shift in np.arange(-5, 5): - y = du.rotate_transpose(x, shift) - self.assertAllEqual( - self._np_rotate_transpose(x, shift), self.evaluate(y)) - self.assertAllEqual(np.roll(x.shape, shift), y.get_shape().as_list()) + if context.executing_eagerly(): + error_message = r"Attempt to convert a value \(None\)" + else: + error_message = "None values not supported." + with self.assertRaisesRegexp(ValueError, error_message): + du.rotate_transpose(None, 1) + for x in (np.ones(1), np.ones((2, 1)), np.ones((3, 2, 1))): + for shift in np.arange(-5, 5): + y = du.rotate_transpose(x, shift) + self.assertAllEqual( + self._np_rotate_transpose(x, shift), self.evaluate(y)) + self.assertAllEqual(np.roll(x.shape, shift), y.get_shape().as_list()) def testRollDynamic(self): - with self.test_session() as sess: + with self.cached_session() as sess: x = array_ops.placeholder(dtypes.float32) shift = array_ops.placeholder(dtypes.int32) for x_value in (np.ones( @@ -530,7 +512,7 @@ class RotateTransposeTest(test.TestCase): class PickVectorTest(test.TestCase): def testCorrectlyPicksVector(self): - with self.test_session(): + with self.cached_session(): x = np.arange(10, 12) y = np.arange(15, 18) self.assertAllEqual( @@ -568,19 +550,19 @@ class PreferStaticRankTest(test.TestCase): def testDynamicRankEndsUpBeingNonEmpty(self): x = array_ops.placeholder(np.float64, shape=None) rank = du.prefer_static_rank(x) - with self.test_session(): + with self.cached_session(): self.assertAllEqual(2, rank.eval(feed_dict={x: np.zeros((2, 3))})) def testDynamicRankEndsUpBeingEmpty(self): x = array_ops.placeholder(np.int32, shape=None) rank = du.prefer_static_rank(x) - with self.test_session(): + with self.cached_session(): self.assertAllEqual(1, rank.eval(feed_dict={x: []})) def testDynamicRankEndsUpBeingScalar(self): x = array_ops.placeholder(np.int32, shape=None) rank = du.prefer_static_rank(x) - with self.test_session(): + with self.cached_session(): self.assertAllEqual(0, rank.eval(feed_dict={x: 1})) @@ -607,19 +589,19 @@ class PreferStaticShapeTest(test.TestCase): def testDynamicShapeEndsUpBeingNonEmpty(self): x = array_ops.placeholder(np.float64, shape=None) shape = du.prefer_static_shape(x) - with self.test_session(): + with self.cached_session(): self.assertAllEqual((2, 3), shape.eval(feed_dict={x: np.zeros((2, 3))})) def testDynamicShapeEndsUpBeingEmpty(self): x = array_ops.placeholder(np.int32, shape=None) shape = du.prefer_static_shape(x) - with self.test_session(): + with self.cached_session(): self.assertAllEqual(np.array([0]), shape.eval(feed_dict={x: []})) def testDynamicShapeEndsUpBeingScalar(self): x = array_ops.placeholder(np.int32, shape=None) shape = du.prefer_static_shape(x) - with self.test_session(): + with self.cached_session(): self.assertAllEqual(np.array([]), shape.eval(feed_dict={x: 1})) @@ -646,20 +628,20 @@ class PreferStaticValueTest(test.TestCase): def testDynamicValueEndsUpBeingNonEmpty(self): x = array_ops.placeholder(np.float64, shape=None) value = du.prefer_static_value(x) - with self.test_session(): + with self.cached_session(): self.assertAllEqual(np.zeros((2, 3)), value.eval(feed_dict={x: np.zeros((2, 3))})) def testDynamicValueEndsUpBeingEmpty(self): x = array_ops.placeholder(np.int32, shape=None) value = du.prefer_static_value(x) - with self.test_session(): + with self.cached_session(): self.assertAllEqual(np.array([]), value.eval(feed_dict={x: []})) def testDynamicValueEndsUpBeingScalar(self): x = array_ops.placeholder(np.int32, shape=None) value = du.prefer_static_value(x) - with self.test_session(): + with self.cached_session(): self.assertAllEqual(np.array(1), value.eval(feed_dict={x: 1})) @@ -691,7 +673,7 @@ class FillTriangularTest(test.TestCase): def _run_test(self, x_, use_deferred_shape=False, **kwargs): x_ = np.asarray(x_) - with self.test_session() as sess: + with self.cached_session() as sess: static_shape = None if use_deferred_shape else x_.shape x_pl = array_ops.placeholder_with_default(x_, shape=static_shape) # Add `zeros_like(x)` such that x's value and gradient are identical. We @@ -761,7 +743,7 @@ class FillTriangularInverseTest(FillTriangularTest): def _run_test(self, x_, use_deferred_shape=False, **kwargs): x_ = np.asarray(x_) - with self.test_session() as sess: + with self.cached_session() as sess: static_shape = None if use_deferred_shape else x_.shape x_pl = array_ops.placeholder_with_default(x_, shape=static_shape) zeros_like_x_pl = (x_pl * array_ops.stop_gradient(x_pl - 1.) @@ -795,7 +777,7 @@ class ReduceWeightedLogSumExp(test.TestCase): logx_ = np.array([[0., -1, 1000.], [0, 1, -1000.], [-5, 0, 5]]) - with self.test_session() as sess: + with self.cached_session() as sess: logx = constant_op.constant(logx_) expected = math_ops.reduce_logsumexp(logx, axis=-1) grad_expected = gradients_impl.gradients(expected, logx)[0] @@ -818,7 +800,7 @@ class ReduceWeightedLogSumExp(test.TestCase): [1, -2, 1], [1, 0, 1]]) expected, _ = self._reduce_weighted_logsumexp(logx_, w_, axis=-1) - with self.test_session() as sess: + with self.cached_session() as sess: logx = constant_op.constant(logx_) w = constant_op.constant(w_) actual, actual_sgn = du.reduce_weighted_logsumexp( @@ -836,7 +818,7 @@ class ReduceWeightedLogSumExp(test.TestCase): [1, 0, 1]]) expected, _ = self._reduce_weighted_logsumexp( logx_, w_, axis=-1, keep_dims=True) - with self.test_session() as sess: + with self.cached_session() as sess: logx = constant_op.constant(logx_) w = constant_op.constant(w_) actual, actual_sgn = du.reduce_weighted_logsumexp( @@ -848,7 +830,7 @@ class ReduceWeightedLogSumExp(test.TestCase): def testDocString(self): """This test verifies the correctness of the docstring examples.""" - with self.test_session(): + with self.cached_session(): x = constant_op.constant([[0., 0, 0], [0, 0, 0]]) @@ -952,7 +934,7 @@ class SoftplusTest(test.TestCase): use_gpu=True) def testGradient(self): - with self.test_session(): + with self.cached_session(): x = constant_op.constant( [-0.9, -0.7, -0.5, -0.3, -0.1, 0.1, 0.3, 0.5, 0.7, 0.9], shape=[2, 5], @@ -968,7 +950,7 @@ class SoftplusTest(test.TestCase): self.assertLess(err, 1e-4) def testInverseSoftplusGradientNeverNan(self): - with self.test_session(): + with self.cached_session(): # Note that this range contains both zero and inf. x = constant_op.constant(np.logspace(-8, 6).astype(np.float16)) y = du.softplus_inverse(x) @@ -977,7 +959,7 @@ class SoftplusTest(test.TestCase): self.assertAllEqual(np.zeros_like(grads).astype(np.bool), np.isnan(grads)) def testInverseSoftplusGradientFinite(self): - with self.test_session(): + with self.cached_session(): # This range of x is all finite, and so is 1 / x. So the # gradient and its approximations should be finite as well. x = constant_op.constant(np.logspace(-4.8, 4.5).astype(np.float16)) diff --git a/tensorflow/python/kernel_tests/functional_ops_test.py b/tensorflow/python/kernel_tests/functional_ops_test.py index 1e76ad7476..3ddb5e06c9 100644 --- a/tensorflow/python/kernel_tests/functional_ops_test.py +++ b/tensorflow/python/kernel_tests/functional_ops_test.py @@ -59,42 +59,48 @@ class FunctionalOpsTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def testFoldl_Simple(self): - with self.test_session(): - elems = constant_op.constant([1, 2, 3, 4, 5, 6], name="data") + elems = constant_op.constant([1, 2, 3, 4, 5, 6], name="data") - r = functional_ops.foldl( - lambda a, x: math_ops.multiply(math_ops.add(a, x), 2), - elems) - self.assertAllEqual(208, self.evaluate(r)) + r = functional_ops.foldl( + lambda a, x: math_ops.multiply(math_ops.add(a, x), 2), + elems) + self.assertAllEqual(208, self.evaluate(r)) - r = functional_ops.foldl( - lambda a, x: math_ops.multiply(math_ops.add(a, x), 2), - elems, - initializer=10) - self.assertAllEqual(880, self.evaluate(r)) + r = functional_ops.foldl( + lambda a, x: math_ops.multiply(math_ops.add(a, x), 2), + elems, + initializer=10) + self.assertAllEqual(880, self.evaluate(r)) @test_util.run_in_graph_and_eager_modes def testFoldl_SingleInputMultiOutput(self): - with self.test_session(): - elems = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]) - initializer = np.array([1, -1.0]) - r = functional_ops.foldl(lambda a, x: a + x, elems, initializer) - r_value = self.evaluate(r) + elems = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]) + initializer = np.array([1, -1.0]) + r = functional_ops.foldl(lambda a, x: a + x, elems, initializer) + r_value = self.evaluate(r) - self.assertAllEqual(22, r_value[0]) - self.assertAllEqual(20, r_value[1]) + self.assertAllEqual(22, r_value[0]) + self.assertAllEqual(20, r_value[1]) @test_util.run_in_graph_and_eager_modes def testFoldl_MultiInputSingleOutput(self): - with self.test_session(): - elems = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]) - initializer = np.array(1.0) - r = functional_ops.foldl(lambda a, x: a + x[0] + x[1], (elems, -elems), - initializer) - self.assertAllEqual(1, self.evaluate(r)) + elems = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]) + initializer = np.array(1.0) + r = functional_ops.foldl(lambda a, x: a + x[0] + x[1], (elems, -elems), + initializer) + self.assertAllEqual(1, self.evaluate(r)) + + @test_util.run_in_graph_and_eager_modes + def testFoldl_MultiInputDifferentDimsSingleOutput(self): + elems = np.array([[1.0, 1.0, 1.0], [2.0, 3.0, 4.0]]) + other_elems = np.array([-1.0, 1.0]) + initializer = np.array([0.0, 0.0, 0.0]) + r = functional_ops.foldl(lambda a, x: a + x[0] * x[1], + (elems, other_elems), initializer) + self.assertAllEqual([1.0, 2.0, 3.0], self.evaluate(r)) def testFoldl_Scoped(self): - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope("root") as varscope: elems = constant_op.constant([1, 2, 3, 4, 5, 6], name="data") @@ -114,42 +120,39 @@ class FunctionalOpsTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def testFoldr_Simple(self): - with self.test_session(): - elems = constant_op.constant([1, 2, 3, 4, 5, 6], name="data") + elems = constant_op.constant([1, 2, 3, 4, 5, 6], name="data") - r = functional_ops.foldr( - lambda a, x: math_ops.multiply(math_ops.add(a, x), 2), - elems) - self.assertAllEqual(450, self.evaluate(r)) + r = functional_ops.foldr( + lambda a, x: math_ops.multiply(math_ops.add(a, x), 2), + elems) + self.assertAllEqual(450, self.evaluate(r)) - r = functional_ops.foldr( - lambda a, x: math_ops.multiply(math_ops.add(a, x), 2), - elems, - initializer=10) - self.assertAllEqual(1282, self.evaluate(r)) + r = functional_ops.foldr( + lambda a, x: math_ops.multiply(math_ops.add(a, x), 2), + elems, + initializer=10) + self.assertAllEqual(1282, self.evaluate(r)) @test_util.run_in_graph_and_eager_modes def testFoldr_SingleInputMultiOutput(self): - with self.test_session(): - elems = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]) - initializer = np.array([1, -1.0]) - r = functional_ops.foldr(lambda a, x: a + x, elems, initializer) - r_value = self.evaluate(r) + elems = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]) + initializer = np.array([1, -1.0]) + r = functional_ops.foldr(lambda a, x: a + x, elems, initializer) + r_value = self.evaluate(r) - self.assertAllEqual(22, r_value[0]) - self.assertAllEqual(20, r_value[1]) + self.assertAllEqual(22, r_value[0]) + self.assertAllEqual(20, r_value[1]) @test_util.run_in_graph_and_eager_modes def testFoldr_MultiInputSingleOutput(self): - with self.test_session(): - elems = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]) - initializer = np.array(1.0) - r = functional_ops.foldr(lambda a, x: a + x[0] + x[1], (elems, -elems), - initializer) - self.assertAllEqual(1, self.evaluate(r)) + elems = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]) + initializer = np.array(1.0) + r = functional_ops.foldr(lambda a, x: a + x[0] + x[1], (elems, -elems), + initializer) + self.assertAllEqual(1, self.evaluate(r)) def testFoldr_Scoped(self): - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope("root") as varscope: elems = constant_op.constant([1, 2, 3, 4, 5, 6], name="data") @@ -169,7 +172,7 @@ class FunctionalOpsTest(test.TestCase): # pylint: disable=unnecessary-lambda def testFold_Grad(self): - with self.test_session(): + with self.cached_session(): elems = constant_op.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], name="data") v = constant_op.constant(2.0, name="v") r = functional_ops.foldl( @@ -185,16 +188,15 @@ class FunctionalOpsTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def testMap_Simple(self): - with self.test_session(): - nums = [1, 2, 3, 4, 5, 6] - elems = constant_op.constant(nums, name="data") - r = functional_ops.map_fn( - lambda x: math_ops.multiply(math_ops.add(x, 3), 2), elems) - self.assertAllEqual( - np.array([(x + 3) * 2 for x in nums]), self.evaluate(r)) + nums = [1, 2, 3, 4, 5, 6] + elems = constant_op.constant(nums, name="data") + r = functional_ops.map_fn( + lambda x: math_ops.multiply(math_ops.add(x, 3), 2), elems) + self.assertAllEqual( + np.array([(x + 3) * 2 for x in nums]), self.evaluate(r)) def testMapSparseTensor(self): - with self.test_session(): + with self.cached_session(): with self.assertRaises(TypeError): functional_ops.map_fn( lambda x: x, @@ -211,7 +213,7 @@ class FunctionalOpsTest(test.TestCase): functional_ops.map_fn(lambda x: x, 1) def testMap_Scoped(self): - with self.test_session() as sess: + with self.cached_session() as sess: def double_scoped(x): """2x with a dummy 2 that is scoped.""" @@ -242,7 +244,7 @@ class FunctionalOpsTest(test.TestCase): self.assertAllEqual(doubles, self.evaluate(r)) def testMap_Grad(self): - with self.test_session(): + with self.cached_session(): param = constant_op.constant(2.0) elems = constant_op.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], name="elems") y = functional_ops.map_fn( @@ -254,142 +256,131 @@ class FunctionalOpsTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def testMap_SimpleNotTensor(self): - with self.test_session(): - nums = np.array([1, 2, 3, 4, 5, 6]) - r = functional_ops.map_fn( - lambda x: math_ops.multiply(math_ops.add(x, 3), 2), nums) - self.assertAllEqual( - np.array([(x + 3) * 2 for x in nums]), self.evaluate(r)) + nums = np.array([1, 2, 3, 4, 5, 6]) + r = functional_ops.map_fn( + lambda x: math_ops.multiply(math_ops.add(x, 3), 2), nums) + self.assertAllEqual( + np.array([(x + 3) * 2 for x in nums]), self.evaluate(r)) @test_util.run_in_graph_and_eager_modes def testMap_SingleInputMultiOutput(self): - with self.test_session(): - nums = np.array([1, 2, 3, 4, 5, 6]) - r = functional_ops.map_fn( - lambda x: ((x + 3) * 2, -(x + 3) * 2), - nums, - dtype=(dtypes.int64, dtypes.int64)) - self.assertEqual(2, len(r)) - self.assertEqual((6,), r[0].get_shape()) - self.assertEqual((6,), r[1].get_shape()) - received = self.evaluate(r) - self.assertAllEqual((nums + 3) * 2, received[0]) - self.assertAllEqual(-(nums + 3) * 2, received[1]) + nums = np.array([1, 2, 3, 4, 5, 6]) + r = functional_ops.map_fn( + lambda x: ((x + 3) * 2, -(x + 3) * 2), + nums, + dtype=(dtypes.int64, dtypes.int64)) + self.assertEqual(2, len(r)) + self.assertEqual((6,), r[0].get_shape()) + self.assertEqual((6,), r[1].get_shape()) + received = self.evaluate(r) + self.assertAllEqual((nums + 3) * 2, received[0]) + self.assertAllEqual(-(nums + 3) * 2, received[1]) @test_util.run_in_graph_and_eager_modes def testMap_MultiOutputMismatchedDtype(self): - with self.test_session(): - nums = np.array([1, 2, 3, 4, 5, 6]) - with self.assertRaisesRegexp( - TypeError, r"two structures don't have the same nested structure"): - # lambda emits tuple, but dtype is a list - functional_ops.map_fn( - lambda x: ((x + 3) * 2, -(x + 3) * 2), - nums, - dtype=[dtypes.int64, dtypes.int64]) + nums = np.array([1, 2, 3, 4, 5, 6]) + with self.assertRaisesRegexp( + TypeError, r"two structures don't have the same nested structure"): + # lambda emits tuple, but dtype is a list + functional_ops.map_fn( + lambda x: ((x + 3) * 2, -(x + 3) * 2), + nums, + dtype=[dtypes.int64, dtypes.int64]) @test_util.run_in_graph_and_eager_modes def testMap_MultiInputSingleOutput(self): - with self.test_session(): - nums = np.array([1, 2, 3, 4, 5, 6]) - r = functional_ops.map_fn( - lambda x: x[0] * x[1][0] + x[1][1], (nums, (nums, -nums)), - dtype=dtypes.int64) - self.assertEqual((6,), r.get_shape()) - received = self.evaluate(r) - self.assertAllEqual(nums * nums + (-nums), received) + nums = np.array([1, 2, 3, 4, 5, 6]) + r = functional_ops.map_fn( + lambda x: x[0] * x[1][0] + x[1][1], (nums, (nums, -nums)), + dtype=dtypes.int64) + self.assertEqual((6,), r.get_shape()) + received = self.evaluate(r) + self.assertAllEqual(nums * nums + (-nums), received) @test_util.run_in_graph_and_eager_modes def testMap_MultiInputSameStructureOutput(self): - with self.test_session(): - nums = np.array([1, 2, 3, 4, 5, 6]) - r = functional_ops.map_fn(lambda x: (x[1][0], (x[1][1], x[0])), - (nums, (2 * nums, -nums))) - r = [r[0], r[1][0], r[1][1]] - self.assertEqual((6,), r[0].get_shape()) - self.assertEqual((6,), r[1].get_shape()) - self.assertEqual((6,), r[2].get_shape()) - received = self.evaluate(r) - self.assertAllEqual(2 * nums, received[0]) - self.assertAllEqual(-nums, received[1]) - self.assertAllEqual(nums, received[2]) + nums = np.array([1, 2, 3, 4, 5, 6]) + r = functional_ops.map_fn(lambda x: (x[1][0], (x[1][1], x[0])), + (nums, (2 * nums, -nums))) + r = [r[0], r[1][0], r[1][1]] + self.assertEqual((6,), r[0].get_shape()) + self.assertEqual((6,), r[1].get_shape()) + self.assertEqual((6,), r[2].get_shape()) + received = self.evaluate(r) + self.assertAllEqual(2 * nums, received[0]) + self.assertAllEqual(-nums, received[1]) + self.assertAllEqual(nums, received[2]) @test_util.run_in_graph_and_eager_modes def testScan_Simple(self): - with self.test_session(): - elems = constant_op.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], name="data") - v = constant_op.constant(2.0, name="v") + elems = constant_op.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], name="data") + v = constant_op.constant(2.0, name="v") - # pylint: disable=unnecessary-lambda - r = functional_ops.scan(lambda a, x: math_ops.multiply(a, x), elems) - self.assertAllEqual([1., 2., 6., 24., 120., 720.], self.evaluate(r)) + # pylint: disable=unnecessary-lambda + r = functional_ops.scan(lambda a, x: math_ops.multiply(a, x), elems) + self.assertAllEqual([1., 2., 6., 24., 120., 720.], self.evaluate(r)) - r = functional_ops.scan( - lambda a, x: math_ops.multiply(a, x), elems, initializer=v) - self.assertAllEqual([2., 4., 12., 48., 240., 1440.], self.evaluate(r)) - # pylint: enable=unnecessary-lambda + r = functional_ops.scan( + lambda a, x: math_ops.multiply(a, x), elems, initializer=v) + self.assertAllEqual([2., 4., 12., 48., 240., 1440.], self.evaluate(r)) + # pylint: enable=unnecessary-lambda @test_util.run_in_graph_and_eager_modes def testScan_Reverse(self): - with self.test_session(): - elems = constant_op.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], name="data") - v = constant_op.constant(2.0, name="v") - - # pylint: disable=unnecessary-lambda - r = functional_ops.scan(lambda a, x: math_ops.multiply(a, x), elems, - reverse=True) - self.assertAllEqual([720., 720., 360., 120., 30., 6.], self.evaluate(r)) - r = functional_ops.scan( - lambda a, x: math_ops.multiply(a, x), elems, initializer=v, - reverse=True) - self.assertAllEqual([1440., 1440., 720., 240., 60., 12.], - self.evaluate(r)) - # pylint: enable=unnecessary-lambda + elems = constant_op.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], name="data") + v = constant_op.constant(2.0, name="v") + + # pylint: disable=unnecessary-lambda + r = functional_ops.scan(lambda a, x: math_ops.multiply(a, x), elems, + reverse=True) + self.assertAllEqual([720., 720., 360., 120., 30., 6.], self.evaluate(r)) + r = functional_ops.scan( + lambda a, x: math_ops.multiply(a, x), elems, initializer=v, + reverse=True) + self.assertAllEqual([1440., 1440., 720., 240., 60., 12.], + self.evaluate(r)) + # pylint: enable=unnecessary-lambda @test_util.run_in_graph_and_eager_modes def testScan_SingleInputMultiOutput(self): - with self.test_session(): - elems = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]) - initializer = (np.array(1.0), np.array(-1.0)) - r = functional_ops.scan(lambda a, x: (a[0] * x, -a[1] * x), elems, - initializer) - r_value = self.evaluate(r) + elems = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]) + initializer = (np.array(1.0), np.array(-1.0)) + r = functional_ops.scan(lambda a, x: (a[0] * x, -a[1] * x), elems, + initializer) + r_value = self.evaluate(r) - self.assertAllEqual([1.0, 2.0, 6.0, 24.0, 120.0, 720.0], r_value[0]) - self.assertAllEqual([1.0, -2.0, 6.0, -24.0, 120.0, -720.0], r_value[1]) + self.assertAllEqual([1.0, 2.0, 6.0, 24.0, 120.0, 720.0], r_value[0]) + self.assertAllEqual([1.0, -2.0, 6.0, -24.0, 120.0, -720.0], r_value[1]) @test_util.run_in_graph_and_eager_modes def testScan_MultiInputSingleOutput(self): - with self.test_session(): - elems = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]) - initializer = np.array(1.0) - # Multiply a * 1 each time - r = functional_ops.scan(lambda a, x: a * (x[0] + x[1]), - (elems + 1, -elems), initializer) - self.assertAllEqual([1.0, 1.0, 1.0, 1.0, 1.0, 1.0], self.evaluate(r)) + elems = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]) + initializer = np.array(1.0) + # Multiply a * 1 each time + r = functional_ops.scan(lambda a, x: a * (x[0] + x[1]), + (elems + 1, -elems), initializer) + self.assertAllEqual([1.0, 1.0, 1.0, 1.0, 1.0, 1.0], self.evaluate(r)) @test_util.run_in_graph_and_eager_modes def testScan_MultiInputSameTypeOutput(self): - with self.test_session(): - elems = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]) - r = functional_ops.scan(lambda a, x: (a[0] + x[0], a[1] + x[1]), - (elems, -elems)) - r_value = self.evaluate(r) - self.assertAllEqual(np.cumsum(elems), r_value[0]) - self.assertAllEqual(np.cumsum(-elems), r_value[1]) + elems = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]) + r = functional_ops.scan(lambda a, x: (a[0] + x[0], a[1] + x[1]), + (elems, -elems)) + r_value = self.evaluate(r) + self.assertAllEqual(np.cumsum(elems), r_value[0]) + self.assertAllEqual(np.cumsum(-elems), r_value[1]) @test_util.run_in_graph_and_eager_modes def testScan_MultiOutputMismatchedInitializer(self): - with self.test_session(): - elems = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]) - initializer = np.array(1.0) - # Multiply a * 1 each time - with self.assertRaisesRegexp( - ValueError, "two structures don't have the same nested structure"): - functional_ops.scan(lambda a, x: (a, -a), elems, initializer) + elems = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0]) + initializer = np.array(1.0) + # Multiply a * 1 each time + with self.assertRaisesRegexp( + ValueError, "two structures don't have the same nested structure"): + functional_ops.scan(lambda a, x: (a, -a), elems, initializer) def testScan_Scoped(self): - with self.test_session() as sess: + with self.cached_session() as sess: with variable_scope.variable_scope("root") as varscope: elems = constant_op.constant([1, 2, 3, 4, 5, 6], name="data") @@ -411,30 +402,29 @@ class FunctionalOpsTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def testScanFoldl_Nested(self): - with self.test_session(): - elems = constant_op.constant([1.0, 2.0, 3.0, 4.0], name="data") - inner_elems = constant_op.constant([0.5, 0.5], name="data") - - def r_inner(a, x): - return functional_ops.foldl( - lambda b, y: b * y * x, inner_elems, initializer=a) - - r = functional_ops.scan(r_inner, elems) - - # t == 0 (returns 1) - # t == 1, a == 1, x == 2 (returns 1) - # t_0 == 0, b == a == 1, y == 0.5, returns b * y * x = 1 - # t_1 == 1, b == 1, y == 0.5, returns b * y * x = 1 - # t == 2, a == 1, x == 3 (returns 1.5*1.5 == 2.25) - # t_0 == 0, b == a == 1, y == 0.5, returns b * y * x = 1.5 - # t_1 == 1, b == 1.5, y == 0.5, returns b * y * x = 1.5*1.5 - # t == 3, a == 2.25, x == 4 (returns 9) - # t_0 == 0, b == a == 2.25, y == 0.5, returns b * y * x = 4.5 - # t_1 == 1, b == 4.5, y == 0.5, returns b * y * x = 9 - self.assertAllClose([1., 1., 2.25, 9.], self.evaluate(r)) + elems = constant_op.constant([1.0, 2.0, 3.0, 4.0], name="data") + inner_elems = constant_op.constant([0.5, 0.5], name="data") + + def r_inner(a, x): + return functional_ops.foldl( + lambda b, y: b * y * x, inner_elems, initializer=a) + + r = functional_ops.scan(r_inner, elems) + + # t == 0 (returns 1) + # t == 1, a == 1, x == 2 (returns 1) + # t_0 == 0, b == a == 1, y == 0.5, returns b * y * x = 1 + # t_1 == 1, b == 1, y == 0.5, returns b * y * x = 1 + # t == 2, a == 1, x == 3 (returns 1.5*1.5 == 2.25) + # t_0 == 0, b == a == 1, y == 0.5, returns b * y * x = 1.5 + # t_1 == 1, b == 1.5, y == 0.5, returns b * y * x = 1.5*1.5 + # t == 3, a == 2.25, x == 4 (returns 9) + # t_0 == 0, b == a == 2.25, y == 0.5, returns b * y * x = 4.5 + # t_1 == 1, b == 4.5, y == 0.5, returns b * y * x = 9 + self.assertAllClose([1., 1., 2.25, 9.], self.evaluate(r)) def testScan_Control(self): - with self.test_session() as sess: + with self.cached_session() as sess: s = array_ops.placeholder(dtypes.float32, shape=[None]) b = array_ops.placeholder(dtypes.bool) @@ -445,7 +435,7 @@ class FunctionalOpsTest(test.TestCase): b: True})) def testScan_Grad(self): - with self.test_session(): + with self.cached_session(): elems = constant_op.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], name="data") v = constant_op.constant(2.0, name="v") @@ -470,22 +460,20 @@ class FunctionalOpsTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def testFoldShape(self): - with self.test_session(): - x = constant_op.constant([[1, 2, 3], [4, 5, 6]]) + x = constant_op.constant([[1, 2, 3], [4, 5, 6]]) - def fn(_, current_input): - return current_input + def fn(_, current_input): + return current_input - initializer = constant_op.constant([0, 0, 0]) - y = functional_ops.foldl(fn, x, initializer=initializer) - self.assertAllEqual(y.get_shape(), self.evaluate(y).shape) + initializer = constant_op.constant([0, 0, 0]) + y = functional_ops.foldl(fn, x, initializer=initializer) + self.assertAllEqual(y.get_shape(), self.evaluate(y).shape) @test_util.run_in_graph_and_eager_modes def testMapShape(self): - with self.test_session(): - x = constant_op.constant([[1, 2, 3], [4, 5, 6]]) - y = functional_ops.map_fn(lambda e: e, x) - self.assertAllEqual(y.get_shape(), self.evaluate(y).shape) + x = constant_op.constant([[1, 2, 3], [4, 5, 6]]) + y = functional_ops.map_fn(lambda e: e, x) + self.assertAllEqual(y.get_shape(), self.evaluate(y).shape) def testMapUnknownShape(self): x = array_ops.placeholder(dtypes.float32) @@ -494,15 +482,14 @@ class FunctionalOpsTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def testMapEmptyScalar(self): - with self.test_session(): - map_return = functional_ops.map_fn(lambda x: 1, constant_op.constant([])) - self.assertAllEqual([0], map_return.get_shape().dims) - self.assertAllEqual([0], self.evaluate(map_return).shape) + map_return = functional_ops.map_fn(lambda x: 1, constant_op.constant([])) + self.assertAllEqual([0], map_return.get_shape().dims) + self.assertAllEqual([0], self.evaluate(map_return).shape) # TODO(akshayka): this test fails in eager: the iterable is of length 0 so # so the body of the while loop never executes def testMapEmptyTensor(self): - with self.test_session(): + with self.cached_session(): map_return = functional_ops.map_fn(lambda x: array_ops.zeros([3, 2]), constant_op.constant([])) self.assertAllEqual([0, 3, 2], map_return.get_shape().dims) @@ -510,20 +497,19 @@ class FunctionalOpsTest(test.TestCase): @test_util.run_in_graph_and_eager_modes def testScanShape(self): - with self.test_session(): - x = constant_op.constant([[1, 2, 3], [4, 5, 6]]) + x = constant_op.constant([[1, 2, 3], [4, 5, 6]]) - def fn(_, current_input): - return current_input + def fn(_, current_input): + return current_input - initializer = constant_op.constant([0, 0, 0]) - y = functional_ops.scan(fn, x, initializer=initializer) - self.assertAllEqual(y.get_shape(), self.evaluate(y).shape) + initializer = constant_op.constant([0, 0, 0]) + y = functional_ops.scan(fn, x, initializer=initializer) + self.assertAllEqual(y.get_shape(), self.evaluate(y).shape) # TODO(akshayka): this test fails in eager: the iterable is of length 0 so # so the body of the while loop never executes def testScanEmptyTensor(self): - with self.test_session(): + with self.cached_session(): x = functional_ops.scan( lambda x, _: x, math_ops.range(0), initializer=array_ops.ones([2, 4])) self.assertAllEqual([0, 2, 4], x.get_shape()) @@ -540,7 +526,7 @@ class FunctionalOpsTest(test.TestCase): self.assertIs(None, y.get_shape().dims) def testScanVaryingShape(self): - with self.test_session() as sess: + with self.cached_session() as sess: x = array_ops.placeholder(dtype=dtypes.float32, shape=[None, 2]) x_t = array_ops.transpose(x) # scan over dimension 0 (with shape None) @@ -619,7 +605,7 @@ class FunctionalOpsTest(test.TestCase): remote_op = functional_ops.remote_call( args=[a, b], Tout=[dtypes.int32], f=_remote_fn, target="/cpu:0") - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) mul = sess.run(remote_op) self.assertEqual(mul, [6]) @@ -643,7 +629,7 @@ class FunctionalOpsTest(test.TestCase): f=_remote_fn, target="/job:localhost/replica:0/task:0/device:GPU:0")[0] + 3.0 - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) mul = sess.run(remote_op) self.assertEqual(mul, 9.0) @@ -667,7 +653,7 @@ class FunctionalOpsTest(test.TestCase): f=_remote_fn, target="/job:localhost/replica:0/task:0/cpu:0")[0] + 3.0 - with self.test_session() as sess: + with self.cached_session() as sess: sess.run(variables.global_variables_initializer()) mul = sess.run(remote_op) self.assertEqual(mul, 9.0) @@ -686,7 +672,7 @@ class FunctionalOpsTest(test.TestCase): remote_op = functional_ops.remote_call( args=[a], Tout=[dtypes.string], f=_remote_fn, target="/cpu:0") - with self.test_session() as sess: + with self.cached_session() as sess: ret = sess.run(remote_op) self.assertAllEqual(ret, [b"a"]) diff --git a/tensorflow/python/kernel_tests/list_ops_test.py b/tensorflow/python/kernel_tests/list_ops_test.py index 9b6aee64aa..0f5607712b 100644 --- a/tensorflow/python/kernel_tests/list_ops_test.py +++ b/tensorflow/python/kernel_tests/list_ops_test.py @@ -170,9 +170,8 @@ class ListOpsTest(test_util.TensorFlowTestCase): list_ops.tensor_list_pop_back( l_cpu, element_dtype=dtypes.float32)[1]), 2.0) - @test_util.run_in_graph_and_eager_modes def testGraphStack(self): - with context.graph_mode(), self.test_session(): + with self.cached_session(): tl = list_ops.empty_tensor_list( element_shape=constant_op.constant([1], dtype=dtypes.int32), element_dtype=dtypes.int32) @@ -182,9 +181,8 @@ class ListOpsTest(test_util.TensorFlowTestCase): list_ops.tensor_list_stack(tl, element_dtype=dtypes.int32)), [[1]]) - @test_util.run_in_graph_and_eager_modes def testGraphStackInLoop(self): - with context.graph_mode(), self.test_session(): + with self.cached_session(): t1 = list_ops.empty_tensor_list( element_shape=constant_op.constant([], dtype=dtypes.int32), element_dtype=dtypes.int32) @@ -200,9 +198,8 @@ class ListOpsTest(test_util.TensorFlowTestCase): s1 = list_ops.tensor_list_stack(t1, element_dtype=dtypes.int32) self.assertAllEqual(self.evaluate(s1), [0, 1, 2, 3]) - @test_util.run_in_graph_and_eager_modes def testGraphStackSwitchDtype(self): - with context.graph_mode(), self.test_session(): + with self.cached_session(): list_ = list_ops.empty_tensor_list( element_shape=constant_op.constant([], dtype=dtypes.int32), element_dtype=dtypes.int32) @@ -222,9 +219,8 @@ class ListOpsTest(test_util.TensorFlowTestCase): np_s1 = np.array([[1, 2, 3], [1, 2, 3]], dtype=np.float32) self.assertAllEqual(self.evaluate(s1), np_s1) - @test_util.run_in_graph_and_eager_modes def testGraphStackInLoopSwitchDtype(self): - with context.graph_mode(), self.test_session(): + with self.cached_session(): t1 = list_ops.empty_tensor_list( element_shape=constant_op.constant([], dtype=dtypes.int32), element_dtype=dtypes.int32) @@ -476,6 +472,47 @@ class ListOpsTest(test_util.TensorFlowTestCase): self.evaluate(t_full_zeros), np.zeros( (2,), dtype=dtype.as_numpy_dtype)) + @test_util.run_in_graph_and_eager_modes + def testZerosLikeVariant(self): + for dtype in (dtypes.uint8, dtypes.uint16, dtypes.int8, dtypes.int16, + dtypes.int32, dtypes.int64, dtypes.float16, dtypes.float32, + dtypes.float64, dtypes.complex64, dtypes.complex128, + dtypes.bool): + l = list_ops.empty_tensor_list( + element_dtype=dtypes.variant, element_shape=scalar_shape()) + + sub_l = list_ops.empty_tensor_list( + element_dtype=dtype, element_shape=scalar_shape()) + l = list_ops.tensor_list_push_back(l, sub_l) + sub_l = list_ops.tensor_list_push_back(sub_l, math_ops.cast( + 1, dtype=dtype)) + l = list_ops.tensor_list_push_back(l, sub_l) + sub_l = list_ops.tensor_list_push_back(sub_l, math_ops.cast( + 2, dtype=dtype)) + l = list_ops.tensor_list_push_back(l, sub_l) + + # l : [[], + # [1], + # [1, 2]] + # + # l_zeros : [[], + # [0], + # [0, 0]] + l_zeros = array_ops.zeros_like(l) + + outputs = [] + for _ in range(3): + l_zeros, out = list_ops.tensor_list_pop_back( + l_zeros, element_dtype=dtypes.variant) + outputs.append(list_ops.tensor_list_stack(out, element_dtype=dtype)) + + # Note: `outputs` contains popped values so the order is reversed. + self.assertAllEqual(self.evaluate(outputs[2]), []) + self.assertAllEqual( + self.evaluate(outputs[1]), np.zeros((1,), dtype=dtype.as_numpy_dtype)) + self.assertAllEqual( + self.evaluate(outputs[0]), np.zeros((2,), dtype=dtype.as_numpy_dtype)) + if __name__ == "__main__": test.main() diff --git a/tensorflow/python/kernel_tests/py_func_test.py b/tensorflow/python/kernel_tests/py_func_test.py index 50154a45a8..5f5e24bd63 100644 --- a/tensorflow/python/kernel_tests/py_func_test.py +++ b/tensorflow/python/kernel_tests/py_func_test.py @@ -61,7 +61,7 @@ class PyFuncTest(test.TestCase): for dtype in [dtypes.float16, dtypes.float32, dtypes.float64, dtypes.uint8, dtypes.int8, dtypes.uint16, dtypes.int16, dtypes.int32, dtypes.int64]: - with self.test_session(): + with self.cached_session(): x = constant_op.constant(1, dtype=dtype) y = constant_op.constant(2, dtype=dtype) z = self.evaluate(script_ops.py_func(sum_func, [x, y], dtype)) @@ -71,7 +71,7 @@ class PyFuncTest(test.TestCase): def sub_func(x, y): return x - y for dtype in [dtypes.complex64, dtypes.complex128]: - with self.test_session(): + with self.cached_session(): x = constant_op.constant(1 + 1j, dtype=dtype) y = constant_op.constant(2 - 2j, dtype=dtype) z = self.evaluate(script_ops.py_func(sub_func, [x, y], dtype)) @@ -81,21 +81,21 @@ class PyFuncTest(test.TestCase): def and_func(x, y): return x and y dtype = dtypes.bool - with self.test_session(): + with self.cached_session(): x = constant_op.constant(True, dtype=dtype) y = constant_op.constant(False, dtype=dtype) z = self.evaluate(script_ops.py_func(and_func, [x, y], dtype)) self.assertEqual(z, False) def testSingleType(self): - with self.test_session(): + with self.cached_session(): x = constant_op.constant(1.0, dtypes.float32) y = constant_op.constant(2.0, dtypes.float32) z = self.evaluate(script_ops.py_func(np_func, [x, y], dtypes.float32)) self.assertEqual(z, np_func(1.0, 2.0).astype(np.float32)) def testScalar(self): - with self.test_session(): + with self.cached_session(): x = constant_op.constant(1.0, dtypes.float32) y = constant_op.constant(2.0, dtypes.float32) z = self.evaluate( @@ -103,7 +103,7 @@ class PyFuncTest(test.TestCase): self.assertEqual(z[0], np_func(1.0, 2.0).astype(np.float32)) def testArray(self): - with self.test_session(): + with self.cached_session(): x = constant_op.constant([1.0, 2.0], dtypes.float64) y = constant_op.constant([2.0, 3.0], dtypes.float64) z = self.evaluate(script_ops.py_func(np_func, [x, y], [dtypes.float64])) @@ -111,14 +111,14 @@ class PyFuncTest(test.TestCase): np_func([1.0, 2.0], [2.0, 3.0]).astype(np.float64)) def testComplexType(self): - with self.test_session(): + with self.cached_session(): x = constant_op.constant(1 + 2j, dtypes.complex64) y = constant_op.constant(3 + 4j, dtypes.complex64) z = self.evaluate(script_ops.py_func(np_func, [x, y], dtypes.complex64)) self.assertAllClose(z, np_func(1 + 2j, 3 + 4j)) def testRFFT(self): - with self.test_session(): + with self.cached_session(): x = constant_op.constant([1., 2., 3., 4.], dtypes.float32) def rfft(x): @@ -128,7 +128,7 @@ class PyFuncTest(test.TestCase): self.assertAllClose(y, np.fft.rfft([1., 2., 3., 4.])) def testPythonLiteral(self): - with self.test_session(): + with self.cached_session(): def literal(x): return 1.0 if float(x) == 0.0 else 0.0 @@ -138,7 +138,7 @@ class PyFuncTest(test.TestCase): self.assertAllClose(y, 1.0) def testList(self): - with self.test_session(): + with self.cached_session(): def list_func(x): return [x, x + 1] @@ -150,7 +150,7 @@ class PyFuncTest(test.TestCase): def testTuple(self): # returns a tuple - with self.test_session(): + with self.cached_session(): def tuple_func(x): return x, x + 1 @@ -161,7 +161,7 @@ class PyFuncTest(test.TestCase): self.assertAllClose(y, [0.0, 1.0]) # returns a tuple, Tout and inp a tuple - with self.test_session(): + with self.cached_session(): x = constant_op.constant(0.0, dtypes.float64) y = self.evaluate( script_ops.py_func(tuple_func, (x,), @@ -176,7 +176,7 @@ class PyFuncTest(test.TestCase): def read_and_return_strings(x, y): return x + y - with self.test_session(): + with self.cached_session(): x = constant_op.constant([b"hello", b"hi"], dtypes.string) y = self.evaluate( script_ops.py_func(read_fixed_length_numpy_strings, [], @@ -193,7 +193,7 @@ class PyFuncTest(test.TestCase): def read_and_return_strings(x, y): return x + y - with self.test_session(): + with self.cached_session(): x = constant_op.constant(["hello", "hi"], dtypes.string) y = self.evaluate( script_ops.py_func(read_fixed_length_numpy_strings, [], @@ -210,7 +210,7 @@ class PyFuncTest(test.TestCase): def read_and_return_strings(x, y): return x + y - with self.test_session(): + with self.cached_session(): x = constant_op.constant(["hello", "hi"], dtypes.string) y, = script_ops.py_func(read_object_array, [], [dtypes.string]) @@ -219,19 +219,19 @@ class PyFuncTest(test.TestCase): def testStringPadding(self): correct = [b"this", b"is", b"a", b"test"] - with self.test_session(): + with self.cached_session(): s, = script_ops.py_func(lambda: [correct], [], [dtypes.string]) self.assertAllEqual(s.eval(), correct) def testStringPaddingAreConvertedToBytes(self): inp = ["this", "is", "a", "test"] correct = [b"this", b"is", b"a", b"test"] - with self.test_session(): + with self.cached_session(): s, = script_ops.py_func(lambda: [inp], [], [dtypes.string]) self.assertAllEqual(s.eval(), correct) def testLarge(self): - with self.test_session() as sess: + with self.cached_session() as sess: x = array_ops.zeros([1000000], dtype=np.float32) y = script_ops.py_func(lambda x: x + 1, [x], [dtypes.float32]) z = script_ops.py_func(lambda x: x * 2, [x], [dtypes.float32]) @@ -239,12 +239,12 @@ class PyFuncTest(test.TestCase): sess.run([y[0].op, z[0].op]) def testNoInput(self): - with self.test_session(): + with self.cached_session(): x = self.evaluate(script_ops.py_func(lambda: 42.0, [], dtypes.float64)) self.assertAllClose(x, 42.0) def testAlias(self): - with self.test_session(): + with self.cached_session(): np_array = np.array([1.0, 2.0], dtype=np.float32) tf_array = script_ops.py_func(lambda: np_array, [], [dtypes.float32]) value = tf_array + constant_op.constant([2.0, 3.0], dtype=dtypes.float32) @@ -252,7 +252,7 @@ class PyFuncTest(test.TestCase): self.assertAllEqual(np_array, [1.0, 2.0]) def testReturnUnicodeString(self): - with self.test_session(): + with self.cached_session(): correct = u"你好 世界" def unicode_string(): @@ -262,7 +262,7 @@ class PyFuncTest(test.TestCase): self.assertEqual(z.eval(), correct.encode("utf8")) def testBadNumpyReturnType(self): - with self.test_session(): + with self.cached_session(): def bad(): # Structured numpy arrays aren't supported. @@ -275,7 +275,7 @@ class PyFuncTest(test.TestCase): y.eval() def testBadReturnType(self): - with self.test_session(): + with self.cached_session(): def bad(): # Non-string python objects aren't supported. @@ -288,7 +288,7 @@ class PyFuncTest(test.TestCase): z.eval() def testReturnInput(self): - with self.test_session(): + with self.cached_session(): def ident(x): return x[0] @@ -303,7 +303,7 @@ class PyFuncTest(test.TestCase): self.assertEqual(0.0, z.eval(feed_dict={p: [0.0]})) def testStateful(self): - # Not using self.test_session(), which disables optimization. + # Not using self.cached_session(), which disables optimization. with session_lib.Session() as sess: producer = iter(range(3)) x, = script_ops.py_func(lambda: next(producer), [], [dtypes.int64]) @@ -312,7 +312,7 @@ class PyFuncTest(test.TestCase): self.assertEqual(sess.run(x), 2) def testStateless(self): - # Not using self.test_session(), which disables optimization. + # Not using self.cached_session(), which disables optimization. with session_lib.Session() as sess: producer = iter(range(3)) x, = script_ops.py_func( @@ -331,7 +331,7 @@ class PyFuncTest(test.TestCase): self.assertEqual(None, ops.get_gradient_function(y.op)) def testCOrder(self): - with self.test_session(): + with self.cached_session(): val = [[1, 2], [3, 4]] x, = script_ops.py_func(lambda: np.array(val, order="F"), [], [dtypes.int64]) @@ -339,7 +339,7 @@ class PyFuncTest(test.TestCase): def testParallel(self): # Tests that tf.py_func's can run in parallel if they release the GIL. - with self.test_session() as session: + with self.cached_session() as session: q = queue.Queue(1) def blocking_put(): @@ -375,7 +375,7 @@ class PyFuncTest(test.TestCase): def value(self): return self._value - with self.test_session(): + with self.cached_session(): s = State() op = s.increment(constant_op.constant(2, dtypes.int64)) ret = self.evaluate(op) @@ -389,7 +389,7 @@ class PyFuncTest(test.TestCase): f = script_ops.py_func( do_nothing, [constant_op.constant(3, dtypes.int64)], [], stateful=False) - with self.test_session() as sess: + with self.cached_session() as sess: self.assertEqual(sess.run(f), []) def _testExceptionHandling(self, py_exp, tf_exp, eager=False): @@ -417,21 +417,22 @@ class PyFuncTest(test.TestCase): else: f = script_ops.py_func(raise_exception, [], []) - with self.test_session(): - with self.assertRaisesWithPredicateMatch(tf_exp, expected_error_check): - self.evaluate(f) + with self.assertRaisesWithPredicateMatch(tf_exp, expected_error_check): + self.evaluate(f) def testExceptionHandling(self): - self._testExceptionHandling(ValueError, errors.InvalidArgumentError) - self._testExceptionHandling(TypeError, errors.InvalidArgumentError) - self._testExceptionHandling(StopIteration, errors.OutOfRangeError) - self._testExceptionHandling(MemoryError, errors.ResourceExhaustedError) - self._testExceptionHandling(NotImplementedError, errors.UnimplementedError) + with self.cached_session(): + self._testExceptionHandling(ValueError, errors.InvalidArgumentError) + self._testExceptionHandling(TypeError, errors.InvalidArgumentError) + self._testExceptionHandling(StopIteration, errors.OutOfRangeError) + self._testExceptionHandling(MemoryError, errors.ResourceExhaustedError) + self._testExceptionHandling(NotImplementedError, + errors.UnimplementedError) - class WeirdError(Exception): - pass + class WeirdError(Exception): + pass - self._testExceptionHandling(WeirdError, errors.UnknownError) + self._testExceptionHandling(WeirdError, errors.UnknownError) # ----- Tests shared by py_func and eager_py_func ----- def testCleanup(self): @@ -452,7 +453,7 @@ class PyFuncTest(test.TestCase): # (see #18292) _ = script_ops.py_func(lambda x: x + c.shape[0], [c], [dtypes.float32]) _ = script_ops.eager_py_func(lambda x: x + c.shape[0], [c], [dtypes.float32]) - + # Call garbage collector to enforce deletion. make_graphs() ops.reset_default_graph() @@ -565,6 +566,18 @@ class PyFuncTest(test.TestCase): dy_dx = gradients_impl.gradients(y, x)[0] self.assertEqual(self.evaluate(dy_dx), 6.0) + def testEagerGradientGraphTwoOutputs(self): + + def f(x, y): + return x * y, x / y + + x = constant_op.constant(3.0) + y = constant_op.constant(2.0) + fa, fb = script_ops.eager_py_func(f, inp=[x, y], + Tout=[dtypes.float32, dtypes.float32]) + dy_dx = gradients_impl.gradients(fa + fb, x)[0] + self.assertEqual(self.evaluate(dy_dx), 2.5) + @test_util.run_in_graph_and_eager_modes def testEagerGradientTapeMultipleArgs(self): @@ -610,7 +623,7 @@ class PyFuncTest(test.TestCase): func=log_huber, inp=[x, m], Tout=dtypes.float32) dy_dx = gradients_impl.gradients(y, x)[0] - with self.test_session() as sess: + with self.cached_session() as sess: # Takes the first branch of log_huber. y, dy_dx = sess.run([y, dy_dx], feed_dict={x: 1.0, m: 2.0}) self.assertEqual(y, 1.0) diff --git a/tensorflow/python/kernel_tests/resource_variable_ops_test.py b/tensorflow/python/kernel_tests/resource_variable_ops_test.py index d0ed08933d..f90545f84c 100644 --- a/tensorflow/python/kernel_tests/resource_variable_ops_test.py +++ b/tensorflow/python/kernel_tests/resource_variable_ops_test.py @@ -54,7 +54,7 @@ class ResourceVariableOpsTest(test_util.TensorFlowTestCase): self.assertEqual(0, len(gc.garbage)) def testHandleDtypeShapeMatch(self): - with self.test_session(): + with self.cached_session(): handle = resource_variable_ops.var_handle_op(dtype=dtypes.int32, shape=[]) with self.assertRaises(ValueError): resource_variable_ops.assign_variable_op( @@ -123,7 +123,7 @@ class ResourceVariableOpsTest(test_util.TensorFlowTestCase): self.assertFalse(np.allclose(variable.numpy(), copied_variable.numpy())) def testGraphDeepCopy(self): - with self.test_session(): + with self.cached_session(): init_value = np.ones((4, 4, 4)) variable = resource_variable_ops.ResourceVariable(init_value, name="init") @@ -145,13 +145,13 @@ class ResourceVariableOpsTest(test_util.TensorFlowTestCase): # variable graph. def testFetchHandle(self): - with self.test_session(): + with self.cached_session(): handle = resource_variable_ops.var_handle_op( dtype=dtypes.int32, shape=[1], name="foo") self.assertGreater(len(handle.eval()), 0) def testCachedValueReadBeforeWrite(self): - with self.test_session() as sess: + with self.cached_session() as sess: v = resource_variable_ops.ResourceVariable(0.0, caching_device="cpu:0") sess.run(v.initializer) value, _ = sess.run([v, v.assign_add(1.0)]) @@ -492,7 +492,7 @@ class ResourceVariableOpsTest(test_util.TensorFlowTestCase): # TODO(alive): how should this work in Eager mode? def testInitFn(self): - with self.test_session(): + with self.cached_session(): v = resource_variable_ops.ResourceVariable( initial_value=lambda: 1, dtype=dtypes.float32) self.assertEqual(v.handle.op.colocation_groups(), @@ -569,11 +569,11 @@ class ResourceVariableOpsTest(test_util.TensorFlowTestCase): self.assertEqual(2.0, self.evaluate(v.value())) def testVariableDefInitializedInstances(self): - with ops.Graph().as_default(), self.test_session() as sess: + with ops.Graph().as_default(), self.cached_session() as sess: v_def = resource_variable_ops.ResourceVariable( initial_value=constant_op.constant(3.0)).to_proto() - with ops.Graph().as_default(), self.test_session() as sess: + with ops.Graph().as_default(), self.cached_session() as sess: # v describes a VariableDef-based variable without an initial value. v = resource_variable_ops.ResourceVariable(variable_def=v_def) self.assertEqual(3.0, sess.run(v.initialized_value())) @@ -584,7 +584,7 @@ class ResourceVariableOpsTest(test_util.TensorFlowTestCase): self.assertEqual(1.0, v.initialized_value().eval()) v_def.ClearField("initial_value_name") - with ops.Graph().as_default(), self.test_session() as sess: + with ops.Graph().as_default(), self.cached_session() as sess: # Restoring a legacy VariableDef proto that does not have # initial_value_name set should still work. v = resource_variable_ops.ResourceVariable(variable_def=v_def) @@ -615,17 +615,16 @@ class ResourceVariableOpsTest(test_util.TensorFlowTestCase): @test_util.run_in_graph_and_eager_modes def testSparseRead(self): - with self.test_session(): - init_value = np.reshape(np.arange(np.power(4, 3)), (4, 4, 4)) - v = resource_variable_ops.ResourceVariable( - constant_op.constant(init_value, dtype=dtypes.int32), name="var3") - self.evaluate(variables.global_variables_initializer()) + init_value = np.reshape(np.arange(np.power(4, 3)), (4, 4, 4)) + v = resource_variable_ops.ResourceVariable( + constant_op.constant(init_value, dtype=dtypes.int32), name="var3") + self.evaluate(variables.global_variables_initializer()) - value = self.evaluate(v.sparse_read([0, 3, 1, 2])) - self.assertAllEqual(init_value[[0, 3, 1, 2], ...], value) + value = self.evaluate(v.sparse_read([0, 3, 1, 2])) + self.assertAllEqual(init_value[[0, 3, 1, 2], ...], value) def testToFromProto(self): - with self.test_session(): + with self.cached_session(): v = resource_variable_ops.ResourceVariable(1.0) variables.global_variables_initializer().run() @@ -686,7 +685,7 @@ class ResourceVariableOpsTest(test_util.TensorFlowTestCase): handle, ignore_lookup_error=True)) def testAssignDifferentShapes(self): - with self.test_session() as sess, variable_scope.variable_scope( + with self.cached_session() as sess, variable_scope.variable_scope( "foo", use_resource=True): var = variable_scope.get_variable("x", shape=[1, 1], dtype=dtypes.float32) placeholder = array_ops.placeholder(dtypes.float32) @@ -728,7 +727,7 @@ class ResourceVariableOpsTest(test_util.TensorFlowTestCase): _ = w.value().op.get_attr("_class") def testSharedName(self): - with self.test_session(): + with self.cached_session(): v = resource_variable_ops.ResourceVariable(300.0, name="var4") variables.global_variables_initializer().run() @@ -746,7 +745,7 @@ class ResourceVariableOpsTest(test_util.TensorFlowTestCase): resource_variable_ops.read_variable_op(x, v.dtype.base_dtype).eval() def testSharedNameWithNamescope(self): - with self.test_session(): + with self.cached_session(): with ops.name_scope("foo"): v = resource_variable_ops.ResourceVariable(300.0, name="var6") self.assertEqual("foo/var6", v._shared_name) # pylint: disable=protected-access @@ -774,7 +773,7 @@ class ResourceVariableOpsTest(test_util.TensorFlowTestCase): str(v.sparse_read(array_ops.placeholder(dtypes.int32)).shape)) def testSetInitialValue(self): - with self.test_session(): + with self.cached_session(): # Initialize variable with a value different from the initial value passed # in the constructor. v = resource_variable_ops.ResourceVariable(2.0) diff --git a/tensorflow/python/kernel_tests/rnn_test.py b/tensorflow/python/kernel_tests/rnn_test.py index 562d11f0b0..a28cdc3b26 100644 --- a/tensorflow/python/kernel_tests/rnn_test.py +++ b/tensorflow/python/kernel_tests/rnn_test.py @@ -197,7 +197,7 @@ class RNNTest(test.TestCase): else: inputs = array_ops.placeholder(dtypes.float32, shape=(1, 4, 1)) - with self.test_session() as sess: + with self.cached_session(use_gpu=True) as sess: outputs, state = rnn.dynamic_rnn( cell, inputs, dtype=dtypes.float32, sequence_length=[4]) if not in_eager_mode: @@ -217,7 +217,7 @@ class RNNTest(test.TestCase): else: inputs = array_ops.placeholder(dtypes.float32, shape=(1, 4, 1)) - with self.test_session() as sess: + with self.cached_session(use_gpu=True) as sess: outputs, state = rnn.dynamic_rnn( cell, inputs, dtype=dtypes.float32, sequence_length=[4]) if not in_eager_mode: @@ -246,7 +246,7 @@ class RNNTest(test.TestCase): else: inputs = array_ops.placeholder(dtypes.float32, shape=(1, 4, 1)) - with self.test_session() as sess: + with self.cached_session(use_gpu=True) as sess: outputs, state = rnn.dynamic_rnn( cell, inputs, dtype=dtypes.float32, sequence_length=[4]) state = (state[0], state[1].stack()) @@ -321,7 +321,7 @@ class RNNTest(test.TestCase): self._assert_cell_builds(contrib_rnn.IndyLSTMCell, f64, 5, 7, 3) def testRNNWithKerasSimpleRNNCell(self): - with self.test_session() as sess: + with self.cached_session() as sess: input_shape = 10 output_shape = 5 timestep = 4 @@ -354,7 +354,7 @@ class RNNTest(test.TestCase): self.assertEqual(len(state), batch) def testRNNWithKerasGRUCell(self): - with self.test_session() as sess: + with self.cached_session() as sess: input_shape = 10 output_shape = 5 timestep = 4 @@ -387,7 +387,7 @@ class RNNTest(test.TestCase): self.assertEqual(len(state), batch) def testRNNWithKerasLSTMCell(self): - with self.test_session() as sess: + with self.cached_session() as sess: input_shape = 10 output_shape = 5 timestep = 4 @@ -424,7 +424,7 @@ class RNNTest(test.TestCase): self.assertEqual(len(state[1]), batch) def testRNNWithStackKerasCell(self): - with self.test_session() as sess: + with self.cached_session() as sess: input_shape = 10 output_shape = 5 timestep = 4 @@ -465,7 +465,7 @@ class RNNTest(test.TestCase): self.assertEqual(len(s), batch) def testStaticRNNWithKerasSimpleRNNCell(self): - with self.test_session() as sess: + with self.cached_session() as sess: input_shape = 10 output_shape = 5 timestep = 4 @@ -567,7 +567,7 @@ class RNNTest(test.TestCase): rnn_cell_impl.GRUCell( 32, kernel_initializer="ones", dtype=dtypes.float32) ]: - with self.test_session(): + with self.cached_session(): x = keras.Input((None, 5)) layer = keras.layers.RNN(cell) y = layer(x) diff --git a/tensorflow/python/kernel_tests/sparse_ops_test.py b/tensorflow/python/kernel_tests/sparse_ops_test.py index cb5a66312f..fc39de150e 100644 --- a/tensorflow/python/kernel_tests/sparse_ops_test.py +++ b/tensorflow/python/kernel_tests/sparse_ops_test.py @@ -22,6 +22,7 @@ import numpy as np from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes +from tensorflow.python.framework import ops from tensorflow.python.framework import sparse_tensor from tensorflow.python.framework import test_util from tensorflow.python.ops import array_ops @@ -205,6 +206,22 @@ class SparseMergeTest(test_util.TensorFlowTestCase): output = sess.run(sp_output) self._AssertResultsNotSorted(output, vocab_size) + def testShouldSetLastDimensionInDynamicShape(self): + with ops.Graph().as_default(): + shape = constant_op.constant([2, 2], dtype=dtypes.int64) + dynamic_shape = array_ops.placeholder_with_default(shape, shape=[2]) + ids = sparse_tensor.SparseTensor( + indices=[[0, 0], [0, 1]], + values=[1, 3], + dense_shape=dynamic_shape) + values = sparse_tensor.SparseTensor( + indices=[[0, 0], [0, 1]], + values=[0.4, 0.7], + dense_shape=dynamic_shape) + merged = sparse_ops.sparse_merge( + sp_ids=ids, sp_values=values, vocab_size=5) + self.assertEqual(5, merged.get_shape()[1]) + class SparseMergeHighDimTest(test_util.TensorFlowTestCase): diff --git a/tensorflow/python/lib/core/py_seq_tensor.cc b/tensorflow/python/lib/core/py_seq_tensor.cc index 3b4f12ae31..269142a7c2 100644 --- a/tensorflow/python/lib/core/py_seq_tensor.cc +++ b/tensorflow/python/lib/core/py_seq_tensor.cc @@ -55,6 +55,10 @@ bool IsPyDouble(PyObject* obj) { return PyIsInstance(obj, &PyDoubleArrType_Type); // NumPy double type. } +bool IsNumpyHalf(PyObject* obj) { + return PyIsInstance(obj, &PyHalfArrType_Type); +} + bool IsPyFloat(PyObject* obj) { return PyFloat_Check(obj) || PyIsInstance(obj, &PyFloatingArrType_Type); // NumPy float types @@ -156,6 +160,8 @@ Status InferShapeAndType(PyObject* obj, TensorShape* shape, DataType* dtype) { } } else if (IsPyDouble(obj)) { *dtype = DT_DOUBLE; + } else if (IsNumpyHalf(obj)) { + *dtype = DT_HALF; } else if (IsPyFloat(obj)) { *dtype = DT_FLOAT; } else if (PyBool_Check(obj) || PyIsInstance(obj, &PyBoolArrType_Type)) { @@ -357,6 +363,17 @@ const char* ConvertOneFloat(PyObject* v, T* out) { DEFINE_HELPER(ConvertDouble, double, DT_DOUBLE, ConvertOneFloat<double>); DEFINE_HELPER(ConvertFloat, float, DT_FLOAT, ConvertOneFloat<float>); +const char* ConvertOneNumpyHalf(PyObject* v, Eigen::half* out) { + // NOTE(nareshmodi): Is there a way to convert to C double without the + // intermediate Python double? This will help with ConvertOneFloat as well. + Safe_PyObjectPtr as_float = make_safe(PyNumber_Float(v)); + double v_double = PyFloat_AS_DOUBLE(as_float.get()); + *out = Eigen::half(v_double); + + return nullptr; +} +DEFINE_HELPER(ConvertNumpyHalf, Eigen::half, DT_HALF, ConvertOneNumpyHalf); + // String support const char* ConvertOneString(PyObject* v, string* out) { @@ -452,6 +469,9 @@ Status PySeqToTensor(PyObject* obj, PyObject* dtype, Tensor* ret) { if (ConvertDouble(obj, shape, ret) == nullptr) return Status::OK(); break; + case DT_HALF: + RETURN_STRING_AS_STATUS(ConvertNumpyHalf(obj, shape, ret)); + case DT_INT64: if (ConvertInt64(obj, shape, ret) == nullptr) return Status::OK(); break; @@ -489,8 +509,13 @@ Status PySeqToTensor(PyObject* obj, PyObject* dtype, Tensor* ret) { // final type. RETURN_STRING_AS_STATUS(ConvertDouble(obj, shape, ret)); } + case DT_DOUBLE: RETURN_STRING_AS_STATUS(ConvertDouble(obj, shape, ret)); + + case DT_HALF: + RETURN_STRING_AS_STATUS(ConvertNumpyHalf(obj, shape, ret)); + case DT_INT64: if (requested_dtype == DT_INVALID) { const char* error = ConvertInt32(obj, shape, ret); diff --git a/tensorflow/python/ops/collective_ops_test.py b/tensorflow/python/ops/collective_ops_test.py index 6f3cd74406..78c4b4bfe0 100644 --- a/tensorflow/python/ops/collective_ops_test.py +++ b/tensorflow/python/ops/collective_ops_test.py @@ -29,7 +29,7 @@ from tensorflow.python.platform import test class CollectiveOpTest(test.TestCase): - def _testCollectiveReduce(self, t0, t1, expected): + def _testCollectiveReduce(self, t0, t1, expected, set_graph_key): group_key = 1 instance_key = 1 with self.test_session( @@ -43,7 +43,8 @@ class CollectiveOpTest(test.TestCase): colred1 = collective_ops.all_reduce(in1, 2, group_key, instance_key, 'Add', 'Div') run_options = config_pb2.RunOptions() - run_options.experimental.collective_graph_key = 1 + if set_graph_key: + run_options.experimental.collective_graph_key = 1 results = sess.run([colred0, colred1], options=run_options) self.assertAllClose(results[0], expected, rtol=1e-5, atol=1e-5) self.assertAllClose(results[1], expected, rtol=1e-5, atol=1e-5) @@ -51,10 +52,15 @@ class CollectiveOpTest(test.TestCase): def testCollectiveReduce(self): self._testCollectiveReduce([0.1, 1.1, 2.1, 3.1, 4.1, 5.1, 6.1, 7.1], [0.3, 1.3, 2.3, 3.3, 4.3, 5.3, 6.3, 7.3], - [0.2, 1.2, 2.2, 3.2, 4.2, 5.2, 6.2, 7.2]) + [0.2, 1.2, 2.2, 3.2, 4.2, 5.2, 6.2, 7.2], True) + + def testCollectiveAutoGraphKey(self): + self._testCollectiveReduce([0.1, 1.1, 2.1, 3.1, 4.1, 5.1, 6.1, 7.1], + [0.3, 1.3, 2.3, 3.3, 4.3, 5.3, 6.3, 7.3], + [0.2, 1.2, 2.2, 3.2, 4.2, 5.2, 6.2, 7.2], False) def testCollectiveReduceScalar(self): - self._testCollectiveReduce(0.1, 0.3, 0.2) + self._testCollectiveReduce(0.1, 0.3, 0.2, True) def _testCollectiveBroadcast(self, t0): group_key = 1 diff --git a/tensorflow/python/ops/cond_v2_impl.py b/tensorflow/python/ops/cond_v2_impl.py index c4e9c982b5..c6a6b2a7fa 100644 --- a/tensorflow/python/ops/cond_v2_impl.py +++ b/tensorflow/python/ops/cond_v2_impl.py @@ -180,16 +180,16 @@ def _IfGrad(op, *grads): # pylint: disable=invalid-name def _get_func_graphs(if_op): - """Returns `_FuncGraph`s for the input op branches. + """Returns `FuncGraph`s for the input op branches. Args: if_op: The _If Operation. Returns: - A 2-tuple of the `_FuncGraph`s of the then_branch and else_branch. + A 2-tuple of the `FuncGraph`s of the then_branch and else_branch. """ def _get_func_graph_for_branch(branch_name): - """Generates and returns a _FuncGraph for the given branch.""" + """Generates and returns a FuncGraph for the given branch.""" inputs = if_op.inputs[1:] # First input is pred. input_shapes = [t.shape for t in inputs] func_name = if_op.get_attr(branch_name).name @@ -197,7 +197,7 @@ def _get_func_graphs(if_op): # `if_op.graph` may not be the same as `ops.get_default_graph()` e.g. # in the case of nested if ops or when the gradient is being computed # from inside a Defun. We build the `func_graph` with `if_op.graph` as its - # `outer_graph`. This resembles how the `_FuncGraph` was built in the + # `outer_graph`. This resembles how the `FuncGraph` was built in the # forward pass. We need this so that we can resolve references to tensors # in `func_graph` from its gradient graph in `_resolve_grad_inputs`. with if_op.graph.as_default(): @@ -221,7 +221,7 @@ def _grad_fn(func_graph, grads): func_graph's outputs w.r.t. its inputs. Args: - func_graph: function._FuncGraph. The corresponding forward-pass function. + func_graph: function.FuncGraph. The corresponding forward-pass function. grads: The list of input gradient Tensors. Returns: @@ -259,7 +259,7 @@ def _grad_fn(func_graph, grads): def _create_grad_func(func_graph, grads, name): - """Returns the _FuncGraph representation of _grad_fn.""" + """Returns the FuncGraph representation of _grad_fn.""" return _function.func_graph_from_py_func( name, lambda: _grad_fn(func_graph, grads), [], {}) @@ -277,8 +277,8 @@ def _resolve_grad_inputs(cond_graph, grad_graph): functions, this is always possible. Args: - cond_graph: function._FuncGraph. The forward-pass function. - grad_graph: function._FuncGraph. The gradients function. + cond_graph: function.FuncGraph. The forward-pass function. + grad_graph: function.FuncGraph. The gradients function. Returns: A list of inputs tensors to be passed to grad_graph. @@ -313,7 +313,7 @@ def _create_new_tf_function(func_graph): """Converts func_graph to a TF_Function and adds it to the current graph. Args: - func_graph: function._FuncGraph + func_graph: function.FuncGraph Returns: The name of the new TF_Function. @@ -365,8 +365,8 @@ def _pad_params(true_graph, false_graph, true_params, false_params): There is no merging of params. Args: - true_graph: function._FuncGraph - false_graph: function._FuncGraph + true_graph: function.FuncGraph + false_graph: function.FuncGraph true_params: a list of Tensors from true_graph false_params: a list of Tensors from false_graph @@ -391,8 +391,8 @@ def _make_inputs_match(true_graph, false_graph, true_inputs, false_inputs): graph to avoid duplicating shared arguments. Args: - true_graph: function._FuncGraph - false_graph: function._FuncGraph + true_graph: function.FuncGraph + false_graph: function.FuncGraph true_inputs: a list of Tensors in the outer graph. The inputs for true_graph. false_inputs: a list of Tensors in the outer graph. The inputs for @@ -421,7 +421,7 @@ def _make_inputs_match(true_graph, false_graph, true_inputs, false_inputs): _create_dummy_params(false_graph, true_only_inputs) + [false_input_to_param[t] for t in false_only_inputs]) - # Rewrite the _FuncGraphs' state to reflect the new inputs. + # Rewrite the FuncGraphs' state to reflect the new inputs. true_graph.captures = collections.OrderedDict(zip(new_inputs, true_graph.inputs)) false_graph.captures = collections.OrderedDict(zip(new_inputs, @@ -434,7 +434,7 @@ def _create_dummy_params(func_graph, template_tensors): """Creates tensors in func_graph to represent template_tensors. Args: - func_graph: function._FuncGraph. + func_graph: function.FuncGraph. template_tensors: a list of tensors in the outer graph. Returns: @@ -451,27 +451,16 @@ def _get_grad_fn_name(func_graph): Ensures this name is unique in the entire hierarchy. Args: - func_graph: The _FuncGraph. + func_graph: The FuncGraph. Returns: A string, the name to use for the gradient function. """ name = "%s_grad" % func_graph.name - - base_name = name - counter = 1 - has_conflict = True - while has_conflict: - curr_graph = func_graph.outer_graph - has_conflict = curr_graph._is_function(name) - while not has_conflict and isinstance(curr_graph, _function.FuncGraph): - curr_graph = curr_graph.outer_graph - has_conflict = curr_graph._is_function(name) - if has_conflict: - name = "%s_%s" % (base_name, counter) - counter += 1 - - return name + outer_most_graph = func_graph + while isinstance(outer_most_graph, _function.FuncGraph): + outer_most_graph = outer_most_graph.outer_graph + return outer_most_graph.unique_name(name) def _check_same_outputs(true_graph, false_graph): diff --git a/tensorflow/python/ops/custom_gradient.py b/tensorflow/python/ops/custom_gradient.py index 871f236f78..d7834ba350 100644 --- a/tensorflow/python/ops/custom_gradient.py +++ b/tensorflow/python/ops/custom_gradient.py @@ -82,11 +82,10 @@ def custom_gradient(f): scope must be using `ResourceVariable`s. Args: - f: function `f(x)` that returns a tuple `(y, grad_fn)` where: - - `x` is a `Tensor` or sequence of `Tensor` inputs to the function. + f: function `f(*x)` that returns a tuple `(y, grad_fn)` where: + - `x` is a sequence of `Tensor` inputs to the function. - `y` is a `Tensor` or sequence of `Tensor` outputs of applying - TensorFlow - operations in `f` to `x`. + TensorFlow operations in `f` to `x`. - `grad_fn` is a function with the signature `g(*grad_ys)` which returns a list of `Tensor`s - the derivatives of `Tensor`s in `y` with respect to the `Tensor`s in `x`. `grad_ys` is a `Tensor` or sequence of @@ -96,7 +95,8 @@ def custom_gradient(f): signature `g(*grad_ys, variables=None)`, where `variables` is a list of the `Variable`s, and return a 2-tuple `(grad_xs, grad_vars)`, where `grad_xs` is the same as above, and `grad_vars` is a `list<Tensor>` - with the derivatives of `Tensor`s in `y` with respect to the variables. + with the derivatives of `Tensor`s in `y` with respect to the variables + (that is, grad_vars has one Tensor per variable in variables). Returns: A function `h(x)` which returns the same value as `f(x)[0]` and whose diff --git a/tensorflow/python/ops/distributions/distribution.py b/tensorflow/python/ops/distributions/distribution.py index ddf9442cd2..578e7b7dd2 100644 --- a/tensorflow/python/ops/distributions/distribution.py +++ b/tensorflow/python/ops/distributions/distribution.py @@ -446,6 +446,24 @@ class Distribution(_BaseDistribution): self._graph_parents = graph_parents self._name = name + @property + def _parameters(self): + return self._parameter_dict + + @_parameters.setter + def _parameters(self, value): + """Intercept assignments to self._parameters to avoid reference cycles. + + Parameters are often created using locals(), so we need to clean out any + references to `self` before assigning it to an attribute. + + Args: + value: A dictionary of parameters to assign to the `_parameters` property. + """ + if "self" in value: + del value["self"] + self._parameter_dict = value + @classmethod def param_shapes(cls, sample_shape, name="DistributionParamShapes"): """Shapes of parameters given the desired shape of a call to `sample()`. diff --git a/tensorflow/python/ops/gradients.py b/tensorflow/python/ops/gradients.py index 9fa8e27d5c..1dc666e78b 100644 --- a/tensorflow/python/ops/gradients.py +++ b/tensorflow/python/ops/gradients.py @@ -19,10 +19,10 @@ from __future__ import division from __future__ import print_function # pylint: disable=unused-import +from tensorflow.python.eager import function from tensorflow.python.eager.backprop import GradientTape from tensorflow.python.ops.custom_gradient import custom_gradient from tensorflow.python.ops.gradients_impl import AggregationMethod from tensorflow.python.ops.gradients_impl import gradients from tensorflow.python.ops.gradients_impl import hessians # pylint: enable=unused-import - diff --git a/tensorflow/python/ops/gradients_impl.py b/tensorflow/python/ops/gradients_impl.py index a68f680224..3268b38b86 100644 --- a/tensorflow/python/ops/gradients_impl.py +++ b/tensorflow/python/ops/gradients_impl.py @@ -31,7 +31,7 @@ from tensorflow.core.framework import attr_value_pb2 from tensorflow.python.eager import context from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes -from tensorflow.python.framework import function +from tensorflow.python.framework import function as framework_function from tensorflow.python.framework import ops from tensorflow.python.framework import tensor_shape from tensorflow.python.framework import tensor_util @@ -58,6 +58,10 @@ from tensorflow.python.platform import tf_logging as logging from tensorflow.python.util import compat from tensorflow.python.util.tf_export import tf_export +# This is to avoid a circular dependency (eager.function depends on +# gradients_impl). This is set in eager/function.py. +_function = None + # This is to avoid a circular dependency with cond_v2_impl. cond_v2_impl._gradients_impl = sys.modules[__name__] # pylint: disable=protected-access @@ -121,7 +125,7 @@ def _MarkReachedOps(from_ops, reached_ops, func_graphs): Args: from_ops: list of Operations. reached_ops: set of Operations. - func_graphs: list of function._FuncGraphs. This method will traverse through + func_graphs: list of _function.FuncGraphs. This method will traverse through these functions if they capture from_ops or any reachable ops. """ queue = collections.deque() @@ -146,7 +150,7 @@ def _PendingCount(to_ops, from_ops, colocate_gradients_with_ops, func_graphs, to_ops: list of Operations. from_ops: list of Operations. colocate_gradients_with_ops: Python bool. See docstring of gradients(). - func_graphs: list of function._FuncGraphs. This method will traverse through + func_graphs: list of _function.FuncGraphs. This method will traverse through these functions if they capture from_ops or any reachable ops. This is useful if to_ops occur in a function and from_ops are in an outer function or graph. @@ -441,6 +445,19 @@ def _RaiseNoGradWrtInitialLoopValError(op, from_ops, xs): % target_op.name) +def _IsFunction(graph): + return (isinstance(graph, _function.FuncGraph) or + isinstance(graph, framework_function._FuncGraph)) # pylint: disable=protected-access + + +def _Captures(func_graph): + if isinstance(func_graph, _function.FuncGraph): + return func_graph.captures + else: + assert isinstance(func_graph, framework_function._FuncGraph) # pylint: disable=protected-access + return func_graph._captured # pylint: disable=protected-access + + def _MaybeCaptured(t): """If t is a captured value placeholder, returns the original captured value. @@ -448,11 +465,11 @@ def _MaybeCaptured(t): t: Tensor Returns: - A tensor, potentially from a different Graph/function._FuncGraph. + A tensor, potentially from a different Graph/_function.FuncGraph. """ # pylint: disable=protected-access - if isinstance(t.op.graph, function._FuncGraph) and t.op.type == "Placeholder": - for input_t, placeholder_t in t.op.graph._captured.items(): + if _IsFunction(t.op.graph) and t.op.type == "Placeholder": + for input_t, placeholder_t in _Captures(t.op.graph).items(): if t == placeholder_t: return _MaybeCaptured(input_t) # pylint: enable=protected-access @@ -470,10 +487,10 @@ def _Inputs(op, xs): Returns: A list of tensors. The tensors may be from multiple - Graph/function._FuncGraphs if op is in a function._FuncGraph and has + Graph/_function.FuncGraphs if op is in a _function.FuncGraph and has captured inputs. """ - if isinstance(op.graph, function._FuncGraph): # pylint: disable=protected-access + if _IsFunction(op.graph): # pylint: disable=protected-access # If we're differentiating w.r.t. `t`, do not attempt to traverse through it # to a captured value. The algorithm needs to "see" `t` in this case, even # if it's a function input for a captured value, whereas usually we'd like @@ -489,7 +506,7 @@ def _Consumers(t, func_graphs): Args: t: Tensor - func_graphs: a list of function._FuncGraphs that may have captured t. + func_graphs: a list of _function.FuncGraphs that may have captured t. Returns: A list of tensors. The tensors will be from the current graph and/or @@ -497,7 +514,7 @@ def _Consumers(t, func_graphs): """ consumers = t.consumers() for func in func_graphs: - for input_t, placeholder in func._captured.items(): # pylint: disable=protected-access + for input_t, placeholder in _Captures(func).items(): if input_t == t: consumers.extend(_Consumers(placeholder, func_graphs)) return consumers @@ -616,9 +633,13 @@ def _GradientsHelper(ys, # ancestor graphs. This is necessary for correctly handling captured values. func_graphs = [] curr_graph = src_graph - while isinstance(curr_graph, function._FuncGraph): # pylint: disable=protected-access + while _IsFunction(curr_graph): func_graphs.append(curr_graph) - curr_graph = curr_graph._outer_graph # pylint: disable=protected-access + if isinstance(curr_graph, _function.FuncGraph): + curr_graph = curr_graph.outer_graph + else: + assert isinstance(curr_graph, framework_function._FuncGraph) # pylint: disable=protected-access + curr_graph = curr_graph._outer_graph # pylint: disable=protected-access ys = _AsList(ys) xs = _AsList(xs) diff --git a/tensorflow/python/ops/gradients_test.py b/tensorflow/python/ops/gradients_test.py index fa9910b351..3759d8a543 100644 --- a/tensorflow/python/ops/gradients_test.py +++ b/tensorflow/python/ops/gradients_test.py @@ -26,9 +26,10 @@ import numpy as np from tensorflow.python.client import session from tensorflow.python.eager import backprop from tensorflow.python.eager import context +from tensorflow.python.eager import function from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes -from tensorflow.python.framework import function +from tensorflow.python.framework import function as framework_function from tensorflow.python.framework import ops from tensorflow.python.framework import test_ops from tensorflow.python.framework import test_util @@ -369,8 +370,8 @@ class FunctionGradientsTest(test_util.TensorFlowTestCase): @classmethod def _GetFunc(cls, **kwargs): - return function.Defun(dtypes.float32, dtypes.float32, ** - kwargs)(cls.XSquarePlusB) + return framework_function.Defun(dtypes.float32, dtypes.float32, ** + kwargs)(cls.XSquarePlusB) def _GetFuncGradients(self, f, x_value, b_value): x = constant_op.constant(x_value, name="x") @@ -408,8 +409,9 @@ class FunctionGradientsTest(test_util.TensorFlowTestCase): def testFunctionGradientsWithGradFunc(self): g = ops.Graph() with g.as_default(): - grad_func = function.Defun(dtypes.float32, dtypes.float32, - dtypes.float32)(self.XSquarePlusBGradient) + grad_func = framework_function.Defun(dtypes.float32, dtypes.float32, + dtypes.float32)( + self.XSquarePlusBGradient) f = self._GetFunc(grad_func=grad_func) # Get gradients (should add SymbolicGradient node for function, which # uses the grad_func above, which multiplies all gradients by 2). @@ -430,8 +432,9 @@ class FunctionGradientsTest(test_util.TensorFlowTestCase): def testFunctionGradientWithGradFuncAndRegistration(self): g = ops.Graph() with g.as_default(): - grad_func = function.Defun(dtypes.float32, dtypes.float32, - dtypes.float32)(self.XSquarePlusBGradient) + grad_func = framework_function.Defun(dtypes.float32, dtypes.float32, + dtypes.float32)( + self.XSquarePlusBGradient) with self.assertRaisesRegexp(ValueError, "Gradient defined twice"): f = self._GetFunc( grad_func=grad_func, python_grad_func=self._PythonGradient) @@ -441,7 +444,7 @@ class FunctionGradientsTest(test_util.TensorFlowTestCase): with ops.Graph().as_default(): x = constant_op.constant(1.0, name="x") - @function.Defun() + @function.defun() def Foo(): y = math_ops.multiply(x, 2.0, name="y") g = gradients_impl.gradients(y, x) @@ -456,7 +459,7 @@ class FunctionGradientsTest(test_util.TensorFlowTestCase): x = constant_op.constant(1.0, name="x") y = math_ops.multiply(x, 2.0, name="y") - @function.Defun() + @framework_function.Defun() def Foo(): g = gradients_impl.gradients(y, x) return g[0] @@ -469,7 +472,7 @@ class FunctionGradientsTest(test_util.TensorFlowTestCase): with ops.Graph().as_default(): var = resource_variable_ops.ResourceVariable(1.0, name="var") - @function.Defun() + @function.defun() def Foo(): y = math_ops.multiply(var, 2.0, name="y") g = gradients_impl.gradients(y, var) @@ -486,11 +489,11 @@ class FunctionGradientsTest(test_util.TensorFlowTestCase): x2 = constant_op.constant(2.0, name="x2") x3 = math_ops.multiply(x1, x2, name="x3") - @function.Defun() + @function.defun() def Outer(): outer1 = array_ops.identity(x1, name="outer1") - @function.Defun() + @function.defun() def Inner(): inner1 = array_ops.identity(outer1, name="inner1") inner2 = array_ops.identity(x2, name="inner2") @@ -511,11 +514,11 @@ class FunctionGradientsTest(test_util.TensorFlowTestCase): with ops.Graph().as_default(): x = constant_op.constant(1.0, name="x") - @function.Defun() + @function.defun() def Outer(): y = math_ops.multiply(x, 2.0, name="y") - @function.Defun() + @function.defun() def Inner(): z = math_ops.multiply(y, 3.0, name="z") g = gradients_impl.gradients(z, y) diff --git a/tensorflow/python/ops/init_ops.py b/tensorflow/python/ops/init_ops.py index e0695f01e6..fff3d9b930 100644 --- a/tensorflow/python/ops/init_ops.py +++ b/tensorflow/python/ops/init_ops.py @@ -36,13 +36,11 @@ import math import numpy as np -from tensorflow.python.eager import context from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes -from tensorflow.python.framework import ops from tensorflow.python.ops import array_ops -from tensorflow.python.ops import linalg_ops_impl from tensorflow.python.ops import gen_linalg_ops +from tensorflow.python.ops import linalg_ops_impl from tensorflow.python.ops import math_ops from tensorflow.python.ops import random_ops from tensorflow.python.util.deprecation import deprecated @@ -542,11 +540,7 @@ class Orthogonal(Initializer): # Generate a random matrix a = random_ops.random_normal(flat_shape, dtype=dtype, seed=self.seed) # Compute the qr factorization - if context.executing_eagerly(): - with ops.device("cpu:0"): # TODO(b/73102536) - q, r = gen_linalg_ops.qr(a, full_matrices=False) - else: - q, r = gen_linalg_ops.qr(a, full_matrices=False) + q, r = gen_linalg_ops.qr(a, full_matrices=False) # Make Q uniform d = array_ops.diag_part(r) q *= math_ops.sign(d) @@ -596,11 +590,7 @@ class ConvolutionDeltaOrthogonal(Initializer): a = random_ops.random_normal([shape[-1], shape[-1]], dtype=dtype, seed=self.seed) # Compute the qr factorization - if context.executing_eagerly(): - with ops.device("cpu:0"): # TODO(b/73102536) - q, r = gen_linalg_ops.qr(a, full_matrices=False) - else: - q, r = gen_linalg_ops.qr(a, full_matrices=False) + q, r = gen_linalg_ops.qr(a, full_matrices=False) # Make Q uniform d = array_ops.diag_part(r) q *= math_ops.sign(d) @@ -1120,29 +1110,10 @@ class Identity(Initializer): def get_config(self): return {"gain": self.gain, "dtype": self.dtype.name} -# Aliases. - -# pylint: disable=invalid-name -zeros_initializer = Zeros -ones_initializer = Ones -constant_initializer = Constant -random_uniform_initializer = RandomUniform -random_normal_initializer = RandomNormal -truncated_normal_initializer = TruncatedNormal -uniform_unit_scaling_initializer = UniformUnitScaling -variance_scaling_initializer = VarianceScaling -orthogonal_initializer = Orthogonal -identity_initializer = Identity -convolutional_delta_orthogonal = ConvolutionDeltaOrthogonal -convolutional_orthogonal_1d = ConvolutionOrthogonal1D -convolutional_orthogonal_2d = ConvolutionOrthogonal2D -convolutional_orthogonal_3d = ConvolutionOrthogonal3D -# pylint: enable=invalid-name - @tf_export("glorot_uniform_initializer", "keras.initializers.glorot_uniform", "initializers.glorot_uniform") -def glorot_uniform_initializer(seed=None, dtype=dtypes.float32): +class GlorotUniform(VarianceScaling): """The Glorot uniform initializer, also called Xavier uniform initializer. It draws samples from a uniform distribution within [-limit, limit] @@ -1157,17 +1128,28 @@ def glorot_uniform_initializer(seed=None, dtype=dtypes.float32): `tf.set_random_seed` for behavior. dtype: The data type. Only floating point types are supported. - - Returns: - An initializer. """ - return variance_scaling_initializer( - scale=1.0, mode="fan_avg", distribution="uniform", seed=seed, dtype=dtype) + + def __init__(self, + seed=None, + dtype=dtypes.float32): + super(GlorotUniform, self).__init__( + scale=1.0, + mode="fan_avg", + distribution="uniform", + seed=seed, + dtype=dtype) + + def get_config(self): + return { + "seed": self.seed, + "dtype": self.dtype.name + } @tf_export("glorot_normal_initializer", "keras.initializers.glorot_normal", "initializers.glorot_normal") -def glorot_normal_initializer(seed=None, dtype=dtypes.float32): +class GlorotNormal(VarianceScaling): """The Glorot normal initializer, also called Xavier normal initializer. It draws samples from a truncated normal distribution centered on 0 @@ -1182,16 +1164,45 @@ def glorot_normal_initializer(seed=None, dtype=dtypes.float32): `tf.set_random_seed` for behavior. dtype: The data type. Only floating point types are supported. - - Returns: - An initializer. """ - return variance_scaling_initializer( - scale=1.0, - mode="fan_avg", - distribution="truncated_normal", - seed=seed, - dtype=dtype) + + def __init__(self, + seed=None, + dtype=dtypes.float32): + super(GlorotNormal, self).__init__( + scale=1.0, + mode="fan_avg", + distribution="truncated_normal", + seed=seed, + dtype=dtype) + + def get_config(self): + return { + "seed": self.seed, + "dtype": self.dtype.name + } + + +# Aliases. + +# pylint: disable=invalid-name +zeros_initializer = Zeros +ones_initializer = Ones +constant_initializer = Constant +random_uniform_initializer = RandomUniform +random_normal_initializer = RandomNormal +truncated_normal_initializer = TruncatedNormal +uniform_unit_scaling_initializer = UniformUnitScaling +variance_scaling_initializer = VarianceScaling +glorot_uniform_initializer = GlorotUniform +glorot_normal_initializer = GlorotNormal +orthogonal_initializer = Orthogonal +identity_initializer = Identity +convolutional_delta_orthogonal = ConvolutionDeltaOrthogonal +convolutional_orthogonal_1d = ConvolutionOrthogonal1D +convolutional_orthogonal_2d = ConvolutionOrthogonal2D +convolutional_orthogonal_3d = ConvolutionOrthogonal3D +# pylint: enable=invalid-name @tf_export("keras.initializers.lecun_normal", "initializers.lecun_normal") diff --git a/tensorflow/python/ops/init_ops_test.py b/tensorflow/python/ops/init_ops_test.py index 6a1fe17119..5693c3caaf 100644 --- a/tensorflow/python/ops/init_ops_test.py +++ b/tensorflow/python/ops/init_ops_test.py @@ -20,10 +20,14 @@ from __future__ import print_function import numpy as np +from tensorflow.core.protobuf import config_pb2 +from tensorflow.python.client import session from tensorflow.python.eager import context from tensorflow.python.framework import ops from tensorflow.python.ops import init_ops from tensorflow.python.ops import resource_variable_ops +from tensorflow.python.ops import variable_scope +from tensorflow.python.ops import variables from tensorflow.python.platform import test @@ -163,6 +167,40 @@ class InitializersTest(test.TestCase): with self.cached_session(): self._runner(init_ops.Orthogonal(seed=123), tensor_shape, target_mean=0.) + def testVariablePlacementWithOrthogonalInitializer(self): + if not context.context().num_gpus(): + self.skipTest('No devices other than CPUs found') + with ops.Graph().as_default() as g: + with ops.device('gpu:0'): + variable_scope.get_variable( + name='v', shape=[8, 2], initializer=init_ops.Orthogonal) + variable_scope.get_variable( + name='w', shape=[8, 2], initializer=init_ops.RandomNormal) + run_metadata = config_pb2.RunMetadata() + run_options = config_pb2.RunOptions( + trace_level=config_pb2.RunOptions.FULL_TRACE) + config = config_pb2.ConfigProto( + allow_soft_placement=False, log_device_placement=True) + + # Note: allow_soft_placement=False will fail whenever we cannot satisfy + # the colocation constraints. + with session.Session(config=config, graph=g) as sess: + sess.run( + variables.global_variables_initializer(), + options=run_options, + run_metadata=run_metadata) + + def test_eager_orthogonal_gpu(self): + if not context.context().num_gpus(): + self.skipTest('No devices other than CPUs found') + with context.eager_mode(): + v = variable_scope.get_variable( + name='v', shape=[8, 2], initializer=init_ops.Orthogonal) + w = variable_scope.get_variable( + name='w', shape=[8, 2], initializer=init_ops.RandomNormal) + self.assertTrue('GPU' in v.handle.device) + self.assertTrue('GPU' in w.handle.device) + def test_Identity(self): with self.cached_session(): tensor_shape = (3, 4, 5) diff --git a/tensorflow/python/ops/nn_ops.py b/tensorflow/python/ops/nn_ops.py index 474e0bb295..ef9afd9e8e 100644 --- a/tensorflow/python/ops/nn_ops.py +++ b/tensorflow/python/ops/nn_ops.py @@ -2454,7 +2454,7 @@ def conv1d(value, returned to the caller. Args: - value: A 3D `Tensor`. Must be of type `float16` or `float32`. + value: A 3D `Tensor`. Must be of type `float16`, `float32`, or `float64`. filters: A 3D `Tensor`. Must have the same type as `value`. stride: An `integer`. The number of entries by which the filter is moved right at each step. diff --git a/tensorflow/python/ops/parallel_for/pfor.py b/tensorflow/python/ops/parallel_for/pfor.py index 3c914f6ff6..f9153b6d7d 100644 --- a/tensorflow/python/ops/parallel_for/pfor.py +++ b/tensorflow/python/ops/parallel_for/pfor.py @@ -21,8 +21,6 @@ from __future__ import print_function import collections -from absl import flags - from tensorflow.python.framework import constant_op from tensorflow.python.framework import dtypes from tensorflow.python.framework import ops @@ -41,6 +39,7 @@ from tensorflow.python.ops import nn_ops from tensorflow.python.ops import parsing_ops from tensorflow.python.ops import sparse_ops from tensorflow.python.ops import tensor_array_ops +from tensorflow.python.platform import flags from tensorflow.python.platform import tf_logging as logging from tensorflow.python.util import nest @@ -2013,6 +2012,7 @@ def _convert_biasaddgrad(pfor_input): @RegisterPForWithArgs("ReluGrad") @RegisterPForWithArgs("TanhGrad") @RegisterPForWithArgs("SigmoidGrad") +@RegisterPForWithArgs("SoftplusGrad") def _convert_grads(pfor_input, op_type, *args, **kw_args): del args del kw_args diff --git a/tensorflow/python/ops/script_ops.py b/tensorflow/python/ops/script_ops.py index 8d66de6b20..2ec4b540fb 100644 --- a/tensorflow/python/ops/script_ops.py +++ b/tensorflow/python/ops/script_ops.py @@ -287,19 +287,19 @@ def _internal_py_func(func, # TODO(akshayka): Implement higher-order derivatives. @ops.RegisterGradient("EagerPyFunc") -def _EagerPyFuncGrad(op, dy): +def _EagerPyFuncGrad(op, *dy): """Computes the gradient of an EagerPyFunc.""" token = op.get_attr("token") - def eagerly_executed_grad(dy): + def eagerly_executed_grad(*dy): tape, eager_inputs, eager_outputs = tape_cache.pop(compat.as_bytes(token)) return tape.gradient(eager_outputs, eager_inputs, output_gradients=dy) with ops.control_dependencies(op.outputs): return _internal_py_func( func=eagerly_executed_grad, - inp=[dy] if isinstance(dy, ops.Tensor) else dy, + inp=dy, Tout=[tensor.dtype for tensor in op.inputs], eager=True, is_grad_func=True) diff --git a/tensorflow/python/ops/sparse_ops.py b/tensorflow/python/ops/sparse_ops.py index d1b8be4df7..400a42a3c0 100644 --- a/tensorflow/python/ops/sparse_ops.py +++ b/tensorflow/python/ops/sparse_ops.py @@ -1351,7 +1351,11 @@ def sparse_merge(sp_ids, sp_values, vocab_size, name=None, new_shape = array_ops.concat([sp_ids[0].dense_shape[:-1], vocab_size], 0) result = sparse_tensor.SparseTensor(new_indices, new_values, new_shape) - return result if already_sorted else sparse_reorder(result) + if already_sorted: + return result + sorted_result = sparse_reorder(result) + return sparse_tensor.SparseTensor( + sorted_result.indices, sorted_result.values, new_shape) @tf_export("sparse_retain") diff --git a/tensorflow/python/pywrap_tfe.i b/tensorflow/python/pywrap_tfe.i index e1c233cdd9..a31861ae40 100755 --- a/tensorflow/python/pywrap_tfe.i +++ b/tensorflow/python/pywrap_tfe.i @@ -50,11 +50,11 @@ limitations under the License. %rename("%s") TFE_Py_TapeSetRestartOnThread; %rename("%s") TFE_Py_TapeSetIsEmpty; %rename("%s") TFE_Py_TapeSetShouldRecord; -%rename("%s") TFE_Py_TapeSetWatch; %rename("%s") TFE_Py_TapeSetDeleteTrace; %rename("%s") TFE_Py_TapeSetRecordOperation; %rename("%s") TFE_Py_TapeSetWatchVariable; %rename("%s") TFE_Py_TapeGradient; +%rename("%s") TFE_Py_TapeWatch; %rename("%s") TFE_Py_TapeWatchedVariables; %rename("%s") TFE_NewContextOptions; %rename("%s") TFE_ContextOptionsSetConfig; diff --git a/tensorflow/python/tools/component_api_helper.py b/tensorflow/python/tools/component_api_helper.py index 988ecc61f0..97f46719e5 100644 --- a/tensorflow/python/tools/component_api_helper.py +++ b/tensorflow/python/tools/component_api_helper.py @@ -65,9 +65,10 @@ def package_hook(parent_package_str, child_package_str, error_msg=None): Will allow the following import statement to work. >>> import parent.child """ - child_pkg_path = [os.path.join(os.path.dirname(child_pkg.__file__), "..")] + child_pkg_path = [os.path.abspath( + os.path.join(os.path.dirname(child_pkg.__file__), ".."))] try: - parent_pkg.__path__ += child_pkg_path + parent_pkg.__path__ = child_pkg_path + parent_pkg.__path__ except AttributeError: parent_pkg.__path__ = child_pkg_path diff --git a/tensorflow/python/tools/print_selective_registration_header_test.py b/tensorflow/python/tools/print_selective_registration_header_test.py index 4b3d98242c..cce8060fb9 100644 --- a/tensorflow/python/tools/print_selective_registration_header_test.py +++ b/tensorflow/python/tools/print_selective_registration_header_test.py @@ -59,6 +59,9 @@ GRAPH_DEF_TXT = """ } """ +# AccumulateNV2 is included because it should be included in the header despite +# lacking a kernel (it's rewritten by AccumulateNV2RemovePass; see +# core/common_runtime/accumulate_n_optimizer.cc. GRAPH_DEF_TXT_2 = """ node: { name: "node_4" @@ -67,6 +70,12 @@ GRAPH_DEF_TXT_2 = """ device: "/cpu:0" attr: { key: "T" value: { type: DT_FLOAT } } } + node: { + name: "node_5" + op: "AccumulateNV2" + attr: { key: "T" value: { type: DT_INT32 } } + attr: { key : "N" value: { i: 3 } } + } """ @@ -100,6 +109,7 @@ class PrintOpFilegroupTest(test.TestCase): self.assertListEqual( [ + ('AccumulateNV2', None), # ('BiasAdd', 'BiasOp<CPUDevice, float>'), # ('MatMul', matmul_prefix + 'MatMulOp<CPUDevice, double, false >'), # @@ -117,6 +127,7 @@ class PrintOpFilegroupTest(test.TestCase): 'rawproto', self.WriteGraphFiles(graphs), default_ops) self.assertListEqual( [ + ('AccumulateNV2', None), # ('BiasAdd', 'BiasOp<CPUDevice, float>'), # ('MatMul', matmul_prefix + 'MatMulOp<CPUDevice, double, false >'), # @@ -196,6 +207,7 @@ class PrintOpFilegroupTest(test.TestCase): constexpr inline bool ShouldRegisterOp(const char op[]) { return false + || isequal(op, "AccumulateNV2") || isequal(op, "BiasAdd") ; } diff --git a/tensorflow/python/tools/selective_registration_header_lib.py b/tensorflow/python/tools/selective_registration_header_lib.py index dc0612bb3f..b99c632c3e 100644 --- a/tensorflow/python/tools/selective_registration_header_lib.py +++ b/tensorflow/python/tools/selective_registration_header_lib.py @@ -32,6 +32,16 @@ from tensorflow.python import pywrap_tensorflow from tensorflow.python.platform import gfile from tensorflow.python.platform import tf_logging +# Usually, we use each graph node to induce registration of an op and +# corresponding kernel; nodes without a corresponding kernel (perhaps due to +# attr types) generate a warning but are otherwise ignored. Ops in this set are +# registered even if there's no corresponding kernel. +OPS_WITHOUT_KERNEL_WHITELIST = frozenset([ + # AccumulateNV2 is rewritten away by AccumulateNV2RemovePass; see + # core/common_runtime/accumulate_n_optimizer.cc. + 'AccumulateNV2' +]) + def get_ops_and_kernels(proto_fileformat, proto_files, default_ops_str): """Gets the ops and kernels needed from the model files.""" @@ -53,8 +63,10 @@ def get_ops_and_kernels(proto_fileformat, proto_files, default_ops_str): node_def.device = '/cpu:0' kernel_class = pywrap_tensorflow.TryFindKernelClass( node_def.SerializeToString()) - if kernel_class: - op_and_kernel = (str(node_def.op), str(kernel_class.decode('utf-8'))) + op = str(node_def.op) + if kernel_class or op in OPS_WITHOUT_KERNEL_WHITELIST: + op_and_kernel = (op, str(kernel_class.decode('utf-8')) + if kernel_class else None) if op_and_kernel not in ops: ops.add(op_and_kernel) else: @@ -129,6 +141,7 @@ def get_header_from_ops_and_kernels(ops_and_kernels, ''' line += 'constexpr const char* kNecessaryOpKernelClasses[] = {\n' for _, kernel_class in ops_and_kernels: + if kernel_class is None: continue line += '"%s",\n' % kernel_class line += '};' append(line) diff --git a/tensorflow/python/training/checkpointable/util.py b/tensorflow/python/training/checkpointable/util.py index 45d217e8b1..13dddd37ac 100644 --- a/tensorflow/python/training/checkpointable/util.py +++ b/tensorflow/python/training/checkpointable/util.py @@ -685,6 +685,11 @@ def _serialize_object_graph(root_checkpointable, saveables_cache): saveables_cache=saveables_cache) +def named_saveables(root_checkpointable): + """Gather list of all SaveableObjects in the Checkpointable object.""" + return _serialize_object_graph(root_checkpointable, None)[0] + + def list_objects(root_checkpointable): """Traverse the object graph and list all accessible objects. diff --git a/tensorflow/python/training/distribute.py b/tensorflow/python/training/distribute.py index ac92238d57..21ca1735e0 100644 --- a/tensorflow/python/training/distribute.py +++ b/tensorflow/python/training/distribute.py @@ -372,7 +372,7 @@ class DistributionStrategy(object): use its API, including `merge_call()` to get back to cross-tower context), once for each tower. May use values with locality T or M, and any variable. - * `d.reduce(m, t)`: in cross-tower context, accepts t with locality T + * `d.reduce(m, t, t)`: in cross-tower context, accepts t with locality T and produces a value with locality M. * `d.reduce(m, t, v)`: in cross-tower context, accepts t with locality T and produces a value with locality V(`v`). @@ -405,10 +405,11 @@ class DistributionStrategy(object): Another thing you might want to do in the middle of your tower function is an all-reduce of some intermediate value, using `d.reduce()` or - `d.batch_reduce()` without supplying a variable as the destination. + `d.batch_reduce()`. You simply provide the same tensor as the input and + destination. Layers should expect to be called in a tower context, and can use - the `get_tower_context()` function to get a `TowerContext` object. The + the `get_tower_context()` function to get a `TowerContext` object. The `TowerContext` object has a `merge_call()` method for entering cross-tower context where you can use `reduce()` (or `batch_reduce()`) and then optionally `update()` to update state. @@ -719,7 +720,7 @@ class DistributionStrategy(object): def _call_for_each_tower(self, fn, *args, **kwargs): raise NotImplementedError("must be implemented in descendants") - def reduce(self, aggregation, value, destinations=None): + def reduce(self, aggregation, value, destinations): """Combine (via e.g. sum or mean) values across towers. Args: @@ -727,11 +728,10 @@ class DistributionStrategy(object): are `tf.VariableAggregation.SUM`, `tf.VariableAggregation.MEAN`, `tf.VariableAggregation.ONLY_FIRST_TOWER`. value: A per-device value with one value per tower. - destinations: An optional mirrored variable, a device string, - list of device strings. The return value will be copied to all - destination devices (or all the devices where the mirrored - variable resides). If `None` or unspecified, the destinations - will match the devices `value` resides on. + destinations: A mirrored variable, a per-device tensor, a device string, + or list of device strings. The return value will be copied to all + destination devices (or all the devices where the `destinations` value + resides). To perform an all-reduction, pass `value` to `destinations`. Returns: A value mirrored to `destinations`. @@ -1077,10 +1077,15 @@ class TowerContext(object): require_tower_context(self) return device_util.current() - # TODO(josh11b): Implement `start_all_reduce(method, t)` that returns - # a function returning the result of reducing `t` across all - # towers. Most likely can be implemented in terms of `merge_call()` - # and `batch_reduce()`. + # TODO(josh11b): Implement `start_all_reduce(method, t)` for efficient + # all-reduce. It would return a function returning the result of reducing `t` + # across all towers. The caller would wait to call this function until they + # needed the reduce result, allowing an efficient implementation: + # * With eager execution, the reduction could be performed asynchronously + # in the background, not blocking until the result was needed. + # * When constructing a graph, it could batch up all reduction requests up + # to that point that the first result is needed. Most likely this can be + # implemented in terms of `merge_call()` and `batch_reduce()`. # ------------------------------------------------------------------------------ diff --git a/tensorflow/python/training/input.py b/tensorflow/python/training/input.py index 0d6207f8c4..94c6b47027 100644 --- a/tensorflow/python/training/input.py +++ b/tensorflow/python/training/input.py @@ -45,6 +45,7 @@ from tensorflow.python.ops import sparse_ops from tensorflow.python.ops import variable_scope as vs from tensorflow.python.summary import summary from tensorflow.python.training import queue_runner +from tensorflow.python.util import deprecation from tensorflow.python.util.tf_export import tf_export @@ -894,7 +895,11 @@ def _shuffle_batch_join(tensors_list, batch_size, capacity, # Batching functions ---------------------------------------------------------- -@tf_export("train.batch") +@tf_export(v1=["train.batch"]) +@deprecation.deprecated( + None, "Queue-based input pipelines have been replaced by `tf.data`. Use " + "`tf.data.Dataset.batch(batch_size)` (or `padded_batch(...)` if " + "`dynamic_pad=True`).") def batch(tensors, batch_size, num_threads=1, capacity=32, enqueue_many=False, shapes=None, dynamic_pad=False, allow_smaller_final_batch=False, shared_name=None, name=None): @@ -989,7 +994,11 @@ def batch(tensors, batch_size, num_threads=1, capacity=32, name=name) -@tf_export("train.maybe_batch") +@tf_export(v1=["train.maybe_batch"]) +@deprecation.deprecated( + None, "Queue-based input pipelines have been replaced by `tf.data`. Use " + "`tf.data.Dataset.filter(...).batch(batch_size)` (or `padded_batch(...)`" + " if `dynamic_pad=True`).") def maybe_batch(tensors, keep_input, batch_size, num_threads=1, capacity=32, enqueue_many=False, shapes=None, dynamic_pad=False, allow_smaller_final_batch=False, shared_name=None, name=None): @@ -1042,7 +1051,11 @@ def maybe_batch(tensors, keep_input, batch_size, num_threads=1, capacity=32, name=name) -@tf_export("train.batch_join") +@tf_export(v1=["train.batch_join"]) +@deprecation.deprecated( + None, "Queue-based input pipelines have been replaced by `tf.data`. Use " + "`tf.data.Dataset.interleave(...).batch(batch_size)` (or " + "`padded_batch(...)` if `dynamic_pad=True`).") def batch_join(tensors_list, batch_size, capacity=32, enqueue_many=False, shapes=None, dynamic_pad=False, allow_smaller_final_batch=False, shared_name=None, name=None): @@ -1148,7 +1161,11 @@ def batch_join(tensors_list, batch_size, capacity=32, enqueue_many=False, name=name) -@tf_export("train.maybe_batch_join") +@tf_export(v1=["train.maybe_batch_join"]) +@deprecation.deprecated( + None, "Queue-based input pipelines have been replaced by `tf.data`. Use " + "`tf.data.Dataset.interleave(...).filter(...).batch(batch_size)` (or " + "`padded_batch(...)` if `dynamic_pad=True`).") def maybe_batch_join(tensors_list, keep_input, batch_size, capacity=32, enqueue_many=False, shapes=None, dynamic_pad=False, allow_smaller_final_batch=False, shared_name=None, @@ -1201,7 +1218,10 @@ def maybe_batch_join(tensors_list, keep_input, batch_size, capacity=32, name=name) -@tf_export("train.shuffle_batch") +@tf_export(v1=["train.shuffle_batch"]) +@deprecation.deprecated( + None, "Queue-based input pipelines have been replaced by `tf.data`. Use " + "`tf.data.Dataset.shuffle(min_after_dequeue).batch(batch_size)`.") def shuffle_batch(tensors, batch_size, capacity, min_after_dequeue, num_threads=1, seed=None, enqueue_many=False, shapes=None, allow_smaller_final_batch=False, shared_name=None, name=None): @@ -1301,7 +1321,11 @@ def shuffle_batch(tensors, batch_size, capacity, min_after_dequeue, name=name) -@tf_export("train.maybe_shuffle_batch") +@tf_export(v1=["train.maybe_shuffle_batch"]) +@deprecation.deprecated( + None, "Queue-based input pipelines have been replaced by `tf.data`. Use " + "`tf.data.Dataset.filter(...).shuffle(min_after_dequeue).batch(batch_size)`" + ".") def maybe_shuffle_batch(tensors, batch_size, capacity, min_after_dequeue, keep_input, num_threads=1, seed=None, enqueue_many=False, shapes=None, @@ -1361,7 +1385,11 @@ def maybe_shuffle_batch(tensors, batch_size, capacity, min_after_dequeue, name=name) -@tf_export("train.shuffle_batch_join") +@tf_export(v1=["train.shuffle_batch_join"]) +@deprecation.deprecated( + None, "Queue-based input pipelines have been replaced by `tf.data`. Use " + "`tf.data.Dataset.interleave(...).shuffle(min_after_dequeue).batch" + "(batch_size)`.") def shuffle_batch_join(tensors_list, batch_size, capacity, min_after_dequeue, seed=None, enqueue_many=False, shapes=None, allow_smaller_final_batch=False, @@ -1455,7 +1483,11 @@ def shuffle_batch_join(tensors_list, batch_size, capacity, name=name) -@tf_export("train.maybe_shuffle_batch_join") +@tf_export(v1=["train.maybe_shuffle_batch_join"]) +@deprecation.deprecated( + None, "Queue-based input pipelines have been replaced by `tf.data`. Use " + "`tf.data.Dataset.interleave(...).filter(...).shuffle(min_after_dequeue)" + ".batch(batch_size)`.") def maybe_shuffle_batch_join(tensors_list, batch_size, capacity, min_after_dequeue, keep_input, seed=None, enqueue_many=False, shapes=None, diff --git a/tensorflow/stream_executor/blas.h b/tensorflow/stream_executor/blas.h index 7f851e3646..f25ed700d6 100644 --- a/tensorflow/stream_executor/blas.h +++ b/tensorflow/stream_executor/blas.h @@ -41,6 +41,7 @@ limitations under the License. #define TENSORFLOW_STREAM_EXECUTOR_BLAS_H_ #include <complex> +#include <vector> #include "tensorflow/stream_executor/host_or_device_scalar.h" #include "tensorflow/stream_executor/lib/array_slice.h" diff --git a/tensorflow/tools/api/golden/v1/tensorflow.-config-proto.-experimental.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.-config-proto.-experimental.pbtxt index eb41deee13..9f6dcd8fdb 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.-config-proto.-experimental.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.-config-proto.-experimental.pbtxt @@ -9,16 +9,14 @@ tf_proto { type: TYPE_STRING } field { - name: "client_handles_error_formatting" - number: 2 - label: LABEL_OPTIONAL - type: TYPE_BOOL - } - field { name: "executor_type" number: 3 label: LABEL_OPTIONAL type: TYPE_STRING } + reserved_range { + start: 2 + end: 3 + } } } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.-config-proto.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.-config-proto.pbtxt index e565b903d2..f3a515163d 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.-config-proto.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.-config-proto.pbtxt @@ -132,17 +132,15 @@ tf_proto { type: TYPE_STRING } field { - name: "client_handles_error_formatting" - number: 2 - label: LABEL_OPTIONAL - type: TYPE_BOOL - } - field { name: "executor_type" number: 3 label: LABEL_OPTIONAL type: TYPE_STRING } + reserved_range { + start: 2 + end: 3 + } } } } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.glorot_normal_initializer.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.glorot_normal_initializer.pbtxt new file mode 100644 index 0000000000..483d1f8ba0 --- /dev/null +++ b/tensorflow/tools/api/golden/v1/tensorflow.glorot_normal_initializer.pbtxt @@ -0,0 +1,19 @@ +path: "tensorflow.glorot_normal_initializer" +tf_class { + is_instance: "<class \'tensorflow.python.ops.init_ops.GlorotNormal\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.VarianceScaling\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.Initializer\'>" + is_instance: "<type \'object\'>" + member_method { + name: "__init__" + argspec: "args=[\'self\', \'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " + } + member_method { + name: "from_config" + argspec: "args=[\'cls\', \'config\'], varargs=None, keywords=None, defaults=None" + } + member_method { + name: "get_config" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } +} diff --git a/tensorflow/tools/api/golden/v1/tensorflow.glorot_uniform_initializer.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.glorot_uniform_initializer.pbtxt new file mode 100644 index 0000000000..bb8540d0fd --- /dev/null +++ b/tensorflow/tools/api/golden/v1/tensorflow.glorot_uniform_initializer.pbtxt @@ -0,0 +1,19 @@ +path: "tensorflow.glorot_uniform_initializer" +tf_class { + is_instance: "<class \'tensorflow.python.ops.init_ops.GlorotUniform\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.VarianceScaling\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.Initializer\'>" + is_instance: "<type \'object\'>" + member_method { + name: "__init__" + argspec: "args=[\'self\', \'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " + } + member_method { + name: "from_config" + argspec: "args=[\'cls\', \'config\'], varargs=None, keywords=None, defaults=None" + } + member_method { + name: "get_config" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } +} diff --git a/tensorflow/tools/api/golden/v1/tensorflow.initializers.glorot_normal.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.initializers.glorot_normal.pbtxt new file mode 100644 index 0000000000..4a81e52df9 --- /dev/null +++ b/tensorflow/tools/api/golden/v1/tensorflow.initializers.glorot_normal.pbtxt @@ -0,0 +1,19 @@ +path: "tensorflow.initializers.glorot_normal" +tf_class { + is_instance: "<class \'tensorflow.python.ops.init_ops.GlorotNormal\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.VarianceScaling\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.Initializer\'>" + is_instance: "<type \'object\'>" + member_method { + name: "__init__" + argspec: "args=[\'self\', \'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " + } + member_method { + name: "from_config" + argspec: "args=[\'cls\', \'config\'], varargs=None, keywords=None, defaults=None" + } + member_method { + name: "get_config" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } +} diff --git a/tensorflow/tools/api/golden/v1/tensorflow.initializers.glorot_uniform.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.initializers.glorot_uniform.pbtxt new file mode 100644 index 0000000000..815dc81dff --- /dev/null +++ b/tensorflow/tools/api/golden/v1/tensorflow.initializers.glorot_uniform.pbtxt @@ -0,0 +1,19 @@ +path: "tensorflow.initializers.glorot_uniform" +tf_class { + is_instance: "<class \'tensorflow.python.ops.init_ops.GlorotUniform\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.VarianceScaling\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.Initializer\'>" + is_instance: "<type \'object\'>" + member_method { + name: "__init__" + argspec: "args=[\'self\', \'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " + } + member_method { + name: "from_config" + argspec: "args=[\'cls\', \'config\'], varargs=None, keywords=None, defaults=None" + } + member_method { + name: "get_config" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } +} diff --git a/tensorflow/tools/api/golden/v1/tensorflow.initializers.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.initializers.pbtxt index bc0426f2f1..d499c67d89 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.initializers.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.initializers.pbtxt @@ -5,6 +5,14 @@ tf_module { mtype: "<type \'type\'>" } member { + name: "glorot_normal" + mtype: "<type \'type\'>" + } + member { + name: "glorot_uniform" + mtype: "<type \'type\'>" + } + member { name: "identity" mtype: "<type \'type\'>" } @@ -45,14 +53,6 @@ tf_module { argspec: "args=[], varargs=None, keywords=None, defaults=None" } member_method { - name: "glorot_normal" - argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " - } - member_method { - name: "glorot_uniform" - argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " - } - member_method { name: "he_normal" argspec: "args=[\'seed\'], varargs=None, keywords=None, defaults=[\'None\'], " } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.initializers.glorot_normal.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.initializers.glorot_normal.pbtxt new file mode 100644 index 0000000000..ef0815972d --- /dev/null +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.initializers.glorot_normal.pbtxt @@ -0,0 +1,19 @@ +path: "tensorflow.keras.initializers.glorot_normal" +tf_class { + is_instance: "<class \'tensorflow.python.ops.init_ops.GlorotNormal\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.VarianceScaling\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.Initializer\'>" + is_instance: "<type \'object\'>" + member_method { + name: "__init__" + argspec: "args=[\'self\', \'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " + } + member_method { + name: "from_config" + argspec: "args=[\'cls\', \'config\'], varargs=None, keywords=None, defaults=None" + } + member_method { + name: "get_config" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } +} diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.initializers.glorot_uniform.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.initializers.glorot_uniform.pbtxt new file mode 100644 index 0000000000..439b5ada9b --- /dev/null +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.initializers.glorot_uniform.pbtxt @@ -0,0 +1,19 @@ +path: "tensorflow.keras.initializers.glorot_uniform" +tf_class { + is_instance: "<class \'tensorflow.python.ops.init_ops.GlorotUniform\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.VarianceScaling\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.Initializer\'>" + is_instance: "<type \'object\'>" + member_method { + name: "__init__" + argspec: "args=[\'self\', \'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " + } + member_method { + name: "from_config" + argspec: "args=[\'cls\', \'config\'], varargs=None, keywords=None, defaults=None" + } + member_method { + name: "get_config" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } +} diff --git a/tensorflow/tools/api/golden/v1/tensorflow.keras.initializers.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.keras.initializers.pbtxt index 8645e54302..1540c2915b 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.keras.initializers.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.keras.initializers.pbtxt @@ -45,6 +45,14 @@ tf_module { mtype: "<type \'type\'>" } member { + name: "glorot_normal" + mtype: "<type \'type\'>" + } + member { + name: "glorot_uniform" + mtype: "<type \'type\'>" + } + member { name: "identity" mtype: "<type \'type\'>" } @@ -89,14 +97,6 @@ tf_module { argspec: "args=[\'identifier\'], varargs=None, keywords=None, defaults=None" } member_method { - name: "glorot_normal" - argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " - } - member_method { - name: "glorot_uniform" - argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " - } - member_method { name: "he_normal" argspec: "args=[\'seed\'], varargs=None, keywords=None, defaults=[\'None\'], " } diff --git a/tensorflow/tools/api/golden/v1/tensorflow.pbtxt b/tensorflow/tools/api/golden/v1/tensorflow.pbtxt index e30f9d034d..dd9f7c49e0 100644 --- a/tensorflow/tools/api/golden/v1/tensorflow.pbtxt +++ b/tensorflow/tools/api/golden/v1/tensorflow.pbtxt @@ -365,6 +365,14 @@ tf_module { mtype: "<type \'module\'>" } member { + name: "glorot_normal_initializer" + mtype: "<type \'type\'>" + } + member { + name: "glorot_uniform_initializer" + mtype: "<type \'type\'>" + } + member { name: "graph_util" mtype: "<type \'module\'>" } @@ -1217,14 +1225,6 @@ tf_module { argspec: "args=[], varargs=None, keywords=None, defaults=None" } member_method { - name: "glorot_normal_initializer" - argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " - } - member_method { - name: "glorot_uniform_initializer" - argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " - } - member_method { name: "gradients" argspec: "args=[\'ys\', \'xs\', \'grad_ys\', \'name\', \'colocate_gradients_with_ops\', \'gate_gradients\', \'aggregation_method\', \'stop_gradients\'], varargs=None, keywords=None, defaults=[\'None\', \'gradients\', \'False\', \'False\', \'None\', \'None\'], " } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.-config-proto.-experimental.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.-config-proto.-experimental.pbtxt index eb41deee13..9f6dcd8fdb 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.-config-proto.-experimental.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.-config-proto.-experimental.pbtxt @@ -9,16 +9,14 @@ tf_proto { type: TYPE_STRING } field { - name: "client_handles_error_formatting" - number: 2 - label: LABEL_OPTIONAL - type: TYPE_BOOL - } - field { name: "executor_type" number: 3 label: LABEL_OPTIONAL type: TYPE_STRING } + reserved_range { + start: 2 + end: 3 + } } } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.-config-proto.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.-config-proto.pbtxt index e565b903d2..f3a515163d 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.-config-proto.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.-config-proto.pbtxt @@ -132,17 +132,15 @@ tf_proto { type: TYPE_STRING } field { - name: "client_handles_error_formatting" - number: 2 - label: LABEL_OPTIONAL - type: TYPE_BOOL - } - field { name: "executor_type" number: 3 label: LABEL_OPTIONAL type: TYPE_STRING } + reserved_range { + start: 2 + end: 3 + } } } } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.glorot_normal_initializer.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.glorot_normal_initializer.pbtxt new file mode 100644 index 0000000000..483d1f8ba0 --- /dev/null +++ b/tensorflow/tools/api/golden/v2/tensorflow.glorot_normal_initializer.pbtxt @@ -0,0 +1,19 @@ +path: "tensorflow.glorot_normal_initializer" +tf_class { + is_instance: "<class \'tensorflow.python.ops.init_ops.GlorotNormal\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.VarianceScaling\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.Initializer\'>" + is_instance: "<type \'object\'>" + member_method { + name: "__init__" + argspec: "args=[\'self\', \'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " + } + member_method { + name: "from_config" + argspec: "args=[\'cls\', \'config\'], varargs=None, keywords=None, defaults=None" + } + member_method { + name: "get_config" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } +} diff --git a/tensorflow/tools/api/golden/v2/tensorflow.glorot_uniform_initializer.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.glorot_uniform_initializer.pbtxt new file mode 100644 index 0000000000..bb8540d0fd --- /dev/null +++ b/tensorflow/tools/api/golden/v2/tensorflow.glorot_uniform_initializer.pbtxt @@ -0,0 +1,19 @@ +path: "tensorflow.glorot_uniform_initializer" +tf_class { + is_instance: "<class \'tensorflow.python.ops.init_ops.GlorotUniform\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.VarianceScaling\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.Initializer\'>" + is_instance: "<type \'object\'>" + member_method { + name: "__init__" + argspec: "args=[\'self\', \'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " + } + member_method { + name: "from_config" + argspec: "args=[\'cls\', \'config\'], varargs=None, keywords=None, defaults=None" + } + member_method { + name: "get_config" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } +} diff --git a/tensorflow/tools/api/golden/v2/tensorflow.initializers.glorot_normal.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.initializers.glorot_normal.pbtxt new file mode 100644 index 0000000000..4a81e52df9 --- /dev/null +++ b/tensorflow/tools/api/golden/v2/tensorflow.initializers.glorot_normal.pbtxt @@ -0,0 +1,19 @@ +path: "tensorflow.initializers.glorot_normal" +tf_class { + is_instance: "<class \'tensorflow.python.ops.init_ops.GlorotNormal\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.VarianceScaling\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.Initializer\'>" + is_instance: "<type \'object\'>" + member_method { + name: "__init__" + argspec: "args=[\'self\', \'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " + } + member_method { + name: "from_config" + argspec: "args=[\'cls\', \'config\'], varargs=None, keywords=None, defaults=None" + } + member_method { + name: "get_config" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } +} diff --git a/tensorflow/tools/api/golden/v2/tensorflow.initializers.glorot_uniform.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.initializers.glorot_uniform.pbtxt new file mode 100644 index 0000000000..815dc81dff --- /dev/null +++ b/tensorflow/tools/api/golden/v2/tensorflow.initializers.glorot_uniform.pbtxt @@ -0,0 +1,19 @@ +path: "tensorflow.initializers.glorot_uniform" +tf_class { + is_instance: "<class \'tensorflow.python.ops.init_ops.GlorotUniform\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.VarianceScaling\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.Initializer\'>" + is_instance: "<type \'object\'>" + member_method { + name: "__init__" + argspec: "args=[\'self\', \'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " + } + member_method { + name: "from_config" + argspec: "args=[\'cls\', \'config\'], varargs=None, keywords=None, defaults=None" + } + member_method { + name: "get_config" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } +} diff --git a/tensorflow/tools/api/golden/v2/tensorflow.initializers.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.initializers.pbtxt index bc0426f2f1..d499c67d89 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.initializers.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.initializers.pbtxt @@ -5,6 +5,14 @@ tf_module { mtype: "<type \'type\'>" } member { + name: "glorot_normal" + mtype: "<type \'type\'>" + } + member { + name: "glorot_uniform" + mtype: "<type \'type\'>" + } + member { name: "identity" mtype: "<type \'type\'>" } @@ -45,14 +53,6 @@ tf_module { argspec: "args=[], varargs=None, keywords=None, defaults=None" } member_method { - name: "glorot_normal" - argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " - } - member_method { - name: "glorot_uniform" - argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " - } - member_method { name: "he_normal" argspec: "args=[\'seed\'], varargs=None, keywords=None, defaults=[\'None\'], " } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.initializers.glorot_normal.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.initializers.glorot_normal.pbtxt new file mode 100644 index 0000000000..ef0815972d --- /dev/null +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.initializers.glorot_normal.pbtxt @@ -0,0 +1,19 @@ +path: "tensorflow.keras.initializers.glorot_normal" +tf_class { + is_instance: "<class \'tensorflow.python.ops.init_ops.GlorotNormal\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.VarianceScaling\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.Initializer\'>" + is_instance: "<type \'object\'>" + member_method { + name: "__init__" + argspec: "args=[\'self\', \'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " + } + member_method { + name: "from_config" + argspec: "args=[\'cls\', \'config\'], varargs=None, keywords=None, defaults=None" + } + member_method { + name: "get_config" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } +} diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.initializers.glorot_uniform.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.initializers.glorot_uniform.pbtxt new file mode 100644 index 0000000000..439b5ada9b --- /dev/null +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.initializers.glorot_uniform.pbtxt @@ -0,0 +1,19 @@ +path: "tensorflow.keras.initializers.glorot_uniform" +tf_class { + is_instance: "<class \'tensorflow.python.ops.init_ops.GlorotUniform\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.VarianceScaling\'>" + is_instance: "<class \'tensorflow.python.ops.init_ops.Initializer\'>" + is_instance: "<type \'object\'>" + member_method { + name: "__init__" + argspec: "args=[\'self\', \'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " + } + member_method { + name: "from_config" + argspec: "args=[\'cls\', \'config\'], varargs=None, keywords=None, defaults=None" + } + member_method { + name: "get_config" + argspec: "args=[\'self\'], varargs=None, keywords=None, defaults=None" + } +} diff --git a/tensorflow/tools/api/golden/v2/tensorflow.keras.initializers.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.keras.initializers.pbtxt index 8645e54302..1540c2915b 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.keras.initializers.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.keras.initializers.pbtxt @@ -45,6 +45,14 @@ tf_module { mtype: "<type \'type\'>" } member { + name: "glorot_normal" + mtype: "<type \'type\'>" + } + member { + name: "glorot_uniform" + mtype: "<type \'type\'>" + } + member { name: "identity" mtype: "<type \'type\'>" } @@ -89,14 +97,6 @@ tf_module { argspec: "args=[\'identifier\'], varargs=None, keywords=None, defaults=None" } member_method { - name: "glorot_normal" - argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " - } - member_method { - name: "glorot_uniform" - argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " - } - member_method { name: "he_normal" argspec: "args=[\'seed\'], varargs=None, keywords=None, defaults=[\'None\'], " } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.pbtxt index 695bd1c522..7d45ea22c8 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.pbtxt @@ -365,6 +365,14 @@ tf_module { mtype: "<type \'module\'>" } member { + name: "glorot_normal_initializer" + mtype: "<type \'type\'>" + } + member { + name: "glorot_uniform_initializer" + mtype: "<type \'type\'>" + } + member { name: "graph_util" mtype: "<type \'module\'>" } @@ -1193,14 +1201,6 @@ tf_module { argspec: "args=[], varargs=None, keywords=None, defaults=None" } member_method { - name: "glorot_normal_initializer" - argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " - } - member_method { - name: "glorot_uniform_initializer" - argspec: "args=[\'seed\', \'dtype\'], varargs=None, keywords=None, defaults=[\'None\', \"<dtype: \'float32\'>\"], " - } - member_method { name: "gradients" argspec: "args=[\'ys\', \'xs\', \'grad_ys\', \'name\', \'colocate_gradients_with_ops\', \'gate_gradients\', \'aggregation_method\', \'stop_gradients\'], varargs=None, keywords=None, defaults=[\'None\', \'gradients\', \'False\', \'False\', \'None\', \'None\'], " } diff --git a/tensorflow/tools/api/golden/v2/tensorflow.train.pbtxt b/tensorflow/tools/api/golden/v2/tensorflow.train.pbtxt index c35e254843..e2b74e4d67 100644 --- a/tensorflow/tools/api/golden/v2/tensorflow.train.pbtxt +++ b/tensorflow/tools/api/golden/v2/tensorflow.train.pbtxt @@ -249,14 +249,6 @@ tf_module { argspec: "args=[\'supervisor\', \'train_step_fn\', \'args\', \'kwargs\', \'master\'], varargs=None, keywords=None, defaults=[\'None\', \'None\', \'\'], " } member_method { - name: "batch" - argspec: "args=[\'tensors\', \'batch_size\', \'num_threads\', \'capacity\', \'enqueue_many\', \'shapes\', \'dynamic_pad\', \'allow_smaller_final_batch\', \'shared_name\', \'name\'], varargs=None, keywords=None, defaults=[\'1\', \'32\', \'False\', \'None\', \'False\', \'False\', \'None\', \'None\'], " - } - member_method { - name: "batch_join" - argspec: "args=[\'tensors_list\', \'batch_size\', \'capacity\', \'enqueue_many\', \'shapes\', \'dynamic_pad\', \'allow_smaller_final_batch\', \'shared_name\', \'name\'], varargs=None, keywords=None, defaults=[\'32\', \'False\', \'None\', \'False\', \'False\', \'None\', \'None\'], " - } - member_method { name: "checkpoint_exists" argspec: "args=[\'checkpoint_prefix\'], varargs=None, keywords=None, defaults=None" } @@ -353,22 +345,6 @@ tf_module { argspec: "args=[\'pattern\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " } member_method { - name: "maybe_batch" - argspec: "args=[\'tensors\', \'keep_input\', \'batch_size\', \'num_threads\', \'capacity\', \'enqueue_many\', \'shapes\', \'dynamic_pad\', \'allow_smaller_final_batch\', \'shared_name\', \'name\'], varargs=None, keywords=None, defaults=[\'1\', \'32\', \'False\', \'None\', \'False\', \'False\', \'None\', \'None\'], " - } - member_method { - name: "maybe_batch_join" - argspec: "args=[\'tensors_list\', \'keep_input\', \'batch_size\', \'capacity\', \'enqueue_many\', \'shapes\', \'dynamic_pad\', \'allow_smaller_final_batch\', \'shared_name\', \'name\'], varargs=None, keywords=None, defaults=[\'32\', \'False\', \'None\', \'False\', \'False\', \'None\', \'None\'], " - } - member_method { - name: "maybe_shuffle_batch" - argspec: "args=[\'tensors\', \'batch_size\', \'capacity\', \'min_after_dequeue\', \'keep_input\', \'num_threads\', \'seed\', \'enqueue_many\', \'shapes\', \'allow_smaller_final_batch\', \'shared_name\', \'name\'], varargs=None, keywords=None, defaults=[\'1\', \'None\', \'False\', \'None\', \'False\', \'None\', \'None\'], " - } - member_method { - name: "maybe_shuffle_batch_join" - argspec: "args=[\'tensors_list\', \'batch_size\', \'capacity\', \'min_after_dequeue\', \'keep_input\', \'seed\', \'enqueue_many\', \'shapes\', \'allow_smaller_final_batch\', \'shared_name\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\', \'False\', \'None\', \'None\'], " - } - member_method { name: "natural_exp_decay" argspec: "args=[\'learning_rate\', \'global_step\', \'decay_steps\', \'decay_rate\', \'staircase\', \'name\'], varargs=None, keywords=None, defaults=[\'False\', \'None\'], " } @@ -409,14 +385,6 @@ tf_module { argspec: "args=[\'weights\', \'l1\', \'l2\', \'name\'], varargs=None, keywords=None, defaults=[\'None\'], " } member_method { - name: "shuffle_batch" - argspec: "args=[\'tensors\', \'batch_size\', \'capacity\', \'min_after_dequeue\', \'num_threads\', \'seed\', \'enqueue_many\', \'shapes\', \'allow_smaller_final_batch\', \'shared_name\', \'name\'], varargs=None, keywords=None, defaults=[\'1\', \'None\', \'False\', \'None\', \'False\', \'None\', \'None\'], " - } - member_method { - name: "shuffle_batch_join" - argspec: "args=[\'tensors_list\', \'batch_size\', \'capacity\', \'min_after_dequeue\', \'seed\', \'enqueue_many\', \'shapes\', \'allow_smaller_final_batch\', \'shared_name\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'False\', \'None\', \'False\', \'None\', \'None\'], " - } - member_method { name: "slice_input_producer" argspec: "args=[\'tensor_list\', \'num_epochs\', \'shuffle\', \'seed\', \'capacity\', \'shared_name\', \'name\'], varargs=None, keywords=None, defaults=[\'None\', \'True\', \'None\', \'32\', \'None\', \'None\'], " } diff --git a/tensorflow/tools/ci_build/Dockerfile.gpu b/tensorflow/tools/ci_build/Dockerfile.gpu index f05c7a4809..a4cad4b6c6 100644 --- a/tensorflow/tools/ci_build/Dockerfile.gpu +++ b/tensorflow/tools/ci_build/Dockerfile.gpu @@ -30,3 +30,4 @@ RUN mkdir /usr/local/cuda-9.0/lib && \ # Configure the build for our CUDA configuration. ENV TF_NEED_CUDA 1 +ENV TF_NEED_TENSORRT 1 diff --git a/tensorflow/tools/ci_build/install/install_deb_packages.sh b/tensorflow/tools/ci_build/install/install_deb_packages.sh index 9640810533..179fc42d60 100755 --- a/tensorflow/tools/ci_build/install/install_deb_packages.sh +++ b/tensorflow/tools/ci_build/install/install_deb_packages.sh @@ -67,6 +67,12 @@ apt-get install -y --no-install-recommends \ zip \ zlib1g-dev +apt-get update && \ + apt-get install nvinfer-runtime-trt-repo-ubuntu1604-4.0.1-ga-cuda9.0 && \ + apt-get update && \ + apt-get install libnvinfer4=4.1.2-1+cuda9.0 && \ + apt-get install libnvinfer-dev=4.1.2-1+cuda9.0 + # populate the database updatedb diff --git a/tensorflow/tools/ci_build/linux/libtensorflow_docker.sh b/tensorflow/tools/ci_build/linux/libtensorflow_docker.sh index f958b3c9b7..60c974c36b 100755 --- a/tensorflow/tools/ci_build/linux/libtensorflow_docker.sh +++ b/tensorflow/tools/ci_build/linux/libtensorflow_docker.sh @@ -52,6 +52,7 @@ ${DOCKER_BINARY} run \ -e "PYTHON_BIN_PATH=/usr/bin/python" \ -e "TF_NEED_HDFS=0" \ -e "TF_NEED_CUDA=${TF_NEED_CUDA}" \ + -e "TF_NEED_TENSORRT=${TF_NEED_CUDA}" \ -e "TF_NEED_OPENCL_SYCL=0" \ "${DOCKER_IMAGE}" \ "/workspace/tensorflow/tools/ci_build/linux/libtensorflow.sh" diff --git a/tensorflow/tools/docker/Dockerfile.devel-gpu-cuda9-cudnn7 b/tensorflow/tools/docker/Dockerfile.devel-gpu-cuda9-cudnn7 deleted file mode 100644 index 62b04fe540..0000000000 --- a/tensorflow/tools/docker/Dockerfile.devel-gpu-cuda9-cudnn7 +++ /dev/null @@ -1,124 +0,0 @@ -FROM nvidia/cuda:9.0-cudnn7-devel-ubuntu16.04 - -LABEL maintainer="Gunhan Gulsoy <gunan@google.com>" - -# It is possible to override these for releases. -ARG TF_BRANCH=master -ARG BAZEL_VERSION=0.15.0 -ARG TF_AVAILABLE_CPUS=32 - -RUN apt-get update && apt-get install -y --no-install-recommends \ - build-essential \ - curl \ - git \ - golang \ - libcurl3-dev \ - libfreetype6-dev \ - libpng12-dev \ - libzmq3-dev \ - pkg-config \ - python-dev \ - python-pip \ - rsync \ - software-properties-common \ - unzip \ - zip \ - zlib1g-dev \ - openjdk-8-jdk \ - openjdk-8-jre-headless \ - wget \ - && \ - apt-get clean && \ - rm -rf /var/lib/apt/lists/* - -RUN apt-get update && \ - apt-get install nvinfer-runtime-trt-repo-ubuntu1604-4.0.1-ga-cuda9.0 && \ - apt-get update && \ - apt-get install libnvinfer4=4.1.2-1+cuda9.0 && \ - apt-get install libnvinfer-dev=4.1.2-1+cuda9.0 - -RUN pip --no-cache-dir install --upgrade \ - pip setuptools - -RUN pip --no-cache-dir install \ - ipykernel \ - jupyter \ - keras_applications==1.0.5 \ - keras_preprocessing==1.0.3 \ - matplotlib \ - numpy \ - scipy \ - sklearn \ - pandas \ - wheel \ - && \ - python -m ipykernel.kernelspec - -# Set up our notebook config. -COPY jupyter_notebook_config.py /root/.jupyter/ - -# Jupyter has issues with being run directly: -# https://github.com/ipython/ipython/issues/7062 -# We just add a little wrapper script. -COPY run_jupyter.sh / - -# Set up Bazel. - -# Running bazel inside a `docker build` command causes trouble, cf: -# https://github.com/bazelbuild/bazel/issues/134 -# The easiest solution is to set up a bazelrc file forcing --batch. -RUN echo "startup --batch" >>/etc/bazel.bazelrc -# Similarly, we need to workaround sandboxing issues: -# https://github.com/bazelbuild/bazel/issues/418 -RUN echo "build --spawn_strategy=standalone --genrule_strategy=standalone" \ - >>/etc/bazel.bazelrc -WORKDIR / -RUN mkdir /bazel && \ - cd /bazel && \ - wget --quiet https://github.com/bazelbuild/bazel/releases/download/$BAZEL_VERSION/bazel-$BAZEL_VERSION-installer-linux-x86_64.sh && \ - wget --quiet https://raw.githubusercontent.com/bazelbuild/bazel/master/LICENSE && \ - chmod +x bazel-*.sh && \ - ./bazel-$BAZEL_VERSION-installer-linux-x86_64.sh && \ - rm -f /bazel/bazel-$BAZEL_VERSION-installer-linux-x86_64.sh - -# Download and build TensorFlow. -WORKDIR / -RUN git clone https://github.com/tensorflow/tensorflow.git && \ - cd tensorflow && \ - git checkout ${TF_BRANCH} -WORKDIR /tensorflow - -# Configure the build for our CUDA configuration. -ENV CI_BUILD_PYTHON=python \ - LD_LIBRARY_PATH=/usr/local/cuda/extras/CUPTI/lib64:${LD_LIBRARY_PATH} \ - CUDNN_INSTALL_PATH=/usr/lib/x86_64-linux-gnu \ - PYTHON_BIN_PATH=/usr/bin/python \ - PYTHON_LIB_PATH=/usr/local/lib/python2.7/dist-packages \ - TF_NEED_CUDA=1 \ - TF_NEED_TENSORRT 1 \ - TF_CUDA_VERSION=9.0 \ - TF_CUDA_COMPUTE_CAPABILITIES=3.0,3.5,5.2,6.0,6.1,7.0 \ - TF_CUDNN_VERSION=7 -RUN ./configure - -# Build and Install TensorFlow. -RUN ln -s /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/stubs/libcuda.so.1 && \ - LD_LIBRARY_PATH=/usr/local/cuda/lib64/stubs:${LD_LIBRARY_PATH} \ - bazel build -c opt \ - --config=cuda \ - --cxxopt="-D_GLIBCXX_USE_CXX11_ABI=0" \ - --jobs=${TF_AVAILABLE_CPUS} \ - tensorflow/tools/pip_package:build_pip_package && \ - mkdir /pip_pkg && \ - bazel-bin/tensorflow/tools/pip_package/build_pip_package /pip_pkg && \ - pip --no-cache-dir install --upgrade /pip_pkg/tensorflow-*.whl && \ - rm -rf /pip_pkg && \ - rm -rf /root/.cache -# Clean up pip wheel and Bazel cache when done. - -WORKDIR /root - -# TensorBoard -EXPOSE 6006 -# IPython -EXPOSE 8888 diff --git a/tensorflow/tools/docs/parser.py b/tensorflow/tools/docs/parser.py index 997afc6ac7..549056c6c4 100644 --- a/tensorflow/tools/docs/parser.py +++ b/tensorflow/tools/docs/parser.py @@ -947,6 +947,7 @@ class _ClassPageInfo(object): self._aliases = None self._doc = None self._guides = None + self._namedtuplefields = None self._bases = None self._properties = [] @@ -1030,6 +1031,17 @@ class _ClassPageInfo(object): self._guides = guides @property + def namedtuplefields(self): + return self._namedtuplefields + + def set_namedtuplefields(self, py_class): + if issubclass(py_class, tuple): + if all( + hasattr(py_class, attr) + for attr in ('_asdict', '_fields', '_make', '_replace')): + self._namedtuplefields = py_class._fields + + @property def bases(self): """Returns a list of `_LinkInfo` objects pointing to the class' parents.""" return self._bases @@ -1066,7 +1078,15 @@ class _ClassPageInfo(object): @property def properties(self): """Returns a list of `_PropertyInfo` describing the class' properties.""" - return self._properties + props_dict = {prop.short_name: prop for prop in self._properties} + props = [] + if self.namedtuplefields: + for field in self.namedtuplefields: + props.append(props_dict.pop(field)) + + props.extend(sorted(props_dict.values())) + + return props def _add_property(self, short_name, full_name, obj, doc): """Adds a `_PropertyInfo` entry to the `properties` list. @@ -1077,6 +1097,9 @@ class _ClassPageInfo(object): obj: The property object itself doc: The property's parsed docstring, a `_DocstringInfo`. """ + # Hide useless namedtuple docs-trings + if re.match('Alias for field number [0-9]+', doc.docstring): + doc = doc._replace(docstring='', brief='') property_info = _PropertyInfo(short_name, full_name, obj, doc) self._properties.append(property_info) @@ -1156,6 +1179,7 @@ class _ClassPageInfo(object): py_class: The class object being documented parser_config: An instance of ParserConfig. """ + self.set_namedtuplefields(py_class) doc_path = documentation_path(self.full_name) relative_path = os.path.relpath( path='.', start=os.path.dirname(doc_path) or '.') diff --git a/tensorflow/tools/docs/parser_test.py b/tensorflow/tools/docs/parser_test.py index 9f6b185e81..71e96afa10 100644 --- a/tensorflow/tools/docs/parser_test.py +++ b/tensorflow/tools/docs/parser_test.py @@ -18,6 +18,7 @@ from __future__ import absolute_import from __future__ import division from __future__ import print_function +import collections import functools import os import sys @@ -190,6 +191,50 @@ class ParserTest(googletest.TestCase): # Make sure this file is contained as the definition location. self.assertEqual(os.path.relpath(__file__, '/'), page_info.defined_in.path) + def test_namedtuple_field_order(self): + namedtupleclass = collections.namedtuple('namedtupleclass', + {'z', 'y', 'x', 'w', 'v', 'u'}) + + index = { + 'namedtupleclass': namedtupleclass, + 'namedtupleclass.u': namedtupleclass.u, + 'namedtupleclass.v': namedtupleclass.v, + 'namedtupleclass.w': namedtupleclass.w, + 'namedtupleclass.x': namedtupleclass.x, + 'namedtupleclass.y': namedtupleclass.y, + 'namedtupleclass.z': namedtupleclass.z, + } + + visitor = DummyVisitor(index=index, duplicate_of={}) + + reference_resolver = parser.ReferenceResolver.from_visitor( + visitor=visitor, doc_index={}, py_module_names=['tf']) + + tree = {'namedtupleclass': {'u', 'v', 'w', 'x', 'y', 'z'}} + parser_config = parser.ParserConfig( + reference_resolver=reference_resolver, + duplicates={}, + duplicate_of={}, + tree=tree, + index=index, + reverse_index={}, + guide_index={}, + base_dir='/') + + page_info = parser.docs_for_object( + full_name='namedtupleclass', + py_object=namedtupleclass, + parser_config=parser_config) + + # Each namedtiple field has a docstring of the form: + # 'Alias for field number ##'. These props are returned sorted. + + def sort_key(prop_info): + return int(prop_info.obj.__doc__.split(' ')[-1]) + + self.assertSequenceEqual(page_info.properties, + sorted(page_info.properties, key=sort_key)) + def test_docs_for_class_should_skip(self): class Parent(object): @@ -736,6 +781,5 @@ class TestGenerateSignature(googletest.TestCase): sig = parser._generate_signature(example_fun, reverse_index={}) self.assertEqual(sig, ['arg1=a.b.c.d', 'arg2=a.b.c.d(1, 2)', "arg3=e['f']"]) - if __name__ == '__main__': googletest.main() diff --git a/tensorflow/tools/docs/pretty_docs.py b/tensorflow/tools/docs/pretty_docs.py index aecf753a58..448f246e0e 100644 --- a/tensorflow/tools/docs/pretty_docs.py +++ b/tensorflow/tools/docs/pretty_docs.py @@ -136,7 +136,7 @@ def _build_class_page(page_info): if page_info.properties: parts.append('## Properties\n\n') - for prop_info in sorted(page_info.properties): + for prop_info in page_info.properties: h3 = '<h3 id="{short_name}"><code>{short_name}</code></h3>\n\n' parts.append(h3.format(short_name=prop_info.short_name)) diff --git a/tensorflow/tools/graph_transforms/freeze_requantization_ranges.cc b/tensorflow/tools/graph_transforms/freeze_requantization_ranges.cc index c8dc2a7c4d..d97496cbeb 100644 --- a/tensorflow/tools/graph_transforms/freeze_requantization_ranges.cc +++ b/tensorflow/tools/graph_transforms/freeze_requantization_ranges.cc @@ -92,7 +92,7 @@ Status ExtractMinMaxRecords(const string& log_file_name, if (!str_util::EndsWith(name_string, print_suffix)) { continue; } - string name = std::string( + string name( name_string.substr(0, name_string.size() - print_suffix.size())); records->push_back({name, min, max}); } diff --git a/tensorflow/tools/graph_transforms/sparsify_gather_test.cc b/tensorflow/tools/graph_transforms/sparsify_gather_test.cc index dd95779a1f..b8d6ba00de 100644 --- a/tensorflow/tools/graph_transforms/sparsify_gather_test.cc +++ b/tensorflow/tools/graph_transforms/sparsify_gather_test.cc @@ -42,8 +42,8 @@ class SparsifyGatherTest : public ::testing::Test { const std::vector<NodeDef*>& inputs, GraphDef* graph_def, bool control_dep = false) { NodeDef* node_def = graph_def->add_node(); - node_def->set_name(std::string(name)); - node_def->set_op(std::string(op)); + node_def->set_name(string(name)); + node_def->set_op(string(op)); if (!control_dep) { std::for_each(inputs.begin(), inputs.end(), [&node_def](NodeDef* input) { node_def->add_input(input->name()); diff --git a/tensorflow/tools/graph_transforms/transform_graph.cc b/tensorflow/tools/graph_transforms/transform_graph.cc index 5cae8f8d8f..7efe450710 100644 --- a/tensorflow/tools/graph_transforms/transform_graph.cc +++ b/tensorflow/tools/graph_transforms/transform_graph.cc @@ -65,19 +65,19 @@ Status ParseTransformParameters(const string& transforms_string, .GetResult(&remaining, &transform_name); if (!found_transform_name) { return errors::InvalidArgument("Looking for transform name, but found ", - std::string(remaining).c_str()); + string(remaining).c_str()); } if (Scanner(remaining).OneLiteral("(").GetResult(&remaining, &match)) { state = TRANSFORM_PARAM_NAME; } else { // Add a transform with no parameters. - params_list->push_back({std::string(transform_name), func_parameters}); + params_list->push_back({string(transform_name), func_parameters}); transform_name = ""; state = TRANSFORM_NAME; } } else if (state == TRANSFORM_PARAM_NAME) { if (Scanner(remaining).OneLiteral(")").GetResult(&remaining, &match)) { - params_list->push_back({std::string(transform_name), func_parameters}); + params_list->push_back({string(transform_name), func_parameters}); transform_name = ""; state = TRANSFORM_NAME; } else { @@ -92,13 +92,13 @@ Status ParseTransformParameters(const string& transforms_string, if (!found_parameter_name) { return errors::InvalidArgument( "Looking for parameter name, but found ", - std::string(remaining).c_str()); + string(remaining).c_str()); } if (Scanner(remaining).OneLiteral("=").GetResult(&remaining, &match)) { state = TRANSFORM_PARAM_VALUE; } else { return errors::InvalidArgument("Looking for =, but found ", - std::string(remaining).c_str()); + string(remaining).c_str()); } } } else if (state == TRANSFORM_PARAM_VALUE) { @@ -120,10 +120,9 @@ Status ParseTransformParameters(const string& transforms_string, } if (!found_parameter_value) { return errors::InvalidArgument("Looking for parameter name, but found ", - std::string(remaining).c_str()); + string(remaining).c_str()); } - func_parameters[std::string(parameter_name)].push_back( - std::string(parameter_value)); + func_parameters[string(parameter_name)].emplace_back(parameter_value); // Eat up any trailing quotes. Scanner(remaining).ZeroOrOneLiteral("\"").GetResult(&remaining, &match); Scanner(remaining).ZeroOrOneLiteral("'").GetResult(&remaining, &match); diff --git a/tensorflow/tools/graph_transforms/transform_utils.cc b/tensorflow/tools/graph_transforms/transform_utils.cc index cb084e49b7..c715380aae 100644 --- a/tensorflow/tools/graph_transforms/transform_utils.cc +++ b/tensorflow/tools/graph_transforms/transform_utils.cc @@ -93,7 +93,7 @@ void NodeNamePartsFromInput(const string& input_name, string* prefix, } else { *prefix = ""; } - *node_name = std::string(node_name_piece); + *node_name = string(node_name_piece); } string NodeNameFromInput(const string& input_name) { diff --git a/tensorflow/workspace.bzl b/tensorflow/workspace.bzl index 758c94c542..1e7c5d6790 100755 --- a/tensorflow/workspace.bzl +++ b/tensorflow/workspace.bzl @@ -106,11 +106,11 @@ def tf_workspace(path_prefix = "", tf_repo_name = ""): tf_http_archive( name = "com_google_absl", urls = [ - "https://mirror.bazel.build/github.com/abseil/abseil-cpp/archive/f0f15c2778b0e4959244dd25e63f445a455870f5.tar.gz", - "https://github.com/abseil/abseil-cpp/archive/f0f15c2778b0e4959244dd25e63f445a455870f5.tar.gz", + "https://mirror.bazel.build/github.com/abseil/abseil-cpp/archive/c075ad321696fa5072e097f0a51e4fe76a6fe13e.tar.gz", + "https://github.com/abseil/abseil-cpp/archive/c075ad321696fa5072e097f0a51e4fe76a6fe13e.tar.gz", ], - sha256 = "4ee36dacb75846eaa209ce8060bb269a42b7b3903612ca6d9e86a692659fe8c1", - strip_prefix = "abseil-cpp-f0f15c2778b0e4959244dd25e63f445a455870f5", + sha256 = "cb4e11259742954f88802be6f33c1007c16502d90d68e8898b5e5084264ca8a9", + strip_prefix = "abseil-cpp-c075ad321696fa5072e097f0a51e4fe76a6fe13e", build_file = clean_dep("//third_party:com_google_absl.BUILD"), ) @@ -491,11 +491,11 @@ def tf_workspace(path_prefix = "", tf_repo_name = ""): tf_http_archive( name = "llvm", urls = [ - "https://mirror.bazel.build/github.com/llvm-mirror/llvm/archive/10a4287278d70f44ea14cee48aef3697b2ef1321.tar.gz", - "https://github.com/llvm-mirror/llvm/archive/10a4287278d70f44ea14cee48aef3697b2ef1321.tar.gz", + "https://mirror.bazel.build/github.com/llvm-mirror/llvm/archive/dc6d9ec3646865125d057b6f515b4543df79920a.tar.gz", + "https://github.com/llvm-mirror/llvm/archive/dc6d9ec3646865125d057b6f515b4543df79920a.tar.gz", ], - sha256 = "ef679201e323429ca65a25d7ac42dbfbd6c9368613de6d82faee952bb72827d3", - strip_prefix = "llvm-10a4287278d70f44ea14cee48aef3697b2ef1321", + sha256 = "c7252290a113f694cccbb4b325c67b56f3aa6f5b3044524302c0e79db2da7e2a", + strip_prefix = "llvm-dc6d9ec3646865125d057b6f515b4543df79920a", build_file = clean_dep("//third_party/llvm:llvm.autogenerated.BUILD"), ) diff --git a/third_party/clang_toolchain/download_clang.bzl b/third_party/clang_toolchain/download_clang.bzl index 5ef47cdd0d..e782739661 100644 --- a/third_party/clang_toolchain/download_clang.bzl +++ b/third_party/clang_toolchain/download_clang.bzl @@ -39,15 +39,15 @@ def download_clang(repo_ctx, out_folder): # Latest CLANG_REVISION and CLANG_SUB_REVISION of the Chromiums's release # can be found in https://chromium.googlesource.com/chromium/src/tools/clang/+/master/scripts/update.py - CLANG_REVISION = "338452" + CLANG_REVISION = "340427" CLANG_SUB_REVISION = 1 package_version = "%s-%s" % (CLANG_REVISION, CLANG_SUB_REVISION) checksums = { - "Linux_x64": "213ba23a0a9855ede5041f66661caa9c5c59a573ec60b82a31839f9a97f397bf", - "Mac": "4267774201f8cb50c25e081375e87038d58db80064a20a0d9d7fe57ea4357ece", - "Win": "a8a5d5b25443c099e2c20d1a0cdce2f1d17e2dba84de66a6dc6a239ce3e78c34", + "Linux_x64": "8a8f21fb624fc7be7e91e439a13114847185375bb932db51ba590174ecaf764b", + "Mac": "ba894536b7c8d37103a5ddba784f268d55e65bb2ea1200a2cf9f2ef1590eaacd", + "Win": "c3f5bd977266dfd011411c94a13e00974b643b70fb0225a5fb030f7f703fa474", } platform_folder = _get_platform_folder(repo_ctx.os.name) diff --git a/third_party/gpus/crosstool/CROSSTOOL.tpl b/third_party/gpus/crosstool/CROSSTOOL.tpl index 3972c96a2f..3189cf8e31 100644 --- a/third_party/gpus/crosstool/CROSSTOOL.tpl +++ b/third_party/gpus/crosstool/CROSSTOOL.tpl @@ -208,7 +208,7 @@ toolchain { action: "c++-link-dynamic-library" action: "c++-link-nodeps-dynamic-library" flag_group { - flag: "-B/usr/bin/" + %{linker_bin_path_flag} } } } @@ -446,7 +446,7 @@ toolchain { action: "c++-link-dynamic-library" action: "c++-link-nodeps-dynamic-library" flag_group { - flag: "-B/usr/bin/" + %{linker_bin_path_flag} } } } diff --git a/third_party/gpus/cuda_configure.bzl b/third_party/gpus/cuda_configure.bzl index f6a39aeaf1..5648b1525a 100644 --- a/third_party/gpus/cuda_configure.bzl +++ b/third_party/gpus/cuda_configure.bzl @@ -1303,6 +1303,19 @@ def _create_local_cuda_repository(repository_ctx): host_compiler_includes = _host_compiler_includes(repository_ctx, cc_fullpath) cuda_defines = {} + # Bazel sets '-B/usr/bin' flag to workaround build errors on RHEL (see + # https://github.com/bazelbuild/bazel/issues/760). + # However, this stops our custom clang toolchain from picking the provided + # LLD linker, so we're only adding '-B/usr/bin' when using non-downloaded + # toolchain. + # TODO: when bazel stops adding '-B/usr/bin' by default, remove this + # flag from the CROSSTOOL completely (see + # https://github.com/bazelbuild/bazel/issues/5634) + if should_download_clang: + cuda_defines["%{linker_bin_path_flag}"] = "" + else: + cuda_defines["%{linker_bin_path_flag}"] = 'flag: "-B/usr/bin"' + if is_cuda_clang: cuda_defines["%{host_compiler_path}"] = str(cc) cuda_defines["%{host_compiler_warnings}"] = """ diff --git a/third_party/jpeg/jpeg.BUILD b/third_party/jpeg/jpeg.BUILD index 946f13de12..5edf4f8120 100644 --- a/third_party/jpeg/jpeg.BUILD +++ b/third_party/jpeg/jpeg.BUILD @@ -443,7 +443,7 @@ JCONFIGINT_COMMON_SUBSTITUTIONS = { JCONFIGINT_NOWIN_SUBSTITUTIONS = { "#cmakedefine HAVE_BUILTIN_CTZL": "#define HAVE_BUILTIN_CTZL", - "@INLINE@" : "inline __attribute__((always_inline))", + "@INLINE@": "inline __attribute__((always_inline))", "#define SIZEOF_SIZE_T @SIZE_T@": "#if (__WORDSIZE==64 && !defined(__native_client__))\n" + "#define SIZEOF_SIZE_T 8\n" + "#else\n" + @@ -453,13 +453,13 @@ JCONFIGINT_NOWIN_SUBSTITUTIONS = { JCONFIGINT_WIN_SUBSTITUTIONS = { "#cmakedefine HAVE_BUILTIN_CTZL": "", - "#define INLINE @INLINE@" : "#if defined(__GNUC__)\n" + - "#define INLINE inline __attribute__((always_inline))\n" + - "#elif defined(_MSC_VER)\n" + - "#define INLINE __forceinline\n" + - "#else\n" + - "#define INLINE\n" + - "#endif\n", + "#define INLINE @INLINE@": "#if defined(__GNUC__)\n" + + "#define INLINE inline __attribute__((always_inline))\n" + + "#elif defined(_MSC_VER)\n" + + "#define INLINE __forceinline\n" + + "#else\n" + + "#define INLINE\n" + + "#endif\n", "#define SIZEOF_SIZE_T @SIZE_T@": "#if (__WORDSIZE==64)\n" + "#define SIZEOF_SIZE_T 8\n" + "#else\n" + diff --git a/tools/bazel.rc b/tools/bazel.rc index 660e3d3280..601e07ffdd 100644 --- a/tools/bazel.rc +++ b/tools/bazel.rc @@ -33,6 +33,11 @@ build:mkl_open_source_only --define=using_mkl_dnn_only=true build:download_clang --crosstool_top=@local_config_download_clang//:toolchain build:download_clang --define=using_clang=true +# Instruct clang to use LLD for linking. +# This only works with GPU builds currently, since Bazel sets -B/usr/bin in +# auto-generated CPU crosstool, forcing /usr/bin/ld.lld to be preferred over +# the downloaded one. +build:download_clang_use_lld --linkopt='-fuse-ld=lld' build:cuda --crosstool_top=@local_config_cuda//crosstool:toolchain build:cuda --define=using_cuda=true --define=using_cuda_nvcc=true |